COMP 5331: Knowledge Discovery and Data Mining
|
|
|
- Dortha Watson
- 5 years ago
- Views:
Transcription
1 COMP 5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Tan, Steinbach, Kumar And Jiawei Han, Micheline Kamber, and Jian Pei 1
2 10 Continuous and Categorical Attributes How to apply association analysis formulation to non-asymmetric binary variables? Session Id Country Session Length (sec) Number of Web Pages viewed Gender Browser Type Buy 1 USA Male IE No 2 China Female Netscape No 3 USA Female Mozilla Yes 4 Germany Male IE Yes 5 Australia Male Mozilla No Example of Association Rule: No} {Number of Pages [5,10) (Browser=Mozilla)} {Buy =
3 Handling Categorical Attributes Transform categorical attribute into asymmetric binary variables Introduce a new item for each distinct attribute-value pair Example: replace Browser Type attribute with Browser Type = Internet Explorer Browser Type = Mozilla Browser Type = Mozilla
4 Handling Categorical Attributes Potential Issues What if attribute has many possible values Example: attribute country has more than 200 possible values Many of the attribute values may have very low support Potential solution: Aggregate the low-support attribute values What if distribution of attribute values is highly skewed Example: 95% of the visitors have Buy = No Most of the items will be associated with (Buy=No) item Potential solution: drop the highly frequent items
5 Handling Continuous Attributes Different kinds of rules: Age [21,35) Salary [70k,120k) Buy Salary [70k,120k) Buy Age: =28, =4 Different methods: Discretization-based Statistics-based Non-discretization based minapriori
6 Handling Continuous Attributes Use discretization Unsupervised: Equal-width binning Equal-depth binning Clustering Supervised: Attribute values, v Class v 1 v 2 v 3 v 4 v 5 v 6 v 7 v 8 v 9 Anomalous Normal bin 1 bin 2 bin 3
7 Discretization Issues Size of the discretized intervals affect support & confidence {Refund = No, (Income = $51,250)} {Cheat = No} {Refund = No, (60K Income 80K)} {Cheat = No} {Refund = No, (0K Income 1B)} {Cheat = No} If intervals too small may not have enough support If intervals too large may not have enough confidence Potential solution: use all possible intervals
8 Execution time Discretization Issues If intervals contain n values, there are on average O(n 2 ) possible ranges Too many rules {Refund = No, (Income = $51,250)} {Cheat = No} {Refund = No, (51K Income 52K)} {Cheat = No} {Refund = No, (50K Income 60K)} {Cheat = No}
9 Approach by Srikant & Agrawal Preprocess the data Discretize attribute using equi-depth partitioning Use partial completeness measure to determine number of partitions Merge adjacent intervals as long as support is less than max-support Apply existing association rule mining algorithms Determine interesting rules in the output
10 Approach by Srikant & Agrawal Discretization will lose information Approximated X X Use partial completeness measure to determine how much information is lost C: frequent itemsets obtained by considering all ranges of attribute values P: frequent itemsets obtained by considering all ranges over the partitions P is K-complete w.r.t C if P C,and X C, X P such that: 1. X is a generalization of X and support (X ) K support(x) (K 1) 2. Y X, Y X such that support (Y ) K support(y) Given K (partial completeness level), can determine number of intervals (N)
11 Interestingness Measure {Refund = No, (Income = $51,250)} {Cheat = No} {Refund = No, (51K Income 52K)} {Cheat = No} {Refund = No, (50K Income 60K)} {Cheat = No} Given an itemset: Z = {z 1, z 2,, z k } and its generalization Z = {z 1, z 2,, z k } P(Z): support of Z E Z (Z): expected support of Z based on Z E Z ' ( Z) P( z ) 1 P( z ') 1 P( z P( z 2 2 ) ') P( z P( z ) P( Z') ') Z is R-interesting w.r.t. Z if P(Z) R E Z (Z) k k
12 Interestingness Measure For S: X Y, and its generalization S : X Y P(Y X): confidence of X Y P(Y X ): confidence of X Y E S (Y X): expected support of Z based on Z E( Y X ) P( y ) P( y ) P( y ) 1 2 k P( Y' X ') P( y ') P( y ') P( y ') 1 2 k Rule S is R-interesting w.r.t its ancestor rule S if Support, P(S) R E S (S) or Confidence, P(Y X) R E S (Y X)
13 Statistics-based Methods Example: Browser=Mozilla Buy=Yes Age: =23 Rule consequent consists of a continuous variable, characterized by their statistics mean, median, standard deviation, etc. Approach: Withhold the target variable from the rest of the data Apply existing frequent itemset generation on the rest of the data For each frequent itemset, compute the descriptive statistics for the corresponding target variable Frequent itemset becomes a rule by introducing the target variable as rule consequent Apply statistical test to determine interestingness of the rule
14 Statistics-based Methods How to determine whether an association rule interesting? Compare the statistics for segment of population covered by the rule vs segment of population not covered by the rule: A B: versus A B: Statistical hypothesis testing: Null hypothesis: H0: = + Alternative hypothesis: H1: > + Z has zero mean and variance 1 under null hypothesis Z ' 2 2 s1 s2 n n 1 2
15 Statistics-based Methods Example: r: Browser=Mozilla Buy=Yes Age: =23 Rule is interesting if difference between and is greater than 5 years (i.e., = 5) For r, suppose n1 = 50, s1 = 3.5 For r (complement): n2 = 250, s2 = 6.5 ' Z s1 s n n For 1-sided test at 95% confidence level, critical Z-value for rejecting null hypothesis is Since Z is greater than 1.64, r is an interesting rule
16 Min-Apriori (Han et al) Document-term matrix: Example: TID W1 W2 W3 W4 W5 D D D D D W1 and W2 tends to appear together in the same document
17 Min-Apriori Data contains only continuous attributes of the same type e.g., frequency of words in a document Potential solution: Convert into 0/1 matrix and then apply existing algorithms lose word frequency information TID W1 W2 W3 W4 W5 D D D D D Discretization does not apply as users want association among words not ranges of words
18 Min-Apriori How to determine the support of a word? If we simply sum up its frequency, support count will be greater than total number of documents! Normalize the word vectors e.g., using L 1 norm Each word has a support equals to 1.0 TID W1 W2 W3 W4 W5 D D D D D Normalize TID W1 W2 W3 W4 W5 D D D D D
19 Min-Apriori New definition of support: sup( C ) min D( i, j) i T j C TID W1 W2 W3 W4 W5 D D D D D Example: Sup(W1,W2,W3) = = 0.17
20 Anti-monotone property of Support Example: TID W1 W2 W3 W4 W5 D D D D D Sup(W1) = = 1 Sup(W1, W2) = = 0.9 Sup(W1, W2, W3) = = 0.17
21 Multi-level Association Rules Food Electronics Bread Milk Computers Home Wheat White Skim 2% Desktop Laptop Accessory TV DVD Foremost Kemps Printer Scanner
22 Multi-level Association Rules Why should we incorporate concept hierarchy? Rules at lower levels may not have enough support to appear in any frequent itemsets Rules at lower levels of the hierarchy are overly specific e.g., skim milk white bread, 2% milk wheat bread, skim milk wheat bread, etc. are indicative of association between milk and bread
23 Multi-level Association Rules How do support and confidence vary as we traverse the concept hierarchy? If X is the parent item for both X1 and X2, then (X) (X1) + (X2) If (X1 Y1) minsup, and X is parent of X1, Y is parent of Y1 then (X Y1) minsup, (X1 Y) minsup (X Y) minsup If conf(x1 Y1) minconf, then conf(x1 Y) minconf
24 Multi-level Association Rules Approach 1: Extend current association rule formulation by augmenting each transaction with higher level items Original Transaction: {skim milk, wheat bread} Augmented Transaction: {skim milk, wheat bread, milk, bread, food} Issues: Items that reside at higher levels have much higher support counts if support threshold is low, too many frequent patterns involving items from the higher levels Increased dimensionality of the data
25 Multi-level Association Rules Approach 2: Generate frequent patterns at highest level first Then, generate frequent patterns at the next highest level, and so on Issues: I/O requirements will increase dramatically because we need to perform more passes over the data May miss some potentially interesting cross-level association patterns
26 Sequence Data Sequence Database: Timeline Object Timestamp Events A 10 2, 3, 5 A 20 6, 1 A 23 1 B 11 4, 5, 6 B 17 2 B 21 7, 8, 1, 2 B 28 1, 6 C 14 1, 8, 7 Object A: Object B: Object C: 1 7 8
27 Examples of Sequence Data Sequence Database Sequence Element (Transaction) Event (Item) Customer Purchase history of a given customer A set of items bought by a customer at time t Books, diary products, CDs, etc Web Data Browsing activity of a particular Web visitor A collection of files viewed by a Web visitor after a single mouse click Home page, index page, contact info, etc Event data History of events generated by a given sensor Events triggered by a sensor at time t Types of alarms generated by sensors Genome sequences DNA sequence of a particular species An element of the DNA sequence Bases A,T,G,C Element (Transaction) Sequence E1 E2 E1 E3 E2 E2 E3 E4 Event (Item)
28 Formal Definition of a Sequence A sequence is an ordered list of elements (transactions) s = < e 1 e 2 e 3 > Each element contains a collection of events (items) e i = {i 1, i 2,, i k } Each element is attributed to a specific time or location Length of a sequence, s, is given by the number of elements of the sequence A k-sequence is a sequence that contains k events (items)
29 Examples of Sequence Web sequence: < {Homepage} {Electronics} {Digital Cameras} {Canon Digital Camera} {Shopping Cart} {Order Confirmation} {Return to Shopping} > Sequence of initiating events causing the nuclear accident at 3-mile Island: ( < {clogged resin} {outlet valve closure} {loss of feedwater} {condenser polisher outlet valve shut} {booster pumps trip} {main waterpump trips} {main turbine trips} {reactor pressure increases}> Sequence of books checked out at a library: <{Fellowship of the Ring} {The Two Towers} {Return of the King}>
30 Formal Definition of a Subsequence A sequence <a 1 a 2 a n > is contained in another sequence <b 1 b 2 b m > (m n) if there exist integers i 1 < i 2 < < i n such that a 1 b i1, a 2 b i1,, a n b in Data sequence Subsequence Contain? < {2,4} {3,5,6} {8} > < {2} {3,5} > Yes < {1,2} {3,4} > < {1} {2} > No < {2,4} {2,4} {2,5} > < {2} {4} > Yes The support of a subsequence w is defined as the fraction of data sequences that contain w A sequential pattern is a frequent subsequence (i.e., a subsequence whose support is minsup)
31 Sequential Pattern Mining: Definition Given: a database of sequences a user-specified minimum support threshold, minsup Task: Find all subsequences with support minsup

32 Sequential Pattern Mining: Challenge
33 Sequential Pattern Mining: Example Object Timestamp Events A 1 1,2,4 A 2 2,3 A 3 5 B 1 1,2 B 2 2,3,4 C 1 1, 2 C 2 2,3,4 C 3 2,4,5 D 1 2 D 2 3, 4 D 3 4, 5 E 1 1, 3 E 2 2, 4, 5 Minsup = 50% Examples of Frequent Subsequences: < {1,2} > s=60% < {2,3} > s=60% < {2,4}> s=80% < {3} {5}> s=80% < {1} {2} > s=80% < {2} {2} > s=60% < {1} {2,3} > s=60% < {2} {2,3} > s=60% < {1,2} {2,3} > s=60%

34 Extracting Sequential Patterns
35 Generalized Sequential Pattern (GSP) Step 1: Make the first pass over the sequence database D to yield all the 1- element frequent sequences Step 2: Repeat until no new frequent sequences are found Candidate Generation: Merge pairs of frequent subsequences found in the (k-1)th pass to generate candidate sequences that contain k items Candidate Pruning: Prune candidate k-sequences that contain infrequent (k-1)-subsequences Support Counting: Make a new pass over the sequence database D to find the support for these candidate sequences Candidate Elimination: Eliminate candidate k-sequences whose actual support is less than minsup
