Latent Variable Models in NLP
|
|
|
- Marcus Little
- 5 years ago
- Views:
Transcription

1 Latent Variable Models in NLP Aria Haghighi with Slav Petrov, John DeNero, and Dan Klein UC Berkeley, CS Division
2 Latent Variable Models
3 Latent Variable Models
4 Latent Variable Models Observed
5 Latent Variable Models Observed Hidden
6 Latent Variable Models Observed Hidden e.g. Word Alignment
7 Latent Variable Models Observed Hidden e.g. Word Alignment
8 Latent Variable Models Observed Hidden e.g. Word Alignment Observed Bitext


9 Latent Variable Models Observed Hidden e.g. Word Alignment Observed Bitext Hidden Alignment
10 Latent Variable Models Observed Hidden
11 Latent Variable Models Observed Hidden Basic question for LV models
12 Latent Variable Models Observed Hidden Basic question for LV models Q: How do I make latent variables behave the way I want them too.
13 Latent Variable Models Observed Hidden Basic question for LV models Q: How do I make latent variables behave the way I want them too. A: Very careful model design!
14 Recent Applications
15 Recent Applications Parsing PCFG Annotation
16 Recent Applications Parsing PCFG Annotation Machine Translation Learning Phrase Tables
17 Recent Applications Parsing PCFG Annotation Machine Translation Learning Phrase Tables Information Extraction / Discourse Unsupervised Coref Resolution

18 Recent Applications Parsing Machine Translation Learning Phrase Tables Information Extraction / Discourse Disclaimer There are many other excellent examples of PCFG LV models Annotation in NLP, these examples are from the Berkeley group. Unsupervised Coref Resolution
19 PCFG Annotation
20 PCFG Annotation
21 Subject NP PCFG Annotation
22 PCFG Annotation Subject NP Object NP
23 PCFG Annotation
24 PCFG Annotation Annotation refines base treebank symbols to improve statistical fit of the grammar


25 PCFG Annotation Annotation refines base treebank symbols to improve statistical fit of the grammar Parent annotation [Johnson 98]


26 PCFG Annotation Annotation refines base treebank symbols to improve statistical fit of the grammar Parent annotation [Johnson 98] Head Lexicalization [Collins 99]

![Parent annotation [Johnson 98] Head Lexicalization](/docs-images/89/100177646/images/27-4.jpg "[Collins 99] Automatic Clustering?")
27 PCFG Annotation Annotation refines base treebank symbols to improve statistical fit of the grammar Parent annotation [Johnson 98] Head Lexicalization [Collins 99] Automatic Clustering? [Matsuzaki 05, Petrov 06]
28 [Matsuzaki et. al., 05] Learning Latent Annotations EM algorithm:
29 [Matsuzaki et. al., 05] Learning Latent Annotations EM algorithm: Brackets are known Base categories are known Only subcategories hidden
30 [Matsuzaki et. al., 05] Learning Latent Annotations EM algorithm: Brackets are known Base categories are known Only subcategories hidden Just like Forward-Backward for HMMs
31 [Matsuzaki et. al., 05] Learning Latent Annotations EM algorithm: Brackets are known Base categories are known Only subcategories hidden Just like Forward-Backward for HMMs
32 [Matsuzaki et. al., 05] Learning Latent Annotations EM algorithm: Brackets are known Base categories are known Only subcategories hidden Forward X 1 X X 2 X4 7 X 3 X 5 X 6. Just like Forward-Backward for HMMs He was right Backward
33 Learning Latent Annotations DT

34 Learning Latent Annotations DT DT-1 DT-2 DT-3 DT-4
35 Learning Latent Annotations DT
36 [Petrov et. al., 06] Hierarchical Split/Merge Train DT
37 [Petrov et. al., 06] Hierarchical Split/Merge Train DT
38 [Petrov et. al., 06] Hierarchical Split/Merge Train DT
39 [Petrov et. al., 06] Hierarchical Split/Merge Train DT
40 [Petrov et. al., 06] Hierarchical Split/Merge Train DT
41 [Petrov et. al., 06] Hierarchical Split/Merge Train DT Unhelpful Split
42 [Petrov et. al., 06] Hierarchical Split/Merge Train DT Unhelpful Split
43 [Petrov et. al., 06] Hierarchical Split/Merge Train DT
44 [Petrov et. al., 06] Hierarchical Split/Merge Train DT
45 Hierarchical Split/Merge Train DT Model k=16 F1 Flat Training 87.3 Split Merge 89.5 [Petrov et. al., 06]
46 Hierarchical Split/Merge Train DT Lesson Don t give EM too much of a leash Model k=16 F1 Flat Training 87.3 Split Merge 89.5 [Petrov et. al., 06]
47 Linguistic Candy Proper Nouns (NNP): NNP-14 Oct. Nov. Sept. NNP-12 John Robert James NNP-2 J. E. L. NNP-1 Bush Noriega Peters NNP-15 New San Wall NNP-3 York Francisco Street Personal pronouns (PRP): PRP-0 It He I PRP-1 it he they PRP-2 it them him [Petrov et. al., 06]
48 [Petrov et. al., 07] Learning Latent Annotations 40 words F1 all F1 E N G G E R C H N Charniak&Johnson 05 (generative) Petrov et. al Dubey Petrov et. al Chiang et al Petrov et. al
49 [Petrov et. al., 07] Learning Latent Annotations 40 words F1 all F1 E N G G E R C H N Charniak&Johnson 05 (generative) Petrov et. al Download Parser Dubey Petrov et. al Chiang et al Petrov et. al
50 Outline Parsing PCFG Annotation Machine Translation Learning Phrase Tables Information Extraction / Discourse Unsupervised Coref Resolution
51 Phrase-Based Model
52 Phrase-Based Model Sentence-aligned corpus
53 Phrase-Based Model Sentence-aligned corpus
54 Phrase-Based Model Sentence-aligned corpus Directional word alignments
55 Phrase-Based Model Sentence-aligned corpus Directional word alignments
56 Phrase-Based Model Sentence-aligned corpus Directional word alignments Intersected and grown word alignments
57 Phrase-Based Model Sentence-aligned corpus Directional word alignments Intersected and grown word alignments

")
58 Phrase-Based Model cat chat 0.9 the cat le chat 0.8 dog chien 0.8 house maison 0.6 my house ma maison 0.9 language langue 0.9 Sentence-aligned corpus Phrase table (translation model) Directional word alignments Intersected and grown word alignments
59 Overview: Phrase Extraction appelle un chat un chat call a spade a spade
60 Overview: Phrase Extraction appelle un chat un chat appelle call call a spade a spade
61 Overview: Phrase Extraction appelle un chat un chat appelle call call a spade a spade chat un chat spade a spade
62 Overview: Phrase Extraction appelle un chat un chat appelle call call a spade a spade chat un chat spade a spade What s Hidden: Sentence segmentation and phrasal alignment
63 Overview: Phrase Extraction appelle un chat un chat call a spade a spade
64 Overview: Phrase Extraction appelle un chat un chat call a spade a spade appelle appelle un appelle un chat un un chat un chat un chat chat un chat un chat call call a call a spade a x2 a spade x2 a spade a spade x2 spade a spade a spade
65 Overview: Phrase Extraction appelle un chat un chat call a spade a spade appelle appelle un appelle un chat un un chat un chat un chat chat un chat un chat call call a call a spade a x2 a spade x2 a spade a spade x2 spade a spade a spade Extract all phrases, no competition for which are more useful.
66 Learning Phrases
67 Learning Phrases Sentence-aligned corpus
68 Learning Phrases Phrase-level generative model Sentence-aligned corpus
69 Learning Phrases Phrase-level generative model cat chat 0.9 the cat le chat 0.8 dog chien 0.8 house maison 0.6 my house ma maison 0.9 language langue 0.9 Sentence-aligned corpus Phrase table (translation model)
70 Learning Phrases Phrase-level generative model cat chat 0.9 the cat le chat 0.8 dog chien 0.8 house maison 0.6 my house ma maison 0.9 language langue 0.9 Sentence-aligned corpus Phrase table (translation model) DeNero et. al. (2006) argues underperforms surface statistic
71 Learning Phrases Phrase-level generative model cat chat 0.9 the cat le chat 0.8 dog chien 0.8 house maison 0.6 my house ma maison 0.9 language langue 0.9 Sentence-aligned corpus Phrase table (translation model) DeNero et. al. (2006) argues underperforms surface statistic Latent variables abused, EM finds bad solution
72 Learning Phrases Phrase-level generative model cat chat 0.9 the cat le chat 0.8 dog chien 0.8 house maison 0.6 my house ma maison 0.9 language langue 0.9 Sentence-aligned corpus Phrase table (translation model) DeNero et. al. (2006) argues underperforms surface statistic Latent variables abused, EM finds bad solution DeNero et. al. (2008) model outperforms surface statistics
73 Dirichlet Process (DP) Prior
74 Dirichlet Process (DP) Prior Distribution over distributions
75 Dirichlet Process (DP) Prior Distribution over distributions
76 Dirichlet Process (DP) Prior Distribution over distributions Base Measure
77 Dirichlet Process (DP) Prior Concentration Distribution over distributions Base Measure
78 Dirichlet Process (DP) Prior Concentration Distribution over distributions Base Measure Almost surely discrete (even if base isn t)
79 Dirichlet Process (DP) Prior Concentration Distribution over distributions Base Measure Almost surely discrete (even if base isn t) G = π i δ xi ( ) i=1
80 Dirichlet Process (DP) Prior Concentration Distribution over distributions Base Measure Almost surely discrete (even if base isn t) G = π i δ xi ( ) i=1 Each point x i represent params of a latent cluster
81 Dirichlet Process (DP) Prior Concentration Distribution over distributions Base Measure Almost surely discrete (even if base isn t) G = π i δ xi ( ) i=1 Each point Nonparametric x i represent params of a latent cluster
 i=1 Each point represent params of a latent cluster Nonparametric # of params grows with data (logn for N")
82 Dirichlet Process (DP) Prior Concentration Distribution over distributions Base Measure Almost surely discrete (even if base isn t) G = x i π i δ xi ( ) i=1 Each point represent params of a latent cluster Nonparametric # of params grows with data (logn for N points)
83 Chinese Restaurant Process
84 Chinese Restaurant Process
85 Chinese Restaurant Process
86 Chinese Restaurant Process
87 Chinese Restaurant Process
88 Chinese Restaurant Process
89 Chinese Restaurant Process
90 Chinese Restaurant Process
91 Chinese Restaurant Process
92 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
93 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
94 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
95 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
96 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
97 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
98 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
99 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
100 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
101 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
102 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
103 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
104 Bayesian Phrase Learning Given: Sentence pair (e, f) 1. Generate l phrase pairs: P (l) =p $ (1 p $ ) l 1 2. Generate l Phrase Pairs {(e i,f i )} (e i,f i ) G, G DP(α,P 0 ) P 0 (f, e) =P f (f)p e (e) P e (e) = ( p s (1 p s ) e 1) ( 1 n e ) e 3. Align and Reorder foreign phrases {f i } Output: Aligned phrase pairs {(e i,f i )} [DeNero et. al., 2008]
105 Bayesian Phrase Learning [DeNero et. al.,2006] [DeNero et. al., 2008]
106 Bayesian Phrase Learning [DeNero et. al.,2006] [DeNero et. al., 2008]


![al.,2006]](/docs-images/89/100177646/images/107-4.jpg "al., 2008]")
107 Bayesian Phrase Learning [DeNero et. al.,2006] [DeNero et. al., 2008]
108 Gibbs Sampling Inference [DeNero et. al., 2008]
109 Gibbs Sampling Inference [DeNero et. al., 2008]
110 Gibbs Sampling Inference [DeNero et. al., 2008]
111 Gibbs Sampling Inference [DeNero et. al., 2008]
112 Gibbs Sampling Inference [DeNero et. al., 2008]



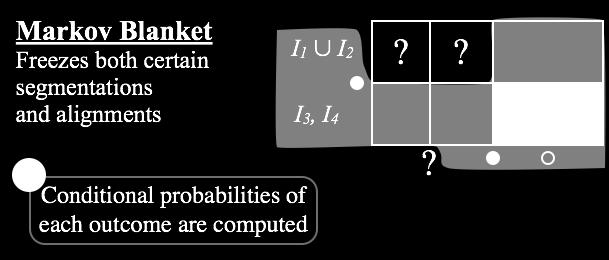
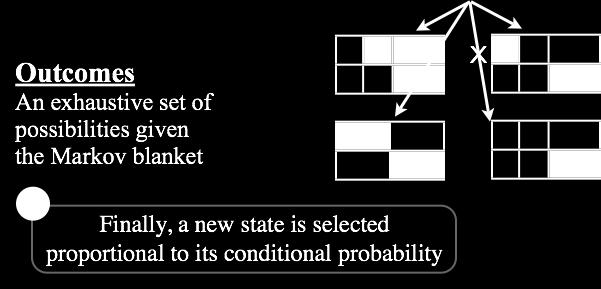
113 Gibbs Sampling Inference [DeNero et. al., 2008]
114 [DeNero et. al., 2008] Phrase Learning Results EN-ES Europarl, evaluate on BLEU 10k 100k Heuristic Baseline Learned
115 Outline Parsing PCFG Annotation Machine Translation Learning Phrase Tables Information Extraction / Discourse Unsupervised Coref Resolution
116 Coreference Resolution Weir group.. whose.. headquarters.. U.S.. corporation.. power plant.. which.. Jiangsu..
117 Coreference Resolution Weir group.. whose.. headquarters.. U.S.. corporation.. power plant.. which.. Jiangsu..
118 Coreference Resolution Weir group.. whose.. headquarters Mention.. U.S.. corporation.. power plant.. which.. Jiangsu..
119 Coreference Resolution Weir group.. whose.. headquarters.. U.S.. corporation.. power plant.. which.. Jiangsu..
120 Coreference Resolution Weir Group Weir Group Weir HQ Weir group.. whose.. headquarters United States Weir Group.. U.S.. corporation.. Weir Plant Weir Plant Jiangsu power plant.. which.. Jiangsu..
121 Coreference Resolution Weir Group Weir Group Weir HQ Weir group.. whose.. headquarters Entity United States Weir Group.. U.S.. corporation.. Weir Plant Weir Plant Jiangsu power plant.. which.. Jiangsu..
122 Coreference Resolution Weir Group Weir Group Weir HQ Weir group.. whose.. headquarters United States Weir Group.. U.S.. corporation.. Weir Plant Weir Plant Jiangsu power plant.. which.. Jiangsu..
123 Finite Mixture Model [Haghighi & Klein, 2007]
124 [Haghighi & Klein, 2007] Finite Mixture Model Z1= Weir Group Z2= Weir Group Z3= Weir HQ
125 [Haghighi & Klein, 2007] Finite Mixture Model Entity Distribution P(Weir Group) = 0.2,... P(Weir HQ) = 0.5, Z1= Weir Group Z2= Weir Group Z3= Weir HQ
126 [Haghighi & Klein, 2007] Finite Mixture Model Entity Distribution P(Weir Group) = 0.2,... P(Weir HQ) = 0.5, Z1= Weir Group Z2= Weir Group Z3= Weir HQ W1= Weir Group W2= whose W3= headquart.
127 Finite Mixture Model Entity Distribution Z1= Weir Group P(Weir Group) = 0.2,... P(Weir HQ) = 0.5, Z2= Weir Group Z3= Weir HQ Mention Distribution P(W Weir Group): Weir Group =0.4, whose =0.2,... W1= Weir Group W2= whose W3= headquart. [Haghighi & Klein, 2007]
128 Bayesian Finite Mixture Model Entity Distribution β K Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ P(W Weir Group): Weir Group =0.4, whose =0.2,... W1= Weir Group W2= whose W3= headquart. [Haghighi & Klein, 2007]
129 [Haghighi & Klein, 2007] Bayesian Finite Mixture Model Z1= Weir Group Entity Distribution β Z2= Weir Group K Z3= Weir HQ This is how many entities there are Mention Distribution P(W Weir Group): Weir Group =0.4, whose =0.2,... W1= Weir Group W2= whose W3= headquart.
130 Bayesian Finite Mixture Model Entity Distribution β K Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ P(W Weir Group): Weir Group =0.4, whose =0.2,... W1= Weir Group W2= whose W3= headquart. [Haghighi & Klein, 2007]
131 [Haghighi & Klein, 2007] Bayesian Finite Mixture Model Entity Distribution β K Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ φ K W1= Weir Group W2= whose W3= headquart.
132 Bayesian Finite Mixture Model Entity Distribution How do you choose K? β K Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ φ K W1= Weir Group W2= whose W3= headquart. [Haghighi & Klein, 2007]
133 [Haghighi & Klein, 2007] Bayesian Finite Mixture Model Entity Distribution β K Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ φ K W1= Weir Group W2= whose W3= headquart.
134 [Haghighi & Klein, 2007] Infinite Mixture Model Entity Distribution β Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ φ W1= Weir Group W2= whose W3= headquart.
135 [Haghighi & Klein, 2007] Infinite Mixture Model Drawn from a Dirichlet Entity Distribution β Process (DP) prior [Teh et al., 2006] Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ φ W1= Weir Group W2= whose W3= headquart.
136 [Haghighi & Klein, 2007] Infinite Mixture Model Entity Distribution β Mention Distribution Z1= Weir Group Z2= Weir Group Z3= Weir HQ φ W1= Weir Group W2= whose W3= headquart.
