Supervised Learning (contd) Decision Trees. Mausam (based on slides by UW-AI faculty)
|
|
|
- Julie Lawson
- 6 years ago
- Views:
Transcription

1 Supervised Learning (contd) Decision Trees Mausam (based on slides by UW-AI faculty)

2 Decision Trees To play or not to play? 2
3 Example data for learning the concept Good day for tennis Day Outlook Humid Wind PlayTennis? d1 s h w n d2 s h s n d3 o h w y d4 r h w y d5 r n w y d6 r n s y d7 o n s y d8 s h w n d9 s n w y d10 r n w y d11 s n s y d12 o h s y d13 o n w y d14 r h s n Outlook = sunny, overcast, rain Humidity = high, normal Wind = weak, strong 3
4 A Decision Tree for the Same Data Decision Tree for PlayTennis? Leaves = classification output Outlook Arcs = choice of value for parent attribute Sunny Overcast Rain Humidity Yes Wind Normal High Strong Weak Yes No Decision tree is equivalent to logic in disjunctive normal form PlayTennis (Sunny Normal) Overcast (Rain Weak) No Yes 4
5 Example: Decision Tree for Continuous Valued Features and Discrete Output Input real number attributes (x1,x2), Classification output: 0 or 1 x 2 How do we branch using attribute values x1 and x2 to partition the space correctly? x1 6
6 Example: Classification of Continuous Valued Inputs x2 Decision Tree 3 4 x1 7

7 Expressiveness of Decision Trees Decision trees can express any function of the input attributes. E.g., for Boolean functions, truth table row = path to leaf: Trivially, there is a consistent decision tree for any training set with one path to leaf for each example But most likely won't generalize to new examples Prefer to find more compact decision trees 8
8 Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate: is there an alternative restaurant nearby? 2. Bar: is there a comfortable bar area to wait in? 3. Fri/Sat: is today Friday or Saturday? 4. Hungry: are we hungry? 5. Patrons: number of people in the restaurant (None, Some, Full) 6. Price: price range ($, $$, $$$) 7. Raining: is it raining outside? 8. Reservation: have we made a reservation? 9. Type: kind of restaurant (French, Italian, Thai, Burger) 10. WaitEstimate: estimated waiting time (0-10, 10-30, 30-60, >60) 9

9 Example Decision tree A decision tree for Wait? based on personal rules of thumb : 10
10 Input Data for Learning Past examples when I did/did not wait for a table: Classification of examples is positive (T) or negative (F) 11
11 Decision Tree Learning Aim: find a small tree consistent with training examples Idea: (recursively) choose "most significant" attribute as root of (sub)tree 12
12 Choosing an attribute to split on Idea: a good attribute should reduce uncertainty E.g., splits the examples into subsets that are (ideally) "all positive" or "all negative" Patrons? is a better choice For Type?, to wait or not to wait is still at 50% 13

13 How do we quantify uncertainty?
 of an answer to a question with possible answers v 1,, v n : I(P(v 1 ),, P(v n )) = Σ i=1 -P(v i ) log 2 P(v i )")
14 Using information theory to quantify uncertainty Entropy measures the amount of uncertainty in a probability distribution Entropy (or Information Content) of an answer to a question with possible answers v 1,, v n : I(P(v 1 ),, P(v n )) = Σ i=1 -P(v i ) log 2 P(v i ) 15
15 Using information theory Imagine we have p examples with Wait = True (positive) and n examples with Wait = false (negative). Our best estimate of the probabilities of Wait = true or false is given by: P true p p n ( ) / p( false) n / p n Hence the entropy of Wait is given by: I( p p n, n p ) n p p n p n log 2 log 2 p n p n n p n 16

16 Entropy I Entropy is highest when uncertainty is greatest Wait = F Wait = T P(Wait = T) 17
17 Choosing an attribute to split on Idea: a good attribute should reduce uncertainty and result in gain in information How much information do we gain if we disclose the value of some attribute? Answer: uncertainty before uncertainty after 18
18 Back at the Restaurant Before choosing an attribute: Entropy = - 6/12 log(6/12) 6/12 log(6/12) = - log(1/2) = log(2) = 1 bit There is 1 bit of information to be discovered 19
-4/6 log(4/6) = 0.92 Info gain = (1-0) or (1-0.")
19 Back at the Restaurant If we choose Type: Go along branch French : we have entropy = 1 bit; similarly for the others. Information gain = 1-1 = 0 along any branch If we choose Patrons: In branch None and Some, entropy = 0 For Full, entropy = -2/6 log(2/6)-4/6 log(4/6) = 0.92 Info gain = (1-0) or (1-0.92) bits > 0 in both cases So choosing Patrons gains more information! 20

20 Entropy across branches How do we combine entropy of different branches? Answer: Compute average entropy Weight entropies according to probabilities of branches 2/12 times we enter None, so weight for None = 1/6 Some has weight: 4/12 = 1/3 Full has weight 6/12 = ½ n p i ni pi ni AvgEntropy ( A) Entropy (, ) p n p n p n i 1 i i i i weight for each branch entropy for each branch 21
21 Information gain Information Gain (IG) or reduction in entropy from using attribute A: IG(A) = Entropy before AvgEntropy after choosing A Choose the attribute with the largest IG 22
] 6 2 ) 4.")
22 Information gain in our example 2 4 IG( Patrons ) 1 [ I(0,1) IG( Type) 1 [ I(, ) I I(1,0) 1 ( 2 1, ) I(, I(, )] 6 2 ) bits 4 12 I 2 ( 4, 2 )] 4 0 bits Patrons has the highest IG of all attributes DTL algorithm chooses Patrons as the root 23
23 Should I stay or should I go? Learned Decision Tree Decision tree learned from the 12 examples: Substantially simpler than rules-of-thumb tree more complex hypothesis not justified by small amount of data 24
24 Performance Evaluation How do we know that the learned tree h f? Answer: Try h on a new test set of examples Learning curve = % correct on test set as a function of training set size 25
25 Overfitting Accuracy On training data On test data Number of Nodes in Decision tree 26
26 27
27 Rule #2 of Machine Learning The best hypothesis almost never achieves 100% accuracy on the training data. (Rule #1 was: you can t learn anything without inductive bias) 28
28 Avoiding overfitting Stop growing when data split not statistically significant Grow full tree and then prune How to select best tree? Measure performance over the training data Measure performance over separate validation set Add complexity penalty to performance measure 29

29 0.9 Accuracy Early Stopping Remember this tree and use it as the final classifier On training data On validation data On test data 0.6 Number of Nodes in Decision tree 30
30 Tune Tune Tune Test Reduced Error Pruning Split data into train and validation set Repeat until pruning is harmful Remove each subtree and replace it with majority class and evaluate on validation set Remove subtree that leads to largest gain in accuracy 31
31 Reduced Error Pruning Example Sunny Outlook Overcast Rain High Humidity Low Play Wind Strong Weak Don t play Play Don t play Play Validation set accuracy =
32 Reduced Error Pruning Example Sunny Don t play Outlook Overcast Play Rain Wind Strong Weak Don t play Play Validation set accuracy =
33 Reduced Error Pruning Example High Sunny Humidity Low Outlook Overcast Play Rain Play Don t play Play Validation set accuracy =
34 Reduced Error Pruning Example Sunny Don t play Outlook Overcast Play Rain Wind Strong Weak Don t play Play Use this as final tree 35
35 Scaling Up ID3 and C4.5 assume data fits in main memory (ok for 100,000s examples) SPRINT, SLIQ: multiple sequential scans of data (ok for millions of examples) VFDT: at most one sequential scan (ok for billions of examples) 38
36 Decision Trees Strengths Very Popular Technique Fast Useful when Target Function is discrete Concepts are likely to be disjunctions Attributes may be noisy 39
37 Decision Trees Weaknesses Less useful for continuous outputs Can have difficulty with continuous input features as well E.g., what if your target concept is a circle in the x1, x2 plane? Hard to represent with decision trees Very simple with instance-based methods we ll discuss later 40
38 Supervised Learning (contd) Linear Separation Mausam (based on slides by UW-AI faculty) 41

")
39 Images as Vectors Binary handwritten characters Treat an image as a highdimensional vector (e.g., by reading pixel values left to right, top to bottom row) Greyscale images I p p p N 2 p 1 2 N Pixel value p i can be 0 or 1 (binary image) or 0 to 255 (greyscale) 42

40 The human brain is extremely good at classifying images Can we develop classification methods by emulating the brain? 43
41 Brain Computer: What is it? Human brain contains a massively interconnected net of (10 billion) neurons (cortical cells) Biological Neuron - The simple arithmetic computing element 44
42 45
43 Biological Neurons 1. Soma or body cell - is a large, round central body in which almost all the logical functions of the neuron are realized. 2. The axon (output), is a nerve fibre attached to the soma which can serve as a final output channel of the neuron. An axon is usually highly branched. 3. The dendrites (inputs)- represent a highly branching tree of fibres. These long irregularly shaped nerve fibres (processes) are attached to the soma. 4. Synapses are specialized contacts on a neuron which are the termination points for the axons from other neurons. Synapses Soma Axon from other neuron Dendrites Axon Dendrite from other The schematic model of a biological neuron 46
44 Neurons communicate via spikes Inputs Output spike (electrical pulse) Output spike roughly dependent on whether sum of all inputs reaches a threshold 47
45 Neurons as Threshold Units Artificial neuron: m binary inputs (-1 or 1), 1 output (-1 or 1) Synaptic weights w ji Threshold i w 1i Weighted Sum Threshold Inputs u j (-1 or +1) w 2i w 3i Output v i (-1 or +1) v i ( wjiu j i j ) (x) = 1 if x > 0 and -1 if x 0 48
46 Perceptrons for Classification Fancy name for a type of layered feed-forward networks (no loops) Uses artificial neurons ( units ) with binary inputs and outputs Single-layer Multilayer 49
47 Perceptrons and Classification Consider a single-layer perceptron Weighted sum forms a linear hyperplane wjiu 0 j i j Everything on one side of this hyperplane is in class 1 (output = +1) and everything on other side is class 2 (output = -1) Any function that is linearly separable can be computed by a perceptron 50
48 Linear Separability Example: AND is linearly separable Linear hyperplane u 1 u 2 AND u 2 1 (1,1) v = u 1-1 u 1 u 2 v = 1 iff u 1 + u > 0 Similarly for OR and NOT 51
?")
49 How do we learn the appropriate weights given only examples of (input,output)? Idea: Change the weights to decrease the error in output 52
50 Perceptron Training Rule 53
51 What about the XOR function? u 1 u 2 XOR ? u 2 1 (1,1) u Can a perceptron separate the +1 outputs from the -1 outputs? 54
52 Linear Inseparability Perceptron with threshold units fails if classification task is not linearly separable Example: XOR No single line can separate the yes (+1) outputs from the no (-1) outputs! Minsky and Papert s book showing such negative results put a damper on neural networks research for over a decade! -1-1 u 2 1 X 1 (1,1) u 1 55

53 How do we deal with linear inseparability? 56
54 Idea 1: Multilayer Perceptrons Removes limitations of single-layer networks Can solve XOR Example: Two-layer perceptron that computes XOR x y Output is +1 if and only if x + y 2 (x + y 1.5) 0.5 > 0 57
55 Multilayer Perceptron: What does it do? out y ? x y 1 2 x 58
56 Multilayer Perceptron: What does it do? out y x y 2 0 =-1 =1 1 y x 1 1 x y x y 1 2 x 59
57 Multilayer Perceptron: What does it do? out y 2 =-1 = =1 =-1 2 x y 0 2 x y 0 x y 1 2 x 60
58 Multilayer Perceptron: What does it do? out y 2 =-1 = >0 =1 =-1 1 x y 1 2 x 61
59 Perceptrons as Constraint Satisfaction Networks 1 out y 2 =-1 =1 1 1 x y =1 =-1 2 x y 0 x y 1 2 x 62
60 Artificial Neuron: Most Popular Activation Functions Linear activation Logistic activation Σ z z z 1 0 z 1 1 z e z Threshold activation z 1, if z 0, sign( z) 1, if z 0. 1 Hyperbolic tangent activation 1 e 1 e 2 u u tanh u u z z 63
61 Neural Network Issues Multi-layer perceptrons can represent any function Training multi-layer perceptrons hard Backpropagation Early successes Keeping the car on the road Difficult to debug Opaque 64
62 Back to Linear Separability Recall: Weighted sum in perceptron forms a linear hyperplane i w x i i b 0 Due to threshold function, everything on one side of this hyperplane is labeled as class 1 (output = +1) and everything on other side is labeled as class 2 (output = -1) 65
63 Separating Hyperplane Class 1 i wi x i b 0 denotes +1 output denotes -1 output Class 2 Need to choose w and b based on training data 66
64 Separating Hyperplanes Different choices of w and b give different hyperplanes Class 1 denotes +1 output denotes -1 output Class 2 (This and next few slides adapted from Andrew Moore s) 67
65 Which hyperplane is best? Class 1 denotes +1 output denotes -1 output Class 2 68
66 How about the one right in the middle? Intuitively, this boundary seems good Avoids misclassification of new test points if they are generated from the same distribution as training points 69
67 Margin Define the margin of a linear classifier as the width that the boundary could be increased by before hitting a datapoint. 70
68 Maximum Margin and Support Vector Machine Support Vectors are those datapoints that the margin pushes up against The maximum margin classifier is called a Support Vector Machine (in this case, a Linear SVM or LSVM) 71
69 Why Maximum Margin? Robust to small perturbations of data points near boundary There exists theory showing this is best for generalization to new points Empirically works great 72
70 What if data is not linearly separable? Outliers (due to noise) 73
71 Approach 1: Soft Margin SVMs ξ Allow errors ξ i (deviations from margin) Trade off margin with errors. Minimize: margin + error-penalty 74
72 What if data is not linearly separable: Other ideas? Not linearly separable 76
73 What if data is not linearly separable? Approach 2: Map original input space to higherdimensional feature space; use linear classifier in higher-dim. space x φ(x) Kernel: additional bias to convert into high d space 77
74 Problem with high dimensional spaces x φ(x) Computation in high-dimensional feature space can be costly The high dimensional projection function φ(x) may be too complicated to compute Kernel trick to the rescue! 78
75 The Kernel Trick Dual Formulation: SVM maximizes the quadratic function: i 1 i 2 i, j y subject to 0 and i i j i y j ( x i i x i j y i ) 0 Insight: The data points only appear as inner product No need to compute high-dimensional φ(x) explicitly! Just replace inner product x i x j with a kernel function K(x i,x j ) = φ(x i ) φ(x j ) E.g., Gaussian kernel K(x i,x j ) = exp(- x i -x j 2 /2 2 ) E.g., Polynomial kernel K(x i,x j ) = x i x j +1) d 79
76 K-Nearest Neighbors A simple non-parametric classification algorithm Idea: Look around you to see how your neighbors classify data Classify a new data-point according to a majority vote of your k nearest neighbors 81
77 Distance Metric How do we measure what it means to be a neighbor (what is close )? Appropriate distance metric depends on the problem Examples: x discrete (e.g., strings): Hamming distance d(x 1,x 2 ) = # features on which x 1 and x 2 differ x continuous (e.g., vectors over reals): Euclidean distance d(x 1,x 2 ) = x 1 -x 2 = square root of sum of squared differences between corresponding elements of data vectors 82

78 Example Input Data: 2-D points (x 1,x 2 ) Two classes: C 1 and C 2. New Data Point + K = 4: Look at 4 nearest neighbors of + 3 are in C 1, so classify + as C 1 83
79 Decision Boundary using K-NN Some points near the boundary may be misclassified (but maybe noise) 84
80 What if we want to learn continuous-valued functions? Output Input 85
 minimizing the regression error/loss Neural Networks remove the threshold")
81 Regression K-Nearest neighbor take the average of k-close by points Linear/Non-linear Regression fit parameters (gradient descent) minimizing the regression error/loss Neural Networks remove the threshold function 86
82 Large Feature Spaces Easy to overfit Regularization add penalty for large weights prefer weights that are zero or close to zero minimize regression error + C.regularization penalty 87
83 Regularizations L1 : diamond L2 : circle Derivatives L1 : constant L2 : high for large weights L1 harder to optimize, but not too hard. - discontinuous but convex 88

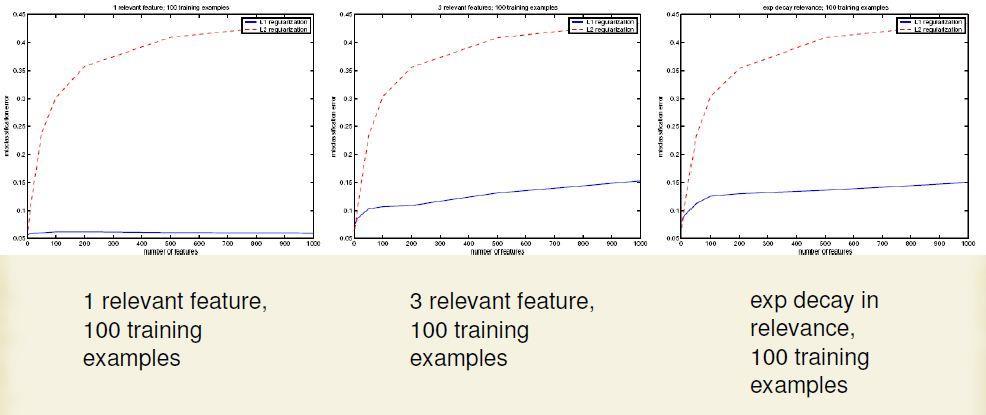
84 L1 vs. L2 89
85 Ensemble Classifiers Mausam (based on slides of Dan Weld) 90
86 Ensembles of Classifiers Traditional approach: Use one classifier Alternative approach: Use lots of classifiers Approaches: Cross-validated committees Bagging Boosting Stacking Daniel S. Weld 91
87 Ensembles of Classifiers Assume Errors are independent (suppose 30% error) Majority vote Probability that majority is wrong = area under binomial distribution Prob If individual area is 0.3 Area under curve for 11 wrong is Order of magnitude improvement! Daniel S. Weld Number of classifiers in error 92

88 Voting Daniel S. Weld 93
89 Constructing Ensembles Holdout Cross-validated committees Partition examples into k disjoint equiv classes Now create k training sets Each set is union of all equiv classes except one So each set has (k-1)/k of the original training data Now train a classifier on each set Daniel S. Weld 94
90 Ensemble Construction II Bagging Generate k sets of training examples For each set Draw m examples randomly (with replacement) From the original set of m examples Each training set corresponds to 63.2% of original (+ duplicates) Now train classifier on each set Intuition: Sampling helps algorithm become more robust to noise/outliers in the data Daniel S. Weld 95
91 Ensemble Creation III Boosting Maintain prob distribution over set of training examples Create k sets of training data iteratively: On iteration i Draw m examples randomly (like bagging) But use probability distribution to bias selection Train classifier number i on this training set Test partial ensemble (of i classifiers) on all training exs Modify distribution: increase P of each error example Daniel S. Weld 96

92 Ensemble Creation IV Stacking Train several base learners Next train meta-learner Learns when base learners are right / wrong Now meta learner arbitrates Train using cross validated committees Meta-L inputs = base learner predictions Training examples = test set from cross validation Daniel S. Weld 97
93 Why do ensembles work? Statistical Search through hypothesis space average: reduces risk of wrong classifier Computational Intractable to get best hypothesis Representational Increases the representable hypotheses 98
94 Example: Random Forests Create k decision trees For each decision tree Pick training data as in bagging Randomly sample f features in the data Construct best tree based only on these features Voting for final prediction Advantages Efficient, highly accurate, thousands of vars 99
Chapter 18. Decision Trees and Ensemble Learning. Recall: Learning Decision Trees
 CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
Learning and Neural Networks
 Artificial Intelligence Learning and Neural Networks Readings: Chapter 19 & 20.5 of Russell & Norvig Example: A Feed-forward Network w 13 I 1 H 3 w 35 w 14 O 5 I 2 w 23 w 24 H 4 w 45 a 5 = g 5 (W 3,5 a
Artificial Intelligence Learning and Neural Networks Readings: Chapter 19 & 20.5 of Russell & Norvig Example: A Feed-forward Network w 13 I 1 H 3 w 35 w 14 O 5 I 2 w 23 w 24 H 4 w 45 a 5 = g 5 (W 3,5 a
Learning from Examples
 Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING Santiago Ontañón so367@drexel.edu Summary so far: Rational Agents Problem Solving Systematic Search: Uninformed Informed Local Search Adversarial Search
CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING Santiago Ontañón so367@drexel.edu Summary so far: Rational Agents Problem Solving Systematic Search: Uninformed Informed Local Search Adversarial Search
Introduction To Artificial Neural Networks
 Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Learning Decision Trees
 Learning Decision Trees CS194-10 Fall 2011 Lecture 8 CS194-10 Fall 2011 Lecture 8 1 Outline Decision tree models Tree construction Tree pruning Continuous input features CS194-10 Fall 2011 Lecture 8 2
Learning Decision Trees CS194-10 Fall 2011 Lecture 8 CS194-10 Fall 2011 Lecture 8 1 Outline Decision tree models Tree construction Tree pruning Continuous input features CS194-10 Fall 2011 Lecture 8 2
EECS 349:Machine Learning Bryan Pardo
 EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
CS6375: Machine Learning Gautam Kunapuli. Decision Trees
 Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
1. Courses are either tough or boring. 2. Not all courses are boring. 3. Therefore there are tough courses. (Cx, Tx, Bx, )
") Logic FOL Syntax FOL Rules (Copi) 1. Courses are either tough or boring. 2. Not all courses are boring. 3. Therefore there are tough courses. (Cx, Tx, Bx, ) Dealing with Time Translate into first-order
Logic FOL Syntax FOL Rules (Copi) 1. Courses are either tough or boring. 2. Not all courses are boring. 3. Therefore there are tough courses. (Cx, Tx, Bx, ) Dealing with Time Translate into first-order
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
CS 6375 Machine Learning
 CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
Chapter 6: Classification
 Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Artificial Intelligence Roman Barták
 Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Incremental Stochastic Gradient Descent
 Incremental Stochastic Gradient Descent Batch mode : gradient descent w=w - η E D [w] over the entire data D E D [w]=1/2σ d (t d -o d ) 2 Incremental mode: gradient descent w=w - η E d [w] over individual
Incremental Stochastic Gradient Descent Batch mode : gradient descent w=w - η E D [w] over the entire data D E D [w]=1/2σ d (t d -o d ) 2 Incremental mode: gradient descent w=w - η E d [w] over individual
Bayesian learning Probably Approximately Correct Learning
 Bayesian learning Probably Approximately Correct Learning Peter Antal antal@mit.bme.hu A.I. December 1, 2017 1 Learning paradigms Bayesian learning Falsification hypothesis testing approach Probably Approximately
Bayesian learning Probably Approximately Correct Learning Peter Antal antal@mit.bme.hu A.I. December 1, 2017 1 Learning paradigms Bayesian learning Falsification hypothesis testing approach Probably Approximately
Learning Decision Trees
 Learning Decision Trees Machine Learning Fall 2018 Some slides from Tom Mitchell, Dan Roth and others 1 Key issues in machine learning Modeling How to formulate your problem as a machine learning problem?
Learning Decision Trees Machine Learning Fall 2018 Some slides from Tom Mitchell, Dan Roth and others 1 Key issues in machine learning Modeling How to formulate your problem as a machine learning problem?
Decision Trees. CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore
 Decision Trees Claude Monet, The Mulberry Tree Slides from Pedro Domingos, CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Michael Guerzhoy
Decision Trees Claude Monet, The Mulberry Tree Slides from Pedro Domingos, CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Michael Guerzhoy
Learning from Observations. Chapter 18, Sections 1 3 1
 Learning from Observations Chapter 18, Sections 1 3 Chapter 18, Sections 1 3 1 Outline Learning agents Inductive learning Decision tree learning Measuring learning performance Chapter 18, Sections 1 3
Learning from Observations Chapter 18, Sections 1 3 Chapter 18, Sections 1 3 1 Outline Learning agents Inductive learning Decision tree learning Measuring learning performance Chapter 18, Sections 1 3
CS 380: ARTIFICIAL INTELLIGENCE
 CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING 11/11/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Summary so far: Rational Agents Problem
CS 380: ARTIFICIAL INTELLIGENCE MACHINE LEARNING 11/11/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Summary so far: Rational Agents Problem
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Learning Decision Trees
 Learning Decision Trees Machine Learning Spring 2018 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning decision trees The ID3 algorithm: A greedy
Learning Decision Trees Machine Learning Spring 2018 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning decision trees The ID3 algorithm: A greedy
Notes on Machine Learning for and
 Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Learning = improving with experience Improve over task T (e.g, Classification, control tasks) with respect
Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Learning = improving with experience Improve over task T (e.g, Classification, control tasks) with respect
Decision Trees. Machine Learning CSEP546 Carlos Guestrin University of Washington. February 3, 2014
 Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
Classification Algorithms
 Classification Algorithms UCSB 290N, 2015. T. Yang Slides based on R. Mooney UT Austin 1 Table of Content roblem Definition Rocchio K-nearest neighbor case based Bayesian algorithm Decision trees 2 Given:
Classification Algorithms UCSB 290N, 2015. T. Yang Slides based on R. Mooney UT Austin 1 Table of Content roblem Definition Rocchio K-nearest neighbor case based Bayesian algorithm Decision trees 2 Given:
From inductive inference to machine learning
 From inductive inference to machine learning ADAPTED FROM AIMA SLIDES Russel&Norvig:Artificial Intelligence: a modern approach AIMA: Inductive inference AIMA: Inductive inference 1 Outline Bayesian inferences
From inductive inference to machine learning ADAPTED FROM AIMA SLIDES Russel&Norvig:Artificial Intelligence: a modern approach AIMA: Inductive inference AIMA: Inductive inference 1 Outline Bayesian inferences
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
the tree till a class assignment is reached
 Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Introduction to Machine Learning
 Introduction to Machine Learning Reading for today: R&N 18.1-18.4 Next lecture: R&N 18.6-18.12, 20.1-20.3.2 Outline The importance of a good representation Different types of learning problems Different
Introduction to Machine Learning Reading for today: R&N 18.1-18.4 Next lecture: R&N 18.6-18.12, 20.1-20.3.2 Outline The importance of a good representation Different types of learning problems Different
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Decision Trees. CS 341 Lectures 8/9 Dan Sheldon
 Decision rees CS 341 Lectures 8/9 Dan Sheldon Review: Linear Methods Y! So far, we ve looked at linear methods! Linear regression! Fit a line/plane/hyperplane X 2 X 1! Logistic regression! Decision boundary
Decision rees CS 341 Lectures 8/9 Dan Sheldon Review: Linear Methods Y! So far, we ve looked at linear methods! Linear regression! Fit a line/plane/hyperplane X 2 X 1! Logistic regression! Decision boundary
Decision Trees. Tirgul 5
 Decision Trees Tirgul 5 Using Decision Trees It could be difficult to decide which pet is right for you. We ll find a nice algorithm to help us decide what to choose without having to think about it. 2
Decision Trees Tirgul 5 Using Decision Trees It could be difficult to decide which pet is right for you. We ll find a nice algorithm to help us decide what to choose without having to think about it. 2
Decision Trees.
 . Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Decision Tree Learning
 Decision Tree Learning Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Machine Learning, Chapter 3 2. Data Mining: Concepts, Models,
Decision Tree Learning Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Machine Learning, Chapter 3 2. Data Mining: Concepts, Models,
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
EE04 804(B) Soft Computing Ver. 1.2 Class 2. Neural Networks - I Feb 23, Sasidharan Sreedharan
 Soft Computing Ver. 1.2 Class 2. Neural Networks - I Feb 23, Sasidharan Sreedharan") EE04 804(B) Soft Computing Ver. 1.2 Class 2. Neural Networks - I Feb 23, 2012 Sasidharan Sreedharan www.sasidharan.webs.com 3/1/2012 1 Syllabus Artificial Intelligence Systems- Neural Networks, fuzzy logic,
EE04 804(B) Soft Computing Ver. 1.2 Class 2. Neural Networks - I Feb 23, 2012 Sasidharan Sreedharan www.sasidharan.webs.com 3/1/2012 1 Syllabus Artificial Intelligence Systems- Neural Networks, fuzzy logic,
Decision Trees. Data Science: Jordan Boyd-Graber University of Maryland MARCH 11, Data Science: Jordan Boyd-Graber UMD Decision Trees 1 / 1
 Decision Trees Data Science: Jordan Boyd-Graber University of Maryland MARCH 11, 2018 Data Science: Jordan Boyd-Graber UMD Decision Trees 1 / 1 Roadmap Classification: machines labeling data for us Last
Decision Trees Data Science: Jordan Boyd-Graber University of Maryland MARCH 11, 2018 Data Science: Jordan Boyd-Graber UMD Decision Trees 1 / 1 Roadmap Classification: machines labeling data for us Last
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan
 Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan") Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Decision Tree Learning Mitchell, Chapter 3. CptS 570 Machine Learning School of EECS Washington State University
 Decision Tree Learning Mitchell, Chapter 3 CptS 570 Machine Learning School of EECS Washington State University Outline Decision tree representation ID3 learning algorithm Entropy and information gain
Decision Tree Learning Mitchell, Chapter 3 CptS 570 Machine Learning School of EECS Washington State University Outline Decision tree representation ID3 learning algorithm Entropy and information gain
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Classification and Regression Trees
 Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
Decision Trees. CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore
 Decision Trees Claude Monet, The Mulberry Tree Slides from Pedro Domingos, CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Michael Guerzhoy
Decision Trees Claude Monet, The Mulberry Tree Slides from Pedro Domingos, CSC411/2515: Machine Learning and Data Mining, Winter 2018 Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Michael Guerzhoy
Statistical Learning. Philipp Koehn. 10 November 2015
 Statistical Learning Philipp Koehn 10 November 2015 Outline 1 Learning agents Inductive learning Decision tree learning Measuring learning performance Bayesian learning Maximum a posteriori and maximum
Statistical Learning Philipp Koehn 10 November 2015 Outline 1 Learning agents Inductive learning Decision tree learning Measuring learning performance Bayesian learning Maximum a posteriori and maximum
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Classification Algorithms
 Classification Algorithms UCSB 293S, 2017. T. Yang Slides based on R. Mooney UT Austin 1 Table of Content Problem Definition Rocchio K-nearest neighbor case based Bayesian algorithm Decision trees 2 Classification
Classification Algorithms UCSB 293S, 2017. T. Yang Slides based on R. Mooney UT Austin 1 Table of Content Problem Definition Rocchio K-nearest neighbor case based Bayesian algorithm Decision trees 2 Classification
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Lecture 3: Decision Trees
 Lecture 3: Decision Trees Cognitive Systems - Machine Learning Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning last change November 26, 2014 Ute Schmid (CogSys,
Lecture 3: Decision Trees Cognitive Systems - Machine Learning Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning last change November 26, 2014 Ute Schmid (CogSys,
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
Question of the Day. Machine Learning 2D1431. Decision Tree for PlayTennis. Outline. Lecture 4: Decision Tree Learning
 Question of the Day Machine Learning 2D1431 How can you make the following equation true by drawing only one straight line? 5 + 5 + 5 = 550 Lecture 4: Decision Tree Learning Outline Decision Tree for PlayTennis
Question of the Day Machine Learning 2D1431 How can you make the following equation true by drawing only one straight line? 5 + 5 + 5 = 550 Lecture 4: Decision Tree Learning Outline Decision Tree for PlayTennis
Classification II: Decision Trees and SVMs
 Classification II: Decision Trees and SVMs Digging into Data: Jordan Boyd-Graber February 25, 2013 Slides adapted from Tom Mitchell, Eric Xing, and Lauren Hannah Digging into Data: Jordan Boyd-Graber ()
Classification II: Decision Trees and SVMs Digging into Data: Jordan Boyd-Graber February 25, 2013 Slides adapted from Tom Mitchell, Eric Xing, and Lauren Hannah Digging into Data: Jordan Boyd-Graber ()
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Artificial neural networks
 Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Midterm, Fall 2003
 5-78 Midterm, Fall 2003 YOUR ANDREW USERID IN CAPITAL LETTERS: YOUR NAME: There are 9 questions. The ninth may be more time-consuming and is worth only three points, so do not attempt 9 unless you are
5-78 Midterm, Fall 2003 YOUR ANDREW USERID IN CAPITAL LETTERS: YOUR NAME: There are 9 questions. The ninth may be more time-consuming and is worth only three points, so do not attempt 9 unless you are
Machine Learning 2nd Edi7on
 Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Decision Trees.
 . Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Decision Trees Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Holdout and Cross-Validation Methods Overfitting Avoidance
 Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
CS:4420 Artificial Intelligence
 CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
} It is non-zero, and maximized given a uniform distribution } Thus, for any distribution possible, we have:
 Review: Entropy and Information H(P) = X i p i log p i Class #04: Mutual Information & Decision rees Machine Learning (CS 419/519): M. Allen, 1 Sept. 18 } Entropy is the information gained on average when
Review: Entropy and Information H(P) = X i p i log p i Class #04: Mutual Information & Decision rees Machine Learning (CS 419/519): M. Allen, 1 Sept. 18 } Entropy is the information gained on average when
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Machine Learning Recitation 8 Oct 21, Oznur Tastan
 Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Decision Tree Learning
 Topics Decision Tree Learning Sattiraju Prabhakar CS898O: DTL Wichita State University What are decision trees? How do we use them? New Learning Task ID3 Algorithm Weka Demo C4.5 Algorithm Weka Demo Implementation
Topics Decision Tree Learning Sattiraju Prabhakar CS898O: DTL Wichita State University What are decision trees? How do we use them? New Learning Task ID3 Algorithm Weka Demo C4.5 Algorithm Weka Demo Implementation
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
ML techniques. symbolic techniques different types of representation value attribute representation representation of the first order
 MACHINE LEARNING Definition 1: Learning is constructing or modifying representations of what is being experienced [Michalski 1986], p. 10 Definition 2: Learning denotes changes in the system That are adaptive
MACHINE LEARNING Definition 1: Learning is constructing or modifying representations of what is being experienced [Michalski 1986], p. 10 Definition 2: Learning denotes changes in the system That are adaptive
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Decision Trees. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. February 5 th, Carlos Guestrin 1
 Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
UVA CS 4501: Machine Learning
 UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Lecture 7 Artificial neural networks: Supervised learning
 Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
22c145-Fall 01: Neural Networks. Neural Networks. Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1
 Neural Networks Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1 Brains as Computational Devices Brains advantages with respect to digital computers: Massively parallel Fault-tolerant Reliable
Neural Networks Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1 Brains as Computational Devices Brains advantages with respect to digital computers: Massively parallel Fault-tolerant Reliable
Regularization. CSCE 970 Lecture 3: Regularization. Stephen Scott and Vinod Variyam. Introduction. Outline
 Other Measures 1 / 52 sscott@cse.unl.edu learning can generally be distilled to an optimization problem Choose a classifier (function, hypothesis) from a set of functions that minimizes an objective function
Other Measures 1 / 52 sscott@cse.unl.edu learning can generally be distilled to an optimization problem Choose a classifier (function, hypothesis) from a set of functions that minimizes an objective function
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning
 LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning") CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
Final Exam, Fall 2002
 15-781 Final Exam, Fall 22 1. Write your name and your andrew email address below. Name: Andrew ID: 2. There should be 17 pages in this exam (excluding this cover sheet). 3. If you need more room to work
15-781 Final Exam, Fall 22 1. Write your name and your andrew email address below. Name: Andrew ID: 2. There should be 17 pages in this exam (excluding this cover sheet). 3. If you need more room to work