Multilayer Neural Networks
|
|
|
- Junior Maxwell
- 5 years ago
- Views:
Transcription
1 Multilayer Neural Networs

2 Brain s. Coputer Designed to sole logic and arithetic probles Can sole a gazillion arithetic and logic probles in an hour absolute precision Usually one ery fast procesor high reliability Eoled (in a large part) for pattern recognition Can sole a gazillion of PR probles in an hour Huge nuber of parallel but relatiely slow and unreliable processors not perfectly precise not perfectly reliable See an inspiration fro huan brain for PR?

 Most neurons a person is eer going to hae are already present at")
3 Neuron: Basic Brain Processor Neurons are nere cells that transit signals to and fro brains at the speed of around 200ph Each neuron cell counicates to anywhere fro 000 to 0,000 other neurons, uscle cells, glands, so on Hae around 0 0 neurons in our brain (networ of neurons) Most neurons a person is eer going to hae are already present at birth
4 Neuron: Basic Brain Processor nucleus cell body axon dendrites Main coponents of a neuron Cell body which holds DNA inforation in nucleus Dendrites ay hae thousands of dendrites, usually short axon long structure, which splits in possibly thousands branches at the end. May be up to eter long
5 dendrites Neuron in Action (siplified) neuron body axon Input : neuron collects signals fro other neurons through dendrites, ay hae thousands of dendrites Processor: Signals are accuulated and processed by the cell body Output: If the strength of incoing signals is large enough, the cell body sends a signal (a spie of electrical actiity) to the axon
6 Neural Networ
7 ANN History: Birth 943, faous paper by W. McCulloch (neurophysiologist) and W. Pitts (atheatician) Using only ath and algoriths, constructed a odel of how neural networ ay wor Showed it is possible to construct any coputable function with their networ Was it possible to ae a odel of thoughts of a huan being? Considered to be the birth of AI 949, D. Hebb, introduced the first (purely pshychological) theory of learning Brain learns at tass through life, thereby it goes through treendous changes If two neurons fire together, they strengthen each other s responses and are liely to fire together in the future
8 ANN History: First Successes 958, F. Rosenblatt, perceptron, oldest neural networ still in use today Algorith to train the perceptron networ (training is still the ost actiely researched area today) Built in hardware Proed conergence in linearly separable case 959, B. Widrow and M. Hoff Madaline First ANN applied to real proble (eliinate echoes in phone lines) Still in coercial use
9 ANN History: Stagnation Early success lead to a lot of clais which were not fulfilled 969, M. Minsy and S. Pappert Boo Perceptrons Proed that perceptrons can learn only linearly separable classes In particular cannot learn ery siple XOR function Conectured that ultilayer neural networs also liited by linearly separable functions No funding and alost no research (at least in North Aerica) in 970 s as the result of 2 things aboe
10 ANN History: Reial Reial of ANN in 980 s 982, J. Hopfield New ind of networs (Hopfield s networs) Bidirectional connections between neurons Ipleents associatie eory 982 oint US-Japanese conference on ANN US worries that it will stay behind Many exaples of ulitlayer NN appear 982, discoery of bacpropagation algorith Allows a networ to learn not linearly separable classes Discoered independently by. Y. Lecunn 2. D. Parer 3. Ruelhart, Hinton, Willias
11 ANN: Perceptron Input and output layers g(x) w t x + w 0 Liitation: can learn only linearly separable classes
12 MNN: Feed Forward Operation input layer: d features hidden layer: output layer: outputs, one for each class x () w i z x (2) x (d) z bias unit
13 MNN: Notation for Weights Use w i to denote the weight between input unit i and hidden unit x (i) input unit i w i w i x (i) hidden unit y Use to denote the weight between hidden unit and output unit hidden unit y y output unit z
14 MNN: Notation for Actiation Use net i to denote the actiation and hidden unit net d i x ( i) w i + w 0 x () w x (2) w 2 w 0 hidden unit y Use net to denote the actiation at output unit net N H y + 0 y y 2 2 output unit z 0
15 Discriinant Function Discriinant function for class (the output of the th output unit) g ( x) z N H d f f i actiation at th hidden unit w i x ( i ) + w actiation at th output unit
16 Discriinant Function
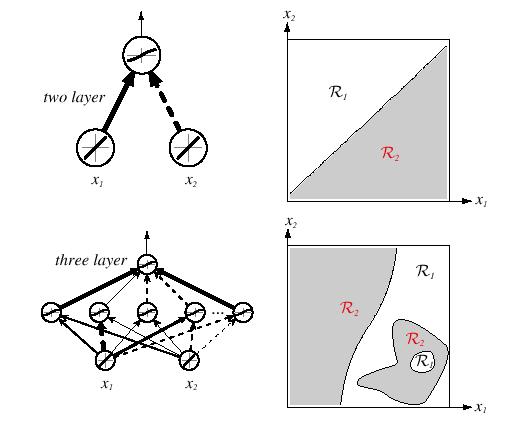
17 Expressie Power of MNN It can be shown that eery continuous function fro input to output can be ipleented with enough hidden units, hidden layer, and proper nonlinear actiation functions This is ore of theoretical than practical interest The proof is not constructie (does not tell us exactly how to construct the MNN) Een if it were constructie, would be of no use since we do not now the desired function anyway, our goal is to learn it through the saples But this result does gie us confidence that we are on the right trac MNN is general enough to construct the correct decision boundaries, unlie the Perceptron
18 MNN Actiation function Must be nonlinear for expressie power larger than that of perceptron If use linear actiation function at hidden layer, can only deal with linearly separable classes Suppose at hidden unit, h(u)a u g f d f i d f x i N H d ( i ) ( x) f h w x + w + N H i d a i N H N w i i x ( i ) + w ( ) ( i ) a w x + a w + H w i new i + ( i ) a w i N H a 0 w 0 new w
19 MNN Actiation function could use a discontinuous actiation function f ( ) net if if net net < 0 0 Howeer, we will use gradient descent for learning, so we need to use a continuous actiation function sigoid function Fro now on, assue f is a differentiable function
20 MNN: Modes of Operation Networ hae two odes of operation: Feedforward The feedforward operations consists of presenting a pattern to the input units and passing (or feeding) the signals through the networ in order to get outputs units (no cycles!) Learning The superised learning consists of presenting an input pattern and odifying the networ paraeters (weights) to reduce distances between the coputed output and the desired output
21 MNN Can ary nuber of hidden layers Nonlinear actiation function Can use different function for hidden and output layers Can use different function at each hidden and output node
22 MNN: Class Representation Training saples x,, x n each of class,, Let networ output z represent class c as target t (c) saple of class c z M z zc M z t ( c) 0 M M 0 MNN with weights w i and cth row Our Ultiate Goal For FeedForward Operation MNN training to achiee the Ultiate Goal Modify (learn) MNN paraeters w i and so that for each training saple of class c MNN output z t (c) t (c)
23 Networ Training (learning). Initialize weights w i and randoly but not to 0 2. Iterate until a stopping criterion is reached choose p input saple x p MNN with weights w i and output z z M z Copare output z with the desired target t; adust w i and to oe closer to the goal t (by bacpropagation)
24 BacPropagation Learn w i and by iniizing the training error What is the training error? Suppose the output of MNN for saple x is z and the target (desired output for x ) is t Error on one saple: J 2 ( w, ) ( ) c t c z c 2 Training error: J 2 n ( i) ( i) ( w, ) t c z ( ) c i c 2 Use gradient descent: ( 0 ) (,w 0) rando repeat until conergence: w w η J ( w ) ( t ) ( t+ ) ( t) ( t) ( t+ ) ( t) ( ) η w J
25 BacPropagation For siplicity, first tae training error for one saple x i J 2 ( w, ) ( t c z c ) c fixed constant 2 function of w, z f N H f d i w i x ( i) + w Need to copute. partial deriatie w.r.t. hidden-to-output weights 2. partial deriatie w.r.t. input-to-hidden weights J J w i
26 BacPropagation: Layered Model actiation at hidden unit net d i x ( i) w i + w 0 output at hidden unit y ( ) f net actiation at output unit actiation at output unit net N H y + ( z ) f net 0 chain rule chain rule obectie function J 2 ( w, ) ( t c z c ) c 2 J J w i
27 BacPropagation ( ) ( ) c t c z c w J 2 2, ( ) net z f + H N y net 0 J ( ) net net z z t ( ) c c c z t 2 2 ( ) ( ) c c c c c z t z t ( ) ( ) z t z t ( ) ( ) z z t ( ) ( ) ( ) ( ) 0 ' 0 ' if net f z t if y net f z t J First copute hidden-to-output deriaties
28 BacPropagation Gradient Descent Single Saple Update Rule for hidden-to-output weights > 0: 0 (bias weight): ( t+ ) ( t) ( ) ( ) + η t z f ' net y ( t+ ) ( t) ( ) ( + η t z f net ) 0 0 '
29 BacPropagation Now copute input-to-hidden J w i ( t z) ( t z) ( t z) z w ( t z ) f ( net ) i w ( t z ) f ( net ) i net y ( t z ) y y w net i net w z net ( ) ( ) ( ) ( i t z f net f net x ) ( t z ) f ( net ) f ( net ) i net w J i if i 0 if i 0 w i net J h net y f( net ) d h N H s z f( net ) 2 x ( i) y ( w, ) ( ) s c w hi s + w + t c z c h0 0 2
30 BacPropagation J w i f f ( i) ( net ) x ( t z ) f ( net ) ( net ) ( t z ) f ( net ) if if i i 0 0 Gradient Descent Single Saple Update Rule for input-to-hidden weights w i i > 0: w i 0 (bias weight): ( t+ ) ( t) ( ) ( i) ( ) ( ) i w i + η f net x t z f net w t+ t w f net t z f η ( ) ( ) ( ) ( ) ( net ) (t) (t)
31 BacPropagation of Errors J w i f ( ) i ( net ) x ( t z) f ( net) J ( t z) f '( net ) y unit i unit error z z Nae bacpropagation because during training, errors propagated bac fro output to hidden layer
32 BacPropagation Consider update rule for hidden-to-output weights: Suppose t z > 0 ( t+ ) ( t) ( ) ( ) + η t z f ' net y Then output of the th hidden unit is too sall: t > z Typically actiation function f is s.t. f > 0 Thus ( ) ( t z f ' net ) > 0 There are 2 cases:. y > 0, then to increase z, should increase weight η t z f ' net y > which is exactly what we do since y z ( ) ( ) 0 2. y < 0, then to increase z, should decrease weight η t z f ' net y < which is exactly what we do since ( ) ( ) 0
33 BacPropagation The case t z < 0 is analogous Siilarly, can show that input-to-hidden weights ae sense Iportant: weights should be initialized to rando nonzero nubers J w i f ( ) ( i) ( ) ( net ) x t z f net if 0, input-to-hidden weights w i neer updated
34 Training Protocols How to present saples in training set and update the weights? Three aor training protocols:. Stochastic Patterns are chosen randoly fro the training set, and networ weights are updated after eery saple presentation 2. Batch weights are update based on all saples; iterate weight update 3. Online each saple is presented only once, weight update after each saple presentation
35 Stochastic Bac Propagation. Initialize nuber of hidden layers n H weights w, conergence criterion θ and learning rate η tie t 0 2. do x randoly chosen training pattern for all w w t t + until J 3. return, w 0 i d, 0 nh, 0 + η + η ( t z) f '( net) y ( t z) f ( net ) ( i) f ( net ) x ( t z) f ( net) f ( net ) ( t z) f ( net ) 0 0 ' i w i + η 0 w 0 + η < θ