36 Candidate Generation Base case (k=2): Merging two frequent 1-sequences <{i 1 }> and <{i 2 }> will produce two candidate 2-sequences: <{i 1 } {i 2 }> and <{i 1 i 2 }> General case (k>2): A frequent (k-1)-sequence w 1 is merged with another frequent (k-1)-sequence w 2 to produce a candidate k-sequence if the subsequence obtained by removing the first event in w 1 is the same as the subsequence obtained by removing the last event in w 2 The resulting candidate after merging is given by the sequence w 1 extended with the last event of w 2. If the last two events in w 2 belong to the same element, then the last event in w 2 becomes part of the last element in w 1 Otherwise, the last event in w 2 becomes a separate element appended to the end of w 1
37 Candidate Generation Examples Merging the sequences w 1 =<{1} {2 3} {4}> and w 2 =<{2 3} {4 5}> will produce the candidate sequence < {1} {2 3} {4 5}> because the last two events in w 2 (4 and 5) belong to the same element Merging the sequences w 1 =<{1} {2 3} {4}> and w 2 =<{2 3} {4} {5}> will produce the candidate sequence < {1} {2 3} {4} {5}> because the last two events in w 2 (4 and 5) do not belong to the same element We do not have to merge the sequences w 1 =<{1} {2 6} {4}> and w 2 =<{1} {2} {4 5}> to produce the candidate < {1} {2 6} {4 5}> because if the latter is a viable candidate, then it can be obtained by merging w 1 with < {1} {2 6} {5}>
38 Generalized Sequential Pattern (GSP) Step 1: Make the first pass over the sequence database D to yield all the 1- element frequent sequences Step 2: Repeat until no new frequent sequences are found Candidate Generation: Merge pairs of frequent subsequences found in the (k-1)th pass to generate candidate sequences that contain k items Candidate Pruning: Prune candidate k-sequences that contain infrequent (k-1)-subsequences Support Counting: Make a new pass over the sequence database D to find the support for these candidate sequences Candidate Elimination: Eliminate candidate k-sequences whose actual support is less than minsup
39 GSP Example Suppose now we have 3 events: 1, 2, 3, and let min-support be 50%. The sequence database is shown in following table: Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3)
40 Step 1: Make the first pass over the sequence database D to yield all the 1-element frequent sequences Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3) Candidate 1-sequences are: <{1}>, <{2}>, <{3}>
41 generate candidate sequences that contain k items Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3) Candidate 1-sequences are: <{1}>, <{2}>, <{3}> Base case (k=2): Merging two frequent 1-sequences <{i 1 }> and <{i 2 }> will produce two candidate 2-sequences: <{i 1 } {i 2 }> and <{i 1 i 2 }> Candidate 2-sequences are: <{1, 2}>, <{1, 3}>, <{2, 3}>, <{1}, {1}>, <{1}, {2}>, <{1}, {3}>, <{2}, {1}>, <{2}, {2}>, <{2}, {3}>, <{3}, {1}>, <{3}, {2}>, <{3}, {3}>
42 Step 2: Candidate Pruning: Prune candidate k-sequences that contain infrequent (k-1)- subsequences Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3) After candidate pruning, the 2-sequences should remain the same: <{1, 2}>, <{1, 3}>, <{2, 3}>, <{1}, {1}>, <{1}, {2}>, <{1}, {3}>, <{2}, {1}>, <{2}, {2}>, <{2}, {3}>, <{3}, {1}>, <{3}, {2}>, <{3}, {3}>
43 Step 2: Support Counting and Candidate Elimination: Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3) After candidate elimination, the remaining frequent 2-sequences are: <{1, 2}> (support=0.6), <{2, 3}> (support=0.6), <{1}, {2}> (support=0.6), <{1}, {3}> (support=0.8), <{2}, {3}> (support=0.6)
44 Repeat Step 2: Candidate Generation General case (k>2): A frequent (k-1)-sequence w 1 is merged with another frequent (k-1)-sequence w 2 to produce a candidate k-sequence if the subsequence obtained by removing the first event in w 1 is the same as the subsequence obtained by removing the last event in w 2 The resulting candidate after merging is given by the sequence w 1 extended with the last event of w 2. If the last two events in w 2 belong to the same element, then the last event in w 2 becomes part of the last element in w 1 Otherwise, the last event in w 2 becomes a separate element appended to the end of w 1
45 Repeat Step 2: Candidate Generation Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3) Generate 3-sequences from the remaining 2-sequences : <{1, 2}>, <{2, 3}>, <{1}, {2}>, <{1}, {3}>, <{2}, {3}> 3-sequences are: <{1, 2, 3}> (generated from <{1, 2}> and <{2, 3}>), <{1, 2}, {3}> (generated from <{1, 2}> and <{2}, {3}>), <{1}, {2}, {3}> (generated from <{1}, {2}> and <{2}, {3}>)
46 Repeat Step 2: Candidate Pruning Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3) 3-sequences : <{1, 2, 3}> should be pruned because one 2-subsequences <{1, 3}> is not frequent. <{1, 2}, {3}> should not be pruned because all 2-subsequences <{1}, {3}> and <{2}, {3}> are frequent. <{1}, {2}, {3}> should not be pruned because all 2-subsequences <{1}, {2}>, <{2}, {3}> and <{1}, {3}> are frequent. So after pruning, the remaining 3-sequences are: <{1, 2}, {3}> and <{1}, {2}, {3}>
47 Repeat Step 2: Support Counting Object Sequence A (1), (2), (3) B (1, 2), (3) C (1), (2, 3) D (1, 2, 3) E (1, 2), (2, 3), (1, 3) Remaining 3-sequences : <{1, 2}, {3}>, support = 0.4 < 0.5, should be eliminated <{1}, {2}, {3}>, support = 0.4 < 0.5, should be eliminated. Thus, there are no 3-sequences left. So the final frequent sequences are: <{1}>, <{2}>, <{3}>, <{1, 2}>, <{2, 3}>, <{1}, {2}>, <{1}, {3}>, <{2}, {3}>
48 GSP Example Frequent 3-sequences < {1} {2} {3} > < {1} {2 5} > < {1} {5} {3} > < {2} {3} {4} > < {2 5} {3} > < {3} {4} {5} > < {5} {3 4} > Candidate Generation < {1} {2} {3} {4} > < {1} {2 5} {3} > < {1} {5} {3 4} > < {2} {3} {4} {5} > < {2 5} {3 4} > Candidate Pruning < {1} {2 5} {3} >
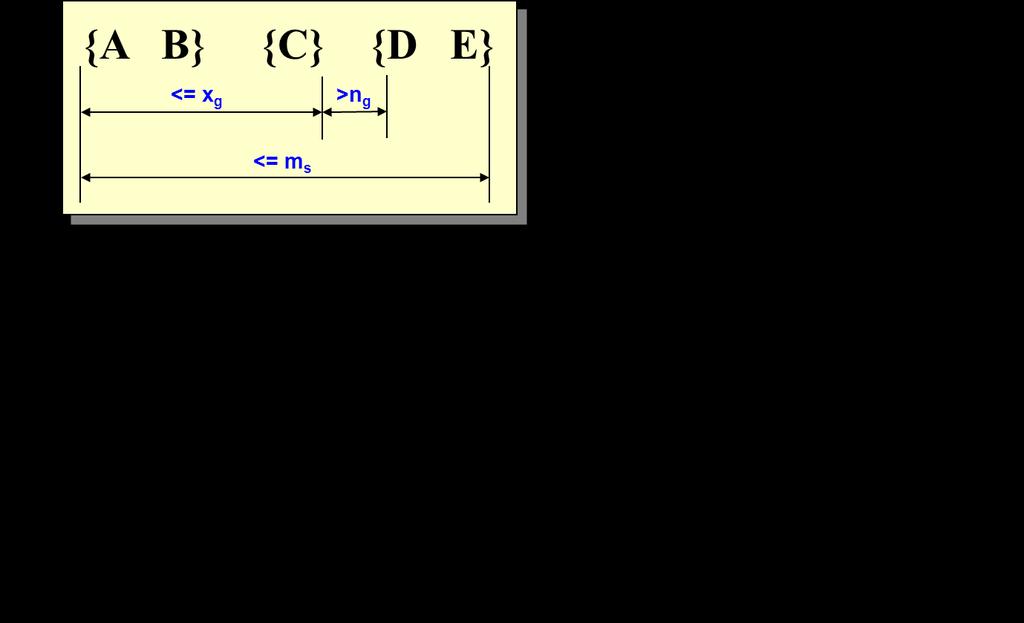
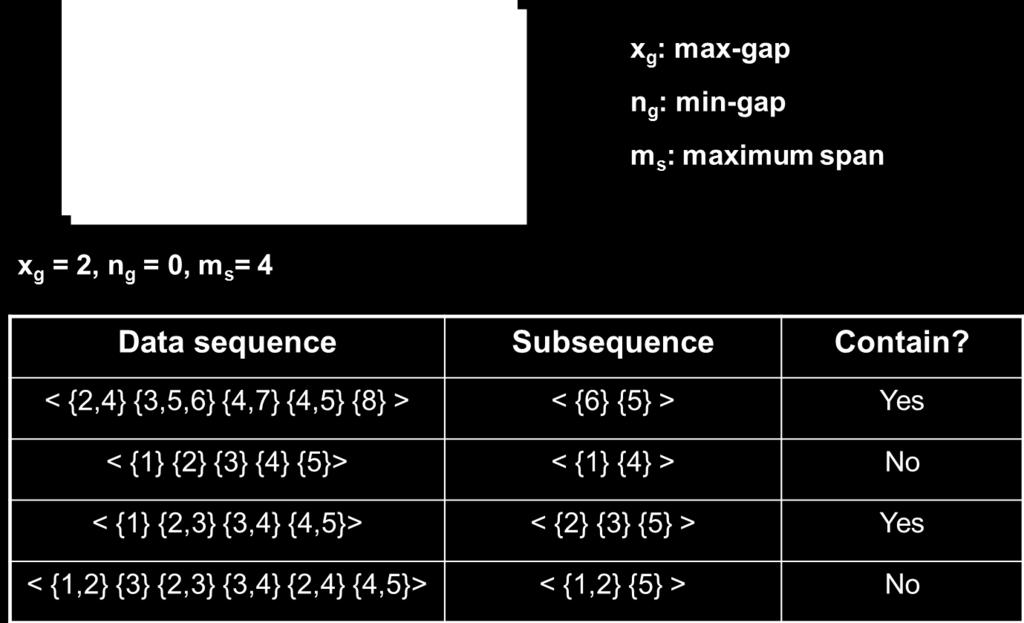
49 Timing Constraints (I)
50 Mining Sequential Patterns with Timing Constraints Approach 1: Mine sequential patterns without timing constraints Postprocess the discovered patterns Approach 2: Modify GSP to directly prune candidates that violate timing constraints Question: Does Apriori principle still hold?

51 Apriori Principle for Sequence Data
52 Contiguous Subsequences s is a contiguous subsequence of w = <e 1 >< e 2 > < e k > if any of the following conditions hold: 1. s is obtained from w by deleting an item from either e 1 or e k 2. s is obtained from w by deleting an item from any element e i that contains more than 2 items 3. s is a contiguous subsequence of s and s is a contiguous subsequence of w (recursive definition) Examples: s = < {1} {2} > is a contiguous subsequence of < {1} {2 3}>, < {1 2} {2} {3}>, and < {3 4} {1 2} {2 3} {4} > is not a contiguous subsequence of < {1} {3} {2}> and < {2} {1} {3} {2}>
53 Modified Candidate Pruning Step Without maxgap constraint: A candidate k-sequence is pruned if at least one of its (k-1)-subsequences is infrequent With maxgap constraint: A candidate k-sequence is pruned if at least one of its contiguous (k-1)-subsequences is infrequent
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Handling a Concept Hierarchy
 Food Electronics Handling a Concept Hierarchy Bread Milk Computers Home Wheat White Skim 2% Desktop Laptop Accessory TV DVD Foremost Kemps Printer Scanner Data Mining: Association Rules 5 Why should we
Food Electronics Handling a Concept Hierarchy Bread Milk Computers Home Wheat White Skim 2% Desktop Laptop Accessory TV DVD Foremost Kemps Printer Scanner Data Mining: Association Rules 5 Why should we
Sequential Pattern Mining
 Sequential Pattern Mining Lecture Notes for Chapter 7 Introduction to Data Mining Tan, Steinbach, Kumar From itemsets to sequences Frequent itemsets and association rules focus on transactions and the
Sequential Pattern Mining Lecture Notes for Chapter 7 Introduction to Data Mining Tan, Steinbach, Kumar From itemsets to sequences Frequent itemsets and association rules focus on transactions and the
Data Mining Association Rules: Advanced Concepts and Algorithms. Lecture Notes for Chapter 7. Introduction to Data Mining
 Data Mining Association Rules: Advanced Concets and Algorithms Lecture Notes for Chater 7 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/24 1
Data Mining Association Rules: Advanced Concets and Algorithms Lecture Notes for Chater 7 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/24 1
Data mining, 4 cu Lecture 7:
 582364 Data mining, 4 cu Lecture 7: Sequential Patterns Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Sequential Patterns In many data mining tasks the order and timing of events contains
582364 Data mining, 4 cu Lecture 7: Sequential Patterns Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Sequential Patterns In many data mining tasks the order and timing of events contains
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 05 Sequential Pattern Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Mining Concepts & Techniques Lecture No. 05 Sequential Pattern Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Association Rules Information Retrieval and Data Mining. Prof. Matteo Matteucci
 Association Rules Information Retrieval and Data Mining Prof. Matteo Matteucci Learning Unsupervised Rules!?! 2 Market-Basket Transactions 3 Bread Peanuts Milk Fruit Jam Bread Jam Soda Chips Milk Fruit
Association Rules Information Retrieval and Data Mining Prof. Matteo Matteucci Learning Unsupervised Rules!?! 2 Market-Basket Transactions 3 Bread Peanuts Milk Fruit Jam Bread Jam Soda Chips Milk Fruit
COMP 5331: Knowledge Discovery and Data Mining
 COMP 5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Jiawei Han, Micheline Kamber, and Jian Pei And slides provide by Raymond
COMP 5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Jiawei Han, Micheline Kamber, and Jian Pei And slides provide by Raymond
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
DATA MINING - 1DL360
 DATA MINING - 1DL36 Fall 212" An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht12 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
DATA MINING - 1DL36 Fall 212" An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht12 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
732A61/TDDD41 Data Mining - Clustering and Association Analysis
 732A61/TDDD41 Data Mining - Clustering and Association Analysis Lecture 6: Association Analysis I Jose M. Peña IDA, Linköping University, Sweden 1/14 Outline Content Association Rules Frequent Itemsets
732A61/TDDD41 Data Mining - Clustering and Association Analysis Lecture 6: Association Analysis I Jose M. Peña IDA, Linköping University, Sweden 1/14 Outline Content Association Rules Frequent Itemsets
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 04 Association Analysis Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Mining Concepts & Techniques Lecture No. 04 Association Analysis Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Apriori algorithm. Seminar of Popular Algorithms in Data Mining and Machine Learning, TKK. Presentation Lauri Lahti
 Apriori algorithm Seminar of Popular Algorithms in Data Mining and Machine Learning, TKK Presentation 12.3.2008 Lauri Lahti Association rules Techniques for data mining and knowledge discovery in databases
Apriori algorithm Seminar of Popular Algorithms in Data Mining and Machine Learning, TKK Presentation 12.3.2008 Lauri Lahti Association rules Techniques for data mining and knowledge discovery in databases
DATA MINING - 1DL360
 DATA MINING - DL360 Fall 200 An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht0 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
DATA MINING - DL360 Fall 200 An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht0 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
Lecture Notes for Chapter 6. Introduction to Data Mining
 Data Mining Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
Data Mining Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
CS 484 Data Mining. Association Rule Mining 2
 CS 484 Data Mining Association Rule Mining 2 Review: Reducing Number of Candidates Apriori principle: If an itemset is frequent, then all of its subsets must also be frequent Apriori principle holds due
CS 484 Data Mining Association Rule Mining 2 Review: Reducing Number of Candidates Apriori principle: If an itemset is frequent, then all of its subsets must also be frequent Apriori principle holds due
Association Rule. Lecturer: Dr. Bo Yuan. LOGO
 Association Rule Lecturer: Dr. Bo Yuan LOGO E-mail: yuanb@sz.tsinghua.edu.cn Overview Frequent Itemsets Association Rules Sequential Patterns 2 A Real Example 3 Market-Based Problems Finding associations
Association Rule Lecturer: Dr. Bo Yuan LOGO E-mail: yuanb@sz.tsinghua.edu.cn Overview Frequent Itemsets Association Rules Sequential Patterns 2 A Real Example 3 Market-Based Problems Finding associations
Mining Infrequent Patter ns
 Mining Infrequent Patter ns JOHAN BJARNLE (JOHBJ551) PETER ZHU (PETZH912) LINKÖPING UNIVERSITY, 2009 TNM033 DATA MINING Contents 1 Introduction... 2 2 Techniques... 3 2.1 Negative Patterns... 3 2.2 Negative
Mining Infrequent Patter ns JOHAN BJARNLE (JOHBJ551) PETER ZHU (PETZH912) LINKÖPING UNIVERSITY, 2009 TNM033 DATA MINING Contents 1 Introduction... 2 2 Techniques... 3 2.1 Negative Patterns... 3 2.2 Negative
Chapter 6. Frequent Pattern Mining: Concepts and Apriori. Meng Jiang CSE 40647/60647 Data Science Fall 2017 Introduction to Data Mining
 Chapter 6. Frequent Pattern Mining: Concepts and Apriori Meng Jiang CSE 40647/60647 Data Science Fall 2017 Introduction to Data Mining Pattern Discovery: Definition What are patterns? Patterns: A set of
Chapter 6. Frequent Pattern Mining: Concepts and Apriori Meng Jiang CSE 40647/60647 Data Science Fall 2017 Introduction to Data Mining Pattern Discovery: Definition What are patterns? Patterns: A set of
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/17/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/17/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
Chapters 6 & 7, Frequent Pattern Mining
 CSI 4352, Introduction to Data Mining Chapters 6 & 7, Frequent Pattern Mining Young-Rae Cho Associate Professor Department of Computer Science Baylor University CSI 4352, Introduction to Data Mining Chapters
CSI 4352, Introduction to Data Mining Chapters 6 & 7, Frequent Pattern Mining Young-Rae Cho Associate Professor Department of Computer Science Baylor University CSI 4352, Introduction to Data Mining Chapters
Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Chapter 5 Association Analysis: Basic Concepts Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 2/3/28 Introduction to Data Mining Association Rule Mining Given
Data Mining Chapter 5 Association Analysis: Basic Concepts Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 2/3/28 Introduction to Data Mining Association Rule Mining Given
DATA MINING LECTURE 3. Frequent Itemsets Association Rules
 DATA MINING LECTURE 3 Frequent Itemsets Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
DATA MINING LECTURE 3 Frequent Itemsets Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
Association Rule Mining on Web
 Association Rule Mining on Web What Is Association Rule Mining? Association rule mining: Finding interesting relationships among items (or objects, events) in a given data set. Example: Basket data analysis
Association Rule Mining on Web What Is Association Rule Mining? Association rule mining: Finding interesting relationships among items (or objects, events) in a given data set. Example: Basket data analysis
Meelis Kull Autumn Meelis Kull - Autumn MTAT Data Mining - Lecture 05
 Meelis Kull meelis.kull@ut.ee Autumn 2017 1 Sample vs population Example task with red and black cards Statistical terminology Permutation test and hypergeometric test Histogram on a sample vs population
Meelis Kull meelis.kull@ut.ee Autumn 2017 1 Sample vs population Example task with red and black cards Statistical terminology Permutation test and hypergeometric test Histogram on a sample vs population
Data Mining and Analysis: Fundamental Concepts and Algorithms
 Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
D B M G Data Base and Data Mining Group of Politecnico di Torino
 Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
Association Rules. Fundamentals
 Politecnico di Torino Politecnico di Torino 1 Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket counter Association rule
Politecnico di Torino Politecnico di Torino 1 Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket counter Association rule
D B M G. Association Rules. Fundamentals. Fundamentals. Association rules. Association rule mining. Definitions. Rule quality metrics: example
 Association rules Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
Association rules Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 2017 Road map The Apriori algorithm Step 1: Mining all frequent
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 2017 Road map The Apriori algorithm Step 1: Mining all frequent
D B M G. Association Rules. Fundamentals. Fundamentals. Elena Baralis, Silvia Chiusano. Politecnico di Torino 1. Definitions.
 Definitions Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Itemset is a set including one or more items Example: {Beer, Diapers} k-itemset is an itemset that contains k
Definitions Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Itemset is a set including one or more items Example: {Beer, Diapers} k-itemset is an itemset that contains k
CS 584 Data Mining. Association Rule Mining 2
 CS 584 Data Mining Association Rule Mining 2 Recall from last time: Frequent Itemset Generation Strategies Reduce the number of candidates (M) Complete search: M=2 d Use pruning techniques to reduce M
CS 584 Data Mining Association Rule Mining 2 Recall from last time: Frequent Itemset Generation Strategies Reduce the number of candidates (M) Complete search: M=2 d Use pruning techniques to reduce M
Association Analysis: Basic Concepts. and Algorithms. Lecture Notes for Chapter 6. Introduction to Data Mining
 Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Association
Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Association
Data preprocessing. DataBase and Data Mining Group 1. Data set types. Tabular Data. Document Data. Transaction Data. Ordered Data
 Elena Baralis and Tania Cerquitelli Politecnico di Torino Data set types Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures Ordered Spatial Data Temporal Data Sequential
Elena Baralis and Tania Cerquitelli Politecnico di Torino Data set types Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures Ordered Spatial Data Temporal Data Sequential
Data Analytics Beyond OLAP. Prof. Yanlei Diao
 Data Analytics Beyond OLAP Prof. Yanlei Diao OPERATIONAL DBs DB 1 DB 2 DB 3 EXTRACT TRANSFORM LOAD (ETL) METADATA STORE DATA WAREHOUSE SUPPORTS OLAP DATA MINING INTERACTIVE DATA EXPLORATION Overview of
Data Analytics Beyond OLAP Prof. Yanlei Diao OPERATIONAL DBs DB 1 DB 2 DB 3 EXTRACT TRANSFORM LOAD (ETL) METADATA STORE DATA WAREHOUSE SUPPORTS OLAP DATA MINING INTERACTIVE DATA EXPLORATION Overview of
Lars Schmidt-Thieme, Information Systems and Machine Learning Lab (ISMLL), University of Hildesheim, Germany
, University of Hildesheim, Germany") Syllabus Fri. 21.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 27.10. (2) A.1 Linear Regression Fri. 3.11. (3) A.2 Linear Classification Fri. 10.11. (4) A.3 Regularization
Syllabus Fri. 21.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 27.10. (2) A.1 Linear Regression Fri. 3.11. (3) A.2 Linear Classification Fri. 10.11. (4) A.3 Regularization
Associa'on Rule Mining
 Associa'on Rule Mining Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 4 and 7, 2014 1 Market Basket Analysis Scenario: customers shopping at a supermarket Transaction
Associa'on Rule Mining Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 4 and 7, 2014 1 Market Basket Analysis Scenario: customers shopping at a supermarket Transaction
Association Analysis Part 2. FP Growth (Pei et al 2000)
") Association Analysis art 2 Sanjay Ranka rofessor Computer and Information Science and Engineering University of Florida F Growth ei et al 2 Use a compressed representation of the database using an F-tree
Association Analysis art 2 Sanjay Ranka rofessor Computer and Information Science and Engineering University of Florida F Growth ei et al 2 Use a compressed representation of the database using an F-tree
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 10 What is Data? Collection of data objects
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 10 What is Data? Collection of data objects
Density-Based Clustering
 Density-Based Clustering idea: Clusters are dense regions in feature space F. density: objects volume ε here: volume: ε-neighborhood for object o w.r.t. distance measure dist(x,y) dense region: ε-neighborhood
Density-Based Clustering idea: Clusters are dense regions in feature space F. density: objects volume ε here: volume: ε-neighborhood for object o w.r.t. distance measure dist(x,y) dense region: ε-neighborhood
DATA MINING LECTURE 4. Frequent Itemsets, Association Rules Evaluation Alternative Algorithms
 DATA MINING LECTURE 4 Frequent Itemsets, Association Rules Evaluation Alternative Algorithms RECAP Mining Frequent Itemsets Itemset A collection of one or more items Example: {Milk, Bread, Diaper} k-itemset
DATA MINING LECTURE 4 Frequent Itemsets, Association Rules Evaluation Alternative Algorithms RECAP Mining Frequent Itemsets Itemset A collection of one or more items Example: {Milk, Bread, Diaper} k-itemset
CISC 4631 Data Mining
 CISC 4631 Data Mining Lecture 02: Data Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) 1 10 What is Data? Collection of data objects and their attributes An attribute
CISC 4631 Data Mining Lecture 02: Data Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) 1 10 What is Data? Collection of data objects and their attributes An attribute
Association Rules. Acknowledgements. Some parts of these slides are modified from. n C. Clifton & W. Aref, Purdue University
 Association Rules CS 5331 by Rattikorn Hewett Texas Tech University 1 Acknowledgements Some parts of these slides are modified from n C. Clifton & W. Aref, Purdue University 2 1 Outline n Association Rule
Association Rules CS 5331 by Rattikorn Hewett Texas Tech University 1 Acknowledgements Some parts of these slides are modified from n C. Clifton & W. Aref, Purdue University 2 1 Outline n Association Rule
Frequent Itemset Mining
 ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team (PART I) IMAGINA 17/18 Webpage: http://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge
ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team (PART I) IMAGINA 17/18 Webpage: http://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge
Lecture Notes for Chapter 6. Introduction to Data Mining. (modified by Predrag Radivojac, 2017)
") Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 27) Association Rule Mining Given a set of transactions, find rules that will predict the
Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 27) Association Rule Mining Given a set of transactions, find rules that will predict the
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar 1 Types of data sets Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar 1 Types of data sets Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures
Unit II Association Rules
 Unit II Association Rules Basic Concepts Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set Frequent Itemset
Unit II Association Rules Basic Concepts Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set Frequent Itemset
Data mining, 4 cu Lecture 5:
 582364 Data mining, 4 cu Lecture 5: Evaluation of Association Patterns Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Evaluation of Association Patterns Association rule algorithms
582364 Data mining, 4 cu Lecture 5: Evaluation of Association Patterns Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Evaluation of Association Patterns Association rule algorithms
Frequent Itemsets and Association Rule Mining. Vinay Setty Slides credit:
 Frequent Itemsets and Association Rule Mining Vinay Setty vinay.j.setty@uis.no Slides credit: http://www.mmds.org/ Association Rule Discovery Supermarket shelf management Market-basket model: Goal: Identify
Frequent Itemsets and Association Rule Mining Vinay Setty vinay.j.setty@uis.no Slides credit: http://www.mmds.org/ Association Rule Discovery Supermarket shelf management Market-basket model: Goal: Identify
Introduction to Data Mining
 Introduction to Data Mining Lecture #12: Frequent Itemsets Seoul National University 1 In This Lecture Motivation of association rule mining Important concepts of association rules Naïve approaches for
Introduction to Data Mining Lecture #12: Frequent Itemsets Seoul National University 1 In This Lecture Motivation of association rule mining Important concepts of association rules Naïve approaches for
Knowledge Discovery and Data Mining I
 Ludwig-Maximilians-Universität München Lehrstuhl für Datenbanksysteme und Data Mining Prof. Dr. Thomas Seidl Knowledge Discovery and Data Mining I Winter Semester 2018/19 Agenda 1. Introduction 2. Basics
Ludwig-Maximilians-Universität München Lehrstuhl für Datenbanksysteme und Data Mining Prof. Dr. Thomas Seidl Knowledge Discovery and Data Mining I Winter Semester 2018/19 Agenda 1. Introduction 2. Basics
Encyclopedia of Machine Learning Chapter Number Book CopyRight - Year 2010 Frequent Pattern. Given Name Hannu Family Name Toivonen
 Book Title Encyclopedia of Machine Learning Chapter Number 00403 Book CopyRight - Year 2010 Title Frequent Pattern Author Particle Given Name Hannu Family Name Toivonen Suffix Email hannu.toivonen@cs.helsinki.fi
Book Title Encyclopedia of Machine Learning Chapter Number 00403 Book CopyRight - Year 2010 Title Frequent Pattern Author Particle Given Name Hannu Family Name Toivonen Suffix Email hannu.toivonen@cs.helsinki.fi
Machine Learning: Pattern Mining
 Machine Learning: Pattern Mining Information Systems and Machine Learning Lab (ISMLL) University of Hildesheim Wintersemester 2007 / 2008 Pattern Mining Overview Itemsets Task Naive Algorithm Apriori Algorithm
Machine Learning: Pattern Mining Information Systems and Machine Learning Lab (ISMLL) University of Hildesheim Wintersemester 2007 / 2008 Pattern Mining Overview Itemsets Task Naive Algorithm Apriori Algorithm
Association Rules. Jones & Bartlett Learning, LLC NOT FOR SALE OR DISTRIBUTION. Jones & Bartlett Learning, LLC NOT FOR SALE OR DISTRIBUTION
 CHAPTER2 Association Rules 2.1 Introduction Many large retail organizations are interested in instituting information-driven marketing processes, managed by database technology, that enable them to Jones
CHAPTER2 Association Rules 2.1 Introduction Many large retail organizations are interested in instituting information-driven marketing processes, managed by database technology, that enable them to Jones
Outline. Fast Algorithms for Mining Association Rules. Applications of Data Mining. Data Mining. Association Rule. Discussion
 Outline Fast Algorithms for Mining Association Rules Rakesh Agrawal Ramakrishnan Srikant Introduction Algorithm Apriori Algorithm AprioriTid Comparison of Algorithms Conclusion Presenter: Dan Li Discussion:
Outline Fast Algorithms for Mining Association Rules Rakesh Agrawal Ramakrishnan Srikant Introduction Algorithm Apriori Algorithm AprioriTid Comparison of Algorithms Conclusion Presenter: Dan Li Discussion:
Mining Positive and Negative Fuzzy Association Rules
 Mining Positive and Negative Fuzzy Association Rules Peng Yan 1, Guoqing Chen 1, Chris Cornelis 2, Martine De Cock 2, and Etienne Kerre 2 1 School of Economics and Management, Tsinghua University, Beijing
Mining Positive and Negative Fuzzy Association Rules Peng Yan 1, Guoqing Chen 1, Chris Cornelis 2, Martine De Cock 2, and Etienne Kerre 2 1 School of Economics and Management, Tsinghua University, Beijing
Data Warehousing & Data Mining
 Data Warehousing & Data Mining Wolf-Tilo Balke Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence 9. Business Intelligence
Data Warehousing & Data Mining Wolf-Tilo Balke Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence 9. Business Intelligence
Frequent Pattern Mining: Exercises
 Frequent Pattern Mining: Exercises Christian Borgelt School of Computer Science tto-von-guericke-university of Magdeburg Universitätsplatz 2, 39106 Magdeburg, Germany christian@borgelt.net http://www.borgelt.net/
Frequent Pattern Mining: Exercises Christian Borgelt School of Computer Science tto-von-guericke-university of Magdeburg Universitätsplatz 2, 39106 Magdeburg, Germany christian@borgelt.net http://www.borgelt.net/
FP-growth and PrefixSpan
 FP-growth and PrefixSpan n Challenges of Frequent Pattern Mining n Improving Apriori n Fp-growth n Fp-tree n Mining frequent patterns with FP-tree n PrefixSpan Challenges of Frequent Pattern Mining n Challenges
FP-growth and PrefixSpan n Challenges of Frequent Pattern Mining n Improving Apriori n Fp-growth n Fp-tree n Mining frequent patterns with FP-tree n PrefixSpan Challenges of Frequent Pattern Mining n Challenges
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 10 What is Data? Collection of data objects
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 10 What is Data? Collection of data objects
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar 10 What is Data? Collection of data objects and their attributes Attributes An attribute is a property
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar 10 What is Data? Collection of data objects and their attributes Attributes An attribute is a property
EFFICIENT MINING OF WEIGHTED QUANTITATIVE ASSOCIATION RULES AND CHARACTERIZATION OF FREQUENT ITEMSETS
 EFFICIENT MINING OF WEIGHTED QUANTITATIVE ASSOCIATION RULES AND CHARACTERIZATION OF FREQUENT ITEMSETS Arumugam G Senior Professor and Head, Department of Computer Science Madurai Kamaraj University Madurai,
EFFICIENT MINING OF WEIGHTED QUANTITATIVE ASSOCIATION RULES AND CHARACTERIZATION OF FREQUENT ITEMSETS Arumugam G Senior Professor and Head, Department of Computer Science Madurai Kamaraj University Madurai,
Association Analysis. Part 1
 Association Analysis Part 1 1 Market-basket analysis DATA: A large set of items: e.g., products sold in a supermarket A large set of baskets: e.g., each basket represents what a customer bought in one
Association Analysis Part 1 1 Market-basket analysis DATA: A large set of items: e.g., products sold in a supermarket A large set of baskets: e.g., each basket represents what a customer bought in one
Data Warehousing & Data Mining
 9. Business Intelligence Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence
9. Business Intelligence Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence
Descrip9ve data analysis. Example. Example. Example. Example. Data Mining MTAT (6EAP)
") 3.9.2 Descrip9ve data analysis Data Mining MTAT.3.83 (6EAP) hp://courses.cs.ut.ee/2/dm/ Frequent itemsets and associa@on rules Jaak Vilo 2 Fall Aims to summarise the main qualita9ve traits of data. Used
3.9.2 Descrip9ve data analysis Data Mining MTAT.3.83 (6EAP) hp://courses.cs.ut.ee/2/dm/ Frequent itemsets and associa@on rules Jaak Vilo 2 Fall Aims to summarise the main qualita9ve traits of data. Used
ASSOCIATION ANALYSIS FREQUENT ITEMSETS MINING. Alexandre Termier, LIG
 ASSOCIATION ANALYSIS FREQUENT ITEMSETS MINING, LIG M2 SIF DMV course 207/208 Market basket analysis Analyse supermarket s transaction data Transaction = «market basket» of a customer Find which items are
ASSOCIATION ANALYSIS FREQUENT ITEMSETS MINING, LIG M2 SIF DMV course 207/208 Market basket analysis Analyse supermarket s transaction data Transaction = «market basket» of a customer Find which items are
Similarity and Dissimilarity
 1//015 Similarity and Dissimilarity COMP 465 Data Mining Similarity of Data Data Preprocessing Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed.
1//015 Similarity and Dissimilarity COMP 465 Data Mining Similarity of Data Data Preprocessing Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed.
15 Introduction to Data Mining
 15 Introduction to Data Mining 15.1 Introduction to principle methods 15.2 Mining association rule see also: A. Kemper, Chap. 17.4, Kifer et al.: chap 17.7 ff 15.1 Introduction "Discovery of useful, possibly
15 Introduction to Data Mining 15.1 Introduction to principle methods 15.2 Mining association rule see also: A. Kemper, Chap. 17.4, Kifer et al.: chap 17.7 ff 15.1 Introduction "Discovery of useful, possibly
ECLT 5810 Data Preprocessing. Prof. Wai Lam
 ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
Data Warehousing. Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig
 Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary How to build a DW The DW Project:
Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary How to build a DW The DW Project:
1 Frequent Pattern Mining
 Decision Support Systems MEIC - Alameda 2010/2011 Homework #5 Due date: 31.Oct.2011 1 Frequent Pattern Mining 1. The Apriori algorithm uses prior knowledge about subset support properties. In particular,
Decision Support Systems MEIC - Alameda 2010/2011 Homework #5 Due date: 31.Oct.2011 1 Frequent Pattern Mining 1. The Apriori algorithm uses prior knowledge about subset support properties. In particular,
Summary. 8.1 BI Overview. 8. Business Intelligence. 8.1 BI Overview. 8.1 BI Overview 12/17/ Business Intelligence
 Summary Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de How to build a DW The DW Project:
Summary Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de How to build a DW The DW Project:
.. Cal Poly CSC 466: Knowledge Discovery from Data Alexander Dekhtyar..
 .. Cal Poly CSC 4: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Mining Association Rules Examples Course Enrollments Itemset. I = { CSC3, CSC3, CSC40, CSC40, CSC4, CSC44, CSC4, CSC44,
.. Cal Poly CSC 4: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Mining Association Rules Examples Course Enrollments Itemset. I = { CSC3, CSC3, CSC40, CSC40, CSC4, CSC44, CSC4, CSC44,
DATA MINING LECTURE 4. Frequent Itemsets and Association Rules
 DATA MINING LECTURE 4 Frequent Itemsets and Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
DATA MINING LECTURE 4 Frequent Itemsets and Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
Association Analysis. Part 2
 Association Analysis Part 2 1 Limitations of the Support/Confidence framework 1 Redundancy: many of the returned patterns may refer to the same piece of information 2 Difficult control of output size:
Association Analysis Part 2 1 Limitations of the Support/Confidence framework 1 Redundancy: many of the returned patterns may refer to the same piece of information 2 Difficult control of output size:
Frequent Itemset Mining
 ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team IMAGINA 16/17 Webpage: h;p://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge Discovery
ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team IMAGINA 16/17 Webpage: h;p://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge Discovery
Association Analysis 1
 Association Analysis 1 Association Rules 1 3 Learning Outcomes Motivation Association Rule Mining Definition Terminology Apriori Algorithm Reducing Output: Closed and Maximal Itemsets 4 Overview One of
Association Analysis 1 Association Rules 1 3 Learning Outcomes Motivation Association Rule Mining Definition Terminology Apriori Algorithm Reducing Output: Closed and Maximal Itemsets 4 Overview One of
Mining Approximate Top-K Subspace Anomalies in Multi-Dimensional Time-Series Data
 Mining Approximate Top-K Subspace Anomalies in Multi-Dimensional -Series Data Xiaolei Li, Jiawei Han University of Illinois at Urbana-Champaign VLDB 2007 1 Series Data Many applications produce time series
Mining Approximate Top-K Subspace Anomalies in Multi-Dimensional -Series Data Xiaolei Li, Jiawei Han University of Illinois at Urbana-Champaign VLDB 2007 1 Series Data Many applications produce time series
10/19/2017 MIST.6060 Business Intelligence and Data Mining 1. Association Rules
 10/19/2017 MIST6060 Business Intelligence and Data Mining 1 Examples of Association Rules Association Rules Sixty percent of customers who buy sheets and pillowcases order a comforter next, followed by
10/19/2017 MIST6060 Business Intelligence and Data Mining 1 Examples of Association Rules Association Rules Sixty percent of customers who buy sheets and pillowcases order a comforter next, followed by
Type of data Interval-scaled variables: Binary variables: Nominal, ordinal, and ratio variables: Variables of mixed types: Attribute Types Nominal: Pr
 Foundation of Data Mining i Topic: Data CMSC 49D/69D CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Data Data types Quality of data
Foundation of Data Mining i Topic: Data CMSC 49D/69D CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Data Data types Quality of data
Quantitative Association Rule Mining on Weighted Transactional Data
 Quantitative Association Rule Mining on Weighted Transactional Data D. Sujatha and Naveen C. H. Abstract In this paper we have proposed an approach for mining quantitative association rules. The aim of
Quantitative Association Rule Mining on Weighted Transactional Data D. Sujatha and Naveen C. H. Abstract In this paper we have proposed an approach for mining quantitative association rules. The aim of
Frequent Itemset Mining
 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM IMAGINA 15/16 2 Frequent Itemset Mining: Motivations Frequent Itemset Mining is a method for market basket analysis. It aims at finding regulariges in
1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM IMAGINA 15/16 2 Frequent Itemset Mining: Motivations Frequent Itemset Mining is a method for market basket analysis. It aims at finding regulariges in
Selecting a Right Interestingness Measure for Rare Association Rules
 Selecting a Right Interestingness Measure for Rare Association Rules Akshat Surana R. Uday Kiran P. Krishna Reddy Center for Data Engineering International Institute of Information Technology-Hyderabad
Selecting a Right Interestingness Measure for Rare Association Rules Akshat Surana R. Uday Kiran P. Krishna Reddy Center for Data Engineering International Institute of Information Technology-Hyderabad
3. Problem definition
 3. Problem definition In this section, we first define a multi-dimension transaction database MD, to differentiate it between the transaction databases D in traditional association rules. Then, we discuss
3. Problem definition In this section, we first define a multi-dimension transaction database MD, to differentiate it between the transaction databases D in traditional association rules. Then, we discuss
CS738 Class Notes. Steve Revilak
 CS738 Class Notes Steve Revilak January 2008 May 2008 Copyright c 2008 Steve Revilak. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation
CS738 Class Notes Steve Revilak January 2008 May 2008 Copyright c 2008 Steve Revilak. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation
Discovering Non-Redundant Association Rules using MinMax Approximation Rules
 Discovering Non-Redundant Association Rules using MinMax Approximation Rules R. Vijaya Prakash Department Of Informatics Kakatiya University, Warangal, India vijprak@hotmail.com Dr.A. Govardhan Department.
Discovering Non-Redundant Association Rules using MinMax Approximation Rules R. Vijaya Prakash Department Of Informatics Kakatiya University, Warangal, India vijprak@hotmail.com Dr.A. Govardhan Department.
Temporal Data Mining
 Temporal Data Mining Christian Moewes cmoewes@ovgu.de Otto-von-Guericke University of Magdeburg Faculty of Computer Science Department of Knowledge Processing and Language Engineering Zittau Fuzzy Colloquium
Temporal Data Mining Christian Moewes cmoewes@ovgu.de Otto-von-Guericke University of Magdeburg Faculty of Computer Science Department of Knowledge Processing and Language Engineering Zittau Fuzzy Colloquium
Course Content. Association Rules Outline. Chapter 6 Objectives. Chapter 6: Mining Association Rules. Dr. Osmar R. Zaïane. University of Alberta 4
 Principles of Knowledge Discovery in Data Fall 2004 Chapter 6: Mining Association Rules Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Data warehousing and OLAP Data
Principles of Knowledge Discovery in Data Fall 2004 Chapter 6: Mining Association Rules Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Data warehousing and OLAP Data
CS5112: Algorithms and Data Structures for Applications
 CS5112: Algorithms and Data Structures for Applications Lecture 19: Association rules Ramin Zabih Some content from: Wikipedia/Google image search; Harrington; J. Leskovec, A. Rajaraman, J. Ullman: Mining
CS5112: Algorithms and Data Structures for Applications Lecture 19: Association rules Ramin Zabih Some content from: Wikipedia/Google image search; Harrington; J. Leskovec, A. Rajaraman, J. Ullman: Mining
Discovering Threshold-based Frequent Closed Itemsets over Probabilistic Data
 Discovering Threshold-based Frequent Closed Itemsets over Probabilistic Data Yongxin Tong #1, Lei Chen #, Bolin Ding *3 # Department of Computer Science and Engineering, Hong Kong Univeristy of Science
Discovering Threshold-based Frequent Closed Itemsets over Probabilistic Data Yongxin Tong #1, Lei Chen #, Bolin Ding *3 # Department of Computer Science and Engineering, Hong Kong Univeristy of Science
Assignment 7 (Sol.) Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran
 Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran") Assignment 7 (Sol.) Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran 1. Let X, Y be two itemsets, and let denote the support of itemset X. Then the confidence of the rule X Y,
Assignment 7 (Sol.) Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran 1. Let X, Y be two itemsets, and let denote the support of itemset X. Then the confidence of the rule X Y,
CSE-4412(M) Midterm. There are five major questions, each worth 10 points, for a total of 50 points. Points for each sub-question are as indicated.
 Midterm. There are five major questions, each worth 10 points, for a total of 50 points. Points for each sub-question are as indicated.") 22 February 2007 CSE-4412(M) Midterm p. 1 of 12 CSE-4412(M) Midterm Sur / Last Name: Given / First Name: Student ID: Instructor: Parke Godfrey Exam Duration: 75 minutes Term: Winter 2007 Answer the following
22 February 2007 CSE-4412(M) Midterm p. 1 of 12 CSE-4412(M) Midterm Sur / Last Name: Given / First Name: Student ID: Instructor: Parke Godfrey Exam Duration: 75 minutes Term: Winter 2007 Answer the following
Distributed Mining of Frequent Closed Itemsets: Some Preliminary Results
 Distributed Mining of Frequent Closed Itemsets: Some Preliminary Results Claudio Lucchese Ca Foscari University of Venice clucches@dsi.unive.it Raffaele Perego ISTI-CNR of Pisa perego@isti.cnr.it Salvatore
Distributed Mining of Frequent Closed Itemsets: Some Preliminary Results Claudio Lucchese Ca Foscari University of Venice clucches@dsi.unive.it Raffaele Perego ISTI-CNR of Pisa perego@isti.cnr.it Salvatore
Mining Strong Positive and Negative Sequential Patterns
 Mining Strong Positive and Negative Sequential Patter NANCY P. LIN, HUNG-JEN CHEN, WEI-HUA HAO, HAO-EN CHUEH, CHUNG-I CHANG Department of Computer Science and Information Engineering Tamang University,
Mining Strong Positive and Negative Sequential Patter NANCY P. LIN, HUNG-JEN CHEN, WEI-HUA HAO, HAO-EN CHUEH, CHUNG-I CHANG Department of Computer Science and Information Engineering Tamang University,
NEGATED ITEMSETS OBTAINING METHODS FROM TREE- STRUCTURED STREAM DATA
 NEGATED ITEMSETS OBTAINING METHODS FROM TREE- STRUCTURED STREAM DATA JURYON PAIK Pyeongtaek University, Department of Digital Information and Statistics, Gyeonggi-do 17869, South Korea E-mail: jrpaik@ptu.ac.kr
NEGATED ITEMSETS OBTAINING METHODS FROM TREE- STRUCTURED STREAM DATA JURYON PAIK Pyeongtaek University, Department of Digital Information and Statistics, Gyeonggi-do 17869, South Korea E-mail: jrpaik@ptu.ac.kr
An Optimized Interestingness Hotspot Discovery Framework for Large Gridded Spatio-temporal Datasets
 IEEE Big Data 2015 Big Data in Geosciences Workshop An Optimized Interestingness Hotspot Discovery Framework for Large Gridded Spatio-temporal Datasets Fatih Akdag and Christoph F. Eick Department of Computer
IEEE Big Data 2015 Big Data in Geosciences Workshop An Optimized Interestingness Hotspot Discovery Framework for Large Gridded Spatio-temporal Datasets Fatih Akdag and Christoph F. Eick Department of Computer
From statistics to data science. BAE 815 (Fall 2017) Dr. Zifei Liu
 Dr. Zifei Liu") From statistics to data science BAE 815 (Fall 2017) Dr. Zifei Liu Zifeiliu@ksu.edu Why? How? What? How much? How many? Individual facts (quantities, characters, or symbols) The Data-Information-Knowledge-Wisdom
From statistics to data science BAE 815 (Fall 2017) Dr. Zifei Liu Zifeiliu@ksu.edu Why? How? What? How much? How many? Individual facts (quantities, characters, or symbols) The Data-Information-Knowledge-Wisdom
Mining Class-Dependent Rules Using the Concept of Generalization/Specialization Hierarchies
 Mining Class-Dependent Rules Using the Concept of Generalization/Specialization Hierarchies Juliano Brito da Justa Neves 1 Marina Teresa Pires Vieira {juliano,marina}@dc.ufscar.br Computer Science Department
Mining Class-Dependent Rules Using the Concept of Generalization/Specialization Hierarchies Juliano Brito da Justa Neves 1 Marina Teresa Pires Vieira {juliano,marina}@dc.ufscar.br Computer Science Department
CS 412 Intro. to Data Mining
 CS 412 Intro. to Data Mining Chapter 6. Mining Frequent Patterns, Association and Correlations: Basic Concepts and Methods Jiawei Han, Computer Science, Univ. Illinois at Urbana -Champaign, 2017 1 2 3
CS 412 Intro. to Data Mining Chapter 6. Mining Frequent Patterns, Association and Correlations: Basic Concepts and Methods Jiawei Han, Computer Science, Univ. Illinois at Urbana -Champaign, 2017 1 2 3