CS540 Machine learning L9 Bayesian statistics
|
|
|
- Antony Francis
- 6 years ago
- Views:
Transcription
1 CS540 Machine learning L9 Bayesian statistics 1
2 Last time Naïve Bayes Beta-Bernoulli 2
3 Outline Bayesian concept learning Beta-Bernoulli model (review) Dirichlet-multinomial model Credible intervals 3
4 Bayesian concept learning Based on Josh Tenenbaum s PhD thesis (MIT BCS 1999) 4
5 Concept learning (binary classification) from positive and negative examples 5
6 Concept learning from positive only examples How far out should the rectangle go? No negative examples to act as an upper bound. 6
7 Human learning vs machine learning/ statistics Most ML methods for learning "concepts" such as "dog" require a large number of positive and negative examples But people can learn from small numbers of positive only examples (look at the doggy!) This is called "one shot learning" 7
8 Everyday inductive leaps How can we learn so much about... Meanings of words Properties of natural kinds Future outcomes of a dynamic process Hidden causal properties of an object Causes of a person s action (beliefs, goals) Causal laws governing a domain... from such limited data? 8
9 The Challenge How do we generalize successfully from very limited data? Just one or a few examples Often only positive examples Philosophy: Induction called a problem, a riddle, a paradox, a scandal, or a myth. Machine learning and statistics: Focus on generalization from many examples, both positive and negative. 9
10 The solution: Bayesian inference Bayes rule: P( H ) P( D H ) P ( H D) = P( D) Various compelling (theoretical and experimental) arguments that one should represent one s beliefs using probability and update them using Bayes rule 10
11 11 Bayesian inference: key ingredients Hypothesis space H Prior p(h) Likelihood p(d h) Algorithm for computing posterior p(h D) = H h h p h d p h p h d p d h p ) ( ) ( ) ( ) ( ) (
12 The number game Learning task: Observe one or more examples (numbers) Judge whether other numbers are yes or no. 12
13 The number game Examples of yes numbers Hypotheses multiples of 10 even numbers??? multiples of 10 even numbers numbers near 60 13
14 Human performance Diffuse similarity Rule: multiples of 10 Focused similarity: numbers near
15 Human performance Diffuse similarity Rule: multiples of 10 Focused similarity: numbers near Some phenomena to explain: People can generalize from just positive examples. Generalization can appear either graded (uncertain) or all-or-none (confident). 15
16 H: Hypothesis space of possible concepts: X = {x 1,..., x n }: n examples of a concept C. Evaluate hypotheses given data using Bayes rule: p( h X ) = Bayesian model h H p( X h) p( h) p( X h ) p( h ) p(h) [ prior ]: domain knowledge, pre-existing biases p(x h) [ likelihood ]: statistical information in examples. p(h X) [ posterior ]: degree of belief that h is the true extension of C. 16
17 Hypothesis space Mathematical properties (~50): odd, even, square, cube, prime, multiples of small integers powers of small integers same first (or last) digit Magnitude intervals (~5000): all intervals of integers with endpoints between 1 and 100 Hypothesis can be defined by its extension h={x:h(x)=1, x=1,2,...,100} 17
18 Likelihood p(x h) Size principle: Smaller hypotheses receive greater likelihood, and exponentially more so as n increases. p n 1 ( ) = if x,, 1 X h h size( ) = 0 if any x i h Follows from assumption of randomly sampled examples (strong sampling). Captures the intuition of a representative sample. x n h 18
19 Example of likelihood X={20,40,60} H1 = multiples of 10 = {10,20,,100} H2 = even numbers = {2,4,,100} H3 = odd numbers = {1,3,,99} P(X H1) = 1/10 * 1/10 * 1/10 p(x H2) = 1/50 * 1/50 * 1/50 P(X H3) = 0 19
20 20
21 Size principle Illustrating the size principle h 1 h 2 21
22 Size principle Illustrating the size principle h 1 h 2 Data slightly more of a coincidence under h 1 22
23 Size principle Illustrating the size principle h 1 h 2 Data much more of a coincidence under h 1 23
24 Prior p(h) X={60,80,10,30} Why prefer multiples of 10 over even numbers? Size principle (likelihood) Why prefer multiples of 10 over multiples of 10 except 50 and 20? Prior Cannot learn efficiently if we have a uniform prior over all logically possible hypotheses 24

25 Need for prior (inductive bias) Consider all 2 22 = 16 possible binary functions on 2 binary inputs If we observe (x 1 =0, x 2 =1, y=0), this removes h 5, h 6, h 7, h 8, h 13, h 14, h 15, h 16 Still leaves exponentially many hypotheses! Cannot learn efficiently without assumptions (no free lunch theorem) 25
26 Hierarchical prior 26
27 27 Computing the posterior In this talk, we will not worry about computational issues (we will perform brute force enumeration or derive analytical expressions). = H h h p h X p h p h X p X h p ) ( ) ( ) ( ) ( ) (
28 Prior Likelihoods Posteriors 28
29 Generalizing to new objects Given p(h X), how do we compute the probability that C applies to some new stimulus y? p ( y C X ) Posterior predictive distribution 29
30 30 Posterior predictive distribution Compute the probability that C applies to some new object y by averaging the predictions of all hypotheses h, weighted by p(h X) (Bayesian model averaging): = H h X h p h C y p X C y p ) ( ) ( ) ( = h y h y if 0 if 1
31 Examples: 16 31
32 Examples:
33 Examples:
34 + Examples Human generalization Bayesian Model
35 Rules and exemplars in the number game Hyp. space is a mixture of sparse (mathematical concepts) and dense (intervals) hypotheses. If data supports mathematical rule (eg X={16,8,2,64}), we rapidly learn a rule ( aha! moment), otherwise (eg X={6,23,19,20}) we learn by similarity, and need many examples to get sharp boundary. 35
36 Summary of the Bayesian approach 1. Constrained hypothesis space H 2. Prior p(h) 3. Likelihood p(x h) 4. Hypothesis (model) averaging: 36
37 MAP (maximum a posterior) learning Instead of Bayes model averaging, we can find the mode of the posterior, and use it as a plug-in. As N, the posterior peaks around the mode, so MAP and BMA converge Cannot explain transition from similarity-based (broad posterior) to rule-based (narrow posterior) 37
38 Maximum likelihood learning ML = no prior, no averaging. Plug-in the MLE for prediction: X={16} -> h= "powers of 4" X={16,8,2,64} -> h= "powers of 2". So predictive distribution gets broader as we get more data, in contrast to Bayes. ML is initially very conservative. 38
39 Large sample size behavior As the amount of data goes to, ML, MAP and BMA all converge to the same solution, since the likelihood overwhelms the prior, since p(x h) grows with N, but p(h) is constant. If truth is in the hypothesis class, all methods will find it; thus they are consistent estimators. 39
40 40
41 Beta-Bernoulli model p(θ D) p(d θ)p(θ) = p(d θ)beta(θ α 0,α 1 ) = [θ N 1 (1 θ) N 0 ][θ α1 1 (1 θ) α0 1 ] = θ N 1+α 1 1 (1 θ) N 0+α 0 1 Beta(θ N 1 +α 1,N 0 +α 0 ) 41

42 Sequential updating 42
dθ def = Bb(x α 0,α 1,m)= B(x+α 1,m x+α 0 ) B(α 1,α 0 ) ( m x)")
43 p(x) = Prior predictive density p(x θ)p(θ)dθ = 1 0 Bin(x θ,m)beta(θ α 0,α 1 )dθ def = Bb(x α 0,α 1,m)= B(x+α 1,m x+α 0 ) B(α 1,α 0 ) ( m x) 43
= B(x+α 1,n x+α 0 ) B(α 1,α 0 ) ( m x) Plugin approximation p(x D) = p(x θ)δˆθ(θ)dθ=p(x ˆθ) = Bin(x")
44 Posterior predictive density p(x D) = p(x θ)p(θ D)dθ = 1 0 Bin(x θ,m)beta(θ α 0,α 1)dθ def = Bb(x α 0,α 1,m)= B(x+α 1,n x+α 0 ) B(α 1,α 0 ) ( m x) Plugin approximation p(x D) = p(x θ)δˆθ(θ)dθ=p(x ˆθ) = Bin(x ˆθ,m) 44
45 Posterior predictive E[x] = m α 1 α 0 +α 1 mα 0 Var[x] = α 1 (α 0 +α 1 +m) (α 0 +α 1 )2 α 0 +α 1 +1 If m=1, X in {0,1}, E[x D] = p(x=1 D) = a1(a1+a0) p(x=1 D) = = p(x = 1 θ)p(θ D)dθ θ Beta(θ α 1,α 0 )dθ=e[θ D]= α 1 α 0 +α 1 Laplace s rule of succession p(x=1 D)= N 1 +1 N 1 +N
46 Prior Likelihood Posterior Summary of beta-bernoulli model p(θ)=beta(θ α 1,α 0 )= Posterior predictive p(d θ)=θ N 1 (1 θ) N 0 1 B(α 1,α 0 ) θα 1 1 (1 θ) α 0 1 p(θ D)=Beta(θ α 1 +N 1,α 0 +N 0 ) p(x=1 D)= α 1+N 1 α 1 +α 0 +N 46
47 Dirichlet-multinomial model X i Mult(θ,1), p(x i =k) = θ k Prior Likelihood Posterior p(θ)=dir(θ α 1,...,α K ) K p(d θ) = Posterior predictive k=1 θ N k k K k=1 p(θ D)=Dir(θ α 1 +N 1,...,α K +N K ) p(x=k D)= θ α k 1 k α k +N k k α k +N k 47
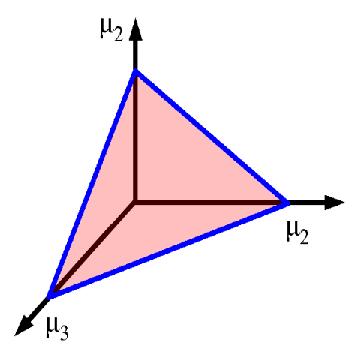
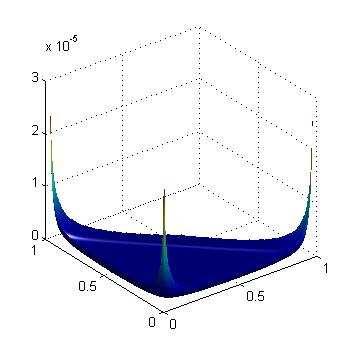
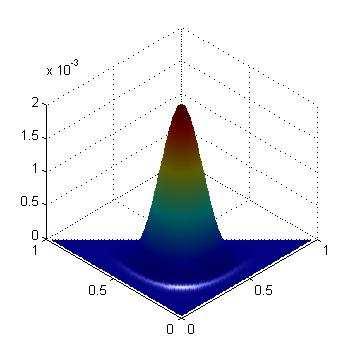
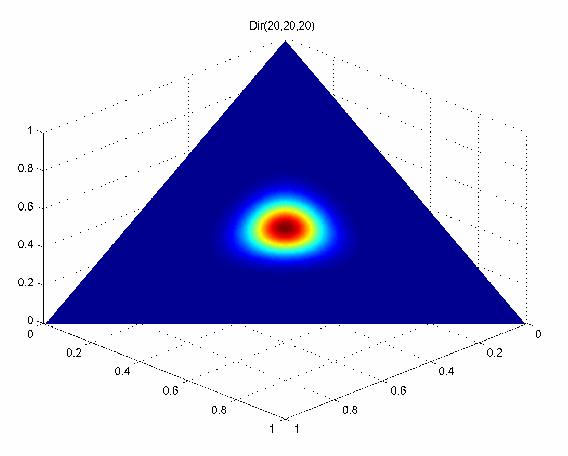
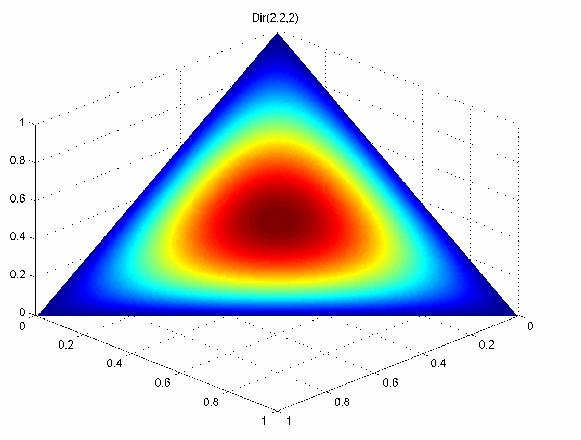
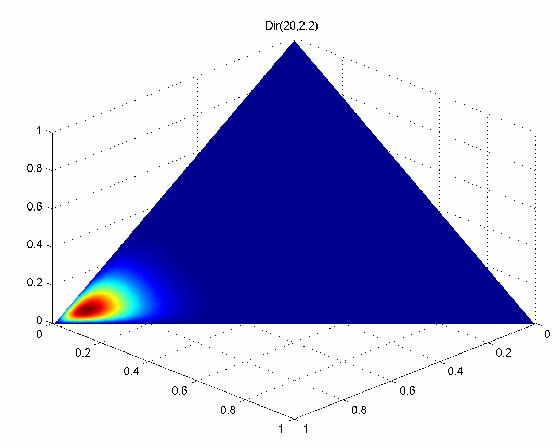
48 Dirichlet (20,20,20) (2,2,2) (20,2,2) 48
49 Summarizing the posterior If p(θ D) is too complex to plot, we can compute various summary statistics, such as posterior mean, mode and median ˆθ mean = E[θ D] ˆθ MAP = argmaxp(θ D) θ ˆθ median = t:p(θ>t D)=0.5 49
50 Bayesian credible intervals We can represent our uncertainty using a posterior credible interval We set p(l θ u D) 1 α l=f 1 (α/2),u=f 1 (1 α/2) 50
51 Example We see 47 heads out of 100 trials. Using a Beta(1,1) prior, what is the 95% credible interval for probability of heads? S = 47; N = 100; a = S+1; b = (N-S)+1; alpha = 0.05; l = betainv(alpha/2, a, b); u = betainv(1-alpha/2, a, b); CI = [l,u]
CS340: Bayesian concept learning. Kevin Murphy Based on Josh Tenenbaum s PhD thesis (MIT BCS 1999)
") CS340: Bayesian concept learning Kevin Murpy Based on Jos Tenenbaum s PD tesis (MIT BCS 1999) Concept learning (binary classification) from positive and negative examples Concept learning from positive
CS340: Bayesian concept learning Kevin Murpy Based on Jos Tenenbaum s PD tesis (MIT BCS 1999) Concept learning (binary classification) from positive and negative examples Concept learning from positive
Lecture 2: Priors and Conjugacy
 Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Outline. Limits of Bayesian classification Bayesian concept learning Probabilistic models for unsupervised and semi-supervised category learning
 Outline Limits of Bayesian classification Bayesian concept learning Probabilistic models for unsupervised and semi-supervised category learning Limitations Is categorization just discrimination among mutually
Outline Limits of Bayesian classification Bayesian concept learning Probabilistic models for unsupervised and semi-supervised category learning Limitations Is categorization just discrimination among mutually
Introduction to Machine Learning
 Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Computational Cognitive Science
 Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
CS540 Machine learning L8
 CS540 Machine learning L8 Announcements Linear algebra tutorial by Mark Schmidt, 5:30 to 6:30 pm today, in the CS X-wing 8th floor lounge (X836). Move midterm from Tue Oct 14 to Thu Oct 16? Hw3sol handed
CS540 Machine learning L8 Announcements Linear algebra tutorial by Mark Schmidt, 5:30 to 6:30 pm today, in the CS X-wing 8th floor lounge (X836). Move midterm from Tue Oct 14 to Thu Oct 16? Hw3sol handed
Computational Cognitive Science
 Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Overview of Course. Nevin L. Zhang (HKUST) Bayesian Networks Fall / 58
 Bayesian Networks Fall / 58") Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Bayesian Methods. David S. Rosenberg. New York University. March 20, 2018
 Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Data Analysis and Uncertainty Part 2: Estimation
 Data Analysis and Uncertainty Part 2: Estimation Instructor: Sargur N. University at Buffalo The State University of New York srihari@cedar.buffalo.edu 1 Topics in Estimation 1. Estimation 2. Desirable
Data Analysis and Uncertainty Part 2: Estimation Instructor: Sargur N. University at Buffalo The State University of New York srihari@cedar.buffalo.edu 1 Topics in Estimation 1. Estimation 2. Desirable
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
Lecture 2: Conjugate priors
 (Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
(Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
Bayesian Concept Learning
 Learning from positive and negative examples Bayesian Concept Learning Chen Yu Indiana University With both positive and negative examples, it is easy to define a boundary to separate these two. Just with
Learning from positive and negative examples Bayesian Concept Learning Chen Yu Indiana University With both positive and negative examples, it is easy to define a boundary to separate these two. Just with
Probability and Estimation. Alan Moses
 Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Bayesian RL Seminar. Chris Mansley September 9, 2008
 Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Computational Perception. Bayesian Inference
 Computational Perception 15-485/785 January 24, 2008 Bayesian Inference The process of probabilistic inference 1. define model of problem 2. derive posterior distributions and estimators 3. estimate parameters
Computational Perception 15-485/785 January 24, 2008 Bayesian Inference The process of probabilistic inference 1. define model of problem 2. derive posterior distributions and estimators 3. estimate parameters
Learning Bayesian network : Given structure and completely observed data
 Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Decision theory. 1 We may also consider randomized decision rules, where δ maps observed data D to a probability distribution over
 Point estimation Suppose we are interested in the value of a parameter θ, for example the unknown bias of a coin. We have already seen how one may use the Bayesian method to reason about θ; namely, we
Point estimation Suppose we are interested in the value of a parameter θ, for example the unknown bias of a coin. We have already seen how one may use the Bayesian method to reason about θ; namely, we
Computational Cognitive Science
 Computational Cognitive Science Lecture 9: A Bayesian model of concept learning Chris Lucas School of Informatics University of Edinburgh October 16, 218 Reading Rules and Similarity in Concept Learning
Computational Cognitive Science Lecture 9: A Bayesian model of concept learning Chris Lucas School of Informatics University of Edinburgh October 16, 218 Reading Rules and Similarity in Concept Learning
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Introduction to Machine Learning
 Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Lecture 4. Generative Models for Discrete Data - Part 3. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza.
 Lecture 4 Generative Models for Discrete Data - Part 3 Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza October 6, 2017 Luigi Freda ( La Sapienza University) Lecture 4 October 6, 2017 1 / 46 Outline
Lecture 4 Generative Models for Discrete Data - Part 3 Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza October 6, 2017 Luigi Freda ( La Sapienza University) Lecture 4 October 6, 2017 1 / 46 Outline
Predictive Hypothesis Identification
 Marcus Hutter - 1 - Predictive Hypothesis Identification Predictive Hypothesis Identification Marcus Hutter Canberra, ACT, 0200, Australia http://www.hutter1.net/ ANU RSISE NICTA Marcus Hutter - 2 - Predictive
Marcus Hutter - 1 - Predictive Hypothesis Identification Predictive Hypothesis Identification Marcus Hutter Canberra, ACT, 0200, Australia http://www.hutter1.net/ ANU RSISE NICTA Marcus Hutter - 2 - Predictive
Estimation of reliability parameters from Experimental data (Parte 2) Prof. Enrico Zio
 Prof. Enrico Zio") Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Hierarchical Models & Bayesian Model Selection
 Hierarchical Models & Bayesian Model Selection Geoffrey Roeder Departments of Computer Science and Statistics University of British Columbia Jan. 20, 2016 Contact information Please report any typos or
Hierarchical Models & Bayesian Model Selection Geoffrey Roeder Departments of Computer Science and Statistics University of British Columbia Jan. 20, 2016 Contact information Please report any typos or
Introduction to Machine Learning
 Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Conjugate Priors, Uninformative Priors
 Conjugate Priors, Uninformative Priors Nasim Zolaktaf UBC Machine Learning Reading Group January 2016 Outline Exponential Families Conjugacy Conjugate priors Mixture of conjugate prior Uninformative priors
Conjugate Priors, Uninformative Priors Nasim Zolaktaf UBC Machine Learning Reading Group January 2016 Outline Exponential Families Conjugacy Conjugate priors Mixture of conjugate prior Uninformative priors
Introduction into Bayesian statistics
 Introduction into Bayesian statistics Maxim Kochurov EF MSU November 15, 2016 Maxim Kochurov Introduction into Bayesian statistics EF MSU 1 / 7 Content 1 Framework Notations 2 Difference Bayesians vs Frequentists
Introduction into Bayesian statistics Maxim Kochurov EF MSU November 15, 2016 Maxim Kochurov Introduction into Bayesian statistics EF MSU 1 / 7 Content 1 Framework Notations 2 Difference Bayesians vs Frequentists
Fundamentals. CS 281A: Statistical Learning Theory. Yangqing Jia. August, Based on tutorial slides by Lester Mackey and Ariel Kleiner
 Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Parametric Techniques Lecture 3
 Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
NPFL108 Bayesian inference. Introduction. Filip Jurčíček. Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic
 NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
Learning with Probabilities
 Learning with Probabilities CS194-10 Fall 2011 Lecture 15 CS194-10 Fall 2011 Lecture 15 1 Outline Bayesian learning eliminates arbitrary loss functions and regularizers facilitates incorporation of prior
Learning with Probabilities CS194-10 Fall 2011 Lecture 15 CS194-10 Fall 2011 Lecture 15 1 Outline Bayesian learning eliminates arbitrary loss functions and regularizers facilitates incorporation of prior
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
CS 6140: Machine Learning Spring What We Learned Last Week 2/26/16
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Discrete Binary Distributions
 Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
David Giles Bayesian Econometrics
 David Giles Bayesian Econometrics 1. General Background 2. Constructing Prior Distributions 3. Properties of Bayes Estimators and Tests 4. Bayesian Analysis of the Multiple Regression Model 5. Bayesian
David Giles Bayesian Econometrics 1. General Background 2. Constructing Prior Distributions 3. Properties of Bayes Estimators and Tests 4. Bayesian Analysis of the Multiple Regression Model 5. Bayesian
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Modeling Environment
 Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Motif representation using position weight matrix
 Motif representation using position weight matrix Xiaohui Xie University of California, Irvine Motif representation using position weight matrix p.1/31 Position weight matrix Position weight matrix representation
Motif representation using position weight matrix Xiaohui Xie University of California, Irvine Motif representation using position weight matrix p.1/31 Position weight matrix Position weight matrix representation
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 13, 2011 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 13, 2011 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Intro to Probability. Andrei Barbu
 Intro to Probability Andrei Barbu Some problems Some problems A means to capture uncertainty Some problems A means to capture uncertainty You have data from two sources, are they different? Some problems
Intro to Probability Andrei Barbu Some problems Some problems A means to capture uncertainty Some problems A means to capture uncertainty You have data from two sources, are they different? Some problems
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Chapter 5. Bayesian Statistics
 Chapter 5. Bayesian Statistics Principles of Bayesian Statistics Anything unknown is given a probability distribution, representing degrees of belief [subjective probability]. Degrees of belief [subjective
Chapter 5. Bayesian Statistics Principles of Bayesian Statistics Anything unknown is given a probability distribution, representing degrees of belief [subjective probability]. Degrees of belief [subjective
CS 340 Fall 2007: Homework 3
 CS 34 Fall 27: Homework 3 1 Marginal likelihood for the Beta-Bernoulli model We showed that the marginal likelihood is the ratio of the normalizing constants: p(d) = B(α 1 + N 1, α + N ) B(α 1, α ) = Γ(α
CS 34 Fall 27: Homework 3 1 Marginal likelihood for the Beta-Bernoulli model We showed that the marginal likelihood is the ratio of the normalizing constants: p(d) = B(α 1 + N 1, α + N ) B(α 1, α ) = Γ(α
Parametric Techniques
 Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Frequentist Statistics and Hypothesis Testing Spring
 Frequentist Statistics and Hypothesis Testing 18.05 Spring 2018 http://xkcd.com/539/ Agenda Introduction to the frequentist way of life. What is a statistic? NHST ingredients; rejection regions Simple
Frequentist Statistics and Hypothesis Testing 18.05 Spring 2018 http://xkcd.com/539/ Agenda Introduction to the frequentist way of life. What is a statistic? NHST ingredients; rejection regions Simple
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning
 Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA
 BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA Intro: Course Outline and Brief Intro to Marina Vannucci Rice University, USA PASI-CIMAT 04/28-30/2010 Marina Vannucci
BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA Intro: Course Outline and Brief Intro to Marina Vannucci Rice University, USA PASI-CIMAT 04/28-30/2010 Marina Vannucci
A primer on Bayesian statistics, with an application to mortality rate estimation
 A primer on Bayesian statistics, with an application to mortality rate estimation Peter off University of Washington Outline Subjective probability Practical aspects Application to mortality rate estimation
A primer on Bayesian statistics, with an application to mortality rate estimation Peter off University of Washington Outline Subjective probability Practical aspects Application to mortality rate estimation
A Very Brief Summary of Bayesian Inference, and Examples
 A Very Brief Summary of Bayesian Inference, and Examples Trinity Term 009 Prof Gesine Reinert Our starting point are data x = x 1, x,, x n, which we view as realisations of random variables X 1, X,, X
A Very Brief Summary of Bayesian Inference, and Examples Trinity Term 009 Prof Gesine Reinert Our starting point are data x = x 1, x,, x n, which we view as realisations of random variables X 1, X,, X
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Probability and Information Theory. Sargur N. Srihari
 Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Exponential Families
 Exponential Families David M. Blei 1 Introduction We discuss the exponential family, a very flexible family of distributions. Most distributions that you have heard of are in the exponential family. Bernoulli,
Exponential Families David M. Blei 1 Introduction We discuss the exponential family, a very flexible family of distributions. Most distributions that you have heard of are in the exponential family. Bernoulli,
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
Time Series and Dynamic Models
 Time Series and Dynamic Models Section 1 Intro to Bayesian Inference Carlos M. Carvalho The University of Texas at Austin 1 Outline 1 1. Foundations of Bayesian Statistics 2. Bayesian Estimation 3. The
Time Series and Dynamic Models Section 1 Intro to Bayesian Inference Carlos M. Carvalho The University of Texas at Austin 1 Outline 1 1. Foundations of Bayesian Statistics 2. Bayesian Estimation 3. The
7. Estimation and hypothesis testing. Objective. Recommended reading
 7. Estimation and hypothesis testing Objective In this chapter, we show how the election of estimators can be represented as a decision problem. Secondly, we consider the problem of hypothesis testing
7. Estimation and hypothesis testing Objective In this chapter, we show how the election of estimators can be represented as a decision problem. Secondly, we consider the problem of hypothesis testing
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
(1) Introduction to Bayesian statistics
 Introduction to Bayesian statistics") Spring, 2018 A motivating example Student 1 will write down a number and then flip a coin If the flip is heads, they will honestly tell student 2 if the number is even or odd If the flip is tails, they
Spring, 2018 A motivating example Student 1 will write down a number and then flip a coin If the flip is heads, they will honestly tell student 2 if the number is even or odd If the flip is tails, they
STAT 499/962 Topics in Statistics Bayesian Inference and Decision Theory Jan 2018, Handout 01
 STAT 499/962 Topics in Statistics Bayesian Inference and Decision Theory Jan 2018, Handout 01 Nasser Sadeghkhani a.sadeghkhani@queensu.ca There are two main schools to statistical inference: 1-frequentist
STAT 499/962 Topics in Statistics Bayesian Inference and Decision Theory Jan 2018, Handout 01 Nasser Sadeghkhani a.sadeghkhani@queensu.ca There are two main schools to statistical inference: 1-frequentist
Patterns of Scalable Bayesian Inference Background (Session 1)
") Patterns of Scalable Bayesian Inference Background (Session 1) Jerónimo Arenas-García Universidad Carlos III de Madrid jeronimo.arenas@gmail.com June 14, 2017 1 / 15 Motivation. Bayesian Learning principles
Patterns of Scalable Bayesian Inference Background (Session 1) Jerónimo Arenas-García Universidad Carlos III de Madrid jeronimo.arenas@gmail.com June 14, 2017 1 / 15 Motivation. Bayesian Learning principles
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Bayesian Inference and MCMC
 Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference
 COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
T Machine Learning: Basic Principles
 Machine Learning: Basic Principles Bayesian Networks Laboratory of Computer and Information Science (CIS) Department of Computer Science and Engineering Helsinki University of Technology (TKK) Autumn 2007
Machine Learning: Basic Principles Bayesian Networks Laboratory of Computer and Information Science (CIS) Department of Computer Science and Engineering Helsinki University of Technology (TKK) Autumn 2007
Lecture 18: Bayesian Inference
 Lecture 18: Bayesian Inference Hyang-Won Lee Dept. of Internet & Multimedia Eng. Konkuk University Lecture 18 Probability and Statistics, Spring 2014 1 / 10 Bayesian Statistical Inference Statiscal inference
Lecture 18: Bayesian Inference Hyang-Won Lee Dept. of Internet & Multimedia Eng. Konkuk University Lecture 18 Probability and Statistics, Spring 2014 1 / 10 Bayesian Statistical Inference Statiscal inference
Sequential Monitoring of Clinical Trials Session 4 - Bayesian Evaluation of Group Sequential Designs
 Sequential Monitoring of Clinical Trials Session 4 - Bayesian Evaluation of Group Sequential Designs Presented August 8-10, 2012 Daniel L. Gillen Department of Statistics University of California, Irvine
Sequential Monitoring of Clinical Trials Session 4 - Bayesian Evaluation of Group Sequential Designs Presented August 8-10, 2012 Daniel L. Gillen Department of Statistics University of California, Irvine
Bayesian Inference: Posterior Intervals
 Bayesian Inference: Posterior Intervals Simple values like the posterior mean E[θ X] and posterior variance var[θ X] can be useful in learning about θ. Quantiles of π(θ X) (especially the posterior median)
Bayesian Inference: Posterior Intervals Simple values like the posterior mean E[θ X] and posterior variance var[θ X] can be useful in learning about θ. Quantiles of π(θ X) (especially the posterior median)
STAB57: Quiz-1 Tutorial 1 (Show your work clearly) 1. random variable X has a continuous distribution for which the p.d.f.
 1. random variable X has a continuous distribution for which the p.d.f.") STAB57: Quiz-1 Tutorial 1 1. random variable X has a continuous distribution for which the p.d.f. is as follows: { kx 2.5 0 < x < 1 f(x) = 0 otherwise where k > 0 is a constant. (a) (4 points) Determine
STAB57: Quiz-1 Tutorial 1 1. random variable X has a continuous distribution for which the p.d.f. is as follows: { kx 2.5 0 < x < 1 f(x) = 0 otherwise where k > 0 is a constant. (a) (4 points) Determine
Compute f(x θ)f(θ) dθ
f(θ) dθ") Bayesian Updating: Continuous Priors 18.05 Spring 2014 b a Compute f(x θ)f(θ) dθ January 1, 2017 1 /26 Beta distribution Beta(a, b) has density (a + b 1)! f (θ) = θ a 1 (1 θ) b 1 (a 1)!(b 1)! http://mathlets.org/mathlets/beta-distribution/
Bayesian Updating: Continuous Priors 18.05 Spring 2014 b a Compute f(x θ)f(θ) dθ January 1, 2017 1 /26 Beta distribution Beta(a, b) has density (a + b 1)! f (θ) = θ a 1 (1 θ) b 1 (a 1)!(b 1)! http://mathlets.org/mathlets/beta-distribution/
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Introduc)on to Bayesian methods (con)nued) - Lecture 16
on to Bayesian methods (con)nued) - Lecture 16") Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric?
 Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric? Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric? Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Bayesian Statistics. Debdeep Pati Florida State University. February 11, 2016
 Bayesian Statistics Debdeep Pati Florida State University February 11, 2016 Historical Background Historical Background Historical Background Brief History of Bayesian Statistics 1764-1838: called probability
Bayesian Statistics Debdeep Pati Florida State University February 11, 2016 Historical Background Historical Background Historical Background Brief History of Bayesian Statistics 1764-1838: called probability
1 A simple example. A short introduction to Bayesian statistics, part I Math 217 Probability and Statistics Prof. D.
 probabilities, we ll use Bayes formula. We can easily compute the reverse probabilities A short introduction to Bayesian statistics, part I Math 17 Probability and Statistics Prof. D. Joyce, Fall 014 I
probabilities, we ll use Bayes formula. We can easily compute the reverse probabilities A short introduction to Bayesian statistics, part I Math 17 Probability and Statistics Prof. D. Joyce, Fall 014 I
Bayesian philosophy Bayesian computation Bayesian software. Bayesian Statistics. Petter Mostad. Chalmers. April 6, 2017
 Chalmers April 6, 2017 Bayesian philosophy Bayesian philosophy Bayesian statistics versus classical statistics: War or co-existence? Classical statistics: Models have variables and parameters; these are
Chalmers April 6, 2017 Bayesian philosophy Bayesian philosophy Bayesian statistics versus classical statistics: War or co-existence? Classical statistics: Models have variables and parameters; these are
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Chapter 4 HOMEWORK ASSIGNMENTS. 4.1 Homework #1
 Chapter 4 HOMEWORK ASSIGNMENTS These homeworks may be modified as the semester progresses. It is your responsibility to keep up to date with the correctly assigned homeworks. There may be some errors in
Chapter 4 HOMEWORK ASSIGNMENTS These homeworks may be modified as the semester progresses. It is your responsibility to keep up to date with the correctly assigned homeworks. There may be some errors in
10. Exchangeability and hierarchical models Objective. Recommended reading
 10. Exchangeability and hierarchical models Objective Introduce exchangeability and its relation to Bayesian hierarchical models. Show how to fit such models using fully and empirical Bayesian methods.
10. Exchangeability and hierarchical models Objective Introduce exchangeability and its relation to Bayesian hierarchical models. Show how to fit such models using fully and empirical Bayesian methods.
Introduction to Bayesian Statistics
 Bayesian Parameter Estimation Introduction to Bayesian Statistics Harvey Thornburg Center for Computer Research in Music and Acoustics (CCRMA) Department of Music, Stanford University Stanford, California
Bayesian Parameter Estimation Introduction to Bayesian Statistics Harvey Thornburg Center for Computer Research in Music and Acoustics (CCRMA) Department of Music, Stanford University Stanford, California
Hypothesis Testing. Econ 690. Purdue University. Justin L. Tobias (Purdue) Testing 1 / 33
 Testing 1 / 33") Hypothesis Testing Econ 690 Purdue University Justin L. Tobias (Purdue) Testing 1 / 33 Outline 1 Basic Testing Framework 2 Testing with HPD intervals 3 Example 4 Savage Dickey Density Ratio 5 Bartlett
Hypothesis Testing Econ 690 Purdue University Justin L. Tobias (Purdue) Testing 1 / 33 Outline 1 Basic Testing Framework 2 Testing with HPD intervals 3 Example 4 Savage Dickey Density Ratio 5 Bartlett
COS513 LECTURE 8 STATISTICAL CONCEPTS
 COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
Linear Models A linear model is defined by the expression
 Linear Models A linear model is defined by the expression x = F β + ɛ. where x = (x 1, x 2,..., x n ) is vector of size n usually known as the response vector. β = (β 1, β 2,..., β p ) is the transpose
Linear Models A linear model is defined by the expression x = F β + ɛ. where x = (x 1, x 2,..., x n ) is vector of size n usually known as the response vector. β = (β 1, β 2,..., β p ) is the transpose
GWAS IV: Bayesian linear (variance component) models
 models") GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
Bayesian Phylogenetics:
 Bayesian Phylogenetics: an introduction Marc A. Suchard msuchard@ucla.edu UCLA Who is this man? How sure are you? The one true tree? Methods we ve learned so far try to find a single tree that best describes
Bayesian Phylogenetics: an introduction Marc A. Suchard msuchard@ucla.edu UCLA Who is this man? How sure are you? The one true tree? Methods we ve learned so far try to find a single tree that best describes
Introduction to Machine Learning. Lecture 2
 Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Discrete Mathematics and Probability Theory Fall 2015 Lecture 21
 CS 70 Discrete Mathematics and Probability Theory Fall 205 Lecture 2 Inference In this note we revisit the problem of inference: Given some data or observations from the world, what can we infer about
CS 70 Discrete Mathematics and Probability Theory Fall 205 Lecture 2 Inference In this note we revisit the problem of inference: Given some data or observations from the world, what can we infer about
Bayesian Inference. STA 121: Regression Analysis Artin Armagan
 Bayesian Inference STA 121: Regression Analysis Artin Armagan Bayes Rule...s! Reverend Thomas Bayes Posterior Prior p(θ y) = p(y θ)p(θ)/p(y) Likelihood - Sampling Distribution Normalizing Constant: p(y
Bayesian Inference STA 121: Regression Analysis Artin Armagan Bayes Rule...s! Reverend Thomas Bayes Posterior Prior p(θ y) = p(y θ)p(θ)/p(y) Likelihood - Sampling Distribution Normalizing Constant: p(y