36 Batch Bac Propagation This is the true gradient descent, (unlie stochastic propagation) For siplicity, deried bacpropagation for a single saple obectie function: J ( w, ) ( ) The full obectie function: n ( i) ( i) J( w, ) t c z 2 2 c ( ) c i c t c z c Deriatie of full obectie function is ust a su of deriaties for each saple: J 2 ( i) ( i) ( w, ) t c z ( ) c w i w c n already deried this 2 2 2
37 Batch Bac Propagation For exaple, J w i n f ( ) ( i) ( ) ( net x t z f net ) p p
38 Batch Bac Propagation. Initialize n H, w,, θ, η, t 0 2. do one epoch t t + until J for all p n for all 0 <θ + 3. return, w 0 w i w 0 w w + η + η ( t z) f' ( net) y ( t z) f ( net ) ( i) f ( net ) x p( t z) f ( net ) f ( net ) ( t z ) f ( net ) 0 0 ' i 0 i d, 0 nh, 0 w + η i w + η 0 0 ; ; w i w i + w i; w 0 w 0 + w 0
39 Training Protocols. Batch True gradient descent 2. Stochastic Faster than batch ethod Usually the recoended way 3. Online Used when nuber of saples is so large it does not fit in the eory Dependent on the order of saple presentation Should be aoided when possible
40 MNN Training training tie Large training error: in the beginning rando decision regions Sall training error: decision regions iproe with tie Zero training error: decision regions separate training data perfectly, but we oerfited the networ
41 MNN Learning Cures Training data: data on which learning (gradient descent for MNN) is perfored Validation data: used to assess networ generalization capabilities Training error typically goes down, since with enough hidden units, can find discriinant function which classifies training patterns exactly classification error alidation error training error training tie Validation error first goes down, but then goes up since at soe point we start to oerfit the networ to the alidation data
42 Learning Cures classification error alidation error training error training tie this is a good tie to stop training, since after this tie we start to oerfit Stopping criterion is part of training phase, thus alidation data is part of the training data To assess how the networ will wor on the unseen exaples, we still need test data
43 Learning Cures alidation data is used to deterine paraeters, in this case when learning should stop stop training Stop training after the first local iniu on alidation data We are assuing perforance on test data will be siilar to perforance on alidation data
44 Data Sets Training data data on which learning is perfored Validation data alidation data is used to deterine any free paraeters of the classifier in the nn neighbor classifier h for parzen windows nuber of hidden layers in the MNN etc Test data used to assess networ generalization capabilities
45 MNN as Nonlinear Mapping this odule ipleents nonlinear input apping ϕ this odule ipleents linear classifier (Perceptron) x () z x (2) x (d) z
46 MNN as Nonlinear Mapping Thus MNN can be thought as learning 2 things at the sae tie the nonlinear apping of the inputs linear classifier of the nonlinearly apped inputs
; patterns are alost linearly separable MNN finds nonlinear apping yϕ(x) to 3 diensions (3 hidden units) that; patterns are linearly")
47 MNN as Nonlinear Mapping original feature space x; patterns are not linearly separable MNN finds nonlinear apping yϕ(x) to 2 diensions (2 hidden units); patterns are alost linearly separable MNN finds nonlinear apping yϕ(x) to 3 diensions (3 hidden units) that; patterns are linearly separable
48 Concluding Rears Adantages MNN can learn coplex appings fro inputs to outputs, based only on the training saples Easy to use Easy to incorporate a lot of heuristics Disadantages It is a blac box, that is difficult to analyze and predict its behaior May tae a long tie to train May get trapped in a bad local inia A lot of trics to ipleent for the best perforance
CS4442/9542b Artificial Intelligence II prof. Olga Veksler. Lecture 5 Machine Learning. Neural Networks. Many presentation Ideas are due to Andrew NG
 CS4442/9542b Artificial Intelligence II prof. Olga Vesler Lecture 5 Machine Learning Neural Networs Many presentation Ideas are due to Andrew NG Outline Motivation Non linear discriminant functions Introduction
CS4442/9542b Artificial Intelligence II prof. Olga Vesler Lecture 5 Machine Learning Neural Networs Many presentation Ideas are due to Andrew NG Outline Motivation Non linear discriminant functions Introduction
Pattern Recognition and Machine Learning. Artificial Neural networks
 Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2017 Lessons 7 20 Dec 2017 Outline Artificial Neural networks Notation...2 Introduction...3 Key Equations... 3 Artificial
Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2017 Lessons 7 20 Dec 2017 Outline Artificial Neural networks Notation...2 Introduction...3 Key Equations... 3 Artificial
Intelligent Systems: Reasoning and Recognition. Artificial Neural Networks
 Intelligent Systes: Reasoning and Recognition Jaes L. Crowley MOSIG M1 Winter Seester 2018 Lesson 7 1 March 2018 Outline Artificial Neural Networks Notation...2 Introduction...3 Key Equations... 3 Artificial
Intelligent Systes: Reasoning and Recognition Jaes L. Crowley MOSIG M1 Winter Seester 2018 Lesson 7 1 March 2018 Outline Artificial Neural Networks Notation...2 Introduction...3 Key Equations... 3 Artificial
Pattern Recognition and Machine Learning. Artificial Neural networks
 Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2016 Lessons 7 14 Dec 2016 Outline Artificial Neural networks Notation...2 1. Introduction...3... 3 The Artificial
Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2016 Lessons 7 14 Dec 2016 Outline Artificial Neural networks Notation...2 1. Introduction...3... 3 The Artificial
