MAGMA. Matrix Algebra on GPU and Multicore Architectures. Mark Gates. February 2012
|
|
|
- Bertram Russell
- 5 years ago
- Views:
Transcription

1 MAGMA Matrix Algebra on GPU and Multicore Architectures Mark Gates February
 Frequency (MHz) Cores 1.E+03 1000 1.E+02 100 1.")

2 Hardware trends Scale # cores instead of clock speed Hardware issue became software issue Multicore Hybrid 1.E+07 1e7 1.E+06 1e6 1.E+05 1e5 1.E+04 1e4 Transistors (in Thousands) Frequency (MHz) Cores 1.E E E E E Figure from Kathy Yelick, Ten Ways to Waste a Parallel Computer. Data from Kunle Olukotun, Lance Hammond, Herb Sutter, Burton Smith, Chris Batten, and Krste Asanoviç. 2


3 Future systems Most likely hybrid design Multicore + GPU accelerators Today accelerators attached Future accelerators integrated Intel s MIC Knight s Corner AMD s Fusion Nvidia s Project Denver 3
4 Challenges of GPUs High levels of parallelism Hybrid architecture Small, non-parallelizable tasks on CPU Large, parallel tasks on GPU Compute vs. communication gap growing Tesla C2070 has 515 Gflops, 8 GB/s PCIe Control Cache DRAM ALU ALU CPU PCIe ALU ALU DRAM GPU Figure from NVIDIA CUDA C Programming Guide 4

5 Software generations LINPACK (70 s) vector operations LAPACK (80 s) blocked, cache friendly ScaLAPACK (90 s) distributed memory PLASMA tiled, multicore MAGMA hybrid Level-1 BLAS Level-3 BLAS PBLAS message passing DAG + scheduler hybrid kernels critical path 5
6 Nvidia s CUBLAS Level 1, 2, 3 BLAS kernels cublasdgemv cublasdgemm Copy between CPU GPU cublassetmatrix cublasgetmatrix Stream support cublassetkernelstream, magmablassetkernelstream 6

7 MAGMA 1.1 LAPACK column-wise layout LAPACK-like C and Fortran interfaces CPU and GPU interfaces 7
8 MAGMA hybrid LAPACK algorithms 4 precisions (single, double, single complex, double complex) 3 mixed precision algorithms MAGMA BLAS Supplements CUBLAS Improves some routines 8
9 Naming: magma_zgesv_gpu magma_ or magmablas_ prefix Precision (single, double, single complex, z double complex). Mixed precision (ds and zc) Matrix type general symmetric hermetian positive definite orthogonal unitary triangular Operation sv solve trf triangular factorization ev eigenvalue problem gv generalized eigenvalue problem Interface _gpu suffix 9
10 Driver routines Solve entire problem Interface Matrix type Operation Routine CPU GPU General Solve dgesv dsgesv SPD Solve dposv dsposv Least squares Solve dgeqrs dsgeqrsv General SVD dgesvd Eigenvalues dgeev Symmetric Eigenvalues dsyevd* / zheevd* Generalized eigenvalues dsygvd* / zhegvd* * Additional variants; complete list at 10
11 Computational routines Solve one part of problem Interface Matrix type Operation Routine CPU GPU General LU dgetrf Solve (given LU) dgetrs Inverse dgetri SPD Cholesky dpotrf Solve (given LL T ) dpotrs Inverse dpotri General QR dgeqrf Generate Q dorgqr / zungqr Multiply by Q dormqr / zunmqr Selected routines; complete list at 11
12 One-sided factorization LU, Cholesky, QR factorizations for solving linear systems DAG Level 2 CPU Level 3 GPU Look ahead Trailing matrix A = QA 12
13 One-sided factorization LU, Cholesky, QR factorizations for solving linear systems DAG Level 2 CPU Level 3 GPU Look ahead Trailing matrix A = QA Trailing matrix Look ahead 12
14 One-sided factorization LU, Cholesky, QR factorizations for solving linear systems DAG Level 2 CPU Level 3 GPU Look ahead Trailing matrix A = QA Trailing matrix Look ahead 12
15 One-sided factorization LU, Cholesky, QR factorizations for solving linear systems DAG Level 2 CPU Level 3 GPU Look ahead Trailing matrix A = QA Trailing matrix Look ahead Trailing matrix 12
16 One-sided factorization LU, Cholesky, QR factorizations for solving linear systems DAG Level 2 CPU Level 3 GPU Look ahead Trailing matrix A = QA Trailing matrix Look ahead Trailing matrix 12
17 One-sided factorization LU, Cholesky, QR factorizations for solving linear systems DAG Level 2 CPU Level 3 GPU Look ahead Trailing matrix A = QA Trailing matrix Look ahead Trailing matrix critical path 12


18 13

 2 x 6 Intel Cores")
19 Keeneland system, using one node 3 Nvidia GPUs 1.1 GHz, 5.4 GB) 2 x 6 Intel Cores 2.8 GHz, 23 GB) 14
20 Mixed-precision solvers MAGMA solve Single Prec Double Prec Iter Ref Factor in single precision Iterative refinement yields double precision accuracy GFlop/s Matrix size 15
21 Two-sided factorization Hessenberg, tridiagonal factorizations for eigenvalue problems Level 2 CPU Level 2 GPU y i = Av i Trailing matrix A = Q T AQ Level 3 GPU column a i 16
22 MAGMA Hessenberg in double precision Gflop/s GPUs 2 GPUs 1 GPU (MAGMA 1.1) CPU (MKL) Matrix size Keeneland system, using one node 3 Nvidia GPUs 1.1 GHz, 5.4 GB) 2 x 6 Intel Cores 2.8 GHz, 23 GB) 17
23 Autotuning kernels MAGMA BLAS matrix multiply Parameterize code, e.g., blocksize Test kernels Improved zgemm from 308 to 341 Gflops/s Improved up to 2x on specific rectangular shapes 18

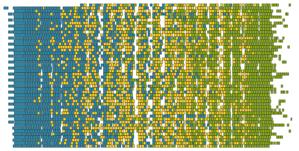



24 Scheduling DAGs 48 cores Matrix is 4000 x 4000, tile is 200 x
25 Dynamic scheduling Parallelism using DAG-based runtime scheduler One-sided factorizations and solvers using StarPU // Sequential Tile Cholesky for k = 1.. ntiles! dpotrf( Akk )! for i = k+1.. ntiles!! dtrsm( Akk, Aik )! for i = k+1.. ntiles!! dsyrk( Aik, Aii )!! for j = i+1.. ntiles!!! dgemm( Ajk, Aik, Aij ) // Hybrid Tile Cholesky for k = 1.. ntiles! Insert_Task( dpotrf,... )! for i = k+1.. ntiles!! Insert_Task( dtrsm,... )! for i = k+1.. ntiles!! Insert_Task( dsyrk,... )!! for j = i+1.. ntiles!!! Insert_Task( dgemm,... ) 20
26 Documentation Nvidia Guides MAGMA PLASMA BLAS and LAPACK index 21




27 Collaborators / Support University of Tennessee, Knoxville University of California, Berkeley University of Colorado, Denver INRIA, France KAUST, Saudi Arabia 22

28 23
A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization)
") A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization) Schodinger equation: Hψ = Eψ Choose a basis set of wave functions Two cases: Orthonormal
A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization) Schodinger equation: Hψ = Eψ Choose a basis set of wave functions Two cases: Orthonormal
Dynamic Scheduling within MAGMA
 Dynamic Scheduling within MAGMA Emmanuel Agullo, Cedric Augonnet, Jack Dongarra, Mathieu Faverge, Julien Langou, Hatem Ltaief, Samuel Thibault and Stanimire Tomov April 5, 2012 Innovative and Computing
Dynamic Scheduling within MAGMA Emmanuel Agullo, Cedric Augonnet, Jack Dongarra, Mathieu Faverge, Julien Langou, Hatem Ltaief, Samuel Thibault and Stanimire Tomov April 5, 2012 Innovative and Computing
MAGMA MIC 1.0: Linear Algebra Library for Intel Xeon Phi Coprocessors
 MAGMA MIC 1.0: Linear Algebra Library for Intel Xeon Phi Coprocessors J. Dongarra, M. Gates, A. Haidar, Y. Jia, K. Kabir, P. Luszczek, and S. Tomov University of Tennessee, Knoxville 05 / 03 / 2013 MAGMA:
MAGMA MIC 1.0: Linear Algebra Library for Intel Xeon Phi Coprocessors J. Dongarra, M. Gates, A. Haidar, Y. Jia, K. Kabir, P. Luszczek, and S. Tomov University of Tennessee, Knoxville 05 / 03 / 2013 MAGMA:
Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers
 UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
Accelerating linear algebra computations with hybrid GPU-multicore systems.
 Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Multicore Parallelization of Determinant Quantum Monte Carlo Simulations
 Multicore Parallelization of Determinant Quantum Monte Carlo Simulations Andrés Tomás, Che-Rung Lee, Zhaojun Bai, Richard Scalettar UC Davis SIAM Conference on Computation Science & Engineering Reno, March
Multicore Parallelization of Determinant Quantum Monte Carlo Simulations Andrés Tomás, Che-Rung Lee, Zhaojun Bai, Richard Scalettar UC Davis SIAM Conference on Computation Science & Engineering Reno, March
Computing least squares condition numbers on hybrid multicore/gpu systems
 Computing least squares condition numbers on hybrid multicore/gpu systems M. Baboulin and J. Dongarra and R. Lacroix Abstract This paper presents an efficient computation for least squares conditioning
Computing least squares condition numbers on hybrid multicore/gpu systems M. Baboulin and J. Dongarra and R. Lacroix Abstract This paper presents an efficient computation for least squares conditioning
MARCH 24-27, 2014 SAN JOSE, CA
 MARCH 24-27, 2014 SAN JOSE, CA Sparse HPC on modern architectures Important scientific applications rely on sparse linear algebra HPCG a new benchmark proposal to complement Top500 (HPL) To solve A x =
MARCH 24-27, 2014 SAN JOSE, CA Sparse HPC on modern architectures Important scientific applications rely on sparse linear algebra HPCG a new benchmark proposal to complement Top500 (HPL) To solve A x =
MagmaDNN High-Performance Data Analytics for Manycore GPUs and CPUs
 MagmaDNN High-Performance Data Analytics for Manycore GPUs and CPUs Lucien Ng The Chinese University of Hong Kong Kwai Wong The Joint Institute for Computational Sciences (JICS), UTK and ORNL Azzam Haidar,
MagmaDNN High-Performance Data Analytics for Manycore GPUs and CPUs Lucien Ng The Chinese University of Hong Kong Kwai Wong The Joint Institute for Computational Sciences (JICS), UTK and ORNL Azzam Haidar,
Accelerating computation of eigenvectors in the nonsymmetric eigenvalue problem
 Accelerating computation of eigenvectors in the nonsymmetric eigenvalue problem Mark Gates 1, Azzam Haidar 1, and Jack Dongarra 1,2,3 1 University of Tennessee, Knoxville, TN, USA 2 Oak Ridge National
Accelerating computation of eigenvectors in the nonsymmetric eigenvalue problem Mark Gates 1, Azzam Haidar 1, and Jack Dongarra 1,2,3 1 University of Tennessee, Knoxville, TN, USA 2 Oak Ridge National
Accelerating computation of eigenvectors in the dense nonsymmetric eigenvalue problem
 Accelerating computation of eigenvectors in the dense nonsymmetric eigenvalue problem Mark Gates 1, Azzam Haidar 1, and Jack Dongarra 1,2,3 1 University of Tennessee, Knoxville, TN, USA 2 Oak Ridge National
Accelerating computation of eigenvectors in the dense nonsymmetric eigenvalue problem Mark Gates 1, Azzam Haidar 1, and Jack Dongarra 1,2,3 1 University of Tennessee, Knoxville, TN, USA 2 Oak Ridge National
Binding Performance and Power of Dense Linear Algebra Operations
 10th IEEE International Symposium on Parallel and Distributed Processing with Applications Binding Performance and Power of Dense Linear Algebra Operations Maria Barreda, Manuel F. Dolz, Rafael Mayo, Enrique
10th IEEE International Symposium on Parallel and Distributed Processing with Applications Binding Performance and Power of Dense Linear Algebra Operations Maria Barreda, Manuel F. Dolz, Rafael Mayo, Enrique
Lightweight Superscalar Task Execution in Distributed Memory
 Lightweight Superscalar Task Execution in Distributed Memory Asim YarKhan 1 and Jack Dongarra 1,2,3 1 Innovative Computing Lab, University of Tennessee, Knoxville, TN 2 Oak Ridge National Lab, Oak Ridge,
Lightweight Superscalar Task Execution in Distributed Memory Asim YarKhan 1 and Jack Dongarra 1,2,3 1 Innovative Computing Lab, University of Tennessee, Knoxville, TN 2 Oak Ridge National Lab, Oak Ridge,
ON THE FUTURE OF HIGH PERFORMANCE COMPUTING: HOW TO THINK FOR PETA AND EXASCALE COMPUTING
 ON THE FUTURE OF HIGH PERFORMANCE COMPUTING: HOW TO THINK FOR PETA AND EXASCALE COMPUTING JACK DONGARRA UNIVERSITY OF TENNESSEE OAK RIDGE NATIONAL LAB What Is LINPACK? LINPACK is a package of mathematical
ON THE FUTURE OF HIGH PERFORMANCE COMPUTING: HOW TO THINK FOR PETA AND EXASCALE COMPUTING JACK DONGARRA UNIVERSITY OF TENNESSEE OAK RIDGE NATIONAL LAB What Is LINPACK? LINPACK is a package of mathematical
Jacobi-Based Eigenvalue Solver on GPU. Lung-Sheng Chien, NVIDIA
 Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
On the design of parallel linear solvers for large scale problems
 On the design of parallel linear solvers for large scale problems ICIAM - August 2015 - Mini-Symposium on Recent advances in matrix computations for extreme-scale computers M. Faverge, X. Lacoste, G. Pichon,
On the design of parallel linear solvers for large scale problems ICIAM - August 2015 - Mini-Symposium on Recent advances in matrix computations for extreme-scale computers M. Faverge, X. Lacoste, G. Pichon,
GPU accelerated Arnoldi solver for small batched matrix
 15. 09. 22 GPU accelerated Arnoldi solver for small batched matrix Samsung Advanced Institute of Technology Hyung-Jin Kim Contents - Eigen value problems - Solution - Arnoldi Algorithm - Target - CUDA
15. 09. 22 GPU accelerated Arnoldi solver for small batched matrix Samsung Advanced Institute of Technology Hyung-Jin Kim Contents - Eigen value problems - Solution - Arnoldi Algorithm - Target - CUDA
Some notes on efficient computing and setting up high performance computing environments
 Some notes on efficient computing and setting up high performance computing environments Andrew O. Finley Department of Forestry, Michigan State University, Lansing, Michigan. April 17, 2017 1 Efficient
Some notes on efficient computing and setting up high performance computing environments Andrew O. Finley Department of Forestry, Michigan State University, Lansing, Michigan. April 17, 2017 1 Efficient
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures
 A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
On the design of parallel linear solvers for large scale problems
 On the design of parallel linear solvers for large scale problems Journée problème de Poisson, IHP, Paris M. Faverge, P. Ramet M. Faverge Assistant Professor Bordeaux INP LaBRI Inria Bordeaux - Sud-Ouest
On the design of parallel linear solvers for large scale problems Journée problème de Poisson, IHP, Paris M. Faverge, P. Ramet M. Faverge Assistant Professor Bordeaux INP LaBRI Inria Bordeaux - Sud-Ouest
Direct Self-Consistent Field Computations on GPU Clusters
 Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
CS 594 Scientific Computing for Engineers Spring Dense Linear Algebra. Mark Gates
 CS 594 Scientific Computing for Engineers Spring 2018 Dense Linear Algebra Mark Gates mgates3@icl.utk.edu http://www.icl.utk.edu/~mgates3/ 1 Outline Legacy Software BLAS LINPACK LAPACK ScaLAPACK New Software
CS 594 Scientific Computing for Engineers Spring 2018 Dense Linear Algebra Mark Gates mgates3@icl.utk.edu http://www.icl.utk.edu/~mgates3/ 1 Outline Legacy Software BLAS LINPACK LAPACK ScaLAPACK New Software
Architecture-Aware Algorithms and Software for Peta and Exascale Computing
 Architecture-Aware Algorithms and Software for Peta and Exascale Computing Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 4/25/2011 1 H. Meuer, H. Simon, E.
Architecture-Aware Algorithms and Software for Peta and Exascale Computing Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 4/25/2011 1 H. Meuer, H. Simon, E.
A hybrid Hermitian general eigenvalue solver
 Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe A hybrid Hermitian general eigenvalue solver Raffaele Solcà *, Thomas C. Schulthess Institute fortheoretical Physics ETHZ,
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe A hybrid Hermitian general eigenvalue solver Raffaele Solcà *, Thomas C. Schulthess Institute fortheoretical Physics ETHZ,
Level-3 BLAS on a GPU
 Level-3 BLAS on a GPU Picking the Low Hanging Fruit Francisco Igual 1 Gregorio Quintana-Ortí 1 Robert A. van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón
Level-3 BLAS on a GPU Picking the Low Hanging Fruit Francisco Igual 1 Gregorio Quintana-Ortí 1 Robert A. van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón
CS 594 Scientific Computing for Engineers Spring Dense Linear Algebra. Mark Gates
 CS 594 Scientific Computing for Engineers Spring 2017 Dense Linear Algebra Mark Gates mgates3@icl.utk.edu http://www.icl.utk.edu/~mgates3/ 1 Outline Legacy Software BLAS LINPACK LAPACK ScaLAPACK New Software
CS 594 Scientific Computing for Engineers Spring 2017 Dense Linear Algebra Mark Gates mgates3@icl.utk.edu http://www.icl.utk.edu/~mgates3/ 1 Outline Legacy Software BLAS LINPACK LAPACK ScaLAPACK New Software
Sparse LU Factorization on GPUs for Accelerating SPICE Simulation
 Nano-scale Integrated Circuit and System (NICS) Laboratory Sparse LU Factorization on GPUs for Accelerating SPICE Simulation Xiaoming Chen PhD Candidate Department of Electronic Engineering Tsinghua University,
Nano-scale Integrated Circuit and System (NICS) Laboratory Sparse LU Factorization on GPUs for Accelerating SPICE Simulation Xiaoming Chen PhD Candidate Department of Electronic Engineering Tsinghua University,
ExaGeoStat: A High Performance Unified Software for Geostatistics on Manycore Systems
 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. XX, NO. X, M YYYY 1 ExaGeoStat: A High Performance Unified Software for Geostatistics on Manycore Systems Sameh Abdulah, Hatem Ltaief, Ying Sun,
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. XX, NO. X, M YYYY 1 ExaGeoStat: A High Performance Unified Software for Geostatistics on Manycore Systems Sameh Abdulah, Hatem Ltaief, Ying Sun,
QR Factorization of Tall and Skinny Matrices in a Grid Computing Environment
 QR Factorization of Tall and Skinny Matrices in a Grid Computing Environment Emmanuel AGULLO (INRIA / LaBRI) Camille COTI (Iowa State University) Jack DONGARRA (University of Tennessee) Thomas HÉRAULT
QR Factorization of Tall and Skinny Matrices in a Grid Computing Environment Emmanuel AGULLO (INRIA / LaBRI) Camille COTI (Iowa State University) Jack DONGARRA (University of Tennessee) Thomas HÉRAULT
INITIAL INTEGRATION AND EVALUATION
 INITIAL INTEGRATION AND EVALUATION OF SLATE PARALLEL BLAS IN LATTE Marc Cawkwell, Danny Perez, Arthur Voter Asim YarKhan, Gerald Ragghianti, Jack Dongarra, Introduction The aim of the joint milestone STMS10-52
INITIAL INTEGRATION AND EVALUATION OF SLATE PARALLEL BLAS IN LATTE Marc Cawkwell, Danny Perez, Arthur Voter Asim YarKhan, Gerald Ragghianti, Jack Dongarra, Introduction The aim of the joint milestone STMS10-52
Re-design of Higher level Matrix Algorithms for Multicore and Heterogeneous Architectures. Based on the presentation at UC Berkeley, October 7, 2009
 III.1 Re-design of Higher level Matrix Algorithms for Multicore and Heterogeneous Architectures Based on the presentation at UC Berkeley, October 7, 2009 Background and motivation Running time of an algorithm
III.1 Re-design of Higher level Matrix Algorithms for Multicore and Heterogeneous Architectures Based on the presentation at UC Berkeley, October 7, 2009 Background and motivation Running time of an algorithm
Julian Merten. GPU Computing and Alternative Architecture
 Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
ACCELERATING SPARSE CHOLESKY FACTORIZATION ON THE GPU
 ACCELERATING SPARSE CHOLESKY FACTORIZATION ON THE GPU STEVE RENNICH, SR. ENGINEER, NVIDIA DEVELOPER TECHNOLOGY DARKO STOSIC, PHD CANDIDATE, UNIV. FEDERAL DE PERNAMBUCO TIM DAVIS, PROFESSOR, CSE, TEXAS
ACCELERATING SPARSE CHOLESKY FACTORIZATION ON THE GPU STEVE RENNICH, SR. ENGINEER, NVIDIA DEVELOPER TECHNOLOGY DARKO STOSIC, PHD CANDIDATE, UNIV. FEDERAL DE PERNAMBUCO TIM DAVIS, PROFESSOR, CSE, TEXAS
Computing least squares condition numbers on hybrid multicore/gpu systems
 Computing least squares condition numbers on hybrid multicore/gpu systems Marc Baboulin, Jack Dongarra, Rémi Lacroix To cite this version: Marc Baboulin, Jack Dongarra, Rémi Lacroix. Computing least squares
Computing least squares condition numbers on hybrid multicore/gpu systems Marc Baboulin, Jack Dongarra, Rémi Lacroix To cite this version: Marc Baboulin, Jack Dongarra, Rémi Lacroix. Computing least squares
A parallel tiled solver for dense symmetric indefinite systems on multicore architectures
 A parallel tiled solver for dense symmetric indefinite systems on multicore architectures Marc Baboulin, Dulceneia Becker, Jack Dongarra INRIA Saclay-Île de France, F-91893 Orsay, France Université Paris
A parallel tiled solver for dense symmetric indefinite systems on multicore architectures Marc Baboulin, Dulceneia Becker, Jack Dongarra INRIA Saclay-Île de France, F-91893 Orsay, France Université Paris
Hybrid static/dynamic scheduling for already optimized dense matrix factorization. Joint Laboratory for Petascale Computing, INRIA-UIUC
 Hybrid static/dynamic scheduling for already optimized dense matrix factorization Simplice Donfack, Laura Grigori, INRIA, France Bill Gropp, Vivek Kale UIUC, USA Joint Laboratory for Petascale Computing,
Hybrid static/dynamic scheduling for already optimized dense matrix factorization Simplice Donfack, Laura Grigori, INRIA, France Bill Gropp, Vivek Kale UIUC, USA Joint Laboratory for Petascale Computing,
Tile QR Factorization with Parallel Panel Processing for Multicore Architectures
 Tile QR Factorization with Parallel Panel Processing for Multicore Architectures Bilel Hadri, Hatem Ltaief, Emmanuel Agullo, Jack Dongarra Department of Electrical Engineering and Computer Science, University
Tile QR Factorization with Parallel Panel Processing for Multicore Architectures Bilel Hadri, Hatem Ltaief, Emmanuel Agullo, Jack Dongarra Department of Electrical Engineering and Computer Science, University
Lecture 13 Stability of LU Factorization; Cholesky Factorization. Songting Luo. Department of Mathematics Iowa State University
 Lecture 13 Stability of LU Factorization; Cholesky Factorization Songting Luo Department of Mathematics Iowa State University MATH 562 Numerical Analysis II ongting Luo ( Department of Mathematics Iowa
Lecture 13 Stability of LU Factorization; Cholesky Factorization Songting Luo Department of Mathematics Iowa State University MATH 562 Numerical Analysis II ongting Luo ( Department of Mathematics Iowa
Performance Analysis and Design of a Hessenberg Reduction using Stabilized Blocked Elementary Transformations for New Architectures
 Performance Analysis and Design of a Hessenberg Reduction using Stabilized Blocked Elementary Transformations for New Architectures Khairul Kabir University of Tennessee kkabir@vols.utk.edu Azzam Haidar
Performance Analysis and Design of a Hessenberg Reduction using Stabilized Blocked Elementary Transformations for New Architectures Khairul Kabir University of Tennessee kkabir@vols.utk.edu Azzam Haidar
c 2015 Society for Industrial and Applied Mathematics
 SIAM J. SCI. COMPUT. Vol. 37, No. 3, pp. C307 C330 c 2015 Society for Industrial and Applied Mathematics MIXED-PRECISION CHOLESKY QR FACTORIZATION AND ITS CASE STUDIES ON MULTICORE CPU WITH MULTIPLE GPUS
SIAM J. SCI. COMPUT. Vol. 37, No. 3, pp. C307 C330 c 2015 Society for Industrial and Applied Mathematics MIXED-PRECISION CHOLESKY QR FACTORIZATION AND ITS CASE STUDIES ON MULTICORE CPU WITH MULTIPLE GPUS
Tall and Skinny QR Matrix Factorization Using Tile Algorithms on Multicore Architectures LAPACK Working Note - 222
 Tall and Skinny QR Matrix Factorization Using Tile Algorithms on Multicore Architectures LAPACK Working Note - 222 Bilel Hadri 1, Hatem Ltaief 1, Emmanuel Agullo 1, and Jack Dongarra 1,2,3 1 Department
Tall and Skinny QR Matrix Factorization Using Tile Algorithms on Multicore Architectures LAPACK Working Note - 222 Bilel Hadri 1, Hatem Ltaief 1, Emmanuel Agullo 1, and Jack Dongarra 1,2,3 1 Department
SPARSE SOLVERS POISSON EQUATION. Margreet Nool. November 9, 2015 FOR THE. CWI, Multiscale Dynamics
 SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
Matrix Eigensystem Tutorial For Parallel Computation
 Matrix Eigensystem Tutorial For Parallel Computation High Performance Computing Center (HPC) http://www.hpc.unm.edu 5/21/2003 1 Topic Outline Slide Main purpose of this tutorial 5 The assumptions made
Matrix Eigensystem Tutorial For Parallel Computation High Performance Computing Center (HPC) http://www.hpc.unm.edu 5/21/2003 1 Topic Outline Slide Main purpose of this tutorial 5 The assumptions made
Tips Geared Towards R. Adam J. Suarez. Arpil 10, 2015
 Tips Geared Towards R Departments of Statistics North Carolina State University Arpil 10, 2015 1 / 30 Advantages of R As an interpretive and interactive language, developing an algorithm in R can be done
Tips Geared Towards R Departments of Statistics North Carolina State University Arpil 10, 2015 1 / 30 Advantages of R As an interpretive and interactive language, developing an algorithm in R can be done
Modeling and Tuning Parallel Performance in Dense Linear Algebra
 Modeling and Tuning Parallel Performance in Dense Linear Algebra Initial Experiences with the Tile QR Factorization on a Multi Core System CScADS Workshop on Automatic Tuning for Petascale Systems Snowbird,
Modeling and Tuning Parallel Performance in Dense Linear Algebra Initial Experiences with the Tile QR Factorization on a Multi Core System CScADS Workshop on Automatic Tuning for Petascale Systems Snowbird,
Accelerating Model Reduction of Large Linear Systems with Graphics Processors
 Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
Porting a sphere optimization program from LAPACK to ScaLAPACK
 Porting a sphere optimization program from LAPACK to ScaLAPACK Mathematical Sciences Institute, Australian National University. For presentation at Computational Techniques and Applications Conference
Porting a sphere optimization program from LAPACK to ScaLAPACK Mathematical Sciences Institute, Australian National University. For presentation at Computational Techniques and Applications Conference
Intel Math Kernel Library (Intel MKL) LAPACK
 LAPACK") Intel Math Kernel Library (Intel MKL) LAPACK Linear equations Victor Kostin Intel MKL Dense Solvers team manager LAPACK http://www.netlib.org/lapack Systems of Linear Equations Linear Least Squares Eigenvalue
Intel Math Kernel Library (Intel MKL) LAPACK Linear equations Victor Kostin Intel MKL Dense Solvers team manager LAPACK http://www.netlib.org/lapack Systems of Linear Equations Linear Least Squares Eigenvalue
Minimizing Communication in Linear Algebra. James Demmel 15 June
 Minimizing Communication in Linear Algebra James Demmel 15 June 2010 www.cs.berkeley.edu/~demmel 1 Outline What is communication and why is it important to avoid? Direct Linear Algebra Lower bounds on
Minimizing Communication in Linear Algebra James Demmel 15 June 2010 www.cs.berkeley.edu/~demmel 1 Outline What is communication and why is it important to avoid? Direct Linear Algebra Lower bounds on
Algorithms and Methods for Fast Model Predictive Control
 Algorithms and Methods for Fast Model Predictive Control Technical University of Denmark Department of Applied Mathematics and Computer Science 13 April 2016 Background: Model Predictive Control Model
Algorithms and Methods for Fast Model Predictive Control Technical University of Denmark Department of Applied Mathematics and Computer Science 13 April 2016 Background: Model Predictive Control Model
Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver
 Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver Sherry Li Lawrence Berkeley National Laboratory Piyush Sao Rich Vuduc Georgia Institute of Technology CUG 14, May 4-8, 14, Lugano,
Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver Sherry Li Lawrence Berkeley National Laboratory Piyush Sao Rich Vuduc Georgia Institute of Technology CUG 14, May 4-8, 14, Lugano,
Note Set 3 Numerical Linear Algebra
 Note Set 3 Numerical Linear Algebra 3.1 Overview Numerical linear algebra includes a class of problems which involves multiplying vectors and matrices, solving linear equations, computing the inverse of
Note Set 3 Numerical Linear Algebra 3.1 Overview Numerical linear algebra includes a class of problems which involves multiplying vectors and matrices, solving linear equations, computing the inverse of
Structured Orthogonal Inversion of Block p-cyclic Matrices on Multicore with GPU Accelerators
 Structured Orthogonal Inversion of Block p-cyclic Matrices on Multicore with GPU Accelerators Sergiy Gogolenko, Zhaojun Bai 2, and Richard Scalettar 2 Donetsk National Technical University, Donetsk, 8300,
Structured Orthogonal Inversion of Block p-cyclic Matrices on Multicore with GPU Accelerators Sergiy Gogolenko, Zhaojun Bai 2, and Richard Scalettar 2 Donetsk National Technical University, Donetsk, 8300,
Block AIR Methods. For Multicore and GPU. Per Christian Hansen Hans Henrik B. Sørensen. Technical University of Denmark
 Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
Power Profiling of Cholesky and QR Factorizations on Distributed Memory Systems
 Noname manuscript No. (will be inserted by the editor) Power Profiling of Cholesky and QR Factorizations on Distributed s George Bosilca Hatem Ltaief Jack Dongarra Received: date / Accepted: date Abstract
Noname manuscript No. (will be inserted by the editor) Power Profiling of Cholesky and QR Factorizations on Distributed s George Bosilca Hatem Ltaief Jack Dongarra Received: date / Accepted: date Abstract
Leveraging Task-Parallelism in Energy-Efficient ILU Preconditioners
 Leveraging Task-Parallelism in Energy-Efficient ILU Preconditioners José I. Aliaga Leveraging task-parallelism in energy-efficient ILU preconditioners Universidad Jaime I (Castellón, Spain) José I. Aliaga
Leveraging Task-Parallelism in Energy-Efficient ILU Preconditioners José I. Aliaga Leveraging task-parallelism in energy-efficient ILU preconditioners Universidad Jaime I (Castellón, Spain) José I. Aliaga
Communication-avoiding parallel and sequential QR factorizations
 Communication-avoiding parallel and sequential QR factorizations James Demmel, Laura Grigori, Mark Hoemmen, and Julien Langou May 30, 2008 Abstract We present parallel and sequential dense QR factorization
Communication-avoiding parallel and sequential QR factorizations James Demmel, Laura Grigori, Mark Hoemmen, and Julien Langou May 30, 2008 Abstract We present parallel and sequential dense QR factorization
Saving Energy in the LU Factorization with Partial Pivoting on Multi-Core Processors
 20th Euromicro International Conference on Parallel, Distributed and Network-Based Special Session on Energy-aware Systems Saving Energy in the on Multi-Core Processors Pedro Alonso 1, Manuel F. Dolz 2,
20th Euromicro International Conference on Parallel, Distributed and Network-Based Special Session on Energy-aware Systems Saving Energy in the on Multi-Core Processors Pedro Alonso 1, Manuel F. Dolz 2,
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters
 Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters Jonathan Lifflander, G. Carl Evans, Anshu Arya, Laxmikant Kale University of Illinois Urbana-Champaign May 25, 2012 Work is overdecomposed
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters Jonathan Lifflander, G. Carl Evans, Anshu Arya, Laxmikant Kale University of Illinois Urbana-Champaign May 25, 2012 Work is overdecomposed
Hydra: Generation and Tuning of parallel solutions for linear algebra equations. Alexandre X. Duchâteau University of Illinois at Urbana Champaign
 Hydra: Generation and Tuning of parallel solutions for linear algebra equations Alexandre X. Duchâteau University of Illinois at Urbana Champaign Collaborators Thesis Advisors Denis Barthou (Labri/INRIA
Hydra: Generation and Tuning of parallel solutions for linear algebra equations Alexandre X. Duchâteau University of Illinois at Urbana Champaign Collaborators Thesis Advisors Denis Barthou (Labri/INRIA
On GPU Acceleration of Common Solvers for (Quasi-) Triangular Generalized Lyapunov Equations
 Triangular Generalized Lyapunov Equations") Max Planck Institute Magdeburg Preprints Martin Köhler Jens Saak On GPU Acceleration of Common Solvers for (Quasi-) Triangular Generalized Lyapunov Equations MAX PLANCK INSTITUT FÜR DYNAMIK KOMPLEXER TECHNISCHER
Max Planck Institute Magdeburg Preprints Martin Köhler Jens Saak On GPU Acceleration of Common Solvers for (Quasi-) Triangular Generalized Lyapunov Equations MAX PLANCK INSTITUT FÜR DYNAMIK KOMPLEXER TECHNISCHER
Power-Aware Execution of Sparse and Dense Linear Algebra Libraries
 Power-Aware Execution of Sparse and Dense Linear Algebra Libraries Enrique S. Quintana-Ortí quintana@icc.uji.es Power-aware execution of linear algebra libraries 1 CECAM Lausanne, Sept. 2011 Motivation
Power-Aware Execution of Sparse and Dense Linear Algebra Libraries Enrique S. Quintana-Ortí quintana@icc.uji.es Power-aware execution of linear algebra libraries 1 CECAM Lausanne, Sept. 2011 Motivation
Practical Combustion Kinetics with CUDA
 Funded by: U.S. Department of Energy Vehicle Technologies Program Program Manager: Gurpreet Singh & Leo Breton Practical Combustion Kinetics with CUDA GPU Technology Conference March 20, 2015 Russell Whitesides
Funded by: U.S. Department of Energy Vehicle Technologies Program Program Manager: Gurpreet Singh & Leo Breton Practical Combustion Kinetics with CUDA GPU Technology Conference March 20, 2015 Russell Whitesides
Designing a QR Factorization for Multicore and Multi-GPU Architectures using Runtime Systems
 Designing a QR Factorization for Multicore and Multi-GPU Architectures using Runtime Systems Emmanuel AGULLO (INRIA HiePACS team) Julien LANGOU (University of Colorado Denver) Joint work with University
Designing a QR Factorization for Multicore and Multi-GPU Architectures using Runtime Systems Emmanuel AGULLO (INRIA HiePACS team) Julien LANGOU (University of Colorado Denver) Joint work with University
TOWARD HIGH PERFORMANCE TILE DIVIDE AND CONQUER ALGORITHM FOR THE DENSE SYMMETRIC EIGENVALUE PROBLEM
 TOWARD HIGH PERFORMANCE TILE DIVIDE AND CONQUER ALGORITHM FOR THE DENSE SYMMETRIC EIGENVALUE PROBLEM AZZAM HAIDAR, HATEM LTAIEF, AND JACK DONGARRA Abstract. Classical solvers for the dense symmetric eigenvalue
TOWARD HIGH PERFORMANCE TILE DIVIDE AND CONQUER ALGORITHM FOR THE DENSE SYMMETRIC EIGENVALUE PROBLEM AZZAM HAIDAR, HATEM LTAIEF, AND JACK DONGARRA Abstract. Classical solvers for the dense symmetric eigenvalue
Claude Tadonki. MINES ParisTech PSL Research University Centre de Recherche Informatique
 Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Panorama des modèles et outils de programmation parallèle
 Panorama des modèles et outils de programmation parallèle Sylvain HENRY sylvain.henry@inria.fr University of Bordeaux - LaBRI - Inria - ENSEIRB April 19th, 2013 1/45 Outline Introduction Accelerators &
Panorama des modèles et outils de programmation parallèle Sylvain HENRY sylvain.henry@inria.fr University of Bordeaux - LaBRI - Inria - ENSEIRB April 19th, 2013 1/45 Outline Introduction Accelerators &
Parallelization of the Molecular Orbital Program MOS-F
 Parallelization of the Molecular Orbital Program MOS-F Akira Asato, Satoshi Onodera, Yoshie Inada, Elena Akhmatskaya, Ross Nobes, Azuma Matsuura, Atsuya Takahashi November 2003 Fujitsu Laboratories of
Parallelization of the Molecular Orbital Program MOS-F Akira Asato, Satoshi Onodera, Yoshie Inada, Elena Akhmatskaya, Ross Nobes, Azuma Matsuura, Atsuya Takahashi November 2003 Fujitsu Laboratories of
Accelerating Band Linear Algebra Operations on GPUs with Application in Model Reduction
 Accelerating Band Linear Algebra Operations on GPUs with Application in Model Reduction Peter Benner 1, Ernesto Dufrechou 2, Pablo Ezzatti 2, Pablo Igounet 2, Enrique S. Quintana-Ortí 3, and Alfredo Remón
Accelerating Band Linear Algebra Operations on GPUs with Application in Model Reduction Peter Benner 1, Ernesto Dufrechou 2, Pablo Ezzatti 2, Pablo Igounet 2, Enrique S. Quintana-Ortí 3, and Alfredo Remón
Verbundprojekt ELPA-AEO. Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen
 Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
Evaluation and Benchmarking of Highly Scalable Parallel Numerical Libraries
 Evaluation and Benchmarking of Highly Scalable Parallel Numerical Libraries Christos Theodosiou (ctheodos@grid.auth.gr) User and Application Support Scientific Computing Centre @ AUTH Presentation Outline
Evaluation and Benchmarking of Highly Scalable Parallel Numerical Libraries Christos Theodosiou (ctheodos@grid.auth.gr) User and Application Support Scientific Computing Centre @ AUTH Presentation Outline
Communication-avoiding LU and QR factorizations for multicore architectures
 Communication-avoiding LU and QR factorizations for multicore architectures DONFACK Simplice INRIA Saclay Joint work with Laura Grigori INRIA Saclay Alok Kumar Gupta BCCS,Norway-5075 16th April 2010 Communication-avoiding
Communication-avoiding LU and QR factorizations for multicore architectures DONFACK Simplice INRIA Saclay Joint work with Laura Grigori INRIA Saclay Alok Kumar Gupta BCCS,Norway-5075 16th April 2010 Communication-avoiding
Spécialité: Informatique. par. Marc Baboulin. Maître de conférences, Université Paris-Sud Chaire Inria Saclay - Île-de-France
 HABILITATION A DIRIGER DES RECHERCHES présentée à l Université Paris-Sud Spécialité: Informatique par Marc Baboulin Maître de conférences, Université Paris-Sud Chaire Inria Saclay - Île-de-France Résolutions
HABILITATION A DIRIGER DES RECHERCHES présentée à l Université Paris-Sud Spécialité: Informatique par Marc Baboulin Maître de conférences, Université Paris-Sud Chaire Inria Saclay - Île-de-France Résolutions
Using Random Butterfly Transformations to Avoid Pivoting in Sparse Direct Methods
 Using Random Butterfly Transformations to Avoid Pivoting in Sparse Direct Methods Marc Baboulin 1, Xiaoye S. Li 2 and François-Henry Rouet 2 1 University of Paris-Sud, Inria Saclay, France 2 Lawrence Berkeley
Using Random Butterfly Transformations to Avoid Pivoting in Sparse Direct Methods Marc Baboulin 1, Xiaoye S. Li 2 and François-Henry Rouet 2 1 University of Paris-Sud, Inria Saclay, France 2 Lawrence Berkeley
Symmetric Pivoting in ScaLAPACK Craig Lucas University of Manchester Cray User Group 8 May 2006, Lugano
 Symmetric Pivoting in ScaLAPACK Craig Lucas University of Manchester Cray User Group 8 May 2006, Lugano Introduction Introduction We wanted to parallelize a serial algorithm for the pivoted Cholesky factorization
Symmetric Pivoting in ScaLAPACK Craig Lucas University of Manchester Cray User Group 8 May 2006, Lugano Introduction Introduction We wanted to parallelize a serial algorithm for the pivoted Cholesky factorization
Avoiding Communication in Linear Algebra
 Avoiding Communication in Linear Algebra Grey Ballard Microsoft Research Faculty Summit July 15, 2014 Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation,
Avoiding Communication in Linear Algebra Grey Ballard Microsoft Research Faculty Summit July 15, 2014 Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation,
Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA
 S7255: CUTT: A HIGH- PERFORMANCE TENSOR TRANSPOSE LIBRARY FOR GPUS Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA MOTIVATION Tensor contractions are the most computationally intensive part of quantum
S7255: CUTT: A HIGH- PERFORMANCE TENSOR TRANSPOSE LIBRARY FOR GPUS Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA MOTIVATION Tensor contractions are the most computationally intensive part of quantum
PRECONDITIONING IN THE PARALLEL BLOCK-JACOBI SVD ALGORITHM
 Proceedings of ALGORITMY 25 pp. 22 211 PRECONDITIONING IN THE PARALLEL BLOCK-JACOBI SVD ALGORITHM GABRIEL OKŠA AND MARIÁN VAJTERŠIC Abstract. One way, how to speed up the computation of the singular value
Proceedings of ALGORITMY 25 pp. 22 211 PRECONDITIONING IN THE PARALLEL BLOCK-JACOBI SVD ALGORITHM GABRIEL OKŠA AND MARIÁN VAJTERŠIC Abstract. One way, how to speed up the computation of the singular value
CS 542G: Conditioning, BLAS, LU Factorization
 CS 542G: Conditioning, BLAS, LU Factorization Robert Bridson September 22, 2008 1 Why some RBF Kernel Functions Fail We derived some sensible RBF kernel functions, like φ(r) = r 2 log r, from basic principles
CS 542G: Conditioning, BLAS, LU Factorization Robert Bridson September 22, 2008 1 Why some RBF Kernel Functions Fail We derived some sensible RBF kernel functions, like φ(r) = r 2 log r, from basic principles
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems
 Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
Dense Arithmetic over Finite Fields with CUMODP
 Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
Uni10 The Universal Tensor Network Library
 Uni0 The Universal Tensor Network Library Ying-Jer Kao Department of Physics National Taiwan University National Center for Theoretical Sciences http://www.uni0.org TNQMP 06, ISSP Graphical Representation
Uni0 The Universal Tensor Network Library Ying-Jer Kao Department of Physics National Taiwan University National Center for Theoretical Sciences http://www.uni0.org TNQMP 06, ISSP Graphical Representation
Accelerating interior point methods with GPUs for smart grid systems
 Downloaded from orbit.dtu.dk on: Dec 18, 2017 Accelerating interior point methods with GPUs for smart grid systems Gade-Nielsen, Nicolai Fog Publication date: 2011 Document Version Publisher's PDF, also
Downloaded from orbit.dtu.dk on: Dec 18, 2017 Accelerating interior point methods with GPUs for smart grid systems Gade-Nielsen, Nicolai Fog Publication date: 2011 Document Version Publisher's PDF, also
Tools for Power and Energy Analysis of Parallel Scientific Applications
 The 41st International Conference on Parallel Processing Tools for Power and Energy Analysis of Parallel Scientific Applications Pedro Alonso 1, Rosa M. Badia 2, Jesús Labarta 2, María Barreda 3, Manuel
The 41st International Conference on Parallel Processing Tools for Power and Energy Analysis of Parallel Scientific Applications Pedro Alonso 1, Rosa M. Badia 2, Jesús Labarta 2, María Barreda 3, Manuel
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters
 A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
The Algorithm of Multiple Relatively Robust Representations for Multi-Core Processors
 Aachen Institute for Advanced Study in Computational Engineering Science Preprint: AICES-2010/09-4 23/September/2010 The Algorithm of Multiple Relatively Robust Representations for Multi-Core Processors
Aachen Institute for Advanced Study in Computational Engineering Science Preprint: AICES-2010/09-4 23/September/2010 The Algorithm of Multiple Relatively Robust Representations for Multi-Core Processors
ACCELERATED LEARNING OF GAUSSIAN PROCESS MODELS
 ACCELERATED LEARNING OF GAUSSIAN PROCESS MODELS Bojan Musizza, Dejan Petelin, Juš Kocijan, Jožef Stefan Institute Jamova 39, Ljubljana, Slovenia University of Nova Gorica Vipavska 3, Nova Gorica, Slovenia
ACCELERATED LEARNING OF GAUSSIAN PROCESS MODELS Bojan Musizza, Dejan Petelin, Juš Kocijan, Jožef Stefan Institute Jamova 39, Ljubljana, Slovenia University of Nova Gorica Vipavska 3, Nova Gorica, Slovenia
Sparse BLAS-3 Reduction
 Sparse BLAS-3 Reduction to Banded Upper Triangular (Spar3Bnd) Gary Howell, HPC/OIT NC State University gary howell@ncsu.edu Sparse BLAS-3 Reduction p.1/27 Acknowledgements James Demmel, Gene Golub, Franc
Sparse BLAS-3 Reduction to Banded Upper Triangular (Spar3Bnd) Gary Howell, HPC/OIT NC State University gary howell@ncsu.edu Sparse BLAS-3 Reduction p.1/27 Acknowledgements James Demmel, Gene Golub, Franc
Communication-avoiding parallel and sequential QR factorizations
 Communication-avoiding parallel and sequential QR factorizations James Demmel Laura Grigori Mark Frederick Hoemmen Julien Langou Electrical Engineering and Computer Sciences University of California at
Communication-avoiding parallel and sequential QR factorizations James Demmel Laura Grigori Mark Frederick Hoemmen Julien Langou Electrical Engineering and Computer Sciences University of California at
A High Throughput FPGA-Based Implementation of the Lanczos Method for the Symmetric Extremal Eigenvalue Problem
 A High Throughput FPGA-Based Implementation of the Lanczos Method for the Symmetric Extremal Eigenvalue Problem Abid Rafique, Nachiket Kapre, and George A. Constantinides Electrical and Electronic Engineering,
A High Throughput FPGA-Based Implementation of the Lanczos Method for the Symmetric Extremal Eigenvalue Problem Abid Rafique, Nachiket Kapre, and George A. Constantinides Electrical and Electronic Engineering,
1 Overview. 2 Adapting to computing system evolution. 11 th European LS-DYNA Conference 2017, Salzburg, Austria
 1 Overview Improving LSTC s Multifrontal Linear Solver Roger Grimes 3, Robert Lucas 3, Nick Meng 2, Francois-Henry Rouet 3, Clement Weisbecker 3, and Ting-Ting Zhu 1 1 Cray Incorporated 2 Intel Corporation
1 Overview Improving LSTC s Multifrontal Linear Solver Roger Grimes 3, Robert Lucas 3, Nick Meng 2, Francois-Henry Rouet 3, Clement Weisbecker 3, and Ting-Ting Zhu 1 1 Cray Incorporated 2 Intel Corporation
LAPACK-Style Codes for Pivoted Cholesky and QR Updating. Hammarling, Sven and Higham, Nicholas J. and Lucas, Craig. MIMS EPrint: 2006.
 LAPACK-Style Codes for Pivoted Cholesky and QR Updating Hammarling, Sven and Higham, Nicholas J. and Lucas, Craig 2007 MIMS EPrint: 2006.385 Manchester Institute for Mathematical Sciences School of Mathematics
LAPACK-Style Codes for Pivoted Cholesky and QR Updating Hammarling, Sven and Higham, Nicholas J. and Lucas, Craig 2007 MIMS EPrint: 2006.385 Manchester Institute for Mathematical Sciences School of Mathematics
Porting a Sphere Optimization Program from lapack to scalapack
 Porting a Sphere Optimization Program from lapack to scalapack Paul C. Leopardi Robert S. Womersley 12 October 2008 Abstract The sphere optimization program sphopt was originally written as a sequential
Porting a Sphere Optimization Program from lapack to scalapack Paul C. Leopardi Robert S. Womersley 12 October 2008 Abstract The sphere optimization program sphopt was originally written as a sequential
Hierarchical QR factorization algorithms for multi-core cluster systems
 Hierarchical QR factorization algorithms for multi-core cluster systems Jack Dongarra Mathieu Faverge Thomas Herault Julien Langou Yves Robert University of Tennessee Knoxville, USA University of Colorado
Hierarchical QR factorization algorithms for multi-core cluster systems Jack Dongarra Mathieu Faverge Thomas Herault Julien Langou Yves Robert University of Tennessee Knoxville, USA University of Colorado
arxiv: v1 [cs.ms] 18 Nov 2016
![arxiv: v1 [cs.ms] 18 Nov 2016](/thumbs/82/85679148.jpg "arxiv: v1 [cs.ms] 18 Nov 2016") Bidiagonalization with Parallel Tiled Algorithms Mathieu Faverge,2, Julien Langou 3, Yves Robert 2,4, and Jack Dongarra 2,5 Bordeaux INP, CNRS, INRIA et Université de Bordeaux, France 2 University of Tennessee,
Bidiagonalization with Parallel Tiled Algorithms Mathieu Faverge,2, Julien Langou 3, Yves Robert 2,4, and Jack Dongarra 2,5 Bordeaux INP, CNRS, INRIA et Université de Bordeaux, France 2 University of Tennessee,
Information Sciences Institute 22 June 2012 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes and
 Accelerating the Multifrontal Method Information Sciences Institute 22 June 2012 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com 3D Finite Element
Accelerating the Multifrontal Method Information Sciences Institute 22 June 2012 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com 3D Finite Element
Parallel sparse direct solvers for Poisson s equation in streamer discharges
 Parallel sparse direct solvers for Poisson s equation in streamer discharges Margreet Nool, Menno Genseberger 2 and Ute Ebert,3 Centrum Wiskunde & Informatica (CWI), P.O.Box 9479, 9 GB Amsterdam, The Netherlands
Parallel sparse direct solvers for Poisson s equation in streamer discharges Margreet Nool, Menno Genseberger 2 and Ute Ebert,3 Centrum Wiskunde & Informatica (CWI), P.O.Box 9479, 9 GB Amsterdam, The Netherlands
Implementing QR Factorization Updating Algorithms on GPUs. Andrew, Robert and Dingle, Nicholas J. MIMS EPrint:
 Implementing QR Factorization Updating Algorithms on GPUs Andrew, Robert and Dingle, Nicholas J. 214 MIMS EPrint: 212.114 Manchester Institute for Mathematical Sciences School of Mathematics The University
Implementing QR Factorization Updating Algorithms on GPUs Andrew, Robert and Dingle, Nicholas J. 214 MIMS EPrint: 212.114 Manchester Institute for Mathematical Sciences School of Mathematics The University
Numerical Linear Algebra
 Numerical Linear Algebra By: David McQuilling; Jesus Caban Deng Li Jan.,31,006 CS51 Solving Linear Equations u + v = 8 4u + 9v = 1 A x b 4 9 u v = 8 1 Gaussian Elimination Start with the matrix representation
Numerical Linear Algebra By: David McQuilling; Jesus Caban Deng Li Jan.,31,006 CS51 Solving Linear Equations u + v = 8 4u + 9v = 1 A x b 4 9 u v = 8 1 Gaussian Elimination Start with the matrix representation