Data Preprocessing. Jilles Vreeken IRDM 15/ Oct 2015
|
|
|
- Erin Fletcher
- 5 years ago
- Views:
Transcription

1 Data Preprocessing Jilles Vreeken 22 Oct 2015




2 So, how do you pronounce Jilles Yill-less Vreeken Fray-can Okay, now we can talk.
3 Questions of the day How do we preprocess data before we can extract anything meaningful? How can we convert, normalise, and reduce, Big Data into Mineable Data? 22 Oct 2015 II-1: 3
4 IRDM Chapter 2.1, overview 1. Data type conversion 2. Data normalisation 3. Sampling 4. Dimensionality Reduction You ll find this covered in Aggarwal Chapter Zaki & Meira, Ch. 1, 2.4, 3.5, 6, 7 (Aggarwal, Chapter ) II-1: 4
5 We re here to stay From now on, all lectures will be in HS 002 That is, Tuesday AND Thursday. II-1: 5
6 Homework action speaks louder than words II-1: 6
7 Homework Guidelines Almost every week, we hand out a new homework assignment. You make these individually at home. Homework Timeline: week nn: Homework ii handed out week nn + 1: Hand in results of Homework ii at start of lecture week nn + 2: Tutorial session on Homework ii Questions are to be asked during Tutorial sessions. in exceptional cases of PANIC you may your tutors and kindly ask for an appointment this is beyond their official duty. II-1: 7
8 Homework Guidelines Almost every week, we hand out a new homework assignment. You make these individually at home. Homework Timeline: week nn: Homework ii handed out week nn + 1: Hand as soon in results as of Homework possible ii at start of lecture week nn + 2: Tutorial session on Homework ii Questions are to be asked during Tutorial sessions. Please register for a tutorial group in exceptional cases of PANIC you may your tutors and kindly ask for an appointment this is beyond their official duty. II-1: 8
9 Conversion From one data type to another Ch II-1: 9
10 Data During IRDM we will consider a lot of data. We will refer to our data as DD. We will consider many types. Depending on context DD can be a table, matrix, sequence, etc., with binary, categorical, or real-valued entries. Most algorithms work only for one type of data. How can we convert DD from one type into another? Today we discuss two basic techniques to get us started. II-1: 10
11 Numeric to Categorical - Discretisation How to go from numeric to categorical? by partitioning the domain of numeric attribute dd ii into kk adjacent ranges, and assigning a symbolic label to each. e.g. we partition attribute age into ranges of 10 years: [0,10), [10,20), etc. Standard approaches to choose ranges include Equi-width: choose [aa, bb] such that bb aa is the same for all ranges Equi-log: choose [aa, bb] such that log bb log aa is the same for all Equi-height: choose ranges such each has the same number of records Choosing kk is difficult. Too low, and you introduce spurious associations. Too high, and your method may not be able to find anything. So, be careful; use domain knowledge, just try, or, use more advanced techniques. II-1: 11
12 Categorical to Numeric - Binarisation How to go from categorical to numeric or binary data? by creating a new attribute per categorical attribute-value combination. for each categorical attribute dd with φφ possible values, we create φφ new attributes, and set their values to 0 or 1 accordingly. For example, for attribute colour with domain {rrrrrr, bbbbbbbb, gggggggggg}, we create 3 new attributes, resp. corresponding to cccccccccccc = rrrrrr, cccccccccccc = bbbbbbbb, and cccccccccccc = gggggggggg. Note! If you are not careful, the downstream method does not know what the old attributes are, and will get lost (or, go wild) with the all the correlations that exist between the new attributes. II-1: 12
13 Cleaning Missing Values and Normalisation Ch. 2.3 II-1: 13
14 Missing Values Missing values are common in real-world data in fact, complete data is the rare case values are often unobserved, wrongly observed, or lost Data with missing values needs to be dealt with care some methods are robust to missing values e.g. naïve Bayes classifiers some methods cannot handle missing values (natively) (at all) e.g. support vector machines II-1: 14
15 Handling missing values Two common techniques to handle missing values are ignoring them imputing them In imputation, we replace them with educated guesses either we use high level statistics, e.g. the mean of the variable perhaps stratified over some class e.g. the mean height vs. the mean height of all professors or, we fit a model to the data, and draw values from it e.g. a Bayesian network, a low-rank matrix factorization, etc, matrix completion is often used when lots of values are missing II-1: 15


16 Some problems Imputed values may be wrong! this may have a significant effect on results especially categorical data is hard the effect of imputation is never smooth Ignoring records or variables with missing values may not be possible there may not be any data left Binary data has the problem of distinguishing non-existent and non-observed data did you never see the polar bear living in the Dudweiler forest, or does it not exist? II-1: 16
17 Centering Consider DD of nn observations over mm variables if you want, you can see this as an nn-by-mm matrix DD We say DD is zero centered if mmmmmmmm(ddii) = 0 for each column ddii of DD We can center any dataset by subtracting the mean from each columns II-1: 17
18 Unit variance An attribute dd has unit variance if vvvvvv dd = 1 A dataset DD has unit variance iff ddii var dd ii = 1 We obtain unit variance by dividing every column by its standard deviation. II-1: 18
19 Standardisation Data that is zero centered and has unit variance is called standardised, or the zz-scores many methods (implicitly) assume data is standardised Of course, we may apply non-linear transformations to the data before standardising. for example, by taking a logarithm, or the cubic root we can diminish the importance of LARGE values II-1: 19
20 Why centering? Consider the red data elipse the main dimension of variance is from the origin to the data the second is orthogonal to the first they don t show the variance of the data! If we center the data, however, the directions are correct! II-1: 20
