Natural Language Processing. Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu
|
|
|
- Tobias Cunningham
- 5 years ago
- Views:
Transcription
1 Natural Language Processing Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu
2 סקר הערכת הוראה Fill it!
3 Presentations next week 21 projects 20/6: 12 presentations 27/6: 9 presentations 10 minutes per presentation + 2 minutes for questions and transition 4 projects per hour Some wiggle room if there are any problems Put presentations in folder
4 Presentations next week Describe precisely the task and its importance Describe prior work What you are planning to do and why Evaluation What are potential problems and how you will address them
5 Last class Sequence to sequence models LSTMs and GRUs Attention Pointer networks
6 Today Weak supervision Tree structured neural networks A nice paper on combining search and learning Stuff we didn t cover Concluding remarks
7 Weak supervision

8 Weak supervision We have assumed that we have as input pairs of natural language and logical form In practice those are hard to collect and we usually have (language, denotation) pairs
9 The problem Before we trained with cross entropy over tokens, but we don t have tokens here softmax Type (0.7) Profession (0.2) argmax Type t t+1
10 This looks familiar Search with CKY Can we do something similar with a seq2seq model?
11 Markov Decision Process Sequence of states, actions and rewards s 0, s 1, s 2,, s T from a set S a 0, a 1, a 2,, a T from a set A Let s assume a deterministic transition function f:sxa->s r 0, r 1, r 2,, r T given by a reward function r(s,a) We want a policy π(a s) providing a distribution over actions that will maximize expected future reward a0 a1 a2 s0 s1 s2 at-1 st
12 Liang et al, 2017, Guu et al., 2017 Seq2seq as MDP s t : h t a t is in A(s t ) Either all symbols in the target vocabulary All valid symbols if we check grammaticality r t is zero in all steps except the last. Then, it is 1 if execution results in a correct answer and 0 otherwise. tall Lebron James? <s> HeightOf
13 Seq2seq as MDP: policy p(z x) = Y t p(z t x, z 0,...,z t 1 ) = Y t p(a t x, a 0,...,a t 1 ) = Y t (a t s t ) (a t s t ) = softmax(w (s) h t ) tall Lebron James? <s> HeightOf How do we learn?
14 Option 1: Maximum marginal likelihood Our data is language-dentation pairs (x,y) We obtain y by constructing a logical form z We can use maximum marginal likelihood like before Interleave search and learning Apply search to get candidate logical forms (with fixed model) Update parameters based on candidates Difference from before: Search was done with CKY and learning was a globally-normalized model Search can be done with beam search and we have a locally-normalized model
15 Maximum marginal likelihood z is independent of x conditioned on y p (y x) = X z p (z x) p(y z) = X z p (z x)r(z) =E p (z x)[r(z)] L MML ( ) = log Y (x,y) p (y x) =log Y (x,y) E p (z x)[r(z)] = X (x,y) log X z p (z x) R(z)
16 Gradient of MML Gradient has similar form to what we have seen in the past, except that we are not in a log-linear model. Let s assume a binary reward: r log X z p (z x) R(z) = X z p (z)r(z)r log p (z x) P 0 z p (z 0 x) R(z 0 ) = X z p(z x, R(z) = 1)r log p (z x) Compute the gradient of the log probability for every logical form, and weight the gradient using the reward.
17 Computing the gradient We can not enumerate all of the logical forms Instead we perform beam search as usual and get a beam Z containing K logical forms. We imagine that this beam is the entire set of possible logical forms X p(z x, R(z) = 1)r log p (z x) z2z For every z we can compute the gradient of log p(z x) since this is now the usual seq2seq setup.
18 Option 2: policy gradient We would like to simply maximize our expected reward E p (z x)[r(z)] = X p (z x)r(z) z L RL ( ) = X X p (z x)r(z) = X E p (z x)[r(z)] (x,y) z (x,y) rl RL ( ) = X X p (z x)r(z)r log p (z x) (x,y) z = X E p (z x)[r(z)r log p (z x)] (x,y) Weight the gradient by the product of the reward and the model probability
19 Computing the gradient Again, we can not sum over all logical forms But the gradient for every example is an expectation over a distribution we can sample from! So we can sample many logical forms, compute the gradient and sum them weighted by the product of the model probability and reward Again, for every sample this is regular seq2seq and we can compute an approximate gradient
20 Some differences Using MML with beam search is a biased estimator and has less exploration - we only observe the approximate top-k logical forms Using RL could be harder to train. If we have a correct logical form z* that has low probability at the beginning of training, then the contribution to the gradient would be very small and it would be hard to boostrap.
21 Intermediate summary Training with a seq2seq model with weak supervision is problematic because the loss function is not a differentiable function of the input We saw both MML and RL approaches for getting around that In both we find a set of logical forms, compute the gradient for them like in supervised learning, and weight them in some way to form a final gradient This let s us train with SGD Often this is still hard to train - more ahead
22 Bengio et al, 2013, Jang et al, 2016 Other approaches Other approaches have been suggested to overcome the non-differentiability problem Using softmax directly Temperature Straight-through estimator
23 Neelakantan et al, 2016 Softmax Replace argmax with softmax at training time Pass as input the average of embeddings Use argmax at test time Could approximate argmax (skewed distributions) Train-test mismatch (you don t train on logical forms) softmax WeightOf (0.7) HeightOf (0.2) Embed and avg.
24 Adding temperature p(a) = s(a) exp( ) t Pa 0 exp( s(a0 ) t ) Start with high temperature: when t = 1 this is softmax when t is high - uniform Anneal temperature towards 0: get close to argmax
25 Bengio, 2013 Straight-through estimator Use argmax at forward pass Pretend that you had softmax in the backward pass
26 Global loss functions Gold I saw the big tree there Pred 1 I saw the the tree there Pred 2 I saw the tree over there The first is better than the second from a maximum likelihood point of view
27 Exposure bias Training time: Model observes correct tokens only I saw the big At test time we observer predicted tokens I saw the the After an error our hidden state might be different from anything we have seen and errors can accumulate - train-test mismatch
28 Solution - RL? We can just define a reward on the entire token sequence! Then we have the same setup as semantic parsing But training with REINFORCE is much harder than training with ML Imitation learning

29 Imitation learning
30 Imitation learning In sequence to sequence the expert is simply the correct sequence. So this is exactly maximum likelihood Imitation learning algorithms provide a way to avoid exposure bias
31 Dagger For an example (x, y) and an expert π* Define a policy π=β π* + (1-β)πt Sample from π, and use (x,y) to define loss Train Reduce β exponentially
32 Dagger This gets rid of exposure bias Problems: in some cases after you sample something wrong, it is hard to define an expert/ oracle at all! Still haven t dealt with the problem of bad reward
33 Choi et al., 2017 Global reward Similar annealing approach can be taken for changing the reward Begin with ML objective slowly transition to your true reward as your model becomes better. Mix somehow your two loss functions and change their weights with time At the end of training you are sampling just from your model and using your true reward - simple RL!
34 Liang et al., 2017 Semantic parsing In semantic parsing there is no expert A way to get around that is to interleave maximum likelihood training with RL training ML training: Run search: find some approximate gold logical form z* Train with an ML objective on z* RL training: Sample from your model and update according to REINFORCE
35 Summary Using sequence to sequence models with delayed reward does not have a consensus solution yet Solutions range from Continuous relaxations REINFORCE like algorithm Mixing ML with RL in various ways Many flavors of curriculum learning/annealing
36 Tree RNNs
37 Back to Trees We learned about constituency parsing with linear models We saw we can replace linear scoring functions with deep neural networks and maintain exact decoding But what if we forego exact decoding and instead use a powerful non-linear model? Can we use LSTM like architecture to build trees?
38 Meaning composition tall Lebron James? tall We compose meanings left-to-right (over prefixes) Lebron
39 But language is hierarchical A snowboarder is leaping over a mogul A person on a snowboard jumps into the air Our understanding of language depends on building larger meaning of units. Having a prior on the structure of language should be beneficial Should we compute meaning up a tree structure?

40
41 Reality Unfortunately it is not always easy to show that using a tree structure over language is better than a sequence because LSTMs are strong learning machines and have good memory Where do you get the trees from? Often trees are wrong and expensive to compute
42 Distributed representations for sentences
43 Embedding a sentence Use compositionality to build the representations This is more than just syntactic parsing! We hope to achieve a semantic representation as well
44 If we have a parse tree
45 Recursive neural networks

46 Socher et al., 2012 Recursive neural networks NN p = tanh(w 1 c 1 + W 2 c 2 + b) s(p) =w > p
47 Combine with greedy parsing
48 Combining with greedy parsing
49 Combining with greedy parsing
50 Global score The score of the tree is the sum of decisions along the way They used a max-margin loss: for a training pair (x, y) maximize s(x, y) max(s(x, y 0 )+ (y, y 0 )) y 0 Solving this max is exponential! Approximate with beam search
51 Syntactic parsing This did not result in state-of-the-art performance Problem: A single matrix that composes all pairs of words regardless of their syntax
52 Socher et al., 2013 Compositional vector grammars Use PCFGs to build the structure of the tree and then compose the meaning with vectors We have a different matrix for every pair of syntactic categories that are on the RHS of a grammar rule The score for category P which has vector p is obtained by multiplying a with a vector and adding the log probability of the rule in the grammar s(p, P ) = log P (P! BC)+w > f(w bc [b; c])
53 Compositional vector grammars
54 Socher et al., 2013 Problems Many parameters Hard to compute everything from scratch Instead they did re-ranking on a simple PCFG model
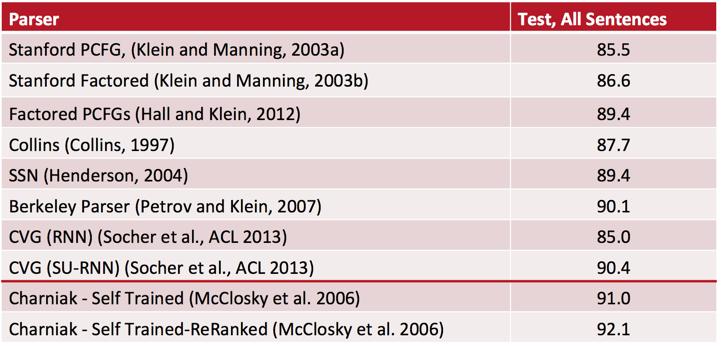

55 Evaluation

56 Sentence representations Anecdotal
57 Tree LSTMs for CCG parsing Nice slides by Kenton Lee!
58 Stuff we didn t cover

59 Coreference resolution Coreference resolution: the task of clustering together of expressions that refer to the same concept/entity Michelle LaVaughn Robinson Obama is an American lawyer and writer. She is the wife of the 44th president of the United States, Barack Obama, and the first African-American first lady of the United States
60 Importance Crucial for general natural language understanding Who is Barack Obama s spouse? Information extraction Anywhere you need to understand more than one sentence there are coreference issues
61 Main sub-tasks Entity extraction Coreference resolution Entity linking
62 Entity extraction Find all mentions of entities in a text Michelle LaVaughn Robinson Obama She The wife of
63 Coreference resolution Clustering of the entities extracted Michelle Obama she the wife of Barack Obama The president

64 Michelle Obama she the wife of Entity linking
65 General approaches Score every pair of entity mentions Find the best clustering In practice this is hard so usually a more greedy approach is used
66 Question answering A central task in NLP One can argue that any task can be reduced to QA with natural language A lot of interest in last couple of years Dominated by many large scale corpora and deep learning

67 SQuAD Rajpurkar et al, 2016

68 Daily Mail Hermann et al, 2015

69 Hewlett et al, 2016 WikiReading Nguyen,
70 Nguyen et al, 2016 Ms-MARCO Q: what is rba A: Results-Based Accountability is a disciplined way of thinking and taking action that communities can use to improve the lives of children, youth, families, adults and the community as a whole p1: Since 2007, the RBA's outstanding reputation has been affected by p2: The Reserve Bank of Australia (RBA) came into being on 14 January p3: Results-Based Accountability (also known as RBA) is a disciplined