137 Infinite Mixture Model β φ L L Z Z S S T N G T N G M W M W
138 Global Coreference Resolution [Haghighi & Klein, 2007]
139 Global Coreference Resolution [Haghighi & Klein, 2007]
140 Global Coreference Resolution [Haghighi & Klein, 2007]
141 Global Coreference Resolution [Haghighi & Klein, 2007]
142 [Haghighi & Klein, 2007] Global Coreference Resolution Global Entities
143 HDP Model ψ β.... φ L Z L Z S T N G S T N G M W M W N
144 HDP Model β 0 ψ β.... φ L Z L Z S T N G S T N G M W M W N
145 HDP Model β 0 Global Entity Distribution drawn from a DP ψ β.... φ L Z L Z S T N G S T N G M W M W N
146 HDP Model β 0 ψ β.... φ L Z L Z S T N G S T N G M W M W N
147 HDP Model β 0 ψ L Z β.... L Document Entity Distribution subsampled from Global Distr. Z φ S T N G S T N G M W M W N

148 HDP Model β 0 ψ β.... φ L Z L Z S T N G S T N G M W M W N
149 Unsupervised Coref Results MUC6: 30 train/test documents Data Set # Doc P R F MUC DRYRUN NWIRE Recent Supervised Number 73.4 F1 [McCallum & Wellner, 2004] [Haghighi & Klein, 2007]
150 Summary Latent Variable Models Flexible Require careful model design Can yield state-of-the-art results for a variety of tasks Many interesting unsupervised problems yet to explore
151 Thanks
152 Latent Variable Models Modeling Capture information missing in annotation Compensate for independence assumptions Induction Only game in town. Careful structural design
153 Manual Annotation Klein & Manning, 2003
154 Manual Annotation Manually split categories NP: subject vs object DT: determiners vs demonstratives IN: sentential vs prepositional Advantages: Fairly compact grammar Linguistic motivations Disadvantages: Performance leveled out Manually annotated Klein & Manning, 2003
155 Manual Annotation Manually split categories NP: subject vs object DT: determiners vs demonstratives IN: sentential vs prepositional Advantages: Fairly compact grammar Linguistic motivations Disadvantages: Performance leveled out Manually annotated Klein & Manning, 2003
156 Manual Annotation Manually split categories NP: subject vs object DT: determiners vs demonstratives IN: sentential vs prepositional Advantages: Fairly compact grammar Linguistic motivations Disadvantages: Performance leveled out Manually annotated Manual Annotation F1 Klein & Manning, 2003
157 Latent Variable Models
158 Latent Variable Models
159 Latent Variable Models Observed
160 Latent Variable Models Observed Hidden
161 Latent Variable Models
162 Latent Variable Models
163 Latent Variable Models Modeling
164 Latent Variable Models Modeling
165 Latent Variable Models Modeling
166 Latent Variable Models Modeling
167 Latent Variable Models Modeling Induction (Unsupervised Learning)


168 Latent Variable Models Modeling Induction (Unsupervised Learning)
169 Learning Latent Annotations
170 Learning Latent Annotations Learning [Petrov et. al. 06] Adaptive Merging Hierarchical Training Inference [Petrov et. al. 07] Coarse-to-fine approximation Max constituent parsing
171 Latent Variable Models
172 Latent Variable Models
173 Latent Variable Models Observed
174 Latent Variable Models Observed Hidden
175 Latent Variable Models Observed Hidden Better model


176 Latent Variable Models Observed Hidden Better model Induce
177 Linguistic Candy [Petrov et. al., 06]
178 Linguistic Candy Proper Nouns (NNP): NNP-14 Oct. Nov. Sept. NNP-12 John Robert James NNP-15 New San Wall NNP-3 York Francisco Street [Petrov et. al., 06]
179 Linguistic Candy Proper Nouns (NNP): NNP-14 Oct. Nov. Sept. NNP-12 John Robert James NNP-15 New San Wall NNP-3 York Francisco Street Personal pronouns (PRP): PRP-0 It He I PRP-1 it he they PRP-2 it them him [Petrov et. al., 06]
The Infinite PCFG using Hierarchical Dirichlet Processes
 S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise
S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise
Natural Language Processing CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
CS 545 Lecture XVI: Parsing
 CS 545 Lecture XVI: Parsing brownies_choco81@yahoo.com brownies_choco81@yahoo.com Benjamin Snyder Parsing Given a grammar G and a sentence x = (x1, x2,..., xn), find the best parse tree. We re not going
CS 545 Lecture XVI: Parsing brownies_choco81@yahoo.com brownies_choco81@yahoo.com Benjamin Snyder Parsing Given a grammar G and a sentence x = (x1, x2,..., xn), find the best parse tree. We re not going
Algorithms for NLP. Machine Translation II. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Machine Translation II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Project 4: Word Alignment! Will be released soon! (~Monday) Phrase-Based System Overview
Algorithms for NLP Machine Translation II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Project 4: Word Alignment! Will be released soon! (~Monday) Phrase-Based System Overview
Statistical Methods for NLP
 Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Multiword Expression Identification with Tree Substitution Grammars
 Multiword Expression Identification with Tree Substitution Grammars Spence Green, Marie-Catherine de Marneffe, John Bauer, and Christopher D. Manning Stanford University EMNLP 2011 Main Idea Use syntactic
Multiword Expression Identification with Tree Substitution Grammars Spence Green, Marie-Catherine de Marneffe, John Bauer, and Christopher D. Manning Stanford University EMNLP 2011 Main Idea Use syntactic
Chapter 14 (Partially) Unsupervised Parsing
 Unsupervised Parsing") Chapter 14 (Partially) Unsupervised Parsing The linguistically-motivated tree transformations we discussed previously are very effective, but when we move to a new language, we may have to come up with
Chapter 14 (Partially) Unsupervised Parsing The linguistically-motivated tree transformations we discussed previously are very effective, but when we move to a new language, we may have to come up with
10/17/04. Today s Main Points
 Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Unsupervised Coreference Resolution in a Nonparametric Bayesian Model
 Unsupervised Coreference Resolution in a Nonparametric Bayesian Model Aria Haghighi and Dan Klein Computer Science Division UC Berkeley {aria42, klein}@cs.berkeley.edu Abstract We present an unsupervised,
Unsupervised Coreference Resolution in a Nonparametric Bayesian Model Aria Haghighi and Dan Klein Computer Science Division UC Berkeley {aria42, klein}@cs.berkeley.edu Abstract We present an unsupervised,
Quasi-Synchronous Phrase Dependency Grammars for Machine Translation. lti
 Quasi-Synchronous Phrase Dependency Grammars for Machine Translation Kevin Gimpel Noah A. Smith 1 Introduction MT using dependency grammars on phrases Phrases capture local reordering and idiomatic translations
Quasi-Synchronous Phrase Dependency Grammars for Machine Translation Kevin Gimpel Noah A. Smith 1 Introduction MT using dependency grammars on phrases Phrases capture local reordering and idiomatic translations
Statistical NLP Spring Corpus-Based MT
 Statistical NLP Spring 2010 Lecture 17: Word / Phrase MT Dan Klein UC Berkeley Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it
Statistical NLP Spring 2010 Lecture 17: Word / Phrase MT Dan Klein UC Berkeley Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it
Corpus-Based MT. Statistical NLP Spring Unsupervised Word Alignment. Alignment Error Rate. IBM Models 1/2. Problems with Model 1
 Statistical NLP Spring 2010 Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it tomorrow Hasta pronto See you soon Hasta pronto See
Statistical NLP Spring 2010 Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it tomorrow Hasta pronto See you soon Hasta pronto See
LECTURER: BURCU CAN Spring
 LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
Lecture 15. Probabilistic Models on Graph
 Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
Discrimina)ve Latent Variable Models. SPFLODD November 15, 2011
ve Latent Variable Models. SPFLODD November 15, 2011") Discrimina)ve Latent Variable Models SPFLODD November 15, 2011 Lecture Plan 1. Latent variables in genera)ve models (review) 2. Latent variables in condi)onal models 3. Latent variables in structural SVMs
Discrimina)ve Latent Variable Models SPFLODD November 15, 2011 Lecture Plan 1. Latent variables in genera)ve models (review) 2. Latent variables in condi)onal models 3. Latent variables in structural SVMs
The Infinite PCFG using Hierarchical Dirichlet Processes
 The Infinite PCFG using Hierarchical Dirichlet Processes Percy Liang Slav Petrov Michael I. Jordan Dan Klein Computer Science Division, EECS Department University of California at Berkeley Berkeley, CA
The Infinite PCFG using Hierarchical Dirichlet Processes Percy Liang Slav Petrov Michael I. Jordan Dan Klein Computer Science Division, EECS Department University of California at Berkeley Berkeley, CA
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Probabilistic Context-Free Grammars. Michael Collins, Columbia University
 Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Natural Language Processing : Probabilistic Context Free Grammars. Updated 5/09
 Natural Language Processing : Probabilistic Context Free Grammars Updated 5/09 Motivation N-gram models and HMM Tagging only allowed us to process sentences linearly. However, even simple sentences require
Natural Language Processing : Probabilistic Context Free Grammars Updated 5/09 Motivation N-gram models and HMM Tagging only allowed us to process sentences linearly. However, even simple sentences require
Sampling Alignment Structure under a Bayesian Translation Model
 Sampling Alignment Structure under a Bayesian Translation Model John DeNero, Alexandre Bouchard-Côté and Dan Klein Computer Science Department University of California, Berkeley {denero, bouchard, klein}@cs.berkeley.edu
Sampling Alignment Structure under a Bayesian Translation Model John DeNero, Alexandre Bouchard-Côté and Dan Klein Computer Science Department University of California, Berkeley {denero, bouchard, klein}@cs.berkeley.edu
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
Probabilistic Context-free Grammars
 Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
A Supertag-Context Model for Weakly-Supervised CCG Parser Learning
 A Supertag-Context Model for Weakly-Supervised CCG Parser Learning Dan Garrette Chris Dyer Jason Baldridge Noah A. Smith U. Washington CMU UT-Austin CMU Contributions 1. A new generative model for learning
A Supertag-Context Model for Weakly-Supervised CCG Parser Learning Dan Garrette Chris Dyer Jason Baldridge Noah A. Smith U. Washington CMU UT-Austin CMU Contributions 1. A new generative model for learning
An Overview of Nonparametric Bayesian Models and Applications to Natural Language Processing
 An Overview of Nonparametric Bayesian Models and Applications to Natural Language Processing Narges Sharif-Razavian and Andreas Zollmann School of Computer Science Carnegie Mellon University Pittsburgh,
An Overview of Nonparametric Bayesian Models and Applications to Natural Language Processing Narges Sharif-Razavian and Andreas Zollmann School of Computer Science Carnegie Mellon University Pittsburgh,
Multilevel Coarse-to-Fine PCFG Parsing
 Multilevel Coarse-to-Fine PCFG Parsing Eugene Charniak, Mark Johnson, Micha Elsner, Joseph Austerweil, David Ellis, Isaac Haxton, Catherine Hill, Shrivaths Iyengar, Jeremy Moore, Michael Pozar, and Theresa
Multilevel Coarse-to-Fine PCFG Parsing Eugene Charniak, Mark Johnson, Micha Elsner, Joseph Austerweil, David Ellis, Isaac Haxton, Catherine Hill, Shrivaths Iyengar, Jeremy Moore, Michael Pozar, and Theresa
Spatial Normalized Gamma Process
 Spatial Normalized Gamma Process Vinayak Rao Yee Whye Teh Presented at NIPS 2009 Discussion and Slides by Eric Wang June 23, 2010 Outline Introduction Motivation The Gamma Process Spatial Normalized Gamma
Spatial Normalized Gamma Process Vinayak Rao Yee Whye Teh Presented at NIPS 2009 Discussion and Slides by Eric Wang June 23, 2010 Outline Introduction Motivation The Gamma Process Spatial Normalized Gamma
Expectation Maximization (EM)
") Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
DT2118 Speech and Speaker Recognition
 DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
Parsing. Based on presentations from Chris Manning s course on Statistical Parsing (Stanford)
") Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Spectral Unsupervised Parsing with Additive Tree Metrics
 Spectral Unsupervised Parsing with Additive Tree Metrics Ankur Parikh, Shay Cohen, Eric P. Xing Carnegie Mellon, University of Edinburgh Ankur Parikh 2014 1 Overview Model: We present a novel approach
Spectral Unsupervised Parsing with Additive Tree Metrics Ankur Parikh, Shay Cohen, Eric P. Xing Carnegie Mellon, University of Edinburgh Ankur Parikh 2014 1 Overview Model: We present a novel approach
Advanced Natural Language Processing Syntactic Parsing
 Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
Marrying Dynamic Programming with Recurrent Neural Networks
 Marrying Dynamic Programming with Recurrent Neural Networks I eat sushi with tuna from Japan Liang Huang Oregon State University Structured Prediction Workshop, EMNLP 2017, Copenhagen, Denmark Marrying
Marrying Dynamic Programming with Recurrent Neural Networks I eat sushi with tuna from Japan Liang Huang Oregon State University Structured Prediction Workshop, EMNLP 2017, Copenhagen, Denmark Marrying
The Infinite PCFG using Hierarchical Dirichlet Processes
 The Infinite PCFG using Hierarchical Dirichlet Processes Liang, Petrov, Jordan & Klein Presented by: Will Allen November 8, 2011 Overview 1. Overview 2. (Very) Brief History of Context Free Grammars 3.
The Infinite PCFG using Hierarchical Dirichlet Processes Liang, Petrov, Jordan & Klein Presented by: Will Allen November 8, 2011 Overview 1. Overview 2. (Very) Brief History of Context Free Grammars 3.
Probabilistic Context Free Grammars. Many slides from Michael Collins
 Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Type-Based MCMC. Michael I. Jordan UC Berkeley 1 In NLP, this is sometimes referred to as simply the collapsed
 Type-Based MCMC Percy Liang UC Berkeley pliang@cs.berkeley.edu Michael I. Jordan UC Berkeley jordan@cs.berkeley.edu Dan Klein UC Berkeley klein@cs.berkeley.edu Abstract Most existing algorithms for learning
Type-Based MCMC Percy Liang UC Berkeley pliang@cs.berkeley.edu Michael I. Jordan UC Berkeley jordan@cs.berkeley.edu Dan Klein UC Berkeley klein@cs.berkeley.edu Abstract Most existing algorithms for learning
Roger Levy Probabilistic Models in the Study of Language draft, October 2,
 Roger Levy Probabilistic Models in the Study of Language draft, October 2, 2012 224 Chapter 10 Probabilistic Grammars 10.1 Outline HMMs PCFGs ptsgs and ptags Highlight: Zuidema et al., 2008, CogSci; Cohn
Roger Levy Probabilistic Models in the Study of Language draft, October 2, 2012 224 Chapter 10 Probabilistic Grammars 10.1 Outline HMMs PCFGs ptsgs and ptags Highlight: Zuidema et al., 2008, CogSci; Cohn
A Support Vector Method for Multivariate Performance Measures
 A Support Vector Method for Multivariate Performance Measures Thorsten Joachims Cornell University Department of Computer Science Thanks to Rich Caruana, Alexandru Niculescu-Mizil, Pierre Dupont, Jérôme
A Support Vector Method for Multivariate Performance Measures Thorsten Joachims Cornell University Department of Computer Science Thanks to Rich Caruana, Alexandru Niculescu-Mizil, Pierre Dupont, Jérôme
Natural Language Processing
 SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University September 27, 2018 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University September 27, 2018 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
Unsupervised Deduplication using Cross-Field Dependencies
 Unsupervised Deduplication using Cross-Field Dependencies Robert Hall Department of Computer Science University of Massachusetts Amherst, MA 01003 rhall@cs.umass.edu Charles Sutton Department of Computer
Unsupervised Deduplication using Cross-Field Dependencies Robert Hall Department of Computer Science University of Massachusetts Amherst, MA 01003 rhall@cs.umass.edu Charles Sutton Department of Computer
A Syntax-based Statistical Machine Translation Model. Alexander Friedl, Georg Teichtmeister
 A Syntax-based Statistical Machine Translation Model Alexander Friedl, Georg Teichtmeister 4.12.2006 Introduction The model Experiment Conclusion Statistical Translation Model (STM): - mathematical model
A Syntax-based Statistical Machine Translation Model Alexander Friedl, Georg Teichtmeister 4.12.2006 Introduction The model Experiment Conclusion Statistical Translation Model (STM): - mathematical model
Collapsed Variational Bayesian Inference for Hidden Markov Models
 Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
Applied Bayesian Nonparametrics 3. Infinite Hidden Markov Models
 Applied Bayesian Nonparametrics 3. Infinite Hidden Markov Models Tutorial at CVPR 2012 Erik Sudderth Brown University Work by E. Fox, E. Sudderth, M. Jordan, & A. Willsky AOAS 2011: A Sticky HDP-HMM with
Applied Bayesian Nonparametrics 3. Infinite Hidden Markov Models Tutorial at CVPR 2012 Erik Sudderth Brown University Work by E. Fox, E. Sudderth, M. Jordan, & A. Willsky AOAS 2011: A Sticky HDP-HMM with
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs
 Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Penn Treebank Parsing. Advanced Topics in Language Processing Stephen Clark
 Penn Treebank Parsing Advanced Topics in Language Processing Stephen Clark 1 The Penn Treebank 40,000 sentences of WSJ newspaper text annotated with phrasestructure trees The trees contain some predicate-argument
Penn Treebank Parsing Advanced Topics in Language Processing Stephen Clark 1 The Penn Treebank 40,000 sentences of WSJ newspaper text annotated with phrasestructure trees The trees contain some predicate-argument
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Natural Language Processing 1. lecture 7: constituent parsing. Ivan Titov. Institute for Logic, Language and Computation
 atural Language Processing 1 lecture 7: constituent parsing Ivan Titov Institute for Logic, Language and Computation Outline Syntax: intro, CFGs, PCFGs PCFGs: Estimation CFGs: Parsing PCFGs: Parsing Parsing
atural Language Processing 1 lecture 7: constituent parsing Ivan Titov Institute for Logic, Language and Computation Outline Syntax: intro, CFGs, PCFGs PCFGs: Estimation CFGs: Parsing PCFGs: Parsing Parsing
Introduction to Probablistic Natural Language Processing
 Introduction to Probablistic Natural Language Processing Alexis Nasr Laboratoire d Informatique Fondamentale de Marseille Natural Language Processing Use computers to process human languages Machine Translation
Introduction to Probablistic Natural Language Processing Alexis Nasr Laboratoire d Informatique Fondamentale de Marseille Natural Language Processing Use computers to process human languages Machine Translation
Unit 2: Tree Models. CS 562: Empirical Methods in Natural Language Processing. Lectures 19-23: Context-Free Grammars and Parsing
 CS 562: Empirical Methods in Natural Language Processing Unit 2: Tree Models Lectures 19-23: Context-Free Grammars and Parsing Oct-Nov 2009 Liang Huang (lhuang@isi.edu) Big Picture we have already covered...
CS 562: Empirical Methods in Natural Language Processing Unit 2: Tree Models Lectures 19-23: Context-Free Grammars and Parsing Oct-Nov 2009 Liang Huang (lhuang@isi.edu) Big Picture we have already covered...
