Machine Learning: Symbolische Ansätze. Decision-Tree Learning. Introduction C4.5 ID3. Regression and Model Trees
|
|
|
- Kelly Molly Lamb
- 5 years ago
- Views:
Transcription
1 Machine Learning: Symbolische Ansätze Decision-Tree Learning Introduction Decision Trees TDIDT: Top-Down Induction of Decision Trees ID3 Attribute selection Entropy, Information, Information Gain Gain Ratio C4.5 Numeric Values Missing Values Pruning Regression and Model Trees Acknowledgements: Many slides based on Frank & Witten, a few on Kan, Steinbach & Kumar

2 Decision Trees a decision tree consists of Nodes: test for the value of a certain attribute Edges: correspond to the outcome of a test connect to the next node or leaf Leaves: terminal nodes that predict the outcome to classifiy an example: 1.start at the root 2.perform the test 3.follow the edge corresponding to outcome 4.goto 2. unless leaf 5.predict that outcome associated with the leaf 2
3 Decision Tree Learning In Decision Tree Learning, a new example is classified by submitting it to a series of tests that determine the class label of the example.these tests are organized in a hierarchical structure called a decision tree. The training examples are used for choosing appropriate tests in the decision tree. Typically, a tree is built from top to bottom, where tests that maximize the information gain about the classification are selected first. Training? New Example Classification 3
4 A Sample Task Day Temperature Outlook Humidity Windy Play Golf? hot sunny high false no hot sunny high true no hot overcast high false yes cool rain normal false yes cool overcast normal true yes mild sunny high false no cool sunny normal false yes mild rain normal false yes mild sunny normal true yes mild overcast high true yes hot overcast normal false yes mild rain high true no cool rain normal true no mild rain high false yes today cool sunny normal false? tomorrow mild sunny normal false? 4
5 Decision Tree Learning tomorrow mild sunny normal 5 false?
6 Divide-And-Conquer Algorithms Family of decision tree learning algorithms TDIDT: Top-Down Induction of Decision Trees Learn trees in a Top-Down fashion: divide the problem in subproblems solve each problem Basic Divide-And-Conquer Algorithm: 1. select a test for root node Create branch for each possible outcome of the test 2. split instances into subsets One for each branch extending from the node 3. repeat recursively for each branch, using only instances that reach the branch 4. stop recursion for a branch if all its instances have the same class 6
7 ID3 Algorithm Function FunctionID3 ID3 Input: Input: Example Exampleset setss Output: Output:Decision DecisionTree TreeDT DT IfIfall allexamples examplesin inssbelong belongto tothe thesame sameclass classcc return returnaanew newleaf leafand andlabel labelititwith withcc Else Else i.i. Select Selectan anattribute attributeaaaccording accordingto tosome someheuristic heuristicfunction function ii.ii. Generate Generateaanew newnode nodedt DTwith withaaas astest test iii. iii.for Foreach eachvalue Valuevvi iof ofaa (a) (a)let LetSSi i==all allexamples examplesininsswith withaa==vvi i (b) (b)use UseID3 ID3to toconstruct constructaadecision decisiontree treedt DTi for forexample exampleset setssi i i (c) (c) Generate Generatean anedge edgethat thatconnects connectsdt DTand anddt DTi i 7
8 A Different Decision Tree also explains all of the training data will it generalize well to new data? 8


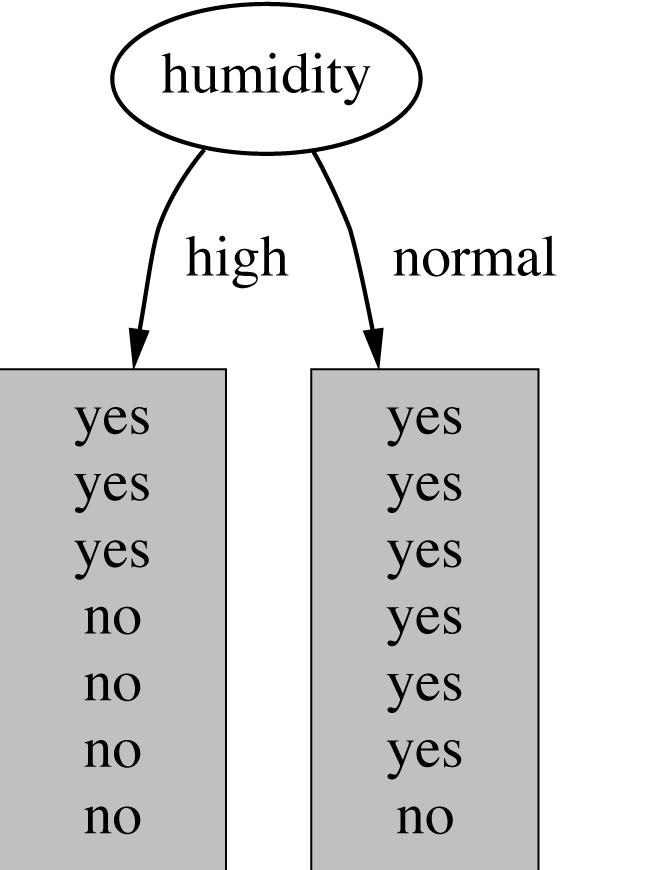
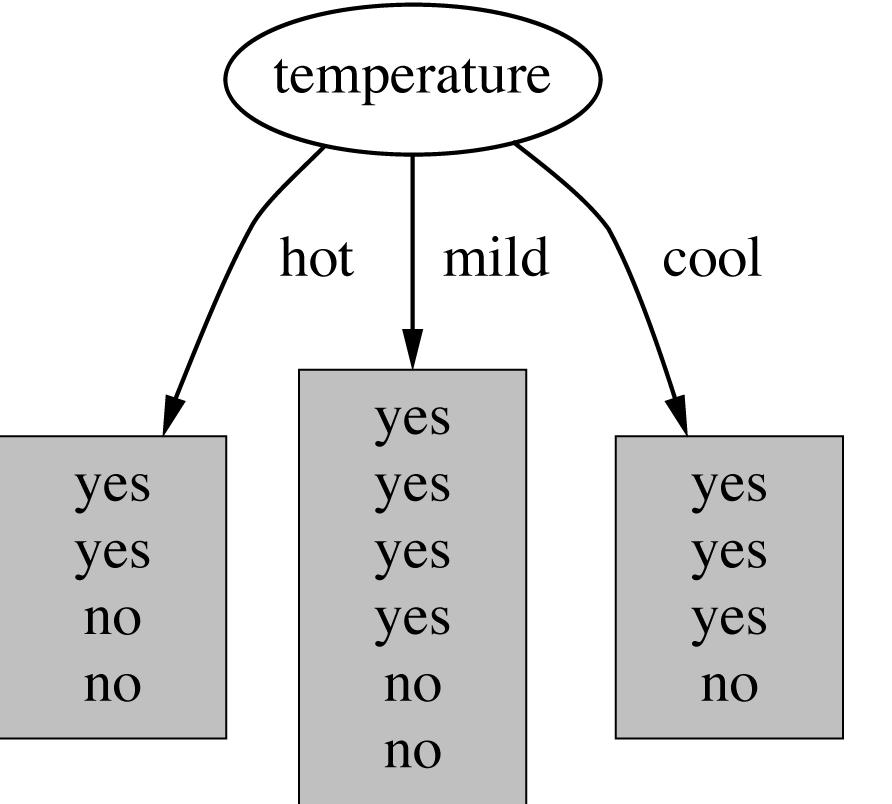
9 Which attribute to select as the root? 9
10 What is a good Attribute? We want to grow a simple tree a good heuristic prefers attributes that split the data so that each successor node is as pure as posssible i.e., the distribution of examples in each node is so that it mostly contains examples of a single class In other words: We want a measure that prefers attributes that have a high degree of order : Maximum order: All examples are of the same class Minimum order: All classes are equally likely Entropy is a measure for (un-)orderedness Another interpretation: Entropy is the amount of information that is contained in the node all examples of the same class no information 10
11 Entropy (for two classes) maximal value at equal class distribution S is a set of examples p is the proportion of examples in class p = 1 p is the proportion of examples in class Entropy: E S = p log 2 p p log 2 p Interpretation: amount of unorderedness in the class distribution of S minimal value if only one class left in S 11
12 Example: Attribute Outlook Outlook = sunny: 2 examples yes, 3 examples no E Outlook =sunny = log 2 log 2 = Outlook = overcast: 4 examples yes, 0 examples no E Outlook =overcast = 1 log log 2 0 =0 Outlook = rainy : Note: this is normally undefined. Here: = 0 3 examples yes, 2 examples no E Outlook =rainy = log 2 log 2 =
13 Entropy (for more classes) Entropy can be easily generalized for n > 2 classes pi is the proportion of examples in S that belong to the i-th class n E (S )= p1 log 2 p1 p 2 log 2 p2... p n log 2 p n = i=1 pi log 2 pi Calculation can be simplified using absolute counts ci of examples in class i instead of fractions ci : S If pi = n E (S )= i=1 n 1 p i log 2 p i = i=1 c i log 2 c i S log 2 S S ( ) Example: E ([2,3,4])= 29 log 2 ( 29 ) 39 log 2 ( 39 ) 49 log 2 ( 49 ) = 19 ( 2 log 2 (2)+3 log 2 (3)+4 log 2 (4) 9 log 2 (9)) 13 V2.2 J. Fürnkranz
14 Average Entropy / Information Problem: Entropy only computes the quality of a single (sub-)set of examples corresponds to a single value How can we compute the quality of the entire split? corresponds to an entire attribute Solution: Compute the weighted average over all sets resulting from the split weighted by their size I S, A = i Example: S i E S i S Average entropy for attribute Outlook: I Outlook = =
15 Information Gain When an attribute A splits the set S into subsets Si we compute the average entropy and compare the sum to the entropy of the original set S Information Gain for Attribute A Gain S, A =E S I S, A = E S i S i E S i S The attribute that maximizes the difference is selected i.e., the attribute that reduces the unorderedness most! Note: maximizing information gain is equivalent to minimizing average entropy, because E(S) is constant for all attributes A 15
16 Example Gain S,Outlook =0.246 Gain S, Temperature =
17 Example (Ctd.) Outlook is selected as the root note? further splitting necessary? Outlook = overcast contains only examples of class yes 17
18 Example (Ctd.) Gain(Temperature ) = bits Gain(Humidity ) = bits Gain(Windy ) = bits Humidity is selected 18
19 Example (Ctd.) Humidity is selected? further splitting necessary Pure leaves No further expansion necessary 19
20 Final decision tree 20
21 Properties of Entropy Entropy is the only function that satisfies all of the following three properties 1. When node is pure, measure should be zero 2. When impurity is maximal (i.e. all classes equally likely), measure should be maximal 3. Measure should obey multistage property: p, q, r are classes in set S, and T are examples of class t = q r T E q, r T S E p, q, r S =E p, t S decisions can be made in several stages For example: E ([2,3,4])=E ([2,7])+ 79 E ([3,4]) 21 V2.1 J. Fürnkranz
22 Highly-branching attributes Problematic: attributes with a large number of values extreme case: each example has its own value e.g. example ID; Day attribute in weather data Subsets are more likely to be pure if there is a large number of different attribute values Information gain is biased towards choosing attributes with a large number of values This may cause several problems: Overfitting selection of an attribute that is non-optimal for prediction Fragmentation data are fragmented into (too) many small sets 22

23 Decision Tree for Day attribute Day Entropy of split: 1 I Day = 14 E [0,1] E [0,1]... E [0,1] =0 Information gain is maximal for Day (0.940 bits) 23
24 Intrinsic Information of an Attribute Intrinsic information of a split entropy of distribution of instances into branches i.e. how much information do we need to tell which branch an instance belongs to IntI S, A = i Example: S i S log 2 S i S Intrinsic information of Day attribute: IntI Day = log =3.807 Observation: Attributes with higher intrinsic information are less useful 24
25 Gain Ratio modification of the information gain that reduces its bias towards multi-valued attributes takes number and size of branches into account when choosing an attribute corrects the information gain by taking the intrinsic information of a split into account Definition of Gain Ratio: Gain S, A GR S, A = IntI S, A Example: Gain Ratio of Day attribute GR Day = = ,807 25
26 Gain ratios for weather data Outlook Temperature Info: Info: Gain: Gain: Split info: info([5,4,5]) Split info: info([4,6,4]) Gain ratio: 0.247/ Gain ratio: 0.029/ Humidity Windy Info: Info: Gain: Gain: Split info: info([7,7]) Split info: info([8,6]) Gain ratio: 0.152/ Gain ratio: 0.048/ Day attribute would still win... one has to be careful which attributes to add... Nevertheless: Gain ratio is more reliable than Information Gain 26
27 Gini Index Many alternative measures to Information Gain Most popular altermative: Gini index used in e.g., in CART (Classification And Regression Trees) impurity measure (instead of entropy) Gini S = p i 1 pi =1 p i 2 i i average Gini index (instead of average entropy / information) Gini S, A = Gini Gain i S i Gini S i S could be defined analogously to information gain but typically averagegini index is minimized instead of maximizing Gini gain 27
28 Comparison of Splitting Criteria f(p) For a 2-class problem: 0.0 Entropy 2*Gini 2*Error p 28 V2.1 J. Fürnkranz
29 Why not use Error as a Splitting Criterion? Reason: The bias towards pure leaves is not strong enough Example 1: Data set with 160 Examples A, 40 Examples B Error rate without splitting is 20% 40 of A For each of the two splits, the total error after splitting is also (0% + 40%)/2 = 20% no improvement 60 of A Split 1 60 of A However, together both splits would give a perfect classfier. 40 of B Split 2 Based on a slide by Richard Lawton 29
30 Why not use Error as a Splitting Criterion? Reason: The bias towards pure leaves is not strong enough Example 2: Dataset with 400 examples of class A and 400 examples of class B 400 of A 400 of B 400 of A 400 of B 200 of A 400 of B 300 of A 100 of B 200 of A 0 of B Error rate = 25% Error rate = 25% 100 of A 300 of B Based on a slide by Richard Lawton 30
31 Industrial-strength algorithms For an algorithm to be useful in a wide range of real-world applications it must: Permit numeric attributes Allow missing values Be robust in the presence of noise Be able to approximate arbitrary concept descriptions (at least in principle) ID3 needs to be extended to be able to deal with real-world data Result: C4.5 Best-known and (probably) most widely-used learning algorithm original C-implementation at Re-implementation of C4.5 Release 8 in Weka: J4.8 Commercial successor: C5.0 31
32 Missing values Examples are classified as usual if we are lucky, attributes with missing values are not tested by the tree If an attribute with a missing value needs to be tested: split the instance into fractional instances (pieces) one piece for each outgoing branch of the node a piece going down a branch receives a weight proportional to the popularity of the branch weights sum to 1 Info gain or gain ratio work with fractional instances use sums of weights instead of counts during classification, split the instance in the same way Merge probability distribution using weights of fractional instances 32
33 Numeric attributes Standard method: binary splits E.g. temp < 45 Unlike nominal attributes, every attribute has many possible split points Solution is straightforward extension: Evaluate info gain (or other measure) for every possible split point of attribute Choose best split point Info gain for best split point is info gain for attribute Computationally more demanding than splits on discrete attributes 33
34 Example Assume a numerical attribute for Temperature First step: Sort all examples according to the value of this attribute Could look like this: 64 Yes 65 No 68 Yes 69 Yes 70 Yes 71 No Temperature < 71.5: yes/4, no/2 I 71.5 = 72 No 72 Yes 75 Yes 75 Yes 80 No 81 Yes 83 Yes 85 No Temperature 71.5: yes/5, no/3 6 8 E Temperature 71.5 E Temperature 71.5 = Split points can be placed between values or directly at values Has to be computed for all pairs of neighboring values 34
35 Efficient Computation Efficient computation needs only one scan through the values! Linearly scan the sorted values, each time updating the count matrix and computing the evaluation measure Choose the split position that has the best value Cheat No No No Yes Yes Yes No No No No Taxable Income 60 Sorted Values Split Positions <= > <= > <= > <= > <= > <= > <= > <= > <= > <= > <= > Yes No Gini
36 Binary vs. Multiway Splits Splitting (multi-way) on a nominal attribute exhausts all information in that attribute Nominal attribute is tested (at most) once on any path in the tree Not so for binary splits on numeric attributes! Numeric attribute may be tested several times along a path in the tree Disadvantage: tree is hard to read Remedy: pre-discretize numeric attributes ( discretization), or use multi-way splits instead of binary ones can, e.g., be computed by building a subtree using a single numerical attribute. subtree can be flattened into a multiway split other methods possible (dynamic programming, greedy...) 36
37 Overfitting and Pruning The smaller the complexity of a concept, the less danger that it overfits the data A polynomial of degree n can always fit n+1 points Thus, learning algorithms try to keep the learned concepts simple Note a perfect fit on the training data can always be found for a decision tree! (except when data are contradictory) Pre-Pruning: stop growing a branch when information becomes unreliable Post-Pruning: grow a decision tree that correctly classifies all training data simplify it later by replacing some nodes with leafs Postpruning preferred in practice prepruning can stop early 37
38 Prepruning Based on statistical significance test Stop growing the tree when there is no statistically significant association between any attribute and the class at a particular node Most popular test: chi-squared test ID3 used chi-squared test in addition to information gain Only statistically significant attributes were allowed to be selected by information gain procedure C4.5 uses a simpler strategy but combines it with post-pruning parameter -m: (default value m=2) each node above a leave must have at least two successors that contain at least m examples 38 V2.1 J. Fürnkranz
39 Early Stopping Pre-pruning may stop the growth process prematurely: early stopping Classic example: XOR/Parity-problem a b class No individual attribute exhibits any significant association to the class In a dataset that contains XOR attributes a and b, and several irrelevant (e.g., random) attributes, ID3 can not distinguish between relevant and irrelevant attributes Prepruning won t expand the root node Structure is only visible in fully expanded tree But: XOR-type problems rare in practice prepruning is faster than postpruning 39
40 Post-Pruning basic idea first grow a full tree to capture all possible attribute interactions later remove those that are due to chance 1.learn a complete and consistent decision tree that classifies all examples in the training set correctly 2.as long as the performance increases try simplification operators on the tree evaluate the resulting trees make the replacement that results in the best estimated performance 3.return the resulting decision tree 40 V2.1 J. Fürnkranz
41 Postpruning Two subtree simplification operators Subtree replacement Subtree raising Possible performance evaluation strategies error estimation on separate pruning set ( reduced error pruning ) with confidence intervals (C4.5's method) significance testing MDL principle 41
42 Subtree Replacement Proceeds Bottom-up: consider replacing a tree only after considering all its subtrees may make a difference for complexity-based heuristics 42
43 Subtree Raising Delete node B Redistribute instances of leaves 4 and 5 into C 43
44 Estimating Error Rates Prune only if it does not increase the estimated error Error on the training data is NOT a useful estimator (would result in almost no pruning) Reduced Error Pruning Use hold-out set for pruning Essentially the same as in rule learning only pruning operators differ (subtree replacement) C4.5 s method Derive confidence interval from training data with a user-provided confidence level Assume that the true error is on the upper bound of this confidence interval (pessimistic error estimate) 44
45 Reduced Error Pruning Basic Idea optimize the accuracy of a decision tree on a separate pruning set 1.split training data into a growing and a pruning set 2.learn a complete and consistent decision tree that classifies all examples in the growing set correctly 3.as long as the error on the pruning set does not increase try to replace each node by a leaf (predicting the majority class) evaluate the resulting (sub-)tree on the pruning set make the replacement that results in the maximum error reduction 4.return the resulting decision tree 45
46 Pessimistic Error Rates Consider classifying E examples incorrectly out of N examples as observing E events in N trials in the binomial distribution. For a given confidence level CF, the upper limit on the error rate over the whole population is U CF ( E, N ) with CF% confidence. Example: 100 examples in a leaf 6 examples misclassified How large is the true error assuming a pessimistic estimate with a confidence of 25%? Note: this is only a heuristic! but one that works well Possibility(%) 75% confidence interval L0.25(100,6) U0.25(100,6) 46
47 C4.5 s method Pessimistic error estimate for a node e= z2 2N f z f N 1 f2 N z2 4N 2 z2 N z is derived from the desired confidence value If c = 25% then z = 0.69 (from normal distribution) f is the error on the training data N is the number of instances covered by the leaf Error estimate for subtree is weighted sum of error estimates for all its leaves A node is pruned if error estimate of subtree is lower than error estimate of the node 47
48 Example f = 5/14 e = 0.46 e < 0.51 so prune! f=0.33 e=0.47 f=0.5 e=0.72 f=0.33 e=0.47 Combined using ratios 6:2:6 gives
49 C4.5: choices and options C4.5 has several parameters -c Confidence value (default 25%): lower values incur heavier pruning -m Minimum number of instances in the two most popular branches (default 2) Others for, e.g., having only two-way splits (also on symbolic attributes), etc. 49
50 Sample Experimental Evaluation Typical behavior with growing m and decreasing c tree size and training accuracy (= purity) always decrease predictive accuracy first increases (overfitting avoidance) then decreases (over-generalization) ideal value on this data set near m = 30 c = 10 50
51 Complexity of tree induction Assume m attributes, n training instances tree depth O(log n) tree has O(n) nodes ( one leaf per example) Costs for Building a tree O(m n log n) Subtree replacement O(n) counts of covered instances can be reused from training Subtree raising O(n (log n)2) Every instance may have to be redistributed at every node between its leaf and the root Cost for redistribution (on average): O(log n) Total cost: O(m n log n) + O(n (log n)2) 51
52 Error-Complexity Measure CART uses the following measure R α (T )= f (T )+α L(T ) f is the error rate on the training data L is the number leaves in the tree α is a parameter that trades off tree complexity vs. test error Different values of α prefer different trees smaller values of α prefer different trees with low training error larger values of α prefer different trees with low training error would nowadays be called a regularization parameter 52 V2.1 J. Fürnkranz
53 Error-Complexity Pruning (CART, Breiman et al. 1984) Generate a sequence of trees with decreasing complexity T 0 T 1 T m T0 is the full tree, Tm is the tree that consists only of the root node Each tree is generated from its predecessor by replacing a subtree with a node. It selects the node which results in the smallest increase in the error function, weighted by the number of leaves in the subtree this sequence of trees optimizes Rα for successive ranges of α-values T0 is optimal for the range [0, α1 ] T1 is optimal for the range [α1, α2 ]... Optimal values for α are then determined with cross-validation on the training data 53 V2.1 J. Fürnkranz
54 From Trees To Rules Simple way: yes :- Outlook = overcast. one rule for each leaf yes :- Outlook = rain, Windy = false. yes :- Outlook = sunny, Humidity = normal. no :- Outlook = sunny, Humidity = high. no :- Outlook = rain, Windy = true. 54
55 C4.5rules and successors C4.5rules: greedily prune conditions from each rule if this reduces its estimated error Can produce duplicate rules Check for this at the end Then look at each class in turn consider the rules for that class find a good subset (guided by MDL) rank the subsets to avoid conflicts Finally, remove rules (greedily) if this decreases error on the training data C4.5rules slow for large and noisy datasets Commercial version C5.0rules uses a different technique Much faster and a bit more accurate 55
56 Decision Lists and Decision Graphs Decision Lists An ordered list of rules the first rule that fires makes the prediction can be learned with a covering approach Decision Graphs Similar to decision trees, but nodes may have multiple predecessors DAGs: Directed, acyclic graphs there are a few algorithms that can learn DAGs learn much smaller structures but in general not very successful Special case: a decision list may be viewed as a special case of a DAG 56
57 Example A decision list for a rule set with rules with 4, 2, 2, 1 conditions, respectively drawn as a decision graph Rule 2 Rule 1 Rule 3 57 Rule 4
58 Rules vs. Trees Each decision tree can be converted into a rule set Rule sets are at least as expressive as decision trees a decision tree can be viewed as a set of non-overlapping rules typically learned via divide-and-conquer algorithms (recursive partitioning) Transformation of rule sets / decision lists into trees is less trivial Many concepts have a shorter description as a rule set low complexity decision lists are more expressive than low complexity decision trees (Rivest, 1987) exceptions: if one or more attributes are relevant for the classification of all examples (e.g., parity) Learning strategies: Separate-and-Conquer vs. Divide-and-Conquer 58
59 Discussion TDIDT The most extensively studied method of machine learning used in data mining Different criteria for attribute/test selection rarely make a large difference Different pruning methods mainly change the size of the resulting pruned tree C4.5 builds univariate decision trees Some TDIDT systems can build multivariate trees (e.g. CART) multi-variate: a split is not based on a single attribute but on a function defined on multiple attributes 59
60 Regression Problems Regression Task the target variable y = f (x) is numerical instead of discrete Various error functions, e.g., Mean-squared error: L( f, f )= x ( f ( x) f ( x))2 Two principal approaches Discretize the numerical target variable e.g., equal-width intervals, or equal-frequency and use a classification learning algorithm Adapt the classification algorithm to regression data Regression Trees and Model Trees 60 V2.1 J. Fürnkranz
61 Regression Trees Differences to Decision Trees (Classification Trees) Leaf Nodes: Predict the average value of all instances in this leaf Splitting criterion: Minimize the variance of the values in each subset Si Standard deviation reduction SDR A, S =SD S Termination criteria: i S i S SD S i Very important! (otherwise only single points in each leaf) lower bound on standard deviation in a node lower bound on number of examples in a node Pruning criterion: Numeric error measures, e.g. Mean-Squared Error 61
62 CART (Breiman et al. 1984) Algorithm for learning Classification And Regression Trees Quite similar to ID3/C4.5, but developed indepedently in the statistics community Splitting criterion: Gini-Index for Classification Sum-of-Squares for Regression Pruning: Cost-Complexity Pruning 62
63 Regression Tree Example Task: understand how computer performance is related to a number of variables which describe the features of a PC Data: the size of the cache, the cycle time of the computer, the memory size the number of channels (both the last two were not measured but minimum and maximum values obtained). Based on a slide by Richard Lawton
64 Regression Tree cach< 27 mmax< 6100 mmax< 2.8e+04 syct>=360 mmax< 1750 mmax< cach< syct< chmax< chmin>= cach< 56 chmin< 5.5 mmax< 1.124e chmax< 4.5 cach< mmax< 1.4e Based on a slide by Richard Lawton
65 Estimated Relative Error over Tree Complexity size of tree X -va l R e la tive E rro r Inf cp Based on a slide by Richard Lawton
66 Model Trees In a Leaf node Classification Trees predict a class value Regression Trees predict the average value of all instances in the model Model Trees use a linear model for making the predictions growing of the tree is as with Regression Trees Linear Model: LM x = w i v i x where vi(x) is the value of attribute Ai i for example x and wi is a weight The attributes that have been used in the path of the tree can be ignored Weights can be fitted with standard math packages Minimize the Mean Squared Error MSE = 66 1 y j r j 2 n j
67 Summary Classification Problems require the prediction of a discrete target value can be solved using decision tree learning iteratively select the best attribute and split up the values according to this attribute Regression Problems require the prediction of a numerical target value can be solved with regression trees and model trees difference is in the models that are used at the leafs are grown like decision trees, but with different splitting criteria Overfitting is a serious problem! simpler, seemingly less accurate trees are often preferable evaluation has to be done on separate test sets 67
 http://xkcd.com/1570/ Strategy: Top Down Recursive divide-and-conquer fashion First: Select attribute for root node Create branch for each possible attribute value Then: Split
http://xkcd.com/1570/ Strategy: Top Down Recursive divide-and-conquer fashion First: Select attribute for root node Create branch for each possible attribute value Then: Split
Decision Trees Entropy, Information Gain, Gain Ratio
 Changelog: 14 Oct, 30 Oct Decision Trees Entropy, Information Gain, Gain Ratio Lecture 3: Part 2 Outline Entropy Information gain Gain ratio Marina Santini Acknowledgements Slides borrowed and adapted
Changelog: 14 Oct, 30 Oct Decision Trees Entropy, Information Gain, Gain Ratio Lecture 3: Part 2 Outline Entropy Information gain Gain ratio Marina Santini Acknowledgements Slides borrowed and adapted
Classification: Decision Trees
 Classification: Decision Trees Outline Top-Down Decision Tree Construction Choosing the Splitting Attribute Information Gain and Gain Ratio 2 DECISION TREE An internal node is a test on an attribute. A
Classification: Decision Trees Outline Top-Down Decision Tree Construction Choosing the Splitting Attribute Information Gain and Gain Ratio 2 DECISION TREE An internal node is a test on an attribute. A
Machine Learning 2nd Edi7on
 Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
C4.5 - pruning decision trees
 C4.5 - pruning decision trees Quiz 1 Quiz 1 Q: Is a tree with only pure leafs always the best classifier you can have? A: No. Quiz 1 Q: Is a tree with only pure leafs always the best classifier you can
C4.5 - pruning decision trees Quiz 1 Quiz 1 Q: Is a tree with only pure leafs always the best classifier you can have? A: No. Quiz 1 Q: Is a tree with only pure leafs always the best classifier you can
the tree till a class assignment is reached
 Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
CS 6375 Machine Learning
 CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
Supervised Learning! Algorithm Implementations! Inferring Rudimentary Rules and Decision Trees!
 Supervised Learning! Algorithm Implementations! Inferring Rudimentary Rules and Decision Trees! Summary! Input Knowledge representation! Preparing data for learning! Input: Concept, Instances, Attributes"
Supervised Learning! Algorithm Implementations! Inferring Rudimentary Rules and Decision Trees! Summary! Input Knowledge representation! Preparing data for learning! Input: Concept, Instances, Attributes"
Decision Trees. Each internal node : an attribute Branch: Outcome of the test Leaf node or terminal node: class label.
 Decision Trees Supervised approach Used for Classification (Categorical values) or regression (continuous values). The learning of decision trees is from class-labeled training tuples. Flowchart like structure.
Decision Trees Supervised approach Used for Classification (Categorical values) or regression (continuous values). The learning of decision trees is from class-labeled training tuples. Flowchart like structure.
Learning Decision Trees
 Learning Decision Trees Machine Learning Spring 2018 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning decision trees The ID3 algorithm: A greedy
Learning Decision Trees Machine Learning Spring 2018 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning decision trees The ID3 algorithm: A greedy
Decision Tree Learning
 Decision Tree Learning Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Machine Learning, Chapter 3 2. Data Mining: Concepts, Models,
Decision Tree Learning Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Machine Learning, Chapter 3 2. Data Mining: Concepts, Models,
CS6375: Machine Learning Gautam Kunapuli. Decision Trees
 Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
Decision trees. Special Course in Computer and Information Science II. Adam Gyenge Helsinki University of Technology
 Decision trees Special Course in Computer and Information Science II Adam Gyenge Helsinki University of Technology 6.2.2008 Introduction Outline: Definition of decision trees ID3 Pruning methods Bibliography:
Decision trees Special Course in Computer and Information Science II Adam Gyenge Helsinki University of Technology 6.2.2008 Introduction Outline: Definition of decision trees ID3 Pruning methods Bibliography:
Decision Tree Analysis for Classification Problems. Entscheidungsunterstützungssysteme SS 18
 Decision Tree Analysis for Classification Problems Entscheidungsunterstützungssysteme SS 18 Supervised segmentation An intuitive way of thinking about extracting patterns from data in a supervised manner
Decision Tree Analysis for Classification Problems Entscheidungsunterstützungssysteme SS 18 Supervised segmentation An intuitive way of thinking about extracting patterns from data in a supervised manner
Learning Decision Trees
 Learning Decision Trees Machine Learning Fall 2018 Some slides from Tom Mitchell, Dan Roth and others 1 Key issues in machine learning Modeling How to formulate your problem as a machine learning problem?
Learning Decision Trees Machine Learning Fall 2018 Some slides from Tom Mitchell, Dan Roth and others 1 Key issues in machine learning Modeling How to formulate your problem as a machine learning problem?
Decision Tree Learning Mitchell, Chapter 3. CptS 570 Machine Learning School of EECS Washington State University
 Decision Tree Learning Mitchell, Chapter 3 CptS 570 Machine Learning School of EECS Washington State University Outline Decision tree representation ID3 learning algorithm Entropy and information gain
Decision Tree Learning Mitchell, Chapter 3 CptS 570 Machine Learning School of EECS Washington State University Outline Decision tree representation ID3 learning algorithm Entropy and information gain
Decision Trees. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Decision Trees CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Classification without Models Well, partially without a model } Today: Decision Trees 2015 Bruno Ribeiro 2 3 Why Trees? } interpretable/intuitive,
Decision Trees CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Classification without Models Well, partially without a model } Today: Decision Trees 2015 Bruno Ribeiro 2 3 Why Trees? } interpretable/intuitive,
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 4: Vector Data: Decision Tree Instructor: Yizhou Sun yzsun@cs.ucla.edu October 10, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING 4: Vector Data: Decision Tree Instructor: Yizhou Sun yzsun@cs.ucla.edu October 10, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification Clustering
Decision Tree Learning and Inductive Inference
 Decision Tree Learning and Inductive Inference 1 Widely used method for inductive inference Inductive Inference Hypothesis: Any hypothesis found to approximate the target function well over a sufficiently
Decision Tree Learning and Inductive Inference 1 Widely used method for inductive inference Inductive Inference Hypothesis: Any hypothesis found to approximate the target function well over a sufficiently
Inductive Learning. Chapter 18. Material adopted from Yun Peng, Chuck Dyer, Gregory Piatetsky-Shapiro & Gary Parker
 Inductive Learning Chapter 18 Material adopted from Yun Peng, Chuck Dyer, Gregory Piatetsky-Shapiro & Gary Parker Chapters 3 and 4 Inductive Learning Framework Induce a conclusion from the examples Raw
Inductive Learning Chapter 18 Material adopted from Yun Peng, Chuck Dyer, Gregory Piatetsky-Shapiro & Gary Parker Chapters 3 and 4 Inductive Learning Framework Induce a conclusion from the examples Raw
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation
 Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Part I Introduction to Data Mining by Tan, Steinbach, Kumar Adapted by Qiang Yang (2010) Tan,Steinbach,
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Part I Introduction to Data Mining by Tan, Steinbach, Kumar Adapted by Qiang Yang (2010) Tan,Steinbach,
Classification and Prediction
 Classification Classification and Prediction Classification: predict categorical class labels Build a model for a set of classes/concepts Classify loan applications (approve/decline) Prediction: model
Classification Classification and Prediction Classification: predict categorical class labels Build a model for a set of classes/concepts Classify loan applications (approve/decline) Prediction: model
Learning Classification Trees. Sargur Srihari
 Learning Classification Trees Sargur srihari@cedar.buffalo.edu 1 Topics in CART CART as an adaptive basis function model Classification and Regression Tree Basics Growing a Tree 2 A Classification Tree
Learning Classification Trees Sargur srihari@cedar.buffalo.edu 1 Topics in CART CART as an adaptive basis function model Classification and Regression Tree Basics Growing a Tree 2 A Classification Tree
Einführung in Web- und Data-Science
 Einführung in Web- und Data-Science Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Übungen) Inductive Learning Chapter 18/19 Chapters 3 and 4 Material adopted
Einführung in Web- und Data-Science Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Übungen) Inductive Learning Chapter 18/19 Chapters 3 and 4 Material adopted
Data Mining. CS57300 Purdue University. Bruno Ribeiro. February 8, 2018
 Data Mining CS57300 Purdue University Bruno Ribeiro February 8, 2018 Decision trees Why Trees? interpretable/intuitive, popular in medical applications because they mimic the way a doctor thinks model
Data Mining CS57300 Purdue University Bruno Ribeiro February 8, 2018 Decision trees Why Trees? interpretable/intuitive, popular in medical applications because they mimic the way a doctor thinks model
Decision Trees.
 . Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Lecture 3: Decision Trees
 Lecture 3: Decision Trees Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning Lecture 3: Decision Trees p. Decision
Lecture 3: Decision Trees Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning Lecture 3: Decision Trees p. Decision
DECISION TREE LEARNING. [read Chapter 3] [recommended exercises 3.1, 3.4]
![DECISION TREE LEARNING. [read Chapter 3] [recommended exercises 3.1, 3.4]](/thumbs/78/78784288.jpg "DECISION TREE LEARNING. [read Chapter 3] [recommended exercises 3.1, 3.4]") 1 DECISION TREE LEARNING [read Chapter 3] [recommended exercises 3.1, 3.4] Decision tree representation ID3 learning algorithm Entropy, Information gain Overfitting Decision Tree 2 Representation: Tree-structured
1 DECISION TREE LEARNING [read Chapter 3] [recommended exercises 3.1, 3.4] Decision tree representation ID3 learning algorithm Entropy, Information gain Overfitting Decision Tree 2 Representation: Tree-structured
Decision Trees Part 1. Rao Vemuri University of California, Davis
 Decision Trees Part 1 Rao Vemuri University of California, Davis Overview What is a Decision Tree Sample Decision Trees How to Construct a Decision Tree Problems with Decision Trees Classification Vs Regression
Decision Trees Part 1 Rao Vemuri University of California, Davis Overview What is a Decision Tree Sample Decision Trees How to Construct a Decision Tree Problems with Decision Trees Classification Vs Regression
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
Decision-Tree Learning. Chapter 3: Decision Tree Learning. Classification Learning. Decision Tree for PlayTennis
 Decision-Tree Learning Chapter 3: Decision Tree Learning CS 536: Machine Learning Littman (Wu, TA) [read Chapter 3] [some of Chapter 2 might help ] [recommended exercises 3.1, 3.2] Decision tree representation
Decision-Tree Learning Chapter 3: Decision Tree Learning CS 536: Machine Learning Littman (Wu, TA) [read Chapter 3] [some of Chapter 2 might help ] [recommended exercises 3.1, 3.2] Decision tree representation
Classification and Regression Trees
 Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
Introduction. Decision Tree Learning. Outline. Decision Tree 9/7/2017. Decision Tree Definition
 Introduction Decision Tree Learning Practical methods for inductive inference Approximating discrete-valued functions Robust to noisy data and capable of learning disjunctive expression ID3 earch a completely
Introduction Decision Tree Learning Practical methods for inductive inference Approximating discrete-valued functions Robust to noisy data and capable of learning disjunctive expression ID3 earch a completely
Decision Support. Dr. Johan Hagelbäck.
 Decision Support Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Decision Support One of the earliest AI problems was decision support The first solution to this problem was expert systems
Decision Support Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Decision Support One of the earliest AI problems was decision support The first solution to this problem was expert systems
Decision Trees.
 . Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Data Mining Classification: Basic Concepts and Techniques. Lecture Notes for Chapter 3. Introduction to Data Mining, 2nd Edition
 Data Mining Classification: Basic Concepts and Techniques Lecture Notes for Chapter 3 by Tan, Steinbach, Karpatne, Kumar 1 Classification: Definition Given a collection of records (training set ) Each
Data Mining Classification: Basic Concepts and Techniques Lecture Notes for Chapter 3 by Tan, Steinbach, Karpatne, Kumar 1 Classification: Definition Given a collection of records (training set ) Each
Decision Tree And Random Forest
 Decision Tree And Random Forest Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni. Koblenz-Landau, Germany) Spring 2019 Contact: mailto: Ammar@cu.edu.eg
Decision Tree And Random Forest Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni. Koblenz-Landau, Germany) Spring 2019 Contact: mailto: Ammar@cu.edu.eg
Decision Tree Learning
 Topics Decision Tree Learning Sattiraju Prabhakar CS898O: DTL Wichita State University What are decision trees? How do we use them? New Learning Task ID3 Algorithm Weka Demo C4.5 Algorithm Weka Demo Implementation
Topics Decision Tree Learning Sattiraju Prabhakar CS898O: DTL Wichita State University What are decision trees? How do we use them? New Learning Task ID3 Algorithm Weka Demo C4.5 Algorithm Weka Demo Implementation
Chapter 3: Decision Tree Learning
 Chapter 3: Decision Tree Learning CS 536: Machine Learning Littman (Wu, TA) Administration Books? New web page: http://www.cs.rutgers.edu/~mlittman/courses/ml03/ schedule lecture notes assignment info.
Chapter 3: Decision Tree Learning CS 536: Machine Learning Littman (Wu, TA) Administration Books? New web page: http://www.cs.rutgers.edu/~mlittman/courses/ml03/ schedule lecture notes assignment info.
Lecture 7 Decision Tree Classifier
 Machine Learning Dr.Ammar Mohammed Lecture 7 Decision Tree Classifier Decision Tree A decision tree is a simple classifier in the form of a hierarchical tree structure, which performs supervised classification
Machine Learning Dr.Ammar Mohammed Lecture 7 Decision Tree Classifier Decision Tree A decision tree is a simple classifier in the form of a hierarchical tree structure, which performs supervised classification
Lecture 7: DecisionTrees
 Lecture 7: DecisionTrees What are decision trees? Brief interlude on information theory Decision tree construction Overfitting avoidance Regression trees COMP-652, Lecture 7 - September 28, 2009 1 Recall:
Lecture 7: DecisionTrees What are decision trees? Brief interlude on information theory Decision tree construction Overfitting avoidance Regression trees COMP-652, Lecture 7 - September 28, 2009 1 Recall:
Imagine we ve got a set of data containing several types, or classes. E.g. information about customers, and class=whether or not they buy anything.
 Decision Trees Defining the Task Imagine we ve got a set of data containing several types, or classes. E.g. information about customers, and class=whether or not they buy anything. Can we predict, i.e
Decision Trees Defining the Task Imagine we ve got a set of data containing several types, or classes. E.g. information about customers, and class=whether or not they buy anything. Can we predict, i.e
Administration. Chapter 3: Decision Tree Learning (part 2) Measuring Entropy. Entropy Function
 Measuring Entropy. Entropy Function") Administration Chapter 3: Decision Tree Learning (part 2) Book on reserve in the math library. Questions? CS 536: Machine Learning Littman (Wu, TA) Measuring Entropy Entropy Function S is a sample of training
Administration Chapter 3: Decision Tree Learning (part 2) Book on reserve in the math library. Questions? CS 536: Machine Learning Littman (Wu, TA) Measuring Entropy Entropy Function S is a sample of training
Data classification (II)
") Lecture 4: Data classification (II) Data Mining - Lecture 4 (2016) 1 Outline Decision trees Choice of the splitting attribute ID3 C4.5 Classification rules Covering algorithms Naïve Bayes Classification
Lecture 4: Data classification (II) Data Mining - Lecture 4 (2016) 1 Outline Decision trees Choice of the splitting attribute ID3 C4.5 Classification rules Covering algorithms Naïve Bayes Classification
Question of the Day. Machine Learning 2D1431. Decision Tree for PlayTennis. Outline. Lecture 4: Decision Tree Learning
 Question of the Day Machine Learning 2D1431 How can you make the following equation true by drawing only one straight line? 5 + 5 + 5 = 550 Lecture 4: Decision Tree Learning Outline Decision Tree for PlayTennis
Question of the Day Machine Learning 2D1431 How can you make the following equation true by drawing only one straight line? 5 + 5 + 5 = 550 Lecture 4: Decision Tree Learning Outline Decision Tree for PlayTennis
Machine Learning & Data Mining
 Group M L D Machine Learning M & Data Mining Chapter 7 Decision Trees Xin-Shun Xu @ SDU School of Computer Science and Technology, Shandong University Top 10 Algorithm in DM #1: C4.5 #2: K-Means #3: SVM
Group M L D Machine Learning M & Data Mining Chapter 7 Decision Trees Xin-Shun Xu @ SDU School of Computer Science and Technology, Shandong University Top 10 Algorithm in DM #1: C4.5 #2: K-Means #3: SVM
ML techniques. symbolic techniques different types of representation value attribute representation representation of the first order
 MACHINE LEARNING Definition 1: Learning is constructing or modifying representations of what is being experienced [Michalski 1986], p. 10 Definition 2: Learning denotes changes in the system That are adaptive
MACHINE LEARNING Definition 1: Learning is constructing or modifying representations of what is being experienced [Michalski 1986], p. 10 Definition 2: Learning denotes changes in the system That are adaptive
UVA CS 4501: Machine Learning
 UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
Decision Trees. CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore
 Decision Trees Claude Monet, The Mulberry Tree Slides from Pedro Domingos, CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Michael Guerzhoy
Decision Trees Claude Monet, The Mulberry Tree Slides from Pedro Domingos, CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Michael Guerzhoy
The Solution to Assignment 6
 The Solution to Assignment 6 Problem 1: Use the 2-fold cross-validation to evaluate the Decision Tree Model for trees up to 2 levels deep (that is, the maximum path length from the root to the leaves is
The Solution to Assignment 6 Problem 1: Use the 2-fold cross-validation to evaluate the Decision Tree Model for trees up to 2 levels deep (that is, the maximum path length from the root to the leaves is
Decision Tree Learning Lecture 2
 Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Decision Trees. Data Science: Jordan Boyd-Graber University of Maryland MARCH 11, Data Science: Jordan Boyd-Graber UMD Decision Trees 1 / 1
 Decision Trees Data Science: Jordan Boyd-Graber University of Maryland MARCH 11, 2018 Data Science: Jordan Boyd-Graber UMD Decision Trees 1 / 1 Roadmap Classification: machines labeling data for us Last
Decision Trees Data Science: Jordan Boyd-Graber University of Maryland MARCH 11, 2018 Data Science: Jordan Boyd-Graber UMD Decision Trees 1 / 1 Roadmap Classification: machines labeling data for us Last
Classification and regression trees
 Classification and regression trees Pierre Geurts p.geurts@ulg.ac.be Last update: 23/09/2015 1 Outline Supervised learning Decision tree representation Decision tree learning Extensions Regression trees
Classification and regression trees Pierre Geurts p.geurts@ulg.ac.be Last update: 23/09/2015 1 Outline Supervised learning Decision tree representation Decision tree learning Extensions Regression trees
Decision Tree Learning
 0. Decision Tree Learning Based on Machine Learning, T. Mitchell, McGRAW Hill, 1997, ch. 3 Acknowledgement: The present slides are an adaptation of slides drawn by T. Mitchell PLAN 1. Concept learning:
0. Decision Tree Learning Based on Machine Learning, T. Mitchell, McGRAW Hill, 1997, ch. 3 Acknowledgement: The present slides are an adaptation of slides drawn by T. Mitchell PLAN 1. Concept learning:
Decision Trees. Danushka Bollegala
 Decision Trees Danushka Bollegala Rule-based Classifiers In rule-based learning, the idea is to learn a rule from train data in the form IF X THEN Y (or a combination of nested conditions) that explains
Decision Trees Danushka Bollegala Rule-based Classifiers In rule-based learning, the idea is to learn a rule from train data in the form IF X THEN Y (or a combination of nested conditions) that explains
Classification Using Decision Trees
 Classification Using Decision Trees 1. Introduction Data mining term is mainly used for the specific set of six activities namely Classification, Estimation, Prediction, Affinity grouping or Association
Classification Using Decision Trees 1. Introduction Data mining term is mainly used for the specific set of six activities namely Classification, Estimation, Prediction, Affinity grouping or Association
EECS 349:Machine Learning Bryan Pardo
 EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
Introduction to ML. Two examples of Learners: Naïve Bayesian Classifiers Decision Trees
 Introduction to ML Two examples of Learners: Naïve Bayesian Classifiers Decision Trees Why Bayesian learning? Probabilistic learning: Calculate explicit probabilities for hypothesis, among the most practical
Introduction to ML Two examples of Learners: Naïve Bayesian Classifiers Decision Trees Why Bayesian learning? Probabilistic learning: Calculate explicit probabilities for hypothesis, among the most practical
Notes on Machine Learning for and
 Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Learning = improving with experience Improve over task T (e.g, Classification, control tasks) with respect
Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Learning = improving with experience Improve over task T (e.g, Classification, control tasks) with respect
M chi h n i e n L e L arni n n i g Decision Trees Mac a h c i h n i e n e L e L a e r a ni n ng
 1 Decision Trees 2 Instances Describable by Attribute-Value Pairs Target Function Is Discrete Valued Disjunctive Hypothesis May Be Required Possibly Noisy Training Data Examples Equipment or medical diagnosis
1 Decision Trees 2 Instances Describable by Attribute-Value Pairs Target Function Is Discrete Valued Disjunctive Hypothesis May Be Required Possibly Noisy Training Data Examples Equipment or medical diagnosis
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 4 Algorithms: The basic methods Simplicity first: 1R Use all attributes: Naïve Bayes Decision trees: ID3 Covering algorithms: decision rules: PRISM Association
Slides for Data Mining by I. H. Witten and E. Frank 4 Algorithms: The basic methods Simplicity first: 1R Use all attributes: Naïve Bayes Decision trees: ID3 Covering algorithms: decision rules: PRISM Association
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Intelligent Data Analysis. Decision Trees
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Intelligent Data Analysis Decision Trees Paul Prasse, Niels Landwehr, Tobias Scheffer Decision Trees One of many applications:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Intelligent Data Analysis Decision Trees Paul Prasse, Niels Landwehr, Tobias Scheffer Decision Trees One of many applications:
Decision Trees. Gavin Brown
 Decision Trees Gavin Brown Every Learning Method has Limitations Linear model? KNN? SVM? Explain your decisions Sometimes we need interpretable results from our techniques. How do you explain the above
Decision Trees Gavin Brown Every Learning Method has Limitations Linear model? KNN? SVM? Explain your decisions Sometimes we need interpretable results from our techniques. How do you explain the above
Lecture 3: Decision Trees
 Lecture 3: Decision Trees Cognitive Systems - Machine Learning Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning last change November 26, 2014 Ute Schmid (CogSys,
Lecture 3: Decision Trees Cognitive Systems - Machine Learning Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning last change November 26, 2014 Ute Schmid (CogSys,
Inductive Learning. Chapter 18. Why Learn?
 Inductive Learning Chapter 18 Material adopted from Yun Peng, Chuck Dyer, Gregory Piatetsky-Shapiro & Gary Parker Why Learn? Understand and improve efficiency of human learning Use to improve methods for
Inductive Learning Chapter 18 Material adopted from Yun Peng, Chuck Dyer, Gregory Piatetsky-Shapiro & Gary Parker Why Learn? Understand and improve efficiency of human learning Use to improve methods for
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan
 Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan") Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
Classification: Rule Induction Information Retrieval and Data Mining. Prof. Matteo Matteucci
 Classification: Rule Induction Information Retrieval and Data Mining Prof. Matteo Matteucci What is Rule Induction? The Weather Dataset 3 Outlook Temp Humidity Windy Play Sunny Hot High False No Sunny
Classification: Rule Induction Information Retrieval and Data Mining Prof. Matteo Matteucci What is Rule Induction? The Weather Dataset 3 Outlook Temp Humidity Windy Play Sunny Hot High False No Sunny
Machine Learning 2010
 Machine Learning 2010 Decision Trees Email: mrichter@ucalgary.ca -- 1 - Part 1 General -- 2 - Representation with Decision Trees (1) Examples are attribute-value vectors Representation of concepts by labeled
Machine Learning 2010 Decision Trees Email: mrichter@ucalgary.ca -- 1 - Part 1 General -- 2 - Representation with Decision Trees (1) Examples are attribute-value vectors Representation of concepts by labeled
CHAPTER-17. Decision Tree Induction
 CHAPTER-17 Decision Tree Induction 17.1 Introduction 17.2 Attribute selection measure 17.3 Tree Pruning 17.4 Extracting Classification Rules from Decision Trees 17.5 Bayesian Classification 17.6 Bayes
CHAPTER-17 Decision Tree Induction 17.1 Introduction 17.2 Attribute selection measure 17.3 Tree Pruning 17.4 Extracting Classification Rules from Decision Trees 17.5 Bayesian Classification 17.6 Bayes
Decision Trees. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. February 5 th, Carlos Guestrin 1
 Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Decision Trees. Tirgul 5
 Decision Trees Tirgul 5 Using Decision Trees It could be difficult to decide which pet is right for you. We ll find a nice algorithm to help us decide what to choose without having to think about it. 2
Decision Trees Tirgul 5 Using Decision Trees It could be difficult to decide which pet is right for you. We ll find a nice algorithm to help us decide what to choose without having to think about it. 2
Chapter 3: Decision Tree Learning (part 2)
") Chapter 3: Decision Tree Learning (part 2) CS 536: Machine Learning Littman (Wu, TA) Administration Books? Two on reserve in the math library. icml-03: instructional Conference on Machine Learning mailing
Chapter 3: Decision Tree Learning (part 2) CS 536: Machine Learning Littman (Wu, TA) Administration Books? Two on reserve in the math library. icml-03: instructional Conference on Machine Learning mailing
Apprentissage automatique et fouille de données (part 2)
") Apprentissage automatique et fouille de données (part 2) Telecom Saint-Etienne Elisa Fromont (basé sur les cours d Hendrik Blockeel et de Tom Mitchell) 1 Induction of decision trees : outline (adapted
Apprentissage automatique et fouille de données (part 2) Telecom Saint-Etienne Elisa Fromont (basé sur les cours d Hendrik Blockeel et de Tom Mitchell) 1 Induction of decision trees : outline (adapted
Outline. Training Examples for EnjoySport. 2 lecture slides for textbook Machine Learning, c Tom M. Mitchell, McGraw Hill, 1997
 Outline Training Examples for EnjoySport Learning from examples General-to-specific ordering over hypotheses [read Chapter 2] [suggested exercises 2.2, 2.3, 2.4, 2.6] Version spaces and candidate elimination
Outline Training Examples for EnjoySport Learning from examples General-to-specific ordering over hypotheses [read Chapter 2] [suggested exercises 2.2, 2.3, 2.4, 2.6] Version spaces and candidate elimination
CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING Santiago Ontañón so367@drexel.edu Summary so far: Rational Agents Problem Solving Systematic Search: Uninformed Informed Local Search Adversarial Search
CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING Santiago Ontañón so367@drexel.edu Summary so far: Rational Agents Problem Solving Systematic Search: Uninformed Informed Local Search Adversarial Search
Machine Learning Recitation 8 Oct 21, Oznur Tastan
 Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Data Mining and Machine Learning (Machine Learning: Symbolische Ansätze)
") Data Mining and Machine Learning (Machine Learning: Symbolische Ansätze) Learning Individual Rules and Subgroup Discovery Introduction Batch Learning Terminology Coverage Spaces Descriptive vs. Predictive
Data Mining and Machine Learning (Machine Learning: Symbolische Ansätze) Learning Individual Rules and Subgroup Discovery Introduction Batch Learning Terminology Coverage Spaces Descriptive vs. Predictive
Algorithms for Classification: The Basic Methods
 Algorithms for Classification: The Basic Methods Outline Simplicity first: 1R Naïve Bayes 2 Classification Task: Given a set of pre-classified examples, build a model or classifier to classify new cases.
Algorithms for Classification: The Basic Methods Outline Simplicity first: 1R Naïve Bayes 2 Classification Task: Given a set of pre-classified examples, build a model or classifier to classify new cases.
Symbolic methods in TC: Decision Trees
 Symbolic methods in TC: Decision Trees ML for NLP Lecturer: Kevin Koidl Assist. Lecturer Alfredo Maldonado https://www.cs.tcd.ie/kevin.koidl/cs0/ kevin.koidl@scss.tcd.ie, maldonaa@tcd.ie 01-017 A symbolic
Symbolic methods in TC: Decision Trees ML for NLP Lecturer: Kevin Koidl Assist. Lecturer Alfredo Maldonado https://www.cs.tcd.ie/kevin.koidl/cs0/ kevin.koidl@scss.tcd.ie, maldonaa@tcd.ie 01-017 A symbolic
2018 CS420, Machine Learning, Lecture 5. Tree Models. Weinan Zhang Shanghai Jiao Tong University
 2018 CS420, Machine Learning, Lecture 5 Tree Models Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html ML Task: Function Approximation Problem setting
2018 CS420, Machine Learning, Lecture 5 Tree Models Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html ML Task: Function Approximation Problem setting
Machine Learning 3. week
 Machine Learning 3. week Entropy Decision Trees ID3 C4.5 Classification and Regression Trees (CART) 1 What is Decision Tree As a short description, decision tree is a data classification procedure which
Machine Learning 3. week Entropy Decision Trees ID3 C4.5 Classification and Regression Trees (CART) 1 What is Decision Tree As a short description, decision tree is a data classification procedure which
Rule Generation using Decision Trees
 Rule Generation using Decision Trees Dr. Rajni Jain 1. Introduction A DT is a classification scheme which generates a tree and a set of rules, representing the model of different classes, from a given
Rule Generation using Decision Trees Dr. Rajni Jain 1. Introduction A DT is a classification scheme which generates a tree and a set of rules, representing the model of different classes, from a given
Machine Learning Chapter 4. Algorithms
 Machine Learning Chapter 4. Algorithms 4 Algorithms: The basic methods Simplicity first: 1R Use all attributes: Naïve Bayes Decision trees: ID3 Covering algorithms: decision rules: PRISM Association rules
Machine Learning Chapter 4. Algorithms 4 Algorithms: The basic methods Simplicity first: 1R Use all attributes: Naïve Bayes Decision trees: ID3 Covering algorithms: decision rules: PRISM Association rules
Decision Tree Learning
 Decision Tree Learning Goals for the lecture you should understand the following concepts the decision tree representation the standard top-down approach to learning a tree Occam s razor entropy and information
Decision Tree Learning Goals for the lecture you should understand the following concepts the decision tree representation the standard top-down approach to learning a tree Occam s razor entropy and information
Decision Tree Learning
 Decision Tree Learning Goals for the lecture you should understand the following concepts the decision tree representation the standard top-down approach to learning a tree Occam s razor entropy and information
Decision Tree Learning Goals for the lecture you should understand the following concepts the decision tree representation the standard top-down approach to learning a tree Occam s razor entropy and information
( D) I(2,3) I(4,0) I(3,2) weighted avg. of entropies
 I(2,3) I(4,0) I(3,2) weighted avg. of entropies") Decision Tree Induction using Information Gain Let I(x,y) as the entropy in a dataset with x number of class 1(i.e., play ) and y number of class (i.e., don t play outcomes. The entropy at the root, i.e.,
Decision Tree Induction using Information Gain Let I(x,y) as the entropy in a dataset with x number of class 1(i.e., play ) and y number of class (i.e., don t play outcomes. The entropy at the root, i.e.,
Holdout and Cross-Validation Methods Overfitting Avoidance
 Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Induction on Decision Trees
 Séance «IDT» de l'ue «apprentissage automatique» Bruno Bouzy bruno.bouzy@parisdescartes.fr www.mi.parisdescartes.fr/~bouzy Outline Induction task ID3 Entropy (disorder) minimization Noise Unknown attribute
Séance «IDT» de l'ue «apprentissage automatique» Bruno Bouzy bruno.bouzy@parisdescartes.fr www.mi.parisdescartes.fr/~bouzy Outline Induction task ID3 Entropy (disorder) minimization Noise Unknown attribute
Decision Tree Learning - ID3
 Decision Tree Learning - ID3 n Decision tree examples n ID3 algorithm n Occam Razor n Top-Down Induction in Decision Trees n Information Theory n gain from property 1 Training Examples Day Outlook Temp.
Decision Tree Learning - ID3 n Decision tree examples n ID3 algorithm n Occam Razor n Top-Down Induction in Decision Trees n Information Theory n gain from property 1 Training Examples Day Outlook Temp.
Chapter 6: Classification
 Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
Machine Learning Alternatives to Manual Knowledge Acquisition
 Machine Learning Alternatives to Manual Knowledge Acquisition Interactive programs which elicit knowledge from the expert during the course of a conversation at the terminal. Programs which learn by scanning
Machine Learning Alternatives to Manual Knowledge Acquisition Interactive programs which elicit knowledge from the expert during the course of a conversation at the terminal. Programs which learn by scanning
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Machine Learning and Data Mining. Decision Trees. Prof. Alexander Ihler
 + Machine Learning and Data Mining Decision Trees Prof. Alexander Ihler Decision trees Func-onal form f(x;µ): nested if-then-else statements Discrete features: fully expressive (any func-on) Structure:
+ Machine Learning and Data Mining Decision Trees Prof. Alexander Ihler Decision trees Func-onal form f(x;µ): nested if-then-else statements Discrete features: fully expressive (any func-on) Structure:
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Induction of Decision Trees
 Induction of Decision Trees Peter Waiganjo Wagacha This notes are for ICS320 Foundations of Learning and Adaptive Systems Institute of Computer Science University of Nairobi PO Box 30197, 00200 Nairobi.
Induction of Decision Trees Peter Waiganjo Wagacha This notes are for ICS320 Foundations of Learning and Adaptive Systems Institute of Computer Science University of Nairobi PO Box 30197, 00200 Nairobi.
Reminders. HW1 out, due 10/19/2017 (Thursday) Group formations for course project due today (1 pt) Join Piazza (
 Group formations for course project due today (1 pt) Join Piazza (") CS 145 Discussion 2 Reminders HW1 out, due 10/19/2017 (Thursday) Group formations for course project due today (1 pt) Join Piazza (email: juwood03@ucla.edu) Overview Linear Regression Z Score Normalization
CS 145 Discussion 2 Reminders HW1 out, due 10/19/2017 (Thursday) Group formations for course project due today (1 pt) Join Piazza (email: juwood03@ucla.edu) Overview Linear Regression Z Score Normalization
brainlinksystem.com $25+ / hr AI Decision Tree Learning Part I Outline Learning 11/9/2010 Carnegie Mellon
 I Decision Tree Learning Part I brainlinksystem.com $25+ / hr Illah Nourbakhsh s version Chapter 8, Russell and Norvig Thanks to all past instructors Carnegie Mellon Outline Learning and philosophy Induction
I Decision Tree Learning Part I brainlinksystem.com $25+ / hr Illah Nourbakhsh s version Chapter 8, Russell and Norvig Thanks to all past instructors Carnegie Mellon Outline Learning and philosophy Induction
Statistics and learning: Big Data
 Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees