An Iterative Descent Method
|
|
|
- Eileen Daniels
- 5 years ago
- Views:
Transcription
1 Conjugate Gradient: An Iterative Descent Method
2 The Plan Review Iterative Descent Conjugate Gradient
3 Review : Iterative Descent Iterative Descent is an unconstrained optimization process x (k+1) = x (k) + αδx Δx is the descent direction α > 0 is the step size along the descent direction Initial point x 0 needs to be chosen
4 Review : Descent Direction Gradient Descent: 1st-order approximation Δx = - f(x) Newton s Method: 2 nd -order approximation Δx = - 2 f(x) -1 f(x)
5 Review : Calculating Line search methods for calculating Exact Backtracking Others
6 Review : Convergence Gradient Descent: Linear rate Newton s Method: Quadratic near x* if certain conditions are met otherwise, linear rate
7 Conjugate Gradient (CG) Is an alternative Iterative Descent Is an alternative Iterative Descent algorithm
8 CG: Focus To more easily explain CG, I will focus on minimizing a quadratic system f(x) = ½x T Ax b T x + c
9 Ais CG: Assumptions Square Symmetric Positive Definite Theorem: - x* minimizes f(x) = ½x T Ax b T x + c iff x* solves Ax = b Will focus on solving Ax = b
10 CG: Philosophy Avoid taking steps in the same direction as Gradient Descent can Coordinate axes as search direction only works if already know answer! CG, instead of orthogonality, uses A- orthogonality Gradient Descent
11 CG: A-orthogonality For descent directions, the CG method uses an A-orthogonal set of nonzero search direction vectors {v (1),, v (n) } <v (i),av (j) > = 0 if i j Each search direction will be evaluated once and a step size of just the right length will be applied in order to line up with x*
12 CG: A-orthogonality Note: With respect to a symmetric, positive definite A, A-orthogonal vectors are linear independent So, they can be used as basis vectors for So, they can be used as basis vectors for components of the algorithm, such as errors and residuals
13 CG: General Idea With regard to an A-orthogonal basis vector, eliminate the component of the error (e (k) = x (k) x*) associated with that basis vector The new error, e (k+1), must be A-orthogonal to all A-orthogonal basis vectors considered so far
14 CG: Algorithm 1. Choose initial point x (0) 2. Generate first search direction v (1) 3. For k = 1, 2,, n 1. Generate (not search for) step size t k 2. x (k) = x (k-1) + t k v (k) (tk is the step size) 3. Generate next A-orthogonal search direction v (k+1) 4. x (n) is the solution to Ax = b



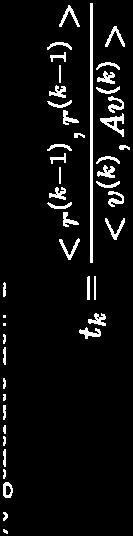
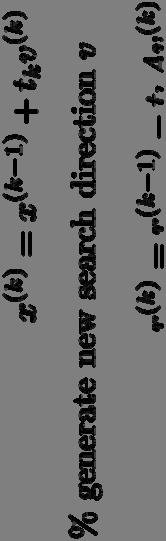
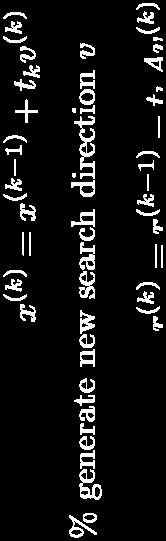


15 CG: Algorithm
16 CG: Notes Generating A-orthogonal vectors as we iterate, and don t have to keep old ones around. Important for storage on large problems. Convergence is quicker than O(n) if there are duplicated d eigenvalues.
17 CG: Notes For a well-conditioned matrix A, a good approximation can sometimes be reached in fewer steps (e.g. n ) Good approximation method for solving large pp g g sparse systems of Ax = b with nonzero entries in A occurring in predictable patterns
18 CG: Reality Intrudes Accumulated roundoff error causes the residual, r (i) = b Ax (i), to gradually lose accuracy Cancellation error causes the search vectors to lose A-orthogonality If A is ill-conditioned, CG is highly subject to rounding errors. can precondition the matrix to ameliorate this
19 CG: Nonlinear f(x) CG can be used if the gradient f(x) can be computed Use of CG in this case is guided by the idea that t near the solution point every problem is approximately quadratic. So, instead of approximating a solution to the actual problem, instead approximate a solution to an approximating problem.
20 CG: Nonlinear f(x) Convergence behavior is similar to that for the pure quadratic situation. Changes to CG algorithm recursive formula for residual r can t be used more complicated to compute the step size t k multiple ways to compute A-orthogonal descent vectors Not guaranteed to converge to global minimum if f has many local minima
21 CG: Nonlinear f(x) Doesn t have same convergence guarantees as linear CG Because CG can only generate n A-orthogonal vectors in n-space, it makes sense to restart CG every n iterations Preconditioning can be used to speed up convergence
22 CG: Roundup CG typically performs better than gradient descent, but not as well as Newton s method CG avoids Newton s information requirements associated with the evaluation, storage, and inversion of the Hessian (or at least a solution of a corresponding system of equations)
23 References Boyd & Vandenberghe, Convex Optimization Burden & Faires, Numerical Analysis, 8 th edition Chong & Zak, An Introduction to Optimization, 1 st edition Shewchuck, An Introduction to the Conjugate Gradient Method Without the Agonizing Pain, 1 ¼ edition, online Luenberger, Linear and Nonlinear Programming, 3 rd edition
Quasi-Newton Methods
 Newton s Method Pros and Cons Quasi-Newton Methods MA 348 Kurt Bryan Newton s method has some very nice properties: It s extremely fast, at least once it gets near the minimum, and with the simple modifications
Newton s Method Pros and Cons Quasi-Newton Methods MA 348 Kurt Bryan Newton s method has some very nice properties: It s extremely fast, at least once it gets near the minimum, and with the simple modifications
Constrained optimization. Unconstrained optimization. One-dimensional. Multi-dimensional. Newton with equality constraints. Active-set method.
 Optimization Unconstrained optimization One-dimensional Multi-dimensional Newton s method Basic Newton Gauss- Newton Quasi- Newton Descent methods Gradient descent Conjugate gradient Constrained optimization
Optimization Unconstrained optimization One-dimensional Multi-dimensional Newton s method Basic Newton Gauss- Newton Quasi- Newton Descent methods Gradient descent Conjugate gradient Constrained optimization
The Conjugate Gradient Method for Solving Linear Systems of Equations
 The Conjugate Gradient Method for Solving Linear Systems of Equations Mike Rambo Mentor: Hans de Moor May 2016 Department of Mathematics, Saint Mary s College of California Contents 1 Introduction 2 2
The Conjugate Gradient Method for Solving Linear Systems of Equations Mike Rambo Mentor: Hans de Moor May 2016 Department of Mathematics, Saint Mary s College of California Contents 1 Introduction 2 2
Nonlinear Optimization for Optimal Control
 Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
Conjugate Gradient Method
 Conjugate Gradient Method Hung M Phan UMass Lowell April 13, 2017 Throughout, A R n n is symmetric and positive definite, and b R n 1 Steepest Descent Method We present the steepest descent method for
Conjugate Gradient Method Hung M Phan UMass Lowell April 13, 2017 Throughout, A R n n is symmetric and positive definite, and b R n 1 Steepest Descent Method We present the steepest descent method for
Conjugate Gradient Tutorial
 Conjugate Gradient Tutorial Prof. Chung-Kuan Cheng Computer Science and Engineering Department University of California, San Diego ckcheng@ucsd.edu December 1, 2015 Prof. Chung-Kuan Cheng (UC San Diego)
Conjugate Gradient Tutorial Prof. Chung-Kuan Cheng Computer Science and Engineering Department University of California, San Diego ckcheng@ucsd.edu December 1, 2015 Prof. Chung-Kuan Cheng (UC San Diego)
The Conjugate Gradient Method
 The Conjugate Gradient Method Jason E. Hicken Aerospace Design Lab Department of Aeronautics & Astronautics Stanford University 14 July 2011 Lecture Objectives describe when CG can be used to solve Ax
The Conjugate Gradient Method Jason E. Hicken Aerospace Design Lab Department of Aeronautics & Astronautics Stanford University 14 July 2011 Lecture Objectives describe when CG can be used to solve Ax
Lecture 11: CMSC 878R/AMSC698R. Iterative Methods An introduction. Outline. Inverse, LU decomposition, Cholesky, SVD, etc.
 Lecture 11: CMSC 878R/AMSC698R Iterative Methods An introduction Outline Direct Solution of Linear Systems Inverse, LU decomposition, Cholesky, SVD, etc. Iterative methods for linear systems Why? Matrix
Lecture 11: CMSC 878R/AMSC698R Iterative Methods An introduction Outline Direct Solution of Linear Systems Inverse, LU decomposition, Cholesky, SVD, etc. Iterative methods for linear systems Why? Matrix
From Stationary Methods to Krylov Subspaces
 Week 6: Wednesday, Mar 7 From Stationary Methods to Krylov Subspaces Last time, we discussed stationary methods for the iterative solution of linear systems of equations, which can generally be written
Week 6: Wednesday, Mar 7 From Stationary Methods to Krylov Subspaces Last time, we discussed stationary methods for the iterative solution of linear systems of equations, which can generally be written
Lec10p1, ORF363/COS323
 Lec10 Page 1 Lec10p1, ORF363/COS323 This lecture: Conjugate direction methods Conjugate directions Conjugate Gram-Schmidt The conjugate gradient (CG) algorithm Solving linear systems Leontief input-output
Lec10 Page 1 Lec10p1, ORF363/COS323 This lecture: Conjugate direction methods Conjugate directions Conjugate Gram-Schmidt The conjugate gradient (CG) algorithm Solving linear systems Leontief input-output
Math 5630: Conjugate Gradient Method Hung M. Phan, UMass Lowell March 29, 2019
 Math 563: Conjugate Gradient Method Hung M. Phan, UMass Lowell March 29, 219 hroughout, A R n n is symmetric and positive definite, and b R n. 1 Steepest Descent Method We present the steepest descent
Math 563: Conjugate Gradient Method Hung M. Phan, UMass Lowell March 29, 219 hroughout, A R n n is symmetric and positive definite, and b R n. 1 Steepest Descent Method We present the steepest descent
Optimization Tutorial 1. Basic Gradient Descent
 E0 270 Machine Learning Jan 16, 2015 Optimization Tutorial 1 Basic Gradient Descent Lecture by Harikrishna Narasimhan Note: This tutorial shall assume background in elementary calculus and linear algebra.
E0 270 Machine Learning Jan 16, 2015 Optimization Tutorial 1 Basic Gradient Descent Lecture by Harikrishna Narasimhan Note: This tutorial shall assume background in elementary calculus and linear algebra.
1 Conjugate gradients
 Notes for 2016-11-18 1 Conjugate gradients We now turn to the method of conjugate gradients (CG), perhaps the best known of the Krylov subspace solvers. The CG iteration can be characterized as the iteration
Notes for 2016-11-18 1 Conjugate gradients We now turn to the method of conjugate gradients (CG), perhaps the best known of the Krylov subspace solvers. The CG iteration can be characterized as the iteration
IPAM Summer School Optimization methods for machine learning. Jorge Nocedal
 IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
Unconstrained minimization of smooth functions
 Unconstrained minimization of smooth functions We want to solve min x R N f(x), where f is convex. In this section, we will assume that f is differentiable (so its gradient exists at every point), and
Unconstrained minimization of smooth functions We want to solve min x R N f(x), where f is convex. In this section, we will assume that f is differentiable (so its gradient exists at every point), and
Introduction to Unconstrained Optimization: Part 2
 Introduction to Unconstrained Optimization: Part 2 James Allison ME 555 January 29, 2007 Overview Recap Recap selected concepts from last time (with examples) Use of quadratic functions Tests for positive
Introduction to Unconstrained Optimization: Part 2 James Allison ME 555 January 29, 2007 Overview Recap Recap selected concepts from last time (with examples) Use of quadratic functions Tests for positive
Iterative Methods for Solving A x = b
 Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
ORIE 6326: Convex Optimization. Quasi-Newton Methods
 ORIE 6326: Convex Optimization Quasi-Newton Methods Professor Udell Operations Research and Information Engineering Cornell April 10, 2017 Slides on steepest descent and analysis of Newton s method adapted
ORIE 6326: Convex Optimization Quasi-Newton Methods Professor Udell Operations Research and Information Engineering Cornell April 10, 2017 Slides on steepest descent and analysis of Newton s method adapted
the method of steepest descent
 MATH 3511 Spring 2018 the method of steepest descent http://www.phys.uconn.edu/ rozman/courses/m3511_18s/ Last modified: February 6, 2018 Abstract The Steepest Descent is an iterative method for solving
MATH 3511 Spring 2018 the method of steepest descent http://www.phys.uconn.edu/ rozman/courses/m3511_18s/ Last modified: February 6, 2018 Abstract The Steepest Descent is an iterative method for solving
, b = 0. (2) 1 2 The eigenvectors of A corresponding to the eigenvalues λ 1 = 1, λ 2 = 3 are
 1 2 The eigenvectors of A corresponding to the eigenvalues λ 1 = 1, λ 2 = 3 are") Quadratic forms We consider the quadratic function f : R 2 R defined by f(x) = 2 xt Ax b T x with x = (x, x 2 ) T, () where A R 2 2 is symmetric and b R 2. We will see that, depending on the eigenvalues
Quadratic forms We consider the quadratic function f : R 2 R defined by f(x) = 2 xt Ax b T x with x = (x, x 2 ) T, () where A R 2 2 is symmetric and b R 2. We will see that, depending on the eigenvalues
Some minimization problems
 Week 13: Wednesday, Nov 14 Some minimization problems Last time, we sketched the following two-step strategy for approximating the solution to linear systems via Krylov subspaces: 1. Build a sequence of
Week 13: Wednesday, Nov 14 Some minimization problems Last time, we sketched the following two-step strategy for approximating the solution to linear systems via Krylov subspaces: 1. Build a sequence of
Lecture 10: September 26
 0-725: Optimization Fall 202 Lecture 0: September 26 Lecturer: Barnabas Poczos/Ryan Tibshirani Scribes: Yipei Wang, Zhiguang Huo Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
0-725: Optimization Fall 202 Lecture 0: September 26 Lecturer: Barnabas Poczos/Ryan Tibshirani Scribes: Yipei Wang, Zhiguang Huo Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
Convex Optimization. Problem set 2. Due Monday April 26th
 Convex Optimization Problem set 2 Due Monday April 26th 1 Gradient Decent without Line-search In this problem we will consider gradient descent with predetermined step sizes. That is, instead of determining
Convex Optimization Problem set 2 Due Monday April 26th 1 Gradient Decent without Line-search In this problem we will consider gradient descent with predetermined step sizes. That is, instead of determining
Performance Surfaces and Optimum Points
 CSC 302 1.5 Neural Networks Performance Surfaces and Optimum Points 1 Entrance Performance learning is another important class of learning law. Network parameters are adjusted to optimize the performance
CSC 302 1.5 Neural Networks Performance Surfaces and Optimum Points 1 Entrance Performance learning is another important class of learning law. Network parameters are adjusted to optimize the performance
Newton s Method. Javier Peña Convex Optimization /36-725
 Newton s Method Javier Peña Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, f ( (y) = max y T x f(x) ) x Properties and
Newton s Method Javier Peña Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, f ( (y) = max y T x f(x) ) x Properties and
Conjugate Gradient (CG) Method
 Method") Conjugate Gradient (CG) Method by K. Ozawa 1 Introduction In the series of this lecture, I will introduce the conjugate gradient method, which solves efficiently large scale sparse linear simultaneous
Conjugate Gradient (CG) Method by K. Ozawa 1 Introduction In the series of this lecture, I will introduce the conjugate gradient method, which solves efficiently large scale sparse linear simultaneous
14. Nonlinear equations
 L. Vandenberghe ECE133A (Winter 2018) 14. Nonlinear equations Newton method for nonlinear equations damped Newton method for unconstrained minimization Newton method for nonlinear least squares 14-1 Set
L. Vandenberghe ECE133A (Winter 2018) 14. Nonlinear equations Newton method for nonlinear equations damped Newton method for unconstrained minimization Newton method for nonlinear least squares 14-1 Set
Programming, numerics and optimization
 Programming, numerics and optimization Lecture C-3: Unconstrained optimization II Łukasz Jankowski ljank@ippt.pan.pl Institute of Fundamental Technological Research Room 4.32, Phone +22.8261281 ext. 428
Programming, numerics and optimization Lecture C-3: Unconstrained optimization II Łukasz Jankowski ljank@ippt.pan.pl Institute of Fundamental Technological Research Room 4.32, Phone +22.8261281 ext. 428
Mathematical optimization
 Optimization Mathematical optimization Determine the best solutions to certain mathematically defined problems that are under constrained determine optimality criteria determine the convergence of the
Optimization Mathematical optimization Determine the best solutions to certain mathematically defined problems that are under constrained determine optimality criteria determine the convergence of the
10. Unconstrained minimization
 Convex Optimization Boyd & Vandenberghe 10. Unconstrained minimization terminology and assumptions gradient descent method steepest descent method Newton s method self-concordant functions implementation
Convex Optimization Boyd & Vandenberghe 10. Unconstrained minimization terminology and assumptions gradient descent method steepest descent method Newton s method self-concordant functions implementation
ECE580 Exam 1 October 4, Please do not write on the back of the exam pages. Extra paper is available from the instructor.
 ECE580 Exam 1 October 4, 2012 1 Name: Solution Score: /100 You must show ALL of your work for full credit. This exam is closed-book. Calculators may NOT be used. Please leave fractions as fractions, etc.
ECE580 Exam 1 October 4, 2012 1 Name: Solution Score: /100 You must show ALL of your work for full credit. This exam is closed-book. Calculators may NOT be used. Please leave fractions as fractions, etc.
Selected Topics in Optimization. Some slides borrowed from
 Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Math 411 Preliminaries
 Math 411 Preliminaries Provide a list of preliminary vocabulary and concepts Preliminary Basic Netwon s method, Taylor series expansion (for single and multiple variables), Eigenvalue, Eigenvector, Vector
Math 411 Preliminaries Provide a list of preliminary vocabulary and concepts Preliminary Basic Netwon s method, Taylor series expansion (for single and multiple variables), Eigenvalue, Eigenvector, Vector
LINEAR AND NONLINEAR PROGRAMMING
 LINEAR AND NONLINEAR PROGRAMMING Stephen G. Nash and Ariela Sofer George Mason University The McGraw-Hill Companies, Inc. New York St. Louis San Francisco Auckland Bogota Caracas Lisbon London Madrid Mexico
LINEAR AND NONLINEAR PROGRAMMING Stephen G. Nash and Ariela Sofer George Mason University The McGraw-Hill Companies, Inc. New York St. Louis San Francisco Auckland Bogota Caracas Lisbon London Madrid Mexico
Gradient descent. Barnabas Poczos & Ryan Tibshirani Convex Optimization /36-725
 Gradient descent Barnabas Poczos & Ryan Tibshirani Convex Optimization 10-725/36-725 1 Gradient descent First consider unconstrained minimization of f : R n R, convex and differentiable. We want to solve
Gradient descent Barnabas Poczos & Ryan Tibshirani Convex Optimization 10-725/36-725 1 Gradient descent First consider unconstrained minimization of f : R n R, convex and differentiable. We want to solve
The Conjugate Gradient Method
 The Conjugate Gradient Method Lecture 5, Continuous Optimisation Oxford University Computing Laboratory, HT 2006 Notes by Dr Raphael Hauser (hauser@comlab.ox.ac.uk) The notion of complexity (per iteration)
The Conjugate Gradient Method Lecture 5, Continuous Optimisation Oxford University Computing Laboratory, HT 2006 Notes by Dr Raphael Hauser (hauser@comlab.ox.ac.uk) The notion of complexity (per iteration)
Iterative Methods for Smooth Objective Functions
 Optimization Iterative Methods for Smooth Objective Functions Quadratic Objective Functions Stationary Iterative Methods (first/second order) Steepest Descent Method Landweber/Projected Landweber Methods
Optimization Iterative Methods for Smooth Objective Functions Quadratic Objective Functions Stationary Iterative Methods (first/second order) Steepest Descent Method Landweber/Projected Landweber Methods
Newton s Method. Ryan Tibshirani Convex Optimization /36-725
 Newton s Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, Properties and examples: f (y) = max x
Newton s Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, Properties and examples: f (y) = max x
ECE580 Partial Solution to Problem Set 3
 ECE580 Fall 2015 Solution to Problem Set 3 October 23, 2015 1 ECE580 Partial Solution to Problem Set 3 These problems are from the textbook by Chong and Zak, 4th edition, which is the textbook for the
ECE580 Fall 2015 Solution to Problem Set 3 October 23, 2015 1 ECE580 Partial Solution to Problem Set 3 These problems are from the textbook by Chong and Zak, 4th edition, which is the textbook for the
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 21: Sensitivity of Eigenvalues and Eigenvectors; Conjugate Gradient Method Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 21: Sensitivity of Eigenvalues and Eigenvectors; Conjugate Gradient Method Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis
Optimization Methods
 Optimization Methods Decision making Examples: determining which ingredients and in what quantities to add to a mixture being made so that it will meet specifications on its composition allocating available
Optimization Methods Decision making Examples: determining which ingredients and in what quantities to add to a mixture being made so that it will meet specifications on its composition allocating available
ECE 680 Modern Automatic Control. Gradient and Newton s Methods A Review
 ECE 680Modern Automatic Control p. 1/1 ECE 680 Modern Automatic Control Gradient and Newton s Methods A Review Stan Żak October 25, 2011 ECE 680Modern Automatic Control p. 2/1 Review of the Gradient Properties
ECE 680Modern Automatic Control p. 1/1 ECE 680 Modern Automatic Control Gradient and Newton s Methods A Review Stan Żak October 25, 2011 ECE 680Modern Automatic Control p. 2/1 Review of the Gradient Properties
6.4 Krylov Subspaces and Conjugate Gradients
 6.4 Krylov Subspaces and Conjugate Gradients Our original equation is Ax = b. The preconditioned equation is P Ax = P b. When we write P, we never intend that an inverse will be explicitly computed. P
6.4 Krylov Subspaces and Conjugate Gradients Our original equation is Ax = b. The preconditioned equation is P Ax = P b. When we write P, we never intend that an inverse will be explicitly computed. P
Gradient Descent. Ryan Tibshirani Convex Optimization /36-725
 Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Lecture 3: Linesearch methods (continued). Steepest descent methods
. Steepest descent methods") Lecture 3: Linesearch methods (continued). Steepest descent methods Coralia Cartis, Mathematical Institute, University of Oxford C6.2/B2: Continuous Optimization Lecture 3: Linesearch methods (continued).
Lecture 3: Linesearch methods (continued). Steepest descent methods Coralia Cartis, Mathematical Institute, University of Oxford C6.2/B2: Continuous Optimization Lecture 3: Linesearch methods (continued).
Introduction to Optimization
 Introduction to Optimization Gradient-based Methods Marc Toussaint U Stuttgart Gradient descent methods Plain gradient descent (with adaptive stepsize) Steepest descent (w.r.t. a known metric) Conjugate
Introduction to Optimization Gradient-based Methods Marc Toussaint U Stuttgart Gradient descent methods Plain gradient descent (with adaptive stepsize) Steepest descent (w.r.t. a known metric) Conjugate
Optimization. Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison
 Optimization Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison optimization () cost constraints might be too much to cover in 3 hours optimization (for big
Optimization Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison optimization () cost constraints might be too much to cover in 3 hours optimization (for big
Conjugate Gradients: Idea
 Overview Steepest Descent often takes steps in the same direction as earlier steps Wouldn t it be better every time we take a step to get it exactly right the first time? Again, in general we choose a
Overview Steepest Descent often takes steps in the same direction as earlier steps Wouldn t it be better every time we take a step to get it exactly right the first time? Again, in general we choose a
Improving the Convergence of Back-Propogation Learning with Second Order Methods
 the of Back-Propogation Learning with Second Order Methods Sue Becker and Yann le Cun, Sept 1988 Kasey Bray, October 2017 Table of Contents 1 with Back-Propagation 2 the of BP 3 A Computationally Feasible
the of Back-Propogation Learning with Second Order Methods Sue Becker and Yann le Cun, Sept 1988 Kasey Bray, October 2017 Table of Contents 1 with Back-Propagation 2 the of BP 3 A Computationally Feasible
The Method of Conjugate Directions 21
 The Method of Conjugate Directions 1 + 1 i : 7. The Method of Conjugate Directions 7.1. Conjugacy Steepest Descent often finds itself taking steps in the same direction as earlier steps (see Figure 8).
The Method of Conjugate Directions 1 + 1 i : 7. The Method of Conjugate Directions 7.1. Conjugacy Steepest Descent often finds itself taking steps in the same direction as earlier steps (see Figure 8).
OPER 627: Nonlinear Optimization Lecture 14: Mid-term Review
 OPER 627: Nonlinear Optimization Lecture 14: Mid-term Review Department of Statistical Sciences and Operations Research Virginia Commonwealth University Oct 16, 2013 (Lecture 14) Nonlinear Optimization
OPER 627: Nonlinear Optimization Lecture 14: Mid-term Review Department of Statistical Sciences and Operations Research Virginia Commonwealth University Oct 16, 2013 (Lecture 14) Nonlinear Optimization
Course Notes: Week 1
 Course Notes: Week 1 Math 270C: Applied Numerical Linear Algebra 1 Lecture 1: Introduction (3/28/11) We will focus on iterative methods for solving linear systems of equations (and some discussion of eigenvalues
Course Notes: Week 1 Math 270C: Applied Numerical Linear Algebra 1 Lecture 1: Introduction (3/28/11) We will focus on iterative methods for solving linear systems of equations (and some discussion of eigenvalues
CPSC 540: Machine Learning
 CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
Matrix Derivatives and Descent Optimization Methods
 Matrix Derivatives and Descent Optimization Methods 1 Qiang Ning Department of Electrical and Computer Engineering Beckman Institute for Advanced Science and Techonology University of Illinois at Urbana-Champaign
Matrix Derivatives and Descent Optimization Methods 1 Qiang Ning Department of Electrical and Computer Engineering Beckman Institute for Advanced Science and Techonology University of Illinois at Urbana-Champaign
Truncated Newton Method
 Truncated Newton Method approximate Newton methods truncated Newton methods truncated Newton interior-point methods EE364b, Stanford University minimize convex f : R n R Newton s method Newton step x nt
Truncated Newton Method approximate Newton methods truncated Newton methods truncated Newton interior-point methods EE364b, Stanford University minimize convex f : R n R Newton s method Newton step x nt
8 Numerical methods for unconstrained problems
 8 Numerical methods for unconstrained problems Optimization is one of the important fields in numerical computation, beside solving differential equations and linear systems. We can see that these fields
8 Numerical methods for unconstrained problems Optimization is one of the important fields in numerical computation, beside solving differential equations and linear systems. We can see that these fields
Lecture 5: September 15
 10-725/36-725: Convex Optimization Fall 2015 Lecture 5: September 15 Lecturer: Lecturer: Ryan Tibshirani Scribes: Scribes: Di Jin, Mengdi Wang, Bin Deng Note: LaTeX template courtesy of UC Berkeley EECS
10-725/36-725: Convex Optimization Fall 2015 Lecture 5: September 15 Lecturer: Lecturer: Ryan Tibshirani Scribes: Scribes: Di Jin, Mengdi Wang, Bin Deng Note: LaTeX template courtesy of UC Berkeley EECS
Numerical Optimization
 Numerical Optimization Emo Todorov Applied Mathematics and Computer Science & Engineering University of Washington Spring 2010 Emo Todorov (UW) AMATH/CSE 579, Spring 2010 Lecture 9 1 / 8 Gradient descent
Numerical Optimization Emo Todorov Applied Mathematics and Computer Science & Engineering University of Washington Spring 2010 Emo Todorov (UW) AMATH/CSE 579, Spring 2010 Lecture 9 1 / 8 Gradient descent
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 20 1 / 20 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 20 1 / 20 Overview
Lecture 9: Krylov Subspace Methods. 2 Derivation of the Conjugate Gradient Algorithm
 CS 622 Data-Sparse Matrix Computations September 19, 217 Lecture 9: Krylov Subspace Methods Lecturer: Anil Damle Scribes: David Eriksson, Marc Aurele Gilles, Ariah Klages-Mundt, Sophia Novitzky 1 Introduction
CS 622 Data-Sparse Matrix Computations September 19, 217 Lecture 9: Krylov Subspace Methods Lecturer: Anil Damle Scribes: David Eriksson, Marc Aurele Gilles, Ariah Klages-Mundt, Sophia Novitzky 1 Introduction
Penalty and Barrier Methods. So we again build on our unconstrained algorithms, but in a different way.
 AMSC 607 / CMSC 878o Advanced Numerical Optimization Fall 2008 UNIT 3: Constrained Optimization PART 3: Penalty and Barrier Methods Dianne P. O Leary c 2008 Reference: N&S Chapter 16 Penalty and Barrier
AMSC 607 / CMSC 878o Advanced Numerical Optimization Fall 2008 UNIT 3: Constrained Optimization PART 3: Penalty and Barrier Methods Dianne P. O Leary c 2008 Reference: N&S Chapter 16 Penalty and Barrier
Nonlinear Optimization: What s important?
 Nonlinear Optimization: What s important? Julian Hall 10th May 2012 Convexity: convex problems A local minimizer is a global minimizer A solution of f (x) = 0 (stationary point) is a minimizer A global
Nonlinear Optimization: What s important? Julian Hall 10th May 2012 Convexity: convex problems A local minimizer is a global minimizer A solution of f (x) = 0 (stationary point) is a minimizer A global
4 Newton Method. Unconstrained Convex Optimization 21. H(x)p = f(x). Newton direction. Why? Recall second-order staylor series expansion:
p = f(x). Newton direction. Why? Recall second-order staylor series expansion:") Unconstrained Convex Optimization 21 4 Newton Method H(x)p = f(x). Newton direction. Why? Recall second-order staylor series expansion: f(x + p) f(x)+p T f(x)+ 1 2 pt H(x)p ˆf(p) In general, ˆf(p) won
Unconstrained Convex Optimization 21 4 Newton Method H(x)p = f(x). Newton direction. Why? Recall second-order staylor series expansion: f(x + p) f(x)+p T f(x)+ 1 2 pt H(x)p ˆf(p) In general, ˆf(p) won
Unconstrained optimization
 Chapter 4 Unconstrained optimization An unconstrained optimization problem takes the form min x Rnf(x) (4.1) for a target functional (also called objective function) f : R n R. In this chapter and throughout
Chapter 4 Unconstrained optimization An unconstrained optimization problem takes the form min x Rnf(x) (4.1) for a target functional (also called objective function) f : R n R. In this chapter and throughout
Lecture Notes: Geometric Considerations in Unconstrained Optimization
 Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
Gradient Descent. Lecturer: Pradeep Ravikumar Co-instructor: Aarti Singh. Convex Optimization /36-725
 Gradient Descent Lecturer: Pradeep Ravikumar Co-instructor: Aarti Singh Convex Optimization 10-725/36-725 Based on slides from Vandenberghe, Tibshirani Gradient Descent Consider unconstrained, smooth convex
Gradient Descent Lecturer: Pradeep Ravikumar Co-instructor: Aarti Singh Convex Optimization 10-725/36-725 Based on slides from Vandenberghe, Tibshirani Gradient Descent Consider unconstrained, smooth convex
5 Quasi-Newton Methods
 Unconstrained Convex Optimization 26 5 Quasi-Newton Methods If the Hessian is unavailable... Notation: H = Hessian matrix. B is the approximation of H. C is the approximation of H 1. Problem: Solve min
Unconstrained Convex Optimization 26 5 Quasi-Newton Methods If the Hessian is unavailable... Notation: H = Hessian matrix. B is the approximation of H. C is the approximation of H 1. Problem: Solve min
Iterative methods for Linear System of Equations. Joint Advanced Student School (JASS-2009)
") Iterative methods for Linear System of Equations Joint Advanced Student School (JASS-2009) Course #2: Numerical Simulation - from Models to Software Introduction In numerical simulation, Partial Differential
Iterative methods for Linear System of Equations Joint Advanced Student School (JASS-2009) Course #2: Numerical Simulation - from Models to Software Introduction In numerical simulation, Partial Differential
min f(x). (2.1) Objectives consisting of a smooth convex term plus a nonconvex regularization term;
. (2.1) Objectives consisting of a smooth convex term plus a nonconvex regularization term;") Chapter 2 Gradient Methods The gradient method forms the foundation of all of the schemes studied in this book. We will provide several complementary perspectives on this algorithm that highlight the many
Chapter 2 Gradient Methods The gradient method forms the foundation of all of the schemes studied in this book. We will provide several complementary perspectives on this algorithm that highlight the many
Numerical Optimization
 Numerical Optimization Unit 2: Multivariable optimization problems Che-Rung Lee Scribe: February 28, 2011 (UNIT 2) Numerical Optimization February 28, 2011 1 / 17 Partial derivative of a two variable function
Numerical Optimization Unit 2: Multivariable optimization problems Che-Rung Lee Scribe: February 28, 2011 (UNIT 2) Numerical Optimization February 28, 2011 1 / 17 Partial derivative of a two variable function
Lecture 14: Newton s Method
 10-725/36-725: Conve Optimization Fall 2016 Lecturer: Javier Pena Lecture 14: Newton s ethod Scribes: Varun Joshi, Xuan Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These notes
10-725/36-725: Conve Optimization Fall 2016 Lecturer: Javier Pena Lecture 14: Newton s ethod Scribes: Varun Joshi, Xuan Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These notes
Line Search Methods for Unconstrained Optimisation
 Line Search Methods for Unconstrained Optimisation Lecture 8, Numerical Linear Algebra and Optimisation Oxford University Computing Laboratory, MT 2007 Dr Raphael Hauser (hauser@comlab.ox.ac.uk) The Generic
Line Search Methods for Unconstrained Optimisation Lecture 8, Numerical Linear Algebra and Optimisation Oxford University Computing Laboratory, MT 2007 Dr Raphael Hauser (hauser@comlab.ox.ac.uk) The Generic
Iterative methods for Linear System
 Iterative methods for Linear System JASS 2009 Student: Rishi Patil Advisor: Prof. Thomas Huckle Outline Basics: Matrices and their properties Eigenvalues, Condition Number Iterative Methods Direct and
Iterative methods for Linear System JASS 2009 Student: Rishi Patil Advisor: Prof. Thomas Huckle Outline Basics: Matrices and their properties Eigenvalues, Condition Number Iterative Methods Direct and
Linear Solvers. Andrew Hazel
 Linear Solvers Andrew Hazel Introduction Thus far we have talked about the formulation and discretisation of physical problems...... and stopped when we got to a discrete linear system of equations. Introduction
Linear Solvers Andrew Hazel Introduction Thus far we have talked about the formulation and discretisation of physical problems...... and stopped when we got to a discrete linear system of equations. Introduction
NonlinearOptimization
 1/35 NonlinearOptimization Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Jiří Kašpar, Pavel Tvrdík, 2011 Unconstrained nonlinear optimization,
1/35 NonlinearOptimization Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Jiří Kašpar, Pavel Tvrdík, 2011 Unconstrained nonlinear optimization,
Introduction to unconstrained optimization - direct search methods
 Introduction to unconstrained optimization - direct search methods Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi Structure of optimization methods Typically Constraint handling converts the
Introduction to unconstrained optimization - direct search methods Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi Structure of optimization methods Typically Constraint handling converts the
2. Quasi-Newton methods
 L. Vandenberghe EE236C (Spring 2016) 2. Quasi-Newton methods variable metric methods quasi-newton methods BFGS update limited-memory quasi-newton methods 2-1 Newton method for unconstrained minimization
L. Vandenberghe EE236C (Spring 2016) 2. Quasi-Newton methods variable metric methods quasi-newton methods BFGS update limited-memory quasi-newton methods 2-1 Newton method for unconstrained minimization
Part 5: Penalty and augmented Lagrangian methods for equality constrained optimization. Nick Gould (RAL)
") Part 5: Penalty and augmented Lagrangian methods for equality constrained optimization Nick Gould (RAL) x IR n f(x) subject to c(x) = Part C course on continuoue optimization CONSTRAINED MINIMIZATION x
Part 5: Penalty and augmented Lagrangian methods for equality constrained optimization Nick Gould (RAL) x IR n f(x) subject to c(x) = Part C course on continuoue optimization CONSTRAINED MINIMIZATION x
CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares
 CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares Robert Bridson October 29, 2008 1 Hessian Problems in Newton Last time we fixed one of plain Newton s problems by introducing line search
CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares Robert Bridson October 29, 2008 1 Hessian Problems in Newton Last time we fixed one of plain Newton s problems by introducing line search
M.A. Botchev. September 5, 2014
 Rome-Moscow school of Matrix Methods and Applied Linear Algebra 2014 A short introduction to Krylov subspaces for linear systems, matrix functions and inexact Newton methods. Plan and exercises. M.A. Botchev
Rome-Moscow school of Matrix Methods and Applied Linear Algebra 2014 A short introduction to Krylov subspaces for linear systems, matrix functions and inexact Newton methods. Plan and exercises. M.A. Botchev
University of Maryland at College Park. limited amount of computer memory, thereby allowing problems with a very large number
 Limited-Memory Matrix Methods with Applications 1 Tamara Gibson Kolda 2 Applied Mathematics Program University of Maryland at College Park Abstract. The focus of this dissertation is on matrix decompositions
Limited-Memory Matrix Methods with Applications 1 Tamara Gibson Kolda 2 Applied Mathematics Program University of Maryland at College Park Abstract. The focus of this dissertation is on matrix decompositions
Design and Analysis of Algorithms Lecture Notes on Convex Optimization CS 6820, Fall Nov 2 Dec 2016
 Design and Analysis of Algorithms Lecture Notes on Convex Optimization CS 6820, Fall 206 2 Nov 2 Dec 206 Let D be a convex subset of R n. A function f : D R is convex if it satisfies f(tx + ( t)y) tf(x)
Design and Analysis of Algorithms Lecture Notes on Convex Optimization CS 6820, Fall 206 2 Nov 2 Dec 206 Let D be a convex subset of R n. A function f : D R is convex if it satisfies f(tx + ( t)y) tf(x)
Jordan Journal of Mathematics and Statistics (JJMS) 5(3), 2012, pp A NEW ITERATIVE METHOD FOR SOLVING LINEAR SYSTEMS OF EQUATIONS
 5(3), 2012, pp A NEW ITERATIVE METHOD FOR SOLVING LINEAR SYSTEMS OF EQUATIONS") Jordan Journal of Mathematics and Statistics JJMS) 53), 2012, pp.169-184 A NEW ITERATIVE METHOD FOR SOLVING LINEAR SYSTEMS OF EQUATIONS ADEL H. AL-RABTAH Abstract. The Jacobi and Gauss-Seidel iterative
Jordan Journal of Mathematics and Statistics JJMS) 53), 2012, pp.169-184 A NEW ITERATIVE METHOD FOR SOLVING LINEAR SYSTEMS OF EQUATIONS ADEL H. AL-RABTAH Abstract. The Jacobi and Gauss-Seidel iterative
Higher-Order Methods
 Higher-Order Methods Stephen J. Wright 1 2 Computer Sciences Department, University of Wisconsin-Madison. PCMI, July 2016 Stephen Wright (UW-Madison) Higher-Order Methods PCMI, July 2016 1 / 25 Smooth
Higher-Order Methods Stephen J. Wright 1 2 Computer Sciences Department, University of Wisconsin-Madison. PCMI, July 2016 Stephen Wright (UW-Madison) Higher-Order Methods PCMI, July 2016 1 / 25 Smooth
6.252 NONLINEAR PROGRAMMING LECTURE 10 ALTERNATIVES TO GRADIENT PROJECTION LECTURE OUTLINE. Three Alternatives/Remedies for Gradient Projection
 6.252 NONLINEAR PROGRAMMING LECTURE 10 ALTERNATIVES TO GRADIENT PROJECTION LECTURE OUTLINE Three Alternatives/Remedies for Gradient Projection Two-Metric Projection Methods Manifold Suboptimization Methods
6.252 NONLINEAR PROGRAMMING LECTURE 10 ALTERNATIVES TO GRADIENT PROJECTION LECTURE OUTLINE Three Alternatives/Remedies for Gradient Projection Two-Metric Projection Methods Manifold Suboptimization Methods
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Report due date. Please note: report has to be handed in by Monday, May 16 noon.
 Lecture 23 18.86 Report due date Please note: report has to be handed in by Monday, May 16 noon. Course evaluation: Please submit your feedback (you should have gotten an email) From the weak form to finite
Lecture 23 18.86 Report due date Please note: report has to be handed in by Monday, May 16 noon. Course evaluation: Please submit your feedback (you should have gotten an email) From the weak form to finite
Constrained Optimization
 1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange
1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange
1 Introduction
 2018-06-12 1 Introduction The title of this course is Numerical Methods for Data Science. What does that mean? Before we dive into the course technical material, let s put things into context. I will not
2018-06-12 1 Introduction The title of this course is Numerical Methods for Data Science. What does that mean? Before we dive into the course technical material, let s put things into context. I will not
ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints
 ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints Instructor: Prof. Kevin Ross Scribe: Nitish John October 18, 2011 1 The Basic Goal The main idea is to transform a given constrained
ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints Instructor: Prof. Kevin Ross Scribe: Nitish John October 18, 2011 1 The Basic Goal The main idea is to transform a given constrained
Determination of Feasible Directions by Successive Quadratic Programming and Zoutendijk Algorithms: A Comparative Study
 International Journal of Mathematics And Its Applications Vol.2 No.4 (2014), pp.47-56. ISSN: 2347-1557(online) Determination of Feasible Directions by Successive Quadratic Programming and Zoutendijk Algorithms:
International Journal of Mathematics And Its Applications Vol.2 No.4 (2014), pp.47-56. ISSN: 2347-1557(online) Determination of Feasible Directions by Successive Quadratic Programming and Zoutendijk Algorithms:
Convex Optimization. Prof. Nati Srebro. Lecture 12: Infeasible-Start Newton s Method Interior Point Methods
 Convex Optimization Prof. Nati Srebro Lecture 12: Infeasible-Start Newton s Method Interior Point Methods Equality Constrained Optimization f 0 (x) s. t. A R p n, b R p Using access to: 2 nd order oracle
Convex Optimization Prof. Nati Srebro Lecture 12: Infeasible-Start Newton s Method Interior Point Methods Equality Constrained Optimization f 0 (x) s. t. A R p n, b R p Using access to: 2 nd order oracle
Linear Algebraic Equations
 Linear Algebraic Equations 1 Fundamentals Consider the set of linear algebraic equations n a ij x i b i represented by Ax b j with [A b ] [A b] and (1a) r(a) rank of A (1b) Then Axb has a solution iff
Linear Algebraic Equations 1 Fundamentals Consider the set of linear algebraic equations n a ij x i b i represented by Ax b j with [A b ] [A b] and (1a) r(a) rank of A (1b) Then Axb has a solution iff
Methods that avoid calculating the Hessian. Nonlinear Optimization; Steepest Descent, Quasi-Newton. Steepest Descent
 Nonlinear Optimization Steepest Descent and Niclas Börlin Department of Computing Science Umeå University niclas.borlin@cs.umu.se A disadvantage with the Newton method is that the Hessian has to be derived
Nonlinear Optimization Steepest Descent and Niclas Börlin Department of Computing Science Umeå University niclas.borlin@cs.umu.se A disadvantage with the Newton method is that the Hessian has to be derived
Nonlinear equations and optimization
 Notes for 2017-03-29 Nonlinear equations and optimization For the next month or so, we will be discussing methods for solving nonlinear systems of equations and multivariate optimization problems. We will
Notes for 2017-03-29 Nonlinear equations and optimization For the next month or so, we will be discussing methods for solving nonlinear systems of equations and multivariate optimization problems. We will
ECE580 Exam 2 November 01, Name: Score: / (20 points) You are given a two data sets
 You are given a two data sets") ECE580 Exam 2 November 01, 2011 1 Name: Score: /100 You must show ALL of your work for full credit. This exam is closed-book. Calculators may NOT be used. Please leave fractions as fractions, etc. I do
ECE580 Exam 2 November 01, 2011 1 Name: Score: /100 You must show ALL of your work for full credit. This exam is closed-book. Calculators may NOT be used. Please leave fractions as fractions, etc. I do
Convex Optimization. Newton s method. ENSAE: Optimisation 1/44
 Convex Optimization Newton s method ENSAE: Optimisation 1/44 Unconstrained minimization minimize f(x) f convex, twice continuously differentiable (hence dom f open) we assume optimal value p = inf x f(x)
Convex Optimization Newton s method ENSAE: Optimisation 1/44 Unconstrained minimization minimize f(x) f convex, twice continuously differentiable (hence dom f open) we assume optimal value p = inf x f(x)
Lecture 15 Newton Method and Self-Concordance. October 23, 2008
 Newton Method and Self-Concordance October 23, 2008 Outline Lecture 15 Self-concordance Notion Self-concordant Functions Operations Preserving Self-concordance Properties of Self-concordant Functions Implications
Newton Method and Self-Concordance October 23, 2008 Outline Lecture 15 Self-concordance Notion Self-concordant Functions Operations Preserving Self-concordance Properties of Self-concordant Functions Implications
MATHEMATICS FOR COMPUTER VISION WEEK 8 OPTIMISATION PART 2. Dr Fabio Cuzzolin MSc in Computer Vision Oxford Brookes University Year
 MATHEMATICS FOR COMPUTER VISION WEEK 8 OPTIMISATION PART 2 1 Dr Fabio Cuzzolin MSc in Computer Vision Oxford Brookes University Year 2013-14 OUTLINE OF WEEK 8 topics: quadratic optimisation, least squares,
MATHEMATICS FOR COMPUTER VISION WEEK 8 OPTIMISATION PART 2 1 Dr Fabio Cuzzolin MSc in Computer Vision Oxford Brookes University Year 2013-14 OUTLINE OF WEEK 8 topics: quadratic optimisation, least squares,
Trajectory-based optimization
 Trajectory-based optimization Emo Todorov Applied Mathematics and Computer Science & Engineering University of Washington Winter 2012 Emo Todorov (UW) AMATH/CSE 579, Winter 2012 Lecture 6 1 / 13 Using
Trajectory-based optimization Emo Todorov Applied Mathematics and Computer Science & Engineering University of Washington Winter 2012 Emo Todorov (UW) AMATH/CSE 579, Winter 2012 Lecture 6 1 / 13 Using