Lecture 5: UDOP, Dependency Grammars
 Lecture 5: UDOP, Dependency Grammars Jelle Zuidema ILLC, Universiteit van Amsterdam Unsupervised Language Learning, 2014 Generative Model objective PCFG PTSG CCM DMV heuristic Wolff (1984) UDOP ML IO K&M
Lecture 5: UDOP, Dependency Grammars Jelle Zuidema ILLC, Universiteit van Amsterdam Unsupervised Language Learning, 2014 Generative Model objective PCFG PTSG CCM DMV heuristic Wolff (1984) UDOP ML IO K&M
Hierarchical Bayesian Nonparametrics
 Hierarchical Bayesian Nonparametrics Micha Elsner April 11, 2013 2 For next time We ll tackle a paper: Green, de Marneffe, Bauer and Manning: Multiword Expression Identification with Tree Substitution
Hierarchical Bayesian Nonparametrics Micha Elsner April 11, 2013 2 For next time We ll tackle a paper: Green, de Marneffe, Bauer and Manning: Multiword Expression Identification with Tree Substitution
Spatial Bayesian Nonparametrics for Natural Image Segmentation
 Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Bringing machine learning & compositional semantics together: central concepts
 Bringing machine learning & compositional semantics together: central concepts https://githubcom/cgpotts/annualreview-complearning Chris Potts Stanford Linguistics CS 244U: Natural language understanding
Bringing machine learning & compositional semantics together: central concepts https://githubcom/cgpotts/annualreview-complearning Chris Potts Stanford Linguistics CS 244U: Natural language understanding
Logistic Normal Priors for Unsupervised Probabilistic Grammar Induction
 Logistic Normal Priors for Unsupervised Probabilistic Grammar Induction Shay B. Cohen Kevin Gimpel Noah A. Smith Language Technologies Institute School of Computer Science Carnegie Mellon University {scohen,gimpel,nasmith}@cs.cmu.edu
Logistic Normal Priors for Unsupervised Probabilistic Grammar Induction Shay B. Cohen Kevin Gimpel Noah A. Smith Language Technologies Institute School of Computer Science Carnegie Mellon University {scohen,gimpel,nasmith}@cs.cmu.edu
Lecture 9: Hidden Markov Model
 Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Machine Translation: Examples. Statistical NLP Spring Levels of Transfer. Corpus-Based MT. World-Level MT: Examples
 Statistical NLP Spring 2009 Machine Translation: Examples Lecture 17: Word Alignment Dan Klein UC Berkeley Corpus-Based MT Levels of Transfer Modeling correspondences between languages Sentence-aligned
Statistical NLP Spring 2009 Machine Translation: Examples Lecture 17: Word Alignment Dan Klein UC Berkeley Corpus-Based MT Levels of Transfer Modeling correspondences between languages Sentence-aligned
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Bayesian Tools for Natural Language Learning. Yee Whye Teh Gatsby Computational Neuroscience Unit UCL
 Bayesian Tools for Natural Language Learning Yee Whye Teh Gatsby Computational Neuroscience Unit UCL Bayesian Learning of Probabilistic Models Potential outcomes/observations X. Unobserved latent variables
Bayesian Tools for Natural Language Learning Yee Whye Teh Gatsby Computational Neuroscience Unit UCL Bayesian Learning of Probabilistic Models Potential outcomes/observations X. Unobserved latent variables
Variational Decoding for Statistical Machine Translation
 Variational Decoding for Statistical Machine Translation Zhifei Li, Jason Eisner, and Sanjeev Khudanpur Center for Language and Speech Processing Computer Science Department Johns Hopkins University 1
Variational Decoding for Statistical Machine Translation Zhifei Li, Jason Eisner, and Sanjeev Khudanpur Center for Language and Speech Processing Computer Science Department Johns Hopkins University 1
Shared Segmentation of Natural Scenes. Dependent Pitman-Yor Processes
 Shared Segmentation of Natural Scenes using Dependent Pitman-Yor Processes Erik Sudderth & Michael Jordan University of California, Berkeley Parsing Visual Scenes sky skyscraper sky dome buildings trees
Shared Segmentation of Natural Scenes using Dependent Pitman-Yor Processes Erik Sudderth & Michael Jordan University of California, Berkeley Parsing Visual Scenes sky skyscraper sky dome buildings trees
Probabilistic Context Free Grammars. Many slides from Michael Collins and Chris Manning
 Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
Part A. P (w 1 )P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )
P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )") Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
A Context-Free Grammar
 Statistical Parsing A Context-Free Grammar S VP VP Vi VP Vt VP VP PP DT NN PP PP P Vi sleeps Vt saw NN man NN dog NN telescope DT the IN with IN in Ambiguity A sentence of reasonable length can easily
Statistical Parsing A Context-Free Grammar S VP VP Vi VP Vt VP VP PP DT NN PP PP P Vi sleeps Vt saw NN man NN dog NN telescope DT the IN with IN in Ambiguity A sentence of reasonable length can easily
Unsupervised Coreference of Publication Venues
 Unsupervised Coreference of Publication Venues Robert Hall, Charles Sutton, and Andrew McCallum Deparment of Computer Science University of Massachusetts Amherst Amherst, MA 01003 {rhall,casutton,mccallum}@cs.umass.edu
Unsupervised Coreference of Publication Venues Robert Hall, Charles Sutton, and Andrew McCallum Deparment of Computer Science University of Massachusetts Amherst Amherst, MA 01003 {rhall,casutton,mccallum}@cs.umass.edu
The effect of non-tightness on Bayesian estimation of PCFGs
 The effect of non-tightness on Bayesian estimation of PCFGs hay B. Cohen Department of Computer cience Columbia University scohen@cs.columbia.edu Mark Johnson Department of Computing Macquarie University
The effect of non-tightness on Bayesian estimation of PCFGs hay B. Cohen Department of Computer cience Columbia University scohen@cs.columbia.edu Mark Johnson Department of Computing Macquarie University
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lexical Translation Models 1I
 Lexical Translation Models 1I Machine Translation Lecture 5 Instructor: Chris Callison-Burch TAs: Mitchell Stern, Justin Chiu Website: mt-class.org/penn Last Time... X p( Translation)= p(, Translation)
Lexical Translation Models 1I Machine Translation Lecture 5 Instructor: Chris Callison-Burch TAs: Mitchell Stern, Justin Chiu Website: mt-class.org/penn Last Time... X p( Translation)= p(, Translation)
Statistical methods in NLP, lecture 7 Tagging and parsing
 Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Probabilistic Context-Free Grammar
 Probabilistic Context-Free Grammar Petr Horáček, Eva Zámečníková and Ivana Burgetová Department of Information Systems Faculty of Information Technology Brno University of Technology Božetěchova 2, 612
Probabilistic Context-Free Grammar Petr Horáček, Eva Zámečníková and Ivana Burgetová Department of Information Systems Faculty of Information Technology Brno University of Technology Božetěchova 2, 612
Latent Dirichlet Allocation Introduction/Overview
 Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Spatial Role Labeling CS365 Course Project
 Spatial Role Labeling CS365 Course Project Amit Kumar, akkumar@iitk.ac.in Chandra Sekhar, gchandra@iitk.ac.in Supervisor : Dr.Amitabha Mukerjee ABSTRACT In natural language processing one of the important
Spatial Role Labeling CS365 Course Project Amit Kumar, akkumar@iitk.ac.in Chandra Sekhar, gchandra@iitk.ac.in Supervisor : Dr.Amitabha Mukerjee ABSTRACT In natural language processing one of the important
AN ABSTRACT OF THE DISSERTATION OF
 AN ABSTRACT OF THE DISSERTATION OF Kai Zhao for the degree of Doctor of Philosophy in Computer Science presented on May 30, 2017. Title: Structured Learning with Latent Variables: Theory and Algorithms
AN ABSTRACT OF THE DISSERTATION OF Kai Zhao for the degree of Doctor of Philosophy in Computer Science presented on May 30, 2017. Title: Structured Learning with Latent Variables: Theory and Algorithms
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
A DOP Model for LFG. Rens Bod and Ronald Kaplan. Kathrin Spreyer Data-Oriented Parsing, 14 June 2005
 A DOP Model for LFG Rens Bod and Ronald Kaplan Kathrin Spreyer Data-Oriented Parsing, 14 June 2005 Lexical-Functional Grammar (LFG) Levels of linguistic knowledge represented formally differently (non-monostratal):
A DOP Model for LFG Rens Bod and Ronald Kaplan Kathrin Spreyer Data-Oriented Parsing, 14 June 2005 Lexical-Functional Grammar (LFG) Levels of linguistic knowledge represented formally differently (non-monostratal):
Processing/Speech, NLP and the Web
 CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 25 Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 14 th March, 2011 Bracketed Structure: Treebank Corpus [ S1[
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 25 Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 14 th March, 2011 Bracketed Structure: Treebank Corpus [ S1[
Statistical NLP Spring HW2: PNP Classification
 Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
HW2: PNP Classification. Statistical NLP Spring Levels of Transfer. Phrasal / Syntactic MT: Examples. Lecture 16: Word Alignment
 Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
Features of Statistical Parsers
 Features of tatistical Parsers Preliminary results Mark Johnson Brown University TTI, October 2003 Joint work with Michael Collins (MIT) upported by NF grants LI 9720368 and II0095940 1 Talk outline tatistical
Features of tatistical Parsers Preliminary results Mark Johnson Brown University TTI, October 2003 Joint work with Michael Collins (MIT) upported by NF grants LI 9720368 and II0095940 1 Talk outline tatistical
A Probabilistic Forest-to-String Model for Language Generation from Typed Lambda Calculus Expressions
 A Probabilistic Forest-to-String Model for Language Generation from Typed Lambda Calculus Expressions Wei Lu and Hwee Tou Ng National University of Singapore 1/26 The Task (Logical Form) λx 0.state(x 0
A Probabilistic Forest-to-String Model for Language Generation from Typed Lambda Calculus Expressions Wei Lu and Hwee Tou Ng National University of Singapore 1/26 The Task (Logical Form) λx 0.state(x 0
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing
 Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Bayesian Structure Modeling. SPFLODD December 1, 2011
 Bayesian Structure Modeling SPFLODD December 1, 2011 Outline Defining Bayesian Parametric Bayesian models Latent Dirichlet allocabon (Blei et al., 2003) Bayesian HMM (Goldwater and Griffiths, 2007) A limle
Bayesian Structure Modeling SPFLODD December 1, 2011 Outline Defining Bayesian Parametric Bayesian models Latent Dirichlet allocabon (Blei et al., 2003) Bayesian HMM (Goldwater and Griffiths, 2007) A limle
CSCI 5822 Probabilistic Model of Human and Machine Learning. Mike Mozer University of Colorado
 CSCI 5822 Probabilistic Model of Human and Machine Learning Mike Mozer University of Colorado Topics Language modeling Hierarchical processes Pitman-Yor processes Based on work of Teh (2006), A hierarchical
CSCI 5822 Probabilistic Model of Human and Machine Learning Mike Mozer University of Colorado Topics Language modeling Hierarchical processes Pitman-Yor processes Based on work of Teh (2006), A hierarchical
NLP Homework: Dependency Parsing with Feed-Forward Neural Network
 NLP Homework: Dependency Parsing with Feed-Forward Neural Network Submission Deadline: Monday Dec. 11th, 5 pm 1 Background on Dependency Parsing Dependency trees are one of the main representations used
NLP Homework: Dependency Parsing with Feed-Forward Neural Network Submission Deadline: Monday Dec. 11th, 5 pm 1 Background on Dependency Parsing Dependency trees are one of the main representations used
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Hidden Markov Models
 CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models. The ischool University of Maryland. Wednesday, September 30, 2009
 CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
The Noisy Channel Model. Statistical NLP Spring Mel Freq. Cepstral Coefficients. Frame Extraction ... Lecture 9: Acoustic Models
 Statistical NLP Spring 2010 The Noisy Channel Model Lecture 9: Acoustic Models Dan Klein UC Berkeley Acoustic model: HMMs over word positions with mixtures of Gaussians as emissions Language model: Distributions
Statistical NLP Spring 2010 The Noisy Channel Model Lecture 9: Acoustic Models Dan Klein UC Berkeley Acoustic model: HMMs over word positions with mixtures of Gaussians as emissions Language model: Distributions
NLP Programming Tutorial 11 - The Structured Perceptron
 NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
Recurrent neural network grammars
 Widespread phenomenon: Polarity items can only appear in certain contexts Recurrent neural network grammars lide credits: Chris Dyer, Adhiguna Kuncoro Example: anybody is a polarity item that tends to
Widespread phenomenon: Polarity items can only appear in certain contexts Recurrent neural network grammars lide credits: Chris Dyer, Adhiguna Kuncoro Example: anybody is a polarity item that tends to
Lagrangian Relaxation Algorithms for Inference in Natural Language Processing
 Lagrangian Relaxation Algorithms for Inference in Natural Language Processing Alexander M. Rush and Michael Collins (based on joint work with Yin-Wen Chang, Tommi Jaakkola, Terry Koo, Roi Reichart, David
Lagrangian Relaxation Algorithms for Inference in Natural Language Processing Alexander M. Rush and Michael Collins (based on joint work with Yin-Wen Chang, Tommi Jaakkola, Terry Koo, Roi Reichart, David
c(a) = X c(a! Ø) (13.1) c(a! Ø) ˆP(A! Ø A) = c(a)
 = X c(a! Ø) (13.1) c(a! Ø) ˆP(A! Ø A) = c(a)") Chapter 13 Statistical Parsg Given a corpus of trees, it is easy to extract a CFG and estimate its parameters. Every tree can be thought of as a CFG derivation, and we just perform relative frequency estimation
Chapter 13 Statistical Parsg Given a corpus of trees, it is easy to extract a CFG and estimate its parameters. Every tree can be thought of as a CFG derivation, and we just perform relative frequency estimation
The Infinite Markov Model
 The Infinite Markov Model Daichi Mochihashi NTT Communication Science Laboratories, Japan daichi@cslab.kecl.ntt.co.jp NIPS 2007 The Infinite Markov Model (NIPS 2007) p.1/20 Overview ɛ ɛ is of will is of
The Infinite Markov Model Daichi Mochihashi NTT Communication Science Laboratories, Japan daichi@cslab.kecl.ntt.co.jp NIPS 2007 The Infinite Markov Model (NIPS 2007) p.1/20 Overview ɛ ɛ is of will is of
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic