Introduction to Information Retrieval
|
|
|
- Jodie Robinson
- 6 years ago
- Views:
Transcription
1 Introduction to Information Retrieval IIR 19: Size Estimation & Duplicate Detection Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart Schütze: Size estimation & Duplicate detection 1 / 55
2 Overview 1 Size of the web 2 Duplication detection Schütze: Size estimation & Duplicate detection 2 / 55
3 Outline 1 Size of the web 2 Duplication detection Schütze: Size estimation & Duplicate detection 3 / 55
4 Size of the web: Who cares? Media Users They may switch to the search engine that has the best coverage of the web. Users (sometimes) care about recall. If we underestimate the size of the web, search engine results may have low recall. Search engine designers (how many pages do I need to be able to handle?) Crawler designers (which policy will crawl close to N pages?) Schütze: Size estimation & Duplicate detection 4 / 55
5 What is the size of the web? Any guesses? Schütze: Size estimation & Duplicate detection 5 / 55
6 Simple method for determining a lower bound OR-query of frequent words in a number of languages According to this query: Size of web 21,450,000,000 on Big if: Page counts of google search results are correct. (Generally, they are just rough estimates.) But this is just a lower bound, based on one search engine. How can we do better? Schütze: Size estimation & Duplicate detection 6 / 55
7 Size of the web: Issues The dynamic web is infinite. Any sum of two numbers is its own dynamic page on Google. (Example: 2+4 ) Many other dynamic sites generating infinite number of pages The static web contains duplicates each equivalence class should only be counted once. Some servers are seldom connected. Example: Your laptop Is it part of the web? Schütze: Size estimation & Duplicate detection 7 / 55
8 Search engine index contains N pages : Issues Can I claim a page is in the index if I only index the first 4000 bytes? Can I claim a page is in the index if I only index anchor text pointing to the page? There used to be (and still are?) billions of pages that are only indexed by anchor text. Schütze: Size estimation & Duplicate detection 8 / 55
9 How can we estimate the size of the web? Schütze: Size estimation & Duplicate detection 9 / 55
10 Sampling methods Random queries Random searches Random IP addresses Random walks Schütze: Size estimation & Duplicate detection 10 / 55
11 Variant: Estimate relative sizes of indexes There are significant differences between indexes of different search engines. Different engines have different preferences. max url depth, max count/host, anti-spam rules, priority rules etc. Different engines index different things under the same URL. anchor text, frames, meta-keywords, size of prefix etc. Schütze: Size estimation & Duplicate detection 11 / 55
12
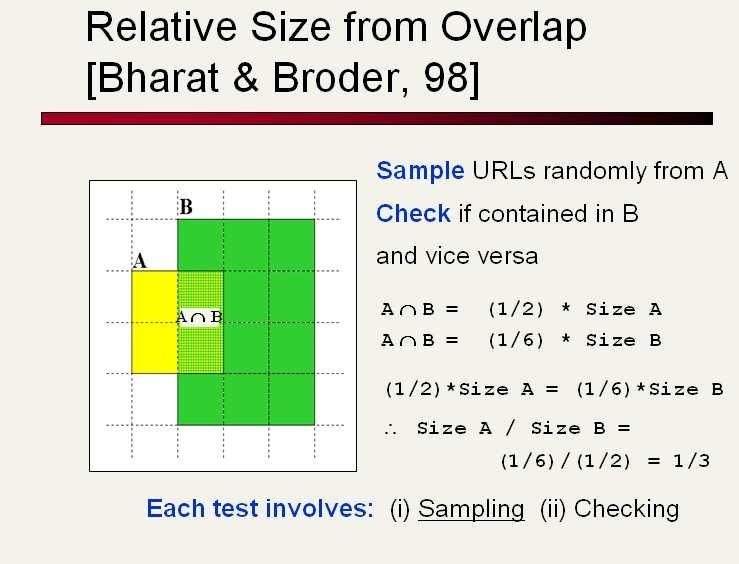
13 Sampling URLs Ideal strategy: Generate a random URL Problem: Random URLs are hard to find (and sampling distribution should reflect user interest ) Approach 1: Random walks / IP addresses In theory: might give us a true estimate of the size of the web (as opposed to just relative sizes of indexex) Approach 2: Generate a random URL contained in a given engine Suffices for accurate estimation of relative size Schütze: Size estimation & Duplicate detection 13 / 55
14 Random URLs from random queries Idea: Use vocabulary of the web for query generation Vocabulary can be generated from web crawl Use conjunctive queries w 1 AND w 2 Example: vocalists AND rsi Get result set of one hundred URLs from the source engine Choose a random URL from the result set This sampling method induces a weight W(p) for each page p. Method was used by Bharat and Broder (1998). Schütze: Size estimation & Duplicate detection 14 / 55
15 Checking if a page is in the index Either: Search for URL if the engine supports this Or: Create a query that will find doc d with high probability Download doc, extract words Use 8 low frequency word as AND query Call this a strong query for d Run query Check if d is in result set Problems Near duplicates Redirects Engine time-outs Schütze: Size estimation & Duplicate detection 15 / 55

16

17
18 Random searches Choose random searches extracted from a search engine log (Lawrence & Giles 97) Use only queries with small result sets For each random query: compute ratio size(r 1 )/size(r 2 ) of the two result sets Average over random searches Schütze: Size estimation & Duplicate detection 18 / 55
19 Advantages & disadvantages Advantage Might be a better reflection of the human perception of coverage Issues Samples are correlated with source of log (unfair advantage for originating search engine) Duplicates Technical statistical problems (must have non-zero results, ratio average not statistically sound) Schütze: Size estimation & Duplicate detection 19 / 55

20

21

22
23 Random IP addresses [ONei97,Lawr99] [Lawr99] exhaustively crawled 2500 servers and extrapolated Estimated size of the web to be 800 million Schütze: Size estimation & Duplicate detection 23 / 55
24 Advantages and disadvantages Advantages Can, in theory, estimate the size of the accessible web (as opposed to the (relative) size of an index) Clean statistics Independent of crawling strategies Disadvantages Many hosts share one IP ( oversampling) Hosts with large web sites don t get more weight than hosts with small web sites ( possible undersampling) Sensitive to spam (multiple IPs for same spam server) Again, duplicates Schütze: Size estimation & Duplicate detection 24 / 55

25
26

27
28 Conclusion Many different approaches to web size estimation. None is perfect. The problem has gotten much harder. There hasn t been a good study for a couple of years. Great topic for a thesis! Schütze: Size estimation & Duplicate detection 28 / 55
29 Outline 1 Size of the web 2 Duplication detection Schütze: Size estimation & Duplicate detection 29 / 55

30
31 How to detect exact duplicates? Schütze: Size estimation & Duplicate detection 31 / 55

32

33

34

35

36
37

38

39

40

41
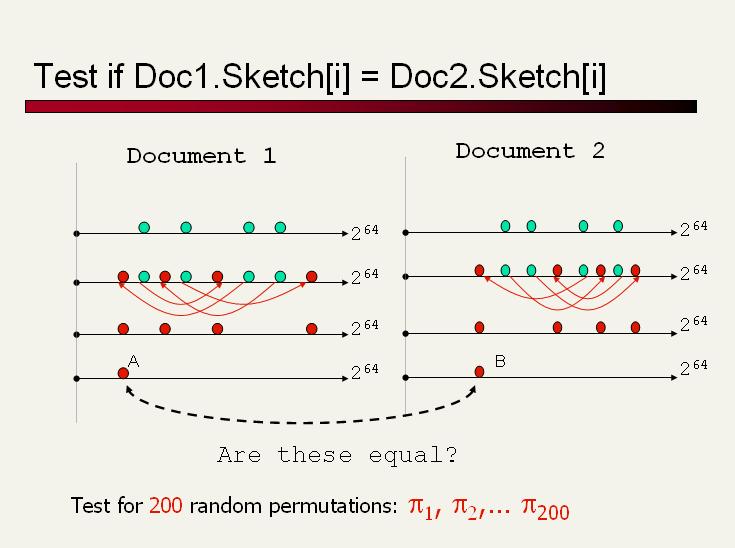
42 Estimating P[h(C 1 ) = h(c 2 )] For a particular permutation, the value of h(c 1 ) = h(c 2 ) is either 0 or 1. The average of values of h(c 1 ) = h(c 2 ) over many permutations is an estimate of P[h(C 1 ) = h(c 2 )]. P[h(C 1 ) = h(c 2 )] = E h [h(c 1 ) = h(c 2 )]. We estimate P[h(C 1 ) = h(c 2 )] by computing the average of h(c 1 ) = h(c 2 ) for the 200 permutations that correspond to the elements of the sketch vector. Schütze: Size estimation & Duplicate detection 42 / 55

43

44
45 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 Schütze: Size estimation & Duplicate detection 45 / 55
46 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 h(1) = 1 g(1) = 3 h(2) = 2 g(2) = 0 h(3) = 3 g(3) = 2 h(4) = 4 g(4) = 4 h(5) = 0 g(5) = 1 C 1 slots C 2 slots Schütze: Size estimation & Duplicate detection 46 / 55
47 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 C 1 slots C 2 slots h(1) = 1 g(1) = 3 h(2) = 2 g(2) = 0 h(3) = 3 g(3) = 2 h(4) = 4 g(4) = 4 h(5) = 0 g(5) = 1 Schütze: Size estimation & Duplicate detection 47 / 55
48 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 C 1 slots C 2 slots h(1) = 1 1 g(1) = 3 3 h(2) = 2 2 g(2) = 0 0 h(3) = g(3) = h(4) = 4 4 g(4) = 4 4 h(5) = 0 0 g(5) = 1 1 Schütze: Size estimation & Duplicate detection 48 / 55
49 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 C 1 slots C 2 slots h(1) = g(1) = h(2) = 2 2 g(2) = 0 0 h(3) = g(3) = h(4) = 4 4 g(4) = 4 4 h(5) = 0 0 g(5) = 1 1 Schütze: Size estimation & Duplicate detection 49 / 55
50 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 C 1 slots C 2 slots h(1) = g(1) = h(2) = g(2) = h(3) = g(3) = h(4) = 4 4 g(4) = 4 4 h(5) = 0 0 g(5) = 1 1 Schütze: Size estimation & Duplicate detection 50 / 55
51 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 C 1 slots C 2 slots h(1) = g(1) = h(2) = g(2) = h(3) = g(3) = h(4) = 4 4 g(4) = 4 4 h(5) = 0 0 g(5) = 1 1 Schütze: Size estimation & Duplicate detection 51 / 55
52 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 C 1 slots C 2 slots h(1) = g(1) = h(2) = g(2) = h(3) = g(3) = h(4) = g(4) = h(5) = 0 0 g(5) = 1 1 Schütze: Size estimation & Duplicate detection 52 / 55
53 Example C 1 C 2 R R R R R h(x) = x mod 5 g(x) = (2x + 1) mod 5 C 1 slots C 2 slots h(1) = g(1) = h(2) = g(2) = h(3) = g(3) = h(4) = g(4) = h(5) = g(5) = Schütze: Size estimation & Duplicate detection 53 / 55
54 Efficient near-duplicate detection Now we have an extremely efficient method for estimating a Jaccard coefficient for a single pair of two documents. But we still have to estimate N 2 coefficients where N is the number of weg pages. Still intractable One solution: locality sensitive hashing (LSH) Another solution: sorting (Henzinger 2006) Schütze: Size estimation & Duplicate detection 54 / 55
55 Resources IIR 19 Phelps & Wilensky, Robust hyperlinks & locations, Bar-Yossef & Gurevich, Random sampling from a search engine s index, WWW Broder et al., Estimating corpus size via queries, ACM CIKM Henzinger, Finding near-duplicate web pages: A large-scale evaluation of algorithms, ACM SIGIR Schütze: Size estimation & Duplicate detection 55 / 55
COMPUTING SIMILARITY BETWEEN DOCUMENTS (OR ITEMS) This part is to a large extent based on slides obtained from
 This part is to a large extent based on slides obtained from") COMPUTING SIMILARITY BETWEEN DOCUMENTS (OR ITEMS) This part is to a large extent based on slides obtained from http://www.mmds.org Distance Measures For finding similar documents, we consider the Jaccard
COMPUTING SIMILARITY BETWEEN DOCUMENTS (OR ITEMS) This part is to a large extent based on slides obtained from http://www.mmds.org Distance Measures For finding similar documents, we consider the Jaccard
DATA MINING LECTURE 6. Similarity and Distance Sketching, Locality Sensitive Hashing
 DATA MINING LECTURE 6 Similarity and Distance Sketching, Locality Sensitive Hashing SIMILARITY AND DISTANCE Thanks to: Tan, Steinbach, and Kumar, Introduction to Data Mining Rajaraman and Ullman, Mining
DATA MINING LECTURE 6 Similarity and Distance Sketching, Locality Sensitive Hashing SIMILARITY AND DISTANCE Thanks to: Tan, Steinbach, and Kumar, Introduction to Data Mining Rajaraman and Ullman, Mining
Link Analysis. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
Estimating Corpus Size via Queries
 Estimating Corpus Size via Queries Andrei Broder Marcus Fontura Vanja Josifovski Ravi Kumar Rajeev Motwani Shubha Nabar Rina Panigrahy Andrew Tomkins Ying u Yahoo! Research, 701 First Avenue, Sunnyvale,
Estimating Corpus Size via Queries Andrei Broder Marcus Fontura Vanja Josifovski Ravi Kumar Rajeev Motwani Shubha Nabar Rina Panigrahy Andrew Tomkins Ying u Yahoo! Research, 701 First Avenue, Sunnyvale,
Why duplicate detection?
 Near-Duplicates Detection Naama Kraus Slides are based on Introduction to Information Retrieval Book by Manning, Raghavan and Schütze Some slides are courtesy of Kira Radinsky Why duplicate detection?
Near-Duplicates Detection Naama Kraus Slides are based on Introduction to Information Retrieval Book by Manning, Raghavan and Schütze Some slides are courtesy of Kira Radinsky Why duplicate detection?
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
V.4 MapReduce. 1. System Architecture 2. Programming Model 3. Hadoop. Based on MRS Chapter 4 and RU Chapter 2 IR&DM 13/ 14 !74
 V.4 MapReduce. System Architecture 2. Programming Model 3. Hadoop Based on MRS Chapter 4 and RU Chapter 2!74 Why MapReduce? Large clusters of commodity computers (as opposed to few supercomputers) Challenges:
V.4 MapReduce. System Architecture 2. Programming Model 3. Hadoop Based on MRS Chapter 4 and RU Chapter 2!74 Why MapReduce? Large clusters of commodity computers (as opposed to few supercomputers) Challenges:
Part I: Web Structure Mining Chapter 1: Information Retrieval and Web Search
 Part I: Web Structure Mining Chapter : Information Retrieval an Web Search The Web Challenges Crawling the Web Inexing an Keywor Search Evaluating Search Quality Similarity Search The Web Challenges Tim
Part I: Web Structure Mining Chapter : Information Retrieval an Web Search The Web Challenges Crawling the Web Inexing an Keywor Search Evaluating Search Quality Similarity Search The Web Challenges Tim
Finding Similar Sets. Applications Shingling Minhashing Locality-Sensitive Hashing Distance Measures. Modified from Jeff Ullman
 Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Distance Measures Modified from Jeff Ullman Goals Many Web-mining problems can be expressed as finding similar sets:. Pages
Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Distance Measures Modified from Jeff Ullman Goals Many Web-mining problems can be expressed as finding similar sets:. Pages
Introduction to Search Engine Technology Introduction to Link Structure Analysis. Ronny Lempel Yahoo Labs, Haifa
 Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
Data Mining and Matrices
 Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics Querying
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics Querying
Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page
![Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page](/thumbs/95/125556981.jpg "Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page") IV.3 HITS Hyperlinked-Induced Topic Search (HITS) identifies authorities as good content sources (~high indegree) hubs as good link sources (~high outdegree) HITS [Kleinberg 99] considers a web page a
IV.3 HITS Hyperlinked-Induced Topic Search (HITS) identifies authorities as good content sources (~high indegree) hubs as good link sources (~high outdegree) HITS [Kleinberg 99] considers a web page a
How Latent Semantic Indexing Solves the Pachyderm Problem
 How Latent Semantic Indexing Solves the Pachyderm Problem Michael A. Covington Institute for Artificial Intelligence The University of Georgia 2011 1 Introduction Here I present a brief mathematical demonstration
How Latent Semantic Indexing Solves the Pachyderm Problem Michael A. Covington Institute for Artificial Intelligence The University of Georgia 2011 1 Introduction Here I present a brief mathematical demonstration
Lecture 26: Arthur-Merlin Games
 CS 710: Complexity Theory 12/09/2011 Lecture 26: Arthur-Merlin Games Instructor: Dieter van Melkebeek Scribe: Chetan Rao and Aaron Gorenstein Last time we compared counting versus alternation and showed
CS 710: Complexity Theory 12/09/2011 Lecture 26: Arthur-Merlin Games Instructor: Dieter van Melkebeek Scribe: Chetan Rao and Aaron Gorenstein Last time we compared counting versus alternation and showed
Analysis of Algorithms I: Perfect Hashing
 Analysis of Algorithms I: Perfect Hashing Xi Chen Columbia University Goal: Let U = {0, 1,..., p 1} be a huge universe set. Given a static subset V U of n keys (here static means we will never change the
Analysis of Algorithms I: Perfect Hashing Xi Chen Columbia University Goal: Let U = {0, 1,..., p 1} be a huge universe set. Given a static subset V U of n keys (here static means we will never change the
High Dimensional Search Min- Hashing Locality Sensi6ve Hashing
 High Dimensional Search Min- Hashing Locality Sensi6ve Hashing Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata September 8 and 11, 2014 High Support Rules vs Correla6on of
High Dimensional Search Min- Hashing Locality Sensi6ve Hashing Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata September 8 and 11, 2014 High Support Rules vs Correla6on of
IS4200/CS6200 Informa0on Retrieval. PageRank Con+nued. with slides from Hinrich Schütze and Chris6na Lioma
 IS4200/CS6200 Informa0on Retrieval PageRank Con+nued with slides from Hinrich Schütze and Chris6na Lioma Exercise: Assump0ons underlying PageRank Assump0on 1: A link on the web is a quality signal the
IS4200/CS6200 Informa0on Retrieval PageRank Con+nued with slides from Hinrich Schütze and Chris6na Lioma Exercise: Assump0ons underlying PageRank Assump0on 1: A link on the web is a quality signal the
How does Google rank webpages?
 Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics
Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics
CSCE 561 Information Retrieval System Models
 CSCE 561 Information Retrieval System Models Satya Katragadda 26 August 2015 Agenda Introduction to Information Retrieval Inverted Index IR System Models Boolean Retrieval Model 2 Introduction Information
CSCE 561 Information Retrieval System Models Satya Katragadda 26 August 2015 Agenda Introduction to Information Retrieval Inverted Index IR System Models Boolean Retrieval Model 2 Introduction Information
CS276A Text Information Retrieval, Mining, and Exploitation. Lecture 4 15 Oct 2002
 CS276A Text Information Retrieval, Mining, and Exploitation Lecture 4 15 Oct 2002 Recap of last time Index size Index construction techniques Dynamic indices Real world considerations 2 Back of the envelope
CS276A Text Information Retrieval, Mining, and Exploitation Lecture 4 15 Oct 2002 Recap of last time Index size Index construction techniques Dynamic indices Real world considerations 2 Back of the envelope
Behavioral Data Mining. Lecture 2
 Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 11: Probabilistic Information Retrieval Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 11: Probabilistic Information Retrieval Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
15-451/651: Design & Analysis of Algorithms September 13, 2018 Lecture #6: Streaming Algorithms last changed: August 30, 2018
 15-451/651: Design & Analysis of Algorithms September 13, 2018 Lecture #6: Streaming Algorithms last changed: August 30, 2018 Today we ll talk about a topic that is both very old (as far as computer science
15-451/651: Design & Analysis of Algorithms September 13, 2018 Lecture #6: Streaming Algorithms last changed: August 30, 2018 Today we ll talk about a topic that is both very old (as far as computer science
Pivoted Length Normalization I. Summary idf II. Review
 2 Feb 2006 1/11 COM S/INFO 630: Representing and Accessing [Textual] Digital Information Lecturer: Lillian Lee Lecture 3: 2 February 2006 Scribes: Siavash Dejgosha (sd82) and Ricardo Hu (rh238) Pivoted
2 Feb 2006 1/11 COM S/INFO 630: Representing and Accessing [Textual] Digital Information Lecturer: Lillian Lee Lecture 3: 2 February 2006 Scribes: Siavash Dejgosha (sd82) and Ricardo Hu (rh238) Pivoted
B u i l d i n g a n d E x p l o r i n g
 B u i l d i n g a n d E x p l o r i n g ( Web) Corpora EMLS 2008, Stuttgart 23-25 July 2008 Pavel Rychlý pary@fi.muni.cz NLPlab, Masaryk University, Brno O u t l i n e (1)Introduction to text/web corpora
B u i l d i n g a n d E x p l o r i n g ( Web) Corpora EMLS 2008, Stuttgart 23-25 July 2008 Pavel Rychlý pary@fi.muni.cz NLPlab, Masaryk University, Brno O u t l i n e (1)Introduction to text/web corpora
Hash-based Indexing: Application, Impact, and Realization Alternatives
 : Application, Impact, and Realization Alternatives Benno Stein and Martin Potthast Bauhaus University Weimar Web-Technology and Information Systems Text-based Information Retrieval (TIR) Motivation Consider
: Application, Impact, and Realization Alternatives Benno Stein and Martin Potthast Bauhaus University Weimar Web-Technology and Information Systems Text-based Information Retrieval (TIR) Motivation Consider
Hash tables. Hash tables
 Dictionary Definition A dictionary is a data-structure that stores a set of elements where each element has a unique key, and supports the following operations: Search(S, k) Return the element whose key
Dictionary Definition A dictionary is a data-structure that stores a set of elements where each element has a unique key, and supports the following operations: Search(S, k) Return the element whose key
Lecture 24: Bloom Filters. Wednesday, June 2, 2010
 Lecture 24: Bloom Filters Wednesday, June 2, 2010 1 Topics for the Final SQL Conceptual Design (BCNF) Transactions Indexes Query execution and optimization Cardinality Estimation Parallel Databases 2 Lecture
Lecture 24: Bloom Filters Wednesday, June 2, 2010 1 Topics for the Final SQL Conceptual Design (BCNF) Transactions Indexes Query execution and optimization Cardinality Estimation Parallel Databases 2 Lecture
The effect on accuracy of tweet sample size for hashtag segmentation dictionary construction
 The effect on accuracy of tweet sample size for hashtag segmentation dictionary construction Laurence A. F. Park and Glenn Stone School of Computing, Engineering and Mathematics Western Sydney University,
The effect on accuracy of tweet sample size for hashtag segmentation dictionary construction Laurence A. F. Park and Glenn Stone School of Computing, Engineering and Mathematics Western Sydney University,
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Hash tables. Hash tables
 Dictionary Definition A dictionary is a data-structure that stores a set of elements where each element has a unique key, and supports the following operations: Search(S, k) Return the element whose key
Dictionary Definition A dictionary is a data-structure that stores a set of elements where each element has a unique key, and supports the following operations: Search(S, k) Return the element whose key
Lecture 5: Hashing. David Woodruff Carnegie Mellon University
 Lecture 5: Hashing David Woodruff Carnegie Mellon University Hashing Universal hashing Perfect hashing Maintaining a Dictionary Let U be a universe of keys U could be all strings of ASCII characters of
Lecture 5: Hashing David Woodruff Carnegie Mellon University Hashing Universal hashing Perfect hashing Maintaining a Dictionary Let U be a universe of keys U could be all strings of ASCII characters of
CS 277: Data Mining. Mining Web Link Structure. CS 277: Data Mining Lectures Analyzing Web Link Structure Padhraic Smyth, UC Irvine
 CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
University of Illinois at Urbana-Champaign. Midterm Examination
 University of Illinois at Urbana-Champaign Midterm Examination CS410 Introduction to Text Information Systems Professor ChengXiang Zhai TA: Azadeh Shakery Time: 2:00 3:15pm, Mar. 14, 2007 Place: Room 1105,
University of Illinois at Urbana-Champaign Midterm Examination CS410 Introduction to Text Information Systems Professor ChengXiang Zhai TA: Azadeh Shakery Time: 2:00 3:15pm, Mar. 14, 2007 Place: Room 1105,
Data Mining Recitation Notes Week 3
 Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Algorithms for Data Science: Lecture on Finding Similar Items
 Algorithms for Data Science: Lecture on Finding Similar Items Barna Saha 1 Finding Similar Items Finding similar items is a fundamental data mining task. We may want to find whether two documents are similar
Algorithms for Data Science: Lecture on Finding Similar Items Barna Saha 1 Finding Similar Items Finding similar items is a fundamental data mining task. We may want to find whether two documents are similar
CS246 Final Exam, Winter 2011
 CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
B669 Sublinear Algorithms for Big Data
 B669 Sublinear Algorithms for Big Data Qin Zhang 1-1 2-1 Part 1: Sublinear in Space The model and challenge The data stream model (Alon, Matias and Szegedy 1996) a n a 2 a 1 RAM CPU Why hard? Cannot store
B669 Sublinear Algorithms for Big Data Qin Zhang 1-1 2-1 Part 1: Sublinear in Space The model and challenge The data stream model (Alon, Matias and Szegedy 1996) a n a 2 a 1 RAM CPU Why hard? Cannot store
On the Foundations of Diverse Information Retrieval. Scott Sanner, Kar Wai Lim, Shengbo Guo, Thore Graepel, Sarvnaz Karimi, Sadegh Kharazmi
 On the Foundations of Diverse Information Retrieval Scott Sanner, Kar Wai Lim, Shengbo Guo, Thore Graepel, Sarvnaz Karimi, Sadegh Kharazmi 1 Outline Need for diversity The answer: MMR But what was the
On the Foundations of Diverse Information Retrieval Scott Sanner, Kar Wai Lim, Shengbo Guo, Thore Graepel, Sarvnaz Karimi, Sadegh Kharazmi 1 Outline Need for diversity The answer: MMR But what was the
Topical Sequence Profiling
 Tim Gollub Nedim Lipka Eunyee Koh Erdan Genc Benno Stein TIR @ DEXA 5. Sept. 2016 Webis Group Bauhaus-Universität Weimar www.webis.de Big Data Experience Lab Adobe Systems www.research.adobe.com R e
Tim Gollub Nedim Lipka Eunyee Koh Erdan Genc Benno Stein TIR @ DEXA 5. Sept. 2016 Webis Group Bauhaus-Universität Weimar www.webis.de Big Data Experience Lab Adobe Systems www.research.adobe.com R e
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
1998: enter Link Analysis
 1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
Introduction to Randomized Algorithms III
 Introduction to Randomized Algorithms III Joaquim Madeira Version 0.1 November 2017 U. Aveiro, November 2017 1 Overview Probabilistic counters Counting with probability 1 / 2 Counting with probability
Introduction to Randomized Algorithms III Joaquim Madeira Version 0.1 November 2017 U. Aveiro, November 2017 1 Overview Probabilistic counters Counting with probability 1 / 2 Counting with probability
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model
 Chapter 6 Scoring term weighting and the vector space model") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Topic 1: Digital Data
 Term paper: Judging the feasibility of a topic Is it a topic you are excited about? Is there enough existing research in this area to conduct a scholarly study? Topic 1: Digital Data ECS 15, Winter 2015
Term paper: Judging the feasibility of a topic Is it a topic you are excited about? Is there enough existing research in this area to conduct a scholarly study? Topic 1: Digital Data ECS 15, Winter 2015
Asymmetric Minwise Hashing for Indexing Binary Inner Products and Set Containment
 Asymmetric Minwise Hashing for Indexing Binary Inner Products and Set Containment Anshumali Shrivastava and Ping Li Cornell University and Rutgers University WWW 25 Florence, Italy May 2st 25 Will Join
Asymmetric Minwise Hashing for Indexing Binary Inner Products and Set Containment Anshumali Shrivastava and Ping Li Cornell University and Rutgers University WWW 25 Florence, Italy May 2st 25 Will Join
Piazza Recitation session: Review of linear algebra Location: Thursday, April 11, from 3:30-5:20 pm in SIG 134 (here)
") 4/0/9 Tim Althoff, UW CS547: Machine Learning for Big Data, http://www.cs.washington.edu/cse547 Piazza Recitation session: Review of linear algebra Location: Thursday, April, from 3:30-5:20 pm in SIG 34
4/0/9 Tim Althoff, UW CS547: Machine Learning for Big Data, http://www.cs.washington.edu/cse547 Piazza Recitation session: Review of linear algebra Location: Thursday, April, from 3:30-5:20 pm in SIG 34
B490 Mining the Big Data
 B490 Mining the Big Data 1 Finding Similar Items Qin Zhang 1-1 Motivations Finding similar documents/webpages/images (Approximate) mirror sites. Application: Don t want to show both when Google. 2-1 Motivations
B490 Mining the Big Data 1 Finding Similar Items Qin Zhang 1-1 Motivations Finding similar documents/webpages/images (Approximate) mirror sites. Application: Don t want to show both when Google. 2-1 Motivations
CS168: The Modern Algorithmic Toolbox Lecture #4: Dimensionality Reduction
 CS168: The Modern Algorithmic Toolbox Lecture #4: Dimensionality Reduction Tim Roughgarden & Gregory Valiant April 12, 2017 1 The Curse of Dimensionality in the Nearest Neighbor Problem Lectures #1 and
CS168: The Modern Algorithmic Toolbox Lecture #4: Dimensionality Reduction Tim Roughgarden & Gregory Valiant April 12, 2017 1 The Curse of Dimensionality in the Nearest Neighbor Problem Lectures #1 and
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
Information Retrieval
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture; IIR Sections
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture; IIR Sections
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 6: Scoring, term weighting, the vector space model Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics,
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 6: Scoring, term weighting, the vector space model Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics,
DATA MINING LECTURE 13. Link Analysis Ranking PageRank -- Random walks HITS
 DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
CS60021: Scalable Data Mining. Similarity Search and Hashing. Sourangshu Bha>acharya
 CS62: Scalable Data Mining Similarity Search and Hashing Sourangshu Bha>acharya Finding Similar Items Distance Measures Goal: Find near-neighbors in high-dim. space We formally define near neighbors as
CS62: Scalable Data Mining Similarity Search and Hashing Sourangshu Bha>acharya Finding Similar Items Distance Measures Goal: Find near-neighbors in high-dim. space We formally define near neighbors as
Lab 8: Measuring Graph Centrality - PageRank. Monday, November 5 CompSci 531, Fall 2018
 Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
text statistics October 24, 2018 text statistics 1 / 20
 text statistics October 24, 2018 text statistics 1 / 20 Overview 1 2 text statistics 2 / 20 Outline 1 2 text statistics 3 / 20 Model collection: The Reuters collection symbol statistic value N documents
text statistics October 24, 2018 text statistics 1 / 20 Overview 1 2 text statistics 2 / 20 Outline 1 2 text statistics 3 / 20 Model collection: The Reuters collection symbol statistic value N documents
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org Challenges
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org Challenges
Ranked Retrieval (2)
") Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 26/26: Feature Selection and Exam Overview Paul Ginsparg Cornell University,
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 26/26: Feature Selection and Exam Overview Paul Ginsparg Cornell University,
Information Retrieval. Lecture 6
 Information Retrieval Lecture 6 Recap of the last lecture Parametric and field searches Zones in documents Scoring documents: zone weighting Index support for scoring tf idf and vector spaces This lecture
Information Retrieval Lecture 6 Recap of the last lecture Parametric and field searches Zones in documents Scoring documents: zone weighting Index support for scoring tf idf and vector spaces This lecture
1 Searching the World Wide Web
 Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
1 Information retrieval fundamentals
 CS 630 Lecture 1: 01/26/2006 Lecturer: Lillian Lee Scribes: Asif-ul Haque, Benyah Shaparenko This lecture focuses on the following topics Information retrieval fundamentals Vector Space Model (VSM) Deriving
CS 630 Lecture 1: 01/26/2006 Lecturer: Lillian Lee Scribes: Asif-ul Haque, Benyah Shaparenko This lecture focuses on the following topics Information retrieval fundamentals Vector Space Model (VSM) Deriving
Secret Sharing CPT, Version 3
 Secret Sharing CPT, 2006 Version 3 1 Introduction In all secure systems that use cryptography in practice, keys have to be protected by encryption under other keys when they are stored in a physically
Secret Sharing CPT, 2006 Version 3 1 Introduction In all secure systems that use cryptography in practice, keys have to be protected by encryption under other keys when they are stored in a physically
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Spatial Information Retrieval
 Spatial Information Retrieval Wenwen LI 1, 2, Phil Yang 1, Bin Zhou 1, 3 [1] Joint Center for Intelligent Spatial Computing, and Earth System & GeoInformation Sciences College of Science, George Mason
Spatial Information Retrieval Wenwen LI 1, 2, Phil Yang 1, Bin Zhou 1, 3 [1] Joint Center for Intelligent Spatial Computing, and Earth System & GeoInformation Sciences College of Science, George Mason
Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search
 Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search Xutao Li 1 Michael Ng 2 Yunming Ye 1 1 Department of Computer Science, Shenzhen Graduate School, Harbin Institute of Technology,
Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search Xutao Li 1 Michael Ng 2 Yunming Ye 1 1 Department of Computer Science, Shenzhen Graduate School, Harbin Institute of Technology,
15-855: Intensive Intro to Complexity Theory Spring Lecture 7: The Permanent, Toda s Theorem, XXX
 15-855: Intensive Intro to Complexity Theory Spring 2009 Lecture 7: The Permanent, Toda s Theorem, XXX 1 #P and Permanent Recall the class of counting problems, #P, introduced last lecture. It was introduced
15-855: Intensive Intro to Complexity Theory Spring 2009 Lecture 7: The Permanent, Toda s Theorem, XXX 1 #P and Permanent Recall the class of counting problems, #P, introduced last lecture. It was introduced
Link Mining PageRank. From Stanford C246
 Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Lecture 5. 1 Review (Pairwise Independence and Derandomization)
") 6.842 Randomness and Computation September 20, 2017 Lecture 5 Lecturer: Ronitt Rubinfeld Scribe: Tom Kolokotrones 1 Review (Pairwise Independence and Derandomization) As we discussed last time, we can
6.842 Randomness and Computation September 20, 2017 Lecture 5 Lecturer: Ronitt Rubinfeld Scribe: Tom Kolokotrones 1 Review (Pairwise Independence and Derandomization) As we discussed last time, we can
Embeddings Learned By Matrix Factorization
 Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Slides credits: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
CS 572: Information Retrieval
 CS 572: Information Retrieval Lecture 5: Term Weighting and Ranking Acknowledgment: Some slides in this lecture are adapted from Chris Manning (Stanford) and Doug Oard (Maryland) Lecture Plan Skip for
CS 572: Information Retrieval Lecture 5: Term Weighting and Ranking Acknowledgment: Some slides in this lecture are adapted from Chris Manning (Stanford) and Doug Oard (Maryland) Lecture Plan Skip for
Introduction to Data Mining
 Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Term Weighting and the Vector Space Model. borrowing from: Pandu Nayak and Prabhakar Raghavan
 Term Weighting and the Vector Space Model borrowing from: Pandu Nayak and Prabhakar Raghavan IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes
Term Weighting and the Vector Space Model borrowing from: Pandu Nayak and Prabhakar Raghavan IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes
Finding similar items
 Finding similar items CSE 344, section 10 June 2, 2011 In this section, we ll go through some examples of finding similar item sets. We ll directly compare all pairs of sets being considered using the
Finding similar items CSE 344, section 10 June 2, 2011 In this section, we ll go through some examples of finding similar item sets. We ll directly compare all pairs of sets being considered using the
Outline for today. Information Retrieval. Cosine similarity between query and document. tf-idf weighting
 Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Introduction to Algebra: The First Week
 Introduction to Algebra: The First Week Background: According to the thermostat on the wall, the temperature in the classroom right now is 72 degrees Fahrenheit. I want to write to my friend in Europe,
Introduction to Algebra: The First Week Background: According to the thermostat on the wall, the temperature in the classroom right now is 72 degrees Fahrenheit. I want to write to my friend in Europe,
boolean queries Inverted index query processing Query optimization boolean model January 15, / 35
 boolean model January 15, 2017 1 / 35 Outline 1 boolean queries 2 3 4 2 / 35 taxonomy of IR models Set theoretic fuzzy extended boolean set-based IR models Boolean vector probalistic algebraic generalized
boolean model January 15, 2017 1 / 35 Outline 1 boolean queries 2 3 4 2 / 35 taxonomy of IR models Set theoretic fuzzy extended boolean set-based IR models Boolean vector probalistic algebraic generalized
What is this Page Known for? Computing Web Page Reputations. Outline
 What is this Page Known for? Computing Web Page Reputations Davood Rafiei University of Alberta http://www.cs.ualberta.ca/~drafiei Joint work with Alberto Mendelzon (U. of Toronto) 1 Outline Scenarios
What is this Page Known for? Computing Web Page Reputations Davood Rafiei University of Alberta http://www.cs.ualberta.ca/~drafiei Joint work with Alberto Mendelzon (U. of Toronto) 1 Outline Scenarios
Probabilistic Information Retrieval
 Probabilistic Information Retrieval Sumit Bhatia July 16, 2009 Sumit Bhatia Probabilistic Information Retrieval 1/23 Overview 1 Information Retrieval IR Models Probability Basics 2 Document Ranking Problem
Probabilistic Information Retrieval Sumit Bhatia July 16, 2009 Sumit Bhatia Probabilistic Information Retrieval 1/23 Overview 1 Information Retrieval IR Models Probability Basics 2 Document Ranking Problem
Lecture 12: Link Analysis for Web Retrieval
 Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
MATRIX DECOMPOSITION AND LATENT SEMANTIC INDEXING (LSI) Introduction to Information Retrieval CS 150 Donald J. Patterson
 Introduction to Information Retrieval CS 150 Donald J. Patterson") MATRIX DECOMPOSITION AND LATENT SEMANTIC INDEXING (LSI) Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Latent
MATRIX DECOMPOSITION AND LATENT SEMANTIC INDEXING (LSI) Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Latent
IR Models: The Probabilistic Model. Lecture 8
 IR Models: The Probabilistic Model Lecture 8 ' * ) ( % $ $ +#! "#! '& & Probability of Relevance? ' ', IR is an uncertain process Information need to query Documents to index terms Query terms and index
IR Models: The Probabilistic Model Lecture 8 ' * ) ( % $ $ +#! "#! '& & Probability of Relevance? ' ', IR is an uncertain process Information need to query Documents to index terms Query terms and index
Analyzing Evolution of Web Communities using a Series of Japanese Web Archives
 53 8505 4 6 E-mail: {toyoda,kitsure}@tkl.iis.u-tokyo.ac.jp 999 2002 4 Analyzing Evolution of Web Communities using a Series of Japanese Web Archives Masashi TOYODA and Masaru KITSUREGAWA Institute of Industrial
53 8505 4 6 E-mail: {toyoda,kitsure}@tkl.iis.u-tokyo.ac.jp 999 2002 4 Analyzing Evolution of Web Communities using a Series of Japanese Web Archives Masashi TOYODA and Masaru KITSUREGAWA Institute of Industrial
Lecture 9 - One Way Permutations
 Lecture 9 - One Way Permutations Boaz Barak October 17, 2007 From time immemorial, humanity has gotten frequent, often cruel, reminders that many things are easier to do than to reverse. Leonid Levin Quick
Lecture 9 - One Way Permutations Boaz Barak October 17, 2007 From time immemorial, humanity has gotten frequent, often cruel, reminders that many things are easier to do than to reverse. Leonid Levin Quick
CPSC 467: Cryptography and Computer Security
 CPSC 467: Cryptography and Computer Security Michael J. Fischer Lecture 16 October 30, 2017 CPSC 467, Lecture 16 1/52 Properties of Hash Functions Hash functions do not always look random Relations among
CPSC 467: Cryptography and Computer Security Michael J. Fischer Lecture 16 October 30, 2017 CPSC 467, Lecture 16 1/52 Properties of Hash Functions Hash functions do not always look random Relations among
Analyzing Evolution of Web Communities using a Series of Japanese Web Archives
 DEWS2003 2-P-05 53 8505 4 6 E-mail: {toyoda,kitsure}@tkl.iis.u-tokyo.ac.jp 999 2002 4 Analyzing Evolution of Web Communities using a Series of Japanese Web Archives Masashi TOYODA and Masaru KITSUREGAWA
DEWS2003 2-P-05 53 8505 4 6 E-mail: {toyoda,kitsure}@tkl.iis.u-tokyo.ac.jp 999 2002 4 Analyzing Evolution of Web Communities using a Series of Japanese Web Archives Masashi TOYODA and Masaru KITSUREGAWA
TDDD43. Information Retrieval. Fang Wei-Kleiner. ADIT/IDA Linköping University. Fang Wei-Kleiner ADIT/IDA LiU TDDD43 Information Retrieval 1
 TDDD43 Information Retrieval Fang Wei-Kleiner ADIT/IDA Linköping University Fang Wei-Kleiner ADIT/IDA LiU TDDD43 Information Retrieval 1 Outline 1. Introduction 2. Inverted index 3. Ranked Retrieval tf-idf
TDDD43 Information Retrieval Fang Wei-Kleiner ADIT/IDA Linköping University Fang Wei-Kleiner ADIT/IDA LiU TDDD43 Information Retrieval 1 Outline 1. Introduction 2. Inverted index 3. Ranked Retrieval tf-idf
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 23 Sep 2010
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 23 Sep 2010
PageRank. Ryan Tibshirani /36-662: Data Mining. January Optional reading: ESL 14.10
 PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
A Framework of Detecting Burst Events from Micro-blogging Streams
 , pp.379-384 http://dx.doi.org/10.14257/astl.2013.29.78 A Framework of Detecting Burst Events from Micro-blogging Streams Kaifang Yang, Yongbo Yu, Lizhou Zheng, Peiquan Jin School of Computer Science and
, pp.379-384 http://dx.doi.org/10.14257/astl.2013.29.78 A Framework of Detecting Burst Events from Micro-blogging Streams Kaifang Yang, Yongbo Yu, Lizhou Zheng, Peiquan Jin School of Computer Science and
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Probabilistic Near-Duplicate. Detection Using Simhash
 Probabilistic Near-Duplicate Detection Using Simhash Sadhan Sood, Dmitri Loguinov Presented by Matt Smith Internet Research Lab Department of Computer Science and Engineering Texas A&M University 27 October
Probabilistic Near-Duplicate Detection Using Simhash Sadhan Sood, Dmitri Loguinov Presented by Matt Smith Internet Research Lab Department of Computer Science and Engineering Texas A&M University 27 October
An Analysis on Link Structure Evolution Pattern of Web Communities
 DEWS2005 5-C-01 153-8505 4-6-1 E-mail: {imafuji,kitsure}@tkl.iis.u-tokyo.ac.jp 1999 2002 HITS An Analysis on Link Structure Evolution Pattern of Web Communities Noriko IMAFUJI and Masaru KITSUREGAWA Institute
DEWS2005 5-C-01 153-8505 4-6-1 E-mail: {imafuji,kitsure}@tkl.iis.u-tokyo.ac.jp 1999 2002 HITS An Analysis on Link Structure Evolution Pattern of Web Communities Noriko IMAFUJI and Masaru KITSUREGAWA Institute