Machine Learning A Geometric Approach
|
|
|
- Muriel Walton
- 5 years ago
- Views:
Transcription
1 Machine Learning A Geometric Approach CIML book Chap 7.7 Linear Classification: Support Vector Machines (SVM) Professor Liang Huang some slides from Alex Smola (CMU)
2 Linear Separator Ham Spam
3 From Perceptron to SVM 1959 osenblatt invention +max margin batch online 1962 Novikoff proof +kernels 1964 Vapnik Chervonenkis +soft-margin fall of USSR conservative updates inseparable case 1997 Cortes/Vapnik SVM online approx. max margin 1999 Freund/Schapire voted/avg: revived subgradient descent 2003 Crammer/Singer MIRA minibatch * Singer group Pegasos 2006 Singer group aggressive *mentioned in lectures but optional (others papers all covered in detail) AT&T Research 2002 Collins structured 2005* McDonald/Crammer/Pereira structured MIRA ex-at&t and students 3
4 Large Margin Classifier hw, xi + b apple 1 hw, xi + b 1 linear function f(x) =hw, xi + b
5 Large Margin Classifier hw, xi + b apple 1 hw, xi + b 1 linear function f(x) =hw, xi + b
6 Why large margins? Maximum o robustness relative o o r + to uncertainty Symmetry breaking Independent of o ρ + + correctly classified instances Easy to find for + easy problems


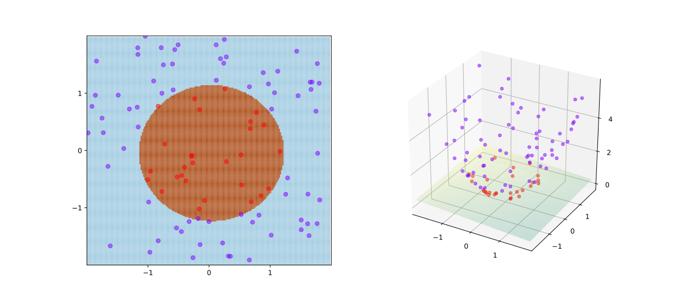
7 Feature Map Φ SVM is often used with kernels
8 Large Margin Classifier hw, xi + b apple 1 hw, xi + b = 1 hw, xi + b =1 hw, xi + b 1 w functional margin: y i (w x i ) geometric margin: y i (w x i ) kwk = 1 kwk
9 Large Margin Classifier Q1: what if we want functional margin of 2? Q2: what if we want geometric margin of 1? hw, xi + b apple 1 hw, xi + b = 1 hw, xi + b =1 hw, xi + b 1 w SVM objective (max version): max w 1 kwk s.t. 8(x,y) 2 D, y(w x) 1 max. geometric margin s.t. functional margin is at least 1
10 Large Margin Classifier hw, xi + b apple 1 hw, xi + b = 1 hw, xi + b =1 hw, xi + b 1 w SVM objective (min version): min w kwk s.t. 8(x,y) 2 D, y(w x) 1 interpretation: small models generalize better min. weight vector s.t. functional margin is at least 1
11 Large Margin Classifier hw, xi + b apple 1 hw, xi + b = 1 hw, xi + b =1 hw, xi + b 1 w SVM objective (min version): min w 1 2 kwk2 s.t. 8(x,y) 2 D, y(w x) 1 w not differentiable, w 2 is. min. weight vector s.t. functional margin is at least 1
12 SVM vs. MIRA SVM: min weight vector to enforce functional margin of at least 1 on ALL EXAMPLES MIRA: min weight change to enforce functional margin of at least 1 on THIS EXAMPLE MIRA is 1-step or online approximation of SVM Aggressive MIRA SVM as p 1 min w 1 2 kwk2 s.t. 8(x,y) 2 D, y(w x) 1 min kw 0 wk 2 w 0 s.t. w 0 x 1 perceptron w MIRA x i
13 Convex Hull Interpretation max. distance between convex hulls how many support vectors in 2D? weight vector is determined by the support vectors alone X c.f. perceptron: w = what about MIRA? (x,y)2errors y x why don t use convex hulls for SVMs in practice??

14 Convexity and Convex Hulls convex combination
 2 D, y(w x) 1 constraint Convex")

15 Optimization Primal optimization problem 1 min w 2 kwk2 s.t. 8(x,y) 2 D, y(w x) 1 constraint Convex optimization: convex function over convex set! Quadratic prog.: quadratic function w/ linear constraints linear quadratic
16 MIRA as QP MIRA is a trivial QP; can be solved geometrically what about multiple constraints (e.g. minibatch)? min kw 0 wk 2 w 0 s.t. w 0 x 1 kx i k w i x i 1 kx i k x i MIRA w i kx i k 1 w i x i
17 Optimization Primal optimization problem 1 min w 2 kwk2 s.t. 8(x,y) 2 D, y(w x) 1 Convex optimization: convex function over convex set! Lagrange function L(w, b, ) = 1 2 kwk2 X Derivatives in w need to w L(w, b, αa) b L(w, b, a) w = X i i X i y i y i x=0 i i [y i [hx i,wi + b] 1] i y i x i =0 constraint model is a linear combo of a small subset of input (the support vectors) i.e., those with α i > 0




18 Lagrangian & Saddle Point equality: min x 2 s.t. x = 1 inequality: min x 2 s.t. x >= 1 Lagrangian: L(x, α)=x 2 - α(x-1) derivative in x need to vanish optimality is at saddle point with α x min x in primal => max α in dual α
19 Constrained Optimization minimize w,b 1 Quadratic Programming Quadratic Objective Linear Constraints 2 kwk2 subject to y i [hx i,wi + b] 1 Karush Kuhn Tucker w = X i constraint y i i x i KKT condition (complementary slackness) optimal point is achieved at active constraints where α i > 0 (α i =0 => inactive) i [y i [hw, x i i + b] 1] = 0
20 KKT => Support Vectors minimize w,b 1 2 kwk2 subject to y i [hx i,wi + b] 1 w = X i y i i x i w Karush Kuhn Tucker (KKT) Optimality Condition i [y i [hw, x i i + b] 1] = 0 i =0 i > 0=) y i [hw, x i i + b] =1
21 Properties w = X i y i i x i w Weight vector w as weighted linear combination of instances Only points on margin matter (ignore the rest and get same solution) Only inner products matter Quadratic program We can replace the inner product by a kernel Keeps instances away from the margin
22 Alternative: Primal=>Dual Lagrange function L(w, b, ) = 1 2 kwk2 X i [y i [hx i,wi + b] 1] Derivatives in w need to vanish w L(w, b, a) =w i X i i y i x i =0 b L(w, b, a) w = i y i y i x=0 i Plugging w back into L yields maximize 1 2 X i,j i j y i y j hx i,x j i + X i i dual variables subject to X i y i = 0 and i 0
23 Primal vs. Dual Primal minimize w,b 1 2 kwk2 subject to y i [hx i,wi + b] 1 w = X i y i i x i w Dual maximize 1 2 X i,j i j y i y j hx i,x j i + X i i subject to X i y i = 0 and i 0 dual variables
24 Solving the optimization problem Dual problem maximize 1 2 X i,j i j y i y j hx i,x j i + X i i subject to X i i y i = 0 and i 0 dual variables If problem is small enough (1000s of variables) we can use off-the-shelf solver (CVXOPT, CPLEX, OOQP, LOQO) For larger problem use fact that only SVs matter and solve in blocks (active set method).
25 Quadratic Program in Dual Dual problem maximize 1 subject to 0 2 T Q T b Q: what s the Q in SVM primal? how about Q in SVM dual? Methods Gradient Descent Coordinate Descent aka., Hildreth Algorithm Sequential Minimal Optimization (SMO) Quadratic Programming Objective: Quadratic function Q is positive semidefinite Constraints: Linear functions



26 Convex QP if Q is positive (semi) definite, i.e., x T Qx 0 for all x, then convex QP => local min/max is global min/max if Q = 0, it reduces to linear programming if Q is indefinite => saddlepoint CP general QP is NP-hard; convex QP is polynomial-time svm LP QP
27 QP: Hildreth Algorithm idea 1: update one coordinate while fixing all other coordinates e.g., update coordinate i is to solve: 1 argmax 2 T Q T b i subject to 0 Quadratic function with only one variable Maximum => first-order derivative is 0
28 QP: Hildreth Algorithm idea 2: choose another coordinate and repeat until meet stopping criterion reach maximum or increase between 2 consecutive iterations is very small or after some # of iterations how to choose coordinate: sweep pattern Sequential: 1, 2,..., n, 1, 2,..., n,... 1, 2,..., n, n-1, n-2,...,1, 2,... Random: permutation of 1,2,..., n Maximal Descent choose i with maximal descent in objective
29 QP: Hildreth Algorithm initialize i =0 for all i repeat pick i following sweep pattern solve i 1 argmax 2 T Q T b i subject to 0 until meet stopping criterion

30 QP: Hildreth Algorithm maximize 1 2 T T 6 4 subject to 0 choose coordinates 1, 2, 1, 2,...
31 QP: Hildreth Algorithm pros: extremely simple no gradient calculation easy to implement cons: converges slow, compared to other methods can t deal with too many constraints works for minibatch MIRA but not SVM
32 Linear Separator Ham Spam
33 Large Margin Classifier hw, xi + b apple 1 hw, xi + b linear function f(x) =hw, xi + b linear separator is impossible
34 Large Margin Classifier hw, xi + b apple 1 hw, xi + b 1 + minimum error separator Theorem (Minsky & Papert) is impossible Finding the minimum error separating hyperplane is NP hard
35 Adding slack variables hw, xi + b apple 1+ hw, xi + b minimize amount Convex optimization problem of slack
36 margin violation vs. misclassification misclassification is also margin violation (ξ>0)
![Adding slack variables Hard margin problem minimize w,b 1 2 kwk2 subject to y i [hw, x i i + b] 1 With slack variables w determines ξ 1 minimize w,b 2 kwk2 + C X i ξ i subject](/docs-images/85/92790214/images/37-0.jpg "to y i [hw, x i i + b] 1 i and i 0 Problem is always feasible. Proof: w = 0 and b = 0 and i =1 C=0? C=+?")
37 Adding slack variables Hard margin problem minimize w,b 1 2 kwk2 subject to y i [hw, x i i + b] 1 With slack variables w determines ξ 1 minimize w,b 2 kwk2 + C X i ξ i subject to y i [hw, x i i + b] 1 i and i 0 Problem is always feasible. Proof: w = 0 and b = 0 and i =1 C=0? C=+? (also yields upper bound) C=+ => not tolerant on violation => hard margin
38 Review: Convex Optimization Primal optimization problem minimize x f(x) subjecttoc i (x) apple 0 Lagrange function L(x, ) =f(x)+ X i i c i (x) First order optimality conditions in x L(x, ) =@ x f(x)+ X i x c i (x) =0 Solve for x and plug it back into L maximize (keep explicit constraints) L(x( ), )
39 Dual Problem Primal optimization problem 1 minimize w,b 2 kwk2 + C X i ξ i subject to y i [hw, x i i + b] 1 i and i 0 Lagrange function L(w, b, ) = 1 2 kwk2 + C X ξ,,η) i i X i [y i [hx i,wi + b]+ i 1] X i i i i optimality in (w, ξ) is at saddle point with α,η Derivatives in (w, ξ) need to vanish
40 Dual Problem Lagrange function L(w, b, ) = 1 2 kwk2 + C X ξ,,η) i Derivatives in w need to vanish w L(w, b,,, ) =w X i [y i [hx i,wi + b]+ i 1] i X i i y i x i =0 X i i b L(w, b,,, ) = X i i y i i L(w, b,,, ) =C i i =0 Plugging terms back into L yields maximize subject to X i 1 2 X i,j i j y i y j hx i,x j i + X i i y i = 0 and i 2 [0,C] dual variables i bound influence
41 Karush Kuhn Tucker Conditions L(w, b, ) = 1 2 kwk2 + C X ξ,,η) i i X i [y i [hx i,wi + b]+ i 1] X i i i i w = X i y i i x i α=c α=0 0<α<C 0<α<C w α=0 i [y i [hw, x i i + b]+ i 1] = 0 i i =0 0 apple i = C i apple C α=c i =0=) y i [hw, x i i + b] 1 0 < i <C=) y i [hw, x i i + b] =1 i = C =) y i [hw, x i i + b] apple 1 why these are not disjoint?
42 Support Vectors and Violations all circled and squared examples are support vectors (α>0) they include ξ=0 (hard-margin SVs), ξ>0 (margin violations), and ξ>1 (misclassifications)
43 Support Vectors and Violations non-support vectors (α=0, ξ=0) (0<α C, ξ 0) support vectors (α=c, ξ>0) margin violations α=c (α=c, ξ>1) misclassifications all circled and squared examples are support vectors (α>0) they include ξ=0 (hard-margin SVs), ξ>0 (margin violations), and ξ>1 (misclassifications)
44 SVM with sklearn python demo.py 1e10 python demo.py 1e10

45 SVM with sklearn python demo.py 0.1 python demo.py 0.01
46 SVM with sklearn + + In [2]: clf = svm.svc(kernel='linear', C=1e10) In [3]: X = [[1,1], [1,-1], [-1,1], [-1,-1]] In [4]: Y = [1,1,-1,-1] In [5]: clf.fit(x, Y) In [6]: clf.support_ Out[6]: array([3, 1], dtype=int32) In [7]: clf.dual_coef_ Out[7]: array([[-0.5, 0.5]]) In [8]: clf.coef_ Out[8]: array([[ 1., 0.]]) In [9]: clf.intercept_ Out[9]: array([-0.]) In [10]: clf.support_vectors_ Out[10]: array([[-1., -1.], [ 1., -1.]]) In [11]: clf.n_support_ Out[11]: array([1, 1], dtype=int32) In [2]: X = [[1,1], [1,-1], [-1,1], [-1,-1], [-0.1,-0.1]] In [3]: Y = [1,1,-1,-1, 1] In [4]: clf = svm.svc(kernel='linear', C=1) In [5]: clf.fit(x, Y) In [6]: clf.support_vectors_ Out[6]: array([[-1., 1. ], [-1., -1. ], [ 1., -1. ], [-0.1, -0.1]]) In [7]: clf.dual_coef_ α=c Out[7]: array([[-0.45, -0.6, 0.05, 1. ]]) In [8]: clf.coef_ Out[8]: array([[ e+00, e-09]]) In [9]: clf.intercept_ Out[9]: array([-0.]) + α=c + +
47 SVM with sklearn + + In [2]: X = [[1,1], [1,-1], [-1,1], [-1,-1], [-0.1,-0.1]] In [3]: Y = [1,1,-1,-1, 1] In [12]: clf = svm.svc(kernel='linear', C=1e10) In [13]: clf.fit(x, Y) In [14]: clf.coef_ Out[14]: array([[ e+00, e-04]]) In [15]: clf.intercept_ Out[15]: array([ ]) In [16]: clf.support_vectors_ Out[16]: array([[-1., 1. ], [-1., -1. ], [-0.01, -0.01]]) In [17]: clf.dual_coef_ Out[17]: array([[ , , ]]) In [2]: clf = svm.svc(kernel='linear', C=1e10) In [3]: X = [[1,1], [1,-1], [-1,1], [-1,-1]] In [4]: Y = [1,1,-1,-1] In [5]: clf.fit(x, Y) In [6]: clf.support_ Out[6]: array([3, 1], dtype=int32) In [7]: clf.dual_coef_ Out[7]: array([[-0.5, 0.5]]) In [8]: clf.coef_ Out[8]: array([[ 1., 0.]]) In [9]: clf.intercept_ Out[9]: array([-0.]) In [10]: clf.support_vectors_ Out[10]: array([[-1., -1.], [ 1., -1.]]) In [11]: clf.n_support_ Out[11]: array([1, 1], dtype=int32) + + +
48 SVM with sklearn + + In [2]: clf = svm.svc(kernel='linear', C=1e10) In [3]: X = [[1,1], [1,-1], [-1,1], [-1,-1]] In [4]: Y = [1,1,-1,-1] In [5]: clf.fit(x, Y) In [6]: clf.support_ Out[6]: array([3, 1], dtype=int32) In [7]: clf.dual_coef_ Out[7]: array([[-0.5, 0.5]]) In [8]: clf.coef_ Out[8]: array([[ 1., 0.]]) In [9]: clf.intercept_ Out[9]: array([-0.]) In [10]: clf.support_vectors_ Out[10]: array([[-1., -1.], [ 1., -1.]]) In [11]: clf.n_support_ Out[11]: array([1, 1], dtype=int32) In [2]: X = [[1,1], [1,-1], [-1,1], [-1,-1], [-2,0]] In [3]: Y = [1,1,-1,-1, 1] In [4]: clf = svm.svc(kernel='linear', C=1) what if C=1e10? In [5]: clf.fit(x, Y) In [6]: clf.coef_ Out[6]: array([[ 1., 0.]]) In [7]: clf.support_vectors_ Out[7]: array([[-1., 1.], + [-1., -1.], α=c [ 1., 1.], [ 1., -1.], i =0=) y i [hw, x i i + b] 1 [-2., 0.]]) In [8]: clf.dual_coef_ 0 < i <C=) y i [hw, x i i + b] =1 Out[8]: array([[-1., -1., 0.5, 0.5, 1. ]]) i = C =) y i [hw, x i i + b] apple 1 In [9]: clf.intercept_ Out[9]: array([-0.]) α=c α=c + +
49 hard vs. soft margins

50 hard vs. soft margins
51 C=1 51
52 C=20 52
53 From Constrained Optimization to Unconstrained Optimization Optimization (back to Primal) Learning an SVM has been formulated as a constrained optimization problem over w and ξ min w R d,ξ i R w 2 + C + NX i ξ i subject to y i ³ w > x i + b 1 ξ i for i =1...N The constraint y i ³ w > x i + b 1 ξ i, can be written more concisely as y i f(x i ) 1 ξ i which, together with ξ i 0, is equivalent to ξ i = max (0, 1 y i f(x i )) w determines ξ Hence the learning problem is equivalent to the unconstrained optimization problem over w min w R w 2 + C d regularization NX i max (0, 1 y i f(x i )) loss function slides from Andrew Zisserman (Oxford/DeepMind); with annotations 53
54 Loss function min w 2 + C w R d NX i max (0, 1 y i f(x i )) loss function w T x + b = 0 Points are in three categories: Support Vector 1. y i f(x i ) > 1 Point is outside margin. No contribution to loss 2. y i f(x i )=1 Point is on margin. No contribution to loss. As in hard margin case. 3. y i f(x i ) < 1 Point violates margin constraint. Contributes to loss (margin violation ξ>0, including misclassification ξ>1) w Support Vector 54
55 Loss functions very bad (misclassification) not good enough! good SVM uses hinge loss an approximation to the 0-1 loss max (0, 1 y i f(x i )) y i f(x i ) (perceptron uses a shifted hinge-loss touching the origin) 55
56 + SVM min w R d C N X i max (0, 1 y i f(x i )) + w 2 convex convex + convex = convex! 56
57 Gradient (or steepest) descent algorithm for SVM To minimize a cost function C(w) use the iterative update where η is the learning rate. First, rewrite the optimization problem as an average min w C(w) = λ 2 w N = 1 N NX i w t+1 w t η t w C(w t ) NX i max (0, 1 y i f(x i )) µ λ 2 w 2 +max(0, 1 y i f(x i )) (with λ =2/(NC)uptoanoverallscaleoftheproblem)and f(x) =w > x + b Because the hinge loss is not differentiable, a sub-gradient is computed 57
58 Sub-gradient for hinge loss L(x i,y i ; w) =max(0, 1 y i f(x i )) f(x i )=w > x i + b L w = y ix i sub-gradients L w =0 y i f(x i ) 58
59 Sub-gradient descent algorithm for SVM The iterative update is C(w) = 1 N NX i µ λ 2 w 2 + L(x i,y i ; w) w t+1 w t η wt C(w t ) w t η 1 N where η is the learning rate. NX i (λw t + w L(x i,y i ; w t )) batch gradient Then each iteration t involves cycling through the training data with the updates: just like perceptron! perc: 0 w t+1 w t η(λw t y i x i ) if y i f(x i ) < 1 w t ηλw t otherwise In the Pegasos algorithm the learning rate is set at η t = λt 1 online gradient 59
60 60
61 Pegasos Stochastic Gradient Descent Algorithm (SGD) Randomly sample from the training data energy SGD is online update: gradient on one example (unbiasedly) approximates the gradient on the whole training data slides from Andrew Zisserman (Oxford/DeepMind); with annotations 61
Machine Learning A Geometric Approach
 Machine Learning A Geometric Approach Linear Classification: Perceptron Professor Liang Huang some slides from Alex Smola (CMU) Perceptron Frank Rosenblatt deep learning multilayer perceptron linear regression
Machine Learning A Geometric Approach Linear Classification: Perceptron Professor Liang Huang some slides from Alex Smola (CMU) Perceptron Frank Rosenblatt deep learning multilayer perceptron linear regression
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Multi-class SVMs. Lecture 17: Aykut Erdem April 2016 Hacettepe University
 Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Support Vector Machine
 Andrea Passerini passerini@disi.unitn.it Machine Learning Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
Andrea Passerini passerini@disi.unitn.it Machine Learning Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Machine Learning. Support Vector Machines. Manfred Huber
 Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
ICS-E4030 Kernel Methods in Machine Learning
 ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
L5 Support Vector Classification
 L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Lecture 18: Optimization Programming
 Fall, 2016 Outline Unconstrained Optimization 1 Unconstrained Optimization 2 Equality-constrained Optimization Inequality-constrained Optimization Mixture-constrained Optimization 3 Quadratic Programming
Fall, 2016 Outline Unconstrained Optimization 1 Unconstrained Optimization 2 Equality-constrained Optimization Inequality-constrained Optimization Mixture-constrained Optimization 3 Quadratic Programming
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 27. September, 2017 Juho Rousu 27. September, 2017 1 / 45 Convex optimization Convex optimisation This
CS-E4830 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 27. September, 2017 Juho Rousu 27. September, 2017 1 / 45 Convex optimization Convex optimisation This
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Machine Learning. Lecture 6: Support Vector Machine. Feng Li.
 Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Structured Prediction
 Machine Learning Fall 2017 (structured perceptron, HMM, structured SVM) Professor Liang Huang (Chap. 17 of CIML) x x the man bit the dog x the man bit the dog x DT NN VBD DT NN S =+1 =-1 the man bit the
Machine Learning Fall 2017 (structured perceptron, HMM, structured SVM) Professor Liang Huang (Chap. 17 of CIML) x x the man bit the dog x the man bit the dog x DT NN VBD DT NN S =+1 =-1 the man bit the
Machine Learning. Kernels. Fall (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang. (Chap. 12 of CIML)
 Professor Liang Huang. (Chap. 12 of CIML)") Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
LECTURE 7 Support vector machines
 LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
Support Vector Machines
 Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Support Vector Machines
 Support Vector Machines Ryan M. Rifkin Google, Inc. 2008 Plan Regularization derivation of SVMs Geometric derivation of SVMs Optimality, Duality and Large Scale SVMs The Regularization Setting (Again)
Support Vector Machines Ryan M. Rifkin Google, Inc. 2008 Plan Regularization derivation of SVMs Geometric derivation of SVMs Optimality, Duality and Large Scale SVMs The Regularization Setting (Again)
Support Vector Machines
 Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Convex Optimization. Dani Yogatama. School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA. February 12, 2014
 Convex Optimization Dani Yogatama School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA February 12, 2014 Dani Yogatama (Carnegie Mellon University) Convex Optimization February 12,
Convex Optimization Dani Yogatama School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA February 12, 2014 Dani Yogatama (Carnegie Mellon University) Convex Optimization February 12,
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Support Vector Machines, Kernel SVM
 Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Support vector machines
 Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Machine Learning Lecture 6 Note
 Machine Learning Lecture 6 Note Compiled by Abhi Ashutosh, Daniel Chen, and Yijun Xiao February 16, 2016 1 Pegasos Algorithm The Pegasos Algorithm looks very similar to the Perceptron Algorithm. In fact,
Machine Learning Lecture 6 Note Compiled by Abhi Ashutosh, Daniel Chen, and Yijun Xiao February 16, 2016 1 Pegasos Algorithm The Pegasos Algorithm looks very similar to the Perceptron Algorithm. In fact,
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Outline. Basic concepts: SVM and kernels SVM primal/dual problems. Chih-Jen Lin (National Taiwan Univ.) 1 / 22
 1 / 22") Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
10701 Recitation 5 Duality and SVM. Ahmed Hefny
 10701 Recitation 5 Duality and SVM Ahmed Hefny Outline Langrangian and Duality The Lagrangian Duality Eamples Support Vector Machines Primal Formulation Dual Formulation Soft Margin and Hinge Loss Lagrangian
10701 Recitation 5 Duality and SVM Ahmed Hefny Outline Langrangian and Duality The Lagrangian Duality Eamples Support Vector Machines Primal Formulation Dual Formulation Soft Margin and Hinge Loss Lagrangian
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Recita,on: Loss, Regulariza,on, and Dual*
 10-701 Recita,on: Loss, Regulariza,on, and Dual* Jay- Yoon Lee 02/26/2015 *Adopted figures from 10725 lecture slides and from the book Elements of Sta,s,cal Learning Loss and Regulariza,on Op,miza,on problem
10-701 Recita,on: Loss, Regulariza,on, and Dual* Jay- Yoon Lee 02/26/2015 *Adopted figures from 10725 lecture slides and from the book Elements of Sta,s,cal Learning Loss and Regulariza,on Op,miza,on problem
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Lecture 18: Kernels Risk and Loss Support Vector Regression. Aykut Erdem December 2016 Hacettepe University
 Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Incorporating detractors into SVM classification
 Incorporating detractors into SVM classification AGH University of Science and Technology 1 2 3 4 5 (SVM) SVM - are a set of supervised learning methods used for classification and regression SVM maximal
Incorporating detractors into SVM classification AGH University of Science and Technology 1 2 3 4 5 (SVM) SVM - are a set of supervised learning methods used for classification and regression SVM maximal
LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
EE613 Machine Learning for Engineers. Kernel methods Support Vector Machines. jean-marc odobez 2015
 EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
Constrained Optimization and Support Vector Machines
 Constrained Optimization and Support Vector Machines Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/
Constrained Optimization and Support Vector Machines Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Chapter 9. Support Vector Machine. Yongdai Kim Seoul National University
 Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
COMP 875 Announcements
 Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Support Vector Machines
 Support Vector Machines Bingyu Wang, Virgil Pavlu March 30, 2015 based on notes by Andrew Ng. 1 What s SVM The original SVM algorithm was invented by Vladimir N. Vapnik 1 and the current standard incarnation
Support Vector Machines Bingyu Wang, Virgil Pavlu March 30, 2015 based on notes by Andrew Ng. 1 What s SVM The original SVM algorithm was invented by Vladimir N. Vapnik 1 and the current standard incarnation
Lecture 2: Linear SVM in the Dual
 Lecture 2: Linear SVM in the Dual Stéphane Canu stephane.canu@litislab.eu São Paulo 2015 July 22, 2015 Road map 1 Linear SVM Optimization in 10 slides Equality constraints Inequality constraints Dual formulation
Lecture 2: Linear SVM in the Dual Stéphane Canu stephane.canu@litislab.eu São Paulo 2015 July 22, 2015 Road map 1 Linear SVM Optimization in 10 slides Equality constraints Inequality constraints Dual formulation
Support Vector Machines for Classification and Regression. 1 Linearly Separable Data: Hard Margin SVMs
 E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Machine Learning and Data Mining. Support Vector Machines. Kalev Kask
 Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Support Vector Machines for Classification and Regression
 CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
Data Mining - SVM. Dr. Jean-Michel RICHER Dr. Jean-Michel RICHER Data Mining - SVM 1 / 55
 Data Mining - SVM Dr. Jean-Michel RICHER 2018 jean-michel.richer@univ-angers.fr Dr. Jean-Michel RICHER Data Mining - SVM 1 / 55 Outline 1. Introduction 2. Linear regression 3. Support Vector Machine 4.
Data Mining - SVM Dr. Jean-Michel RICHER 2018 jean-michel.richer@univ-angers.fr Dr. Jean-Michel RICHER Data Mining - SVM 1 / 55 Outline 1. Introduction 2. Linear regression 3. Support Vector Machine 4.
Motivation. Lecture 2 Topics from Optimization and Duality. network utility maximization (NUM) problem:
 problem:") CDS270 Maryam Fazel Lecture 2 Topics from Optimization and Duality Motivation network utility maximization (NUM) problem: consider a network with S sources (users), each sending one flow at rate x s, through
CDS270 Maryam Fazel Lecture 2 Topics from Optimization and Duality Motivation network utility maximization (NUM) problem: consider a network with S sources (users), each sending one flow at rate x s, through
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Linear Support Vector Machine. Classification. Linear SVM. Huiping Cao. Huiping Cao, Slide 1/26
 Huiping Cao, Slide 1/26 Classification Linear SVM Huiping Cao linear hyperplane (decision boundary) that will separate the data Huiping Cao, Slide 2/26 Support Vector Machines rt Vector Find a linear Machines
Huiping Cao, Slide 1/26 Classification Linear SVM Huiping Cao linear hyperplane (decision boundary) that will separate the data Huiping Cao, Slide 2/26 Support Vector Machines rt Vector Find a linear Machines
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Module - 5 Lecture - 22 SVM: The Dual Formulation Good morning.
Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Module - 5 Lecture - 22 SVM: The Dual Formulation Good morning.
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Soft-Margin Support Vector Machine
 Soft-Margin Support Vector Machine Chih-Hao Chang Institute of Statistics, National University of Kaohsiung @ISS Academia Sinica Aug., 8 Chang (8) Soft-margin SVM Aug., 8 / 35 Review for Hard-Margin SVM
Soft-Margin Support Vector Machine Chih-Hao Chang Institute of Statistics, National University of Kaohsiung @ISS Academia Sinica Aug., 8 Chang (8) Soft-margin SVM Aug., 8 / 35 Review for Hard-Margin SVM
COMP 652: Machine Learning. Lecture 12. COMP Lecture 12 1 / 37
 COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
The Lagrangian L : R d R m R r R is an (easier to optimize) lower bound on the original problem:
 lower bound on the original problem:") HT05: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford Convex Optimization and slides based on Arthur Gretton s Advanced Topics in Machine Learning course
HT05: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford Convex Optimization and slides based on Arthur Gretton s Advanced Topics in Machine Learning course
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
UVA CS 4501: Machine Learning
 UVA CS 4501: Machine Learning Lecture 16 Extra: Support Vector Machine Optimization with Dual Dr. Yanjun Qi University of Virginia Department of Computer Science Today Extra q Optimization of SVM ü SVM
UVA CS 4501: Machine Learning Lecture 16 Extra: Support Vector Machine Optimization with Dual Dr. Yanjun Qi University of Virginia Department of Computer Science Today Extra q Optimization of SVM ü SVM
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Applied inductive learning - Lecture 7
 Applied inductive learning - Lecture 7 Louis Wehenkel & Pierre Geurts Department of Electrical Engineering and Computer Science University of Liège Montefiore - Liège - November 5, 2012 Find slides: http://montefiore.ulg.ac.be/
Applied inductive learning - Lecture 7 Louis Wehenkel & Pierre Geurts Department of Electrical Engineering and Computer Science University of Liège Montefiore - Liège - November 5, 2012 Find slides: http://montefiore.ulg.ac.be/
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Lecture 16: Modern Classification (I) - Separating Hyperplanes
 - Separating Hyperplanes") Lecture 16: Modern Classification (I) - Separating Hyperplanes Outline 1 2 Separating Hyperplane Binary SVM for Separable Case Bayes Rule for Binary Problems Consider the simplest case: two classes are
Lecture 16: Modern Classification (I) - Separating Hyperplanes Outline 1 2 Separating Hyperplane Binary SVM for Separable Case Bayes Rule for Binary Problems Consider the simplest case: two classes are
Support Vector Machines for Regression
 COMP-566 Rohan Shah (1) Support Vector Machines for Regression Provided with n training data points {(x 1, y 1 ), (x 2, y 2 ),, (x n, y n )} R s R we seek a function f for a fixed ɛ > 0 such that: f(x
COMP-566 Rohan Shah (1) Support Vector Machines for Regression Provided with n training data points {(x 1, y 1 ), (x 2, y 2 ),, (x n, y n )} R s R we seek a function f for a fixed ɛ > 0 such that: f(x
CS269: Machine Learning Theory Lecture 16: SVMs and Kernels November 17, 2010
 CS269: Machine Learning Theory Lecture 6: SVMs and Kernels November 7, 200 Lecturer: Jennifer Wortman Vaughan Scribe: Jason Au, Ling Fang, Kwanho Lee Today, we will continue on the topic of support vector
CS269: Machine Learning Theory Lecture 6: SVMs and Kernels November 7, 200 Lecturer: Jennifer Wortman Vaughan Scribe: Jason Au, Ling Fang, Kwanho Lee Today, we will continue on the topic of support vector
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Support Vector Machines
 Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
WHY DUALITY? Gradient descent Newton s method Quasi-newton Conjugate gradients. No constraints. Non-differentiable ???? Constrained problems? ????
 DUALITY WHY DUALITY? No constraints f(x) Non-differentiable f(x) Gradient descent Newton s method Quasi-newton Conjugate gradients etc???? Constrained problems? f(x) subject to g(x) apple 0???? h(x) =0
DUALITY WHY DUALITY? No constraints f(x) Non-differentiable f(x) Gradient descent Newton s method Quasi-newton Conjugate gradients etc???? Constrained problems? f(x) subject to g(x) apple 0???? h(x) =0
Lecture 10: A brief introduction to Support Vector Machine
 Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Kernels. Machine Learning CSE446 Carlos Guestrin University of Washington. October 28, Carlos Guestrin
 Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Constrained Optimization and Lagrangian Duality
 CIS 520: Machine Learning Oct 02, 2017 Constrained Optimization and Lagrangian Duality Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may
CIS 520: Machine Learning Oct 02, 2017 Constrained Optimization and Lagrangian Duality Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may
Numerical Optimization
 Numerical Optimization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) Numerical Optimization Machine Learning
Numerical Optimization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) Numerical Optimization Machine Learning
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification