10. Linear Models and Maximum Likelihood Estimation
|
|
|
- Leslie Freeman
- 6 years ago
- Views:
Transcription
1 10. Linear Models and Maximum Likelihood Estimation ECE 830, Spring 2017 Rebecca Willett 1 / 34
2 Primary Goal General problem statement: We observe y i iid pθ, θ Θ and the goal is to determine the θ that produced {y i } n i=1. Given a collection of observations y 1,..., y n and a probability model p(y 1,..., y n θ) parameterized by the parameter θ, determine the value of θ that best matches the observations. 2 / 34
3 Estimation Using the Likelihood Definition: Likelihood function p(y θ) as a function of θ with y fixed is called the likelihood function. If the likelihood function carries the information about θ brought by the observations y = {y i } i, how do we use it to obtain an estimator? Definition: Maximum Likelihood Estimation θ MLE = arg max θ Θ p(y θ) is the value of θ that maximizes the density at y. Intuitively, we are choosing θ to maximize the probability of occurrence for y. 3 / 34
4 Maximum Likelihood Estimation MLEs are a very important type of estimator for the following reasons: MLE occurs naturally in composite hypothesis testing and signal detection (i.e., GLRT) The MLE is often simple and easy to compute MLEs are invariant under reparameterization MLEs often have asymptotic optimal properties (e.g. consistency (MSE 0 as N ) 4 / 34
5 Computing the MLE If the likelihood function is differentiable, then θ is found from log p(y θ) θ = 0 If multiple solutions exist, then the MLE is the solution that maximizes log p(y θ). That is, take the global maximizer. Note: It is possible to have multiple global maximizers that are all MLEs! 5 / 34
6 Example: Estimating the mean and variance of a Gaussian y i = A + ν i, ν i iid N (0, σ 2 ), i = 1,, n log p(y θ) A Note: σ 2 is biased! θ = [A, σ 2 ] = 1 n σ 2 (y i A) i=1 log p(y θ) σ 2 = n 2σ σ 4 Â = 1 n σ 2 = 1 n n i=1 y i n (y i A) 2 i=1 n (y i Â)2 i=1 6 / 34
7 Example: Stock Market (Dow-Jones Industrial Avg.) p({y i } i A, B) = 1 (2πσ 2 exp ) n/2 Based on this plot we might conjecture that the data is on average increasing. Probability model: y i = A + Bi + ν i A, B are unknown parameters, ν i white Gaussian noise to model fluctuations. { 1 2σ 2 } n (y i A Bi) 2 i=1 7 / 34

8 Example: A modern Example - Imaging Image processing can involve complicated estimation problems. For example, suppose we observe a moving object with noise. This image is blurry and noisy and our goal is to restore this image by debarring and denoising. 8 / 34
9 Example: A modern Example - Imaging We can model the moving part of the observed image as y = }{{} θ + }{{} ν noise-free blurry image noise = x}{{ w} +ν motion blur (convolution) where the parameter of interest w is the ideal (non-blurry) image and x represents the blur model or point spread function. Observation model: y =Xw + ν, ν N(0, σ 2 I) y N (Xw, σ 2 I) where X is a circulant matrix with the first row corresponding to x. 9 / 34
10 Linear Models and Subspaces The basic linear model is: θ = Xw where θ R n, X R n p with n > p is known and full rank, and w R p is a p-dimensional parameter or weight vector. In other words, we can write p θ = w i x i i=1 where w i is the i th element of w and x i is the i th column of X. We say that θ is in a subspace spanned by the columns of X 10 / 34
11 Subspaces Consider a set of vectors x 1, x 2,..., x p R n. The span of these vectors is the set of all vectors θ R n that can be generated from linear combinations of the set } p span ({x i } p i=1 {θ ) := : θ = w i x i, w 1,..., w p R i=1 p-dimensional subspace If the x 1,..., x p R n are linearly independent, then their span is a p-dimensional subspace of R n. Hence, even though the signal θ is a length-n vector, the fact that it lies in the subspace X means that it is actually a function of only p n free parameters or degrees of freedom. 11 / 34
12 Example: n = 3 x 1 = x 2 = X = span (x 1, x 2 ) = a b : a, b R Example: n = 3 x 1 = 1/ 2 1/ 2 0 X = span (x 1, x 2 ) = x 2 = a a b : a, b R 12 / 34
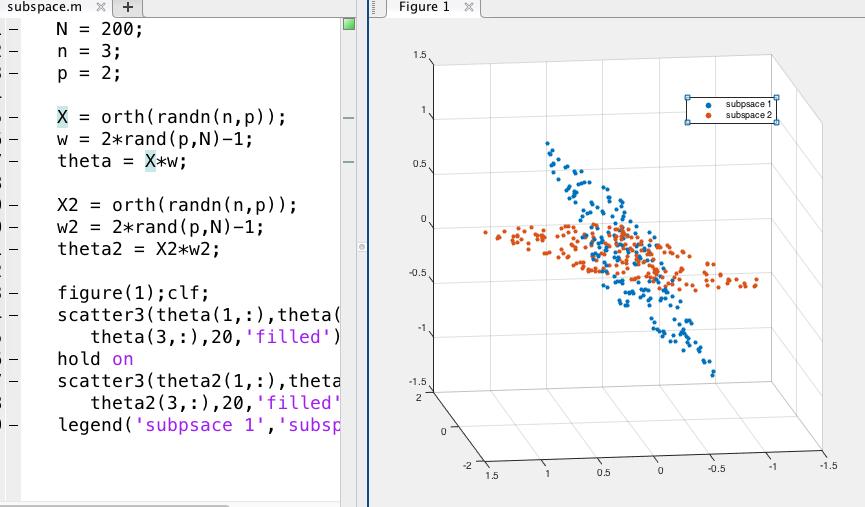
13 13 / 34
14 Examples Example: Constant subspace p = 1, X = x 1 = (1/ 1 n). R n 1 θ = x 1 w 1 is a constant signal with unknown amplitude. Example: Recommender system We have n movies in a database, and for a new client want to estimate how much they will like each movie, denoted θ R n. We have p existing archetype clients for whom we know their movie preferences; the preferences of the i th archetype client are denoted x i R n, i = 1,..., p. We will assume that θ is a weighted combination of these archetype profiles. 14 / 34

15 Example: Polynomial regression θ i = w 1 + w 2 i + w 3 i w p i p 1 X = Vandermonde matrix 15 / 34
16 Using subspace models Imagine we measure a function or signal in noise, y = θ + ν, where elements of ν are independent realizations from a Gaussian density and θ = Xw Question: How can we use knowledge of X to estimate θ from y? Let X be the subspace spanned by the columns of X, and let X be its orthogonal subspace. Then we can uniquely write y = u + v, where u X and v X. Since we know θ X, v can be considered pure noise and it makes sense to remove it. Answer: Orthogonal projection find the point in u X which is closest to the observed y. In general θ u because ν has some component in X. 16 / 34
 1 X y.")
17 Orthogonal projection Given a point y R n and subspace X, let s say we want to find the point ŷ X which is closest to y: ŷ = arg min θ y 2 θ X = arg min θ y 2 θ=xw,w Rp = arg min Xw y 2 θ=xw,w Rp = X (X X) 1 X y. }{{} pseudoinverse of X }{{} =:P X, projection matrix Essentially, we want to keep the component of y that lies in the subspace X and remove or kill the component in the orthogonal subspace. 17 / 34
18 Sinusoid subspace Example: Sinusoid subspace Let θ i = A cos(2πfi + φ), i = 1,..., n where frequency f is known but amplitude A and phase φ are unknown. Goal: estimate A and φ from where ν is white Gaussian noise. y = θ + ν First we need to express θ = [θ 1,..., θ n ] as an element in a 2-dimensional subspace; i.e. write θ = Xw where X is a known n 2 matrix and w is unknown. Then we can apply orthogonal projection. 18 / 34
19 Real solution: First note that cos(α + β) = cos(α) cos(β) sin(α) sin(β), so that θ i = A cos(2πfi + φ) = A cos(2πfi) cos(φ) A sin(2πfi) sin(φ). Let w 1 := A cos(φ) and w 2 := A sin(φ), and cos(2πf) sin(2πf) cos(4πf) sin(4πf) X =.. cos(2nπf) sin(2nπf). Note θ = Xw where X R n 2 and w R 2. Use pseudoinverse to compute ŵ, then set  = ŵ1 2 + ŵ2 2 φ = arctan( ŵ 2 /ŵ 1 ) 19 / 34
20 MLE and Linear Models When we observe y = θ + ν = Xw + ν and ν N (0, σ 2 I n ), then the MLE of w (and hence θ) can be computed by projection onto the subspace spanned by the columns of X. For more general probability models, the MLE may not have this form. Generalized linear models provide a unifying framework for modeling the relationship between y and w. The basic idea is that we define a link function g such that g(ey) = Xw. Typically there is no closed-form expression for ŵ MLE and it must be computed numerically. 20 / 34
21 Example: Colored Gaussian Noise y N (Xw, Σ), w R p, Σ, X known 1 p(y w) = (2π) n/2 Σ 1/2 exp{ 1 2 (y Xw) Σ 1 (y Xw)} The value of ŵ is given by, ŵ = arg min log p(y w) w = arg min (y w Xw) Σ 1 (y Xw) = (X Σ 1 X) 1 X Σ 1 y 21 / 34
22 Invariance of MLE Suppose we wish to estimate the function g = G(θ) and not θ itself. Intuitively we might try where θ is the MLE of θ. ĝ = G( θ) Remarkably, it turns out that ĝ is the MLE of g. This very special invariance principle is summarized in the following theorem. Theorem: Invariance of the MLE Let θ denote the MLE of θ. Then ĝ = G( θ) is the MLE of g = G(θ). 22 / 34
23 Example: Let y = [y 1,, y n ] where y i Poisson(λ). Given y, find the MLE of the probability that y Poisson(λ) exceeds the mean λ. G(λ) = P(y > λ) = λ λk e k! k= λ+1 ; z = largest integer z The MLE of g is ĝ = k= λ+1 λ λ k e k! where λ is the MLE of λ: λ = 1 n n i=1 y i 23 / 34
24 Sketch Proof: Define the induced log likelihood function: L(y g) max log p(y θ) θ:g(θ)=g Θ G g The MLE of g is ĝ = arg max L(y g) g = arg max g max θ:g(θ)=g log p(y θ) = G( θ), where θ = MLE of θ 24 / 34
25 Terminology in Estimation Theory Define ɛ( θ) := θ θ Recall that θ = θ(y) is a function of data = ɛ( θ) is a statistic! Mean Squared Error: Bias: Variance / Covariance: E[ɛ ɛ] := MSE( θ) Bias( θ) := E[ θ] θ Var( θ) := E[( θ E[ θ])( θ E[ θ]) ] 25 / 34
26 Bias-variance decomposition Key fact: Bias 2 ( θ) + Var( θ) = MSE[ θ] Bias 2 ( θ) + Var( θ) =(θ E[ θ]) 2 + E[ θ 2 ] (E[ θ]) 2 =θ 2 2θE[ θ] + (E[ θ]) 2 + E[ θ 2 ] (E[ θ]) 2 =E[ θ 2 ] 2θE[ θ] + θ 2 =E[ θ 2 ] 2θE[ θ] + E[θ 2 ] =E[ θ 2 2θ θ + θ 2 ] =E[( θ θ) 2 ] =MSE[ θ] 26 / 34
27 Asymptotics Estimators are often studied as a function of the number of observations: θ(y) = θ n where n = dim y θ is asymptotically unbiased if An estimator is consistent if lim Bias( θ n ) = 0 n lim MSE( θ n ) = 0 n A consistent estimator is at least asymptotically unbiased. Some estimators are unbiased, but inconsistent. The latter basically means that our estimation does not improve as the number of data increase. Inconsistent estimators can provide reasonable estimates when we have a small number of data. However, consistent estimators are usually favored in practice. 27 / 34
28 Estimator Accuracy Consider the likelihood function p(y θ) where θ is a scalar unknown (parameter). We can plot the likelihood as a function of the unknown. The more peaky or spiky the likelihood function, the easier it is to determine the unknown parameter. The peakiness is effectively measured by the negative of the second derivative of the log-likelihood at its peak. 28 / 34
29 Fisher Information In general, the curvature will depend on the observed data: 2 log p(y θ) θ 2 is a function of y Thus an average measure of curvature is more appropriate. [ 2 ] log p(y θ) E θ 2 The expectation averages out randomness due to the data and is a function of θ alone. Definition: Fisher Information [ ( ) ] log p(y θ) 2 [ 2 ] log p(y θ) I(θ) := E = E θ θ 2 is the Fisher Information. Here the derivative is evaluated at the true value of θ and the expectation is with respect to p(y θ). 29 / 34
30 Asymptotic Distribution of MLE Let y i iid pθ, i = 1,..., n, where θ R p, L n (θ) := n i=1 log p(y i θ) and θn = arg max θ L n (θ), assume Ln(θ) θ j and 2 L n(θ) [ θ j θ ] k condition E log p(y θ) θ exist for all j, k, and the regularity = 0 for all θ holds. Then θ n asymp. N (θ, n 1 I 1 (θ )) where I(θ ) is the Fisher-Information Matrix (FIM), whose elements are given by [ [I(θ 2 log p(y θ) ] θ=θ )] j,k = E θ j θ k 30 / 34
31 Regularity condition The regularity condition amounts to assuming that we can interchange order of differentiation and integration to compute [ log p(y θ) ] log p(y θ) E = θ θ=θ θ p(y θ )dx θ=θ 1 p(y θ) p(y θ) = p(y θ ) θ p(y θ )dx = θ=θ θ dx θ=θ = [ p(y θ)dx] θ θ=θ = 0, since p(y θ)dx = 1 for all θ and the derivative of a constant is 0. The last line, where integration and differentiation are interchanged, is only possible for regular likelihood functions. This is simply the Fundamental Theorem of Calculus applied to p(y θ). As long as p(y θ) is absolutely continuous w.r.t. Lebesgue measure (i.e., when the derivative is well-defined), this is possible. This is true for many distributions, but not true when the support of y depends on θ ( e.g. y Unif(0, θ)). 31 / 34
32 Note: E[ θ] θ Cov( θ) 1 n I 1 (θ ) θ is consistent and efficient asymptotically (i.e., asymptotically achieves CRLB) Example: y N (A 1 n 1, σ 2 I n ) θ = [A, σ 2 ] Â = 1 n y i N n s := i=1 i=1 σ 2 ) (A, σ2 n n (y i Â)2 χ 2 n 1 ( ) σ 2 σ 2 = s n 32 / 34
33 Example: (cont.) For large n, the CLT tells us that Therefore, Hence, χ 2 n N (n, 2n). s N (n 1, 2(n 1)) approximately distributed σ 2 = 1 n (y i n Â)2 = σ2 n s i=1 ( ) (n 1) N σ 2 2(n 1)σ4, n n 2 33 / 34
34 Example: (cont.) Moreover, for large n ] [ ] [ ] A A E [ θ = n 1 n σ2 σ 2 = θ [ ] σ 2 /n 0 = C θ 0 2(n 1)σ 4 n 2 [ σ 2 /n 0 0 2σ 4 n = I 1 (θ ) inverse Fisher Info. Matrix ] Hence, θ N (θ, I 1 (θ )) for large n 34 / 34
13. Parameter Estimation. ECE 830, Spring 2014
 13. Parameter Estimation ECE 830, Spring 2014 1 / 18 Primary Goal General problem statement: We observe X p(x θ), θ Θ and the goal is to determine the θ that produced X. Given a collection of observations
13. Parameter Estimation ECE 830, Spring 2014 1 / 18 Primary Goal General problem statement: We observe X p(x θ), θ Θ and the goal is to determine the θ that produced X. Given a collection of observations
ECE531 Lecture 10b: Maximum Likelihood Estimation
 ECE531 Lecture 10b: Maximum Likelihood Estimation D. Richard Brown III Worcester Polytechnic Institute 05-Apr-2011 Worcester Polytechnic Institute D. Richard Brown III 05-Apr-2011 1 / 23 Introduction So
ECE531 Lecture 10b: Maximum Likelihood Estimation D. Richard Brown III Worcester Polytechnic Institute 05-Apr-2011 Worcester Polytechnic Institute D. Richard Brown III 05-Apr-2011 1 / 23 Introduction So
Composite Hypotheses and Generalized Likelihood Ratio Tests
 Composite Hypotheses and Generalized Likelihood Ratio Tests Rebecca Willett, 06 In many real world problems, it is difficult to precisely specify probability distributions. Our models for data may involve
Composite Hypotheses and Generalized Likelihood Ratio Tests Rebecca Willett, 06 In many real world problems, it is difficult to precisely specify probability distributions. Our models for data may involve
10. Composite Hypothesis Testing. ECE 830, Spring 2014
 10. Composite Hypothesis Testing ECE 830, Spring 2014 1 / 25 In many real world problems, it is difficult to precisely specify probability distributions. Our models for data may involve unknown parameters
10. Composite Hypothesis Testing ECE 830, Spring 2014 1 / 25 In many real world problems, it is difficult to precisely specify probability distributions. Our models for data may involve unknown parameters
A Few Notes on Fisher Information (WIP)
") A Few Notes on Fisher Information (WIP) David Meyer dmm@{-4-5.net,uoregon.edu} Last update: April 30, 208 Definitions There are so many interesting things about Fisher Information and its theoretical properties
A Few Notes on Fisher Information (WIP) David Meyer dmm@{-4-5.net,uoregon.edu} Last update: April 30, 208 Definitions There are so many interesting things about Fisher Information and its theoretical properties
EIE6207: Estimation Theory
 EIE6207: Estimation Theory Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: Steven M.
EIE6207: Estimation Theory Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: Steven M.
Maximum Likelihood Estimation
 Connexions module: m11446 1 Maximum Likelihood Estimation Clayton Scott Robert Nowak This work is produced by The Connexions Project and licensed under the Creative Commons Attribution License Abstract
Connexions module: m11446 1 Maximum Likelihood Estimation Clayton Scott Robert Nowak This work is produced by The Connexions Project and licensed under the Creative Commons Attribution License Abstract
Introduction to Estimation Methods for Time Series models Lecture 2
 Introduction to Estimation Methods for Time Series models Lecture 2 Fulvio Corsi SNS Pisa Fulvio Corsi Introduction to Estimation () Methods for Time Series models Lecture 2 SNS Pisa 1 / 21 Estimators:
Introduction to Estimation Methods for Time Series models Lecture 2 Fulvio Corsi SNS Pisa Fulvio Corsi Introduction to Estimation () Methods for Time Series models Lecture 2 SNS Pisa 1 / 21 Estimators:
MA 575 Linear Models: Cedric E. Ginestet, Boston University Midterm Review Week 7
 MA 575 Linear Models: Cedric E. Ginestet, Boston University Midterm Review Week 7 1 Random Vectors Let a 0 and y be n 1 vectors, and let A be an n n matrix. Here, a 0 and A are non-random, whereas y is
MA 575 Linear Models: Cedric E. Ginestet, Boston University Midterm Review Week 7 1 Random Vectors Let a 0 and y be n 1 vectors, and let A be an n n matrix. Here, a 0 and A are non-random, whereas y is
ECE531 Lecture 8: Non-Random Parameter Estimation
 ECE531 Lecture 8: Non-Random Parameter Estimation D. Richard Brown III Worcester Polytechnic Institute 19-March-2009 Worcester Polytechnic Institute D. Richard Brown III 19-March-2009 1 / 25 Introduction
ECE531 Lecture 8: Non-Random Parameter Estimation D. Richard Brown III Worcester Polytechnic Institute 19-March-2009 Worcester Polytechnic Institute D. Richard Brown III 19-March-2009 1 / 25 Introduction
Hypothesis Testing. 1 Definitions of test statistics. CB: chapter 8; section 10.3
 Hypothesis Testing CB: chapter 8; section 0.3 Hypothesis: statement about an unknown population parameter Examples: The average age of males in Sweden is 7. (statement about population mean) The lowest
Hypothesis Testing CB: chapter 8; section 0.3 Hypothesis: statement about an unknown population parameter Examples: The average age of males in Sweden is 7. (statement about population mean) The lowest
ECE 275A Homework 6 Solutions
 ECE 275A Homework 6 Solutions. The notation used in the solutions for the concentration (hyper) ellipsoid problems is defined in the lecture supplement on concentration ellipsoids. Note that θ T Σ θ =
ECE 275A Homework 6 Solutions. The notation used in the solutions for the concentration (hyper) ellipsoid problems is defined in the lecture supplement on concentration ellipsoids. Note that θ T Σ θ =
Module 2. Random Processes. Version 2, ECE IIT, Kharagpur
 Module Random Processes Version, ECE IIT, Kharagpur Lesson 9 Introduction to Statistical Signal Processing Version, ECE IIT, Kharagpur After reading this lesson, you will learn about Hypotheses testing
Module Random Processes Version, ECE IIT, Kharagpur Lesson 9 Introduction to Statistical Signal Processing Version, ECE IIT, Kharagpur After reading this lesson, you will learn about Hypotheses testing
y Xw 2 2 y Xw λ w 2 2
 CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
Classical Estimation Topics
 Classical Estimation Topics Namrata Vaswani, Iowa State University February 25, 2014 This note fills in the gaps in the notes already provided (l0.pdf, l1.pdf, l2.pdf, l3.pdf, LeastSquares.pdf). 1 Min
Classical Estimation Topics Namrata Vaswani, Iowa State University February 25, 2014 This note fills in the gaps in the notes already provided (l0.pdf, l1.pdf, l2.pdf, l3.pdf, LeastSquares.pdf). 1 Min
DS-GA 1002 Lecture notes 12 Fall Linear regression
 DS-GA Lecture notes 1 Fall 16 1 Linear models Linear regression In statistics, regression consists of learning a function relating a certain quantity of interest y, the response or dependent variable,
DS-GA Lecture notes 1 Fall 16 1 Linear models Linear regression In statistics, regression consists of learning a function relating a certain quantity of interest y, the response or dependent variable,
DS-GA 1002 Lecture notes 10 November 23, Linear models
 DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
ECE 275A Homework 7 Solutions
 ECE 275A Homework 7 Solutions Solutions 1. For the same specification as in Homework Problem 6.11 we want to determine an estimator for θ using the Method of Moments (MOM). In general, the MOM estimator
ECE 275A Homework 7 Solutions Solutions 1. For the same specification as in Homework Problem 6.11 we want to determine an estimator for θ using the Method of Moments (MOM). In general, the MOM estimator
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
[y i α βx i ] 2 (2) Q = i=1
![[y i α βx i ] 2 (2) Q = i=1](/thumbs/75/72005858.jpg "[y i α βx i ] 2 (2) Q = i=1") Least squares fits This section has no probability in it. There are no random variables. We are given n points (x i, y i ) and want to find the equation of the line that best fits them. We take the equation
Least squares fits This section has no probability in it. There are no random variables. We are given n points (x i, y i ) and want to find the equation of the line that best fits them. We take the equation
Regression Estimation - Least Squares and Maximum Likelihood. Dr. Frank Wood
 Regression Estimation - Least Squares and Maximum Likelihood Dr. Frank Wood Least Squares Max(min)imization Function to minimize w.r.t. β 0, β 1 Q = n (Y i (β 0 + β 1 X i )) 2 i=1 Minimize this by maximizing
Regression Estimation - Least Squares and Maximum Likelihood Dr. Frank Wood Least Squares Max(min)imization Function to minimize w.r.t. β 0, β 1 Q = n (Y i (β 0 + β 1 X i )) 2 i=1 Minimize this by maximizing
Introduction to Maximum Likelihood Estimation
 Introduction to Maximum Likelihood Estimation Eric Zivot July 26, 2012 The Likelihood Function Let 1 be an iid sample with pdf ( ; ) where is a ( 1) vector of parameters that characterize ( ; ) Example:
Introduction to Maximum Likelihood Estimation Eric Zivot July 26, 2012 The Likelihood Function Let 1 be an iid sample with pdf ( ; ) where is a ( 1) vector of parameters that characterize ( ; ) Example:
Introduction to Simple Linear Regression
 Introduction to Simple Linear Regression Yang Feng http://www.stat.columbia.edu/~yangfeng Yang Feng (Columbia University) Introduction to Simple Linear Regression 1 / 68 About me Faculty in the Department
Introduction to Simple Linear Regression Yang Feng http://www.stat.columbia.edu/~yangfeng Yang Feng (Columbia University) Introduction to Simple Linear Regression 1 / 68 About me Faculty in the Department
System Identification, Lecture 4
 System Identification, Lecture 4 Kristiaan Pelckmans (IT/UU, 2338) Course code: 1RT880, Report code: 61800 - Spring 2016 F, FRI Uppsala University, Information Technology 13 April 2016 SI-2016 K. Pelckmans
System Identification, Lecture 4 Kristiaan Pelckmans (IT/UU, 2338) Course code: 1RT880, Report code: 61800 - Spring 2016 F, FRI Uppsala University, Information Technology 13 April 2016 SI-2016 K. Pelckmans
Variations. ECE 6540, Lecture 10 Maximum Likelihood Estimation
 Variations ECE 6540, Lecture 10 Last Time BLUE (Best Linear Unbiased Estimator) Formulation Advantages Disadvantages 2 The BLUE A simplification Assume the estimator is a linear system For a single parameter
Variations ECE 6540, Lecture 10 Last Time BLUE (Best Linear Unbiased Estimator) Formulation Advantages Disadvantages 2 The BLUE A simplification Assume the estimator is a linear system For a single parameter
Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics)
") Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics) Probability quantifies randomness and uncertainty How do I estimate the normalization and logarithmic slope of a X ray continuum, assuming
Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics) Probability quantifies randomness and uncertainty How do I estimate the normalization and logarithmic slope of a X ray continuum, assuming
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
10-704: Information Processing and Learning Fall Lecture 24: Dec 7
 0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 24: Dec 7 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy of
0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 24: Dec 7 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy of
ELEG 5633 Detection and Estimation Minimum Variance Unbiased Estimators (MVUE)
") 1 ELEG 5633 Detection and Estimation Minimum Variance Unbiased Estimators (MVUE) Jingxian Wu Department of Electrical Engineering University of Arkansas Outline Minimum Variance Unbiased Estimators (MVUE)
1 ELEG 5633 Detection and Estimation Minimum Variance Unbiased Estimators (MVUE) Jingxian Wu Department of Electrical Engineering University of Arkansas Outline Minimum Variance Unbiased Estimators (MVUE)
Lecture 8: Signal Detection and Noise Assumption
 ECE 830 Fall 0 Statistical Signal Processing instructor: R. Nowak Lecture 8: Signal Detection and Noise Assumption Signal Detection : X = W H : X = S + W where W N(0, σ I n n and S = [s, s,..., s n ] T
ECE 830 Fall 0 Statistical Signal Processing instructor: R. Nowak Lecture 8: Signal Detection and Noise Assumption Signal Detection : X = W H : X = S + W where W N(0, σ I n n and S = [s, s,..., s n ] T
Linear Models A linear model is defined by the expression
 Linear Models A linear model is defined by the expression x = F β + ɛ. where x = (x 1, x 2,..., x n ) is vector of size n usually known as the response vector. β = (β 1, β 2,..., β p ) is the transpose
Linear Models A linear model is defined by the expression x = F β + ɛ. where x = (x 1, x 2,..., x n ) is vector of size n usually known as the response vector. β = (β 1, β 2,..., β p ) is the transpose
Vector spaces. DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis.
 Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
Statistics 3858 : Maximum Likelihood Estimators
 Statistics 3858 : Maximum Likelihood Estimators 1 Method of Maximum Likelihood In this method we construct the so called likelihood function, that is L(θ) = L(θ; X 1, X 2,..., X n ) = f n (X 1, X 2,...,
Statistics 3858 : Maximum Likelihood Estimators 1 Method of Maximum Likelihood In this method we construct the so called likelihood function, that is L(θ) = L(θ; X 1, X 2,..., X n ) = f n (X 1, X 2,...,
2 Statistical Estimation: Basic Concepts
 Technion Israel Institute of Technology, Department of Electrical Engineering Estimation and Identification in Dynamical Systems (048825) Lecture Notes, Fall 2009, Prof. N. Shimkin 2 Statistical Estimation:
Technion Israel Institute of Technology, Department of Electrical Engineering Estimation and Identification in Dynamical Systems (048825) Lecture Notes, Fall 2009, Prof. N. Shimkin 2 Statistical Estimation:
Estimation Theory Fredrik Rusek. Chapters
 Estimation Theory Fredrik Rusek Chapters 3.5-3.10 Recap We deal with unbiased estimators of deterministic parameters Performance of an estimator is measured by the variance of the estimate (due to the
Estimation Theory Fredrik Rusek Chapters 3.5-3.10 Recap We deal with unbiased estimators of deterministic parameters Performance of an estimator is measured by the variance of the estimate (due to the
System Identification, Lecture 4
 System Identification, Lecture 4 Kristiaan Pelckmans (IT/UU, 2338) Course code: 1RT880, Report code: 61800 - Spring 2012 F, FRI Uppsala University, Information Technology 30 Januari 2012 SI-2012 K. Pelckmans
System Identification, Lecture 4 Kristiaan Pelckmans (IT/UU, 2338) Course code: 1RT880, Report code: 61800 - Spring 2012 F, FRI Uppsala University, Information Technology 30 Januari 2012 SI-2012 K. Pelckmans
Spring 2012 Math 541A Exam 1. X i, S 2 = 1 n. n 1. X i I(X i < c), T n =
, T n =") Spring 2012 Math 541A Exam 1 1. (a) Let Z i be independent N(0, 1), i = 1, 2,, n. Are Z = 1 n n Z i and S 2 Z = 1 n 1 n (Z i Z) 2 independent? Prove your claim. (b) Let X 1, X 2,, X n be independent identically
Spring 2012 Math 541A Exam 1 1. (a) Let Z i be independent N(0, 1), i = 1, 2,, n. Are Z = 1 n n Z i and S 2 Z = 1 n 1 n (Z i Z) 2 independent? Prove your claim. (b) Let X 1, X 2,, X n be independent identically
Estimation Theory Fredrik Rusek. Chapters 6-7
 Estimation Theory Fredrik Rusek Chapters 6-7 All estimation problems Summary All estimation problems Summary Efficient estimator exists All estimation problems Summary MVU estimator exists Efficient estimator
Estimation Theory Fredrik Rusek Chapters 6-7 All estimation problems Summary All estimation problems Summary Efficient estimator exists All estimation problems Summary MVU estimator exists Efficient estimator
Covariance function estimation in Gaussian process regression
 Covariance function estimation in Gaussian process regression François Bachoc Department of Statistics and Operations Research, University of Vienna WU Research Seminar - May 2015 François Bachoc Gaussian
Covariance function estimation in Gaussian process regression François Bachoc Department of Statistics and Operations Research, University of Vienna WU Research Seminar - May 2015 François Bachoc Gaussian
Introduction to Machine Learning (67577) Lecture 3
 Lecture 3") Introduction to Machine Learning (67577) Lecture 3 Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem General Learning Model and Bias-Complexity tradeoff Shai Shalev-Shwartz
Introduction to Machine Learning (67577) Lecture 3 Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem General Learning Model and Bias-Complexity tradeoff Shai Shalev-Shwartz
Regression Estimation Least Squares and Maximum Likelihood
 Regression Estimation Least Squares and Maximum Likelihood Dr. Frank Wood Frank Wood, fwood@stat.columbia.edu Linear Regression Models Lecture 3, Slide 1 Least Squares Max(min)imization Function to minimize
Regression Estimation Least Squares and Maximum Likelihood Dr. Frank Wood Frank Wood, fwood@stat.columbia.edu Linear Regression Models Lecture 3, Slide 1 Least Squares Max(min)imization Function to minimize
Brief Review on Estimation Theory
 Brief Review on Estimation Theory K. Abed-Meraim ENST PARIS, Signal and Image Processing Dept. abed@tsi.enst.fr This presentation is essentially based on the course BASTA by E. Moulines Brief review on
Brief Review on Estimation Theory K. Abed-Meraim ENST PARIS, Signal and Image Processing Dept. abed@tsi.enst.fr This presentation is essentially based on the course BASTA by E. Moulines Brief review on
Graduate Econometrics I: Maximum Likelihood I
 Graduate Econometrics I: Maximum Likelihood I Yves Dominicy Université libre de Bruxelles Solvay Brussels School of Economics and Management ECARES Yves Dominicy Graduate Econometrics I: Maximum Likelihood
Graduate Econometrics I: Maximum Likelihood I Yves Dominicy Université libre de Bruxelles Solvay Brussels School of Economics and Management ECARES Yves Dominicy Graduate Econometrics I: Maximum Likelihood
Estimators as Random Variables
 Estimation Theory Overview Properties Bias, Variance, and Mean Square Error Cramér-Rao lower bound Maimum likelihood Consistency Confidence intervals Properties of the mean estimator Introduction Up until
Estimation Theory Overview Properties Bias, Variance, and Mean Square Error Cramér-Rao lower bound Maimum likelihood Consistency Confidence intervals Properties of the mean estimator Introduction Up until
4 Bias-Variance for Ridge Regression (24 points)
") Implement Ridge Regression with λ = 0.00001. Plot the Squared Euclidean test error for the following values of k (the dimensions you reduce to): k = {0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500,
Implement Ridge Regression with λ = 0.00001. Plot the Squared Euclidean test error for the following values of k (the dimensions you reduce to): k = {0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500,
Linear Regression and Its Applications
 Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Chapter 3: Maximum Likelihood Theory
 Chapter 3: Maximum Likelihood Theory Florian Pelgrin HEC September-December, 2010 Florian Pelgrin (HEC) Maximum Likelihood Theory September-December, 2010 1 / 40 1 Introduction Example 2 Maximum likelihood
Chapter 3: Maximum Likelihood Theory Florian Pelgrin HEC September-December, 2010 Florian Pelgrin (HEC) Maximum Likelihood Theory September-December, 2010 1 / 40 1 Introduction Example 2 Maximum likelihood
P n. This is called the law of large numbers but it comes in two forms: Strong and Weak.
 Large Sample Theory Large Sample Theory is a name given to the search for approximations to the behaviour of statistical procedures which are derived by computing limits as the sample size, n, tends to
Large Sample Theory Large Sample Theory is a name given to the search for approximations to the behaviour of statistical procedures which are derived by computing limits as the sample size, n, tends to
Distributed Estimation, Information Loss and Exponential Families. Qiang Liu Department of Computer Science Dartmouth College
 Distributed Estimation, Information Loss and Exponential Families Qiang Liu Department of Computer Science Dartmouth College Statistical Learning / Estimation Learning generative models from data Topic
Distributed Estimation, Information Loss and Exponential Families Qiang Liu Department of Computer Science Dartmouth College Statistical Learning / Estimation Learning generative models from data Topic
Rowan University Department of Electrical and Computer Engineering
 Rowan University Department of Electrical and Computer Engineering Estimation and Detection Theory Fall 2013 to Practice Exam II This is a closed book exam. There are 8 problems in the exam. The problems
Rowan University Department of Electrical and Computer Engineering Estimation and Detection Theory Fall 2013 to Practice Exam II This is a closed book exam. There are 8 problems in the exam. The problems
MS&E 226: Small Data. Lecture 11: Maximum likelihood (v2) Ramesh Johari
 Ramesh Johari") MS&E 226: Small Data Lecture 11: Maximum likelihood (v2) Ramesh Johari ramesh.johari@stanford.edu 1 / 18 The likelihood function 2 / 18 Estimating the parameter This lecture develops the methodology behind
MS&E 226: Small Data Lecture 11: Maximum likelihood (v2) Ramesh Johari ramesh.johari@stanford.edu 1 / 18 The likelihood function 2 / 18 Estimating the parameter This lecture develops the methodology behind
STATS 200: Introduction to Statistical Inference. Lecture 29: Course review
 STATS 200: Introduction to Statistical Inference Lecture 29: Course review Course review We started in Lecture 1 with a fundamental assumption: Data is a realization of a random process. The goal throughout
STATS 200: Introduction to Statistical Inference Lecture 29: Course review Course review We started in Lecture 1 with a fundamental assumption: Data is a realization of a random process. The goal throughout
Statistics Ph.D. Qualifying Exam
 Department of Statistics Carnegie Mellon University May 7 2008 Statistics Ph.D. Qualifying Exam You are not expected to solve all five problems. Complete solutions to few problems will be preferred to
Department of Statistics Carnegie Mellon University May 7 2008 Statistics Ph.D. Qualifying Exam You are not expected to solve all five problems. Complete solutions to few problems will be preferred to
f(x θ)dx with respect to θ. Assuming certain smoothness conditions concern differentiating under the integral the integral sign, we first obtain
dx with respect to θ. Assuming certain smoothness conditions concern differentiating under the integral the integral sign, we first obtain") 0.1. INTRODUCTION 1 0.1 Introduction R. A. Fisher, a pioneer in the development of mathematical statistics, introduced a measure of the amount of information contained in an observaton from f(x θ). Fisher
0.1. INTRODUCTION 1 0.1 Introduction R. A. Fisher, a pioneer in the development of mathematical statistics, introduced a measure of the amount of information contained in an observaton from f(x θ). Fisher
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Multivariate Analysis and Likelihood Inference
 Multivariate Analysis and Likelihood Inference Outline 1 Joint Distribution of Random Variables 2 Principal Component Analysis (PCA) 3 Multivariate Normal Distribution 4 Likelihood Inference Joint density
Multivariate Analysis and Likelihood Inference Outline 1 Joint Distribution of Random Variables 2 Principal Component Analysis (PCA) 3 Multivariate Normal Distribution 4 Likelihood Inference Joint density
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 254 Part V
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 254 Part V
Linear Models for Regression CS534
 Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Lecture Notes 1: Vector spaces
 Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Linear Models Review
 Linear Models Review Vectors in IR n will be written as ordered n-tuples which are understood to be column vectors, or n 1 matrices. A vector variable will be indicted with bold face, and the prime sign
Linear Models Review Vectors in IR n will be written as ordered n-tuples which are understood to be column vectors, or n 1 matrices. A vector variable will be indicted with bold face, and the prime sign
Math 423/533: The Main Theoretical Topics
 Math 423/533: The Main Theoretical Topics Notation sample size n, data index i number of predictors, p (p = 2 for simple linear regression) y i : response for individual i x i = (x i1,..., x ip ) (1 p)
Math 423/533: The Main Theoretical Topics Notation sample size n, data index i number of predictors, p (p = 2 for simple linear regression) y i : response for individual i x i = (x i1,..., x ip ) (1 p)
Fall 2017 STAT 532 Homework Peter Hoff. 1. Let P be a probability measure on a collection of sets A.
 1. Let P be a probability measure on a collection of sets A. (a) For each n N, let H n be a set in A such that H n H n+1. Show that P (H n ) monotonically converges to P ( k=1 H k) as n. (b) For each n
1. Let P be a probability measure on a collection of sets A. (a) For each n N, let H n be a set in A such that H n H n+1. Show that P (H n ) monotonically converges to P ( k=1 H k) as n. (b) For each n
IEOR 165 Lecture 7 1 Bias-Variance Tradeoff
 IEOR 165 Lecture 7 Bias-Variance Tradeoff 1 Bias-Variance Tradeoff Consider the case of parametric regression with β R, and suppose we would like to analyze the error of the estimate ˆβ in comparison to
IEOR 165 Lecture 7 Bias-Variance Tradeoff 1 Bias-Variance Tradeoff Consider the case of parametric regression with β R, and suppose we would like to analyze the error of the estimate ˆβ in comparison to
Linear Models. DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis.
 Linear Models DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Linear regression Least-squares estimation
Linear Models DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Linear regression Least-squares estimation
Hypothesis Testing. Econ 690. Purdue University. Justin L. Tobias (Purdue) Testing 1 / 33
 Testing 1 / 33") Hypothesis Testing Econ 690 Purdue University Justin L. Tobias (Purdue) Testing 1 / 33 Outline 1 Basic Testing Framework 2 Testing with HPD intervals 3 Example 4 Savage Dickey Density Ratio 5 Bartlett
Hypothesis Testing Econ 690 Purdue University Justin L. Tobias (Purdue) Testing 1 / 33 Outline 1 Basic Testing Framework 2 Testing with HPD intervals 3 Example 4 Savage Dickey Density Ratio 5 Bartlett
A Very Brief Summary of Statistical Inference, and Examples
 A Very Brief Summary of Statistical Inference, and Examples Trinity Term 2009 Prof. Gesine Reinert Our standard situation is that we have data x = x 1, x 2,..., x n, which we view as realisations of random
A Very Brief Summary of Statistical Inference, and Examples Trinity Term 2009 Prof. Gesine Reinert Our standard situation is that we have data x = x 1, x 2,..., x n, which we view as realisations of random
MA/ST 810 Mathematical-Statistical Modeling and Analysis of Complex Systems
 MA/ST 810 Mathematical-Statistical Modeling and Analysis of Complex Systems Principles of Statistical Inference Recap of statistical models Statistical inference (frequentist) Parametric vs. semiparametric
MA/ST 810 Mathematical-Statistical Modeling and Analysis of Complex Systems Principles of Statistical Inference Recap of statistical models Statistical inference (frequentist) Parametric vs. semiparametric
Linear regression. DS GA 1002 Statistical and Mathematical Models. Carlos Fernandez-Granda
 Linear regression DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall15 Carlos Fernandez-Granda Linear models Least-squares estimation Overfitting Example:
Linear regression DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall15 Carlos Fernandez-Granda Linear models Least-squares estimation Overfitting Example:
ECON 4160, Autumn term Lecture 1
 ECON 4160, Autumn term 2017. Lecture 1 a) Maximum Likelihood based inference. b) The bivariate normal model Ragnar Nymoen University of Oslo 24 August 2017 1 / 54 Principles of inference I Ordinary least
ECON 4160, Autumn term 2017. Lecture 1 a) Maximum Likelihood based inference. b) The bivariate normal model Ragnar Nymoen University of Oslo 24 August 2017 1 / 54 Principles of inference I Ordinary least
EIE6207: Maximum-Likelihood and Bayesian Estimation
 EIE6207: Maximum-Likelihood and Bayesian Estimation Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak
EIE6207: Maximum-Likelihood and Bayesian Estimation Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak
Normed & Inner Product Vector Spaces
 Normed & Inner Product Vector Spaces ECE 174 Introduction to Linear & Nonlinear Optimization Ken Kreutz-Delgado ECE Department, UC San Diego Ken Kreutz-Delgado (UC San Diego) ECE 174 Fall 2016 1 / 27 Normed
Normed & Inner Product Vector Spaces ECE 174 Introduction to Linear & Nonlinear Optimization Ken Kreutz-Delgado ECE Department, UC San Diego Ken Kreutz-Delgado (UC San Diego) ECE 174 Fall 2016 1 / 27 Normed
Ph.D. Qualifying Exam Friday Saturday, January 3 4, 2014
 Ph.D. Qualifying Exam Friday Saturday, January 3 4, 2014 Put your solution to each problem on a separate sheet of paper. Problem 1. (5166) Assume that two random samples {x i } and {y i } are independently
Ph.D. Qualifying Exam Friday Saturday, January 3 4, 2014 Put your solution to each problem on a separate sheet of paper. Problem 1. (5166) Assume that two random samples {x i } and {y i } are independently
Least Squares Regression
 CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
Unbiased Estimation. Binomial problem shows general phenomenon. An estimator can be good for some values of θ and bad for others.
 Unbiased Estimation Binomial problem shows general phenomenon. An estimator can be good for some values of θ and bad for others. To compare ˆθ and θ, two estimators of θ: Say ˆθ is better than θ if it
Unbiased Estimation Binomial problem shows general phenomenon. An estimator can be good for some values of θ and bad for others. To compare ˆθ and θ, two estimators of θ: Say ˆθ is better than θ if it
Regression #3: Properties of OLS Estimator
 Regression #3: Properties of OLS Estimator Econ 671 Purdue University Justin L. Tobias (Purdue) Regression #3 1 / 20 Introduction In this lecture, we establish some desirable properties associated with
Regression #3: Properties of OLS Estimator Econ 671 Purdue University Justin L. Tobias (Purdue) Regression #3 1 / 20 Introduction In this lecture, we establish some desirable properties associated with
Properties of the least squares estimates
 Properties of the least squares estimates 2019-01-18 Warmup Let a and b be scalar constants, and X be a scalar random variable. Fill in the blanks E ax + b) = Var ax + b) = Goal Recall that the least squares
Properties of the least squares estimates 2019-01-18 Warmup Let a and b be scalar constants, and X be a scalar random variable. Fill in the blanks E ax + b) = Var ax + b) = Goal Recall that the least squares
Association studies and regression
 Association studies and regression CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar Association studies and regression 1 / 104 Administration
Association studies and regression CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar Association studies and regression 1 / 104 Administration
9. Model Selection. statistical models. overview of model selection. information criteria. goodness-of-fit measures
 FE661 - Statistical Methods for Financial Engineering 9. Model Selection Jitkomut Songsiri statistical models overview of model selection information criteria goodness-of-fit measures 9-1 Statistical models
FE661 - Statistical Methods for Financial Engineering 9. Model Selection Jitkomut Songsiri statistical models overview of model selection information criteria goodness-of-fit measures 9-1 Statistical models
COMPLETELY RANDOMIZED DESIGNS (CRD) For now, t unstructured treatments (e.g. no factorial structure)
 For now, t unstructured treatments (e.g. no factorial structure)") STAT 52 Completely Randomized Designs COMPLETELY RANDOMIZED DESIGNS (CRD) For now, t unstructured treatments (e.g. no factorial structure) Completely randomized means no restrictions on the randomization
STAT 52 Completely Randomized Designs COMPLETELY RANDOMIZED DESIGNS (CRD) For now, t unstructured treatments (e.g. no factorial structure) Completely randomized means no restrictions on the randomization
SYSM 6303: Quantitative Introduction to Risk and Uncertainty in Business Lecture 4: Fitting Data to Distributions
 SYSM 6303: Quantitative Introduction to Risk and Uncertainty in Business Lecture 4: Fitting Data to Distributions M. Vidyasagar Cecil & Ida Green Chair The University of Texas at Dallas Email: M.Vidyasagar@utdallas.edu
SYSM 6303: Quantitative Introduction to Risk and Uncertainty in Business Lecture 4: Fitting Data to Distributions M. Vidyasagar Cecil & Ida Green Chair The University of Texas at Dallas Email: M.Vidyasagar@utdallas.edu
Estimation theory. Parametric estimation. Properties of estimators. Minimum variance estimator. Cramer-Rao bound. Maximum likelihood estimators
 Estimation theory Parametric estimation Properties of estimators Minimum variance estimator Cramer-Rao bound Maximum likelihood estimators Confidence intervals Bayesian estimation 1 Random Variables Let
Estimation theory Parametric estimation Properties of estimators Minimum variance estimator Cramer-Rao bound Maximum likelihood estimators Confidence intervals Bayesian estimation 1 Random Variables Let
Advanced Signal Processing Minimum Variance Unbiased Estimation (MVU)
") Advanced Signal Processing Minimum Variance Unbiased Estimation (MVU) Danilo Mandic room 813, ext: 46271 Department of Electrical and Electronic Engineering Imperial College London, UK d.mandic@imperial.ac.uk,
Advanced Signal Processing Minimum Variance Unbiased Estimation (MVU) Danilo Mandic room 813, ext: 46271 Department of Electrical and Electronic Engineering Imperial College London, UK d.mandic@imperial.ac.uk,
Statistics: Learning models from data
 DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
Inference in non-linear time series
 Intro LS MLE Other Erik Lindström Centre for Mathematical Sciences Lund University LU/LTH & DTU Intro LS MLE Other General Properties Popular estimatiors Overview Introduction General Properties Estimators
Intro LS MLE Other Erik Lindström Centre for Mathematical Sciences Lund University LU/LTH & DTU Intro LS MLE Other General Properties Popular estimatiors Overview Introduction General Properties Estimators
Linear Models and Estimation by Least Squares
 Linear Models and Estimation by Least Squares Jin-Lung Lin 1 Introduction Causal relation investigation lies in the heart of economics. Effect (Dependent variable) cause (Independent variable) Example:
Linear Models and Estimation by Least Squares Jin-Lung Lin 1 Introduction Causal relation investigation lies in the heart of economics. Effect (Dependent variable) cause (Independent variable) Example:
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Mathematical Statistics
 Mathematical Statistics Chapter Three. Point Estimation 3.4 Uniformly Minimum Variance Unbiased Estimator(UMVUE) Criteria for Best Estimators MSE Criterion Let F = {p(x; θ) : θ Θ} be a parametric distribution
Mathematical Statistics Chapter Three. Point Estimation 3.4 Uniformly Minimum Variance Unbiased Estimator(UMVUE) Criteria for Best Estimators MSE Criterion Let F = {p(x; θ) : θ Θ} be a parametric distribution
COS513: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 9: LINEAR REGRESSION
 COS513: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 9: LINEAR REGRESSION SEAN GERRISH AND CHONG WANG 1. WAYS OF ORGANIZING MODELS In probabilistic modeling, there are several ways of organizing models:
COS513: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 9: LINEAR REGRESSION SEAN GERRISH AND CHONG WANG 1. WAYS OF ORGANIZING MODELS In probabilistic modeling, there are several ways of organizing models:
STAT Financial Time Series
 STAT 6104 - Financial Time Series Chapter 4 - Estimation in the time Domain Chun Yip Yau (CUHK) STAT 6104:Financial Time Series 1 / 46 Agenda 1 Introduction 2 Moment Estimates 3 Autoregressive Models (AR
STAT 6104 - Financial Time Series Chapter 4 - Estimation in the time Domain Chun Yip Yau (CUHK) STAT 6104:Financial Time Series 1 / 46 Agenda 1 Introduction 2 Moment Estimates 3 Autoregressive Models (AR
Model Checking and Improvement
 Model Checking and Improvement Statistics 220 Spring 2005 Copyright c 2005 by Mark E. Irwin Model Checking All models are wrong but some models are useful George E. P. Box So far we have looked at a number
Model Checking and Improvement Statistics 220 Spring 2005 Copyright c 2005 by Mark E. Irwin Model Checking All models are wrong but some models are useful George E. P. Box So far we have looked at a number
Ph.D. Qualifying Exam Friday Saturday, January 6 7, 2017
 Ph.D. Qualifying Exam Friday Saturday, January 6 7, 2017 Put your solution to each problem on a separate sheet of paper. Problem 1. (5106) Let X 1, X 2,, X n be a sequence of i.i.d. observations from a
Ph.D. Qualifying Exam Friday Saturday, January 6 7, 2017 Put your solution to each problem on a separate sheet of paper. Problem 1. (5106) Let X 1, X 2,, X n be a sequence of i.i.d. observations from a
Statement: With my signature I confirm that the solutions are the product of my own work. Name: Signature:.
 MATHEMATICAL STATISTICS Homework assignment Instructions Please turn in the homework with this cover page. You do not need to edit the solutions. Just make sure the handwriting is legible. You may discuss
MATHEMATICAL STATISTICS Homework assignment Instructions Please turn in the homework with this cover page. You do not need to edit the solutions. Just make sure the handwriting is legible. You may discuss
Multivariate Statistics
 Multivariate Statistics Chapter 2: Multivariate distributions and inference Pedro Galeano Departamento de Estadística Universidad Carlos III de Madrid pedro.galeano@uc3m.es Course 2016/2017 Master in Mathematical
Multivariate Statistics Chapter 2: Multivariate distributions and inference Pedro Galeano Departamento de Estadística Universidad Carlos III de Madrid pedro.galeano@uc3m.es Course 2016/2017 Master in Mathematical
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
Statistics. Lecture 2 August 7, 2000 Frank Porter Caltech. The Fundamentals; Point Estimation. Maximum Likelihood, Least Squares and All That
 Statistics Lecture 2 August 7, 2000 Frank Porter Caltech The plan for these lectures: The Fundamentals; Point Estimation Maximum Likelihood, Least Squares and All That What is a Confidence Interval? Interval
Statistics Lecture 2 August 7, 2000 Frank Porter Caltech The plan for these lectures: The Fundamentals; Point Estimation Maximum Likelihood, Least Squares and All That What is a Confidence Interval? Interval
Control Function Instrumental Variable Estimation of Nonlinear Causal Effect Models
 Journal of Machine Learning Research 17 (2016) 1-35 Submitted 9/14; Revised 2/16; Published 2/16 Control Function Instrumental Variable Estimation of Nonlinear Causal Effect Models Zijian Guo Department
Journal of Machine Learning Research 17 (2016) 1-35 Submitted 9/14; Revised 2/16; Published 2/16 Control Function Instrumental Variable Estimation of Nonlinear Causal Effect Models Zijian Guo Department
Terminology Suppose we have N observations {x(n)} N 1. Estimators as Random Variables. {x(n)} N 1
} N 1. Estimators as Random Variables. {x(n)} N 1") Estimation Theory Overview Properties Bias, Variance, and Mean Square Error Cramér-Rao lower bound Maximum likelihood Consistency Confidence intervals Properties of the mean estimator Properties of the
Estimation Theory Overview Properties Bias, Variance, and Mean Square Error Cramér-Rao lower bound Maximum likelihood Consistency Confidence intervals Properties of the mean estimator Properties of the
1 Bayesian Linear Regression (BLR)
") Statistical Techniques in Robotics (STR, S15) Lecture#10 (Wednesday, February 11) Lecturer: Byron Boots Gaussian Properties, Bayesian Linear Regression 1 Bayesian Linear Regression (BLR) In linear regression,
Statistical Techniques in Robotics (STR, S15) Lecture#10 (Wednesday, February 11) Lecturer: Byron Boots Gaussian Properties, Bayesian Linear Regression 1 Bayesian Linear Regression (BLR) In linear regression,
Advanced Signal Processing Introduction to Estimation Theory
 Advanced Signal Processing Introduction to Estimation Theory Danilo Mandic, room 813, ext: 46271 Department of Electrical and Electronic Engineering Imperial College London, UK d.mandic@imperial.ac.uk,
Advanced Signal Processing Introduction to Estimation Theory Danilo Mandic, room 813, ext: 46271 Department of Electrical and Electronic Engineering Imperial College London, UK d.mandic@imperial.ac.uk,