Interior Point Methods for Mathematical Programming
|
|
|
- Merilyn Caldwell
- 5 years ago
- Views:
Transcription
1 Interior Point Methods for Mathematical Programming Clóvis C. Gonzaga Federal University of Santa Catarina, Florianópolis, Brazil EURO Roma



2 Our heroes Cauchy Newton Lagrange
3 Early results Unconstrained minimization minimize f (x) Inequality constraints minimize f (x) subject to g(x) 0 Cauchy (steepest descent): x + = x λ f (x) Newton: x + = x H(x) 1 f (x) For the constrained problem: Frisch, Fiacco, McCormick: F(x) = f (x) µ log( g i (x))
4 Early results Unconstrained minimization minimize f (x) Inequality constraints minimize f (x) subject to g(x) 0 Cauchy (steepest descent): x + = x λ f (x) Newton: x + = x H(x) 1 f (x) For the constrained problem: Frisch, Fiacco, McCormick: F(x) = f (x) µ log( g i (x))
5 Early results Unconstrained minimization minimize f (x) Inequality constraints minimize f (x) subject to g(x) 0 Cauchy (steepest descent): x + = x λ f (x) Newton: x + = x H(x) 1 f (x) For the constrained problem: Frisch, Fiacco, McCormick: F(x) = f (x) µ log( g i (x))
6 The barrier function Problem P1

7 Near the boundary, the barrier function tends to +.
8 The Linear Programming Problem Inequality constraints minimize c T x subject to Ax b Equality and non-negativity minimize subject to c T x Ax = b x 0 Interior point: x > 0. Solution: Ax = b. Feasible solution: Ax = b, x 0. Interior (feasible) solution: Ax = b, x > 0.
9 The Linear Programming Problem Inequality constraints minimize c T x subject to Ax b Equality and non-negativity minimize subject to c T x Ax = b x 0 Interior point: x > 0. Solution: Ax = b. Feasible solution: Ax = b, x 0. Interior (feasible) solution: Ax = b, x > 0.
10 The Linear Programming Problem Inequality constraints minimize c T x subject to Ax b Equality and non-negativity minimize subject to c T x Ax = b x 0 Interior point: x > 0. Solution: Ax = b. Feasible solution: Ax = b, x 0. Interior (feasible) solution: Ax = b, x > 0.
11 The Linear Programming Problem Inequality constraints minimize c T x subject to Ax b Equality and non-negativity minimize subject to c T x Ax = b x 0 Interior point: x > 0. Solution: Ax = b. Feasible solution: Ax = b, x 0. Interior (feasible) solution: Ax = b, x > 0.
12 Simplex Method: Dantzig 1948 Exponential in the worst case Good for usual problems.
13 Centers of gravity
14
15
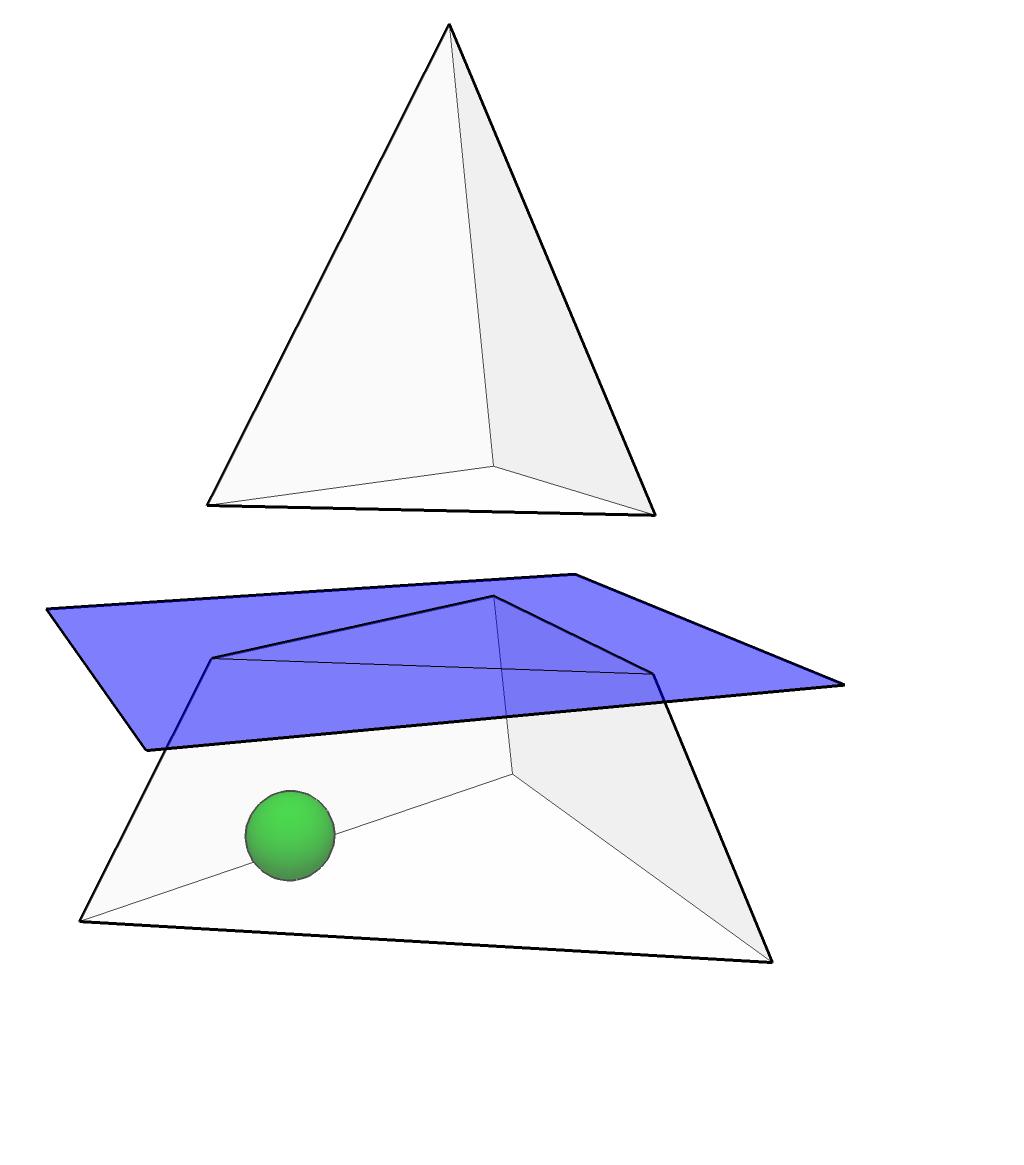
16
17
18
19
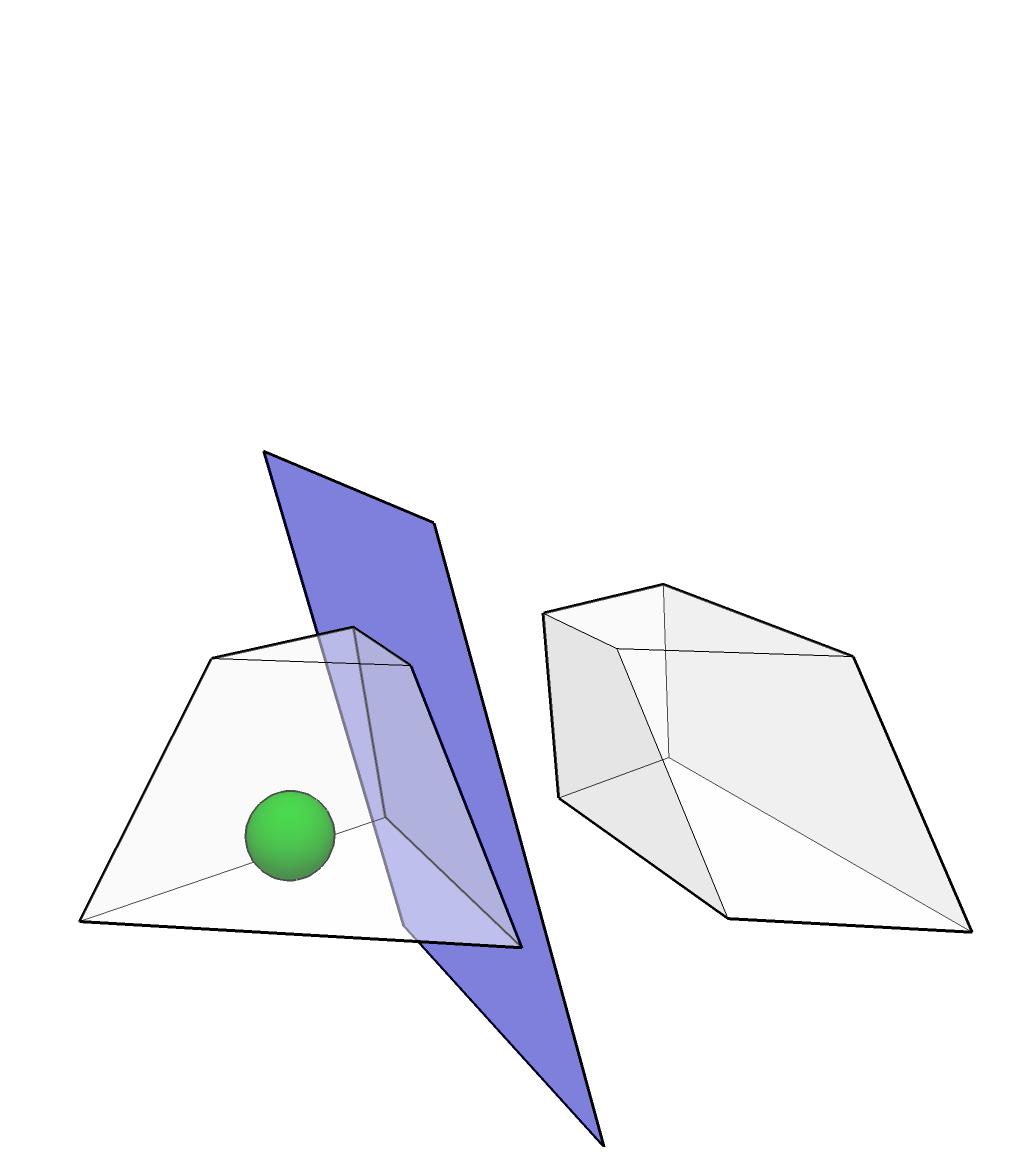
20
21
22 Centers of gravity Conclusions Worst case performance: O(n ln(1/ε)) calls to the oracle.
23 Centers of gravity Conclusions Worst case performance: O(n ln(1/ε)) calls to the oracle. The method is generally not realizable: too difficult to compute the center of gravity. Work with simpler shapes: ellipsoids.
24
25
26
27
28
29
30
31
32
33
34 The ellipsoid method: Shor, Nemirovsky, Yudin, Khachyian Performance The computation of each new ellipsoid needs O(n 2 ) arithmetical operations. Worst case performance: O(n 2 ln(1/ε)) calls to the oracle, and O(n 4 ln(1/ε)) operations.
35 The Khachiyan Sputnik 1978 Khachiyan applied the ellipsoidal method to LP, and defined the number L=number of bits in the input for a problem with rational data. A solution with precision 2 L can be purified to an exact vertex solution of LP. Performance: O(n 4 )L computations.
36
37 Interior point methods Karmarkar 1984: projective IP method: O(n 3.5 L) computations. Renegar 1986: path following algorithm: O(n 3.5 L) computations. Vajdya and G. (independently) 1987: path following algorithms: O(n 3 L) computations.
38 Extensions Linear programming and quadratic programming: Jaceck Gonzio solved a Portfolio Optimization problem based on Markowitz analysis using 16 million scenarios, 1.10 billion variables, 353 million constraints in 53 iterations of an IP method in 50 minutes of a system of 1280 parallel processors. Second Order Cone Programming: extension of the Lorentz cone. Applications to Quadratically constrained quadratic programming, robust LP, robust Least Squares, Filter design, Portfolio Optimization, Truss design,... Semi-definite programming. A huge body of theory and applications to Structural Optimization, Optimal Control, Combinatorial Optimization,...
39 Extensions Linear programming and quadratic programming: Jaceck Gonzio solved a Portfolio Optimization problem based on Markowitz analysis using 16 million scenarios, 1.10 billion variables, 353 million constraints in 53 iterations of an IP method in 50 minutes of a system of 1280 parallel processors. Second Order Cone Programming: extension of the Lorentz cone. Applications to Quadratically constrained quadratic programming, robust LP, robust Least Squares, Filter design, Portfolio Optimization, Truss design,... Semi-definite programming. A huge body of theory and applications to Structural Optimization, Optimal Control, Combinatorial Optimization,...
40 Extensions Linear programming and quadratic programming: Jaceck Gonzio solved a Portfolio Optimization problem based on Markowitz analysis using 16 million scenarios, 1.10 billion variables, 353 million constraints in 53 iterations of an IP method in 50 minutes of a system of 1280 parallel processors. Second Order Cone Programming: extension of the Lorentz cone. Applications to Quadratically constrained quadratic programming, robust LP, robust Least Squares, Filter design, Portfolio Optimization, Truss design,... Semi-definite programming. A huge body of theory and applications to Structural Optimization, Optimal Control, Combinatorial Optimization,...
41 The Affine-Scaling direction Projection matrix Given c R n and a matrix A, c can be decomposed as c = P A c + A T y, where P A c N (A) is the projection of c into N (A).
42 The Affine-Scaling direction Linearly constrained problem: minimize subject to f (x) Ax = b x 0 Define c = f (x 0 ). The projected gradient (Cauchy) direction is c P = P A c, and the steepest descent direction is d = c P. It solves the trust region problem minimize{c T h Ah = 0, d }.
43 c c p h
44 Largest ball centered in xk
45 Largest simple ellipsoid centered in xk
46 The affine scaling direction c c p h
47 Largest ball centered in e = (1,1,...,1)
48 The Affine-Scaling direction Given a feasible point x 0, X = diag(x 0 ) and c = f (x 0 ) minimize subject to c T x Ax = b x 0 x = X x d = X d minimize subject to Scaled steepest descent direction: x = Xe (x is scaled into e): Dikin s direction: d = P AX Xc d = X d = XP AX Xc d = P AX Xc d = X d/ d. (Xc) T x AX x = b x 0
49 Dikin s algorithm Problem P1
50 Dikin s algorithm Problem P1
51 Dikin s algorithm Problem P1
52 Dikin s algorithm Problem P1
53 Affine scaling algorithm Problem P1
54 Affine scaling algorithm Problem P1
55 Affine scaling algorithm Problem P1
56 Affine scaling algorithm Problem P1
57 The logarithmic barrier function x R n ++ p(x) = Scaling: for a diagonal matrix D > 0 Derivatives: n i=1 logx i. p(dx) = p(x) + constant, p(dx) p(dy) = p(x) p(y). p(x) = x 1 p(e) = e 2 p(x) = X 2 2 p(e) = I. At x = e, the Hessian matrix is the identity, and hence the Newton direction coincides with the Cauchy direction.
58 The logarithmic barrier function x R n ++ p(x) = Scaling: for a diagonal matrix D > 0 Derivatives: n i=1 logx i. p(dx) = p(x) + constant, p(dx) p(dy) = p(x) p(y). p(x) = x 1 p(e) = e 2 p(x) = X 2 2 p(e) = I. At x = e, the Hessian matrix is the identity, and hence the Newton direction coincides with the Cauchy direction. At any x > 0, the affine scaling direction coincides with the Newton direction.
59 The penalized function in linear programming For x > 0, µ > 0 and α = 1/µ, minimize subject to f α (x) = αc T x + p(x) or f µ (x) = c T x + µp(x) c T x Ax = b x 0 minimize subject to c T x + µp(x) Ax = b x > 0 For α 0, f α is strictly convex and grows indefinitely near the boundary of the feasible set. Whenever the minimizers exist, they are defined uniquely by x α = argmin x Ω f α (x). In particular, if Ω is bounded, x 0 is the analytic center of Ω If the optimal face of the problem is bounded, then the curve α > 0 x α is well defined and is called the primal central path.
60 The penalized function in linear programming For x > 0, µ > 0 and α = 1/µ, minimize subject to f α (x) = αc T x + p(x) or f µ (x) = c T x + µp(x) c T x Ax = b x 0 minimize subject to c T x + µp(x) Ax = b x > 0 For α 0, f α is strictly convex and grows indefinitely near the boundary of the feasible set. Whenever the minimizers exist, they are defined uniquely by x α = argmin x Ω f α (x). In particular, if Ω is bounded, x 0 is the analytic center of Ω If the optimal face of the problem is bounded, then the curve α > 0 x α is well defined and is called the primal central path.
61 The penalized function in linear programming For x > 0, µ > 0 and α = 1/µ, minimize subject to f α (x) = αc T x + p(x) or f µ (x) = c T x + µp(x) c T x Ax = b x 0 minimize subject to c T x + µp(x) Ax = b x > 0 For α 0, f α is strictly convex and grows indefinitely near the boundary of the feasible set. Whenever the minimizers exist, they are defined uniquely by x α = argmin x Ω f α (x). In particular, if Ω is bounded, x 0 is the analytic center of Ω If the optimal face of the problem is bounded, then the curve α > 0 x α is well defined and is called the primal central path.
62 The central path Problem P1
63 Equivalent definitions of the central path There are four equivalent ways of defining central points: Minimizers of the penalized function: argmin x Ω f α (x). Analytic centers of constant cost slices argmin x Ω {p(x) c T x = K} Renegar centers: Analytic centers of Ω with an extra constraint c T x. argmin x Ω {p(x) log(k c T x) c T x < K} Primal-dual central points (seen ahead).
64 Constant cost slices Enter the new cut position (one point) and then the initial point
65 Constant cost slices Enter the new cut position (one point) and then the initial point
66 Constant cost slices Enter the new cut position (one point) and then the initial point
67 Renegar cuts Problem Ptemp
68 Renegar cuts Problem Ptemp
69 Renegar cuts Problem Ptemp
70 Renegar cuts Problem Ptemp
71 Renegar cuts Problem Ptemp
72 Renegar cuts Problem Ptemp
73 Centering The most important problem in interior point methods is the following: Centering problem Given a feasible interior point x 0 and a value α 0, solve approximately the problem minimize x Ω 0 αc T x + p(x). The Newton direction from x 0 coincides with the affine-scaling direction, and hence is the best possible. It is given by d = X d, d = P AX X(αc x 1 ) = αp AX Xc + P AX e.
74 Centering The most important problem in interior point methods is the following: Centering problem Given a feasible interior point x 0 and a value α 0, solve approximately the problem minimize x Ω 0 αc T x + p(x). The Newton direction from x 0 coincides with the affine-scaling direction, and hence is the best possible. It is given by d = X d, d = P AX X(αc x 1 ) = αp AX Xc + P AX e.
75 Efficiency of the Newton step for centering Newton direction: d = X d, d = P AX X(αc x 1 ) = αp AX Xc + P AX e. We define the Proximity to the central point as δ(x,α) = d = αp AX Xc + P AX e. The following important theorem says how efficient it is: Theorem Consider a feasible point x and a parameter α. Let x + = x + d be the point resulting from a Newton centering step. If δ(x,α) = δ < 1, then δ(x +,α) < δ 2. If δ(x,α) 0.5, then this value is a very good approximation to the euclidean distance between e and X 1 x α, i. e., between x and x α in the scaled space.
76 Efficiency of the Newton step for centering Newton direction: d = X d, d = P AX X(αc x 1 ) = αp AX Xc + P AX e. We define the Proximity to the central point as δ(x,α) = d = αp AX Xc + P AX e. The following important theorem says how efficient it is: Theorem Consider a feasible point x and a parameter α. Let x + = x + d be the point resulting from a Newton centering step. If δ(x,α) = δ < 1, then δ(x +,α) < δ 2. If δ(x,α) 0.5, then this value is a very good approximation to the euclidean distance between e and X 1 x α, i. e., between x and x α in the scaled space.
77 Short steps
78 Primal results as we saw are important to give a geometrical meaning to the procedures, and to develop the intuition. Also, these results can be generalized to a large class of problems, by generalizing the idea of barrier functions. From now on we shall deal with primal-dual results, which are more efficient for linear and non-linear programming.
79 The Linear Programming Problem LP LD minimize subject to c T x Ax = b x 0 maximize subject to b T y A T y c
80 The Linear Programming Problem LP LD minimize subject to c T x Ax = b x 0 maximize subject to b T y A T y + s = c s 0
81 The Linear Programming Problem LP minimize subject to KKT: multipliers y, s c T x Ax = b x 0 A T y + s = c Ax = b xs = 0 x,s 0 LD maximize subject to b T y A T y + s = c s 0
82 The Linear Programming Problem LP minimize subject to c T x Ax = b x 0 LD maximize subject to b T y A T y + s = c s 0 KKT: multipliers y, s A T y + s = c Ax = b xs = 0 x,s 0 KKT: multipliers x A T y + s = c Ax = b xs = 0 x,s 0
83 The Linear Programming Problem LP minimize subject to c T x Ax = b x 0 LD maximize subject to b T y A T y + s = c s 0 Primal-dual optimality A T y + s = c Ax = b xs = 0 x,s 0 Duality gap For x, y, s feasible, c T x b T y = x T s 0
84 The Linear Programming Problem LP minimize subject to c T x Ax = b x 0 LD maximize subject to b T y A T y + s = c s 0 Primal-dual optimality A T y + s = c Ax = b xs = 0 x,s 0 Duality gap For x, y, s feasible, c T x b T y = x T s 0 (LP) has solution x and (LD) has solution y,s if and only if the optimality conditions have solution x, y, s.
85 Primal-dual centering Let us write the KKT conditions for the centering problem (now using µ instead of α = 1/µ). minimize c T x µ logx i subject to Ax = b x > 0 Primal-dual center: KKT conditions xs = µe A T y + s = c Ax = b x,s > 0
86 Primal-dual centering Let us write the KKT conditions for the centering problem (now using µ instead of α = 1/µ). minimize c T x µ logx i subject to Ax = b x > 0 Primal-dual center: KKT conditions xs = µe A T y + s = c Ax = b x,s > 0
87 Generalization Let us write the KKT conditions for the convex quadratic programming problem minimize subject to c T x xt Hx Ax = b x > 0 The first KKT condition is written as c + Hx A T y s = 0 To obtain a symmetrical formulation for the problem, we may multiply this equation by a matrix B whose rows form a basis for the null space of A. Then BA T y = 0, and we obtain the following conditions conditions: xs = 0 BHx + Bs = Bc Ax = b x,s 0
88 Horizontal linear complementarity problem In any case, the problem can be written as xs = 0 Qx + Rs = b x,s 0 This is a linear complementarity problem, which includes linear and quadratic programming as particular problems. The techniques studied here apply to these problems, as long as the following monotonicity condition holds: For any feasible pair of directions (u,v) such that Qu + Rv = 0, we have u T v 0. The optimal face: the optimal solutions must satisfy x i s i = 0 for i = 1,...,n. This is a combinatorial constraint, responsible for all the difficulty in the solution.
89 Horizontal linear complementarity problem In any case, the problem can be written as xs = 0 Qx + Rs = b x,s 0 This is a linear complementarity problem, which includes linear and quadratic programming as particular problems. The techniques studied here apply to these problems, as long as the following monotonicity condition holds: For any feasible pair of directions (u,v) such that Qu + Rv = 0, we have u T v 0. The optimal face: the optimal solutions must satisfy x i s i = 0 for i = 1,...,n. This is a combinatorial constraint, responsible for all the difficulty in the solution.
90 Primal-dual centering: the Newton step Given x,s feasible and µ > 0, find x + = x + u s + = s + v such that x + s + = µe Qx + + Rs + = b xs + su + xv + uv = µe Qu + Rv = 0 Newton step Xv + Su = xs + µe Qu + Rv = 0 Solving this linear system is all the work. In the case of linear programming one should keep the multipliers y and simplify the resulting system of equations
91 Primal-dual centering: the Newton step Given x,s feasible and µ > 0, find x + = x + u s + = s + v such that x + s + = µe Qx + + Rs + = b xs + su + xv + uv = µe Qu + Rv = 0 Newton step Xv + Su = xs + µe Qu + Rv = 0 Solving this linear system is all the work. In the case of linear programming one should keep the multipliers y and simplify the resulting system of equations
92 Primal-dual centering: the Newton step Given x,s feasible and µ > 0, find x + = x + u s + = s + v such that x + s + = µe Qx + + Rs + = b xs + su + xv + uv = µe Qu + Rv = 0 Newton step Xv + Su = xs + µe Qu + Rv = 0 Solving this linear system is all the work. In the case of linear programming one should keep the multipliers y and simplify the resulting system of equations
93 Primal-dual centering: Proximity measure Given x,s feasible and µ > 0, we want xs = µe or equivalently xs µ e = 0 The actual error in this equation gives the proximity measure: Proximity measure Theorem x,s,µ δ(x,s,µ) = xs µ e. Given a feasible pair (x,s) and a parameter µ, Let x + = x + u and s + = s + v be the point resulting from a Newton centering step. If δ(x,s,µ) = δ < 1, then δ(x +,s +,µ) < 1 8 δ 2 1 δ. In particular, if δ 0.7, then δ(x +,s +,µ) < δ 2.
94 Primal-dual centering: Proximity measure Given x,s feasible and µ > 0, we want xs = µe or equivalently xs µ e = 0 The actual error in this equation gives the proximity measure: Proximity measure Theorem x,s,µ δ(x,s,µ) = xs µ e. Given a feasible pair (x,s) and a parameter µ, Let x + = x + u and s + = s + v be the point resulting from a Newton centering step. If δ(x,s,µ) = δ < 1, then δ(x +,s +,µ) < 1 8 δ 2 1 δ. In particular, if δ 0.7, then δ(x +,s +,µ) < δ 2.
95 Primal-dual path following: Traditional approach Assume that we have x,s,µ such that (x,s) is feasible and δ(x,s,µ) α < 1 Choose µ + = γµ, with γ < 1. Use Newton s algorithm (with line searches to avoid infeasible points) to find (x +,s + ) such that δ(x +,s +,µ + ) α Neighborhood of the central path Given β (0,1), we define the neighborhood η(α) as the set of all feasible pairs (x,s) such that for some µ > 0 δ(x,s,µ) β The methods must ensure that all points are in such a neighborhood, using line searches
96 Primal-dual path following: Traditional approach Assume that we have x,s,µ such that (x,s) is feasible and δ(x,s,µ) α < 1 Choose µ + = γµ, with γ < 1. Use Newton s algorithm (with line searches to avoid infeasible points) to find (x +,s + ) such that δ(x +,s +,µ + ) α Neighborhood of the central path Given β (0,1), we define the neighborhood η(α) as the set of all feasible pairs (x,s) such that for some µ > 0 δ(x,s,µ) β The methods must ensure that all points are in such a neighborhood, using line searches
97 Primal-dual path following: Traditional approach Assume that we have x,s,µ such that (x,s) is feasible and δ(x,s,µ) α < 1 Choose µ + = γµ, with γ < 1. Use Newton s algorithm (with line searches to avoid infeasible points) to find (x +,s + ) such that δ(x +,s +,µ + ) α Neighborhood of the central path Given β (0,1), we define the neighborhood η(α) as the set of all feasible pairs (x,s) such that for some µ > 0 δ(x,s,µ) β The methods must ensure that all points are in such a neighborhood, using line searches
98 A neighborhood of the central path
99 Short steps Using γ near 1, we obtain short steps. With γ = 0.4/ n, only one Newton step is needed at each iteration, and the algorithm is polynomial: it finds a solution with precision 2 L in O( nl) iterations.
100 Short steps Problem P1

101 Large steps Using γ small, say γ = 0.1, we obtain large steps. This uses to work well in practice, but some sort of line search is needed, to avoid leaving the neighborhood. Predictor-corrector methods are better, as we shall see.
102 Large steps Problem P1
103 Adaptive methods Assume that (x,s) feasible is given in η(β), but no value of µ is given. Then we know: if (x,s) is a central point, then xs = µe implies x T s = nµ. Hence the best choice for µ is µ = x T s/n. If (x,s) is not a central point, the value µ(x,s) = x T s/n gives a parameter value which in a certain sense is the best possible. An adaptive algorithm does not use a value of µ coming from a former iteration: it computes µ(x, s) and then chooses a value γµ(x, s) as new target. The target may be far. Compute a direction (u,v) and follow it until δ(x + λu,s + λv,µ(x + λu,s + λv)) = β
104 Adaptive steps
105 Predictor-corrector methods Alternate two kinds of iterations: Predictor: An iteration starts with (x, s) near the central path, and computes a Newton step (u, v) with goal γµ(x, s), γ small. Follow it until δ(x + λu,s + λv,µ(x + λu,s + λv)) = β Corrector: Set x + = x + λu, s + = s + λv, compute µ = µ(x +,s + ) and take a Newton step with target µ If the predictor uses γ = 0, it is called the affine scaling step. It has no centering, and tries to solve the original problem in one step. Using a neighborhood with β = 0.5, the resulting algorithm (the Mizuno-Todd-Ye algorithm) converges quadratically to an optimal solution, keeping the complexity at its best value of O( nl) iterations.
106 Predictor-corrector methods Alternate two kinds of iterations: Predictor: An iteration starts with (x, s) near the central path, and computes a Newton step (u, v) with goal γµ(x, s), γ small. Follow it until δ(x + λu,s + λv,µ(x + λu,s + λv)) = β Corrector: Set x + = x + λu, s + = s + λv, compute µ = µ(x +,s + ) and take a Newton step with target µ If the predictor uses γ = 0, it is called the affine scaling step. It has no centering, and tries to solve the original problem in one step. Using a neighborhood with β = 0.5, the resulting algorithm (the Mizuno-Todd-Ye algorithm) converges quadratically to an optimal solution, keeping the complexity at its best value of O( nl) iterations.
107 Predictor-corrector
108 Mehrotra Predictor-corrector method: second order When computing the Newton step, we eliminated the nonlinear term uv in the equation xs + su + xv + uv = µe Qu + Rv = 0 The second order method corrects the values of u,v by estimating the value of the term uv by a predictor step. Predictor: An iteration starts with (x, s) near the central path, and computes a Newton step (u,v) with goal µ +, small. The first equation is Compute a correction ( u, v) by xv + su = xs + µ + e x v + s u = uv. Line search: Set x + = x + λu + λ 2 u, s + = s + λv + λ 2 v, by a line search so that δ(x +,s +,µ(x +,s + )) = β.
109 Mehrotra Predictor-corrector
110 Thank you
Interior Point Methods in Mathematical Programming
 Interior Point Methods in Mathematical Programming Clóvis C. Gonzaga Federal University of Santa Catarina, Brazil Journées en l honneur de Pierre Huard Paris, novembre 2008 01 00 11 00 000 000 000 000
Interior Point Methods in Mathematical Programming Clóvis C. Gonzaga Federal University of Santa Catarina, Brazil Journées en l honneur de Pierre Huard Paris, novembre 2008 01 00 11 00 000 000 000 000
Interior Point Methods. We ll discuss linear programming first, followed by three nonlinear problems. Algorithms for Linear Programming Problems
 AMSC 607 / CMSC 764 Advanced Numerical Optimization Fall 2008 UNIT 3: Constrained Optimization PART 4: Introduction to Interior Point Methods Dianne P. O Leary c 2008 Interior Point Methods We ll discuss
AMSC 607 / CMSC 764 Advanced Numerical Optimization Fall 2008 UNIT 3: Constrained Optimization PART 4: Introduction to Interior Point Methods Dianne P. O Leary c 2008 Interior Point Methods We ll discuss
Primal-dual relationship between Levenberg-Marquardt and central trajectories for linearly constrained convex optimization
 Primal-dual relationship between Levenberg-Marquardt and central trajectories for linearly constrained convex optimization Roger Behling a, Clovis Gonzaga b and Gabriel Haeser c March 21, 2013 a Department
Primal-dual relationship between Levenberg-Marquardt and central trajectories for linearly constrained convex optimization Roger Behling a, Clovis Gonzaga b and Gabriel Haeser c March 21, 2013 a Department
10 Numerical methods for constrained problems
 10 Numerical methods for constrained problems min s.t. f(x) h(x) = 0 (l), g(x) 0 (m), x X The algorithms can be roughly divided the following way: ˆ primal methods: find descent direction keeping inside
10 Numerical methods for constrained problems min s.t. f(x) h(x) = 0 (l), g(x) 0 (m), x X The algorithms can be roughly divided the following way: ˆ primal methods: find descent direction keeping inside
 Penalty and Barrier Methods General classical constrained minimization problem minimize f(x) subject to g(x) 0 h(x) =0 Penalty methods are motivated by the desire to use unconstrained optimization techniques
Penalty and Barrier Methods General classical constrained minimization problem minimize f(x) subject to g(x) 0 h(x) =0 Penalty methods are motivated by the desire to use unconstrained optimization techniques
Semidefinite Programming
 Chapter 2 Semidefinite Programming 2.0.1 Semi-definite programming (SDP) Given C M n, A i M n, i = 1, 2,..., m, and b R m, the semi-definite programming problem is to find a matrix X M n for the optimization
Chapter 2 Semidefinite Programming 2.0.1 Semi-definite programming (SDP) Given C M n, A i M n, i = 1, 2,..., m, and b R m, the semi-definite programming problem is to find a matrix X M n for the optimization
Numerical Optimization
 Linear Programming - Interior Point Methods Computer Science and Automation Indian Institute of Science Bangalore 560 012, India. NPTEL Course on Example 1 Computational Complexity of Simplex Algorithm
Linear Programming - Interior Point Methods Computer Science and Automation Indian Institute of Science Bangalore 560 012, India. NPTEL Course on Example 1 Computational Complexity of Simplex Algorithm
Lecture 9 Sequential unconstrained minimization
 S. Boyd EE364 Lecture 9 Sequential unconstrained minimization brief history of SUMT & IP methods logarithmic barrier function central path UMT & SUMT complexity analysis feasibility phase generalized inequalities
S. Boyd EE364 Lecture 9 Sequential unconstrained minimization brief history of SUMT & IP methods logarithmic barrier function central path UMT & SUMT complexity analysis feasibility phase generalized inequalities
Nonlinear Optimization: What s important?
 Nonlinear Optimization: What s important? Julian Hall 10th May 2012 Convexity: convex problems A local minimizer is a global minimizer A solution of f (x) = 0 (stationary point) is a minimizer A global
Nonlinear Optimization: What s important? Julian Hall 10th May 2012 Convexity: convex problems A local minimizer is a global minimizer A solution of f (x) = 0 (stationary point) is a minimizer A global
Interior-Point Methods
 Interior-Point Methods Stephen Wright University of Wisconsin-Madison Simons, Berkeley, August, 2017 Wright (UW-Madison) Interior-Point Methods August 2017 1 / 48 Outline Introduction: Problems and Fundamentals
Interior-Point Methods Stephen Wright University of Wisconsin-Madison Simons, Berkeley, August, 2017 Wright (UW-Madison) Interior-Point Methods August 2017 1 / 48 Outline Introduction: Problems and Fundamentals
Algorithms for constrained local optimization
 Algorithms for constrained local optimization Fabio Schoen 2008 http://gol.dsi.unifi.it/users/schoen Algorithms for constrained local optimization p. Feasible direction methods Algorithms for constrained
Algorithms for constrained local optimization Fabio Schoen 2008 http://gol.dsi.unifi.it/users/schoen Algorithms for constrained local optimization p. Feasible direction methods Algorithms for constrained
Interior-Point Methods for Linear Optimization
 Interior-Point Methods for Linear Optimization Robert M. Freund and Jorge Vera March, 204 c 204 Robert M. Freund and Jorge Vera. All rights reserved. Linear Optimization with a Logarithmic Barrier Function
Interior-Point Methods for Linear Optimization Robert M. Freund and Jorge Vera March, 204 c 204 Robert M. Freund and Jorge Vera. All rights reserved. Linear Optimization with a Logarithmic Barrier Function
A Second-Order Path-Following Algorithm for Unconstrained Convex Optimization
 A Second-Order Path-Following Algorithm for Unconstrained Convex Optimization Yinyu Ye Department is Management Science & Engineering and Institute of Computational & Mathematical Engineering Stanford
A Second-Order Path-Following Algorithm for Unconstrained Convex Optimization Yinyu Ye Department is Management Science & Engineering and Institute of Computational & Mathematical Engineering Stanford
More First-Order Optimization Algorithms
 More First-Order Optimization Algorithms Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapters 3, 8, 3 The SDM
More First-Order Optimization Algorithms Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapters 3, 8, 3 The SDM
Convex Optimization. Newton s method. ENSAE: Optimisation 1/44
 Convex Optimization Newton s method ENSAE: Optimisation 1/44 Unconstrained minimization minimize f(x) f convex, twice continuously differentiable (hence dom f open) we assume optimal value p = inf x f(x)
Convex Optimization Newton s method ENSAE: Optimisation 1/44 Unconstrained minimization minimize f(x) f convex, twice continuously differentiable (hence dom f open) we assume optimal value p = inf x f(x)
4TE3/6TE3. Algorithms for. Continuous Optimization
 4TE3/6TE3 Algorithms for Continuous Optimization (Algorithms for Constrained Nonlinear Optimization Problems) Tamás TERLAKY Computing and Software McMaster University Hamilton, November 2005 terlaky@mcmaster.ca
4TE3/6TE3 Algorithms for Continuous Optimization (Algorithms for Constrained Nonlinear Optimization Problems) Tamás TERLAKY Computing and Software McMaster University Hamilton, November 2005 terlaky@mcmaster.ca
CS711008Z Algorithm Design and Analysis
 CS711008Z Algorithm Design and Analysis Lecture 8 Linear programming: interior point method Dongbo Bu Institute of Computing Technology Chinese Academy of Sciences, Beijing, China 1 / 31 Outline Brief
CS711008Z Algorithm Design and Analysis Lecture 8 Linear programming: interior point method Dongbo Bu Institute of Computing Technology Chinese Academy of Sciences, Beijing, China 1 / 31 Outline Brief
Primal-Dual Interior-Point Methods. Ryan Tibshirani Convex Optimization /36-725
 Primal-Dual Interior-Point Methods Ryan Tibshirani Convex Optimization 10-725/36-725 Given the problem Last time: barrier method min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h i, i = 1,...
Primal-Dual Interior-Point Methods Ryan Tibshirani Convex Optimization 10-725/36-725 Given the problem Last time: barrier method min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h i, i = 1,...
2.098/6.255/ Optimization Methods Practice True/False Questions
 2.098/6.255/15.093 Optimization Methods Practice True/False Questions December 11, 2009 Part I For each one of the statements below, state whether it is true or false. Include a 1-3 line supporting sentence
2.098/6.255/15.093 Optimization Methods Practice True/False Questions December 11, 2009 Part I For each one of the statements below, state whether it is true or false. Include a 1-3 line supporting sentence
Primal-Dual Interior-Point Methods. Javier Peña Convex Optimization /36-725
 Primal-Dual Interior-Point Methods Javier Peña Convex Optimization 10-725/36-725 Last time: duality revisited Consider the problem min x subject to f(x) Ax = b h(x) 0 Lagrangian L(x, u, v) = f(x) + u T
Primal-Dual Interior-Point Methods Javier Peña Convex Optimization 10-725/36-725 Last time: duality revisited Consider the problem min x subject to f(x) Ax = b h(x) 0 Lagrangian L(x, u, v) = f(x) + u T
An O(nL) Infeasible-Interior-Point Algorithm for Linear Programming arxiv: v2 [math.oc] 29 Jun 2015
![An O(nL) Infeasible-Interior-Point Algorithm for Linear Programming arxiv: v2 [math.oc] 29 Jun 2015](/thumbs/90/104141466.jpg "An O(nL) Infeasible-Interior-Point Algorithm for Linear Programming arxiv: v2 [math.oc] 29 Jun 2015") An O(nL) Infeasible-Interior-Point Algorithm for Linear Programming arxiv:1506.06365v [math.oc] 9 Jun 015 Yuagang Yang and Makoto Yamashita September 8, 018 Abstract In this paper, we propose an arc-search
An O(nL) Infeasible-Interior-Point Algorithm for Linear Programming arxiv:1506.06365v [math.oc] 9 Jun 015 Yuagang Yang and Makoto Yamashita September 8, 018 Abstract In this paper, we propose an arc-search
Lecture 6: Conic Optimization September 8
 IE 598: Big Data Optimization Fall 2016 Lecture 6: Conic Optimization September 8 Lecturer: Niao He Scriber: Juan Xu Overview In this lecture, we finish up our previous discussion on optimality conditions
IE 598: Big Data Optimization Fall 2016 Lecture 6: Conic Optimization September 8 Lecturer: Niao He Scriber: Juan Xu Overview In this lecture, we finish up our previous discussion on optimality conditions
Optimization: Then and Now
 Optimization: Then and Now Optimization: Then and Now Optimization: Then and Now Why would a dynamicist be interested in linear programming? Linear Programming (LP) max c T x s.t. Ax b αi T x b i for i
Optimization: Then and Now Optimization: Then and Now Optimization: Then and Now Why would a dynamicist be interested in linear programming? Linear Programming (LP) max c T x s.t. Ax b αi T x b i for i
Part 4: Active-set methods for linearly constrained optimization. Nick Gould (RAL)
") Part 4: Active-set methods for linearly constrained optimization Nick Gould RAL fx subject to Ax b Part C course on continuoue optimization LINEARLY CONSTRAINED MINIMIZATION fx subject to Ax { } b where
Part 4: Active-set methods for linearly constrained optimization Nick Gould RAL fx subject to Ax b Part C course on continuoue optimization LINEARLY CONSTRAINED MINIMIZATION fx subject to Ax { } b where
Written Examination
 Division of Scientific Computing Department of Information Technology Uppsala University Optimization Written Examination 202-2-20 Time: 4:00-9:00 Allowed Tools: Pocket Calculator, one A4 paper with notes
Division of Scientific Computing Department of Information Technology Uppsala University Optimization Written Examination 202-2-20 Time: 4:00-9:00 Allowed Tools: Pocket Calculator, one A4 paper with notes
Primal-Dual Interior-Point Methods for Linear Programming based on Newton s Method
 Primal-Dual Interior-Point Methods for Linear Programming based on Newton s Method Robert M. Freund March, 2004 2004 Massachusetts Institute of Technology. The Problem The logarithmic barrier approach
Primal-Dual Interior-Point Methods for Linear Programming based on Newton s Method Robert M. Freund March, 2004 2004 Massachusetts Institute of Technology. The Problem The logarithmic barrier approach
Primal-Dual Interior-Point Methods. Ryan Tibshirani Convex Optimization
 Primal-Dual Interior-Point Methods Ryan Tibshirani Convex Optimization 10-725 Given the problem Last time: barrier method min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h i, i = 1,... m are
Primal-Dual Interior-Point Methods Ryan Tibshirani Convex Optimization 10-725 Given the problem Last time: barrier method min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h i, i = 1,... m are
Lagrangian Duality Theory
 Lagrangian Duality Theory Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapter 14.1-4 1 Recall Primal and Dual
Lagrangian Duality Theory Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapter 14.1-4 1 Recall Primal and Dual
January 29, Introduction to optimization and complexity. Outline. Introduction. Problem formulation. Convexity reminder. Optimality Conditions
 Olga Galinina olga.galinina@tut.fi ELT-53656 Network Analysis Dimensioning II Department of Electronics Communications Engineering Tampere University of Technology, Tampere, Finl January 29, 2014 1 2 3
Olga Galinina olga.galinina@tut.fi ELT-53656 Network Analysis Dimensioning II Department of Electronics Communications Engineering Tampere University of Technology, Tampere, Finl January 29, 2014 1 2 3
Computational Finance
 Department of Mathematics at University of California, San Diego Computational Finance Optimization Techniques [Lecture 2] Michael Holst January 9, 2017 Contents 1 Optimization Techniques 3 1.1 Examples
Department of Mathematics at University of California, San Diego Computational Finance Optimization Techniques [Lecture 2] Michael Holst January 9, 2017 Contents 1 Optimization Techniques 3 1.1 Examples
CS295: Convex Optimization. Xiaohui Xie Department of Computer Science University of California, Irvine
 CS295: Convex Optimization Xiaohui Xie Department of Computer Science University of California, Irvine Course information Prerequisites: multivariate calculus and linear algebra Textbook: Convex Optimization
CS295: Convex Optimization Xiaohui Xie Department of Computer Science University of California, Irvine Course information Prerequisites: multivariate calculus and linear algebra Textbook: Convex Optimization
A full-newton step infeasible interior-point algorithm for linear programming based on a kernel function
 A full-newton step infeasible interior-point algorithm for linear programming based on a kernel function Zhongyi Liu, Wenyu Sun Abstract This paper proposes an infeasible interior-point algorithm with
A full-newton step infeasible interior-point algorithm for linear programming based on a kernel function Zhongyi Liu, Wenyu Sun Abstract This paper proposes an infeasible interior-point algorithm with
On well definedness of the Central Path
 On well definedness of the Central Path L.M.Graña Drummond B. F. Svaiter IMPA-Instituto de Matemática Pura e Aplicada Estrada Dona Castorina 110, Jardim Botânico, Rio de Janeiro-RJ CEP 22460-320 Brasil
On well definedness of the Central Path L.M.Graña Drummond B. F. Svaiter IMPA-Instituto de Matemática Pura e Aplicada Estrada Dona Castorina 110, Jardim Botânico, Rio de Janeiro-RJ CEP 22460-320 Brasil
IE 5531 Midterm #2 Solutions
 IE 5531 Midterm #2 s Prof. John Gunnar Carlsson November 9, 2011 Before you begin: This exam has 9 pages and a total of 5 problems. Make sure that all pages are present. To obtain credit for a problem,
IE 5531 Midterm #2 s Prof. John Gunnar Carlsson November 9, 2011 Before you begin: This exam has 9 pages and a total of 5 problems. Make sure that all pages are present. To obtain credit for a problem,
Lecture 18: Optimization Programming
 Fall, 2016 Outline Unconstrained Optimization 1 Unconstrained Optimization 2 Equality-constrained Optimization Inequality-constrained Optimization Mixture-constrained Optimization 3 Quadratic Programming
Fall, 2016 Outline Unconstrained Optimization 1 Unconstrained Optimization 2 Equality-constrained Optimization Inequality-constrained Optimization Mixture-constrained Optimization 3 Quadratic Programming
A FULL-NEWTON STEP INFEASIBLE-INTERIOR-POINT ALGORITHM COMPLEMENTARITY PROBLEMS
 Yugoslav Journal of Operations Research 25 (205), Number, 57 72 DOI: 0.2298/YJOR3055034A A FULL-NEWTON STEP INFEASIBLE-INTERIOR-POINT ALGORITHM FOR P (κ)-horizontal LINEAR COMPLEMENTARITY PROBLEMS Soodabeh
Yugoslav Journal of Operations Research 25 (205), Number, 57 72 DOI: 0.2298/YJOR3055034A A FULL-NEWTON STEP INFEASIBLE-INTERIOR-POINT ALGORITHM FOR P (κ)-horizontal LINEAR COMPLEMENTARITY PROBLEMS Soodabeh
An Infeasible Interior-Point Algorithm with full-newton Step for Linear Optimization
 An Infeasible Interior-Point Algorithm with full-newton Step for Linear Optimization H. Mansouri M. Zangiabadi Y. Bai C. Roos Department of Mathematical Science, Shahrekord University, P.O. Box 115, Shahrekord,
An Infeasible Interior-Point Algorithm with full-newton Step for Linear Optimization H. Mansouri M. Zangiabadi Y. Bai C. Roos Department of Mathematical Science, Shahrekord University, P.O. Box 115, Shahrekord,
Lecture 13: Constrained optimization
 2010-12-03 Basic ideas A nonlinearly constrained problem must somehow be converted relaxed into a problem which we can solve (a linear/quadratic or unconstrained problem) We solve a sequence of such problems
2010-12-03 Basic ideas A nonlinearly constrained problem must somehow be converted relaxed into a problem which we can solve (a linear/quadratic or unconstrained problem) We solve a sequence of such problems
Convex Optimization and l 1 -minimization
 Convex Optimization and l 1 -minimization Sangwoon Yun Computational Sciences Korea Institute for Advanced Study December 11, 2009 2009 NIMS Thematic Winter School Outline I. Convex Optimization II. l
Convex Optimization and l 1 -minimization Sangwoon Yun Computational Sciences Korea Institute for Advanced Study December 11, 2009 2009 NIMS Thematic Winter School Outline I. Convex Optimization II. l
Operations Research Lecture 4: Linear Programming Interior Point Method
 Operations Research Lecture 4: Linear Programg Interior Point Method Notes taen by Kaiquan Xu@Business School, Nanjing University April 14th 2016 1 The affine scaling algorithm one of the most efficient
Operations Research Lecture 4: Linear Programg Interior Point Method Notes taen by Kaiquan Xu@Business School, Nanjing University April 14th 2016 1 The affine scaling algorithm one of the most efficient
Nonlinear optimization
 Nonlinear optimization Anders Forsgren Optimization and Systems Theory Department of Mathematics Royal Institute of Technology (KTH) Stockholm, Sweden evita Winter School 2009 Geilo, Norway January 11
Nonlinear optimization Anders Forsgren Optimization and Systems Theory Department of Mathematics Royal Institute of Technology (KTH) Stockholm, Sweden evita Winter School 2009 Geilo, Norway January 11
IE 5531: Engineering Optimization I
 IE 5531: Engineering Optimization I Lecture 19: Midterm 2 Review Prof. John Gunnar Carlsson November 22, 2010 Prof. John Gunnar Carlsson IE 5531: Engineering Optimization I November 22, 2010 1 / 34 Administrivia
IE 5531: Engineering Optimization I Lecture 19: Midterm 2 Review Prof. John Gunnar Carlsson November 22, 2010 Prof. John Gunnar Carlsson IE 5531: Engineering Optimization I November 22, 2010 1 / 34 Administrivia
Optimality Conditions for Constrained Optimization
 72 CHAPTER 7 Optimality Conditions for Constrained Optimization 1. First Order Conditions In this section we consider first order optimality conditions for the constrained problem P : minimize f 0 (x)
72 CHAPTER 7 Optimality Conditions for Constrained Optimization 1. First Order Conditions In this section we consider first order optimality conditions for the constrained problem P : minimize f 0 (x)
Numerical Optimization. Review: Unconstrained Optimization
 Numerical Optimization Finding the best feasible solution Edward P. Gatzke Department of Chemical Engineering University of South Carolina Ed Gatzke (USC CHE ) Numerical Optimization ECHE 589, Spring 2011
Numerical Optimization Finding the best feasible solution Edward P. Gatzke Department of Chemical Engineering University of South Carolina Ed Gatzke (USC CHE ) Numerical Optimization ECHE 589, Spring 2011
Lecture 10. Primal-Dual Interior Point Method for LP
 IE 8534 1 Lecture 10. Primal-Dual Interior Point Method for LP IE 8534 2 Consider a linear program (P ) minimize c T x subject to Ax = b x 0 and its dual (D) maximize b T y subject to A T y + s = c s 0.
IE 8534 1 Lecture 10. Primal-Dual Interior Point Method for LP IE 8534 2 Consider a linear program (P ) minimize c T x subject to Ax = b x 0 and its dual (D) maximize b T y subject to A T y + s = c s 0.
CSCI 1951-G Optimization Methods in Finance Part 01: Linear Programming
 CSCI 1951-G Optimization Methods in Finance Part 01: Linear Programming January 26, 2018 1 / 38 Liability/asset cash-flow matching problem Recall the formulation of the problem: max w c 1 + p 1 e 1 = 150
CSCI 1951-G Optimization Methods in Finance Part 01: Linear Programming January 26, 2018 1 / 38 Liability/asset cash-flow matching problem Recall the formulation of the problem: max w c 1 + p 1 e 1 = 150
Conditional Gradient (Frank-Wolfe) Method
 Method") Conditional Gradient (Frank-Wolfe) Method Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 1 Outline Today: Conditional gradient method Convergence analysis Properties
Conditional Gradient (Frank-Wolfe) Method Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 1 Outline Today: Conditional gradient method Convergence analysis Properties
Lecture 3. Optimization Problems and Iterative Algorithms
 Lecture 3 Optimization Problems and Iterative Algorithms January 13, 2016 This material was jointly developed with Angelia Nedić at UIUC for IE 598ns Outline Special Functions: Linear, Quadratic, Convex
Lecture 3 Optimization Problems and Iterative Algorithms January 13, 2016 This material was jointly developed with Angelia Nedić at UIUC for IE 598ns Outline Special Functions: Linear, Quadratic, Convex
Convex Optimization. Prof. Nati Srebro. Lecture 12: Infeasible-Start Newton s Method Interior Point Methods
 Convex Optimization Prof. Nati Srebro Lecture 12: Infeasible-Start Newton s Method Interior Point Methods Equality Constrained Optimization f 0 (x) s. t. A R p n, b R p Using access to: 2 nd order oracle
Convex Optimization Prof. Nati Srebro Lecture 12: Infeasible-Start Newton s Method Interior Point Methods Equality Constrained Optimization f 0 (x) s. t. A R p n, b R p Using access to: 2 nd order oracle
On the iterate convergence of descent methods for convex optimization
 On the iterate convergence of descent methods for convex optimization Clovis C. Gonzaga March 1, 2014 Abstract We study the iterate convergence of strong descent algorithms applied to convex functions.
On the iterate convergence of descent methods for convex optimization Clovis C. Gonzaga March 1, 2014 Abstract We study the iterate convergence of strong descent algorithms applied to convex functions.
Lecture 3 Interior Point Methods and Nonlinear Optimization
 Lecture 3 Interior Point Methods and Nonlinear Optimization Robert J. Vanderbei April 16, 2012 Machine Learning Summer School La Palma http://www.princeton.edu/ rvdb Example: Basis Pursuit Denoising L
Lecture 3 Interior Point Methods and Nonlinear Optimization Robert J. Vanderbei April 16, 2012 Machine Learning Summer School La Palma http://www.princeton.edu/ rvdb Example: Basis Pursuit Denoising L
Lecture 15 Newton Method and Self-Concordance. October 23, 2008
 Newton Method and Self-Concordance October 23, 2008 Outline Lecture 15 Self-concordance Notion Self-concordant Functions Operations Preserving Self-concordance Properties of Self-concordant Functions Implications
Newton Method and Self-Concordance October 23, 2008 Outline Lecture 15 Self-concordance Notion Self-concordant Functions Operations Preserving Self-concordance Properties of Self-concordant Functions Implications
ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints
 ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints Instructor: Prof. Kevin Ross Scribe: Nitish John October 18, 2011 1 The Basic Goal The main idea is to transform a given constrained
ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints Instructor: Prof. Kevin Ross Scribe: Nitish John October 18, 2011 1 The Basic Goal The main idea is to transform a given constrained
LINEAR AND NONLINEAR PROGRAMMING
 LINEAR AND NONLINEAR PROGRAMMING Stephen G. Nash and Ariela Sofer George Mason University The McGraw-Hill Companies, Inc. New York St. Louis San Francisco Auckland Bogota Caracas Lisbon London Madrid Mexico
LINEAR AND NONLINEAR PROGRAMMING Stephen G. Nash and Ariela Sofer George Mason University The McGraw-Hill Companies, Inc. New York St. Louis San Francisco Auckland Bogota Caracas Lisbon London Madrid Mexico
2.3 Linear Programming
 2.3 Linear Programming Linear Programming (LP) is the term used to define a wide range of optimization problems in which the objective function is linear in the unknown variables and the constraints are
2.3 Linear Programming Linear Programming (LP) is the term used to define a wide range of optimization problems in which the objective function is linear in the unknown variables and the constraints are
Constrained Optimization and Lagrangian Duality
 CIS 520: Machine Learning Oct 02, 2017 Constrained Optimization and Lagrangian Duality Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may
CIS 520: Machine Learning Oct 02, 2017 Constrained Optimization and Lagrangian Duality Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may
On Superlinear Convergence of Infeasible Interior-Point Algorithms for Linearly Constrained Convex Programs *
 Computational Optimization and Applications, 8, 245 262 (1997) c 1997 Kluwer Academic Publishers. Manufactured in The Netherlands. On Superlinear Convergence of Infeasible Interior-Point Algorithms for
Computational Optimization and Applications, 8, 245 262 (1997) c 1997 Kluwer Academic Publishers. Manufactured in The Netherlands. On Superlinear Convergence of Infeasible Interior-Point Algorithms for
A Generalized Homogeneous and Self-Dual Algorithm. for Linear Programming. February 1994 (revised December 1994)
") A Generalized Homogeneous and Self-Dual Algorithm for Linear Programming Xiaojie Xu Yinyu Ye y February 994 (revised December 994) Abstract: A generalized homogeneous and self-dual (HSD) infeasible-interior-point
A Generalized Homogeneous and Self-Dual Algorithm for Linear Programming Xiaojie Xu Yinyu Ye y February 994 (revised December 994) Abstract: A generalized homogeneous and self-dual (HSD) infeasible-interior-point
Conic Linear Programming. Yinyu Ye
 Conic Linear Programming Yinyu Ye December 2004, revised October 2017 i ii Preface This monograph is developed for MS&E 314, Conic Linear Programming, which I am teaching at Stanford. Information, lecture
Conic Linear Programming Yinyu Ye December 2004, revised October 2017 i ii Preface This monograph is developed for MS&E 314, Conic Linear Programming, which I am teaching at Stanford. Information, lecture
Nonlinear Optimization for Optimal Control
 Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
A Full Newton Step Infeasible Interior Point Algorithm for Linear Optimization
 A Full Newton Step Infeasible Interior Point Algorithm for Linear Optimization Kees Roos e-mail: C.Roos@tudelft.nl URL: http://www.isa.ewi.tudelft.nl/ roos 37th Annual Iranian Mathematics Conference Tabriz,
A Full Newton Step Infeasible Interior Point Algorithm for Linear Optimization Kees Roos e-mail: C.Roos@tudelft.nl URL: http://www.isa.ewi.tudelft.nl/ roos 37th Annual Iranian Mathematics Conference Tabriz,
Enlarging neighborhoods of interior-point algorithms for linear programming via least values of proximity measure functions
 Enlarging neighborhoods of interior-point algorithms for linear programming via least values of proximity measure functions Y B Zhao Abstract It is well known that a wide-neighborhood interior-point algorithm
Enlarging neighborhoods of interior-point algorithms for linear programming via least values of proximity measure functions Y B Zhao Abstract It is well known that a wide-neighborhood interior-point algorithm
Apolynomialtimeinteriorpointmethodforproblemswith nonconvex constraints
 Apolynomialtimeinteriorpointmethodforproblemswith nonconvex constraints Oliver Hinder, Yinyu Ye Department of Management Science and Engineering Stanford University June 28, 2018 The problem I Consider
Apolynomialtimeinteriorpointmethodforproblemswith nonconvex constraints Oliver Hinder, Yinyu Ye Department of Management Science and Engineering Stanford University June 28, 2018 The problem I Consider
Lecture 1. 1 Conic programming. MA 796S: Convex Optimization and Interior Point Methods October 8, Consider the conic program. min.
 MA 796S: Convex Optimization and Interior Point Methods October 8, 2007 Lecture 1 Lecturer: Kartik Sivaramakrishnan Scribe: Kartik Sivaramakrishnan 1 Conic programming Consider the conic program min s.t.
MA 796S: Convex Optimization and Interior Point Methods October 8, 2007 Lecture 1 Lecturer: Kartik Sivaramakrishnan Scribe: Kartik Sivaramakrishnan 1 Conic programming Consider the conic program min s.t.
Advances in Convex Optimization: Theory, Algorithms, and Applications
 Advances in Convex Optimization: Theory, Algorithms, and Applications Stephen Boyd Electrical Engineering Department Stanford University (joint work with Lieven Vandenberghe, UCLA) ISIT 02 ISIT 02 Lausanne
Advances in Convex Optimization: Theory, Algorithms, and Applications Stephen Boyd Electrical Engineering Department Stanford University (joint work with Lieven Vandenberghe, UCLA) ISIT 02 ISIT 02 Lausanne
Newton s Method. Javier Peña Convex Optimization /36-725
 Newton s Method Javier Peña Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, f ( (y) = max y T x f(x) ) x Properties and
Newton s Method Javier Peña Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, f ( (y) = max y T x f(x) ) x Properties and
Convex Optimization. Ofer Meshi. Lecture 6: Lower Bounds Constrained Optimization
 Convex Optimization Ofer Meshi Lecture 6: Lower Bounds Constrained Optimization Lower Bounds Some upper bounds: #iter μ 2 M #iter 2 M #iter L L μ 2 Oracle/ops GD κ log 1/ε M x # ε L # x # L # ε # με f
Convex Optimization Ofer Meshi Lecture 6: Lower Bounds Constrained Optimization Lower Bounds Some upper bounds: #iter μ 2 M #iter 2 M #iter L L μ 2 Oracle/ops GD κ log 1/ε M x # ε L # x # L # ε # με f
An interior-point trust-region polynomial algorithm for convex programming
 An interior-point trust-region polynomial algorithm for convex programming Ye LU and Ya-xiang YUAN Abstract. An interior-point trust-region algorithm is proposed for minimization of a convex quadratic
An interior-point trust-region polynomial algorithm for convex programming Ye LU and Ya-xiang YUAN Abstract. An interior-point trust-region algorithm is proposed for minimization of a convex quadratic
LMI Methods in Optimal and Robust Control
 LMI Methods in Optimal and Robust Control Matthew M. Peet Arizona State University Lecture 02: Optimization (Convex and Otherwise) What is Optimization? An Optimization Problem has 3 parts. x F f(x) :
LMI Methods in Optimal and Robust Control Matthew M. Peet Arizona State University Lecture 02: Optimization (Convex and Otherwise) What is Optimization? An Optimization Problem has 3 parts. x F f(x) :
1 Computing with constraints
 Notes for 2017-04-26 1 Computing with constraints Recall that our basic problem is minimize φ(x) s.t. x Ω where the feasible set Ω is defined by equality and inequality conditions Ω = {x R n : c i (x)
Notes for 2017-04-26 1 Computing with constraints Recall that our basic problem is minimize φ(x) s.t. x Ω where the feasible set Ω is defined by equality and inequality conditions Ω = {x R n : c i (x)
Semidefinite Programming. Yinyu Ye
 Semidefinite Programming Yinyu Ye December 2002 i ii Preface This is a monograph for MS&E 314, Semidefinite Programming, which I am teaching at Stanford. Information, supporting materials, and computer
Semidefinite Programming Yinyu Ye December 2002 i ii Preface This is a monograph for MS&E 314, Semidefinite Programming, which I am teaching at Stanford. Information, supporting materials, and computer
Barrier Method. Javier Peña Convex Optimization /36-725
 Barrier Method Javier Peña Convex Optimization 10-725/36-725 1 Last time: Newton s method For root-finding F (x) = 0 x + = x F (x) 1 F (x) For optimization x f(x) x + = x 2 f(x) 1 f(x) Assume f strongly
Barrier Method Javier Peña Convex Optimization 10-725/36-725 1 Last time: Newton s method For root-finding F (x) = 0 x + = x F (x) 1 F (x) For optimization x f(x) x + = x 2 f(x) 1 f(x) Assume f strongly
Following The Central Trajectory Using The Monomial Method Rather Than Newton's Method
 Following The Central Trajectory Using The Monomial Method Rather Than Newton's Method Yi-Chih Hsieh and Dennis L. Bricer Department of Industrial Engineering The University of Iowa Iowa City, IA 52242
Following The Central Trajectory Using The Monomial Method Rather Than Newton's Method Yi-Chih Hsieh and Dennis L. Bricer Department of Industrial Engineering The University of Iowa Iowa City, IA 52242
Conic Linear Programming. Yinyu Ye
 Conic Linear Programming Yinyu Ye December 2004, revised January 2015 i ii Preface This monograph is developed for MS&E 314, Conic Linear Programming, which I am teaching at Stanford. Information, lecture
Conic Linear Programming Yinyu Ye December 2004, revised January 2015 i ii Preface This monograph is developed for MS&E 314, Conic Linear Programming, which I am teaching at Stanford. Information, lecture
Interior Point Methods for Convex Quadratic and Convex Nonlinear Programming
 School of Mathematics T H E U N I V E R S I T Y O H F E D I N B U R G Interior Point Methods for Convex Quadratic and Convex Nonlinear Programming Jacek Gondzio Email: J.Gondzio@ed.ac.uk URL: http://www.maths.ed.ac.uk/~gondzio
School of Mathematics T H E U N I V E R S I T Y O H F E D I N B U R G Interior Point Methods for Convex Quadratic and Convex Nonlinear Programming Jacek Gondzio Email: J.Gondzio@ed.ac.uk URL: http://www.maths.ed.ac.uk/~gondzio
CONSTRAINED NONLINEAR PROGRAMMING
 149 CONSTRAINED NONLINEAR PROGRAMMING We now turn to methods for general constrained nonlinear programming. These may be broadly classified into two categories: 1. TRANSFORMATION METHODS: In this approach
149 CONSTRAINED NONLINEAR PROGRAMMING We now turn to methods for general constrained nonlinear programming. These may be broadly classified into two categories: 1. TRANSFORMATION METHODS: In this approach
A QUADRATIC CONE RELAXATION-BASED ALGORITHM FOR LINEAR PROGRAMMING
 A QUADRATIC CONE RELAXATION-BASED ALGORITHM FOR LINEAR PROGRAMMING A Dissertation Presented to the Faculty of the Graduate School of Cornell University in Partial Fulfillment of the Requirements for the
A QUADRATIC CONE RELAXATION-BASED ALGORITHM FOR LINEAR PROGRAMMING A Dissertation Presented to the Faculty of the Graduate School of Cornell University in Partial Fulfillment of the Requirements for the
Constrained Optimization
 1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange
1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange
Motivating examples Introduction to algorithms Simplex algorithm. On a particular example General algorithm. Duality An application to game theory
 Instructor: Shengyu Zhang 1 LP Motivating examples Introduction to algorithms Simplex algorithm On a particular example General algorithm Duality An application to game theory 2 Example 1: profit maximization
Instructor: Shengyu Zhang 1 LP Motivating examples Introduction to algorithms Simplex algorithm On a particular example General algorithm Duality An application to game theory 2 Example 1: profit maximization
CSCI 1951-G Optimization Methods in Finance Part 09: Interior Point Methods
 CSCI 1951-G Optimization Methods in Finance Part 09: Interior Point Methods March 23, 2018 1 / 35 This material is covered in S. Boyd, L. Vandenberge s book Convex Optimization https://web.stanford.edu/~boyd/cvxbook/.
CSCI 1951-G Optimization Methods in Finance Part 09: Interior Point Methods March 23, 2018 1 / 35 This material is covered in S. Boyd, L. Vandenberge s book Convex Optimization https://web.stanford.edu/~boyd/cvxbook/.
MATH 4211/6211 Optimization Basics of Optimization Problems
 MATH 4211/6211 Optimization Basics of Optimization Problems Xiaojing Ye Department of Mathematics & Statistics Georgia State University Xiaojing Ye, Math & Stat, Georgia State University 0 A standard minimization
MATH 4211/6211 Optimization Basics of Optimization Problems Xiaojing Ye Department of Mathematics & Statistics Georgia State University Xiaojing Ye, Math & Stat, Georgia State University 0 A standard minimization
Lecture 15: October 15
 10-725: Optimization Fall 2012 Lecturer: Barnabas Poczos Lecture 15: October 15 Scribes: Christian Kroer, Fanyi Xiao Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These notes have
10-725: Optimization Fall 2012 Lecturer: Barnabas Poczos Lecture 15: October 15 Scribes: Christian Kroer, Fanyi Xiao Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These notes have
Interior-point methods Optimization Geoff Gordon Ryan Tibshirani
 Interior-point methods 10-725 Optimization Geoff Gordon Ryan Tibshirani SVM duality Review min v T v/2 + 1 T s s.t. Av yd + s 1 0 s 0 max 1 T α α T Kα/2 s.t. y T α = 0 0 α 1 Gram matrix K Interpretation
Interior-point methods 10-725 Optimization Geoff Gordon Ryan Tibshirani SVM duality Review min v T v/2 + 1 T s s.t. Av yd + s 1 0 s 0 max 1 T α α T Kα/2 s.t. y T α = 0 0 α 1 Gram matrix K Interpretation
Optimization. Escuela de Ingeniería Informática de Oviedo. (Dpto. de Matemáticas-UniOvi) Numerical Computation Optimization 1 / 30
 Numerical Computation Optimization 1 / 30") Optimization Escuela de Ingeniería Informática de Oviedo (Dpto. de Matemáticas-UniOvi) Numerical Computation Optimization 1 / 30 Unconstrained optimization Outline 1 Unconstrained optimization 2 Constrained
Optimization Escuela de Ingeniería Informática de Oviedo (Dpto. de Matemáticas-UniOvi) Numerical Computation Optimization 1 / 30 Unconstrained optimization Outline 1 Unconstrained optimization 2 Constrained
A PREDICTOR-CORRECTOR PATH-FOLLOWING ALGORITHM FOR SYMMETRIC OPTIMIZATION BASED ON DARVAY'S TECHNIQUE
 Yugoslav Journal of Operations Research 24 (2014) Number 1, 35-51 DOI: 10.2298/YJOR120904016K A PREDICTOR-CORRECTOR PATH-FOLLOWING ALGORITHM FOR SYMMETRIC OPTIMIZATION BASED ON DARVAY'S TECHNIQUE BEHROUZ
Yugoslav Journal of Operations Research 24 (2014) Number 1, 35-51 DOI: 10.2298/YJOR120904016K A PREDICTOR-CORRECTOR PATH-FOLLOWING ALGORITHM FOR SYMMETRIC OPTIMIZATION BASED ON DARVAY'S TECHNIQUE BEHROUZ
AM 205: lecture 19. Last time: Conditions for optimality, Newton s method for optimization Today: survey of optimization methods
 AM 205: lecture 19 Last time: Conditions for optimality, Newton s method for optimization Today: survey of optimization methods Quasi-Newton Methods General form of quasi-newton methods: x k+1 = x k α
AM 205: lecture 19 Last time: Conditions for optimality, Newton s method for optimization Today: survey of optimization methods Quasi-Newton Methods General form of quasi-newton methods: x k+1 = x k α
Scientific Computing: Optimization
 Scientific Computing: Optimization Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 Course MATH-GA.2043 or CSCI-GA.2112, Spring 2012 March 8th, 2011 A. Donev (Courant Institute) Lecture
Scientific Computing: Optimization Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 Course MATH-GA.2043 or CSCI-GA.2112, Spring 2012 March 8th, 2011 A. Donev (Courant Institute) Lecture
10-725/ Optimization Midterm Exam
 10-725/36-725 Optimization Midterm Exam November 6, 2012 NAME: ANDREW ID: Instructions: This exam is 1hr 20mins long Except for a single two-sided sheet of notes, no other material or discussion is permitted
10-725/36-725 Optimization Midterm Exam November 6, 2012 NAME: ANDREW ID: Instructions: This exam is 1hr 20mins long Except for a single two-sided sheet of notes, no other material or discussion is permitted
Curvature as a Complexity Bound in Interior-Point Methods
 Lehigh University Lehigh Preserve Theses and Dissertations 2014 Curvature as a Complexity Bound in Interior-Point Methods Murat Mut Lehigh University Follow this and additional works at: http://preserve.lehigh.edu/etd
Lehigh University Lehigh Preserve Theses and Dissertations 2014 Curvature as a Complexity Bound in Interior-Point Methods Murat Mut Lehigh University Follow this and additional works at: http://preserve.lehigh.edu/etd
Chapter 6 Interior-Point Approach to Linear Programming
 Chapter 6 Interior-Point Approach to Linear Programming Objectives: Introduce Basic Ideas of Interior-Point Methods. Motivate further research and applications. Slide#1 Linear Programming Problem Minimize
Chapter 6 Interior-Point Approach to Linear Programming Objectives: Introduce Basic Ideas of Interior-Point Methods. Motivate further research and applications. Slide#1 Linear Programming Problem Minimize
An E cient A ne-scaling Algorithm for Hyperbolic Programming
 An E cient A ne-scaling Algorithm for Hyperbolic Programming Jim Renegar joint work with Mutiara Sondjaja 1 Euclidean space A homogeneous polynomial p : E!R is hyperbolic if there is a vector e 2E such
An E cient A ne-scaling Algorithm for Hyperbolic Programming Jim Renegar joint work with Mutiara Sondjaja 1 Euclidean space A homogeneous polynomial p : E!R is hyperbolic if there is a vector e 2E such
Examination paper for TMA4180 Optimization I
 Department of Mathematical Sciences Examination paper for TMA4180 Optimization I Academic contact during examination: Phone: Examination date: 26th May 2016 Examination time (from to): 09:00 13:00 Permitted
Department of Mathematical Sciences Examination paper for TMA4180 Optimization I Academic contact during examination: Phone: Examination date: 26th May 2016 Examination time (from to): 09:00 13:00 Permitted
Linear programming II
 Linear programming II Review: LP problem 1/33 The standard form of LP problem is (primal problem): max z = cx s.t. Ax b, x 0 The corresponding dual problem is: min b T y s.t. A T y c T, y 0 Strong Duality
Linear programming II Review: LP problem 1/33 The standard form of LP problem is (primal problem): max z = cx s.t. Ax b, x 0 The corresponding dual problem is: min b T y s.t. A T y c T, y 0 Strong Duality
AM 205: lecture 19. Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods
 AM 205: lecture 19 Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods Optimality Conditions: Equality Constrained Case As another example of equality
AM 205: lecture 19 Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods Optimality Conditions: Equality Constrained Case As another example of equality
A new primal-dual path-following method for convex quadratic programming
 Volume 5, N., pp. 97 0, 006 Copyright 006 SBMAC ISSN 00-805 www.scielo.br/cam A new primal-dual path-following method for convex quadratic programming MOHAMED ACHACHE Département de Mathématiques, Faculté
Volume 5, N., pp. 97 0, 006 Copyright 006 SBMAC ISSN 00-805 www.scielo.br/cam A new primal-dual path-following method for convex quadratic programming MOHAMED ACHACHE Département de Mathématiques, Faculté
Midterm Review. Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A.
 Midterm Review Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye (LY, Chapter 1-4, Appendices) 1 Separating hyperplane
Midterm Review Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye (LY, Chapter 1-4, Appendices) 1 Separating hyperplane
Introduction and Math Preliminaries
 Introduction and Math Preliminaries Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Appendices A, B, and C, Chapter
Introduction and Math Preliminaries Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Appendices A, B, and C, Chapter
Lecture: Algorithms for LP, SOCP and SDP
 1/53 Lecture: Algorithms for LP, SOCP and SDP Zaiwen Wen Beijing International Center For Mathematical Research Peking University http://bicmr.pku.edu.cn/~wenzw/bigdata2018.html wenzw@pku.edu.cn Acknowledgement:
1/53 Lecture: Algorithms for LP, SOCP and SDP Zaiwen Wen Beijing International Center For Mathematical Research Peking University http://bicmr.pku.edu.cn/~wenzw/bigdata2018.html wenzw@pku.edu.cn Acknowledgement:
Primal-dual IPM with Asymmetric Barrier
 Primal-dual IPM with Asymmetric Barrier Yurii Nesterov, CORE/INMA (UCL) September 29, 2008 (IFOR, ETHZ) Yu. Nesterov Primal-dual IPM with Asymmetric Barrier 1/28 Outline 1 Symmetric and asymmetric barriers
Primal-dual IPM with Asymmetric Barrier Yurii Nesterov, CORE/INMA (UCL) September 29, 2008 (IFOR, ETHZ) Yu. Nesterov Primal-dual IPM with Asymmetric Barrier 1/28 Outline 1 Symmetric and asymmetric barriers
Primal-Dual Interior-Point Methods
 Primal-Dual Interior-Point Methods Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 Outline Today: Primal-dual interior-point method Special case: linear programming
Primal-Dual Interior-Point Methods Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 Outline Today: Primal-dual interior-point method Special case: linear programming