Distributed Optimization. Song Chong EE, KAIST
|
|
|
- Ashlyn Osborne
- 5 years ago
- Views:
Transcription
1 Distributed Optimization Song Chong EE, KAIST
2 Dynamic Programming for Path Planning A path-planning problem consists of a weighted directed graph with a set of n nodes N, directed links L, a weight function w: L R +, and two nodes s, t N. The goal is to find a directed path from s to t having minimal total weight. More generally, the destination nodes t can be multiple. We are interested in distributed solutions, in which each node performs a local computation, with access only to the state of its neighbors Principle of optimality If node x lies on a shortest path from s to t, then the portion of the path from s to x (or, respectively, from x to t) must also be the shortest paths between s and x (resp., x and t) This allows an incremental divide-and-conquer procedure, also known as dynamic programming Let h (i) be the shortest distance from any node i to the goal t. Then, the shortest distance from i to t via a node j neighboring i is given by f i, j = w i, j + h j and h i = min f i, j, which is known as Bellman s optimality equation j 1
3 Asynchronous Dynamic Programming 2
4 Asynchronous Dynamic Programming One can prove that the ASYNCHDP procedure is guaranteed to converge to the true values, that is, h will converge to h. Moreover, the worst case convergence will require n iterations For realistic problems where n is large, however, not only can convergence be slow, but this procedure requires n processes (or agents) since the procedure assumes an agent for each node. So to be practical we turn to heuristic versions of the procedure, which require a smaller number of agents 3
5 Learning Real-Time A* (LRTA*) In the learning real-time A*, or LRTA*, algorithm, the agent starts at a given node, performs an operation similar to that of asynchronous dynamic programming, and then moves to the neighboring node with the shortest estimated distance to the goal, and repeats Assume that the set of nodes is finite, that all weights w(i, j) are positive and finite, and that there exists some path from every node in the graph to a goal node Note that this procedure uses a given heuristic function h( ) that serves as the initial value for each newly encountered node. To guarantee certain properties of LRTA*, we must assume that h is admissible, which means that h never overestimates the distance to the goal, that is, h(i) h (i) One can ensure admissibility by setting h i = 0 for all i, although less conservative admissible heuristic functions (built using knowledge of the problem domain) can speed up the convergence to the optimal solution 4
6 LRTA* With these assumptions, LRTA* has the following properties: The h-values never decrease, and remain admissible LRTA* terminates; the complete execution from the start node to termination at the goal node is called a trial If LRTA* is repeated while maintaining the h-values from one trial to the next, it eventually discovers the shortest path from the start to a goal node If LRTA* find the same path on two sequential trials, this is the shortest path (However, this path may also be found in one or more previous trials before it is found twice in a row) 5
7 LRTA* in Action 6
8 LRTA*(2) in Action LRTA is a centralized procedure. However, rather than have a single agent execute this procedure, one can have multiple agents execute it The properties of the algorithm (call it LRTA*(n), with n agents) are not altered, but the convergence to the shortest path can be speed up dramatically First, if the agents break ties differently, some will reach the goal much faster than others. Second, if they all have access to a shared h-value table, the learning of one agent can teach the others. Specifically, after every round and for every i, h(i) = max h j (i), where h j i is agent j s updated value for h(i) j 7
9 Action Selection in Multiagent MDPs Recall that in a single-agent Markov Decision Process (MDP), the optimal policy π is characterized by the Bellman optimality equations: Q π s, a = r s, a + γ V π s s = max a Qπ s, a p a ss V π (s ) These equations turn into an algorithm specifically, the dynamic-programmingstyle value iteration algorithm However, in real-world applications the situation is not that simple. The MDP may not be known by the planning agent and thus may have to be learned (This case is discussed in Chapter 7) The MDP may simply be too large to iterate over all instances of the equations 8
10 Action Selection in Multiagent MDPs Consider a multiagent MDP with some modularity of actions where (global) action a is a vector of local actions (a 1,, a n ), one by each of n agents. The assumption here is that the reward is common, so there is no issue of competition among the agents. There is not even a problem of coordination; we have the luxury of a central planner Suppose that the Q values for the optimal policy, Q π, have already been computed. Then, the optimal policy is easily recovered; the optimal action in state s is argmax Q π. But if a ranges over an exponential number of choices by all agents, easy becomes hard. The question is: can we do better than naively enumerating over all action combinations by the agents? In general the answer is no, but in practice, the interaction among the agents actions can be quite limited, which can be exploited both in the representation of the Q function and in the maximization process. Specifically, in some cases we can associate an individual Q i function with each agent i, and express the Q function (either precisely or approximately) as a linear sum of the individual Q i s: a n Q s, a = Q i (s, a) i=1 argmax a σ i=1 n Q i (s, a) This in and of itself is not very useful. However, it is often also the case that each individual Q i depends only on a small subset of the variables 9
11 Action Selection in Multiagent MDPs Q a 1, a 2, a 3, a 4 = Q 1 a 1, a 2 + Q 2 a 2, a 4 + Q 3 a 1, a 3 + Q 4 a 3, a 4 argmax Q 1 a 1, a 2 + Q 2 a 2, a 4 + Q 3 a 1, a 3 + Q 4 a 3, a 4 a 1,a 2,a 3,a 4 10
12 By employing a variable elimination algorithm, one can compute a conditional strategy, from the following set of equations: where Action Selection in Multiagent MDPs a + e (a, a )] a, a + e (a, a )] a 1 = argmax e 2 ( a 1 ) a 1 a 2 = argmax[q 1 a 1, a a 3 = argmax[q a a 4 = argmax[q 2 a 2, a 4 + Q 4 (a 3, a 4 )] a 4 e 2 (a 1 ) = max a 2 [Q 1 a 1, a 2 + e 3 (a 1, a 2 )] e 3 (a 1, a 2 ) = max a 3 [Q 3 a 1, a 3 + e 4 (a 2, a 3 )] e 4 (a 2, a 3 ) = max a 4 [Q 2 a 2, a 4 + Q 4 (a 3, a 4 )] 11
13 Infinite-Horizon Dynamic Programing Model for sequential decision-making problems under dynamics Markov Decision Process (MDP) a special case of infinite-horizon DP Set of possible states s S Set of possible actions a A Transition probability P a ss = Pr(s s, a) Deterministic policy function a = π(s) Reward function r = r s, a with discount factor γ [0,1) Episode τ a s 0 a 1 a 2 a 0 s 1 s 2 s 3 3 s 4 Return R π τ r 0 + γr 1 + γ 2 r 2 + γ 3 r 3 Expected return R π = E τ [R π τ ] = E τ σ t=0 γ t r t 12
14 Two Main Tasks in DP Value prediction: evaluate how good a policy π is for given s or (s, a) State-value function V π s = E τ R π τ s 0 = s = r s, π s Action-value function (Q-factor function) π(s) + γσ s P ss V π s, Q π s, a = E τ R π τ s 0 = s, a 0 = a = r s, a + γσ s P a ss V π s = r s, a + γσ s P a ss Q π s, π(s ) s S, a A Policy optimization: find optimal policy π maximizing R π s S π s = argmax V π (s) π = argmax[r s, a + γσ s P a ss V π s ], s S a A π s = argmax Q π s, π(s) π = argmax a A Q π s, a, s S 13
15 a Suppose that P ss Value Iteration (VI) method How to Find π in DP and r s, a are known Bellman s optimality equation for Q π, known as principle of optimality Q π = T Q π where T is contraction, written as for s S, a A, Q π s, a = r s, a + γσ s P a ss V π s = r s, a + γσ s P a ss max a A Qπ s, a π Solve Bellman s equation by value iteration, staring with arbitrary Q 0 Q π π Q π k+1 = T(Q k ), k = 0,1, Find optimal policy π by maximization π s = argmax Q π s, a, s S a A 14
16 Policy Iteration (PI) method How to Find π in DP Policy evaluation (critic) phase For a given policy π, compute Q-factor Q π by value iteration Q π Q π k+1 = T π (Q π k ), k = 0,1, where T π is contraction, written as for s S, a A, Q π s, a = r s, a + γσ s P a ss Q π s, π(s ) Policy improvement (actor) phase For a given Q-factor Q π, compute a new policy π by maximization π s = argmax Q π s, a, a A Policy improvement theorem s S critic Q π s, π s = max a A Qπ s, a Q π s, π s = V π (s), s S V π (s) V π (s), s S Q π π 15 actor
17 DP requires to solve Bellman s equation to get Q π or Q π a P ss From DP to RL VI: Q π s, a = r s, a + γσ s P a ss max a A Qπ s, a, s S, a A PI: Q π s, a = r s, a + γσ s P a ss Q π s, π(s ), s S, a A and r s, a are unknown in practice => curse of modelling (uncertainty) Cardinalities of sets S and A are extremely high => curse of dimensionality Category of RL algorithms based on what to learn a Model-based RL learn models, P ss and r s, a, from samples to compute Q π or Q π Value-based RL learn value functions, Q π or Q π, directly from samples Policy search RL search optimal policy function π based on samples Summation over a huge number of states can be approximated by Monte Carlo estimation and stochastic approximation techniques 16
18 Auction-Like Distributed Optimization Consider two classical optimization problems Assignment problem (weighted matching problem in bipartite graph) Scheduling problem The aim is to derive distributed problem solving (optimization) that has a certain economic flavor, in particular, auction-style solutions for them The assignment problem is a linear programming (LP) problem, which is relatively easy to solve (specifically, solvable in polynomial time), and admits an auction-like optimization procedure with tight guarantees The scheduling problem is an integer programming (IP) problem, which is more complex (specifically, NP-complete), and also admits an auction-like optimization procedure but does not come with such guarantees 17
19 Assignment Problem and Linear Programming Definition (Assignment problem) An assignment problem consists of A set N of n agents A set X of n objects A set M N X of possible assignment pairs, and A function v: M R giving the value of each assignment pair An assignment is a set of pairs S M such that each agent i N and each object j X is in at most one pair in S. A feasible assignment is one in which all agents are assigned an object. A feasible assignment S is optimal if it maximizes σ (i,j) s v(i, j) An assignment problem can be encoded as a linear program with fractional matches (i.e., 0 x i,j 1) Any linear program can be solved in polynomial time 18
20 Assignment Problem and Linear Programming Lemma The LP encoding of the assignment problem has at least one integral solution such that for every i, j it is the case that x i,j = 0 or x i,j = 1. Furthermore, any optimal fractional solution can be converted in polynomial time to an optimal integral solution Corollary The assignment problem can be solved in polynomial time However, the polynomial-time solution to the LP problem is of complexity roughly O(n 3 ), which may be too high in some cases. Furthermore, the solution is not parallelizable One alternative is based on the economic notion of competitive equilibrium 19
21 Assignment Problem and Competitive Equilibrium Imagine that each of the objects in X has an associated price; the price vector is p = (p 1,, p n ) where p j is the price of object j Given an assignment S M and a price vector p, define the utility from an assignment j to agent i as u i, j = v i, j p j An assignment and a set of prices are in competitive equilibrium when each agent is assigned the object that maximizes his utility given the current prices Definition (Competitive equilibrium) A feasible assignment S and a price vector p are in competitive equilibrium when for every pairing (i, j) S it is the case that k, u(i, j) u(i, k) Theorem If a feasible assignment S and a price vector p satisfy the competitive equilibrium condition then S is an optimal assignment. Furthermore, for any optimal solution S, there exists a price vector p such that p and S satisfy the competitive equilibrium condition This theorem means that one way to search for solutions of the LP is to search the space of competitive equilibria. And a natural way to search that space involves auction-like procedures, in which the individual agents bid for the different resources in a pre-specified way 20
22 Connection between Optimization and Competitive Equilibrium Primal problem of an LP A meaningful economic interpretation, namely, production economy Each product consumes a certain amount of each resource, and each product is sold at a certain price. Interpret x i as the amount of product i produced, c i as the price of product i, b j as the available amount of resource j and a ij as the amount of resource j needed to produce a unit of product i The optimization problem can be interpreted as profit maximization with constraints capturing the limitation on resources 21
23 Connection between Optimization and Competitive Equilibrium Dual problem of an LP y i can be given a meaningful economic interpretation, namely, as the marginal value of resource i, also known as its shadow price The shadow price captures the sensitivity of the optimal solution to a small change in the availability of that particular resource, holding everything else constant To be precise, the shadow price is the value of the Lagrange multiplier at the optimal solution 22
24 A Naive Auction Algorithm Theorem The naive algorithm terminates only at a competitive equilibrium X = x 1, x 2, x 3, N = {1,2,3} 23
25 The naive auction algorithm may fail to terminate. This can occur when more than one object offers maximal value for a given agent; in this case the agent s bid increment will be zero X = x 1, x 2, x 3, N = {1,2,3} A Naive Auction Algorithm 24
26 A Terminating Auction Algorithm To remedy the flaw, we must ensure that prices continue to increase when objects are contested by a group of agents. The extension is quite straightforward: we add a small amount to the bidding increment. Otherwise, the algorithm is as stated earlier Because the prices must increase by at least ε at every round, the competitive equilibrium property is no longer preserved over the iteration. Agents may overbid on some objects Definition (ε-competitive equilibrium) S and p satisfy ε-competitive equilibrium when for each i N, if there exists a pair (i, j) S then k, u i, j + ε u i, k Theorem A feasible assignment S with n objects that forms an ε-competitive equilibrium with some price vector is within nε of optimal 25
27 Corollary Consider an assignment problem with an integer valuation function v: M Z. If ε < 1 then any feasible assignment found by the terminating auction algorithm will be optimal One can show that the algorithm indeed terminates and its running time is v i,j A Terminating Auction Algorithm O n 2 max i,j ε Observe that if ε = O(1/n) the algorithm s running time is O(n 3 k), where k is a constant that does not depend on n, yielding worst case performance similar to the LP solution approach 26
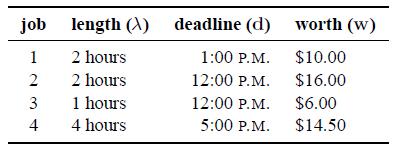
28 Scheduling Problem and Integer Programming Definition (Scheduling problem) A scheduling problem consists of a tuple C = (N, X, q, v), where N is a set of n agents X is a set of m discrete and consecutive time slots q = (q 1,, q m ) is a reserve price vector, where q j is a reserve value for time slot x j ; q can be thought of as the value for the slot of the owner of the resource v = v 1,, v n, where v i, the valuation function of agent i, is a function over possible allocations of time slots that is parameterized by two arguments: d i, the deadlines of agent i, and λ i, the required number of time slots required by agent i. Thus for an allocation F i 2 X of agent i, we have that 27
29 Scheduling Problem and Integer Programming A solution to a scheduling problem is a vector F = F 0, F 1,, F n, where F i is the set of time slots assigned to agent i, and F o is the time slots that are not assigned. The value of a solution is defined as The scheduling problem is inherently more complex than the assignment problem. Specifically, the scheduling problem is NP-complete, whereas the assignment problem is P The scheduling problem can be defined much more broadly. It could involve earliest start times as well as deadlines, could require contiguous blocks of time for a given agent, could involve more than one resource, and so on 28
30 Scheduling Problem and Integer Programming A scheduling problem can be encoded as an integer program where for every subset S X, the boolean variable x i,s will represent the fact that agent i was allocated the bundle S, and v i (S) his valuation for that bundle IPs are not in general solvable in polynomial time. However, it turns out that a generalization of the auction-like procedure can be applied in this case too The price we will pay for is that the generalized algorithm will not come with the same guarantees that we had in the case of the assignment problem 29
31 Scheduling Problem and Generalized Competitive Equilibrium Definition (Competitive equilibrium, generalized form) Given a scheduling problem, a solution F is in competitive equilibrium at prices p if and only if For all i N it is the case that F i = argmax(v i T σ j xj T p j ) (the set of time T X slots allocated to agent i maximizes his surplus at prices p); For all j such that x j F 0, it is the case that p j = q j (the price of all unallocated time slots is the reserve price); and For all j such that x j F 0 it is the case that p j q j (the price of all allocated time slots is greater than or equal to the reserve price) Theorem If a solution F to a scheduling problem C is in competitive equilibrium at prices p, then F is also optimal for C Show that the value of F is higher than the value of any other solution F 30
32 Scheduling Problem and Generalized Competitive Equilibrium V F = q j + v i (F i ) j x j F 0 i N = p j + v i (F i ) j x j F 0 i N = p j + j x j X i N p j + j x j X i N v i F i j x j F i p j v i F i j x j F i p j j x p j + v j F i F i 0 i N j x q j + v j F i F i = V(F ) 0 i N Theorem A scheduling problem has a competitive equilibrium solution if and only if the LP relaxation of the associated integer program has a integer solution 31
33 Ascending-Auction Algorithm The best-known distributed protocol for finding a competitive equilibrium is the socalled ascending-auction algorithm In this protocol, the center advertises an ask price, and the agents bid the ask price for bundles of time slots that maximize their surplus at the given ask prices. This process repeats until there is no change Let b = b 1,, b m be the bid price vector, where b j is the highest bid so far for time slot x j X. Let F = (F 1,, F n ) be the set of allocated slots for each agent. Finally, let ε be the price increment The ascending-auction algorithm is very similar to the assignment problem auction with one notable difference that the bid increment is always constant It is also possible for the ascending-auction algorithm to not converge to an equilibrium independently of how small the increment is Even if the algorithm converges, we have no guarantee that it converges to an optimal solution. Moreover, we cannot even bound how far the solution is from optimal One property we can guarantee, however, is termination. The algorithm must terminate, giving us the worst-case running time O(n max ) σ i N v i (F i ) F i ε 32
34 Ascending-Auction Algorithm 33
35 Totally Asynchronous Iterative Algorithms Let X 1, X 2,, X n be given sets, and let X be the Cartesian product X = X 1 X 2 X n For x X, we write x = (x 1, x 2,, x n ) where x i X i, i. Let f i : X X i be given functions and let f: X X be the function defined by f x = f 1 x, f 2 x,, f n x, x X The problem is to find a fixed point of f, that is, an element x X with x = f(x ) or, equivalently, x i = f i x, i There is a set of times T = {0,1,2, } and let T i T be the set of times at which x i is updated by agent i Assume that each agent i updating x i may not have access to the most recent value of the component of x; thus, we assume that x i t + 1 = ቐ f i x 1 τ 1 i t,, x n τ n i t, t T i x i t, where τ j i t are times satisfying 0 τ j i t t, t T t T i 34
36 Asynchronous Convergence Theorem Assumption 1.1 (Total asynchronism) The sets T i are infinite and if {t k } is a sequence of elements of T i that tends to infinity, then lim τ i j t k = for every j k Assumption 2.1 There is a sequence of nonempty sets {X k } with X(k + 1) X(k) X satisfying two conditions: (a) (Synchronous convergence condition) We have f x X k + 1, k and x X k. Furthermore, if y k is a sequence such that y k X(k) for every k, then every limit point of y k is a fixed point of f (b) (Box condition) For every k, there exists sets X i (k) X i such that X k = X 1 (k) X 2 (k) X n (k) Proposition 2.1 (Asynchronous convergence theorem) If Assumptions 1.1 and 2.1 hold, and the initial solution estimate x 0 = x 1 0,, x n 0 belongs to the set X 0, then every limit point of x t is a fixed point of f If X = R n, X i = R, i and f: R n R n is a contraction mapping w.r.t. some weighted maximum norm w with modulus α, Assumption 2.1 is satisfied with sets {X k } defined by X k = {x R n x x w α k x 0 x w } 35
Markov Decision Processes Chapter 17. Mausam
 Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Internet Monetization
 Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
Probabilistic Planning. George Konidaris
 Probabilistic Planning George Konidaris gdk@cs.brown.edu Fall 2017 The Planning Problem Finding a sequence of actions to achieve some goal. Plans It s great when a plan just works but the world doesn t
Probabilistic Planning George Konidaris gdk@cs.brown.edu Fall 2017 The Planning Problem Finding a sequence of actions to achieve some goal. Plans It s great when a plan just works but the world doesn t
CS 7180: Behavioral Modeling and Decisionmaking
 CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
Lecture 6: Communication Complexity of Auctions
 Algorithmic Game Theory October 13, 2008 Lecture 6: Communication Complexity of Auctions Lecturer: Sébastien Lahaie Scribe: Rajat Dixit, Sébastien Lahaie In this lecture we examine the amount of communication
Algorithmic Game Theory October 13, 2008 Lecture 6: Communication Complexity of Auctions Lecturer: Sébastien Lahaie Scribe: Rajat Dixit, Sébastien Lahaie In this lecture we examine the amount of communication
Lecture notes for Analysis of Algorithms : Markov decision processes
 Lecture notes for Analysis of Algorithms : Markov decision processes Lecturer: Thomas Dueholm Hansen June 6, 013 Abstract We give an introduction to infinite-horizon Markov decision processes (MDPs) with
Lecture notes for Analysis of Algorithms : Markov decision processes Lecturer: Thomas Dueholm Hansen June 6, 013 Abstract We give an introduction to infinite-horizon Markov decision processes (MDPs) with
Real Time Value Iteration and the State-Action Value Function
 MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
Planning in Markov Decision Processes
 Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Elements of Reinforcement Learning
 Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
CSE250A Fall 12: Discussion Week 9
 CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
Optimal Auctions with Correlated Bidders are Easy
 Optimal Auctions with Correlated Bidders are Easy Shahar Dobzinski Department of Computer Science Cornell Unversity shahar@cs.cornell.edu Robert Kleinberg Department of Computer Science Cornell Unversity
Optimal Auctions with Correlated Bidders are Easy Shahar Dobzinski Department of Computer Science Cornell Unversity shahar@cs.cornell.edu Robert Kleinberg Department of Computer Science Cornell Unversity
Section Notes 9. Midterm 2 Review. Applied Math / Engineering Sciences 121. Week of December 3, 2018
 Section Notes 9 Midterm 2 Review Applied Math / Engineering Sciences 121 Week of December 3, 2018 The following list of topics is an overview of the material that was covered in the lectures and sections
Section Notes 9 Midterm 2 Review Applied Math / Engineering Sciences 121 Week of December 3, 2018 The following list of topics is an overview of the material that was covered in the lectures and sections
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Computing Solution Concepts of Normal-Form Games. Song Chong EE, KAIST
 Computing Solution Concepts of Normal-Form Games Song Chong EE, KAIST songchong@kaist.edu Computing Nash Equilibria of Two-Player, Zero-Sum Games Can be expressed as a linear program (LP), which means
Computing Solution Concepts of Normal-Form Games Song Chong EE, KAIST songchong@kaist.edu Computing Nash Equilibria of Two-Player, Zero-Sum Games Can be expressed as a linear program (LP), which means
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
The Simplex and Policy Iteration Methods are Strongly Polynomial for the Markov Decision Problem with Fixed Discount
 The Simplex and Policy Iteration Methods are Strongly Polynomial for the Markov Decision Problem with Fixed Discount Yinyu Ye Department of Management Science and Engineering and Institute of Computational
The Simplex and Policy Iteration Methods are Strongly Polynomial for the Markov Decision Problem with Fixed Discount Yinyu Ye Department of Management Science and Engineering and Institute of Computational
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
Algorithms for MDPs and Their Convergence
 MS&E338 Reinforcement Learning Lecture 2 - April 4 208 Algorithms for MDPs and Their Convergence Lecturer: Ben Van Roy Scribe: Matthew Creme and Kristen Kessel Bellman operators Recall from last lecture
MS&E338 Reinforcement Learning Lecture 2 - April 4 208 Algorithms for MDPs and Their Convergence Lecturer: Ben Van Roy Scribe: Matthew Creme and Kristen Kessel Bellman operators Recall from last lecture
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
Reinforcement Learning
 CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
Module 8 Linear Programming. CS 886 Sequential Decision Making and Reinforcement Learning University of Waterloo
 Module 8 Linear Programming CS 886 Sequential Decision Making and Reinforcement Learning University of Waterloo Policy Optimization Value and policy iteration Iterative algorithms that implicitly solve
Module 8 Linear Programming CS 886 Sequential Decision Making and Reinforcement Learning University of Waterloo Policy Optimization Value and policy iteration Iterative algorithms that implicitly solve
Markov Decision Processes Chapter 17. Mausam
 Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
1 Markov decision processes
 2.997 Decision-Making in Large-Scale Systems February 4 MI, Spring 2004 Handout #1 Lecture Note 1 1 Markov decision processes In this class we will study discrete-time stochastic systems. We can describe
2.997 Decision-Making in Large-Scale Systems February 4 MI, Spring 2004 Handout #1 Lecture Note 1 1 Markov decision processes In this class we will study discrete-time stochastic systems. We can describe
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
CS 781 Lecture 9 March 10, 2011 Topics: Local Search and Optimization Metropolis Algorithm Greedy Optimization Hopfield Networks Max Cut Problem Nash
 CS 781 Lecture 9 March 10, 2011 Topics: Local Search and Optimization Metropolis Algorithm Greedy Optimization Hopfield Networks Max Cut Problem Nash Equilibrium Price of Stability Coping With NP-Hardness
CS 781 Lecture 9 March 10, 2011 Topics: Local Search and Optimization Metropolis Algorithm Greedy Optimization Hopfield Networks Max Cut Problem Nash Equilibrium Price of Stability Coping With NP-Hardness
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
16.410/413 Principles of Autonomy and Decision Making
 16.410/413 Principles of Autonomy and Decision Making Lecture 23: Markov Decision Processes Policy Iteration Emilio Frazzoli Aeronautics and Astronautics Massachusetts Institute of Technology December
16.410/413 Principles of Autonomy and Decision Making Lecture 23: Markov Decision Processes Policy Iteration Emilio Frazzoli Aeronautics and Astronautics Massachusetts Institute of Technology December
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Lecture 3: Markov Decision Processes
 Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Q-Learning for Markov Decision Processes*
 McGill University ECSE 506: Term Project Q-Learning for Markov Decision Processes* Authors: Khoa Phan khoa.phan@mail.mcgill.ca Sandeep Manjanna sandeep.manjanna@mail.mcgill.ca (*Based on: Convergence of
McGill University ECSE 506: Term Project Q-Learning for Markov Decision Processes* Authors: Khoa Phan khoa.phan@mail.mcgill.ca Sandeep Manjanna sandeep.manjanna@mail.mcgill.ca (*Based on: Convergence of
Stochastic Shortest Path Problems
 Chapter 8 Stochastic Shortest Path Problems 1 In this chapter, we study a stochastic version of the shortest path problem of chapter 2, where only probabilities of transitions along different arcs can
Chapter 8 Stochastic Shortest Path Problems 1 In this chapter, we study a stochastic version of the shortest path problem of chapter 2, where only probabilities of transitions along different arcs can
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CO759: Algorithmic Game Theory Spring 2015
 CO759: Algorithmic Game Theory Spring 2015 Instructor: Chaitanya Swamy Assignment 1 Due: By Jun 25, 2015 You may use anything proved in class directly. I will maintain a FAQ about the assignment on the
CO759: Algorithmic Game Theory Spring 2015 Instructor: Chaitanya Swamy Assignment 1 Due: By Jun 25, 2015 You may use anything proved in class directly. I will maintain a FAQ about the assignment on the
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Oblivious Equilibrium: A Mean Field Approximation for Large-Scale Dynamic Games
 Oblivious Equilibrium: A Mean Field Approximation for Large-Scale Dynamic Games Gabriel Y. Weintraub, Lanier Benkard, and Benjamin Van Roy Stanford University {gweintra,lanierb,bvr}@stanford.edu Abstract
Oblivious Equilibrium: A Mean Field Approximation for Large-Scale Dynamic Games Gabriel Y. Weintraub, Lanier Benkard, and Benjamin Van Roy Stanford University {gweintra,lanierb,bvr}@stanford.edu Abstract
CS 6901 (Applied Algorithms) Lecture 3
 Lecture 3") CS 6901 (Applied Algorithms) Lecture 3 Antonina Kolokolova September 16, 2014 1 Representative problems: brief overview In this lecture we will look at several problems which, although look somewhat similar
CS 6901 (Applied Algorithms) Lecture 3 Antonina Kolokolova September 16, 2014 1 Representative problems: brief overview In this lecture we will look at several problems which, although look somewhat similar
A Shadow Simplex Method for Infinite Linear Programs
 A Shadow Simplex Method for Infinite Linear Programs Archis Ghate The University of Washington Seattle, WA 98195 Dushyant Sharma The University of Michigan Ann Arbor, MI 48109 May 25, 2009 Robert L. Smith
A Shadow Simplex Method for Infinite Linear Programs Archis Ghate The University of Washington Seattle, WA 98195 Dushyant Sharma The University of Michigan Ann Arbor, MI 48109 May 25, 2009 Robert L. Smith
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
CS364B: Frontiers in Mechanism Design Lecture #3: The Crawford-Knoer Auction
 CS364B: Frontiers in Mechanism Design Lecture #3: The Crawford-Knoer Auction Tim Roughgarden January 15, 2014 1 The Story So Far Our current theme is the design of ex post incentive compatible (EPIC) ascending
CS364B: Frontiers in Mechanism Design Lecture #3: The Crawford-Knoer Auction Tim Roughgarden January 15, 2014 1 The Story So Far Our current theme is the design of ex post incentive compatible (EPIC) ascending
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
5. Solving the Bellman Equation
 5. Solving the Bellman Equation In the next two lectures, we will look at several methods to solve Bellman s Equation (BE) for the stochastic shortest path problem: Value Iteration, Policy Iteration and
5. Solving the Bellman Equation In the next two lectures, we will look at several methods to solve Bellman s Equation (BE) for the stochastic shortest path problem: Value Iteration, Policy Iteration and
Reinforcement Learning and Deep Reinforcement Learning
 Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Procedia Computer Science 00 (2011) 000 6
 000 6") Procedia Computer Science (211) 6 Procedia Computer Science Complex Adaptive Systems, Volume 1 Cihan H. Dagli, Editor in Chief Conference Organized by Missouri University of Science and Technology 211-
Procedia Computer Science (211) 6 Procedia Computer Science Complex Adaptive Systems, Volume 1 Cihan H. Dagli, Editor in Chief Conference Organized by Missouri University of Science and Technology 211-
Motivation for introducing probabilities
 for introducing probabilities Reaching the goals is often not sufficient: it is important that the expected costs do not outweigh the benefit of reaching the goals. 1 Objective: maximize benefits - costs.
for introducing probabilities Reaching the goals is often not sufficient: it is important that the expected costs do not outweigh the benefit of reaching the goals. 1 Objective: maximize benefits - costs.
Reinforcement Learning
 Reinforcement Learning March May, 2013 Schedule Update Introduction 03/13/2015 (10:15-12:15) Sala conferenze MDPs 03/18/2015 (10:15-12:15) Sala conferenze Solving MDPs 03/20/2015 (10:15-12:15) Aula Alpha
Reinforcement Learning March May, 2013 Schedule Update Introduction 03/13/2015 (10:15-12:15) Sala conferenze MDPs 03/18/2015 (10:15-12:15) Sala conferenze Solving MDPs 03/20/2015 (10:15-12:15) Aula Alpha
Reinforcement Learning
 Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
CSE 573. Markov Decision Processes: Heuristic Search & Real-Time Dynamic Programming. Slides adapted from Andrey Kolobov and Mausam
 CSE 573 Markov Decision Processes: Heuristic Search & Real-Time Dynamic Programming Slides adapted from Andrey Kolobov and Mausam 1 Stochastic Shortest-Path MDPs: Motivation Assume the agent pays cost
CSE 573 Markov Decision Processes: Heuristic Search & Real-Time Dynamic Programming Slides adapted from Andrey Kolobov and Mausam 1 Stochastic Shortest-Path MDPs: Motivation Assume the agent pays cost
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Linearly-solvable Markov decision problems
 Advances in Neural Information Processing Systems 2 Linearly-solvable Markov decision problems Emanuel Todorov Department of Cognitive Science University of California San Diego todorov@cogsci.ucsd.edu
Advances in Neural Information Processing Systems 2 Linearly-solvable Markov decision problems Emanuel Todorov Department of Cognitive Science University of California San Diego todorov@cogsci.ucsd.edu
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Formal models of interaction Daniel Hennes 27.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Taxonomy of domains Models of
Grundlagen der Künstlichen Intelligenz Formal models of interaction Daniel Hennes 27.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Taxonomy of domains Models of
Sequential decision making under uncertainty. Department of Computer Science, Czech Technical University in Prague
 Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Heuristic Search Algorithms
 CHAPTER 4 Heuristic Search Algorithms 59 4.1 HEURISTIC SEARCH AND SSP MDPS The methods we explored in the previous chapter have a serious practical drawback the amount of memory they require is proportional
CHAPTER 4 Heuristic Search Algorithms 59 4.1 HEURISTIC SEARCH AND SSP MDPS The methods we explored in the previous chapter have a serious practical drawback the amount of memory they require is proportional
Prioritized Sweeping Converges to the Optimal Value Function
 Technical Report DCS-TR-631 Prioritized Sweeping Converges to the Optimal Value Function Lihong Li and Michael L. Littman {lihong,mlittman}@cs.rutgers.edu RL 3 Laboratory Department of Computer Science
Technical Report DCS-TR-631 Prioritized Sweeping Converges to the Optimal Value Function Lihong Li and Michael L. Littman {lihong,mlittman}@cs.rutgers.edu RL 3 Laboratory Department of Computer Science
Lectures 6, 7 and part of 8
 Lectures 6, 7 and part of 8 Uriel Feige April 26, May 3, May 10, 2015 1 Linear programming duality 1.1 The diet problem revisited Recall the diet problem from Lecture 1. There are n foods, m nutrients,
Lectures 6, 7 and part of 8 Uriel Feige April 26, May 3, May 10, 2015 1 Linear programming duality 1.1 The diet problem revisited Recall the diet problem from Lecture 1. There are n foods, m nutrients,
12. LOCAL SEARCH. gradient descent Metropolis algorithm Hopfield neural networks maximum cut Nash equilibria
 12. LOCAL SEARCH gradient descent Metropolis algorithm Hopfield neural networks maximum cut Nash equilibria Lecture slides by Kevin Wayne Copyright 2005 Pearson-Addison Wesley h ttp://www.cs.princeton.edu/~wayne/kleinberg-tardos
12. LOCAL SEARCH gradient descent Metropolis algorithm Hopfield neural networks maximum cut Nash equilibria Lecture slides by Kevin Wayne Copyright 2005 Pearson-Addison Wesley h ttp://www.cs.princeton.edu/~wayne/kleinberg-tardos
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Recall that in finite dynamic optimization we are trying to optimize problems of the form. T β t u(c t ) max. c t. t=0 T. c t = W max. subject to.
 max. c t. t=0 T. c t = W max. subject to.") 19 Policy Function Iteration Lab Objective: Learn how iterative methods can be used to solve dynamic optimization problems. Implement value iteration and policy iteration in a pseudo-infinite setting where
19 Policy Function Iteration Lab Objective: Learn how iterative methods can be used to solve dynamic optimization problems. Implement value iteration and policy iteration in a pseudo-infinite setting where
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
On the Approximate Linear Programming Approach for Network Revenue Management Problems
 On the Approximate Linear Programming Approach for Network Revenue Management Problems Chaoxu Tong School of Operations Research and Information Engineering, Cornell University, Ithaca, New York 14853,
On the Approximate Linear Programming Approach for Network Revenue Management Problems Chaoxu Tong School of Operations Research and Information Engineering, Cornell University, Ithaca, New York 14853,
Algorithms. NP -Complete Problems. Dong Kyue Kim Hanyang University
 Algorithms NP -Complete Problems Dong Kyue Kim Hanyang University dqkim@hanyang.ac.kr The Class P Definition 13.2 Polynomially bounded An algorithm is said to be polynomially bounded if its worst-case
Algorithms NP -Complete Problems Dong Kyue Kim Hanyang University dqkim@hanyang.ac.kr The Class P Definition 13.2 Polynomially bounded An algorithm is said to be polynomially bounded if its worst-case
Practicable Robust Markov Decision Processes
 Practicable Robust Markov Decision Processes Huan Xu Department of Mechanical Engineering National University of Singapore Joint work with Shiau-Hong Lim (IBM), Shie Mannor (Techion), Ofir Mebel (Apple)
Practicable Robust Markov Decision Processes Huan Xu Department of Mechanical Engineering National University of Singapore Joint work with Shiau-Hong Lim (IBM), Shie Mannor (Techion), Ofir Mebel (Apple)
An Introduction to Markov Decision Processes. MDP Tutorial - 1
 An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
Chapter 16 Planning Based on Markov Decision Processes
 Lecture slides for Automated Planning: Theory and Practice Chapter 16 Planning Based on Markov Decision Processes Dana S. Nau University of Maryland 12:48 PM February 29, 2012 1 Motivation c a b Until
Lecture slides for Automated Planning: Theory and Practice Chapter 16 Planning Based on Markov Decision Processes Dana S. Nau University of Maryland 12:48 PM February 29, 2012 1 Motivation c a b Until
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
16.4 Multiattribute Utility Functions
 285 Normalized utilities The scale of utilities reaches from the best possible prize u to the worst possible catastrophe u Normalized utilities use a scale with u = 0 and u = 1 Utilities of intermediate
285 Normalized utilities The scale of utilities reaches from the best possible prize u to the worst possible catastrophe u Normalized utilities use a scale with u = 0 and u = 1 Utilities of intermediate
On the Complexity of Computing an Equilibrium in Combinatorial Auctions
 On the Complexity of Computing an Equilibrium in Combinatorial Auctions Shahar Dobzinski Hu Fu Robert Kleinberg April 8, 2014 Abstract We study combinatorial auctions where each item is sold separately
On the Complexity of Computing an Equilibrium in Combinatorial Auctions Shahar Dobzinski Hu Fu Robert Kleinberg April 8, 2014 Abstract We study combinatorial auctions where each item is sold separately
Markov Decision Processes Infinite Horizon Problems
 Markov Decision Processes Infinite Horizon Problems Alan Fern * * Based in part on slides by Craig Boutilier and Daniel Weld 1 What is a solution to an MDP? MDP Planning Problem: Input: an MDP (S,A,R,T)
Markov Decision Processes Infinite Horizon Problems Alan Fern * * Based in part on slides by Craig Boutilier and Daniel Weld 1 What is a solution to an MDP? MDP Planning Problem: Input: an MDP (S,A,R,T)
On bilevel machine scheduling problems
 Noname manuscript No. (will be inserted by the editor) On bilevel machine scheduling problems Tamás Kis András Kovács Abstract Bilevel scheduling problems constitute a hardly studied area of scheduling
Noname manuscript No. (will be inserted by the editor) On bilevel machine scheduling problems Tamás Kis András Kovács Abstract Bilevel scheduling problems constitute a hardly studied area of scheduling
Tropical Geometry in Economics
 Tropical Geometry in Economics Josephine Yu School of Mathematics, Georgia Tech joint work with: Ngoc Mai Tran UT Austin and Hausdorff Center for Mathematics in Bonn ARC 10 Georgia Tech October 24, 2016
Tropical Geometry in Economics Josephine Yu School of Mathematics, Georgia Tech joint work with: Ngoc Mai Tran UT Austin and Hausdorff Center for Mathematics in Bonn ARC 10 Georgia Tech October 24, 2016
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Optimization under Uncertainty: An Introduction through Approximation. Kamesh Munagala
 Optimization under Uncertainty: An Introduction through Approximation Kamesh Munagala Contents I Stochastic Optimization 5 1 Weakly Coupled LP Relaxations 6 1.1 A Gentle Introduction: The Maximum Value
Optimization under Uncertainty: An Introduction through Approximation Kamesh Munagala Contents I Stochastic Optimization 5 1 Weakly Coupled LP Relaxations 6 1.1 A Gentle Introduction: The Maximum Value
Some AI Planning Problems
 Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Topics in Approximation Algorithms Solution for Homework 3
 Topics in Approximation Algorithms Solution for Homework 3 Problem 1 We show that any solution {U t } can be modified to satisfy U τ L τ as follows. Suppose U τ L τ, so there is a vertex v U τ but v L
Topics in Approximation Algorithms Solution for Homework 3 Problem 1 We show that any solution {U t } can be modified to satisfy U τ L τ as follows. Suppose U τ L τ, so there is a vertex v U τ but v L
Temporal Difference. Learning KENNETH TRAN. Principal Research Engineer, MSR AI
 Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
- Well-characterized problems, min-max relations, approximate certificates. - LP problems in the standard form, primal and dual linear programs
 LP-Duality ( Approximation Algorithms by V. Vazirani, Chapter 12) - Well-characterized problems, min-max relations, approximate certificates - LP problems in the standard form, primal and dual linear programs
LP-Duality ( Approximation Algorithms by V. Vazirani, Chapter 12) - Well-characterized problems, min-max relations, approximate certificates - LP problems in the standard form, primal and dual linear programs
Primal-Dual Algorithms for Deterministic Inventory Problems
 Primal-Dual Algorithms for Deterministic Inventory Problems Retsef Levi Robin Roundy David B. Shmoys Abstract We consider several classical models in deterministic inventory theory: the single-item lot-sizing
Primal-Dual Algorithms for Deterministic Inventory Problems Retsef Levi Robin Roundy David B. Shmoys Abstract We consider several classical models in deterministic inventory theory: the single-item lot-sizing
Semi-Infinite Relaxations for a Dynamic Knapsack Problem
 Semi-Infinite Relaxations for a Dynamic Knapsack Problem Alejandro Toriello joint with Daniel Blado, Weihong Hu Stewart School of Industrial and Systems Engineering Georgia Institute of Technology MIT
Semi-Infinite Relaxations for a Dynamic Knapsack Problem Alejandro Toriello joint with Daniel Blado, Weihong Hu Stewart School of Industrial and Systems Engineering Georgia Institute of Technology MIT
Recoverable Robustness in Scheduling Problems
 Master Thesis Computing Science Recoverable Robustness in Scheduling Problems Author: J.M.J. Stoef (3470997) J.M.J.Stoef@uu.nl Supervisors: dr. J.A. Hoogeveen J.A.Hoogeveen@uu.nl dr. ir. J.M. van den Akker
Master Thesis Computing Science Recoverable Robustness in Scheduling Problems Author: J.M.J. Stoef (3470997) J.M.J.Stoef@uu.nl Supervisors: dr. J.A. Hoogeveen J.A.Hoogeveen@uu.nl dr. ir. J.M. van den Akker
Stochastic Safest and Shortest Path Problems
 Stochastic Safest and Shortest Path Problems Florent Teichteil-Königsbuch AAAI-12, Toronto, Canada July 24-26, 2012 Path optimization under probabilistic uncertainties Problems coming to searching for
Stochastic Safest and Shortest Path Problems Florent Teichteil-Königsbuch AAAI-12, Toronto, Canada July 24-26, 2012 Path optimization under probabilistic uncertainties Problems coming to searching for
Chapter 3 Deterministic planning
 Chapter 3 Deterministic planning In this chapter we describe a number of algorithms for solving the historically most important and most basic type of planning problem. Two rather strong simplifying assumptions
Chapter 3 Deterministic planning In this chapter we describe a number of algorithms for solving the historically most important and most basic type of planning problem. Two rather strong simplifying assumptions
Value and Policy Iteration
 Chapter 7 Value and Policy Iteration 1 For infinite horizon problems, we need to replace our basic computational tool, the DP algorithm, which we used to compute the optimal cost and policy for finite
Chapter 7 Value and Policy Iteration 1 For infinite horizon problems, we need to replace our basic computational tool, the DP algorithm, which we used to compute the optimal cost and policy for finite
Markov Decision Processes and Dynamic Programming
 Markov Decision Processes and Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) ENS Cachan - Master 2 MVA SequeL INRIA Lille MVA-RL Course How to model an RL problem The Markov Decision Process
Markov Decision Processes and Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) ENS Cachan - Master 2 MVA SequeL INRIA Lille MVA-RL Course How to model an RL problem The Markov Decision Process
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction