Web-Mining Agents Topic Analysis: plsi and LDA. Tanya Braun Ralf Möller Universität zu Lübeck Institut für Informationssysteme
|
|
|
- Dominic Carpenter
- 5 years ago
- Views:
Transcription
1 Web-Mining Agents Topic Analysis: plsi and LDA Tanya Braun Ralf Möller Universität zu Lübeck Institut für Informationssysteme
2 Acknowledgments Pilfered from: Ramesh M. Nallapati Machine Learning applied to Natural Language Processing Thomas J. Watson Research Center, Yorktown Heights, NY USA from his presentation on Generative Topic Models for Community Analysis & David M. Blei MLSS 2012 from his presentation on Probabilistic Topic Models & Sina Miran CS 290D Paper Presentation on Probabilistic Latent Semantic Indexing (PLSI) 2
3 Recap Agents Task/goal: Information retrieval Environment: Document repository Means: Vector space (bag-of-words) Dimension reduction (LSI) Probability based retrieval (binary) Language models Today: Topic models as special language models Probabilistic LSI (plsi) Latent Dirichlet Allocation (LDA) Soon: What agents can take with them What agents can leave at the repository (win-win) 3
4 Objectives Topic Models: statistical methods that analyze the words of texts in order to: Discover the themes that run through them (topics) How those themes are connected to each other How they change over time "Theoretical Physics" "Neuroscience" FORCE LASER o o o o o o o o o o o o o o o o o o o o o o o o RELATIVITY o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o NEURON o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o NERVE OXYGEN
5 Topic Modeling Scenario Each topic is a distribution over words Each document is a mixture of corpus-wide topics Each word is drawn from one of those topics 5

6 Topic Modeling Scenario Topics Documents Topic proportions and assignments In reality, we only observe the documents The other structures are hidden variables Topic modeling algorithms infer these variables from data 6
7 Plate Notation Naïve Bayes Model: Compact representation C = topic/class (name for a word distribution) N = number of words in considered document W i one specific word in corpus M documents, W now words in document C C w 1 w 2 w 3.. w N Idea: Generate doc from P(W, C) M W N M 7
8 Generative vs. Descriptive Models Generative models: Learn P(x, y) Tasks: Transform P(x,y) into P(y x) for classification Use the model to predict (infer) new data Advantages Assumptions and model are explicit Use well-known algorithms (e.g., MCMC, EM) Descriptive models: Learn P(y x) Task: Classify data Advantages Fewer parameters to learn Better performance for classification 8

9 Earlier Topic Models: Topics Known W Unigram No context information N P w #,, w & = ( P(w * ) * fifth, an, of, futures, the, an, incorporated, a, a, the, inflation, most, dollars, quarter, in, is, mass!! thrift, did, eighty, said, hard, 'm, july, bullish!! that, or, limited, the! Automatically generated sentences from a unigram model 9
 * ( P(w * c. ) W.1#.1# * N M How to specify P(c.")
10 Earlier Topic Models: Topics Known W Unigram No context information N C P w #,, w & = ( P(w * ) Mixture of Unigrams One topic per document 0 0 ( P w #,, w &, c. = ( P(c. ) * ( P(w * c. ) W.1#.1# * N M How to specify P(c. )? 10
11 Mixture of Unigrams: Known Topics p Multinomial Naïve Bayes For each document d = 1,, M Generate c d ~ Mult(. p) C Indication vector c=(z 1, z k ) {0, 1} K P(C=c)= = p zk k >1# For each position i = 1,..., N d Generate w i ~ Mult(. b, c d ) 0 W ( P w #,, w &3, c. β, π.1# N M 0 & 3 = ( P(c. π) ( P w * β, c. 0 & 3 = ( π 63 ( β 63,7 8 b.1# *1#.1# π 63 P c. π β 63,7 8 P w * β, c. multinomial *1# 11
12 Multinomial Distribution Generalization of binomial distribution K possible outcomes instead of 2 Probability mass function n = number of trials x j = count for how often class j occurring p j = probability of class j occurring f x #,, x = ; p #,, p = = Γ * x * + 1 * Γ(x * + 1) Here, the input to is a positive integer, so = ( p * H 8 *1# Γ n = n 1! 12
13 Mixture of Unigrams: Unknown Topics p Topics/classes are hidden Joint probability of words and classes Z 0 ( P w #,, w &3, c. β, π.1# 0 & 3 = ( π 63 ( β 63,7 8.1# *1# W Sum over topics (K = number of topics) N M 0 0 = & 3 b ( P w #,, w &3 β, π.1# = ( L π z> ( β M>,7 8.1# >1# *1# π MN P z > π β MN,7 8 P w * β, z > 13
14 Mixture of Unigrams: Learning Learn parameters π and β Use likelihood Solve 0 ( P w #,, w &3 β, π.1# 0 L log P w #,, w &3 β, π.1# 0 = ( L π M> ( β M>,7 8 Not a concave/convex function Note: a non-concave/non-convex function is not necessarily convex/concave Possibly no unique max, many saddle or turning points No easy way to find roots of derivative 0 =.1# >1# 0 = & 3 *1# & 3 = L log L π z> ( β M>,7 8.1# argmax βπ L log L π z> ( β M>,7 8.1# = >1# & 3 *1# >1# *1# 14
15 Trick: Optimize Lower Bound (γ.>, θ) 15
16 Mixture of Unigrams: Learning The problem Optimize w.r.t. each document Derive lower bound 0 argmax βπ L log L π z> ( β M>,7 8.1# = >1# & 3 *1# log L γ * x * L γ * log x * where γ * 0 L γ * = 1 Jensen's inequality * * * log L x * * = log L γ * x * γ * * 0 = & 3 L γ * log x * γ * log γ * * H(g) argmax βπ L log L π z> ( β M>,7 8.1# >1# *1# The problem again = & 3 = & 3 log L π > ( β >,78 >1# *1# L γ > log(π > ( β >,78 ) >1# *1# + H(γ) 16