21 When not to center? Centering cannot be applied to all sorts of data It destroys non-negativity e.g. NMF becomes impossible Centered data won t contain integers e.g. no more count or binary data can hurt integratability itemset mining becomes impossible Centering destroys sparsity bad for algorithmic efficiency (we can retain sparsity by only changing non-zero values) II-1: 21
22 Why unit variance? Assume one observation is height in meters, and one observation is weight in grams now weight contains much higher values (for humans, at least) weight has more weight in calculations Division by standard deviation makes all observations equally important most values now fall between -1 and 1 Question to the audience: What s the catch? What s the assumption? II-1: 22
23 What s wrong with unit variance? Dividing by standard deviation is based on the assumption that the values follow a Gaussian distribution often this is plausible: Law of Large Numbers, Central Limit Theorem, etc. Not all data is Gaussian. integer counts (especially over small ranges_ transaction data Not all data distributions have a mean powerlaw distributions II-1: 23
24 Dimensionality Reduction From many to few(er) dimensions Ch II-1: 24
25 Curse of Dimensionality Life gets harder, exponentially harder as dimensionality increases. Not just computationally The data volume grows too fast 100 evenly-spaced points in a unit interval have a max distance of 0.01 to get the same distance for adjacent points in a 10-dimensional unit hypercube we need points that is an increase of factor (!) And, ten dimensions is really not so many II-1: 25
26 Hypercube and Hypersphere A hypercube is a dd-dimensional cube with edge length 2rr, its volume is vvvvvv(hh dd (2rr)) = 2rr dd A Hypersphere is the dd-dimensional ball of radius rr vvvvvv SS 1 rr = 2rr vvvvvv SS 2 rr = ππrr 2 vvvvvv SS 3 rr = 4 3 ππrr3 vvvvvv SS dd rr = KK dd rr dd where KK dd = ππdd/2 Γ dd/2+1 Γ dd = dd 2! for even dd II-1: 26
27 Where is Waldo? (1) Let s say we consider that any two points within the hypersphere are close to each other. The question then is, how many points are close? Or, better, how large is the ball in the box? II-1: 27
28 Hypersphere within a Hypercube Mass is in the corners! Fraction of volume hypersphere has of surrounding hypercube: vvvvvv SS dd rr ππ dd/2 lim = lim dd vvvvvv HH dd 2rr dd 2 dd Γ dd II-1: 28



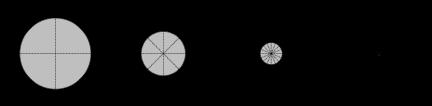
29 Hypersphere within a Hypercube Mass is in the corners! 2D 3D 4D higher dimensions II-1: 29
30 Where is Waldo? (2) Let s now say we consider any two points outside the sphere, in the same corner of the box, are close to each other. Then, the question is, how many points will be close? Or, better, how cornered is the data? II-1: 30
) = vvvvvv(ss dd (rr)) vvvvvv(ss dd (rr εε)) = KK dd rr dd")

31 Volume of thin shell of hypersphere SS dd (rr, εε) Mass is in the shell! vvvvvv(ss dd (rr, εε)) = vvvvvv(ss dd (rr)) vvvvvv(ss dd (rr εε)) = KK dd rr dd KK dd rr εε dd Fraction of volume in the shell: vvvvvv SS dd rr,εε vvvvvv SS dd rr = 1 1 εε rr dd vvvvvv SS dd rr, εε lim dd vvvvvv SS dd rr = lim dd 1 1 εε rr dd 1 II-1: 31
32 Back to the Future Dimensionality Reduction II-1: 32
33 Dimensionality Reduction Aim: reduce the number of dimensions by replacing them with new ones the new features should capture the essential part of the data what is considered essential is defined by method you want to use using wrong dimensionality reduction can lead to useless results Usually dimensionality reduction methods work on numerical data for categorical or binary data, feature selection is often more appropriate II-1: 33
34 Feature Subset Selection Data DD may include attributes that are redundant and/or irrelevant to the task at hand. Removing these will improve efficiency and performance. That is, given data DD over attributes AA, we want that subset SS AA of kk attributes such that performance is maximal. Two big problems: 1) how to quantify performance? 2) how to search for good subsets? II-1: 34
35 Searching for Subsets How many subsets of AA are there? 2 AA When do we need to do feature selection? when AA is large oops. Can we efficiently search for the optimal kk-subset? the theoretical answer: depends on your score the practical answer: almost never II-1: 35
36 Scoring Feature Subsets There are two main approaches for scoring feature spaces Wrapper methods optimise for your method directly score each candidate subset by running your method only makes sense when your score is comparable slow, as it needs to run your method for every candidate Filter methods use an external quality measure score each candidate subset using a proxy only makes sense when the proxy optimises your goal can be fast, but may optimise the wrong thing II-1: 36
37 Principle component analysis II-1: 37
38 Principle component analysis The goal of principle component analysis (PCA) is to project the data onto linearly uncorrelated variables in a (possibly) lower-dimensional subspace that preserves as much of the variance of the original data as possible it is also known as Karhunen Lòeve transform or Hotelling transform and goes by many other names In matrix terms, we want to find a column-orthogonal nn-by-rr matrix UU that projects an nn-dimensional data vector xx into an rr-dimensional vector aa = UU TT xx II-1: 38
39 Linear Algebra Recap II-1: 39
40 Vectors A vector is a 1D array of numbers a geometric entity with magnitude and direction The norm of a vector defines its magnitude Euclidean (LL 2 ) norm: xx = xx 2 = nn 2 ii=1 xx 1/2 ii LL pp norm (1 pp ) xx pp = nn ii=1 xx ii pp 1/pp (1.2, 0.8) (2, 0.8) rad (33.69 ) The direction is the angle 40 II-1:
41 Basic operations on vectors A transpose vv TT transposes a row vector into a column vector and vice versa If vv, ww R nn, vv + ww is a vector with vv + ww ii = vv ii + ww ii For vector vv and scalar αα, ααvv ii = ααvv ii A dot product of two vectors vv, ww R nn is vv ww = nn ii=1 a.k.a. scalar product or inner product alternative notation: vv, ww, vv TT ww, vvww TT in Euclidean space vv ww = vv ww cos θθ vv ii ww ii II-1: 41
 must agree (!")
42 Basic operations on matrices Matrix transpose AA TT has the rows of AA as its columns If AA and BB are nn-by-mm matrices, then AA + BB is an nn-by-mm matrix with AA + BB iiii = mm iiii + nn iiii If AA is nn-by-kk and BB is kk-by-mm, then AABB is an nn-by-mm matrix with the inner dimension (kk) must agree (!) vector outer product vvww TT (for column vectors) is the matrix product of nn-by-1 and 1-by-mm matrices II-1: 42

43 Types of matrices Diagonal nn-by-nn matrix identity matrix II nn is a diagonal nn-by-nn matrix with 1s in diagonal Upper triangular matrix lower triangular is the transpose if diagonal is full of 0s, matrix is strictly triangular Permutation matrix Each row and column has exactly one 1, rest are 0 Symmetric matrix: MM = MM TT II-1: 43
44 Basic concepts Two vectors xx and yy are orthogonal if their inner product xx, yy is 0 vectors are orthonormal if they have unit norm, xx = yy = 1 in Euclidean space, this means that xx yy cos θθ = 0 which happens iff cos θθ = 0 which means xx and yy are perpendicular to each other A square matrix X is orthogonal if its rows and columns are orthonormal an nn-by-mm matrix XX is row-orthogonal if nn < mm and its rows are orthogonal and column-orthogonal if nn > mm and its columns are orthogonal II-1: 44
45 Linear Independency Vector vv R nn is linearly dependent from a set of vectors WW = {wwii R nn ii = 1,, mm} if there exists a set of coefficients ααii such that if vv is not linearly dependent, it is linearly independent that is, vv cannot be expressed as a linear combination of the vectors in WW A set of vectors VV = {vvvv R nn ii = 1,, mm} is linearly independent if vvii is linearly independent from VV {vvii} for all ii II-1: 45
46 Matrix rank The column rank of an nn-by-mm matrix MM is the number of linearly independent columns of MM The row rank is the number of linearly independent rows of MM The Schein rank of MM is the least integer kk such that MM = AAAA for some nn-by-kk matrix AA and kk-by-mm matrix BB equivalently, the least kk such that MM is a sum of kk vector outer products All these ranks are equivalent! II-1: 46
47 The matrix inverse The inverse of a matrix MM is the unique matrix NN for which MMMM = NNNN = II the inverse is denoted by MM 1 MM has an inverse (is invertible) iff MM is square (nn-by-nn) the rank of MM is nn (full rank) Non-square matrices can have left or right inverses MMMM = II or LLLL = II If MM is orthogonal, then (and only then) MM 1 = MM TT that is, MMMM TT = MM TT MM = II II-1: 47
48 Fundamental decompositions A matrix decomposition (or factorization) presents an nn-by- mm matrix AA as a product of two (or more) factor matrices AA = BBBB For approximate decompositions, AA BBBB The decomposition size is the inner dimension of BB and CC number of columns in BB and number of rows in CC for exact decompositions, the size is no less than the rank of the matrix II-1: 48
49 Eigenvalues and eigenvectors If XX is an nn-by-nn matrix and vv is a vector such that XXXX = λλvv for some scalar λλ, then λλ is an eigenvalue of XX vv is an eigenvector of XX associated to λλ That is, eigenvectors are those vectors vv for which XXXX only changes their magnitude, not direction it is possible to exactly reverse the direction the change in magnitude is the eigenvalue If vv is an eigenvector of XX and αα is a scalar, then ααvv is also an eigenvector with the same eigenvalue II-1: 49
50 Properties of eigenvalues Multiple linearly independent eigenvectors can be associated with the same eigenvalue the algebraic multiplicity of the eigenvalue Every nn-by-nn matrix has nn eigenvectors and nn eigenvalues (counting multiplicity) some of these can be complex numbers If a matrix is symmetric, then all its eigenvalues are real Matrix is invertible iff all its eigenvalues are non-zero II-1: 50
51 Eigendecomposition The (real-valued) eigendecomposition of an nn-by-nn matrix XX is XX = QQΛΛQQ 1 ΛΛ is a diagonal matrix with eigenvalues in the diagonal columns of QQ are the eigenvectors associated with the eigenvalues in ΛΛ Matrix XX has to be diagonalizable PPPPPP 1 is a diagonal matrix for some invertible matrix PP Matrix XX has to have nn real eigenvalues (counting multiplicity) II-1: 51
52 Some useful facts Not all matrices have eigendecomposition not all invertible matrices have eigendecomposition not all matrices that have eigendecomposition are invertible if XX is invertible and has eigendecomposition, then XX 1 = QQΛΛ 1 QQ 1 If XX is symmetric and invertible (and real), then XX has eigendecomposition XX = QQΛΛQQ TT II-1: 52
53 Back to PCA II-1: 53
54 Example of 1-D PCA (again) II-1: 54
55 Principle component analysis, again The goal of principle component analysis (PCA) is to project the data onto linearly uncorrelated variables in a (possibly) lower-dimensional subspace that preserves as much of the variance of the original data as possible it is also known as Karhunen Lòeve transform or Hotelling transform and goes by many other names In matrix terms, we want to find a column-orthogonal nn-by-rr matrix UU that projects an nn-dimensional data vector xx into an rr-dimensional vector aa = UU TT xx II-1: 55
56 Deriving PCA: 1-D case (1) We assume our data is standardised. We want to find a unit vector uu that maximises the variance of the projections uu TT xx ii UU. Scalar uu TT xx ii gives the coordinate of xx ii along uu. As our data is centered the mean is 0, projected to uu this has coordinate 0. The variance of the projection is nn σσ 2 = 1 nn uu TT xx ii μμ uu ii=1 nn ΣΣ = 1 n ii xx ii xx ii TT = uu TT ΣΣuu The covariance matrix for centered data II-1: 56
57 Deriving PCA: 1-D case (2) To maximise the variance σσ 2, we maximise JJ uu = uu TT ΣΣuu λλ(uu TT uu 1) where the second term ensures uu is a unit vector Solving the derivative gives ΣΣuu = λλuu uu is an eigenvector and λλ is an eigenvalue further, uu TT ΣΣuu = uu TT λλuu implies that σσ 2 = λλ so, to maximise variance, we need to take the largest eigenvalue Thus, the first principal component uu is the dominant eigenvector of the covariance matrix ΣΣ II-1: 57

58 Example of 1-D PCA II-1: 58
59 Deriving PCA: rr-dimensions The second principal component should be orthogonal to the first one, and maximise variance adding this constraint and doing the derivation shows that the second principal component is the eigenvector associated with the second highest eigenvalue in fact, to find rr principal components we simply take the rr eigenvectors of ΣΣ associated to the rr highest eigenvalues the total variance is the sum of the eigenvalues It also turns out that maximising the variance minimises the mean squared error nn 1 nn xx ii UU TT xxxx ii=1 II-1: 59
60 Computing PCA We have two options. Either we compute the covariance matrix, and its top-kk eigenvectors, or we use singular value decomposition (SVD) because the covariance matrix ΣΣ = XXXX TT and if XX = UUUUVV TT, the columns of UU are the eigenvectors of XXXX TT as computing the covariance matrix can cause numerical stability issues with the eigendecomposition, this approach is preferred II-1: 60
61 SVD: The Definition Theorem. For every AA R nn mm there exists an nn-by-nn orthogonal matrix UU and an mm-by-mm orthogonal matrix V such that UU TT AAAA is an nn-by-mm diagonal matrix ΣΣ with values σσ 1 σσ 2 σσ min nn,mm 0 in its diagonal That is, every AA has decomposition AA = UUΣΣVV TT It is called the singular value decomposition of AA II-1: 61
62 SVD in a Picture vv ii are the right singular vectors σσ ii are the singular values uu ii are the left singular vectors II-1: 62
63 SVD, some useful equations AA = UUΣΣVV TT = ii σσ ii uu ii vv ii TT SVD expresses AA as a sum of rank-1 matrices AA 1 = UUΣΣVV TT 1 = VVΣΣ 1 UU TT if AA is invertible, so is its SVD AA TT AAvv ii = σσ ii 2 vv ii (for any AA) AAAA TT uu ii = σσ ii 2 uu ii (for any AA) II-1: 63
64 Truncated SVD The rank of the matrix is the number of its non-zero singular values (write AA = ii σσ ii uu ii vv ii TT ) The truncated SVD takes the first kk columns of UU and VV and the main kk-by-kk submatrix of ΣΣ TT AA kk = UU kk ΣΣ kk VV kk UU kk and VV kk are column-orthogonal II-1: 64



65 Truncated SVD Full Truncated II-1: 65
66 Why is SVD important? It lets us compute various norms It tells about the sensitivity of linear systems It shows the dimensions of the fundamental subspaces It gives optimal solutions to least-square linear systems It gives the least-error rank-k-decomposition Every matrix has one II-1: 66
67 SVD as Low-Rank Approximation Theorem: Let AA be an mm-by-nn matrix with rank rr, and let AA kk = UU kk ΣΣ kk VV kktt, where the kk kk diagonal matrix ΣΣ kk contains the kk largest singular values of AA and the mm kk matrix UU kk and the nn kk matrix VV kk contain the corresponding Eigenvectors from the SVD of A. Among all mm-by-nn matrices CC with rank at most kk AA kk is the matrix that minimizes the Frobenius norm mm nn AA CC 2 FF = ii=1 jj=1 AA iiii CC iiii 2 y Example: mm = 2, nn = 8, kk = 1 projection onto xxx axis minimizes error or maximizes variance in kk-dimensional space x II-1: 67
68 SVD as Low-Rank Approximation Theorem: Let AA be an mm-by-nn matrix with rank rr, and let AA kk = UU kk ΣΣ kk VV kktt, where the kk kk diagonal matrix ΣΣ kk contains the kk largest singular values of AA and the mm kk matrix UU kk and the nn kk matrix VV kk contain the corresponding Eigenvectors from the SVD of A. Among all mm-by-nn matrices CC with rank at most kk AA kk is the matrix that minimizes the Frobenius norm AA CC 2 FF = mm nn ii=1 jj=1 AA iiii CC iiii 2 Example: mm = 2, nn = 8, kk = 1 projection onto xxx axis minimizes error or maximizes variance in kk-dimensional space y II-1: 68 x
69 SVD as Low-Rank Approximation Theorem: Let AA be an mm-by-nn matrix with rank rr, and let AA kk = UU kk ΣΣ kk VV kktt, where the kk kk diagonal matrix ΣΣ kk contains the kk largest singular values of AA and the mm kk matrix UU kk and the nn kk matrix VV kk contain the corresponding Eigenvectors from the SVD of A. Among all mm-by-nn matrices CC with rank at most kk AA kk is the matrix that minimizes the Frobenius norm mm nn AA CC 2 FF = ii=1 jj=1 AA iiii CC iiii 2 Example: mm = 2, nn = 8, kk = 1 projection onto xx axis minimizes error or maximizes variance in kk-dimensional space II-1: 69
70 Problems with PCA and SVD Many characteristics of the input data are lost non-negativity integrality sparsity Also, computation is costly for big matrices approximate methods exist that can do SVD in a single sweep II-1: 70
71 Conclusions Preprocessing your data is crucial Conversion, normalisation, and dealing with missing values Too much data is a problem computational complexity can solved by sampling Too high dimensional data is a problem everything is evenly far from everything feature selections retains important features of the data PCA and SVD reduce dimensionality with global guarantees II-1: 71
72 Thank you! Preprocessing your data is crucial Conversion, normalisation, and dealing with missing values Too much data is a problem computational complexity can solved by sampling Too high dimensional data is a problem everything is evenly far from everything feature selections retains important features of the data PCA and SVD reduce dimensionality with global guarantees II-1: 72
Chapter XII: Data Pre and Post Processing
 Chapter XII: Data Pre and Post Processing Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 XII.1 4-1 Chapter XII: Data Pre and Post Processing 1. Data
Chapter XII: Data Pre and Post Processing Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 XII.1 4-1 Chapter XII: Data Pre and Post Processing 1. Data
Large Scale Data Analysis Using Deep Learning
 Large Scale Data Analysis Using Deep Learning Linear Algebra U Kang Seoul National University U Kang 1 In This Lecture Overview of linear algebra (but, not a comprehensive survey) Focused on the subset
Large Scale Data Analysis Using Deep Learning Linear Algebra U Kang Seoul National University U Kang 1 In This Lecture Overview of linear algebra (but, not a comprehensive survey) Focused on the subset
Variations. ECE 6540, Lecture 02 Multivariate Random Variables & Linear Algebra
 Variations ECE 6540, Lecture 02 Multivariate Random Variables & Linear Algebra Last Time Probability Density Functions Normal Distribution Expectation / Expectation of a function Independence Uncorrelated
Variations ECE 6540, Lecture 02 Multivariate Random Variables & Linear Algebra Last Time Probability Density Functions Normal Distribution Expectation / Expectation of a function Independence Uncorrelated
Review of Linear Algebra
 Review of Linear Algebra Definitions An m n (read "m by n") matrix, is a rectangular array of entries, where m is the number of rows and n the number of columns. 2 Definitions (Con t) A is square if m=
Review of Linear Algebra Definitions An m n (read "m by n") matrix, is a rectangular array of entries, where m is the number of rows and n the number of columns. 2 Definitions (Con t) A is square if m=
Advanced data analysis
 Advanced data analysis Akisato Kimura ( 木村昭悟 ) NTT Communication Science Laboratories E-mail: akisato@ieee.org Advanced data analysis 1. Introduction (Aug 20) 2. Dimensionality reduction (Aug 20,21) PCA,
Advanced data analysis Akisato Kimura ( 木村昭悟 ) NTT Communication Science Laboratories E-mail: akisato@ieee.org Advanced data analysis 1. Introduction (Aug 20) 2. Dimensionality reduction (Aug 20,21) PCA,
Lecture 3. STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher
 Lecture 3 STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher Previous lectures What is machine learning? Objectives of machine learning Supervised and
Lecture 3 STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher Previous lectures What is machine learning? Objectives of machine learning Supervised and
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Linear Algebra (Review) Volker Tresp 2017
 Volker Tresp 2017") Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Lecture 3. Linear Regression
 Lecture 3. Linear Regression COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne Weeks 2 to 8 inclusive Lecturer: Andrey Kan MS: Moscow, PhD:
Lecture 3. Linear Regression COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne Weeks 2 to 8 inclusive Lecturer: Andrey Kan MS: Moscow, PhD:
Support Vector Machines. CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
7.3 The Jacobi and Gauss-Seidel Iterative Methods
 7.3 The Jacobi and Gauss-Seidel Iterative Methods 1 The Jacobi Method Two assumptions made on Jacobi Method: 1.The system given by aa 11 xx 1 + aa 12 xx 2 + aa 1nn xx nn = bb 1 aa 21 xx 1 + aa 22 xx 2
7.3 The Jacobi and Gauss-Seidel Iterative Methods 1 The Jacobi Method Two assumptions made on Jacobi Method: 1.The system given by aa 11 xx 1 + aa 12 xx 2 + aa 1nn xx nn = bb 1 aa 21 xx 1 + aa 22 xx 2
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Linear Algebra (Review) Volker Tresp 2018
 Volker Tresp 2018") Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
CS168: The Modern Algorithmic Toolbox Lecture #8: How PCA Works
 CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
A Tutorial on Data Reduction. Principal Component Analysis Theoretical Discussion. By Shireen Elhabian and Aly Farag
 A Tutorial on Data Reduction Principal Component Analysis Theoretical Discussion By Shireen Elhabian and Aly Farag University of Louisville, CVIP Lab November 2008 PCA PCA is A backbone of modern data
A Tutorial on Data Reduction Principal Component Analysis Theoretical Discussion By Shireen Elhabian and Aly Farag University of Louisville, CVIP Lab November 2008 PCA PCA is A backbone of modern data
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Linear Algebra Review. Vectors
 Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
Grover s algorithm. We want to find aa. Search in an unordered database. QC oracle (as usual) Usual trick
 Usual trick") Grover s algorithm Search in an unordered database Example: phonebook, need to find a person from a phone number Actually, something else, like hard (e.g., NP-complete) problem 0, xx aa Black box ff xx
Grover s algorithm Search in an unordered database Example: phonebook, need to find a person from a phone number Actually, something else, like hard (e.g., NP-complete) problem 0, xx aa Black box ff xx
Singular Value Decomposition. 1 Singular Value Decomposition and the Four Fundamental Subspaces
 Singular Value Decomposition This handout is a review of some basic concepts in linear algebra For a detailed introduction, consult a linear algebra text Linear lgebra and its pplications by Gilbert Strang
Singular Value Decomposition This handout is a review of some basic concepts in linear algebra For a detailed introduction, consult a linear algebra text Linear lgebra and its pplications by Gilbert Strang
SECTION 2: VECTORS AND MATRICES. ENGR 112 Introduction to Engineering Computing
 SECTION 2: VECTORS AND MATRICES ENGR 112 Introduction to Engineering Computing 2 Vectors and Matrices The MAT in MATLAB 3 MATLAB The MATrix (not MAThematics) LABoratory MATLAB assumes all numeric variables
SECTION 2: VECTORS AND MATRICES ENGR 112 Introduction to Engineering Computing 2 Vectors and Matrices The MAT in MATLAB 3 MATLAB The MATrix (not MAThematics) LABoratory MATLAB assumes all numeric variables
Preprocessing & dimensionality reduction
 Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
COMP6237 Data Mining Covariance, EVD, PCA & SVD. Jonathon Hare
 COMP6237 Data Mining Covariance, EVD, PCA & SVD Jonathon Hare jsh2@ecs.soton.ac.uk Variance and Covariance Random Variables and Expected Values Mathematicians talk variance (and covariance) in terms of
COMP6237 Data Mining Covariance, EVD, PCA & SVD Jonathon Hare jsh2@ecs.soton.ac.uk Variance and Covariance Random Variables and Expected Values Mathematicians talk variance (and covariance) in terms of
Prof. Dr.-Ing. Armin Dekorsy Department of Communications Engineering. Stochastic Processes and Linear Algebra Recap Slides
 Prof. Dr.-Ing. Armin Dekorsy Department of Communications Engineering Stochastic Processes and Linear Algebra Recap Slides Stochastic processes and variables XX tt 0 = XX xx nn (tt) xx 2 (tt) XX tt XX
Prof. Dr.-Ing. Armin Dekorsy Department of Communications Engineering Stochastic Processes and Linear Algebra Recap Slides Stochastic processes and variables XX tt 0 = XX xx nn (tt) xx 2 (tt) XX tt XX
Singular Value Decomposition
 Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
[Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty.]
![[Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty.]](/thumbs/82/86615903.jpg "[Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty.]") Math 43 Review Notes [Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty Dot Product If v (v, v, v 3 and w (w, w, w 3, then the
Math 43 Review Notes [Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty Dot Product If v (v, v, v 3 and w (w, w, w 3, then the
4 ORTHOGONALITY ORTHOGONALITY OF THE FOUR SUBSPACES 4.1
 4 ORTHOGONALITY ORTHOGONALITY OF THE FOUR SUBSPACES 4.1 Two vectors are orthogonal when their dot product is zero: v w = orv T w =. This chapter moves up a level, from orthogonal vectors to orthogonal
4 ORTHOGONALITY ORTHOGONALITY OF THE FOUR SUBSPACES 4.1 Two vectors are orthogonal when their dot product is zero: v w = orv T w =. This chapter moves up a level, from orthogonal vectors to orthogonal
Final Review Sheet. B = (1, 1 + 3x, 1 + x 2 ) then 2 + 3x + 6x 2
 then 2 + 3x + 6x 2") Final Review Sheet The final will cover Sections Chapters 1,2,3 and 4, as well as sections 5.1-5.4, 6.1-6.2 and 7.1-7.3 from chapters 5,6 and 7. This is essentially all material covered this term. Watch
Final Review Sheet The final will cover Sections Chapters 1,2,3 and 4, as well as sections 5.1-5.4, 6.1-6.2 and 7.1-7.3 from chapters 5,6 and 7. This is essentially all material covered this term. Watch
Data Preprocessing Tasks
 Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Dimensionality reduction
 Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Text Processing and High-Dimensional Data
 Lecture Notes to Winter Term 2017/2018 Text Processing and High-Dimensional Data Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid, Daniyal Kazempour,
Lecture Notes to Winter Term 2017/2018 Text Processing and High-Dimensional Data Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid, Daniyal Kazempour,
Applied Mathematics 205. Unit II: Numerical Linear Algebra. Lecturer: Dr. David Knezevic
 Applied Mathematics 205 Unit II: Numerical Linear Algebra Lecturer: Dr. David Knezevic Unit II: Numerical Linear Algebra Chapter II.3: QR Factorization, SVD 2 / 66 QR Factorization 3 / 66 QR Factorization
Applied Mathematics 205 Unit II: Numerical Linear Algebra Lecturer: Dr. David Knezevic Unit II: Numerical Linear Algebra Chapter II.3: QR Factorization, SVD 2 / 66 QR Factorization 3 / 66 QR Factorization
Dot Products, Transposes, and Orthogonal Projections
 Dot Products, Transposes, and Orthogonal Projections David Jekel November 13, 2015 Properties of Dot Products Recall that the dot product or standard inner product on R n is given by x y = x 1 y 1 + +
Dot Products, Transposes, and Orthogonal Projections David Jekel November 13, 2015 Properties of Dot Products Recall that the dot product or standard inner product on R n is given by x y = x 1 y 1 + +
Independent Component Analysis and FastICA. Copyright Changwei Xiong June last update: July 7, 2016
 Independent Component Analysis and FastICA Copyright Changwei Xiong 016 June 016 last update: July 7, 016 TABLE OF CONTENTS Table of Contents...1 1. Introduction.... Independence by Non-gaussianity....1.
Independent Component Analysis and FastICA Copyright Changwei Xiong 016 June 016 last update: July 7, 016 TABLE OF CONTENTS Table of Contents...1 1. Introduction.... Independence by Non-gaussianity....1.
Lecture 4: Applications of Orthogonality: QR Decompositions
 Math 08B Professor: Padraic Bartlett Lecture 4: Applications of Orthogonality: QR Decompositions Week 4 UCSB 204 In our last class, we described the following method for creating orthonormal bases, known
Math 08B Professor: Padraic Bartlett Lecture 4: Applications of Orthogonality: QR Decompositions Week 4 UCSB 204 In our last class, we described the following method for creating orthonormal bases, known
Data Mining Lecture 4: Covariance, EVD, PCA & SVD
 Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Exercises * on Principal Component Analysis
 Exercises * on Principal Component Analysis Laurenz Wiskott Institut für Neuroinformatik Ruhr-Universität Bochum, Germany, EU 4 February 207 Contents Intuition 3. Problem statement..........................................
Exercises * on Principal Component Analysis Laurenz Wiskott Institut für Neuroinformatik Ruhr-Universität Bochum, Germany, EU 4 February 207 Contents Intuition 3. Problem statement..........................................
Getting Started with Communications Engineering
 1 Linear algebra is the algebra of linear equations: the term linear being used in the same sense as in linear functions, such as: which is the equation of a straight line. y ax c (0.1) Of course, if we
1 Linear algebra is the algebra of linear equations: the term linear being used in the same sense as in linear functions, such as: which is the equation of a straight line. y ax c (0.1) Of course, if we
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Applied Linear Algebra in Geoscience Using MATLAB
 Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
Eigenvalues and diagonalization
 Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
Robustness of Principal Components
 PCA for Clustering An objective of principal components analysis is to identify linear combinations of the original variables that are useful in accounting for the variation in those original variables.
PCA for Clustering An objective of principal components analysis is to identify linear combinations of the original variables that are useful in accounting for the variation in those original variables.
The value of a problem is not so much coming up with the answer as in the ideas and attempted ideas it forces on the would be solver I.N.
 Math 410 Homework Problems In the following pages you will find all of the homework problems for the semester. Homework should be written out neatly and stapled and turned in at the beginning of class
Math 410 Homework Problems In the following pages you will find all of the homework problems for the semester. Homework should be written out neatly and stapled and turned in at the beginning of class
Review problems for MA 54, Fall 2004.
 Review problems for MA 54, Fall 2004. Below are the review problems for the final. They are mostly homework problems, or very similar. If you are comfortable doing these problems, you should be fine on
Review problems for MA 54, Fall 2004. Below are the review problems for the final. They are mostly homework problems, or very similar. If you are comfortable doing these problems, you should be fine on
F.1 Greatest Common Factor and Factoring by Grouping
 section F1 214 is the reverse process of multiplication. polynomials in algebra has similar role as factoring numbers in arithmetic. Any number can be expressed as a product of prime numbers. For example,
section F1 214 is the reverse process of multiplication. polynomials in algebra has similar role as factoring numbers in arithmetic. Any number can be expressed as a product of prime numbers. For example,
CS 143 Linear Algebra Review
 CS 143 Linear Algebra Review Stefan Roth September 29, 2003 Introductory Remarks This review does not aim at mathematical rigor very much, but instead at ease of understanding and conciseness. Please see
CS 143 Linear Algebra Review Stefan Roth September 29, 2003 Introductory Remarks This review does not aim at mathematical rigor very much, but instead at ease of understanding and conciseness. Please see
General Strong Polarization
 General Strong Polarization Madhu Sudan Harvard University Joint work with Jaroslaw Blasiok (Harvard), Venkatesan Gurswami (CMU), Preetum Nakkiran (Harvard) and Atri Rudra (Buffalo) December 4, 2017 IAS:
General Strong Polarization Madhu Sudan Harvard University Joint work with Jaroslaw Blasiok (Harvard), Venkatesan Gurswami (CMU), Preetum Nakkiran (Harvard) and Atri Rudra (Buffalo) December 4, 2017 IAS:
Math, Stats, and Mathstats Review ECONOMETRICS (ECON 360) BEN VAN KAMMEN, PHD
 BEN VAN KAMMEN, PHD") Math, Stats, and Mathstats Review ECONOMETRICS (ECON 360) BEN VAN KAMMEN, PHD Outline These preliminaries serve to signal to students what tools they need to know to succeed in ECON 360 and refresh their
Math, Stats, and Mathstats Review ECONOMETRICS (ECON 360) BEN VAN KAMMEN, PHD Outline These preliminaries serve to signal to students what tools they need to know to succeed in ECON 360 and refresh their
10.4 The Cross Product
 Math 172 Chapter 10B notes Page 1 of 9 10.4 The Cross Product The cross product, or vector product, is defined in 3 dimensions only. Let aa = aa 1, aa 2, aa 3 bb = bb 1, bb 2, bb 3 then aa bb = aa 2 bb
Math 172 Chapter 10B notes Page 1 of 9 10.4 The Cross Product The cross product, or vector product, is defined in 3 dimensions only. Let aa = aa 1, aa 2, aa 3 bb = bb 1, bb 2, bb 3 then aa bb = aa 2 bb
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
10.1 Three Dimensional Space
 Math 172 Chapter 10A notes Page 1 of 12 10.1 Three Dimensional Space 2D space 0 xx.. xx-, 0 yy yy-, PP(xx, yy) [Fig. 1] Point PP represented by (xx, yy), an ordered pair of real nos. Set of all ordered
Math 172 Chapter 10A notes Page 1 of 12 10.1 Three Dimensional Space 2D space 0 xx.. xx-, 0 yy yy-, PP(xx, yy) [Fig. 1] Point PP represented by (xx, yy), an ordered pair of real nos. Set of all ordered
PHY103A: Lecture # 4
 Semester II, 2017-18 Department of Physics, IIT Kanpur PHY103A: Lecture # 4 (Text Book: Intro to Electrodynamics by Griffiths, 3 rd Ed.) Anand Kumar Jha 10-Jan-2018 Notes The Solutions to HW # 1 have been
Semester II, 2017-18 Department of Physics, IIT Kanpur PHY103A: Lecture # 4 (Text Book: Intro to Electrodynamics by Griffiths, 3 rd Ed.) Anand Kumar Jha 10-Jan-2018 Notes The Solutions to HW # 1 have been
Mathematics Ext 2. HSC 2014 Solutions. Suite 403, 410 Elizabeth St, Surry Hills NSW 2010 keystoneeducation.com.
 Mathematics Ext HSC 4 Solutions Suite 43, 4 Elizabeth St, Surry Hills NSW info@keystoneeducation.com.au keystoneeducation.com.au Mathematics Extension : HSC 4 Solutions Contents Multiple Choice... 3 Question...
Mathematics Ext HSC 4 Solutions Suite 43, 4 Elizabeth St, Surry Hills NSW info@keystoneeducation.com.au keystoneeducation.com.au Mathematics Extension : HSC 4 Solutions Contents Multiple Choice... 3 Question...
Angular Momentum, Electromagnetic Waves
 Angular Momentum, Electromagnetic Waves Lecture33: Electromagnetic Theory Professor D. K. Ghosh, Physics Department, I.I.T., Bombay As before, we keep in view the four Maxwell s equations for all our discussions.
Angular Momentum, Electromagnetic Waves Lecture33: Electromagnetic Theory Professor D. K. Ghosh, Physics Department, I.I.T., Bombay As before, we keep in view the four Maxwell s equations for all our discussions.
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Lecture No. 1 Introduction to Method of Weighted Residuals. Solve the differential equation L (u) = p(x) in V where L is a differential operator
 = p(x) in V where L is a differential operator") Lecture No. 1 Introduction to Method of Weighted Residuals Solve the differential equation L (u) = p(x) in V where L is a differential operator with boundary conditions S(u) = g(x) on Γ where S is a differential
Lecture No. 1 Introduction to Method of Weighted Residuals Solve the differential equation L (u) = p(x) in V where L is a differential operator with boundary conditions S(u) = g(x) on Γ where S is a differential
1 Singular Value Decomposition and Principal Component
 Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Independent Component Analysis and Its Application on Accelerator Physics
 Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
Signal Analysis. Principal Component Analysis
 Multi dimensional Signal Analysis Lecture 2E Principal Component Analysis Subspace representation Note! Given avector space V of dimension N a scalar product defined by G 0 a subspace U of dimension M
Multi dimensional Signal Analysis Lecture 2E Principal Component Analysis Subspace representation Note! Given avector space V of dimension N a scalar product defined by G 0 a subspace U of dimension M
Lecture 11. Kernel Methods
 Lecture 11. Kernel Methods COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture The kernel trick Efficient computation of a dot product
Lecture 11. Kernel Methods COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture The kernel trick Efficient computation of a dot product
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 The Singular Value Decomposition (SVD) continued Linear Algebra Methods for Data Mining, Spring 2007, University
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 The Singular Value Decomposition (SVD) continued Linear Algebra Methods for Data Mining, Spring 2007, University
7 Principal Component Analysis
 7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
Conceptual Questions for Review
 Conceptual Questions for Review Chapter 1 1.1 Which vectors are linear combinations of v = (3, 1) and w = (4, 3)? 1.2 Compare the dot product of v = (3, 1) and w = (4, 3) to the product of their lengths.
Conceptual Questions for Review Chapter 1 1.1 Which vectors are linear combinations of v = (3, 1) and w = (4, 3)? 1.2 Compare the dot product of v = (3, 1) and w = (4, 3) to the product of their lengths.
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T. KEMP)
") MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
Work, Energy, and Power. Chapter 6 of Essential University Physics, Richard Wolfson, 3 rd Edition
 Work, Energy, and Power Chapter 6 of Essential University Physics, Richard Wolfson, 3 rd Edition 1 With the knowledge we got so far, we can handle the situation on the left but not the one on the right.
Work, Energy, and Power Chapter 6 of Essential University Physics, Richard Wolfson, 3 rd Edition 1 With the knowledge we got so far, we can handle the situation on the left but not the one on the right.
IV. Matrix Approximation using Least-Squares
 IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
Classical RSA algorithm
 Classical RSA algorithm We need to discuss some mathematics (number theory) first Modulo-NN arithmetic (modular arithmetic, clock arithmetic) 9 (mod 7) 4 3 5 (mod 7) congruent (I will also use = instead
Classical RSA algorithm We need to discuss some mathematics (number theory) first Modulo-NN arithmetic (modular arithmetic, clock arithmetic) 9 (mod 7) 4 3 5 (mod 7) congruent (I will also use = instead
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
CS168: The Modern Algorithmic Toolbox Lecture #8: PCA and the Power Iteration Method
 CS168: The Modern Algorithmic Toolbox Lecture #8: PCA and the Power Iteration Method Tim Roughgarden & Gregory Valiant April 15, 015 This lecture began with an extended recap of Lecture 7. Recall that
CS168: The Modern Algorithmic Toolbox Lecture #8: PCA and the Power Iteration Method Tim Roughgarden & Gregory Valiant April 15, 015 This lecture began with an extended recap of Lecture 7. Recall that
18.06 Quiz 2 April 7, 2010 Professor Strang
 18.06 Quiz 2 April 7, 2010 Professor Strang Your PRINTED name is: 1. Your recitation number or instructor is 2. 3. 1. (33 points) (a) Find the matrix P that projects every vector b in R 3 onto the line
18.06 Quiz 2 April 7, 2010 Professor Strang Your PRINTED name is: 1. Your recitation number or instructor is 2. 3. 1. (33 points) (a) Find the matrix P that projects every vector b in R 3 onto the line
Lecture 3: Review of Linear Algebra
 ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
Math 102, Winter Final Exam Review. Chapter 1. Matrices and Gaussian Elimination
 Math 0, Winter 07 Final Exam Review Chapter. Matrices and Gaussian Elimination { x + x =,. Different forms of a system of linear equations. Example: The x + 4x = 4. [ ] [ ] [ ] vector form (or the column
Math 0, Winter 07 Final Exam Review Chapter. Matrices and Gaussian Elimination { x + x =,. Different forms of a system of linear equations. Example: The x + 4x = 4. [ ] [ ] [ ] vector form (or the column
Lecture 3: Review of Linear Algebra
 ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak, scribe: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters,
ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak, scribe: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters,
LINEAR ALGEBRA KNOWLEDGE SURVEY
 LINEAR ALGEBRA KNOWLEDGE SURVEY Instructions: This is a Knowledge Survey. For this assignment, I am only interested in your level of confidence about your ability to do the tasks on the following pages.
LINEAR ALGEBRA KNOWLEDGE SURVEY Instructions: This is a Knowledge Survey. For this assignment, I am only interested in your level of confidence about your ability to do the tasks on the following pages.
DS-GA 1002 Lecture notes 0 Fall Linear Algebra. These notes provide a review of basic concepts in linear algebra.
 DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
Singular Value Decomposition and Principal Component Analysis (PCA) I
 I") Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
General Strong Polarization
 General Strong Polarization Madhu Sudan Harvard University Joint work with Jaroslaw Blasiok (Harvard), Venkatesan Gurswami (CMU), Preetum Nakkiran (Harvard) and Atri Rudra (Buffalo) May 1, 018 G.Tech:
General Strong Polarization Madhu Sudan Harvard University Joint work with Jaroslaw Blasiok (Harvard), Venkatesan Gurswami (CMU), Preetum Nakkiran (Harvard) and Atri Rudra (Buffalo) May 1, 018 G.Tech:
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
A brief summary of the chapters and sections that we cover in Math 141. Chapter 2 Matrices
 A brief summary of the chapters and sections that we cover in Math 141 Chapter 2 Matrices Section 1 Systems of Linear Equations with Unique Solutions 1. A system of linear equations is simply a collection
A brief summary of the chapters and sections that we cover in Math 141 Chapter 2 Matrices Section 1 Systems of Linear Equations with Unique Solutions 1. A system of linear equations is simply a collection
CS168: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA)
") CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
Mathematical foundations - linear algebra
 Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
18.06SC Final Exam Solutions
 18.06SC Final Exam Solutions 1 (4+7=11 pts.) Suppose A is 3 by 4, and Ax = 0 has exactly 2 special solutions: 1 2 x 1 = 1 and x 2 = 1 1 0 0 1 (a) Remembering that A is 3 by 4, find its row reduced echelon
18.06SC Final Exam Solutions 1 (4+7=11 pts.) Suppose A is 3 by 4, and Ax = 0 has exactly 2 special solutions: 1 2 x 1 = 1 and x 2 = 1 1 0 0 1 (a) Remembering that A is 3 by 4, find its row reduced echelon
Dimensionality Reduction and Principle Components
 Dimensionality Reduction and Principle Components Ken Kreutz-Delgado (Nuno Vasconcelos) UCSD ECE Department Winter 2012 Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,...,
Dimensionality Reduction and Principle Components Ken Kreutz-Delgado (Nuno Vasconcelos) UCSD ECE Department Winter 2012 Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,...,
Maths for Signals and Systems Linear Algebra in Engineering
 Maths for Signals and Systems Linear Algebra in Engineering Lectures 13 15, Tuesday 8 th and Friday 11 th November 016 DR TANIA STATHAKI READER (ASSOCIATE PROFFESOR) IN SIGNAL PROCESSING IMPERIAL COLLEGE
Maths for Signals and Systems Linear Algebra in Engineering Lectures 13 15, Tuesday 8 th and Friday 11 th November 016 DR TANIA STATHAKI READER (ASSOCIATE PROFFESOR) IN SIGNAL PROCESSING IMPERIAL COLLEGE
Foundations of Computer Vision
 Foundations of Computer Vision Wesley. E. Snyder North Carolina State University Hairong Qi University of Tennessee, Knoxville Last Edited February 8, 2017 1 3.2. A BRIEF REVIEW OF LINEAR ALGEBRA Apply
Foundations of Computer Vision Wesley. E. Snyder North Carolina State University Hairong Qi University of Tennessee, Knoxville Last Edited February 8, 2017 1 3.2. A BRIEF REVIEW OF LINEAR ALGEBRA Apply
Bare minimum on matrix algebra. Psychology 588: Covariance structure and factor models
 Bare minimum on matrix algebra Psychology 588: Covariance structure and factor models Matrix multiplication 2 Consider three notations for linear combinations y11 y1 m x11 x 1p b11 b 1m y y x x b b n1
Bare minimum on matrix algebra Psychology 588: Covariance structure and factor models Matrix multiplication 2 Consider three notations for linear combinations y11 y1 m x11 x 1p b11 b 1m y y x x b b n1
Example: 2x y + 3z = 1 5y 6z = 0 x + 4z = 7. Definition: Elementary Row Operations. Example: Type I swap rows 1 and 3
 Linear Algebra Row Reduced Echelon Form Techniques for solving systems of linear equations lie at the heart of linear algebra. In high school we learn to solve systems with or variables using elimination
Linear Algebra Row Reduced Echelon Form Techniques for solving systems of linear equations lie at the heart of linear algebra. In high school we learn to solve systems with or variables using elimination
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Recitation 8: Graphs and Adjacency Matrices
 Math 1b TA: Padraic Bartlett Recitation 8: Graphs and Adjacency Matrices Week 8 Caltech 2011 1 Random Question Suppose you take a large triangle XY Z, and divide it up with straight line segments into
Math 1b TA: Padraic Bartlett Recitation 8: Graphs and Adjacency Matrices Week 8 Caltech 2011 1 Random Question Suppose you take a large triangle XY Z, and divide it up with straight line segments into
REVIEW FOR EXAM III SIMILARITY AND DIAGONALIZATION
 REVIEW FOR EXAM III The exam covers sections 4.4, the portions of 4. on systems of differential equations and on Markov chains, and..4. SIMILARITY AND DIAGONALIZATION. Two matrices A and B are similar
REVIEW FOR EXAM III The exam covers sections 4.4, the portions of 4. on systems of differential equations and on Markov chains, and..4. SIMILARITY AND DIAGONALIZATION. Two matrices A and B are similar
Linear Algebra for Machine Learning. Sargur N. Srihari
 Linear Algebra for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Overview Linear Algebra is based on continuous math rather than discrete math Computer scientists have little experience with it
Linear Algebra for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Overview Linear Algebra is based on continuous math rather than discrete math Computer scientists have little experience with it
Image Registration Lecture 2: Vectors and Matrices
 Image Registration Lecture 2: Vectors and Matrices Prof. Charlene Tsai Lecture Overview Vectors Matrices Basics Orthogonal matrices Singular Value Decomposition (SVD) 2 1 Preliminary Comments Some of this
Image Registration Lecture 2: Vectors and Matrices Prof. Charlene Tsai Lecture Overview Vectors Matrices Basics Orthogonal matrices Singular Value Decomposition (SVD) 2 1 Preliminary Comments Some of this
Orthogonality. Orthonormal Bases, Orthogonal Matrices. Orthogonality
 Orthonormal Bases, Orthogonal Matrices The Major Ideas from Last Lecture Vector Span Subspace Basis Vectors Coordinates in different bases Matrix Factorization (Basics) The Major Ideas from Last Lecture
Orthonormal Bases, Orthogonal Matrices The Major Ideas from Last Lecture Vector Span Subspace Basis Vectors Coordinates in different bases Matrix Factorization (Basics) The Major Ideas from Last Lecture
Dimensionality Reduction and Principal Components
 Dimensionality Reduction and Principal Components Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,..., M} and observations of X
Dimensionality Reduction and Principal Components Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,..., M} and observations of X