Mul7layer Perceptrons
|
|
|
- Dulcie Ward
- 5 years ago
- Views:
Transcription

1 Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 11: Mul7layer Perceptrons ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins h1p://
2 Overview Neural networks, brains, and computers Perceptrons Training Classification and regression Linear separability Multilayer perceptrons Universal approximation Backpropagation 2
3 Neural Networks Networks of processing units (neurons) with connec7ons (synapses) between them Large number of neurons: Large connec7vity: 10 5 Parallel processing Distributed computa7on/memory Robust to noise, failures 3
4 Understanding the Brain Levels of analysis (Marr, 1982) 1. ComputaOonal theory 2. RepresentaOon and algorithm 3. Hardware implementaoon Reverse engineering: From hardware to theory Parallel processing: SIMD vs MIMD Neural net: SIMD with modifiable local memory Learning: Update by training/experience 4

5 Perceptron (RosenblaS, 1962) 5
6 What a Perceptron Does Regression: y=wx+w 0 Classifica7on: y=1(wx+w 0 >0) y y s y w 0 x 0 =+1 w x x w 0 w x w 0 Linear fit Linear discrimination 6

7 Regression: K Outputs ClassificaOon: 7
8 Training Online (instances seen one by one) vs batch (whole sample) learning: No need to store the whole sample Problem may change in Ome Wear and degradaoon in system components Stochas7c gradient- descent: Update ayer a single pazern Generic update rule (LMS rule): 8
9 Training a Perceptron: Regression Regression (Linear output): to Machine Learning The MIT Press (V1.1) 9
10 ClassificaOon Single sigmoid output K>2 so4max outputs Same as for linear discriminants from chapter 10 except we update after each instance 10
11 Learning Boolean AND 11
12 XOR No w 0, w 1, w 2 sa7sfy: (Minsky and Papert, 1969) to Machine Learning The MIT Press (V1.1) 12
13 MulOlayer Perceptrons (Rumelhart et al., 1986) 13
14 MLP as Universal Approximator x 1 XOR x 2 = (x 1 AND ~x Lecture Notes 2 ) OR (~x for E Alpaydın 1 AND x 2004 Introduction 2 ) 14
15 BackpropagaOon 15
16 Regression Backward Forward x 16
17 Regression with MulOple Outputs y i v ih w hj z h x j 17
18 18
19 19
20 w h x+w 0 z h v h z h 20
21 Two- Class DiscriminaOon One sigmoid output y t for P(C 1 x t ) and P(C 2 x t ) 1- y t 21
22 K>2 Classes 22
23 MulOple Hidden Layers MLP with one hidden layer is a universal approximator (Hornik et al., 1989), but using mul7ple layers may lead to simpler networks 23
24 Improving Convergence Momentum Adap7ve learning rate 24
25 Overfibng/Overtraining Number of weights: H (d+1)+(h+1)k 25
26 Conclusion Perceptrons handle linearly separable problems Multilayer perceptrons handle any problem Logistic discrimination functions enable gradient descent- based packpropagation Solves the structural credit assignment problem Susceptible to local optima Susceptible to overfitting 26
27 27
")
28 Structured MLP (Le Cun et al, 1989) 28

29 Weight Sharing 29
30 Hints (Abu- Mostafa, 1995) Invariance to translaoon, rotaoon, size Virtual examples Augmented error: E =E+λ h E h If x and x are the same : E h =[g(x θ)- g(x θ)] 2 ApproximaOon hint: 30
 (Fahlman and")
31 Tuning the Network Size DestrucOve Weight decay: ConstrucOve Growing networks (Ash, 1989) (Fahlman and Lebiere, 1989) 31
32 Bayesian Learning Consider weights w i as random vars, prior p(w i ) Weight decay, ridge regression, regularizaoon cost=data- misfit + λ complexity More about Bayesian methods in chapter 14 32
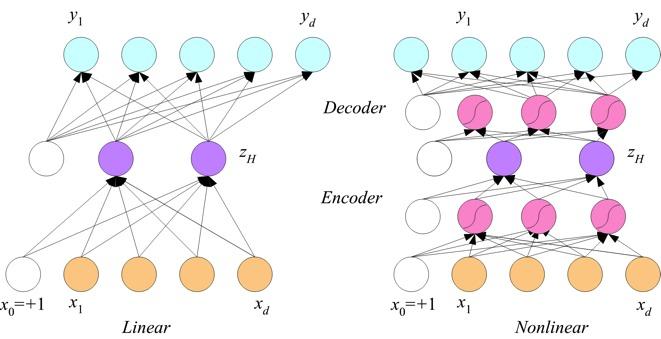
33 Dimensionality ReducOon 33
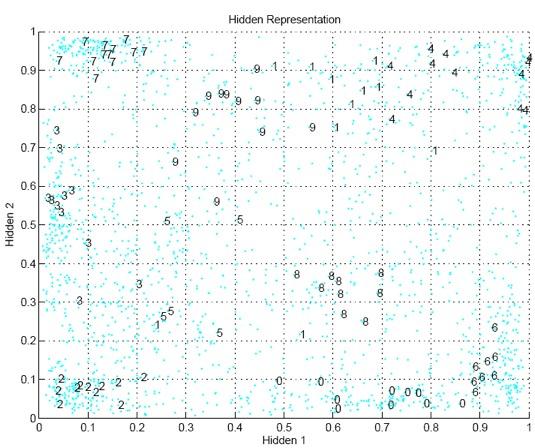
34 34
35 Learning Time Applica7ons: Sequence recognioon: Speech recognioon Sequence reproducoon: Time- series predicoon Sequence associaoon Network architectures Time- delay networks (Waibel et al., 1989) Recurrent networks (Rumelhart et al., 1986) 35
36 Time- Delay Neural Networks 36
37 Recurrent Networks 37
38 Unfolding in Time 38
10. Artificial Neural Networks
 Foundations of Machine Learning CentraleSupélec Fall 217 1. Artificial Neural Networks Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
Foundations of Machine Learning CentraleSupélec Fall 217 1. Artificial Neural Networks Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Multilayer Perceptron
 Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Artificial Neural Networks
 Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
100 inference steps doesn't seem like enough. Many neuron-like threshold switching units. Many weighted interconnections among units
 Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
COMP-4360 Machine Learning Neural Networks
 COMP-4360 Machine Learning Neural Networks Jacky Baltes Autonomous Agents Lab University of Manitoba Winnipeg, Canada R3T 2N2 Email: jacky@cs.umanitoba.ca WWW: http://www.cs.umanitoba.ca/~jacky http://aalab.cs.umanitoba.ca
COMP-4360 Machine Learning Neural Networks Jacky Baltes Autonomous Agents Lab University of Manitoba Winnipeg, Canada R3T 2N2 Email: jacky@cs.umanitoba.ca WWW: http://www.cs.umanitoba.ca/~jacky http://aalab.cs.umanitoba.ca
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Machine Learning. Neural Networks. Le Song. CSE6740/CS7641/ISYE6740, Fall Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Machine Learning 2nd Edi7on
 Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Artificial Neural Networks. Q550: Models in Cognitive Science Lecture 5
 Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Back-Propagation Algorithm. Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples
 Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92
 ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
Chapter ML:VI (continued)
") Chapter ML:VI (continued) VI Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-64 Neural Networks STEIN 2005-2018 Definition 1 (Linear Separability)
Chapter ML:VI (continued) VI Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-64 Neural Networks STEIN 2005-2018 Definition 1 (Linear Separability)
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Artificial Neural Networks
 0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Artificial Neural Networks
 Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks
 Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Machine Learning
 Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Learning and Memory in Neural Networks
 Learning and Memory in Neural Networks Guy Billings, Neuroinformatics Doctoral Training Centre, The School of Informatics, The University of Edinburgh, UK. Neural networks consist of computational units
Learning and Memory in Neural Networks Guy Billings, Neuroinformatics Doctoral Training Centre, The School of Informatics, The University of Edinburgh, UK. Neural networks consist of computational units
April 9, Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá. Linear Classification Models. Fabio A. González Ph.D.
 Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 9, 2018 Content 1 2 3 4 Outline 1 2 3 4 problems { C 1, y(x) threshold predict(x) = C 2, y(x) < threshold, with threshold
Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 9, 2018 Content 1 2 3 4 Outline 1 2 3 4 problems { C 1, y(x) threshold predict(x) = C 2, y(x) < threshold, with threshold
CS:4420 Artificial Intelligence
 CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
Chapter ML:VI (continued)
") Chapter ML:VI (continued) VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-56 Neural Networks STEIN 2005-2013 Definition 1 (Linear Separability)
Chapter ML:VI (continued) VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-56 Neural Networks STEIN 2005-2013 Definition 1 (Linear Separability)
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
ECE 471/571 - Lecture 17. Types of NN. History. Back Propagation. Recurrent (feedback during operation) Feedforward
 Feedforward") ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
Neural Networks. Haiming Zhou. Division of Statistics Northern Illinois University.
 Neural Networks Haiming Zhou Division of Statistics Northern Illinois University zhouh@niu.edu Neural Networks The term neural network has evolved to encompass a large class of models and learning methods.
Neural Networks Haiming Zhou Division of Statistics Northern Illinois University zhouh@niu.edu Neural Networks The term neural network has evolved to encompass a large class of models and learning methods.
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Artificial neural networks
 Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural
 learning techniques for neural") 1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Neural Networks. Xiaojin Zhu Computer Sciences Department University of Wisconsin, Madison. slide 1
 Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
CS 730/730W/830: Intro AI
 CS 730/730W/830: Intro AI 1 handout: slides Wheeler Ruml (UNH) Lecture 20, CS 730 1 / 13 Summary k-nn Wheeler Ruml (UNH) Lecture 20, CS 730 2 / 13 Summary Summary k-nn supervised learning: induction, generalization
CS 730/730W/830: Intro AI 1 handout: slides Wheeler Ruml (UNH) Lecture 20, CS 730 1 / 13 Summary k-nn Wheeler Ruml (UNH) Lecture 20, CS 730 2 / 13 Summary Summary k-nn supervised learning: induction, generalization
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Computational Intelligence Winter Term 2017/18
 Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning Lesson 39 Neural Networks - III 12.4.4 Multi-Layer Perceptrons In contrast to perceptrons, multilayer networks can learn not only multiple decision boundaries, but the boundaries
Module 12 Machine Learning Lesson 39 Neural Networks - III 12.4.4 Multi-Layer Perceptrons In contrast to perceptrons, multilayer networks can learn not only multiple decision boundaries, but the boundaries
Lecture 12. Neural Networks Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks