BAYESIAN CLASSIFICATION OF HIGH DIMENSIONAL DATA WITH GAUSSIAN PROCESS USING DIFFERENT KERNELS
|
|
|
- Tracy McKinney
- 5 years ago
- Views:
Transcription
1 BAYESIAN CLASSIFICATION OF HIGH DIMENSIONAL DATA WITH GAUSSIAN PROCESS USING DIFFERENT KERNELS Oloyede I. Department of Statistics, University of Ilorin, Ilorin, Nigeria Corresponding Author: Oloyede I., ABSTRACT: The study investigates asymptotic classification of high dimensional data by adopting Gaussian Process, five different kernels(covariance functions) were employed and compared to showcase the outperformed kernel asymptotically. Log marginal likelihood, Accuracy and log loss were the measurement criteria adopted to measure classification performances. The study therefore observed that the classification performed well asymptotically and found out that Gaussian Process Maximum Likelihood(GPML) had overall best model improvement asymptotically and across the covariance structures. K3 and K4 had the best accuracy in classification paradigm at the lower sample s but GPML and learned kernel had best model accuracy as the sample s tend to large s. KEYWORDS: Bayesian, Kernels, Classification and Gaussian Process. 1. INTRODUCTION Gaussian processes attempt to use mean and covariance function in lieu of mean and covariance used in Gaussian distribution. Though support vector machine is a celebrated classifier (SVM), it is not specifically designed to select features relevant to the predictor. In genetic research with thirty-five patients, if each patient has genes out of which only 32 genes may be relevant to the specific ailment that those patients are suffering from. The SVM cannot in anyway select those genes for classification since it does not have automatic relevance detection (ARD) which had been built specifically into Bayesian Gaussian processes. In network intrusion, there is need to have relevant information for the network defense. Bayesian learning algorithm is built with Automatic Relevant Determination that is able to predict the posterior probability ([Olo17]). Gaussian processes are the prior distribution for regression and classification models where they are not limited to only simple parametric form. It is affirmed that Gaussian process had variety of covariance function with which it can be chosen from for different degree of smoothness. In this study four different classes of kernels are adopted. 164 GP proved to be the easiest way for classification though in a Bayesian paradigm where there is need to integrate over posterior density for the hyperparameter of the covariance function ([Rad98]). Yi et al ([YSC11]) claimed that GP classification is best fit high dimensional covariates compared with other non-parametric approaches that can only model one to two dimensional covariates. GP has Automatic Relevance Determination (ARD) which takes care of the irrelevant features by removing them for the model whenever the covariance structure is irrelevant to the features input. They proposed penalized regression approach to the Gaussian process regression model where they opined that dealing with high dimensional data often resulted in large variances of parameter estimation and high predictive errors. Shi et al ([SMT03]) examined Bayesian regression and classification by mixing Gaussian Process, their study concluded that Bayesian approach leads to robust models as compared with optimization approach. Kemmler et al ([K+13]) considered homoscedastic Gaussian noise in their experiment of one-class classification Gaussian process and concluded that the Gaussian process based measures is suitable for regression and classification of novelty detection problems. In Bayesian classification paradigm, Gaussian prior is adopted since the marginal and conditional posteriors are normal, this is advantageous over other distribution ([Fon17]). The Gaussian process can be regarded as distribution over function and is fully specified as. Both the mean and covariance function of the GP can be expressed as ;. The GP involves the covariance function and its hyperparameter. There will be no need to adopt complicated mean function ([Fon17]). There are fundamental task in statistics which comprises estimation, classification, selection and prediction with the ex ante belief (prior) combined with likelihood which lead to posterior density in a
2 Bayesian treatment. Williams and Rasmussen ([WR86]) claimed that GP prior application over function outperformed other state of the art method of classification. Shi et al ([SMT03]) claimed that Bayesian learning using GP priors elicit knowledge from covariance based kernel parameter with ex ante information (prior belief) that yield posterior density with respect to training datasets. Kaiguang et al ([KPX00]) compared GPC model with k-nearest neighbor and support vector machine then concluded that GPC outperformed KNN and SVM thus yielded classification accuracy. By and large, most of the renown authors working on GP had not examined asymptotic behaviour both at lower and high dimensional data subject to some redundancy, this is the gap this study is try to fill. Kemmler ([K+13]) claimed that machine learning conjugated with Gaussian prior gave room for the formulation of kernel based learning algorithm in a Bayesian paradigm. They derived one-class classification approach which is based on kernel based algorithm of Bayesian framework. They claimed that their one class classification approach outperformed the well-known support vector data description, this may be due to the presence of Automatic Relevance Determination (ARD) which is embedded in Gaussian process. In pattern recognition, it is main goal is to classifying the data in to c regions with the decision boundaries as the boundaries between the regions. It has been opined in the literature that the optimum classification is based on the use of posterior probability of class membership ([AS06]). The supervised learning algorithm usually predict outcomes(y) given a new set of predictor(x) - testing datasets which is totally different from the training datasets D that is used to fit the model ([Fon17]). In lieu of the above scenario, Gaussian Process adopted posterior predictive distribution which is probabilistic with mean and covariance functions. 2. METHODOLOGY Let the input pattern x be assigned to one of C classes. Probabilistic classification is adopted in the study where test predictive is of the form of class probability rather than guessing of the class label. Let be the joint probability where y denotes the class label. The generative approach(sampling paradigm) models the classconditional distribution for with the prior probability for each class (2.1) 165 Discriminative approach (diagnostic approach) models. Due to hard problem that usually resulted from the density estimation of the class conditional distribution, the generative approach may be chosen. It could be established that discriminative approach can model directly but failed in an attempt to proffer solution to overfitting and hard problems of Rasmussen and Williams ([RW06]) (2.2) The case of multi-class GP classification models is observed where t=-1, 0 or 1 to label three distinctive classes of latent target variable; often denoted by. The input vector of n-dimensional features is denoted by x-covariates as.the feature variables were generated by uniform distribution with 25 redundant variables. Given a set of training data 1,.., ; =0,1,2 with input dimension and target value, with a fixed hyperparameter. In GP classification there are possibility of selecting covariance prior from sets of covariance available. ( )2+ 1 (2.3) where as the hyperparameters. For multi class where target variable has characteristic of three or more categories form the set [0,1,,k]. The k latent variable is defined as (2.4) where Gaussian process. The class of a large training set is denoted as with a different value of features and the class conditional probability is expressed as for feature vector x. the Bayes theorem based on one classification is. (2.5) Thus is the likelihood( class conditional probability) which is expressed with Gaussian Distribution(this uses mean and covariance), is the prior which is evaluated with Gaussian Prior (Process- it uses mean and covariance functions) while is the evidence that is set as unity. The study therefore measures the feature, obtain the
3 posterior probability for each of the classes and thereafter select the one with the larger posterior. Under the high dimensional features, the Gaussian Distribution is Then the class conditional probability is (2.6) (2.7) The expression can be regarded as mehalonobis distance as similar to. Let where be the regressors or features and e is the disturbance term with zero mean and covariance function. Considering the expectation: (2.8) (2.9) thus by adopting the Gaussian Process and the covariance function. This is obtainable after the model had been fitted as (2.10) drawn from uniform distribution that is contaminated with some redundant input, it should be noted that Bayesian classification with Gaussian process has Automatic Relevance Detection (ARD) that can identify the relevant input for classification using the transfer function of multinomial logistic function. We define the multi-class problem as with the hyperparameter v assigned with Gaussian priors as. The mean function is attributed with while the implies covariance function is of the various Kernels such as (2.13) is the jitter that is added to improve the efficiency of the sample ([SMT03]). Classification Problems: Thus posterior mean is obtained as (2.11) 2 1, (2.12) 3. RESULTS The covariance function is expressed as adopting the single feature vector xi with we have. Thus the study imposed redundancy in the data generation process. This is therefore affected the covariance function thereby corrupting the variances, we have where. Exponential Squared Kernel: this is the setting of the element of the covariance matrix for the univariate feature vector:. The prior indicates that and are less correlated with reference to the distance between and. Linear kernel let x and y be on the basis function such that The target vector is drawn from multinomial distribution of the set classes and the feature 166 Gaussian prior conjugated with likelihood choosing different covariance structure, five different covariance functions were adopted out of which two were combination of four covariance function features (high dimensional data) with the sample s: 26; 54; 100; 200; 500 and 1000, 1000 features were generated and infused with multicollinearity, the study specified 20 redundant features with three clases of dependent variables, 2 classes per cluster. We used K1 to capture a long term, smooth rising trend with RBF kernel with a large length-scale enforces the component to be smooth. K2 was used to capture a seasonal component of periodic ExpSineSquared kernel with a fixed periodicity of 1 year. The length-scale of this periodic component, controlling its smoothness, is a free parameter. K3 was adopted to captured smaller, medium term irregularities of RationalQuadratic kernel component, those length scale and alpha parameter,
4 which determines the diffuseness of the lengthscales, are to be determined whereas K4 captured a noise term, consisting of an RBF kernel contribution of the correlated noise components such as local weather phenomena, and a WhiteKernel contribution for the white noise. We therefore sum up the four covariance functions with different parameters to derive Gaussian process maximum likelihood(gpml) and learned kernels. Table 3.1. The asymptotic Gaussian Process Sample LML Accuracy Log-loss GPML Table 3.1 showed the asymptotic classification of high dimensional data with GPML kernel. It was observed that as the sample increases from 26 to log likelihood from to , thus obeyed law of large number. The study observed the accuracy and precision of the classification as the sample as the sample increases from 26 to 100 with increased in accuracy from 0.17 to 0.7 at sample 100 but it upturned when the sample increased to 200, the study revealed that the accuracy got increased as the sample increased from 200 up till The log loss improved strategically from sample s from 26 to 100 as it decreased from 1.11 to 1.06 but upturned as the sample increased to 200, thereafter improved as the sample increased from 200 up to obeyed law of large number. The study observed in the accuracy and precision of the classification, as the sample increases from 26 to 100, the accuracy increased from to 0.75 but it upturned when the sample increased to 200, the study revealed that the accuracy got increased as the sample increased from 200 up till The log loss improved strategically from sample s 26 to 100 as it decreased from 0 to but upturned as the sample increased to 200, thereafter improved as the sample increased from 200 up to 1000 it decreases from to Table 3.3. The asymptotic Gaussian Process Sample LML Accuracy Log-loss K Table 3.3 showed the asymptotic classification of high dimensional data with learned kernel. It was observed that as the sample increases from 26 to log likelihood from to , thus obeyed law of large number. The study observed in the accuracy and precision of the classification, as the sample increases from 26 to 100, the accuracy increased from 0.17 to 0.7 but it upturned when the sample increased to 200, the study revealed that the accuracy got increased as the sample increased from 200 up till The log loss improved strategically from sample s 26 to 1000 as it decreased from to Table 3.2. The asymptotic Gaussian Process classification using learn covariance function for high dimension data Sample LML Accuracy Logloss learned Table 3.2 showed the asymptotic classification of high dimensional data with learned kernel. It was observed that as the sample increases from 26 to log likelihood from to , thus Table 3.4. The asymptotic Gaussian Process Sample LML Accuracy Log-loss K Table 3.4 showed the asymptotic classification of high dimensional data with GPML kernel. It was observed that as the sample increases from 26 to log likelihood from to , thus 167
5 obeyed law of large number. The study observed the accuracy and precision of the classification as the sample as the sample increases from 26 to 54 with decrease in accuracy from 0.33 to at sample increases to 100, it upturns with accuracy of 0.30, the study revealed that the accuracy got increased as the sample increased from 200 up till The log loss when the sample is 26 is started with improvement of then later upturn when the sample increases from 54 to 100 then later upturned as the sample increased to 200 up till Table 3.5. The asymptotic Gaussian Process Sample LML Accuracy Log-loss K Table 3.5 showed the asymptotic classification of high dimensional data with GPML kernel. It was observed that as the sample increases from 26 to log likelihood from to , thus obeyed law of large number. The study observed the accuracy and precision of the classification as the sample as the sample increases from 26 to 54 with decreases in accuracy from 0.33 to Later it upturn when the sample increases to 100 remains the same till sample is 200 with increases in accuracy to The study revealed that the accuracy got constant increased as the sample increased from 500 to The log loss improved strategically from sample s increases from 26 to 1000 has a constant value of COMPARISON OF THE KERNELS(COVARIANCE FUNCTIONS) In sample 26, GPML has overall best model improvement with LML value of , with sample 54, GPML has the overall best model improvement with LML value of , as the sample increases to 100, GPML also has overall best model improvement with LML of , for sample 200 and 500 the GPML has overall best model improvement with LML value of and respectively. Then as the sample increases to 1000, the K1 has the overall best model improvement with LML value of In another words In sample 26,54,100,200 and 500 GPML has overall best model improvement with LML value of , , , and respectively. Then as the sample increases to 1000, the K1 has the overall best model improvement with LML value of For accuracy, as the sample is 26, K3 and K4 model has the best accuracy of 0.333, when the sample increases to 54, GPML model and K1 model are the best accuracy with accuracy value, as the sample increases to 100, the best model is learned with accuracy value of 0.75, when sample s increase to 200 the best model are GPML and learned with accuracy value of 0.4, as the sample s increase to 500 and 1000 the best model is learned with accuracy values of 0.51 and 0.55 respectively. For log loss, in sample 54, the overall best log loss is GPML and K1 model with value of log loss of 1.086, in sample 100 the overall best log loss is GPML model with a log loss value of 1.056, as the sample increases to 200 and 500 the overall best log loss model is learned with log loss value of and respectively, as the sample increases to 1000 the best log loss model is K1 with a log loss value of CONCLUSION The study modelled and classified high dimensional data using Gaussian process with varying covariance functions. The classification found that GPML had overall best model improvement asymptotically and across the covariance structures. K3 and K4 had the best accuracy in classification paradigm at the lower sample s but GPML and learned kernel had best model accuracy as the sample s tend to large scales. 168
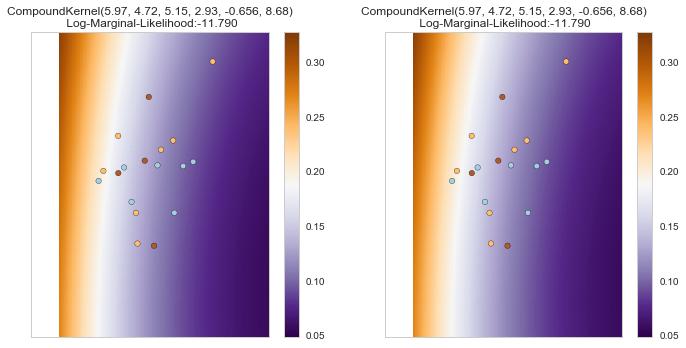

6 169

7 Figure 4.1. The classification of the multiclass high dimensional data The charts above depicted the classification of the multiclass high dimensional data using Gaussian process of different kernels. REFERENCES [AS06] [Fon17] Amine B., Sofiane B. B. - Bayesian Learning using Gaussian for Gas Identification, IEEE Transactions on instrumentation and measurement vol. 55, No 36, Fonnesbeck C. - Fitting Gaussian Process Models in Python, [KPX00] Kaiguang Z., Popescu S., Xuesong Z. - Bayesian learing with Gaussian process for supervised classification of Hyperspectral Data, American Society for Photogrammetry and Remote Sensing, vol. 74, No. 10 pp , [K+13] Kemmler M., Rodner E., Wacker E. S., Denzler J. - One-class classification with Gaussian Process, Pattern recognition 46 ( ) [Olo17] Oloyede I. - Bootstrapping Supervised Classifier Paradigm Annals. Computer 170 [Rad98] Science Series. 15th Tome 2nd Fasc., , Radford M. N. - Regression and classification using Gaussian process priors, Bayesian statistics 6, J.M. Bernardo, J.O. Berger, A.P. Dawid and A.F.M. Smith (EDs.), [RW06] Rasmussen C. E., William C. K. - Gaussian Process for machine learning, The MIT press pp [SMT03] Shi J. Q., Murray-Smith R., Titterington D. M. - Bayesian regression and classification using mixtures of Gaussian processes, Int. J. Adapt. Control Signal Process.; 17: (DOI: /acs.744), [WR96] Williams C. K. I., Rasmussen C. E. - Gaussian Process for Regression, in D.S. Touretsky, M.C.Mozer and M.E. Hasselmo (Eds.): Advances in Neural Information Processing Systems 8, pp MIT press, [YSC11] Yi G., Shi J.Q., Choi T. - Penalized Gaussian Process Regression and Classification for High-Dimensional Nonlinear Data. Biometrics 67, DOI: /j x, 2011.
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Introduction. Chapter 1
 Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
Gaussian Processes (10/16/13)
") STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Learning Gaussian Process Models from Uncertain Data
 Learning Gaussian Process Models from Uncertain Data Patrick Dallaire, Camille Besse, and Brahim Chaib-draa DAMAS Laboratory, Computer Science & Software Engineering Department, Laval University, Canada
Learning Gaussian Process Models from Uncertain Data Patrick Dallaire, Camille Besse, and Brahim Chaib-draa DAMAS Laboratory, Computer Science & Software Engineering Department, Laval University, Canada
Introduction to Gaussian Process
 Introduction to Gaussian Process CS 778 Chris Tensmeyer CS 478 INTRODUCTION 1 What Topic? Machine Learning Regression Bayesian ML Bayesian Regression Bayesian Non-parametric Gaussian Process (GP) GP Regression
Introduction to Gaussian Process CS 778 Chris Tensmeyer CS 478 INTRODUCTION 1 What Topic? Machine Learning Regression Bayesian ML Bayesian Regression Bayesian Non-parametric Gaussian Process (GP) GP Regression
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING. Non-linear regression techniques Part - II
 1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
Gaussian Processes. Le Song. Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012
 Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Gaussian Process Regression
 Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Model Selection for Gaussian Processes
 Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
Gaussian process for nonstationary time series prediction
 Computational Statistics & Data Analysis 47 (2004) 705 712 www.elsevier.com/locate/csda Gaussian process for nonstationary time series prediction Soane Brahim-Belhouari, Amine Bermak EEE Department, Hong
Computational Statistics & Data Analysis 47 (2004) 705 712 www.elsevier.com/locate/csda Gaussian process for nonstationary time series prediction Soane Brahim-Belhouari, Amine Bermak EEE Department, Hong
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Introduction to Gaussian Processes
 Introduction to Gaussian Processes Neil D. Lawrence GPSS 10th June 2013 Book Rasmussen and Williams (2006) Outline The Gaussian Density Covariance from Basis Functions Basis Function Representations Constructing
Introduction to Gaussian Processes Neil D. Lawrence GPSS 10th June 2013 Book Rasmussen and Williams (2006) Outline The Gaussian Density Covariance from Basis Functions Basis Function Representations Constructing
Neutron inverse kinetics via Gaussian Processes
 Neutron inverse kinetics via Gaussian Processes P. Picca Politecnico di Torino, Torino, Italy R. Furfaro University of Arizona, Tucson, Arizona Outline Introduction Review of inverse kinetics techniques
Neutron inverse kinetics via Gaussian Processes P. Picca Politecnico di Torino, Torino, Italy R. Furfaro University of Arizona, Tucson, Arizona Outline Introduction Review of inverse kinetics techniques
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Chemometrics: Classification of spectra
 Chemometrics: Classification of spectra Vladimir Bochko Jarmo Alander University of Vaasa November 1, 2010 Vladimir Bochko Chemometrics: Classification 1/36 Contents Terminology Introduction Big picture
Chemometrics: Classification of spectra Vladimir Bochko Jarmo Alander University of Vaasa November 1, 2010 Vladimir Bochko Chemometrics: Classification 1/36 Contents Terminology Introduction Big picture
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Bayesian Data Fusion with Gaussian Process Priors : An Application to Protein Fold Recognition
 Bayesian Data Fusion with Gaussian Process Priors : An Application to Protein Fold Recognition Mar Girolami 1 Department of Computing Science University of Glasgow girolami@dcs.gla.ac.u 1 Introduction
Bayesian Data Fusion with Gaussian Process Priors : An Application to Protein Fold Recognition Mar Girolami 1 Department of Computing Science University of Glasgow girolami@dcs.gla.ac.u 1 Introduction
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Probabilistic Graphical Models Lecture 20: Gaussian Processes
 Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
STAT 518 Intro Student Presentation
 STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
Optimization of Gaussian Process Hyperparameters using Rprop
 Optimization of Gaussian Process Hyperparameters using Rprop Manuel Blum and Martin Riedmiller University of Freiburg - Department of Computer Science Freiburg, Germany Abstract. Gaussian processes are
Optimization of Gaussian Process Hyperparameters using Rprop Manuel Blum and Martin Riedmiller University of Freiburg - Department of Computer Science Freiburg, Germany Abstract. Gaussian processes are
INTRODUCTION TO PATTERN RECOGNITION
 INTRODUCTION TO PATTERN RECOGNITION INSTRUCTOR: WEI DING 1 Pattern Recognition Automatic discovery of regularities in data through the use of computer algorithms With the use of these regularities to take
INTRODUCTION TO PATTERN RECOGNITION INSTRUCTOR: WEI DING 1 Pattern Recognition Automatic discovery of regularities in data through the use of computer algorithms With the use of these regularities to take
Active and Semi-supervised Kernel Classification
 Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Machine Learning. Regression-Based Classification & Gaussian Discriminant Analysis. Manfred Huber
 Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
EEL 851: Biometrics. An Overview of Statistical Pattern Recognition EEL 851 1
 EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Machine Learning! in just a few minutes. Jan Peters Gerhard Neumann
 Machine Learning! in just a few minutes Jan Peters Gerhard Neumann 1 Purpose of this Lecture Foundations of machine learning tools for robotics We focus on regression methods and general principles Often
Machine Learning! in just a few minutes Jan Peters Gerhard Neumann 1 Purpose of this Lecture Foundations of machine learning tools for robotics We focus on regression methods and general principles Often
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Gaussian Processes in Machine Learning
 Gaussian Processes in Machine Learning November 17, 2011 CharmGil Hong Agenda Motivation GP : How does it make sense? Prior : Defining a GP More about Mean and Covariance Functions Posterior : Conditioning
Gaussian Processes in Machine Learning November 17, 2011 CharmGil Hong Agenda Motivation GP : How does it make sense? Prior : Defining a GP More about Mean and Covariance Functions Posterior : Conditioning
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees
 Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Least Absolute Shrinkage is Equivalent to Quadratic Penalization
 Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes
 CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Discriminant Analysis and Statistical Pattern Recognition
 Discriminant Analysis and Statistical Pattern Recognition GEOFFREY J. McLACHLAN Department of Mathematics The University of Queensland St. Lucia, Queensland, Australia A Wiley-Interscience Publication
Discriminant Analysis and Statistical Pattern Recognition GEOFFREY J. McLACHLAN Department of Mathematics The University of Queensland St. Lucia, Queensland, Australia A Wiley-Interscience Publication
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
9/26/17. Ridge regression. What our model needs to do. Ridge Regression: L2 penalty. Ridge coefficients. Ridge coefficients
 What our model needs to do regression Usually, we are not just trying to explain observed data We want to uncover meaningful trends And predict future observations Our questions then are Is β" a good estimate
What our model needs to do regression Usually, we are not just trying to explain observed data We want to uncover meaningful trends And predict future observations Our questions then are Is β" a good estimate
Bayesian Support Vector Machines for Feature Ranking and Selection
 Bayesian Support Vector Machines for Feature Ranking and Selection written by Chu, Keerthi, Ong, Ghahramani Patrick Pletscher pat@student.ethz.ch ETH Zurich, Switzerland 12th January 2006 Overview 1 Introduction
Bayesian Support Vector Machines for Feature Ranking and Selection written by Chu, Keerthi, Ong, Ghahramani Patrick Pletscher pat@student.ethz.ch ETH Zurich, Switzerland 12th January 2006 Overview 1 Introduction
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Chap 1. Overview of Statistical Learning (HTF, , 2.9) Yongdai Kim Seoul National University
 Yongdai Kim Seoul National University") Chap 1. Overview of Statistical Learning (HTF, 2.1-2.6, 2.9) Yongdai Kim Seoul National University 0. Learning vs Statistical learning Learning procedure Construct a claim by observing data or using logics
Chap 1. Overview of Statistical Learning (HTF, 2.1-2.6, 2.9) Yongdai Kim Seoul National University 0. Learning vs Statistical learning Learning procedure Construct a claim by observing data or using logics
Lecture 5: GPs and Streaming regression
 Lecture 5: GPs and Streaming regression Gaussian Processes Information gain Confidence intervals COMP-652 and ECSE-608, Lecture 5 - September 19, 2017 1 Recall: Non-parametric regression Input space X
Lecture 5: GPs and Streaming regression Gaussian Processes Information gain Confidence intervals COMP-652 and ECSE-608, Lecture 5 - September 19, 2017 1 Recall: Non-parametric regression Input space X
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning, Fall 2009: Midterm
 10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn
, Bayes Rule, knn") Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn CMU 10-701: Machine Learning (Fall 2016) https://piazza.com/class/is95mzbrvpn63d OUT: September 13th DUE: September
Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn CMU 10-701: Machine Learning (Fall 2016) https://piazza.com/class/is95mzbrvpn63d OUT: September 13th DUE: September
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
GWAS V: Gaussian processes
 GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
Support Vector Machines. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Support Vector Machines CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Linear Classifier Naive Bayes Assume each attribute is drawn from Gaussian distribution with the same variance Generative model:
Support Vector Machines CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Linear Classifier Naive Bayes Assume each attribute is drawn from Gaussian distribution with the same variance Generative model:
SINGLE-TASK AND MULTITASK SPARSE GAUSSIAN PROCESSES
 SINGLE-TASK AND MULTITASK SPARSE GAUSSIAN PROCESSES JIANG ZHU, SHILIANG SUN Department of Computer Science and Technology, East China Normal University 500 Dongchuan Road, Shanghai 20024, P. R. China E-MAIL:
SINGLE-TASK AND MULTITASK SPARSE GAUSSIAN PROCESSES JIANG ZHU, SHILIANG SUN Department of Computer Science and Technology, East China Normal University 500 Dongchuan Road, Shanghai 20024, P. R. China E-MAIL:
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Computational Genomics
 Computational Genomics http://www.cs.cmu.edu/~02710 Introduction to probability, statistics and algorithms (brief) intro to probability Basic notations Random variable - referring to an element / event
Computational Genomics http://www.cs.cmu.edu/~02710 Introduction to probability, statistics and algorithms (brief) intro to probability Basic notations Random variable - referring to an element / event
Probabilistic Machine Learning. Industrial AI Lab.
 Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Gaussian Processes. 1 What problems can be solved by Gaussian Processes?
 Statistical Techniques in Robotics (16-831, F1) Lecture#19 (Wednesday November 16) Gaussian Processes Lecturer: Drew Bagnell Scribe:Yamuna Krishnamurthy 1 1 What problems can be solved by Gaussian Processes?
Statistical Techniques in Robotics (16-831, F1) Lecture#19 (Wednesday November 16) Gaussian Processes Lecturer: Drew Bagnell Scribe:Yamuna Krishnamurthy 1 1 What problems can be solved by Gaussian Processes?
20: Gaussian Processes
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Kernel expansions with unlabeled examples
 Kernel expansions with unlabeled examples Martin Szummer MIT AI Lab & CBCL Cambridge, MA szummer@ai.mit.edu Tommi Jaakkola MIT AI Lab Cambridge, MA tommi@ai.mit.edu Abstract Modern classification applications
Kernel expansions with unlabeled examples Martin Szummer MIT AI Lab & CBCL Cambridge, MA szummer@ai.mit.edu Tommi Jaakkola MIT AI Lab Cambridge, MA tommi@ai.mit.edu Abstract Modern classification applications
Computer Vision Group Prof. Daniel Cremers. 4. Gaussian Processes - Regression
 Group Prof. Daniel Cremers 4. Gaussian Processes - Regression Definition (Rep.) Definition: A Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution.
Group Prof. Daniel Cremers 4. Gaussian Processes - Regression Definition (Rep.) Definition: A Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution.
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume