Latent Dirichlet Allocation (LDA)
|
|
|
- Kathleen Roxanne McDowell
- 5 years ago
- Views:
Transcription
1 Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3: , January Following slides borrowed ant then heavily modified from: Jonathan Huang
2 Bag of Words Models Assume that all the words within a document are exchangeable. The order of the words doesn t matter, just the count 2
3 Mixture of Unigrams = Naïve Bayes (NB) Z i z Mixture of Unigrams = Naïve Bayes Model: For each document: p p w i1 w 2i w 3i Choose a topic z d with p(topic i ) = θ Choose N words w n by drawing each one independently from a multinomial conditioned on z d with p(w n =word j topic i =z) = β z p Multinomial: take a (non-uniform prior) dice with a word on each side; roll the dice N times and count how often each word comes up w 4i In NB, we have exactly one topic per document 3 w Plate Model (equivalent) N
4 LDA: Each doc is a mixture of topics LDA lets each document be a (different) mixture of topics Naïve Bayes assumes each document is on a single topic LDA lets each word be on a different topic For each document, Choose a multinomial distribution θ d over topics for that document For each of the N words w n in the document Choose a topic z n with p(topic) = θ d Choose a word w n from a multinomial conditioned on z n with p(w=w j topic=z n ) Note: each topic has a different probability of generating each word 4
5 Dirichlet Distributions In the LDA model, we want the topic mixture proportions for each document to be drawn from some distribution. distribution = probability distribution, so it sums to one So, we want to put a prior distribution on multinomials. That is, k-tuples of non-negative numbers that sum to one. We want probabilities of probabilities These multinomials lie in a (k-1)-simplex Our prior: Simplex = generalization of a triangle to (k-1) dimensions. Needs to be defined for a (k-1)-simplex. Conjugate to the multinomial 5

6 3 Dirichlet Examples (over 3 topics) Corners: only one topic Center: uniform mixture of topics Colors indicate probability of seeing the topic distribution 6
7 Dirichlet Distribution Dirichlet distribution is defined over a (k-1)-simplex. I.e., it takes k nonnegative arguments which sum to one. is the conjugate prior to the multinomial distribution. I.e. if our likelihood is multinomial with a Dirichlet prior, then the posterior is also Dirichlet The Dirichlet parameter α i can be thought of as the prior count of the i th class. For LDA, we often use a symmetric Dirichlet where all the α are equal; α is then a concentration parameter 7
8 Effect of α When α < 1.0, the majority of the probability mass is in the "corners" of the simplex, generating mostly documents that have a small number of topics. When α > 1.0, the most documents contain most of the topics. 8
9 The LDA Model α θ θ θ z 1 z 2 z 3 z 4 z 1 z 2 z 3 z 4 z 1 z 2 z 3 z 4 w 1 w 2 w 3 w4 w 1 w 2 w 3 w4 w 1 w 2 w 3 w4 For each document, Choose the topic distribution θ ~ Dirichlet(α) For each of the N words w n : Choose a topic z ~ Multinomial(θ) Then choose a word w n ~ Multinomial(β z ) β Where each topic has a different parameter vector β for the words 9
10 The LDA Model: Plate representation For each of M documents, Choose the topic distribution θ ~ Dirichlet(α) For each of the N words w n : Choose a topic z ~ Multinomial(θ) Choose a word w n ~ Multinomial(β z ) 10
11 Parameter Estimation Given a corpus of documents, find the parameters α and β which maximize the likelihood of the observed data (words in documents), marginalizing over the hidden variables θ, z E-step: Compute p(θ,z w,α,β), the posterior of the hidden variables (θ,z) given a document w, and hyper-parameters α and β. M-step Estimate parameters α and β given the current hidden variable distribution estimates Unfortunately, the E-step cannot be solved in a closed form So people use a variational approximation θ: topic distribution for the document, z: topic for each word in the document 11
12 Variational Inference In variational inference, we consider a simplified graphical model with variational parameters γ, φ and minimize the KL Divergence between the variational and posterior distributions. q approximates p 12
13 Parameter Estimation: Variational EM Given a corpus of documents, find the parameters α and β which maximize the likelihood of the observed data. E-step: Estimate the variational parameters γ and φ in q(γ,φ;α,β) by minimizing the KL-divergence to p (with α and β fixed) M-step Maximize (over α and β) the lower bound on the log likelihood obtained using q in place of p (with γ and φ fixed) 13
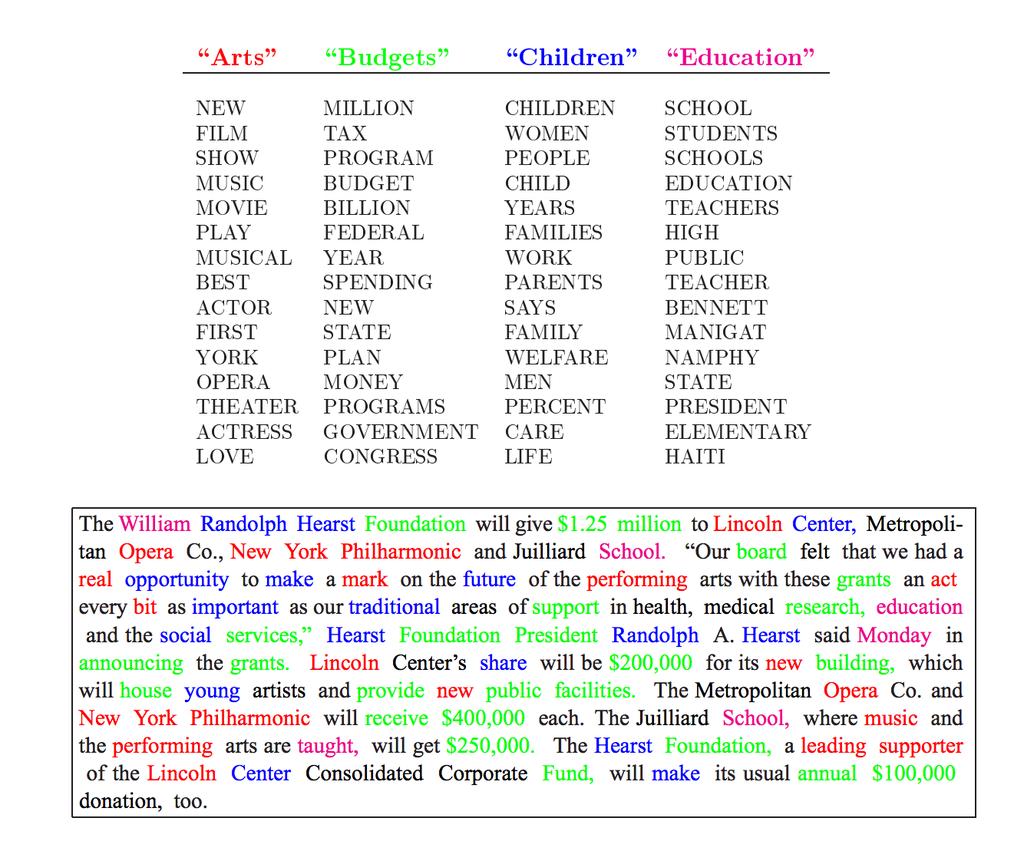
14 14

15 LDA topics can be used for semisupervised learning 15
16 LDA requires fewer topics than NB perplexity = 2 H(p) per word I.e., log 2 (perplexity) = entropy 16
17 There are many LDA extensions The author-topic model z = topic x = author 17
18 Ailment Topic Aspect Model Observed word w aspect y = symptom, treatment or other Hidden topic type: background? (l), non-ailment (x) topic distribution Paul & Dredze
19 What you should know about LDA Each document is a mixture over topics Each topic looks like a Naïve Bayes model It produces words with some probability Estimation of LDA is messy Requires variational EM or Gibbs sampling In a plate model, each plate represents repeated nodes in a network The model shows conditional independence, but not the form of the statistical distribution (e.g. Gaussian, Poisson, Dirichlet,.) 19
20 LDA generation - example Topics = {sports, politics} Words = {football, baseball, TV, win, president} α = (0.8,0.2) β = sports football baseball TV win president OOV politics 20
21 LDA generation - example For each document, d Pick a topic distribution, θ d using α For each word in the document pick a topic, z given that topic, pick a word using β α = (0.8,0.2) β = sports politics football baseball TV win president OOV
Information retrieval LSI, plsi and LDA. Jian-Yun Nie
 Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Introduction To Machine Learning
 Introduction To Machine Learning David Sontag New York University Lecture 21, April 14, 2016 David Sontag (NYU) Introduction To Machine Learning Lecture 21, April 14, 2016 1 / 14 Expectation maximization
Introduction To Machine Learning David Sontag New York University Lecture 21, April 14, 2016 David Sontag (NYU) Introduction To Machine Learning Lecture 21, April 14, 2016 1 / 14 Expectation maximization
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Applying LDA topic model to a corpus of Italian Supreme Court decisions
 Applying LDA topic model to a corpus of Italian Supreme Court decisions Paolo Fantini Statistical Service of the Ministry of Justice - Italy CESS Conference - Rome - November 25, 2014 Our goal finding
Applying LDA topic model to a corpus of Italian Supreme Court decisions Paolo Fantini Statistical Service of the Ministry of Justice - Italy CESS Conference - Rome - November 25, 2014 Our goal finding
CS Lecture 18. Topic Models and LDA
 CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
Document and Topic Models: plsa and LDA
 Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Latent Dirichlet Alloca/on
 Latent Dirichlet Alloca/on Blei, Ng and Jordan ( 2002 ) Presented by Deepak Santhanam What is Latent Dirichlet Alloca/on? Genera/ve Model for collec/ons of discrete data Data generated by parameters which
Latent Dirichlet Alloca/on Blei, Ng and Jordan ( 2002 ) Presented by Deepak Santhanam What is Latent Dirichlet Alloca/on? Genera/ve Model for collec/ons of discrete data Data generated by parameters which
Another Walkthrough of Variational Bayes. Bevan Jones Machine Learning Reading Group Macquarie University
 Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Topic Modeling Using Latent Dirichlet Allocation (LDA)
") Topic Modeling Using Latent Dirichlet Allocation (LDA) Porter Jenkins and Mimi Brinberg Penn State University prj3@psu.edu mjb6504@psu.edu October 23, 2017 Porter Jenkins and Mimi Brinberg (PSU) LDA October
Topic Modeling Using Latent Dirichlet Allocation (LDA) Porter Jenkins and Mimi Brinberg Penn State University prj3@psu.edu mjb6504@psu.edu October 23, 2017 Porter Jenkins and Mimi Brinberg (PSU) LDA October
Latent Dirichlet Allocation Introduction/Overview
 Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
RECSM Summer School: Facebook + Topic Models. github.com/pablobarbera/big-data-upf
 RECSM Summer School: Facebook + Topic Models Pablo Barberá School of International Relations University of Southern California pablobarbera.com Networked Democracy Lab www.netdem.org Course website: github.com/pablobarbera/big-data-upf
RECSM Summer School: Facebook + Topic Models Pablo Barberá School of International Relations University of Southern California pablobarbera.com Networked Democracy Lab www.netdem.org Course website: github.com/pablobarbera/big-data-upf
Gibbs Sampling. Héctor Corrada Bravo. University of Maryland, College Park, USA CMSC 644:
 Gibbs Sampling Héctor Corrada Bravo University of Maryland, College Park, USA CMSC 644: 2019 03 27 Latent semantic analysis Documents as mixtures of topics (Hoffman 1999) 1 / 60 Latent semantic analysis
Gibbs Sampling Héctor Corrada Bravo University of Maryland, College Park, USA CMSC 644: 2019 03 27 Latent semantic analysis Documents as mixtures of topics (Hoffman 1999) 1 / 60 Latent semantic analysis
Topic Modelling and Latent Dirichlet Allocation
 Topic Modelling and Latent Dirichlet Allocation Stephen Clark (with thanks to Mark Gales for some of the slides) Lent 2013 Machine Learning for Language Processing: Lecture 7 MPhil in Advanced Computer
Topic Modelling and Latent Dirichlet Allocation Stephen Clark (with thanks to Mark Gales for some of the slides) Lent 2013 Machine Learning for Language Processing: Lecture 7 MPhil in Advanced Computer
AN INTRODUCTION TO TOPIC MODELS
 AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
Lecture 22 Exploratory Text Analysis & Topic Models
 Lecture 22 Exploratory Text Analysis & Topic Models Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor [Some slides borrowed from Michael Paul] 1 Text Corpus
Lecture 22 Exploratory Text Analysis & Topic Models Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor [Some slides borrowed from Michael Paul] 1 Text Corpus
Introduction to Bayesian inference
 Introduction to Bayesian inference Thomas Alexander Brouwer University of Cambridge tab43@cam.ac.uk 17 November 2015 Probabilistic models Describe how data was generated using probability distributions
Introduction to Bayesian inference Thomas Alexander Brouwer University of Cambridge tab43@cam.ac.uk 17 November 2015 Probabilistic models Describe how data was generated using probability distributions
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Topic Models. Brandon Malone. February 20, Latent Dirichlet Allocation Success Stories Wrap-up
 Much of this material is adapted from Blei 2003. Many of the images were taken from the Internet February 20, 2014 Suppose we have a large number of books. Each is about several unknown topics. How can
Much of this material is adapted from Blei 2003. Many of the images were taken from the Internet February 20, 2014 Suppose we have a large number of books. Each is about several unknown topics. How can
LDA with Amortized Inference
 LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
Latent Dirichlet Allocation
 Latent Dirichlet Allocation 1 Directed Graphical Models William W. Cohen Machine Learning 10-601 2 DGMs: The Burglar Alarm example Node ~ random variable Burglar Earthquake Arcs define form of probability
Latent Dirichlet Allocation 1 Directed Graphical Models William W. Cohen Machine Learning 10-601 2 DGMs: The Burglar Alarm example Node ~ random variable Burglar Earthquake Arcs define form of probability
Gaussian Mixture Model
 Case Study : Document Retrieval MAP EM, Latent Dirichlet Allocation, Gibbs Sampling Machine Learning/Statistics for Big Data CSE599C/STAT59, University of Washington Emily Fox 0 Emily Fox February 5 th,
Case Study : Document Retrieval MAP EM, Latent Dirichlet Allocation, Gibbs Sampling Machine Learning/Statistics for Big Data CSE599C/STAT59, University of Washington Emily Fox 0 Emily Fox February 5 th,
Latent Dirichlet Allocation
 Outlines Advanced Artificial Intelligence October 1, 2009 Outlines Part I: Theoretical Background Part II: Application and Results 1 Motive Previous Research Exchangeability 2 Notation and Terminology
Outlines Advanced Artificial Intelligence October 1, 2009 Outlines Part I: Theoretical Background Part II: Application and Results 1 Motive Previous Research Exchangeability 2 Notation and Terminology
Lecture 8: Graphical models for Text
 Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Distributed ML for DOSNs: giving power back to users
 Distributed ML for DOSNs: giving power back to users Amira Soliman KTH isocial Marie Curie Initial Training Networks Part1 Agenda DOSNs and Machine Learning DIVa: Decentralized Identity Validation for
Distributed ML for DOSNs: giving power back to users Amira Soliman KTH isocial Marie Curie Initial Training Networks Part1 Agenda DOSNs and Machine Learning DIVa: Decentralized Identity Validation for
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Statistical Debugging with Latent Topic Models
 Statistical Debugging with Latent Topic Models David Andrzejewski, Anne Mulhern, Ben Liblit, Xiaojin Zhu Department of Computer Sciences University of Wisconsin Madison European Conference on Machine Learning,
Statistical Debugging with Latent Topic Models David Andrzejewski, Anne Mulhern, Ben Liblit, Xiaojin Zhu Department of Computer Sciences University of Wisconsin Madison European Conference on Machine Learning,
Non-parametric Clustering with Dirichlet Processes
 Non-parametric Clustering with Dirichlet Processes Timothy Burns SUNY at Buffalo Mar. 31 2009 T. Burns (SUNY at Buffalo) Non-parametric Clustering with Dirichlet Processes Mar. 31 2009 1 / 24 Introduction
Non-parametric Clustering with Dirichlet Processes Timothy Burns SUNY at Buffalo Mar. 31 2009 T. Burns (SUNY at Buffalo) Non-parametric Clustering with Dirichlet Processes Mar. 31 2009 1 / 24 Introduction
Text Mining for Economics and Finance Latent Dirichlet Allocation
 Text Mining for Economics and Finance Latent Dirichlet Allocation Stephen Hansen Text Mining Lecture 5 1 / 45 Introduction Recall we are interested in mixed-membership modeling, but that the plsi model
Text Mining for Economics and Finance Latent Dirichlet Allocation Stephen Hansen Text Mining Lecture 5 1 / 45 Introduction Recall we are interested in mixed-membership modeling, but that the plsi model
Mixtures of Multinomials
 Mixtures of Multinomials Jason D. M. Rennie jrennie@gmail.com September, 25 Abstract We consider two different types of multinomial mixtures, () a wordlevel mixture, and (2) a document-level mixture. We
Mixtures of Multinomials Jason D. M. Rennie jrennie@gmail.com September, 25 Abstract We consider two different types of multinomial mixtures, () a wordlevel mixture, and (2) a document-level mixture. We
Mixed-membership Models (and an introduction to variational inference)
") Mixed-membership Models (and an introduction to variational inference) David M. Blei Columbia University November 24, 2015 Introduction We studied mixture models in detail, models that partition data into
Mixed-membership Models (and an introduction to variational inference) David M. Blei Columbia University November 24, 2015 Introduction We studied mixture models in detail, models that partition data into
Applying hlda to Practical Topic Modeling
 Joseph Heng lengerfulluse@gmail.com CIST Lab of BUPT March 17, 2013 Outline 1 HLDA Discussion 2 the nested CRP GEM Distribution Dirichlet Distribution Posterior Inference Outline 1 HLDA Discussion 2 the
Joseph Heng lengerfulluse@gmail.com CIST Lab of BUPT March 17, 2013 Outline 1 HLDA Discussion 2 the nested CRP GEM Distribution Dirichlet Distribution Posterior Inference Outline 1 HLDA Discussion 2 the
CS 6140: Machine Learning Spring 2017
 CS 6140: Machine Learning Spring 2017 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis@cs Assignment
CS 6140: Machine Learning Spring 2017 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis@cs Assignment
cross-language retrieval (by concatenate features of different language in X and find co-shared U). TOEFL/GRE synonym in the same way.
. TOEFL/GRE synonym in the same way.") 10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
Modeling Environment
 Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Topic Modeling: Beyond Bag-of-Words
 University of Cambridge hmw26@cam.ac.uk June 26, 2006 Generative Probabilistic Models of Text Used in text compression, predictive text entry, information retrieval Estimate probability of a word in a
University of Cambridge hmw26@cam.ac.uk June 26, 2006 Generative Probabilistic Models of Text Used in text compression, predictive text entry, information retrieval Estimate probability of a word in a
RETRIEVAL MODELS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
Topic Models and Applications to Short Documents
 Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Topic Models. Charles Elkan November 20, 2008
 Topic Models Charles Elan elan@cs.ucsd.edu November 20, 2008 Suppose that we have a collection of documents, and we want to find an organization for these, i.e. we want to do unsupervised learning. One
Topic Models Charles Elan elan@cs.ucsd.edu November 20, 2008 Suppose that we have a collection of documents, and we want to find an organization for these, i.e. we want to do unsupervised learning. One
Understanding Comments Submitted to FCC on Net Neutrality. Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014
 Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014") Understanding Comments Submitted to FCC on Net Neutrality Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014 Abstract We aim to understand and summarize themes in the 1.65 million
Understanding Comments Submitted to FCC on Net Neutrality Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014 Abstract We aim to understand and summarize themes in the 1.65 million
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Expectation Maximization Mixture Models HMMs
 11-755 Machine Learning for Signal rocessing Expectation Maximization Mixture Models HMMs Class 9. 21 Sep 2010 1 Learning Distributions for Data roblem: Given a collection of examples from some data, estimate
11-755 Machine Learning for Signal rocessing Expectation Maximization Mixture Models HMMs Class 9. 21 Sep 2010 1 Learning Distributions for Data roblem: Given a collection of examples from some data, estimate
Dirichlet Enhanced Latent Semantic Analysis
 Dirichlet Enhanced Latent Semantic Analysis Kai Yu Siemens Corporate Technology D-81730 Munich, Germany Kai.Yu@siemens.com Shipeng Yu Institute for Computer Science University of Munich D-80538 Munich,
Dirichlet Enhanced Latent Semantic Analysis Kai Yu Siemens Corporate Technology D-81730 Munich, Germany Kai.Yu@siemens.com Shipeng Yu Institute for Computer Science University of Munich D-80538 Munich,
Web-Mining Agents Topic Analysis: plsi and LDA. Tanya Braun Ralf Möller Universität zu Lübeck Institut für Informationssysteme
 Web-Mining Agents Topic Analysis: plsi and LDA Tanya Braun Ralf Möller Universität zu Lübeck Institut für Informationssysteme Acknowledgments Pilfered from: Ramesh M. Nallapati Machine Learning applied
Web-Mining Agents Topic Analysis: plsi and LDA Tanya Braun Ralf Möller Universität zu Lübeck Institut für Informationssysteme Acknowledgments Pilfered from: Ramesh M. Nallapati Machine Learning applied
Some Probability and Statistics
 Some Probability and Statistics David M. Blei COS424 Princeton University February 13, 2012 Card problem There are three cards Red/Red Red/Black Black/Black I go through the following process. Close my
Some Probability and Statistics David M. Blei COS424 Princeton University February 13, 2012 Card problem There are three cards Red/Red Red/Black Black/Black I go through the following process. Close my
Deep Sequence Models. Context Representation, Regularization, and Application to Language. Adji Bousso Dieng
 Deep Sequence Models Context Representation, Regularization, and Application to Language Adji Bousso Dieng All Data Are Born Sequential Time underlies many interesting human behaviors. Elman, 1990. Why
Deep Sequence Models Context Representation, Regularization, and Application to Language Adji Bousso Dieng All Data Are Born Sequential Time underlies many interesting human behaviors. Elman, 1990. Why
Sampling from Bayes Nets
 from Bayes Nets http://www.youtube.com/watch?v=mvrtaljp8dm http://www.youtube.com/watch?v=geqip_0vjec Paper reviews Should be useful feedback for the authors A critique of the paper No paper is perfect!
from Bayes Nets http://www.youtube.com/watch?v=mvrtaljp8dm http://www.youtube.com/watch?v=geqip_0vjec Paper reviews Should be useful feedback for the authors A critique of the paper No paper is perfect!
Hybrid Models for Text and Graphs. 10/23/2012 Analysis of Social Media
 Hybrid Models for Text and Graphs 10/23/2012 Analysis of Social Media Newswire Text Formal Primary purpose: Inform typical reader about recent events Broad audience: Explicitly establish shared context
Hybrid Models for Text and Graphs 10/23/2012 Analysis of Social Media Newswire Text Formal Primary purpose: Inform typical reader about recent events Broad audience: Explicitly establish shared context
Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs
 Lawrence Livermore National Laboratory Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs Keith Henderson and Tina Eliassi-Rad keith@llnl.gov and eliassi@llnl.gov This work was performed
Lawrence Livermore National Laboratory Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs Keith Henderson and Tina Eliassi-Rad keith@llnl.gov and eliassi@llnl.gov This work was performed
Contents. Part I: Fundamentals of Bayesian Inference 1
 Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Collaborative Topic Modeling for Recommending Scientific Articles
 Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
16 : Approximate Inference: Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Hierarchical Bayesian Nonparametrics
 Hierarchical Bayesian Nonparametrics Micha Elsner April 11, 2013 2 For next time We ll tackle a paper: Green, de Marneffe, Bauer and Manning: Multiword Expression Identification with Tree Substitution
Hierarchical Bayesian Nonparametrics Micha Elsner April 11, 2013 2 For next time We ll tackle a paper: Green, de Marneffe, Bauer and Manning: Multiword Expression Identification with Tree Substitution
Content-based Recommendation
 Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Note 1: Varitional Methods for Latent Dirichlet Allocation
 Technical Note Series Spring 2013 Note 1: Varitional Methods for Latent Dirichlet Allocation Version 1.0 Wayne Xin Zhao batmanfly@gmail.com Disclaimer: The focus of this note was to reorganie the content
Technical Note Series Spring 2013 Note 1: Varitional Methods for Latent Dirichlet Allocation Version 1.0 Wayne Xin Zhao batmanfly@gmail.com Disclaimer: The focus of this note was to reorganie the content
Note for plsa and LDA-Version 1.1
 Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Mixed Membership Stochastic Blockmodels
 Mixed Membership Stochastic Blockmodels Journal of Machine Learning Research, 2008 by E.M. Airoldi, D.M. Blei, S.E. Fienberg, E.P. Xing as interpreted by Ted Westling STAT 572 Final Talk May 8, 2014 Ted
Mixed Membership Stochastic Blockmodels Journal of Machine Learning Research, 2008 by E.M. Airoldi, D.M. Blei, S.E. Fienberg, E.P. Xing as interpreted by Ted Westling STAT 572 Final Talk May 8, 2014 Ted
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank
 A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
Machine Learning for Signal Processing Expectation Maximization Mixture Models. Bhiksha Raj 27 Oct /
 Machine Learning for Signal rocessing Expectation Maximization Mixture Models Bhiksha Raj 27 Oct 2016 11755/18797 1 Learning Distributions for Data roblem: Given a collection of examples from some data,
Machine Learning for Signal rocessing Expectation Maximization Mixture Models Bhiksha Raj 27 Oct 2016 11755/18797 1 Learning Distributions for Data roblem: Given a collection of examples from some data,
Topic Models. Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW. Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1
 Topic Models Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1 Low-Dimensional Space for Documents Last time: embedding space
Topic Models Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1 Low-Dimensional Space for Documents Last time: embedding space
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Language Information Processing, Advanced. Topic Models
 Language Information Processing, Advanced Topic Models mcuturi@i.kyoto-u.ac.jp Kyoto University - LIP, Adv. - 2011 1 Today s talk Continue exploring the representation of text as histogram of words. Objective:
Language Information Processing, Advanced Topic Models mcuturi@i.kyoto-u.ac.jp Kyoto University - LIP, Adv. - 2011 1 Today s talk Continue exploring the representation of text as histogram of words. Objective:
Replicated Softmax: an Undirected Topic Model. Stephen Turner
 Replicated Softmax: an Undirected Topic Model Stephen Turner 1. Introduction 2. Replicated Softmax: A Generative Model of Word Counts 3. Evaluating Replicated Softmax as a Generative Model 4. Experimental
Replicated Softmax: an Undirected Topic Model Stephen Turner 1. Introduction 2. Replicated Softmax: A Generative Model of Word Counts 3. Evaluating Replicated Softmax as a Generative Model 4. Experimental
CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr Dirichlet Process I
 X i Ν CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr 2004 Dirichlet Process I Lecturer: Prof. Michael Jordan Scribe: Daniel Schonberg dschonbe@eecs.berkeley.edu 22.1 Dirichlet
X i Ν CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr 2004 Dirichlet Process I Lecturer: Prof. Michael Jordan Scribe: Daniel Schonberg dschonbe@eecs.berkeley.edu 22.1 Dirichlet
Parallelized Variational EM for Latent Dirichlet Allocation: An Experimental Evaluation of Speed and Scalability
 Parallelized Variational EM for Latent Dirichlet Allocation: An Experimental Evaluation of Speed and Scalability Ramesh Nallapati, William Cohen and John Lafferty Machine Learning Department Carnegie Mellon
Parallelized Variational EM for Latent Dirichlet Allocation: An Experimental Evaluation of Speed and Scalability Ramesh Nallapati, William Cohen and John Lafferty Machine Learning Department Carnegie Mellon
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Bayesian Nonparametric Models
 Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Evaluation Methods for Topic Models
 University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
Variational Inference (11/04/13)
") STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
Dimension Reduction (PCA, ICA, CCA, FLD,
 Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine
 Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
Graphical Models and Kernel Methods
 Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
Web Search and Text Mining. Lecture 16: Topics and Communities
 Web Search and Tet Mining Lecture 16: Topics and Communities Outline Latent Dirichlet Allocation (LDA) Graphical models for social netorks Eploration, discovery, and query-ansering in the contet of the
Web Search and Tet Mining Lecture 16: Topics and Communities Outline Latent Dirichlet Allocation (LDA) Graphical models for social netorks Eploration, discovery, and query-ansering in the contet of the
Naïve Bayes, Maxent and Neural Models
 Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Latent Dirichlet Conditional Naive-Bayes Models
 Latent Dirichlet Conditional Naive-Bayes Models Arindam Banerjee Dept of Computer Science & Engineering University of Minnesota, Twin Cities banerjee@cs.umn.edu Hanhuai Shan Dept of Computer Science &
Latent Dirichlet Conditional Naive-Bayes Models Arindam Banerjee Dept of Computer Science & Engineering University of Minnesota, Twin Cities banerjee@cs.umn.edu Hanhuai Shan Dept of Computer Science &
Probabilistic Graphical Models
 School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
Notes on Machine Learning for and
 Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Incorporating Domain Knowledge into Topic Modeling via Dirichlet Forest Priors
 Incorporating Domain Knowledge into Topic Modeling via Dirichlet Forest Priors David Andrzejewski, Xiaojin Zhu, Mark Craven University of Wisconsin Madison ICML 2009 Andrzejewski (Wisconsin) Dirichlet
Incorporating Domain Knowledge into Topic Modeling via Dirichlet Forest Priors David Andrzejewski, Xiaojin Zhu, Mark Craven University of Wisconsin Madison ICML 2009 Andrzejewski (Wisconsin) Dirichlet
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Latent variable models for discrete data
 Latent variable models for discrete data Jianfei Chen Department of Computer Science and Technology Tsinghua University, Beijing 100084 chris.jianfei.chen@gmail.com Janurary 13, 2014 Murphy, Kevin P. Machine
Latent variable models for discrete data Jianfei Chen Department of Computer Science and Technology Tsinghua University, Beijing 100084 chris.jianfei.chen@gmail.com Janurary 13, 2014 Murphy, Kevin P. Machine
Collapsed Variational Bayesian Inference for Hidden Markov Models
 Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
COS 424: Interacting with Data. Lecturer: Dave Blei Lecture #11 Scribe: Andrew Ferguson March 13, 2007
 COS 424: Interacting with ata Lecturer: ave Blei Lecture #11 Scribe: Andrew Ferguson March 13, 2007 1 Graphical Models Wrap-up We began the lecture with some final words on graphical models. Choosing a
COS 424: Interacting with ata Lecturer: ave Blei Lecture #11 Scribe: Andrew Ferguson March 13, 2007 1 Graphical Models Wrap-up We began the lecture with some final words on graphical models. Choosing a
Present and Future of Text Modeling
 Present and Future of Text Modeling Daichi Mochihashi NTT Communication Science Laboratories daichi@cslab.kecl.ntt.co.jp T-FaNT2, University of Tokyo 2008-2-13 (Wed) Present and Future of Text Modeling
Present and Future of Text Modeling Daichi Mochihashi NTT Communication Science Laboratories daichi@cslab.kecl.ntt.co.jp T-FaNT2, University of Tokyo 2008-2-13 (Wed) Present and Future of Text Modeling