Markov-Chain Monte Carlo
|
|
|
- Andrew Jared McGee
- 6 years ago
- Views:
Transcription
1 Markov-Chain Monte Carlo CSE586 Computer Vision II Spring 2010, Penn State Univ.

2 References
3 Recall: Sampling Motivation If we can generate random samples x i from a given distribution P(x), then we can estimate expected values of functions under this distribution by summation, rather than integration. That is, we can approximate: by first generating N i.i.d. samples from P(x) and then forming the empirical estimate:
4 unknown normalization factor we only know how to sample from a few nice multidimensional distributions (uniform, normal)
5 Recall: Sampling Methods Inverse Transform Sampling (CDF) Rejection Sampling Importance Sampling
6 Problem Intuition: In high dimension problems, the Typical Set (volume of nonnegligable prob in state space) is a small fraction of the total space.
7
8 Recall: Markov Chain Question Assume you start in some state, and then run the simulation for a large number of time steps. What percentage of time do you spend at X1, X2 and X3? Recall: Transpose of transition matrix (columns sum to one)

9 four possible initial distributions [ ] initial distribution distribution after one time step all eventually end up with same distribution -- this is the stationary distribution!
10 in matlab: [E,D] = eigs(k)
11 General Idea Start in some state, and then run the simulation for some number of time steps. After you have run it long enough start keeping track of the states you visit. {... X1 X2 X1 X3 X3 X2 X1 X2 X1 X1 X3 X3 X2...} These are samples from the distribution you want, so you can now compute any expected values with respect to that distribution empirically.
12 Theory (cause it s important) every state is accessible from every other state. expected return time to every state is finite If the Markov chain is positive recurrent, there exists a stationary distribution. If it is positive recurrent and irreducible, there exists a unique stationary distribution. Then, the average of a function f over samples of the Markov chain is equal to the average with respect to the stationary distribution We can compute this empirically as we generate samples. This is what we want to compute, and is infeasible to compute in any other way.
13 But how to design the chain? Assume you want to spend a particular percentage of time at X1, X2 and X3. What should the transition probabilities be? P(x1) =.2 P(x2) =.3 X1 P(x3) =.5 K = [????????? ] X3 X2
14 Let s consider a specific example
15 Example: People counting Problem statement: Given a foreground image, and personsized bounding box*, find a configuration (number and locations) of bounding boxes that cover a majority of foreground pixels while leaving a majority of background pixels uncovered. foreground image person-sized bounding box *note: height, width and orientation of the bounding box may depend on image location we determine these relationships beforehand through a calibration procedure.

16 Likelihood Score To measure how good a proposed configuration is, we generate a foreground image from it and compare with the observed foreground image to get a likelihood score. config = {{x 1,y 1,w 1,h 1,theta 1 },{x 2,y 2,w 2,h 2,theta 2 },{x 3,y 3,w 3,h 3,theta 3 }} generated foreground image observed foreground image compare Likelihood Score



17 Likelihood Score Bernoulli distribution model likelihood simplify, by assuming log likelihood Number of pixels that disagree!
18 Searching for the Max The space of configurations is very large. We can t exhaustively search for the max likelihood configuration. We can t even really uniformly sample the space to a reasonable degree of accuracy. config k = {{x 1,y 1,w 1,h 1,theta 1 },{x 2,y 2,w 2,h 2,theta 2 },,{x k,y k,w k,h k,theta k }} Let N = number of possible locations for (x i,y i ) in a k-person configuration. Size of config k = N k And we don t even know how many people there are... Size of config space = N 0 + N 1 + N 2 + N 3 + If we also wanted to search for width, height and orientation, this space would be even more huge.
19 Searching for the Max Local Search Approach Given a current configuration, propose a small change to it Compare likelihood of proposed config with likelihood of the current config Decide whether to accept the change
20 Proposals Add a rectangle (birth) add current configuration proposed configuration
21 Proposals Remove a rectangle (death) remove current configuration proposed configuration
22 Move a rectangle Proposals move current configuration proposed configuration
23 Naïve Acceptance Searching for the Max Accept proposed configuration if it has a larger likelihood score, i.e. Compute a = L(proposed) L(current) Accept if a > 1 Problem: leads to hill-climbing behavior that gets stuck in local maxima Brings us here But we really want to be over here! start Likelihood
24 The MCMC approach Searching for the Max Generate random configurations from a distribution proportional to the likelihood! Generates many high likelihood configurations Likelihood Generates few low likelihood ones.
25 The MCMC approach Searching for the Max Generate random configurations from a distribution proportional to the likelihood! This searches the space of configurations in an efficient way. Now just remember the generated configuration with the highest likelihood.
 death birth config A birth death config C config B move move birth death move move")
26 Sounds good, but how to do it? Think of configurations as nodes in a graph. Put a link between nodes if you can get from one config to the other in one step (birth, death, move) death birth config A birth death config C config B move move birth death move move move move birth death config D move move config E death birth Note links come in pairs: birth/death; move/move
27 Detailed Balance Consider a pair of configuration nodes r,s Want to generate them with frequency relative to their likelihoods L(r) and L(s) Let q(r,s) be relative frequency of proposing configuration s when the current state is r (and vice versa) A sufficient condition to generate r,s with the desired frequency is L(r) r q(r,s) L(r) q(r,s) = L(s) q(s,r) s L(s) detailed balance q(s,r)
28 Detailed Balance Typically, your proposal frequencies do NOT satisfy detailed balance (unless you are extremely lucky). To fix this, we introduce a computational fudge factor a Detailed balance: a* L(r) q(r,s) = L(s) q(s,r) a * q(r,s) Solve for a: L(r) r a = L(s) q(s,r) L(r) q(r,s) q(s,r) s L(s)
29 MCMC Sampling Metropolis Hastings algorithm Propose a new configuration Compute a = L(proposed) q(proposed,current) L(current) q(current,proposed) Accept if a > 1 Else accept anyways with probability a Difference from Naïve algorithm
30 Trans-dimensional MCMC Green s reversible-jump approach (RJMCMC) gives a general template for exploring and comparing states of differing dimension (diff numbers of rectangles in our case). Proposals come in reversible pairs: birth/death and move/move. We should add another term to the acceptance ratio for pairs that jump across dimensions. However, that term is 1 for our simple proposals.
31 MCMC in Action Sequence of proposed configurations Sequence of accepted configurations movies


32 MCMC in Action Max likelihood configuration Looking good!


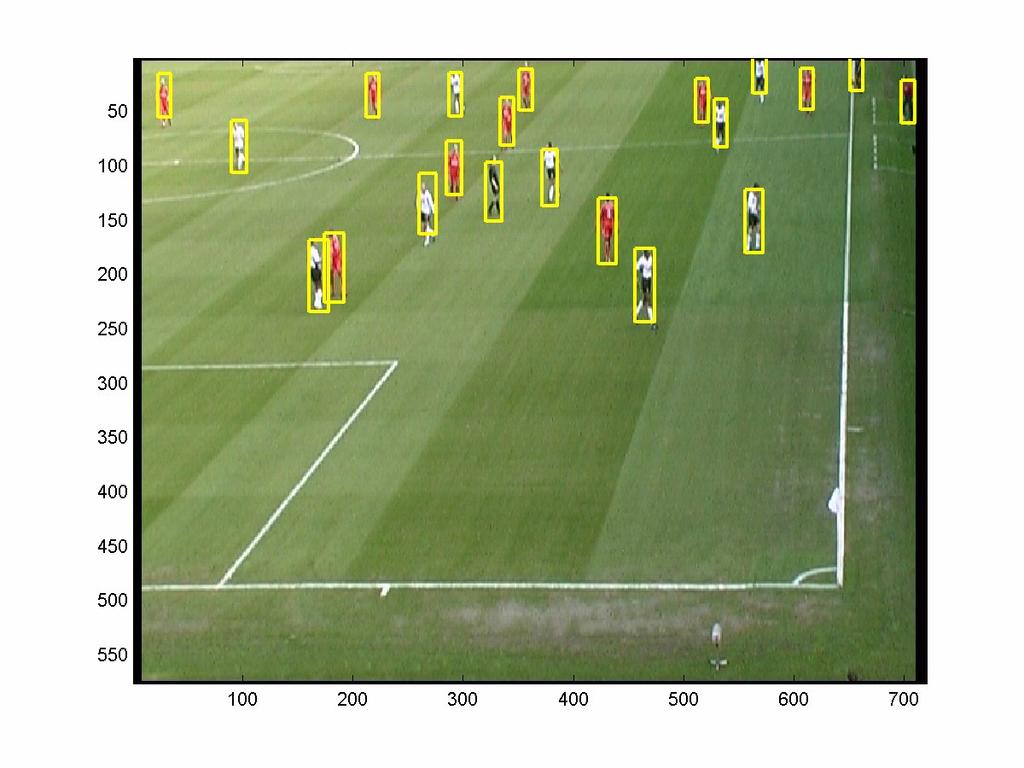

33 Examples
34 Note: you can just make q up on-the-fly. diff with rejection sampling: instead of throwing away rejections, you replicate them into next time step.
35
36 Metropolis Hastings Example P(x1) =.2 P(x2) =.3 P(x3) =.5 X1 Matlab demo X3 X2 Proposal distribution q(xi, (xi-1)mod3 ) =.4 q(xi, (xi+1)mod3) =.6
37 Variants of MCMC there are many variations on this general approach, some derived as special cases of the Metropolis-Hastings algorithm
38 cancels q(x,x) q(x, x ) e.g. Gaussian
39 simpler version, using 1D conditional distributions or line search, or...
40 1D marginal wrt x1 1D marginal wrt x2 interleave
41 Gibbs Sampler Special case of MH with acceptance ratio always 1 (so you always accept the proposal). where S.Brooks, Markov Chain Monte Carlo and its Application
42 Simulated Annealing introduce a temperature term that makes it more likely to accept proposals early on. This leads to more aggressive exploration of the state space. Gradually reduce the temperature, causing the process to spend more time exploring high likelihood states. Rather than remember all states visited, keep track of the best state you ve seen so far. This is a method that attempts to find the global max (MAP) state.
43 Trans-dimensional MCMC Exploring alternative state spaces of differing dimensions (example, when doing EM, also try to estimate number of clusters along with parameters of each cluster). Green s reversible-jump approach (RJMCMC) gives a general template for exploring and comparing states of differing dimension.
References. Markov-Chain Monte Carlo. Recall: Sampling Motivation. Problem. Recall: Sampling Methods. CSE586 Computer Vision II
 References Markov-Chain Monte Carlo CSE586 Computer Vision II Spring 2010, Penn State Univ. Recall: Sampling Motivation If we can generate random samples x i from a given distribution P(x), then we can
References Markov-Chain Monte Carlo CSE586 Computer Vision II Spring 2010, Penn State Univ. Recall: Sampling Motivation If we can generate random samples x i from a given distribution P(x), then we can
Robert Collins CSE586, PSU. Markov-Chain Monte Carlo
 Markov-Chain Monte Carlo References Problem Intuition: In high dimension problems, the Typical Set (volume of nonnegligable prob in state space) is a small fraction of the total space. High-Dimensional
Markov-Chain Monte Carlo References Problem Intuition: In high dimension problems, the Typical Set (volume of nonnegligable prob in state space) is a small fraction of the total space. High-Dimensional
Robert Collins CSE586, PSU Intro to Sampling Methods
 Robert Collins Intro to Sampling Methods CSE586 Computer Vision II Penn State Univ Robert Collins A Brief Overview of Sampling Monte Carlo Integration Sampling and Expected Values Inverse Transform Sampling
Robert Collins Intro to Sampling Methods CSE586 Computer Vision II Penn State Univ Robert Collins A Brief Overview of Sampling Monte Carlo Integration Sampling and Expected Values Inverse Transform Sampling
Robert Collins CSE586, PSU Intro to Sampling Methods
 Intro to Sampling Methods CSE586 Computer Vision II Penn State Univ Topics to be Covered Monte Carlo Integration Sampling and Expected Values Inverse Transform Sampling (CDF) Ancestral Sampling Rejection
Intro to Sampling Methods CSE586 Computer Vision II Penn State Univ Topics to be Covered Monte Carlo Integration Sampling and Expected Values Inverse Transform Sampling (CDF) Ancestral Sampling Rejection
Robert Collins CSE586, PSU Intro to Sampling Methods
 Intro to Sampling Methods CSE586 Computer Vision II Penn State Univ Topics to be Covered Monte Carlo Integration Sampling and Expected Values Inverse Transform Sampling (CDF) Ancestral Sampling Rejection
Intro to Sampling Methods CSE586 Computer Vision II Penn State Univ Topics to be Covered Monte Carlo Integration Sampling and Expected Values Inverse Transform Sampling (CDF) Ancestral Sampling Rejection
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Markov chain Monte Carlo Lecture 9
 Markov chain Monte Carlo Lecture 9 David Sontag New York University Slides adapted from Eric Xing and Qirong Ho (CMU) Limitations of Monte Carlo Direct (unconditional) sampling Hard to get rare events
Markov chain Monte Carlo Lecture 9 David Sontag New York University Slides adapted from Eric Xing and Qirong Ho (CMU) Limitations of Monte Carlo Direct (unconditional) sampling Hard to get rare events
Quantifying Uncertainty
 Sai Ravela M. I. T Last Updated: Spring 2013 1 Markov Chain Monte Carlo Monte Carlo sampling made for large scale problems via Markov Chains Monte Carlo Sampling Rejection Sampling Importance Sampling
Sai Ravela M. I. T Last Updated: Spring 2013 1 Markov Chain Monte Carlo Monte Carlo sampling made for large scale problems via Markov Chains Monte Carlo Sampling Rejection Sampling Importance Sampling
Computer Vision Group Prof. Daniel Cremers. 14. Sampling Methods
 Prof. Daniel Cremers 14. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Prof. Daniel Cremers 14. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
Computer Vision Group Prof. Daniel Cremers. 11. Sampling Methods: Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 11. Sampling Methods: Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative
Group Prof. Daniel Cremers 11. Sampling Methods: Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative
17 : Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models, Spring 2015 17 : Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Heran Lin, Bin Deng, Yun Huang 1 Review of Monte Carlo Methods 1.1 Overview Monte Carlo
10-708: Probabilistic Graphical Models, Spring 2015 17 : Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Heran Lin, Bin Deng, Yun Huang 1 Review of Monte Carlo Methods 1.1 Overview Monte Carlo
Machine Learning for Data Science (CS4786) Lecture 24
 Lecture 24") Machine Learning for Data Science (CS4786) Lecture 24 Graphical Models: Approximate Inference Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ BELIEF PROPAGATION OR MESSAGE PASSING Each
Machine Learning for Data Science (CS4786) Lecture 24 Graphical Models: Approximate Inference Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ BELIEF PROPAGATION OR MESSAGE PASSING Each
Computer Vision Group Prof. Daniel Cremers. 11. Sampling Methods
 Prof. Daniel Cremers 11. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Prof. Daniel Cremers 11. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Markov Chains Handout for Stat 110
 Markov Chains Handout for Stat 0 Prof. Joe Blitzstein (Harvard Statistics Department) Introduction Markov chains were first introduced in 906 by Andrey Markov, with the goal of showing that the Law of
Markov Chains Handout for Stat 0 Prof. Joe Blitzstein (Harvard Statistics Department) Introduction Markov chains were first introduced in 906 by Andrey Markov, with the goal of showing that the Law of
April 20th, Advanced Topics in Machine Learning California Institute of Technology. Markov Chain Monte Carlo for Machine Learning
 for for Advanced Topics in California Institute of Technology April 20th, 2017 1 / 50 Table of Contents for 1 2 3 4 2 / 50 History of methods for Enrico Fermi used to calculate incredibly accurate predictions
for for Advanced Topics in California Institute of Technology April 20th, 2017 1 / 50 Table of Contents for 1 2 3 4 2 / 50 History of methods for Enrico Fermi used to calculate incredibly accurate predictions
MCMC: Markov Chain Monte Carlo
 I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Convex Optimization CMU-10725
 Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Monte Carlo Methods. Geoff Gordon February 9, 2006
 Monte Carlo Methods Geoff Gordon ggordon@cs.cmu.edu February 9, 2006 Numerical integration problem 5 4 3 f(x,y) 2 1 1 0 0.5 0 X 0.5 1 1 0.8 0.6 0.4 Y 0.2 0 0.2 0.4 0.6 0.8 1 x X f(x)dx Used for: function
Monte Carlo Methods Geoff Gordon ggordon@cs.cmu.edu February 9, 2006 Numerical integration problem 5 4 3 f(x,y) 2 1 1 0 0.5 0 X 0.5 1 1 0.8 0.6 0.4 Y 0.2 0 0.2 0.4 0.6 0.8 1 x X f(x)dx Used for: function
6 Markov Chain Monte Carlo (MCMC)
") 6 Markov Chain Monte Carlo (MCMC) The underlying idea in MCMC is to replace the iid samples of basic MC methods, with dependent samples from an ergodic Markov chain, whose limiting (stationary) distribution
6 Markov Chain Monte Carlo (MCMC) The underlying idea in MCMC is to replace the iid samples of basic MC methods, with dependent samples from an ergodic Markov chain, whose limiting (stationary) distribution
Stochastic optimization Markov Chain Monte Carlo
 Stochastic optimization Markov Chain Monte Carlo Ethan Fetaya Weizmann Institute of Science 1 Motivation Markov chains Stationary distribution Mixing time 2 Algorithms Metropolis-Hastings Simulated Annealing
Stochastic optimization Markov Chain Monte Carlo Ethan Fetaya Weizmann Institute of Science 1 Motivation Markov chains Stationary distribution Mixing time 2 Algorithms Metropolis-Hastings Simulated Annealing
Markov Chains and MCMC
 Markov Chains and MCMC CompSci 590.02 Instructor: AshwinMachanavajjhala Lecture 4 : 590.02 Spring 13 1 Recap: Monte Carlo Method If U is a universe of items, and G is a subset satisfying some property,
Markov Chains and MCMC CompSci 590.02 Instructor: AshwinMachanavajjhala Lecture 4 : 590.02 Spring 13 1 Recap: Monte Carlo Method If U is a universe of items, and G is a subset satisfying some property,
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos Contents Markov Chain Monte Carlo Methods Sampling Rejection Importance Hastings-Metropolis Gibbs Markov Chains
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos Contents Markov Chain Monte Carlo Methods Sampling Rejection Importance Hastings-Metropolis Gibbs Markov Chains
16 : Approximate Inference: Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
Markov chain Monte Carlo methods in atmospheric remote sensing
 1 / 45 Markov chain Monte Carlo methods in atmospheric remote sensing Johanna Tamminen johanna.tamminen@fmi.fi ESA Summer School on Earth System Monitoring and Modeling July 3 Aug 11, 212, Frascati July,
1 / 45 Markov chain Monte Carlo methods in atmospheric remote sensing Johanna Tamminen johanna.tamminen@fmi.fi ESA Summer School on Earth System Monitoring and Modeling July 3 Aug 11, 212, Frascati July,
SAMPLING ALGORITHMS. In general. Inference in Bayesian models
 SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
Lecture 5. G. Cowan Lectures on Statistical Data Analysis Lecture 5 page 1
 Lecture 5 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Lecture 5 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Computational statistics
 Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
CPSC 540: Machine Learning
 CPSC 540: Machine Learning More Approximate Inference Mark Schmidt University of British Columbia Winter 2018 Last Time: Approximate Inference We ve been discussing graphical models for density estimation,
CPSC 540: Machine Learning More Approximate Inference Mark Schmidt University of British Columbia Winter 2018 Last Time: Approximate Inference We ve been discussing graphical models for density estimation,
CS242: Probabilistic Graphical Models Lecture 7B: Markov Chain Monte Carlo & Gibbs Sampling
 CS242: Probabilistic Graphical Models Lecture 7B: Markov Chain Monte Carlo & Gibbs Sampling Professor Erik Sudderth Brown University Computer Science October 27, 2016 Some figures and materials courtesy
CS242: Probabilistic Graphical Models Lecture 7B: Markov Chain Monte Carlo & Gibbs Sampling Professor Erik Sudderth Brown University Computer Science October 27, 2016 Some figures and materials courtesy
Simulation of point process using MCMC
 Simulation of point process using MCMC Jakob G. Rasmussen Department of Mathematics Aalborg University Denmark March 2, 2011 1/14 Today When do we need MCMC? Case 1: Fixed number of points Metropolis-Hastings,
Simulation of point process using MCMC Jakob G. Rasmussen Department of Mathematics Aalborg University Denmark March 2, 2011 1/14 Today When do we need MCMC? Case 1: Fixed number of points Metropolis-Hastings,
Lecture 6: Markov Chain Monte Carlo
 Lecture 6: Markov Chain Monte Carlo D. Jason Koskinen koskinen@nbi.ku.dk Photo by Howard Jackman University of Copenhagen Advanced Methods in Applied Statistics Feb - Apr 2016 Niels Bohr Institute 2 Outline
Lecture 6: Markov Chain Monte Carlo D. Jason Koskinen koskinen@nbi.ku.dk Photo by Howard Jackman University of Copenhagen Advanced Methods in Applied Statistics Feb - Apr 2016 Niels Bohr Institute 2 Outline
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Markov Chain Monte Carlo The Metropolis-Hastings Algorithm
 Markov Chain Monte Carlo The Metropolis-Hastings Algorithm Anthony Trubiano April 11th, 2018 1 Introduction Markov Chain Monte Carlo (MCMC) methods are a class of algorithms for sampling from a probability
Markov Chain Monte Carlo The Metropolis-Hastings Algorithm Anthony Trubiano April 11th, 2018 1 Introduction Markov Chain Monte Carlo (MCMC) methods are a class of algorithms for sampling from a probability
MCMC notes by Mark Holder
 MCMC notes by Mark Holder Bayesian inference Ultimately, we want to make probability statements about true values of parameters, given our data. For example P(α 0 < α 1 X). According to Bayes theorem:
MCMC notes by Mark Holder Bayesian inference Ultimately, we want to make probability statements about true values of parameters, given our data. For example P(α 0 < α 1 X). According to Bayes theorem:
Introduction to MCMC. DB Breakfast 09/30/2011 Guozhang Wang
 Introduction to MCMC DB Breakfast 09/30/2011 Guozhang Wang Motivation: Statistical Inference Joint Distribution Sleeps Well Playground Sunny Bike Ride Pleasant dinner Productive day Posterior Estimation
Introduction to MCMC DB Breakfast 09/30/2011 Guozhang Wang Motivation: Statistical Inference Joint Distribution Sleeps Well Playground Sunny Bike Ride Pleasant dinner Productive day Posterior Estimation
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
Monte Carlo Methods. Leon Gu CSD, CMU
 Monte Carlo Methods Leon Gu CSD, CMU Approximate Inference EM: y-observed variables; x-hidden variables; θ-parameters; E-step: q(x) = p(x y, θ t 1 ) M-step: θ t = arg max E q(x) [log p(y, x θ)] θ Monte
Monte Carlo Methods Leon Gu CSD, CMU Approximate Inference EM: y-observed variables; x-hidden variables; θ-parameters; E-step: q(x) = p(x y, θ t 1 ) M-step: θ t = arg max E q(x) [log p(y, x θ)] θ Monte
Introduction to Computational Biology Lecture # 14: MCMC - Markov Chain Monte Carlo
 Introduction to Computational Biology Lecture # 14: MCMC - Markov Chain Monte Carlo Assaf Weiner Tuesday, March 13, 2007 1 Introduction Today we will return to the motif finding problem, in lecture 10
Introduction to Computational Biology Lecture # 14: MCMC - Markov Chain Monte Carlo Assaf Weiner Tuesday, March 13, 2007 1 Introduction Today we will return to the motif finding problem, in lecture 10
Chapter 10. Optimization Simulated annealing
 Chapter 10 Optimization In this chapter we consider a very different kind of problem. Until now our prototypical problem is to compute the expected value of some random variable. We now consider minimization
Chapter 10 Optimization In this chapter we consider a very different kind of problem. Until now our prototypical problem is to compute the expected value of some random variable. We now consider minimization
Markov Chain Monte Carlo Inference. Siamak Ravanbakhsh Winter 2018
 Graphical Models Markov Chain Monte Carlo Inference Siamak Ravanbakhsh Winter 2018 Learning objectives Markov chains the idea behind Markov Chain Monte Carlo (MCMC) two important examples: Gibbs sampling
Graphical Models Markov Chain Monte Carlo Inference Siamak Ravanbakhsh Winter 2018 Learning objectives Markov chains the idea behind Markov Chain Monte Carlo (MCMC) two important examples: Gibbs sampling
Results: MCMC Dancers, q=10, n=500
 Motivation Sampling Methods for Bayesian Inference How to track many INTERACTING targets? A Tutorial Frank Dellaert Results: MCMC Dancers, q=10, n=500 1 Probabilistic Topological Maps Results Real-Time
Motivation Sampling Methods for Bayesian Inference How to track many INTERACTING targets? A Tutorial Frank Dellaert Results: MCMC Dancers, q=10, n=500 1 Probabilistic Topological Maps Results Real-Time
Markov Chain Monte Carlo (MCMC) and Model Evaluation. August 15, 2017
 and Model Evaluation. August 15, 2017") Markov Chain Monte Carlo (MCMC) and Model Evaluation August 15, 2017 Frequentist Linking Frequentist and Bayesian Statistics How can we estimate model parameters and what does it imply? Want to find the
Markov Chain Monte Carlo (MCMC) and Model Evaluation August 15, 2017 Frequentist Linking Frequentist and Bayesian Statistics How can we estimate model parameters and what does it imply? Want to find the
A Search and Jump Algorithm for Markov Chain Monte Carlo Sampling. Christopher Jennison. Adriana Ibrahim. Seminar at University of Kuwait
 A Search and Jump Algorithm for Markov Chain Monte Carlo Sampling Christopher Jennison Department of Mathematical Sciences, University of Bath, UK http://people.bath.ac.uk/mascj Adriana Ibrahim Institute
A Search and Jump Algorithm for Markov Chain Monte Carlo Sampling Christopher Jennison Department of Mathematical Sciences, University of Bath, UK http://people.bath.ac.uk/mascj Adriana Ibrahim Institute
18 : Advanced topics in MCMC. 1 Gibbs Sampling (Continued from the last lecture)
") 10-708: Probabilistic Graphical Models 10-708, Spring 2014 18 : Advanced topics in MCMC Lecturer: Eric P. Xing Scribes: Jessica Chemali, Seungwhan Moon 1 Gibbs Sampling (Continued from the last lecture)
10-708: Probabilistic Graphical Models 10-708, Spring 2014 18 : Advanced topics in MCMC Lecturer: Eric P. Xing Scribes: Jessica Chemali, Seungwhan Moon 1 Gibbs Sampling (Continued from the last lecture)
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Bayes Nets: Sampling Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Bayes Nets: Sampling Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Bayesian model selection in graphs by using BDgraph package
 Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
MCMC Sampling for Bayesian Inference using L1-type Priors
 MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
A quick introduction to Markov chains and Markov chain Monte Carlo (revised version)
") A quick introduction to Markov chains and Markov chain Monte Carlo (revised version) Rasmus Waagepetersen Institute of Mathematical Sciences Aalborg University 1 Introduction These notes are intended to
A quick introduction to Markov chains and Markov chain Monte Carlo (revised version) Rasmus Waagepetersen Institute of Mathematical Sciences Aalborg University 1 Introduction These notes are intended to
Bayesian GLMs and Metropolis-Hastings Algorithm
 Bayesian GLMs and Metropolis-Hastings Algorithm We have seen that with conjugate or semi-conjugate prior distributions the Gibbs sampler can be used to sample from the posterior distribution. In situations,
Bayesian GLMs and Metropolis-Hastings Algorithm We have seen that with conjugate or semi-conjugate prior distributions the Gibbs sampler can be used to sample from the posterior distribution. In situations,
MCMC for Cut Models or Chasing a Moving Target with MCMC
 MCMC for Cut Models or Chasing a Moving Target with MCMC Martyn Plummer International Agency for Research on Cancer MCMSki Chamonix, 6 Jan 2014 Cut models What do we want to do? 1. Generate some random
MCMC for Cut Models or Chasing a Moving Target with MCMC Martyn Plummer International Agency for Research on Cancer MCMSki Chamonix, 6 Jan 2014 Cut models What do we want to do? 1. Generate some random
1 Probabilities. 1.1 Basics 1 PROBABILITIES
 1 PROBABILITIES 1 Probabilities Probability is a tricky word usually meaning the likelyhood of something occuring or how frequent something is. Obviously, if something happens frequently, then its probability
1 PROBABILITIES 1 Probabilities Probability is a tricky word usually meaning the likelyhood of something occuring or how frequent something is. Obviously, if something happens frequently, then its probability
Computer intensive statistical methods
 Lecture 13 MCMC, Hybrid chains October 13, 2015 Jonas Wallin jonwal@chalmers.se Chalmers, Gothenburg university MH algorithm, Chap:6.3 The metropolis hastings requires three objects, the distribution of
Lecture 13 MCMC, Hybrid chains October 13, 2015 Jonas Wallin jonwal@chalmers.se Chalmers, Gothenburg university MH algorithm, Chap:6.3 The metropolis hastings requires three objects, the distribution of
Metropolis Hastings. Rebecca C. Steorts Bayesian Methods and Modern Statistics: STA 360/601. Module 9
 Metropolis Hastings Rebecca C. Steorts Bayesian Methods and Modern Statistics: STA 360/601 Module 9 1 The Metropolis-Hastings algorithm is a general term for a family of Markov chain simulation methods
Metropolis Hastings Rebecca C. Steorts Bayesian Methods and Modern Statistics: STA 360/601 Module 9 1 The Metropolis-Hastings algorithm is a general term for a family of Markov chain simulation methods
Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo
 Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 18, 2015 1 / 45 Resources and Attribution Image credits,
Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 18, 2015 1 / 45 Resources and Attribution Image credits,
Stat 451 Lecture Notes Markov Chain Monte Carlo. Ryan Martin UIC
 Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Markov chain Monte Carlo
 Markov chain Monte Carlo Peter Beerli October 10, 2005 [this chapter is highly influenced by chapter 1 in Markov chain Monte Carlo in Practice, eds Gilks W. R. et al. Chapman and Hall/CRC, 1996] 1 Short
Markov chain Monte Carlo Peter Beerli October 10, 2005 [this chapter is highly influenced by chapter 1 in Markov chain Monte Carlo in Practice, eds Gilks W. R. et al. Chapman and Hall/CRC, 1996] 1 Short
Announcements. Inference. Mid-term. Inference by Enumeration. Reminder: Alarm Network. Introduction to Artificial Intelligence. V22.
 Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 15: Bayes Nets 3 Midterms graded Assignment 2 graded Announcements Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides
Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 15: Bayes Nets 3 Midterms graded Assignment 2 graded Announcements Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides
Convergence Rate of Markov Chains
 Convergence Rate of Markov Chains Will Perkins April 16, 2013 Convergence Last class we saw that if X n is an irreducible, aperiodic, positive recurrent Markov chain, then there exists a stationary distribution
Convergence Rate of Markov Chains Will Perkins April 16, 2013 Convergence Last class we saw that if X n is an irreducible, aperiodic, positive recurrent Markov chain, then there exists a stationary distribution
MCMC and Gibbs Sampling. Sargur Srihari
 MCMC and Gibbs Sampling Sargur srihari@cedar.buffalo.edu 1 Topics 1. Markov Chain Monte Carlo 2. Markov Chains 3. Gibbs Sampling 4. Basic Metropolis Algorithm 5. Metropolis-Hastings Algorithm 6. Slice
MCMC and Gibbs Sampling Sargur srihari@cedar.buffalo.edu 1 Topics 1. Markov Chain Monte Carlo 2. Markov Chains 3. Gibbs Sampling 4. Basic Metropolis Algorithm 5. Metropolis-Hastings Algorithm 6. Slice
Markov Chain Monte Carlo (MCMC)
") Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov chain Monte Carlo
 Markov chain Monte Carlo Probabilistic Models of Cognition, 2011 http://www.ipam.ucla.edu/programs/gss2011/ Roadmap: Motivation Monte Carlo basics What is MCMC? Metropolis Hastings and Gibbs...more tomorrow.
Markov chain Monte Carlo Probabilistic Models of Cognition, 2011 http://www.ipam.ucla.edu/programs/gss2011/ Roadmap: Motivation Monte Carlo basics What is MCMC? Metropolis Hastings and Gibbs...more tomorrow.
CS 188: Artificial Intelligence. Bayes Nets
 CS 188: Artificial Intelligence Probabilistic Inference: Enumeration, Variable Elimination, Sampling Pieter Abbeel UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew
CS 188: Artificial Intelligence Probabilistic Inference: Enumeration, Variable Elimination, Sampling Pieter Abbeel UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew
 SC7/SM6 Bayes Methods HT18 Lecturer: Geoff Nicholls Lecture 2: Monte Carlo Methods Notes and Problem sheets are available at http://www.stats.ox.ac.uk/~nicholls/bayesmethods/ and via the MSc weblearn pages.
SC7/SM6 Bayes Methods HT18 Lecturer: Geoff Nicholls Lecture 2: Monte Carlo Methods Notes and Problem sheets are available at http://www.stats.ox.ac.uk/~nicholls/bayesmethods/ and via the MSc weblearn pages.
An Introduction to Reversible Jump MCMC for Bayesian Networks, with Application
 An Introduction to Reversible Jump MCMC for Bayesian Networks, with Application, CleverSet, Inc. STARMAP/DAMARS Conference Page 1 The research described in this presentation has been funded by the U.S.
An Introduction to Reversible Jump MCMC for Bayesian Networks, with Application, CleverSet, Inc. STARMAP/DAMARS Conference Page 1 The research described in this presentation has been funded by the U.S.
CSC 446 Notes: Lecture 13
 CSC 446 Notes: Lecture 3 The Problem We have already studied how to calculate the probability of a variable or variables using the message passing method. However, there are some times when the structure
CSC 446 Notes: Lecture 3 The Problem We have already studied how to calculate the probability of a variable or variables using the message passing method. However, there are some times when the structure
Math 456: Mathematical Modeling. Tuesday, April 9th, 2018
 Math 456: Mathematical Modeling Tuesday, April 9th, 2018 The Ergodic theorem Tuesday, April 9th, 2018 Today 1. Asymptotic frequency (or: How to use the stationary distribution to estimate the average amount
Math 456: Mathematical Modeling Tuesday, April 9th, 2018 The Ergodic theorem Tuesday, April 9th, 2018 Today 1. Asymptotic frequency (or: How to use the stationary distribution to estimate the average amount
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Lect4: Exact Sampling Techniques and MCMC Convergence Analysis
 Lect4: Exact Sampling Techniques and MCMC Convergence Analysis. Exact sampling. Convergence analysis of MCMC. First-hit time analysis for MCMC--ways to analyze the proposals. Outline of the Module Definitions
Lect4: Exact Sampling Techniques and MCMC Convergence Analysis. Exact sampling. Convergence analysis of MCMC. First-hit time analysis for MCMC--ways to analyze the proposals. Outline of the Module Definitions
Doing Bayesian Integrals
 ASTR509-13 Doing Bayesian Integrals The Reverend Thomas Bayes (c.1702 1761) Philosopher, theologian, mathematician Presbyterian (non-conformist) minister Tunbridge Wells, UK Elected FRS, perhaps due to
ASTR509-13 Doing Bayesian Integrals The Reverend Thomas Bayes (c.1702 1761) Philosopher, theologian, mathematician Presbyterian (non-conformist) minister Tunbridge Wells, UK Elected FRS, perhaps due to
CS281A/Stat241A Lecture 22
 CS281A/Stat241A Lecture 22 p. 1/4 CS281A/Stat241A Lecture 22 Monte Carlo Methods Peter Bartlett CS281A/Stat241A Lecture 22 p. 2/4 Key ideas of this lecture Sampling in Bayesian methods: Predictive distribution
CS281A/Stat241A Lecture 22 p. 1/4 CS281A/Stat241A Lecture 22 Monte Carlo Methods Peter Bartlett CS281A/Stat241A Lecture 22 p. 2/4 Key ideas of this lecture Sampling in Bayesian methods: Predictive distribution
Markov Chain Monte Carlo
 1 Motivation 1.1 Bayesian Learning Markov Chain Monte Carlo Yale Chang In Bayesian learning, given data X, we make assumptions on the generative process of X by introducing hidden variables Z: p(z): prior
1 Motivation 1.1 Bayesian Learning Markov Chain Monte Carlo Yale Chang In Bayesian learning, given data X, we make assumptions on the generative process of X by introducing hidden variables Z: p(z): prior
Minicourse on: Markov Chain Monte Carlo: Simulation Techniques in Statistics
 Minicourse on: Markov Chain Monte Carlo: Simulation Techniques in Statistics Eric Slud, Statistics Program Lecture 1: Metropolis-Hastings Algorithm, plus background in Simulation and Markov Chains. Lecture
Minicourse on: Markov Chain Monte Carlo: Simulation Techniques in Statistics Eric Slud, Statistics Program Lecture 1: Metropolis-Hastings Algorithm, plus background in Simulation and Markov Chains. Lecture
MCMC Methods: Gibbs and Metropolis
 MCMC Methods: Gibbs and Metropolis Patrick Breheny February 28 Patrick Breheny BST 701: Bayesian Modeling in Biostatistics 1/30 Introduction As we have seen, the ability to sample from the posterior distribution
MCMC Methods: Gibbs and Metropolis Patrick Breheny February 28 Patrick Breheny BST 701: Bayesian Modeling in Biostatistics 1/30 Introduction As we have seen, the ability to sample from the posterior distribution
Lecture 15: MCMC Sanjeev Arora Elad Hazan. COS 402 Machine Learning and Artificial Intelligence Fall 2016
 Lecture 15: MCMC Sanjeev Arora Elad Hazan COS 402 Machine Learning and Artificial Intelligence Fall 2016 Course progress Learning from examples Definition + fundamental theorem of statistical learning,
Lecture 15: MCMC Sanjeev Arora Elad Hazan COS 402 Machine Learning and Artificial Intelligence Fall 2016 Course progress Learning from examples Definition + fundamental theorem of statistical learning,
Markov Chains and MCMC
 Markov Chains and MCMC Markov chains Let S = {1, 2,..., N} be a finite set consisting of N states. A Markov chain Y 0, Y 1, Y 2,... is a sequence of random variables, with Y t S for all points in time
Markov Chains and MCMC Markov chains Let S = {1, 2,..., N} be a finite set consisting of N states. A Markov chain Y 0, Y 1, Y 2,... is a sequence of random variables, with Y t S for all points in time
1 Probabilities. 1.1 Basics 1 PROBABILITIES
 1 PROBABILITIES 1 Probabilities Probability is a tricky word usually meaning the likelyhood of something occuring or how frequent something is. Obviously, if something happens frequently, then its probability
1 PROBABILITIES 1 Probabilities Probability is a tricky word usually meaning the likelyhood of something occuring or how frequent something is. Obviously, if something happens frequently, then its probability
Markov chain Monte Carlo
 1 / 26 Markov chain Monte Carlo Timothy Hanson 1 and Alejandro Jara 2 1 Division of Biostatistics, University of Minnesota, USA 2 Department of Statistics, Universidad de Concepción, Chile IAP-Workshop
1 / 26 Markov chain Monte Carlo Timothy Hanson 1 and Alejandro Jara 2 1 Division of Biostatistics, University of Minnesota, USA 2 Department of Statistics, Universidad de Concepción, Chile IAP-Workshop
Markov Networks. l Like Bayes Nets. l Graph model that describes joint probability distribution using tables (AKA potentials)
") Markov Networks l Like Bayes Nets l Graph model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Markov Networks l Like Bayes Nets l Graph model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Winter 2019 Math 106 Topics in Applied Mathematics. Lecture 9: Markov Chain Monte Carlo
 Winter 2019 Math 106 Topics in Applied Mathematics Data-driven Uncertainty Quantification Yoonsang Lee (yoonsang.lee@dartmouth.edu) Lecture 9: Markov Chain Monte Carlo 9.1 Markov Chain A Markov Chain Monte
Winter 2019 Math 106 Topics in Applied Mathematics Data-driven Uncertainty Quantification Yoonsang Lee (yoonsang.lee@dartmouth.edu) Lecture 9: Markov Chain Monte Carlo 9.1 Markov Chain A Markov Chain Monte
Stat 535 C - Statistical Computing & Monte Carlo Methods. Lecture 18-16th March Arnaud Doucet
 Stat 535 C - Statistical Computing & Monte Carlo Methods Lecture 18-16th March 2006 Arnaud Doucet Email: arnaud@cs.ubc.ca 1 1.1 Outline Trans-dimensional Markov chain Monte Carlo. Bayesian model for autoregressions.
Stat 535 C - Statistical Computing & Monte Carlo Methods Lecture 18-16th March 2006 Arnaud Doucet Email: arnaud@cs.ubc.ca 1 1.1 Outline Trans-dimensional Markov chain Monte Carlo. Bayesian model for autoregressions.
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation. EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016
 Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
Lecture 8: PGM Inference
 15 September 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I 1 Variable elimination Max-product Sum-product 2 LP Relaxations QP Relaxations 3 Marginal and MAP X1 X2 X3 X4
15 September 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I 1 Variable elimination Max-product Sum-product 2 LP Relaxations QP Relaxations 3 Marginal and MAP X1 X2 X3 X4
Announcements. CS 188: Artificial Intelligence Fall Causality? Example: Traffic. Topology Limits Distributions. Example: Reverse Traffic
 CS 188: Artificial Intelligence Fall 2008 Lecture 16: Bayes Nets III 10/23/2008 Announcements Midterms graded, up on glookup, back Tuesday W4 also graded, back in sections / box Past homeworks in return
CS 188: Artificial Intelligence Fall 2008 Lecture 16: Bayes Nets III 10/23/2008 Announcements Midterms graded, up on glookup, back Tuesday W4 also graded, back in sections / box Past homeworks in return
9 Markov chain Monte Carlo integration. MCMC
 9 Markov chain Monte Carlo integration. MCMC Markov chain Monte Carlo integration, or MCMC, is a term used to cover a broad range of methods for numerically computing probabilities, or for optimization.
9 Markov chain Monte Carlo integration. MCMC Markov chain Monte Carlo integration, or MCMC, is a term used to cover a broad range of methods for numerically computing probabilities, or for optimization.
Homework 2 will be posted by tomorrow morning, due Friday, October 16 at 5 PM.
 Stationary Distributions: Application Monday, October 05, 2015 2:04 PM Homework 2 will be posted by tomorrow morning, due Friday, October 16 at 5 PM. To prepare to describe the conditions under which the
Stationary Distributions: Application Monday, October 05, 2015 2:04 PM Homework 2 will be posted by tomorrow morning, due Friday, October 16 at 5 PM. To prepare to describe the conditions under which the
Bayes Networks. CS540 Bryan R Gibson University of Wisconsin-Madison. Slides adapted from those used by Prof. Jerry Zhu, CS540-1
 Bayes Networks CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 59 Outline Joint Probability: great for inference, terrible to obtain
Bayes Networks CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 59 Outline Joint Probability: great for inference, terrible to obtain
F denotes cumulative density. denotes probability density function; (.)
") BAYESIAN ANALYSIS: FOREWORDS Notation. System means the real thing and a model is an assumed mathematical form for the system.. he probability model class M contains the set of the all admissible models
BAYESIAN ANALYSIS: FOREWORDS Notation. System means the real thing and a model is an assumed mathematical form for the system.. he probability model class M contains the set of the all admissible models
The Ising model and Markov chain Monte Carlo
 The Ising model and Markov chain Monte Carlo Ramesh Sridharan These notes give a short description of the Ising model for images and an introduction to Metropolis-Hastings and Gibbs Markov Chain Monte
The Ising model and Markov chain Monte Carlo Ramesh Sridharan These notes give a short description of the Ising model for images and an introduction to Metropolis-Hastings and Gibbs Markov Chain Monte
Advances and Applications in Perfect Sampling
 and Applications in Perfect Sampling Ph.D. Dissertation Defense Ulrike Schneider advisor: Jem Corcoran May 8, 2003 Department of Applied Mathematics University of Colorado Outline Introduction (1) MCMC
and Applications in Perfect Sampling Ph.D. Dissertation Defense Ulrike Schneider advisor: Jem Corcoran May 8, 2003 Department of Applied Mathematics University of Colorado Outline Introduction (1) MCMC
Lecture 7 and 8: Markov Chain Monte Carlo
 Lecture 7 and 8: Markov Chain Monte Carlo 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/ Ghahramani
Lecture 7 and 8: Markov Chain Monte Carlo 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/ Ghahramani
DAG models and Markov Chain Monte Carlo methods a short overview
 DAG models and Markov Chain Monte Carlo methods a short overview Søren Højsgaard Institute of Genetics and Biotechnology University of Aarhus August 18, 2008 Printed: August 18, 2008 File: DAGMC-Lecture.tex
DAG models and Markov Chain Monte Carlo methods a short overview Søren Højsgaard Institute of Genetics and Biotechnology University of Aarhus August 18, 2008 Printed: August 18, 2008 File: DAGMC-Lecture.tex
Monte Carlo integration
 Monte Carlo integration Eample of a Monte Carlo sampler in D: imagine a circle radius L/ within a square of LL. If points are randoml generated over the square, what s the probabilit to hit within circle?
Monte Carlo integration Eample of a Monte Carlo sampler in D: imagine a circle radius L/ within a square of LL. If points are randoml generated over the square, what s the probabilit to hit within circle?
INTRODUCTION TO MARKOV CHAIN MONTE CARLO
 INTRODUCTION TO MARKOV CHAIN MONTE CARLO 1. Introduction: MCMC In its simplest incarnation, the Monte Carlo method is nothing more than a computerbased exploitation of the Law of Large Numbers to estimate
INTRODUCTION TO MARKOV CHAIN MONTE CARLO 1. Introduction: MCMC In its simplest incarnation, the Monte Carlo method is nothing more than a computerbased exploitation of the Law of Large Numbers to estimate
Transdimensional Markov Chain Monte Carlo Methods. Jesse Kolb, Vedran Lekić (Univ. of MD) Supervisor: Kris Innanen
 Supervisor: Kris Innanen") Transdimensional Markov Chain Monte Carlo Methods Jesse Kolb, Vedran Lekić (Univ. of MD) Supervisor: Kris Innanen Motivation for Different Inversion Technique Inversion techniques typically provide a single
Transdimensional Markov Chain Monte Carlo Methods Jesse Kolb, Vedran Lekić (Univ. of MD) Supervisor: Kris Innanen Motivation for Different Inversion Technique Inversion techniques typically provide a single
Bayes Nets: Sampling
 Bayes Nets: Sampling [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.] Approximate Inference:
Bayes Nets: Sampling [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.] Approximate Inference:
MSc MT15. Further Statistical Methods: MCMC. Lecture 5-6: Markov chains; Metropolis Hastings MCMC. Notes and Practicals available at
 MSc MT15. Further Statistical Methods: MCMC Lecture 5-6: Markov chains; Metropolis Hastings MCMC Notes and Practicals available at www.stats.ox.ac.uk\ nicholls\mscmcmc15 Markov chain Monte Carlo Methods
MSc MT15. Further Statistical Methods: MCMC Lecture 5-6: Markov chains; Metropolis Hastings MCMC Notes and Practicals available at www.stats.ox.ac.uk\ nicholls\mscmcmc15 Markov chain Monte Carlo Methods