7 Rate-Based Recurrent Networks of Threshold Neurons: Basis for Associative Memory
|
|
|
- Stuart Murphy
- 5 years ago
- Views:
Transcription
1 Physics 178/278 - David Kleinfeld - Fall 2005; Revised for Winter Rate-Based Recurrent etworks of Threshold eurons: Basis for Associative Memory 7.1 A recurrent network with threshold elements The basic challenge in associative networks is this: Store a set of p patterns ξ µ in such a way that when presented with a new pattern S test, the network responds by producing whichever one of the stored patterns most closely resembles S test. Close is defined in terms if the Hamming distance, the number of different bits in the pattern. The patterns are labelled by µ = 1, 2,..., p, while the neurons or units in the network are labelled by i = 1, 2,...,. We donate the activity of the i th neuron by S i. The dynamics of the network are: S i sgn W ij S j θ i (7.7) where we take the sign function sign sgn(h) to be { 1 if h 0 sgn(h) = 1 if h < 0 where h i W ij S j θ; (7.8) is the input to the neuron. In the rest of this chapter we drop the threshold terms, taking θ i = 0 as befits the case of random patterns. Thus we have S i sgn W ij S j. (7.9) There are at least two ways in which we might carry out the updating specified by the above equation. We could do it synchronously, updating all units simultaneously at each time step. Or we could do it asynchronously, updating them one at a time. Both kinds of models are interesting, but the asynchronous choice is more natural for both brains and artificial networks. The synchronous choice requires a central clock or pacemaker, and is potentially sensitive to timing errors. In the asynchronous case, which we adopt henceforth, we can proceed in either of two ways: 1
2 At each time step, select at random a unit i to be updated, and apply the update rule. Let each unit independently choose to update itself according to the update rule, with some constant probability per unit time. These choices are equivalent, except for the distribution of update intervals, because the second gives a random sequence; there is vanishing small probability of two units choosing to update at exactly the same moment. Rather than study a specific problem such as memorizing a particular set of pictures, we examine the more generic problem of a random set of patterns drawn from a distribution. For convenience we will usually take the patterns to be made up of independent bits ξ i that can each take on the values +1 and -1 with equal probability. Our procedure for testing whether a proposed form of W ij is acceptable is first to see whether the patterns to be memorized are themselves stable, and then to check whether small deviations from these patterns are corrected as the network evolves. 7.2 Storing one pattern To motivate our choice for the connection weights, we consider first the simple case whether there is just one pattern ξ i that we want to memorize. The condition for this pattern to be stable is just sgn W ij ξ j = ξ i i (7.10) because then the update rule produces no changes. It is easy to see that this is true if we take W ij ξ i ξ j (7.11) since ξj 2 = 1. We take the constant of proportionality to be 1/, where is the number of units in the network, giving W ij = 1 ξ iξ j. (7.12) Furthermore, it is also obvious that even if a number (fewer than half) of the bits of the starting pattern S i are wrong, i.e., not equal to ξ i, they will be overwhelmed in the sum for the net input h i = W ij S j (7.13) by the majority that are right, and sgn(h i ) will still give ξ i. An initial configuration near to ξ i will therefore quickly relax to ξ i. This means that the network will correct errors as desired, and we can say that the pattern ξ i is an attractor. 2
3 Actually there are two attractors in this simple case; the other one is at ξ i. This is called a reversed state. All starting configurations with more than half the bits different from the original pattern will end up in the reversed state. 7.3 Storing many patterns This is fine for one pattern, but how do we get the system to recall the most similar of many patterns? The simplest answer is just to make w ij by an outer product rule, which corresponds to W ij = 1 p ξ µ i ξ µ j. (7.14) µ=1 Here p is the total number of stored patterns labelled by µ. This is called the Hebb rule because of the similarity with a hypothesis made by Hebb (1949) about the way in which synaptic strengths in the brain change in response to experience: Hebb suggested changes proportional to the correlation between the firing of the pre- and post-synaptic neurons. Let us examine the stability of a particular pattern ξ ν i. The stability condition generalizes to where the net input h ν i sgn(h ν i ) = ξ ν i i (7.15) to unit i in pattern ν is h ν i W ij ξj ν = 1 p ξ µ i ξ µ j ξj ν. (7.16) µ=1 We now separate the sum on µ into the special term µ = ν and all the rest: h ν i = ξi ν + 1 p ξ µ i ξ µ j ξj ν. (7.17) µ ν If the second term were zero, we could immediately conclude that pattern number ν was stable according to the stability condition. This is still true if the second term is small enough: if its magnitude is smaller than 1 it cannot change the sign of h ν i. It turns out that the second term is less than 1 in many cases of interest if p, the number of patterns, is small enough. Then the stored patterns are all stable if we start the system from one of them it will stay there. Furthermore, a small fraction of bits different from a stored pattern will be corrected in the same way as in the single-pattern case; they are overwhelmed in the sum j W ij S j by the vast majority of correct bits. A configuration near to ξi ν thus relaxes to ξi ν. This shows that the chosen patterns are truly attractors of the system. The system works as a content-addressable memory. 3
4 7.4 Scaling for error-free storage of many patterns We consider a Hopfield network with the standard Hebb-like learning rule and ask how many memories we can imbed in a network of neurons with the constraint that we will accept at most one bit (one neuron s output in only one memory state) of error. The input h i is h i = W ij S j (7.18) j i = 1 p ξ µ i ξ µ j S j µ=1 j i where p is the number of stored memories, is the number of neurons and W ij 1 p ξ µ i ξ µ j (7.19) µ=1 is the synaptic weight matrix given by the Hebb rule. ow, check the stability of a stored state. Make S j = ξ 1 j, one of the stored memory states, so that h i = 1 p ξ µ i ξ µ j ξj 1 µ=1 j i (7.20) = 1 p ξ µ i ξ µ j ξj 1 µ=1 j i = 1 ξ1 i ξj 1 ξj p ξ µ i ξ µ j ξj 1 j i µ 1 j i On average, the second term is zero, so that the average input is < h i >= 1 ξ1 i ( 1) ξ 1 i (7.21) What is the variance, denoted σ 2? The second term, summed over random vectors with zero mean, consists of the sum of (p 1) inner products of vectors with ( 1) terms. Each term is +1 or -1, i..e., binomially distributed, so that the fluctuation to the input is σ = 1 p. p 1 1 (7.22) 4
5 This results in a fluctuation to the input with a standard deviation, σ. oise hurts only if the magnitude of the noise term exceeds 1. The noise becomes Gaussian for large p and, but constant p/, which is the limit of interest, Thus the probability of an error in the recall of all stored states is P error = = [ 1 2π σ 2 π σ +1 = 2 π 2p ( ) erfc 2p 1 e x2 /2σ 2 dx + +1 e x2 /2σ 2 e x2 dx dx e x2 /2σ 2 ] dx (7.23) where efrc(x) is the complementary error function and we again note that the average of the error term is zero. ote that for >> 1 the complementary error function 2p may be approximated by an asymptotic form given by P error 2 π p e /2p (7.24) We have a nice and closed expression in a relevant limit! ow p is total number of bits in the network. Suppose only less than one bit can be in error. Then we equate probabilities of correct to within a factor of one bit, or 1 p. Thus (1 P error ) p 1 1 p (7.25) But p is large and P error will be small by construction, so 1 p P error 1 1 p and thus P error < 1 (p) 2 (7.26) From the above expansion of the gaussian error: log [P error ] 1 2 log π 2p log 2p (7.27) From the constraint on the desired error: 5
6 Thus log [P error ] < 2 log(p) (7.28) 1 2 log π 2p log 2p < 2 log (p) (7.29) We now let with /p constant. Keeping zero-th and first order terms, we have: so 2p > 2 log (p) > 2 log () (7.30) p < 1 4 log (7.31) ote that p has a similar scaling for the choice of a fixed, nonzero error rate. Thus we see that an associate memory based on a recurrent Hopfield network stores a number of memories that scales more weakly than the number of neurons if one cannot tolerate any errors upon recall. Keep a mind that a linear network stores only one stable state, e.g., an integrator state. So things are looking good. 7.5 Energy description and convergence These notes were abstracted from chapter 2 of the book by Hertz, Krogh and Palmer (Introduction to the Theory of eural Computation, Addison Wesley, 1991) One of the most important contributions of Hopfield was to introduce the idea of an energy function into neural network theory. For the networks we are considering, the energy function E is E = 1 2 W ij S i S j. (7.32) ij The double sum is over all i and all j. The i = j terms are of no consequence because Si 2 = 1; they just contribute a constant to E, and in any case we could choose W ii = 0. The energy function is a function of the configuration S i of the system, where S i means the set of all the S i s. Typically this surface is quite hilly. The central property of an energy function is that it always decreases (or remains constant) as the system evolves according to its dynamical rule. Thus the attractors (memorized patterns) are at local minima of the energy surface. For neural networks in general an energy function exists if the connection strengths are symmetric, i.e., W ij = W ji. In real networks of neurons this is an unreasonable assumption, but it is useful to study the symmetric case because of the extra insight 6
7 that the existence of an energy function affords us. The Hebb prescription that we are now studying automatically yields symmetric W ij s. For symmetric connections we can write the energy in the alternative form E = W ij S i S j + constant (7.33) (ij) where (ij) means all the distinct pairs of ij, counting for example 1,2 as the same pair as 2,1. We exclude the ii terms from (ij); they give the constant. It now is easy to show that the dynamical rule can only decrease the energy. Let S i be the new value of S i for some particular unit i: S i = sgn W ij S j. (7.34) Obviously if S i = S i the energy is unchanged. In the other case S i = S i so, picking out the terms that involve S i E E = W ij S is j + W ij S i S j (7.35) j i j i = 2S i W ij S j j i = 2S i W ij S j 2W ii. ow the first term is negative from the update rule, and the second term is negative because the Hebb rule gives W ii = p/ i. Thus the energy decreases every time an S i changes, as claimed. The self-coupling terms W ii may actually be omitted altogether, both from the Hebb rule (where we can simply define W ii = 0) and from the energy function as they make no appreciable difference to the stability of the ξi ν patterns in the large limit. The idea of the energy function as something to be minimized in the stable states gives us an alternate way to derive the Hebb prescription. Let us start again with the single-pattern case. We want the energy to be minimized when the overlap between the network configuration and the stored pattern ξ i is largest. So we choose Multiplying this out gives E = 1 2 ( p ) 2 S i ξ µ i. (7.36) µ=1 i=1 7
8 E = 1 ( p ) S i ξ µ i S j ξ µ j (7.37) 2 µ=1 i=1 = 1 1 p ξ µ i ξ µ j S i S j 2 ij µ=1 which is exactly the same as our original energy function if w ij is given by the Hebb rule. This approach to finding appropriate W ij s is generally useful. If we can write down an energy function whose minimum satisfies a problem of interest, then we can multiply it out and identify the appropriate strength W ij from the coefficient of S i S j. 7.6 The issue of spurious attractors These notes were abstracted from chapter 2 of the book by Hertz, Krogh and Palmer (Introduction to the Theory of eural Computation, Addison Wesley, 1991) We have shown that the Hebb prescription gives us (for small enough p) a dynamical system that has attractors local minima of the energy function at the desired points ξ µ i. These are sometimes called the retrieval states. But we have not shown that these are the only attractors. And indeed there are others, as discovered by by Amit, Gottfried and Sompolinsky (1985). First of all, the reversed states ξ µ i are minima and have the same energy as the original patterns. The dynamics and the energy function both have a perfect symmetry, S i S i i. This is not too troublesome for the retrieved patterns; we could agree to reverse all the remaining bits when a particular sign bit is 1 for example. Second, there are stable mixture states ξi mix, which are not equal to any single pattern, but instead correspond to linear combinations of an odd number of patterns. The simplest of these are symmetric combinations of three stored patterns: ξ mix i = sgn(±ξ 1 i ± ξ 2 i ± ξ 3 i ). (7.38) All 2 3 = 8 sign combinations are possible, but we consider for definiteness the case where all the signs are chosen as + s. The other cases are similar. Observe that on average ξi mix has the same sign at ξi 1 three times out of four; only if ξi 2 and ξi 3 both have the opposite sign can the overall sign be reversed? So ξi mix is Hamming distance /4 from ξi 1, and of course from ξi 2 and ξi 3 too; the mixture states lie at points equidistant from their components. This also implies that i ξi 1 ξi mix = /2 on average. To check the stability pick out the three special states with µ = 1, 2, 3, still with all + signs, to find: 8
9 h mix i = 1 ξ µ i ξ µ j ξj mix = 1 2 ξ1 i ξ2 i ξ3 i + cross terms. (7.39) µ Thus the stability condition is satisfied for the mixture state. Similarly 5, 7,... patterns may be combined. The system does not choose an even number of patterns because they can add up to zero on some sites, whereas the units have to have nonzero inputs to have defined outputs of ±1. Third, for large p there are local minima that are not correlated with any finite number of the original patters ξ µ i. 7.7 The phase diagram of the Hopfield model A statistical mechanical analysis by Amit, Gottfried and Sompolinsky (1985) shows that there is a crucial value α c of α p/ where memory states no longer exist. A numerical evaluation gives α c (7.40) The jump in the number of memory states is considerable: from near-perfect recall to zero. This tells us that with no internal noise we go discontinuously from a very good working memory with only a few bits in error for α < α c to a useless one for a α > α c. The attached figure shows the whole phase diagram for the Hopfield model, delineating different regimes of behavior in the T α plane, where T is the variance of the random input. There is a roughly triangular region where the network is a good memory device, as indicated by regions A and a of the figure. The result corresponds to the upper limit on the α axis, while the critical noise level T c = 1 for the p case sets the limit on the T axis. Between these limits there is a critical noise level T c (α), or equivalently a critical load α c (T ), as shown. As T 1, α c (T ) goes to zero like (1 T ) 2. In region C the network still turns out to have many stable states, called spin glass states, but these are not correlated with any of the patterns ξ µ i. However, if T is raised to a sufficiently high value, into region D, the output of the network continuously fluctuates with S i = 0. Regions A, A, and B both have the desired retrieval states, beside some percentage of wrong bits, but also have spin glass states. The spin states are the most stable states in region B, lower in energy than the desired states, whereas in region A the desired states are the global minima. For small enough α and T there are also mixture states that are correlated with an odd number of the patterns as discussed earlier. These always have higher free energy than the desired states. Each type of mixture state is stable in a triangular region (A, A and B), but with smaller intercepts on both axes. The most stable mixture states extend to 0.46 on the T axis and 0.03 on the α axis (region A ). 9
10 7.8 oise and spontaneous excitatory states Before we leave the subject of the Hopfield model, it it worth stepping back and asking if, by connection with ferromagnetic systems, rate equations of the form used for the Hopfield model naturally go into an epileptic state of continuous firing, but not necessarily with every cell firing. This exercise also allows us to bring up the issue of fast noise that is uncorrelated from cell to cell. We consider binary neurons, with >> 1, each of which is connected to all other neighboring neurons. For simplicity, we assume that the synaptic weights W ij are the same for each connections, i.e., W ij = W 0. Then there is no spatial structure in the network and the total input to a given cell has two contributions. One term from the neighboring cells and one from an external input, which we also take to be the same for all cells and denote h 0. Then the input is Input = W 0 The Energy per neuron, denoted ɛ, is then S j + h 0. (7.41) ɛ i = S i W 0 S j S i h 0. (7.42) The insight for solving this system is the mean-field approach. We replace the sum of all neurons by the mean value of S i, denoted < S >, where < S > = 1 S j. (7.43) so that ɛ i = S i (W 0 < S > + h 0 ). (7.44) We can now use the expression for the value of the energy in term of the average spike rat, < S >, to solve self consistently for < S >. We know that the average rate is given by a Boltzman factor over all of the S i. Thus < S > = = +1 S i = 1 e ɛ i/k B T S i +1 S i = 1 e ɛ i/k B T +1 S i = 1 e S i(w 0 <S>+h 0 )/k B T S i +1 S i = 1 e S i(w 0 <S>+h 0 )/k B T = e (W 0<S>+h 0 )/k B T + e (W 0<S>+h 0 )/k B T e (W 0<S>+h 0 )/k BT + e (W 0<S>+h 0 )/k B T ( ) W0 < S > +h 0 = tanh. k B T (7.45) 10
11 where we made of of the fact that S i = ±1. This is the neuronal equivalent of the famous Weiss equation for ferromagnetism. The properties of the solution clearly depend on the ratio W 0, which pits the connection strength W k B T 0 against the noise level T/. For W 0 k B < 1, the high noise limit, there is only the solution < S >= 0 in T the absence of an external input h 0. For W 0 k B T > 1, the low noise limit, there are three solutions in the absence of an external input h 0. One has < S > = 0 but is unstable. The other two solutions have < S > 0 and must be found graphically or numerically. For sufficiently large h 0 the network is pushed to a state with < S >= sgn(h 0 /k B T ) independent of the interactions. We see that there is a critical noise level for the onset of an active state and that this level depends on the strength of the connections and the number of cells. We also see that an active state can occur spontaneously for W 0 k B > 1 or T < W 0 T k B. This is a metaphor for epilepsy, in which recurrent excitatory connections maintain a spiking output. 11
12
13
14
15
16 D C A A B
7 Recurrent Networks of Threshold (Binary) Neurons: Basis for Associative Memory
 Neurons: Basis for Associative Memory") Physics 178/278 - David Kleinfeld - Winter 2019 7 Recurrent etworks of Threshold (Binary) eurons: Basis for Associative Memory 7.1 The network The basic challenge in associative networks, also referred
Physics 178/278 - David Kleinfeld - Winter 2019 7 Recurrent etworks of Threshold (Binary) eurons: Basis for Associative Memory 7.1 The network The basic challenge in associative networks, also referred
A. The Hopfield Network. III. Recurrent Neural Networks. Typical Artificial Neuron. Typical Artificial Neuron. Hopfield Network.
 III. Recurrent Neural Networks A. The Hopfield Network 2/9/15 1 2/9/15 2 Typical Artificial Neuron Typical Artificial Neuron connection weights linear combination activation function inputs output net
III. Recurrent Neural Networks A. The Hopfield Network 2/9/15 1 2/9/15 2 Typical Artificial Neuron Typical Artificial Neuron connection weights linear combination activation function inputs output net
A. The Hopfield Network. III. Recurrent Neural Networks. Typical Artificial Neuron. Typical Artificial Neuron. Hopfield Network.
 Part 3A: Hopfield Network III. Recurrent Neural Networks A. The Hopfield Network 1 2 Typical Artificial Neuron Typical Artificial Neuron connection weights linear combination activation function inputs
Part 3A: Hopfield Network III. Recurrent Neural Networks A. The Hopfield Network 1 2 Typical Artificial Neuron Typical Artificial Neuron connection weights linear combination activation function inputs
In biological terms, memory refers to the ability of neural systems to store activity patterns and later recall them when required.
 In biological terms, memory refers to the ability of neural systems to store activity patterns and later recall them when required. In humans, association is known to be a prominent feature of memory.
In biological terms, memory refers to the ability of neural systems to store activity patterns and later recall them when required. In humans, association is known to be a prominent feature of memory.
Artificial Intelligence Hopfield Networks
 Artificial Intelligence Hopfield Networks Andrea Torsello Network Topologies Single Layer Recurrent Network Bidirectional Symmetric Connection Binary / Continuous Units Associative Memory Optimization
Artificial Intelligence Hopfield Networks Andrea Torsello Network Topologies Single Layer Recurrent Network Bidirectional Symmetric Connection Binary / Continuous Units Associative Memory Optimization
( ) T. Reading. Lecture 22. Definition of Covariance. Imprinting Multiple Patterns. Characteristics of Hopfield Memory
 T. Reading. Lecture 22. Definition of Covariance. Imprinting Multiple Patterns. Characteristics of Hopfield Memory") Part 3: Autonomous Agents /8/07 Reading Lecture 22 Flake, ch. 20 ( Genetics and Evolution ) /8/07 /8/07 2 Imprinting Multiple Patterns Let x, x 2,, x p be patterns to be imprinted Define the sum-of-outer-products
Part 3: Autonomous Agents /8/07 Reading Lecture 22 Flake, ch. 20 ( Genetics and Evolution ) /8/07 /8/07 2 Imprinting Multiple Patterns Let x, x 2,, x p be patterns to be imprinted Define the sum-of-outer-products
Hopfield Neural Network and Associative Memory. Typical Myelinated Vertebrate Motoneuron (Wikipedia) Topic 3 Polymers and Neurons Lecture 5
 Topic 3 Polymers and Neurons Lecture 5") Hopfield Neural Network and Associative Memory Typical Myelinated Vertebrate Motoneuron (Wikipedia) PHY 411-506 Computational Physics 2 1 Wednesday, March 5 1906 Nobel Prize in Physiology or Medicine.
Hopfield Neural Network and Associative Memory Typical Myelinated Vertebrate Motoneuron (Wikipedia) PHY 411-506 Computational Physics 2 1 Wednesday, March 5 1906 Nobel Prize in Physiology or Medicine.
Hopfield Network for Associative Memory
 CSE 5526: Introduction to Neural Networks Hopfield Network for Associative Memory 1 The next few units cover unsupervised models Goal: learn the distribution of a set of observations Some observations
CSE 5526: Introduction to Neural Networks Hopfield Network for Associative Memory 1 The next few units cover unsupervised models Goal: learn the distribution of a set of observations Some observations
Hopfield networks. Lluís A. Belanche Soft Computing Research Group
 Lluís A. Belanche belanche@lsi.upc.edu Soft Computing Research Group Dept. de Llenguatges i Sistemes Informàtics (Software department) Universitat Politècnica de Catalunya 2010-2011 Introduction Content-addressable
Lluís A. Belanche belanche@lsi.upc.edu Soft Computing Research Group Dept. de Llenguatges i Sistemes Informàtics (Software department) Universitat Politècnica de Catalunya 2010-2011 Introduction Content-addressable
Hopfield Networks. (Excerpt from a Basic Course at IK 2008) Herbert Jaeger. Jacobs University Bremen
 Herbert Jaeger. Jacobs University Bremen") Hopfield Networks (Excerpt from a Basic Course at IK 2008) Herbert Jaeger Jacobs University Bremen Building a model of associative memory should be simple enough... Our brain is a neural network Individual
Hopfield Networks (Excerpt from a Basic Course at IK 2008) Herbert Jaeger Jacobs University Bremen Building a model of associative memory should be simple enough... Our brain is a neural network Individual
Hopfield Neural Network
 Lecture 4 Hopfield Neural Network Hopfield Neural Network A Hopfield net is a form of recurrent artificial neural network invented by John Hopfield. Hopfield nets serve as content-addressable memory systems
Lecture 4 Hopfield Neural Network Hopfield Neural Network A Hopfield net is a form of recurrent artificial neural network invented by John Hopfield. Hopfield nets serve as content-addressable memory systems
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
CSE 5526: Introduction to Neural Networks Hopfield Network for Associative Memory
 CSE 5526: Introduction to Neural Networks Hopfield Network for Associative Memory Part VII 1 The basic task Store a set of fundamental memories {ξξ 1, ξξ 2,, ξξ MM } so that, when presented a new pattern
CSE 5526: Introduction to Neural Networks Hopfield Network for Associative Memory Part VII 1 The basic task Store a set of fundamental memories {ξξ 1, ξξ 2,, ξξ MM } so that, when presented a new pattern
Using a Hopfield Network: A Nuts and Bolts Approach
 Using a Hopfield Network: A Nuts and Bolts Approach November 4, 2013 Gershon Wolfe, Ph.D. Hopfield Model as Applied to Classification Hopfield network Training the network Updating nodes Sequencing of
Using a Hopfield Network: A Nuts and Bolts Approach November 4, 2013 Gershon Wolfe, Ph.D. Hopfield Model as Applied to Classification Hopfield network Training the network Updating nodes Sequencing of
CHAPTER 3. Pattern Association. Neural Networks
 CHAPTER 3 Pattern Association Neural Networks Pattern Association learning is the process of forming associations between related patterns. The patterns we associate together may be of the same type or
CHAPTER 3 Pattern Association Neural Networks Pattern Association learning is the process of forming associations between related patterns. The patterns we associate together may be of the same type or
Iterative Autoassociative Net: Bidirectional Associative Memory
 POLYTECHNIC UNIVERSITY Department of Computer and Information Science Iterative Autoassociative Net: Bidirectional Associative Memory K. Ming Leung Abstract: Iterative associative neural networks are introduced.
POLYTECHNIC UNIVERSITY Department of Computer and Information Science Iterative Autoassociative Net: Bidirectional Associative Memory K. Ming Leung Abstract: Iterative associative neural networks are introduced.
Week 4: Hopfield Network
 Week 4: Hopfield Network Phong Le, Willem Zuidema November 20, 2013 Last week we studied multi-layer perceptron, a neural network in which information is only allowed to transmit in one direction (from
Week 4: Hopfield Network Phong Le, Willem Zuidema November 20, 2013 Last week we studied multi-layer perceptron, a neural network in which information is only allowed to transmit in one direction (from
3.3 Discrete Hopfield Net An iterative autoassociative net similar to the nets described in the previous sections has been developed by Hopfield
 3.3 Discrete Hopfield Net An iterative autoassociative net similar to the nets described in the previous sections has been developed by Hopfield (1982, 1984). - The net is a fully interconnected neural
3.3 Discrete Hopfield Net An iterative autoassociative net similar to the nets described in the previous sections has been developed by Hopfield (1982, 1984). - The net is a fully interconnected neural
Learning and Memory in Neural Networks
 Learning and Memory in Neural Networks Guy Billings, Neuroinformatics Doctoral Training Centre, The School of Informatics, The University of Edinburgh, UK. Neural networks consist of computational units
Learning and Memory in Neural Networks Guy Billings, Neuroinformatics Doctoral Training Centre, The School of Informatics, The University of Edinburgh, UK. Neural networks consist of computational units
Consider the way we are able to retrieve a pattern from a partial key as in Figure 10 1.
 CompNeuroSci Ch 10 September 8, 2004 10 Associative Memory Networks 101 Introductory concepts Consider the way we are able to retrieve a pattern from a partial key as in Figure 10 1 Figure 10 1: A key
CompNeuroSci Ch 10 September 8, 2004 10 Associative Memory Networks 101 Introductory concepts Consider the way we are able to retrieve a pattern from a partial key as in Figure 10 1 Figure 10 1: A key
Hertz, Krogh, Palmer: Introduction to the Theory of Neural Computation. Addison-Wesley Publishing Company (1991). (v ji (1 x i ) + (1 v ji )x i )
. (v ji (1 x i ) + (1 v ji )x i )") Symmetric Networks Hertz, Krogh, Palmer: Introduction to the Theory of Neural Computation. Addison-Wesley Publishing Company (1991). How can we model an associative memory? Let M = {v 1,..., v m } be a
Symmetric Networks Hertz, Krogh, Palmer: Introduction to the Theory of Neural Computation. Addison-Wesley Publishing Company (1991). How can we model an associative memory? Let M = {v 1,..., v m } be a
Neural Network Essentials 1
 Neural Network Essentials Draft: Associative Memory Chapter Anthony S. Maida University of Louisiana at Lafayette, USA June 6, 205 Copyright c 2000 2003 by Anthony S. Maida Contents 0. Associative memory.............................
Neural Network Essentials Draft: Associative Memory Chapter Anthony S. Maida University of Louisiana at Lafayette, USA June 6, 205 Copyright c 2000 2003 by Anthony S. Maida Contents 0. Associative memory.............................
Storage Capacity of Letter Recognition in Hopfield Networks
 Storage Capacity of Letter Recognition in Hopfield Networks Gang Wei (gwei@cs.dal.ca) Zheyuan Yu (zyu@cs.dal.ca) Faculty of Computer Science, Dalhousie University, Halifax, N.S., Canada B3H 1W5 Abstract:
Storage Capacity of Letter Recognition in Hopfield Networks Gang Wei (gwei@cs.dal.ca) Zheyuan Yu (zyu@cs.dal.ca) Faculty of Computer Science, Dalhousie University, Halifax, N.S., Canada B3H 1W5 Abstract:
2- AUTOASSOCIATIVE NET - The feedforward autoassociative net considered in this section is a special case of the heteroassociative net.
 2- AUTOASSOCIATIVE NET - The feedforward autoassociative net considered in this section is a special case of the heteroassociative net. - For an autoassociative net, the training input and target output
2- AUTOASSOCIATIVE NET - The feedforward autoassociative net considered in this section is a special case of the heteroassociative net. - For an autoassociative net, the training input and target output
Logic Learning in Hopfield Networks
 Logic Learning in Hopfield Networks Saratha Sathasivam (Corresponding author) School of Mathematical Sciences, University of Science Malaysia, Penang, Malaysia E-mail: saratha@cs.usm.my Wan Ahmad Tajuddin
Logic Learning in Hopfield Networks Saratha Sathasivam (Corresponding author) School of Mathematical Sciences, University of Science Malaysia, Penang, Malaysia E-mail: saratha@cs.usm.my Wan Ahmad Tajuddin
1 Balanced networks: Trading speed for noise
 Physics 178/278 - David leinfeld - Winter 2017 (Corrected yet incomplete notes) 1 Balanced networks: Trading speed for noise 1.1 Scaling of neuronal inputs An interesting observation is that the subthresold
Physics 178/278 - David leinfeld - Winter 2017 (Corrected yet incomplete notes) 1 Balanced networks: Trading speed for noise 1.1 Scaling of neuronal inputs An interesting observation is that the subthresold
Dynamical Systems and Deep Learning: Overview. Abbas Edalat
 Dynamical Systems and Deep Learning: Overview Abbas Edalat Dynamical Systems The notion of a dynamical system includes the following: A phase or state space, which may be continuous, e.g. the real line,
Dynamical Systems and Deep Learning: Overview Abbas Edalat Dynamical Systems The notion of a dynamical system includes the following: A phase or state space, which may be continuous, e.g. the real line,
Neural Nets and Symbolic Reasoning Hopfield Networks
 Neural Nets and Symbolic Reasoning Hopfield Networks Outline The idea of pattern completion The fast dynamics of Hopfield networks Learning with Hopfield networks Emerging properties of Hopfield networks
Neural Nets and Symbolic Reasoning Hopfield Networks Outline The idea of pattern completion The fast dynamics of Hopfield networks Learning with Hopfield networks Emerging properties of Hopfield networks
Memories Associated with Single Neurons and Proximity Matrices
 Memories Associated with Single Neurons and Proximity Matrices Subhash Kak Oklahoma State University, Stillwater Abstract: This paper extends the treatment of single-neuron memories obtained by the use
Memories Associated with Single Neurons and Proximity Matrices Subhash Kak Oklahoma State University, Stillwater Abstract: This paper extends the treatment of single-neuron memories obtained by the use
Marr's Theory of the Hippocampus: Part I
 Marr's Theory of the Hippocampus: Part I Computational Models of Neural Systems Lecture 3.3 David S. Touretzky October, 2015 David Marr: 1945-1980 10/05/15 Computational Models of Neural Systems 2 Marr
Marr's Theory of the Hippocampus: Part I Computational Models of Neural Systems Lecture 3.3 David S. Touretzky October, 2015 David Marr: 1945-1980 10/05/15 Computational Models of Neural Systems 2 Marr
Artificial Neural Networks Examination, March 2004
 Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Notes on the Matrix-Tree theorem and Cayley s tree enumerator
 Notes on the Matrix-Tree theorem and Cayley s tree enumerator 1 Cayley s tree enumerator Recall that the degree of a vertex in a tree (or in any graph) is the number of edges emanating from it We will
Notes on the Matrix-Tree theorem and Cayley s tree enumerator 1 Cayley s tree enumerator Recall that the degree of a vertex in a tree (or in any graph) is the number of edges emanating from it We will
Neural Networks. Hopfield Nets and Auto Associators Fall 2017
 Neural Networks Hopfield Nets and Auto Associators Fall 2017 1 Story so far Neural networks for computation All feedforward structures But what about.. 2 Loopy network Θ z = ቊ +1 if z > 0 1 if z 0 y i
Neural Networks Hopfield Nets and Auto Associators Fall 2017 1 Story so far Neural networks for computation All feedforward structures But what about.. 2 Loopy network Θ z = ቊ +1 if z > 0 1 if z 0 y i
Hopfield and Potts-Hopfield Networks
 Hopfield and Potts-Hopfield Networks Andy Somogyi Dec 10, 2010 1 Introduction Many early models of neural networks lacked mathematical rigor or analysis. They were, by and large, ad hoc models. John Hopfield
Hopfield and Potts-Hopfield Networks Andy Somogyi Dec 10, 2010 1 Introduction Many early models of neural networks lacked mathematical rigor or analysis. They were, by and large, ad hoc models. John Hopfield
Motivation. Lecture 23. The Stochastic Neuron ( ) Properties of Logistic Sigmoid. Logistic Sigmoid With Varying T. Logistic Sigmoid T = 0.
 Properties of Logistic Sigmoid. Logistic Sigmoid With Varying T. Logistic Sigmoid T = 0.") Motivation Lecture 23 Idea: with low probability, go against the local field move up the energy surface make the wrong microdecision Potential value for optimization: escape from local optima Potential
Motivation Lecture 23 Idea: with low probability, go against the local field move up the energy surface make the wrong microdecision Potential value for optimization: escape from local optima Potential
Effects of Interactive Function Forms in a Self-Organized Critical Model Based on Neural Networks
 Commun. Theor. Phys. (Beijing, China) 40 (2003) pp. 607 613 c International Academic Publishers Vol. 40, No. 5, November 15, 2003 Effects of Interactive Function Forms in a Self-Organized Critical Model
Commun. Theor. Phys. (Beijing, China) 40 (2003) pp. 607 613 c International Academic Publishers Vol. 40, No. 5, November 15, 2003 Effects of Interactive Function Forms in a Self-Organized Critical Model
Effects of refractory periods in the dynamics of a diluted neural network
 Effects of refractory periods in the dynamics of a diluted neural network F. A. Tamarit, 1, * D. A. Stariolo, 2, * S. A. Cannas, 2, *, and P. Serra 2, 1 Facultad de Matemática, Astronomía yfísica, Universidad
Effects of refractory periods in the dynamics of a diluted neural network F. A. Tamarit, 1, * D. A. Stariolo, 2, * S. A. Cannas, 2, *, and P. Serra 2, 1 Facultad de Matemática, Astronomía yfísica, Universidad
arxiv:cond-mat/ v1 [cond-mat.dis-nn] 10 Aug 2004
![arxiv:cond-mat/ v1 [cond-mat.dis-nn] 10 Aug 2004](/thumbs/88/115107924.jpg "arxiv:cond-mat/ v1 [cond-mat.dis-nn] 10 Aug 2004") arxiv:cond-mat/4829v [cond-mat.dis-nn] Aug 24 Competition between ferro-retrieval and anti-ferro orders in a Hopfield-like network model for plant intelligence Jun-ichi Inoue a Bikas K. Chakrabarti b a
arxiv:cond-mat/4829v [cond-mat.dis-nn] Aug 24 Competition between ferro-retrieval and anti-ferro orders in a Hopfield-like network model for plant intelligence Jun-ichi Inoue a Bikas K. Chakrabarti b a
Computational Intelligence Lecture 6: Associative Memory
 Computational Intelligence Lecture 6: Associative Memory Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Fall 2011 Farzaneh Abdollahi Computational Intelligence
Computational Intelligence Lecture 6: Associative Memory Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Fall 2011 Farzaneh Abdollahi Computational Intelligence
Shigetaka Fujita. Rokkodai, Nada, Kobe 657, Japan. Haruhiko Nishimura. Yashiro-cho, Kato-gun, Hyogo , Japan. Abstract
 KOBE-TH-94-07 HUIS-94-03 November 1994 An Evolutionary Approach to Associative Memory in Recurrent Neural Networks Shigetaka Fujita Graduate School of Science and Technology Kobe University Rokkodai, Nada,
KOBE-TH-94-07 HUIS-94-03 November 1994 An Evolutionary Approach to Associative Memory in Recurrent Neural Networks Shigetaka Fujita Graduate School of Science and Technology Kobe University Rokkodai, Nada,
Neural Networks for Machine Learning. Lecture 11a Hopfield Nets
 Neural Networks for Machine Learning Lecture 11a Hopfield Nets Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed Hopfield Nets A Hopfield net is composed of binary threshold
Neural Networks for Machine Learning Lecture 11a Hopfield Nets Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed Hopfield Nets A Hopfield net is composed of binary threshold
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Memory capacity of networks with stochastic binary synapses
 Memory capacity of networks with stochastic binary synapses Alexis M. Dubreuil 1,, Yali Amit 3 and Nicolas Brunel 1, 1 UMR 8118, CNRS, Université Paris Descartes, Paris, France Departments of Statistics
Memory capacity of networks with stochastic binary synapses Alexis M. Dubreuil 1,, Yali Amit 3 and Nicolas Brunel 1, 1 UMR 8118, CNRS, Université Paris Descartes, Paris, France Departments of Statistics
How can ideas from quantum computing improve or speed up neuromorphic models of computation?
 Neuromorphic Computation: Architectures, Models, Applications Associative Memory Models with Adiabatic Quantum Optimization Kathleen Hamilton, Alexander McCaskey, Jonathan Schrock, Neena Imam and Travis
Neuromorphic Computation: Architectures, Models, Applications Associative Memory Models with Adiabatic Quantum Optimization Kathleen Hamilton, Alexander McCaskey, Jonathan Schrock, Neena Imam and Travis
Chapter 10 Associative Memory Networks We are in for a surprise though!
 We are in for a surprise though! 11 If we return to our calculated W based on the stored ξ and use x = (-1,1,-1,-1,-1,1) T as the input then we get the output y = (-1,1,-1,-1,-1,1) T, i.e. the same output
We are in for a surprise though! 11 If we return to our calculated W based on the stored ξ and use x = (-1,1,-1,-1,-1,1) T as the input then we get the output y = (-1,1,-1,-1,-1,1) T, i.e. the same output
Generalization in a Hopfield network
 Generalization in a Hopfield network J.F. Fontanari To cite this version: J.F. Fontanari. Generalization in a Hopfield network. Journal de Physique, 1990, 51 (21), pp.2421-2430. .
Generalization in a Hopfield network J.F. Fontanari To cite this version: J.F. Fontanari. Generalization in a Hopfield network. Journal de Physique, 1990, 51 (21), pp.2421-2430. .
Computing Neural Network Gradients
 Computing Neural Network Gradients Kevin Clark 1 Introduction The purpose of these notes is to demonstrate how to quickly compute neural network gradients in a completely vectorized way. It is complementary
Computing Neural Network Gradients Kevin Clark 1 Introduction The purpose of these notes is to demonstrate how to quickly compute neural network gradients in a completely vectorized way. It is complementary
Supporting Online Material for
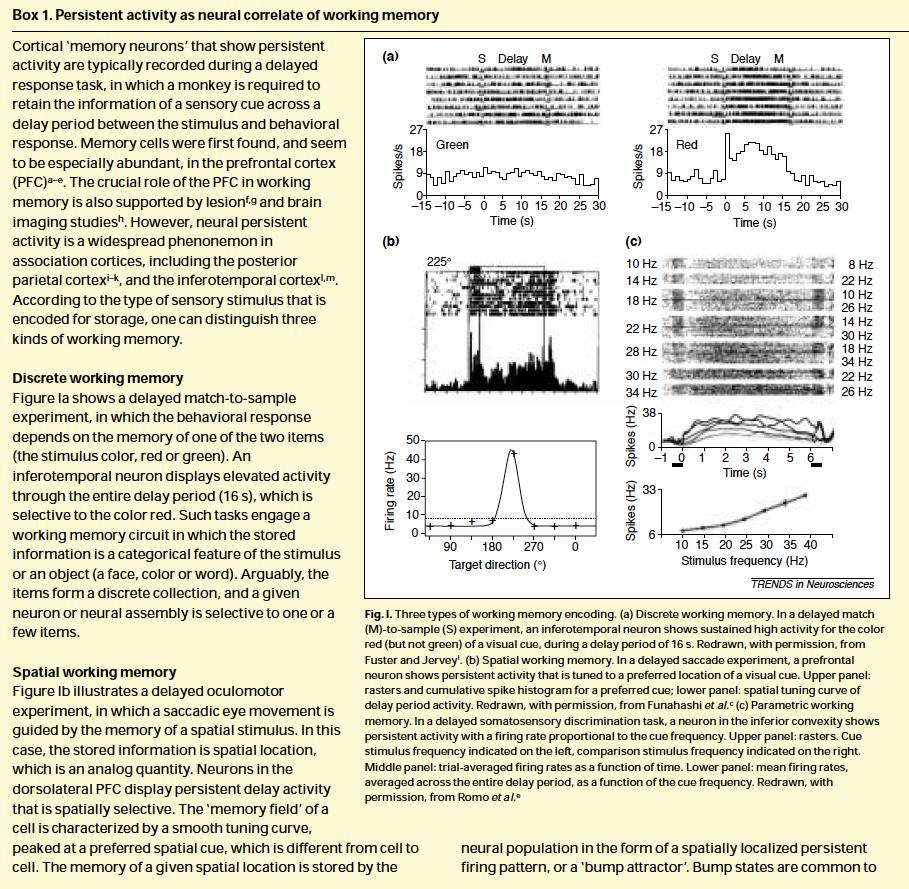
 www.sciencemag.org/cgi/content/full/319/5869/1543/dc1 Supporting Online Material for Synaptic Theory of Working Memory Gianluigi Mongillo, Omri Barak, Misha Tsodyks* *To whom correspondence should be addressed.
www.sciencemag.org/cgi/content/full/319/5869/1543/dc1 Supporting Online Material for Synaptic Theory of Working Memory Gianluigi Mongillo, Omri Barak, Misha Tsodyks* *To whom correspondence should be addressed.
arxiv:cond-mat/ v1 [cond-mat.dis-nn] 30 Sep 1999
![arxiv:cond-mat/ v1 [cond-mat.dis-nn] 30 Sep 1999](/thumbs/86/94418156.jpg "arxiv:cond-mat/ v1 [cond-mat.dis-nn] 30 Sep 1999") arxiv:cond-mat/9909443v1 [cond-mat.dis-nn] 30 Sep 1999 Thresholds in layered neural networks with variable activity 1. Introduction D Bollé and G Massolo Instituut voor Theoretische Fysica, K.U. Leuven,
arxiv:cond-mat/9909443v1 [cond-mat.dis-nn] 30 Sep 1999 Thresholds in layered neural networks with variable activity 1. Introduction D Bollé and G Massolo Instituut voor Theoretische Fysica, K.U. Leuven,
Slide10 Haykin Chapter 14: Neurodynamics (3rd Ed. Chapter 13)
") Slie10 Haykin Chapter 14: Neuroynamics (3r E. Chapter 13) CPSC 636-600 Instructor: Yoonsuck Choe Spring 2012 Neural Networks with Temporal Behavior Inclusion of feeback gives temporal characteristics to
Slie10 Haykin Chapter 14: Neuroynamics (3r E. Chapter 13) CPSC 636-600 Instructor: Yoonsuck Choe Spring 2012 Neural Networks with Temporal Behavior Inclusion of feeback gives temporal characteristics to
Physics 115/242 Monte Carlo simulations in Statistical Physics
 Physics 115/242 Monte Carlo simulations in Statistical Physics Peter Young (Dated: May 12, 2007) For additional information on the statistical Physics part of this handout, the first two sections, I strongly
Physics 115/242 Monte Carlo simulations in Statistical Physics Peter Young (Dated: May 12, 2007) For additional information on the statistical Physics part of this handout, the first two sections, I strongly
T sg. α c (0)= T=1/β. α c (T ) α=p/n
= T=1/β. α c (T ) α=p/n") Taejon, Korea, vol. 2 of 2, pp. 779{784, Nov. 2. Capacity Analysis of Bidirectional Associative Memory Toshiyuki Tanaka y, Shinsuke Kakiya y, and Yoshiyuki Kabashima z ygraduate School of Engineering,
Taejon, Korea, vol. 2 of 2, pp. 779{784, Nov. 2. Capacity Analysis of Bidirectional Associative Memory Toshiyuki Tanaka y, Shinsuke Kakiya y, and Yoshiyuki Kabashima z ygraduate School of Engineering,
Neurophysiology of a VLSI spiking neural network: LANN21
 Neurophysiology of a VLSI spiking neural network: LANN21 Stefano Fusi INFN, Sezione Roma I Università di Roma La Sapienza Pza Aldo Moro 2, I-185, Roma fusi@jupiter.roma1.infn.it Paolo Del Giudice Physics
Neurophysiology of a VLSI spiking neural network: LANN21 Stefano Fusi INFN, Sezione Roma I Università di Roma La Sapienza Pza Aldo Moro 2, I-185, Roma fusi@jupiter.roma1.infn.it Paolo Del Giudice Physics
Markov Chains and MCMC
 Markov Chains and MCMC Markov chains Let S = {1, 2,..., N} be a finite set consisting of N states. A Markov chain Y 0, Y 1, Y 2,... is a sequence of random variables, with Y t S for all points in time
Markov Chains and MCMC Markov chains Let S = {1, 2,..., N} be a finite set consisting of N states. A Markov chain Y 0, Y 1, Y 2,... is a sequence of random variables, with Y t S for all points in time
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Communication Engineering Prof. Surendra Prasad Department of Electrical Engineering Indian Institute of Technology, Delhi
 Communication Engineering Prof. Surendra Prasad Department of Electrical Engineering Indian Institute of Technology, Delhi Lecture - 41 Pulse Code Modulation (PCM) So, if you remember we have been talking
Communication Engineering Prof. Surendra Prasad Department of Electrical Engineering Indian Institute of Technology, Delhi Lecture - 41 Pulse Code Modulation (PCM) So, if you remember we have been talking
The Derivative of a Function
 The Derivative of a Function James K Peterson Department of Biological Sciences and Department of Mathematical Sciences Clemson University March 1, 2017 Outline A Basic Evolutionary Model The Next Generation
The Derivative of a Function James K Peterson Department of Biological Sciences and Department of Mathematical Sciences Clemson University March 1, 2017 Outline A Basic Evolutionary Model The Next Generation
Lecture 7 Artificial neural networks: Supervised learning
 Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
The Mixed States of Associative Memories Realize Unimodal Distribution of Dominance Durations in Multistable Perception
 The Mixed States of Associative Memories Realize Unimodal Distribution of Dominance Durations in Multistable Perception Takashi Kanamaru Department of Mechanical Science and ngineering, School of Advanced
The Mixed States of Associative Memories Realize Unimodal Distribution of Dominance Durations in Multistable Perception Takashi Kanamaru Department of Mechanical Science and ngineering, School of Advanced
Slope Fields: Graphing Solutions Without the Solutions
 8 Slope Fields: Graphing Solutions Without the Solutions Up to now, our efforts have been directed mainly towards finding formulas or equations describing solutions to given differential equations. Then,
8 Slope Fields: Graphing Solutions Without the Solutions Up to now, our efforts have been directed mainly towards finding formulas or equations describing solutions to given differential equations. Then,
Q520: Answers to the Homework on Hopfield Networks. 1. For each of the following, answer true or false with an explanation:
 Q50: Answers to the Homework on Hopfield Networks 1. For each of the following, answer true or false with an explanation: a. Fix a Hopfield net. If o and o are neighboring observation patterns then Φ(
Q50: Answers to the Homework on Hopfield Networks 1. For each of the following, answer true or false with an explanation: a. Fix a Hopfield net. If o and o are neighboring observation patterns then Φ(
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Potts And XY, Together At Last
 Potts And XY, Together At Last Daniel Kolodrubetz Massachusetts Institute of Technology, Center for Theoretical Physics (Dated: May 16, 212) We investigate the behavior of an XY model coupled multiplicatively
Potts And XY, Together At Last Daniel Kolodrubetz Massachusetts Institute of Technology, Center for Theoretical Physics (Dated: May 16, 212) We investigate the behavior of an XY model coupled multiplicatively
The (magnetic) Helmholtz free energy has proper variables T and B. In differential form. and the entropy and magnetisation are thus given by
 Helmholtz free energy has proper variables T and B. In differential form. and the entropy and magnetisation are thus given by") 4.5 Landau treatment of phase transitions 4.5.1 Landau free energy In order to develop a general theory of phase transitions it is necessary to extend the concept of the free energy. For definiteness we
4.5 Landau treatment of phase transitions 4.5.1 Landau free energy In order to develop a general theory of phase transitions it is necessary to extend the concept of the free energy. For definiteness we
Using Variable Threshold to Increase Capacity in a Feedback Neural Network
 Using Variable Threshold to Increase Capacity in a Feedback Neural Network Praveen Kuruvada Abstract: The article presents new results on the use of variable thresholds to increase the capacity of a feedback
Using Variable Threshold to Increase Capacity in a Feedback Neural Network Praveen Kuruvada Abstract: The article presents new results on the use of variable thresholds to increase the capacity of a feedback
J. Marro Institute Carlos I, University of Granada. Net-Works 08, Pamplona, 9-11 June 2008
 J. Marro http://ergodic.ugr.es/jmarro Institute Carlos I, University of Granada Net-Works 08, Pamplona, 9-11 June 2008 Networks? mathematical objects Königsberg bridges + Euler graphs (s. XVIII),... models
J. Marro http://ergodic.ugr.es/jmarro Institute Carlos I, University of Granada Net-Works 08, Pamplona, 9-11 June 2008 Networks? mathematical objects Königsberg bridges + Euler graphs (s. XVIII),... models
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
arxiv: v2 [nlin.ao] 19 May 2015
![arxiv: v2 [nlin.ao] 19 May 2015](/thumbs/89/98121223.jpg "arxiv: v2 [nlin.ao] 19 May 2015") Efficient and optimal binary Hopfield associative memory storage using minimum probability flow arxiv:1204.2916v2 [nlin.ao] 19 May 2015 Christopher Hillar Redwood Center for Theoretical Neuroscience University
Efficient and optimal binary Hopfield associative memory storage using minimum probability flow arxiv:1204.2916v2 [nlin.ao] 19 May 2015 Christopher Hillar Redwood Center for Theoretical Neuroscience University
Properties of Associative Memory Model with the β-th-order Synaptic Decay
 Regular Paper Properties of Associative Memory Model with the β-th-order Synaptic Decay Ryota Miyata 1,2 Toru Aonishi 1 Jun Tsuzurugi 3 Koji Kurata 4,a) Received: January 30, 2013, Revised: March 20, 2013/June
Regular Paper Properties of Associative Memory Model with the β-th-order Synaptic Decay Ryota Miyata 1,2 Toru Aonishi 1 Jun Tsuzurugi 3 Koji Kurata 4,a) Received: January 30, 2013, Revised: March 20, 2013/June
Artificial Neural Networks Examination, June 2004
 Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Linear Regression, Neural Networks, etc.
 Linear Regression, Neural Networks, etc. Gradient Descent Many machine learning problems can be cast as optimization problems Define a function that corresponds to learning error. (More on this later)
Linear Regression, Neural Networks, etc. Gradient Descent Many machine learning problems can be cast as optimization problems Define a function that corresponds to learning error. (More on this later)
Determinants in detail
 Determinants in detail Kyle Miller September 27, 2016 The book s introduction to the determinant det A of an n n square matrix A is to say there is a quantity which determines exactly when A is invertible,
Determinants in detail Kyle Miller September 27, 2016 The book s introduction to the determinant det A of an n n square matrix A is to say there is a quantity which determines exactly when A is invertible,
Mathematical Models of Dynamic Behavior of Individual Neural Networks of Central Nervous System
 Mathematical Models of Dynamic Behavior of Individual Neural Networks of Central Nervous System Dimitra Despoina Pagania 1, Adam Adamopoulos 1,2 and Spiridon D. Likothanassis 1 1 Pattern Recognition Laboratory,
Mathematical Models of Dynamic Behavior of Individual Neural Networks of Central Nervous System Dimitra Despoina Pagania 1, Adam Adamopoulos 1,2 and Spiridon D. Likothanassis 1 1 Pattern Recognition Laboratory,
Neural Networks. Associative memory 12/30/2015. Associative memories. Associative memories
 //5 Neural Netors Associative memory Lecture Associative memories Associative memories The massively parallel models of associative or content associative memory have been developed. Some of these models
//5 Neural Netors Associative memory Lecture Associative memories Associative memories The massively parallel models of associative or content associative memory have been developed. Some of these models
Associative Memories (I) Hopfield Networks
 Hopfield Networks") Associative Memories (I) Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Applied Brain Science - Computational Neuroscience (CNS) A Pun Associative Memories Introduction
Associative Memories (I) Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Applied Brain Science - Computational Neuroscience (CNS) A Pun Associative Memories Introduction
Fundamentals of Mathematics I
 Fundamentals of Mathematics I Kent State Department of Mathematical Sciences Fall 2008 Available at: http://www.math.kent.edu/ebooks/10031/book.pdf August 4, 2008 Contents 1 Arithmetic 2 1.1 Real Numbers......................................................
Fundamentals of Mathematics I Kent State Department of Mathematical Sciences Fall 2008 Available at: http://www.math.kent.edu/ebooks/10031/book.pdf August 4, 2008 Contents 1 Arithmetic 2 1.1 Real Numbers......................................................
Branislav K. Nikolić
 Interdisciplinary Topics in Complex Systems: Cellular Automata, Self-Organized Criticality, Neural Networks and Spin Glasses Branislav K. Nikolić Department of Physics and Astronomy, University of Delaware,
Interdisciplinary Topics in Complex Systems: Cellular Automata, Self-Organized Criticality, Neural Networks and Spin Glasses Branislav K. Nikolić Department of Physics and Astronomy, University of Delaware,
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Implementing Competitive Learning in a Quantum System
 Implementing Competitive Learning in a Quantum System Dan Ventura fonix corporation dventura@fonix.com http://axon.cs.byu.edu/dan Abstract Ideas from quantum computation are applied to the field of neural
Implementing Competitive Learning in a Quantum System Dan Ventura fonix corporation dventura@fonix.com http://axon.cs.byu.edu/dan Abstract Ideas from quantum computation are applied to the field of neural
The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural
 learning techniques for neural") 1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
SCHOOL OF MATHEMATICS MATHEMATICS FOR PART I ENGINEERING. Self-paced Course
 SCHOOL OF MATHEMATICS MATHEMATICS FOR PART I ENGINEERING Self-paced Course MODULE ALGEBRA Module Topics Simplifying expressions and algebraic functions Rearranging formulae Indices 4 Rationalising a denominator
SCHOOL OF MATHEMATICS MATHEMATICS FOR PART I ENGINEERING Self-paced Course MODULE ALGEBRA Module Topics Simplifying expressions and algebraic functions Rearranging formulae Indices 4 Rationalising a denominator
Correlation. We don't consider one variable independent and the other dependent. Does x go up as y goes up? Does x go down as y goes up?
 Comment: notes are adapted from BIOL 214/312. I. Correlation. Correlation A) Correlation is used when we want to examine the relationship of two continuous variables. We are not interested in prediction.
Comment: notes are adapted from BIOL 214/312. I. Correlation. Correlation A) Correlation is used when we want to examine the relationship of two continuous variables. We are not interested in prediction.
[Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty.]
![[Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty.]](/thumbs/82/86615903.jpg "[Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty.]") Math 43 Review Notes [Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty Dot Product If v (v, v, v 3 and w (w, w, w 3, then the
Math 43 Review Notes [Disclaimer: This is not a complete list of everything you need to know, just some of the topics that gave people difficulty Dot Product If v (v, v, v 3 and w (w, w, w 3, then the
A = , A 32 = n ( 1) i +j a i j det(a i j). (1) j=1
 i +j a i j det(a i j). (1) j=1") Lecture Notes: Determinant of a Square Matrix Yufei Tao Department of Computer Science and Engineering Chinese University of Hong Kong taoyf@cse.cuhk.edu.hk 1 Determinant Definition Let A [a ij ] be an
Lecture Notes: Determinant of a Square Matrix Yufei Tao Department of Computer Science and Engineering Chinese University of Hong Kong taoyf@cse.cuhk.edu.hk 1 Determinant Definition Let A [a ij ] be an
At the Edge of Chaos: Real-time Computations and Self-Organized Criticality in Recurrent Neural Networks
 At the Edge of Chaos: Real-time Computations and Self-Organized Criticality in Recurrent Neural Networks Thomas Natschläger Software Competence Center Hagenberg A-4232 Hagenberg, Austria Thomas.Natschlaeger@scch.at
At the Edge of Chaos: Real-time Computations and Self-Organized Criticality in Recurrent Neural Networks Thomas Natschläger Software Competence Center Hagenberg A-4232 Hagenberg, Austria Thomas.Natschlaeger@scch.at
Content-Addressable Memory Associative Memory Lernmatrix Association Heteroassociation Learning Retrieval Reliability of the answer
 Associative Memory Content-Addressable Memory Associative Memory Lernmatrix Association Heteroassociation Learning Retrieval Reliability of the answer Storage Analysis Sparse Coding Implementation on a
Associative Memory Content-Addressable Memory Associative Memory Lernmatrix Association Heteroassociation Learning Retrieval Reliability of the answer Storage Analysis Sparse Coding Implementation on a
Neural Networks. Fundamentals Framework for distributed processing Network topologies Training of ANN s Notation Perceptron Back Propagation
 Neural Networks Fundamentals Framework for distributed processing Network topologies Training of ANN s Notation Perceptron Back Propagation Neural Networks Historical Perspective A first wave of interest
Neural Networks Fundamentals Framework for distributed processing Network topologies Training of ANN s Notation Perceptron Back Propagation Neural Networks Historical Perspective A first wave of interest
High-Capacity Quantum Associative Memories
 High-Capacity Quantum Associative Memories M. Cristina Diamantini INFN and Dipartimento di Fisica, University of Perugia, via A. Pascoli, I-06100 Perugia, Italy Carlo A. Trugenberger SwissScientific, chemin
High-Capacity Quantum Associative Memories M. Cristina Diamantini INFN and Dipartimento di Fisica, University of Perugia, via A. Pascoli, I-06100 Perugia, Italy Carlo A. Trugenberger SwissScientific, chemin
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
Treatment of Error in Experimental Measurements
 in Experimental Measurements All measurements contain error. An experiment is truly incomplete without an evaluation of the amount of error in the results. In this course, you will learn to use some common
in Experimental Measurements All measurements contain error. An experiment is truly incomplete without an evaluation of the amount of error in the results. In this course, you will learn to use some common
The Hypercube Graph and the Inhibitory Hypercube Network
 The Hypercube Graph and the Inhibitory Hypercube Network Michael Cook mcook@forstmannleff.com William J. Wolfe Professor of Computer Science California State University Channel Islands william.wolfe@csuci.edu
The Hypercube Graph and the Inhibitory Hypercube Network Michael Cook mcook@forstmannleff.com William J. Wolfe Professor of Computer Science California State University Channel Islands william.wolfe@csuci.edu
Sample Exam COMP 9444 NEURAL NETWORKS Solutions
 FAMILY NAME OTHER NAMES STUDENT ID SIGNATURE Sample Exam COMP 9444 NEURAL NETWORKS Solutions (1) TIME ALLOWED 3 HOURS (2) TOTAL NUMBER OF QUESTIONS 12 (3) STUDENTS SHOULD ANSWER ALL QUESTIONS (4) QUESTIONS
FAMILY NAME OTHER NAMES STUDENT ID SIGNATURE Sample Exam COMP 9444 NEURAL NETWORKS Solutions (1) TIME ALLOWED 3 HOURS (2) TOTAL NUMBER OF QUESTIONS 12 (3) STUDENTS SHOULD ANSWER ALL QUESTIONS (4) QUESTIONS
THE N-VALUE GAME OVER Z AND R
 THE N-VALUE GAME OVER Z AND R YIDA GAO, MATT REDMOND, ZACH STEWARD Abstract. The n-value game is an easily described mathematical diversion with deep underpinnings in dynamical systems analysis. We examine
THE N-VALUE GAME OVER Z AND R YIDA GAO, MATT REDMOND, ZACH STEWARD Abstract. The n-value game is an easily described mathematical diversion with deep underpinnings in dynamical systems analysis. We examine
Stochastic Learning in a Neural Network with Adapting. Synapses. Istituto Nazionale di Fisica Nucleare, Sezione di Bari
 Stochastic Learning in a Neural Network with Adapting Synapses. G. Lattanzi 1, G. Nardulli 1, G. Pasquariello and S. Stramaglia 1 Dipartimento di Fisica dell'universita di Bari and Istituto Nazionale di
Stochastic Learning in a Neural Network with Adapting Synapses. G. Lattanzi 1, G. Nardulli 1, G. Pasquariello and S. Stramaglia 1 Dipartimento di Fisica dell'universita di Bari and Istituto Nazionale di
Simple Neural Nets for Pattern Classification: McCulloch-Pitts Threshold Logic CS 5870
 Simple Neural Nets for Pattern Classification: McCulloch-Pitts Threshold Logic CS 5870 Jugal Kalita University of Colorado Colorado Springs Fall 2014 Logic Gates and Boolean Algebra Logic gates are used
Simple Neural Nets for Pattern Classification: McCulloch-Pitts Threshold Logic CS 5870 Jugal Kalita University of Colorado Colorado Springs Fall 2014 Logic Gates and Boolean Algebra Logic gates are used
Plasticity and learning in a network of coupled phase oscillators
 PHYSICAL REVIEW E, VOLUME 65, 041906 Plasticity and learning in a network of coupled phase oscillators Philip Seliger, Stephen C. Young, and Lev S. Tsimring Institute for onlinear Science, University of
PHYSICAL REVIEW E, VOLUME 65, 041906 Plasticity and learning in a network of coupled phase oscillators Philip Seliger, Stephen C. Young, and Lev S. Tsimring Institute for onlinear Science, University of
A description of a math circle set of activities around polynomials, especially interpolation.
 A description of a math circle set of activities around polynomials, especially interpolation. Bob Sachs Department of Mathematical Sciences George Mason University Fairfax, Virginia 22030 rsachs@gmu.edu
A description of a math circle set of activities around polynomials, especially interpolation. Bob Sachs Department of Mathematical Sciences George Mason University Fairfax, Virginia 22030 rsachs@gmu.edu
Time Series 2. Robert Almgren. Sept. 21, 2009
 Time Series 2 Robert Almgren Sept. 21, 2009 This week we will talk about linear time series models: AR, MA, ARMA, ARIMA, etc. First we will talk about theory and after we will talk about fitting the models
Time Series 2 Robert Almgren Sept. 21, 2009 This week we will talk about linear time series models: AR, MA, ARMA, ARIMA, etc. First we will talk about theory and after we will talk about fitting the models
Chapter 9: The Perceptron
 Chapter 9: The Perceptron 9.1 INTRODUCTION At this point in the book, we have completed all of the exercises that we are going to do with the James program. These exercises have shown that distributed
Chapter 9: The Perceptron 9.1 INTRODUCTION At this point in the book, we have completed all of the exercises that we are going to do with the James program. These exercises have shown that distributed