Artificial Neural Networks
|
|
|
- Berenice Houston
- 5 years ago
- Views:
Transcription
1 Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1
2 Connectionist Models Consider humans: Neuron switching time.001 second Number of neurons Connections per neuron Scene recognition time.1 second 100 inference steps doesn t seem like enough much parallel computation 2
3 Connectionist Models Properties of artificial neural nets (ANN s): Many neuron-like threshold switching units Many weighted interconnections among units Highly parallel, distributed process Emphasis on tuning weights automatically 3
4 When to Consider Neural Networks Input is high-dimensional discrete or real-valued (e.g. raw sensor input) Output is discrete or real valued Output is a vector of values Possibly noisy data Form of target function is unknown Human readability of result is unimportant 4
5 When to Consider Neural Networks Examples: Speech phoneme recognition [Waibel] Image classification [Kanade, Baluja, Rowley] Financial prediction 5


6 ALVINN drives 70 mph on highways Sharp Left Straight Ahead Sharp Right 30 Output Units 4 Hidden Units 30x32 Sensor Input Retina 6
7 Perceptron x 1 w 1 x 0 =1 x 2 x n... w 2 w n w 0 Σ n Σ w i x i i=0 { n 1 if Σ w > 0 o = i x i=0 i -1 otherwise { 1 if w0 + w o(x 1,..., x n ) = 1 x w n x n > 0 1 otherwise. Sometimes we ll use simpler vector notation: o( x) = { 1 if w x > 0 1 otherwise. 7
8 Decision Surface of a Perceptron + + x x x 1 x (a) Represents some useful functions What weights represent g(x 1, x 2 ) = AND(x 1, x 2 )? But some functions not representable e.g., not linearly separable Will need more complicated models to represent these. (b) 8
9 Perceptron training rule w i w i + w i where w i = η(t o)x i Where: t = c( x) is target value o is perceptron output η is small constant (e.g.,.1) called learning rate 9
10 Perceptron training rule Can prove it will converge If training data is linearly separable and η sufficiently small 10
11 Gradient Descent To understand, consider simpler linear unit, where o = w 0 + w 1 x w n x n Let s learn w i s that minimize the squared error E[ w] 1 2 (t d o d ) 2 d D Where D is set of training examples This defines the Loss function that you want to minimize! 11
12 Gradient Descent E[w] w0 Gradient w1 E[ w] -1-2 [ E, E, E ] w 0 w 1 w n 12
13 Training rule: i.e., Update: w = η E[ w] w i = η E w i w i w i + w i 13
14 Gradient Descent Derivation: E = 1 (t w i w i 2 d o d ) 2 = 1 2 = 1 2 = d E = w i d d d d w i (t d o d ) 2 2(t d o d ) w i (t d o d ) (t d o d ) w i (t d w x d ) (t d o d )( x i,d ) 14
15 Gradient Descent GRADIENT-DESCENT(training examples, η) Each training example is a pair of the form x, t, where x is the vector of input values, and t is the target output value. η is the learning rate (e.g.,.05). Initialize each w i to some small random value Until the termination condition is met, Do Initialize each w i to zero. For each x, t in training examples, Do Input the instance x to the unit and compute the output o 15
16 For each linear unit weight w i, Do w i w i + η(t o)x i For each linear unit weight w i, Do w i w i + w i 16
17 Summary Perceptron training rule guaranteed to succeed if Training examples are linearly separable Sufficiently small learning rate η Linear unit training rule uses gradient descent Guaranteed to converge to hypothesis with minimum squared error Given sufficiently small learning rate η Even when training data contains noise Even when training data not separable by H 17
18 Incremental (Stochastic) Gradient Descent Batch mode Gradient Descent: Do until satisfied 1. Compute the gradient E D [ w] 2. w w η E D [ w] Incremental mode Gradient Descent: Do until satisfied For each training example d in D 1. Compute the gradient E d [ w] 2. w w η E d [ w] 18
19 E D [ w] 1 2 (t d o d ) 2 d D E d [ w] 1 2 (t d o d ) 2 Incremental Gradient Descent can approximate Batch Gradient Descent arbitrarily closely if η made small enough 19
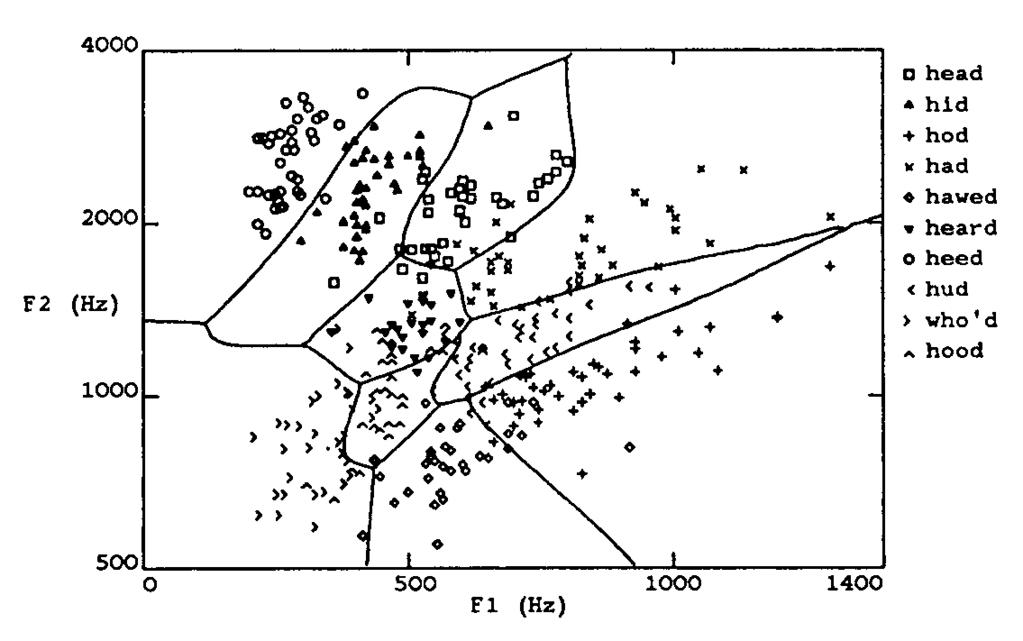
20 Multilayer Networks of Sigmoid Units head hid who d hood F1 F2 20
21 21
22 Sigmoid Unit x 1 w 1 x 0 = 1 x 2 x n... w 2 w n w 0 Σ n net = Σ w i x i=0 i σ(x) is the sigmoid function 1 1+e x Nice property: dσ(x) dx = σ(x)(1 σ(x)) o = σ(net) = We can derive gradient decent rules to train One sigmoid unit ē net Multilayer networks of sigmoids Backpropagation 22
23 Error Gradient for a Sigmoid Unit E = 1 (t w i w i 2 d o d ) 2 d D = 1 (t 2 w d o d ) 2 d i = 1 2(t 2 d o d ) (t w d o d ) d i = ( (t d o d ) o ) d w d i = d (t d o d ) o d net d net d w i 23
24 But we know: So: o d net d = σ(net d) net d = o d (1 o d ) net d w i = ( w x d) w i = x i,d E = (t w d o d )o d (1 o d )x i,d i d D 24
25 Backpropagation Algorithm Initialize all weights to small random numbers. Until satisfied, Do For each training example, Do 1. Input the training example to the network and compute the network outputs 2. For each output unit k 3. For each hidden unit h δ k o k (1 o k )(t k o k ) 25
26 δ h o h (1 o h ) k outputs w h,k δ k 4. Update each network weight w i,j where w i,j w i,j + w i,j w i,j = ηδ j x i,j 26
27 More on Backpropagation Gradient descent over entire network weight vector Easily generalized to arbitrary directed graphs Will find a local, not necessarily global error minimum In practice, often works well (can run multiple times) Often include weight momentum α w i,j (n) = ηδ j x i,j + α w i,j (n 1) Minimizes error over training examples Will it generalize well to subsequent examples? 27
28 Training can take thousands of iterations slow! Using network after training is very fast 28
29 Learning Hidden Layer Representations Inputs Outputs A target function: Input Output Can this be learned?? 29
30 Learning Hidden Layer Representations A network: Learned hidden layer: Inputs Outputs Input Hidden Output Values
31 Training Sum of squared errors for each output unit
32 Training Hidden unit encoding for input
33 Training Weights from inputs to one hidden unit
34 Convergence of Backpropagation Gradient descent to some local minimum Perhaps not global minimum... Add momentum Stochastic gradient descent Train multiple nets with different inital weights Nature of convergence Initialize weights near zero Therefore, initial networks near-linear Increasing non-linearity possible as training progresses 34
35 Expressive Capabilities of ANNs Boolean functions: Every boolean function can be represented by network with single hidden layer but might require exponential (in number of inputs) hidden units Continuous functions: Every bounded continuous function can be approximated with arbitrarily small error, by network with one hidden layer [Cybenko 1989; Hornik et al. 1989] 35
36 36 Any function can be approximated to arbitrary accuracy by a network with two hidden layers [Cybenko 1988].
37 Overfitting in ANNs Error Error versus weight updates (example 1) Training set error Validation set error Number of weight updates 37
38 Error Error versus weight updates (example 2) Training set error Validation set error Number of weight updates 38
39 Neural Nets for Face Recognition left strt rght up x32 inputs 39
40 Typical input images 90% accurate learning head pose, and recognizing 1-of-20 faces 40



41 Learned Hidden Unit Weights left strt rght up Learned Weights x32 inputs 41
42 Alternative Error Functions Penalize large weights: E( w) 1 2 d D k outputs(t kd o kd ) 2 + γ i,j Train on target slopes as well as values: w 2 ji [ (tkd o kd ) 2 E( w) 1 2 d D k outputs +µ j inputs ( t kd x j d o kd x j d ) 2 ] 42
43 Tie together weights: e.g., in phoneme recognition network 43
44 Recurrent Networks y(t + 1) y(t + 1) b x(t) x(t) c(t) (a) Feedforward network (b) Recurrent network y(t + 1) x(t) c(t) y(t) x(t 1) c(t 1) y(t 1) (c) Recurrent network unfolded in time x(t 2) c(t 2) 44
100 inference steps doesn't seem like enough. Many neuron-like threshold switching units. Many weighted interconnections among units
 Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
Artificial Neural Networks
 0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
COMP-4360 Machine Learning Neural Networks
 COMP-4360 Machine Learning Neural Networks Jacky Baltes Autonomous Agents Lab University of Manitoba Winnipeg, Canada R3T 2N2 Email: jacky@cs.umanitoba.ca WWW: http://www.cs.umanitoba.ca/~jacky http://aalab.cs.umanitoba.ca
COMP-4360 Machine Learning Neural Networks Jacky Baltes Autonomous Agents Lab University of Manitoba Winnipeg, Canada R3T 2N2 Email: jacky@cs.umanitoba.ca WWW: http://www.cs.umanitoba.ca/~jacky http://aalab.cs.umanitoba.ca
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Machine Learning
 Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Back-Propagation Algorithm. Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples
 Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning. Neural Networks. Le Song. CSE6740/CS7641/ISYE6740, Fall Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks DWML, /25
 DWML, 2007 /25 Neural networks: Biological and artificial Consider humans: Neuron switching time 0.00 second Number of neurons 0 0 Connections per neuron 0 4-0 5 Scene recognition time 0. sec 00 inference
DWML, 2007 /25 Neural networks: Biological and artificial Consider humans: Neuron switching time 0.00 second Number of neurons 0 0 Connections per neuron 0 4-0 5 Scene recognition time 0. sec 00 inference
Incremental Stochastic Gradient Descent
 Incremental Stochastic Gradient Descent Batch mode : gradient descent w=w - η E D [w] over the entire data D E D [w]=1/2σ d (t d -o d ) 2 Incremental mode: gradient descent w=w - η E d [w] over individual
Incremental Stochastic Gradient Descent Batch mode : gradient descent w=w - η E D [w] over the entire data D E D [w]=1/2σ d (t d -o d ) 2 Incremental mode: gradient descent w=w - η E d [w] over individual
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Unit 8: Introduction to neural networks. Perceptrons
 Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
CMSC 421: Neural Computation. Applications of Neural Networks
 CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Multilayer Neural Networks
 Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Slide04 Haykin Chapter 4: Multi-Layer Perceptrons
 Introduction Slide4 Hayin Chapter 4: Multi-Layer Perceptrons CPSC 636-6 Instructor: Yoonsuc Choe Spring 28 Networs typically consisting of input, hidden, and output layers. Commonly referred to as Multilayer
Introduction Slide4 Hayin Chapter 4: Multi-Layer Perceptrons CPSC 636-6 Instructor: Yoonsuc Choe Spring 28 Networs typically consisting of input, hidden, and output layers. Commonly referred to as Multilayer
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CS:4420 Artificial Intelligence
 CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning Lesson 39 Neural Networks - III 12.4.4 Multi-Layer Perceptrons In contrast to perceptrons, multilayer networks can learn not only multiple decision boundaries, but the boundaries
Module 12 Machine Learning Lesson 39 Neural Networks - III 12.4.4 Multi-Layer Perceptrons In contrast to perceptrons, multilayer networks can learn not only multiple decision boundaries, but the boundaries
The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural
 learning techniques for neural") 1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Artificial Neural Network
 Artificial Neural Network Eung Je Woo Department of Biomedical Engineering Impedance Imaging Research Center (IIRC) Kyung Hee University Korea ejwoo@khu.ac.kr Neuron and Neuron Model McCulloch and Pitts
Artificial Neural Network Eung Je Woo Department of Biomedical Engineering Impedance Imaging Research Center (IIRC) Kyung Hee University Korea ejwoo@khu.ac.kr Neuron and Neuron Model McCulloch and Pitts
22c145-Fall 01: Neural Networks. Neural Networks. Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1
 Neural Networks Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1 Brains as Computational Devices Brains advantages with respect to digital computers: Massively parallel Fault-tolerant Reliable
Neural Networks Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1 Brains as Computational Devices Brains advantages with respect to digital computers: Massively parallel Fault-tolerant Reliable
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
Machine Learning in Bioinformatics
 Machine Learning in Bioinformatics Arlindo Oliveira aml@inesc-id.pt Data Mining: Concepts and Techniques Data mining concepts Learning from examples Decision trees Neural Networks 1 Typical Supervised
Machine Learning in Bioinformatics Arlindo Oliveira aml@inesc-id.pt Data Mining: Concepts and Techniques Data mining concepts Learning from examples Decision trees Neural Networks 1 Typical Supervised
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Multilayer Perceptrons (MLPs)
") CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Neural Networks. Xiaojin Zhu Computer Sciences Department University of Wisconsin, Madison. slide 1
 Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Gradient Descent Training Rule: The Details
 Gradient Descent Training Rule: The Details 1 For Perceptrons The whole idea behind gradient descent is to gradually, but consistently, decrease the output error by adjusting the weights. The trick is
Gradient Descent Training Rule: The Details 1 For Perceptrons The whole idea behind gradient descent is to gradually, but consistently, decrease the output error by adjusting the weights. The trick is
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Introduction to feedforward neural networks
 . Problem statement and historical context A. Learning framework Figure below illustrates the basic framework that we will see in artificial neural network learning. We assume that we want to learn a classification
. Problem statement and historical context A. Learning framework Figure below illustrates the basic framework that we will see in artificial neural network learning. We assume that we want to learn a classification
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Linear Discrimination Functions
 Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari November 4, 2009 Outline Linear models Gradient descent Perceptron Minimum square error approach
Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari November 4, 2009 Outline Linear models Gradient descent Perceptron Minimum square error approach
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Introduction To Artificial Neural Networks
 Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Artificial Neural Networks Examination, June 2004
 Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
NN V: The generalized delta learning rule
 NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
Learning Neural Networks
 Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Mul7layer Perceptrons
 Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 11: Mul7layer Perceptrons ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr
Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 11: Mul7layer Perceptrons ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr
Revision: Neural Network
 Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Supervised Learning in Neural Networks
 The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no March 7, 2011 Supervised Learning Constant feedback from an instructor, indicating not only right/wrong, but
The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no March 7, 2011 Supervised Learning Constant feedback from an instructor, indicating not only right/wrong, but
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks. Todd W. Neller
 2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks Todd W. Neller Machine Learning Learning is such an important part of what we consider "intelligence" that
2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks Todd W. Neller Machine Learning Learning is such an important part of what we consider "intelligence" that
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Artificial Neural Networks
 Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction to Machine Learning Spring 2018 Note Neural Networks
 CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
Introduction to Artificial Neural Networks
 Introduction to Artificial Neural Networks Ahmed Guessoum Natural Language Processing and Machine Learning Research Group Laboratory for Research in Artificial Intelligence Université des Sciences et de
Introduction to Artificial Neural Networks Ahmed Guessoum Natural Language Processing and Machine Learning Research Group Laboratory for Research in Artificial Intelligence Université des Sciences et de
Multilayer Perceptron
 Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
ECE 471/571 - Lecture 17. Types of NN. History. Back Propagation. Recurrent (feedback during operation) Feedforward
 Feedforward") ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination