Representing Images Detecting faces in images
|
|
|
- Bryce Harper
- 5 years ago
- Views:
Transcription
1 Machine Learning for Signal Processing Representing Images Detecting faces in images Class Sep 2009 Instructor: Bhiksha Raj


2 Last Class: Representing Audio n Basic DFT n Computing a Spectrogram n Computing additional features from a spectrogram

3 What about images? Npixels / 64 columns DCT n DCT of small segments q 8x8 q Each image becomes a matrix of DCT vectors n DCT of the image n Haar transform (checkerboard) n Or data-driven representations..
4 Returning to Eigen Computation n A collection of faces q All normalized to 100x100 pixels n What is common among all of them? q Do we have a common descriptor?
5 A least squares typical face The typical face n n n n Can we do better than a blank screen to find the most common portion of faces? q The first checkerboard; the zeroth frequency component.. Assumption: There is a typical face that captures most of what is common to all faces q Every face can be represented by a scaled version of a typical face n What is this face? Approximate every face f as f = w f V Estimate V to minimize the squared error q How? q What is V?
6 A collection of least squares typical faces n n Assumption: There are a set of K typical faces that captures most of all faces Approximate every face f as f = w f,1 V 1 + w f,2 V 2 + w f,3 V w f,k V k q V 2 is used to correct errors resulting from using only V 1 n So the total energy in w f,2 (S w f,2 2 ) must be lesser than the total energy in w f,1 (S w f,1 2 ) q V 3 corrects errors remaining after correction with V 2 n n The total energy in w f,3 must be lesser than that even in w f,2 q And so on.. q V = [V 1 V 2 V 3 ] Estimate V to minimize the squared error q How? q What is V?
*M W = U =?")
7 A recollection M = V=PINV(W)*M W = U =?
8 How about the other way? M = V = W =? U =? n W = M * Pinv(V)
9 How about the other way? M = V =? W =? U =? n W V \approx = M



10 Eigen Faces! M = Data Matrix V W U = Approximation n Here W, V and U are ALL unknown and must be determined q Such that the squared error between U and M is minimum n Eigen analysis allows you to find W and V such that U = WV has the least squared error with respect to the original data M n If the original data are a collection of faces, the columns of W are eigen faces.
11 Eigen faces 300x x300 M = Data Matrix M T = Transposed Data Matrix = 10000x10000 Correlation n Lay all faces side by side in vector form to form a matrix q In my example: 300 faces. So the matrix is x 300 n Multiply the matrix by its transpose q The correlation matrix is 10000x10000
12 Eigen faces n Compute the eigen vectors q Only 300 of the eigen values are non-zero n Why? n Retain eigen vectors with high eigen values (>0) q Could use a higher threshold [U,S] = eig(correlation) = l l l S = U eigenface1 eigenface2
13 Eigen Faces eigenface1 eigenface2 U = eigenface1 eigenface2 n The eigen vector with the highest eigen value is the first typical face n The vector with the second highest eigen value is the second typical face. n Etc. eigenface3
14 Representing a face = w 1 + w 2 + w 3 Representation = [w 1 w 2 w 3. ] T n The weights with which the eigen faces must be combined to compose the face are used to represent the face!
15 SVD instead of Eigen 10000x300 M = Data Matrix = U=10000x300 S=300x300 V=300x300 U = eigenface1 eigenface2 n Do we need to compute a x correlation matrix and then perform Eigen analysis? q n SVD q Will take a very long time on your laptop Only need to perform Thin SVD. Very fast n U = x 300 q The columns of U are the eigen faces! q The Us corresponding to the zero eigen values are not computed n S = 300 x 300 n V = 300 x 300
16 NORMALIZING OUT VARIATIONS
17 Images: Accounting for variations n What are the obvious differences in the above images n How can we capture these differences q Hint image histograms..
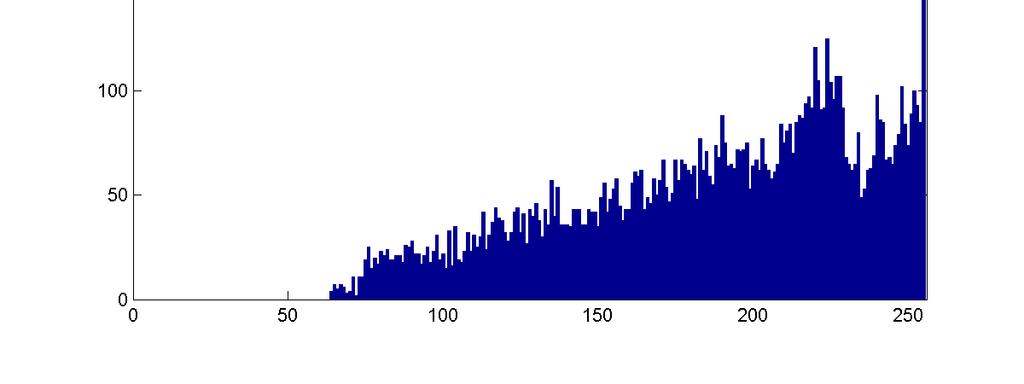
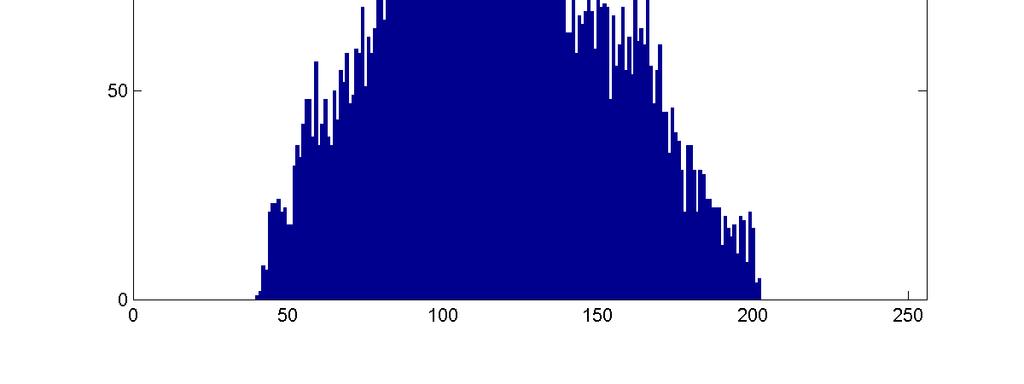
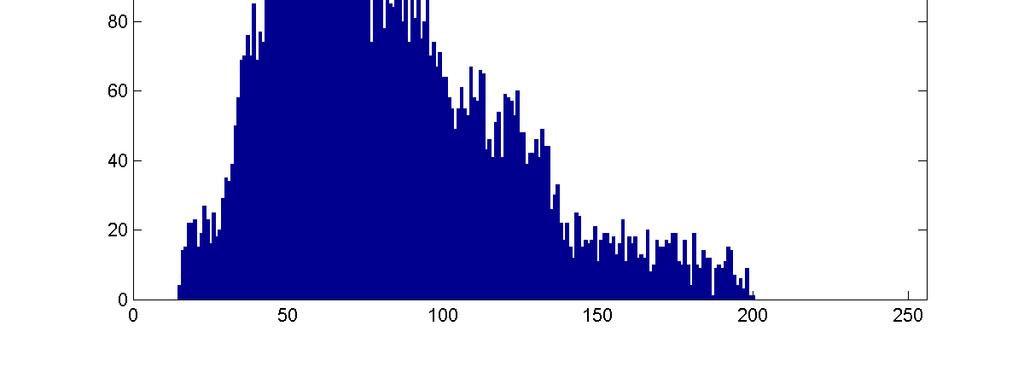
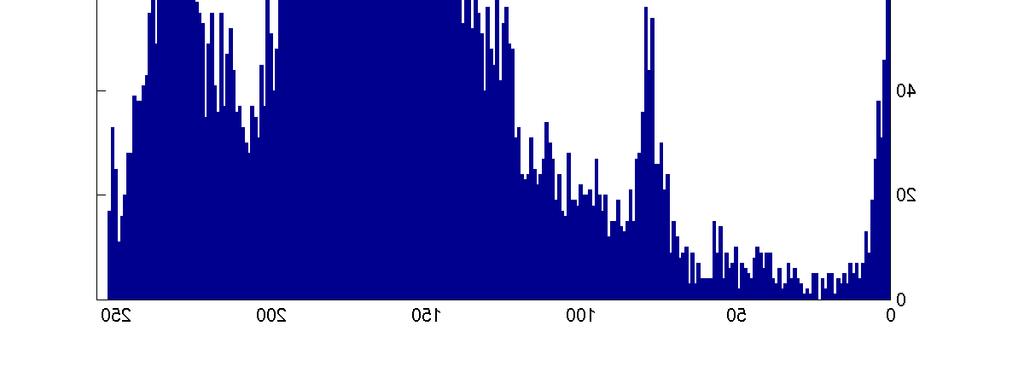
18 Images -- Variations n Pixel histograms: what are the differences
19 Normalizing Image Characteristics n Normalize the pictures q Eliminate lighting/contrast variations q All pictures must have similar lighting n How? n Lighting and contrast are represented in the image histograms:
20 Histogram Equalization n Normalize histograms of images q Maximize the contrast n n Contrast is defined as the flatness of the histogram For maximal contrast, every greyscale must happen as frequently as every other greyscale n Maximizing the contrast: Flattening the histogram q Doing it for every image ensures that every image has the same constrast n I.e. exactly the same histogram of pixel values q Which should be flat
21 Histogram Equalization n Modify pixel values such that histogram becomes flat. n For each pixel q New pixel value = f(old pixel value) q What is f()? n Easy way to compute this function: map cumulative counts
22 Cumulative Count Function n The histogram (count) of a pixel value X is the number of pixels in the image that have value X q E.g. in the above image, the count of pixel value 180 is about 110 n The cumulative count at pixel value X is the total number of pixels that have values in the range 0 <= x <= X q CCF(X) = H(1) + H(2) +.. H(X)
23 Cumulative Count Function n The cumulative count function of a uniform histogram is a line n We must modify the pixel values of the image so that its cumulative count is a line
24 Mapping CCFs Move x axis levels around until the plot to the left looks like the plot to the right n CCF(f(x)) -> a*f(x) [of a*(f(x)+1) if pixels can take value 0] q x = pixel value q f() is the function that converts the old pixel value to a new (normalized) pixel value q a = (total no. of pixels in image) / (total no. of pixel levels) n The no. of pixel levels is 256 in our examples n Total no. of pixels is in a 100x100 image
25 Mapping CCFs n For each pixel value x: q Find the location on the red line that has the closet Y value to the observed CCF at x
26 Mapping CCFs f(x1) = x2 f(x3) = x4 Etc. x3 x1 n For each pixel value x: x4 q Find the location on the red line that has the closet Y value to the observed CCF at x x2
27 Mapping CCFs Move x axis levels around until the plot to the left looks like the plot to the right n For each pixel in the image to the left q The pixel has a value x q Find the CCF at that pixel value CCF(x) q Find x such that CCF(x ) in the function to the right equals CCF(x) n x such that CCF_flat(x ) = CCF(x) q Modify the pixel value to x
28 Doing it Formulaically CCF( x) -CCF f ( x) = round min Max. pixel. value Npixels-CCFmin n CCF min is the smallest non-zero value of CCF(x) q The value of the CCF at the smallest observed pixel value n Npixels is the total no. of pixels in the image q for a 100x100 image n Max.pixel.value is the highest pixel value q 255 for 8-bit pixel representations
29 Or even simpler n Matlab: q Newimage = histeq(oldimage)



30 Histogram Equalization n Left column: Original image n Right column: Equalized image n All images now have similar contrast levels


31 Eigenfaces after Equalization n Left panel : Without HEQ n Right panel: With HEQ q Eigen faces are more face like.. n Need not always be the case
32 Detecting Faces in Images

33 Detecting Faces in Images n Finding face like patterns q How do we find if a picture has faces in it q Where are the faces? n A simple solution: q Define a typical face q Find the typical face in the image

34 Finding faces in an image n Picture is larger than the typical face q E.g. typical face is 100x100, picture is 600x800 n First convert to greyscale q R + G + B q Not very useful to work in color
35 Finding faces in an image n Goal.. To find out if and where images that look like the typical face occur in the picture
36 Finding faces in an image n Try to match the typical face to each location in the picture
37 Finding faces in an image n Try to match the typical face to each location in the picture
38 Finding faces in an image n Try to match the typical face to each location in the picture
39 Finding faces in an image n Try to match the typical face to each location in the picture
40 Finding faces in an image n Try to match the typical face to each location in the picture
41 Finding faces in an image n Try to match the typical face to each location in the picture
42 Finding faces in an image n Try to match the typical face to each location in the picture
43 Finding faces in an image n Try to match the typical face to each location in the picture
44 Finding faces in an image n Try to match the typical face to each location in the picture
45 Finding faces in an image n Try to match the typical face to each location in the picture n The typical face will explain some spots on the image much better than others q These are the spots at which we probably have a face!
46 How to match n What exactly is the match q What is the match score n The DOT Product q Express the typical face as a vector q Express the region of the image being evaluated as a vector n But first histogram equalize the region q Just the section being evaluated, without considering the rest of the image q Compute the dot product of the typical face vector and the region vector
47 What do we get n The right panel shows the dot product a various loctions q Redder is higher n The locations of peaks indicate locations of faces!

48 What do we get n The right panel shows the dot product a various loctions q Redder is higher n The locations of peaks indicate locations of faces! n Correctly detects all three faces q Likes George s face most n He looks most like the typical face n Also finds a face where there is none! q A false alarm


49 Scaling and Rotation Problems n Scaling q Not all faces are the same size q Some people have bigger faces q The size of the face on the image changes with perspective q Our typical face only represents one of these sizes n Rotation q The head need not always be upright! n Our typical face image was upright

50 Solution n Create many typical faces q One for each scaling factor q One for each rotation n How will we do this? n Match them all n Does this work q Kind of.. Not well enough at all q We need more sophisticated models
 and employ them in complex neural networks.")
51 Face Detection: A Quick Historical Perspective n Many more complex methods q Use edge detectors and search for face like patterns q Find feature detectors (noses, ears..) and employ them in complex neural networks.. n The Viola Jones method q Boosted cascaded classifiers n But first, what is boosting
52 And even before that what is classification? n Given features describing an entity, determine the category it belongs to q Walks on two legs, has no hair. Is this n A Chimpanizee n A Human q Has long hair, is 5 4 tall, is this n A man n A woman q Matches eye pattern with score 0.5, mouth pattern with score 0.25, nose pattern with score 0.1. Are we looking at n A face n Not a face?
53 Classification n Multi-class classification q Many possible categories n E.g. Sounds AH, IY, UW, EY.. n E.g. Images Tree, dog, house, person.. n Binary classification q Only two categories n Man vs. Woman n Face vs. not a face.. n Face detection: Recast as binary face classification q For each little square of the image, determine if the square represents a face or not
54 Face Detection as Classification For each square, run a classifier to find out if it is a face or not n Faces can be many sizes n They can happen anywhere in the image n For each face size q For each location n Classify a rectangular region of the face size, at that location, as a face or not a face n This is a series of binary classification problems
55 Introduction to Boosting n An ensemble method that sequentially combines many simple BINARY classifiers to construct a final complex classifier q Simple classifiers are often called weak learners q The complex classifiers are called strong learners n Each weak learner focuses on instances where the previous classifier failed q Give greater weight to instances that have been incorrectly classified by previous learners n Restrictions for weak learners q Better than 50% correct n Final classifier is weighted sum of weak classifiers
56 Boosting: A very simple idea n One can come up with many rules to classify q E.g. Chimpanzee vs. Human classifier: q If arms == long, entity is chimpanzee q If height > 5 6 entity is human q If lives in house == entity is human q If lives in zoo == entity is chimpanzee n Each of them is a reasonable rule, but makes many mistakes q Each rule has an intrinsic error rate n Combine the predictions of these rules q But not equally q Rules that are less accurate should be given lesser weight

57 Boosting and the Chimpanzee Problem Arm length? a armlength Height? a height Lives in house? a house Lives in zoo? a zoo human human chimp chimp n n n The total confidence in all classifiers that classify the entity as a chimpanzee is Scorechimp = classifier classifier favors chimpanzee The total confidence in all classifiers that classify it as a human is Scorehuman = If Score chimpanzee > Score human then the our belief that we have a chimpanzee is greater than the belief that we have a human a a classifier classifier favors human
58 Boosting as defined by Freund n A gambler wants to write a program to predict winning horses. His program must encode the expertise of his brilliant winner friend n The friend has no single, encodable algorithm. Instead he has many rules of thumb q He uses a different rule of thumb for each set of races n E.g. in this set, go with races that have black horses with stars on their foreheads q But cannot really enumerate what rules of thumbs go with what sets of races: he simply knows when he encounters a set n Problem: n A common problem that faces us in many situations q How best to combine all of the friend s rules of thumb q What is the best set of races to present to the friend, to extract the various rules of thumb
59 Boosting n The basic idea: Can a weak learning algorithm that performs just slightly better than random guessing be boosted into an arbitrarily accurate strong learner q Each of the gambler s rules may be just better than random guessing n This is a meta algorithm, that poses no constraints on the form of the weak learners themselves q The gambler s rules of thumb can be anything
60 Boosting: A Voting Perspective n Boosting can be considered a form of voting q Let a number of different classifiers classify the data q Go with the majority q Intuition says that as the number of classifiers increases, the dependability of the majority vote increases n The corresponding algorithms were called Boosting by majority q A (weighted) majority vote taken over all the classifiers q How do we compute weights for the classifiers? q How do we actually train the classifiers
61 ADA Boost: Adaptive algorithm for learning the weights n ADA Boost: Not named of ADA Lovelace n An adaptive algorithm that learns the weights of each classifier sequentially q Learning adapts to the current accuracy n Iteratively: q Train a simple classifier from training data n It will make errors even on training data n Train a new classifier that focuses on the training data points that have been misclassified
62 Boosting: An Example n Red dots represent training data from Red class n Blue dots represent training data from Blue class
63 Boosting: An Example Red class Blue class n Very simple weak learner q A line that is parallel to one of the two axes
64 Boosting: An Example Red class Blue class n First weak learner makes many mistakes q Errors coloured black
65 Boosting: An Example Blue class Red class Red class Blue class n Second weak learner focuses on errors made by first learner
66 Boosting: An Example RED BLUE RED RED Second strong learner: weighted combination of first and second weak learners Decision boundary shown by black lines
67 Boosting: An Example RED BLUE RED RED n The second strong learner also makes mistakes q Errors colored black
68 Boosting: An Example RED Blue class BLUE RED Red class RED n Third weak learner concentrates on errors made by second strong learner
69 Boosting: An Example Blue class Blue class Red class Red class Red class Blue class Third weak learner concentrates on errors made by combination of previous weak learners Continue adding weak learners until.
70 Boosting: An Example n Voila! Final strong learner: very few errors on the training data
71 Boosting: An Example n The final strong learner has learnt a complicated decision boundary
72 Boosting: An Example n The final strong learner has learnt a complicated decision boundary n Decision boundaries in areas with low density of training points assumed inconsequential
73 Overall Learning Pattern Strong learner increasingly accurate with increasing number of weak learners Residual errors increasingly difficult to correct Additional weak learners less and less effective Error of n th weak learner Error of n th strong learner number of weak learners
74 ADABoost n Cannot just add new classifiers that work well only the the previously misclassified data n Problem: The new classifier will make errors on the points that the earlier classifiers got right q Not good q On test data we have no way of knowing which points were correctly classified by the first classifier n Solution: Weight the data when training the second classifier q Use all the data but assign them weights n Data that are already correctly classified have less weight n Data that are currently incorrectly classified have more weight
75 ADA Boost n The red and blue points (correctly classified) will have a weight a < 1 n Black points (incorrectly classified) will have a weight b (= 1/a)> 1 n To compute the optimal second classifier, we minimize the total weighted error q Each data point contributes a or b to the total count of correctly and incorrectly classified points n E.g. if one of the red points is misclassified by the new classifier, the total error of the new classifier goes up by a
76 ADA Boost n Each new classifier modifies the weights of the data points based on the accuracy of the current classifier n The final classifier too is a weighted combination of all component classifiers
77 Formalizing the Boosting Concept n Given a set of instances (x 1, y 1 ), (x 2, y 2 ), (x N, y N ) q x i is the set of attributes of the i th instance q y 1 is the class for the i th instance n y 1 can be 1 or -1 (binary classification only) n Given a set of classifiers h 1, h 2,, h T q h i classifies an instance with attributes x as h i (x) q h i (x) is either -1 or +1 (for a binary classifier) q y*h(x) is 1 for all correctly classified points and -1 for incorrectly classified points n Devise a function f (h 1 (x), h 2 (x),, h T (x)) such that classification based on f () is superior to classification by any h i (x) q The function is succinctly represented as f (x)
78 The Boosting Concept n A simple combiner function: Voting q f (x) = S i h i (x) q Classifier H(x) = sign(f (x)) = sign(s i h i (x)) q Simple majority classifier n A simple voting scheme n A better combiner function: Boosting q f (x) = S i a i h i (x) n Can be any real number q Classifier H(x) = sign(f (x)) = sign(s i a i h i (x)) q A weighted majority classifier n The weight a i for any h i (x) is a measure of our trust in h i (x)
79 Adaptive Boosting n As before: q y is either -1 or +1 q H(x) is +1 or -1 q If the instance is correctly classified, both y and H(x) will have the same sign n The product y.h(x) is 1 n For incorrectly classified instances the product is -1 n Define the error for x : ½(1 yh(x)) q For a correctly classified instance, this is 0 q For an incorrectly classified instance, this is 1
80 The ADABoost Algorithm n Given: a set (x 1, y 1 ), (x N, y N ) of training instances q x i is the set of attributes for the i th instance q y i is the class for the i th instance and can be either +1 or -1
81 The ADABoost Algorithm n Initialize D 1 (x i ) = 1/N n For t = 1,, T q Train a weak classifier h t using distribution D t q Compute total error on training data n e t = Sum {½ (1 y i h t (x i ))} q Set a t = ½ ln ((1 e t ) / e t ) q For i = 1 N n set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) q Normalize D t+1 to make it a distribution n The final classifier is q H(x) = sign(s t a t h t (x))
82 The ADABoost Algorithm n Initialize D 1 (x i ) = 1/N n For t = 1,, T q Train a weak classifier h t using distribution D t q Compute total error on training data n e t = Sum {½ (1 y i h t (x i ))} q Set a t = ½ ln ((1 e t ) / e t ) q For i = 1 N n set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) q Normalize D t+1 to make it a distribution n The final classifier is q H(x) = sign(s t a t h t (x))
83 ADA Boost n Initialize D 1 (x i ) = 1/N n Just a normalization: total weight of all instances is 1 q Makes the algorithm invariant to training data set size
84 The ADABoost Algorithm n Initialize D 1 (x i ) = 1/N n For t = 1,, T q Train a weak classifier h t using distribution D t q Compute total error on training data n e t = Sum {½ (1 y i h t (x i ))} q Set a t = ½ ln ((1 e t ) / e t ) q For i = 1 N n set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) q Normalize D t+1 to make it a distribution n The final classifier is q H(x) = sign(s t a t h t (x)) 32
85 ADA Boost n Train a weak classifier h t using distribution D t n Simply train the simple classifier that that classifies data with error 50% q Where each data x point contributes D(x) towards the count of errors or correct classification q Initially D(x) = 1/N for all data n Better to actually train a good classifier
86 The ADABoost Algorithm n Initialize D 1 (x i ) = 1/N n For t = 1,, T q Train a weak classifier h t using distribution D t q Compute total error on training data n e t = Sum {½ (1 y i h t (x i ))} q Set a t = ½ ln ((1 e t ) / e t ) q For i = 1 N n set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) q Normalize D t+1 to make it a distribution n The final classifier is q H(x) = sign(s t a t h t (x)) 32
87 ADA Boost n Compute total error on training data q e t = Sum {½ (1 y i h t (x i ))} n For each data point x, ½(1-y.h(x)) = 0 for correct classification, 1 for error n e t is simply the sum of the weights D(x) for all points that are misclassified by the latest classifier h t (x) q Will lie between 0 and 1 e = t x such that D( x) x is misclassified by h t ( x)
88 The ADABoost Algorithm n Initialize D 1 (x i ) = 1/N n For t = 1,, T q Train a weak classifier h t using distribution D t q Compute total error on training data n e t = Sum {½ (1 y i h t (x i ))} q Set a t = ½ ln ((1 e t ) / e t ) q For i = 1 N n set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) q Normalize D t+1 to make it a distribution n The final classifier is q H(x) = sign(s t a t h t (x)) 32
89 Classifier Weight n Set a t = ½ ln ((1-e t )/e t ) n The a t for any classifier is always positive n The weight for the t th classifier is a function of its error q The poorer the classifier is, the closer a t is to 0 q If the error of the classifier is exactly 0.5, a t is 0. n We don t trust such classifiers at all J q If the error approaches 0, a t becomes high n We trust these classifiers 49
90 The ADABoost Algorithm n Initialize D 1 (x i ) = 1/N n For t = 1,, T q Train a weak classifier h t using distribution D t q Compute total error on training data n e t = Average {½ (1 y i h t (x i ))} q Set a t = ½ ln ((1 e t ) / e t ) q For i = 1 N n set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) q Normalize D t+1 to make it a distribution n The final classifier is q H(x) = sign(s t a t h t (x)) 32
91 ADA Boost n For i = 1 N q set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) n Normalize D t+1 to make it a distribution n Readjusting the weights of all training instances q If the instance is correctly classified, multiply its weight by b (= exp(-a t )) < 1 q If it is misclassified, multiply its weight by b (= exp(a t )) > 1 n Renormalize, so they all sum to 1 q D renormalized ( x) = D( x) / x' D( x')
92 The ADABoost Algorithm n Initialize D 1 (x i ) = 1/N n For t = 1,, T q Train a weak classifier h t using distribution D t q Compute total error on training data n e t = Average {½ (1 y i h t (x i ))} q Set a t = ½ ln ((1 e t ) / e t ) q For i = 1 N n set D t+1 (x i ) = D t (x i ) exp(-a t y i h t (x i )) q Normalize D t+1 to make it a distribution n The final classifier is q H(x) = sign(s t a t h t (x)) 32
93 ADA Boost n The final classifier is q H(x) = sign(s t a t h t (x)) n The output is 1 if the total weight of all weak learners that classify x as 1 is greater than the total weight of all weak learners that classify it as -1
94 Next Class n Fernando De La Torre n We will continue with Viola Jones after a few classes
Machine Learning for Signal Processing Detecting faces in images
 Machine Learning for Signal Processing Detecting faces in images Class 7. 19 Sep 2013 Instructor: Bhiksha Raj 19 Sep 2013 11755/18979 1 Administrivia Project teams? Project proposals? 19 Sep 2013 11755/18979
Machine Learning for Signal Processing Detecting faces in images Class 7. 19 Sep 2013 Instructor: Bhiksha Raj 19 Sep 2013 11755/18979 1 Administrivia Project teams? Project proposals? 19 Sep 2013 11755/18979
Lecture 8. Instructor: Haipeng Luo
 Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
Boosting. CAP5610: Machine Learning Instructor: Guo-Jun Qi
 Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Outline: Ensemble Learning. Ensemble Learning. The Wisdom of Crowds. The Wisdom of Crowds - Really? Crowd wiser than any individual
 Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Boosting: Foundations and Algorithms. Rob Schapire
 Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Data Warehousing & Data Mining
 13. Meta-Algorithms for Classification Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 13.
13. Meta-Algorithms for Classification Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 13.
Chapter 18. Decision Trees and Ensemble Learning. Recall: Learning Decision Trees
 CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
The Boosting Approach to. Machine Learning. Maria-Florina Balcan 10/31/2016
 The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Ensembles. Léon Bottou COS 424 4/8/2010
 Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Background. Adaptive Filters and Machine Learning. Bootstrap. Combining models. Boosting and Bagging. Poltayev Rassulzhan
 Adaptive Filters and Machine Learning Boosting and Bagging Background Poltayev Rassulzhan rasulzhan@gmail.com Resampling Bootstrap We are using training set and different subsets in order to validate results
Adaptive Filters and Machine Learning Boosting and Bagging Background Poltayev Rassulzhan rasulzhan@gmail.com Resampling Bootstrap We are using training set and different subsets in order to validate results
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
An overview of Boosting. Yoav Freund UCSD
 An overview of Boosting Yoav Freund UCSD Plan of talk Generative vs. non-generative modeling Boosting Alternating decision trees Boosting and over-fitting Applications 2 Toy Example Computer receives telephone
An overview of Boosting Yoav Freund UCSD Plan of talk Generative vs. non-generative modeling Boosting Alternating decision trees Boosting and over-fitting Applications 2 Toy Example Computer receives telephone
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
2D Image Processing Face Detection and Recognition
 2D Image Processing Face Detection and Recognition Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de
2D Image Processing Face Detection and Recognition Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de
Reconnaissance d objetsd et vision artificielle
 Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
What makes good ensemble? CS789: Machine Learning and Neural Network. Introduction. More on diversity
 What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
PCA FACE RECOGNITION
 PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
Decision Trees: Overfitting
 Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
Boosting: Algorithms and Applications
 Boosting: Algorithms and Applications Lecture 11, ENGN 4522/6520, Statistical Pattern Recognition and Its Applications in Computer Vision ANU 2 nd Semester, 2008 Chunhua Shen, NICTA/RSISE Boosting Definition
Boosting: Algorithms and Applications Lecture 11, ENGN 4522/6520, Statistical Pattern Recognition and Its Applications in Computer Vision ANU 2 nd Semester, 2008 Chunhua Shen, NICTA/RSISE Boosting Definition
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Robotics 2 AdaBoost for People and Place Detection
 Robotics 2 AdaBoost for People and Place Detection Giorgio Grisetti, Cyrill Stachniss, Kai Arras, Wolfram Burgard v.1.0, Kai Arras, Oct 09, including material by Luciano Spinello and Oscar Martinez Mozos
Robotics 2 AdaBoost for People and Place Detection Giorgio Grisetti, Cyrill Stachniss, Kai Arras, Wolfram Burgard v.1.0, Kai Arras, Oct 09, including material by Luciano Spinello and Oscar Martinez Mozos
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m
 At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m") ) Set W () i The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m m =.5 1 n W (m 1) i y i h(x i ; 2 ˆθ
) Set W () i The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m m =.5 1 n W (m 1) i y i h(x i ; 2 ˆθ
ECE 661: Homework 10 Fall 2014
 ECE 661: Homework 10 Fall 2014 This homework consists of the following two parts: (1) Face recognition with PCA and LDA for dimensionality reduction and the nearest-neighborhood rule for classification;
ECE 661: Homework 10 Fall 2014 This homework consists of the following two parts: (1) Face recognition with PCA and LDA for dimensionality reduction and the nearest-neighborhood rule for classification;
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS7267 MACHINE LEARNING
 CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
Algorithm-Independent Learning Issues
 Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
COS 511: Theoretical Machine Learning. Lecturer: Rob Schapire Lecture 24 Scribe: Sachin Ravi May 2, 2013
 COS 5: heoretical Machine Learning Lecturer: Rob Schapire Lecture 24 Scribe: Sachin Ravi May 2, 203 Review of Zero-Sum Games At the end of last lecture, we discussed a model for two player games (call
COS 5: heoretical Machine Learning Lecturer: Rob Schapire Lecture 24 Scribe: Sachin Ravi May 2, 203 Review of Zero-Sum Games At the end of last lecture, we discussed a model for two player games (call
FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE You are allowed a two-page cheat sheet. You are also allowed to use a calculator. Answer the questions in the spaces provided on the question sheets.
FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE You are allowed a two-page cheat sheet. You are also allowed to use a calculator. Answer the questions in the spaces provided on the question sheets.
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Hierarchical Boosting and Filter Generation
 January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Decision Trees. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Multi-Layer Boosting for Pattern Recognition
 Multi-Layer Boosting for Pattern Recognition François Fleuret IDIAP Research Institute, Centre du Parc, P.O. Box 592 1920 Martigny, Switzerland fleuret@idiap.ch Abstract We extend the standard boosting
Multi-Layer Boosting for Pattern Recognition François Fleuret IDIAP Research Institute, Centre du Parc, P.O. Box 592 1920 Martigny, Switzerland fleuret@idiap.ch Abstract We extend the standard boosting
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c /9/9 page 331 le-tex
 Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
Metric Embedding of Task-Specific Similarity. joint work with Trevor Darrell (MIT)
") Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
2 Upper-bound of Generalization Error of AdaBoost
 COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #10 Scribe: Haipeng Zheng March 5, 2008 1 Review of AdaBoost Algorithm Here is the AdaBoost Algorithm: input: (x 1,y 1 ),...,(x m,y
COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #10 Scribe: Haipeng Zheng March 5, 2008 1 Review of AdaBoost Algorithm Here is the AdaBoost Algorithm: input: (x 1,y 1 ),...,(x m,y
Big Data Analytics. Special Topics for Computer Science CSE CSE Feb 24
 Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Machine Learning, Fall 2011: Homework 5
 0-60 Machine Learning, Fall 0: Homework 5 Machine Learning Department Carnegie Mellon University Due:??? Instructions There are 3 questions on this assignment. Please submit your completed homework to
0-60 Machine Learning, Fall 0: Homework 5 Machine Learning Department Carnegie Mellon University Due:??? Instructions There are 3 questions on this assignment. Please submit your completed homework to
Boosting & Deep Learning
 Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
11-755/ Machine Learning for Signal Processing. Algebra. Class Sep Instructor: Bhiksha Raj
 11-755/18-797 Machine Learning for Signal Processing Fundamentals of Linear Algebra Class 2-3. 6 Sep 2011 Instructor: Bhiksha Raj 57 Administrivia TA Times: Anoop Ramakrishna: Thursday 12.30-1.30pm Manuel
11-755/18-797 Machine Learning for Signal Processing Fundamentals of Linear Algebra Class 2-3. 6 Sep 2011 Instructor: Bhiksha Raj 57 Administrivia TA Times: Anoop Ramakrishna: Thursday 12.30-1.30pm Manuel
CS 231A Section 1: Linear Algebra & Probability Review
 CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
10701/15781 Machine Learning, Spring 2007: Homework 2
 070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
Information Gain, Decision Trees and Boosting ML recitation 9 Feb 2006 by Jure
 Information Gain, Decision Trees and Boosting 10-701 ML recitation 9 Feb 2006 by Jure Entropy and Information Grain Entropy & Bits You are watching a set of independent random sample of X X has 4 possible
Information Gain, Decision Trees and Boosting 10-701 ML recitation 9 Feb 2006 by Jure Entropy and Information Grain Entropy & Bits You are watching a set of independent random sample of X X has 4 possible
Large-Margin Thresholded Ensembles for Ordinal Regression
 Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin (accepted by ALT 06, joint work with Ling Li) Learning Systems Group, Caltech Workshop Talk in MLSS 2006, Taipei, Taiwan, 07/25/2006
Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin (accepted by ALT 06, joint work with Ling Li) Learning Systems Group, Caltech Workshop Talk in MLSS 2006, Taipei, Taiwan, 07/25/2006
Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example
 Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example Günther Eibl and Karl Peter Pfeiffer Institute of Biostatistics, Innsbruck, Austria guenther.eibl@uibk.ac.at Abstract.
Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example Günther Eibl and Karl Peter Pfeiffer Institute of Biostatistics, Innsbruck, Austria guenther.eibl@uibk.ac.at Abstract.
COMS 4771 Lecture Boosting 1 / 16
 COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
Machine Learning. Ensemble Methods. Manfred Huber
 Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Lecture 13: Introduction to Neural Networks
 Lecture 13: Introduction to Neural Networks Instructor: Aditya Bhaskara Scribe: Dietrich Geisler CS 5966/6966: Theory of Machine Learning March 8 th, 2017 Abstract This is a short, two-line summary of
Lecture 13: Introduction to Neural Networks Instructor: Aditya Bhaskara Scribe: Dietrich Geisler CS 5966/6966: Theory of Machine Learning March 8 th, 2017 Abstract This is a short, two-line summary of
Useful Equations for solving SVM questions
 Support Vector Machines (send corrections to yks at csail.mit.edu) In SVMs we are trying to find a decision boundary that maximizes the "margin" or the "width of the road" separating the positives from
Support Vector Machines (send corrections to yks at csail.mit.edu) In SVMs we are trying to find a decision boundary that maximizes the "margin" or the "width of the road" separating the positives from
Introduction to Machine Learning
 Outline Contents Introduction to Machine Learning Concept Learning Varun Chandola February 2, 2018 1 Concept Learning 1 1.1 Example Finding Malignant Tumors............. 2 1.2 Notation..............................
Outline Contents Introduction to Machine Learning Concept Learning Varun Chandola February 2, 2018 1 Concept Learning 1 1.1 Example Finding Malignant Tumors............. 2 1.2 Notation..............................
AdaBoost. S. Sumitra Department of Mathematics Indian Institute of Space Science and Technology
 AdaBoost S. Sumitra Department of Mathematics Indian Institute of Space Science and Technology 1 Introduction In this chapter, we are considering AdaBoost algorithm for the two class classification problem.
AdaBoost S. Sumitra Department of Mathematics Indian Institute of Space Science and Technology 1 Introduction In this chapter, we are considering AdaBoost algorithm for the two class classification problem.
A Gentle Introduction to Gradient Boosting. Cheng Li College of Computer and Information Science Northeastern University
 A Gentle Introduction to Gradient Boosting Cheng Li chengli@ccs.neu.edu College of Computer and Information Science Northeastern University Gradient Boosting a powerful machine learning algorithm it can
A Gentle Introduction to Gradient Boosting Cheng Li chengli@ccs.neu.edu College of Computer and Information Science Northeastern University Gradient Boosting a powerful machine learning algorithm it can
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
CS 231A Section 1: Linear Algebra & Probability Review. Kevin Tang
 CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Visual Object Detection
 Visual Object Detection Ying Wu Electrical Engineering and Computer Science Northwestern University, Evanston, IL 60208 yingwu@northwestern.edu http://www.eecs.northwestern.edu/~yingwu 1 / 47 Visual Object
Visual Object Detection Ying Wu Electrical Engineering and Computer Science Northwestern University, Evanston, IL 60208 yingwu@northwestern.edu http://www.eecs.northwestern.edu/~yingwu 1 / 47 Visual Object
CS446: Machine Learning Fall Final Exam. December 6 th, 2016
 CS446: Machine Learning Fall 2016 Final Exam December 6 th, 2016 This is a closed book exam. Everything you need in order to solve the problems is supplied in the body of this exam. This exam booklet contains
CS446: Machine Learning Fall 2016 Final Exam December 6 th, 2016 This is a closed book exam. Everything you need in order to solve the problems is supplied in the body of this exam. This exam booklet contains
CS 6375 Machine Learning
 CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
Learning Ensembles. 293S T. Yang. UCSB, 2017.
 Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Pattern Recognition and Machine Learning. Learning and Evaluation of Pattern Recognition Processes
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lesson 1 5 October 2016 Learning and Evaluation of Pattern Recognition Processes Outline Notation...2 1. The
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lesson 1 5 October 2016 Learning and Evaluation of Pattern Recognition Processes Outline Notation...2 1. The
Theory and Applications of A Repeated Game Playing Algorithm. Rob Schapire Princeton University [currently visiting Yahoo!
 Theory and Applications of A Repeated Game Playing Algorithm Rob Schapire Princeton University [currently visiting Yahoo! Research] Learning Is (Often) Just a Game some learning problems: learn from training
Theory and Applications of A Repeated Game Playing Algorithm Rob Schapire Princeton University [currently visiting Yahoo! Research] Learning Is (Often) Just a Game some learning problems: learn from training
Randomized Decision Trees
 Randomized Decision Trees compiled by Alvin Wan from Professor Jitendra Malik s lecture Discrete Variables First, let us consider some terminology. We have primarily been dealing with real-valued data,
Randomized Decision Trees compiled by Alvin Wan from Professor Jitendra Malik s lecture Discrete Variables First, let us consider some terminology. We have primarily been dealing with real-valued data,
Module 03 Lecture 14 Inferential Statistics ANOVA and TOI
 Introduction of Data Analytics Prof. Nandan Sudarsanam and Prof. B Ravindran Department of Management Studies and Department of Computer Science and Engineering Indian Institute of Technology, Madras Module
Introduction of Data Analytics Prof. Nandan Sudarsanam and Prof. B Ravindran Department of Management Studies and Department of Computer Science and Engineering Indian Institute of Technology, Madras Module
Qualifier: CS 6375 Machine Learning Spring 2015
 Qualifier: CS 6375 Machine Learning Spring 2015 The exam is closed book. You are allowed to use two double-sided cheat sheets and a calculator. If you run out of room for an answer, use an additional sheet
Qualifier: CS 6375 Machine Learning Spring 2015 The exam is closed book. You are allowed to use two double-sided cheat sheets and a calculator. If you run out of room for an answer, use an additional sheet
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
Robotics 2. AdaBoost for People and Place Detection. Kai Arras, Cyrill Stachniss, Maren Bennewitz, Wolfram Burgard
 Robotics 2 AdaBoost for People and Place Detection Kai Arras, Cyrill Stachniss, Maren Bennewitz, Wolfram Burgard v.1.1, Kai Arras, Jan 12, including material by Luciano Spinello and Oscar Martinez Mozos
Robotics 2 AdaBoost for People and Place Detection Kai Arras, Cyrill Stachniss, Maren Bennewitz, Wolfram Burgard v.1.1, Kai Arras, Jan 12, including material by Luciano Spinello and Oscar Martinez Mozos
Large-Margin Thresholded Ensembles for Ordinal Regression
 Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology, U.S.A. Conf. on Algorithmic Learning Theory, October 9,
Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology, U.S.A. Conf. on Algorithmic Learning Theory, October 9,
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017
 COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University BOOSTING Robert E. Schapire and Yoav
COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University BOOSTING Robert E. Schapire and Yoav
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
COS 429: COMPUTER VISON Face Recognition
 COS 429: COMPUTER VISON Face Recognition Intro to recognition PCA and Eigenfaces LDA and Fisherfaces Face detection: Viola & Jones (Optional) generic object models for faces: the Constellation Model Reading:
COS 429: COMPUTER VISON Face Recognition Intro to recognition PCA and Eigenfaces LDA and Fisherfaces Face detection: Viola & Jones (Optional) generic object models for faces: the Constellation Model Reading:
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
Introduction to Boosting and Joint Boosting
 Introduction to Boosting and Learning Systems Group, Caltech 2005/04/26, Presentation in EE150 Boosting and Outline Introduction to Boosting 1 Introduction to Boosting Intuition of Boosting Adaptive Boosting
Introduction to Boosting and Learning Systems Group, Caltech 2005/04/26, Presentation in EE150 Boosting and Outline Introduction to Boosting 1 Introduction to Boosting Intuition of Boosting Adaptive Boosting
Course 10. Kernel methods. Classical and deep neural networks.
 Course 10 Kernel methods. Classical and deep neural networks. Kernel methods in similarity-based learning Following (Ionescu, 2018) The Vector Space Model ò The representation of a set of objects as vectors
Course 10 Kernel methods. Classical and deep neural networks. Kernel methods in similarity-based learning Following (Ionescu, 2018) The Vector Space Model ò The representation of a set of objects as vectors
Ensemble learning 11/19/13. The wisdom of the crowds. Chapter 11. Ensemble methods. Ensemble methods
 The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
Ensemble Methods. NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan
 Ensemble Methods NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan How do you make a decision? What do you want for lunch today?! What did you have last night?! What are your favorite
Ensemble Methods NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan How do you make a decision? What do you want for lunch today?! What did you have last night?! What are your favorite
) (d o f. For the previous layer in a neural network (just the rightmost layer if a single neuron), the required update equation is: 2.
 (d o f. For the previous layer in a neural network (just the rightmost layer if a single neuron), the required update equation is: 2.") 1 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2011 Recitation 8, November 3 Corrected Version & (most) solutions
1 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2011 Recitation 8, November 3 Corrected Version & (most) solutions
A Posteriori Corrections to Classification Methods.
 A Posteriori Corrections to Classification Methods. Włodzisław Duch and Łukasz Itert Department of Informatics, Nicholas Copernicus University, Grudziądzka 5, 87-100 Toruń, Poland; http://www.phys.uni.torun.pl/kmk
A Posteriori Corrections to Classification Methods. Włodzisław Duch and Łukasz Itert Department of Informatics, Nicholas Copernicus University, Grudziądzka 5, 87-100 Toruń, Poland; http://www.phys.uni.torun.pl/kmk
Support Vector Machines
 Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machine. Industrial AI Lab. Prof. Seungchul Lee
 Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
i=1 = H t 1 (x) + α t h t (x)
 + α t h t (x)") AdaBoost AdaBoost, which stands for ``Adaptive Boosting", is an ensemble learning algorithm that uses the boosting paradigm []. We will discuss AdaBoost for binary classification. That is, we assume that
AdaBoost AdaBoost, which stands for ``Adaptive Boosting", is an ensemble learning algorithm that uses the boosting paradigm []. We will discuss AdaBoost for binary classification. That is, we assume that