Using Local Spectral Methods in Theory and in Practice
|
|
|
- Christal Warner
- 6 years ago
- Views:
Transcription
1 Using Local Spectral Methods in Theory and in Practice Michael W. Mahoney ICSI and Dept of Statistics, UC Berkeley ( For more info, see: http: // www. stat. berkeley. edu/ ~ mmahoney or Google on Michael Mahoney ) December /33
2 Global spectral methods Given the Laplacian L of a graph G = (V, E), solve the following: minimize x T Lx subject to x T Dx = 1 x T D1 = 0 Good News: Things one can prove about this. Solution can be found by computing an eigenvector of L. Solution can be found by running a random walk to. Solution is quadratically good (i.e., Cheeger s Inequality). Solution can be used for clustering, classification, ranking, etc. Bad News: This is a very global thing and so often not useful. Can we localize it in some meaningful way? 2/33
3 Outline Motivation 1: Social and information networks Motivation 2: Machine learning data graphs Local spectral methods in worst-case theory Local spectral methods to robustify graph construction
4 Networks and networked data Lots of networked data!! technological networks (AS, power-grid, road networks) biological networks (food-web, protein networks) social networks (collaboration networks, friendships) information networks (co-citation, blog cross-postings, advertiser-bidded phrase graphs...) language networks (semantic networks...)... Interaction graph model of networks: Nodes represent entities Edges represent interaction between pairs of entities 4/33
5 Three different types of real networks conductance size CA-GrQc FB-Johns55 US-Senate (a) NCP: conductance value of best conductance set, as function of size conductance ratio size CA-GrQc FB-Johns55 US-Senate (b) CRP: ratio of internal to external conductance, as function of size (c) CA-GrQc (d) FB-Johns55 (e) US-Senate 5/33

6 Information propagates local-to-glocal in different networks in different ways 6/33
7 Outline Motivation 1: Social and information networks Motivation 2: Machine learning data graphs Local spectral methods in worst-case theory Local spectral methods to robustify graph construction
8 Use case 1 : Galactic spectra from SDSS x i R 3841, N 500k photon fluxes in 10 Å wavelength bins preprocessing corrects for redshift, gappy regions normalized by median flux at certain wavelengths raw spectrum in observed frame raw spectrum in rest frame gap corrected spectrum in rest frame Also results in neuroscience as well as genetics and mass spec imaging. 8/33
")
 blue galaxy")
")
9 Red vs. blue galaxies (a) red galaxy image (b) blue galaxy image (c) red galaxy spectrum (d) blue galaxy spectrum 9/33
10 Dimension reduction in astronomy An incomplete history: (Connolly et al., 1995): principal components analysis (Vanderplas & Connolly, 2009): locally linear embedding (Richards et al., 2009): diffusion maps regression (Yip, Mahoney, et al., 2013): CUR low-rank decompositions Here: Apply global/local spectral methods to astronomical spectra Address both nonlinear structure and nonuniform density Explore locally-biased versions of these embeddings for a downstream classification task 10/33
11 Constructing global diffusion embeddings (Belkin & Niyogi, 2003; Coifman & Lafon, 2006) Given data {x j } N j=1, form graph with edge weights W ij = exp ( x i x j 2 ), D ii = ε i ε j j W ij In practice, only add k nearest-neighbor edges Set ε i = distance to point i s k/2 nearest-neighbor The lazy transition matrix is M = 1 2 D 1/2 (D + W )D 1/2 Embedding given by leading non-trivial eigenvectors of M 11/33
12 Global embedding: effect of k Figure: Eigenvectors 3 and 4 of Lazy Markov operator, k = 2 : /33
13 Global embedding: average spectra A5 scaled flux + offset A4 A3 A2 A wavelength (10 10 m) R5 scaled flux + offset E5 scaled flux + offset R4 E4 R3 E3 R2 E2 E wavelength (10 10 m) wavelength (10 10 m) R1 13/33
14 Optimization approach to global spectral methods Markov matrix related to combinatorial graph Laplacian L: L def = D W = 2D 1/2 (I M)D 1/2 Can write v 2, the first nontrivial eigenvector of L, as the solution to minimize x T Lx subject to x T Dx = 1 x T D1 = 0 Similarly for v t with additional constraints x T Dv j = 0, j < t. Theorem. Solution can be found by computing an eigenvector. It it is quadratically good (i.e., Cheeger s Inequality). 14/33
15 MOV optimization approach to local spectral methods (Mahoney, Orecchia, and Vishnoi, 2009; Hansen and Mahoney, 2013; Lawlor, Budavari, Mahoney, 2015) Suppose we have: 1. a seed vector s = χ S, where S is a subset of data points 2. a correlation parameter κ MOV objective. The first semi-supervised eigenvector w 2 solves: minimize x T Lx subject to x T Dx = 1 x T D1 = 0 x T Ds κ Similarly for w t with addition constraints x T Dw j = 0, j < t. Theorem. Solution can be found by solving a linear equation. It is quadratically good (with a local version of Cheeger s Inequality). 15/33
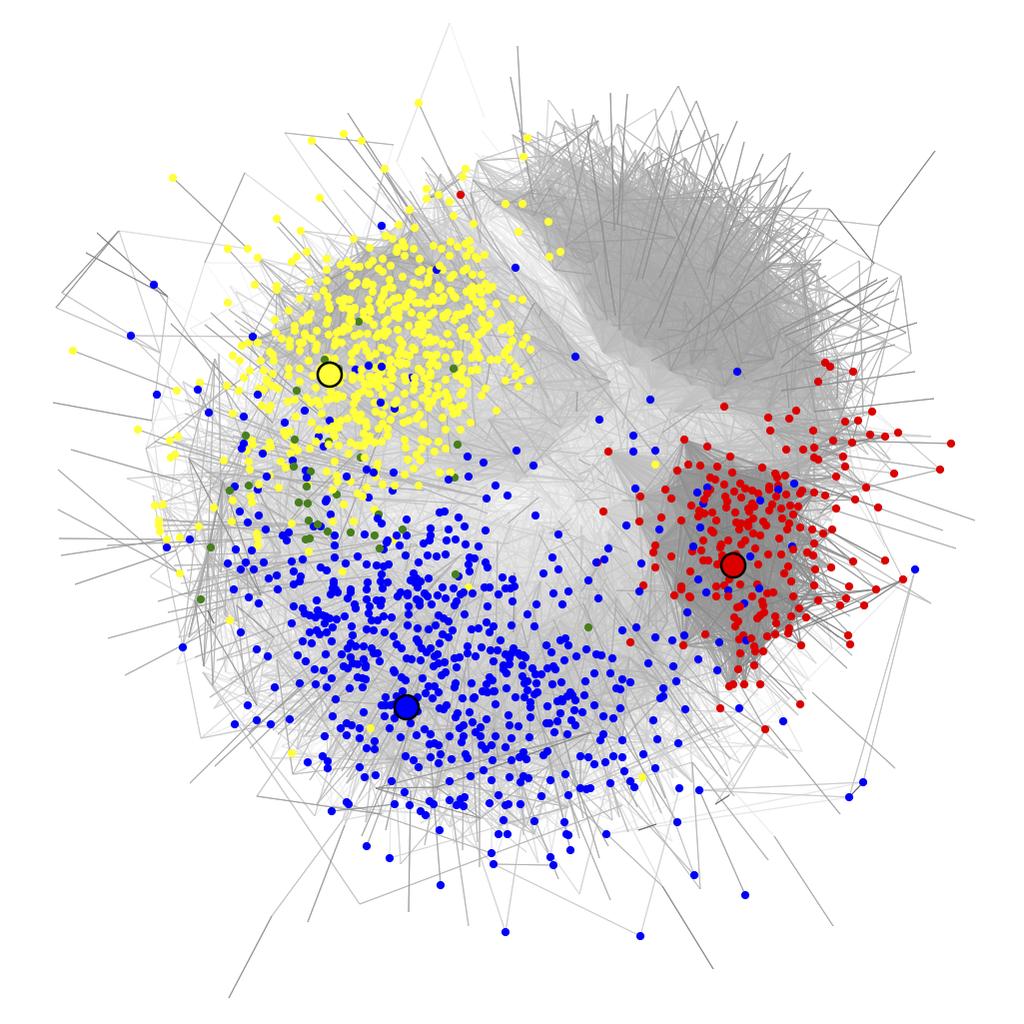
16 Local embedding: scale parameter and effect of seed For an appropriate choice of c and γ = γ(κ) < λ 2, one can show w 2 = c(l γd) + Ds = c(l G γl kn ) + Ds (In practice, binary search to find correct γ.) Figure: (left) Global embedding with seeds in black. (middle, right) Local embeddings using specified seeds. 16/33

 Global embedding, colored by class.")
17 Classification on global and local embeddings Try to reproduce 5 astronomer-defined classes Train multiclass logistic regression on global and local embeddings Seeds chosen to discriminate one class (e.g., AGN) vs. rest Figure: (left) Global embedding, colored by class. (middle, right) Confusion matrices for classification on global and local embeddings. 17/33
18 Outline Motivation 1: Social and information networks Motivation 2: Machine learning data graphs Local spectral methods in worst-case theory Local spectral methods to robustify graph construction
19 Local versus global spectral methods Global spectral methods: Compute eigenvectors of matrices related to the graph. Provide quadratically good approximations to the best partitioning of the graph (Cheeger s Inequality). This provide inference control for classification, regression, etc. Local spectral methods: Use random walks to find locally-biased partitions in large graphs. Can prove locally-biased versions of Cheeger s Inequality. Scalable worst-case running time; non-trivial statistical properties. Success stories for local spectral methods: Getting nearly-linear time Laplacian-based linear solvers. For finding local clusters in very large graphs. For analyzing large social and information graphs. 19/33
20 Two different types of local spectral methods Strongly-local methods: ST; ACL; C; AP: run short random walks. Theorem: If there is a small cluster near the seed node, they you will find it, otherwise you will stop; and running time depends on size of output, not the graph. You don t even touch most of the nodes in a large graph. Very good in practice, especially the ACL push algorithm. Weakly-local methods: MOV; HM: optimization objective with locality constraints. Theorem: If there is a small cluster near the seed node, they you will find it, otherwise you will stop; and running time depends on time to solve linear systems. You do touch all of the nodes in a large graph. Many semi-supervised learning methods have similar form. 20/33
21 The ACL push procedure 1. x (1) = 0, r (1) = (1 β) e i, k = 1 2. while any r j > τd j d j is the degree of node j 3. x (k+1) = x (k) + (r j τd j ρ) e j τd j ρ i = j 4. x (k+1) i = r (k) i + β(r j τd j ρ)/d j i j otherwise 5. k k + 1 r (k) i Things to note: This approximates the solution to the personalized PageRank problem: (I βad 1 ) x = (1 β) v; { (I βa) y = (1 β)d 1/2 v, where A = D 1/2 AD 1/2 x = D 1/2 y [αd + L] z = α v, where β = 1/(1 + α) and x = D z. The global invariant r = (1 β) v (I βad 1 ) x is maintained throughout, even though r and x are supported locally. Question: What does this algorithm compute approximately or exactly? 21/33
22 ACL theory, TCS style Informally, here is the ACL algorithm: Diffuse from a localized seed set of nodes. Maintain two localized vectors such that a global invariant is satisfied. Stop according to a stopping rule. Informally, here is the ACL worst-case theory: If there is a good conductance cluster near the initial seed set, then the algorithm will find it, and otherwise it will stop. The output satisfied Cheeger-like quality-of-approximation guarantees. The running time of the algorithm depends on the size of the output but is independent of the size of the graph. Note: This is an approximation algorithm. Question: What does this algorithm compute exactly? 22/33
23 Constructing graphs that algorithms implicitly optimize Given G = (V, E), add extra nodes, s and t, with weights connected to nodes in S V or to S. Then, the s, t-minimum cut problem is: min B x C,1 = x s =1,x t =0 The l 2-minorant of this problem is: min B x C,2 = x s =1,x t =0 or, equivalently, of this problem: 1 min x s =1,x t =0 2 B x 2 C,2 = 1 2 (u,v) E (u,v) E (u,v) E C (u,v) x u x v C (u,v) x u x v 2 C (u,v) x u x v 2 = 1 2 x T L x 23/33
24 Implicit regularization in the ACL approximation algorithm Let B(S) be the incidence matrix for the localized cut graph, for vertex subset S, and let C(α) be the edge-weight matrix. Theorem. The PageRank vector z that solves (αd + L) z = α v, with v = d S /vol(s) is a renormalized solution of the 2-norm cut computation: min x s=1,x t=0 B(S) x C(α),2. Theorem. Let x be the output from the ACL push procedure, set parameters right, and let z G be the solution of: 1 min z s=1,z t=0, z 0 2 B(S) z 2 C(α),2 + κ D z 1, where z = (1 z G 0) T. Then x = D z G /vol(s). 24/33
25 Outline Motivation 1: Social and information networks Motivation 2: Machine learning data graphs Local spectral methods in worst-case theory Local spectral methods to robustify graph construction
26 Problems that arise with explicit graph construction Question: What is the effct of noise or perturbations or arbitrary decisions in the construction of the graph on the output of the subsequent graph algorithm. Common problems with constructing graphs. Problems with edges/nonedges in explicit graphs (where arbitrary decisions are hidden from the user). Problems with edges/nonedges in constructed graphs (where arbitrary decisions are made by the user). Problems with labels associated with the nodes or edges (since the ground truth may be unreliable). 26/33
27 Semi-supervised learning and implicit graph construction Zhou et al. Andersen-Lang Joachims ZGL 3α 4α 5α 4α 5α α s 5α 3α α 4α 6α 5α 3α 5α 4α 5α t 2α 4α s 5α 3α t 5α 6α 5α 3α 5α 4α 5α 2α 1 s t s t (a) Zhou (b) AL (c) Joachims (d) ZGL Figure: The s, t-cut graphs associated with four different constructions for semi-supervised learning on a graph. The labeled nodes are indicated by the blue and red colors. This construction is to predict the blue-class. To do semi-supervised learning, these methods propose a diffusion equation: Y = (L + αd) 1 S. This equation propagates labels from a small set S of labeled nodes. This is equivalent to the minorant of an s, t-cut problem where the problem varies based on the class. This is exactly the MOV local spectral formulation that ACL approximates the solution of and exactly solves a regularized version of. 27/33
28 Comparing diffusions: sparse and dense graphs, low and high error rates number of mistakes number of labels (a) dense; low label error number of mistakes number of labels (b) sparse; low label error number of mistakes number of labels (c) dense; high label error number of mistakes Joachims Zhou ZGL 5 10 number of labels (d) sparse; high label error 28/33
29 Case study with toy digits data set Zhou Zhou+Push Zhou Zhou+Push error rate 0.2 error rate σ (e) Varying σ nearest neighbors (f) Varying nearest neighbors Performance of the diffusions while varying the density by changing (a) σ or (b) varying r in the nearest neighbor construction. In both cases, making the graph denser results in worse performance. 29/33
30 Densifying sparse graphs with matrix polynomials Do it the usual way: Vary the kernel density width parameter σ. Convert the weighted graph into a highly sparse unweighted graph through a nearest neighbor construction. Do it by coundint paths of different lengths: Run the A k construction: given a graph with adjacency matrix A, the graph A k counts the number of paths of length up to k between pairs of nodes: A k = k A l. That is, oversparsify, compute A k for k = 2, 3, 4, and then do nearest neighbor construction. l=1 (BTW, this is essentially what local spectral methods do.) 30/33
31 Error rates on densified sparse graphs Neighs. Avg. Deg Neighs. k Avg. Deg Table: Paired sets of parameters that give us the same non-zeros in a nearest neighbor graph and a densified nearest neighborgraph A k. Zhou Zhou w. Push Avg. Deg k = 1 k 1 k = 1 k Table: Median error rates show the benefit to densifying a sparse graph with the A k construction. Using average degree of 138 outperforms all of the nearest neighbor trials from previous figure. 31/33
32 Pictorial illustration Avoidable errors Unavoidable errors Correct (g) Zhou on sparse graph (h) Zhou on dense graph (i) Zhou+Push on sparse graph (j) Zhou+Push on dense graph We artificially densify this graph to A k (for k = 2, 3, 4, 5) to compare sparse and dense diffusions and implicit ACL regularization. (Unavoidable errors are caused by a mislabeled node.) Things to note: On dense graphs, regularizing diffusions has smaller effect (b vs. d). In sparse graphs, regularizing diffusions has bigger effect (a vs. c). Regularized diffusions less sensitive to density changes than unregularized diffusions (c vs. d). 32/33
33 Conclusion Many real data graphs are very not nice: data analysis design decisions are often reasonable but somewhat arbitrary noise from label errors, node/edge errors, arbitrary decisions hurt diffusion-bsed algorithms in different ways Many preprocessing design decisions make data more nice: good when algorithm users do it it helps algorithms return something meaningful bad when algorithm developers do it algorithms don t get stress-tested on not nice data Local and locally-biased spectral algorithms: have very nice algorithmic and statistical properties can also be used to robustify the graph construction step to arbitrariness of data preprocessing decisions 33/33
Locally-biased analytics
 Locally-biased analytics You have BIG data and want to analyze a small part of it: Solution 1: Cut out small part and use traditional methods Challenge: cutting out may be difficult a priori Solution 2:
Locally-biased analytics You have BIG data and want to analyze a small part of it: Solution 1: Cut out small part and use traditional methods Challenge: cutting out may be difficult a priori Solution 2:
Lecture: Local Spectral Methods (1 of 4)
") Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Lecture: Local Spectral Methods (3 of 4) 20 An optimization perspective on local spectral methods
 20 An optimization perspective on local spectral methods") Stat260/CS294: Spectral Graph Methods Lecture 20-04/07/205 Lecture: Local Spectral Methods (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 20-04/07/205 Lecture: Local Spectral Methods (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Facebook Friends! and Matrix Functions
 Facebook Friends! and Matrix Functions! Graduate Research Day Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Network Analysis Use linear algebra
Facebook Friends! and Matrix Functions! Graduate Research Day Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Network Analysis Use linear algebra
Lecture: Local Spectral Methods (2 of 4) 19 Computing spectral ranking with the push procedure
 19 Computing spectral ranking with the push procedure") Stat260/CS294: Spectral Graph Methods Lecture 19-04/02/2015 Lecture: Local Spectral Methods (2 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 19-04/02/2015 Lecture: Local Spectral Methods (2 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Exploiting Sparse Non-Linear Structure in Astronomical Data
 Exploiting Sparse Non-Linear Structure in Astronomical Data Ann B. Lee Department of Statistics and Department of Machine Learning, Carnegie Mellon University Joint work with P. Freeman, C. Schafer, and
Exploiting Sparse Non-Linear Structure in Astronomical Data Ann B. Lee Department of Statistics and Department of Machine Learning, Carnegie Mellon University Joint work with P. Freeman, C. Schafer, and
Graph Partitioning Using Random Walks
 Graph Partitioning Using Random Walks A Convex Optimization Perspective Lorenzo Orecchia Computer Science Why Spectral Algorithms for Graph Problems in practice? Simple to implement Can exploit very efficient
Graph Partitioning Using Random Walks A Convex Optimization Perspective Lorenzo Orecchia Computer Science Why Spectral Algorithms for Graph Problems in practice? Simple to implement Can exploit very efficient
Three right directions and three wrong directions for tensor research
 Three right directions and three wrong directions for tensor research Michael W. Mahoney Stanford University ( For more info, see: http:// cs.stanford.edu/people/mmahoney/ or Google on Michael Mahoney
Three right directions and three wrong directions for tensor research Michael W. Mahoney Stanford University ( For more info, see: http:// cs.stanford.edu/people/mmahoney/ or Google on Michael Mahoney
Spectral Graph Theory and its Applications. Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity
 Spectral Graph Theory and its Applications Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity Outline Adjacency matrix and Laplacian Intuition, spectral graph drawing
Spectral Graph Theory and its Applications Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity Outline Adjacency matrix and Laplacian Intuition, spectral graph drawing
First, parse the title...
 First, parse the title... Eigenvector localization: Eigenvectors are usually global entities But they can be localized in extremely sparse/noisy graphs/matrices Implicit regularization: Usually exactly
First, parse the title... Eigenvector localization: Eigenvectors are usually global entities But they can be localized in extremely sparse/noisy graphs/matrices Implicit regularization: Usually exactly
Lecture: Some Practical Considerations (3 of 4)
") Stat260/CS294: Spectral Graph Methods Lecture 14-03/10/2015 Lecture: Some Practical Considerations (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Stat260/CS294: Spectral Graph Methods Lecture 14-03/10/2015 Lecture: Some Practical Considerations (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Mapping the Similarities of Spectra: Global and Locally-biased Approaches to SDSS Galaxy Data
 Mapping the Similarities of Spectra: Global and Locally-biased Approaches to SDSS Galaxy Data David Lawlor 1,2, Tamás Budavári 3, and Michael W. Mahoney 4,5 arxiv:1609.03932v1 [astro-ph.im] 13 Sep 2016
Mapping the Similarities of Spectra: Global and Locally-biased Approaches to SDSS Galaxy Data David Lawlor 1,2, Tamás Budavári 3, and Michael W. Mahoney 4,5 arxiv:1609.03932v1 [astro-ph.im] 13 Sep 2016
Semi-supervised Eigenvectors for Locally-biased Learning
 Semi-supervised Eigenvectors for Locally-biased Learning Toke Jansen Hansen Section for Cognitive Systems DTU Informatics Technical University of Denmark tjha@imm.dtu.dk Michael W. Mahoney Department of
Semi-supervised Eigenvectors for Locally-biased Learning Toke Jansen Hansen Section for Cognitive Systems DTU Informatics Technical University of Denmark tjha@imm.dtu.dk Michael W. Mahoney Department of
Learning gradients: prescriptive models
 Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Spectral Graph Theory Lecture 2. The Laplacian. Daniel A. Spielman September 4, x T M x. ψ i = arg min
 Spectral Graph Theory Lecture 2 The Laplacian Daniel A. Spielman September 4, 2015 Disclaimer These notes are not necessarily an accurate representation of what happened in class. The notes written before
Spectral Graph Theory Lecture 2 The Laplacian Daniel A. Spielman September 4, 2015 Disclaimer These notes are not necessarily an accurate representation of what happened in class. The notes written before
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH
 HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
Predicting Graph Labels using Perceptron. Shuang Song
 Predicting Graph Labels using Perceptron Shuang Song shs037@eng.ucsd.edu Online learning over graphs M. Herbster, M. Pontil, and L. Wainer, Proc. 22nd Int. Conf. Machine Learning (ICML'05), 2005 Prediction
Predicting Graph Labels using Perceptron Shuang Song shs037@eng.ucsd.edu Online learning over graphs M. Herbster, M. Pontil, and L. Wainer, Proc. 22nd Int. Conf. Machine Learning (ICML'05), 2005 Prediction
CMPSCI 791BB: Advanced ML: Laplacian Learning
 CMPSCI 791BB: Advanced ML: Laplacian Learning Sridhar Mahadevan Outline! Spectral graph operators! Combinatorial graph Laplacian! Normalized graph Laplacian! Random walks! Machine learning on graphs! Clustering!
CMPSCI 791BB: Advanced ML: Laplacian Learning Sridhar Mahadevan Outline! Spectral graph operators! Combinatorial graph Laplacian! Normalized graph Laplacian! Random walks! Machine learning on graphs! Clustering!
Graphs, Geometry and Semi-supervised Learning
 Graphs, Geometry and Semi-supervised Learning Mikhail Belkin The Ohio State University, Dept of Computer Science and Engineering and Dept of Statistics Collaborators: Partha Niyogi, Vikas Sindhwani In
Graphs, Geometry and Semi-supervised Learning Mikhail Belkin The Ohio State University, Dept of Computer Science and Engineering and Dept of Statistics Collaborators: Partha Niyogi, Vikas Sindhwani In
Lecture 24: Element-wise Sampling of Graphs and Linear Equation Solving. 22 Element-wise Sampling of Graphs and Linear Equation Solving
 Stat260/CS294: Randomized Algorithms for Matrices and Data Lecture 24-12/02/2013 Lecture 24: Element-wise Sampling of Graphs and Linear Equation Solving Lecturer: Michael Mahoney Scribe: Michael Mahoney
Stat260/CS294: Randomized Algorithms for Matrices and Data Lecture 24-12/02/2013 Lecture 24: Element-wise Sampling of Graphs and Linear Equation Solving Lecturer: Michael Mahoney Scribe: Michael Mahoney
Spectral Clustering. Guokun Lai 2016/10
 Spectral Clustering Guokun Lai 2016/10 1 / 37 Organization Graph Cut Fundamental Limitations of Spectral Clustering Ng 2002 paper (if we have time) 2 / 37 Notation We define a undirected weighted graph
Spectral Clustering Guokun Lai 2016/10 1 / 37 Organization Graph Cut Fundamental Limitations of Spectral Clustering Ng 2002 paper (if we have time) 2 / 37 Notation We define a undirected weighted graph
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
Four graph partitioning algorithms. Fan Chung University of California, San Diego
 Four graph partitioning algorithms Fan Chung University of California, San Diego History of graph partitioning NP-hard approximation algorithms Spectral method, Fiedler 73, Folklore Multicommunity flow,
Four graph partitioning algorithms Fan Chung University of California, San Diego History of graph partitioning NP-hard approximation algorithms Spectral method, Fiedler 73, Folklore Multicommunity flow,
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking p. 1/31
 Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
A New Space for Comparing Graphs
 A New Space for Comparing Graphs Anshumali Shrivastava and Ping Li Cornell University and Rutgers University August 18th 2014 Anshumali Shrivastava and Ping Li ASONAM 2014 August 18th 2014 1 / 38 Main
A New Space for Comparing Graphs Anshumali Shrivastava and Ping Li Cornell University and Rutgers University August 18th 2014 Anshumali Shrivastava and Ping Li ASONAM 2014 August 18th 2014 1 / 38 Main
A Local Spectral Method for Graphs: With Applications to Improving Graph Partitions and Exploring Data Graphs Locally
 Journal of Machine Learning Research 13 (2012) 2339-2365 Submitted 11/12; Published 9/12 A Local Spectral Method for Graphs: With Applications to Improving Graph Partitions and Exploring Data Graphs Locally
Journal of Machine Learning Research 13 (2012) 2339-2365 Submitted 11/12; Published 9/12 A Local Spectral Method for Graphs: With Applications to Improving Graph Partitions and Exploring Data Graphs Locally
Cutting Graphs, Personal PageRank and Spilling Paint
 Graphs and Networks Lecture 11 Cutting Graphs, Personal PageRank and Spilling Paint Daniel A. Spielman October 3, 2013 11.1 Disclaimer These notes are not necessarily an accurate representation of what
Graphs and Networks Lecture 11 Cutting Graphs, Personal PageRank and Spilling Paint Daniel A. Spielman October 3, 2013 11.1 Disclaimer These notes are not necessarily an accurate representation of what
An Optimization Approach to Locally-Biased Graph Algorithms
 An Optimization Approach to Locally-Biased Graph Algorithms his paper investigates a class of locally-biased graph algorithms for finding local or small-scale structures in large graphs. By K imon Fou
An Optimization Approach to Locally-Biased Graph Algorithms his paper investigates a class of locally-biased graph algorithms for finding local or small-scale structures in large graphs. By K imon Fou
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering
 Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
How to learn from very few examples?
 How to learn from very few examples? Dengyong Zhou Department of Empirical Inference Max Planck Institute for Biological Cybernetics Spemannstr. 38, 72076 Tuebingen, Germany Outline Introduction Part A
How to learn from very few examples? Dengyong Zhou Department of Empirical Inference Max Planck Institute for Biological Cybernetics Spemannstr. 38, 72076 Tuebingen, Germany Outline Introduction Part A
Spectral Graph Theory and You: Matrix Tree Theorem and Centrality Metrics
 Spectral Graph Theory and You: and Centrality Metrics Jonathan Gootenberg March 11, 2013 1 / 19 Outline of Topics 1 Motivation Basics of Spectral Graph Theory Understanding the characteristic polynomial
Spectral Graph Theory and You: and Centrality Metrics Jonathan Gootenberg March 11, 2013 1 / 19 Outline of Topics 1 Motivation Basics of Spectral Graph Theory Understanding the characteristic polynomial
Regularized Laplacian Estimation and Fast Eigenvector Approximation
 Regularized Laplacian Estimation and Fast Eigenvector Approximation Patrick O. Perry Information, Operations, and Management Sciences NYU Stern School of Business New York, NY 1001 pperry@stern.nyu.edu
Regularized Laplacian Estimation and Fast Eigenvector Approximation Patrick O. Perry Information, Operations, and Management Sciences NYU Stern School of Business New York, NY 1001 pperry@stern.nyu.edu
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Personal PageRank and Spilling Paint
 Graphs and Networks Lecture 11 Personal PageRank and Spilling Paint Daniel A. Spielman October 7, 2010 11.1 Overview These lecture notes are not complete. The paint spilling metaphor is due to Berkhin
Graphs and Networks Lecture 11 Personal PageRank and Spilling Paint Daniel A. Spielman October 7, 2010 11.1 Overview These lecture notes are not complete. The paint spilling metaphor is due to Berkhin
Graph Metrics and Dimension Reduction
 Graph Metrics and Dimension Reduction Minh Tang 1 Michael Trosset 2 1 Applied Mathematics and Statistics The Johns Hopkins University 2 Department of Statistics Indiana University, Bloomington November
Graph Metrics and Dimension Reduction Minh Tang 1 Michael Trosset 2 1 Applied Mathematics and Statistics The Johns Hopkins University 2 Department of Statistics Indiana University, Bloomington November
Fitting a Graph to Vector Data. Samuel I. Daitch (Yale) Jonathan A. Kelner (MIT) Daniel A. Spielman (Yale)
 Jonathan A. Kelner (MIT) Daniel A. Spielman (Yale)") Fitting a Graph to Vector Data Samuel I. Daitch (Yale) Jonathan A. Kelner (MIT) Daniel A. Spielman (Yale) Machine Learning Summer School, June 2009 Given a collection of vectors x 1,..., x n IR d 1,, n
Fitting a Graph to Vector Data Samuel I. Daitch (Yale) Jonathan A. Kelner (MIT) Daniel A. Spielman (Yale) Machine Learning Summer School, June 2009 Given a collection of vectors x 1,..., x n IR d 1,, n
Lecture 13: Spectral Graph Theory
 CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 13: Spectral Graph Theory Lecturer: Shayan Oveis Gharan 11/14/18 Disclaimer: These notes have not been subjected to the usual scrutiny reserved
CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 13: Spectral Graph Theory Lecturer: Shayan Oveis Gharan 11/14/18 Disclaimer: These notes have not been subjected to the usual scrutiny reserved
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
 Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Analysis of Spectral Kernel Design based Semi-supervised Learning
 Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Networks and Their Spectra
 Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
Algorithmic Primitives for Network Analysis: Through the Lens of the Laplacian Paradigm
 Algorithmic Primitives for Network Analysis: Through the Lens of the Laplacian Paradigm Shang-Hua Teng Computer Science, Viterbi School of Engineering USC Massive Data and Massive Graphs 500 billions web
Algorithmic Primitives for Network Analysis: Through the Lens of the Laplacian Paradigm Shang-Hua Teng Computer Science, Viterbi School of Engineering USC Massive Data and Massive Graphs 500 billions web
Graphs, Vectors, and Matrices Daniel A. Spielman Yale University. AMS Josiah Willard Gibbs Lecture January 6, 2016
 Graphs, Vectors, and Matrices Daniel A. Spielman Yale University AMS Josiah Willard Gibbs Lecture January 6, 2016 From Applied to Pure Mathematics Algebraic and Spectral Graph Theory Sparsification: approximating
Graphs, Vectors, and Matrices Daniel A. Spielman Yale University AMS Josiah Willard Gibbs Lecture January 6, 2016 From Applied to Pure Mathematics Algebraic and Spectral Graph Theory Sparsification: approximating
Nonlinear Data Transformation with Diffusion Map
 Nonlinear Data Transformation with Diffusion Map Peter Freeman Ann Lee Joey Richards* Chad Schafer Department of Statistics Carnegie Mellon University www.incagroup.org * now at U.C. Berkeley t! " 3 3
Nonlinear Data Transformation with Diffusion Map Peter Freeman Ann Lee Joey Richards* Chad Schafer Department of Statistics Carnegie Mellon University www.incagroup.org * now at U.C. Berkeley t! " 3 3
Link Prediction. Eman Badr Mohammed Saquib Akmal Khan
 Link Prediction Eman Badr Mohammed Saquib Akmal Khan 11-06-2013 Link Prediction Which pair of nodes should be connected? Applications Facebook friend suggestion Recommendation systems Monitoring and controlling
Link Prediction Eman Badr Mohammed Saquib Akmal Khan 11-06-2013 Link Prediction Which pair of nodes should be connected? Applications Facebook friend suggestion Recommendation systems Monitoring and controlling
Laplacian Matrices of Graphs: Spectral and Electrical Theory
 Laplacian Matrices of Graphs: Spectral and Electrical Theory Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale University Toronto, Sep. 28, 2 Outline Introduction to graphs
Laplacian Matrices of Graphs: Spectral and Electrical Theory Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale University Toronto, Sep. 28, 2 Outline Introduction to graphs
Data-dependent representations: Laplacian Eigenmaps
 Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Is Manifold Learning for Toy Data only?
 s Manifold Learning for Toy Data only? Marina Meilă University of Washington mmp@stat.washington.edu MMDS Workshop 2016 Outline What is non-linear dimension reduction? Metric Manifold Learning Estimating
s Manifold Learning for Toy Data only? Marina Meilă University of Washington mmp@stat.washington.edu MMDS Workshop 2016 Outline What is non-linear dimension reduction? Metric Manifold Learning Estimating
Lecture 14: Random Walks, Local Graph Clustering, Linear Programming
 CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 14: Random Walks, Local Graph Clustering, Linear Programming Lecturer: Shayan Oveis Gharan 3/01/17 Scribe: Laura Vonessen Disclaimer: These
CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 14: Random Walks, Local Graph Clustering, Linear Programming Lecturer: Shayan Oveis Gharan 3/01/17 Scribe: Laura Vonessen Disclaimer: These
Contribution from: Springer Verlag Berlin Heidelberg 2005 ISBN
 Contribution from: Mathematical Physics Studies Vol. 7 Perspectives in Analysis Essays in Honor of Lennart Carleson s 75th Birthday Michael Benedicks, Peter W. Jones, Stanislav Smirnov (Eds.) Springer
Contribution from: Mathematical Physics Studies Vol. 7 Perspectives in Analysis Essays in Honor of Lennart Carleson s 75th Birthday Michael Benedicks, Peter W. Jones, Stanislav Smirnov (Eds.) Springer
Graph-Based Semi-Supervised Learning
 Graph-Based Semi-Supervised Learning Olivier Delalleau, Yoshua Bengio and Nicolas Le Roux Université de Montréal CIAR Workshop - April 26th, 2005 Graph-Based Semi-Supervised Learning Yoshua Bengio, Olivier
Graph-Based Semi-Supervised Learning Olivier Delalleau, Yoshua Bengio and Nicolas Le Roux Université de Montréal CIAR Workshop - April 26th, 2005 Graph-Based Semi-Supervised Learning Yoshua Bengio, Olivier
Lecture: Flow-based Methods for Partitioning Graphs (1 of 2)
") Stat260/CS294: Spectral Graph Methods Lecture 10-02/24/2015 Lecture: Flow-based Methods for Partitioning Graphs (1 of 2) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still
Stat260/CS294: Spectral Graph Methods Lecture 10-02/24/2015 Lecture: Flow-based Methods for Partitioning Graphs (1 of 2) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still
Link Analysis Ranking
 Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Lecture: Some Statistical Inference Issues (2 of 3)
") Stat260/CS294: Spectral Graph Methods Lecture 23-04/16/2015 Lecture: Some Statistical Inference Issues (2 of 3) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Stat260/CS294: Spectral Graph Methods Lecture 23-04/16/2015 Lecture: Some Statistical Inference Issues (2 of 3) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Structured deep models: Deep learning on graphs and beyond
 Structured deep models: Deep learning on graphs and beyond Hidden layer Hidden layer Input Output ReLU ReLU, 25 May 2018 CompBio Seminar, University of Cambridge In collaboration with Ethan Fetaya, Rianne
Structured deep models: Deep learning on graphs and beyond Hidden layer Hidden layer Input Output ReLU ReLU, 25 May 2018 CompBio Seminar, University of Cambridge In collaboration with Ethan Fetaya, Rianne
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning
 Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Linear and Sublinear Linear Algebra Algorithms: Preconditioning Stochastic Gradient Algorithms with Randomized Linear Algebra
 Linear and Sublinear Linear Algebra Algorithms: Preconditioning Stochastic Gradient Algorithms with Randomized Linear Algebra Michael W. Mahoney ICSI and Dept of Statistics, UC Berkeley ( For more info,
Linear and Sublinear Linear Algebra Algorithms: Preconditioning Stochastic Gradient Algorithms with Randomized Linear Algebra Michael W. Mahoney ICSI and Dept of Statistics, UC Berkeley ( For more info,
Overview of Statistical Tools. Statistical Inference. Bayesian Framework. Modeling. Very simple case. Things are usually more complicated
 Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Algebraic Representation of Networks
 Algebraic Representation of Networks 0 1 2 1 1 0 0 1 2 0 0 1 1 1 1 1 Hiroki Sayama sayama@binghamton.edu Describing networks with matrices (1) Adjacency matrix A matrix with rows and columns labeled by
Algebraic Representation of Networks 0 1 2 1 1 0 0 1 2 0 0 1 1 1 1 1 Hiroki Sayama sayama@binghamton.edu Describing networks with matrices (1) Adjacency matrix A matrix with rows and columns labeled by
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Diffusion and random walks on graphs
 Diffusion and random walks on graphs Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural
Diffusion and random walks on graphs Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
Parallel Local Graph Clustering
 Parallel Local Graph Clustering Kimon Fountoulakis, joint work with J. Shun, X. Cheng, F. Roosta-Khorasani, M. Mahoney, D. Gleich University of California Berkeley and Purdue University Based on J. Shun,
Parallel Local Graph Clustering Kimon Fountoulakis, joint work with J. Shun, X. Cheng, F. Roosta-Khorasani, M. Mahoney, D. Gleich University of California Berkeley and Purdue University Based on J. Shun,
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian
 Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian Amit Singer Princeton University Department of Mathematics and Program in Applied and Computational Mathematics
Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian Amit Singer Princeton University Department of Mathematics and Program in Applied and Computational Mathematics
THE HIDDEN CONVEXITY OF SPECTRAL CLUSTERING
 THE HIDDEN CONVEXITY OF SPECTRAL CLUSTERING Luis Rademacher, Ohio State University, Computer Science and Engineering. Joint work with Mikhail Belkin and James Voss This talk A new approach to multi-way
THE HIDDEN CONVEXITY OF SPECTRAL CLUSTERING Luis Rademacher, Ohio State University, Computer Science and Engineering. Joint work with Mikhail Belkin and James Voss This talk A new approach to multi-way
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings
 Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
CS168: The Modern Algorithmic Toolbox Lectures #11 and #12: Spectral Graph Theory
 CS168: The Modern Algorithmic Toolbox Lectures #11 and #12: Spectral Graph Theory Tim Roughgarden & Gregory Valiant May 2, 2016 Spectral graph theory is the powerful and beautiful theory that arises from
CS168: The Modern Algorithmic Toolbox Lectures #11 and #12: Spectral Graph Theory Tim Roughgarden & Gregory Valiant May 2, 2016 Spectral graph theory is the powerful and beautiful theory that arises from
Communities, Spectral Clustering, and Random Walks
 Communities, Spectral Clustering, and Random Walks David Bindel Department of Computer Science Cornell University 26 Sep 2011 20 21 19 16 22 28 17 18 29 26 27 30 23 1 25 5 8 24 2 4 14 3 9 13 15 11 10 12
Communities, Spectral Clustering, and Random Walks David Bindel Department of Computer Science Cornell University 26 Sep 2011 20 21 19 16 22 28 17 18 29 26 27 30 23 1 25 5 8 24 2 4 14 3 9 13 15 11 10 12
Lecture 10. Lecturer: Aleksander Mądry Scribes: Mani Bastani Parizi and Christos Kalaitzis
 CS-621 Theory Gems October 18, 2012 Lecture 10 Lecturer: Aleksander Mądry Scribes: Mani Bastani Parizi and Christos Kalaitzis 1 Introduction In this lecture, we will see how one can use random walks to
CS-621 Theory Gems October 18, 2012 Lecture 10 Lecturer: Aleksander Mądry Scribes: Mani Bastani Parizi and Christos Kalaitzis 1 Introduction In this lecture, we will see how one can use random walks to
Lecture 12: Introduction to Spectral Graph Theory, Cheeger s inequality
 CSE 521: Design and Analysis of Algorithms I Spring 2016 Lecture 12: Introduction to Spectral Graph Theory, Cheeger s inequality Lecturer: Shayan Oveis Gharan May 4th Scribe: Gabriel Cadamuro Disclaimer:
CSE 521: Design and Analysis of Algorithms I Spring 2016 Lecture 12: Introduction to Spectral Graph Theory, Cheeger s inequality Lecturer: Shayan Oveis Gharan May 4th Scribe: Gabriel Cadamuro Disclaimer:
Randomized Algorithms
 Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Machine Learning for NLP
 Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
Heat Kernel Based Community Detection
 Heat Kernel Based Community Detection Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Local Community Detection Given seed(s) S in G, find a
Heat Kernel Based Community Detection Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Local Community Detection Given seed(s) S in G, find a
8.1 Concentration inequality for Gaussian random matrix (cont d)
") MGMT 69: Topics in High-dimensional Data Analysis Falll 26 Lecture 8: Spectral clustering and Laplacian matrices Lecturer: Jiaming Xu Scribe: Hyun-Ju Oh and Taotao He, October 4, 26 Outline Concentration
MGMT 69: Topics in High-dimensional Data Analysis Falll 26 Lecture 8: Spectral clustering and Laplacian matrices Lecturer: Jiaming Xu Scribe: Hyun-Ju Oh and Taotao He, October 4, 26 Outline Concentration
Learning on Graphs and Manifolds. CMPSCI 689 Sridhar Mahadevan U.Mass Amherst
 Learning on Graphs and Manifolds CMPSCI 689 Sridhar Mahadevan U.Mass Amherst Outline Manifold learning is a relatively new area of machine learning (2000-now). Main idea Model the underlying geometry of
Learning on Graphs and Manifolds CMPSCI 689 Sridhar Mahadevan U.Mass Amherst Outline Manifold learning is a relatively new area of machine learning (2000-now). Main idea Model the underlying geometry of
Probabilistic Machine Learning. Industrial AI Lab.
 Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering
 Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
Collaborative topic models: motivations cont
 Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
1 Searching the World Wide Web
 Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Semi-Supervised Learning
 Semi-Supervised Learning getting more for less in natural language processing and beyond Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning many human
Semi-Supervised Learning getting more for less in natural language processing and beyond Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning many human
Intrinsic Structure Study on Whale Vocalizations
 1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Unsupervised dimensionality reduction
 Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Markov Chains and Spectral Clustering
 Markov Chains and Spectral Clustering Ning Liu 1,2 and William J. Stewart 1,3 1 Department of Computer Science North Carolina State University, Raleigh, NC 27695-8206, USA. 2 nliu@ncsu.edu, 3 billy@ncsu.edu
Markov Chains and Spectral Clustering Ning Liu 1,2 and William J. Stewart 1,3 1 Department of Computer Science North Carolina State University, Raleigh, NC 27695-8206, USA. 2 nliu@ncsu.edu, 3 billy@ncsu.edu
An Introduction to Machine Learning
 An Introduction to Machine Learning L6: Structured Estimation Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune, January
An Introduction to Machine Learning L6: Structured Estimation Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune, January
Diffusion Wavelets and Applications
 Diffusion Wavelets and Applications J.C. Bremer, R.R. Coifman, P.W. Jones, S. Lafon, M. Mohlenkamp, MM, R. Schul, A.D. Szlam Demos, web pages and preprints available at: S.Lafon: www.math.yale.edu/~sl349
Diffusion Wavelets and Applications J.C. Bremer, R.R. Coifman, P.W. Jones, S. Lafon, M. Mohlenkamp, MM, R. Schul, A.D. Szlam Demos, web pages and preprints available at: S.Lafon: www.math.yale.edu/~sl349
DATA MINING LECTURE 13. Link Analysis Ranking PageRank -- Random walks HITS
 DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information