71 TriviaQA Joshi et al, 2017

72 MCTest Richardson et al, 2013

73 ProcessBank Berant et al, 2014

74 Bowman et al., 2015 Natural Language Inference
75 Dependency parsing In constituency parsing: We saw both greedy an graph-based method Similar distinctions also occur in dependency parsing, but the algorithms are different
76 Character-based models Ling et al., 2015
77 More Multi-task learning ILP inference and LP relaxation Summarization Interactive learning
78 Broad takeaways
79 What did we cover? Word embeddings Language models Sequence tagging Syntactic parsing Semantic parsing
80 Main technical tools Structured prediction Deep learning General recipe: Define a parameterized mapping from input to output Define a loss function Optimize Find best output at test time
81 High-level observations Often linear models can be replaced with nonlinear ones without change to the guarantees A growing trend is to move the burden from inference to learning. Let information flow between various variables in a neural network and make inference very simple It is still an active research area
82 Hopefully you Appreciate the complexity of building systems for natural language Understand the main tools used to build state-ofthe-art systems nowadays Have solid background to read papers Have solid background to develop models for NLP
83 Apology This is the first time this class is taught under hard time constraints. Sorry for The typos in the slides The clarify of HW We will learn and improve next time Thanks for helping us debug the class!
84 Thank you!
Natural Language Processing. Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu
 Natural Language Processing Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu Projects Project descriptions due today! Last class Sequence to sequence models Attention Pointer networks Today Weak
Natural Language Processing Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu Projects Project descriptions due today! Last class Sequence to sequence models Attention Pointer networks Today Weak
Natural Language Processing
 Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
with Local Dependencies
 CS11-747 Neural Networks for NLP Structured Prediction with Local Dependencies Xuezhe Ma (Max) Site https://phontron.com/class/nn4nlp2017/ An Example Structured Prediction Problem: Sequence Labeling Sequence
CS11-747 Neural Networks for NLP Structured Prediction with Local Dependencies Xuezhe Ma (Max) Site https://phontron.com/class/nn4nlp2017/ An Example Structured Prediction Problem: Sequence Labeling Sequence
Natural Language Processing
 Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Conditional Language modeling with attention
 Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Neural Architectures for Image, Language, and Speech Processing
 Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Statistical Methods for NLP
 Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
 Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation Y. Wu, M. Schuster, Z. Chen, Q.V. Le, M. Norouzi, et al. Google arxiv:1609.08144v2 Reviewed by : Bill
Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation Y. Wu, M. Schuster, Z. Chen, Q.V. Le, M. Norouzi, et al. Google arxiv:1609.08144v2 Reviewed by : Bill
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
lecture 6: modeling sequences (final part)
") Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Lab 12: Structured Prediction
 December 4, 2014 Lecture plan structured perceptron application: confused messages application: dependency parsing structured SVM Class review: from modelization to classification What does learning mean?
December 4, 2014 Lecture plan structured perceptron application: confused messages application: dependency parsing structured SVM Class review: from modelization to classification What does learning mean?
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
Deep Learning For Mathematical Functions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
CSC321 Lecture 7 Neural language models
 CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models. The ischool University of Maryland. Wednesday, September 30, 2009
 CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Soft Inference and Posterior Marginals. September 19, 2013
 Soft Inference and Posterior Marginals September 19, 2013 Soft vs. Hard Inference Hard inference Give me a single solution Viterbi algorithm Maximum spanning tree (Chu-Liu-Edmonds alg.) Soft inference
Soft Inference and Posterior Marginals September 19, 2013 Soft vs. Hard Inference Hard inference Give me a single solution Viterbi algorithm Maximum spanning tree (Chu-Liu-Edmonds alg.) Soft inference
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Recurrent and Recursive Networks
 Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
N-gram Language Modeling
 N-gram Language Modeling Outline: Statistical Language Model (LM) Intro General N-gram models Basic (non-parametric) n-grams Class LMs Mixtures Part I: Statistical Language Model (LM) Intro What is a statistical
N-gram Language Modeling Outline: Statistical Language Model (LM) Intro General N-gram models Basic (non-parametric) n-grams Class LMs Mixtures Part I: Statistical Language Model (LM) Intro What is a statistical
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Final Exam, Machine Learning, Spring 2009
 Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields
 Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
arxiv: v1 [cs.cl] 21 May 2017
![arxiv: v1 [cs.cl] 21 May 2017](/thumbs/92/109535705.jpg "arxiv: v1 [cs.cl] 21 May 2017") Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Marrying Dynamic Programming with Recurrent Neural Networks
 Marrying Dynamic Programming with Recurrent Neural Networks I eat sushi with tuna from Japan Liang Huang Oregon State University Structured Prediction Workshop, EMNLP 2017, Copenhagen, Denmark Marrying
Marrying Dynamic Programming with Recurrent Neural Networks I eat sushi with tuna from Japan Liang Huang Oregon State University Structured Prediction Workshop, EMNLP 2017, Copenhagen, Denmark Marrying
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Neural Networks in Structured Prediction. November 17, 2015
 Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
CSC321 Lecture 15: Recurrent Neural Networks
 CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
Seq2Seq Losses (CTC)
") Seq2Seq Losses (CTC) Jerry Ding & Ryan Brigden 11-785 Recitation 6 February 23, 2018 Outline Tasks suited for recurrent networks Losses when the output is a sequence Kinds of errors Losses to use CTC Loss
Seq2Seq Losses (CTC) Jerry Ding & Ryan Brigden 11-785 Recitation 6 February 23, 2018 Outline Tasks suited for recurrent networks Losses when the output is a sequence Kinds of errors Losses to use CTC Loss
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Deep Learning Basics Lecture 10: Neural Language Models. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
CS395T: Structured Models for NLP Lecture 19: Advanced NNs I
 CS395T: Structured Models for NLP Lecture 19: Advanced NNs I Greg Durrett Administrivia Kyunghyun Cho (NYU) talk Friday 11am GDC 6.302 Project 3 due today! Final project out today! Proposal due in 1 week
CS395T: Structured Models for NLP Lecture 19: Advanced NNs I Greg Durrett Administrivia Kyunghyun Cho (NYU) talk Friday 11am GDC 6.302 Project 3 due today! Final project out today! Proposal due in 1 week
Natural Language Processing
 Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
Contents. (75pts) COS495 Midterm. (15pts) Short answers
 COS495 Midterm. (15pts) Short answers") Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
arxiv: v2 [cs.cl] 1 Jan 2019
![arxiv: v2 [cs.cl] 1 Jan 2019](/thumbs/93/111679653.jpg "arxiv: v2 [cs.cl] 1 Jan 2019") Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Structured Prediction
 Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
Do not tear exam apart!
 6.036: Final Exam: Fall 2017 Do not tear exam apart! This is a closed book exam. Calculators not permitted. Useful formulas on page 1. The problems are not necessarily in any order of di culty. Record
6.036: Final Exam: Fall 2017 Do not tear exam apart! This is a closed book exam. Calculators not permitted. Useful formulas on page 1. The problems are not necessarily in any order of di culty. Record
LECTURER: BURCU CAN Spring
 LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
Logic and machine learning review. CS 540 Yingyu Liang
 Logic and machine learning review CS 540 Yingyu Liang Propositional logic Logic If the rules of the world are presented formally, then a decision maker can use logical reasoning to make rational decisions.
Logic and machine learning review CS 540 Yingyu Liang Propositional logic Logic If the rules of the world are presented formally, then a decision maker can use logical reasoning to make rational decisions.
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
(2pts) What is the object being embedded (i.e. a vector representing this object is computed) when one uses
 What is the object being embedded (i.e. a vector representing this object is computed) when one uses") Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Deep Learning for NLP
 Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
CS395T: Structured Models for NLP Lecture 19: Advanced NNs I. Greg Durrett
 CS395T: Structured Models for NLP Lecture 19: Advanced NNs I Greg Durrett Administrivia Kyunghyun Cho (NYU) talk Friday 11am GDC 6.302 Project 3 due today! Final project out today! Proposal due in 1 week