17 Mixture of Unigrams: Learning For each document d = log L π > ( β >,78 >1# & 3 *1# Chicken-and-egg problem: = L γ.> log(π > ( β >,78 ) >1# If we knew γ.> we could find π > and β >,78 with ML If we knew π > and β >,78 we could find γ.> with ML Finally we need π z> and β M >,7 8 Solution: Expectation Maximization Iterative algorithm to find local optimum Guaranteed to maximize a lower bound on the loglikelihood of the observed data & 3 *1# + H(γ) 17
18 Graphical Idea of the EM Algorithm (γ.>, θ) θ = (π >, β >,78 ) 18
19 Mixture of Unigrams: Learning For each document d EM solution E step M step = & 3 log L π > ( β >,78 L γ.> log(π > ( β >,78 ) & 3 >1# *1# >1# *1# γ.> = & 3 (`) π (`a#) > + *1# β>,78 = = & 3 π (`) b1# b β >,78 *1# ` (`) + H(γ) 0.1# (`a#) γ π > =.> M ` (`a#) 0 γ `.1# =.> n(d, w * ) 0 γ (`) &.> 3.1# n(d, w b ) β >,78 b1# 19
20 Back to Topic Modeling Scenario Topics Documents Topic proportions and assignments 20
21 Probabilistic LSI d Select a document d with probability P(d) For each word of d in the training set z Choose a topic z with probability P(z d) w N M Generate a word with probability P(w z) P d, w * = = P d L P w * z > P(z > d) >1# Documents can have multiple topics Thomas Hofmann, Probabilistic Latent Semantic Indexing, Proceedings of the 22 nd Annual International SIGIR Conference on Research and Development in Information Retrieval (SIGIR-99),
22 plsi Joint probability for all documents, words 0 & 3 ( ( P d, w * e(.,7 8 ).1# *1# Distribution for document d, word w i = P d, w * = P d L P w * z > P(z > d) >1# d z k w i P(d) P(z k d) P(w i z k ) Reformulate P(z > d) with Bayes Rule z k P(z k ) = P d, w * = L P d z > P(z > )P(w * z > ) >1# w i P(d z k ) d P(z k w i ) 22
23 plsi: Learning Using EM Model 0 & 3 ( ( P d, w e(.,7 8 ) * P d, w * = L P d z > P(z > )P(w * z > ).1# *1# Likelihood 0 & 3 L = L L n d, w * log P(d, w * ) = L L n(d, w * ) log L P d z > P(z > )P(w * z > ).1# *1#.1# *1# >1# Parameters to learn (M step) 0 & 3 = >1# = P(d z > ) P z > P w * z > (E step) P z > d, w * 23
24 plsi: Learning Using EM EM solution E step P(z > d, w * ) = P(z > )P d z > P(w * z > ) = g1# P(z g )P d z g P(w * z g ) M step P w * z > = 0.1# n d, w * P z > d, w * 0 & 3 n d, w b P z > d, w b.1# b1# P d z > = & 3 *1# n d, w * P z > d, w * 0 & h n c, w * P z > c, w * 61# 0 *1# & 3 P z > = 1 R L L n d, w * P z > d, w *,.1# *1# 0 & 3 R = L L n d, w *.1# *1# 24
25 plsi: Overview More realistic than mixture model Documents can discuss multiple topics! Problems Very many parameters Danger of overfitting 25
26 plsi Testrun PLSI topics (TDT-1 corpus) Approx. 7 million words, documents, K = 128 The two most probable topics that generate the term flight (left) and love (right). List of most probable words per topic, with decreasing probability going down the list. 26
 norm plsi: log-likelihood of")
27 Relation with LSI P = U > Σ l V > n P d, w * = L P d z > P(z > )P(w * z > ) = >1# U > = P d z >.,> Σ l = diag P z > > V > = P w * z > *,> Difference: LSI: minimize Frobenius (L-2) norm plsi: log-likelihood of training data 27
28 plsi with Multinomials q d p d Multinomial Naïve Bayes Select document d ~ Mult( p) For each position i = 1,..., N d Generate z i ~ Mult( d, θ. ) Generate w i ~ Mult( z i, b k ) z 0 ( P w #,, w &3, d β, θ, π.1# w N M 0 & 3 = = ( P(d π) ( L P(z * = k d, θ. )P w * β >.1# *1# >1# 0 & 3 = b = ( π. ( L θ.,> β >,78.1# *1# >1# 28
29 Prior Distribution for Topic Mixture Goal: topic mixture proportions for each document are drawn from some distribution. Distribution on multinomials (k-tuples of non-negative numbers that sum to one) The space is of all of these multinomials can be interpreted geometrically as a (k-1)-simplex Generalization of a triangle to (k-1) dimensions Criteria for selecting our prior: It needs to be defined for a (k-1)-simplex Should have nice properties In Bayesian probability theory, if the posterior distributions p(θ x) are in the same family as the prior probability distribution p(θ), the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood function. [Wikipedia] 29
30 Latent Dirichlet Allocation Document = mixture of topics (as in plsi), but according to a Dirichlet prior When we use a uniform Dirichlet prior, plsi=lda D. Blei, A. Ng, and M. Jordan. Latent Dirichlet Allocation. Journal of Machine Learning Research, 3: , January
31 Dirichlet Distributions p(θ α) = Γ * α * * Γ(α * ) Defined over a (k-1)-simplex Takes K non-negative arguments which sum to one. Consequently it is a natural distribution to use over multinomial distributions. The Dirichlet parameter a i can be thought of as a prior count of the i th class Conjugate prior to the multinomial distribution Conjugate prior: if our likelihood is multinomial with a Dirichlet prior, then the posterior is also a Dirichlet f x #,, x = ; p #,, p = = Γ * x * + 1 * Γ(x * + 1) = ( θ * s 8 t# *1# = ( p * H 8 *1# 31
32 LDA Model a q q q z 1 z 2 z 3 z 4 z 1 z 2 z 3 z 4 z 1 z 2 z 3 z 4 w 1 w 2 w 3 w 4 w 1 w 2 w 3 w 4 w 1 w 2 w 3 w 4 b 32
33 LDA Model Parameters a Proportions parameter (k-dimensional vector of real numbers) q Per-document topic distribution (k-dimensional vector of probabilities summing up to 1) z Per-word topic assignment (number from 1 to k) w N M Observed word (number from 1 to v, where v is the number of words in the vocabulary) b Word prior (v-dimensional) 33
: (1.3, 1.3, 1.3), (3,3,3), (7,7,7), (2,6,11), (14, 9, 5), (6,2,6).")
34 Dirichlet Distribution over a 2-Simplex A panel illustrating probability density functions of a few Dirichlet distributions over a 2-simplex, for the following α vectors (clockwise, starting from the upper left corner): (1.3, 1.3, 1.3), (3,3,3), (7,7,7), (2,6,11), (14, 9, 5), (6,2,6). [Wikipedia] 34
35 LDA Model Plate Notation a q For each document d, Generate q d ~ Dirichlet( a) For each position i = 1,..., N d Generate a topic z i ~ Mult( q d ) Generate a word w i ~ Mult( z i,b) z P β, θ, z #,, z &3, w #,, w &3 w N M 0 & 3 = ( P θ. α ( P z * θ. P(w * β, z * ).1# *1# b 35
36 Corpus-level Parameter α= K -1 Σ i α i Let α = 1 Per-document topic distribution: K = 10, D = value item
37 Corpus-level Parameter α α = 10 α = value value item item
38 Corpus-level Parameter α α = 0.1 α = value value item item
39 Back to Topic Modeling Scenario Topics Documents Topic proportions and assignments 39
40 Smoothed LDA Model a Give a different word distribution to each topic q β is K V matrix (V vocabulary size), each row denotes word distribution of a topic z η For each document d Choose q d ~ Dirichlet( a) Choose β > ~ Dirichlet(η ) w N β > K For each position i = 1,..., N d Generate a topic z i ~ Mult( q d ) M Generate a word w i ~ Mult( z i,b k ) 40
41 Smoothed LDA Model a P β, θ, z #,, z &3, w #,, w &3 = = ( P(β > η) q >1# 0 & 3 ( P θ. α ( P z.,* θ. P(w.,* β #:=, z.,* ) z η.1# *1# w N β > K M 41

42 Back to Topic Modeling Scenario But 42
43 Why does LDA work? Trade-off between two goals 1. For each document, allocate its words to as few topics as possible. 2. For each topic, assign high probability to as few terms as possible. These goals are at odds. Putting a document in a single topic makes #2 hard: All of its words must have probability under that topic. Putting very few words in each topic makes #1 hard: To cover a document s words, it must assign many topics to it. Trading off these goals finds groups of tightly cooccurring words 43
44 Inference: The Problem (non-smoothed version) To which topics does a given document belong? Compute the posterior distribution of the hidden variables given a document: P θ, z, w α, β P θ, z w, α, β = P w α, β P θ, z, w α, β = P(θ α) ( P z * θ P(w * z *, β) P w α, β = Γ α = & * * = s ( θ N t# 7 Γ(α * ) > ( L ( θ > β 8 >b * >1# This not only looks awkward, but is as well computationally intractable in general. Coupling between and ij. Solution: Approximations. & *1# *1# >1# b1# dθ 44
45 LDA Learning Parameter learning: Variational EM Numerical approximation using lower-bounds Results in biased solutions Convergence has numerical guarantees Gibbs Sampling Stochastic simulation Unbiased solutions Stochastic convergence D. Blei, A. Ng, and M. Jordan. Latent Dirichlet allocation. Journal of Machine Learning Research, 3: , January
46 LDA: Variational Inference Replace LDA model with simpler one z w N M z N M Minimize the Kullback-Leibler divergence between the two distributions. KL 46
47 LDA: Gibbs Sampling MCMC algorithm Fix all current values but one and sample that value, e.g, for z P(z * = k z t*, w) Eventually converges to true posterior 47
48 Variational Inference vs. Gibbs Sampling Gibbs sampling is slower (takes days for mod.-sized datasets), variational inference takes a few hours. Gibbs sampling is more accurate. Gibbs sampling convergence is difficult to test, although quite a few machine learning approximate inference techniques also have the same problem. 48
49 LDA Application: Reuters Data Setup 100-topic LDA trained on a 16,000 documents corpus of news articles by Reuters Some standard stop words removed Top words from some of the P(w z) Arts Budgets Children Education new million children school film tax women students show program people schools music budget child education movie billion years teachers play federal families high musical year work public 49
50 LDA Application: Reuters Data Result Again: Arts, Budgets, Children, Education. The William Randolph Hearst Foundation will give $1.25 million to Lincoln Center, Metropolitan Opera Co., New York Philharmonic and Juilliard School. Our board felt that we had a real opportunity to make a mark on the future of the performing arts with these grants an act every bit as important as our traditional areas of support in health, medical research, education and the social services, Hearst Foundation President Randolph A. Hearst said Monday in announcing the grants. 50
51 Measuring Performance Perplexity of a probability model How well a probability distribution or probability model predicts a sample q: Model of an unknown probability distribution p based on a training sample drawn from p Evaluate q by asking how well it predicts a separate test sample x #,, x & also drawn from p Perplexity of q w.r.t. sample x #,, x & defined as 2 t# & 8Š ˆ H 8 A better model q will tend to assign higher probabilities to q x * lower perplexity ( less surprised by sample ) [Wikipedia] 51
52 Perplexity of Various Models Unigram LDA 52
53 Use of LDA A widely used topic model (Griffiths, Steyvers, 04) Complexity is an issue Use in IR: Ad hoc retrieval (Wei and Croft, SIGIR 06: TREC benchmarks) Improvements over traditional LM (e.g., LSI techniques) But no consensus on whether there is any improvement over Relevance model, i.e., model with relevance feedback (relevance feedback part of the TREC tests) T. Griffiths, M. Steyvers, Finding Scientific Topics. Proceedings of the National Academy of Sciences, 101 (suppl. 1), Xing Wei and W. Bruce Croft. LDA-based document models for ad-hoc retrieval. In Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '06). ACM, New York, NY, USA, TREC=Text REtrieval Conference 53
54 Generative Topic Models for Community Analysis Pilfered from: Ramesh Nallapati & Arthur Asuncion, Qiang Liu, Padhraic Smyth: Statistical Approaches to Joint Modeling of Text and Network Data 54
55 What if the corpus has network structure? CORA citation network. Figure from [Chang, Blei, AISTATS 2009] J. Chang, and D. Blei. Relational Topic Models for Document Networks. AISTATS, volume 5 of JMLR Proceedings, page JMLR.org,
56 Outline Topic Models for Community Analysis Citation Modeling with plsi with LDA Modeling influence of citations Relational Topic Models 56
57 Hyperlink Modeling Using plsi p d z w q d z c Select document d ~ Mult(π) For each position n = 1,, N d Generate z n ~ Mult(@ θ. ) Generate w n ~ Mult(@ β M ) For each citation j = 1,, L d Generate z j ~ Mult(@ θ. ) Generate c j ~ Mult(@ γ M ) N L M b g D. A. Cohn, Th. Hofmann, The Missing Link - A Probabilistic Model of Document Content and Hypertext Connectivity, In: Proc. NIPS, pp ,
58 Hyperlink Modeling Using plsi p d q d plsi likelihood 0 ( P w #,, w &3, d θ, β, π.1# 0 & 3 = = ( π. ( L θ.> β >7 z z.1# *1# >1# New likelihood 0 w c ( P w #,, w &3, c #,, c Ž3, d θ, β, γ, π N L.1# M 0 & 3 = Ž 3 = = ( π. ( L θ.> β >7 ( L θ.> γ >6 b g.1# *1# >1# Learning using EM b1# >1# 58
59 Hyperlink Modeling Using plsi Heuristic 0 < a < 1 determines the relative importance of content and hyperlinks 0 ( P w #,, w &3, c #,, c Ž3, d θ, β, γ, π.1# 0 & 3 = s Ž 3 = #ts = ( π. ( L θ.> β >7 ( L θ.> γ >6.1# *1# >1# b1# >1# 59
60 Hyperlink Modeling Using plsi Classification performance Hyperlink Content Hyperlink Content 60
61 Hyperlink modeling using LDA a q z w z c For each document d, Generate q d ~ Dirichlet(a) For each position i = 1,..., N d Generate a topic z i ~ Mult(@ θ. ) Generate a word w i ~ Mult (@ β M ) For each citation j = 1,, L c Generate z i ~ Mult(q d ) Generate c i ~ Mult (@ γ M ) N L b M g Learning using variational EM, Gibbs sampling E. Erosheva, S Fienberg, J. Lafferty, Mixed-membership models of scientific publications. Proc National Academy Science U S A Apr 6;101 Suppl 1: Epub 2004 Mar

62 Link-pLSI-LDA: Topic Influence in Blogs γ R. Nallapati, A. Ahmed, E. Xing, W.W. Cohen, Joint Latent Topic Models for Text and Citations, In: Proc. KDD,
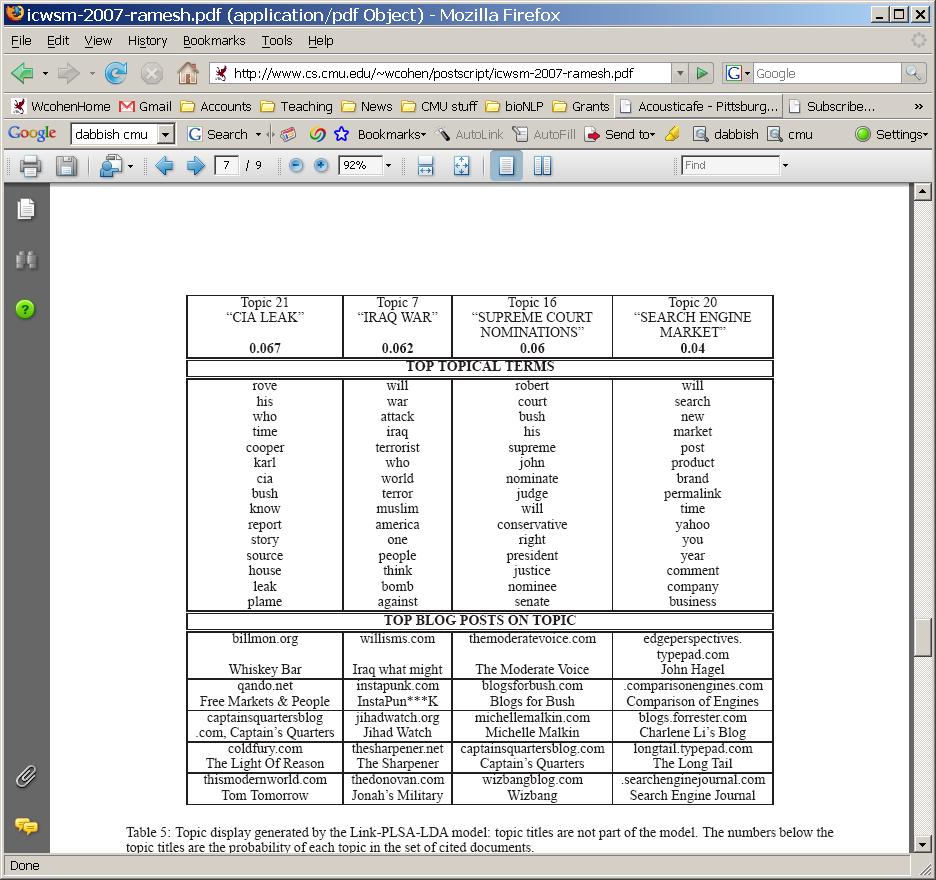
63 63
64 Modeling Citation Influences - Copycat Model Each topic in a citing document is drawn from one of the topic mixtures of cited publications L. Dietz, St. Bickel, and T. Scheffer, Unsupervised Prediction of Citation Influences, In: Proc. ICML
65 Modeling Citation Influences Citation influence model: Combination of LDA and Copycat model L. Dietz, St. Bickel, and T. Scheffer, Unsupervised Prediction of Citation Influences, In: Proc. ICML
66 Modeling Citation Influences Citation influence graph for LDA paper 66
67 Modeling Citation Influences Words in LDA paper assigned to citations 67
68 Modeling Citation Influences Predictive Performance 68
69 Relational Topic Model (RTM) [ChangBlei 2009] Same setup as LDA, except now we have observed network information across documents α y.,. ~ ψ y.,. z., z., η) Link probability function θ. η θ. N. z.,e w.,e M y.,. β > K z.,e w.,e N. J. Chang, and D. Blei. Relational Topic Models for Document Networks. AISTATS, volume 5 of JMLR Proceedings, page JMLR.org, Documents with similar topics are more likely to be linked. 69
70 Relational Topic Model (RTM) [ChangBlei 2009] For each document d α Draw topic proportions θ. α ~ Dir α θ. η θ. For each word w.,e Draw assignment z.,e θ. ~ Mult(θ. ) Draw word w.,e z.,e, β #:= ~ Mult(β M3, ) z.,e y.,. z.,e For each pair of documents d, d w.,e N. β > K w.,e N. Draw binary link indicator y z., z. ~ ψ( z., z. ) 70
71 Collapsed Gibbs Sampling for RTM Conditional distribution of each z: P z.,e = k z.,e, N.,e.> + α N.,e >7 + β N.,e > + Wβ ( ψ ž y.,. = 1 z., z., η. Ÿ.: 3,3 1# ( ψ ž y.,. = 0 z., z., η. Ÿ.: 3,3 1 LDA term Edge term Non-edge term Using the exponential link probability function, it is computationally efficient to calculate the edge term. It is very costly to compute the non-edge term exactly. 71
72 Approximating the Non-edges 1. Assume non-edges are missing and ignore the term entirely (Chang/Blei) 2. Make the following fast approximation: ( 1 exp c * * 1 exp c * &, where c * = 1 N L c * * 3. Subsample non-edges and exactly calculate the term over subset. 4. Subsample non-edges but instead of recalculating statistics for every z.,e token, calculate statistics once per document and cache them over each Gibbs sweep. 72
73 Document networks # Docs # Links Ave. Doc- Length Vocab-Size Link Semantics CORA 4,000 17,000 1,200 60,000 Paper citation (undirected) Netflix Movies Enron (Undirected) Enron (Directed) 10,000 43, ,000 Common actor/director 1,000 16,000 7,000 55,000 Communication between person i and person j 2,000 21,000 3,500 55,000 from person i to person j 73
74 Link Rank Link rank on held-out data as evaluation metric Lower is better d test {d train } Black-box Edges among {d train } predictor Ranking over {d train } Edges between d test and {d train } Link ranks How to compute link rank (simplified): 1. Train model with {d train }. 2. Given the model, calculate probability that d test would link to each d train. Rank {d train } according to these probabilities. 3. For each observed link between d test and {d train }, find the rank, and average all these ranks to obtain the link rank 74
75 Results on CORA data Comparison on CORA, K= Link Rank Baseline (TFIDF/Cosine) LDA + Regression Ignoring non-edges Fast approximation of non-edges Subsampling nonedges (20%)+Caching 8-fold cross-validation. Random guessing gives link rank =
76 Results on CORA data Baseline RTM, Fast Approximation Baseline LDA + Regression (K=40) Ignoring Non-Edges (K=40) Fast Approximation (K=40) Subsampling (5%) + Caching (K=40) Link Rank Link Rank Number of Topics Percentage of Words Model does better with more topics Model does better with more words in each document 76
77 Timing Results on CORA LDA + Regression Ignoring Non-Edges CORA, K=20 Fast Approximation Subsampling (5%) + Caching Subsampling (20%) + Caching Time (in seconds) Number of Documents Subsampling (20%) without caching not shown since it takes 62,000 seconds for D=1000 and 3,720,150 seconds for D=
78 Conclusion Relational topic modeling provides a useful start for combining text and network data in a single statistical framework RTM can improve over simpler approaches for link prediction Opportunities for future work: Faster algorithms for larger data sets Better understanding of non-edge modeling Extended models 78
Latent Dirichlet Allocation
 Outlines Advanced Artificial Intelligence October 1, 2009 Outlines Part I: Theoretical Background Part II: Application and Results 1 Motive Previous Research Exchangeability 2 Notation and Terminology
Outlines Advanced Artificial Intelligence October 1, 2009 Outlines Part I: Theoretical Background Part II: Application and Results 1 Motive Previous Research Exchangeability 2 Notation and Terminology
Information retrieval LSI, plsi and LDA. Jian-Yun Nie
 Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Hybrid Models for Text and Graphs. 10/23/2012 Analysis of Social Media
 Hybrid Models for Text and Graphs 10/23/2012 Analysis of Social Media Newswire Text Formal Primary purpose: Inform typical reader about recent events Broad audience: Explicitly establish shared context
Hybrid Models for Text and Graphs 10/23/2012 Analysis of Social Media Newswire Text Formal Primary purpose: Inform typical reader about recent events Broad audience: Explicitly establish shared context
Document and Topic Models: plsa and LDA
 Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
CS Lecture 18. Topic Models and LDA
 CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
Latent Dirichlet Allocation Introduction/Overview
 Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank
 A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
Topic Models and Applications to Short Documents
 Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Topic Modelling and Latent Dirichlet Allocation
 Topic Modelling and Latent Dirichlet Allocation Stephen Clark (with thanks to Mark Gales for some of the slides) Lent 2013 Machine Learning for Language Processing: Lecture 7 MPhil in Advanced Computer
Topic Modelling and Latent Dirichlet Allocation Stephen Clark (with thanks to Mark Gales for some of the slides) Lent 2013 Machine Learning for Language Processing: Lecture 7 MPhil in Advanced Computer
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
Applying LDA topic model to a corpus of Italian Supreme Court decisions
 Applying LDA topic model to a corpus of Italian Supreme Court decisions Paolo Fantini Statistical Service of the Ministry of Justice - Italy CESS Conference - Rome - November 25, 2014 Our goal finding
Applying LDA topic model to a corpus of Italian Supreme Court decisions Paolo Fantini Statistical Service of the Ministry of Justice - Italy CESS Conference - Rome - November 25, 2014 Our goal finding
Parallelized Variational EM for Latent Dirichlet Allocation: An Experimental Evaluation of Speed and Scalability
 Parallelized Variational EM for Latent Dirichlet Allocation: An Experimental Evaluation of Speed and Scalability Ramesh Nallapati, William Cohen and John Lafferty Machine Learning Department Carnegie Mellon
Parallelized Variational EM for Latent Dirichlet Allocation: An Experimental Evaluation of Speed and Scalability Ramesh Nallapati, William Cohen and John Lafferty Machine Learning Department Carnegie Mellon
RETRIEVAL MODELS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
Text Mining for Economics and Finance Latent Dirichlet Allocation
 Text Mining for Economics and Finance Latent Dirichlet Allocation Stephen Hansen Text Mining Lecture 5 1 / 45 Introduction Recall we are interested in mixed-membership modeling, but that the plsi model
Text Mining for Economics and Finance Latent Dirichlet Allocation Stephen Hansen Text Mining Lecture 5 1 / 45 Introduction Recall we are interested in mixed-membership modeling, but that the plsi model
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
Gaussian Mixture Model
 Case Study : Document Retrieval MAP EM, Latent Dirichlet Allocation, Gibbs Sampling Machine Learning/Statistics for Big Data CSE599C/STAT59, University of Washington Emily Fox 0 Emily Fox February 5 th,
Case Study : Document Retrieval MAP EM, Latent Dirichlet Allocation, Gibbs Sampling Machine Learning/Statistics for Big Data CSE599C/STAT59, University of Washington Emily Fox 0 Emily Fox February 5 th,
Dirichlet Enhanced Latent Semantic Analysis
 Dirichlet Enhanced Latent Semantic Analysis Kai Yu Siemens Corporate Technology D-81730 Munich, Germany Kai.Yu@siemens.com Shipeng Yu Institute for Computer Science University of Munich D-80538 Munich,
Dirichlet Enhanced Latent Semantic Analysis Kai Yu Siemens Corporate Technology D-81730 Munich, Germany Kai.Yu@siemens.com Shipeng Yu Institute for Computer Science University of Munich D-80538 Munich,
HTM: A Topic Model for Hypertexts
 HTM: A Topic Model for Hypertexts Congkai Sun Department of Computer Science Shanghai Jiaotong University Shanghai, P. R. China martinsck@hotmail.com Bin Gao Microsoft Research Asia No.49 Zhichun Road
HTM: A Topic Model for Hypertexts Congkai Sun Department of Computer Science Shanghai Jiaotong University Shanghai, P. R. China martinsck@hotmail.com Bin Gao Microsoft Research Asia No.49 Zhichun Road
Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs
 Lawrence Livermore National Laboratory Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs Keith Henderson and Tina Eliassi-Rad keith@llnl.gov and eliassi@llnl.gov This work was performed
Lawrence Livermore National Laboratory Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs Keith Henderson and Tina Eliassi-Rad keith@llnl.gov and eliassi@llnl.gov This work was performed
Topic Models. Brandon Malone. February 20, Latent Dirichlet Allocation Success Stories Wrap-up
 Much of this material is adapted from Blei 2003. Many of the images were taken from the Internet February 20, 2014 Suppose we have a large number of books. Each is about several unknown topics. How can
Much of this material is adapted from Blei 2003. Many of the images were taken from the Internet February 20, 2014 Suppose we have a large number of books. Each is about several unknown topics. How can
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Evaluation Methods for Topic Models
 University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text
 Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
A Continuous-Time Model of Topic Co-occurrence Trends
 A Continuous-Time Model of Topic Co-occurrence Trends Wei Li, Xuerui Wang and Andrew McCallum Department of Computer Science University of Massachusetts 140 Governors Drive Amherst, MA 01003-9264 Abstract
A Continuous-Time Model of Topic Co-occurrence Trends Wei Li, Xuerui Wang and Andrew McCallum Department of Computer Science University of Massachusetts 140 Governors Drive Amherst, MA 01003-9264 Abstract
