Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008)
|
|
|
- Vivien Anderson
- 5 years ago
- Views:
Transcription
 RHUL Physics www.pp.rhul.ac.")
1 Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics Academic Training Lectures CERN June,
2 Outline Statement of the problem Brief review of statistical formalism Some general considerations Multivariate classifiers: Linear discriminant function Neural networks Naive Bayes classifier Density estimation methods Decision trees Support Vector Machines Thursday start 2
3 Decision trees In a decision tree repeated cuts are made on a single variable until some stop criterion is reached. The decision as to which variable is used is based on best achieved separation. Iterate until stop criterion reached, based e.g. on purity and minimum number of events in a node. Classify resulting cut regions as signal or background based on the signal fraction above/below a specified value (e.g. ½) in the terminal nodes (leaves). Example by MiniBooNE experiment, B. Roe et al., NIM 543 (2005) 577 3
4 Separation measure Suppose the ith event has a weight wi. The purity at a given node is signal wi P= signal wi background wi Measure of s/b separation in a node can be taken as e.g. Gini=P 1 P Cross entropy = P ln P 1 P ln 1 P Misclassification error = 1 max (P, 1 P) These are maximum for P = 0.5 and zero for P = 0 or 1. Tend to give similar results in real examples; Gini index most common. 4
5 What variable to cut on The variable is found that provides the greatest increase in the separation measure (e.g., Gini) in the two daughter nodes relative to the parent. Continue splitting until the number of events in a node falls below a specified threshold (could be 1). Terminal nodes called leaves. The leaves are classified as signal or background depending on majority vote (or e.g. signal fraction greater than a specified threshold). This classifies every point in input variable space as either signal or background: a decision tree classifier. Define a discriminant function f(x) as f x =1 if x signal region, 1 otherwise 5
6 Decision tree size The same variable may be used at several nodes; others may not be used at all. In principle a decision tree classifier can have perfect separation between the event classes (will happen e.g. if the terminal nodes have a single event). This would clearly be a very over trained classifier. Usually one grows the tree first to a very large (e.g. maximum) size and then applies pruning. For example one can recombine leaves based on some measure of generalization performance (e.g. using statistical error of purity estimates). 6
7 Decision tree stability Decision trees tend to be very sensitive to statistical fluctuations in the training sample. If e.g. two variables have similar separating power, then a small fluctuation in the training data could cause either of the two variables to be chosen to split the tree; all subsequent development of the tree is thereby affected. Methods such as boosting can be used to stabilize the tree. 7
8 Boosting Boosting is a general method of creating a set of classifiers which can be combined to achieve a new classifier that is more stable and has a smaller error than any individual one. Often applied to decision trees but, can be applied to any classifier. Suppose we have a training sample T consisting of N events with x1,..., xn event data vectors (each x multivariate) y1,..., yn true class labels, +1 for signal, 1 for background w1,..., wn event weights Now define a rule to create from this an ensemble of training samples T1, T2,..., derive a classifier from each and average them. 8
9 Boosting (2) The framework of a general boosting algorithm can be written: Initialize the first training sample T1 Determine a classifier f1(x, T1) from T1 and assign a weight 1 Determine a new training sample T2 from T1 Iterate K times, so we have: K training samples, T1,..., TK K classifiers f1(x, T1),..., fk(x, TK) K classifier weights, 1,..., K Form the final classifier as a function of those from the individual steps, usually as a weighted sum: K y x = k f k x, T k k =1 9
10 Boosting (3) The important point is that each classifier fk depends on a modified version of the training sample with different event weights. Trick is to create modifications that give smaller error rates than those of the preceding classifiers. A number of ways exist for doing this a successful one is AdaBoost (Freund and Schapire, 1997); short for Adaptive Boosting. 10
11 AdaBoost First initialize the training sample T1 using the original x1,..., xn event data vectors y1,..., yn true class labels (+1 or 1) w1(1),..., wn(1) event weights with the weights equal and normalized such that N w i=1 1 i =1 Then train the classifier f1(x) (e.g. a decision tree) with a method that incorporates the event weights. At each step k, associate a weight k with the classifier fk. 11
12 Updating the event weights Define the training sample for step k+1 from that of k by updating the event weights according to w k 1 i =w k i k f k x i yi / 2 e Zk i = event index k = training sample index where Zk is a normalization factor defined such that the sum of the weights over all events is equal to one. 12
13 Updating the event weights (2) We can use the sign of fk(x) as a classifier. For an event with data xi, fk(xi) > 0 classify as signal fk(xi) < 0 classify as background Therefore the product of the classifier value fk(xi) and class label yi is yi fk(xi) > 0 if the event is classified correctly yi fk(xi) < 0 if the event is classified incorrectly Therefore event weight for event i is increased in the k+1 training sample if it was classified incorrectly in sample k. Idea is that next time around the classifier should pay more attention to this event and try to get it right. 13
14 Error rate of the kth classifier Therefore the classification error rate k is N k = w k I yi f k x i 0 i i=1 where I(X) = 1 if X is true and is zero otherwise. 14
15 Assigning the classifier weight Define the classifier fk(x) such that it minimizes the error rate k. Assign a score to the kth classifier based on its error rate, k =ln 1 k k If we define the final classifier as f x = K k f k x,t k k=1 then one can show that its error rate on the training data satisfies the bound K 2 k 1 k k=1 15
16 AdaBoost error rate So providing each classifier in the ensemble has k > ½, i.e., better than random guessing, then the error rate for the final classifier on the training data (not on unseen data) drops to zero. That is, for sufficiently large K the training data will be over fitted. The error rate on a validation sample would reach some minimum after a certain number of steps and then could rise. So the procedure is to monitor the error rate of the combined classifier at each step with a validation sample and to stop before it starts to rise. Although in principle AdaBoost must overfit, in practice following this procedure overtraining is not a big problem. 16
17 Boosted decision tree example First use of boosted decision trees in HEP was for particle identification for the MiniBoone neutrino oscillation experiment. H.J.Yang, B.P. Roe, J. Zhu, Studies of Boosted Decision Trees for MiniBooNE Particle Identification, Physics/ , Nucl. Instum. & Meth. A 555(2005) B.P. Roe, H.J. Yang, J. Zhu, Y. Liu, I. Stancu, G. McGregor, Boosted decision trees as an alternative to artificial neural networks for particle identification, physics/ , NIMA 543 (2005)




 input")

18 Particle i.d. in MiniBooNE Search for to e oscillations required particle i.d. using information from Cherenkov detector. Large number (~200) input variables measured for each event. H.J. Yang, MiniBooNE PID, DNP06 18

19 Boosted decision tree example Each individual tree is relatively weak, with a misclassification error rate ~
20 Monitoring overtraining From MiniBooNE example 20
21 MiniBoone boosted decision tree Here performance stable after a few hundred trees 21

22 Comparison of boosting algorithms A number of boosting algorithms on the market; differ in the update rule for the tree weight. 22
23 Decision tree summary Advantage of boosted decision tree is it can handle a large number of inputs. Those that provide little/no separation are rarely used as tree splitters are effectively ignored. Easy to deal with inputs of mixed types (real, integer, categorical...) If a tree has only a few leaves it is easy to visualize (but rarely work with an individual tree). Other ways of combining weaker classifiers: Bagging (Boostrap Aggregating), generates the ensemble of classifiers by random sampling with replacement from the full training sample. 23
24 Support Vector Machines Support Vector Machines (SVMs) are an example of a kernel based classifier, which exploits a nonlinear mapping of the input variables onto a higher dimensional feature space. The SVM finds a linear decision boundary in the higher dimensional space. But thanks to the kernel trick one does not every have to write down explicitly the feature space transformation. Some references for kernel methods and SVMs: The books mentioned on Monday C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, research.microsoft.com/~cburges/papers/svmtutorial.pdf N. Cristianini and J.Shawe Taylor. An Introduction to Support Vector Machines and other kernel based learning methods. Cambridge University Press, The TMVA manual (!) 24
25 Linear SVMs Consider a training data set consisting of x1,..., xn event data vectors y1,..., yn true class labels (+1 or 1) Suppose the classes can be separated by a hyperplane defined by a normal vector w and scalar offset b (the bias ). We have x i w b 1 for all yi = +1 x i w b 1 for all yi = 1 or equivalently yi x i w b 1 0 for all i Bishop Ch. 7 25
26 Margin and support vectors The distance between the hyperplanes defined by y(x) = 1 and y(x) = 1 is called the margin, which is: margin= 2 w If the training data are perfectly separated then this means there are no points inside the margin. Suppose there are points on the margin (this is equivalent to defining the scale of w). These points are called support vectors. 26
27 Linear SVM classifier We can define the classifier using y x =sign x w b which is +1 for points on one side of the hyperplane and 1 on the other. The best classifier should have a large margin, so to maximize margin= 2 w 2 we can minimize w subject to the constraints yi x i w b 1 0 for all i 27
28 Lagrangian formulation This constrained minimization problem can be reformulated using a Lagrangian N 1 L= w 2 i yi x i w b 1 2 i=1 positive Lagrange multipliers i We need to minimize L with respect to w and b and maximize with respect to i. There is an i for every training point. Those that lie on the margin (the support vectors) have i > 0, all others have i = 0. The solution can be written w= i y i x i i (sum only contains support vectors) 28
29 Dual formulation The classifier function is thus y x =sign x w b =sign i yi x xi b i It can be shown that one finds the same solution a by minimizing the dual Lagrangian L D = i i 1 2 i j yi y j xi x j i, j So this means that both the classifier function and the Lagrangian only involve dot products of vectors in the input variable space. 29
30 Nonseparable data If the training data points cannot be separated by a hyperplane, one can redefine the constraints by adding slack variables i: yi x i w b i 1 0 with i 0 for all i Thus the training point xi is allowed to be up to a distance i on the wrong side of the boundary, and i = 0 at or on the right side of the boundary. For an error to occur we have i > 1, so i i is an upper bound on the number of training errors. 30
31 Cost function for nonseparable case To limit the magnitudes of the i we can define the error function that we minimize to determine w to be E w = 1 2 k w C 2 i i where C is a cost parameter we must choose that limits the amount of misclassification. It turns out that for k=1 or 2 this is a quadratic programming problem and furthermore for k=1 it corresponds to minimizing the same dual Lagrangian L D = i i 1 2 i j yi y j xi x j i, j where the constraints on the i become 0 i C. 31
32 Nonlinear SVM So far we have only reformulated a way to determine a linear classifier, which we know is useful only in limited circumstances. But the important extension to nonlinear classifiers comes from first transforming the input variables to feature space: x = 1 x,, m x These will behave just as our new input variables. Everything about the mathematical formulation of the SVM will look the same as before except with (x) appearing in the place of x. 32
33 Only dot products Recall the SVM problem was formulated entirely in terms of dot products of the input variables, e.g., the classifier is y x =sign i yi x xi b i so in the feature space this becomes y x =sign x xi b i yi i 33
34 The Kernel trick How do the dot products help? It turns on that a broad class of kernel functions can be written in the form: x K x, x ' = x ' Functions having this property must satisfy Mercer's condition K x, x ' g x g x ' d x d x ' 0 for any function g where 2 g x d x is finite. So we don't even need to find explicitly the feature space transformation (x), we only need a kernel. 34
35 Finding kernels There are a number of techniques for finding kernels, e.g., constructing new ones from known ones according to certain rules (cf. Bishop Ch 6). Frequently used kernels to construct classifiers are e.g. polynomial K x, x ' = x x ' p K x, x ' =exp 2 x x ' 2 2 K x, x ' =tanh x x ' Gaussian sigmoidal 35
36 Using an SVM To use an SVM the user must as a minimum choose a kernel function (e.g. Gaussian) any free parameters in the kernel (e.g. the of the Gaussian) the cost parameter C (plays role of regularization parameter) The training is relatively straightforward because, in contrast to neural networks, the function to be minimized has a single global minimum. Furthermore evaluating the classifier only requires that one retain and sum over the support vectors, a relatively small number of points. 36
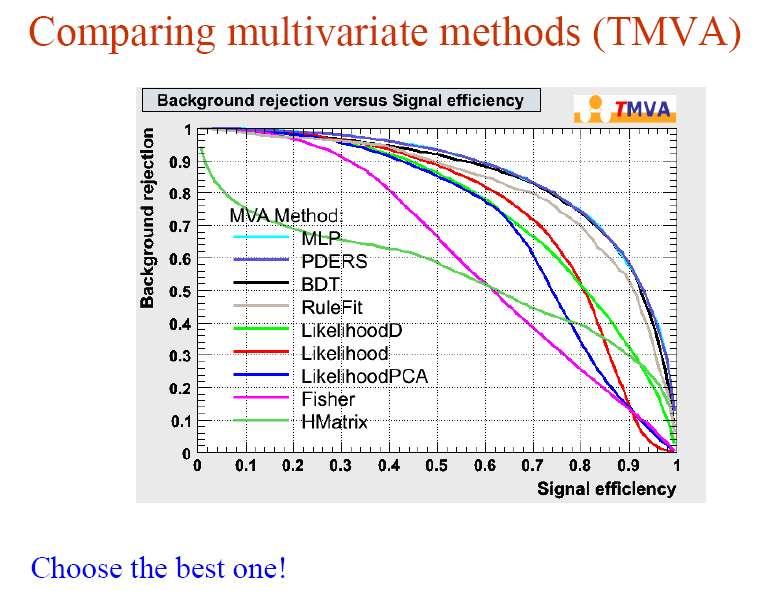
37 SVM in HEP SVMs are very popular in the Machine Learning community but have yet to find wide application in HEP. Here is an early example from a CDF top quark anlaysis (A. Vaiciulis, contribution to PHYSTAT02). signal eff. 37

38 38

39 39
40 40
41 Lecture 4 summary Boosted Decision Trees and Support Vector Machines are two examples of relatively modern developments in Machine Learning that are only recently attracting attention in HEP. There are now many multivariate methods on the market and it is difficult to make general statements about performance; this is often very specific to the problem. Expect advanced multivariate methods to have a major impact in areas where one struggles for statistical significance, not in precision measurements. Fortunately tools to investigate these methods are now widely available. 41
42 Extra slides 42
43 Imperfect pdf estimation What if the approximation we use (e.g., parametric form, assumption of variable independence, etc.) to estimate p(x) is wrong? If we use poor estimates to construct the test variable y x = p x H 0 p x H 1 then the discrimination between the event classes will not be optimal. But can this cause us e.g. to make a false discovery? Even if the estimate of p(x) used in the discriminating variable are imperfect, this will not affect the accuracy of the distributions f(y H0), f(y H1); this only depends on the reliability of the training data. 43
44 Using the classifier output for discovery signal f(y) N(y) background background y Normalized to unity search region excess? ycut y Normalized to expected number of events Discovery = number of events found in search region incompatible with background only hypothesis. Maximize the probability of this happening by setting ycut for maximum s/ b (roughly true). 44
45 Controlling false discovery So for a reliable discovery what we depend on is an accurate estimate of the expected number of background events, and this accuracy only depends on the quality of the training data; works for any function y(x). But we do not blindly rely on the MC model for the training data for background; we need to test it by comparing to real data in control samples where no signal is expected. The ability to perform these tests will depend on on the complexity of the analysis methods. 45



46 AdaBoost study with linear classifier J. Sochman, J. Matas, cmp.felk.cvut.cz Start with a problem for which a linear classifier is weak: 46


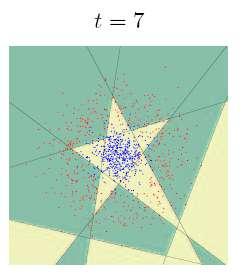
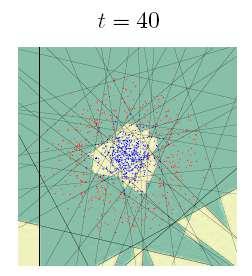
47 AdaBoost study with linear classifier J. Sochman, J. Matas, cmp.felk.cvut.cz 47

48 MiniBooNE Decision tree performance ~ b / b 48
49 Quotes I like Keep it simple. As simple as possible. Not any simpler. A. Einstein If you believe in something you don't understand, you suffer,.. Stevie Wonder 49
Statistical Methods for LHC Physics
 RHUL Physics www.pp.rhul.ac.uk/~cowan Particle Physics Seminar University of Glasgow 26 February, 2009 1 Outline Quick overview of physics at the Large Hadron Collider (LHC) New multivariate methods for
RHUL Physics www.pp.rhul.ac.uk/~cowan Particle Physics Seminar University of Glasgow 26 February, 2009 1 Outline Quick overview of physics at the Large Hadron Collider (LHC) New multivariate methods for
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Advanced statistical methods for data analysis Lecture 1
 Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods
 Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Data Mining. Linear & nonlinear classifiers. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Machine Learning : Support Vector Machines
 Machine Learning Support Vector Machines 05/01/2014 Machine Learning : Support Vector Machines Linear Classifiers (recap) A building block for almost all a mapping, a partitioning of the input space into
Machine Learning Support Vector Machines 05/01/2014 Machine Learning : Support Vector Machines Linear Classifiers (recap) A building block for almost all a mapping, a partitioning of the input space into
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Support Vector Machines Explained
 December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
Statistical Methods in Particle Physics
 Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
ML (cont.): SUPPORT VECTOR MACHINES
: SUPPORT VECTOR MACHINES") ML (cont.): SUPPORT VECTOR MACHINES CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 40 Support Vector Machines (SVMs) The No-Math Version
ML (cont.): SUPPORT VECTOR MACHINES CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 40 Support Vector Machines (SVMs) The No-Math Version
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Support Vector Machine & Its Applications
 Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
Pattern Recognition 2018 Support Vector Machines
 Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Statistical Methods for Particle Physics Lecture 2: multivariate methods
 Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c /9/9 page 331 le-tex
 Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Chapter 6: Classification
 Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Support Vector Machines II. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Statistical Pattern Recognition
 Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE You are allowed a two-page cheat sheet. You are also allowed to use a calculator. Answer the questions in the spaces provided on the question sheets.
FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE You are allowed a two-page cheat sheet. You are also allowed to use a calculator. Answer the questions in the spaces provided on the question sheets.
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Support'Vector'Machines. Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan
 Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Linear Classification and SVM. Dr. Xin Zhang
 Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
CS 484 Data Mining. Classification 7. Some slides are from Professor Padhraic Smyth at UC Irvine
 CS 484 Data Mining Classification 7 Some slides are from Professor Padhraic Smyth at UC Irvine Bayesian Belief networks Conditional independence assumption of Naïve Bayes classifier is too strong. Allows
CS 484 Data Mining Classification 7 Some slides are from Professor Padhraic Smyth at UC Irvine Bayesian Belief networks Conditional independence assumption of Naïve Bayes classifier is too strong. Allows
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Support Vector Machines and Kernel Methods
 Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Artificial Intelligence Roman Barták
 Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Support Vector Machines
 Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Support Vector Machines
 Support Vector Machines Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Overview Motivation
Support Vector Machines Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Overview Motivation
What makes good ensemble? CS789: Machine Learning and Neural Network. Introduction. More on diversity
 What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
Lecture 10: Support Vector Machine and Large Margin Classifier
 Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
Review: Support vector machines. Machine learning techniques and image analysis
 Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Lecture 10: A brief introduction to Support Vector Machine
 Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Machine Learning, Fall 2011: Homework 5
 0-60 Machine Learning, Fall 0: Homework 5 Machine Learning Department Carnegie Mellon University Due:??? Instructions There are 3 questions on this assignment. Please submit your completed homework to
0-60 Machine Learning, Fall 0: Homework 5 Machine Learning Department Carnegie Mellon University Due:??? Instructions There are 3 questions on this assignment. Please submit your completed homework to
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Non-linear Support Vector Machines
 Non-linear Support Vector Machines Andrea Passerini passerini@disi.unitn.it Machine Learning Non-linear Support Vector Machines Non-linearly separable problems Hard-margin SVM can address linearly separable
Non-linear Support Vector Machines Andrea Passerini passerini@disi.unitn.it Machine Learning Non-linear Support Vector Machines Non-linearly separable problems Hard-margin SVM can address linearly separable
Indirect Rule Learning: Support Vector Machines. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
Background. Adaptive Filters and Machine Learning. Bootstrap. Combining models. Boosting and Bagging. Poltayev Rassulzhan
 Adaptive Filters and Machine Learning Boosting and Bagging Background Poltayev Rassulzhan rasulzhan@gmail.com Resampling Bootstrap We are using training set and different subsets in order to validate results
Adaptive Filters and Machine Learning Boosting and Bagging Background Poltayev Rassulzhan rasulzhan@gmail.com Resampling Bootstrap We are using training set and different subsets in order to validate results
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Introduction to SVM and RVM
 Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
A Tutorial on Support Vector Machine
 A Tutorial on School of Computing National University of Singapore Contents Theory on Using with Other s Contents Transforming Theory on Using with Other s What is a classifier? A function that maps instances
A Tutorial on School of Computing National University of Singapore Contents Theory on Using with Other s Contents Transforming Theory on Using with Other s What is a classifier? A function that maps instances
Linear, threshold units. Linear Discriminant Functions and Support Vector Machines. Biometrics CSE 190 Lecture 11. X i : inputs W i : weights
 Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Lecture 8. Instructor: Haipeng Luo
 Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
CS 6375 Machine Learning
 CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
ECE662: Pattern Recognition and Decision Making Processes: HW TWO
 ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Statistics and learning: Big Data
 Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
CS7267 MACHINE LEARNING
 CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
Useful Equations for solving SVM questions
 Support Vector Machines (send corrections to yks at csail.mit.edu) In SVMs we are trying to find a decision boundary that maximizes the "margin" or the "width of the road" separating the positives from
Support Vector Machines (send corrections to yks at csail.mit.edu) In SVMs we are trying to find a decision boundary that maximizes the "margin" or the "width of the road" separating the positives from
Brief Introduction to Machine Learning
 Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Support Vector Machines
 Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function