CS 6120/CS4120: Natural Language Processing
|
|
|
- Hope Preston
- 5 years ago
- Views:
Transcription
1 CS 6120/CS4120: Natural Language Processing Instructor: Prof. Lu Wang College of Computer and Information Science Northeastern University Webpage:
2 Outline Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing [Modified from Dan Jurafsky s slides]
3 Probabilistic Language Models Assign a probability to a sentence Machine Translation: P(high winds tonight) > P(large winds tonight) Spell Correction The office is about fifteen minuets from my house P(about fifteen minutes from) > P(about fifteen minuets from) Speech Recognition P(I saw a van) >> P(eyes awe of an) Text Generation in general: Summarization, question-answering
4 Probabilistic Language Modeling Goal: compute the probability of a sentence or sequence of words: P(W) = P(w 1,w 2,w 3,w 4,w 5 w n ) Related task: probability of an upcoming word: P(w 5 w 1,w 2,w 3,w 4 ) A model that computes either of these: P(W) or P(w n w 1,w 2 w n-1 ) is called a language model. Better: the grammar But language model (or LM) is standard
5 How to compute P(W) How to compute this joint probability: P(its, water, is, so, transparent, that) Intuition: let s rely on the Chain Rule of Probability
6 Quick Review: Probability Recall the definition of conditional probabilities p(b A) = P(A,B)/P(A) Rewriting: P(A,B) = P(A)P(B A) More variables: P(A,B,C,D) = P(A)P(B A)P(C A,B)P(D A,B,C) The Chain Rule in General P(x 1,x 2,x 3,,x n ) = P(x 1 )P(x 2 x 1 )P(x 3 x 1,x 2 ) P(x n x 1,,x n-1 )
7 The Chain Rule applied to compute joint probability of words in sentence i P(w 1 w 2 w n ) = P(w i w 1 w 2 w i 1 )
8 The Chain Rule applied to compute joint probability of words in sentence i P(w 1 w 2 w n ) = P(w i w 1 w 2 w i 1 ) P( its water is so transparent ) = P(its) P(water its) P(is its water) P(so its water is) P(transparent its water is so)
9 How to estimate these probabilities Could we just count and divide? P(the its water is so transparent that) = Count(its water is so transparent that the) Count(its water is so transparent that)
10 How to estimate these probabilities Could we just count and divide? P(the its water is so transparent that) = Count(its water is so transparent that the) Count(its water is so transparent that) No! Too many possible sentences! We ll never see enough data for estimating these
11 Markov Assumption Simplifying assumption: P(the its water is so transparent that) P(the that) Or maybe P(the its water is so transparent that) P(the transparent that)
12 Markov Assumption i P(w 1 w 2 w n ) P(w i w i k w i 1 ) In other words, we approximate each component in the product P(w i w 1 w 2 w i 1 ) P(w i w i k w i 1 )
13 Simplest case: Unigram model P(w 1 w 2 w n ) P(w i ) Some automatically generated sentences from a unigram model fifth, an, of, futures, the, an, incorporated, a, a, the, inflation, most, dollars, quarter, in, is, mass thrift, did, eighty, said, hard, 'm, july, bullish that, or, limited, the i
14 Bigram model Condition on the previous word: P(w i w 1 w 2 w i 1 ) P(w i w i 1 ) texaco, rose, one, in, this, issue, is, pursuing, growth, in, a, boiler, house, said, mr., gurria, mexico, 's, motion, control, proposal, without, permission, from, five, hundred, fifty, five, yen outside, new, car, parking, lot, of, the, agreement, reached this, would, be, a, record, november
15 N-gram models We can extend to trigrams, 4-grams, 5-grams
16 N-gram models We can extend to trigrams, 4-grams, 5-grams In general this is an insufficient model of language because language has long-distance dependencies: The computer(s) which I had just put into the machine room on the fifth floor is (are) crashing. But we can often get away with N-gram models
17 Today s Outline Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing
18 Estimating bigram probabilities The Maximum Likelihood Estimate for bigram probability P(w i w i 1 ) = count(w i 1,w i ) count(w i 1 ) P(w i w i 1 ) = c(w i 1,w i ) c(w i 1 )
19 An example P(w i w i 1 ) = c(w i 1,w i ) c(w i 1 ) <s> I am Sam </s> <s> Sam I am </s> <s> I do not like green eggs and ham </s>
20 An example P(w i w i 1 ) = c(w i 1,w i ) c(w i 1 ) <s> I am Sam </s> <s> Sam I am </s> <s> I do not like green eggs and ham </s>
21 More examples: Berkeley Restaurant Project sentences can you tell me about any good cantonese restaurants close by mid priced thai food is what i m looking for tell me about chez panisse can you give me a listing of the kinds of food that are available i m looking for a good place to eat breakfast when is caffe venezia open during the day
22 Raw bigram counts Out of 9222 sentences
23 Raw bigram probabilities Normalize by unigrams: Result:
24 Bigram estimates of sentence probabilities P(<s> I want english food </s>) = P(I <s>) P(want I) P(english want) P(food english) P(</s> food) =
25 Knowledge P(english want) =.0011 P(chinese want) =.0065 P(to want) =.66 P(eat to) =.28 P(food to) = 0 P(want spend) = 0 P (i <s>) =.25
26 Practical Issues We do everything in log space Avoid underflow (also adding is faster than multiplying) log(p 1 p 2 p 3 p 4 ) = log p 1 + log p 2 + log p 3 + log p 4
27 Language Modeling Toolkits SRILM
28 Google N-Gram Release, August 2006
29 Google N-Gram Release serve as the incoming 92 serve as the incubator 99 serve as the independent 794 serve as the index 223 serve as the indication 72 serve as the indicator 120 serve as the indicators 45 serve as the indispensable 111 serve as the indispensible 40 serve as the individual 234
30 Today s Outline Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing
31 Evaluation: How good is our model?
32 Evaluation: How good is our model? Does our language model prefer good sentences to bad ones? Assign higher probability to real or frequently observed sentences Than ungrammatical or rarely observed sentences? We train parameters of our model on a training set. We test the model s performance on data we haven t seen. A test set is an unseen dataset that is different from our training set, totally unused. An evaluation metric tells us how well our model does on the test set.
33 Training on the test set We can t allow test sentences into the training set We will assign it an artificially high probability when we set it in the test set Training on the test set Bad science! And violates the honor code
34 Extrinsic evaluation of N-gram models Best evaluation for comparing models A and B Put each model in a task spelling corrector, speech recognizer, MT system Run the task, get an accuracy for A and for B How many misspelled words corrected properly How many words translated correctly Compare accuracy for A and B
35 Difficulty of extrinsic evaluation of N-gram models Extrinsic evaluation Time-consuming; can take days or weeks So Sometimes use intrinsic evaluation: perplexity
36 Difficulty of extrinsic evaluation of N-gram models Extrinsic evaluation Time-consuming; can take days or weeks So Sometimes use intrinsic evaluation: perplexity Bad approximation unless the test data looks just like the training data So generally only useful in pilot experiments But is helpful to think about.
37 Intuition of Perplexity The Shannon Game: How well can we predict the next word? I always order pizza with cheese and The 33 rd President of the US was I saw a Unigrams are terrible at this game. (Why?) A better model of a text is one which assigns a higher probability to the word that actually occurs
38 Intuition of Perplexity The Shannon Game: How well can we predict the next word? I always order pizza with cheese and The 33 rd President of the US was I saw a Unigrams are terrible at this game. (Why?) mushrooms 0.1 pepperoni 0.1 anchovies 0.01 A better model of a text is one which assigns a higher probability to the word that actually occurs. fried rice and 1e-100
39 Perplexity The best language model is one that best predicts an unseen test set Gives the highest P(sentence) Perplexity is the inverse probability of the test set, normalized by the number of words: PP(W ) = P(w 1 w 2...w N ) 1 N = N 1 P(w 1 w 2...w N )
40 Perplexity The best language model is one that best predicts an unseen test set Gives the highest P(sentence) Perplexity is the inverse probability of the test set, normalized by the number of words: Chain rule: PP(W ) = P(w 1 w 2...w N ) 1 N = N 1 P(w 1 w 2...w N ) For bigrams:
41 Perplexity The best language model is one that best predicts an unseen test set Gives the highest P(sentence) Perplexity is the inverse probability of the test set, normalized by the number of words: Chain rule: PP(W ) = P(w 1 w 2...w N ) 1 N = N 1 P(w 1 w 2...w N ) For bigrams: Minimizing perplexity is the same as maximizing probability
42 Perplexity as branching factor Let s suppose a sentence consisting of random digits What is the perplexity of this sentence according to a model that assign P=1/10 to each digit?
43 Perplexity as branching factor Let s suppose a sentence consisting of random digits What is the perplexity of this sentence according to a model that assign P=1/10 to each digit?
44 Lower perplexity = better model Training 38 million words, test 1.5 million words, WSJ N-gram Order Unigram Bigram Trigram Perplexity
45 Today s Outline Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing
46 The perils of overfitting N-grams only work well for word prediction if the test corpus looks like the training corpus In real life, it often doesn t We need to train robust models that generalize!
47 The perils of overfitting N-grams only work well for word prediction if the test corpus looks like the training corpus In real life, it often doesn t We need to train robust models that generalize! One kind of generalization: Zeros! Things that don t ever occur in the training set But occur in the test set
48 Zeros In training set, we see denied the allegations denied the reports denied the claims denied the request But in test set, denied the offer denied the loan P( offer denied the) = 0
49 Zero probability bigrams Bigrams with zero probability mean that we will assign 0 probability to the test set! And hence we cannot compute perplexity (can t divide by 0)!
50 Today s Outline Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing
51 The intuition of smoothing (from Dan Klein) When we have sparse statistics: P(w denied the) 3 allegations 2 reports 1 claims 1 request 7 total allegations reports claims request attack man outcome Steal probability mass to generalize better P(w denied the) 2.5 allegations 1.5 reports 0.5 claims 0.5 request 2 other 7 total allegations reports claims request attack man outcome
52 Add-one estimation Also called Laplace smoothing Pretend we saw each word one more time than we did Just add one to all the counts! (Instead of taking away counts) P MLE estimate: MLE (w i w i 1 ) = c(w, w ) i 1 i c(w i 1 ) Add-1 estimate: P Add 1 (w i w i 1 ) = c(w i 1, w i )+1 c(w i 1 )+V
53 Add-one estimation Also called Laplace smoothing Pretend we saw each word one more time than we did Just add one to all the counts! MLE estimate: Add-1 estimate: P MLE (w i w i 1 ) = c(w i 1, w i ) c(w i 1 ) P Add 1 (w i w i 1 ) = c(w i 1, w i )+1 c(w i 1 )+V Why add V?
54 Berkeley Restaurant Corpus: Laplace smoothed bigram counts
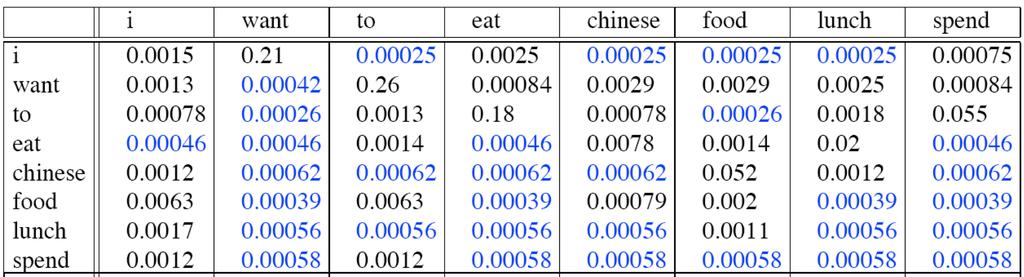
55 Laplace-smoothed bigrams
56 Add-1 estimation is a blunt instrument So add-1 isn t used for N-grams: We ll see better methods (nowadays, neural LM becomes popular, will discuss later) But add-1 is used to smooth other NLP models For text classification (coming soon!) In domains where the number of zeros isn t so huge.
57 Today s Outline Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing
58 Backoff and Interpolation Sometimes it helps to use less context Condition on less context for contexts you haven t learned much about Backoff: use trigram if you have good evidence otherwise bigram otherwise unigram Interpolation: mix unigram, bigram, trigram In general, interpolation works better
59 Linear Interpolation Simple interpolation ˆP(w n w n 2 w n 1 ) = l 1 P(w n w n 2 w n 1 ) +l 2 P(w n w n 1 ) +l 3 P(w n ) X l i = 1 i X
60 How to set the lambdas? Use a held-out corpus Held-Out Test Training Data Data Data Choose λs to maximize the probability of held-out data: Fix the N-gram probabilities (on the training data) Then search for λs that give largest probability to held-out set: log P(w 1...w n M(λ 1...λ k )) = log P M (λ1...λ k )(w i w i 1 ) i
61 A Common Method Grid Search Take a list of possible values, e.g. [0.1, 0.2,,0.9] Try all combinations
62 Linear Interpolation Simple interpolation ˆP(w n w n 2 w n 1 ) = l 1 P(w n w n 2 w n 1 ) +l 2 P(w n w n 1 ) +l 3 P(w n ) Lambdas conditional on context: X X l i = 1 i
63 Linear Interpolation Simple interpolation ˆP(w n w n 2 w n 1 ) = l 1 P(w n w n 2 w n 1 ) +l 2 P(w n w n 1 ) +l 3 P(w n ) Lambdas conditional on context: X X l i = 1 i How to estimate?
64 Unknown words: Open versus closed vocabulary tasks If we know all the words in advanced Vocabulary V is fixed Closed vocabulary task Often we don t know this Out Of Vocabulary = OOV words Open vocabulary task
65 Unknown words: Open versus closed vocabulary tasks If we know all the words in advanced Vocabulary V is fixed Closed vocabulary task Often we don t know this Out Of Vocabulary = OOV words Open vocabulary task Instead: create an unknown word token <UNK> Training of <UNK> probabilities Create a fixed lexicon L of size V (e.g. selecting high frequency words) At text normalization phase, any training word not in L changed to <UNK> Now we train its probabilities like a normal word At test time If text input: Use UNK probabilities for any word not in training
66 Smoothing for Web-scale N-grams Stupid backoff (Brants et al. 2007) No discounting, just use relative frequencies i 1 S(w i w i k+1 ) = " $ # $ % $ i count(w i k+1 i 1 count(w i k+1 ) ) i 1 0.4S(w i w i k+2 i if count(w i k+1 ) > 0 ) otherwise S(w i ) = count(w i) N Until unigram probability
67 Today s Outline Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing
68 Absolute discounting: just subtract a little from each count Suppose we wanted to subtract a little from a count of 4 to save probability mass for the zeros How much to subtract? Church and Gale (1991) s clever idea Divide up 22 million words of AP Newswire Training and held-out set for each bigram in the training set see the actual count in the held-out set! It sure looks like c* = (c -.75) Bigram count Bigram count in in training heldout set
69 Absolute Discounting Interpolation Save ourselves some time and just subtract 0.75 (or some d)! discounted bigram P AbsoluteDiscounting (w i w i 1 ) = c(w i 1, w i ) d c(w i 1 ) Interpolation weight + λ(w i 1 )P(w) unigram But should we really just use the regular unigram P(w)?
70 Kneser-Ney Smoothing I Better estimate for probabilities of lower-order unigrams! Shannon game: I can t see without my reading? Francisco is more common than glasses but Francisco always follows San The unigram is useful exactly when we haven t seen this bigram! Instead of P(w): How likely is w glasses Francisco P continuation (w): How likely is w to appear as a novel continuation? For each word, count the number of unique bigrams it completes Every unique bigram was a novel continuation the first time it was seen P CONTINUATION (w) {w i 1 : c(w i 1, w) > 0} Unique bigrams w is in
71 Kneser-Ney Smoothing II How many times does w appear as a novel continuation (unique bigrams): P CONTINUATION (w) {w i 1 : c(w i 1, w) > 0} Normalized by the total number of word bigram types {(w j 1, w j ) : c(w j 1, w j ) > 0} All unique bigrams in the corpus P CONTINUATION (w) = {w i 1 : c(w i 1, w) > 0} {(w j 1, w j ) : c(w j 1, w j ) > 0}
72 Kneser-Ney Smoothing III Alternative metaphor: The number of # of unique words seen to precede w normalized by the # of words preceding all words: P CONTINUATION (w) = {w i 1 : c(w i 1, w) > 0} w' {w i 1 : c(w i 1, w) > 0} {w' i 1 : c(w' i 1, w') > 0} A frequent word (Francisco) occurring in only one context (San) will have a low continuation probability
73 Kneser-Ney Smoothing IV P KN (w i w i 1 ) = max(c(w i 1, w i ) d, 0) c(w i 1 ) + λ(w i 1 )P CONTINUATION (w i ) λ is a normalizing constant; the probability mass we ve discounted λ(w i 1 ) = d c(w i 1 ) {w : c(w i 1, w) > 0} the normalized discount The number of word types that can follow w i-1 = # of word types we discounted = # of times we applied normalized discount
74 Kneser-Ney Smoothing: Recursive formulation i 1 P KN (w i w i n+1 ) = max(c i KN (w i n+1 i 1 c KN (w i n+1 ) d, 0) ) i 1 i 1 + λ(w i n+1 )P KN (w i w i n+2 ) c KN ( ) =!# " $# count( ) for the highest order continuationcount( ) for lower order Continuation count = Number of unique single word contexts for
75 Language Modeling Probabilistic language model and n-grams Estimating n-gram probabilities Language model evaluation and perplexity Generalization and zeros Smoothing: add-one Interpolation, backoff, and web-scale LMs Smoothing: Kneser-Ney Smoothing
76 Homework Reading J&M ch1 and ch Start thinking about course project and find a team Project proposal due Oct 1 st The format of the proposal will be posted on Piazza
Language Modeling. Introduction to N-grams. Many Slides are adapted from slides by Dan Jurafsky
 Language Modeling Introduction to N-grams Many Slides are adapted from slides by Dan Jurafsky Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation: P(high
Language Modeling Introduction to N-grams Many Slides are adapted from slides by Dan Jurafsky Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation: P(high
Language Modeling. Introduction to N-grams. Many Slides are adapted from slides by Dan Jurafsky
 Language Modeling Introduction to N-grams Many Slides are adapted from slides by Dan Jurafsky Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation: P(high
Language Modeling Introduction to N-grams Many Slides are adapted from slides by Dan Jurafsky Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation: P(high
Language Modeling. Introduction to N-grams. Klinton Bicknell. (borrowing from: Dan Jurafsky and Jim Martin)
") Language Modeling Introduction to N-grams Klinton Bicknell (borrowing from: Dan Jurafsky and Jim Martin) Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation:
Language Modeling Introduction to N-grams Klinton Bicknell (borrowing from: Dan Jurafsky and Jim Martin) Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation:
CS 6120/CS4120: Natural Language Processing
 CS 6120/CS4120: Natural Language Processing Instructor: Prof. Lu Wang College of Computer and Information Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Today s Outline Probabilistic
CS 6120/CS4120: Natural Language Processing Instructor: Prof. Lu Wang College of Computer and Information Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Today s Outline Probabilistic
Language Modeling. Introduc*on to N- grams. Many Slides are adapted from slides by Dan Jurafsky
 Language Modeling Introduc*on to N- grams Many Slides are adapted from slides by Dan Jurafsky Probabilis1c Language Models Today s goal: assign a probability to a sentence Machine Transla*on: Why? P(high
Language Modeling Introduc*on to N- grams Many Slides are adapted from slides by Dan Jurafsky Probabilis1c Language Models Today s goal: assign a probability to a sentence Machine Transla*on: Why? P(high
Language Modeling. Introduction to N- grams
 Language Modeling Introduction to N- grams Probabilistic Language Models Today s goal: assign a probability to a sentence Machine Translation: P(high winds tonite) > P(large winds tonite) Why? Spell Correction
Language Modeling Introduction to N- grams Probabilistic Language Models Today s goal: assign a probability to a sentence Machine Translation: P(high winds tonite) > P(large winds tonite) Why? Spell Correction
Language Modeling. Introduction to N- grams
 Language Modeling Introduction to N- grams Probabilistic Language Models Today s goal: assign a probability to a sentence Machine Translation: P(high winds tonite) > P(large winds tonite) Why? Spell Correction
Language Modeling Introduction to N- grams Probabilistic Language Models Today s goal: assign a probability to a sentence Machine Translation: P(high winds tonite) > P(large winds tonite) Why? Spell Correction
Introduction to N-grams
 Lecture Notes, Artificial Intelligence Course, University of Birzeit, Palestine Spring Semester, 2014 (Advanced/) Artificial Intelligence Probabilistic Language Modeling Introduction to N-grams Dr. Mustafa
Lecture Notes, Artificial Intelligence Course, University of Birzeit, Palestine Spring Semester, 2014 (Advanced/) Artificial Intelligence Probabilistic Language Modeling Introduction to N-grams Dr. Mustafa
Language Modeling. Introduc*on to N- grams. Many Slides are adapted from slides by Dan Jurafsky
 Language Modeling Introduc*on to N- grams Many Slides are adapted from slides by Dan Jurafsky Probabilis1c Language Models Today s goal: assign a probability to a sentence Machine Transla*on: Why? P(high
Language Modeling Introduc*on to N- grams Many Slides are adapted from slides by Dan Jurafsky Probabilis1c Language Models Today s goal: assign a probability to a sentence Machine Transla*on: Why? P(high
language modeling: n-gram models
 language modeling: n-gram models CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
language modeling: n-gram models CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Ngram Review. CS 136 Lecture 10 Language Modeling. Thanks to Dan Jurafsky for these slides. October13, 2017 Professor Meteer
 + Ngram Review October13, 2017 Professor Meteer CS 136 Lecture 10 Language Modeling Thanks to Dan Jurafsky for these slides + ASR components n Feature Extraction, MFCCs, start of Acoustic n HMMs, the Forward
+ Ngram Review October13, 2017 Professor Meteer CS 136 Lecture 10 Language Modeling Thanks to Dan Jurafsky for these slides + ASR components n Feature Extraction, MFCCs, start of Acoustic n HMMs, the Forward
Language Model. Introduction to N-grams
 Language Model Introduction to N-grams Probabilistic Language Model Goal: assign a probability to a sentence Application: Machine Translation P(high winds tonight) > P(large winds tonight) Spelling Correction
Language Model Introduction to N-grams Probabilistic Language Model Goal: assign a probability to a sentence Application: Machine Translation P(high winds tonight) > P(large winds tonight) Spelling Correction
Machine Learning for natural language processing
 Machine Learning for natural language processing N-grams and language models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 25 Introduction Goals: Estimate the probability that a
Machine Learning for natural language processing N-grams and language models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 25 Introduction Goals: Estimate the probability that a
CSCI 5832 Natural Language Processing. Today 1/31. Probability Basics. Lecture 6. Probability. Language Modeling (N-grams)
") CSCI 5832 Natural Language Processing Jim Martin Lecture 6 1 Today 1/31 Probability Basic probability Conditional probability Bayes Rule Language Modeling (N-grams) N-gram Intro The Chain Rule Smoothing:
CSCI 5832 Natural Language Processing Jim Martin Lecture 6 1 Today 1/31 Probability Basic probability Conditional probability Bayes Rule Language Modeling (N-grams) N-gram Intro The Chain Rule Smoothing:
Foundations of Natural Language Processing Lecture 5 More smoothing and the Noisy Channel Model
 Foundations of Natural Language Processing Lecture 5 More smoothing and the Noisy Channel Model Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipop Koehn) 30 January
Foundations of Natural Language Processing Lecture 5 More smoothing and the Noisy Channel Model Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipop Koehn) 30 January
Empirical Methods in Natural Language Processing Lecture 10a More smoothing and the Noisy Channel Model
 Empirical Methods in Natural Language Processing Lecture 10a More smoothing and the Noisy Channel Model (most slides from Sharon Goldwater; some adapted from Philipp Koehn) 5 October 2016 Nathan Schneider
Empirical Methods in Natural Language Processing Lecture 10a More smoothing and the Noisy Channel Model (most slides from Sharon Goldwater; some adapted from Philipp Koehn) 5 October 2016 Nathan Schneider
Natural Language Processing. Statistical Inference: n-grams
 Natural Language Processing Statistical Inference: n-grams Updated 3/2009 Statistical Inference Statistical Inference consists of taking some data (generated in accordance with some unknown probability
Natural Language Processing Statistical Inference: n-grams Updated 3/2009 Statistical Inference Statistical Inference consists of taking some data (generated in accordance with some unknown probability
N-grams. Motivation. Simple n-grams. Smoothing. Backoff. N-grams L545. Dept. of Linguistics, Indiana University Spring / 24
 L545 Dept. of Linguistics, Indiana University Spring 2013 1 / 24 Morphosyntax We just finished talking about morphology (cf. words) And pretty soon we re going to discuss syntax (cf. sentences) In between,
L545 Dept. of Linguistics, Indiana University Spring 2013 1 / 24 Morphosyntax We just finished talking about morphology (cf. words) And pretty soon we re going to discuss syntax (cf. sentences) In between,
We have a sitting situation
 We have a sitting situation 447 enrollment: 67 out of 64 547 enrollment: 10 out of 10 2 special approved cases for audits ---------------------------------------- 67 + 10 + 2 = 79 students in the class!
We have a sitting situation 447 enrollment: 67 out of 64 547 enrollment: 10 out of 10 2 special approved cases for audits ---------------------------------------- 67 + 10 + 2 = 79 students in the class!
Recap: Language models. Foundations of Natural Language Processing Lecture 4 Language Models: Evaluation and Smoothing. Two types of evaluation in NLP
 Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
Natural Language Processing SoSe Language Modelling. (based on the slides of Dr. Saeedeh Momtazi)
") Natural Language Processing SoSe 2015 Language Modelling Dr. Mariana Neves April 20th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Motivation Estimation Evaluation Smoothing Outline 3 Motivation
Natural Language Processing SoSe 2015 Language Modelling Dr. Mariana Neves April 20th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Motivation Estimation Evaluation Smoothing Outline 3 Motivation
NLP: N-Grams. Dan Garrette December 27, Predictive text (text messaging clients, search engines, etc)
") NLP: N-Grams Dan Garrette dhg@cs.utexas.edu December 27, 2013 1 Language Modeling Tasks Language idenfication / Authorship identification Machine Translation Speech recognition Optical character recognition
NLP: N-Grams Dan Garrette dhg@cs.utexas.edu December 27, 2013 1 Language Modeling Tasks Language idenfication / Authorship identification Machine Translation Speech recognition Optical character recognition
perplexity = 2 cross-entropy (5.1) cross-entropy = 1 N log 2 likelihood (5.2) likelihood = P(w 1 w N ) (5.3)
 cross-entropy = 1 N log 2 likelihood (5.2) likelihood = P(w 1 w N ) (5.3)") Chapter 5 Language Modeling 5.1 Introduction A language model is simply a model of what strings (of words) are more or less likely to be generated by a speaker of English (or some other language). More
Chapter 5 Language Modeling 5.1 Introduction A language model is simply a model of what strings (of words) are more or less likely to be generated by a speaker of English (or some other language). More
Natural Language Processing SoSe Words and Language Model
 Natural Language Processing SoSe 2016 Words and Language Model Dr. Mariana Neves May 2nd, 2016 Outline 2 Words Language Model Outline 3 Words Language Model Tokenization Separation of words in a sentence
Natural Language Processing SoSe 2016 Words and Language Model Dr. Mariana Neves May 2nd, 2016 Outline 2 Words Language Model Outline 3 Words Language Model Tokenization Separation of words in a sentence
Probabilistic Language Modeling
 Predicting String Probabilities Probabilistic Language Modeling Which string is more likely? (Which string is more grammatical?) Grill doctoral candidates. Regina Barzilay EECS Department MIT November
Predicting String Probabilities Probabilistic Language Modeling Which string is more likely? (Which string is more grammatical?) Grill doctoral candidates. Regina Barzilay EECS Department MIT November
Natural Language Processing
 Natural Language Processing Language models Based on slides from Michael Collins, Chris Manning and Richard Soccer Plan Problem definition Trigram models Evaluation Estimation Interpolation Discounting
Natural Language Processing Language models Based on slides from Michael Collins, Chris Manning and Richard Soccer Plan Problem definition Trigram models Evaluation Estimation Interpolation Discounting
Week 13: Language Modeling II Smoothing in Language Modeling. Irina Sergienya
 Week 13: Language Modeling II Smoothing in Language Modeling Irina Sergienya 07.07.2015 Couple of words first... There are much more smoothing techniques, [e.g. Katz back-off, Jelinek-Mercer,...] and techniques
Week 13: Language Modeling II Smoothing in Language Modeling Irina Sergienya 07.07.2015 Couple of words first... There are much more smoothing techniques, [e.g. Katz back-off, Jelinek-Mercer,...] and techniques
Language Models. CS5740: Natural Language Processing Spring Instructor: Yoav Artzi
 CS5740: Natural Language Processing Spring 2017 Language Models Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer, and Yejin Choi Overview
CS5740: Natural Language Processing Spring 2017 Language Models Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer, and Yejin Choi Overview
{ Jurafsky & Martin Ch. 6:! 6.6 incl.
 N-grams Now Simple (Unsmoothed) N-grams Smoothing { Add-one Smoothing { Backo { Deleted Interpolation Reading: { Jurafsky & Martin Ch. 6:! 6.6 incl. 1 Word-prediction Applications Augmentative Communication
N-grams Now Simple (Unsmoothed) N-grams Smoothing { Add-one Smoothing { Backo { Deleted Interpolation Reading: { Jurafsky & Martin Ch. 6:! 6.6 incl. 1 Word-prediction Applications Augmentative Communication
Language Models. Philipp Koehn. 11 September 2018
 Language Models Philipp Koehn 11 September 2018 Language models 1 Language models answer the question: How likely is a string of English words good English? Help with reordering p LM (the house is small)
Language Models Philipp Koehn 11 September 2018 Language models 1 Language models answer the question: How likely is a string of English words good English? Help with reordering p LM (the house is small)
ANLP Lecture 6 N-gram models and smoothing
 ANLP Lecture 6 N-gram models and smoothing Sharon Goldwater (some slides from Philipp Koehn) 27 September 2018 Sharon Goldwater ANLP Lecture 6 27 September 2018 Recap: N-gram models We can model sentence
ANLP Lecture 6 N-gram models and smoothing Sharon Goldwater (some slides from Philipp Koehn) 27 September 2018 Sharon Goldwater ANLP Lecture 6 27 September 2018 Recap: N-gram models We can model sentence
N-gram Language Modeling
 N-gram Language Modeling Outline: Statistical Language Model (LM) Intro General N-gram models Basic (non-parametric) n-grams Class LMs Mixtures Part I: Statistical Language Model (LM) Intro What is a statistical
N-gram Language Modeling Outline: Statistical Language Model (LM) Intro General N-gram models Basic (non-parametric) n-grams Class LMs Mixtures Part I: Statistical Language Model (LM) Intro What is a statistical
CSEP 517 Natural Language Processing Autumn 2013
 CSEP 517 Natural Language Processing Autumn 2013 Language Models Luke Zettlemoyer Many slides from Dan Klein and Michael Collins Overview The language modeling problem N-gram language models Evaluation:
CSEP 517 Natural Language Processing Autumn 2013 Language Models Luke Zettlemoyer Many slides from Dan Klein and Michael Collins Overview The language modeling problem N-gram language models Evaluation:
Language Modeling. Michael Collins, Columbia University
 Language Modeling Michael Collins, Columbia University Overview The language modeling problem Trigram models Evaluating language models: perplexity Estimation techniques: Linear interpolation Discounting
Language Modeling Michael Collins, Columbia University Overview The language modeling problem Trigram models Evaluating language models: perplexity Estimation techniques: Linear interpolation Discounting
N-gram Language Modeling Tutorial
 N-gram Language Modeling Tutorial Dustin Hillard and Sarah Petersen Lecture notes courtesy of Prof. Mari Ostendorf Outline: Statistical Language Model (LM) Basics n-gram models Class LMs Cache LMs Mixtures
N-gram Language Modeling Tutorial Dustin Hillard and Sarah Petersen Lecture notes courtesy of Prof. Mari Ostendorf Outline: Statistical Language Model (LM) Basics n-gram models Class LMs Cache LMs Mixtures
ACS Introduction to NLP Lecture 3: Language Modelling and Smoothing
 ACS Introduction to NLP Lecture 3: Language Modelling and Smoothing Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk Language Modelling 2 A language model is a probability
ACS Introduction to NLP Lecture 3: Language Modelling and Smoothing Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk Language Modelling 2 A language model is a probability
CMPT-825 Natural Language Processing
 CMPT-825 Natural Language Processing Anoop Sarkar http://www.cs.sfu.ca/ anoop February 27, 2008 1 / 30 Cross-Entropy and Perplexity Smoothing n-gram Models Add-one Smoothing Additive Smoothing Good-Turing
CMPT-825 Natural Language Processing Anoop Sarkar http://www.cs.sfu.ca/ anoop February 27, 2008 1 / 30 Cross-Entropy and Perplexity Smoothing n-gram Models Add-one Smoothing Additive Smoothing Good-Turing
Statistical Methods for NLP
 Statistical Methods for NLP Language Models, Graphical Models Sameer Maskey Week 13, April 13, 2010 Some slides provided by Stanley Chen and from Bishop Book Resources 1 Announcements Final Project Due,
Statistical Methods for NLP Language Models, Graphical Models Sameer Maskey Week 13, April 13, 2010 Some slides provided by Stanley Chen and from Bishop Book Resources 1 Announcements Final Project Due,
CS4705. Probability Review and Naïve Bayes. Slides from Dragomir Radev
 CS4705 Probability Review and Naïve Bayes Slides from Dragomir Radev Classification using a Generative Approach Previously on NLP discriminative models P C D here is a line with all the social media posts
CS4705 Probability Review and Naïve Bayes Slides from Dragomir Radev Classification using a Generative Approach Previously on NLP discriminative models P C D here is a line with all the social media posts
Empirical Methods in Natural Language Processing Lecture 5 N-gram Language Models
 Empirical Methods in Natural Language Processing Lecture 5 N-gram Language Models (most slides from Sharon Goldwater; some adapted from Alex Lascarides) 29 January 2017 Nathan Schneider ENLP Lecture 5
Empirical Methods in Natural Language Processing Lecture 5 N-gram Language Models (most slides from Sharon Goldwater; some adapted from Alex Lascarides) 29 January 2017 Nathan Schneider ENLP Lecture 5
Kneser-Ney smoothing explained
 foldl home blog contact feed Kneser-Ney smoothing explained 18 January 2014 Language models are an essential element of natural language processing, central to tasks ranging from spellchecking to machine
foldl home blog contact feed Kneser-Ney smoothing explained 18 January 2014 Language models are an essential element of natural language processing, central to tasks ranging from spellchecking to machine
Language Modelling: Smoothing and Model Complexity. COMP-599 Sept 14, 2016
 Language Modelling: Smoothing and Model Complexity COMP-599 Sept 14, 2016 Announcements A1 has been released Due on Wednesday, September 28th Start code for Question 4: Includes some of the package import
Language Modelling: Smoothing and Model Complexity COMP-599 Sept 14, 2016 Announcements A1 has been released Due on Wednesday, September 28th Start code for Question 4: Includes some of the package import
DT2118 Speech and Speaker Recognition
 DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
Natural Language Processing (CSE 490U): Language Models
: Language Models") Natural Language Processing (CSE 490U): Language Models Noah Smith c 2017 University of Washington nasmith@cs.washington.edu January 6 9, 2017 1 / 67 Very Quick Review of Probability Event space (e.g.,
Natural Language Processing (CSE 490U): Language Models Noah Smith c 2017 University of Washington nasmith@cs.washington.edu January 6 9, 2017 1 / 67 Very Quick Review of Probability Event space (e.g.,
Lecture 2: N-gram. Kai-Wei Chang University of Virginia Couse webpage:
 Lecture 2: N-gram Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS 6501: Natural Language Processing 1 This lecture Language Models What are
Lecture 2: N-gram Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS 6501: Natural Language Processing 1 This lecture Language Models What are
CS 188: Artificial Intelligence Spring Today
 CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Language Models. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
9/10/18. CS 6120/CS4120: Natural Language Processing. Outline. Probabilistic Language Models. Probabilistic Language Modeling
 Outlne CS 6120/CS4120: Natural Language Processng Instructor: Prof. Lu Wang College of Computer and Informaton Scence Northeastern Unversty Webpage: www.ccs.neu.edu/home/luwang Probablstc language model
Outlne CS 6120/CS4120: Natural Language Processng Instructor: Prof. Lu Wang College of Computer and Informaton Scence Northeastern Unversty Webpage: www.ccs.neu.edu/home/luwang Probablstc language model
The Noisy Channel Model and Markov Models
 1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
Classification: Naïve Bayes. Nathan Schneider (slides adapted from Chris Dyer, Noah Smith, et al.) ENLP 19 September 2016
 ENLP 19 September 2016") Classification: Naïve Bayes Nathan Schneider (slides adapted from Chris Dyer, Noah Smith, et al.) ENLP 19 September 2016 1 Sentiment Analysis Recall the task: Filled with horrific dialogue, laughable characters,
Classification: Naïve Bayes Nathan Schneider (slides adapted from Chris Dyer, Noah Smith, et al.) ENLP 19 September 2016 1 Sentiment Analysis Recall the task: Filled with horrific dialogue, laughable characters,
CS4442/9542b Artificial Intelligence II prof. Olga Veksler
 CS4442/9542b Artificial Intelligence II prof. Olga Veksler Lecture 14 Natural Language Processing Language Models Many slides from: Joshua Goodman, L. Kosseim, D. Klein, D. Jurafsky Outline Why we need
CS4442/9542b Artificial Intelligence II prof. Olga Veksler Lecture 14 Natural Language Processing Language Models Many slides from: Joshua Goodman, L. Kosseim, D. Klein, D. Jurafsky Outline Why we need
The Language Modeling Problem (Fall 2007) Smoothed Estimation, and Language Modeling. The Language Modeling Problem (Continued) Overview
 Smoothed Estimation, and Language Modeling. The Language Modeling Problem (Continued) Overview") The Language Modeling Problem We have some (finite) vocabulary, say V = {the, a, man, telescope, Beckham, two, } 6.864 (Fall 2007) Smoothed Estimation, and Language Modeling We have an (infinite) set of
The Language Modeling Problem We have some (finite) vocabulary, say V = {the, a, man, telescope, Beckham, two, } 6.864 (Fall 2007) Smoothed Estimation, and Language Modeling We have an (infinite) set of
Naïve Bayes, Maxent and Neural Models
 Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Statistical Natural Language Processing
 Statistical Natural Language Processing N-gram Language Models Çağrı Çöltekin University of Tübingen Seminar für Sprachwissenschaft Summer Semester 2017 N-gram language models A language model answers
Statistical Natural Language Processing N-gram Language Models Çağrı Çöltekin University of Tübingen Seminar für Sprachwissenschaft Summer Semester 2017 N-gram language models A language model answers
Conditional Language Modeling. Chris Dyer
 Conditional Language Modeling Chris Dyer Unconditional LMs A language model assigns probabilities to sequences of words,. w =(w 1,w 2,...,w`) It is convenient to decompose this probability using the chain
Conditional Language Modeling Chris Dyer Unconditional LMs A language model assigns probabilities to sequences of words,. w =(w 1,w 2,...,w`) It is convenient to decompose this probability using the chain
Chapter 3: Basics of Language Modelling
 Chapter 3: Basics of Language Modelling Motivation Language Models are used in Speech Recognition Machine Translation Natural Language Generation Query completion For research and development: need a simple
Chapter 3: Basics of Language Modelling Motivation Language Models are used in Speech Recognition Machine Translation Natural Language Generation Query completion For research and development: need a simple
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Graphical Models. Mark Gales. Lent Machine Learning for Language Processing: Lecture 3. MPhil in Advanced Computer Science
 Graphical Models Mark Gales Lent 2011 Machine Learning for Language Processing: Lecture 3 MPhil in Advanced Computer Science MPhil in Advanced Computer Science Graphical Models Graphical models have their
Graphical Models Mark Gales Lent 2011 Machine Learning for Language Processing: Lecture 3 MPhil in Advanced Computer Science MPhil in Advanced Computer Science Graphical Models Graphical models have their
CSCI 5832 Natural Language Processing. Today 2/19. Statistical Sequence Classification. Lecture 9
 CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
CS 188: Artificial Intelligence. Machine Learning
 CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Language Models. Data Science: Jordan Boyd-Graber University of Maryland SLIDES ADAPTED FROM PHILIP KOEHN
 Language Models Data Science: Jordan Boyd-Graber University of Maryland SLIDES ADAPTED FROM PHILIP KOEHN Data Science: Jordan Boyd-Graber UMD Language Models 1 / 8 Language models Language models answer
Language Models Data Science: Jordan Boyd-Graber University of Maryland SLIDES ADAPTED FROM PHILIP KOEHN Data Science: Jordan Boyd-Graber UMD Language Models 1 / 8 Language models Language models answer
Deep Learning Basics Lecture 10: Neural Language Models. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
CSA4050: Advanced Topics Natural Language Processing. Lecture Statistics III. Statistical Approaches to NLP
 University of Malta BSc IT (Hons)Year IV CSA4050: Advanced Topics Natural Language Processing Lecture Statistics III Statistical Approaches to NLP Witten-Bell Discounting Unigrams Bigrams Dept Computer
University of Malta BSc IT (Hons)Year IV CSA4050: Advanced Topics Natural Language Processing Lecture Statistics III Statistical Approaches to NLP Witten-Bell Discounting Unigrams Bigrams Dept Computer
Language Processing with Perl and Prolog
 Language Processing with Perl and Prolog Chapter 5: Counting Words Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ Pierre Nugues Language Processing with Perl and
Language Processing with Perl and Prolog Chapter 5: Counting Words Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ Pierre Nugues Language Processing with Perl and
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
Language Technology. Unit 1: Sequence Models. CUNY Graduate Center Spring Lectures 5-6: Language Models and Smoothing. required hard optional
 Language Technology CUNY Graduate Center Spring 2013 Unit 1: Sequence Models Lectures 5-6: Language Models and Smoothing required hard optional Professor Liang Huang liang.huang.sh@gmail.com Python Review:
Language Technology CUNY Graduate Center Spring 2013 Unit 1: Sequence Models Lectures 5-6: Language Models and Smoothing required hard optional Professor Liang Huang liang.huang.sh@gmail.com Python Review:
Language Modelling. Steve Renals. Automatic Speech Recognition ASR Lecture 11 6 March ASR Lecture 11 Language Modelling 1
 Language Modelling Steve Renals Automatic Speech Recognition ASR Lecture 11 6 March 2017 ASR Lecture 11 Language Modelling 1 HMM Speech Recognition Recorded Speech Decoded Text (Transcription) Acoustic
Language Modelling Steve Renals Automatic Speech Recognition ASR Lecture 11 6 March 2017 ASR Lecture 11 Language Modelling 1 HMM Speech Recognition Recorded Speech Decoded Text (Transcription) Acoustic
Hierarchical Bayesian Nonparametrics
 Hierarchical Bayesian Nonparametrics Micha Elsner April 11, 2013 2 For next time We ll tackle a paper: Green, de Marneffe, Bauer and Manning: Multiword Expression Identification with Tree Substitution
Hierarchical Bayesian Nonparametrics Micha Elsner April 11, 2013 2 For next time We ll tackle a paper: Green, de Marneffe, Bauer and Manning: Multiword Expression Identification with Tree Substitution
Speech Recognition Lecture 5: N-gram Language Models. Eugene Weinstein Google, NYU Courant Institute Slide Credit: Mehryar Mohri
 Speech Recognition Lecture 5: N-gram Language Models Eugene Weinstein Google, NYU Courant Institute eugenew@cs.nyu.edu Slide Credit: Mehryar Mohri Components Acoustic and pronunciation model: Pr(o w) =
Speech Recognition Lecture 5: N-gram Language Models Eugene Weinstein Google, NYU Courant Institute eugenew@cs.nyu.edu Slide Credit: Mehryar Mohri Components Acoustic and pronunciation model: Pr(o w) =
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Language Models & Hidden Markov Models
 1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
Mid-term Reviews. Preprocessing, language models Sequence models, Syntactic Parsing
 Mid-term Reviews Preprocessing, language models Sequence models, Syntactic Parsing Preprocessing What is a Lemma? What is a wordform? What is a word type? What is a token? What is tokenization? What is
Mid-term Reviews Preprocessing, language models Sequence models, Syntactic Parsing Preprocessing What is a Lemma? What is a wordform? What is a word type? What is a token? What is tokenization? What is
N-gram Language Model. Language Models. Outline. Language Model Evaluation. Given a text w = w 1...,w t,...,w w we can compute its probability by:
 N-gram Language Model 2 Given a text w = w 1...,w t,...,w w we can compute its probability by: Language Models Marcello Federico FBK-irst Trento, Italy 2016 w Y Pr(w) =Pr(w 1 ) Pr(w t h t ) (1) t=2 where
N-gram Language Model 2 Given a text w = w 1...,w t,...,w w we can compute its probability by: Language Models Marcello Federico FBK-irst Trento, Italy 2016 w Y Pr(w) =Pr(w 1 ) Pr(w t h t ) (1) t=2 where
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 23: Perceptrons 11/20/2008 Dan Klein UC Berkeley 1 General Naïve Bayes A general naive Bayes model: C E 1 E 2 E n We only specify how each feature depends
CS 188: Artificial Intelligence Fall 2008 Lecture 23: Perceptrons 11/20/2008 Dan Klein UC Berkeley 1 General Naïve Bayes A general naive Bayes model: C E 1 E 2 E n We only specify how each feature depends
General Naïve Bayes. CS 188: Artificial Intelligence Fall Example: Overfitting. Example: OCR. Example: Spam Filtering. Example: Spam Filtering
 CS 188: Artificial Intelligence Fall 2008 General Naïve Bayes A general naive Bayes model: C Lecture 23: Perceptrons 11/20/2008 E 1 E 2 E n Dan Klein UC Berkeley We only specify how each feature depends
CS 188: Artificial Intelligence Fall 2008 General Naïve Bayes A general naive Bayes model: C Lecture 23: Perceptrons 11/20/2008 E 1 E 2 E n Dan Klein UC Berkeley We only specify how each feature depends
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Neural Network Language Modeling
 Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
P(t w) = arg maxp(t, w) (5.1) P(t,w) = P(t)P(w t). (5.2) The first term, P(t), can be described using a language model, for example, a bigram model:
 = arg maxp(t, w) (5.1) P(t,w) = P(t)P(w t). (5.2) The first term, P(t), can be described using a language model, for example, a bigram model:") Chapter 5 Text Input 5.1 Problem In the last two chapters we looked at language models, and in your first homework you are building language models for English and Chinese to enable the computer to guess
Chapter 5 Text Input 5.1 Problem In the last two chapters we looked at language models, and in your first homework you are building language models for English and Chinese to enable the computer to guess
Probability Review and Naïve Bayes
 Probability Review and Naïve Bayes Instructor: Alan Ritter Some slides adapted from Dan Jurfasky and Brendan O connor What is Probability? The probability the coin will land heads is 0.5 Q: what does this
Probability Review and Naïve Bayes Instructor: Alan Ritter Some slides adapted from Dan Jurfasky and Brendan O connor What is Probability? The probability the coin will land heads is 0.5 Q: what does this
Language Models. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Language Models CS6200: Information Retrieval Slides by: Jesse Anderton What s wrong with VSMs? Vector Space Models work reasonably well, but have a few problems: They are based on bag-of-words, so they
Language Models CS6200: Information Retrieval Slides by: Jesse Anderton What s wrong with VSMs? Vector Space Models work reasonably well, but have a few problems: They are based on bag-of-words, so they
Sequences and Information
 Sequences and Information Rahul Siddharthan The Institute of Mathematical Sciences, Chennai, India http://www.imsc.res.in/ rsidd/ Facets 16, 04/07/2016 This box says something By looking at the symbols
Sequences and Information Rahul Siddharthan The Institute of Mathematical Sciences, Chennai, India http://www.imsc.res.in/ rsidd/ Facets 16, 04/07/2016 This box says something By looking at the symbols
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
LING 473: Day 10. START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars
 LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
TnT Part of Speech Tagger
 TnT Part of Speech Tagger By Thorsten Brants Presented By Arghya Roy Chaudhuri Kevin Patel Satyam July 29, 2014 1 / 31 Outline 1 Why Then? Why Now? 2 Underlying Model Other technicalities 3 Evaluation
TnT Part of Speech Tagger By Thorsten Brants Presented By Arghya Roy Chaudhuri Kevin Patel Satyam July 29, 2014 1 / 31 Outline 1 Why Then? Why Now? 2 Underlying Model Other technicalities 3 Evaluation
(today we are assuming sentence segmentation) Wednesday, September 10, 14
 Wednesday, September 10, 14") (today we are assuming sentence segmentation) 1 Your TA: David Belanger http://people.cs.umass.edu/~belanger/ I am a third year PhD student advised by Professor Andrew McCallum. Before that, I was an Associate
(today we are assuming sentence segmentation) 1 Your TA: David Belanger http://people.cs.umass.edu/~belanger/ I am a third year PhD student advised by Professor Andrew McCallum. Before that, I was an Associate
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Sequential Decision Problems
 Sequential Decision Problems Michael A. Goodrich November 10, 2006 If I make changes to these notes after they are posted and if these changes are important (beyond cosmetic), the changes will highlighted
Sequential Decision Problems Michael A. Goodrich November 10, 2006 If I make changes to these notes after they are posted and if these changes are important (beyond cosmetic), the changes will highlighted
CSC321 Lecture 7 Neural language models
 CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
Chapter 3: Basics of Language Modeling
 Chapter 3: Basics of Language Modeling Section 3.1. Language Modeling in Automatic Speech Recognition (ASR) All graphs in this section are from the book by Schukat-Talamazzini unless indicated otherwise
Chapter 3: Basics of Language Modeling Section 3.1. Language Modeling in Automatic Speech Recognition (ASR) All graphs in this section are from the book by Schukat-Talamazzini unless indicated otherwise
Introduction to Artificial Intelligence (AI)
") Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
SYNTHER A NEW M-GRAM POS TAGGER
 SYNTHER A NEW M-GRAM POS TAGGER David Sündermann and Hermann Ney RWTH Aachen University of Technology, Computer Science Department Ahornstr. 55, 52056 Aachen, Germany {suendermann,ney}@cs.rwth-aachen.de
SYNTHER A NEW M-GRAM POS TAGGER David Sündermann and Hermann Ney RWTH Aachen University of Technology, Computer Science Department Ahornstr. 55, 52056 Aachen, Germany {suendermann,ney}@cs.rwth-aachen.de
Ranked Retrieval (2)
") Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
Hidden Markov Models, I. Examples. Steven R. Dunbar. Toy Models. Standard Mathematical Models. Realistic Hidden Markov Models.
 , I. Toy Markov, I. February 17, 2017 1 / 39 Outline, I. Toy Markov 1 Toy 2 3 Markov 2 / 39 , I. Toy Markov A good stack of examples, as large as possible, is indispensable for a thorough understanding
, I. Toy Markov, I. February 17, 2017 1 / 39 Outline, I. Toy Markov 1 Toy 2 3 Markov 2 / 39 , I. Toy Markov A good stack of examples, as large as possible, is indispensable for a thorough understanding
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs
 Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Machine Learning. Hal Daumé III. Computer Science University of Maryland CS 421: Introduction to Artificial Intelligence 8 May 2012
 Machine Learning Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421 Introduction to Artificial Intelligence 8 May 2012 g 1 Many slides courtesy of Dan Klein, Stuart Russell, or Andrew
Machine Learning Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421 Introduction to Artificial Intelligence 8 May 2012 g 1 Many slides courtesy of Dan Klein, Stuart Russell, or Andrew
Naive Bayes Classifier. Danushka Bollegala
 Naive Bayes Classifier Danushka Bollegala Bayes Rule The probability of hypothesis H, given evidence E P(H E) = P(E H)P(H)/P(E) Terminology P(E): Marginal probability of the evidence E P(H): Prior probability
Naive Bayes Classifier Danushka Bollegala Bayes Rule The probability of hypothesis H, given evidence E P(H E) = P(E H)P(H)/P(E) Terminology P(E): Marginal probability of the evidence E P(H): Prior probability
Forward algorithm vs. particle filtering
 Particle Filtering ØSometimes X is too big to use exact inference X may be too big to even store B(X) E.g. X is continuous X 2 may be too big to do updates ØSolution: approximate inference Track samples
Particle Filtering ØSometimes X is too big to use exact inference X may be too big to even store B(X) E.g. X is continuous X 2 may be too big to do updates ØSolution: approximate inference Track samples
Machine Learning for natural language processing
 Machine Learning for natural language processing Classification: Naive Bayes Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 Introduction Classification = supervised method for
Machine Learning for natural language processing Classification: Naive Bayes Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 Introduction Classification = supervised method for
Language Modelling. Marcello Federico FBK-irst Trento, Italy. MT Marathon, Edinburgh, M. Federico SLM MT Marathon, Edinburgh, 2012
 Language Modelling Marcello Federico FBK-irst Trento, Italy MT Marathon, Edinburgh, 2012 Outline 1 Role of LM in ASR and MT N-gram Language Models Evaluation of Language Models Smoothing Schemes Discounting
Language Modelling Marcello Federico FBK-irst Trento, Italy MT Marathon, Edinburgh, 2012 Outline 1 Role of LM in ASR and MT N-gram Language Models Evaluation of Language Models Smoothing Schemes Discounting