Intelligent Systems: Reasoning and Recognition. Perceptrons and Support Vector Machines
 Intelligent Systes: Reasoning and Recognition Jaes L. Crowley osig 1 Winter Seester 2018 Lesson 6 27 February 2018 Outline Perceptrons and Support Vector achines Notation...2 Linear odels...3 Lines, Planes
Intelligent Systes: Reasoning and Recognition Jaes L. Crowley osig 1 Winter Seester 2018 Lesson 6 27 February 2018 Outline Perceptrons and Support Vector achines Notation...2 Linear odels...3 Lines, Planes
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Feedforward Networks
 Feedforward Networks Gradient Descent Learning and Backpropagation Christian Jacob CPSC 433 Christian Jacob Dept.of Coputer Science,University of Calgary CPSC 433 - Feedforward Networks 2 Adaptive "Prograing"
Feedforward Networks Gradient Descent Learning and Backpropagation Christian Jacob CPSC 433 Christian Jacob Dept.of Coputer Science,University of Calgary CPSC 433 - Feedforward Networks 2 Adaptive "Prograing"
Feedforward Networks. Gradient Descent Learning and Backpropagation. Christian Jacob. CPSC 533 Winter 2004
 Feedforward Networks Gradient Descent Learning and Backpropagation Christian Jacob CPSC 533 Winter 2004 Christian Jacob Dept.of Coputer Science,University of Calgary 2 05-2-Backprop-print.nb Adaptive "Prograing"
Feedforward Networks Gradient Descent Learning and Backpropagation Christian Jacob CPSC 533 Winter 2004 Christian Jacob Dept.of Coputer Science,University of Calgary 2 05-2-Backprop-print.nb Adaptive "Prograing"
Artificial Neural Networks. Historical description
 Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Multilayer Perceptron = FeedForward Neural Network
 Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Kernel Methods and Support Vector Machines
 Intelligent Systes: Reasoning and Recognition Jaes L. Crowley ENSIAG 2 / osig 1 Second Seester 2012/2013 Lesson 20 2 ay 2013 Kernel ethods and Support Vector achines Contents Kernel Functions...2 Quadratic
Intelligent Systes: Reasoning and Recognition Jaes L. Crowley ENSIAG 2 / osig 1 Second Seester 2012/2013 Lesson 20 2 ay 2013 Kernel ethods and Support Vector achines Contents Kernel Functions...2 Quadratic
Feedforward Networks
 Feedforward Neural Networks - Backpropagation Feedforward Networks Gradient Descent Learning and Backpropagation CPSC 533 Fall 2003 Christian Jacob Dept.of Coputer Science,University of Calgary Feedforward
Feedforward Neural Networks - Backpropagation Feedforward Networks Gradient Descent Learning and Backpropagation CPSC 533 Fall 2003 Christian Jacob Dept.of Coputer Science,University of Calgary Feedforward
Qualitative Modelling of Time Series Using Self-Organizing Maps: Application to Animal Science
 Proceedings of the 6th WSEAS International Conference on Applied Coputer Science, Tenerife, Canary Islands, Spain, Deceber 16-18, 2006 183 Qualitative Modelling of Tie Series Using Self-Organizing Maps:
Proceedings of the 6th WSEAS International Conference on Applied Coputer Science, Tenerife, Canary Islands, Spain, Deceber 16-18, 2006 183 Qualitative Modelling of Tie Series Using Self-Organizing Maps:
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Course Notes for EE227C (Spring 2018): Convex Optimization and Approximation
: Convex Optimization and Approximation") Course Notes for EE227C (Spring 2018): Convex Optiization and Approxiation Instructor: Moritz Hardt Eail: hardt+ee227c@berkeley.edu Graduate Instructor: Max Sichowitz Eail: sichow+ee227c@berkeley.edu October
Course Notes for EE227C (Spring 2018): Convex Optiization and Approxiation Instructor: Moritz Hardt Eail: hardt+ee227c@berkeley.edu Graduate Instructor: Max Sichowitz Eail: sichow+ee227c@berkeley.edu October
Ch 12: Variations on Backpropagation
 Ch 2: Variations on Backpropagation The basic backpropagation algorith is too slow for ost practical applications. It ay take days or weeks of coputer tie. We deonstrate why the backpropagation algorith
Ch 2: Variations on Backpropagation The basic backpropagation algorith is too slow for ost practical applications. It ay take days or weeks of coputer tie. We deonstrate why the backpropagation algorith
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Part 8: Neural Networks
 METU Informatics Institute Min720 Pattern Classification ith Bio-Medical Applications Part 8: Neural Netors - INTRODUCTION: BIOLOGICAL VS. ARTIFICIAL Biological Neural Netors A Neuron: - A nerve cell as
METU Informatics Institute Min720 Pattern Classification ith Bio-Medical Applications Part 8: Neural Netors - INTRODUCTION: BIOLOGICAL VS. ARTIFICIAL Biological Neural Netors A Neuron: - A nerve cell as
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Lecture 7 Artificial neural networks: Supervised learning
 Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Block designs and statistics
 Bloc designs and statistics Notes for Math 447 May 3, 2011 The ain paraeters of a bloc design are nuber of varieties v, bloc size, nuber of blocs b. A design is built on a set of v eleents. Each eleent
Bloc designs and statistics Notes for Math 447 May 3, 2011 The ain paraeters of a bloc design are nuber of varieties v, bloc size, nuber of blocs b. A design is built on a set of v eleents. Each eleent
Pattern Recognition and Machine Learning. Learning and Evaluation for Pattern Recognition
 Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2017 Lesson 1 4 October 2017 Outline Learning and Evaluation for Pattern Recognition Notation...2 1. The Pattern Recognition
Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2017 Lesson 1 4 October 2017 Outline Learning and Evaluation for Pattern Recognition Notation...2 1. The Pattern Recognition
Neural Networks. Learning and Computer Vision Prof. Olga Veksler CS9840. Lecture 10
 CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
ZISC Neural Network Base Indicator for Classification Complexity Estimation
 ZISC Neural Network Base Indicator for Classification Coplexity Estiation Ivan Budnyk, Abdennasser Сhebira and Kurosh Madani Iages, Signals and Intelligent Systes Laboratory (LISSI / EA 3956) PARIS XII
ZISC Neural Network Base Indicator for Classification Coplexity Estiation Ivan Budnyk, Abdennasser Сhebira and Kurosh Madani Iages, Signals and Intelligent Systes Laboratory (LISSI / EA 3956) PARIS XII
Feature Extraction Techniques
 Feature Extraction Techniques Unsupervised Learning II Feature Extraction Unsupervised ethods can also be used to find features which can be useful for categorization. There are unsupervised ethods that
Feature Extraction Techniques Unsupervised Learning II Feature Extraction Unsupervised ethods can also be used to find features which can be useful for categorization. There are unsupervised ethods that
Pattern Classification using Simplified Neural Networks with Pruning Algorithm
 Pattern Classification using Siplified Neural Networks with Pruning Algorith S. M. Karuzzaan 1 Ahed Ryadh Hasan 2 Abstract: In recent years, any neural network odels have been proposed for pattern classification,
Pattern Classification using Siplified Neural Networks with Pruning Algorith S. M. Karuzzaan 1 Ahed Ryadh Hasan 2 Abstract: In recent years, any neural network odels have been proposed for pattern classification,
VI. Backpropagation Neural Networks (BPNN)
") VI. Backpropagation Neural Networks (BPNN) Review of Adaline Newton s ethod Backpropagation algorith definition derivative coputation weight/bias coputation function approxiation exaple network generalization
VI. Backpropagation Neural Networks (BPNN) Review of Adaline Newton s ethod Backpropagation algorith definition derivative coputation weight/bias coputation function approxiation exaple network generalization
CS Lecture 13. More Maximum Likelihood
 CS 6347 Lecture 13 More Maxiu Likelihood Recap Last tie: Introduction to axiu likelihood estiation MLE for Bayesian networks Optial CPTs correspond to epirical counts Today: MLE for CRFs 2 Maxiu Likelihood
CS 6347 Lecture 13 More Maxiu Likelihood Recap Last tie: Introduction to axiu likelihood estiation MLE for Bayesian networks Optial CPTs correspond to epirical counts Today: MLE for CRFs 2 Maxiu Likelihood
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
An artificial neural networks (ANNs) model is a functional abstraction of the
 model is a functional abstraction of the") CHAPER 3 3. Introduction An artificial neural networs (ANNs) model is a functional abstraction of the biological neural structures of the central nervous system. hey are composed of many simple and highly
CHAPER 3 3. Introduction An artificial neural networs (ANNs) model is a functional abstraction of the biological neural structures of the central nervous system. hey are composed of many simple and highly
CHARACTER RECOGNITION USING A SELF-ADAPTIVE TRAINING
 CHARACTER RECOGNITION USING A SELF-ADAPTIVE TRAINING Dr. Eng. Shasuddin Ahed $ College of Business and Econoics (AACSB Accredited) United Arab Eirates University, P O Box 7555, Al Ain, UAE. and $ Edith
CHARACTER RECOGNITION USING A SELF-ADAPTIVE TRAINING Dr. Eng. Shasuddin Ahed $ College of Business and Econoics (AACSB Accredited) United Arab Eirates University, P O Box 7555, Al Ain, UAE. and $ Edith
Analyzing Simulation Results
 Analyzing Siulation Results Dr. John Mellor-Cruey Departent of Coputer Science Rice University johnc@cs.rice.edu COMP 528 Lecture 20 31 March 2005 Topics for Today Model verification Model validation Transient
Analyzing Siulation Results Dr. John Mellor-Cruey Departent of Coputer Science Rice University johnc@cs.rice.edu COMP 528 Lecture 20 31 March 2005 Topics for Today Model verification Model validation Transient
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
Figure 1: Equivalent electric (RC) circuit of a neurons membrane
 circuit of a neurons membrane") Exercise: Leaky integrate and fire odel of neural spike generation This exercise investigates a siplified odel of how neurons spike in response to current inputs, one of the ost fundaental properties of
Exercise: Leaky integrate and fire odel of neural spike generation This exercise investigates a siplified odel of how neurons spike in response to current inputs, one of the ost fundaental properties of
Experimental Design For Model Discrimination And Precise Parameter Estimation In WDS Analysis
 City University of New York (CUNY) CUNY Acadeic Works International Conference on Hydroinforatics 8-1-2014 Experiental Design For Model Discriination And Precise Paraeter Estiation In WDS Analysis Giovanna
City University of New York (CUNY) CUNY Acadeic Works International Conference on Hydroinforatics 8-1-2014 Experiental Design For Model Discriination And Precise Paraeter Estiation In WDS Analysis Giovanna
COS 424: Interacting with Data. Written Exercises
 COS 424: Interacting with Data Hoework #4 Spring 2007 Regression Due: Wednesday, April 18 Written Exercises See the course website for iportant inforation about collaboration and late policies, as well
COS 424: Interacting with Data Hoework #4 Spring 2007 Regression Due: Wednesday, April 18 Written Exercises See the course website for iportant inforation about collaboration and late policies, as well
Quantum algorithms (CO 781, Winter 2008) Prof. Andrew Childs, University of Waterloo LECTURE 15: Unstructured search and spatial search
 Prof. Andrew Childs, University of Waterloo LECTURE 15: Unstructured search and spatial search") Quantu algoriths (CO 781, Winter 2008) Prof Andrew Childs, University of Waterloo LECTURE 15: Unstructured search and spatial search ow we begin to discuss applications of quantu walks to search algoriths
Quantu algoriths (CO 781, Winter 2008) Prof Andrew Childs, University of Waterloo LECTURE 15: Unstructured search and spatial search ow we begin to discuss applications of quantu walks to search algoriths
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Combining Classifiers
 Cobining Classifiers Generic ethods of generating and cobining ultiple classifiers Bagging Boosting References: Duda, Hart & Stork, pg 475-480. Hastie, Tibsharini, Friedan, pg 246-256 and Chapter 10. http://www.boosting.org/
Cobining Classifiers Generic ethods of generating and cobining ultiple classifiers Bagging Boosting References: Duda, Hart & Stork, pg 475-480. Hastie, Tibsharini, Friedan, pg 246-256 and Chapter 10. http://www.boosting.org/
Artificial Neural Networks The Introduction
 Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
1 Proof of learning bounds
 COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #4 Scribe: Akshay Mittal February 13, 2013 1 Proof of learning bounds For intuition of the following theore, suppose there exists a
COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #4 Scribe: Akshay Mittal February 13, 2013 1 Proof of learning bounds For intuition of the following theore, suppose there exists a
e-companion ONLY AVAILABLE IN ELECTRONIC FORM
 OPERATIONS RESEARCH doi 10.1287/opre.1070.0427ec pp. ec1 ec5 e-copanion ONLY AVAILABLE IN ELECTRONIC FORM infors 07 INFORMS Electronic Copanion A Learning Approach for Interactive Marketing to a Custoer
OPERATIONS RESEARCH doi 10.1287/opre.1070.0427ec pp. ec1 ec5 e-copanion ONLY AVAILABLE IN ELECTRONIC FORM infors 07 INFORMS Electronic Copanion A Learning Approach for Interactive Marketing to a Custoer
Pattern Recognition and Machine Learning. Artificial Neural networks
 Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2016/2017 Lessons 9 11 Jan 2017 Outline Artificial Neural networks Notation...2 Convolutional Neural Networks...3
Pattern Recognition and Machine Learning Jaes L. Crowley ENSIMAG 3 - MMIS Fall Seester 2016/2017 Lessons 9 11 Jan 2017 Outline Artificial Neural networks Notation...2 Convolutional Neural Networks...3
CS:4420 Artificial Intelligence
 CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
Machine Learning Basics: Estimators, Bias and Variance
 Machine Learning Basics: Estiators, Bias and Variance Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Basics
Machine Learning Basics: Estiators, Bias and Variance Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Basics
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
GREY FORECASTING AND NEURAL NETWORK MODEL OF SPORT PERFORMANCE
 Journal of heoretical and Applied Inforation echnology 3 st March 03 Vol 49 No3 005-03 JAI & LLS All rights reserved ISSN: 99-8645 wwwatitorg E-ISSN: 87-395 GREY FORECASING AND NEURAL NEWORK MODEL OF SPOR
Journal of heoretical and Applied Inforation echnology 3 st March 03 Vol 49 No3 005-03 JAI & LLS All rights reserved ISSN: 99-8645 wwwatitorg E-ISSN: 87-395 GREY FORECASING AND NEURAL NEWORK MODEL OF SPOR
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
One Dimensional Collisions
 One Diensional Collisions These notes will discuss a few different cases of collisions in one diension, arying the relatie ass of the objects and considering particular cases of who s oing. Along the way,
One Diensional Collisions These notes will discuss a few different cases of collisions in one diension, arying the relatie ass of the objects and considering particular cases of who s oing. Along the way,
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Estimating Parameters for a Gaussian pdf
 Pattern Recognition and achine Learning Jaes L. Crowley ENSIAG 3 IS First Seester 00/0 Lesson 5 7 Noveber 00 Contents Estiating Paraeters for a Gaussian pdf Notation... The Pattern Recognition Proble...3
Pattern Recognition and achine Learning Jaes L. Crowley ENSIAG 3 IS First Seester 00/0 Lesson 5 7 Noveber 00 Contents Estiating Paraeters for a Gaussian pdf Notation... The Pattern Recognition Proble...3
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Chapter 2 Single Layer Feedforward Networks
 Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Neural Networks and Fuzzy Logic Rajendra Dept.of CSE ASCET
 Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
Ştefan ŞTEFĂNESCU * is the minimum global value for the function h (x)
") 7Applying Nelder Mead s Optiization Algorith APPLYING NELDER MEAD S OPTIMIZATION ALGORITHM FOR MULTIPLE GLOBAL MINIMA Abstract Ştefan ŞTEFĂNESCU * The iterative deterinistic optiization ethod could not
7Applying Nelder Mead s Optiization Algorith APPLYING NELDER MEAD S OPTIMIZATION ALGORITHM FOR MULTIPLE GLOBAL MINIMA Abstract Ştefan ŞTEFĂNESCU * The iterative deterinistic optiization ethod could not
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
This model assumes that the probability of a gap has size i is proportional to 1/i. i.e., i log m e. j=1. E[gap size] = i P r(i) = N f t.
![This model assumes that the probability of a gap has size i is proportional to 1/i. i.e., i log m e. j=1. E[gap size] = i P r(i) = N f t.](/thumbs/73/69472191.jpg "This model assumes that the probability of a gap has size i is proportional to 1/i. i.e., i log m e. j=1. E[gap size] = i P r(i) = N f t.") CS 493: Algoriths for Massive Data Sets Feb 2, 2002 Local Models, Bloo Filter Scribe: Qin Lv Local Models In global odels, every inverted file entry is copressed with the sae odel. This work wells when
CS 493: Algoriths for Massive Data Sets Feb 2, 2002 Local Models, Bloo Filter Scribe: Qin Lv Local Models In global odels, every inverted file entry is copressed with the sae odel. This work wells when
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
LECTURE # - NEURAL COMPUTATION, Feb 04, Linear Regression. x 1 θ 1 output... θ M x M. Assumes a functional form
 LECTURE # - EURAL COPUTATIO, Feb 4, 4 Linear Regression Assumes a functional form f (, θ) = θ θ θ K θ (Eq) where = (,, ) are the attributes and θ = (θ, θ, θ ) are the function parameters Eample: f (, θ)
LECTURE # - EURAL COPUTATIO, Feb 4, 4 Linear Regression Assumes a functional form f (, θ) = θ θ θ K θ (Eq) where = (,, ) are the attributes and θ = (θ, θ, θ ) are the function parameters Eample: f (, θ)
NBN Algorithm Introduction Computational Fundamentals. Bogdan M. Wilamoswki Auburn University. Hao Yu Auburn University
 NBN Algorith Bogdan M. Wilaoswki Auburn University Hao Yu Auburn University Nicholas Cotton Auburn University. Introduction. -. Coputational Fundaentals - Definition of Basic Concepts in Neural Network
NBN Algorith Bogdan M. Wilaoswki Auburn University Hao Yu Auburn University Nicholas Cotton Auburn University. Introduction. -. Coputational Fundaentals - Definition of Basic Concepts in Neural Network
Grafting: Fast, Incremental Feature Selection by Gradient Descent in Function Space
 Journal of Machine Learning Research 3 (2003) 1333-1356 Subitted 5/02; Published 3/03 Grafting: Fast, Increental Feature Selection by Gradient Descent in Function Space Sion Perkins Space and Reote Sensing
Journal of Machine Learning Research 3 (2003) 1333-1356 Subitted 5/02; Published 3/03 Grafting: Fast, Increental Feature Selection by Gradient Descent in Function Space Sion Perkins Space and Reote Sensing
Revision: Neural Network
 Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Lecture 2: Differential-Delay equations.
 Lecture : Differential-Delay equations. D. Gurarie A differential equation, or syste:, ; of the syste:, 0 0 0 0 y f y t y t y, predicts a (near) future state 0 0 y t dt y f y t dt, fro its current state,
Lecture : Differential-Delay equations. D. Gurarie A differential equation, or syste:, ; of the syste:, 0 0 0 0 y f y t y t y, predicts a (near) future state 0 0 y t dt y f y t dt, fro its current state,
EEE 241: Linear Systems
 EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
SPECTRUM sensing is a core concept of cognitive radio
 World Acadey of Science, Engineering and Technology International Journal of Electronics and Counication Engineering Vol:6, o:2, 202 Efficient Detection Using Sequential Probability Ratio Test in Mobile
World Acadey of Science, Engineering and Technology International Journal of Electronics and Counication Engineering Vol:6, o:2, 202 Efficient Detection Using Sequential Probability Ratio Test in Mobile
PAC-Bayes Analysis Of Maximum Entropy Learning
 PAC-Bayes Analysis Of Maxiu Entropy Learning John Shawe-Taylor and David R. Hardoon Centre for Coputational Statistics and Machine Learning Departent of Coputer Science University College London, UK, WC1E
PAC-Bayes Analysis Of Maxiu Entropy Learning John Shawe-Taylor and David R. Hardoon Centre for Coputational Statistics and Machine Learning Departent of Coputer Science University College London, UK, WC1E
Introduction to Artificial Neural Networks
 Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Efficient Filter Banks And Interpolators
 Efficient Filter Banks And Interpolators A. G. DEMPSTER AND N. P. MURPHY Departent of Electronic Systes University of Westinster 115 New Cavendish St, London W1M 8JS United Kingdo Abstract: - Graphical
Efficient Filter Banks And Interpolators A. G. DEMPSTER AND N. P. MURPHY Departent of Electronic Systes University of Westinster 115 New Cavendish St, London W1M 8JS United Kingdo Abstract: - Graphical
A MESHSIZE BOOSTING ALGORITHM IN KERNEL DENSITY ESTIMATION
 A eshsize boosting algorith in kernel density estiation A MESHSIZE BOOSTING ALGORITHM IN KERNEL DENSITY ESTIMATION C.C. Ishiekwene, S.M. Ogbonwan and J.E. Osewenkhae Departent of Matheatics, University
A eshsize boosting algorith in kernel density estiation A MESHSIZE BOOSTING ALGORITHM IN KERNEL DENSITY ESTIMATION C.C. Ishiekwene, S.M. Ogbonwan and J.E. Osewenkhae Departent of Matheatics, University
Lecture 16: Introduction to Neural Networks
 Lecture 16: Introduction to Neural Networs Instructor: Aditya Bhasara Scribe: Philippe David CS 5966/6966: Theory of Machine Learning March 20 th, 2017 Abstract In this lecture, we consider Bacpropagation,
Lecture 16: Introduction to Neural Networs Instructor: Aditya Bhasara Scribe: Philippe David CS 5966/6966: Theory of Machine Learning March 20 th, 2017 Abstract In this lecture, we consider Bacpropagation,
A nonstandard cubic equation
 MATH-Jan-05-0 A nonstandard cubic euation J S Markoitch PO Box West Brattleboro, VT 050 Dated: January, 05 A nonstandard cubic euation is shown to hae an unusually econoical solution, this solution incorporates
MATH-Jan-05-0 A nonstandard cubic euation J S Markoitch PO Box West Brattleboro, VT 050 Dated: January, 05 A nonstandard cubic euation is shown to hae an unusually econoical solution, this solution incorporates
Artificial neural networks
 Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Projectile Motion with Air Resistance (Numerical Modeling, Euler s Method)
") Projectile Motion with Air Resistance (Nuerical Modeling, Euler s Method) Theory Euler s ethod is a siple way to approxiate the solution of ordinary differential equations (ode s) nuerically. Specifically,
Projectile Motion with Air Resistance (Nuerical Modeling, Euler s Method) Theory Euler s ethod is a siple way to approxiate the solution of ordinary differential equations (ode s) nuerically. Specifically,
Artificial Neural Networks. Q550: Models in Cognitive Science Lecture 5
 Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Training an RBM: Contrastive Divergence. Sargur N. Srihari
 Training an RBM: Contrastive Divergence Sargur N. srihari@cedar.buffalo.edu Topics in Partition Function Definition of Partition Function 1. The log-likelihood gradient 2. Stochastic axiu likelihood and
Training an RBM: Contrastive Divergence Sargur N. srihari@cedar.buffalo.edu Topics in Partition Function Definition of Partition Function 1. The log-likelihood gradient 2. Stochastic axiu likelihood and
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Computational and Statistical Learning Theory
 Coputational and Statistical Learning Theory Proble sets 5 and 6 Due: Noveber th Please send your solutions to learning-subissions@ttic.edu Notations/Definitions Recall the definition of saple based Radeacher
Coputational and Statistical Learning Theory Proble sets 5 and 6 Due: Noveber th Please send your solutions to learning-subissions@ttic.edu Notations/Definitions Recall the definition of saple based Radeacher
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Exact Classification with Two-Layer Neural Nets
 journal of coputer and syste sciences 52, 349356 (1996) article no. 0026 Exact Classification with Two-Layer Neural Nets Gavin J. Gibson Bioatheatics and Statistics Scotland, University of Edinburgh, The
journal of coputer and syste sciences 52, 349356 (1996) article no. 0026 Exact Classification with Two-Layer Neural Nets Gavin J. Gibson Bioatheatics and Statistics Scotland, University of Edinburgh, The
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Non-Parametric Non-Line-of-Sight Identification 1
 Non-Paraetric Non-Line-of-Sight Identification Sinan Gezici, Hisashi Kobayashi and H. Vincent Poor Departent of Electrical Engineering School of Engineering and Applied Science Princeton University, Princeton,
Non-Paraetric Non-Line-of-Sight Identification Sinan Gezici, Hisashi Kobayashi and H. Vincent Poor Departent of Electrical Engineering School of Engineering and Applied Science Princeton University, Princeton,
Model Fitting. CURM Background Material, Fall 2014 Dr. Doreen De Leon
 Model Fitting CURM Background Material, Fall 014 Dr. Doreen De Leon 1 Introduction Given a set of data points, we often want to fit a selected odel or type to the data (e.g., we suspect an exponential
Model Fitting CURM Background Material, Fall 014 Dr. Doreen De Leon 1 Introduction Given a set of data points, we often want to fit a selected odel or type to the data (e.g., we suspect an exponential
E0 370 Statistical Learning Theory Lecture 6 (Aug 30, 2011) Margin Analysis
 Margin Analysis") E0 370 tatistical Learning Theory Lecture 6 (Aug 30, 20) Margin Analysis Lecturer: hivani Agarwal cribe: Narasihan R Introduction In the last few lectures we have seen how to obtain high confidence bounds
E0 370 tatistical Learning Theory Lecture 6 (Aug 30, 20) Margin Analysis Lecturer: hivani Agarwal cribe: Narasihan R Introduction In the last few lectures we have seen how to obtain high confidence bounds
A Theoretical Analysis of a Warm Start Technique
 A Theoretical Analysis of a War Start Technique Martin A. Zinkevich Yahoo! Labs 701 First Avenue Sunnyvale, CA Abstract Batch gradient descent looks at every data point for every step, which is wasteful
A Theoretical Analysis of a War Start Technique Martin A. Zinkevich Yahoo! Labs 701 First Avenue Sunnyvale, CA Abstract Batch gradient descent looks at every data point for every step, which is wasteful
Fault Diagnosis of Planetary Gear Based on Fuzzy Entropy of CEEMDAN and MLP Neural Network by Using Vibration Signal
 ITM Web of Conferences 11, 82 (217) DOI: 1.151/ itconf/2171182 IST217 Fault Diagnosis of Planetary Gear Based on Fuzzy Entropy of CEEMDAN and MLP Neural Networ by Using Vibration Signal Xi-Hui CHEN, Gang
ITM Web of Conferences 11, 82 (217) DOI: 1.151/ itconf/2171182 IST217 Fault Diagnosis of Planetary Gear Based on Fuzzy Entropy of CEEMDAN and MLP Neural Networ by Using Vibration Signal Xi-Hui CHEN, Gang
Sharp Time Data Tradeoffs for Linear Inverse Problems
 Sharp Tie Data Tradeoffs for Linear Inverse Probles Saet Oyak Benjain Recht Mahdi Soltanolkotabi January 016 Abstract In this paper we characterize sharp tie-data tradeoffs for optiization probles used
Sharp Tie Data Tradeoffs for Linear Inverse Probles Saet Oyak Benjain Recht Mahdi Soltanolkotabi January 016 Abstract In this paper we characterize sharp tie-data tradeoffs for optiization probles used
Support Vector Machines. Machine Learning Series Jerry Jeychandra Blohm Lab
 Support Vector Machines Machine Learning Series Jerry Jeychandra Bloh Lab Outline Main goal: To understand how support vector achines (SVMs) perfor optial classification for labelled data sets, also a
Support Vector Machines Machine Learning Series Jerry Jeychandra Bloh Lab Outline Main goal: To understand how support vector achines (SVMs) perfor optial classification for labelled data sets, also a
1 Bounding the Margin
 COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #12 Scribe: Jian Min Si March 14, 2013 1 Bounding the Margin We are continuing the proof of a bound on the generalization error of AdaBoost
COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #12 Scribe: Jian Min Si March 14, 2013 1 Bounding the Margin We are continuing the proof of a bound on the generalization error of AdaBoost
Supervised assessment: Modelling and problem-solving task
 Matheatics C 2008 Saple assessent instruent and indicative student response Supervised assessent: Modelling and proble-solving tas This saple is intended to infor the design of assessent instruents in
Matheatics C 2008 Saple assessent instruent and indicative student response Supervised assessent: Modelling and proble-solving tas This saple is intended to infor the design of assessent instruents in