Lecture Notes 2: Matrices
|
|
|
- Shanna Collins
- 6 years ago
- Views:
Transcription
1 Optimization-based data analysis Fall 2017 Lecture Notes 2: Matrices Matrices are rectangular arrays of numbers, which are extremely useful for data analysis. They can be interpreted as vectors in a vector space, linear functions or sets of vectors. 1 Basic properties 1.1 Column and row space A matrix can be used to represent a set of vectors stored as columns or rows. The span of these vectors are called the column and row space of the matrix respectively. Definition 1.1 (Column and row space). The column space col (A) of a matrix A is the span of its columns. The row space row (A) is the span of its rows. Interestingly, the row space and the column space of all matrices have the same dimension. We name this quantity the rank of the matrix. Definition 1.2 (Rank). The rank of a matrix is the dimension of its column and of its row space. Theorem 1.3 (Proof in Section 5.1). The rank is well defined. For any matrix A dim (col (A)) = dim (row (A)). (1) If the dimension of the row and column space of an m n matrix where m < n is equal to m then the the rows are all linearly independent. Similarly, if m > n and the rank is n then the columns are all linearly independent. In general, when the rank equals min {n, m} we say that the matrix is full rank. Recall that the inner product between two matrices A, B R m n is given by the trace of A T B, and the norm induced by this inner product is the Frobenius norm. If the column spaces of two matrices are orthogonal, then the matrices are also orthogonal. Lemma 1.4. If the column spaces of any pair of matrices A, B R m n are orthogonal then A, B = 0. (2) Proof. We can write the inner product as a sum of products between the columns of A 1
2 and B, which are all zero under the assumption of the lemma A, B := tr ( A T B ) (3) = A :,i, B :,i (4) = 0. (5) The following corollary follows immediately from Lemma 1.4 and the Pythagorean theorem. Corollary 1.5. If the column spaces of any pair of matrices A, B R m n are orthogonal A + B 2 F = A 2 F + B 2 F. (6) 1.2 Linear maps A map is a transformation that assigns a vector to another vector, possible belonging to a different vector space. The transformation is linear if it maps any linear combination of input vectors to the same linear combination of the corresponding outputs. Definition 1.6 (Linear map). Given two vector spaces V and R associated to the same scalar field, a linear map f : V R is a map from vectors in V to vectors in R such that for any scalar α and any vectors x 1, x 2 V f ( x 1 + x 2 ) = f ( x 1 ) + f ( x 2 ), (7) f (α x 1 ) = α f ( x 1 ). (8) Every complex or real matrix of dimensions m n defines a map from the space of n- dimensional vectors to the space of m-dimensional vectors through an operation called matrix-vector product. We denote the ith row of a matrix A by A i:, the jth column by A :j and the (i, j) entry by A ij. Definition 1.7 (Matrix-vector product). The product of a matrix A C m n and a vector x C n is a vector A x C m, such that (A x) [i] = A ij x [j]. (9) j=1 For real matrices, each entry in the matrix-vector product is the dot product between a row of the matrix and the vector, (A x) [i] = A i:, x. (10) 2
3 The matrix-vector product can also be interpreted in terms of the column of the matrix, A x = x [j] A :j. (11) A x is a linear combination of the columns of A weighted by the entries in x. j=1 Matrix-vector multiplication is clearly linear. Perhaps surprisingly, the converse is also true: any linear map between C n and C m (or between R n and R m ) can be represented by a matrix. Theorem 1.8 (Equivalence between matrices and linear maps). For finite m, n every linear map f : C m C n can be uniquely represented by a matrix F C m n. Proof. The matrix is F := [ f ( e 1 ) f ( e 2 ) f ( e n ) ], (12) i.e., the columns of the matrix are the result of applying f to the standard basis. Indeed, for any vector x C n ( ) f (x) = f x[i] e i (13) = x[i]f ( e i ) by (7) and (8) (14) = F x. (15) The ith column of any matrix that represents the linear map must equal f ( e i ) by (11), so the representation is unique. When a matrix C m n is fat, i.e., n > m, we often say that it projects vectors onto a lower dimensional space. Note that such projections are not the same as the orthogonal projections we described in Lecture Notes 1. When a matrix is tall, i.e., m > n, we say that it lifts vectors to a higher-dimensional space. 1.3 Adjoint The adjoint of a linear map f from an inner-product space V and another inner product space R maps elements of R back to V in a way that preserves their inner product with images of f. Definition 1.9 (Adjoint). Given two vector spaces V and R associated to the same scalar field with inner products, V and, R respectively, the adjoint f : R V of a linear map f : V R satisfies for all x V and y R. f ( x), y R = x, f ( y) V (16) 3
4 In the case of finite-dimensional spaces, the adjoint corresponds to the conjugate Hermitian transpose of the matrix associated to the linear map. Definition 1.10 (Conjugate transpose). The entries of the conjugate transpose A C n m of a matrix A C m n are of the form (A ) ij = A ji, 1 i n, 1 j m. (17) If the entries of the matrix are all real, this is just the transpose of the matrix. Lemma 1.11 (Equivalence between conjugate transpose and adjoint). For finite m, n the adjoint f : C n C m of a linear map f : C m C n represented by a matrix F corresponds to the conjugate transpose of the matrix F. Proof. For any x C n and y C m, f ( x), y C m = = = m f ( x) i y i (18) m y i F ij x j (19) j=1 m x j F ij y i (20) j=1 = x, F y C n. (21) By Theorem 1.8 a linear map is represented by a unique matrix (you can check that the adjoint map is linear), which completes the proof. A matrix that is equal to its adjoint is called self-adjoint. Self-adjoint real matrices are symmetric: they are equal to their transpose. Self-adjoint complex matrices are Hermitian: they are equal to their conjugate transpose. 1.4 Range and null space The range of a linear map is the set of all possible vectors that can be reached by applying the map. Definition 1.12 (Range). Let V and R be vector spaces associated to the same scalar field, the range of a map f : V R is the set of vectors in R that can be reached by applying f to a vector in V: range (f) := { y y = f ( x) for some x V}. (22) The range of a matrix is the range of its associated linear map. 4
5 The range of a matrix is the same as its column space. Lemma 1.13 (The range is the column space). For any matrix A C m n range (A) = col (A). (23) Proof. For any x, A x is a linear combination of the columns of A, so the range is a subset of the column space. In addition, every column of A is in the range, since A :i = A e i for 1 i n, so the column space is a subset of the range and both sets are equal. The null space of a map is the set of vectors that are mapped to zero. Definition 1.14 (Null space). Let V and R be vector spaces associated to the same scalar field, the null space of a map f : V R is the set of vectors in V that are mapped to the zero vector in R by f: { } null (f) := x f ( x) = 0. (24) The null space of a matrix is the null space of its associated linear map. It is not difficult to prove that the null space of a map is a vector space, as long as the map is linear, since in that case scaling or adding elements of the null space yield vectors that are mapped to zero by the map. The following lemma shows that for real matrices the null space is the orthogonal complement of the row space of the matrix. Lemma For any matrix A R m n null (A) = row (A). (25) Proof. Any vector x in the row space of A can be written as x = A T z, for some vector z R m. If y null (A) then So null (A) row (A). y, x = y, A T z (26) = A y, z (27) = 0. (28) If x row (A) then in particular it is orthogonal to every row of A, so Ax = 0 and row (A) null (A). An immediate corollary of Lemmas 1.13 and 1.15 is that the dimension of the range and the null space add up to the ambient dimension of the row space. Corollary Let A R m n dim (range (A)) + dim (null (A)) = n. (29) This means that for every matrix A R m n we can decompose any vector in R n into two components: one is in the row space and is mapped to a nonzero vector in C m, the other is in the null space and is mapped to the zero vector. 5
6 1.5 Identity matrix and inverse The identity matrix is a matrix that maps any vector to itself. Definition 1.17 (Identity matrix). The identity matrix of dimensions n n is I = (30) For any x C n, I x = x. Square matrices have a unique inverse if they are full rank, since in that case the null space has dimension 0 and the associated linear map is a bijection. The inverse is a matrix that reverses the effect of the matrix on any vector. Definition 1.18 (Matrix inverse). The inverse of a square matrix A C n n is a matrix A 1 C n n such that AA 1 = A 1 A = I. (31) 1.6 Orthogonal and projection matrices We often use the letters U R m n or V R m n for matrices with orthonormal columns. If such matrices are square then they are said to be orthogonal. Orthogonal matrices represent linear maps that do not affect the magnitude of a vector, just its direction. Definition 1.19 (Orthogonal matrix). An orthogonal matrix is a real-valued square matrix such that its inverse is equal to its transpose, U T U = UU T = I. (32) By definition, the columns U :1, U :2,..., U :n of any n n orthogonal matrix have unit norm and orthogonal to each other, so they form an orthonormal basis (it s somewhat confusing that orthogonal matrices are not called orthonormal matrices instead). Applying U T to a vector x R n is equivalent to computing the coefficients of its representation in the basis formed by the columns of U. Applying U to U T x recovers x by scaling each basis vector with the corresponding coefficient: x = UU T x = U :i, x U :i. (33) Since orthogonal matrices only rotate vectors, it is quite intuitive that the product of two orthogonal matrices yields another orthogonal matrix. 6
7 Lemma 1.20 (Product of orthogonal matrices). If U, V R n n are orthogonal matrices, then U V is also an orthogonal matrix. Proof. (UV ) T (UV ) = V T U T UV = I. (34) The following lemma proves that orthogonal matrices preserve the l 2 norms of vectors. Lemma Let U R n n be an orthogonal matrix. For any vector x R n, U x 2 = x 2. (35) Proof. By the definition of orthogonal matrix U x 2 2 = xt U T U x (36) = x T x (37) = x 2 2. (38) Matrices with orthonormal columns can also be used to construct orthogonal-projection matrices, which represent orthogonal projections onto a subspace. Lemma 1.22 (Orthogonal-projection matrix). Given a subspace S R n of dimension d, the matrix P := UU T, (39) where the columns of U :1, U :2,..., U :d are an orthonormal basis of S, maps any vector x to its orthogonal projection onto S. Proof. For any vector x R n P x = UU T x (40) d = U :i, x U :i (41) = P S x by (64) in the lecture notes on vector spaces. (42) 2 Singular-value decomposition In this section we introduce the singular-value decomposition, a fundamental tool for manipulating matrices, and describe several applications in data analysis. 7
8 2.1 Definition Every real matrix has a singular-value decomposition. Theorem 2.1. Every rank r real matrix A R m n, has a singular-value decomposition (SVD) of the form σ v 1 T A = [ ] 0 σ 2 0 v T u 1 u 2 u r... (43) σ r = USV T, (44) where the singular values σ 1 σ 2 σ r are positive real numbers, the left singular vectors u 1, u 2,... u r form an orthonormal set, and the right singular vectors v 1, v 2,... v r also form an orthonormal set. The SVD is unique if all the singular values are different. If several singular values are the same, their left singular vectors can be replaced by any orthonormal basis of their span, and the same holds for the right singular vectors. The SVD of an m n matrix with m n can be computed in O (mn 2 ). We refer to any graduate linear algebra book for the proof of Theorem 2.1 and for the details on how to compute the SVD. The SVD provides orthonormal bases for the column and row spaces of the matrix. Lemma 2.2. The left singular vectors are an orthonormal basis for the column space, whereas the right singular vectors are an orthonormal basis for the row space. Proof. We prove the statement for the column space, the proof for the row space is identical. All left singular vectors belong to the column space because u i = A ( ) σ 1 i v i. In addition, every column of A is in their span because A :i = U ( ) SV T e i. Since they form an orthonormal set by Theorem 2.1, this completes the proof. The SVD presented in Theorem 2.1 can be augmented so that the number of singular values equals min (m, n). The additional singular values are all equal to zero. Their corresponding left and right singular vectors are orthonormal sets of vectors in the orthogonal complements of the column and row space respectively. If the matrix is tall or square, the additional right singular vectors are a basis of the null space of the matrix. Corollary 2.3 (Singular-value decomposition). Every rank r real matrix A R m n, v T r 8
9 where m n, has a singular-value decomposition (SVD) of the form σ σ A := [ u 1 u 2 u }{{} r u r+1 u n ] 0 0 σ r 0 0 Basis of range(a) [ v 1 v 2 v r }{{} Basis of row(a) v r+1 v }{{ n ] T, } Basis of null(a) where the singular values σ 1 σ 2 σ r are positive real numbers, the left singular vectors u 1, u 2,..., u m form an orthonormal set in R m, and the right singular vectors v 1, v 2,..., v m form an orthonormal basis for R n. If the matrix is fat, we can define a similar augmentation, where the additional left singular vectors form an orthonormal basis of the orthogonal complement of the range. By the definition of rank and Lemma 2.2 the rank of a matrix is equal to the number of nonzero singular values. Corollary 2.4. The rank of a matrix is equal to the number of nonzero singular values. This interpretation of the rank allows to define an alternative definition that is very useful in practice, since matrices are often full rank due to numerical error, even if their columns or rows are almost linearly dependent. Definition 2.5 (Numerical rank). Given a tolerance ɛ > 0, the numerical rank of a matrix is the number of singular values that are greater than ɛ. The SVD decomposes the action of a matrix A R m n on a vector x R n into three simple steps: 1. Rotation of x to align the component of x in the direction of the ith right singular vector v i with the ith axis: V T x = v i, x e i. (46) 2. Scaling of each axis by the corresponding singular value SV T x = σ i v i, x e i. (47) 3. Rotation to align the ith axis with the ith left singular vector USV T x = σ i v i, x u i. (48) (45) 9
10 (a) σ 1 = 3, σ 2 = 1. x v 2 V T x e 2 V T y y V T e 1 v 1 S SV T x σ 2 e 2 SV T y U σ2 u 2 USV T y σ 1 u 1 σ 1 e 1 USV T x (b) σ 1 = 3, σ 2 = 0. x v 2 V T x e 2 V T y y V T e 1 v 1 S USV T y σ 1 u 1 SV T x 0 SV T y σ 1 e 1 U 0 USV T x Figure 1: Any linear map can be decomposed into three steps: rotation to align the right singular vectors to the axes, scaling by the singular values and a final rotation to align the axes with the left singular vectors. In image (b) the second singular value is zero, so the linear map projects two-dimensional vectors onto a one-dimensional subspace. 10
11 Figure 1 illustrates this geometric analysis of the action of a linear map. We end the section by showing that multiplying a matrix by an orthogonal matrix does not affect its singular values. This makes sense since it just modifies the rotation carried out by the left or right singular vectors. Lemma 2.6. For any matrix A R m n and any orthogonal matrices Ũ Rm m and Ṽ R m m the singular values of ŨA and AṼ are the same as the singular values of A. Proof. Let A = USV T be the SVD of A. By Lemma 1.20 the matrices U := ŨU and V T := V T Ṽ are orthogonal matrices, so USV T and USV T are valid SVDs for ŨA and AṼ respectively. The result follows by unicity of the SVD. 2.2 Optimal approximations via the SVD In the previous section, we show that linear maps rotate vectors, scale them according to the singular values and then rotate them again. This means that the maximum scaling possible is equal to the maximum singular value and occurs in the direction of the right singular vector v 1. The following theorem makes this precise, showing that if we restrict our attention to the orthogonal complement of v 1, then the maximum scaling is the second singular value, due to the orthogonality of the singular vectors. In general, the direction of maximum scaling orthogonal to the first i 1 left singular vectors is equal to the ith singular value and occurs in the direction of the ith singular vector. Theorem 2.7. For any matrix A R m n, with SVD given by (45), the singular values satisfy σ 1 = max { x 2 =1 x R n } A x 2 (49) = max A T y 2, (50) { y 2 =1 y R m } σ i = max A x 2, (51) { x 2 =1 x R n, x v 1,..., v i 1} = max A T y 2, 2 i min {m, n}, (52) { y 2 =1 y R m, y u 1,..., u i 1} the right singular vectors satisfy v 1 = v i = arg max A x 2, (53) { x 2 =1 x R n } arg max A x 2, 2 i m, (54) { x 2 =1 x R n, x v 1,..., v i 1} 11
12 and the left singular vectors satisfy u 1 = u i = arg max { y 2 =1 y R m } A T y 2, (55) arg max A T y 2, 2 i n. (56) { y 2 =1 y R m, y u 1,..., u i 1} Proof. Consider a vector x R n with unit l 2 norm that is orthogonal to v 1,..., v i 1, where 1 i n (if i = 1 then x is just an arbitrary vector). We express x in terms of the right singular vectors of A and a component that is orthogonal to their span x = α j v j + P row(a) x (57) j=i where 1 = x 2 2 n j=i α2 j. By the ordering of the singular values in Theorem 2.1 A x 2 2 = σ k v k, x u k, σ k v k, x u k by (48) (58) k=1 = = = k=1 σk 2 v k, x 2 because u 1,..., u n are orthonormal (59) k=1 k=1 σ 2 k v k, 2 α j v j + P row(a) x (60) j=i σj 2 αj 2 because v 1,..., v n are orthonormal (61) j=i σ 2 i αj 2 because σ i σ i+1... σ n (62) j=i This establishes (49) and (51). maximum σ 2 i by (57). (63) To prove (53) and (54) we show that v i achieves the A v i 2 2 = σk 2 v k, v i 2 (64) k=1 = σ 2 i. (65) The same argument applied to A T establishes (50), (55), (56) and (52). Given a set of vectors, it is often of interest to determine whether they are oriented in particular directions of the ambient space. This can be quantified in terms of the l 2 norms of their projections on low-dimensional subspaces. The SVD provides an optimal k-dimensional subspace in this sense for any value of k. 12
13 Theorem 2.8 (Optimal subspace for orthogonal projection). For any matrix with SVD given by (45), we have A := [ a 1 a 2 a n ] R m n, (66) P span( u1, u 2,..., u k ) a i 2 P 2 S a i 2 2, (67) for any subspace S of dimension k min {m, n}. Proof. Note that Pspan( u1, u 2,..., u k ) a i 2 = 2 = k u j, a i 2 (68) j=1 k A T u j 2. (69) 2 We prove the result by induction on k. The base case k = 1 follows immediately from (55). To complete the proof we show that if the result is true for k 1 1 (the induction hypothesis) then it also holds for k. Let S be an arbitrary subspace of dimension k. The intersection of S and the orthogonal complement to the span of u 1, u 2,..., u k 1 contains a nonzero vector b due to the following lemma. Lemma 2.9 (Proof in Section 5.2). In a vector space of dimension n, the intersection of two subspaces with dimensions d 1 and d 2 such that d 1 + d 2 > n has dimension at least one. We choose an orthonormal basis b 1, b 2,..., b k for S such that b k := b is orthogonal to u 1, u 2,..., u k 1 (we can construct such a basis by Gram-Schmidt, starting with b). By the induction hypothesis, j=1 k 1 A T u i 2 = Pspan( u1 2, u 2,..., u k 1 ) a i 2 (70) 2 P span( b 1, b 2,..., b k 1) a i 2 2 (71) k 1 = A T 2 bi. (72) 2 By (56) A T u k 2 A T 2 bk 2 2. (73) 13
14 Combining (72) and (73) we conclude k Pspan( u1, u 2,..., u k ) a i 2 = 2 A T u i 2 (74) 2 = k A T 2 bi 2 (75) P S a i 2 2. (76) The SVD also allows to compute the optimal k-rank approximation to a matrix in Frobenius norm, for any value of k. For any matrix A, we denote by A 1:i,1:j to denote the i j submatrix formed by taking the entries that are both in the first i rows and the first j columns. Similarly, we denote by A :,i:j the matrix formed by columns i to j. Theorem 2.10 (Best rank-k approximation). Let USV T be the SVD of a matrix A R m n. The truncated SVD U :,1:k S 1:k,1:k V:,1:k T is the best rank-k approximation of A in the sense that U :,1:k S 1:k,1:k V:,1:k T = arg min A Ã. (77) F {à rank(ã)=k} Proof. Let à be an arbitrary matrix in Rm n with rank(ã) = k, and let Ũ Rm k be a matrix with orthonormal columns such that col(ũ) = col(ã). By Theorem 2.8, U:,1:k U:,1:kA T 2 = P F col(u :,1:k) a i (78) P col(ũ) a i = ŨŨT A 2 F (79). (80) The column space of A ŨŨT A is orthogonal to the column space of à and Ũ, so by Corollary 1.5 A à 2 = A ŨŨT A 2 + à ŨŨT A 2 (81) F F F A ŨŨT A 2 (82) F = A 2 F ŨŨT A also by Corollary 1.5 (83) 2 F A 2 F U:,1:k U T :,1:kA 2 F = A U:,1:k U T :,1:kA 2 F by (80) (84) again by Corollary 1.5. (85) 14
15 2.3 Matrix norms As we discussed in Lecture Notes 1, the inner-product norm in the vector space of matrices is the Frobenius norm. The following lemma establishes that the Frobenius norm of a matrix equals the l 2 norm of its singular values. Lemma For any matrix A R m n, with singular values σ 1,..., σ min{m,n} A F = min{m,n} σi 2. (86) Proof. Let us denote the SVD of A by USV T, A 2 F = tr ( A T A ) (87) = tr ( V SU T USV T ) by Lemma 2.5 in Lecture Notes 1 (88) = tr ( V SSV T ) because U T U = I (89) = tr ( V T V SS ) (90) = tr (SS) because V T V = I. (91) The operator norm quantifies how much a linear map can scale a vector in l 2 norm. Definition 2.12 (Operator norm). The operator norm of a linear map and of the corresponding matrix A R m n is defined by A := max { x 2 =1 x R n } A x 2. (92) By Theorem 2.7 (see equation (49)) the operator norm is equal to the l norm of the singular values, i.e. the largest one, is also a norm. Corollary For any matrix A R m n, with singular values σ 1,..., σ min{m,n} A := σ 1. (93) We end the section by defining an additional matrix norm, this time directly in term of the singular values. Definition 2.14 (Nuclear norm). The nuclear norm of a matrix A R m n is equal to the l 1 norm of its singular values σ 1,..., σ min{m,n} A := min{m,n} σ i. (94) 15
16 Any matrix norm that is a function of the singular values of a matrix is preserved after multiplication by an orthogonal matrix. This is a direct corollary of Lemma 2.6. Corollary For any matrix A R m n and any orthogonal matrices Ũ Rm m and Ṽ R n n the operator, Frobenius and nuclear norm of ŨA and AṼ are the same as those of A. The following theorem is analogous to Hölder s inequality for vectors. Theorem 2.16 (Proof in Section 5.3). For any matrix A R m n, A = sup A, B. (95) { B 1 B R m n } A direct consequence of the result is that the nuclear norm satisfies the triangle inequality. This implies that it is a norm, since it clearly satisfies the remaining properties. Corollary For any m n matrices A and B Proof. A + B = A + B A + B. (96) sup A + B, C (97) { C 1 C R m n } sup A, C + sup B, D (98) { C 1 C R m n } { D 1 D R m n } = A + B. (99) 2.4 Denoising via low-rank matrix estimation In this section we consider the problem of denoising a set of n m-dimensional signals x 1, x 2,..., x n R m. We model the noisy data as the sum between each signal and a noise vector y i = x i + z i, 1 i n. (100) Our first assumption is that the signals are similar, in the sense that they approximately span a low-dimensional subspace due to the correlations between them. If this is the case, then the matrix X := [ x 1 x 2 x n ] (101) obtained by stacking the signals as columns is approximately low rank. Note that in contrast to the subspace-projection denoising method described in Lecture Notes 1, we do not assume that the subspace is known. 16
17 Our second assumption is that the noise vectors are independent from each other, so that the noise matrix Z := [ ] z 1 z 2 z n (102) is full rank. If the noise is not too large with respect to the signals, under these assumptions a low-rank approximation to the data matrix Y := [ y 1 y 2 y n ] (103) = X + Z (104) should mostly suppress the noise and extract the component corresponding to the signals. Theorem 2.10 establishes that the best rank-k approximation to a matrix in Frobenius norm is achieved by truncating the SVD, for any value of k. Algorithm 2.18 (Denoising via SVD truncation). Given n noisy data vectors y 1, y 2,..., y n R m, we denoise the data by 1. Stacking the vectors as the columns of a matrix Y R m n. 2. Computing the SVD of Y = USV T. 3. Truncating the SVD to produce the low-rank estimate L for a fixed value of k min {m, n}. L := U :,1:k S 1:k,1:k V T :,1:k, (105) An important decision is what rank k to choose. Higher ranks yield more accurate approximations to the original signals than lower-rank approximations, but they do not suppress the noise component in the data as much. The following example illustrates this tradeoff. Example 2.19 (Denoising of digit images). In this example we use the MNIST data set 1 to illustrate image denoising using SVD truncation. The signals consist of images of the number 3. The images are corrupted by noise sampled independently from a Gaussian distribution and scaled so that the signal-to-noise ratio (defined as the ratio between the l 2 norms of the clean image and the noise) is 0.5 (there is more noise than signal!). Our assumption is that because of their similarities, the images interpreted as vectors in R 784 form a low-dimensional (but unknown subspace), whereas the noise is uncorrelated and therefore is not restricted to a subspace. This assumption holds: Figure 11 shows the singular values of matrix formed by stacking the clean images, the noisy images and the noise. We center each noisy image by subtracting the average of all the noisy images. Subtracting the average is a common preprocessing step in low-rank approximations (see Figure 5 for a geometric justification). We then apply SVD truncation to obtain a low-rank estimate of the image matrix. The noisy average is then added back to the images to produce the final estimate of the images. Figure 3 shows the results for rank-10 and rank-40 estimates. The lower-rank estimate suppresses the noise more, but does not approximate the original signals as effectively. 1 Available at 17




















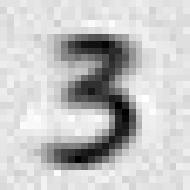









18 1,500 1,000 1,500 1,000 Data Signals Noise σi σi i i Figure 2: Plots of the singular values of the clean images, the noisy images and the noise in Example Signals Rank 40 approx. Rank 10 approx. Rank 40 est. Rank 10 est. Data Figure 3: The images show 9 examples from the 6131 images used in Example The top row shows the original clean images. The second and third rows show rank-40 and rank-10 approximations to the clean images. The fourth and fifth rows shows the results of applying SVD truncation to obtain rank-40 and rank-10 estimates respectively. The sixth row shows the noisy data. 18
19 2.5 Collaborative filtering The aim of collaborative filtering is to pool together information from many users to obtain a model of their behavior. To illustrate the use of low-rank models in this application we consider a toy example. Bob, Molly, Mary and Larry rate the following six movies from 1 to 5, A := Bob Molly Mary Larry The Dark Knight Spiderman Love Actually Bridget Jones s Diary Pretty Woman Superman 2 (106) A common assumption in collaborative filtering is that there are people that have similar tastes and hence produce similar ratings, and that there are movies that are similar and hence elicit similar reactions. Interestingly, this tends to induce low-rank structure in the matrix of ratings. To uncover this low-rank structure, we first subtract the average rating µ := 1 mn m A ij, (107) from each entry in the matrix to obtain a centered matrix C and then compute its singularvalue decomposition A µ 1 1 T = USV T = U V T. (108) where 1 R 4 is a vector of ones. The fact that the first singular value is significantly larger than the rest suggests that the matrix may be well approximated by a rank-1 matrix. This is indeed the case: Bob Molly Mary Larry 1.34 (1) 1.19 (1) 4.66 (5) 4.81 (4) The Dark Knight 1.55 (2) 1.42 (1) 4.45 (4) 4.58 (5) Spiderman 3 µ 1 1 T + σ 1 u 1 v 1 T = 4.45 (4) 4.58 (5) 1.55 (2) 1.42 (1) Love Actually 4.43 (5) 4.56 (4) 1.57 (2) 1.44 (1) Bridget Jones s Diary 4.43 (4) 4.56 (5) 1.57 (1) 1.44 (2) Pretty Woman 1.34 (1) 1.19 (2) 4.66 (5) 4.81 (5) Superman 2 j=1 (109) 19
20 For ease of comparison the values of A are shown in brackets. The first left singular vector is equal to u 1 := D. Knight Spiderman 3 Love Act. B.J. s Diary P. Woman Superman 2 ( ). This vector allows us to cluster the movies: movies with negative entries are similar (in this case they correspond to action movies) and movies with positive entries are similar (in this case they are romantic movies). The first right singular vector is equal to v 1 = Bob Molly Mary Larry ( ). (110) This vector allows to cluster the users: negative entries indicate users that like action movies but hate romantic movies (Bob and Molly), whereas positive entries indicate the contrary (Mary and Larry). For larger data sets, the model generalizes to a rank-k approximation, which approximates each ranking by a sum of k terms rating (movie i, user j) = k σ l u l [i] v l [j]. (111) l=1 The singular vectors cluster users and movies in different ways, whereas the singular values weight the importance of the different factors. 3 Principal component analysis In Lecture Notes 1 we introduced the sample variance of a set of one-dimensional data, which measures the variation of measurements in a one-dimensional data set, as well as the sample covariance, which measures the joint fluctuations of two features. We now consider data sets where each example contains m features, and can therefore be interpreted as a vector in an m-dimensional ambient space. We are interested in analyzing the variation of the data in different directions of this space. 3.1 Sample covariance matrix The sample covariance matrix of a data set contains the pairwise sample covariance between every pair of features in a data set. If the data are sampled from a multivariate distribution, then the sample covariance matrix can be interpreted as an estimate of the covariance matrix (see Section 3.3). 20
21 Definition 3.1 (Sample covariance matrix). Let { x 1, x 2,..., x n } be a set of m-dimensional real-valued data vectors, where each dimension corresponds to a different feature. The sample covariance matrix of these vectors is the m m matrix Σ ( x 1,..., x n ) := 1 n 1 ( x i av ( x 1,..., x n )) ( x i av ( x 1,..., x n )) T, (112) where the center or average is defined as av ( x 1, x 2,..., x n ) := 1 n x i (113) contains the sample mean of each feature. The (i, j) entry of the covariance matrix, where 1 i, j d, is given by { var ( x 1 [i],..., x n [i]) if i = j, Σ ( x 1,..., x n ) ij = (114) cov (( x 1 [i], x 1 [j]),..., ( x n [i], x n [j])) if i j. In order to characterize the variation of a multidimensional data set around its center, we consider its variation in different directions. The average variation of the data in a certain direction is quantified by the sample variance of the projections of the data onto that direction. Let d R m be a unit-norm vector aligned with a direction of interest, the sample variance of the data set in the direction of d is given by ( var d T x 1,..., d ) T x n = 1 n 1 = 1 n 1 ( = d T 1 n 1 ( ( d T x i av d T x 1,..., d )) 2 T x n (115) ( ) 2 d T ( x i av ( x 1,..., x n )) (116) ) ( x i av ( x 1,..., x n )) ( x i av ( x 1,..., x n )) T d = d T Σ ( x 1,..., x n ) d. (117) Using the sample covariance matrix we can express the variation in every direction! This is a deterministic analog of the fact that the covariance matrix of a random vector encodes its variance in every direction. 3.2 Principal component analysis Principal-component analysis is a popular tool for data analysis, which consists of computing the singular-value decomposition of a set of vectors grouped as the columns of a matrix. 21
22 σ 1 / n 1 = 0.705, σ 2 / n 1 = σ 1 / n 1 = 0.983, σ 2 / n 1 = σ 1 / n 1 = 1.349, σ 2 / n 1 = u 1 u 1 u 1 u 2 v Figure 4: PCA of a dataset with n = 100 2D vectors with different configurations. The two first singular values reflect how much energy is preserved by projecting onto the two first principal directions. u 2 u 2 Algorithm 3.2 (Principal component analysis). Given n data vectors x 1, x 2,..., x n R d, we apply the following steps. 1. Center the data, c i = x i av ( x 1, x 2,..., x n ), 1 i n. (118) 2. Group the centered data as columns of a matrix C = [ c 1 c 2 c n ]. (119) 3. Compute the SVD of C. The left singular vectors are the principal directions. The principal values are the coefficients of the centered vectors when expressed in the basis of principal directions. The sample covariance matrix can be expressed in terms of the centered data matrix C Σ ( x 1,..., x n ) = 1 n 1 CCT. (120) This implies that by Theorem 2.7 the principal directions reveal the directions of maximum variation of the data. Corollary 3.3. Let u 1,..., u k be the k min {m, n} first principal directions obtained by applying Algorithm 3.2 to a set of vectors x 1,..., x n R m. Then the principal directions satisfy u 1 = u i = ( arg max var d T x 1,..., ) d T x n, (121) { d =1 d R n 2 } arg max var { d =1 d R n, d u 1,..., u 2 i 1} ( d T x 1,..., d T x n ), 2 i k, (122) 22
23 σ 1 / n 1 = σ 1 / n 1 = σ 2 / n 1 = σ 2 / n 1 = u 2 u 1 u 2 u 1 Uncentered data Centered data Figure 5: PCA applied to n = 100 2D data points. On the left the data are not centered. As a result the dominant principal direction u 1 lies in the direction of the mean of the data and PCA does not reflect the actual structure. Once we center, u 1 becomes aligned with the direction of maximal variation. and the associated singular values satisfy σ 1 n 1 = σ i n 1 = max { d =1 d R n 2 } std max { d std =1 d R n, d u 1,..., u 2 i 1} ( d T x 1,..., d T x n ), (123) ( d T x 1,..., d T x n ), 2 i k. (124) Proof. For any vector d ( var d T x 1,..., d ) T x n = d T Σ ( x 1,..., x n ) d (125) so the result follows from Theorem 2.7 applied to C. = 1 d n 1 T CC T d (126) = 1 C T 2 d, (127) n 1 2 In words, u 1 is the direction of maximum variation, u 2 is the direction of maximum variation orthogonal to u 1, and in general u i is the direction of maximum variation that is orthogonal to u 1, u 2,..., u i 1. Figure 4 shows the principal directions for several 2D examples. Figure 5 illustrates the importance of centering, i.e., subtracting the sample mean of each feature, before applying PCA. Theorem 2.7 still holds if the data are not centered. 23












24 Center PD 1 PD 2 PD 3 PD 4 PD 5 σ i / n PD 10 PD 15 PD 20 PD 30 PD 40 PD PD 100 PD 150 PD 200 PD 250 PD 300 PD Figure 6: Average and principal directions (PD) of the faces data set in Example 3.4, along with their associated singular values. However, the norm of the projection onto a certain direction no longer reflects the variation of the data. In fact, if the data are concentrated around a point that is far from the origin, the first principal direction tends be aligned with that point. This makes sense as projecting onto that direction captures more energy. As a result, the principal directions do not reflect the directions of maximum variation within the cloud of data. Centering the data set before applying PCA solves the issue. In the following example, we apply PCA to a set of images. Example 3.4 (PCA of faces). In this example we consider the Olivetti Faces data set, which we described in Lecture Notes 1. We apply Algorithm 3.2 to a data set of images taken from 40 different subjects (10 per subject). We vectorize each image so that each pixel is interpreted as a different feature. Figure 6 shows the center of the data and several principal directions, together with their associated singular values. The principal directions corresponding to the larger singular values seem to capture low-resolution structure, whereas the ones corresponding to the smallest singular values incorporate more intricate details. 24




25 Center PD 1 PD 2 PD 3 = PD 4 PD 5 PD 6 PD 7 Figure 7: Projection of one of the faces x onto the first 7 principal directions and the corresponding decomposition into the 7 first principal components. Signal 5 PDs 10 PDs 20 PDs 30 PDs 50 PDs 100 PDs 150 PDs 200 PDs 250 PDs 300 PDs 359 PDs Figure 8: Projection of a face on different numbers of principal directions. Figure 7 shows the projection of one of the faces onto the first 7 principal directions and the corresponding decomposition into its 7 first principal components. Figure 8 shows the projection of the same face onto increasing numbers of principal directions. As suggested by the visualization of the principal directions in Figure 6, the lower-dimensional projections produce blurry images. 3.3 Probabilistic interpretation To provide a probabilistic interpretation of PCA, we first review some background on covariance matrices. The covariance matrix of a random vector captures the interaction between the components of the vector. It contains the variance of each component in the 25
26 diagonal and the covariances between different components in the off diagonals. Definition 3.5. The covariance matrix of a random vector x is defined as Var ( x [1]) Cov ( x [1], x [2]) Cov ( x [1], x [n]) Cov ( x [2], x [1]) Var ( x [2]) Cov ( x [2], x [n]) Σ x := Cov ( x [n], x [1]) Cov ( x [n], x [2]) Var ( x [n]) (128) = E ( x x T ) E( x)e( x) T. (129) Note that if all the entries of a vector are uncorrelated, then its covariance matrix is diagonal. Using linearity of expectation, we obtain a simple expression for the covariance matrix of the linear transformation of a random vector. Theorem 3.6 (Covariance matrix after a linear transformation). Let x be a random vector of dimension n with covariance matrix Σ. For any matrix A R m n, Σ A x = AΣ x A T. (130) Proof. By linearity of expectation ( ) Σ A x = E (A x) (A x) T E (A x) E (A x) T (131) = A ( E ( x x T ) E( x)e( x) T ) A T (132) = AΣ x A T. (133) An immediate corollary of this result is that we can easily decode the variance of the random vector in any direction from the covariance matrix. Mathematically, the variance of the random vector in the direction of a unit vector v is equal to the variance of its projection onto v. Corollary 3.7. Let v be a unit-l 2 -norm vector, Var ( v T x ) = v T Σ x v. (134) Consider the SVD of the covariance matrix of an n-dimensional random vector X Σ x = UΛU T (135) σ = [ ] u 1 u 2 u n 0 σ 2 0 [ ] T u1 u 2 u n. (136) 0 0 σ n Covariance matrices are symmetric by definition, so by Theorem 4.3 the eigenvectors u 1, u 2,..., u n can be chosen to be orthogonal. These singular vectors and singular values completely characterize the variance of the random vector in different directions. The theorem is a direct consequence of Corollary 3.7 and Theorem
27 σ1 = 1.22, σ 2 = 0.71 σ1 = 1, σ 2 = 1 σ1 = 1.38, σ 2 = 0.32 Figure 9: Samples from bivariate Gaussian random vectors with different covariance matrices are shown in gray. The eigenvectors of the covariance matrices are plotted in red. Each is scaled by the square roof of the corresponding singular value σ 1 or σ 2. Theorem 3.8. Let x be a random vector of dimension n with covariance matrix Σ x. The SVD of Σ x given by (136) satisfies σ 1 = max Var ( v T x ), (137) v 2 =1 u 1 = arg max v 2 =1 Var ( v T x ), (138) σ k = max v 2 =1, v u 1,..., u k 1 Var ( v T x ), (139) u k = arg max Var ( v T x ). (140) v 2 =1, v u 1,..., u k 1 In words, u 1 is the direction of maximum variance. The second singular vector u 2 is the direction of maximum variation that is orthogonal to u 1. In general, the eigenvector u k reveals the direction of maximum variation that is orthogonal to u 1, u 2,..., u k 1. Finally, u n is the direction of minimum variance. Figure 9 illustrates this with an example, where n = 2. The sample variance and covariance are consistent estimators of the variance and covariance respectively, under certain assumptions on the higher moments of the underlying distributions. This provides an intuitive interpretation for principal component analysis under the assumption that the data are realizations of an iid sequence of random vectors: the principal components approximate the eigenvectors of the true covariance matrix, and hence the directions of maximum variance of the multidimensional distribution. Figure 10 illustrates this with a numerical example, where the principal directions indeed converge to the singular vectors as the number of data increases. 27
28 n = 5 n = 20 n = 100 True covariance Sample covariance Figure 10: Principal directions of n samples from a bivariate Gaussian distribution (red) compared to the eigenvectors of the covariance matrix of the distribution (black). 3.4 Dimensionality reduction via PCA Data containing a large number of features can be difficult to analyze or process. Dimensionality reduction is a useful preprocessing step for many data-analysis tasks, which consists of representing the data with a smaller number of variables. For data modeled as vectors in an ambient space R m where each dimension corresponds to a feature, this can be achieved by projecting the vectors onto a lower-dimensional space R k, where k < m. If the projection is orthogonal, the new representation can be computed using an orthogonal basis for the lower-dimensional subspace b 1, b 2,..., b k : each data vector x R m is described using the coefficients of its representation in the basis: b 1, x, b 2, x,..., b k, x. Given a data set of n vectors x 1, x 2,..., x n R m, the first k principal directions span the subspace that preserves the most energy (measured in l 2 norm) in the centered data among all possible k-dimensional orthogonal projections by Theorem 2.8. This motivates the application of PCA for dimensionality reduction. Example 3.9 (Nearest neighbors in principal-component space). The nearest neighbors algorithm for classification (Algorithm 4.2 in Lecture Notes 1) requires computing n distances in an m-dimensional space (where m is the number of features) to classify each new example. The computational cost is O (nm), so if we need to classify p points the total cost is O (nmp). If we project each of the points onto a lower-dimensional space k computed via PCA before classifying them, then the computational cost is: O (mn min {m, n}) to compute the principal directions from the training data. kmn operations to project the training data onto the first k principal directions. kmp operations to project each point in the test set onto the first k principal directions. knp to perform nearest-neighbor classification in the lower-dimensional space. 28









29 30 Errors Number of principal components Figure 11: Errors for nearest-neighbor classification combined with PCA-based dimensionality reduction for different dimensions. Test image Projection Closest projection Corresponding image Figure 12: Results of nearest-neighbor classification combined with PCA-based dimensionality reduction of order 41 for four of the people in Example 3.9. The assignments of the first three examples are correct, but the fourth is wrong. 29
30 2.0 First two PCs 2.0 Last two PCs Projection onto second PC Projection onto dth PC Projection onto first PC Projection onto (d-1)th PC Figure 13: Projection of 7-dimensional vectors describing different wheat seeds onto the first two (left) and the last two (right) principal dimensions of the data set. Each color represents a variety of wheat. If we have to classify a large number of points (i.e. p max {m, n}) the computational cost is reduced by operating in the lower-dimensional space. Figure 11 shows the accuracy of the algorithm on the same data as Example 4.3 in Lecture Notes 1. The accuracy increases with the dimension at which the algorithm operates. This is not necessarily always the case because projections may actually be helpful for tasks such as classification (for example, factoring out small shifts and deformations). The same precision as in the ambient dimension (4 errors out of 40 test images) is achieved using just k = 41 principal components (in this example n = 360 and m = 4096). Figure 12 shows some examples of the projected data represented in the original m-dimensional space along with their nearest neighbors in the k-dimensional space. Example 3.10 (Dimensionality reduction for visualization). Dimensionality reduction is often useful for visualization. The objective is to project the data onto 2D or 3D in a way that preserves its structure as much as possible. In this example, we consider a data set where each data point corresponds to a seed with seven features: area, perimeter, compactness, length of kernel, width of kernel, asymmetry coefficient and length of kernel groove. The seeds belong to three different varieties of wheat: Kama, Rosa and Canadian. 2 To visualize the data in 2D, we project each point onto the two first principal dimensions of the data set. Figure 13 shows the projection of the data onto the first two and the last two principal directions. In the latter case, there is almost no discernible variation. As predicted by our theoretical analysis of PCA, the structure in the data is much better conserved by the two first directions, which allow to clearly visualize the difference between the three types of seeds. Note however that projection onto the first principal directions only ensures 2 The data can be found at 30
31 x 1,..., x n U T x 1,..., U T x n S 1 U T x 1,..., S 1 U T x n Figure 14: Effect of whitening a set of data. The original data are dominated by a linear skew (left). Applying U T aligns the axes with the eigenvectors of the sample covariance matrix (center). Finally, S 1 reweights the data along those axes so that they have the same average variation, revealing the nonlinear structure that was obscured by the linear skew (right). that we preserve as much variation as possible, but it does not necessarily preserve useful features for tasks such as clustering or classification. 3.5 Whitening The principal directions in a data set do not necessarily capture the most useful features for certain tasks. For instance, in the case of the faces data set in Example 3.4 the principal directions correspond to low-resolution images, so that the corresponding principal components capture low-resolution features. These features do not include important information contained in fine-scale details, which could be useful for tasks such as classification. Whitening is a preprocessing technique that reweights the principal components of every vector so every principal dimension has the same contribution. Algorithm 3.11 (Whitening). Given n data vectors x 1, x 2,..., x n R d, we apply the following steps. 1. Center the data, c i = x i av ( x 1, x 2,..., x n ), 1 i n. (141) 2. Group the centered data as columns of a matrix 3. Compute the SVD of C = USV T. C = [ c 1 c 2 c n ]. (142) 4. Whiten each centered vector by applying the linear map US 1 U T w i := US 1 U T c i. (143) 31



 j=1 1 σ j u j, c i u j.")

 The covariance matrix of the whitened")
 = 1 n 1 W W T (146) = 1 n 1 US 1 U")
 = 1 I, (149) n 1 This")




32 x US 1 U T x Figure 15: Centered faces in the data set from Example 3.4 before and after whitening. The linear map US 1 U T scales the components of the centered vector in each principal direction by a factor inversely proportional to its corresponding singular value, w i := min(m,n) j=1 1 σ j u j, c i u j. (144) If we group the whitened vectors as columns of a matrix, the matrix can be expressed as W = US 1 U T C. (145) The covariance matrix of the whitened data is proportional to the identity Σ ( c 1,..., c n ) = 1 n 1 W W T (146) = 1 n 1 US 1 U T CC T US 1 U T (147) = 1 n 1 US 1 U T USV T V SU T US 1 U T (148) = 1 I, (149) n 1 This means that the whitened data have no linear skews, there are no directions in space that contain more variation than others. As illustrated in Figure 14, this may reveal nonlinear structure in the data. Figure 15 shows some of the centered faces in the data set from Example 3.4 before and after whitening. Whitening enhances fine-detail features of the faces. 4 Eigendecomposition An eigenvector q of a square matrix A R n n satisfies A q = λ q (150) 32
33 for a scalar λ which is the corresponding eigenvalue. Even if A is real, its eigenvectors and eigenvalues can be complex. If a matrix has n linearly independent eigenvectors then it is diagonalizable. Lemma 4.1 (Eigendecomposition). If a square matrix A R n n has n linearly independent eigenvectors q 1,..., q n with eigenvalues λ 1,..., λ n it can be expressed in terms of a matrix Q, whose columns are the eigenvectors, and a diagonal matrix containing the eigenvalues, λ A = [ ] q 1 q 2 q n 0 λ λ n [ q1 q 2 q n ] 1 (151) = QΛQ 1 (152) Proof. AQ = [ ] A q 1 A q 2 A q n (153) = [ ] λ 1 q 1 λ 2 q 2 λ 2 q n (154) = QΛ. (155) If the columns of a square matrix are all linearly independent, then the matrix has an inverse, so multiplying the expression by Q 1 on both sides completes the proof. Lemma 4.2. Not all matrices have an eigendecomposition. Proof. Consider the matrix [ ] 0 1. (156) 0 0 Assume an eigenvector q associated to an eigenvalue λ, then [ ] [ ] [ ] [ ] q [2] 0 1 q [1] λ q [1] = =, (157) q [2] λ q [2] which implies that q [2] = 0 and q [1] = 0, so the matrix does not have eigenvectors associated to nonzero eigenvalues. Symmetric matrices are always diagonalizable. Theorem 4.3 (Spectral theorem for symmetric matrices). If A R n is symmetric, then it has an eigendecomposition of the form where the matrix of eigenvectors U is an orthogonal matrix. A = UΛU T (158) 33
The Singular-Value Decomposition
 Mathematical Tools for Data Science Spring 2019 1 Motivation The Singular-Value Decomposition The singular-value decomposition (SVD) is a fundamental tool in linear algebra. In this section, we introduce
Mathematical Tools for Data Science Spring 2019 1 Motivation The Singular-Value Decomposition The singular-value decomposition (SVD) is a fundamental tool in linear algebra. In this section, we introduce
Lecture Notes 1: Vector spaces
 Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
DS-GA 1002 Lecture notes 10 November 23, Linear models
 DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
Vector spaces. DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis.
 Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
DS-GA 1002 Lecture notes 0 Fall Linear Algebra. These notes provide a review of basic concepts in linear algebra.
 DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
Descriptive Statistics
 Descriptive Statistics DS GA 1002 Probability and Statistics for Data Science http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall17 Carlos Fernandez-Granda Descriptive statistics Techniques to visualize
Descriptive Statistics DS GA 1002 Probability and Statistics for Data Science http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall17 Carlos Fernandez-Granda Descriptive statistics Techniques to visualize
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Learning representations
 Learning representations Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 4/11/2016 General problem For a dataset of n signals X := [ x 1 x
Learning representations Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 4/11/2016 General problem For a dataset of n signals X := [ x 1 x
Statistical Data Analysis
 DS-GA 0 Lecture notes 8 Fall 016 1 Descriptive statistics Statistical Data Analysis In this section we consider the problem of analyzing a set of data. We describe several techniques for visualizing the
DS-GA 0 Lecture notes 8 Fall 016 1 Descriptive statistics Statistical Data Analysis In this section we consider the problem of analyzing a set of data. We describe several techniques for visualizing the
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Lecture Notes 10: Matrix Factorization
 Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
Lecture 2: Linear Algebra Review
 EE 227A: Convex Optimization and Applications January 19 Lecture 2: Linear Algebra Review Lecturer: Mert Pilanci Reading assignment: Appendix C of BV. Sections 2-6 of the web textbook 1 2.1 Vectors 2.1.1
EE 227A: Convex Optimization and Applications January 19 Lecture 2: Linear Algebra Review Lecturer: Mert Pilanci Reading assignment: Appendix C of BV. Sections 2-6 of the web textbook 1 2.1 Vectors 2.1.1
Designing Information Devices and Systems II
 EECS 16B Fall 2016 Designing Information Devices and Systems II Linear Algebra Notes Introduction In this set of notes, we will derive the linear least squares equation, study the properties symmetric
EECS 16B Fall 2016 Designing Information Devices and Systems II Linear Algebra Notes Introduction In this set of notes, we will derive the linear least squares equation, study the properties symmetric
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Review of some mathematical tools
 MATHEMATICAL FOUNDATIONS OF SIGNAL PROCESSING Fall 2016 Benjamín Béjar Haro, Mihailo Kolundžija, Reza Parhizkar, Adam Scholefield Teaching assistants: Golnoosh Elhami, Hanjie Pan Review of some mathematical
MATHEMATICAL FOUNDATIONS OF SIGNAL PROCESSING Fall 2016 Benjamín Béjar Haro, Mihailo Kolundžija, Reza Parhizkar, Adam Scholefield Teaching assistants: Golnoosh Elhami, Hanjie Pan Review of some mathematical
The Singular Value Decomposition
 The Singular Value Decomposition Philippe B. Laval KSU Fall 2015 Philippe B. Laval (KSU) SVD Fall 2015 1 / 13 Review of Key Concepts We review some key definitions and results about matrices that will
The Singular Value Decomposition Philippe B. Laval KSU Fall 2015 Philippe B. Laval (KSU) SVD Fall 2015 1 / 13 Review of Key Concepts We review some key definitions and results about matrices that will
Lecture 8. Principal Component Analysis. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 13, 2016
 Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
7 Principal Component Analysis
 7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
Review of Linear Algebra
 Review of Linear Algebra Definitions An m n (read "m by n") matrix, is a rectangular array of entries, where m is the number of rows and n the number of columns. 2 Definitions (Con t) A is square if m=
Review of Linear Algebra Definitions An m n (read "m by n") matrix, is a rectangular array of entries, where m is the number of rows and n the number of columns. 2 Definitions (Con t) A is square if m=
Lecture Notes 5: Multiresolution Analysis
 Optimization-based data analysis Fall 2017 Lecture Notes 5: Multiresolution Analysis 1 Frames A frame is a generalization of an orthonormal basis. The inner products between the vectors in a frame and
Optimization-based data analysis Fall 2017 Lecture Notes 5: Multiresolution Analysis 1 Frames A frame is a generalization of an orthonormal basis. The inner products between the vectors in a frame and
Linear Algebra Massoud Malek
 CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Singular Value Decomposition
 Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Chapter 3 Transformations
 Chapter 3 Transformations An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Linear Transformations A function is called a linear transformation if 1. for every and 2. for every If we fix the bases
Chapter 3 Transformations An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Linear Transformations A function is called a linear transformation if 1. for every and 2. for every If we fix the bases
Basic Elements of Linear Algebra
 A Basic Review of Linear Algebra Nick West nickwest@stanfordedu September 16, 2010 Part I Basic Elements of Linear Algebra Although the subject of linear algebra is much broader than just vectors and matrices,
A Basic Review of Linear Algebra Nick West nickwest@stanfordedu September 16, 2010 Part I Basic Elements of Linear Algebra Although the subject of linear algebra is much broader than just vectors and matrices,
SUMMARY OF MATH 1600
 SUMMARY OF MATH 1600 Note: The following list is intended as a study guide for the final exam. It is a continuation of the study guide for the midterm. It does not claim to be a comprehensive list. You
SUMMARY OF MATH 1600 Note: The following list is intended as a study guide for the final exam. It is a continuation of the study guide for the midterm. It does not claim to be a comprehensive list. You
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T. KEMP)
") MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
Singular Value Decomposition and Principal Component Analysis (PCA) I
 I") Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Linear Models. DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis.
 Linear Models DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Linear regression Least-squares estimation
Linear Models DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Linear regression Least-squares estimation
Linear Algebra Review. Vectors
 Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
Elementary linear algebra
 Chapter 1 Elementary linear algebra 1.1 Vector spaces Vector spaces owe their importance to the fact that so many models arising in the solutions of specific problems turn out to be vector spaces. The
Chapter 1 Elementary linear algebra 1.1 Vector spaces Vector spaces owe their importance to the fact that so many models arising in the solutions of specific problems turn out to be vector spaces. The
Math 350 Fall 2011 Notes about inner product spaces. In this notes we state and prove some important properties of inner product spaces.
 Math 350 Fall 2011 Notes about inner product spaces In this notes we state and prove some important properties of inner product spaces. First, recall the dot product on R n : if x, y R n, say x = (x 1,...,
Math 350 Fall 2011 Notes about inner product spaces In this notes we state and prove some important properties of inner product spaces. First, recall the dot product on R n : if x, y R n, say x = (x 1,...,
Machine Learning. B. Unsupervised Learning B.2 Dimensionality Reduction. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
The Singular Value Decomposition
 The Singular Value Decomposition An Important topic in NLA Radu Tiberiu Trîmbiţaş Babeş-Bolyai University February 23, 2009 Radu Tiberiu Trîmbiţaş ( Babeş-Bolyai University)The Singular Value Decomposition
The Singular Value Decomposition An Important topic in NLA Radu Tiberiu Trîmbiţaş Babeş-Bolyai University February 23, 2009 Radu Tiberiu Trîmbiţaş ( Babeş-Bolyai University)The Singular Value Decomposition
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
MATH 240 Spring, Chapter 1: Linear Equations and Matrices
 MATH 240 Spring, 2006 Chapter Summaries for Kolman / Hill, Elementary Linear Algebra, 8th Ed. Sections 1.1 1.6, 2.1 2.2, 3.2 3.8, 4.3 4.5, 5.1 5.3, 5.5, 6.1 6.5, 7.1 7.2, 7.4 DEFINITIONS Chapter 1: Linear
MATH 240 Spring, 2006 Chapter Summaries for Kolman / Hill, Elementary Linear Algebra, 8th Ed. Sections 1.1 1.6, 2.1 2.2, 3.2 3.8, 4.3 4.5, 5.1 5.3, 5.5, 6.1 6.5, 7.1 7.2, 7.4 DEFINITIONS Chapter 1: Linear
Vectors To begin, let us describe an element of the state space as a point with numerical coordinates, that is x 1. x 2. x =
 Linear Algebra Review Vectors To begin, let us describe an element of the state space as a point with numerical coordinates, that is x 1 x x = 2. x n Vectors of up to three dimensions are easy to diagram.
Linear Algebra Review Vectors To begin, let us describe an element of the state space as a point with numerical coordinates, that is x 1 x x = 2. x n Vectors of up to three dimensions are easy to diagram.
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Recall the convention that, for us, all vectors are column vectors.
 Some linear algebra Recall the convention that, for us, all vectors are column vectors. 1. Symmetric matrices Let A be a real matrix. Recall that a complex number λ is an eigenvalue of A if there exists
Some linear algebra Recall the convention that, for us, all vectors are column vectors. 1. Symmetric matrices Let A be a real matrix. Recall that a complex number λ is an eigenvalue of A if there exists
Chapter 4 Euclid Space
 Chapter 4 Euclid Space Inner Product Spaces Definition.. Let V be a real vector space over IR. A real inner product on V is a real valued function on V V, denoted by (, ), which satisfies () (x, y) = (y,
Chapter 4 Euclid Space Inner Product Spaces Definition.. Let V be a real vector space over IR. A real inner product on V is a real valued function on V V, denoted by (, ), which satisfies () (x, y) = (y,
Chapter 6: Orthogonality
 Chapter 6: Orthogonality (Last Updated: November 7, 7) These notes are derived primarily from Linear Algebra and its applications by David Lay (4ed). A few theorems have been moved around.. Inner products
Chapter 6: Orthogonality (Last Updated: November 7, 7) These notes are derived primarily from Linear Algebra and its applications by David Lay (4ed). A few theorems have been moved around.. Inner products
Lecture 3: Review of Linear Algebra
 ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
7. Dimension and Structure.
 7. Dimension and Structure 7.1. Basis and Dimension Bases for Subspaces Example 2 The standard unit vectors e 1, e 2,, e n are linearly independent, for if we write (2) in component form, then we obtain
7. Dimension and Structure 7.1. Basis and Dimension Bases for Subspaces Example 2 The standard unit vectors e 1, e 2,, e n are linearly independent, for if we write (2) in component form, then we obtain
Math 102, Winter Final Exam Review. Chapter 1. Matrices and Gaussian Elimination
 Math 0, Winter 07 Final Exam Review Chapter. Matrices and Gaussian Elimination { x + x =,. Different forms of a system of linear equations. Example: The x + 4x = 4. [ ] [ ] [ ] vector form (or the column
Math 0, Winter 07 Final Exam Review Chapter. Matrices and Gaussian Elimination { x + x =,. Different forms of a system of linear equations. Example: The x + 4x = 4. [ ] [ ] [ ] vector form (or the column
Lecture 3: Review of Linear Algebra
 ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak, scribe: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters,
ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak, scribe: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters,
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Introduction to Numerical Linear Algebra II
 Introduction to Numerical Linear Algebra II Petros Drineas These slides were prepared by Ilse Ipsen for the 2015 Gene Golub SIAM Summer School on RandNLA 1 / 49 Overview We will cover this material in
Introduction to Numerical Linear Algebra II Petros Drineas These slides were prepared by Ilse Ipsen for the 2015 Gene Golub SIAM Summer School on RandNLA 1 / 49 Overview We will cover this material in
Lecture Summaries for Linear Algebra M51A
 These lecture summaries may also be viewed online by clicking the L icon at the top right of any lecture screen. Lecture Summaries for Linear Algebra M51A refers to the section in the textbook. Lecture
These lecture summaries may also be viewed online by clicking the L icon at the top right of any lecture screen. Lecture Summaries for Linear Algebra M51A refers to the section in the textbook. Lecture
Review problems for MA 54, Fall 2004.
 Review problems for MA 54, Fall 2004. Below are the review problems for the final. They are mostly homework problems, or very similar. If you are comfortable doing these problems, you should be fine on
Review problems for MA 54, Fall 2004. Below are the review problems for the final. They are mostly homework problems, or very similar. If you are comfortable doing these problems, you should be fine on
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
1. General Vector Spaces
 1.1. Vector space axioms. 1. General Vector Spaces Definition 1.1. Let V be a nonempty set of objects on which the operations of addition and scalar multiplication are defined. By addition we mean a rule
1.1. Vector space axioms. 1. General Vector Spaces Definition 1.1. Let V be a nonempty set of objects on which the operations of addition and scalar multiplication are defined. By addition we mean a rule
b 1 b 2.. b = b m A = [a 1,a 2,...,a n ] where a 1,j a 2,j a j = a m,j Let A R m n and x 1 x 2 x = x n
![b 1 b 2.. b = b m A = [a 1,a 2,...,a n ] where a 1,j a 2,j a j = a m,j Let A R m n and x 1 x 2 x = x n](/thumbs/90/102651734.jpg "b 1 b 2.. b = b m A = [a 1,a 2,...,a n ] where a 1,j a 2,j a j = a m,j Let A R m n and x 1 x 2 x = x n") Lectures -2: Linear Algebra Background Almost all linear and nonlinear problems in scientific computation require the use of linear algebra These lectures review basic concepts in a way that has proven
Lectures -2: Linear Algebra Background Almost all linear and nonlinear problems in scientific computation require the use of linear algebra These lectures review basic concepts in a way that has proven
Glossary of Linear Algebra Terms. Prepared by Vince Zaccone For Campus Learning Assistance Services at UCSB
 Glossary of Linear Algebra Terms Basis (for a subspace) A linearly independent set of vectors that spans the space Basic Variable A variable in a linear system that corresponds to a pivot column in the
Glossary of Linear Algebra Terms Basis (for a subspace) A linearly independent set of vectors that spans the space Basic Variable A variable in a linear system that corresponds to a pivot column in the
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Lecture 1: Review of linear algebra
 Lecture 1: Review of linear algebra Linear functions and linearization Inverse matrix, least-squares and least-norm solutions Subspaces, basis, and dimension Change of basis and similarity transformations
Lecture 1: Review of linear algebra Linear functions and linearization Inverse matrix, least-squares and least-norm solutions Subspaces, basis, and dimension Change of basis and similarity transformations
. = V c = V [x]v (5.1) c 1. c k
![. = V c = V [x]v (5.1) c 1. c k](/thumbs/90/101201642.jpg ". = V c = V [x]v (5.1) c 1. c k") Chapter 5 Linear Algebra It can be argued that all of linear algebra can be understood using the four fundamental subspaces associated with a matrix Because they form the foundation on which we later work,
Chapter 5 Linear Algebra It can be argued that all of linear algebra can be understood using the four fundamental subspaces associated with a matrix Because they form the foundation on which we later work,
Lecture 24: Principal Component Analysis. Aykut Erdem May 2016 Hacettepe University
 Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Applied Mathematics 205. Unit II: Numerical Linear Algebra. Lecturer: Dr. David Knezevic
 Applied Mathematics 205 Unit II: Numerical Linear Algebra Lecturer: Dr. David Knezevic Unit II: Numerical Linear Algebra Chapter II.3: QR Factorization, SVD 2 / 66 QR Factorization 3 / 66 QR Factorization
Applied Mathematics 205 Unit II: Numerical Linear Algebra Lecturer: Dr. David Knezevic Unit II: Numerical Linear Algebra Chapter II.3: QR Factorization, SVD 2 / 66 QR Factorization 3 / 66 QR Factorization
Stat 159/259: Linear Algebra Notes
 Stat 159/259: Linear Algebra Notes Jarrod Millman November 16, 2015 Abstract These notes assume you ve taken a semester of undergraduate linear algebra. In particular, I assume you are familiar with the
Stat 159/259: Linear Algebra Notes Jarrod Millman November 16, 2015 Abstract These notes assume you ve taken a semester of undergraduate linear algebra. In particular, I assume you are familiar with the
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 1: Course Overview & Matrix-Vector Multiplication Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 20 Outline 1 Course
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 1: Course Overview & Matrix-Vector Multiplication Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 20 Outline 1 Course
Quantum Computing Lecture 2. Review of Linear Algebra
 Quantum Computing Lecture 2 Review of Linear Algebra Maris Ozols Linear algebra States of a quantum system form a vector space and their transformations are described by linear operators Vector spaces
Quantum Computing Lecture 2 Review of Linear Algebra Maris Ozols Linear algebra States of a quantum system form a vector space and their transformations are described by linear operators Vector spaces
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
EE731 Lecture Notes: Matrix Computations for Signal Processing
 EE731 Lecture Notes: Matrix Computations for Signal Processing James P. Reilly c Department of Electrical and Computer Engineering McMaster University September 22, 2005 0 Preface This collection of ten
EE731 Lecture Notes: Matrix Computations for Signal Processing James P. Reilly c Department of Electrical and Computer Engineering McMaster University September 22, 2005 0 Preface This collection of ten
Mathematical foundations - linear algebra
 Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
Ir O D = D = ( ) Section 2.6 Example 1. (Bottom of page 119) dim(v ) = dim(l(v, W )) = dim(v ) dim(f ) = dim(v )
 Section 2.6 Example 1. (Bottom of page 119) dim(v ) = dim(l(v, W )) = dim(v ) dim(f ) = dim(v )") Section 3.2 Theorem 3.6. Let A be an m n matrix of rank r. Then r m, r n, and, by means of a finite number of elementary row and column operations, A can be transformed into the matrix ( ) Ir O D = 1 O
Section 3.2 Theorem 3.6. Let A be an m n matrix of rank r. Then r m, r n, and, by means of a finite number of elementary row and column operations, A can be transformed into the matrix ( ) Ir O D = 1 O
Math 291-2: Lecture Notes Northwestern University, Winter 2016
 Math 291-2: Lecture Notes Northwestern University, Winter 2016 Written by Santiago Cañez These are lecture notes for Math 291-2, the second quarter of MENU: Intensive Linear Algebra and Multivariable Calculus,
Math 291-2: Lecture Notes Northwestern University, Winter 2016 Written by Santiago Cañez These are lecture notes for Math 291-2, the second quarter of MENU: Intensive Linear Algebra and Multivariable Calculus,
MATH36001 Generalized Inverses and the SVD 2015
 MATH36001 Generalized Inverses and the SVD 201 1 Generalized Inverses of Matrices A matrix has an inverse only if it is square and nonsingular. However there are theoretical and practical applications
MATH36001 Generalized Inverses and the SVD 201 1 Generalized Inverses of Matrices A matrix has an inverse only if it is square and nonsingular. However there are theoretical and practical applications
October 25, 2013 INNER PRODUCT SPACES
 October 25, 2013 INNER PRODUCT SPACES RODICA D. COSTIN Contents 1. Inner product 2 1.1. Inner product 2 1.2. Inner product spaces 4 2. Orthogonal bases 5 2.1. Existence of an orthogonal basis 7 2.2. Orthogonal
October 25, 2013 INNER PRODUCT SPACES RODICA D. COSTIN Contents 1. Inner product 2 1.1. Inner product 2 1.2. Inner product spaces 4 2. Orthogonal bases 5 2.1. Existence of an orthogonal basis 7 2.2. Orthogonal
CS168: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA)
") CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
33AH, WINTER 2018: STUDY GUIDE FOR FINAL EXAM
 33AH, WINTER 2018: STUDY GUIDE FOR FINAL EXAM (UPDATED MARCH 17, 2018) The final exam will be cumulative, with a bit more weight on more recent material. This outline covers the what we ve done since the
33AH, WINTER 2018: STUDY GUIDE FOR FINAL EXAM (UPDATED MARCH 17, 2018) The final exam will be cumulative, with a bit more weight on more recent material. This outline covers the what we ve done since the
Random projections. 1 Introduction. 2 Dimensionality reduction. Lecture notes 5 February 29, 2016
 Lecture notes 5 February 9, 016 1 Introduction Random projections Random projections are a useful tool in the analysis and processing of high-dimensional data. We will analyze two applications that use
Lecture notes 5 February 9, 016 1 Introduction Random projections Random projections are a useful tool in the analysis and processing of high-dimensional data. We will analyze two applications that use
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
Applied Linear Algebra in Geoscience Using MATLAB
 Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
Lecture notes: Applied linear algebra Part 1. Version 2
 Lecture notes: Applied linear algebra Part 1. Version 2 Michael Karow Berlin University of Technology karow@math.tu-berlin.de October 2, 2008 1 Notation, basic notions and facts 1.1 Subspaces, range and
Lecture notes: Applied linear algebra Part 1. Version 2 Michael Karow Berlin University of Technology karow@math.tu-berlin.de October 2, 2008 1 Notation, basic notions and facts 1.1 Subspaces, range and
Overview. Optimization-Based Data Analysis. Carlos Fernandez-Granda
 Overview Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 1/25/2016 Sparsity Denoising Regression Inverse problems Low-rank models Matrix completion
Overview Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 1/25/2016 Sparsity Denoising Regression Inverse problems Low-rank models Matrix completion
Data Preprocessing Tasks
 Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Notes on singular value decomposition for Math 54. Recall that if A is a symmetric n n matrix, then A has real eigenvalues A = P DP 1 A = P DP T.
 Notes on singular value decomposition for Math 54 Recall that if A is a symmetric n n matrix, then A has real eigenvalues λ 1,, λ n (possibly repeated), and R n has an orthonormal basis v 1,, v n, where
Notes on singular value decomposition for Math 54 Recall that if A is a symmetric n n matrix, then A has real eigenvalues λ 1,, λ n (possibly repeated), and R n has an orthonormal basis v 1,, v n, where
CS168: The Modern Algorithmic Toolbox Lecture #8: How PCA Works
 CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
B553 Lecture 5: Matrix Algebra Review
 B553 Lecture 5: Matrix Algebra Review Kris Hauser January 19, 2012 We have seen in prior lectures how vectors represent points in R n and gradients of functions. Matrices represent linear transformations
B553 Lecture 5: Matrix Algebra Review Kris Hauser January 19, 2012 We have seen in prior lectures how vectors represent points in R n and gradients of functions. Matrices represent linear transformations
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
Principal Components Analysis (PCA) and Singular Value Decomposition (SVD) with applications to Microarrays
 and Singular Value Decomposition (SVD) with applications to Microarrays") Principal Components Analysis (PCA) and Singular Value Decomposition (SVD) with applications to Microarrays Prof. Tesler Math 283 Fall 2015 Prof. Tesler Principal Components Analysis Math 283 / Fall 2015
Principal Components Analysis (PCA) and Singular Value Decomposition (SVD) with applications to Microarrays Prof. Tesler Math 283 Fall 2015 Prof. Tesler Principal Components Analysis Math 283 / Fall 2015
LINEAR ALGEBRA SUMMARY SHEET.
 LINEAR ALGEBRA SUMMARY SHEET RADON ROSBOROUGH https://intuitiveexplanationscom/linear-algebra-summary-sheet/ This document is a concise collection of many of the important theorems of linear algebra, organized
LINEAR ALGEBRA SUMMARY SHEET RADON ROSBOROUGH https://intuitiveexplanationscom/linear-algebra-summary-sheet/ This document is a concise collection of many of the important theorems of linear algebra, organized
I. Multiple Choice Questions (Answer any eight)
") Name of the student : Roll No : CS65: Linear Algebra and Random Processes Exam - Course Instructor : Prashanth L.A. Date : Sep-24, 27 Duration : 5 minutes INSTRUCTIONS: The test will be evaluated ONLY
Name of the student : Roll No : CS65: Linear Algebra and Random Processes Exam - Course Instructor : Prashanth L.A. Date : Sep-24, 27 Duration : 5 minutes INSTRUCTIONS: The test will be evaluated ONLY
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
Principal Component Analysis
 B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
1 9/5 Matrices, vectors, and their applications
 1 9/5 Matrices, vectors, and their applications Algebra: study of objects and operations on them. Linear algebra: object: matrices and vectors. operations: addition, multiplication etc. Algorithms/Geometric
1 9/5 Matrices, vectors, and their applications Algebra: study of objects and operations on them. Linear algebra: object: matrices and vectors. operations: addition, multiplication etc. Algorithms/Geometric
Numerical Linear Algebra
 University of Alabama at Birmingham Department of Mathematics Numerical Linear Algebra Lecture Notes for MA 660 (1997 2014) Dr Nikolai Chernov April 2014 Chapter 0 Review of Linear Algebra 0.1 Matrices
University of Alabama at Birmingham Department of Mathematics Numerical Linear Algebra Lecture Notes for MA 660 (1997 2014) Dr Nikolai Chernov April 2014 Chapter 0 Review of Linear Algebra 0.1 Matrices
4 Linear Algebra Review
 Linear Algebra Review For this topic we quickly review many key aspects of linear algebra that will be necessary for the remainder of the text 1 Vectors and Matrices For the context of data analysis, the
Linear Algebra Review For this topic we quickly review many key aspects of linear algebra that will be necessary for the remainder of the text 1 Vectors and Matrices For the context of data analysis, the
Lecture 7 Spectral methods
 CSE 291: Unsupervised learning Spring 2008 Lecture 7 Spectral methods 7.1 Linear algebra review 7.1.1 Eigenvalues and eigenvectors Definition 1. A d d matrix M has eigenvalue λ if there is a d-dimensional
CSE 291: Unsupervised learning Spring 2008 Lecture 7 Spectral methods 7.1 Linear algebra review 7.1.1 Eigenvalues and eigenvectors Definition 1. A d d matrix M has eigenvalue λ if there is a d-dimensional
Properties of Matrices and Operations on Matrices
 Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,
Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,
Review of Some Concepts from Linear Algebra: Part 2
 Review of Some Concepts from Linear Algebra: Part 2 Department of Mathematics Boise State University January 16, 2019 Math 566 Linear Algebra Review: Part 2 January 16, 2019 1 / 22 Vector spaces A set
Review of Some Concepts from Linear Algebra: Part 2 Department of Mathematics Boise State University January 16, 2019 Math 566 Linear Algebra Review: Part 2 January 16, 2019 1 / 22 Vector spaces A set
Data Mining Lecture 4: Covariance, EVD, PCA & SVD
 Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Linear Algebra Primer
 Linear Algebra Primer David Doria daviddoria@gmail.com Wednesday 3 rd December, 2008 Contents Why is it called Linear Algebra? 4 2 What is a Matrix? 4 2. Input and Output.....................................
Linear Algebra Primer David Doria daviddoria@gmail.com Wednesday 3 rd December, 2008 Contents Why is it called Linear Algebra? 4 2 What is a Matrix? 4 2. Input and Output.....................................
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Review of Linear Algebra Denis Helic KTI, TU Graz Oct 9, 2014 Denis Helic (KTI, TU Graz) KDDM1 Oct 9, 2014 1 / 74 Big picture: KDDM Probability Theory
Knowledge Discovery and Data Mining 1 (VO) (707.003) Review of Linear Algebra Denis Helic KTI, TU Graz Oct 9, 2014 Denis Helic (KTI, TU Graz) KDDM1 Oct 9, 2014 1 / 74 Big picture: KDDM Probability Theory
7. Symmetric Matrices and Quadratic Forms
 Linear Algebra 7. Symmetric Matrices and Quadratic Forms CSIE NCU 1 7. Symmetric Matrices and Quadratic Forms 7.1 Diagonalization of symmetric matrices 2 7.2 Quadratic forms.. 9 7.4 The singular value
Linear Algebra 7. Symmetric Matrices and Quadratic Forms CSIE NCU 1 7. Symmetric Matrices and Quadratic Forms 7.1 Diagonalization of symmetric matrices 2 7.2 Quadratic forms.. 9 7.4 The singular value
Math Camp Lecture 4: Linear Algebra. Xiao Yu Wang. Aug 2010 MIT. Xiao Yu Wang (MIT) Math Camp /10 1 / 88
 Math Camp /10 1 / 88") Math Camp 2010 Lecture 4: Linear Algebra Xiao Yu Wang MIT Aug 2010 Xiao Yu Wang (MIT) Math Camp 2010 08/10 1 / 88 Linear Algebra Game Plan Vector Spaces Linear Transformations and Matrices Determinant
Math Camp 2010 Lecture 4: Linear Algebra Xiao Yu Wang MIT Aug 2010 Xiao Yu Wang (MIT) Math Camp 2010 08/10 1 / 88 Linear Algebra Game Plan Vector Spaces Linear Transformations and Matrices Determinant
LinGloss. A glossary of linear algebra
 LinGloss A glossary of linear algebra Contents: Decompositions Types of Matrices Theorems Other objects? Quasi-triangular A matrix A is quasi-triangular iff it is a triangular matrix except its diagonal
LinGloss A glossary of linear algebra Contents: Decompositions Types of Matrices Theorems Other objects? Quasi-triangular A matrix A is quasi-triangular iff it is a triangular matrix except its diagonal
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x