A New Generation of Brain-Computer Interfaces Driven by Discovery of Latent EEG-fMRI Linkages Using Tensor Decomposition
|
|
|
- Meryl Allen
- 5 years ago
- Views:
Transcription



, Torun, Poland Systems Research Institute,")

1 A New Generation of Brain-Computer Interfaces Driven by Discovery of Latent EEG-fMRI Linkages Using Tensor Decomposition Gopikrishna Deshpande AU MRI Research Center AU Department of Electrical and Computer Engineering AU Department of Psychology Alabama Advanced Imaging Consortium Rangaprakash Deshpande Department of Psychiatry and Biobehavioral Sciences UCLA HYPOTHESIS AND THEORY ARTICLE Frontiers in Neuroscience, 07 June 2017 Andrej Cichocki Skolkovo Institute of Science and Technology (Skoltech), Moscow, Russia Nicolaus Copernicus University (UMK), Torun, Poland Systems Research Institute, Polish Academy of Science, Warsaw, Poland Luke Oeding Department of Mathematics and Statistics Auburn University Xiaoping Hu Professor of Biomedical Engineering University of California, Riverside
2 Brain Computer Interface
3 EEG Based BCI + Non-invasive + High temporal resolution for real-time interaction + Inexpensive, light weight, and highly portable - Poor spatial specificity - EEG Signals in different channels are highly correlated, reducing ability to distinguish neurological processes. - Long training time required



4 Real-time fmri Based BCI + High spatial specificity -- more accuracy - High cost - Non-portable - Low temporal resolution - Restrictive environment


5 Simultaneous EEG fmri data acquisition
 artifact in the EEG signal obtained inside MR scanner is removed.")
6 EEG Data EEG data were epoched with respect to R peaks of EKG signal and averaged over trials. The ballistocardiogram (BCG) artifact in the EEG signal obtained inside MR scanner is removed. Electrode position measurements via Polhemus Fastrak 3D Digitizer System
7 Objective: Discovery of Latent Linkages between EEG and fmri and improve BCI Hypothesis: latent linkages between EEG and fmri can be exploited to estimate fmri-like features from EEG data. This could allow an independently operated EEG-BCI to decode brain states in real time, with better accuracy and lower training time. Hypothesis: Features from a sub-set of subjects can be generalized to new subjects (for a homogeneous set of subjects).
8 Strategies Obtain fmri data with high temporal resolution: Use multiband echo-planar imaging (M-EPI) [Feinberg, et al. 2010] to achieve whole brain coverage with sampling intervals (TR) as short as 200 ms. View fmri as convolution of HDF (Hemodynamic response function) and neuronal states. Use cubature Kalman filter based blind deconvolution of fmri [Havlicek, et al. 2011] to recover driving neuronal state variables with higher effective temporal resolution. Obtain clean EEG data: EEG signal sampled at 5000Hz to ensure accurate gradient artifact removal, then downsampled to 250Hz to make dataset more manageable. Use the complex Morlet wavelet [Teolis, 1998] to give a time-frequency representation of both EEG and fmri for each trial.
9 Discover latent linkages between EEG and fmri Simultaneous EEG/fMRI data collected using a P300 speller based paradigm. EEG modalities: trial time frequency channel 4ms updates, 63+1 channels, 4 trials fmri modalities: trial time neuronal state voxel 200ms updates with whole brain coverage and 3mm voxels Apply Orthogonal Decomposition to each EEG and fmri. [Zhou and Cichocki 2012] The first dimension of trials is the same for both tensors, permitting the application of HOPLS. This important property allows both EEG and fmri to be sampled at different rates. It is not required to downsample EEG to fmri s temporal resolution, as done by most researchers in the EEG-fMRI comparison literature (Goldman, et al. 2002) (Hinterberger, Veit, et al. 2005), which will lead to loss of vital temporal information.
10 Discover latent linkages between EEG and fmri Assumptions: EEG data is the independent variable X, and deconvolved fmri (neuronal states) data is the dependent variable Y. Reasonable assumption because the hemodynamic/metabolic activity is a secondary response to the electrical activity. Goal: Given X and Y over many trials, and assuming F(X) = Y, discover F. Higher Order Multilinear Subspace Regression / Higher Order Partial Least Squares (HOPLS) [Q. Zhao, et al. 2011] to predict the dependent variable (deconvolved fmri) from the independent variable (EEG). HOPLS parameters (latent variables, core tensors and tensor loadings) are likely to provide information on latent EEG-fMRI relationships across the dimensions considered.

11 Partial Least Squares (PLS) Partial least squares: Predicts a set of dependent variables Y from a set of independent variables X. Attempts to explain as much as possible the covariance between X and Y. PLS optimization objective is to maximize pairwise covariance of a set of latent variables by projecting both X and Y onto new subspaces. X = TP % + E = ( t * p % * + E + Y = UQ % + F = ( u * q % * + F *,- + *,- (3) T = t -,t 7,, t + and U = u -,u 7,, u + are matrices of R extracted latent variables from X and Y, respectively. U will have maximum covariance with T column-wise. P and Q are latent vector subspace base loadings. E and F are residuals. The relation between T and U can be approximated as U TD where D is an R R diagonal matrix of regression coefficients.
12 Least Squares (Undergraduate Linear Algebra) Given a linear transformation P Q we want to simultaneously predict the subspaces R R P and R T Q so that the restricted map R R R T gives a good approximation of the mapping. Given an underdetermined matrix equation A x = b, we can attempt to square the system and solve: A \ A x = A \ b Perhaps use QR. The standard least-squares solution is x] = A \ A ^- A \ b. Project to a linear subspace and replace A with a full rank matrix using SVD.
13 Singular Value Decomposition The Singular Value Decomposition A = U Σ V \ The quasi-diagonal matrix of singular values σ -, σ 7, can be truncated to the largest r singular values to give the best rank r approximation. The orthogonal matrices U and V (called loadings) give the embeddings of the respective subspaces on which A is best approximated to rank r. The pseudoinverse of A is A = V Σ U \, where Σ = diag(σ -^-, σ 7^-, ) The minimal norm solution to A x = b is x] = A b = Σ d,- * e f g h i f v d.
14 SVD and PLS Given m data observations of n participants stored in a data matrix X (independent variables). Given k responses of the n participants stored in a data matrix Y (dependent variables). Find a linear function F that explains the maximum covariance between X and Y. Y = XF + E Center and normalize both X and Y. Compute the Covariance Matrix R = Y \ X Perform SVD: R = UΣV \ (compact form, iterative algorithm) The latent variables of X and Y are obtained by projections: L n = XV L o = YU U and V give the embeddings of the subspaces (the loadings of the variables)
15 Structured variables In the situation of EEG-fMRI data, even after a wavelet decomposition of the data, we still have extra structure in the dependent variables (fmri) Y and in the independent variables X. EEG modalities: trial time frequency channel 4ms updates, 63+1 channels, 4 trials So X could be 4 trials x 100 wavelets x 63 channels fmri modalities: trial time neuronal state voxel 200ms updates with whole brain coverage and 3mm voxels So Y could be 4 trials x 200 wavelets x 36,000 voxels Don t think of 100x63 as 6,300, don t think of 200x36,000 as u Unfolding leads to small p large n problem and a loss of information.
16 Modal Products for Tensors For A R x y x z x { and U R } x } the n mode tensor-matrix product is A T U R x y x z x } y } x } y x { A T U = ( a dy,d z,,d }, d { u },d } d } x } This modal product generalizes the matrix product and vector outer product and replaces transpose. If A R x y x z and B R x y z then A - B = B \ A R z x z If x R - T and y R - R then y \ x R R T
17 Matrix SVD using modal product notation SVD Theorem: Every complex I - I 7 matrix F has an expression F = S - U (-) 7 U (7) with U (-) a unitary I - I - matrix U (7) a unitary I 7 I 7 matrix S pseudodiagonal I - I 7 matrix, S = diag(σ -, σ 7,, σ Œ xy,x z ) The singular values are ordered: σ - σ 7, σ Œ xy,x z 0
18 Tensor SVD (Orthogonal Tucker Decomposition) Theorem: Every I - I 7 I array A can be written as a product: A = S - U (-) 7 U (7) U ( ) Each U (T) is a unitary I T I T matrix. S is a I - I 7 I complex tensor with slices having norm S d},d = σ d (T), the n-mode singular values of A For each n the singular values are ordered σ - (T) σ 7 T σ x} T 0 The slices S d},d are all-orthogonal: S d},, S d}, = 0 α β n Compute the n-mode singular matrix U (T) and n-mode singular values by the matrix SVD of the n-th unfolding of size I T I 7 I I T^- I T - I. S is computed by S = A - U - 7 U 7 U [De Lauthawer 2005, Zhao-Cichocki 2013]
19 Tucker Decomposition for EEG--fMRI Take an N - N 7 N N š tensor and express it as a (small) core tensor of size L - L 7 L L š together with changes of bases (loadings) to put the core back into the larger tensor space. Let X and Y be tensors of EEG and deconvolved fmri, respectively with modalities: trials, voxels/channels, time and frequency. Obtain new tensor subspaces via the Tucker model for each trial: Approximate X with a sum of multilinear rank-(1, L 7,L,L š )terms Approximate Y with a sum of multilinear rank-(1,k 7, K,K š ) terms The core tensors model the underlying biophysics and are different for EEG and fmri. Perform HOSVD on the L 7 L L š K 7 K K š contraction X - Y
 and Q * (R) are loading matrices corresponding to latent vector t * on mode-n and mode-m, respectively, G * and D * are core tensors, and is the")
20 Higher order Partial Least Squares (HOPLS) The HOPLS is expressed as + Y = ( D * X = ( G * *,- + *,- - t * 7 Q * (7) Q * ( ) š Q * š + F - t * 7 P * (7) P * ( ) š P * š + E where R is the number of latent vectors, t * is the r th latent vector, P * (T) and Q * (R) are loading matrices corresponding to latent vector t * on mode-n and mode-m, respectively, G * and D * are core tensors, and is the product in the k th mode. Compute the t * as the leading left singular vector of an unfolding, deflate, and repeat.
21 Feasibility Study We performed the simultaneous EEG/fMRI experiment and EEG-only BCI using the P300 speller paradigm in 4 right-handed male subjects (mean age: 21.5 years) with no history of neurological or other illness. fmri data were acquired using the M-EPI sequence (TR=200 ms, multiband factor=8, 3 mm isotropic voxels, full coverage) and deconvolved using the cubature Kalman filter approach. The analyses were carried out on a high performance computer with Intel Core i (Quad Core, 10MB Cache) overclocked up to 4.1GHz processor with a top of the line NVidia GPU Quadro Plex We obtained significantly high correlation using both the full and the significant HOPLS models, with the latter providing better accuracy with run times under a second.
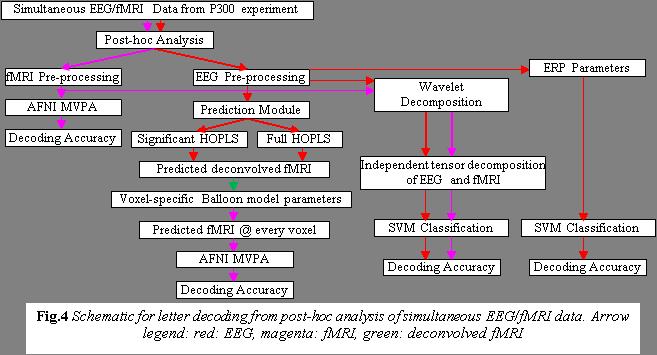
22
23 Preliminary Results Table.2 Prediction of deconvolved fmri from simultaneously acquired EEG using offline analysis Offline analysis of Simultaneous EEG/fMRI Expt Correlation between deconvolved fmri data and that predicted from EEG Approximate run time for prediction module in sec Full HOPLS forward model Significant HOPLS forward model 0.76 ± ± Table.3 Letter decoding accuracy from post-hoc analysis of simultaneous EEG/fMRI data Off line analysis of simultaneous EEG/fMRI Expt Letter decoding accuracy 1 trial block 8 trial blocks Run time per letter decoded (sec) Original fmri MVPA fmri predicted with significant HOPLS + MVPA fmri predicted with full HOPLS + MVPA SVM based on EEG tensors (from sequential model) SVM based on fmri tensors(from sequential model) SVM based on ERP amplitude and latency 0.97± ± ± ± ± ± ± ± ±
24 Preliminary results Table.4 Letter decoding accuracy from real-time analysis of EEG data using predicted fmri (from significant HOPLS) as features for MVPA Online analysis of EEG-only BCI data Letter decoding accuracy from fmri predicted with significant HOPLS + MVPA Parameters from same subject s EEG/fMRI run Parameters from random prior subject s EEG/fMRI run Parameters learned from all prior subjects EEG/fMRI run Subject-2 Subject-3 Subject-4 1 trial block 0.93 ± ± trial blocks ± In spite of these encouraging results, we stress the fact that they are derived from a small, homogeneous sample of 4 subjects. We need to do more trials to demonstrate more broad generalizability.
25 (Extra Slide) Higher Order Partial Least Squares The subspace transformation is optimized using the following objective function, yielding the common latent variable t * instead of 2 latent variables. min { }, } } X [G; t, P 7, P, P š ] 7 + Y [D; t, Q 7, Q, Q š ] 7 such that P T % P T = and Q I } R % Q R = I ª«Simultaneous optimization of subspace representations and latent variable t *. Solutions can be obtained by Multilinear Singular Value Decomposition (MSVD)(see [Q. Zhao, et al. 2011]) Minimizing the errors is equivalent to maximizing the norms G and D simultaneously (accounting for the common latent variable). To do this we maximize the product G 7 D 7. Compute the latent variables t * as leading left singular vectors and then deflate. Repeat until you reach the error bounds you want.
THE Partial Least Squares (PLS) is a well-established
 is a well-established") Higher-Order Partial Least Squares (HOPLS): A Generalized Multi-Linear Regression Method Qibin Zhao, Cesar F. Caiafa, Danilo P. Mandic, Zenas C. Chao, Yasuo Nagasaka, Naotaka Fujii, Liqing Zhang and Andrzej
Higher-Order Partial Least Squares (HOPLS): A Generalized Multi-Linear Regression Method Qibin Zhao, Cesar F. Caiafa, Danilo P. Mandic, Zenas C. Chao, Yasuo Nagasaka, Naotaka Fujii, Liqing Zhang and Andrzej
Recipes for the Linear Analysis of EEG and applications
 Recipes for the Linear Analysis of EEG and applications Paul Sajda Department of Biomedical Engineering Columbia University Can we read the brain non-invasively and in real-time? decoder 1001110 if YES
Recipes for the Linear Analysis of EEG and applications Paul Sajda Department of Biomedical Engineering Columbia University Can we read the brain non-invasively and in real-time? decoder 1001110 if YES
KERNEL-BASED TENSOR PARTIAL LEAST SQUARES FOR RECONSTRUCTION OF LIMB MOVEMENTS
 KERNEL-BASED TENSOR PARTIAL LEAST SQUARES FOR RECONSTRUCTION OF LIMB MOVEMENTS Qibin Zhao, Guoxu Zhou, Tulay Adali 2, Liqing Zhang 3, Andrzej Cichocki RIKEN Brain Science Institute, Japan 2 University
KERNEL-BASED TENSOR PARTIAL LEAST SQUARES FOR RECONSTRUCTION OF LIMB MOVEMENTS Qibin Zhao, Guoxu Zhou, Tulay Adali 2, Liqing Zhang 3, Andrzej Cichocki RIKEN Brain Science Institute, Japan 2 University
TENSOR LAYERS FOR COMPRESSION OF DEEP LEARNING NETWORKS. Cris Cecka Senior Research Scientist, NVIDIA GTC 2018
 TENSOR LAYERS FOR COMPRESSION OF DEEP LEARNING NETWORKS Cris Cecka Senior Research Scientist, NVIDIA GTC 2018 Tensors Computations and the GPU AGENDA Tensor Networks and Decompositions Tensor Layers in
TENSOR LAYERS FOR COMPRESSION OF DEEP LEARNING NETWORKS Cris Cecka Senior Research Scientist, NVIDIA GTC 2018 Tensors Computations and the GPU AGENDA Tensor Networks and Decompositions Tensor Layers in
Multi-Linear Mappings, SVD, HOSVD, and the Numerical Solution of Ill-Conditioned Tensor Least Squares Problems
 Multi-Linear Mappings, SVD, HOSVD, and the Numerical Solution of Ill-Conditioned Tensor Least Squares Problems Lars Eldén Department of Mathematics, Linköping University 1 April 2005 ERCIM April 2005 Multi-Linear
Multi-Linear Mappings, SVD, HOSVD, and the Numerical Solution of Ill-Conditioned Tensor Least Squares Problems Lars Eldén Department of Mathematics, Linköping University 1 April 2005 ERCIM April 2005 Multi-Linear
Slice Oriented Tensor Decomposition of EEG Data for Feature Extraction in Space, Frequency and Time Domains
 Slice Oriented Tensor Decomposition of EEG Data for Feature Extraction in Space, and Domains Qibin Zhao, Cesar F. Caiafa, Andrzej Cichocki, and Liqing Zhang 2 Laboratory for Advanced Brain Signal Processing,
Slice Oriented Tensor Decomposition of EEG Data for Feature Extraction in Space, and Domains Qibin Zhao, Cesar F. Caiafa, Andrzej Cichocki, and Liqing Zhang 2 Laboratory for Advanced Brain Signal Processing,
Online Tensor Factorization for. Feature Selection in EEG
 Online Tensor Factorization for Feature Selection in EEG Alric Althoff Honors Thesis, Department of Cognitive Science, University of California - San Diego Supervised by Dr. Virginia de Sa Abstract Tensor
Online Tensor Factorization for Feature Selection in EEG Alric Althoff Honors Thesis, Department of Cognitive Science, University of California - San Diego Supervised by Dr. Virginia de Sa Abstract Tensor
Towards a Regression using Tensors
 February 27, 2014 Outline Background 1 Background Linear Regression Tensorial Data Analysis 2 Definition Tensor Operation Tensor Decomposition 3 Model Attention Deficit Hyperactivity Disorder Data Analysis
February 27, 2014 Outline Background 1 Background Linear Regression Tensorial Data Analysis 2 Definition Tensor Operation Tensor Decomposition 3 Model Attention Deficit Hyperactivity Disorder Data Analysis
Math 671: Tensor Train decomposition methods II
 Math 671: Tensor Train decomposition methods II Eduardo Corona 1 1 University of Michigan at Ann Arbor December 13, 2016 Table of Contents 1 What we ve talked about so far: 2 The Tensor Train decomposition
Math 671: Tensor Train decomposition methods II Eduardo Corona 1 1 University of Michigan at Ann Arbor December 13, 2016 Table of Contents 1 What we ve talked about so far: 2 The Tensor Train decomposition
Higher-Order Singular Value Decomposition (HOSVD) for structured tensors
 for structured tensors") Higher-Order Singular Value Decomposition (HOSVD) for structured tensors Definition and applications Rémy Boyer Laboratoire des Signaux et Système (L2S) Université Paris-Sud XI GDR ISIS, January 16, 2012
Higher-Order Singular Value Decomposition (HOSVD) for structured tensors Definition and applications Rémy Boyer Laboratoire des Signaux et Système (L2S) Université Paris-Sud XI GDR ISIS, January 16, 2012
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis. Massimiliano Pontil
 2. Least Squares and Principal Components Analysis. Massimiliano Pontil") GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
 https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
Manning & Schuetze, FSNLP (c) 1999,2000
 1999,2000") 558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
Math 671: Tensor Train decomposition methods
 Math 671: Eduardo Corona 1 1 University of Michigan at Ann Arbor December 8, 2016 Table of Contents 1 Preliminaries and goal 2 Unfolding matrices for tensorized arrays The Tensor Train decomposition 3
Math 671: Eduardo Corona 1 1 University of Michigan at Ann Arbor December 8, 2016 Table of Contents 1 Preliminaries and goal 2 Unfolding matrices for tensorized arrays The Tensor Train decomposition 3
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
From Matrix to Tensor. Charles F. Van Loan
 From Matrix to Tensor Charles F. Van Loan Department of Computer Science January 28, 2016 From Matrix to Tensor From Tensor To Matrix 1 / 68 What is a Tensor? Instead of just A(i, j) it s A(i, j, k) or
From Matrix to Tensor Charles F. Van Loan Department of Computer Science January 28, 2016 From Matrix to Tensor From Tensor To Matrix 1 / 68 What is a Tensor? Instead of just A(i, j) it s A(i, j, k) or
Introduction to Deep Learning CMPT 733. Steven Bergner
 Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Index. Copyright (c)2007 The Society for Industrial and Applied Mathematics From: Matrix Methods in Data Mining and Pattern Recgonition By: Lars Elden
2007 The Society for Industrial and Applied Mathematics From: Matrix Methods in Data Mining and Pattern Recgonition By: Lars Elden") Index 1-norm, 15 matrix, 17 vector, 15 2-norm, 15, 59 matrix, 17 vector, 15 3-mode array, 91 absolute error, 15 adjacency matrix, 158 Aitken extrapolation, 157 algebra, multi-linear, 91 all-orthogonality,
Index 1-norm, 15 matrix, 17 vector, 15 2-norm, 15, 59 matrix, 17 vector, 15 3-mode array, 91 absolute error, 15 adjacency matrix, 158 Aitken extrapolation, 157 algebra, multi-linear, 91 all-orthogonality,
Singular Value Decomposition
 Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Linear Algebra (Review) Volker Tresp 2017
 Volker Tresp 2017") Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
Neuroscience Introduction
 Neuroscience Introduction The brain As humans, we can identify galaxies light years away, we can study particles smaller than an atom. But we still haven t unlocked the mystery of the three pounds of matter
Neuroscience Introduction The brain As humans, we can identify galaxies light years away, we can study particles smaller than an atom. But we still haven t unlocked the mystery of the three pounds of matter
Brain Computer Interface Using Tensor Decompositions and Multi-way Analysis
 1 Brain Computer Interface Using Tensor Decompositions and Multi-way Analysis Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing http://www.bsp.brain.riken.jp/~cia/. RIKEN, Brain Science
1 Brain Computer Interface Using Tensor Decompositions and Multi-way Analysis Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing http://www.bsp.brain.riken.jp/~cia/. RIKEN, Brain Science
Preliminary Examination, Numerical Analysis, August 2016
 Preliminary Examination, Numerical Analysis, August 2016 Instructions: This exam is closed books and notes. The time allowed is three hours and you need to work on any three out of questions 1-4 and any
Preliminary Examination, Numerical Analysis, August 2016 Instructions: This exam is closed books and notes. The time allowed is three hours and you need to work on any three out of questions 1-4 and any
EEG/MEG Inverse Solution Driven by fmri
 EEG/MEG Inverse Solution Driven by fmri Yaroslav Halchenko CS @ NJIT 1 Functional Brain Imaging EEG ElectroEncephaloGram MEG MagnetoEncephaloGram fmri Functional Magnetic Resonance Imaging others 2 Functional
EEG/MEG Inverse Solution Driven by fmri Yaroslav Halchenko CS @ NJIT 1 Functional Brain Imaging EEG ElectroEncephaloGram MEG MagnetoEncephaloGram fmri Functional Magnetic Resonance Imaging others 2 Functional
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Unsupervised learning: beyond simple clustering and PCA
 Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
CVPR A New Tensor Algebra - Tutorial. July 26, 2017
 CVPR 2017 A New Tensor Algebra - Tutorial Lior Horesh lhoresh@us.ibm.com Misha Kilmer misha.kilmer@tufts.edu July 26, 2017 Outline Motivation Background and notation New t-product and associated algebraic
CVPR 2017 A New Tensor Algebra - Tutorial Lior Horesh lhoresh@us.ibm.com Misha Kilmer misha.kilmer@tufts.edu July 26, 2017 Outline Motivation Background and notation New t-product and associated algebraic
New Machine Learning Methods for Neuroimaging
 New Machine Learning Methods for Neuroimaging Gatsby Computational Neuroscience Unit University College London, UK Dept of Computer Science University of Helsinki, Finland Outline Resting-state networks
New Machine Learning Methods for Neuroimaging Gatsby Computational Neuroscience Unit University College London, UK Dept of Computer Science University of Helsinki, Finland Outline Resting-state networks
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
Event-related fmri. Christian Ruff. Laboratory for Social and Neural Systems Research Department of Economics University of Zurich
 Event-related fmri Christian Ruff Laboratory for Social and Neural Systems Research Department of Economics University of Zurich Institute of Neurology University College London With thanks to the FIL
Event-related fmri Christian Ruff Laboratory for Social and Neural Systems Research Department of Economics University of Zurich Institute of Neurology University College London With thanks to the FIL
Linear Algebra in Actuarial Science: Slides to the lecture
 Linear Algebra in Actuarial Science: Slides to the lecture Fall Semester 2010/2011 Linear Algebra is a Tool-Box Linear Equation Systems Discretization of differential equations: solving linear equations
Linear Algebra in Actuarial Science: Slides to the lecture Fall Semester 2010/2011 Linear Algebra is a Tool-Box Linear Equation Systems Discretization of differential equations: solving linear equations
Structured tensor missing-trace interpolation in the Hierarchical Tucker format Curt Da Silva and Felix J. Herrmann Sept. 26, 2013
 Structured tensor missing-trace interpolation in the Hierarchical Tucker format Curt Da Silva and Felix J. Herrmann Sept. 6, 13 SLIM University of British Columbia Motivation 3D seismic experiments - 5D
Structured tensor missing-trace interpolation in the Hierarchical Tucker format Curt Da Silva and Felix J. Herrmann Sept. 6, 13 SLIM University of British Columbia Motivation 3D seismic experiments - 5D
Bindel, Fall 2009 Matrix Computations (CS 6210) Week 8: Friday, Oct 17
 Week 8: Friday, Oct 17") Logistics Week 8: Friday, Oct 17 1. HW 3 errata: in Problem 1, I meant to say p i < i, not that p i is strictly ascending my apologies. You would want p i > i if you were simply forming the matrices and
Logistics Week 8: Friday, Oct 17 1. HW 3 errata: in Problem 1, I meant to say p i < i, not that p i is strictly ascending my apologies. You would want p i > i if you were simply forming the matrices and
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
ADAPTIVE FILTER THEORY
 ADAPTIVE FILTER THEORY Fourth Edition Simon Haykin Communications Research Laboratory McMaster University Hamilton, Ontario, Canada Front ice Hall PRENTICE HALL Upper Saddle River, New Jersey 07458 Preface
ADAPTIVE FILTER THEORY Fourth Edition Simon Haykin Communications Research Laboratory McMaster University Hamilton, Ontario, Canada Front ice Hall PRENTICE HALL Upper Saddle River, New Jersey 07458 Preface
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Numerical Linear Algebra Background Cho-Jui Hsieh UC Davis May 15, 2018 Linear Algebra Background Vectors A vector has a direction and a magnitude
STA141C: Big Data & High Performance Statistical Computing Numerical Linear Algebra Background Cho-Jui Hsieh UC Davis May 15, 2018 Linear Algebra Background Vectors A vector has a direction and a magnitude
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 5: Numerical Linear Algebra Cho-Jui Hsieh UC Davis April 20, 2017 Linear Algebra Background Vectors A vector has a direction and a magnitude
STA141C: Big Data & High Performance Statistical Computing Lecture 5: Numerical Linear Algebra Cho-Jui Hsieh UC Davis April 20, 2017 Linear Algebra Background Vectors A vector has a direction and a magnitude
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices
 A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices Ryota Tomioka 1, Taiji Suzuki 1, Masashi Sugiyama 2, Hisashi Kashima 1 1 The University of Tokyo 2 Tokyo Institute of Technology 2010-06-22
A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices Ryota Tomioka 1, Taiji Suzuki 1, Masashi Sugiyama 2, Hisashi Kashima 1 1 The University of Tokyo 2 Tokyo Institute of Technology 2010-06-22
Functional Connectivity and Network Methods
 18/Sep/2013" Functional Connectivity and Network Methods with functional magnetic resonance imaging" Enrico Glerean (MSc), Brain & Mind Lab, BECS, Aalto University" www.glerean.com @eglerean becs.aalto.fi/bml
18/Sep/2013" Functional Connectivity and Network Methods with functional magnetic resonance imaging" Enrico Glerean (MSc), Brain & Mind Lab, BECS, Aalto University" www.glerean.com @eglerean becs.aalto.fi/bml
Fundamentals of Multilinear Subspace Learning
 Chapter 3 Fundamentals of Multilinear Subspace Learning The previous chapter covered background materials on linear subspace learning. From this chapter on, we shall proceed to multiple dimensions with
Chapter 3 Fundamentals of Multilinear Subspace Learning The previous chapter covered background materials on linear subspace learning. From this chapter on, we shall proceed to multiple dimensions with
Postgraduate Course Signal Processing for Big Data (MSc)
") Postgraduate Course Signal Processing for Big Data (MSc) Jesús Gustavo Cuevas del Río E-mail: gustavo.cuevas@upm.es Work Phone: +34 91 549 57 00 Ext: 4039 Course Description Instructor Information Course
Postgraduate Course Signal Processing for Big Data (MSc) Jesús Gustavo Cuevas del Río E-mail: gustavo.cuevas@upm.es Work Phone: +34 91 549 57 00 Ext: 4039 Course Description Instructor Information Course
Image Registration Lecture 2: Vectors and Matrices
 Image Registration Lecture 2: Vectors and Matrices Prof. Charlene Tsai Lecture Overview Vectors Matrices Basics Orthogonal matrices Singular Value Decomposition (SVD) 2 1 Preliminary Comments Some of this
Image Registration Lecture 2: Vectors and Matrices Prof. Charlene Tsai Lecture Overview Vectors Matrices Basics Orthogonal matrices Singular Value Decomposition (SVD) 2 1 Preliminary Comments Some of this
Learning goals: students learn to use the SVD to find good approximations to matrices and to compute the pseudoinverse.
 Application of the SVD: Compression and Pseudoinverse Learning goals: students learn to use the SVD to find good approximations to matrices and to compute the pseudoinverse. Low rank approximation One
Application of the SVD: Compression and Pseudoinverse Learning goals: students learn to use the SVD to find good approximations to matrices and to compute the pseudoinverse. Low rank approximation One
Multilinear Regression Methods in Neuroimaging
 Ahmet Ademoglu, PhD Data Science and AI Workshop İstanbul Şehir University Dragos Campus Aug 4th, 2018 1 Origins of Neuroimaging Data 2 Overview TENSOR Algebra 3 t-operators 4 Brain Connectivity with Tensor
Ahmet Ademoglu, PhD Data Science and AI Workshop İstanbul Şehir University Dragos Campus Aug 4th, 2018 1 Origins of Neuroimaging Data 2 Overview TENSOR Algebra 3 t-operators 4 Brain Connectivity with Tensor
POLYNOMIAL SINGULAR VALUES FOR NUMBER OF WIDEBAND SOURCES ESTIMATION AND PRINCIPAL COMPONENT ANALYSIS
 POLYNOMIAL SINGULAR VALUES FOR NUMBER OF WIDEBAND SOURCES ESTIMATION AND PRINCIPAL COMPONENT ANALYSIS Russell H. Lambert RF and Advanced Mixed Signal Unit Broadcom Pasadena, CA USA russ@broadcom.com Marcel
POLYNOMIAL SINGULAR VALUES FOR NUMBER OF WIDEBAND SOURCES ESTIMATION AND PRINCIPAL COMPONENT ANALYSIS Russell H. Lambert RF and Advanced Mixed Signal Unit Broadcom Pasadena, CA USA russ@broadcom.com Marcel
Bindel, Fall 2016 Matrix Computations (CS 6210) Notes for
 Notes for") 1 A cautionary tale Notes for 2016-10-05 You have been dropped on a desert island with a laptop with a magic battery of infinite life, a MATLAB license, and a complete lack of knowledge of basic geometry.
1 A cautionary tale Notes for 2016-10-05 You have been dropped on a desert island with a laptop with a magic battery of infinite life, a MATLAB license, and a complete lack of knowledge of basic geometry.
linearly indepedent eigenvectors as the multiplicity of the root, but in general there may be no more than one. For further discussion, assume matrice
 3. Eigenvalues and Eigenvectors, Spectral Representation 3.. Eigenvalues and Eigenvectors A vector ' is eigenvector of a matrix K, if K' is parallel to ' and ' 6, i.e., K' k' k is the eigenvalue. If is
3. Eigenvalues and Eigenvectors, Spectral Representation 3.. Eigenvalues and Eigenvectors A vector ' is eigenvector of a matrix K, if K' is parallel to ' and ' 6, i.e., K' k' k is the eigenvalue. If is
arxiv: v2 [math.na] 13 Dec 2014
![arxiv: v2 [math.na] 13 Dec 2014](/thumbs/83/88363230.jpg "arxiv: v2 [math.na] 13 Dec 2014") Very Large-Scale Singular Value Decomposition Using Tensor Train Networks arxiv:1410.6895v2 [math.na] 13 Dec 2014 Namgil Lee a and Andrzej Cichocki a a Laboratory for Advanced Brain Signal Processing,
Very Large-Scale Singular Value Decomposition Using Tensor Train Networks arxiv:1410.6895v2 [math.na] 13 Dec 2014 Namgil Lee a and Andrzej Cichocki a a Laboratory for Advanced Brain Signal Processing,
COMP6237 Data Mining Covariance, EVD, PCA & SVD. Jonathon Hare
 COMP6237 Data Mining Covariance, EVD, PCA & SVD Jonathon Hare jsh2@ecs.soton.ac.uk Variance and Covariance Random Variables and Expected Values Mathematicians talk variance (and covariance) in terms of
COMP6237 Data Mining Covariance, EVD, PCA & SVD Jonathon Hare jsh2@ecs.soton.ac.uk Variance and Covariance Random Variables and Expected Values Mathematicians talk variance (and covariance) in terms of
Spatial Source Filtering. Outline EEG/ERP. ERPs) Event-related Potentials (ERPs( EEG
 Event-related Potentials (ERPs( EEG") Integration of /MEG/fMRI Vince D. Calhoun, Ph.D. Director, Image Analysis & MR Research The MIND Institute Outline fmri/ data Three Approaches to integration/fusion Prediction Constraints 2 nd Level Fusion
Integration of /MEG/fMRI Vince D. Calhoun, Ph.D. Director, Image Analysis & MR Research The MIND Institute Outline fmri/ data Three Approaches to integration/fusion Prediction Constraints 2 nd Level Fusion
HST.582J/6.555J/16.456J
 Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
A new truncation strategy for the higher-order singular value decomposition
 A new truncation strategy for the higher-order singular value decomposition Nick Vannieuwenhoven K.U.Leuven, Belgium Workshop on Matrix Equations and Tensor Techniques RWTH Aachen, Germany November 21,
A new truncation strategy for the higher-order singular value decomposition Nick Vannieuwenhoven K.U.Leuven, Belgium Workshop on Matrix Equations and Tensor Techniques RWTH Aachen, Germany November 21,
RECOGNITION ALGORITHM FOR DEVELOPING A BRAIN- COMPUTER INTERFACE USING FUNCTIONAL NEAR INFRARED SPECTROSCOPY
 The 212 International Conference on Green Technology and Sustainable Development (GTSD212) RECOGNITION ALGORITHM FOR DEVELOPING A BRAIN- COMPUTER INTERFACE USING FUNCTIONAL NEAR INFRARED SPECTROSCOPY Cuong
The 212 International Conference on Green Technology and Sustainable Development (GTSD212) RECOGNITION ALGORITHM FOR DEVELOPING A BRAIN- COMPUTER INTERFACE USING FUNCTIONAL NEAR INFRARED SPECTROSCOPY Cuong
The multiple-vector tensor-vector product
 I TD MTVP C KU Leuven August 29, 2013 In collaboration with: N Vanbaelen, K Meerbergen, and R Vandebril Overview I TD MTVP C 1 Introduction Inspiring example Notation 2 Tensor decompositions The CP decomposition
I TD MTVP C KU Leuven August 29, 2013 In collaboration with: N Vanbaelen, K Meerbergen, and R Vandebril Overview I TD MTVP C 1 Introduction Inspiring example Notation 2 Tensor decompositions The CP decomposition
1 Linearity and Linear Systems
 Mathematical Tools for Neuroscience (NEU 34) Princeton University, Spring 26 Jonathan Pillow Lecture 7-8 notes: Linear systems & SVD Linearity and Linear Systems Linear system is a kind of mapping f( x)
Mathematical Tools for Neuroscience (NEU 34) Princeton University, Spring 26 Jonathan Pillow Lecture 7-8 notes: Linear systems & SVD Linearity and Linear Systems Linear system is a kind of mapping f( x)
Applied Mathematics 205. Unit II: Numerical Linear Algebra. Lecturer: Dr. David Knezevic
 Applied Mathematics 205 Unit II: Numerical Linear Algebra Lecturer: Dr. David Knezevic Unit II: Numerical Linear Algebra Chapter II.3: QR Factorization, SVD 2 / 66 QR Factorization 3 / 66 QR Factorization
Applied Mathematics 205 Unit II: Numerical Linear Algebra Lecturer: Dr. David Knezevic Unit II: Numerical Linear Algebra Chapter II.3: QR Factorization, SVD 2 / 66 QR Factorization 3 / 66 QR Factorization
Exercise Sheet 1. 1 Probability revision 1: Student-t as an infinite mixture of Gaussians
 Exercise Sheet 1 1 Probability revision 1: Student-t as an infinite mixture of Gaussians Show that an infinite mixture of Gaussian distributions, with Gamma distributions as mixing weights in the following
Exercise Sheet 1 1 Probability revision 1: Student-t as an infinite mixture of Gaussians Show that an infinite mixture of Gaussian distributions, with Gamma distributions as mixing weights in the following
Manning & Schuetze, FSNLP, (c)
") page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
Numerical Linear and Multilinear Algebra in Quantum Tensor Networks
 Numerical Linear and Multilinear Algebra in Quantum Tensor Networks Konrad Waldherr October 20, 2013 Joint work with Thomas Huckle QCCC 2013, Prien, October 20, 2013 1 Outline Numerical (Multi-) Linear
Numerical Linear and Multilinear Algebra in Quantum Tensor Networks Konrad Waldherr October 20, 2013 Joint work with Thomas Huckle QCCC 2013, Prien, October 20, 2013 1 Outline Numerical (Multi-) Linear
Singular Value Decomposition and Digital Image Compression
 Singular Value Decomposition and Digital Image Compression Chris Bingham December 1, 016 Page 1 of Abstract The purpose of this document is to be a very basic introduction to the singular value decomposition
Singular Value Decomposition and Digital Image Compression Chris Bingham December 1, 016 Page 1 of Abstract The purpose of this document is to be a very basic introduction to the singular value decomposition
CS540 Machine learning Lecture 5
 CS540 Machine learning Lecture 5 1 Last time Basis functions for linear regression Normal equations QR SVD - briefly 2 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 3
CS540 Machine learning Lecture 5 1 Last time Basis functions for linear regression Normal equations QR SVD - briefly 2 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 3
be a Householder matrix. Then prove the followings H = I 2 uut Hu = (I 2 uu u T u )u = u 2 uut u
u = u 2 uut u") MATH 434/534 Theoretical Assignment 7 Solution Chapter 7 (71) Let H = I 2uuT Hu = u (ii) Hv = v if = 0 be a Householder matrix Then prove the followings H = I 2 uut Hu = (I 2 uu )u = u 2 uut u = u 2u =
MATH 434/534 Theoretical Assignment 7 Solution Chapter 7 (71) Let H = I 2uuT Hu = u (ii) Hv = v if = 0 be a Householder matrix Then prove the followings H = I 2 uut Hu = (I 2 uu )u = u 2 uut u = u 2u =
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 2017-2018 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 2017-2018 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI
On the convergence of higher-order orthogonality iteration and its extension
 On the convergence of higher-order orthogonality iteration and its extension Yangyang Xu IMA, University of Minnesota SIAM Conference LA15, Atlanta October 27, 2015 Best low-multilinear-rank approximation
On the convergence of higher-order orthogonality iteration and its extension Yangyang Xu IMA, University of Minnesota SIAM Conference LA15, Atlanta October 27, 2015 Best low-multilinear-rank approximation
Spectral Graph Wavelets on the Cortical Connectome and Regularization of the EEG Inverse Problem
 Spectral Graph Wavelets on the Cortical Connectome and Regularization of the EEG Inverse Problem David K Hammond University of Oregon / NeuroInformatics Center International Conference on Industrial and
Spectral Graph Wavelets on the Cortical Connectome and Regularization of the EEG Inverse Problem David K Hammond University of Oregon / NeuroInformatics Center International Conference on Industrial and
Theoretical Performance Analysis of Tucker Higher Order SVD in Extracting Structure from Multiple Signal-plus-Noise Matrices
 Theoretical Performance Analysis of Tucker Higher Order SVD in Extracting Structure from Multiple Signal-plus-Noise Matrices Himanshu Nayar Dept. of EECS University of Michigan Ann Arbor Michigan 484 email:
Theoretical Performance Analysis of Tucker Higher Order SVD in Extracting Structure from Multiple Signal-plus-Noise Matrices Himanshu Nayar Dept. of EECS University of Michigan Ann Arbor Michigan 484 email:
Linear Algebra (Review) Volker Tresp 2018
 Volker Tresp 2018") Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
CS168: The Modern Algorithmic Toolbox Lecture #8: How PCA Works
 CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
MRI Physics II: Gradients, Imaging. Douglas C. Noll, Ph.D. Dept. of Biomedical Engineering University of Michigan, Ann Arbor
 MRI Physics II: Gradients, Imaging Douglas C., Ph.D. Dept. of Biomedical Engineering University of Michigan, Ann Arbor Magnetic Fields in MRI B 0 The main magnetic field. Always on (0.5-7 T) Magnetizes
MRI Physics II: Gradients, Imaging Douglas C., Ph.D. Dept. of Biomedical Engineering University of Michigan, Ann Arbor Magnetic Fields in MRI B 0 The main magnetic field. Always on (0.5-7 T) Magnetizes
Dreem Challenge report (team Bussanati)
") Wavelet course, MVA 04-05 Simon Bussy, simon.bussy@gmail.com Antoine Recanati, arecanat@ens-cachan.fr Dreem Challenge report (team Bussanati) Description and specifics of the challenge We worked on the
Wavelet course, MVA 04-05 Simon Bussy, simon.bussy@gmail.com Antoine Recanati, arecanat@ens-cachan.fr Dreem Challenge report (team Bussanati) Description and specifics of the challenge We worked on the
Modelling temporal structure (in noise and signal)
") Modelling temporal structure (in noise and signal) Mark Woolrich, Christian Beckmann*, Salima Makni & Steve Smith FMRIB, Oxford *Imperial/FMRIB temporal noise: modelling temporal autocorrelation temporal
Modelling temporal structure (in noise and signal) Mark Woolrich, Christian Beckmann*, Salima Makni & Steve Smith FMRIB, Oxford *Imperial/FMRIB temporal noise: modelling temporal autocorrelation temporal
Low-rank Promoting Transformations and Tensor Interpolation - Applications to Seismic Data Denoising
 Low-rank Promoting Transformations and Tensor Interpolation - Applications to Seismic Data Denoising Curt Da Silva and Felix J. Herrmann 2 Dept. of Mathematics 2 Dept. of Earth and Ocean Sciences, University
Low-rank Promoting Transformations and Tensor Interpolation - Applications to Seismic Data Denoising Curt Da Silva and Felix J. Herrmann 2 Dept. of Mathematics 2 Dept. of Earth and Ocean Sciences, University
The General Linear Model in Functional MRI
 The General Linear Model in Functional MRI Henrik BW Larsson Functional Imaging Unit, Glostrup Hospital University of Copenhagen Part I 1 2 Preface The General Linear Model (GLM) or multiple regression
The General Linear Model in Functional MRI Henrik BW Larsson Functional Imaging Unit, Glostrup Hospital University of Copenhagen Part I 1 2 Preface The General Linear Model (GLM) or multiple regression
DS-GA 1002 Lecture notes 10 November 23, Linear models
 DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
Incomplete Cholesky preconditioners that exploit the low-rank property
 anapov@ulb.ac.be ; http://homepages.ulb.ac.be/ anapov/ 1 / 35 Incomplete Cholesky preconditioners that exploit the low-rank property (theory and practice) Artem Napov Service de Métrologie Nucléaire, Université
anapov@ulb.ac.be ; http://homepages.ulb.ac.be/ anapov/ 1 / 35 Incomplete Cholesky preconditioners that exploit the low-rank property (theory and practice) Artem Napov Service de Métrologie Nucléaire, Université
Linear Algebra Review. Fei-Fei Li
 Linear Algebra Review Fei-Fei Li 1 / 37 Vectors Vectors and matrices are just collections of ordered numbers that represent something: movements in space, scaling factors, pixel brightnesses, etc. A vector
Linear Algebra Review Fei-Fei Li 1 / 37 Vectors Vectors and matrices are just collections of ordered numbers that represent something: movements in space, scaling factors, pixel brightnesses, etc. A vector
Dynamic Causal Modelling for fmri
 Dynamic Causal Modelling for fmri André Marreiros Friday 22 nd Oct. 2 SPM fmri course Wellcome Trust Centre for Neuroimaging London Overview Brain connectivity: types & definitions Anatomical connectivity
Dynamic Causal Modelling for fmri André Marreiros Friday 22 nd Oct. 2 SPM fmri course Wellcome Trust Centre for Neuroimaging London Overview Brain connectivity: types & definitions Anatomical connectivity
An Introduction to Matrix Algebra
 An Introduction to Matrix Algebra EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #8 EPSY 905: Matrix Algebra In This Lecture An introduction to matrix algebra Ø Scalars, vectors, and matrices
An Introduction to Matrix Algebra EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #8 EPSY 905: Matrix Algebra In This Lecture An introduction to matrix algebra Ø Scalars, vectors, and matrices
Lecture 8. Principal Component Analysis. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 13, 2016
 Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
THERE is an increasing need to handle large multidimensional
 1 Matrix Product State for Feature Extraction of Higher-Order Tensors Johann A. Bengua 1, Ho N. Phien 1, Hoang D. Tuan 1 and Minh N. Do 2 arxiv:1503.00516v4 [cs.cv] 20 Jan 2016 Abstract This paper introduces
1 Matrix Product State for Feature Extraction of Higher-Order Tensors Johann A. Bengua 1, Ho N. Phien 1, Hoang D. Tuan 1 and Minh N. Do 2 arxiv:1503.00516v4 [cs.cv] 20 Jan 2016 Abstract This paper introduces
On Signal to Noise Ratio Tradeoffs in fmri
 On Signal to Noise Ratio Tradeoffs in fmri G. H. Glover April 11, 1999 This monograph addresses the question of signal to noise ratio (SNR) in fmri scanning, when parameters are changed under conditions
On Signal to Noise Ratio Tradeoffs in fmri G. H. Glover April 11, 1999 This monograph addresses the question of signal to noise ratio (SNR) in fmri scanning, when parameters are changed under conditions
Extracting fmri features
 Extracting fmri features PRoNTo course May 2018 Christophe Phillips, GIGA Institute, ULiège, Belgium c.phillips@uliege.be - http://www.giga.ulg.ac.be Overview Introduction Brain decoding problem Subject
Extracting fmri features PRoNTo course May 2018 Christophe Phillips, GIGA Institute, ULiège, Belgium c.phillips@uliege.be - http://www.giga.ulg.ac.be Overview Introduction Brain decoding problem Subject
Part 2: Multivariate fmri analysis using a sparsifying spatio-temporal prior
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 2: Multivariate fmri analysis using a sparsifying spatio-temporal prior Tom Heskes joint work with Marcel van Gerven
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 2: Multivariate fmri analysis using a sparsifying spatio-temporal prior Tom Heskes joint work with Marcel van Gerven
Single-trial P300 detection with Kalman filtering and SVMs
 Single-trial P300 detection with Kalman filtering and SVMs Lucie Daubigney and Olivier Pietquin SUPELEC / UMI 2958 (GeorgiaTech - CNRS) 2 rue Edouard Belin, 57070 Metz - France firstname.lastname@supelec.fr
Single-trial P300 detection with Kalman filtering and SVMs Lucie Daubigney and Olivier Pietquin SUPELEC / UMI 2958 (GeorgiaTech - CNRS) 2 rue Edouard Belin, 57070 Metz - France firstname.lastname@supelec.fr
HST.582J / 6.555J / J Biomedical Signal and Image Processing Spring 2007
 MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
10-725/36-725: Convex Optimization Prerequisite Topics
 10-725/36-725: Convex Optimization Prerequisite Topics February 3, 2015 This is meant to be a brief, informal refresher of some topics that will form building blocks in this course. The content of the
10-725/36-725: Convex Optimization Prerequisite Topics February 3, 2015 This is meant to be a brief, informal refresher of some topics that will form building blocks in this course. The content of the
Beamforming Techniques Applied in EEG Source Analysis
 Beamforming Techniques Applied in EEG Source Analysis G. Van Hoey 1,, R. Van de Walle 1, B. Vanrumste 1,, M. D Havé,I.Lemahieu 1 and P. Boon 1 Department of Electronics and Information Systems, University
Beamforming Techniques Applied in EEG Source Analysis G. Van Hoey 1,, R. Van de Walle 1, B. Vanrumste 1,, M. D Havé,I.Lemahieu 1 and P. Boon 1 Department of Electronics and Information Systems, University
Basic MRI physics and Functional MRI
 Basic MRI physics and Functional MRI Gregory R. Lee, Ph.D Assistant Professor, Department of Radiology June 24, 2013 Pediatric Neuroimaging Research Consortium Objectives Neuroimaging Overview MR Physics
Basic MRI physics and Functional MRI Gregory R. Lee, Ph.D Assistant Professor, Department of Radiology June 24, 2013 Pediatric Neuroimaging Research Consortium Objectives Neuroimaging Overview MR Physics
Applications of High Dimensional Clustering on Riemannian Manifolds in Brain Measurements
 Applications of High Dimensional Clustering on Riemannian Manifolds in Brain Measurements Nathalie Gayraud Supervisor: Maureen Clerc BCI-Lift Project/Team ATHENA Team, Inria Sophia Antipolis - Mediterranee
Applications of High Dimensional Clustering on Riemannian Manifolds in Brain Measurements Nathalie Gayraud Supervisor: Maureen Clerc BCI-Lift Project/Team ATHENA Team, Inria Sophia Antipolis - Mediterranee
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Dimensionality Reduction with Principal Component Analysis
 10 Dimensionality Reduction with Principal Component Analysis Working directly with high-dimensional data, such as images, comes with some difficulties: it is hard to analyze, interpretation is difficult,
10 Dimensionality Reduction with Principal Component Analysis Working directly with high-dimensional data, such as images, comes with some difficulties: it is hard to analyze, interpretation is difficult,
Lecture 4. Tensor-Related Singular Value Decompositions. Charles F. Van Loan
 From Matrix to Tensor: The Transition to Numerical Multilinear Algebra Lecture 4. Tensor-Related Singular Value Decompositions Charles F. Van Loan Cornell University The Gene Golub SIAM Summer School 2010
From Matrix to Tensor: The Transition to Numerical Multilinear Algebra Lecture 4. Tensor-Related Singular Value Decompositions Charles F. Van Loan Cornell University The Gene Golub SIAM Summer School 2010
Tensor Decompositions for Machine Learning. G. Roeder 1. UBC Machine Learning Reading Group, June University of British Columbia
 Network Feature s Decompositions for Machine Learning 1 1 Department of Computer Science University of British Columbia UBC Machine Learning Group, June 15 2016 1/30 Contact information Network Feature
Network Feature s Decompositions for Machine Learning 1 1 Department of Computer Science University of British Columbia UBC Machine Learning Group, June 15 2016 1/30 Contact information Network Feature
ECE 275A Homework # 3 Due Thursday 10/27/2016
 ECE 275A Homework # 3 Due Thursday 10/27/2016 Reading: In addition to the lecture material presented in class, students are to read and study the following: A. The material in Section 4.11 of Moon & Stirling
ECE 275A Homework # 3 Due Thursday 10/27/2016 Reading: In addition to the lecture material presented in class, students are to read and study the following: A. The material in Section 4.11 of Moon & Stirling
Numerical Methods in Matrix Computations
 Ake Bjorck Numerical Methods in Matrix Computations Springer Contents 1 Direct Methods for Linear Systems 1 1.1 Elements of Matrix Theory 1 1.1.1 Matrix Algebra 2 1.1.2 Vector Spaces 6 1.1.3 Submatrices
Ake Bjorck Numerical Methods in Matrix Computations Springer Contents 1 Direct Methods for Linear Systems 1 1.1 Elements of Matrix Theory 1 1.1.1 Matrix Algebra 2 1.1.2 Vector Spaces 6 1.1.3 Submatrices
Multivariate Regression Generalized Likelihood Ratio Tests for FMRI Activation
 Multivariate Regression Generalized Likelihood Ratio Tests for FMRI Activation Daniel B Rowe Division of Biostatistics Medical College of Wisconsin Technical Report 40 November 00 Division of Biostatistics
Multivariate Regression Generalized Likelihood Ratio Tests for FMRI Activation Daniel B Rowe Division of Biostatistics Medical College of Wisconsin Technical Report 40 November 00 Division of Biostatistics
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 22 1 / 21 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 22 1 / 21 Overview