Lecture 19, November 19, 2012
 Machine Learning 0-70/5-78, Fall 0 Latent Space Analysis SVD and Topic Models Eric Xing Lecture 9, November 9, 0 Reading: Tutorial on Topic Model @ ACL Eric Xing @ CMU, 006-0 We are inundated with data
Machine Learning 0-70/5-78, Fall 0 Latent Space Analysis SVD and Topic Models Eric Xing Lecture 9, November 9, 0 Reading: Tutorial on Topic Model @ ACL Eric Xing @ CMU, 006-0 We are inundated with data
Pachinko Allocation: DAG-Structured Mixture Models of Topic Correlations
 : DAG-Structured Mixture Models of Topic Correlations Wei Li and Andrew McCallum University of Massachusetts, Dept. of Computer Science {weili,mccallum}@cs.umass.edu Abstract Latent Dirichlet allocation
: DAG-Structured Mixture Models of Topic Correlations Wei Li and Andrew McCallum University of Massachusetts, Dept. of Computer Science {weili,mccallum}@cs.umass.edu Abstract Latent Dirichlet allocation
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Web Search and Text Mining. Lecture 16: Topics and Communities
 Web Search and Tet Mining Lecture 16: Topics and Communities Outline Latent Dirichlet Allocation (LDA) Graphical models for social netorks Eploration, discovery, and query-ansering in the contet of the
Web Search and Tet Mining Lecture 16: Topics and Communities Outline Latent Dirichlet Allocation (LDA) Graphical models for social netorks Eploration, discovery, and query-ansering in the contet of the
Understanding Comments Submitted to FCC on Net Neutrality. Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014
 Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014") Understanding Comments Submitted to FCC on Net Neutrality Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014 Abstract We aim to understand and summarize themes in the 1.65 million
Understanding Comments Submitted to FCC on Net Neutrality Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014 Abstract We aim to understand and summarize themes in the 1.65 million
Introduction to Bayesian inference
 Introduction to Bayesian inference Thomas Alexander Brouwer University of Cambridge tab43@cam.ac.uk 17 November 2015 Probabilistic models Describe how data was generated using probability distributions
Introduction to Bayesian inference Thomas Alexander Brouwer University of Cambridge tab43@cam.ac.uk 17 November 2015 Probabilistic models Describe how data was generated using probability distributions
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Probabilistic Latent Semantic Analysis Denis Helic KTI, TU Graz Jan 16, 2014 Denis Helic (KTI, TU Graz) KDDM1 Jan 16, 2014 1 / 47 Big picture: KDDM
Knowledge Discovery and Data Mining 1 (VO) (707.003) Probabilistic Latent Semantic Analysis Denis Helic KTI, TU Graz Jan 16, 2014 Denis Helic (KTI, TU Graz) KDDM1 Jan 16, 2014 1 / 47 Big picture: KDDM
Learning Bayesian network : Given structure and completely observed data
 Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Latent Dirichlet Allocation
 Latent Dirichlet Allocation 1 Directed Graphical Models William W. Cohen Machine Learning 10-601 2 DGMs: The Burglar Alarm example Node ~ random variable Burglar Earthquake Arcs define form of probability
Latent Dirichlet Allocation 1 Directed Graphical Models William W. Cohen Machine Learning 10-601 2 DGMs: The Burglar Alarm example Node ~ random variable Burglar Earthquake Arcs define form of probability
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Yuriy Sverchkov Intelligent Systems Program University of Pittsburgh October 6, 2011 Outline Latent Semantic Analysis (LSA) A quick review Probabilistic LSA (plsa)
Probabilistic Latent Semantic Analysis Yuriy Sverchkov Intelligent Systems Program University of Pittsburgh October 6, 2011 Outline Latent Semantic Analysis (LSA) A quick review Probabilistic LSA (plsa)
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Sum-Product Networks. STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 17, 2017
 Sum-Product Networks STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 17, 2017 Introduction Outline What is a Sum-Product Network? Inference Applications In more depth
Sum-Product Networks STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 17, 2017 Introduction Outline What is a Sum-Product Network? Inference Applications In more depth
Latent Dirichlet Alloca/on
 Latent Dirichlet Alloca/on Blei, Ng and Jordan ( 2002 ) Presented by Deepak Santhanam What is Latent Dirichlet Alloca/on? Genera/ve Model for collec/ons of discrete data Data generated by parameters which
Latent Dirichlet Alloca/on Blei, Ng and Jordan ( 2002 ) Presented by Deepak Santhanam What is Latent Dirichlet Alloca/on? Genera/ve Model for collec/ons of discrete data Data generated by parameters which
Sparse Stochastic Inference for Latent Dirichlet Allocation
 Sparse Stochastic Inference for Latent Dirichlet Allocation David Mimno 1, Matthew D. Hoffman 2, David M. Blei 1 1 Dept. of Computer Science, Princeton U. 2 Dept. of Statistics, Columbia U. Presentation
Sparse Stochastic Inference for Latent Dirichlet Allocation David Mimno 1, Matthew D. Hoffman 2, David M. Blei 1 1 Dept. of Computer Science, Princeton U. 2 Dept. of Statistics, Columbia U. Presentation
Mixed-membership Models (and an introduction to variational inference)
") Mixed-membership Models (and an introduction to variational inference) David M. Blei Columbia University November 24, 2015 Introduction We studied mixture models in detail, models that partition data into
Mixed-membership Models (and an introduction to variational inference) David M. Blei Columbia University November 24, 2015 Introduction We studied mixture models in detail, models that partition data into
Measuring Topic Quality in Latent Dirichlet Allocation
 Measuring Topic Quality in Sergei Koltsov Olessia Koltsova Steklov Institute of Mathematics at St. Petersburg Laboratory for Internet Studies, National Research University Higher School of Economics, St.
Measuring Topic Quality in Sergei Koltsov Olessia Koltsova Steklov Institute of Mathematics at St. Petersburg Laboratory for Internet Studies, National Research University Higher School of Economics, St.
Latent variable models for discrete data
 Latent variable models for discrete data Jianfei Chen Department of Computer Science and Technology Tsinghua University, Beijing 100084 chris.jianfei.chen@gmail.com Janurary 13, 2014 Murphy, Kevin P. Machine
Latent variable models for discrete data Jianfei Chen Department of Computer Science and Technology Tsinghua University, Beijing 100084 chris.jianfei.chen@gmail.com Janurary 13, 2014 Murphy, Kevin P. Machine
Topic Models. Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW. Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1
 Topic Models Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1 Low-Dimensional Space for Documents Last time: embedding space
Topic Models Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1 Low-Dimensional Space for Documents Last time: embedding space
Modeling Environment
 Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Introduction to Bayesian Learning
 Course Information Introduction Introduction to Bayesian Learning Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Apprendimento Automatico: Fondamenti - A.A. 2016/2017 Outline
Course Information Introduction Introduction to Bayesian Learning Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Apprendimento Automatico: Fondamenti - A.A. 2016/2017 Outline
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Distributed ML for DOSNs: giving power back to users
 Distributed ML for DOSNs: giving power back to users Amira Soliman KTH isocial Marie Curie Initial Training Networks Part1 Agenda DOSNs and Machine Learning DIVa: Decentralized Identity Validation for
Distributed ML for DOSNs: giving power back to users Amira Soliman KTH isocial Marie Curie Initial Training Networks Part1 Agenda DOSNs and Machine Learning DIVa: Decentralized Identity Validation for
Probabilistic Dyadic Data Analysis with Local and Global Consistency
 Deng Cai DENGCAI@CAD.ZJU.EDU.CN Xuanhui Wang XWANG20@CS.UIUC.EDU Xiaofei He XIAOFEIHE@CAD.ZJU.EDU.CN State Key Lab of CAD&CG, College of Computer Science, Zhejiang University, 100 Zijinggang Road, 310058,
Deng Cai DENGCAI@CAD.ZJU.EDU.CN Xuanhui Wang XWANG20@CS.UIUC.EDU Xiaofei He XIAOFEIHE@CAD.ZJU.EDU.CN State Key Lab of CAD&CG, College of Computer Science, Zhejiang University, 100 Zijinggang Road, 310058,
Latent Dirichlet Conditional Naive-Bayes Models
 Latent Dirichlet Conditional Naive-Bayes Models Arindam Banerjee Dept of Computer Science & Engineering University of Minnesota, Twin Cities banerjee@cs.umn.edu Hanhuai Shan Dept of Computer Science &
Latent Dirichlet Conditional Naive-Bayes Models Arindam Banerjee Dept of Computer Science & Engineering University of Minnesota, Twin Cities banerjee@cs.umn.edu Hanhuai Shan Dept of Computer Science &
Note for plsa and LDA-Version 1.1
 Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
topic modeling hanna m. wallach
 university of massachusetts amherst wallach@cs.umass.edu Ramona Blei-Gantz Helen Moss (Dave's Grandma) The Next 30 Minutes Motivations and a brief history: Latent semantic analysis Probabilistic latent
university of massachusetts amherst wallach@cs.umass.edu Ramona Blei-Gantz Helen Moss (Dave's Grandma) The Next 30 Minutes Motivations and a brief history: Latent semantic analysis Probabilistic latent
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Probabilistic Graphical Models & Applications
 Probabilistic Graphical Models & Applications Learning of Graphical Models Bjoern Andres and Bernt Schiele Max Planck Institute for Informatics The slides of today s lecture are authored by and shown with
Probabilistic Graphical Models & Applications Learning of Graphical Models Bjoern Andres and Bernt Schiele Max Planck Institute for Informatics The slides of today s lecture are authored by and shown with
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Lecture 22 Exploratory Text Analysis & Topic Models
 Lecture 22 Exploratory Text Analysis & Topic Models Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor [Some slides borrowed from Michael Paul] 1 Text Corpus
Lecture 22 Exploratory Text Analysis & Topic Models Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor [Some slides borrowed from Michael Paul] 1 Text Corpus
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine
 Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
Statistical Debugging with Latent Topic Models
 Statistical Debugging with Latent Topic Models David Andrzejewski, Anne Mulhern, Ben Liblit, Xiaojin Zhu Department of Computer Sciences University of Wisconsin Madison European Conference on Machine Learning,
Statistical Debugging with Latent Topic Models David Andrzejewski, Anne Mulhern, Ben Liblit, Xiaojin Zhu Department of Computer Sciences University of Wisconsin Madison European Conference on Machine Learning,
LSI, plsi, LDA and inference methods
 LSI, plsi, LDA and inference methods Guillaume Obozinski INRIA - Ecole Normale Supérieure - Paris RussIR summer school Yaroslavl, August 6-10th 2012 Guillaume Obozinski LSI, plsi, LDA and inference methods
LSI, plsi, LDA and inference methods Guillaume Obozinski INRIA - Ecole Normale Supérieure - Paris RussIR summer school Yaroslavl, August 6-10th 2012 Guillaume Obozinski LSI, plsi, LDA and inference methods
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Bayesian Learning. CSL603 - Fall 2017 Narayanan C Krishnan
 Bayesian Learning CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Bayes Theorem MAP Learners Bayes optimal classifier Naïve Bayes classifier Example text classification Bayesian networks
Bayesian Learning CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Bayes Theorem MAP Learners Bayes optimal classifier Naïve Bayes classifier Example text classification Bayesian networks
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
Fast Collapsed Gibbs Sampling For Latent Dirichlet Allocation
 Fast Collapsed Gibbs Sampling For Latent Dirichlet Allocation Ian Porteous iporteou@ics.uci.edu Arthur Asuncion asuncion@ics.uci.edu David Newman newman@uci.edu Padhraic Smyth smyth@ics.uci.edu Alexander
Fast Collapsed Gibbs Sampling For Latent Dirichlet Allocation Ian Porteous iporteou@ics.uci.edu Arthur Asuncion asuncion@ics.uci.edu David Newman newman@uci.edu Padhraic Smyth smyth@ics.uci.edu Alexander
Benchmarking and Improving Recovery of Number of Topics in Latent Dirichlet Allocation Models
 Benchmarking and Improving Recovery of Number of Topics in Latent Dirichlet Allocation Models Jason Hou-Liu January 4, 2018 Abstract Latent Dirichlet Allocation (LDA) is a generative model describing the
Benchmarking and Improving Recovery of Number of Topics in Latent Dirichlet Allocation Models Jason Hou-Liu January 4, 2018 Abstract Latent Dirichlet Allocation (LDA) is a generative model describing the
Content-based Recommendation
 Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Latent Dirichlet Allocation Based Multi-Document Summarization
 Latent Dirichlet Allocation Based Multi-Document Summarization Rachit Arora Department of Computer Science and Engineering Indian Institute of Technology Madras Chennai - 600 036, India. rachitar@cse.iitm.ernet.in
Latent Dirichlet Allocation Based Multi-Document Summarization Rachit Arora Department of Computer Science and Engineering Indian Institute of Technology Madras Chennai - 600 036, India. rachitar@cse.iitm.ernet.in
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Modeling User Rating Profiles For Collaborative Filtering
 Modeling User Rating Profiles For Collaborative Filtering Benjamin Marlin Department of Computer Science University of Toronto Toronto, ON, M5S 3H5, CANADA marlin@cs.toronto.edu Abstract In this paper
Modeling User Rating Profiles For Collaborative Filtering Benjamin Marlin Department of Computer Science University of Toronto Toronto, ON, M5S 3H5, CANADA marlin@cs.toronto.edu Abstract In this paper
A Collapsed Variational Bayesian Inference Algorithm for Latent Dirichlet Allocation
 THIS IS A DRAFT VERSION. FINAL VERSION TO BE PUBLISHED AT NIPS 06 A Collapsed Variational Bayesian Inference Algorithm for Latent Dirichlet Allocation Yee Whye Teh School of Computing National University
THIS IS A DRAFT VERSION. FINAL VERSION TO BE PUBLISHED AT NIPS 06 A Collapsed Variational Bayesian Inference Algorithm for Latent Dirichlet Allocation Yee Whye Teh School of Computing National University
Generative Models. CS4780/5780 Machine Learning Fall Thorsten Joachims Cornell University
 Generative Models CS4780/5780 Machine Learning Fall 2012 Thorsten Joachims Cornell University Reading: Mitchell, Chapter 6.9-6.10 Duda, Hart & Stork, Pages 20-39 Bayes decision rule Bayes theorem Generative
Generative Models CS4780/5780 Machine Learning Fall 2012 Thorsten Joachims Cornell University Reading: Mitchell, Chapter 6.9-6.10 Duda, Hart & Stork, Pages 20-39 Bayes decision rule Bayes theorem Generative
Relative Performance Guarantees for Approximate Inference in Latent Dirichlet Allocation
 Relative Performance Guarantees for Approximate Inference in Latent Dirichlet Allocation Indraneel Muherjee David M. Blei Department of Computer Science Princeton University 3 Olden Street Princeton, NJ
Relative Performance Guarantees for Approximate Inference in Latent Dirichlet Allocation Indraneel Muherjee David M. Blei Department of Computer Science Princeton University 3 Olden Street Princeton, NJ
Introduction To Machine Learning
 Introduction To Machine Learning David Sontag New York University Lecture 21, April 14, 2016 David Sontag (NYU) Introduction To Machine Learning Lecture 21, April 14, 2016 1 / 14 Expectation maximization
Introduction To Machine Learning David Sontag New York University Lecture 21, April 14, 2016 David Sontag (NYU) Introduction To Machine Learning Lecture 21, April 14, 2016 1 / 14 Expectation maximization
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Topic Models. Charles Elkan November 20, 2008
 Topic Models Charles Elan elan@cs.ucsd.edu November 20, 2008 Suppose that we have a collection of documents, and we want to find an organization for these, i.e. we want to do unsupervised learning. One
Topic Models Charles Elan elan@cs.ucsd.edu November 20, 2008 Suppose that we have a collection of documents, and we want to find an organization for these, i.e. we want to do unsupervised learning. One
Language Information Processing, Advanced. Topic Models
 Language Information Processing, Advanced Topic Models mcuturi@i.kyoto-u.ac.jp Kyoto University - LIP, Adv. - 2011 1 Today s talk Continue exploring the representation of text as histogram of words. Objective:
Language Information Processing, Advanced Topic Models mcuturi@i.kyoto-u.ac.jp Kyoto University - LIP, Adv. - 2011 1 Today s talk Continue exploring the representation of text as histogram of words. Objective:
Replicated Softmax: an Undirected Topic Model. Stephen Turner
 Replicated Softmax: an Undirected Topic Model Stephen Turner 1. Introduction 2. Replicated Softmax: A Generative Model of Word Counts 3. Evaluating Replicated Softmax as a Generative Model 4. Experimental
Replicated Softmax: an Undirected Topic Model Stephen Turner 1. Introduction 2. Replicated Softmax: A Generative Model of Word Counts 3. Evaluating Replicated Softmax as a Generative Model 4. Experimental
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
STATS 306B: Unsupervised Learning Spring Lecture 3 April 7th
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
Machine Learning (CS 567) Lecture 2
 Lecture 2") Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
16 : Approximate Inference: Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
Language as a Stochastic Process
 CS769 Spring 2010 Advanced Natural Language Processing Language as a Stochastic Process Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Basic Statistics for NLP Pick an arbitrary letter x at random from any
CS769 Spring 2010 Advanced Natural Language Processing Language as a Stochastic Process Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Basic Statistics for NLP Pick an arbitrary letter x at random from any
Lecture 13: More uses of Language Models
 Lecture 13: More uses of Language Models William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 13 What we ll learn in this lecture Comparing documents, corpora using LM approaches
Lecture 13: More uses of Language Models William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 13 What we ll learn in this lecture Comparing documents, corpora using LM approaches
Text Mining: Basic Models and Applications
 Introduction Basics Latent Dirichlet Allocation (LDA) Markov Chain Based Models Public Policy Applications Text Mining: Basic Models and Applications Alvaro J. Riascos Villegas University of los Andes
Introduction Basics Latent Dirichlet Allocation (LDA) Markov Chain Based Models Public Policy Applications Text Mining: Basic Models and Applications Alvaro J. Riascos Villegas University of los Andes
Generative Models for Classification
 Generative Models for Classification CS4780/5780 Machine Learning Fall 2014 Thorsten Joachims Cornell University Reading: Mitchell, Chapter 6.9-6.10 Duda, Hart & Stork, Pages 20-39 Generative vs. Discriminative
Generative Models for Classification CS4780/5780 Machine Learning Fall 2014 Thorsten Joachims Cornell University Reading: Mitchell, Chapter 6.9-6.10 Duda, Hart & Stork, Pages 20-39 Generative vs. Discriminative
LDA with Amortized Inference
 LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
Kernel Density Topic Models: Visual Topics Without Visual Words
 Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
Markov Topic Models. Bo Thiesson, Christopher Meek Microsoft Research One Microsoft Way Redmond, WA 98052
 Chong Wang Computer Science Dept. Princeton University Princeton, NJ 08540 Bo Thiesson, Christopher Meek Microsoft Research One Microsoft Way Redmond, WA 9805 David Blei Computer Science Dept. Princeton
Chong Wang Computer Science Dept. Princeton University Princeton, NJ 08540 Bo Thiesson, Christopher Meek Microsoft Research One Microsoft Way Redmond, WA 9805 David Blei Computer Science Dept. Princeton