Lecture 35 Minimization and maximization of functions. Powell s method in multidimensions Conjugate gradient method. Annealing methods.
|
|
|
- Camron Chambers
- 5 years ago
- Views:
Transcription
1 Lecture 35 Minimization and maximization of functions Powell s method in multidimensions Conjugate gradient method. Annealing methods.
 can be minimized along the direction n using the one")
2 We know how to minimize functions in one dimension. If we start at a point P in and N dimensional space and proceed from there along some vector direction n, then any function of N variables f(p) can be minimized along the direction n using the one dimensional methods. One can construct in this way several minimization schemes in multidimensions, whose main difference will be how they choose the direction n. We will discuss a few. In all our discussions we will assume we have a black box sub-algorithm, which we will call linmin whose definition can be taken as: The first possibility is to take a basis of directions e 1, e 2,,e N in your space, and successively minimize along each basis element, and repeat when you used them all until you eventually reach the minimum. For many functions this method is not bad.
3 But in some cases it does not work so well. It is the case of functions that have narrow valleys that do not align with the basis vectors. That will force the algorithm to take many tiny steps before it finds the minimum. This condition is not that unusual, especially in higher dimensions. To deal with this, we obviously need better guesses for the directions. The better guess can come in two different fashions: a) The chosen direction will take us along a narrow valley; b) The directions chosen are non interfering, that is, minimizing along one of them will not be spoiled by then minimizing along another.
4 Conjugate directions First notice that if we minimize a function along a given direction, the gradient vector will be perpendicular to that direction (otherwise there would be a non-zero directional derivative along the direction you supposedly minimized). Next, take some particular point P as the origin of the coordinate system with coordinates x. Any function can be approximated by its Taylor series. In this approximation the gradient is given by: And the change of the gradient as we move along some direction is:
5 Now, suppose you have moved along some direction uto a minimum and now propose to move along a new direction v. The condition that motion along v not spoil our minimization along u is just that the gradient stay perpendicular to u, i.e. that the change of the gradient be perpendicular to u. Given the equation we just discussed, this implies that, When an equation of this sort holds for two vectors u,v, they are said to be conjugate. If you minimize along conjugate directions, then you do not have to re-do the directions. An ideal situation is to come up with N conjugate directions. Then one pass on each will do the job. If the function were exactly quadratic, it will put you exactly at the minimum. For more general functions it will come close, and converge quadratically to the minimum in terms of the number of steps.
6 Powell s quadratically convergent method Powell discovered a direction set that produces N mutually conjugate directions. Initialize your set of directions u i to the basis vectors, u i =e i i=1,,n Now repeat the following sequence of steps, Powell showed that, for a quadratic function, k iterations of this procedure produce a set of directions u i whose last k members are mutually conjugate. Therefore, N iterations, amounting to N(N+1) line minimizations in all will exactly minimize a quadratic functions.
7 Sketch of proof (Brent, Algorithms for minimizations without derivatives ). Theorem: Given f(x)=x T A x-2 b T x +c if its minimum along the direction u from x* i is at x i for i=0,1, then x 1 -x 0 is conjugate to u. Proof: f i λ λ For i=0,1, ( x + u) = 0 T Particularizing for f(x), u ( Axi b) = 0 Subtracting for i=0,1, u T A( x x0) 1 = 0, next to last step in Powell' s proposal.
8 Unfortunately there is a problem with Powell s algorithm. The procedure of throwing away, at each stage, u 1 in favor of P N -P 0 tends to produce sets of directions that fold up on each other and become linearly dependent. Once this happens, the procedure finds the minimum in a subspace of the N dimensional space. That is, it produces the wrong answer. There are several ways of fixing this: 1. You reinitialize the set of directions back to the e i s after N or N+1 iterations of the basic procedure. 2. The set of directions can equally be reset to the columns of any orthogonal matrix. Rather than throw away the information on conjugate directions already built up, reset the direction to calculated principal directions of the matrix A. 3. You can give up quadratic convergence in favor of a more heuristic scheme, which tries to find a few good directions along narrow valleys instead of N necessarily conjugate directions. This is the method that Numerical Recipes implements.
9 Shall we be so quick to abandon quadratic convergence? That depends on the function. Some problems produce functions with long, twisty valleys. A quadratic method tries to extrapolate the minimum along the long direction with a parabola that is not there yet whereas the twists spoil the conjugacy of the N-1 transverse directions. The basic idea of the modified Powell method is still to take P N -P 0 as a new direction; it is, after all, the average direction moved after trying all N possible directions. For a valley whose long direction is twisting slowly, this direction is likely to give a good run along the long direction. The change is to discard the old direction along which the function f made its largest decrease. This seems surprising, since that direction was the best direction of the previous iteration. However, it has a big chance of being a major component of the new direction that we are adding so by dropping we avoid building up linear dependence. There are a couple of exceptions to this basic idea. Sometime it is better not to add a new direction at all. Define With f E the value of the function at an extrapolated point further along the proposed new direction. Also define f the magnitude of the maximum decrease along one particular direction.

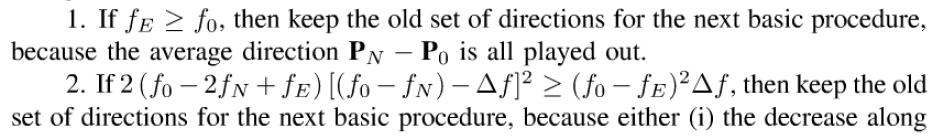
10 Then:
11
12
13 Conjugate gradient method in multidimensions We now consider the case where you are able to calculate, at a given N-dimensional point P, not just the value of the function f(p) but also the gradient (P) Let us assume that the function can be approximated by a quadratic form, as before, f Then the number of unknown parameters in f is equal to the number of free parameters in Aand b, which is N(N+1)/2, so it is of order N 2. Changing any of these parameters will move the location of the minimum. Therefore we should not expect to be able to find the minimum until we have collected an equivalent information content, of the order of N 2 numbers. In the direction set methods we talked about one collected the information by making of the order of N 2 minimizations. Here we can expect to do less, since we will be using information about the gradient. It is not clear that computationally one gains much, since computing the gradient requires N operations. It also matters how one uses the information of the gradient.

14 For instance a not too good use of the gradient information leads to the steepest descent method: The problem with this method (already discussed by Cauchy) is similar to the one we encountered before with narrow valleys. The method will perform many steps descending along the narrow valley, even if it is perfectly quadratic and one could cover it in one step. As you see at each step it is doing its job, but overall it is not doing so well.
15 What we want is not to go down the new gradient, but rather a direction that is conjugate to the old gradient. Such methods are called conjugate gradient methods. We discussed conjugate gradient methods in the context of solving linear algebraic equations by minimizing a quadratic form. That formalism can also be applied to the problem of minimizing a function approximated by a quadratic form. Starting from an initial vector g 0, and letting h 0 =g 0, the conjugate gradient method constructs two sequences of vectors through the recurrence, With The vectors satisfy the orthogonality and conjugacy conditions, So if we knew A, this procedure would provide successively conjugate directions along which to minimize.
16 But we don t know A Here s a remarkable theorem to save the day: suppose that we set g i equal to the gradient at P i. We now proceed from P i along the direction h i to the local minimum of f located at some point P i+1. We then set g i+1 equal to the gradient at that point. Then this g i+1 is the same we would have constructed with the construction we outlined in the previous slide, except that we did it without knowledge of A. Proof: Given the gradient of a quadratic function, we have that, And: with l chosen to take us to the line minimum. But there So combining with the above equation we get the expression for λon the previous slide. The above proposal is due to Fletcher and Reeves. Polakand Ribiereproposed a slightly different version: Which would be completely equivalent for quadratic functions given the orthogonality condition. It seems to work better.
17
18 Simulated annealing methods These methods are especially suited for situations where the dimensionality of space is large and there is a global minimum hidden among many false local minima. The idea is to draw an analogy with thermodynamics, specifically with the way liquids freeze and crystallize or metals cool and anneal. The idea is that at high temperature the molecules of a liquid move freely with respect to one another. If one slowly lowers the temperature eventually a solid with a crystalline structure develops and this configuration is the lowest energy configuration for the system. It is amazing that nature is able to find this configuration provided one cooks slowly. If one cools quickly ( quenching ) then one ends up with an amorphous or policrystalline state that is not the minimum of energy. Nature s own minimization algorithm is based on the Boltzmann probability distribution. Metropolis et al. decided to use this distribution to solve minimization problems.
19 The idea is that given two configurations E 2 and E 1 a simulated thermodynamic system changes its configuration from energy E 1 to E 2 with probability Notice that this number can be bigger than one. In that case we set it to one and the system actually transitions for sure. Otherwise it transitions with the respective probability. Just like in the Metropolis algorithm one takes a trial step and decides to keep it or not based on the probability. An example where this method has been used to in practice solve a problem is the traveling salesperson problem. Given a series of cities characterized by coordinates (x1,x2) in a map, which is the trajectory that minimizes the total traveled distance. In that example the energy is This problem is what is known as an NP-complete problem, which means that that the computation time for the exact solution goes as exp(n) with N the number of cities. A closely related problem is that of the design of integrated circuits, in which one wishes to minimize the interference among connecting wires.
20 Summary Powell s method allows to construct conjugate directions easily. One needs to reset it every once in a while to prevent folding. Conjugate gradient is an alternative way of finding conjugate directions. The annealing method uses thermodynamical analogies and is statistical in nature, akin to the Monte Carlo method.
Optimization Methods via Simulation
 Optimization Methods via Simulation Optimization problems are very important in science, engineering, industry,. Examples: Traveling salesman problem Circuit-board design Car-Parrinello ab initio MD Protein
Optimization Methods via Simulation Optimization problems are very important in science, engineering, industry,. Examples: Traveling salesman problem Circuit-board design Car-Parrinello ab initio MD Protein
Lecture 34 Minimization and maximization of functions
 Lecture 34 Minimization and maximization of functions Introduction Golden section search Parabolic interpolation Search with first derivatives Downhill simplex method Introduction In a nutshell, you are
Lecture 34 Minimization and maximization of functions Introduction Golden section search Parabolic interpolation Search with first derivatives Downhill simplex method Introduction In a nutshell, you are
Summary of Linear Least Squares Problem. Non-Linear Least-Squares Problems
 Lecture 7: Fitting Observed Data 2 Outline 1 Summary of Linear Least Squares Problem 2 Singular Value Decomposition 3 Non-Linear Least-Squares Problems 4 Levenberg-Marquart Algorithm 5 Errors with Poisson
Lecture 7: Fitting Observed Data 2 Outline 1 Summary of Linear Least Squares Problem 2 Singular Value Decomposition 3 Non-Linear Least-Squares Problems 4 Levenberg-Marquart Algorithm 5 Errors with Poisson
Design and Optimization of Energy Systems Prof. C. Balaji Department of Mechanical Engineering Indian Institute of Technology, Madras
 Design and Optimization of Energy Systems Prof. C. Balaji Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 09 Newton-Raphson Method Contd We will continue with our
Design and Optimization of Energy Systems Prof. C. Balaji Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 09 Newton-Raphson Method Contd We will continue with our
Lecture 7: Minimization or maximization of functions (Recipes Chapter 10)
") Lecture 7: Minimization or maximization of functions (Recipes Chapter 10) Actively studied subject for several reasons: Commonly encountered problem: e.g. Hamilton s and Lagrange s principles, economics
Lecture 7: Minimization or maximization of functions (Recipes Chapter 10) Actively studied subject for several reasons: Commonly encountered problem: e.g. Hamilton s and Lagrange s principles, economics
Chapter 10 Conjugate Direction Methods
 Chapter 10 Conjugate Direction Methods An Introduction to Optimization Spring, 2012 1 Wei-Ta Chu 2012/4/13 Introduction Conjugate direction methods can be viewed as being intermediate between the method
Chapter 10 Conjugate Direction Methods An Introduction to Optimization Spring, 2012 1 Wei-Ta Chu 2012/4/13 Introduction Conjugate direction methods can be viewed as being intermediate between the method
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 20 1 / 20 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 20 1 / 20 Overview
1 Heuristics for the Traveling Salesman Problem
 Praktikum Algorithmen-Entwurf (Teil 9) 09.12.2013 1 1 Heuristics for the Traveling Salesman Problem We consider the following problem. We want to visit all the nodes of a graph as fast as possible, visiting
Praktikum Algorithmen-Entwurf (Teil 9) 09.12.2013 1 1 Heuristics for the Traveling Salesman Problem We consider the following problem. We want to visit all the nodes of a graph as fast as possible, visiting
Programming, numerics and optimization
 Programming, numerics and optimization Lecture C-3: Unconstrained optimization II Łukasz Jankowski ljank@ippt.pan.pl Institute of Fundamental Technological Research Room 4.32, Phone +22.8261281 ext. 428
Programming, numerics and optimization Lecture C-3: Unconstrained optimization II Łukasz Jankowski ljank@ippt.pan.pl Institute of Fundamental Technological Research Room 4.32, Phone +22.8261281 ext. 428
Root Finding and Optimization
 Root Finding and Optimization Ramses van Zon SciNet, University o Toronto Scientiic Computing Lecture 11 February 11, 2014 Root Finding It is not uncommon in scientiic computing to want solve an equation
Root Finding and Optimization Ramses van Zon SciNet, University o Toronto Scientiic Computing Lecture 11 February 11, 2014 Root Finding It is not uncommon in scientiic computing to want solve an equation
Learning with Momentum, Conjugate Gradient Learning
 Learning with Momentum, Conjugate Gradient Learning Introduction to Neural Networks : Lecture 8 John A. Bullinaria, 2004 1. Visualising Learning 2. Learning with Momentum 3. Learning with Line Searches
Learning with Momentum, Conjugate Gradient Learning Introduction to Neural Networks : Lecture 8 John A. Bullinaria, 2004 1. Visualising Learning 2. Learning with Momentum 3. Learning with Line Searches
Simulations with MM Force Fields. Monte Carlo (MC) and Molecular Dynamics (MD) Video II.vi
 and Molecular Dynamics (MD) Video II.vi") Simulations with MM Force Fields Monte Carlo (MC) and Molecular Dynamics (MD) Video II.vi Some slides taken with permission from Howard R. Mayne Department of Chemistry University of New Hampshire Walking
Simulations with MM Force Fields Monte Carlo (MC) and Molecular Dynamics (MD) Video II.vi Some slides taken with permission from Howard R. Mayne Department of Chemistry University of New Hampshire Walking
Exploring the energy landscape
 Exploring the energy landscape ChE210D Today's lecture: what are general features of the potential energy surface and how can we locate and characterize minima on it Derivatives of the potential energy
Exploring the energy landscape ChE210D Today's lecture: what are general features of the potential energy surface and how can we locate and characterize minima on it Derivatives of the potential energy
Chapter 10. Optimization Simulated annealing
 Chapter 10 Optimization In this chapter we consider a very different kind of problem. Until now our prototypical problem is to compute the expected value of some random variable. We now consider minimization
Chapter 10 Optimization In this chapter we consider a very different kind of problem. Until now our prototypical problem is to compute the expected value of some random variable. We now consider minimization
Optimization. Totally not complete this is...don't use it yet...
 Optimization Totally not complete this is...don't use it yet... Bisection? Doing a root method is akin to doing a optimization method, but bi-section would not be an effective method - can detect sign
Optimization Totally not complete this is...don't use it yet... Bisection? Doing a root method is akin to doing a optimization method, but bi-section would not be an effective method - can detect sign
Steepest descent algorithm. Conjugate gradient training algorithm. Steepest descent algorithm. Remember previous examples
 Conjugate gradient training algorithm Steepest descent algorithm So far: Heuristic improvements to gradient descent (momentum Steepest descent training algorithm Can we do better? Definitions: weight vector
Conjugate gradient training algorithm Steepest descent algorithm So far: Heuristic improvements to gradient descent (momentum Steepest descent training algorithm Can we do better? Definitions: weight vector
ECE 680 Modern Automatic Control. Gradient and Newton s Methods A Review
 ECE 680Modern Automatic Control p. 1/1 ECE 680 Modern Automatic Control Gradient and Newton s Methods A Review Stan Żak October 25, 2011 ECE 680Modern Automatic Control p. 2/1 Review of the Gradient Properties
ECE 680Modern Automatic Control p. 1/1 ECE 680 Modern Automatic Control Gradient and Newton s Methods A Review Stan Żak October 25, 2011 ECE 680Modern Automatic Control p. 2/1 Review of the Gradient Properties
Mathematical optimization
 Optimization Mathematical optimization Determine the best solutions to certain mathematically defined problems that are under constrained determine optimality criteria determine the convergence of the
Optimization Mathematical optimization Determine the best solutions to certain mathematically defined problems that are under constrained determine optimality criteria determine the convergence of the
Conjugate-Gradient. Learn about the Conjugate-Gradient Algorithm and its Uses. Descent Algorithms and the Conjugate-Gradient Method. Qx = b.
 Lab 1 Conjugate-Gradient Lab Objective: Learn about the Conjugate-Gradient Algorithm and its Uses Descent Algorithms and the Conjugate-Gradient Method There are many possibilities for solving a linear
Lab 1 Conjugate-Gradient Lab Objective: Learn about the Conjugate-Gradient Algorithm and its Uses Descent Algorithms and the Conjugate-Gradient Method There are many possibilities for solving a linear
Lecture 22. r i+1 = b Ax i+1 = b A(x i + α i r i ) =(b Ax i ) α i Ar i = r i α i Ar i
 =(b Ax i ) α i Ar i = r i α i Ar i") 8.409 An Algorithmist s oolkit December, 009 Lecturer: Jonathan Kelner Lecture Last time Last time, we reduced solving sparse systems of linear equations Ax = b where A is symmetric and positive definite
8.409 An Algorithmist s oolkit December, 009 Lecturer: Jonathan Kelner Lecture Last time Last time, we reduced solving sparse systems of linear equations Ax = b where A is symmetric and positive definite
Root Finding and Optimization
 Root Finding and Optimization Root finding, solving equations, and optimization are very closely related subjects, which occur often in practical applications. Root finding : f (x) = 0 Solve for x Equation
Root Finding and Optimization Root finding, solving equations, and optimization are very closely related subjects, which occur often in practical applications. Root finding : f (x) = 0 Solve for x Equation
Practical Numerical Methods in Physics and Astronomy. Lecture 5 Optimisation and Search Techniques
 Practical Numerical Methods in Physics and Astronomy Lecture 5 Optimisation and Search Techniques Pat Scott Department of Physics, McGill University January 30, 2013 Slides available from http://www.physics.mcgill.ca/
Practical Numerical Methods in Physics and Astronomy Lecture 5 Optimisation and Search Techniques Pat Scott Department of Physics, McGill University January 30, 2013 Slides available from http://www.physics.mcgill.ca/
Simulated Annealing for Constrained Global Optimization
 Monte Carlo Methods for Computation and Optimization Final Presentation Simulated Annealing for Constrained Global Optimization H. Edwin Romeijn & Robert L.Smith (1994) Presented by Ariel Schwartz Objective
Monte Carlo Methods for Computation and Optimization Final Presentation Simulated Annealing for Constrained Global Optimization H. Edwin Romeijn & Robert L.Smith (1994) Presented by Ariel Schwartz Objective
(One Dimension) Problem: for a function f(x), find x 0 such that f(x 0 ) = 0. f(x)
 Problem: for a function f(x), find x 0 such that f(x 0 ) = 0. f(x)") Solving Nonlinear Equations & Optimization One Dimension Problem: or a unction, ind 0 such that 0 = 0. 0 One Root: The Bisection Method This one s guaranteed to converge at least to a singularity, i not
Solving Nonlinear Equations & Optimization One Dimension Problem: or a unction, ind 0 such that 0 = 0. 0 One Root: The Bisection Method This one s guaranteed to converge at least to a singularity, i not
Non-Convex Optimization. CS6787 Lecture 7 Fall 2017
 Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Unit 2: Solving Scalar Equations. Notes prepared by: Amos Ron, Yunpeng Li, Mark Cowlishaw, Steve Wright Instructor: Steve Wright
 cs416: introduction to scientific computing 01/9/07 Unit : Solving Scalar Equations Notes prepared by: Amos Ron, Yunpeng Li, Mark Cowlishaw, Steve Wright Instructor: Steve Wright 1 Introduction We now
cs416: introduction to scientific computing 01/9/07 Unit : Solving Scalar Equations Notes prepared by: Amos Ron, Yunpeng Li, Mark Cowlishaw, Steve Wright Instructor: Steve Wright 1 Introduction We now
x k+1 = x k + α k p k (13.1)
") 13 Gradient Descent Methods Lab Objective: Iterative optimization methods choose a search direction and a step size at each iteration One simple choice for the search direction is the negative gradient,
13 Gradient Descent Methods Lab Objective: Iterative optimization methods choose a search direction and a step size at each iteration One simple choice for the search direction is the negative gradient,
Constrained optimization. Unconstrained optimization. One-dimensional. Multi-dimensional. Newton with equality constraints. Active-set method.
 Optimization Unconstrained optimization One-dimensional Multi-dimensional Newton s method Basic Newton Gauss- Newton Quasi- Newton Descent methods Gradient descent Conjugate gradient Constrained optimization
Optimization Unconstrained optimization One-dimensional Multi-dimensional Newton s method Basic Newton Gauss- Newton Quasi- Newton Descent methods Gradient descent Conjugate gradient Constrained optimization
CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares
 CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares Robert Bridson October 29, 2008 1 Hessian Problems in Newton Last time we fixed one of plain Newton s problems by introducing line search
CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares Robert Bridson October 29, 2008 1 Hessian Problems in Newton Last time we fixed one of plain Newton s problems by introducing line search
Physics 403. Segev BenZvi. Numerical Methods, Maximum Likelihood, and Least Squares. Department of Physics and Astronomy University of Rochester
 Physics 403 Numerical Methods, Maximum Likelihood, and Least Squares Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Quadratic Approximation
Physics 403 Numerical Methods, Maximum Likelihood, and Least Squares Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Quadratic Approximation
Plasma Physics Prof. V. K. Tripathi Department of Physics Indian Institute of Technology, Delhi
 Plasma Physics Prof. V. K. Tripathi Department of Physics Indian Institute of Technology, Delhi Module No. # 01 Lecture No. # 22 Adiabatic Invariance of Magnetic Moment and Mirror Confinement Today, we
Plasma Physics Prof. V. K. Tripathi Department of Physics Indian Institute of Technology, Delhi Module No. # 01 Lecture No. # 22 Adiabatic Invariance of Magnetic Moment and Mirror Confinement Today, we
Nonlinear Optimization
 Nonlinear Optimization (Com S 477/577 Notes) Yan-Bin Jia Nov 7, 2017 1 Introduction Given a single function f that depends on one or more independent variable, we want to find the values of those variables
Nonlinear Optimization (Com S 477/577 Notes) Yan-Bin Jia Nov 7, 2017 1 Introduction Given a single function f that depends on one or more independent variable, we want to find the values of those variables
Motivation, Basic Concepts, Basic Methods, Travelling Salesperson Problem (TSP), Algorithms
, Algorithms") Motivation, Basic Concepts, Basic Methods, Travelling Salesperson Problem (TSP), Algorithms 1 What is Combinatorial Optimization? Combinatorial Optimization deals with problems where we have to search
Motivation, Basic Concepts, Basic Methods, Travelling Salesperson Problem (TSP), Algorithms 1 What is Combinatorial Optimization? Combinatorial Optimization deals with problems where we have to search
Gradient Descent Methods
 Lab 18 Gradient Descent Methods Lab Objective: Many optimization methods fall under the umbrella of descent algorithms. The idea is to choose an initial guess, identify a direction from this point along
Lab 18 Gradient Descent Methods Lab Objective: Many optimization methods fall under the umbrella of descent algorithms. The idea is to choose an initial guess, identify a direction from this point along
Conjugate gradient algorithm for training neural networks
 . Introduction Recall that in the steepest-descent neural network training algorithm, consecutive line-search directions are orthogonal, such that, where, gwt [ ( + ) ] denotes E[ w( t + ) ], the gradient
. Introduction Recall that in the steepest-descent neural network training algorithm, consecutive line-search directions are orthogonal, such that, where, gwt [ ( + ) ] denotes E[ w( t + ) ], the gradient
Optimization Tutorial 1. Basic Gradient Descent
 E0 270 Machine Learning Jan 16, 2015 Optimization Tutorial 1 Basic Gradient Descent Lecture by Harikrishna Narasimhan Note: This tutorial shall assume background in elementary calculus and linear algebra.
E0 270 Machine Learning Jan 16, 2015 Optimization Tutorial 1 Basic Gradient Descent Lecture by Harikrishna Narasimhan Note: This tutorial shall assume background in elementary calculus and linear algebra.
MITOCW ocw f99-lec30_300k
 MITOCW ocw-18.06-f99-lec30_300k OK, this is the lecture on linear transformations. Actually, linear algebra courses used to begin with this lecture, so you could say I'm beginning this course again by
MITOCW ocw-18.06-f99-lec30_300k OK, this is the lecture on linear transformations. Actually, linear algebra courses used to begin with this lecture, so you could say I'm beginning this course again by
Projects in Geometry for High School Students
 Projects in Geometry for High School Students Goal: Our goal in more detail will be expressed on the next page. Our journey will force us to understand plane and three-dimensional geometry. We will take
Projects in Geometry for High School Students Goal: Our goal in more detail will be expressed on the next page. Our journey will force us to understand plane and three-dimensional geometry. We will take
Quasi-Newton Methods
 Newton s Method Pros and Cons Quasi-Newton Methods MA 348 Kurt Bryan Newton s method has some very nice properties: It s extremely fast, at least once it gets near the minimum, and with the simple modifications
Newton s Method Pros and Cons Quasi-Newton Methods MA 348 Kurt Bryan Newton s method has some very nice properties: It s extremely fast, at least once it gets near the minimum, and with the simple modifications
NonlinearOptimization
 1/35 NonlinearOptimization Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Jiří Kašpar, Pavel Tvrdík, 2011 Unconstrained nonlinear optimization,
1/35 NonlinearOptimization Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Jiří Kašpar, Pavel Tvrdík, 2011 Unconstrained nonlinear optimization,
Conjugate Directions for Stochastic Gradient Descent
 Conjugate Directions for Stochastic Gradient Descent Nicol N Schraudolph Thore Graepel Institute of Computational Science ETH Zürich, Switzerland {schraudo,graepel}@infethzch Abstract The method of conjugate
Conjugate Directions for Stochastic Gradient Descent Nicol N Schraudolph Thore Graepel Institute of Computational Science ETH Zürich, Switzerland {schraudo,graepel}@infethzch Abstract The method of conjugate
EAD 115. Numerical Solution of Engineering and Scientific Problems. David M. Rocke Department of Applied Science
 EAD 115 Numerical Solution of Engineering and Scientific Problems David M. Rocke Department of Applied Science Multidimensional Unconstrained Optimization Suppose we have a function f() of more than one
EAD 115 Numerical Solution of Engineering and Scientific Problems David M. Rocke Department of Applied Science Multidimensional Unconstrained Optimization Suppose we have a function f() of more than one
Applications of Binary Search
 Applications of Binary Search The basic idea of a binary search can be used in many different places. In particular, any time you are searching for an answer in a search space that is somehow sorted, you
Applications of Binary Search The basic idea of a binary search can be used in many different places. In particular, any time you are searching for an answer in a search space that is somehow sorted, you
Physics 331 Introduction to Numerical Techniques in Physics
 Physics 331 Introduction to Numerical Techniques in Physics Instructor: Joaquín Drut Lecture 12 Last time: Polynomial interpolation: basics; Lagrange interpolation. Today: Quick review. Formal properties.
Physics 331 Introduction to Numerical Techniques in Physics Instructor: Joaquín Drut Lecture 12 Last time: Polynomial interpolation: basics; Lagrange interpolation. Today: Quick review. Formal properties.
12. LOCAL SEARCH. gradient descent Metropolis algorithm Hopfield neural networks maximum cut Nash equilibria
 12. LOCAL SEARCH gradient descent Metropolis algorithm Hopfield neural networks maximum cut Nash equilibria Lecture slides by Kevin Wayne Copyright 2005 Pearson-Addison Wesley h ttp://www.cs.princeton.edu/~wayne/kleinberg-tardos
12. LOCAL SEARCH gradient descent Metropolis algorithm Hopfield neural networks maximum cut Nash equilibria Lecture slides by Kevin Wayne Copyright 2005 Pearson-Addison Wesley h ttp://www.cs.princeton.edu/~wayne/kleinberg-tardos
Sufficient Conditions for Finite-variable Constrained Minimization
 Lecture 4 It is a small de tour but it is important to understand this before we move to calculus of variations. Sufficient Conditions for Finite-variable Constrained Minimization ME 256, Indian Institute
Lecture 4 It is a small de tour but it is important to understand this before we move to calculus of variations. Sufficient Conditions for Finite-variable Constrained Minimization ME 256, Indian Institute
Report due date. Please note: report has to be handed in by Monday, May 16 noon.
 Lecture 23 18.86 Report due date Please note: report has to be handed in by Monday, May 16 noon. Course evaluation: Please submit your feedback (you should have gotten an email) From the weak form to finite
Lecture 23 18.86 Report due date Please note: report has to be handed in by Monday, May 16 noon. Course evaluation: Please submit your feedback (you should have gotten an email) From the weak form to finite
Optimization Methods
 Optimization Methods Decision making Examples: determining which ingredients and in what quantities to add to a mixture being made so that it will meet specifications on its composition allocating available
Optimization Methods Decision making Examples: determining which ingredients and in what quantities to add to a mixture being made so that it will meet specifications on its composition allocating available
Chapter 8 Gradient Methods
 Chapter 8 Gradient Methods An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Introduction Recall that a level set of a function is the set of points satisfying for some constant. Thus, a point
Chapter 8 Gradient Methods An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Introduction Recall that a level set of a function is the set of points satisfying for some constant. Thus, a point
1 Ordinary points and singular points
 Math 70 honors, Fall, 008 Notes 8 More on series solutions, and an introduction to \orthogonal polynomials" Homework at end Revised, /4. Some changes and additions starting on page 7. Ordinary points and
Math 70 honors, Fall, 008 Notes 8 More on series solutions, and an introduction to \orthogonal polynomials" Homework at end Revised, /4. Some changes and additions starting on page 7. Ordinary points and
CLASS NOTES Computational Methods for Engineering Applications I Spring 2015
 CLASS NOTES Computational Methods for Engineering Applications I Spring 2015 Petros Koumoutsakos Gerardo Tauriello (Last update: July 27, 2015) IMPORTANT DISCLAIMERS 1. REFERENCES: Much of the material
CLASS NOTES Computational Methods for Engineering Applications I Spring 2015 Petros Koumoutsakos Gerardo Tauriello (Last update: July 27, 2015) IMPORTANT DISCLAIMERS 1. REFERENCES: Much of the material
Design and Analysis of Algorithms
 CSE 0, Winter 08 Design and Analysis of Algorithms Lecture 8: Consolidation # (DP, Greed, NP-C, Flow) Class URL: http://vlsicad.ucsd.edu/courses/cse0-w8/ Followup on IGO, Annealing Iterative Global Optimization
CSE 0, Winter 08 Design and Analysis of Algorithms Lecture 8: Consolidation # (DP, Greed, NP-C, Flow) Class URL: http://vlsicad.ucsd.edu/courses/cse0-w8/ Followup on IGO, Annealing Iterative Global Optimization
4.4. Closure Property. Commutative Property. Associative Property The system is associative if TABLE 10
 4.4 Finite Mathematical Systems 179 TABLE 10 a b c d a a b c d b b d a c c c a d b d d c b a TABLE 11 a b c d a a b c d b b d a c c c a d b d d c b a 4.4 Finite Mathematical Systems We continue our study
4.4 Finite Mathematical Systems 179 TABLE 10 a b c d a a b c d b b d a c c c a d b d d c b a TABLE 11 a b c d a a b c d b b d a c c c a d b d d c b a 4.4 Finite Mathematical Systems We continue our study
Introduction to Geometry Optimization. Computational Chemistry lab 2009
 Introduction to Geometry Optimization Computational Chemistry lab 9 Determination of the molecule configuration H H Diatomic molecule determine the interatomic distance H O H Triatomic molecule determine
Introduction to Geometry Optimization Computational Chemistry lab 9 Determination of the molecule configuration H H Diatomic molecule determine the interatomic distance H O H Triatomic molecule determine
Note: Please use the actual date you accessed this material in your citation.
 MIT OpenCourseWare http://ocw.mit.edu 18.06 Linear Algebra, Spring 2005 Please use the following citation format: Gilbert Strang, 18.06 Linear Algebra, Spring 2005. (Massachusetts Institute of Technology:
MIT OpenCourseWare http://ocw.mit.edu 18.06 Linear Algebra, Spring 2005 Please use the following citation format: Gilbert Strang, 18.06 Linear Algebra, Spring 2005. (Massachusetts Institute of Technology:
5. Simulated Annealing 5.1 Basic Concepts. Fall 2010 Instructor: Dr. Masoud Yaghini
 5. Simulated Annealing 5.1 Basic Concepts Fall 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Real Annealing and Simulated Annealing Metropolis Algorithm Template of SA A Simple Example References
5. Simulated Annealing 5.1 Basic Concepts Fall 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Real Annealing and Simulated Annealing Metropolis Algorithm Template of SA A Simple Example References
Analysis Methods in Atmospheric and Oceanic Science
 Analysis Methods in Atmospheric and Oceanic Science Copyright 2016 University of Maryland. 1 AOSC 652 Root Finding & Function Minimization Week 7, Day 2 12 Oct 2016 2 Method #3: Newton-Raphson Root is
Analysis Methods in Atmospheric and Oceanic Science Copyright 2016 University of Maryland. 1 AOSC 652 Root Finding & Function Minimization Week 7, Day 2 12 Oct 2016 2 Method #3: Newton-Raphson Root is
AS MATHEMATICS HOMEWORK C1
 Student Teacher AS MATHEMATICS HOMEWORK C September 05 City and Islington Sixth Form College Mathematics Department www.candimaths.uk HOMEWORK INTRODUCTION You should attempt all the questions. If you
Student Teacher AS MATHEMATICS HOMEWORK C September 05 City and Islington Sixth Form College Mathematics Department www.candimaths.uk HOMEWORK INTRODUCTION You should attempt all the questions. If you
Computer Science 385 Analysis of Algorithms Siena College Spring Topic Notes: Limitations of Algorithms
 Computer Science 385 Analysis of Algorithms Siena College Spring 2011 Topic Notes: Limitations of Algorithms We conclude with a discussion of the limitations of the power of algorithms. That is, what kinds
Computer Science 385 Analysis of Algorithms Siena College Spring 2011 Topic Notes: Limitations of Algorithms We conclude with a discussion of the limitations of the power of algorithms. That is, what kinds
Iterative Methods for Solving A x = b
 Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Math 456: Mathematical Modeling. Tuesday, April 9th, 2018
 Math 456: Mathematical Modeling Tuesday, April 9th, 2018 The Ergodic theorem Tuesday, April 9th, 2018 Today 1. Asymptotic frequency (or: How to use the stationary distribution to estimate the average amount
Math 456: Mathematical Modeling Tuesday, April 9th, 2018 The Ergodic theorem Tuesday, April 9th, 2018 Today 1. Asymptotic frequency (or: How to use the stationary distribution to estimate the average amount
HOMEWORK 10 SOLUTIONS
 HOMEWORK 10 SOLUTIONS MATH 170A Problem 0.1. Watkins 8.3.10 Solution. The k-th error is e (k) = G k e (0). As discussed before, that means that e (k+j) ρ(g) k, i.e., the norm of the error is approximately
HOMEWORK 10 SOLUTIONS MATH 170A Problem 0.1. Watkins 8.3.10 Solution. The k-th error is e (k) = G k e (0). As discussed before, that means that e (k+j) ρ(g) k, i.e., the norm of the error is approximately
Chapter Five Notes N P U2C5
 Chapter Five Notes N P UC5 Name Period Section 5.: Linear and Quadratic Functions with Modeling In every math class you have had since algebra you have worked with equations. Most of those equations have
Chapter Five Notes N P UC5 Name Period Section 5.: Linear and Quadratic Functions with Modeling In every math class you have had since algebra you have worked with equations. Most of those equations have
Computer simulation can be thought as a virtual experiment. There are
 13 Estimating errors 105 13 Estimating errors Computer simulation can be thought as a virtual experiment. There are systematic errors statistical errors. As systematical errors can be very complicated
13 Estimating errors 105 13 Estimating errors Computer simulation can be thought as a virtual experiment. There are systematic errors statistical errors. As systematical errors can be very complicated
Conjugate Gradient (CG) Method
 Method") Conjugate Gradient (CG) Method by K. Ozawa 1 Introduction In the series of this lecture, I will introduce the conjugate gradient method, which solves efficiently large scale sparse linear simultaneous
Conjugate Gradient (CG) Method by K. Ozawa 1 Introduction In the series of this lecture, I will introduce the conjugate gradient method, which solves efficiently large scale sparse linear simultaneous
Gradient Descent. Sargur Srihari
 Gradient Descent Sargur srihari@cedar.buffalo.edu 1 Topics Simple Gradient Descent/Ascent Difficulties with Simple Gradient Descent Line Search Brent s Method Conjugate Gradient Descent Weight vectors
Gradient Descent Sargur srihari@cedar.buffalo.edu 1 Topics Simple Gradient Descent/Ascent Difficulties with Simple Gradient Descent Line Search Brent s Method Conjugate Gradient Descent Weight vectors
12. LOCAL SEARCH. gradient descent Metropolis algorithm Hopfield neural networks maximum cut Nash equilibria
 Coping With NP-hardness Q. Suppose I need to solve an NP-hard problem. What should I do? A. Theory says you re unlikely to find poly-time algorithm. Must sacrifice one of three desired features. Solve
Coping With NP-hardness Q. Suppose I need to solve an NP-hard problem. What should I do? A. Theory says you re unlikely to find poly-time algorithm. Must sacrifice one of three desired features. Solve
The Conjugate Gradient Method
 The Conjugate Gradient Method Jason E. Hicken Aerospace Design Lab Department of Aeronautics & Astronautics Stanford University 14 July 2011 Lecture Objectives describe when CG can be used to solve Ax
The Conjugate Gradient Method Jason E. Hicken Aerospace Design Lab Department of Aeronautics & Astronautics Stanford University 14 July 2011 Lecture Objectives describe when CG can be used to solve Ax
High Performance Nonlinear Solvers
 What is a nonlinear system? High Performance Nonlinear Solvers Michael McCourt Division Argonne National Laboratory IIT Meshfree Seminar September 19, 2011 Every nonlinear system of equations can be described
What is a nonlinear system? High Performance Nonlinear Solvers Michael McCourt Division Argonne National Laboratory IIT Meshfree Seminar September 19, 2011 Every nonlinear system of equations can be described
Lecture 17: Numerical Optimization October 2014
 Lecture 17: Numerical Optimization 36-350 22 October 2014 Agenda Basics of optimization Gradient descent Newton s method Curve-fitting R: optim, nls Reading: Recipes 13.1 and 13.2 in The R Cookbook Optional
Lecture 17: Numerical Optimization 36-350 22 October 2014 Agenda Basics of optimization Gradient descent Newton s method Curve-fitting R: optim, nls Reading: Recipes 13.1 and 13.2 in The R Cookbook Optional
Polynomial functions right- and left-hand behavior (end behavior):
:") Lesson 2.2 Polynomial Functions For each function: a.) Graph the function on your calculator Find an appropriate window. Draw a sketch of the graph on your paper and indicate your window. b.) Identify
Lesson 2.2 Polynomial Functions For each function: a.) Graph the function on your calculator Find an appropriate window. Draw a sketch of the graph on your paper and indicate your window. b.) Identify
CS 781 Lecture 9 March 10, 2011 Topics: Local Search and Optimization Metropolis Algorithm Greedy Optimization Hopfield Networks Max Cut Problem Nash
 CS 781 Lecture 9 March 10, 2011 Topics: Local Search and Optimization Metropolis Algorithm Greedy Optimization Hopfield Networks Max Cut Problem Nash Equilibrium Price of Stability Coping With NP-Hardness
CS 781 Lecture 9 March 10, 2011 Topics: Local Search and Optimization Metropolis Algorithm Greedy Optimization Hopfield Networks Max Cut Problem Nash Equilibrium Price of Stability Coping With NP-Hardness
Lecture 8. Root finding II
 1 Introduction Lecture 8 Root finding II In the previous lecture we considered the bisection root-bracketing algorithm. It requires only that the function be continuous and that we have a root bracketed
1 Introduction Lecture 8 Root finding II In the previous lecture we considered the bisection root-bracketing algorithm. It requires only that the function be continuous and that we have a root bracketed
PROBLEM SOLVING AND SEARCH IN ARTIFICIAL INTELLIGENCE
 Artificial Intelligence, Computational Logic PROBLEM SOLVING AND SEARCH IN ARTIFICIAL INTELLIGENCE Lecture 4 Metaheuristic Algorithms Sarah Gaggl Dresden, 5th May 2017 Agenda 1 Introduction 2 Constraint
Artificial Intelligence, Computational Logic PROBLEM SOLVING AND SEARCH IN ARTIFICIAL INTELLIGENCE Lecture 4 Metaheuristic Algorithms Sarah Gaggl Dresden, 5th May 2017 Agenda 1 Introduction 2 Constraint
Statistical inference
 Statistical inference Contents 1. Main definitions 2. Estimation 3. Testing L. Trapani MSc Induction - Statistical inference 1 1 Introduction: definition and preliminary theory In this chapter, we shall
Statistical inference Contents 1. Main definitions 2. Estimation 3. Testing L. Trapani MSc Induction - Statistical inference 1 1 Introduction: definition and preliminary theory In this chapter, we shall
Math (P)Review Part II:
Review Part II:") Math (P)Review Part II: Vector Calculus Computer Graphics Assignment 0.5 (Out today!) Same story as last homework; second part on vector calculus. Slightly fewer questions Last Time: Linear Algebra Touched
Math (P)Review Part II: Vector Calculus Computer Graphics Assignment 0.5 (Out today!) Same story as last homework; second part on vector calculus. Slightly fewer questions Last Time: Linear Algebra Touched
Numerical Optimization of Partial Differential Equations
 Numerical Optimization of Partial Differential Equations Part I: basic optimization concepts in R n Bartosz Protas Department of Mathematics & Statistics McMaster University, Hamilton, Ontario, Canada
Numerical Optimization of Partial Differential Equations Part I: basic optimization concepts in R n Bartosz Protas Department of Mathematics & Statistics McMaster University, Hamilton, Ontario, Canada
Slope Fields: Graphing Solutions Without the Solutions
 8 Slope Fields: Graphing Solutions Without the Solutions Up to now, our efforts have been directed mainly towards finding formulas or equations describing solutions to given differential equations. Then,
8 Slope Fields: Graphing Solutions Without the Solutions Up to now, our efforts have been directed mainly towards finding formulas or equations describing solutions to given differential equations. Then,
An Overly Simplified and Brief Review of Differential Equation Solution Methods. 1. Some Common Exact Solution Methods for Differential Equations
 An Overly Simplified and Brief Review of Differential Equation Solution Methods We will be dealing with initial or boundary value problems. A typical initial value problem has the form y y 0 y(0) 1 A typical
An Overly Simplified and Brief Review of Differential Equation Solution Methods We will be dealing with initial or boundary value problems. A typical initial value problem has the form y y 0 y(0) 1 A typical
Numerical Optimization Professor Horst Cerjak, Horst Bischof, Thomas Pock Mat Vis-Gra SS09
 Numerical Optimization 1 Working Horse in Computer Vision Variational Methods Shape Analysis Machine Learning Markov Random Fields Geometry Common denominator: optimization problems 2 Overview of Methods
Numerical Optimization 1 Working Horse in Computer Vision Variational Methods Shape Analysis Machine Learning Markov Random Fields Geometry Common denominator: optimization problems 2 Overview of Methods
CPSC 540: Machine Learning
 CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
A.I.: Beyond Classical Search
 A.I.: Beyond Classical Search Random Sampling Trivial Algorithms Generate a state randomly Random Walk Randomly pick a neighbor of the current state Both algorithms asymptotically complete. Overview Previously
A.I.: Beyond Classical Search Random Sampling Trivial Algorithms Generate a state randomly Random Walk Randomly pick a neighbor of the current state Both algorithms asymptotically complete. Overview Previously
17 Neural Networks NEURAL NETWORKS. x XOR 1. x Jonathan Richard Shewchuk
 94 Jonathan Richard Shewchuk 7 Neural Networks NEURAL NETWORKS Can do both classification & regression. [They tie together several ideas from the course: perceptrons, logistic regression, ensembles of
94 Jonathan Richard Shewchuk 7 Neural Networks NEURAL NETWORKS Can do both classification & regression. [They tie together several ideas from the course: perceptrons, logistic regression, ensembles of
CSCI3390-Lecture 18: Why is the P =?NP Problem Such a Big Deal?
 CSCI3390-Lecture 18: Why is the P =?NP Problem Such a Big Deal? The conjecture that P is different from NP made its way on to several lists of the most important unsolved problems in Mathematics (never
CSCI3390-Lecture 18: Why is the P =?NP Problem Such a Big Deal? The conjecture that P is different from NP made its way on to several lists of the most important unsolved problems in Mathematics (never
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Chapter 11 - Sequences and Series
 Calculus and Analytic Geometry II Chapter - Sequences and Series. Sequences Definition. A sequence is a list of numbers written in a definite order, We call a n the general term of the sequence. {a, a
Calculus and Analytic Geometry II Chapter - Sequences and Series. Sequences Definition. A sequence is a list of numbers written in a definite order, We call a n the general term of the sequence. {a, a
y 1 x 1 ) 2 + (y 2 ) 2 A circle is a set of points P in a plane that are equidistant from a fixed point, called the center.
 2 + (y 2 ) 2 A circle is a set of points P in a plane that are equidistant from a fixed point, called the center.") Ch 12. Conic Sections Circles, Parabolas, Ellipses & Hyperbolas The formulas for the conic sections are derived by using the distance formula, which was derived from the Pythagorean Theorem. If you know
Ch 12. Conic Sections Circles, Parabolas, Ellipses & Hyperbolas The formulas for the conic sections are derived by using the distance formula, which was derived from the Pythagorean Theorem. If you know
14 Increasing and decreasing functions
 14 Increasing and decreasing functions 14.1 Sketching derivatives READING Read Section 3.2 of Rogawski Reading Recall, f (a) is the gradient of the tangent line of f(x) at x = a. We can use this fact to
14 Increasing and decreasing functions 14.1 Sketching derivatives READING Read Section 3.2 of Rogawski Reading Recall, f (a) is the gradient of the tangent line of f(x) at x = a. We can use this fact to
Queens College, CUNY, Department of Computer Science Numerical Methods CSCI 361 / 761 Spring 2018 Instructor: Dr. Sateesh Mane.
 Queens College, CUNY, Department of Computer Science Numerical Methods CSCI 361 / 761 Spring 2018 Instructor: Dr. Sateesh Mane c Sateesh R. Mane 2018 3 Lecture 3 3.1 General remarks March 4, 2018 This
Queens College, CUNY, Department of Computer Science Numerical Methods CSCI 361 / 761 Spring 2018 Instructor: Dr. Sateesh Mane c Sateesh R. Mane 2018 3 Lecture 3 3.1 General remarks March 4, 2018 This
Lecture 10: Powers of Matrices, Difference Equations
 Lecture 10: Powers of Matrices, Difference Equations Difference Equations A difference equation, also sometimes called a recurrence equation is an equation that defines a sequence recursively, i.e. each
Lecture 10: Powers of Matrices, Difference Equations Difference Equations A difference equation, also sometimes called a recurrence equation is an equation that defines a sequence recursively, i.e. each
Lagrange Multipliers
 Optimization with Constraints As long as algebra and geometry have been separated, their progress have been slow and their uses limited; but when these two sciences have been united, they have lent each
Optimization with Constraints As long as algebra and geometry have been separated, their progress have been slow and their uses limited; but when these two sciences have been united, they have lent each
Methods for finding optimal configurations
 CS 1571 Introduction to AI Lecture 9 Methods for finding optimal configurations Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Search for the optimal configuration Optimal configuration search:
CS 1571 Introduction to AI Lecture 9 Methods for finding optimal configurations Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Search for the optimal configuration Optimal configuration search:
This ensures that we walk downhill. For fixed λ not even this may be the case.
 Gradient Descent Objective Function Some differentiable function f : R n R. Gradient Descent Start with some x 0, i = 0 and learning rate λ repeat x i+1 = x i λ f(x i ) until f(x i+1 ) ɛ Line Search Variant
Gradient Descent Objective Function Some differentiable function f : R n R. Gradient Descent Start with some x 0, i = 0 and learning rate λ repeat x i+1 = x i λ f(x i ) until f(x i+1 ) ɛ Line Search Variant
Context of the project...3. What is protein design?...3. I The algorithms...3 A Dead-end elimination procedure...4. B Monte-Carlo simulation...
 Laidebeure Stéphane Context of the project...3 What is protein design?...3 I The algorithms...3 A Dead-end elimination procedure...4 B Monte-Carlo simulation...5 II The model...6 A The molecular model...6
Laidebeure Stéphane Context of the project...3 What is protein design?...3 I The algorithms...3 A Dead-end elimination procedure...4 B Monte-Carlo simulation...5 II The model...6 A The molecular model...6
Unit 6: Quadratics. Contents
 Unit 6: Quadratics Contents Animated gif Program...6-3 Setting Bounds...6-9 Exploring Quadratic Equations...6-17 Finding Zeros by Factoring...6-3 Finding Zeros Using the Quadratic Formula...6-41 Modeling:
Unit 6: Quadratics Contents Animated gif Program...6-3 Setting Bounds...6-9 Exploring Quadratic Equations...6-17 Finding Zeros by Factoring...6-3 Finding Zeros Using the Quadratic Formula...6-41 Modeling:
Introduction to Simulated Annealing 22c:145
 Introduction to Simulated Annealing 22c:145 Simulated Annealing Motivated by the physical annealing process Material is heated and slowly cooled into a uniform structure Simulated annealing mimics this
Introduction to Simulated Annealing 22c:145 Simulated Annealing Motivated by the physical annealing process Material is heated and slowly cooled into a uniform structure Simulated annealing mimics this
NOTES ON FIRST-ORDER METHODS FOR MINIMIZING SMOOTH FUNCTIONS. 1. Introduction. We consider first-order methods for smooth, unconstrained
 NOTES ON FIRST-ORDER METHODS FOR MINIMIZING SMOOTH FUNCTIONS 1. Introduction. We consider first-order methods for smooth, unconstrained optimization: (1.1) minimize f(x), x R n where f : R n R. We assume
NOTES ON FIRST-ORDER METHODS FOR MINIMIZING SMOOTH FUNCTIONS 1. Introduction. We consider first-order methods for smooth, unconstrained optimization: (1.1) minimize f(x), x R n where f : R n R. We assume
Lecture Notes: Geometric Considerations in Unconstrained Optimization
 Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
Section 1.1. Chapter 1. Quadratics. Parabolas. Example. Example. ( ) = ax 2 + bx + c -2-1
 = ax 2 + bx + c -2-1") Chapter 1 Quadratic Functions and Factoring Section 1.1 Graph Quadratic Functions in Standard Form Quadratics The polynomial form of a quadratic function is: f x The graph of a quadratic function is a
Chapter 1 Quadratic Functions and Factoring Section 1.1 Graph Quadratic Functions in Standard Form Quadratics The polynomial form of a quadratic function is: f x The graph of a quadratic function is a