MLE and Bayesian Estimation. Jie Tang Department of Computer Science & Technology Tsinghua University 2012
|
|
|
- Marion Berry
- 5 years ago
- Views:
Transcription

1 MLE and Bayesan Estmaton Je Tang Department of Computer Scence & Technology Tsnghua Unversty 01 1
2 Lnear Regresson? As the frst step, we need to decde how we re gong to represent the functon f. One example: polynomal curve fttng M M = = j Notatons: f ( x, w) w0 w1 x wm x wjx w 0 +w 1 x j= 0 w T x Now, gven a tranng set, how do we pck, or learn, the parameters w?
3 Least Squares Loss Functon y f(x, w) N 1 L( w) = ( f ( x, w) y = 1 ) 3
4 4 Learnng by Gradent Descent How to choose w n order to mnmze L(w)? General dea s to start wth some ntal guess for w, and that repeatedly changes w to make L(w) smaller, utl we converge to a value of w that mmze L(w). Gradent descent s a natural search algorthm that update w n the drecton of steepest decrease of L: where s the learnng rate Now let us calculate the partal dervatve. Frst consder one tranng nstance (x, y), so the sum n L can be gnored: Intuton: The update s proportonal to the error term (f(x, w) - y). Thus for the tranng examples wth predcton score close to the actual value y, there s lttle need to change the parameters; n contrast, a larger change to the parameters wll be made. j j j w L w w Δ = (w) j M j j j j j j x y x f y x w w y x f y x f w L w ) ), ( ( ) ), ( ( ) ), ( ( 1 ) ( 0 = = = = w w w w j j j x y x f w w ) ), ( Δ( = w The rule s called LMS (least mean squares) update rule, aka Wdrow-Hoff learnng rule.
5 Learnng by Gradent Descent (cont.) Then consder a tranng data set rather than only one example by two ways: Batch gradent descent Scan through the entre tranng set before takng a sngle step of update Repeat untl convergence { w j = w j + ( f (x, w) y ) x j } Stochastc gradent descent Start makng progress rght away, and contnues to make progress wth each example t looks at. Much faster than batch gradent descent. The parameters wll keep oscllatng around the mnmum of L, but n practce most of the values near the mnmum wll be reasonably good approxmatons to the true mnmum. Repeat untl convergence { Foreach x { w j = w j + ( f (x, w) y ) x j } } Partcularly when the tranng set s large, stochastc gradent descent s often preferred. 5
6 0 th Order Polynomal 6 * A number of the followng pages are from Bshop s sldes
7 7 1 st Order Polynomal
8 8 3 rd Order Polynomal
9 9 9 th Order Polynomal
10 Over-fttng Root-Mean-Square (RMS) Error: E RMS = L( w) N 10

11 11 Polynomal Coeffcents
12 Data Set Sze 9 th Order Polynomal 1
13 Data Set Sze 9 th Order Polynomal 13
14 Regularzaton Penalze large coeffcent values N 1 λ L( w) = ( f ( x, w) y ) + w = 1 14
15 15 Regularzaton
16 16 Regularzaton
17 Regularzaton: vs. 17

18 18 Polynomal Coeffcents
19 Let us back to the smple case Lnear functon And the loss functon f ( x, w) = w + w x + + w = p 0 j=0 = 1 w j x 1 j Should all example be treated equally? How about f we assgn dfferent weghts to dfferent examples? 1 = w N 1 L( w) = ( f ( x, w) y ) T x p x p 19
20 Locally Weghted Lnear Regresson Ftng w to mnmze N 1 L( w) = α ( f ( x, w) = 1 y ) where a s a non-negatve valued weght for x α ( x x exp τ q = here x q s the example we want to predct ts y ) Wth ths, we have the frst example of a non-parametrc algorthm The number of parameters s not fxed and may grows wth the ncrease of the sze of the tranng set. 0
21 1 Probablstc Interpretaton Let us assume that each example has an error term to represent unmodeled effects. Also assume that ε satsfes IID, e.g., Then we have Gven data X={x }, and ther correspondng Y T y ε + = x w = exp 1 ) ( σ ε πσ ε p = ) ( exp 1 ) ; ( σ πσ T y x y p x w w = = = = = N T N y x y p X Y p L 1 1 ) ( exp 1 ) ; ( ) ; ( ) ( σ πσ x w w w w
22 Maxmum (log-)lkelhood Log lkelhood * Under certan probablstc assumpton, mnmzng least squares regresson corresponds to maxmzng lkelhood estmaton of w = = = = = = = N T N T N y N y x y p X Y p L ) ( log ) ( exp 1 log ) ; ( log ) ; ( log ) ( x w x w w w w σ πσ σ πσ Whch s the same as mnmzng least squares
23 3 Probablty Dstrbutons

24 The Rules of Probablty Sum Rule Product Rule 4

25 5 Probablty Denstes

26 6 The Gaussan Dstrbuton

27 7 Gaussan Mean and Varance
28 8 The Multvarate Gaussan

29 Examples 1 0 = = = 0 9

30 30 Examples
31 31 Examples

32 Gaussan Parameter Estmaton Lkelhood functon 3
")
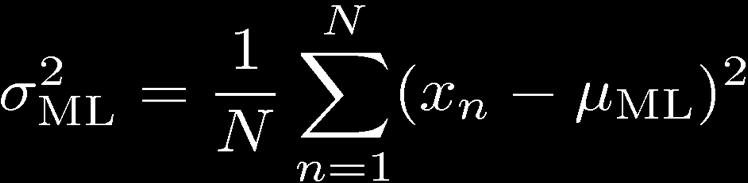
33 33 Maxmum (Log) Lkelhood

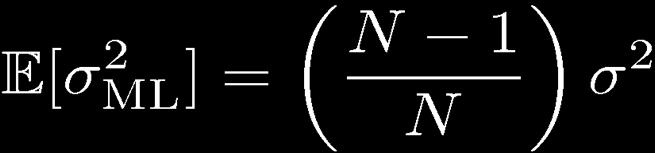
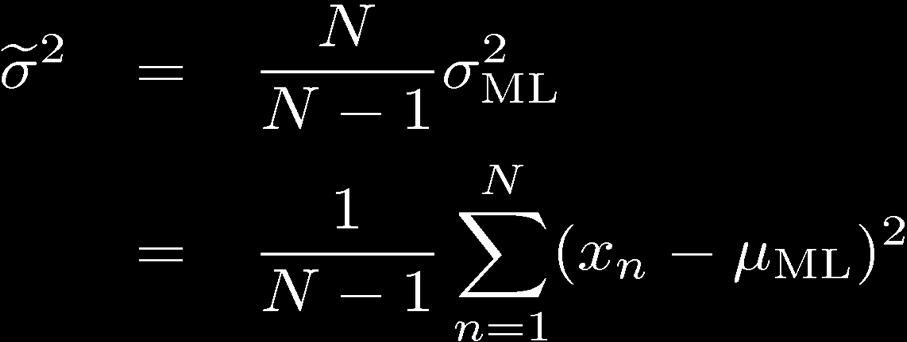
34 Propertes of and 34

35 Bnary Varables (1) Con flppng: heads=1, tals=0 Bernoull Dstrbuton 35


36 N con flps: Bnary Varables () Bnomal Dstrbuton 36

37 37 Bnomal Dstrbuton


38 ML for Bernoull Gven: Parameter Estmaton (1) 38

39 Example: Parameter Estmaton () Predcton: all future tosses wll land heads up Overfttng to D 39

40 Beta Dstrbuton Dstrbuton over. 40

41 Bayesan Bernoull The Beta dstrbuton provdes the conjugate pror for the Bernoull dstrbuton. 41
42 4 Beta Dstrbuton
43 43 Pror Lkelhood = Posteror

44 Propertes of the Posteror As the sze of the data set, N, ncrease 44

45 Predcton under the Posteror What s the probablty that the next con toss wll land heads up? 45



46 Multnomal Varables 1-of-K codng scheme: 46

47 ML Parameter estmaton Gven: Ensure, use a Lagrange multpler 47

48 48 The Multnomal Dstrbuton



49 The Drchlet Dstrbuton Conjugate pror for the multnomal dstrbuton. 49

")
50 50 Bayesan Multnomal (1)
51 51 Bayesan Multnomal ()
52 Thanks! Je Tang, DCST Emal: 5
Logistic Regression. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Lecture Notes on Linear Regression
 Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
CS 2750 Machine Learning. Lecture 5. Density estimation. CS 2750 Machine Learning. Announcements
 CS 750 Machne Learnng Lecture 5 Densty estmaton Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square CS 750 Machne Learnng Announcements Homework Due on Wednesday before the class Reports: hand n before
CS 750 Machne Learnng Lecture 5 Densty estmaton Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square CS 750 Machne Learnng Announcements Homework Due on Wednesday before the class Reports: hand n before
Machine learning: Density estimation
 CS 70 Foundatons of AI Lecture 3 Machne learnng: ensty estmaton Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square ata: ensty estmaton {.. n} x a vector of attrbute values Objectve: estmate the model of
CS 70 Foundatons of AI Lecture 3 Machne learnng: ensty estmaton Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square ata: ensty estmaton {.. n} x a vector of attrbute values Objectve: estmate the model of
INF 5860 Machine learning for image classification. Lecture 3 : Image classification and regression part II Anne Solberg January 31, 2018
 INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
xp(x µ) = 0 p(x = 0 µ) + 1 p(x = 1 µ) = µ
 = 0 p(x = 0 µ) + 1 p(x = 1 µ) = µ") CSE 455/555 Sprng 2013 Homework 7: Parametrc Technques Jason J. Corso Computer Scence and Engneerng SUY at Buffalo jcorso@buffalo.edu Solutons by Yngbo Zhou Ths assgnment does not need to be submtted and
CSE 455/555 Sprng 2013 Homework 7: Parametrc Technques Jason J. Corso Computer Scence and Engneerng SUY at Buffalo jcorso@buffalo.edu Solutons by Yngbo Zhou Ths assgnment does not need to be submtted and
The conjugate prior to a Bernoulli is. A) Bernoulli B) Gaussian C) Beta D) none of the above
 Bernoulli B) Gaussian C) Beta D) none of the above") The conjugate pror to a Bernoull s A) Bernoull B) Gaussan C) Beta D) none of the above The conjugate pror to a Gaussan s A) Bernoull B) Gaussan C) Beta D) none of the above MAP estmates A) argmax θ p(θ
The conjugate pror to a Bernoull s A) Bernoull B) Gaussan C) Beta D) none of the above The conjugate pror to a Gaussan s A) Bernoull B) Gaussan C) Beta D) none of the above MAP estmates A) argmax θ p(θ
Ensemble Methods: Boosting
 Ensemble Methods: Boostng Ncholas Ruozz Unversty of Texas at Dallas Based on the sldes of Vbhav Gogate and Rob Schapre Last Tme Varance reducton va baggng Generate new tranng data sets by samplng wth replacement
Ensemble Methods: Boostng Ncholas Ruozz Unversty of Texas at Dallas Based on the sldes of Vbhav Gogate and Rob Schapre Last Tme Varance reducton va baggng Generate new tranng data sets by samplng wth replacement
The Gaussian classifier. Nuno Vasconcelos ECE Department, UCSD
 he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that we have state of the world X observatons g decson functon L[g,y] loss of predctng y wth g Bayes decson rule s
he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that we have state of the world X observatons g decson functon L[g,y] loss of predctng y wth g Bayes decson rule s
Logistic Classifier CISC 5800 Professor Daniel Leeds
 lon 9/7/8 Logstc Classfer CISC 58 Professor Danel Leeds Classfcaton strategy: generatve vs. dscrmnatve Generatve, e.g., Bayes/Naïve Bayes: 5 5 Identfy probablty dstrbuton for each class Determne class
lon 9/7/8 Logstc Classfer CISC 58 Professor Danel Leeds Classfcaton strategy: generatve vs. dscrmnatve Generatve, e.g., Bayes/Naïve Bayes: 5 5 Identfy probablty dstrbuton for each class Determne class
Linear Regression Introduction to Machine Learning. Matt Gormley Lecture 5 September 14, Readings: Bishop, 3.1
 School of Computer Scence 10-601 Introducton to Machne Learnng Lnear Regresson Readngs: Bshop, 3.1 Matt Gormle Lecture 5 September 14, 016 1 Homework : Remnders Extenson: due Frda (9/16) at 5:30pm Rectaton
School of Computer Scence 10-601 Introducton to Machne Learnng Lnear Regresson Readngs: Bshop, 3.1 Matt Gormle Lecture 5 September 14, 016 1 Homework : Remnders Extenson: due Frda (9/16) at 5:30pm Rectaton
CIS526: Machine Learning Lecture 3 (Sept 16, 2003) Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M
 Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M") CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
Course 395: Machine Learning - Lectures
 Course 395: Machne Learnng - Lectures Lecture 1-2: Concept Learnng (M. Pantc Lecture 3-4: Decson Trees & CC Intro (M. Pantc Lecture 5-6: Artfcal Neural Networks (S.Zaferou Lecture 7-8: Instance ased Learnng
Course 395: Machne Learnng - Lectures Lecture 1-2: Concept Learnng (M. Pantc Lecture 3-4: Decson Trees & CC Intro (M. Pantc Lecture 5-6: Artfcal Neural Networks (S.Zaferou Lecture 7-8: Instance ased Learnng
Logistic Regression Maximum Likelihood Estimation
 Harvard-MIT Dvson of Health Scences and Technology HST.951J: Medcal Decson Support, Fall 2005 Instructors: Professor Lucla Ohno-Machado and Professor Staal Vnterbo 6.873/HST.951 Medcal Decson Support Fall
Harvard-MIT Dvson of Health Scences and Technology HST.951J: Medcal Decson Support, Fall 2005 Instructors: Professor Lucla Ohno-Machado and Professor Staal Vnterbo 6.873/HST.951 Medcal Decson Support Fall
For now, let us focus on a specific model of neurons. These are simplified from reality but can achieve remarkable results.
 Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Maximum Likelihood Estimation of Binary Dependent Variables Models: Probit and Logit. 1. General Formulation of Binary Dependent Variables Models
 ECO 452 -- OE 4: Probt and Logt Models ECO 452 -- OE 4 Maxmum Lkelhood Estmaton of Bnary Dependent Varables Models: Probt and Logt hs note demonstrates how to formulate bnary dependent varables models
ECO 452 -- OE 4: Probt and Logt Models ECO 452 -- OE 4 Maxmum Lkelhood Estmaton of Bnary Dependent Varables Models: Probt and Logt hs note demonstrates how to formulate bnary dependent varables models
10-701/ Machine Learning, Fall 2005 Homework 3
 10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
Generalized Linear Methods
 Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Space of ML Problems. CSE 473: Artificial Intelligence. Parameter Estimation and Bayesian Networks. Learning Topics
 /7/7 CSE 73: Artfcal Intellgence Bayesan - Learnng Deter Fox Sldes adapted from Dan Weld, Jack Breese, Dan Klen, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer What s Beng Learned? Space
/7/7 CSE 73: Artfcal Intellgence Bayesan - Learnng Deter Fox Sldes adapted from Dan Weld, Jack Breese, Dan Klen, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer What s Beng Learned? Space
Discriminative classifier: Logistic Regression. CS534-Machine Learning
 Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng robablstc Classfer Gven an nstance, hat does a probablstc classfer do dfferentl compared to, sa, perceptron? It does not drectl predct Instead,
Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng robablstc Classfer Gven an nstance, hat does a probablstc classfer do dfferentl compared to, sa, perceptron? It does not drectl predct Instead,
Probabilistic Classification: Bayes Classifiers. Lecture 6:
 Probablstc Classfcaton: Bayes Classfers Lecture : Classfcaton Models Sam Rowes January, Generatve model: p(x, y) = p(y)p(x y). p(y) are called class prors. p(x y) are called class condtonal feature dstrbutons.
Probablstc Classfcaton: Bayes Classfers Lecture : Classfcaton Models Sam Rowes January, Generatve model: p(x, y) = p(y)p(x y). p(y) are called class prors. p(x y) are called class condtonal feature dstrbutons.
Discriminative classifier: Logistic Regression. CS534-Machine Learning
 Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng 2 Logstc Regresson Gven tranng set D stc regresson learns the condtonal dstrbuton We ll assume onl to classes and a parametrc form for here s
Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng 2 Logstc Regresson Gven tranng set D stc regresson learns the condtonal dstrbuton We ll assume onl to classes and a parametrc form for here s
8/25/17. Data Modeling. Data Modeling. Data Modeling. Patrice Koehl Department of Biological Sciences National University of Singapore
 8/5/17 Data Modelng Patrce Koehl Department of Bologcal Scences atonal Unversty of Sngapore http://www.cs.ucdavs.edu/~koehl/teachng/bl59 koehl@cs.ucdavs.edu Data Modelng Ø Data Modelng: least squares Ø
8/5/17 Data Modelng Patrce Koehl Department of Bologcal Scences atonal Unversty of Sngapore http://www.cs.ucdavs.edu/~koehl/teachng/bl59 koehl@cs.ucdavs.edu Data Modelng Ø Data Modelng: least squares Ø
MATH 829: Introduction to Data Mining and Analysis The EM algorithm (part 2)
") 1/16 MATH 829: Introducton to Data Mnng and Analyss The EM algorthm (part 2) Domnque Gullot Departments of Mathematcal Scences Unversty of Delaware Aprl 20, 2016 Recall 2/16 We are gven ndependent observatons
1/16 MATH 829: Introducton to Data Mnng and Analyss The EM algorthm (part 2) Domnque Gullot Departments of Mathematcal Scences Unversty of Delaware Aprl 20, 2016 Recall 2/16 We are gven ndependent observatons
Expectation Maximization Mixture Models HMMs
 -755 Machne Learnng for Sgnal Processng Mture Models HMMs Class 9. 2 Sep 200 Learnng Dstrbutons for Data Problem: Gven a collecton of eamples from some data, estmate ts dstrbuton Basc deas of Mamum Lelhood
-755 Machne Learnng for Sgnal Processng Mture Models HMMs Class 9. 2 Sep 200 Learnng Dstrbutons for Data Problem: Gven a collecton of eamples from some data, estmate ts dstrbuton Basc deas of Mamum Lelhood
Retrieval Models: Language models
 CS-590I Informaton Retreval Retreval Models: Language models Luo S Department of Computer Scence Purdue Unversty Introducton to language model Ungram language model Document language model estmaton Maxmum
CS-590I Informaton Retreval Retreval Models: Language models Luo S Department of Computer Scence Purdue Unversty Introducton to language model Ungram language model Document language model estmaton Maxmum
Outline. Multivariate Parametric Methods. Multivariate Data. Basic Multivariate Statistics. Steven J Zeil
 Outlne Multvarate Parametrc Methods Steven J Zel Old Domnon Unv. Fall 2010 1 Multvarate Data 2 Multvarate ormal Dstrbuton 3 Multvarate Classfcaton Dscrmnants Tunng Complexty Dscrete Features 4 Multvarate
Outlne Multvarate Parametrc Methods Steven J Zel Old Domnon Unv. Fall 2010 1 Multvarate Data 2 Multvarate ormal Dstrbuton 3 Multvarate Classfcaton Dscrmnants Tunng Complexty Dscrete Features 4 Multvarate
EEE 241: Linear Systems
 EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
Chapter 1. Probability
 Chapter. Probablty Mcroscopc propertes of matter: quantum mechancs, atomc and molecular propertes Macroscopc propertes of matter: thermodynamcs, E, H, C V, C p, S, A, G How do we relate these two propertes?
Chapter. Probablty Mcroscopc propertes of matter: quantum mechancs, atomc and molecular propertes Macroscopc propertes of matter: thermodynamcs, E, H, C V, C p, S, A, G How do we relate these two propertes?
Maximum Likelihood Estimation
 Maxmum Lkelhood Estmaton INFO-2301: Quanttatve Reasonng 2 Mchael Paul and Jordan Boyd-Graber MARCH 7, 2017 INFO-2301: Quanttatve Reasonng 2 Paul and Boyd-Graber Maxmum Lkelhood Estmaton 1 of 9 Why MLE?
Maxmum Lkelhood Estmaton INFO-2301: Quanttatve Reasonng 2 Mchael Paul and Jordan Boyd-Graber MARCH 7, 2017 INFO-2301: Quanttatve Reasonng 2 Paul and Boyd-Graber Maxmum Lkelhood Estmaton 1 of 9 Why MLE?
MIMA Group. Chapter 2 Bayesian Decision Theory. School of Computer Science and Technology, Shandong University. Xin-Shun SDU
 Group M D L M Chapter Bayesan Decson heory Xn-Shun Xu @ SDU School of Computer Scence and echnology, Shandong Unversty Bayesan Decson heory Bayesan decson theory s a statstcal approach to data mnng/pattern
Group M D L M Chapter Bayesan Decson heory Xn-Shun Xu @ SDU School of Computer Scence and echnology, Shandong Unversty Bayesan Decson heory Bayesan decson theory s a statstcal approach to data mnng/pattern
Classification as a Regression Problem
 Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Support Vector Machines
 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Lecture 12: Classification
 Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
P R. Lecture 4. Theory and Applications of Pattern Recognition. Dept. of Electrical and Computer Engineering /
 Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
SDMML HT MSc Problem Sheet 4
 SDMML HT 06 - MSc Problem Sheet 4. The recever operatng characterstc ROC curve plots the senstvty aganst the specfcty of a bnary classfer as the threshold for dscrmnaton s vared. Let the data space be
SDMML HT 06 - MSc Problem Sheet 4. The recever operatng characterstc ROC curve plots the senstvty aganst the specfcty of a bnary classfer as the threshold for dscrmnaton s vared. Let the data space be
Relevance Vector Machines Explained
 October 19, 2010 Relevance Vector Machnes Explaned Trstan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introducton Ths document has been wrtten n an attempt to make Tppng s [1] Relevance Vector Machnes
October 19, 2010 Relevance Vector Machnes Explaned Trstan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introducton Ths document has been wrtten n an attempt to make Tppng s [1] Relevance Vector Machnes
Maximum Likelihood Estimation of Binary Dependent Variables Models: Probit and Logit. 1. General Formulation of Binary Dependent Variables Models
 ECO 452 -- OE 4: Probt and Logt Models ECO 452 -- OE 4 Mamum Lkelhood Estmaton of Bnary Dependent Varables Models: Probt and Logt hs note demonstrates how to formulate bnary dependent varables models for
ECO 452 -- OE 4: Probt and Logt Models ECO 452 -- OE 4 Mamum Lkelhood Estmaton of Bnary Dependent Varables Models: Probt and Logt hs note demonstrates how to formulate bnary dependent varables models for
Boostrapaggregating (Bagging)
") Boostrapaggregatng (Baggng) An ensemble meta-algorthm desgned to mprove the stablty and accuracy of machne learnng algorthms Can be used n both regresson and classfcaton Reduces varance and helps to avod
Boostrapaggregatng (Baggng) An ensemble meta-algorthm desgned to mprove the stablty and accuracy of machne learnng algorthms Can be used n both regresson and classfcaton Reduces varance and helps to avod
Linear Approximation with Regularization and Moving Least Squares
 Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Online Classification: Perceptron and Winnow
 E0 370 Statstcal Learnng Theory Lecture 18 Nov 8, 011 Onlne Classfcaton: Perceptron and Wnnow Lecturer: Shvan Agarwal Scrbe: Shvan Agarwal 1 Introducton In ths lecture we wll start to study the onlne learnng
E0 370 Statstcal Learnng Theory Lecture 18 Nov 8, 011 Onlne Classfcaton: Perceptron and Wnnow Lecturer: Shvan Agarwal Scrbe: Shvan Agarwal 1 Introducton In ths lecture we wll start to study the onlne learnng
Kernel Methods and SVMs Extension
 Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
The Geometry of Logit and Probit
 The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.
The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.
1 Convex Optimization
 Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
Semi-Supervised Learning
 Sem-Supervsed Learnng Consder the problem of Prepostonal Phrase Attachment. Buy car wth money ; buy car wth wheel There are several ways to generate features. Gven the lmted representaton, we can assume
Sem-Supervsed Learnng Consder the problem of Prepostonal Phrase Attachment. Buy car wth money ; buy car wth wheel There are several ways to generate features. Gven the lmted representaton, we can assume
C4B Machine Learning Answers II. = σ(z) (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )
 (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )") C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
Natural Images, Gaussian Mixtures and Dead Leaves Supplementary Material
 Natural Images, Gaussan Mxtures and Dead Leaves Supplementary Materal Danel Zoran Interdscplnary Center for Neural Computaton Hebrew Unversty of Jerusalem Israel http://www.cs.huj.ac.l/ danez Yar Wess
Natural Images, Gaussan Mxtures and Dead Leaves Supplementary Materal Danel Zoran Interdscplnary Center for Neural Computaton Hebrew Unversty of Jerusalem Israel http://www.cs.huj.ac.l/ danez Yar Wess
Parametric fractional imputation for missing data analysis. Jae Kwang Kim Survey Working Group Seminar March 29, 2010
 Parametrc fractonal mputaton for mssng data analyss Jae Kwang Km Survey Workng Group Semnar March 29, 2010 1 Outlne Introducton Proposed method Fractonal mputaton Approxmaton Varance estmaton Multple mputaton
Parametrc fractonal mputaton for mssng data analyss Jae Kwang Km Survey Workng Group Semnar March 29, 2010 1 Outlne Introducton Proposed method Fractonal mputaton Approxmaton Varance estmaton Multple mputaton
Motion Perception Under Uncertainty. Hongjing Lu Department of Psychology University of Hong Kong
 Moton Percepton Under Uncertanty Hongjng Lu Department of Psychology Unversty of Hong Kong Outlne Uncertanty n moton stmulus Correspondence problem Qualtatve fttng usng deal observer models Based on sgnal
Moton Percepton Under Uncertanty Hongjng Lu Department of Psychology Unversty of Hong Kong Outlne Uncertanty n moton stmulus Correspondence problem Qualtatve fttng usng deal observer models Based on sgnal
An Experiment/Some Intuition (Fall 2006): Lecture 18 The EM Algorithm heads coin 1 tails coin 2 Overview Maximum Likelihood Estimation
: Lecture 18 The EM Algorithm heads coin 1 tails coin 2 Overview Maximum Likelihood Estimation") An Experment/Some Intuton I have three cons n my pocket, 6.864 (Fall 2006): Lecture 18 The EM Algorthm Con 0 has probablty λ of heads; Con 1 has probablty p 1 of heads; Con 2 has probablty p 2 of heads
An Experment/Some Intuton I have three cons n my pocket, 6.864 (Fall 2006): Lecture 18 The EM Algorthm Con 0 has probablty λ of heads; Con 1 has probablty p 1 of heads; Con 2 has probablty p 2 of heads
Maxent Models & Deep Learning
 Maxent Models & Deep Learnng 1. Last bts of maxent (sequence) models 1.MEMMs vs. CRFs 2.Smoothng/regularzaton n maxent models 2. Deep Learnng 1. What s t? Why s t good? (Part 1) 2. From logstc regresson
Maxent Models & Deep Learnng 1. Last bts of maxent (sequence) models 1.MEMMs vs. CRFs 2.Smoothng/regularzaton n maxent models 2. Deep Learnng 1. What s t? Why s t good? (Part 1) 2. From logstc regresson
15-381: Artificial Intelligence. Regression and cross validation
 15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING
 1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
Linear Regression Analysis: Terminology and Notation
 ECON 35* -- Secton : Basc Concepts of Regresson Analyss (Page ) Lnear Regresson Analyss: Termnology and Notaton Consder the generc verson of the smple (two-varable) lnear regresson model. It s represented
ECON 35* -- Secton : Basc Concepts of Regresson Analyss (Page ) Lnear Regresson Analyss: Termnology and Notaton Consder the generc verson of the smple (two-varable) lnear regresson model. It s represented
2E Pattern Recognition Solutions to Introduction to Pattern Recognition, Chapter 2: Bayesian pattern classification
 E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
Maximum Likelihood Estimation (MLE)
") Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Hydrological statistics. Hydrological statistics and extremes
 5--0 Stochastc Hydrology Hydrologcal statstcs and extremes Marc F.P. Berkens Professor of Hydrology Faculty of Geoscences Hydrologcal statstcs Mostly concernes wth the statstcal analyss of hydrologcal
5--0 Stochastc Hydrology Hydrologcal statstcs and extremes Marc F.P. Berkens Professor of Hydrology Faculty of Geoscences Hydrologcal statstcs Mostly concernes wth the statstcal analyss of hydrologcal
Week 5: Neural Networks
 Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Homework Assignment 3 Due in class, Thursday October 15
 Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Limited Dependent Variables
 Lmted Dependent Varables. What f the left-hand sde varable s not a contnuous thng spread from mnus nfnty to plus nfnty? That s, gven a model = f (, β, ε, where a. s bounded below at zero, such as wages
Lmted Dependent Varables. What f the left-hand sde varable s not a contnuous thng spread from mnus nfnty to plus nfnty? That s, gven a model = f (, β, ε, where a. s bounded below at zero, such as wages
Durban Watson for Testing the Lack-of-Fit of Polynomial Regression Models without Replications
 Durban Watson for Testng the Lack-of-Ft of Polynomal Regresson Models wthout Replcatons Ruba A. Alyaf, Maha A. Omar, Abdullah A. Al-Shha ralyaf@ksu.edu.sa, maomar@ksu.edu.sa, aalshha@ksu.edu.sa Department
Durban Watson for Testng the Lack-of-Ft of Polynomal Regresson Models wthout Replcatons Ruba A. Alyaf, Maha A. Omar, Abdullah A. Al-Shha ralyaf@ksu.edu.sa, maomar@ksu.edu.sa, aalshha@ksu.edu.sa Department
Multilayer Perceptron (MLP)
") Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
The big picture. Outline
 The bg pcture Vncent Claveau IRISA - CNRS, sldes from E. Kjak INSA Rennes Notatons classes: C = {ω = 1,.., C} tranng set S of sze m, composed of m ponts (x, ω ) per class ω representaton space: R d (=
The bg pcture Vncent Claveau IRISA - CNRS, sldes from E. Kjak INSA Rennes Notatons classes: C = {ω = 1,.., C} tranng set S of sze m, composed of m ponts (x, ω ) per class ω representaton space: R d (=
ENG 8801/ Special Topics in Computer Engineering: Pattern Recognition. Memorial University of Newfoundland Pattern Recognition
 EG 880/988 - Specal opcs n Computer Engneerng: Pattern Recognton Memoral Unversty of ewfoundland Pattern Recognton Lecture 7 May 3, 006 http://wwwengrmunca/~charlesr Offce Hours: uesdays hursdays 8:30-9:30
EG 880/988 - Specal opcs n Computer Engneerng: Pattern Recognton Memoral Unversty of ewfoundland Pattern Recognton Lecture 7 May 3, 006 http://wwwengrmunca/~charlesr Offce Hours: uesdays hursdays 8:30-9:30
Dr. Shalabh Department of Mathematics and Statistics Indian Institute of Technology Kanpur
 Analyss of Varance and Desgn of Experment-I MODULE VII LECTURE - 3 ANALYSIS OF COVARIANCE Dr Shalabh Department of Mathematcs and Statstcs Indan Insttute of Technology Kanpur Any scentfc experment s performed
Analyss of Varance and Desgn of Experment-I MODULE VII LECTURE - 3 ANALYSIS OF COVARIANCE Dr Shalabh Department of Mathematcs and Statstcs Indan Insttute of Technology Kanpur Any scentfc experment s performed
Classification learning II
 Lecture 8 Classfcaton learnng II Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Logstc regresson model Defnes a lnear decson boundar Dscrmnant functons: g g g g here g z / e z f, g g - s a logstc functon
Lecture 8 Classfcaton learnng II Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Logstc regresson model Defnes a lnear decson boundar Dscrmnant functons: g g g g here g z / e z f, g g - s a logstc functon
Generative classification models
 CS 675 Intro to Machne Learnng Lecture Generatve classfcaton models Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Data: D { d, d,.., dn} d, Classfcaton represents a dscrete class value Goal: learn
CS 675 Intro to Machne Learnng Lecture Generatve classfcaton models Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Data: D { d, d,.., dn} d, Classfcaton represents a dscrete class value Goal: learn
First Year Examination Department of Statistics, University of Florida
 Frst Year Examnaton Department of Statstcs, Unversty of Florda May 7, 010, 8:00 am - 1:00 noon Instructons: 1. You have four hours to answer questons n ths examnaton.. You must show your work to receve
Frst Year Examnaton Department of Statstcs, Unversty of Florda May 7, 010, 8:00 am - 1:00 noon Instructons: 1. You have four hours to answer questons n ths examnaton.. You must show your work to receve
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
Natural Language Processing and Information Retrieval
 Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Which Separator? Spring 1
 Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Singular Value Decomposition: Theory and Applications
 Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
Gaussian process classification: a message-passing viewpoint
 Gaussan process classfcaton: a message-passng vewpont Flpe Rodrgues fmpr@de.uc.pt November 014 Abstract The goal of ths short paper s to provde a message-passng vewpont of the Expectaton Propagaton EP
Gaussan process classfcaton: a message-passng vewpont Flpe Rodrgues fmpr@de.uc.pt November 014 Abstract The goal of ths short paper s to provde a message-passng vewpont of the Expectaton Propagaton EP
INTRODUCTION TO MACHINE LEARNING 3RD EDITION
 ETHEM ALPAYDIN The MIT Press, 2014 Lecture Sldes for INTRODUCTION TO MACHINE LEARNING 3RD EDITION alpaydn@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/2ml3e CHAPTER 3: BAYESIAN DECISION THEORY Probablty
ETHEM ALPAYDIN The MIT Press, 2014 Lecture Sldes for INTRODUCTION TO MACHINE LEARNING 3RD EDITION alpaydn@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/2ml3e CHAPTER 3: BAYESIAN DECISION THEORY Probablty
Finite Mixture Models and Expectation Maximization. Most slides are from: Dr. Mario Figueiredo, Dr. Anil Jain and Dr. Rong Jin
 Fnte Mxture Models and Expectaton Maxmzaton Most sldes are from: Dr. Maro Fgueredo, Dr. Anl Jan and Dr. Rong Jn Recall: The Supervsed Learnng Problem Gven a set of n samples X {(x, y )},,,n Chapter 3 of
Fnte Mxture Models and Expectaton Maxmzaton Most sldes are from: Dr. Maro Fgueredo, Dr. Anl Jan and Dr. Rong Jn Recall: The Supervsed Learnng Problem Gven a set of n samples X {(x, y )},,,n Chapter 3 of
CSC 411 / CSC D11 / CSC C11
 18 Boostng s a general strategy for learnng classfers by combnng smpler ones. The dea of boostng s to take a weak classfer that s, any classfer that wll do at least slghtly better than chance and use t
18 Boostng s a general strategy for learnng classfers by combnng smpler ones. The dea of boostng s to take a weak classfer that s, any classfer that wll do at least slghtly better than chance and use t
3.1 Expectation of Functions of Several Random Variables. )' be a k-dimensional discrete or continuous random vector, with joint PMF p (, E X E X1 E X
' be a k-dimensional discrete or continuous random vector, with joint PMF p (, E X E X1 E X") Statstcs 1: Probablty Theory II 37 3 EPECTATION OF SEVERAL RANDOM VARIABLES As n Probablty Theory I, the nterest n most stuatons les not on the actual dstrbuton of a random vector, but rather on a number
Statstcs 1: Probablty Theory II 37 3 EPECTATION OF SEVERAL RANDOM VARIABLES As n Probablty Theory I, the nterest n most stuatons les not on the actual dstrbuton of a random vector, but rather on a number
Department of Computer Science Artificial Intelligence Research Laboratory. Iowa State University MACHINE LEARNING
 MACHINE LEANING Vasant Honavar Bonformatcs and Computatonal Bology rogram Center for Computatonal Intellgence, Learnng, & Dscovery Iowa State Unversty honavar@cs.astate.edu www.cs.astate.edu/~honavar/
MACHINE LEANING Vasant Honavar Bonformatcs and Computatonal Bology rogram Center for Computatonal Intellgence, Learnng, & Dscovery Iowa State Unversty honavar@cs.astate.edu www.cs.astate.edu/~honavar/
Lecture 10 Support Vector Machines. Oct
 Lecture 10 Support Vector Machnes Oct - 20-2008 Lnear Separators Whch of the lnear separators s optmal? Concept of Margn Recall that n Perceptron, we learned that the convergence rate of the Perceptron
Lecture 10 Support Vector Machnes Oct - 20-2008 Lnear Separators Whch of the lnear separators s optmal? Concept of Margn Recall that n Perceptron, we learned that the convergence rate of the Perceptron
Chapter 9: Statistical Inference and the Relationship between Two Variables
 Chapter 9: Statstcal Inference and the Relatonshp between Two Varables Key Words The Regresson Model The Sample Regresson Equaton The Pearson Correlaton Coeffcent Learnng Outcomes After studyng ths chapter,
Chapter 9: Statstcal Inference and the Relatonshp between Two Varables Key Words The Regresson Model The Sample Regresson Equaton The Pearson Correlaton Coeffcent Learnng Outcomes After studyng ths chapter,
Multilayer Perceptrons and Backpropagation. Perceptrons. Recap: Perceptrons. Informatics 1 CG: Lecture 6. Mirella Lapata
 Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
EM and Structure Learning
 EM and Structure Learnng Le Song Machne Learnng II: Advanced Topcs CSE 8803ML, Sprng 2012 Partally observed graphcal models Mxture Models N(μ 1, Σ 1 ) Z X N N(μ 2, Σ 2 ) 2 Gaussan mxture model Consder
EM and Structure Learnng Le Song Machne Learnng II: Advanced Topcs CSE 8803ML, Sprng 2012 Partally observed graphcal models Mxture Models N(μ 1, Σ 1 ) Z X N N(μ 2, Σ 2 ) 2 Gaussan mxture model Consder
A New Method for Estimating Overdispersion. David Fletcher and Peter Green Department of Mathematics and Statistics
 A New Method for Estmatng Overdsperson Davd Fletcher and Peter Green Department of Mathematcs and Statstcs Byron Morgan Insttute of Mathematcs, Statstcs and Actuaral Scence Unversty of Kent, England Overvew
A New Method for Estmatng Overdsperson Davd Fletcher and Peter Green Department of Mathematcs and Statstcs Byron Morgan Insttute of Mathematcs, Statstcs and Actuaral Scence Unversty of Kent, England Overvew
Clustering & Unsupervised Learning
 Clusterng & Unsupervsed Learnng Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 2012 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Clusterng & Unsupervsed Learnng Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 2012 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Lecture 21: Numerical methods for pricing American type derivatives
 Lecture 21: Numercal methods for prcng Amercan type dervatves Xaoguang Wang STAT 598W Aprl 10th, 2014 (STAT 598W) Lecture 21 1 / 26 Outlne 1 Fnte Dfference Method Explct Method Penalty Method (STAT 598W)
Lecture 21: Numercal methods for prcng Amercan type dervatves Xaoguang Wang STAT 598W Aprl 10th, 2014 (STAT 598W) Lecture 21 1 / 26 Outlne 1 Fnte Dfference Method Explct Method Penalty Method (STAT 598W)
Bayesian Learning. Smart Home Health Analytics Spring Nirmalya Roy Department of Information Systems University of Maryland Baltimore County
 Smart Home Health Analytcs Sprng 2018 Bayesan Learnng Nrmalya Roy Department of Informaton Systems Unversty of Maryland Baltmore ounty www.umbc.edu Bayesan Learnng ombnes pror knowledge wth evdence to
Smart Home Health Analytcs Sprng 2018 Bayesan Learnng Nrmalya Roy Department of Informaton Systems Unversty of Maryland Baltmore ounty www.umbc.edu Bayesan Learnng ombnes pror knowledge wth evdence to
Lecture 3: Probability Distributions
 Lecture 3: Probablty Dstrbutons Random Varables Let us begn by defnng a sample space as a set of outcomes from an experment. We denote ths by S. A random varable s a functon whch maps outcomes nto the
Lecture 3: Probablty Dstrbutons Random Varables Let us begn by defnng a sample space as a set of outcomes from an experment. We denote ths by S. A random varable s a functon whch maps outcomes nto the
Econ107 Applied Econometrics Topic 3: Classical Model (Studenmund, Chapter 4)
") I. Classcal Assumptons Econ7 Appled Econometrcs Topc 3: Classcal Model (Studenmund, Chapter 4) We have defned OLS and studed some algebrac propertes of OLS. In ths topc we wll study statstcal propertes
I. Classcal Assumptons Econ7 Appled Econometrcs Topc 3: Classcal Model (Studenmund, Chapter 4) We have defned OLS and studed some algebrac propertes of OLS. In ths topc we wll study statstcal propertes
Hidden Markov Models & The Multivariate Gaussian (10/26/04)
") CS281A/Stat241A: Statstcal Learnng Theory Hdden Markov Models & The Multvarate Gaussan (10/26/04) Lecturer: Mchael I. Jordan Scrbes: Jonathan W. Hu 1 Hdden Markov Models As a bref revew, hdden Markov models
CS281A/Stat241A: Statstcal Learnng Theory Hdden Markov Models & The Multvarate Gaussan (10/26/04) Lecturer: Mchael I. Jordan Scrbes: Jonathan W. Hu 1 Hdden Markov Models As a bref revew, hdden Markov models
A Robust Method for Calculating the Correlation Coefficient
 A Robust Method for Calculatng the Correlaton Coeffcent E.B. Nven and C. V. Deutsch Relatonshps between prmary and secondary data are frequently quantfed usng the correlaton coeffcent; however, the tradtonal
A Robust Method for Calculatng the Correlaton Coeffcent E.B. Nven and C. V. Deutsch Relatonshps between prmary and secondary data are frequently quantfed usng the correlaton coeffcent; however, the tradtonal
Support Vector Machines
 /14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
/14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
18-660: Numerical Methods for Engineering Design and Optimization
 8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
Predictive Analytics : QM901.1x Prof U Dinesh Kumar, IIMB. All Rights Reserved, Indian Institute of Management Bangalore
 Sesson Outlne Introducton to classfcaton problems and dscrete choce models. Introducton to Logstcs Regresson. Logstc functon and Logt functon. Maxmum Lkelhood Estmator (MLE) for estmaton of LR parameters.
Sesson Outlne Introducton to classfcaton problems and dscrete choce models. Introducton to Logstcs Regresson. Logstc functon and Logt functon. Maxmum Lkelhood Estmator (MLE) for estmaton of LR parameters.
Erratum: A Generalized Path Integral Control Approach to Reinforcement Learning
 Journal of Machne Learnng Research 00-9 Submtted /0; Publshed 7/ Erratum: A Generalzed Path Integral Control Approach to Renforcement Learnng Evangelos ATheodorou Jonas Buchl Stefan Schaal Department of
Journal of Machne Learnng Research 00-9 Submtted /0; Publshed 7/ Erratum: A Generalzed Path Integral Control Approach to Renforcement Learnng Evangelos ATheodorou Jonas Buchl Stefan Schaal Department of
Chapter 11: Simple Linear Regression and Correlation
 Chapter 11: Smple Lnear Regresson and Correlaton 11-1 Emprcal Models 11-2 Smple Lnear Regresson 11-3 Propertes of the Least Squares Estmators 11-4 Hypothess Test n Smple Lnear Regresson 11-4.1 Use of t-tests
Chapter 11: Smple Lnear Regresson and Correlaton 11-1 Emprcal Models 11-2 Smple Lnear Regresson 11-3 Propertes of the Least Squares Estmators 11-4 Hypothess Test n Smple Lnear Regresson 11-4.1 Use of t-tests
Lecture Nov
 Lecture 18 Nov 07 2008 Revew Clusterng Groupng smlar obects nto clusters Herarchcal clusterng Agglomeratve approach (HAC: teratvely merge smlar clusters Dfferent lnkage algorthms for computng dstances
Lecture 18 Nov 07 2008 Revew Clusterng Groupng smlar obects nto clusters Herarchcal clusterng Agglomeratve approach (HAC: teratvely merge smlar clusters Dfferent lnkage algorthms for computng dstances
JAB Chain. Long-tail claims development. ASTIN - September 2005 B.Verdier A. Klinger
 JAB Chan Long-tal clams development ASTIN - September 2005 B.Verder A. Klnger Outlne Chan Ladder : comments A frst soluton: Munch Chan Ladder JAB Chan Chan Ladder: Comments Black lne: average pad to ncurred
JAB Chan Long-tal clams development ASTIN - September 2005 B.Verder A. Klnger Outlne Chan Ladder : comments A frst soluton: Munch Chan Ladder JAB Chan Chan Ladder: Comments Black lne: average pad to ncurred
j) = 1 (note sigma notation) ii. Continuous random variable (e.g. Normal distribution) 1. density function: f ( x) 0 and f ( x) dx = 1
 = 1 (note sigma notation) ii. Continuous random variable (e.g. Normal distribution) 1. density function: f ( x) 0 and f ( x) dx = 1") Random varables Measure of central tendences and varablty (means and varances) Jont densty functons and ndependence Measures of assocaton (covarance and correlaton) Interestng result Condtonal dstrbutons
Random varables Measure of central tendences and varablty (means and varances) Jont densty functons and ndependence Measures of assocaton (covarance and correlaton) Interestng result Condtonal dstrbutons
U.C. Berkeley CS294: Beyond Worst-Case Analysis Luca Trevisan September 5, 2017
 U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
princeton univ. F 13 cos 521: Advanced Algorithm Design Lecture 3: Large deviations bounds and applications Lecturer: Sanjeev Arora
 prnceton unv. F 13 cos 521: Advanced Algorthm Desgn Lecture 3: Large devatons bounds and applcatons Lecturer: Sanjeev Arora Scrbe: Today s topc s devaton bounds: what s the probablty that a random varable
prnceton unv. F 13 cos 521: Advanced Algorthm Desgn Lecture 3: Large devatons bounds and applcatons Lecturer: Sanjeev Arora Scrbe: Today s topc s devaton bounds: what s the probablty that a random varable