CS395T: Structured Models for NLP Lecture 19: Advanced NNs I Greg Durrett Administrivia Kyunghyun Cho (NYU) talk Friday 11am GDC 6.302 Project 3 due today! Final project out today! Proposal due in 1 week
Outline. Parsing. Approximations Some tricks Learning agenda-based parsers
 Outline Parsing CKY Approximations Some tricks Learning agenda-based parsers 0 Parsing We need to compute compute argmax d D(x) p θ (d x) Inference: Find best tree given model 1 Parsing We need to compute
Outline Parsing CKY Approximations Some tricks Learning agenda-based parsers 0 Parsing We need to compute compute argmax d D(x) p θ (d x) Inference: Find best tree given model 1 Parsing We need to compute
Better Conditional Language Modeling. Chris Dyer
 Better Conditional Language Modeling Chris Dyer Conditional LMs A conditional language model assigns probabilities to sequences of words, w =(w 1,w 2,...,w`), given some conditioning context, x. As with
Better Conditional Language Modeling Chris Dyer Conditional LMs A conditional language model assigns probabilities to sequences of words, w =(w 1,w 2,...,w`), given some conditioning context, x. As with
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Sequence to Sequence Models and Attention
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Sequence to Sequence Models and Attention Encode-Decode Architectures for Machine Translation [Figure from Luong et al.] In Sutskever
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Sequence to Sequence Models and Attention Encode-Decode Architectures for Machine Translation [Figure from Luong et al.] In Sutskever
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Lecture 15: Recurrent Neural Nets
 Lecture 15: Recurrent Neural Nets Roger Grosse 1 Introduction Most of the prediction tasks we ve looked at have involved pretty simple kinds of outputs, such as real values or discrete categories. But
Lecture 15: Recurrent Neural Nets Roger Grosse 1 Introduction Most of the prediction tasks we ve looked at have involved pretty simple kinds of outputs, such as real values or discrete categories. But
ML4NLP Multiclass Classification
 ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
Reinforcement Learning for NLP
 Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Discrete Latent Variable Models
 Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Probabilistic Context-free Grammars
 Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
AN INTRODUCTION TO TOPIC MODELS
 AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Neural networks and Bayes Rule Geoff Gordon Research Director, MSR Montreal Joint work with Wen Sun and others The right answer for inference
Research Faculty Summit 2018 Systems Fueling future disruptions Neural networks and Bayes Rule Geoff Gordon Research Director, MSR Montreal Joint work with Wen Sun and others The right answer for inference
Recurrent Neural Network
 Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Reinforcement Learning
 Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Lecture 8: Policy Gradient
 Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS. A Project. Presented to
 A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS A Project Presented to The Faculty of the Department of Computer Science San José State University In
A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS A Project Presented to The Faculty of the Department of Computer Science San José State University In
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Lecture 13: Discriminative Sequence Models (MEMM and Struct. Perceptron)
") Lecture 13: Discriminative Sequence Models (MEMM and Struct. Perceptron) Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor (http://brenocon.com) 1 Models for
Lecture 13: Discriminative Sequence Models (MEMM and Struct. Perceptron) Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor (http://brenocon.com) 1 Models for
P(t w) = arg maxp(t, w) (5.1) P(t,w) = P(t)P(w t). (5.2) The first term, P(t), can be described using a language model, for example, a bigram model:
 = arg maxp(t, w) (5.1) P(t,w) = P(t)P(w t). (5.2) The first term, P(t), can be described using a language model, for example, a bigram model:") Chapter 5 Text Input 5.1 Problem In the last two chapters we looked at language models, and in your first homework you are building language models for English and Chinese to enable the computer to guess
Chapter 5 Text Input 5.1 Problem In the last two chapters we looked at language models, and in your first homework you are building language models for English and Chinese to enable the computer to guess
Learning to translate with neural networks. Michael Auli
 Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Log-Linear Models, MEMMs, and CRFs
 Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx