CS505: Distributed Systems
|
|
|
- Emerald Spencer
- 6 years ago
- Views:
Transcription

1 Cristina Nita-Rotaru CS505: Distributed Systems Ordering events. Lamport and vector clocks. Global states. Detecting failures.
2 Required reading for this topic } Leslie Lamport,"Time, Clocks, and the Ordering of Events in a Distributed System, 1978 } Colin J. Fidge "Timestamps in Message-Passing Systems That Preserve the Partial Ordering, 1988 } K. Mani Chandy and Leslie Lamport, ``Distributed Snapshots: Determining Global States of Distributed Systems,
3 When things go wrong Swich to backup CLIENT CLIENT I am the new Primary!!!! BACKUP CLIENT CLIENT PRIMARY Oops, no Service! 3 CLIENT I am still the Primary
4 1: Clock synchronization
5 System Model Dimensions } Non-deterministic processes } Communication is through messages } Network packets can be lost, duplicated, delivered very late or out of order, spied upon, replayed, corrupted, source or destination can lie } Communication can be authenticated or not } Execution model can be } Asynchronous: no synchronized clocks or time-bounds on message delays. } Synchronous: execution is partitioned in rounds, all messages send in a round are delivered in that round 5
6 Execution, Configuration, Events } Participants: set of processes p i, each process with a state s i } Configuration C t : set of state of each process at some moment } Events: send or deliver a message, events can change the state at a process } Execution: sequence of configuration and events 6
7 Safety and Liveness } Safety: a condition that must hold in every finite prefix of a sequence (from an execution) nothing bad happens } Liveness: a condition that must hold a certain number of times something good happens 7
8 Example } Successfully passing the exam for this course } Safety: in case you take the exam, do not fail it } Liveness: you eventually have to take the exam 8
9 Ordering of Events } Single process: follow the sequence of events, each event has a timestamp and the causality relation between events is given by time } Distributed processes: many events generated at different processes, how to order events? } Time is essential for ordering events in a distributed system } Physical time: local clock; global clock } Logical time: partial ordering, total ordering 9
10 What is Time? } The second is the duration of 9,192,631,770 periods of the radiation corresponding to the transition between the two hyperfine levels of the ground state at the temperature of 0 K of the caesium 133 atom. } Unit for measuring time 10
11 World Time } International Atomic Time (TAI): is a continuous count of seconds based on atomic clocks around the world. } Coordinated Universal Time (UTC): since January 1, 1972, it has been defined to follow TAI with an exact offset of an integer number of seconds, changing only when a leap second is added to keep clock time synchronized with the rotation of the Earth. 11
12 Using Real Clocks to Order Events } Global clock: processes have access to a central global clock, each event will carry a timestamp } Local clock: each process has its own clock } What if the clocks are not synchronized } What if events happened at the same time? 12
13 Clocks in Computers } Real-time Clock: CMOS clock (counter) circuit driven by a quartz oscillator with battery backup to continue measuring time when power is off } OS generally programs a timer circuit to generate an interrupt periodically } e.g., 60, 100, 250, 1000 interrupts per second (Linux 2.6+ adjustable up to 1000 Hz) } Programmable Interval Timer (PIT) Intel 8253, 8254 } Interrupt service procedure adds 1 to a counter in memory } Quartz oscillators oscillate at slightly different frequencies, clocks do not agree in general 13
14 Synchronizing Physical Clocks } External synchronization: Consider the source S and the synchronization bound B > 0, then none of the clocks drift with more than B from S, at any time } Internal synchronization: Consider the synchronization bound B>0, then at any time, the difference between any two clocks is within B } Skew: the instantaneous difference between (the readings of) two clocks } Drift rate: the difference between the clock and a nominal perfect reference clock per unit of time } Networks are asynchronous and unreliable 14
15 Cristian s Algorithm } Assumes a time server has the accurate time and client synchronizes with it } How it works: } Client asks the time server for time } Server sends its time Tserver } Client estimates how long it takes to receive answer from server as RTT/2 where: } RTT = (Tclient_receive Tclient_send) } Client adjusts its clock T client = T server + (RTT / 2)! 15
16 Cristian s Algorithm Accuracy } Assumes that it takes the same amount of time to send the request and receive the answer } Minimum time to transmit a message one-way: min } Time to receive the server s message is [min, RTT min] } Time at client [Tserver + min, Tserver + RTT min] accuracy is ±(RTT /2 - min)! 16
17 Berkeley Algorithm } Assumes no machine has an accurate time source; uses an elected master to synchronize } Master coordinates: } queries the clients for their local time } estimates the clients local time (similar to Cristian s Algorithm) } averages all times including its own, excluding the ones that are too drifted } tells each client the offset with each they need to adjust } Some systems use multiple time servers } Time is more accurate, but still drifts 17
18 Network Time Protocol (NTP) } NTP is a distributed service that synchronizes a computer clock to other computers on the Internet or local time sources } Has the goal of synchronizing clocks to less than a millisecond or two relative to Coordinated Universal Time (UTC) } Trivia: } the most widely-used time synchronization protocol on the Internet today } there are over 2,000 NTP servers on the Internet today for public use } uses UDP as a transport protocol 18
19 On-the-wire Protocol } Client initiates request by recording timestamp T1, placing in packet, then sending to NTP server } NTP Server records timestamp T2 when receiving request packet (and can do other processing if needed) } When ready to send a reply, the NTP server records timestamp T3, places T1, T2, T3 in reply and sends back to client } Client receives reply and records timestamp T4 NTP server client T 2 T 3 T 1 T 1 T 2 T 3 19 T 1 T 4
20 Updating the Clock } Client calculates offset between his clock and server s clock, and updates his clock by that amount } To synchronize exactly, client needs to know one-way delay between server and client } This is difficult in practice to ascertain, so NTP assumes path is symmetrical and one-way delay is half of round trip time } Offset is calculated to be: ½ [(T2 - T1) + (T3 - T4)] 20
21 Reference Clocks } Many NTP servers synchronize directly to UTC using specialized equipment } Atomic clocks: Ultimately are the root source of time in NTP } Global Positioning System (GPS): can synchronize with a satellite s atomic clock } Code Division Multiple Access (CDMA): can synchronize with a local wireless provider (who in turn most likely synchronizes using GPS) } Radio signals: similar to CDMA, can synchronize with time/ frequency radio stations 21
22 From Physical Clocks to Logical Clocks } Synchronized clocks are great if we have them } Why do we need the time anyway? } In distributed systems we care about what happened before what 22
23 2: Lamport clocks
24 ``HAPPENED BEFORE p 1 p 2 p 3 p 4 } If events a and b take place at the same process and a occurs before b then a b } If a is a send event of m at p1 and b is a deliver event of the same m at p2, p1 p2 then a b } If a b and b c then a c 24
25 Reminder: Partial and Total Order } Definition: A relation R over a set S is a partial order iff for each a, b, and c in S: } ara (reflexive). } arb bra a = b (antisymmetric). } arb brc arc (transitive). } Definition: A relation R over a set S is total order if for each distinct a and b in S, R is antisymmetric, transitive and either arb or bra (completeness). 25
26 Logical Clocks: Lamport Clocks } Each process maintains his own clock C i (a counter) } Clock Condition: for any events a and b in process p i if a b then C i (a) < C i (b) } Implementation: } each process p i increments C i between any successive events } on sending a message m, attach to the message local clock T m = C i (a) } on receiving of message m process p k sets C k to C k = max(c k,t m )
27 Lamport Clocks: Example C k = max(c k,t m ) + 1 p p p
28 Lamport Clocks: Total Order } Logical Clocks only provide partial order } Create Total Order by breaking the ties } Example to break ties, use process identifiers, have an order on process identifiers: } If a is event in pi and b is event in p then } C i (a) < C j (b) or a b } C i (a) = C j (b) and p i < p j iff 28
29 Concurrent Events } Concurrent events: If a b and b a then a and b are concurrent } Logical clocks assign order to events that are causally independent, in other words events that are causally independent appear as if they happened in a certain order } For some applications (e.g. debugging) it is important to capture independence 29
30 3: Vector clocks
31 Vector Clocks } Independently developed by Colin Fidge and Friedemann Mattern in } Each process maintains a vector Ci C i = [0, 0,..., 0]. } When p i executes an event, it increments its own clock C i [i] } When p i sends a message m to p j, it attaches its vector C i on m. } When p i receives a message m,increments its own clock and updates the clock for the other processes as follows j: 1 j n, j i: Ci[j] = max(ci[j], m.c[j]) Ci[i] = Ci[i]
32 Vector Clocks: Example p p M1[010] M2[210] M5[412] M6[512] M3[212] M4[213] p
33 How to Order with Vector Clocks } Given two events a and b, a b if and only if } V(a) is less than or equal to V(b) for all process indices, and at least one of those relationships is strictly smaller. } a b i: 1 i n: V(a)[i] V(b)[i] i: 1 i n: V(a)[i] < V(b)[i] } a b i: 1 i n: V(a)[i] < V(b)[i] j: 1 j n: V(b)[j] < V(a)[j] 33
34 What Events Are Independent? p 1 m p m m m p m m
35 3: Determining global states
36 Ordering Events in Distributed Systems } Time is essential for ordering events in a distributed system } Physical time: local clock; global clock } Logical time: Lamport clocks, vector clocks 36
37 History of Events: Some Definitions } Given a process p i } Event e i j is the event j at process i } History of process p i, h i is a sequence of events that happened at p i } h i = <e i0, e i1, > } Prefix history at p i up to k, is the history of p i up to the k th event } h i k = <e i0, e i1,,e i k > } State S i k is the state of process p i immediately before the k th event 37
38 History of Events: More Definitions } Given a set of processes } Global history: the set of all processes histories } H = i (h i ) } Global state: the set of states at each process } S = i (S i k i ) } Cut: a set of prefix histories } C H = h 1 c1 h 2 c2 h n cn } Frontier of a cut: the set of last event that happened in each prefix history } C = {e i ci, i = 1,2, n} 38
39 Consistent Cuts Definition: A cut C is consistent if for any event e in the cut, if an event f happened before e, then f is also in the cut C e C (if f e then f C) p p Consistent cut Inconsistent cut 39
40 Global States: More Definitions } Consistent global state: a global state that corresponds to a consistent cut } Run: a total ordering of events in history H that is consistent with each process history h i s ordering } Linearization: a run consistent with happens-before relation in H; Linearizations pass through consistent global states } Reachability: a global state S k is reachable from global state S i, if there is a linearization, L, that passes through S i and then through S k. 40
41 Global State Predicate } How do we use global states to reason about distributed systems? } Global state predicate: a function from the set of global states to {TRUE, FALSE} } Stable global state predicate: one that once it becomes true, it remains true in all future states reachable from that state. } Examples: } the system is deadlocked } all tokens in a token ring have disappeared } the computation has finished 41
42 Remember Safety and Liveness } Safety: a condition that must hold in every finite prefix of a sequence (from an execution) nothing bad happens } Liveness: a condition that must hold a certain number of times something good happens 42
43 Stable Global States and Safety } Look for undesirable properties, bad things } Assume that a bad thing BT (for example deadlock) is a global state predicate and S 0 is the initial state of the system, then Safety with respect to BT means S reachable from S 0, BT(S) = FALSE 43
44 Stable Global States and Liveness } Look for desirable properties, good things } Assume that a good think GT (for example reaching termination) is a global-state-predicate and S 0 is the initial state of the system then Liveness with respect to GT means: For any linearization L starting at S 0 state,s L reachable from S 0 such that GT(S L ) = TRUE 44
45 Determining Global States } If synchronized clocks are available, each process records its state at a known time t } How to obtain the state of the messages that transit the channels? } What if synchronized clocks are not available? 45
46 Recording Global States } How to distinguish between the messages to be recorded in the snapshot from those not to be recorded? } How to determine when a process takes its snapshot? 46
47 Chandy-Lamport Algorithm: Model } Records a consistent global state of an asynchronous system. } System model: } No failures and all messages arrive intact and only once } Communication channels are unidirectional and FIFO ordered } There is a communication path between any two processes } Other assumptions } Any process may initiate the snapshot algorithm } The snapshot algorithm does not interfere with the normal execution of the processes } Each process in the system records its local state and the state of its incoming channels 47
48 Chandy-Lamport Algorithm } Uses a control message, marker, to separate messages in the channels between those to be included in the snapshot from those not to be recorded in the snapshot. } After a process has recorded its snapshot, it sends a marker before sending out any more messages. } A process must record its snapshot no later than when it receives a marker on any of its incoming channels. 48
49 Chandy-Lamport Algorithm } Can be initiated by any process by executing the Marker Sending Rule } A process executes the Marker Receiving Rule on receiving a marker. If the process has not yet recorded its local state, it records the state of the channel on which the marker is received as empty and executes the Marker Sending Rule to record its local state. } The algorithm terminates after each process has received a marker on all of its incoming channels. } All the local snapshots get disseminated to all other processes and all the processes can determine the global state. 49
50 Chandy/Lamport Snapshot Algorithm } Marker-sending rule for a process p: } Saves its own local state } Sends a marker to all other processes on their corresponding channels before sending any other message } Marker-receiving rule for a process q } 50 If q has not recorded its state then } q records records its state } q record the state of incoming channel c as empty } turn on recording of messages over other incoming channels } for each outgoing channel c, send a marker on c } else } q records the state of incomming channel c as all the messages received over c after q recorded its state and before q received the marker along c
51 Example of Chandy-Lamport Algorithm } Three processes p, q and r. Communications chanels, c1 (p to q), c2 (q to p), c3 (q to r), and c4 (r to p).they all start with state = $500 and the channels are empty. The stable property is that the total amount of money is $1500. } Process p sends $10 to q and then starts the snapshot algorithm: records its current state 490 and sends out a marker on c1. } Meanwhile q has sent $20 to p along c2 and 10 to r along c3. 51

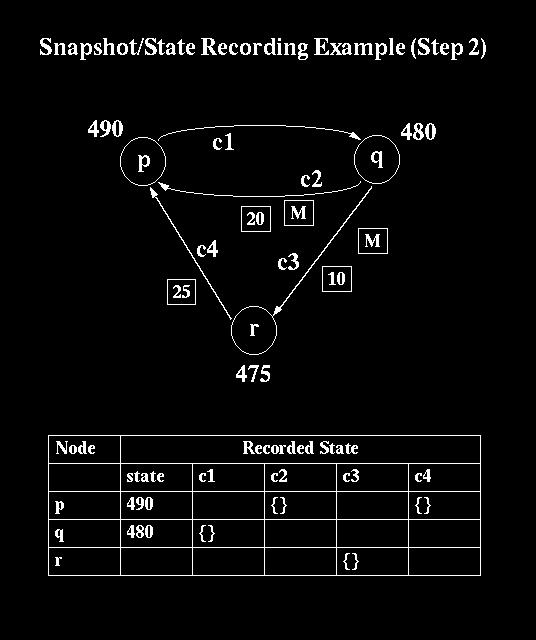
52 52


53 53
54 54
55 4: Detecting failures
56 Detecting failures } Impossibility result: it is impossible to design an asynchronous fault-tolerant consensus algorithm, even when only one process can crash. (FLP85) } Proof Idea: It is shown how an infinite sequence of events can be constructed such that the algorithm never terminates (stays indecisive forever). } The impossibility comes from the fact that in an asynchronous system, it is impossible to distinguish between a faulty-process and a slow process. } We will come back to the proof 56
57 Failure Detectors as an Abstraction } Failure detector: distributed oracle that makes guesses about process failures } Accuracy: the failure detector makes no mistakes when labeling processes as faulty } Completeness: the failure detector eventually (after some time) suspects every process that actually crashes } Detectors classified based on their properties } Used to solve different distributed systems problems 57
58 Completeness } Strong Completeness: There is a time after which every process that crashes is suspected by EVERY correct process. } Weak Completeness: There is a time after which every process that crashes is suspected by SOME correct process. 58
59 Accuracy } Strong Accuracy: No process is suspected before it crashes. } Weak Accuracy: Some correct process is never suspected. (at least one correct process is never suspected) } Eventual Strong Accuracy: There is a time after which correct processes are not suspected by any correct process. } Eventual Weak Accuracy: There is a time after which some correct process is never suspected by any correct process. 59
60 Perfect Failure Detector } A perfect failure detector has strong accuracy and strong completeness } THIS IS AN ABSTRACTION } IT IS IMPOSSIBLE TO HAVE A PERFECT FAILURE DETECTOR } We have to live with unreliable failures detectors 60
61 Unreliable Failure Detectors } Unreliable failure detectors can make mistakes!!! } A process is suspected that it was faulty, that can be true or false, if false the list of alive processes is modified. } Failure detectors can add/remove processes from the list of suspects; different processes have different lists. } The assumptions are that: } After a while the network becomes stable so the failure detector does not make mistakes anymore. } In the unstable period, the failure detector can make mistakes. 61
62 Failure Detection Implementation } Push: processes keep sending heartbeats I am alive to the monitor. If no message is received for awhile from some process, that process is suspected as being dead (faulty). } Pull: monitor asks the processes Are you alive?, and process will respond Yes, I am alive. If no answer is received from some process, the process is suspected as being dead (faulty). } What are advantages and disadvantages of these two approaches? 62
63 Failure Detectors Implementation (2) } Every process must know about who failed } How to disseminate the information } How about if not every node can communicate directly with another node? } Centralized } All-to-All } Gossip based: provides probabilistic guarantees 63
64 Metrics for Failure Detectors } Detection time } Mistake recurrence time } Mistake duration } Average mistake rate } Query accuracy probability } Good period duration } Network load 64
65 Summary } Ordering events with logical clocks } Lamport clocks uses a single clock per process } Vector clocks each process maintains a clock for all the other processes } Determining global states } Chandi-Lamprt algorithm for asynchronous systems, no failures and communication FIFO unidirectional. } Detecting failures } There are no perfect failure detectors, both accurate and complete 65
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems Physical and logical clocks. Global states. Failure detection. Ordering events in distributed systems } Time is essential for ordering events in a distributed
Cristina Nita-Rotaru 7680: Distributed Systems Physical and logical clocks. Global states. Failure detection. Ordering events in distributed systems } Time is essential for ordering events in a distributed
Agreement. Today. l Coordination and agreement in group communication. l Consensus
 Agreement Today l Coordination and agreement in group communication l Consensus Events and process states " A distributed system a collection P of N singlethreaded processes w/o shared memory Each process
Agreement Today l Coordination and agreement in group communication l Consensus Events and process states " A distributed system a collection P of N singlethreaded processes w/o shared memory Each process
CS505: Distributed Systems
 Department of Computer Science CS505: Distributed Systems Lecture 5: Time in Distributed Systems Overview Time and Synchronization Logical Clocks Vector Clocks Distributed Systems Asynchronous systems:
Department of Computer Science CS505: Distributed Systems Lecture 5: Time in Distributed Systems Overview Time and Synchronization Logical Clocks Vector Clocks Distributed Systems Asynchronous systems:
Slides for Chapter 14: Time and Global States
 Slides for Chapter 14: Time and Global States From Coulouris, Dollimore, Kindberg and Blair Distributed Systems: Concepts and Design Edition 5, Addison-Wesley 2012 Overview of Chapter Introduction Clocks,
Slides for Chapter 14: Time and Global States From Coulouris, Dollimore, Kindberg and Blair Distributed Systems: Concepts and Design Edition 5, Addison-Wesley 2012 Overview of Chapter Introduction Clocks,
Time. To do. q Physical clocks q Logical clocks
 Time To do q Physical clocks q Logical clocks Events, process states and clocks A distributed system A collection P of N single-threaded processes (p i, i = 1,, N) without shared memory The processes in
Time To do q Physical clocks q Logical clocks Events, process states and clocks A distributed system A collection P of N single-threaded processes (p i, i = 1,, N) without shared memory The processes in
Chapter 11 Time and Global States
 CSD511 Distributed Systems 分散式系統 Chapter 11 Time and Global States 吳俊興 國立高雄大學資訊工程學系 Chapter 11 Time and Global States 11.1 Introduction 11.2 Clocks, events and process states 11.3 Synchronizing physical
CSD511 Distributed Systems 分散式系統 Chapter 11 Time and Global States 吳俊興 國立高雄大學資訊工程學系 Chapter 11 Time and Global States 11.1 Introduction 11.2 Clocks, events and process states 11.3 Synchronizing physical
Distributed Computing. Synchronization. Dr. Yingwu Zhu
 Distributed Computing Synchronization Dr. Yingwu Zhu Topics to Discuss Physical Clocks Logical Clocks: Lamport Clocks Classic paper: Time, Clocks, and the Ordering of Events in a Distributed System Lamport
Distributed Computing Synchronization Dr. Yingwu Zhu Topics to Discuss Physical Clocks Logical Clocks: Lamport Clocks Classic paper: Time, Clocks, and the Ordering of Events in a Distributed System Lamport
Time in Distributed Systems: Clocks and Ordering of Events
 Time in Distributed Systems: Clocks and Ordering of Events Clocks in Distributed Systems Needed to Order two or more events happening at same or different nodes (Ex: Consistent ordering of updates at different
Time in Distributed Systems: Clocks and Ordering of Events Clocks in Distributed Systems Needed to Order two or more events happening at same or different nodes (Ex: Consistent ordering of updates at different
Clocks in Asynchronous Systems
 Clocks in Asynchronous Systems The Internet Network Time Protocol (NTP) 8 Goals provide the ability to externally synchronize clients across internet to UTC provide reliable service tolerating lengthy
Clocks in Asynchronous Systems The Internet Network Time Protocol (NTP) 8 Goals provide the ability to externally synchronize clients across internet to UTC provide reliable service tolerating lengthy
Time. Today. l Physical clocks l Logical clocks
 Time Today l Physical clocks l Logical clocks Events, process states and clocks " A distributed system a collection P of N singlethreaded processes without shared memory Each process p i has a state s
Time Today l Physical clocks l Logical clocks Events, process states and clocks " A distributed system a collection P of N singlethreaded processes without shared memory Each process p i has a state s
Today. Vector Clocks and Distributed Snapshots. Motivation: Distributed discussion board. Distributed discussion board. 1. Logical Time: Vector clocks
 Vector Clocks and Distributed Snapshots Today. Logical Time: Vector clocks 2. Distributed lobal Snapshots CS 48: Distributed Systems Lecture 5 Kyle Jamieson 2 Motivation: Distributed discussion board Distributed
Vector Clocks and Distributed Snapshots Today. Logical Time: Vector clocks 2. Distributed lobal Snapshots CS 48: Distributed Systems Lecture 5 Kyle Jamieson 2 Motivation: Distributed discussion board Distributed
Our Problem. Model. Clock Synchronization. Global Predicate Detection and Event Ordering
 Our Problem Global Predicate Detection and Event Ordering To compute predicates over the state of a distributed application Model Clock Synchronization Message passing No failures Two possible timing assumptions:
Our Problem Global Predicate Detection and Event Ordering To compute predicates over the state of a distributed application Model Clock Synchronization Message passing No failures Two possible timing assumptions:
Distributed systems Lecture 4: Clock synchronisation; logical clocks. Dr Robert N. M. Watson
 Distributed systems Lecture 4: Clock synchronisation; logical clocks Dr Robert N. M. Watson 1 Last time Started to look at time in distributed systems Coordinating actions between processes Physical clocks
Distributed systems Lecture 4: Clock synchronisation; logical clocks Dr Robert N. M. Watson 1 Last time Started to look at time in distributed systems Coordinating actions between processes Physical clocks
DISTRIBUTED COMPUTER SYSTEMS
 DISTRIBUTED COMPUTER SYSTEMS SYNCHRONIZATION Dr. Jack Lange Computer Science Department University of Pittsburgh Fall 2015 Topics Clock Synchronization Physical Clocks Clock Synchronization Algorithms
DISTRIBUTED COMPUTER SYSTEMS SYNCHRONIZATION Dr. Jack Lange Computer Science Department University of Pittsburgh Fall 2015 Topics Clock Synchronization Physical Clocks Clock Synchronization Algorithms
Clock Synchronization
 Today: Canonical Problems in Distributed Systems Time ordering and clock synchronization Leader election Mutual exclusion Distributed transactions Deadlock detection Lecture 11, page 7 Clock Synchronization
Today: Canonical Problems in Distributed Systems Time ordering and clock synchronization Leader election Mutual exclusion Distributed transactions Deadlock detection Lecture 11, page 7 Clock Synchronization
Coordination. Failures and Consensus. Consensus. Consensus. Overview. Properties for Correct Consensus. Variant I: Consensus (C) P 1. v 1.
 P 1. v 1.") Coordination Failures and Consensus If the solution to availability and scalability is to decentralize and replicate functions and data, how do we coordinate the nodes? data consistency update propagation
Coordination Failures and Consensus If the solution to availability and scalability is to decentralize and replicate functions and data, how do we coordinate the nodes? data consistency update propagation
Time is an important issue in DS
 Chapter 0: Time and Global States Introduction Clocks,events and process states Synchronizing physical clocks Logical time and logical clocks Global states Distributed debugging Summary Time is an important
Chapter 0: Time and Global States Introduction Clocks,events and process states Synchronizing physical clocks Logical time and logical clocks Global states Distributed debugging Summary Time is an important
Distributed Systems. Time, Clocks, and Ordering of Events
 Distributed Systems Time, Clocks, and Ordering of Events Björn Franke University of Edinburgh 2016/2017 Today Last lecture: Basic Algorithms Today: Time, clocks, NTP Ref: CDK Causality, ordering, logical
Distributed Systems Time, Clocks, and Ordering of Events Björn Franke University of Edinburgh 2016/2017 Today Last lecture: Basic Algorithms Today: Time, clocks, NTP Ref: CDK Causality, ordering, logical
Distributed Systems 8L for Part IB
 Distributed Systems 8L for Part IB Handout 2 Dr. Steven Hand 1 Clocks Distributed systems need to be able to: order events produced by concurrent processes; synchronize senders and receivers of messages;
Distributed Systems 8L for Part IB Handout 2 Dr. Steven Hand 1 Clocks Distributed systems need to be able to: order events produced by concurrent processes; synchronize senders and receivers of messages;
Distributed Systems Time and Global State
 Distributed Systems Time and Global State Allan Clark School of Informatics University of Edinburgh http://www.inf.ed.ac.uk/teaching/courses/ds Autumn Term 2012 Distributed Systems Time and Global State
Distributed Systems Time and Global State Allan Clark School of Informatics University of Edinburgh http://www.inf.ed.ac.uk/teaching/courses/ds Autumn Term 2012 Distributed Systems Time and Global State
Chandy-Lamport Snapshotting
 Chandy-Lamport Snapshotting COS 418: Distributed Systems Precept 8 Themis Melissaris and Daniel Suo [Content adapted from I. Gupta] Agenda What are global snapshots? The Chandy-Lamport algorithm Why does
Chandy-Lamport Snapshotting COS 418: Distributed Systems Precept 8 Themis Melissaris and Daniel Suo [Content adapted from I. Gupta] Agenda What are global snapshots? The Chandy-Lamport algorithm Why does
Distributed Systems Principles and Paradigms
 Distributed Systems Principles and Paradigms Chapter 6 (version April 7, 28) Maarten van Steen Vrije Universiteit Amsterdam, Faculty of Science Dept. Mathematics and Computer Science Room R4.2. Tel: (2)
Distributed Systems Principles and Paradigms Chapter 6 (version April 7, 28) Maarten van Steen Vrije Universiteit Amsterdam, Faculty of Science Dept. Mathematics and Computer Science Room R4.2. Tel: (2)
Distributed Systems Principles and Paradigms. Chapter 06: Synchronization
 Distributed Systems Principles and Paradigms Maarten van Steen VU Amsterdam, Dept. Computer Science Room R4.20, steen@cs.vu.nl Chapter 06: Synchronization Version: November 16, 2009 2 / 39 Contents Chapter
Distributed Systems Principles and Paradigms Maarten van Steen VU Amsterdam, Dept. Computer Science Room R4.20, steen@cs.vu.nl Chapter 06: Synchronization Version: November 16, 2009 2 / 39 Contents Chapter
Consistent Global States of Distributed Systems: Fundamental Concepts and Mechanisms. CS 249 Project Fall 2005 Wing Wong
 Consistent Global States of Distributed Systems: Fundamental Concepts and Mechanisms CS 249 Project Fall 2005 Wing Wong Outline Introduction Asynchronous distributed systems, distributed computations,
Consistent Global States of Distributed Systems: Fundamental Concepts and Mechanisms CS 249 Project Fall 2005 Wing Wong Outline Introduction Asynchronous distributed systems, distributed computations,
Distributed Algorithms (CAS 769) Dr. Borzoo Bonakdarpour
 Dr. Borzoo Bonakdarpour") Distributed Algorithms (CAS 769) Week 1: Introduction, Logical clocks, Snapshots Dr. Borzoo Bonakdarpour Department of Computing and Software McMaster University Dr. Borzoo Bonakdarpour Distributed Algorithms
Distributed Algorithms (CAS 769) Week 1: Introduction, Logical clocks, Snapshots Dr. Borzoo Bonakdarpour Department of Computing and Software McMaster University Dr. Borzoo Bonakdarpour Distributed Algorithms
Cuts. Cuts. Consistent cuts and consistent global states. Global states and cuts. A cut C is a subset of the global history of H
 Cuts Cuts A cut C is a subset of the global history of H C = h c 1 1 hc 2 2...hc n n A cut C is a subset of the global history of H The frontier of C is the set of events e c 1 1,ec 2 2,...ec n n C = h
Cuts Cuts A cut C is a subset of the global history of H C = h c 1 1 hc 2 2...hc n n A cut C is a subset of the global history of H The frontier of C is the set of events e c 1 1,ec 2 2,...ec n n C = h
Absence of Global Clock
 Absence of Global Clock Problem: synchronizing the activities of different part of the system (e.g. process scheduling) What about using a single shared clock? two different processes can see the clock
Absence of Global Clock Problem: synchronizing the activities of different part of the system (e.g. process scheduling) What about using a single shared clock? two different processes can see the clock
Figure 10.1 Skew between computer clocks in a distributed system
 Figure 10.1 Skew between computer clocks in a distributed system Network Instructor s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 Pearson Education 2001
Figure 10.1 Skew between computer clocks in a distributed system Network Instructor s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 Pearson Education 2001
CS 425 / ECE 428 Distributed Systems Fall Indranil Gupta (Indy) Oct. 5, 2017 Lecture 12: Time and Ordering All slides IG
 Oct. 5, 2017 Lecture 12: Time and Ordering All slides IG") CS 425 / ECE 428 Distributed Systems Fall 2017 Indranil Gupta (Indy) Oct. 5, 2017 Lecture 12: Time and Ordering All slides IG Why Synchronization? You want to catch a bus at 6.05 pm, but your watch is
CS 425 / ECE 428 Distributed Systems Fall 2017 Indranil Gupta (Indy) Oct. 5, 2017 Lecture 12: Time and Ordering All slides IG Why Synchronization? You want to catch a bus at 6.05 pm, but your watch is
A subtle problem. An obvious problem. An obvious problem. An obvious problem. No!
 A subtle problem An obvious problem when LC = t do S doesn t make sense for Lamport clocks! there is no guarantee that LC will ever be S is anyway executed after LC = t Fixes: if e is internal/send and
A subtle problem An obvious problem when LC = t do S doesn t make sense for Lamport clocks! there is no guarantee that LC will ever be S is anyway executed after LC = t Fixes: if e is internal/send and
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 & Clocks, Clocks, and the Ordering of Events in a Distributed System. L. Lamport, Communications of the ACM, 1978 Notes 15: & Clocks CS 347 Notes
CS 347 Parallel and Distributed Data Processing Spring 2016 & Clocks, Clocks, and the Ordering of Events in a Distributed System. L. Lamport, Communications of the ACM, 1978 Notes 15: & Clocks CS 347 Notes
Distributed Systems. Time, clocks, and Ordering of events. Rik Sarkar. University of Edinburgh Spring 2018
 Distributed Systems Time, clocks, and Ordering of events Rik Sarkar University of Edinburgh Spring 2018 Notes Today: Time, clocks, NTP Ref: CDK Causality, ordering, logical clocks: Ref: VG, CDK Time Ordering
Distributed Systems Time, clocks, and Ordering of events Rik Sarkar University of Edinburgh Spring 2018 Notes Today: Time, clocks, NTP Ref: CDK Causality, ordering, logical clocks: Ref: VG, CDK Time Ordering
Logical Time. 1. Introduction 2. Clock and Events 3. Logical (Lamport) Clocks 4. Vector Clocks 5. Efficient Implementation
 Clocks 4. Vector Clocks 5. Efficient Implementation") Logical Time Nicola Dragoni Embedded Systems Engineering DTU Compute 1. Introduction 2. Clock and Events 3. Logical (Lamport) Clocks 4. Vector Clocks 5. Efficient Implementation 2013 ACM Turing Award:
Logical Time Nicola Dragoni Embedded Systems Engineering DTU Compute 1. Introduction 2. Clock and Events 3. Logical (Lamport) Clocks 4. Vector Clocks 5. Efficient Implementation 2013 ACM Turing Award:
Distributed Algorithms Time, clocks and the ordering of events
 Distributed Algorithms Time, clocks and the ordering of events Alberto Montresor University of Trento, Italy 2016/04/26 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International
Distributed Algorithms Time, clocks and the ordering of events Alberto Montresor University of Trento, Italy 2016/04/26 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International
Failure detectors Introduction CHAPTER
 CHAPTER 15 Failure detectors 15.1 Introduction This chapter deals with the design of fault-tolerant distributed systems. It is widely known that the design and verification of fault-tolerent distributed
CHAPTER 15 Failure detectors 15.1 Introduction This chapter deals with the design of fault-tolerant distributed systems. It is widely known that the design and verification of fault-tolerent distributed
CptS 464/564 Fall Prof. Dave Bakken. Cpt. S 464/564 Lecture January 26, 2014
 Overview of Ordering and Logical Time Prof. Dave Bakken Cpt. S 464/564 Lecture January 26, 2014 Context This material is NOT in CDKB5 textbook Rather, from second text by Verissimo and Rodrigues, chapters
Overview of Ordering and Logical Time Prof. Dave Bakken Cpt. S 464/564 Lecture January 26, 2014 Context This material is NOT in CDKB5 textbook Rather, from second text by Verissimo and Rodrigues, chapters
CS505: Distributed Systems
 Cristina Nita-Rotaru CS505: Distributed Systems. Required reading for this topic } Michael J. Fischer, Nancy A. Lynch, and Michael S. Paterson for "Impossibility of Distributed with One Faulty Process,
Cristina Nita-Rotaru CS505: Distributed Systems. Required reading for this topic } Michael J. Fischer, Nancy A. Lynch, and Michael S. Paterson for "Impossibility of Distributed with One Faulty Process,
Distributed Systems Fundamentals
 February 17, 2000 ECS 251 Winter 2000 Page 1 Distributed Systems Fundamentals 1. Distributed system? a. What is it? b. Why use it? 2. System Architectures a. minicomputer mode b. workstation model c. processor
February 17, 2000 ECS 251 Winter 2000 Page 1 Distributed Systems Fundamentals 1. Distributed system? a. What is it? b. Why use it? 2. System Architectures a. minicomputer mode b. workstation model c. processor
Asynchronous Models For Consensus
 Distributed Systems 600.437 Asynchronous Models for Consensus Department of Computer Science The Johns Hopkins University 1 Asynchronous Models For Consensus Lecture 5 Further reading: Distributed Algorithms
Distributed Systems 600.437 Asynchronous Models for Consensus Department of Computer Science The Johns Hopkins University 1 Asynchronous Models For Consensus Lecture 5 Further reading: Distributed Algorithms
MAD. Models & Algorithms for Distributed systems -- 2/5 -- download slides at
 MAD Models & Algorithms for Distributed systems -- /5 -- download slides at http://people.rennes.inria.fr/eric.fabre/ 1 Today Runs/executions of a distributed system are partial orders of events We introduce
MAD Models & Algorithms for Distributed systems -- /5 -- download slides at http://people.rennes.inria.fr/eric.fabre/ 1 Today Runs/executions of a distributed system are partial orders of events We introduce
Recap. CS514: Intermediate Course in Operating Systems. What time is it? This week. Reminder: Lamport s approach. But what does time mean?
 CS514: Intermediate Course in Operating Systems Professor Ken Birman Vivek Vishnumurthy: TA Recap We ve started a process of isolating questions that arise in big systems Tease out an abstract issue Treat
CS514: Intermediate Course in Operating Systems Professor Ken Birman Vivek Vishnumurthy: TA Recap We ve started a process of isolating questions that arise in big systems Tease out an abstract issue Treat
416 Distributed Systems. Time Synchronization (Part 2: Lamport and vector clocks) Jan 27, 2017
 Jan 27, 2017") 416 Distributed Systems Time Synchronization (Part 2: Lamport and vector clocks) Jan 27, 2017 1 Important Lessons (last lecture) Clocks on different systems will always behave differently Skew and drift
416 Distributed Systems Time Synchronization (Part 2: Lamport and vector clocks) Jan 27, 2017 1 Important Lessons (last lecture) Clocks on different systems will always behave differently Skew and drift
Time. Lakshmi Ganesh. (slides borrowed from Maya Haridasan, Michael George)
") Time Lakshmi Ganesh (slides borrowed from Maya Haridasan, Michael George) The Problem Given a collection of processes that can... only communicate with significant latency only measure time intervals approximately
Time Lakshmi Ganesh (slides borrowed from Maya Haridasan, Michael George) The Problem Given a collection of processes that can... only communicate with significant latency only measure time intervals approximately
Causality and physical time
 Logical Time Causality and physical time Causality is fundamental to the design and analysis of parallel and distributed computing and OS. Distributed algorithms design Knowledge about the progress Concurrency
Logical Time Causality and physical time Causality is fundamental to the design and analysis of parallel and distributed computing and OS. Distributed algorithms design Knowledge about the progress Concurrency
Shared Memory vs Message Passing
 Shared Memory vs Message Passing Carole Delporte-Gallet Hugues Fauconnier Rachid Guerraoui Revised: 15 February 2004 Abstract This paper determines the computational strength of the shared memory abstraction
Shared Memory vs Message Passing Carole Delporte-Gallet Hugues Fauconnier Rachid Guerraoui Revised: 15 February 2004 Abstract This paper determines the computational strength of the shared memory abstraction
Unreliable Failure Detectors for Reliable Distributed Systems
 Unreliable Failure Detectors for Reliable Distributed Systems A different approach Augment the asynchronous model with an unreliable failure detector for crash failures Define failure detectors in terms
Unreliable Failure Detectors for Reliable Distributed Systems A different approach Augment the asynchronous model with an unreliable failure detector for crash failures Define failure detectors in terms
Section 6 Fault-Tolerant Consensus
 Section 6 Fault-Tolerant Consensus CS586 - Panagiota Fatourou 1 Description of the Problem Consensus Each process starts with an individual input from a particular value set V. Processes may fail by crashing.
Section 6 Fault-Tolerant Consensus CS586 - Panagiota Fatourou 1 Description of the Problem Consensus Each process starts with an individual input from a particular value set V. Processes may fail by crashing.
Do we have a quorum?
 Do we have a quorum? Quorum Systems Given a set U of servers, U = n: A quorum system is a set Q 2 U such that Q 1, Q 2 Q : Q 1 Q 2 Each Q in Q is a quorum How quorum systems work: A read/write shared register
Do we have a quorum? Quorum Systems Given a set U of servers, U = n: A quorum system is a set Q 2 U such that Q 1, Q 2 Q : Q 1 Q 2 Each Q in Q is a quorum How quorum systems work: A read/write shared register
Snapshots. Chandy-Lamport Algorithm for the determination of consistent global states <$1000, 0> <$50, 2000> mark. (order 10, $100) mark
 mark") 8 example: P i P j (5 widgets) (order 10, $100) cji 8 ed state P i : , P j : , c ij : , c ji : Distributed Systems
8 example: P i P j (5 widgets) (order 10, $100) cji 8 ed state P i : , P j : , c ij : , c ji : Distributed Systems
CS505: Distributed Systems
 Department of Computer Science CS505: Distributed Systems Lecture 10: Consensus Outline Consensus impossibility result Consensus with S Consensus with Ω Consensus Most famous problem in distributed computing
Department of Computer Science CS505: Distributed Systems Lecture 10: Consensus Outline Consensus impossibility result Consensus with S Consensus with Ω Consensus Most famous problem in distributed computing
AGREEMENT PROBLEMS (1) Agreement problems arise in many practical applications:
 Agreement problems arise in many practical applications:") AGREEMENT PROBLEMS (1) AGREEMENT PROBLEMS Agreement problems arise in many practical applications: agreement on whether to commit or abort the results of a distributed atomic action (e.g. database transaction)
AGREEMENT PROBLEMS (1) AGREEMENT PROBLEMS Agreement problems arise in many practical applications: agreement on whether to commit or abort the results of a distributed atomic action (e.g. database transaction)
The Weakest Failure Detector to Solve Mutual Exclusion
 The Weakest Failure Detector to Solve Mutual Exclusion Vibhor Bhatt Nicholas Christman Prasad Jayanti Dartmouth College, Hanover, NH Dartmouth Computer Science Technical Report TR2008-618 April 17, 2008
The Weakest Failure Detector to Solve Mutual Exclusion Vibhor Bhatt Nicholas Christman Prasad Jayanti Dartmouth College, Hanover, NH Dartmouth Computer Science Technical Report TR2008-618 April 17, 2008
C 1. Recap: Finger Table. CSE 486/586 Distributed Systems Consensus. One Reason: Impossibility of Consensus. Let s Consider This
 Recap: Finger Table Finding a using fingers Distributed Systems onsensus Steve Ko omputer Sciences and Engineering University at Buffalo N102 86 + 2 4 N86 20 + 2 6 N20 2 Let s onsider This
Recap: Finger Table Finding a using fingers Distributed Systems onsensus Steve Ko omputer Sciences and Engineering University at Buffalo N102 86 + 2 4 N86 20 + 2 6 N20 2 Let s onsider This
Finally the Weakest Failure Detector for Non-Blocking Atomic Commit
 Finally the Weakest Failure Detector for Non-Blocking Atomic Commit Rachid Guerraoui Petr Kouznetsov Distributed Programming Laboratory EPFL Abstract Recent papers [7, 9] define the weakest failure detector
Finally the Weakest Failure Detector for Non-Blocking Atomic Commit Rachid Guerraoui Petr Kouznetsov Distributed Programming Laboratory EPFL Abstract Recent papers [7, 9] define the weakest failure detector
Eventually consistent failure detectors
 J. Parallel Distrib. Comput. 65 (2005) 361 373 www.elsevier.com/locate/jpdc Eventually consistent failure detectors Mikel Larrea a,, Antonio Fernández b, Sergio Arévalo b a Departamento de Arquitectura
J. Parallel Distrib. Comput. 65 (2005) 361 373 www.elsevier.com/locate/jpdc Eventually consistent failure detectors Mikel Larrea a,, Antonio Fernández b, Sergio Arévalo b a Departamento de Arquitectura
Easy Consensus Algorithms for the Crash-Recovery Model
 Reihe Informatik. TR-2008-002 Easy Consensus Algorithms for the Crash-Recovery Model Felix C. Freiling, Christian Lambertz, and Mila Majster-Cederbaum Department of Computer Science, University of Mannheim,
Reihe Informatik. TR-2008-002 Easy Consensus Algorithms for the Crash-Recovery Model Felix C. Freiling, Christian Lambertz, and Mila Majster-Cederbaum Department of Computer Science, University of Mannheim,
CS5412: REPLICATION, CONSISTENCY AND CLOCKS
 1 CS5412: REPLICATION, CONSISTENCY AND CLOCKS Lecture X Ken Birman Recall that clouds have tiers 2 Up to now our focus has been on client systems and the network, and the way that the cloud has reshaped
1 CS5412: REPLICATION, CONSISTENCY AND CLOCKS Lecture X Ken Birman Recall that clouds have tiers 2 Up to now our focus has been on client systems and the network, and the way that the cloud has reshaped
Distributed Systems. 06. Logical clocks. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 06. Logical clocks Paul Krzyzanowski Rutgers University Fall 2017 2014-2017 Paul Krzyzanowski 1 Logical clocks Assign sequence numbers to messages All cooperating processes can agree
Distributed Systems 06. Logical clocks Paul Krzyzanowski Rutgers University Fall 2017 2014-2017 Paul Krzyzanowski 1 Logical clocks Assign sequence numbers to messages All cooperating processes can agree
Clock Synchronization
 What s it or? Temporal ordering o events produced by concurrent processes Clock Synchronization Synchronization between senders and receivers o messages Coordination o joint activity Serialization o concurrent
What s it or? Temporal ordering o events produced by concurrent processes Clock Synchronization Synchronization between senders and receivers o messages Coordination o joint activity Serialization o concurrent
Failure Detectors. Seif Haridi. S. Haridi, KTHx ID2203.1x
 Failure Detectors Seif Haridi haridi@kth.se 1 Modeling Timing Assumptions Tedious to model eventual synchrony (partial synchrony) Timing assumptions mostly needed to detect failures Heartbeats, timeouts,
Failure Detectors Seif Haridi haridi@kth.se 1 Modeling Timing Assumptions Tedious to model eventual synchrony (partial synchrony) Timing assumptions mostly needed to detect failures Heartbeats, timeouts,
Time, Clocks, and the Ordering of Events in a Distributed System
 Time, Clocks, and the Ordering of Events in a Distributed System Motivating example: a distributed compilation service FTP server storing source files, object files, executable file stored files have timestamps,
Time, Clocks, and the Ordering of Events in a Distributed System Motivating example: a distributed compilation service FTP server storing source files, object files, executable file stored files have timestamps,
Ordering and Consistent Cuts Nicole Caruso
 Ordering and Consistent Cuts Nicole Caruso Cornell University Dept. of Computer Science Time, Clocks, and the Ordering of Events in a Distributed System Leslie Lamport Stanford Research Institute About
Ordering and Consistent Cuts Nicole Caruso Cornell University Dept. of Computer Science Time, Clocks, and the Ordering of Events in a Distributed System Leslie Lamport Stanford Research Institute About
Distributed Algorithms
 Distributed Algorithms December 17, 2008 Gerard Tel Introduction to Distributed Algorithms (2 nd edition) Cambridge University Press, 2000 Set-Up of the Course 13 lectures: Wan Fokkink room U342 email:
Distributed Algorithms December 17, 2008 Gerard Tel Introduction to Distributed Algorithms (2 nd edition) Cambridge University Press, 2000 Set-Up of the Course 13 lectures: Wan Fokkink room U342 email:
Agreement Protocols. CS60002: Distributed Systems. Pallab Dasgupta Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur
 Agreement Protocols CS60002: Distributed Systems Pallab Dasgupta Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur Classification of Faults Based on components that failed Program
Agreement Protocols CS60002: Distributed Systems Pallab Dasgupta Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur Classification of Faults Based on components that failed Program
Finite-State Model Checking
 EECS 219C: Computer-Aided Verification Intro. to Model Checking: Models and Properties Sanjit A. Seshia EECS, UC Berkeley Finite-State Model Checking G(p X q) Temporal logic q p FSM Model Checker Yes,
EECS 219C: Computer-Aided Verification Intro. to Model Checking: Models and Properties Sanjit A. Seshia EECS, UC Berkeley Finite-State Model Checking G(p X q) Temporal logic q p FSM Model Checker Yes,
Distributed Consensus
 Distributed Consensus Reaching agreement is a fundamental problem in distributed computing. Some examples are Leader election / Mutual Exclusion Commit or Abort in distributed transactions Reaching agreement
Distributed Consensus Reaching agreement is a fundamental problem in distributed computing. Some examples are Leader election / Mutual Exclusion Commit or Abort in distributed transactions Reaching agreement
Fault-Tolerant Consensus
 Fault-Tolerant Consensus CS556 - Panagiota Fatourou 1 Assumptions Consensus Denote by f the maximum number of processes that may fail. We call the system f-resilient Description of the Problem Each process
Fault-Tolerant Consensus CS556 - Panagiota Fatourou 1 Assumptions Consensus Denote by f the maximum number of processes that may fail. We call the system f-resilient Description of the Problem Each process
Causality and Time. The Happens-Before Relation
 Causality and Time The Happens-Before Relation Because executions are sequences of events, they induce a total order on all the events It is possible that two events by different processors do not influence
Causality and Time The Happens-Before Relation Because executions are sequences of events, they induce a total order on all the events It is possible that two events by different processors do not influence
Distributed Mutual Exclusion Based on Causal Ordering
 Journal of Computer Science 5 (5): 398-404, 2009 ISSN 1549-3636 2009 Science Publications Distributed Mutual Exclusion Based on Causal Ordering Mohamed Naimi and Ousmane Thiare Department of Computer Science,
Journal of Computer Science 5 (5): 398-404, 2009 ISSN 1549-3636 2009 Science Publications Distributed Mutual Exclusion Based on Causal Ordering Mohamed Naimi and Ousmane Thiare Department of Computer Science,
THE WEAKEST FAILURE DETECTOR FOR SOLVING WAIT-FREE, EVENTUALLY BOUNDED-FAIR DINING PHILOSOPHERS. A Dissertation YANTAO SONG
 THE WEAKEST FAILURE DETECTOR FOR SOLVING WAIT-FREE, EVENTUALLY BOUNDED-FAIR DINING PHILOSOPHERS A Dissertation by YANTAO SONG Submitted to the Office of Graduate Studies of Texas A&M University in partial
THE WEAKEST FAILURE DETECTOR FOR SOLVING WAIT-FREE, EVENTUALLY BOUNDED-FAIR DINING PHILOSOPHERS A Dissertation by YANTAO SONG Submitted to the Office of Graduate Studies of Texas A&M University in partial
Failure detection and consensus in the crash-recovery model
 Distrib. Comput. (2000) 13: 99 125 c Springer-Verlag 2000 Failure detection and consensus in the crash-recovery model Marcos Kawazoe Aguilera 1, Wei Chen 2, Sam Toueg 1 1 Department of Computer Science,
Distrib. Comput. (2000) 13: 99 125 c Springer-Verlag 2000 Failure detection and consensus in the crash-recovery model Marcos Kawazoe Aguilera 1, Wei Chen 2, Sam Toueg 1 1 Department of Computer Science,
The Weakest Failure Detector for Wait-Free Dining under Eventual Weak Exclusion
 The Weakest Failure Detector for Wait-Free Dining under Eventual Weak Exclusion Srikanth Sastry Computer Science and Engr Texas A&M University College Station, TX, USA sastry@cse.tamu.edu Scott M. Pike
The Weakest Failure Detector for Wait-Free Dining under Eventual Weak Exclusion Srikanth Sastry Computer Science and Engr Texas A&M University College Station, TX, USA sastry@cse.tamu.edu Scott M. Pike
Consensus when failstop doesn't hold
 Consensus when failstop doesn't hold FLP shows that can't solve consensus in an asynchronous system with no other facility. It can be solved with a perfect failure detector. If p suspects q then q has
Consensus when failstop doesn't hold FLP shows that can't solve consensus in an asynchronous system with no other facility. It can be solved with a perfect failure detector. If p suspects q then q has
1 Introduction. 1.1 The Problem Domain. Self-Stablization UC Davis Earl Barr. Lecture 1 Introduction Winter 2007
 Lecture 1 Introduction 1 Introduction 1.1 The Problem Domain Today, we are going to ask whether a system can recover from perturbation. Consider a children s top: If it is perfectly vertically, you can
Lecture 1 Introduction 1 Introduction 1.1 The Problem Domain Today, we are going to ask whether a system can recover from perturbation. Consider a children s top: If it is perfectly vertically, you can
Termination Detection in an Asynchronous Distributed System with Crash-Recovery Failures
 Termination Detection in an Asynchronous Distributed System with Crash-Recovery Failures Technical Report Department for Mathematics and Computer Science University of Mannheim TR-2006-008 Felix C. Freiling
Termination Detection in an Asynchronous Distributed System with Crash-Recovery Failures Technical Report Department for Mathematics and Computer Science University of Mannheim TR-2006-008 Felix C. Freiling
Implementing Uniform Reliable Broadcast with Binary Consensus in Systems with Fair-Lossy Links
 Implementing Uniform Reliable Broadcast with Binary Consensus in Systems with Fair-Lossy Links Jialin Zhang Tsinghua University zhanggl02@mails.tsinghua.edu.cn Wei Chen Microsoft Research Asia weic@microsoft.com
Implementing Uniform Reliable Broadcast with Binary Consensus in Systems with Fair-Lossy Links Jialin Zhang Tsinghua University zhanggl02@mails.tsinghua.edu.cn Wei Chen Microsoft Research Asia weic@microsoft.com
On Equilibria of Distributed Message-Passing Games
 On Equilibria of Distributed Message-Passing Games Concetta Pilotto and K. Mani Chandy California Institute of Technology, Computer Science Department 1200 E. California Blvd. MC 256-80 Pasadena, US {pilotto,mani}@cs.caltech.edu
On Equilibria of Distributed Message-Passing Games Concetta Pilotto and K. Mani Chandy California Institute of Technology, Computer Science Department 1200 E. California Blvd. MC 256-80 Pasadena, US {pilotto,mani}@cs.caltech.edu
Failure Detection and Consensus in the Crash-Recovery Model
 Failure Detection and Consensus in the Crash-Recovery Model Marcos Kawazoe Aguilera Wei Chen Sam Toueg Department of Computer Science Upson Hall, Cornell University Ithaca, NY 14853-7501, USA. aguilera,weichen,sam@cs.cornell.edu
Failure Detection and Consensus in the Crash-Recovery Model Marcos Kawazoe Aguilera Wei Chen Sam Toueg Department of Computer Science Upson Hall, Cornell University Ithaca, NY 14853-7501, USA. aguilera,weichen,sam@cs.cornell.edu
Seeking Fastness in Multi-Writer Multiple- Reader Atomic Register Implementations
 ΚΥΠΡΙΑΚΗ ΔΗΜΟΚΡΑΤΙΑ ΕΥΡΩΠΑΪΚΗ ΕΝΩΣΗ Η ΔΕΣΜΗ 29- ΣΥΓΧΡΗΜΑΤΟΔΟΤΕΙΤΑΙ ΑΠΟ ΤΗΝ ΚΥΠΡΙΑΚΗ ΔΗΜΟΚΡΑΤΙΑ ΚΑΙ ΤΟ ΕΥΡΩΠΑΪΚΟ ΤΑΜΕΙΟ ΠΕΡΙΦΕΡΕΙΑΚΗΣ ΑΝΑΠΤΥΞΗΣ ΤΗΣ ΕΕ Seeking Fastness in Multi-Writer Multiple- Reader Atomic
ΚΥΠΡΙΑΚΗ ΔΗΜΟΚΡΑΤΙΑ ΕΥΡΩΠΑΪΚΗ ΕΝΩΣΗ Η ΔΕΣΜΗ 29- ΣΥΓΧΡΗΜΑΤΟΔΟΤΕΙΤΑΙ ΑΠΟ ΤΗΝ ΚΥΠΡΙΑΚΗ ΔΗΜΟΚΡΑΤΙΑ ΚΑΙ ΤΟ ΕΥΡΩΠΑΪΚΟ ΤΑΜΕΙΟ ΠΕΡΙΦΕΡΕΙΑΚΗΣ ΑΝΑΠΤΥΞΗΣ ΤΗΣ ΕΕ Seeking Fastness in Multi-Writer Multiple- Reader Atomic
Clojure Concurrency Constructs, Part Two. CSCI 5828: Foundations of Software Engineering Lecture 13 10/07/2014
 Clojure Concurrency Constructs, Part Two CSCI 5828: Foundations of Software Engineering Lecture 13 10/07/2014 1 Goals Cover the material presented in Chapter 4, of our concurrency textbook In particular,
Clojure Concurrency Constructs, Part Two CSCI 5828: Foundations of Software Engineering Lecture 13 10/07/2014 1 Goals Cover the material presented in Chapter 4, of our concurrency textbook In particular,
On the Quality of Service of Failure Detectors. Sam Toueg Wei Chen, Marcos K. Aguilera (part of Wei ChenÕs PhD Thesis)
") On the Quality of Service of Failure etectors Sam oueg Wei Chen, Marcos K. Aguilera part of Wei ChenÕs Ph hesis Abstract We study the quality of service QoS of failure detectors. By QoS, we mean a specification
On the Quality of Service of Failure etectors Sam oueg Wei Chen, Marcos K. Aguilera part of Wei ChenÕs Ph hesis Abstract We study the quality of service QoS of failure detectors. By QoS, we mean a specification
6.852: Distributed Algorithms Fall, Class 24
 6.852: Distributed Algorithms Fall, 2009 Class 24 Today s plan Self-stabilization Self-stabilizing algorithms: Breadth-first spanning tree Mutual exclusion Composing self-stabilizing algorithms Making
6.852: Distributed Algorithms Fall, 2009 Class 24 Today s plan Self-stabilization Self-stabilizing algorithms: Breadth-first spanning tree Mutual exclusion Composing self-stabilizing algorithms Making
arxiv: v1 [cs.dc] 22 Oct 2018
![arxiv: v1 [cs.dc] 22 Oct 2018](/thumbs/96/128217989.jpg "arxiv: v1 [cs.dc] 22 Oct 2018") FANTOM: A SCALABLE FRAMEWORK FOR ASYNCHRONOUS DISTRIBUTED SYSTEMS A PREPRINT Sang-Min Choi, Jiho Park, Quan Nguyen, and Andre Cronje arxiv:1810.10360v1 [cs.dc] 22 Oct 2018 FANTOM Lab FANTOM Foundation
FANTOM: A SCALABLE FRAMEWORK FOR ASYNCHRONOUS DISTRIBUTED SYSTEMS A PREPRINT Sang-Min Choi, Jiho Park, Quan Nguyen, and Andre Cronje arxiv:1810.10360v1 [cs.dc] 22 Oct 2018 FANTOM Lab FANTOM Foundation
Generalized Consensus and Paxos
 Generalized Consensus and Paxos Leslie Lamport 3 March 2004 revised 15 March 2005 corrected 28 April 2005 Microsoft Research Technical Report MSR-TR-2005-33 Abstract Theoretician s Abstract Consensus has
Generalized Consensus and Paxos Leslie Lamport 3 March 2004 revised 15 March 2005 corrected 28 April 2005 Microsoft Research Technical Report MSR-TR-2005-33 Abstract Theoretician s Abstract Consensus has
Genuine atomic multicast in asynchronous distributed systems
 Theoretical Computer Science 254 (2001) 297 316 www.elsevier.com/locate/tcs Genuine atomic multicast in asynchronous distributed systems Rachid Guerraoui, Andre Schiper Departement d Informatique, Ecole
Theoretical Computer Science 254 (2001) 297 316 www.elsevier.com/locate/tcs Genuine atomic multicast in asynchronous distributed systems Rachid Guerraoui, Andre Schiper Departement d Informatique, Ecole
Symmetric Rendezvous in Graphs: Deterministic Approaches
 Symmetric Rendezvous in Graphs: Deterministic Approaches Shantanu Das Technion, Haifa, Israel http://www.bitvalve.org/~sdas/pres/rendezvous_lorentz.pdf Coauthors: Jérémie Chalopin, Adrian Kosowski, Peter
Symmetric Rendezvous in Graphs: Deterministic Approaches Shantanu Das Technion, Haifa, Israel http://www.bitvalve.org/~sdas/pres/rendezvous_lorentz.pdf Coauthors: Jérémie Chalopin, Adrian Kosowski, Peter
Benchmarking Model Checkers with Distributed Algorithms. Étienne Coulouma-Dupont
 Benchmarking Model Checkers with Distributed Algorithms Étienne Coulouma-Dupont November 24, 2011 Introduction The Consensus Problem Consensus : application Paxos LastVoting Hypothesis The Algorithm Analysis
Benchmarking Model Checkers with Distributed Algorithms Étienne Coulouma-Dupont November 24, 2011 Introduction The Consensus Problem Consensus : application Paxos LastVoting Hypothesis The Algorithm Analysis
Eventual Leader Election with Weak Assumptions on Initial Knowledge, Communication Reliability, and Synchrony
 Eventual Leader Election with Weak Assumptions on Initial Knowledge, Communication Reliability, and Synchrony Antonio FERNÁNDEZ Ernesto JIMÉNEZ Michel RAYNAL LADyR, GSyC, Universidad Rey Juan Carlos, 28933
Eventual Leader Election with Weak Assumptions on Initial Knowledge, Communication Reliability, and Synchrony Antonio FERNÁNDEZ Ernesto JIMÉNEZ Michel RAYNAL LADyR, GSyC, Universidad Rey Juan Carlos, 28933
Consensus. Consensus problems
 Consensus problems 8 all correct computers controlling a spaceship should decide to proceed with landing, or all of them should decide to abort (after each has proposed one action or the other) 8 in an
Consensus problems 8 all correct computers controlling a spaceship should decide to proceed with landing, or all of them should decide to abort (after each has proposed one action or the other) 8 in an
Impossibility of Distributed Consensus with One Faulty Process
 Impossibility of Distributed Consensus with One Faulty Process Journal of the ACM 32(2):374-382, April 1985. MJ Fischer, NA Lynch, MS Peterson. Won the 2002 Dijkstra Award (for influential paper in distributed
Impossibility of Distributed Consensus with One Faulty Process Journal of the ACM 32(2):374-382, April 1985. MJ Fischer, NA Lynch, MS Peterson. Won the 2002 Dijkstra Award (for influential paper in distributed
THE chase for the weakest system model that allows
 1 Chasing the Weakest System Model for Implementing Ω and Consensus Martin Hutle, Dahlia Malkhi, Ulrich Schmid, Lidong Zhou Abstract Aguilera et al. and Malkhi et al. presented two system models, which
1 Chasing the Weakest System Model for Implementing Ω and Consensus Martin Hutle, Dahlia Malkhi, Ulrich Schmid, Lidong Zhou Abstract Aguilera et al. and Malkhi et al. presented two system models, which
A Realistic Look At Failure Detectors
 A Realistic Look At Failure Detectors C. Delporte-Gallet, H. Fauconnier, R. Guerraoui Laboratoire d Informatique Algorithmique: Fondements et Applications, Université Paris VII - Denis Diderot Distributed
A Realistic Look At Failure Detectors C. Delporte-Gallet, H. Fauconnier, R. Guerraoui Laboratoire d Informatique Algorithmique: Fondements et Applications, Université Paris VII - Denis Diderot Distributed
Abstract. The paper considers the problem of implementing \Virtually. system. Virtually Synchronous Communication was rst introduced
 Primary Partition \Virtually-Synchronous Communication" harder than Consensus? Andre Schiper and Alain Sandoz Departement d'informatique Ecole Polytechnique Federale de Lausanne CH-1015 Lausanne (Switzerland)
Primary Partition \Virtually-Synchronous Communication" harder than Consensus? Andre Schiper and Alain Sandoz Departement d'informatique Ecole Polytechnique Federale de Lausanne CH-1015 Lausanne (Switzerland)
Approximation of δ-timeliness
 Approximation of δ-timeliness Carole Delporte-Gallet 1, Stéphane Devismes 2, and Hugues Fauconnier 1 1 Université Paris Diderot, LIAFA {Carole.Delporte,Hugues.Fauconnier}@liafa.jussieu.fr 2 Université
Approximation of δ-timeliness Carole Delporte-Gallet 1, Stéphane Devismes 2, and Hugues Fauconnier 1 1 Université Paris Diderot, LIAFA {Carole.Delporte,Hugues.Fauconnier}@liafa.jussieu.fr 2 Université
How can one get around FLP? Around FLP in 80 Slides. How can one get around FLP? Paxos. Weaken the problem. Constrain input values
 How can one get around FLP? Around FLP in 80 Slides Weaken termination Weaken the problem use randomization to terminate with arbitrarily high probability guarantee termination only during periods of synchrony
How can one get around FLP? Around FLP in 80 Slides Weaken termination Weaken the problem use randomization to terminate with arbitrarily high probability guarantee termination only during periods of synchrony
On the weakest failure detector ever
 On the weakest failure detector ever The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher Guerraoui, Rachid
On the weakest failure detector ever The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher Guerraoui, Rachid
Automatic Synthesis of Distributed Protocols
 Automatic Synthesis of Distributed Protocols Rajeev Alur Stavros Tripakis 1 Introduction Protocols for coordination among concurrent processes are an essential component of modern multiprocessor and distributed
Automatic Synthesis of Distributed Protocols Rajeev Alur Stavros Tripakis 1 Introduction Protocols for coordination among concurrent processes are an essential component of modern multiprocessor and distributed
Causality & Concurrency. Time-Stamping Systems. Plausibility. Example TSS: Lamport Clocks. Example TSS: Vector Clocks
 Plausible Clocks with Bounded Inaccuracy Causality & Concurrency a b exists a path from a to b Brad Moore, Paul Sivilotti Computer Science & Engineering The Ohio State University paolo@cse.ohio-state.edu
Plausible Clocks with Bounded Inaccuracy Causality & Concurrency a b exists a path from a to b Brad Moore, Paul Sivilotti Computer Science & Engineering The Ohio State University paolo@cse.ohio-state.edu
Causal Broadcast Seif Haridi
 Causal Broadcast Seif Haridi haridi@kth.se Motivation Assume we have a chat application Whatever written is reliably broadcast to group If you get the following output, is it ok? [Paris] Are you sure,
Causal Broadcast Seif Haridi haridi@kth.se Motivation Assume we have a chat application Whatever written is reliably broadcast to group If you get the following output, is it ok? [Paris] Are you sure,
Consensus and Universal Construction"
 Consensus and Universal Construction INF346, 2015 So far Shared-memory communication: safe bits => multi-valued atomic registers atomic registers => atomic/immediate snapshot 2 Today Reaching agreement
Consensus and Universal Construction INF346, 2015 So far Shared-memory communication: safe bits => multi-valued atomic registers atomic registers => atomic/immediate snapshot 2 Today Reaching agreement