1. Probability density function for speech samples. Gamma. Laplacian. 2. Coding paradigms. =(2X max /2 B ) for a B-bit quantizer Δ Δ Δ Δ Δ
|
|
|
- Lydia Hutchinson
- 5 years ago
- Views:
Transcription
1 Digital Speech Processing Lecture 16 Speech Coding Methods Based on Speech Waveform Representations and Speech Models Adaptive and Differential Coding 1
2 Speech Waveform Coding-Summary of Part 1 1. Probability density function for speech samples Gamma Laplacian x σ 1 1 x px ( ) = e p( 0) = σ σ x 1/ 3 x σ 3 x px ( ) = e p( 0) = 8πσ x x x. Coding paradigms uniform -- divide interval from +X X B max to max into intervals of length Δ =(X max / B ) for a B-bit quantizer Δ Δ Δ Δ Δ Δ Δ -X max =4σ x +X max =4σ x
3 Speech Waveform Coding-Summary of Part 1 p(e) xn ˆ( ) = xn ( ) + en ( ) X max SNR = 6B log10 σ x i sensitivity to X / σ ( σ varies a lot!!!) max x i not great use of bits for actual speech densities! X max X max 0log 10 SNR (uniform) (B=8) σx σx x -Δ/ Δ/ over oea3 3:1 range age i Xmax (or equivalently σ x ) varies a lot across sounds, speakers, environments i need dto adapt coder ( Δ ( n))t to time varying σ x or Xmax i key question is how to adapt.. 30 db loss as X max /σ x varies Δ Δ Δ Δ Δ Δ Δ 1/Δ -X 3 max =4σ x +X max =4σ x
4 Speech Waveform Coding-Summary of Part 1 pseudo-logarithmic (constant percentage error) - compress x(n) by pseudo-logarithmic compander - quantize the companded x(n) uniformly - expand the quantized signal [ ] y(n) = F x(n) large xn ( ) xn ( ) log 1 + μ Xmax = X max sign x(n) log( 1+ μ ) X max μ xn ( ) yn ( ) log logμ Xmax [ ] 4 -X max =4σ x +X max =4σ x
5 Speech Waveform Coding-Summary of Part 1 X max X max SNR( db) = 6B log10 [ ln( 1+ μ) ] 10log μσ x μσ x i insensitive to X / σ over a wide range for large μ max x maximum SNR coding match signal quantization intervals to model probability distribution (Gamma, Laplacian) interesting at least theoretically 5
6 Adaptive Quantization linear quantization => SNR depends on σ x being constant t (this is clearly l not the case) instantaneous companding => SNR only weakly dependent on X max /σ x for large μ-law compression ( ) optimum SNR => minimize σ e when σ x is known, nonuniform distribution of quantization levels Quantization dilemma: want to choose quantization step size large enough to accomodate maximum peak-topeak range of x(n); at the same time need to make the quantization step size small so as to minimize the quantization error the non-stationary nature of speech (variability across sounds, speakers, backgrounds) compounds this problem greatly 6
7 Solutions to Quantization Dilemna Adaptive Quantization: Solution 1 -let Δ vary to match the variance of the input signal => Δ(n) Solution - use a variable gain, G(n), followed by a fixed quantizer step size, Δ => keep signal variance of y(n)=g(n)x(n) constant Case 1: Δ(n) proportional to σ x => quantization levels and ranges would be linearly scaled to match σ x => need to reliably estimate σ x Case : G(n) proportional to 1/ σ x to give σ y constant need reliable estimate of σ x for both types of adaptive quantization 7
8 Types of Adaptive Quantization instantaneous-amplitude changes reflect sampleto-sample variations in x[n] => rapid adaptation syllabic-amplitude changes reflect syllable-tosyllable variations in x[n] => slow adaptation feed-forward-adaptive quantizers that estimate σ x from x[n] [ ]itself feedback-adaptive quantizers that adapt the step size, Δ, on the basis of the quantized signal, xˆ[ n ], (or equivalently the codewords, c[n]) 8
9 Feed Forward Adaptation Variable step size assume uniform quantizer with step size Δ[n] x[n] is quantized using Δ[n] => c[n] and Δ[n] need to be transmitted to the decoder if c [n]=c[n] and Δ [n]=δ[n] => no errors in channel, and xˆ [ n[ = xˆ[ n] Don t have x[n] at the decoder to estimate Δ[n] => need to transmit Δ[n]; this is a major drawback of feed forward adaptation 9
10 Feed-Forward Forward Quantizer time varying gain, G[n] => c[n] and G[n] need to be transmitted to the decoder Can t estimate G[n] at the decoder => it has to be transmitted 10
11 Feed Forward Quantizers feed forward systems make estimates of σ x, then make Δ or the quantization levels proportional to σ x, or the gain is inversely proportional to σ x assume σ x σ short-time ti energy [ ] = [ ] [ ] / [ ] where [ ] is a lowpass filter n x m hn m hm hn m= m= 0 E σ [ n] σ x (this can be shown) n 1 consider hn [ ] = α n 1 = 0 otherwise σ [ ] = 1 n ] m= n m 1 n x m α ( 1 α) ( 0< α < 1) σ = ασ + α [ n ] [ n 1 ] + x [ n 1 ]( 1 ) (recursion) this gives Δ [ n] = Δ σ[ n] and G[ n] = G / σ[ n]
12 Slowly Adapting Gain Control α = yn [ ] = Gnxn [ ] [ ] 099. σ [ n] = ασ [ n 1] + x [ n 1](1 α) n 1 n m 1 = x m Gn [ ] = m= = G α 0 σ [ n ] { } yˆ[ n] = Q G[ n] x[ n] Δ [ ](1 α) Δ =Δ [ n] σ 0 [ n] G G[ n] G min Δ Δ[ n] Δ min max max xn ˆ[ ] Q xn [ ] = Δ[ n] { } α =0.99 => brings up level in low amplitude regions => time constant of 100 samples (1.5 msec for 8 khz sampling rate) => syllabic rate 1
 n 1 n m 1 = x m Gn [ ] = m= = α G 0 σ [ n ] { } yn ˆ[ ] = Q Gnxn [ ] [ ] Δ Δ =Δ [ ](1 α) [ n] σ 0 [ n] xn ˆ[ ] = Q xn [ ] = Δ[ n] { } G G[ n]")
13 Rapidly Adapting Gain Control α = 09. yn [ ] = Gnxn [ ] [ ] σ [ n] = ασ [ n 1] + x [ n 1](1 α) n 1 n m 1 = x m Gn [ ] = m= = α G 0 σ [ n ] { } yn ˆ[ ] = Q Gnxn [ ] [ ] Δ Δ =Δ [ ](1 α) [ n] σ 0 [ n] xn ˆ[ ] = Q xn [ ] = Δ[ n] { } G G[ n] G α = 0.9 => system reacts to amplitude variations more min Δ Δ[ n] Δ min max max rapidly => provides better approximation to σ y = constant => time constant of 9 samples (1 msec at 8 khz) for change => instantaneous rate 13
14 Feed Forward Quantizers Δ[n] and G[n] vary slowly compared to x[n] they must be sampled and transmitted as part of the waveform coder parameters rate of sampling depends on the bandwidth of the lowpass filter, h[n] for α = 0.99, the rate is about 13 Hz; for α = 0.9, the rate is about 135 Hz it is reasonable to place limits on the variation of Δ[ n] or G[ n], of the form Gmin G[ n] Gmax Δmin Δ[ n] Δmax for obtaining σ constant over a 40 db range in signal levels => G G max min = Δ Δ y max min = 100 (40dB range) 14
15 Feed Forward Adaptation Gain 1 1 n + σ [ ] = M n x [ m] M m= n Δ[ n] or G[ n] evaluated every M samples used M = 18, 104 samples for estimates adaptive quantizer achieves up to 5.6 db better SNR than non-adaptive quantizers can achieve this SNR with low "idle channel noise" and wide speech dynamic range by suitable choice of Δ and Δ min max feed-forward adaptation gain with B=3 less gain for M=104 than M=18 by 3 db => M=104 is too long an interval 15
16 Feedback Adaptation σ [n] estimated from quantizer output (or the code words) advantage of feedback adaptation is that neither Δ[n] nor G[n] needs to be transmitted to the decoder since they can be derived from the code words disadvantage of feedback adaptation is increased sensitivity to errors in codewords, since such errors affect Δ[n] and G[n] 16
17 Feedback Adaptation σ [ n ] = x ˆ [ m ] h [ n m ] / h [ m ] m= m= 0 ˆ σ [ n] based only on past values of x[ n] two typical windows/filters are n 1 1. hn [ ] = α n 1 = 0 otherwise. hn [ ] = 1/ M 1 n M = 0 otherwise 1 σ [ n] x [ m] 1 = n ˆ M m= n M can use very short window lengths (e.g., 1 db SNR for a B = 3 bit quantizer M = ) to achieve 17
18 Alternative Approach to Adaptation Δ [ n] = P Δ[ n 1]; P = { P, P, P, P } P c [ n 1 ] [ ] Δ[ nsigncn ] [ ] xn ˆ( ) = +Δ[ n] cn [ ] Δ [ n ] only depends ds on Δ[ n 1] and c[ n 1] => only need to transmit codewords also necessary to impose the limits Δmin Δ [n] n Δmax the ratio Δ / Δ controls the dynamic max min range of the quantizer 18
19 Adaptation Gain key issue is how should P vary with c[n-1] if (c[n-1[ [ is either largest positive or largest negative codeword, then quantizer is overloaded and the quantizer step size is too small => P 4 >1 if c[n-1] is either smallest positive or negative codeword, then quantization error is too large => P 1 < 1 need choices for P and P 3 19
20 Adaptation Gain Q = 1+ cn [ 1] B 1 shaded area is variation in range of P values due to different speech sounds or different B values Can see that step size increases (P>1) are more vigorous than step size decreases (P<1) since signal growth needs to be kept within quantizer range to avoid overloads 0
21 Optimal Step Size Multipliers optimal values of P for B=,3,4,5 improvements in SNR 4-7 db improvement over μ-law -4 db improvement over non-adaptive 1 optimum quantizers
22 Quantization of Speech Model Parameters Excitation and vocal tract (linear system) are characterized by sets of parameters which can be estimated from a speech signal by LP or cepstral processing. We can use the set of estimated parameters to synthesize an approximation to the speech signal whose quality depends of a range of factors.
23 Quantization of Speech Model Parameters Quality and data rate of synthesis depends on: the ability of the model to represent speech the ability to reliably and accurately estimate the parameters of the model the ability to quantize the parameters in order to obtain a low data rate digital representation that will yield a high quality reproduction of the speech signal 3
24 Closed-Loop and Open-Loop Speech Coders Closed-looploop used in a feedback loop where the synthetic speech output is compared to the input signal, and the resulting difference used to determine the excitation for the vocal tract model. Open-loop the parameters of the model are estimated directly from the speech signal with no feedback as to the quality of the resulting synthetic ti speech. 4
25 Scalar Quantization Scalar quantization treat each model parameter separately and quantize using a fixed number of bits need to measure (estimate) statistics of each parameter, i.e., mean, variance, minimum/maximum value, pdf, etc. each parameter has a different quantizer with a different number of bits allocated Example of scalar quantization pitch period typically ranges from samples (at 8 khz sampling rate) => need about 18 values (7-bits) uniformly over the range of pitch periods, including value of zero for unvoiced/background amplitude parameter might be quantized with a μ-law quantizer using 4-5 bits per sample using a frame rate of 100 frames/sec, you would need about 700 bps for pitch period and bps for amplitude 5
26 Scalar Quantization 0-th order LPC analysis frame Each PARCOR coefficient transformed to range: π/<sin -1 (k i )<π/ and then quantized with both a 4-bit and a 3-bit uniform quantizer. Total rate of quantized representation of speech about 5000 bps. 6
27 Techniques of Vector Quantization 7
28 Vector Quantization code block of scalars as a vector, rather than individually design an optimal quantization method based on mean-squared distortion metric essential for model-based and hybrid coders 8
29 Vector Quantization 9
30 Waveform Coding Vector Quantizer VQ code pairs of waveform samples, X[n]=(x[n],x[n+1]); [ ], [ ]); (b) Single element codebook with cluster centroid (0-bit codebook) (c) Two element codebook with two cluster centers (1-bit codebook) (d) Four element codebook with four cluster centers (-bit codebook) (e) Eight element codebook with eight cluster centers (3-bit codebook) 30
31 Toy Example of VQ Coding -pole model of the vocal tract => 4 reflection coefficients 4-possible vocal tract shapes => 4 sets of reflection coefficients 1. Scalar Quantization -assume 4 values for each reflection coefficient => -bits x 4 coefficients = 8 bits/frame. Vector Quantization -only 4 possible vectors => -bits to choose which of the 4 vectors to use for each frame (pointer into a codebook) this works because the scalar components of each vector are highly correlated if scalar components are independent => VQ offers no advantage over scalar 31 quantization
32 Elements of a VQ Implementation 1. A large training set of analysis vectors; X={X 1,X,,X L }, L should be much larger than the size of the codebook, M, i.e., times the size of M.. A measure of distance, d ij =d(x i,x j ), between a pair of analysis vectors, both for clustering the training i set as well as for classifying test set vectors into unique codebook entries. 3. A centroid computation procedure and a centroid splitting procedure. 4. A classification procedure for arbitrary analysis vectors that chooses the codebook vector closest in distance to the input vector, providing the codebook index of the resulting nearest codebook vector. 3
33 VQ Implementation 33
34 The VQ Training Set The VQ training set of L 10M vectors should span the anticipated range of: talkers, ranging in age, accent, gender, speaking rate, speaking levels, etc. speaking conditions, range from quiet rooms, to automobiles, to noisy work places transducers and transmission systems, including a range of microphones, telephone handsets, cellphones, speakerphones, etc. speech, including carefully recorded material, conversational speech, telephone queries, etc. 34
35 The VQ Distance Measure The VQ distance measure depends critically on the nature of the analysis vector, X. If X is a log spectral vector, then a possible distance measure would be an L p log spectral distance, of the form: R 1/ p k k p d( Xi, X j) = xi xj k =11 If X is a cepstral vector, then the distance measure might well be a cepstral distance of the form: R k k d ( X i, X j) = ( xi xj ) k = 1 1/ 35
36 Clustering Training Vectors Goal is to cluster the set of L training vectors into a set of M codebook vectors using generalized Lloyd algorithm (also known as the K-means clustering algorithm) with the following steps: 1. Initialization arbitrarily choose M vectors (initially out of the training set of L vectors) as the initial set of codewords in the codebook. Nearest Neighbor Search for each training vector, find the codeword in the current codebook that is closest (in distance) and assign that vector to the corresponding cell 3. Centroid Update update the codeword in each cell to the centroid of all the training vectors assigned to that cell in the current iteration 4. Iteration repeat steps and 3 until the average distance between centroids at successive iterations falls below a preset threshold 36
37 Clustering Training Vectors Voronoi regions and centroids 37
38 Centroid Computation i Assume we have a set of V vectors, C C C C X = { X1, X,..., XV } where all V vectors are assigned to cluster C i The centroid of the set X is defined as the vector Y i that minimizes the average distortion, V 1 C Y = min d( Xi, Y) Y V i = 1 i.e., C. The solution for the centroid is highly dependent C on the choice of distance measure. When both X i and Y are measured in a K-dimensional space with the L norm, the cen troid is the mean of the vector set Y V 1 = X V i = 1 C i i When using an L1 distance measure, the centroid is the median vector of the set of vectors assigned to the given class. 38
39 Vector Classification Procedure i The classification procedure for arbitrary test set vectors is a full search through the codebook to find the "best" (minimum distance) match. i If we denote the codebook vectors of an M -vector codebook as CBi for 1 i M, and we denote the vector to be classified ( and vector quantized) as X, then the index, i, of fthe best codebook entry is: i = arg min d ( X, CB) 1 i M i 39
40 Binary Split Codebook Design 1. Design a 1-vector codebook; the single vector in the codebook is the centroid of the entire set of training vectors. Double the size of the codebook by splitting each current codebook vector, Y m, according to the rule: Y Y + m m = Y (1 + ε ) m = Y (1 ε ) m where m varies from 1 to the size of the current codebook, and epsilon is a splitting parameter (0.01 typically) 3. Use the K-means clustering algorithm to get the best set of centroids for the split codebook 4. Iterate steps and 3 until a codebook of size M is designed. 40
41 Binary Split Algorithm 41
42 VQ Codebook of LPC Vectors 64 vectors in a codebook of spectral shapes 4


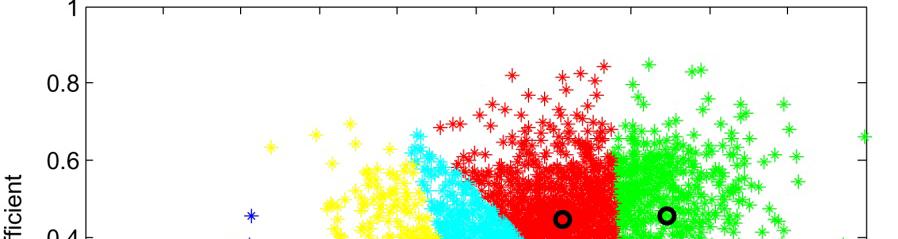


43 VQ Cells 43




44 VQ Cells 44
45 VQ Coding for Speech distortion in coding computed using a spectral distortion measure related to the difference in log spectra between the original and the codebook vectors 10-bit VQ comparable to 4-bit scalar 45 quantization for these examples
46 Differential Quantization Theory and Practice 46
47 Differential Quantization we have carried instantaneous quantization of x[n] as far as possible time to consider correlations between speech samples separated in time => differential quantization high correlation values => signal does not change rapidly in time => difference between adjacent samples should have lower variance than the signal itself differential quantization can increase SNR at a given bit rate, or lower bit rate for a given SNR 47
48 Example of Difference Signal Prediction error from LPC analysis using p=1 Prediction error is about.5 times smaller than signal 48
49 Differential Quantization Δ xn [ ] + dn [ ] dn ˆ[ ] Q[ ] Encoder cn [ ] xn [ ] xn ˆ[ ] P + (a) Coder dn [ ] = xn [ ] xn [ ] where xn [ ] = unquantized input sample x [ n] = estimate or prediction of x[ n] x [ n] is the output of a predictor system, P, whose input is xˆ [ n], a quantized version of xn [ ] dn [ ] = prediction error signal dn ˆ[ ] = quantized difference (prediction error) signal 49
50 Differential Quantization Δ c'[ n ] ˆ '[ [ ] Decoder + d n x ˆ '[ n ] x '[ n] P (b) Decoder dn [ ] = xn [ ] xn [ ] where xn [ ] = unquantized input sample xn [ ] = estimate or prediction of xn [ ) x [ n] is the output of a predictor system, P, whose input is xˆ [ n], a quantized version of xn [ ] dn [ ] = prediction error signal dn ˆ[ ] = quantized difference (prediction error) signal 50
51 Differential Quantization dn [ ] = xn [ ] xn [ ] dˆ [ n] = d[ n] + e[ n] Δ xn [ ] + dn [ ] dn ˆ[ ] Q[ ] Encoder cn [ ] xn [ ] xn ˆ[ ] P + This part reconstructs the p ( ) = α k Pz z k = 1 quantized signal, xn ˆ[ ] xn ˆ( ) = xn ( ) + dn ˆ ( ) xn ˆ( ) = xn ( ) + en ( ) p xn [ ] = α ˆ k xn [ k] k = 1 k 51
52 Differential Quantization difference signal, d[n], is quantized - not x[n] quantizer can be fixed, or adaptive, uniform or non-uniform quantizer parameters are adjusted to match the variance of d[n] dn ˆ[ ] = dn [ ] + en [ ] en [ ] quantization error xn ˆ[ ] = xn [ ] + dn ˆ[ ] predicted xplus quantized d xn ˆ[ ] = xn [ ] + en [ ] quantized input has same quantization error as the difference signal => if σ d < σ x, error is smaller independent of predictor, P, quantized x[ n] differs from unquantized x[ n ]by en [ ], the quantization error of the difference signal! => good prediction gives lower quantization error than quantizing input directly 5
53 Differential Quantization quantized difference signal is encoded into c(n) for transmission ˆ ˆ ˆ H(z) X ( z) = D ( z) + P( z) X ( z) ˆ 1 X ( z ) = Dˆ ( z ) = H ( z ) Dˆ ( z ) 1 Pz ( ) H( z) = p k = α z k k first reconstruct the quantized difference signal from the decoder codeword, c [n] and the step size Δ next reconstruct the quantized input signal using the same predictor, P, as used in the encoder 53
54 SNR for Differential Quantization the SNR of the differential coding system is SNR where E x [ n] = = E e n x d d σ e σ x [ ] σ e σ σ SNR = = GP SNR σ σ d SNRQ = = σ e Q signal-to-quantizing-noise noise ratio of the quantizer σ x G P = = gain due to differential quantization σ d 54
55 SNR for Differential Quantization Q SNR Q depends on chosen quantizer and can be maximized using all of the previous quantization methods (uniform, non-uniform, optimal) G, hopefully, > 1, is the gain in SNR due to P differential coding want to choose the predictor, P, to maximize GP since σ x is fixed, then we need to minimize σ d, i.e., design the best predictor P 55
56 Predictor for Differential Quantization i consider class of linear predictors, P p xn [ ] = α xn ˆ [ k ] k = 1 k xn [ ] is a linear combination of previous quantized values of xn [ ] the predictor z-transform is p k = 1 ( ) α k Pz = z = 1 Az ( ) -- predictor system function pn [ ] = αk 1 k p = 0 otherwise k with predictor impulse response coefficients (FIR filter) 56
57 Predictor for Differential Quantization i the reconstructed signal is the output, xn ˆ [ ], of a system with system function 1 Xz ˆ ( ) 1 1 Hz ( ) = = = = ˆ ( ) 1 ( ) ( ) 1 α k Dz Pz Az z p k = 1 k where the input to the system is the quantized difference signal, dn ˆ[ ] where p k = 1 dn ˆ [ ] = xn ˆ [ ] α xn ˆ [ k ] p k k = 1 k α xˆ[ n k ] = xn [ ] 57
58 Predictor for Differential Quantization i to solve for optimum predictor, need expression for σ ( ) [ ] [ ] [ ] d = E d n = E x n x n p = E x[ n] α ˆ k x[ n k] k = 1 p p = E x [ n ] α [ ] kx n k αk e [ n k ] k= 1 k= 1 ( xn ˆ[ ] = xn [ ] + en [ ]) σ d 58
59 Solution for Optimum Predictor want to choose { αj }, 1 j p, to minimize σd => differentiate σd wrt α j, set derivatives to zero, giving p σ d = E xn [ ] αk ( xn [ k] + en [ k] ) ( xn [ j] + en [ j] ) α j k = 1 = 0 1 j p which can be written in the more compact form ( ) E x[ n] x[ n] xˆ[ n j] = E d[ n] xˆ[ n j] = 0, 1 j p the predictor coefficients that minimize σ d are the ones that make the difference signal, dn [ ], be uncorrelated with past values of the predictor input, xn ˆ [ j ], 1 j p 59
60 Solution for Alphas ( [ ] [ ]) ˆ[ ] [ ] ˆ[ ] 0, 1 E x n x n x n j = E d n x n j = j p basic equations of differential coding dn ˆ[ ] = dn [ ] + en [ ] quantization of difference signal xn ˆ[ ] = xn [ ] + en [ ] error same for original signal xn ˆ[ ] = xn [ ] + dn ˆ[ ] feedback loop for signal p xn [ ] = α ˆ k xn [ k ] prediction loop based on quantized input k = 1 p dn ˆ[ ] = xn ˆ[ ] α xn ˆ[ k] direct substitution k = 1 xn ˆ[ j] = xn [ j] + en [ j] p k p [ + ] xn [ ] = α xn ˆ [ k ] = α xn [ k ] + en [ k ] k k= 1 k= 1 k 60
61 Solution for Alphas ( ) ˆ ˆ E x[ n] x[ n] x[ n j] = E d[ n] x[ n j] = 0, 1 j p xn ˆ[ j ] = xn [ j ] + en [ j ] p k k= 1 k= 1 p [ ] xn [ ] = α xn ˆ[ k] = α xn [ k] + en [ k] k [ [ ] [ ]] + [ [ ] [ ]] [ [ ] [ ]] [ [ ] [ ]] E x n x n j E x n e n j E x n x n j E x n e n j p = E α k [ x[ n k] + e[ n k] ] x[ n j ] + k =1 p E αk [ x[ n k] + e[ n k] ] e[ n j] k = 1 p [ [ ] [ ]] α [ [ ] [ ]] = α E x n k x n j + E e n k x n j + k k= 1 k= 1 p p [ [ ] [ ]] + α [ [ ] [ ]] α E xn ken j E en ken j k k= 1 k= 1 p k k 61
62 Solution for Optimum Predictor solution for α k - first expand terms to give [ [ ] [ ]] + [ [ ] [ ]] = α [ [ ] [ ]] E x n j x n E e n j x n E x n j x n k p p k = 1 [ [ ] [ ]] α [ [ ] [ ]] + α E en j xn k + E xn j en k k k= 1 k= 1 p αk k = 1 [ ] + Een [ j] en [ k], 1 j p assume fine quantization so that en [ ] is uncorrelated with xn [ ], and en [ ] is stationary white noise (zero mean), giving [ ] 0 [ ] σ E x[ n j] e[ n k] = n, j, k Een [ j] en [ k] = δ [ j k] e p k k 6
63 Solution for Optimum Predictor we can now simplify solution to form [ ] p k [ ] e [ ] k = 1 φ[ j] = α φ[ j k] + σ δ [ j k], 1 j p where φ[ j] is the autocorrelation of x[ n]. Defining terms φ [ j ] σ ρ[ ] = = α ρ[ ] δ[ ], 1 p e j k j k + j k j p σx k = 1 σx or in matrix form ρ = Cα ρ[] 1 α1 1+ 1/ SNR ρ[] 1 ρ[ p 1] α / ρ[ ] ρ[ ] SNR ρ[ p ] ρ =., α =., C =.. ρ[ ] α p ρ[ 1] ρ[ ] 1+ 1/ p p p SNR 63
64 Solution for Optimum Predictor ρ = Cα ρ[] 1 α1 1+ 1/ SNR ρ[] 1 ρ[ p 1] ρ[ ] α ρ[ 1] 1 1/ ρ[ ] + SNR p ρ =., α =., C =.. ρ[ p] α ρ[ 1[ ρ[ ] 1+ 1/ p p p SNR with matrix solution 1 α = C ρ (defining SNR = σ / σ ) x e 1 where C is a Toeplitz matrix C can be computed via well understood => numerical methods C SNR = σ x σ e SNR α k coefficients c e of the predicto r, which depend d on SNR => bit of a dilemma the problem here is that depends on /, but depends on k 64
65 Solution for Optimum Predictor special case of p = 1, where we can solve directly for α of this first order linear predictor, as 1 ρ[] 1 α 1 = 1 + 1/ SNR can see that α1 < ρ[ 1] < 1 we will look further at this special case later 65
66 Solution for Optimum Predictor in spite of problems in solving for optimum predictor coefficients, we can solve for the prediction gain,, in terms of the α coefficients, as E ( x [ n ] x [ n ] ) ( x [ n ] x [ n ] ) E ( x[ n] x [ n] ) x[ n ] ( ) ( xn xn ) σ = G P j d = E x n x n x n x n = E x[ n] x[ n] x [ n] where the term [ ] [ ] is the prediction error; we can show that the second dterm in the expression above is zero, i.e., the prediction error is uncorrelated with the prediction value; thus σ = ( [ ] d E x n x[ n] ) x[ n] = [ ] p E x n E αk ( xn [ k] + en [ k]) xn [ ]) k = 1 assuming uncorrelated signal and noise, we get p p σd = σx αkφ[ k] = σx 1 αkρ[ k] k= 1 k= 1 1 ( GP ) opt = for optimum values of α p k 1 αk ρ [ k ] k = 1 66
67 First Order Predictor Solution For the case p = 1 we can examine effects of α σ σ The optimum solution is: 1 ( G P ) = opt 1 αρ[] 1 sub-optimum value of 1 on the quantity GP = x / d. σ = σ 1 α ρ [] 1 + α + α σ Giving the sub-optimum result 1 Consider choosing an arbitrary value for α ; then we get d x e 1 = 1 αρ[] 1 + α ( 1 + 1/ SNR) ( G ) = G P arb SNR Where the term α / represents the increase in variance of d [ n ] due to the feedback of the error signal en [ ]. 1 67
68 First Order Predictor Solution ( G ) P arb Can reformulate as α1 1 SNRQ ( GP ) = arb 1 αρ 1 [] 1 + α1 for any value of α1 (including the optimum value). Consider the case of α = ρ( 1) 1 ρ [] 1 1 SNR 1 Q ρ [ 1) ( GP ) = = 1 subopt 1 ρ [] 1 1 ρ [] 1 SNR Q the gain in prediction is a product of the prediction gain without the quantizer, reduced by the loss due to feedback of the error signal. 68
69 First Order Predictor Solution We showed before that the optimum value of α was ρ [ 1] / 1+ 1/ [ SNR] If we neglect the term in 1/SNR (usually very small), then α1 = ρ[ 1] and the gain due to prediction is 1 ( G P ) = opt 1 ρ [] 1 Thus thereisapredictiongainsolongas so as ρ [] 1 0 It is reasonable to assume that for speech, ρ[ 1] > 0. 8, giving ( ) G P opt > 77. (or 4.43 db) 1 69
70 Differential Quantization ^ x[n] d[n] d[n] + + Q - Δ x[n] ~ x[n] ^ P + σ σ σ SNR = = = G p SNR σ σ σ x x d e d e First Order Predictor: ρ[] 1 α 1 = 1+ 1/ SNR 1 ρ [] 1 Gp = 1 1 ρ [] 1 SNRQ 1 1 ρ [] 1 Q p xn [ ] = α ˆ k xn [ k] k = 1 dn [ ] = xn [ ] xn [ ] dn ˆ[ ] = dn [ ] + en [ ] xn ˆ[ ] = xn [ ] + dn ˆ[ ] xn ˆ[ ] = xn [ ] + en [ ] The error, e[n], in quantizing d[n] is the same as the error in representing x[n] Prediction gain dependent on ρ[1], the first correlation coefficient 70
71 Long-Term Spectrum and Correlation Measured with 3-point Hamming window
72 Computed Prediction Gain 7
73 Actual Prediction Gains for Speech variation in gain across 4 speakers can get about 6 db improvement in SNR => 1 extra bit equivalent in quantization but at a price of increased complexity in quantization differential quantization works!! gain in SNR depends on signal correlations fixed predictor cannot be optimum for all speakers and for all speech material 73
74 Delta Modulation Linear and Adaptive 74
75 Delta Modulation simplest form of differential quantization is in delta modulation (DM) sampling rate chosen to be many times the Nyquist rate for the input signal => adjacent samples are highly correlated in the limit as T 0, we expect φ x [1] σ as T 0 this leads to a high ability to predict x[n] from past samples, with the variance of the prediction error being very low, leading to a high prediction gain => can use simple 1-bit (-level) l) quantizer => >the bit rate for DM systems is just the (high) sampling rate of the signal 75
76 Linear Delta Modulation -level quantizer with fixed step size, Δ, with quantizer form dn ˆ[ ] =Δ ifdn [ ] > 0 ( cn [ ] = 0 ) = Δ if d[ n] < 0 ( c[ n] = 1) using simple first order predictor with optimum prediction gain 1 ( G P ) = opt 1 ρ [1] as ρ[1] 1, (qualitatively ( ) G P opt only since the assumptions under which the equation was derived break down as ρ[1] 1) 76
77 Illustration of DM basic equations of DM are xn ˆ[ ] = α xn ˆ[ 1] + dn ˆ[ ] when α 1 (essentially digital integration or accumulation of increments of ±Δ) d[ n] = x[ n] x ˆ[ n 1] = x[ n] x[ n 1] e[ n 1] dn [ ] is a first backward difference of xn [ ], or an approximation to the derivative of the input how big do we make Δ--at maximum slope of xa () t we need Δ dx () a t max T dt or else the reconstructed signal will lag the actual signal => called 'slope overload' condition--resulting in quantization error called 'slope overload distortion' since xˆ[ n ] can only increase by fixed increments of Δ, fixed DM is called linear DM or LDM slope overload condition granular noise 77
78 DM Granular Noise when xa() t has small slope, Δ determines the peak error => when xa() t = 0, quantizer will be alternating sequence of 0's and 1's, and xn ˆ[ ] will alternate around zero with peak variation of Δ => this condition is called "granular noise" need large step size to handle wide dynamic range need small step size to accurately represent low level signals with LDM we need to worry about dynamic range and amplitude of the difference signal => choose Δ to minimize mean-squared quantization error (a compromise between slope overload and granular noise) 78
79 Performance of DM Systems normalized step size defined as Δ 1/ E ( x[ n] x[ n 1] ) oversampling index defined as F 0 = F S / ( F N ) where FS is the sampling rate of the DM and FN is the Nyquist frequency of the signal the total bit rate of the DM is BR = FS = FN F 0 can see that for given value of F 0, there is an optimum value of Δ optimum SNR increases by 9 db for each doubling of F 0 => this is better than the 6 db obtained by increasing the number of bits/sample by 1 bit curves are very sharp around optimum value of Δ => SNR is very sensitive to input level for SNR=35 db, for F N =3 khz => 00 Kbps rate for toll quality need much higher rates 79
80 Adaptive Delta Mod step size adaptation for DM (from codewords) Δ [ n] = M Δ[ n 1] Δmin Δ[ n] Δmax M is a function of c[ n] and cn [ 1], since cn [ ] depends only on the sign of d[ n] dn [ ] = xn [ ] α xn ˆ[ 1] the sign of dn [ ] can be determined before theactual quantized value dn ˆ[ ] which needs the new value of Δ[ n] for evaluation the algorithm for choosing the step size multiplier is M= P> 1 if cn [ ] = cn [ 1] M = Q< 1 if c[ n] c[ n 1] 80
81 Adaptive DM Performance slope overload condition granular noise slope overload in LDM causes runs of 0 s 0s or1 s 1s granularity causes runs of alternating 0 s and 1 s figure above shows how adaptive DM performs with P=, Q=1/, α=1 during slope overload, step size increases exponentially to follow increase in waveform slope during ggranularity, step size decreases exponentially to Δ min and stays there as long as slope remains small 81
82 ADM Parameter Behavior ADM parameters are P, Q, Δ min and Δ max choose Δ min and Δ max to provide desired dynamic range choose Δ max / Δ min to maintain high SNR over range of input signal levels Δ min should be chosen to minimize idle channel noise PQ should satisfy PQ 1 for stability PQ chosen to be 1 peak of SNR at P=1.5, but for range 1.5<P<, P, the SNR varies only slightly 8
83 Comparison of LDM, ADM and log PCM ADM is 8 db better SNR at 0 Kbps than LDM, and 14 db better SNR at 60 Kbps than LDM ADM gives a 10 db increase in SNR for each doubling of the bit rate; LDM gives about 6 db for bit rate below 40 Kbps, ADM has higher SNR than μ-law PCM; for higher h bit rates log PCM has higher SNR 83
84 Higher Order Prediction in DM first order predictor gave [ ] = α ˆ[ 1] with reconstructed signal satisfying assuming two real poles, we can write H ( ) z as ˆ ( ) 1 ( ) = Xz H z, 0, 1 ˆ 1 1 ( ) = 1 1 < a b Dz az bz < better prediction is achieved using x n xn ( )( ) xn ˆ[ ] = α xn ˆ[ 1] + dn ˆ[ ] with system function Xˆ ( z) 1 H1( z) = = ˆ 1 Dz ( ) 1 α z digital equivalent of a leaky integrator. consider a second order predictor with x [ n] = α xn ˆ[ 1] + α xn ˆ[ ] 1 this "double integration" system with up to 4 db better SNR there are issues of interaction between the adaptive quantizer and the predictor with reconstructed signal xˆ [ n ] = α ˆ ˆ ˆ 1x[ n 1] + αx[ n ] + d [ n ] with system function Xˆ ( z ) 1 H ( z ) = = ˆ 1 Dz ( ) 1 α z α z ( 1 ) 84
85 Differential PCM (DPCM) fixed predictors can give from 4-11 db SNR improvement over direct quantization (PCM) most of the gain occurs with first order predictor prediction up to 4 th or 5 th order helps 85
86 DPCM with Adaptive Quantization quantizer step size proportional to variance at quantizer input can use d[n] or x[n] to control step size get 5 db improvement in SNR over μ-law nonadaptive PCM get 6 db improvement in SNR using differential configuration with fixed prediction => ADPCM is about db SNR better than from a fixed quantizer 86
87 Feedback ADPCM can achieve same improvement in SNR as feed forward system 87
88 DPCM with Adaptive Prediction need adaptive prediction to handle non-stationarity of speech 88
89 DPCM with Adaptive Prediction prediction coefficients assumed to be time-dependent of the form p x [ n] = α [ n] xˆ [ n k] k = 1 k assume speech properties remain fixed over short time intervals choose αk [ n ] to minimize the average s quared prediction error over short intervals the optimum predictor coefficients satisfy the relationships p n αk n k = 1 R [] j = [] n R [ j k], j = 1,,..., p where R [] j is the short-time autocorrelation function of the form n R [] j = x[ m] w[ n m][ x j + m] w[ n m j], 0 j p n m= wn-m [ ] is window positioned at sample nof input update α's every 10-0 msec 89
90 Prediction Gain for DPCM with Adaptive Prediction i E [ ] 10log10 [ ] 10log x n G P = 10 [ ] E d n fixed prediction 10.5 db prediction gain for large p adaptive prediction 14 db gain for large p adaptive prediction more robust to speaker, speech material 90
91 Comparison of Coders 6 db between curves sharp increase in SNR with both fixed prediction and adaptive quantization almost no gain for adapting first order predictor 91
CS578- Speech Signal Processing
 CS578- Speech Signal Processing Lecture 7: Speech Coding Yannis Stylianou University of Crete, Computer Science Dept., Multimedia Informatics Lab yannis@csd.uoc.gr Univ. of Crete Outline 1 Introduction
CS578- Speech Signal Processing Lecture 7: Speech Coding Yannis Stylianou University of Crete, Computer Science Dept., Multimedia Informatics Lab yannis@csd.uoc.gr Univ. of Crete Outline 1 Introduction
Class of waveform coders can be represented in this manner
 Digital Speech Processing Lecture 15 Speech Coding Methods Based on Speech Waveform Representations ti and Speech Models Uniform and Non- Uniform Coding Methods 1 Analog-to-Digital Conversion (Sampling
Digital Speech Processing Lecture 15 Speech Coding Methods Based on Speech Waveform Representations ti and Speech Models Uniform and Non- Uniform Coding Methods 1 Analog-to-Digital Conversion (Sampling
Pulse-Code Modulation (PCM) :
 :") PCM & DPCM & DM 1 Pulse-Code Modulation (PCM) : In PCM each sample of the signal is quantized to one of the amplitude levels, where B is the number of bits used to represent each sample. The rate from
PCM & DPCM & DM 1 Pulse-Code Modulation (PCM) : In PCM each sample of the signal is quantized to one of the amplitude levels, where B is the number of bits used to represent each sample. The rate from
EE 5345 Biomedical Instrumentation Lecture 12: slides
 EE 5345 Biomedical Instrumentation Lecture 1: slides 4-6 Carlos E. Davila, Electrical Engineering Dept. Southern Methodist University slides can be viewed at: http:// www.seas.smu.edu/~cd/ee5345.html EE
EE 5345 Biomedical Instrumentation Lecture 1: slides 4-6 Carlos E. Davila, Electrical Engineering Dept. Southern Methodist University slides can be viewed at: http:// www.seas.smu.edu/~cd/ee5345.html EE
Scalar and Vector Quantization. National Chiao Tung University Chun-Jen Tsai 11/06/2014
 Scalar and Vector Quantization National Chiao Tung University Chun-Jen Tsai 11/06/014 Basic Concept of Quantization Quantization is the process of representing a large, possibly infinite, set of values
Scalar and Vector Quantization National Chiao Tung University Chun-Jen Tsai 11/06/014 Basic Concept of Quantization Quantization is the process of representing a large, possibly infinite, set of values
Multimedia Communications. Differential Coding
 Multimedia Communications Differential Coding Differential Coding In many sources, the source output does not change a great deal from one sample to the next. This means that both the dynamic range and
Multimedia Communications Differential Coding Differential Coding In many sources, the source output does not change a great deal from one sample to the next. This means that both the dynamic range and
SPEECH ANALYSIS AND SYNTHESIS
 16 Chapter 2 SPEECH ANALYSIS AND SYNTHESIS 2.1 INTRODUCTION: Speech signal analysis is used to characterize the spectral information of an input speech signal. Speech signal analysis [52-53] techniques
16 Chapter 2 SPEECH ANALYSIS AND SYNTHESIS 2.1 INTRODUCTION: Speech signal analysis is used to characterize the spectral information of an input speech signal. Speech signal analysis [52-53] techniques
Chapter 10 Applications in Communications
 Chapter 10 Applications in Communications School of Information Science and Engineering, SDU. 1/ 47 Introduction Some methods for digitizing analog waveforms: Pulse-code modulation (PCM) Differential PCM
Chapter 10 Applications in Communications School of Information Science and Engineering, SDU. 1/ 47 Introduction Some methods for digitizing analog waveforms: Pulse-code modulation (PCM) Differential PCM
Chapter 9. Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析
 Chapter 9 Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析 1 LPC Methods LPC methods are the most widely used in speech coding, speech synthesis, speech recognition, speaker recognition and verification
Chapter 9 Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析 1 LPC Methods LPC methods are the most widely used in speech coding, speech synthesis, speech recognition, speaker recognition and verification
Source modeling (block processing)
") Digital Speech Processing Lecture 17 Speech Coding Methods Based on Speech Models 1 Waveform Coding versus Block Waveform coding Processing sample-by-sample matching of waveforms coding gquality measured
Digital Speech Processing Lecture 17 Speech Coding Methods Based on Speech Models 1 Waveform Coding versus Block Waveform coding Processing sample-by-sample matching of waveforms coding gquality measured
Principles of Communications
 Principles of Communications Weiyao Lin, PhD Shanghai Jiao Tong University Chapter 4: Analog-to-Digital Conversion Textbook: 7.1 7.4 2010/2011 Meixia Tao @ SJTU 1 Outline Analog signal Sampling Quantization
Principles of Communications Weiyao Lin, PhD Shanghai Jiao Tong University Chapter 4: Analog-to-Digital Conversion Textbook: 7.1 7.4 2010/2011 Meixia Tao @ SJTU 1 Outline Analog signal Sampling Quantization
Finite Word Length Effects and Quantisation Noise. Professors A G Constantinides & L R Arnaut
 Finite Word Length Effects and Quantisation Noise 1 Finite Word Length Effects Finite register lengths and A/D converters cause errors at different levels: (i) input: Input quantisation (ii) system: Coefficient
Finite Word Length Effects and Quantisation Noise 1 Finite Word Length Effects Finite register lengths and A/D converters cause errors at different levels: (i) input: Input quantisation (ii) system: Coefficient
The Secrets of Quantization. Nimrod Peleg Update: Sept. 2009
 The Secrets of Quantization Nimrod Peleg Update: Sept. 2009 What is Quantization Representation of a large set of elements with a much smaller set is called quantization. The number of elements in the
The Secrets of Quantization Nimrod Peleg Update: Sept. 2009 What is Quantization Representation of a large set of elements with a much smaller set is called quantization. The number of elements in the
C.M. Liu Perceptual Signal Processing Lab College of Computer Science National Chiao-Tung University
 Quantization C.M. Liu Perceptual Signal Processing Lab College of Computer Science National Chiao-Tung University http://www.csie.nctu.edu.tw/~cmliu/courses/compression/ Office: EC538 (03)5731877 cmliu@cs.nctu.edu.tw
Quantization C.M. Liu Perceptual Signal Processing Lab College of Computer Science National Chiao-Tung University http://www.csie.nctu.edu.tw/~cmliu/courses/compression/ Office: EC538 (03)5731877 cmliu@cs.nctu.edu.tw
Module 3 LOSSY IMAGE COMPRESSION SYSTEMS. Version 2 ECE IIT, Kharagpur
 Module 3 LOSSY IMAGE COMPRESSION SYSTEMS Lesson 7 Delta Modulation and DPCM Instructional Objectives At the end of this lesson, the students should be able to: 1. Describe a lossy predictive coding scheme.
Module 3 LOSSY IMAGE COMPRESSION SYSTEMS Lesson 7 Delta Modulation and DPCM Instructional Objectives At the end of this lesson, the students should be able to: 1. Describe a lossy predictive coding scheme.
E303: Communication Systems
 E303: Communication Systems Professor A. Manikas Chair of Communications and Array Processing Imperial College London Principles of PCM Prof. A. Manikas (Imperial College) E303: Principles of PCM v.17
E303: Communication Systems Professor A. Manikas Chair of Communications and Array Processing Imperial College London Principles of PCM Prof. A. Manikas (Imperial College) E303: Principles of PCM v.17
Design of a CELP coder and analysis of various quantization techniques
 EECS 65 Project Report Design of a CELP coder and analysis of various quantization techniques Prof. David L. Neuhoff By: Awais M. Kamboh Krispian C. Lawrence Aditya M. Thomas Philip I. Tsai Winter 005
EECS 65 Project Report Design of a CELP coder and analysis of various quantization techniques Prof. David L. Neuhoff By: Awais M. Kamboh Krispian C. Lawrence Aditya M. Thomas Philip I. Tsai Winter 005
Time-domain representations
 Time-domain representations Speech Processing Tom Bäckström Aalto University Fall 2016 Basics of Signal Processing in the Time-domain Time-domain signals Before we can describe speech signals or modelling
Time-domain representations Speech Processing Tom Bäckström Aalto University Fall 2016 Basics of Signal Processing in the Time-domain Time-domain signals Before we can describe speech signals or modelling
Linear Prediction Coding. Nimrod Peleg Update: Aug. 2007
 Linear Prediction Coding Nimrod Peleg Update: Aug. 2007 1 Linear Prediction and Speech Coding The earliest papers on applying LPC to speech: Atal 1968, 1970, 1971 Markel 1971, 1972 Makhoul 1975 This is
Linear Prediction Coding Nimrod Peleg Update: Aug. 2007 1 Linear Prediction and Speech Coding The earliest papers on applying LPC to speech: Atal 1968, 1970, 1971 Markel 1971, 1972 Makhoul 1975 This is
The Equivalence of ADPCM and CELP Coding
 The Equivalence of ADPCM and CELP Coding Peter Kabal Department of Electrical & Computer Engineering McGill University Montreal, Canada Version.2 March 20 c 20 Peter Kabal 20/03/ You are free: to Share
The Equivalence of ADPCM and CELP Coding Peter Kabal Department of Electrical & Computer Engineering McGill University Montreal, Canada Version.2 March 20 c 20 Peter Kabal 20/03/ You are free: to Share
Signal Modeling Techniques in Speech Recognition. Hassan A. Kingravi
 Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Voiced Speech. Unvoiced Speech
 Digital Speech Processing Lecture 2 Homomorphic Speech Processing General Discrete-Time Model of Speech Production p [ n] = p[ n] h [ n] Voiced Speech L h [ n] = A g[ n] v[ n] r[ n] V V V p [ n ] = u [
Digital Speech Processing Lecture 2 Homomorphic Speech Processing General Discrete-Time Model of Speech Production p [ n] = p[ n] h [ n] Voiced Speech L h [ n] = A g[ n] v[ n] r[ n] V V V p [ n ] = u [
Analysis of methods for speech signals quantization
 INFOTEH-JAHORINA Vol. 14, March 2015. Analysis of methods for speech signals quantization Stefan Stojkov Mihajlo Pupin Institute, University of Belgrade Belgrade, Serbia e-mail: stefan.stojkov@pupin.rs
INFOTEH-JAHORINA Vol. 14, March 2015. Analysis of methods for speech signals quantization Stefan Stojkov Mihajlo Pupin Institute, University of Belgrade Belgrade, Serbia e-mail: stefan.stojkov@pupin.rs
Digital Signal Processing
 COMP ENG 4TL4: Digital Signal Processing Notes for Lecture #3 Wednesday, September 10, 2003 1.4 Quantization Digital systems can only represent sample amplitudes with a finite set of prescribed values,
COMP ENG 4TL4: Digital Signal Processing Notes for Lecture #3 Wednesday, September 10, 2003 1.4 Quantization Digital systems can only represent sample amplitudes with a finite set of prescribed values,
ELEN E4810: Digital Signal Processing Topic 11: Continuous Signals. 1. Sampling and Reconstruction 2. Quantization
 ELEN E4810: Digital Signal Processing Topic 11: Continuous Signals 1. Sampling and Reconstruction 2. Quantization 1 1. Sampling & Reconstruction DSP must interact with an analog world: A to D D to A x(t)
ELEN E4810: Digital Signal Processing Topic 11: Continuous Signals 1. Sampling and Reconstruction 2. Quantization 1 1. Sampling & Reconstruction DSP must interact with an analog world: A to D D to A x(t)
Multimedia Systems Giorgio Leonardi A.A Lecture 4 -> 6 : Quantization
 Multimedia Systems Giorgio Leonardi A.A.2014-2015 Lecture 4 -> 6 : Quantization Overview Course page (D.I.R.): https://disit.dir.unipmn.it/course/view.php?id=639 Consulting: Office hours by appointment:
Multimedia Systems Giorgio Leonardi A.A.2014-2015 Lecture 4 -> 6 : Quantization Overview Course page (D.I.R.): https://disit.dir.unipmn.it/course/view.php?id=639 Consulting: Office hours by appointment:
Gaussian source Assumptions d = (x-y) 2, given D, find lower bound of I(X;Y)
 2, given D, find lower bound of I(X;Y)") Gaussian source Assumptions d = (x-y) 2, given D, find lower bound of I(X;Y) E{(X-Y) 2 } D
Gaussian source Assumptions d = (x-y) 2, given D, find lower bound of I(X;Y) E{(X-Y) 2 } D
Audio Coding. Fundamentals Quantization Waveform Coding Subband Coding P NCTU/CSIE DSPLAB C.M..LIU
 Audio Coding P.1 Fundamentals Quantization Waveform Coding Subband Coding 1. Fundamentals P.2 Introduction Data Redundancy Coding Redundancy Spatial/Temporal Redundancy Perceptual Redundancy Compression
Audio Coding P.1 Fundamentals Quantization Waveform Coding Subband Coding 1. Fundamentals P.2 Introduction Data Redundancy Coding Redundancy Spatial/Temporal Redundancy Perceptual Redundancy Compression
Analysis of Finite Wordlength Effects
 Analysis of Finite Wordlength Effects Ideally, the system parameters along with the signal variables have infinite precision taing any value between and In practice, they can tae only discrete values within
Analysis of Finite Wordlength Effects Ideally, the system parameters along with the signal variables have infinite precision taing any value between and In practice, they can tae only discrete values within
CODING SAMPLE DIFFERENCES ATTEMPT 1: NAIVE DIFFERENTIAL CODING
 5 0 DPCM (Differential Pulse Code Modulation) Making scalar quantization work for a correlated source -- a sequential approach. Consider quantizing a slowly varying source (AR, Gauss, ρ =.95, σ 2 = 3.2).
5 0 DPCM (Differential Pulse Code Modulation) Making scalar quantization work for a correlated source -- a sequential approach. Consider quantizing a slowly varying source (AR, Gauss, ρ =.95, σ 2 = 3.2).
EE5585 Data Compression April 18, Lecture 23
 EE5585 Data Compression April 18, 013 Lecture 3 Instructor: Arya Mazumdar Scribe: Trevor Webster Differential Encoding Suppose we have a signal that is slowly varying For instance, if we were looking at
EE5585 Data Compression April 18, 013 Lecture 3 Instructor: Arya Mazumdar Scribe: Trevor Webster Differential Encoding Suppose we have a signal that is slowly varying For instance, if we were looking at
Digital Image Processing Lectures 25 & 26
 Lectures 25 & 26, Professor Department of Electrical and Computer Engineering Colorado State University Spring 2015 Area 4: Image Encoding and Compression Goal: To exploit the redundancies in the image
Lectures 25 & 26, Professor Department of Electrical and Computer Engineering Colorado State University Spring 2015 Area 4: Image Encoding and Compression Goal: To exploit the redundancies in the image
Speech Coding. Speech Processing. Tom Bäckström. October Aalto University
 Speech Coding Speech Processing Tom Bäckström Aalto University October 2015 Introduction Speech coding refers to the digital compression of speech signals for telecommunication (and storage) applications.
Speech Coding Speech Processing Tom Bäckström Aalto University October 2015 Introduction Speech coding refers to the digital compression of speech signals for telecommunication (and storage) applications.
Multimedia Communications. Scalar Quantization
 Multimedia Communications Scalar Quantization Scalar Quantization In many lossy compression applications we want to represent source outputs using a small number of code words. Process of representing
Multimedia Communications Scalar Quantization Scalar Quantization In many lossy compression applications we want to represent source outputs using a small number of code words. Process of representing
PCM Reference Chapter 12.1, Communication Systems, Carlson. PCM.1
 PCM Reference Chapter 1.1, Communication Systems, Carlson. PCM.1 Pulse-code modulation (PCM) Pulse modulations use discrete time samples of analog signals the transmission is composed of analog information
PCM Reference Chapter 1.1, Communication Systems, Carlson. PCM.1 Pulse-code modulation (PCM) Pulse modulations use discrete time samples of analog signals the transmission is composed of analog information
Feature extraction 2
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 2 Dr Philip Jackson Linear prediction Perceptual linear prediction Comparison of feature methods
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 2 Dr Philip Jackson Linear prediction Perceptual linear prediction Comparison of feature methods
representation of speech
 Digital Speech Processing Lectures 7-8 Time Domain Methods in Speech Processing 1 General Synthesis Model voiced sound amplitude Log Areas, Reflection Coefficients, Formants, Vocal Tract Polynomial, l
Digital Speech Processing Lectures 7-8 Time Domain Methods in Speech Processing 1 General Synthesis Model voiced sound amplitude Log Areas, Reflection Coefficients, Formants, Vocal Tract Polynomial, l
Communication Engineering Prof. Surendra Prasad Department of Electrical Engineering Indian Institute of Technology, Delhi
 Communication Engineering Prof. Surendra Prasad Department of Electrical Engineering Indian Institute of Technology, Delhi Lecture - 41 Pulse Code Modulation (PCM) So, if you remember we have been talking
Communication Engineering Prof. Surendra Prasad Department of Electrical Engineering Indian Institute of Technology, Delhi Lecture - 41 Pulse Code Modulation (PCM) So, if you remember we have been talking
SCELP: LOW DELAY AUDIO CODING WITH NOISE SHAPING BASED ON SPHERICAL VECTOR QUANTIZATION
 SCELP: LOW DELAY AUDIO CODING WITH NOISE SHAPING BASED ON SPHERICAL VECTOR QUANTIZATION Hauke Krüger and Peter Vary Institute of Communication Systems and Data Processing RWTH Aachen University, Templergraben
SCELP: LOW DELAY AUDIO CODING WITH NOISE SHAPING BASED ON SPHERICAL VECTOR QUANTIZATION Hauke Krüger and Peter Vary Institute of Communication Systems and Data Processing RWTH Aachen University, Templergraben
Speech Signal Representations
 Speech Signal Representations Berlin Chen 2003 References: 1. X. Huang et. al., Spoken Language Processing, Chapters 5, 6 2. J. R. Deller et. al., Discrete-Time Processing of Speech Signals, Chapters 4-6
Speech Signal Representations Berlin Chen 2003 References: 1. X. Huang et. al., Spoken Language Processing, Chapters 5, 6 2. J. R. Deller et. al., Discrete-Time Processing of Speech Signals, Chapters 4-6
Objectives of Image Coding
 Objectives of Image Coding Representation of an image with acceptable quality, using as small a number of bits as possible Applications: Reduction of channel bandwidth for image transmission Reduction
Objectives of Image Coding Representation of an image with acceptable quality, using as small a number of bits as possible Applications: Reduction of channel bandwidth for image transmission Reduction
Vector Quantization. Institut Mines-Telecom. Marco Cagnazzo, MN910 Advanced Compression
 Institut Mines-Telecom Vector Quantization Marco Cagnazzo, cagnazzo@telecom-paristech.fr MN910 Advanced Compression 2/66 19.01.18 Institut Mines-Telecom Vector Quantization Outline Gain-shape VQ 3/66 19.01.18
Institut Mines-Telecom Vector Quantization Marco Cagnazzo, cagnazzo@telecom-paristech.fr MN910 Advanced Compression 2/66 19.01.18 Institut Mines-Telecom Vector Quantization Outline Gain-shape VQ 3/66 19.01.18
Basic Principles of Video Coding
 Basic Principles of Video Coding Introduction Categories of Video Coding Schemes Information Theory Overview of Video Coding Techniques Predictive coding Transform coding Quantization Entropy coding Motion
Basic Principles of Video Coding Introduction Categories of Video Coding Schemes Information Theory Overview of Video Coding Techniques Predictive coding Transform coding Quantization Entropy coding Motion
encoding without prediction) (Server) Quantization: Initial Data 0, 1, 2, Quantized Data 0, 1, 2, 3, 4, 8, 16, 32, 64, 128, 256
 (Server) Quantization: Initial Data 0, 1, 2, Quantized Data 0, 1, 2, 3, 4, 8, 16, 32, 64, 128, 256") General Models for Compression / Decompression -they apply to symbols data, text, and to image but not video 1. Simplest model (Lossless ( encoding without prediction) (server) Signal Encode Transmit (client)
General Models for Compression / Decompression -they apply to symbols data, text, and to image but not video 1. Simplest model (Lossless ( encoding without prediction) (server) Signal Encode Transmit (client)
Compression methods: the 1 st generation
 Compression methods: the 1 st generation 1998-2017 Josef Pelikán CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ Still1g 2017 Josef Pelikán, http://cgg.mff.cuni.cz/~pepca 1 / 32 Basic
Compression methods: the 1 st generation 1998-2017 Josef Pelikán CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ Still1g 2017 Josef Pelikán, http://cgg.mff.cuni.cz/~pepca 1 / 32 Basic
BASICS OF COMPRESSION THEORY
 BASICS OF COMPRESSION THEORY Why Compression? Task: storage and transport of multimedia information. E.g.: non-interlaced HDTV: 0x0x0x = Mb/s!! Solutions: Develop technologies for higher bandwidth Find
BASICS OF COMPRESSION THEORY Why Compression? Task: storage and transport of multimedia information. E.g.: non-interlaced HDTV: 0x0x0x = Mb/s!! Solutions: Develop technologies for higher bandwidth Find
Mel-Generalized Cepstral Representation of Speech A Unified Approach to Speech Spectral Estimation. Keiichi Tokuda
 Mel-Generalized Cepstral Representation of Speech A Unified Approach to Speech Spectral Estimation Keiichi Tokuda Nagoya Institute of Technology Carnegie Mellon University Tamkang University March 13,
Mel-Generalized Cepstral Representation of Speech A Unified Approach to Speech Spectral Estimation Keiichi Tokuda Nagoya Institute of Technology Carnegie Mellon University Tamkang University March 13,
ISOLATED WORD RECOGNITION FOR ENGLISH LANGUAGE USING LPC,VQ AND HMM
 ISOLATED WORD RECOGNITION FOR ENGLISH LANGUAGE USING LPC,VQ AND HMM Mayukh Bhaowal and Kunal Chawla (Students)Indian Institute of Information Technology, Allahabad, India Abstract: Key words: Speech recognition
ISOLATED WORD RECOGNITION FOR ENGLISH LANGUAGE USING LPC,VQ AND HMM Mayukh Bhaowal and Kunal Chawla (Students)Indian Institute of Information Technology, Allahabad, India Abstract: Key words: Speech recognition
7.1 Sampling and Reconstruction
 Haberlesme Sistemlerine Giris (ELE 361) 6 Agustos 2017 TOBB Ekonomi ve Teknoloji Universitesi, Guz 2017-18 Dr. A. Melda Yuksel Turgut & Tolga Girici Lecture Notes Chapter 7 Analog to Digital Conversion
Haberlesme Sistemlerine Giris (ELE 361) 6 Agustos 2017 TOBB Ekonomi ve Teknoloji Universitesi, Guz 2017-18 Dr. A. Melda Yuksel Turgut & Tolga Girici Lecture Notes Chapter 7 Analog to Digital Conversion
EE-597 Notes Quantization
 EE-597 Notes Quantization Phil Schniter June, 4 Quantization Given a continuous-time and continuous-amplitude signal (t, processing and storage by modern digital hardware requires discretization in both
EE-597 Notes Quantization Phil Schniter June, 4 Quantization Given a continuous-time and continuous-amplitude signal (t, processing and storage by modern digital hardware requires discretization in both
Vector Quantization Encoder Decoder Original Form image Minimize distortion Table Channel Image Vectors Look-up (X, X i ) X may be a block of l
 X may be a block of l") Vector Quantization Encoder Decoder Original Image Form image Vectors X Minimize distortion k k Table X^ k Channel d(x, X^ Look-up i ) X may be a block of l m image or X=( r, g, b ), or a block of DCT
Vector Quantization Encoder Decoder Original Image Form image Vectors X Minimize distortion k k Table X^ k Channel d(x, X^ Look-up i ) X may be a block of l m image or X=( r, g, b ), or a block of DCT
Quantization 2.1 QUANTIZATION AND THE SOURCE ENCODER
 2 Quantization After the introduction to image and video compression presented in Chapter 1, we now address several fundamental aspects of image and video compression in the remaining chapters of Section
2 Quantization After the introduction to image and video compression presented in Chapter 1, we now address several fundamental aspects of image and video compression in the remaining chapters of Section
AdaptiveFilters. GJRE-F Classification : FOR Code:
 Global Journal of Researches in Engineering: F Electrical and Electronics Engineering Volume 14 Issue 7 Version 1.0 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals
Global Journal of Researches in Engineering: F Electrical and Electronics Engineering Volume 14 Issue 7 Version 1.0 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals
HARMONIC VECTOR QUANTIZATION
 HARMONIC VECTOR QUANTIZATION Volodya Grancharov, Sigurdur Sverrisson, Erik Norvell, Tomas Toftgård, Jonas Svedberg, and Harald Pobloth SMN, Ericsson Research, Ericsson AB 64 8, Stockholm, Sweden ABSTRACT
HARMONIC VECTOR QUANTIZATION Volodya Grancharov, Sigurdur Sverrisson, Erik Norvell, Tomas Toftgård, Jonas Svedberg, and Harald Pobloth SMN, Ericsson Research, Ericsson AB 64 8, Stockholm, Sweden ABSTRACT
Vector Quantization and Subband Coding
 Vector Quantization and Subband Coding 18-796 ultimedia Communications: Coding, Systems, and Networking Prof. Tsuhan Chen tsuhan@ece.cmu.edu Vector Quantization 1 Vector Quantization (VQ) Each image block
Vector Quantization and Subband Coding 18-796 ultimedia Communications: Coding, Systems, and Networking Prof. Tsuhan Chen tsuhan@ece.cmu.edu Vector Quantization 1 Vector Quantization (VQ) Each image block
On Optimal Coding of Hidden Markov Sources
 2014 Data Compression Conference On Optimal Coding of Hidden Markov Sources Mehdi Salehifar, Emrah Akyol, Kumar Viswanatha, and Kenneth Rose Department of Electrical and Computer Engineering University
2014 Data Compression Conference On Optimal Coding of Hidden Markov Sources Mehdi Salehifar, Emrah Akyol, Kumar Viswanatha, and Kenneth Rose Department of Electrical and Computer Engineering University
VID3: Sampling and Quantization
 Video Transmission VID3: Sampling and Quantization By Prof. Gregory D. Durgin copyright 2009 all rights reserved Claude E. Shannon (1916-2001) Mathematician and Electrical Engineer Worked for Bell Labs
Video Transmission VID3: Sampling and Quantization By Prof. Gregory D. Durgin copyright 2009 all rights reserved Claude E. Shannon (1916-2001) Mathematician and Electrical Engineer Worked for Bell Labs
Review of Quantization. Quantization. Bring in Probability Distribution. L-level Quantization. Uniform partition
 Review of Quantization UMCP ENEE631 Slides (created by M.Wu 004) Quantization UMCP ENEE631 Slides (created by M.Wu 001/004) L-level Quantization Minimize errors for this lossy process What L values to
Review of Quantization UMCP ENEE631 Slides (created by M.Wu 004) Quantization UMCP ENEE631 Slides (created by M.Wu 001/004) L-level Quantization Minimize errors for this lossy process What L values to
ECE4270 Fundamentals of DSP Lecture 20. Fixed-Point Arithmetic in FIR and IIR Filters (part I) Overview of Lecture. Overflow. FIR Digital Filter
 Overview of Lecture. Overflow. FIR Digital Filter") ECE4270 Fundamentals of DSP Lecture 20 Fixed-Point Arithmetic in FIR and IIR Filters (part I) School of ECE Center for Signal and Information Processing Georgia Institute of Technology Overview of Lecture
ECE4270 Fundamentals of DSP Lecture 20 Fixed-Point Arithmetic in FIR and IIR Filters (part I) School of ECE Center for Signal and Information Processing Georgia Institute of Technology Overview of Lecture
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
Predictive Coding. Prediction Prediction in Images
 Prediction Prediction in Images Predictive Coding Principle of Differential Pulse Code Modulation (DPCM) DPCM and entropy-constrained scalar quantization DPCM and transmission errors Adaptive intra-interframe
Prediction Prediction in Images Predictive Coding Principle of Differential Pulse Code Modulation (DPCM) DPCM and entropy-constrained scalar quantization DPCM and transmission errors Adaptive intra-interframe
Predictive Coding. Prediction
 Predictive Coding Prediction Prediction in Images Principle of Differential Pulse Code Modulation (DPCM) DPCM and entropy-constrained scalar quantization DPCM and transmission errors Adaptive intra-interframe
Predictive Coding Prediction Prediction in Images Principle of Differential Pulse Code Modulation (DPCM) DPCM and entropy-constrained scalar quantization DPCM and transmission errors Adaptive intra-interframe
Multimedia Networking ECE 599
 Multimedia Networking ECE 599 Prof. Thinh Nguyen School of Electrical Engineering and Computer Science Based on lectures from B. Lee, B. Girod, and A. Mukherjee 1 Outline Digital Signal Representation
Multimedia Networking ECE 599 Prof. Thinh Nguyen School of Electrical Engineering and Computer Science Based on lectures from B. Lee, B. Girod, and A. Mukherjee 1 Outline Digital Signal Representation
EE368B Image and Video Compression
 EE368B Image and Video Compression Homework Set #2 due Friday, October 20, 2000, 9 a.m. Introduction The Lloyd-Max quantizer is a scalar quantizer which can be seen as a special case of a vector quantizer
EE368B Image and Video Compression Homework Set #2 due Friday, October 20, 2000, 9 a.m. Introduction The Lloyd-Max quantizer is a scalar quantizer which can be seen as a special case of a vector quantizer
Proc. of NCC 2010, Chennai, India
 Proc. of NCC 2010, Chennai, India Trajectory and surface modeling of LSF for low rate speech coding M. Deepak and Preeti Rao Department of Electrical Engineering Indian Institute of Technology, Bombay
Proc. of NCC 2010, Chennai, India Trajectory and surface modeling of LSF for low rate speech coding M. Deepak and Preeti Rao Department of Electrical Engineering Indian Institute of Technology, Bombay
Lloyd-Max Quantization of Correlated Processes: How to Obtain Gains by Receiver-Sided Time-Variant Codebooks
 Lloyd-Max Quantization of Correlated Processes: How to Obtain Gains by Receiver-Sided Time-Variant Codebooks Sai Han and Tim Fingscheidt Institute for Communications Technology, Technische Universität
Lloyd-Max Quantization of Correlated Processes: How to Obtain Gains by Receiver-Sided Time-Variant Codebooks Sai Han and Tim Fingscheidt Institute for Communications Technology, Technische Universität
EE5356 Digital Image Processing
 EE5356 Digital Image Processing INSTRUCTOR: Dr KR Rao Spring 007, Final Thursday, 10 April 007 11:00 AM 1:00 PM ( hours) (Room 111 NH) INSTRUCTIONS: 1 Closed books and closed notes All problems carry weights
EE5356 Digital Image Processing INSTRUCTOR: Dr KR Rao Spring 007, Final Thursday, 10 April 007 11:00 AM 1:00 PM ( hours) (Room 111 NH) INSTRUCTIONS: 1 Closed books and closed notes All problems carry weights
Image Compression using DPCM with LMS Algorithm
 Image Compression using DPCM with LMS Algorithm Reenu Sharma, Abhay Khedkar SRCEM, Banmore -----------------------------------------------------------------****---------------------------------------------------------------
Image Compression using DPCM with LMS Algorithm Reenu Sharma, Abhay Khedkar SRCEM, Banmore -----------------------------------------------------------------****---------------------------------------------------------------
ON SCALABLE CODING OF HIDDEN MARKOV SOURCES. Mehdi Salehifar, Tejaswi Nanjundaswamy, and Kenneth Rose
 ON SCALABLE CODING OF HIDDEN MARKOV SOURCES Mehdi Salehifar, Tejaswi Nanjundaswamy, and Kenneth Rose Department of Electrical and Computer Engineering University of California, Santa Barbara, CA, 93106
ON SCALABLE CODING OF HIDDEN MARKOV SOURCES Mehdi Salehifar, Tejaswi Nanjundaswamy, and Kenneth Rose Department of Electrical and Computer Engineering University of California, Santa Barbara, CA, 93106
Frequency Domain Speech Analysis
 Frequency Domain Speech Analysis Short Time Fourier Analysis Cepstral Analysis Windowed (short time) Fourier Transform Spectrogram of speech signals Filter bank implementation* (Real) cepstrum and complex
Frequency Domain Speech Analysis Short Time Fourier Analysis Cepstral Analysis Windowed (short time) Fourier Transform Spectrogram of speech signals Filter bank implementation* (Real) cepstrum and complex
L7: Linear prediction of speech
 L7: Linear prediction of speech Introduction Linear prediction Finding the linear prediction coefficients Alternative representations This lecture is based on [Dutoit and Marques, 2009, ch1; Taylor, 2009,
L7: Linear prediction of speech Introduction Linear prediction Finding the linear prediction coefficients Alternative representations This lecture is based on [Dutoit and Marques, 2009, ch1; Taylor, 2009,
BASIC COMPRESSION TECHNIQUES
 BASIC COMPRESSION TECHNIQUES N. C. State University CSC557 Multimedia Computing and Networking Fall 2001 Lectures # 05 Questions / Problems / Announcements? 2 Matlab demo of DFT Low-pass windowed-sinc
BASIC COMPRESSION TECHNIQUES N. C. State University CSC557 Multimedia Computing and Networking Fall 2001 Lectures # 05 Questions / Problems / Announcements? 2 Matlab demo of DFT Low-pass windowed-sinc
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 11 Adaptive Filtering 14/03/04 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 11 Adaptive Filtering 14/03/04 http://www.ee.unlv.edu/~b1morris/ee482/
Digital Signal Processing 2/ Advanced Digital Signal Processing Lecture 3, SNR, non-linear Quantisation Gerald Schuller, TU Ilmenau
 Digital Signal Processing 2/ Advanced Digital Signal Processing Lecture 3, SNR, non-linear Quantisation Gerald Schuller, TU Ilmenau What is our SNR if we have a sinusoidal signal? What is its pdf? Basically
Digital Signal Processing 2/ Advanced Digital Signal Processing Lecture 3, SNR, non-linear Quantisation Gerald Schuller, TU Ilmenau What is our SNR if we have a sinusoidal signal? What is its pdf? Basically
16.36 Communication Systems Engineering
 MIT OpenCourseWare http://ocw.mit.edu 16.36 Communication Systems Engineering Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. 16.36: Communication
MIT OpenCourseWare http://ocw.mit.edu 16.36 Communication Systems Engineering Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. 16.36: Communication
L used in various speech coding applications for representing
 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 1, NO. 1. JANUARY 1993 3 Efficient Vector Quantization of LPC Parameters at 24 BitsFrame Kuldip K. Paliwal, Member, IEEE, and Bishnu S. Atal, Fellow,
IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 1, NO. 1. JANUARY 1993 3 Efficient Vector Quantization of LPC Parameters at 24 BitsFrame Kuldip K. Paliwal, Member, IEEE, and Bishnu S. Atal, Fellow,
CEPSTRAL ANALYSIS SYNTHESIS ON THE MEL FREQUENCY SCALE, AND AN ADAPTATIVE ALGORITHM FOR IT.
 CEPSTRAL ANALYSIS SYNTHESIS ON THE EL FREQUENCY SCALE, AND AN ADAPTATIVE ALGORITH FOR IT. Summarized overview of the IEEE-publicated papers Cepstral analysis synthesis on the mel frequency scale by Satochi
CEPSTRAL ANALYSIS SYNTHESIS ON THE EL FREQUENCY SCALE, AND AN ADAPTATIVE ALGORITH FOR IT. Summarized overview of the IEEE-publicated papers Cepstral analysis synthesis on the mel frequency scale by Satochi
Oversampling Converters
 Oversampling Converters David Johns and Ken Martin (johns@eecg.toronto.edu) (martin@eecg.toronto.edu) slide 1 of 56 Motivation Popular approach for medium-to-low speed A/D and D/A applications requiring
Oversampling Converters David Johns and Ken Martin (johns@eecg.toronto.edu) (martin@eecg.toronto.edu) slide 1 of 56 Motivation Popular approach for medium-to-low speed A/D and D/A applications requiring
Lecture 7 Predictive Coding & Quantization
 Shujun LI (李树钧): INF-10845-20091 Multimedia Coding Lecture 7 Predictive Coding & Quantization June 3, 2009 Outline Predictive Coding Motion Estimation and Compensation Context-Based Coding Quantization
Shujun LI (李树钧): INF-10845-20091 Multimedia Coding Lecture 7 Predictive Coding & Quantization June 3, 2009 Outline Predictive Coding Motion Estimation and Compensation Context-Based Coding Quantization
Waveform-Based Coding: Outline
 Waveform-Based Coding: Transform and Predictive Coding Yao Wang Polytechnic University, Brooklyn, NY11201 http://eeweb.poly.edu/~yao Based on: Y. Wang, J. Ostermann, and Y.-Q. Zhang, Video Processing and
Waveform-Based Coding: Transform and Predictive Coding Yao Wang Polytechnic University, Brooklyn, NY11201 http://eeweb.poly.edu/~yao Based on: Y. Wang, J. Ostermann, and Y.-Q. Zhang, Video Processing and
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 11 Adaptive Filtering 14/03/04 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 11 Adaptive Filtering 14/03/04 http://www.ee.unlv.edu/~b1morris/ee482/
Adaptive Filter Theory
 0 Adaptive Filter heory Sung Ho Cho Hanyang University Seoul, Korea (Office) +8--0-0390 (Mobile) +8-10-541-5178 dragon@hanyang.ac.kr able of Contents 1 Wiener Filters Gradient Search by Steepest Descent
0 Adaptive Filter heory Sung Ho Cho Hanyang University Seoul, Korea (Office) +8--0-0390 (Mobile) +8-10-541-5178 dragon@hanyang.ac.kr able of Contents 1 Wiener Filters Gradient Search by Steepest Descent
3GPP TS V6.1.1 ( )
") Technical Specification 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Speech codec speech processing functions; Adaptive Multi-Rate - Wideband (AMR-WB)
Technical Specification 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Speech codec speech processing functions; Adaptive Multi-Rate - Wideband (AMR-WB)
ELEC546 Review of Information Theory
 ELEC546 Review of Information Theory Vincent Lau 1/1/004 1 Review of Information Theory Entropy: Measure of uncertainty of a random variable X. The entropy of X, H(X), is given by: If X is a discrete random
ELEC546 Review of Information Theory Vincent Lau 1/1/004 1 Review of Information Theory Entropy: Measure of uncertainty of a random variable X. The entropy of X, H(X), is given by: If X is a discrete random
INTRODUCTION TO DELTA-SIGMA ADCS
 ECE37 Advanced Analog Circuits INTRODUCTION TO DELTA-SIGMA ADCS Richard Schreier richard.schreier@analog.com NLCOTD: Level Translator VDD > VDD2, e.g. 3-V logic? -V logic VDD < VDD2, e.g. -V logic? 3-V
ECE37 Advanced Analog Circuits INTRODUCTION TO DELTA-SIGMA ADCS Richard Schreier richard.schreier@analog.com NLCOTD: Level Translator VDD > VDD2, e.g. 3-V logic? -V logic VDD < VDD2, e.g. -V logic? 3-V
Principles of Communications
 Principles of Communications Weiyao Lin Shanghai Jiao Tong University Chapter 10: Information Theory Textbook: Chapter 12 Communication Systems Engineering: Ch 6.1, Ch 9.1~ 9. 92 2009/2010 Meixia Tao @
Principles of Communications Weiyao Lin Shanghai Jiao Tong University Chapter 10: Information Theory Textbook: Chapter 12 Communication Systems Engineering: Ch 6.1, Ch 9.1~ 9. 92 2009/2010 Meixia Tao @
CMPT 889: Lecture 3 Fundamentals of Digital Audio, Discrete-Time Signals
 CMPT 889: Lecture 3 Fundamentals of Digital Audio, Discrete-Time Signals Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University October 6, 2005 1 Sound Sound waves are longitudinal
CMPT 889: Lecture 3 Fundamentals of Digital Audio, Discrete-Time Signals Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University October 6, 2005 1 Sound Sound waves are longitudinal
Quantization of LSF Parameters Using A Trellis Modeling
 1 Quantization of LSF Parameters Using A Trellis Modeling Farshad Lahouti, Amir K. Khandani Coding and Signal Transmission Lab. Dept. of E&CE, University of Waterloo, Waterloo, ON, N2L 3G1, Canada (farshad,
1 Quantization of LSF Parameters Using A Trellis Modeling Farshad Lahouti, Amir K. Khandani Coding and Signal Transmission Lab. Dept. of E&CE, University of Waterloo, Waterloo, ON, N2L 3G1, Canada (farshad,
Ch. 10 Vector Quantization. Advantages & Design
 Ch. 10 Vector Quantization Advantages & Design 1 Advantages of VQ There are (at least) 3 main characteristics of VQ that help it outperform SQ: 1. Exploit Correlation within vectors 2. Exploit Shape Flexibility
Ch. 10 Vector Quantization Advantages & Design 1 Advantages of VQ There are (at least) 3 main characteristics of VQ that help it outperform SQ: 1. Exploit Correlation within vectors 2. Exploit Shape Flexibility
Example: for source
 Nonuniform scalar quantizer References: Sayood Chap. 9, Gersho and Gray, Chap.'s 5 and 6. The basic idea: For a nonuniform source density, put smaller cells and levels where the density is larger, thereby
Nonuniform scalar quantizer References: Sayood Chap. 9, Gersho and Gray, Chap.'s 5 and 6. The basic idea: For a nonuniform source density, put smaller cells and levels where the density is larger, thereby
Lecture 18: Gaussian Channel
 Lecture 18: Gaussian Channel Gaussian channel Gaussian channel capacity Dr. Yao Xie, ECE587, Information Theory, Duke University Mona Lisa in AWGN Mona Lisa Noisy Mona Lisa 100 100 200 200 300 300 400
Lecture 18: Gaussian Channel Gaussian channel Gaussian channel capacity Dr. Yao Xie, ECE587, Information Theory, Duke University Mona Lisa in AWGN Mona Lisa Noisy Mona Lisa 100 100 200 200 300 300 400
DSP Design Lecture 2. Fredrik Edman.
 DSP Design Lecture Number representation, scaling, quantization and round-off Noise Fredrik Edman fredrik.edman@eit.lth.se Representation of Numbers Numbers is a way to use symbols to describe and model
DSP Design Lecture Number representation, scaling, quantization and round-off Noise Fredrik Edman fredrik.edman@eit.lth.se Representation of Numbers Numbers is a way to use symbols to describe and model
Re-estimation of Linear Predictive Parameters in Sparse Linear Prediction
 Downloaded from vbnaaudk on: januar 12, 2019 Aalborg Universitet Re-estimation of Linear Predictive Parameters in Sparse Linear Prediction Giacobello, Daniele; Murthi, Manohar N; Christensen, Mads Græsbøll;
Downloaded from vbnaaudk on: januar 12, 2019 Aalborg Universitet Re-estimation of Linear Predictive Parameters in Sparse Linear Prediction Giacobello, Daniele; Murthi, Manohar N; Christensen, Mads Græsbøll;
LECTURE NOTES IN AUDIO ANALYSIS: PITCH ESTIMATION FOR DUMMIES
 LECTURE NOTES IN AUDIO ANALYSIS: PITCH ESTIMATION FOR DUMMIES Abstract March, 3 Mads Græsbøll Christensen Audio Analysis Lab, AD:MT Aalborg University This document contains a brief introduction to pitch
LECTURE NOTES IN AUDIO ANALYSIS: PITCH ESTIMATION FOR DUMMIES Abstract March, 3 Mads Græsbøll Christensen Audio Analysis Lab, AD:MT Aalborg University This document contains a brief introduction to pitch
Adaptive Filtering Part II
 Adaptive Filtering Part II In previous Lecture we saw that: Setting the gradient of cost function equal to zero, we obtain the optimum values of filter coefficients: (Wiener-Hopf equation) Adaptive Filtering,
Adaptive Filtering Part II In previous Lecture we saw that: Setting the gradient of cost function equal to zero, we obtain the optimum values of filter coefficients: (Wiener-Hopf equation) Adaptive Filtering,
Linear Prediction 1 / 41
 Linear Prediction 1 / 41 A map of speech signal processing Natural signals Models Artificial signals Inference Speech synthesis Hidden Markov Inference Homomorphic processing Dereverberation, Deconvolution
Linear Prediction 1 / 41 A map of speech signal processing Natural signals Models Artificial signals Inference Speech synthesis Hidden Markov Inference Homomorphic processing Dereverberation, Deconvolution
Noise Robust Isolated Words Recognition Problem Solving Based on Simultaneous Perturbation Stochastic Approximation Algorithm
 EngOpt 2008 - International Conference on Engineering Optimization Rio de Janeiro, Brazil, 0-05 June 2008. Noise Robust Isolated Words Recognition Problem Solving Based on Simultaneous Perturbation Stochastic
EngOpt 2008 - International Conference on Engineering Optimization Rio de Janeiro, Brazil, 0-05 June 2008. Noise Robust Isolated Words Recognition Problem Solving Based on Simultaneous Perturbation Stochastic
The information loss in quantization
 The information loss in quantization The rough meaning of quantization in the frame of coding is representing numerical quantities with a finite set of symbols. The mapping between numbers, which are normally
The information loss in quantization The rough meaning of quantization in the frame of coding is representing numerical quantities with a finite set of symbols. The mapping between numbers, which are normally
Introduction p. 1 Compression Techniques p. 3 Lossless Compression p. 4 Lossy Compression p. 5 Measures of Performance p. 5 Modeling and Coding p.
 Preface p. xvii Introduction p. 1 Compression Techniques p. 3 Lossless Compression p. 4 Lossy Compression p. 5 Measures of Performance p. 5 Modeling and Coding p. 6 Summary p. 10 Projects and Problems
Preface p. xvii Introduction p. 1 Compression Techniques p. 3 Lossless Compression p. 4 Lossy Compression p. 5 Measures of Performance p. 5 Modeling and Coding p. 6 Summary p. 10 Projects and Problems
Lab 4: Quantization, Oversampling, and Noise Shaping
 Lab 4: Quantization, Oversampling, and Noise Shaping Due Friday 04/21/17 Overview: This assignment should be completed with your assigned lab partner(s). Each group must turn in a report composed using
Lab 4: Quantization, Oversampling, and Noise Shaping Due Friday 04/21/17 Overview: This assignment should be completed with your assigned lab partner(s). Each group must turn in a report composed using