Walkthrough for Illustrations. Illustration 1
|
|
|
- Bertina Phelps
- 6 years ago
- Views:
Transcription
1 Tay, L., Meade, A. W., & Cao, M. (in press). An overview and practical guide to IRT measurement equivalence analysis. Organizational Research Methods. doi: / Walkthrough for Illustrations Illustration 1 File Name Simulated_DData.csv Comment Contains simulated data of 2000 individuals. Group = 1 represents the reference group (N = 1000); Group = 2 represents the focal group (N =1000); I1 to I15 represents items 1 to 15. See the simulated item parameters below (Table 8 in paper). Simulated_DData.irtpro Simulated_DData.SSIG Simulated_DData.Model0-irt Simulated_DData.Model1-irt Simulated_DData.Model2-irt Simulated_DData.Model3-irt Simulated_DData.Model4-irt IRTPRO syntax file IRTPRO data file (converted from the.csv file) Model 0 Output Simultaneous estimation (no constraints) Model 1 Output Fully constrained model Model 2 Output Testing anchor items with two-step procedure Model 3 Output Testing non-anchor items for DIF Model 4 Output Further testing non-anchor items for DIF Table 8. Illustration 1: Simulated item and theta parameters Group = 1 (θ mean =0, θ SD = 1) Group = 2 (θ mean =0.2, θ SD = 1) λ γ a b λ γ a b Type of DIF Large ab DIF Large ab DIF Large ab DIF Large ab DIF
 A. Click on Start New Project B.")

2 STEP 1: Creating SSIG file (IRTPRO data file) A. Click on Start New Project B. Select the data file. In this case, we have Simulated_DData.csv as our raw data. Then click OK


3 C. We have 17 variables here: ID, Group, and 15 item responses. Also we have our Variable names at the top of the file. Click OK D. Check that the data is correctly read in.


4 STEP 2: Analyze data using simultaneous estimation (i.e., simultaneous calibration) of both groups (Model 0) A. Because we are conducting a unidimensional IRT analysis, we select: Analysis > Unidimensional IRT B. Optional: You can fill in the Title for the analysis and Comments to keep track of what model you specify. *Note: You do not need to select the data file as that is already selected even though it appears blank


5 C. In the Group tab, add the Group variable to the Group: box. The tells IRTPRO that there are multiple groups ( >=2) in the data. *Note: The first group is automatically selected as the reference group as shown in the check box.

. After clicking Apply to all groups, a box will appear Previous settings will be lost.")
6 D. In the Items tab, we select all the item variables into the Items: box. This tells IRTPRO which items we want to analyze Then we click on Apply to all groups. This tells IRTPRO that the same set of items were administered across both groups (Group 1 and Group 2). After clicking Apply to all groups, a box will appear Previous settings will be lost. Do you want to continue?. Click Yes


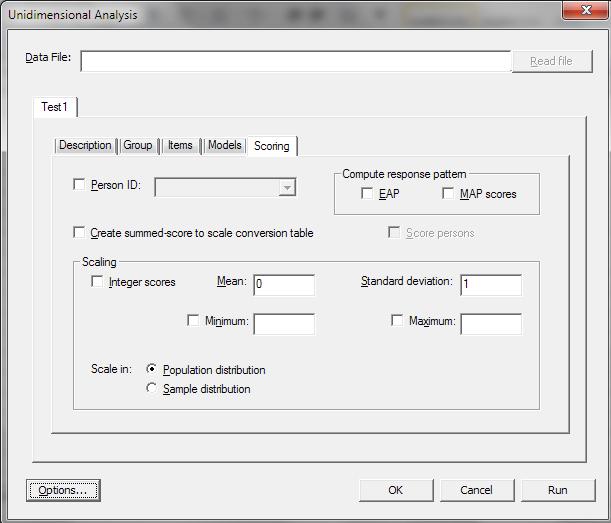
7 E. In the Models tab, we can specify which items to test for DIF and which items (and item parameters) to constrain as equal across groups. For the first analysis, we do not need to specify and DIF analysis or constraints. We note that because the data are dichotomous the model is 2PL by default. F. In the Scoring tab, we do not need to do anything as we are not interested in scoring participants. However, if one is interested to do so, one should specify the Person ID, select the type of scoring method: EAP or MAP scores. The results of EAP or MAP are quite similar and EAP is used more often.


8 G. Finally, to obtain the overall fit statistics (i.e., M 2 and RMSEA), we will need to go into Options In the Options menu, select the Miscellaneous tab. Check the Compute limited-information overall model fit statistics. Note. when checking this box, a text box will appear warning that this can take a long time: This can take a long time if the number of items and/or dimensions is large. Click OK. Then Apply and OK H. After specifying all the necessary model information we can Run the analysis.
9
 and standardized LD χ 2 statistics for Group 1")
10 STEP 3: Interpreting output (for Model 0) The output will be produced in a html format Overview: Content -2PL model item parameter estimates for Group 1-2PL model item parameter estimates for Group 2 -Summed-Score Based Item Diagnostic Tables and χ 2 s for Group 1 -Summed-Score Based Item Diagnostic Tables and χ 2 s for Group 2 -Marginal fit (χ 2 ) and standardized LD χ 2 statistics for Group 1 -Marginal fit (χ 2 ) and standardized LD χ 2 statistics for Group 2 -Likelihood-based values and goodness of fit statistics -Factor loadings for Group 1 -Factor loadings for Group 2 -Group parameter estimates -Item information function values for Group 1 -Item information function values for Group 2 -Summary of the data and control parameters Comment 2PL item parameter estimates for Groups 1 and 2 This shows the S- χ 2 where we can examine individual item fit This shows the standardized LD χ 2 statistics we can examine violations of unidimensionality for pairs of items This shows the M 2 and RMSEA value. We can also obtain different information criteria. We specified Factor Loadings in the Options tab in Step 2G. This produces factor loadings. This shows the estimated focal group latent trait distribution (mean & SD). The reference group is usually constrained as N(0,1). This is the discretized information function for items This displays what data were analyzed and estimation information
![Some things to note when interpreting the output A. The IRTPRO item parameter estimates are: [ ( )] Because we simulated item parameters in with a scaling factor of 1.](/docs-images/74/71235059/images/11-0.jpg "702 [ ( )] The IRTPRO item parameter estimates for the a-parameter ( ) is our simulated item parameter multiplied by 1.702 Here, we see that multiplying the simulated a-parameter by 1.")
11 Some things to note when interpreting the output A. The IRTPRO item parameter estimates are: [ ( )] Because we simulated item parameters in with a scaling factor of [ ( )] The IRTPRO item parameter estimates for the a-parameter ( ) is our simulated item parameter multiplied by Here, we see that multiplying the simulated a-parameter by leads produces values similar to the IRTPRO estimates. We also need to check that the s.e s for the items are small showing that the estimates are fairly accurate. a b a*

12 B. The S- χ 2 statistic shows the fit of each individual item. We hope to see that the modeled and the observed frequencies are not significantly different, implying that there is good/reasonable model-data fit. There may be several items that show misfit but a majority of the items should fit well for the specified IRT model. Otherwise, a different model should be considered. C. Group parameter estimates show the estimated latent trait mean and variance (and sd) for the reference group. In this case G1 is the reference group which has the mean and sd fixed at 0 and 1, respectively.


13 D. The standardized LD χ 2 statistics we can examine violations of unidimensionality for pairs of items. Generally, absolute values smaller than 3 indicate good fit. IRTPRO differentiates the magnitude of the standardized LD χ 2 using different shades of colors. Red represents negative associations beyond the single latent trait; blue represents positive associations beyond the single latent trait. Brighter colors indicate larger magnitudes. E. The likelihood-based values and GOF statistics show the AIC, BIC, M 2, and RMSEA for the fitted model
, click on Constraints Click on Set parameters equal across groups > OK Then RUN This produces a model in which all items are constrained to be equal across groups.")
14 STEP 4: Analyze data using simultaneous estimation (i.e., simultaneous calibration) of both groups: Constraining item parameters to be equal across groups (Model 1) Follow the same procedure in STEP 2 (A) through (H). For part (E), click on Constraints Click on Set parameters equal across groups > OK Then RUN This produces a model in which all items are constrained to be equal across groups.
, click on DIF Select Test all items, anchor all items > OK Then OK > RUN This produces a model in all items are tested for DIF using a two-step procedure.")
15 STEP 5: Analyze data using simultaneous estimation (i.e., simultaneous calibration) of both groups: Testing all items for DIF using two-step procedure (Model 2) Follow the same procedure in STEP 2 (A) through (H). For part (E), click on DIF Select Test all items, anchor all items > OK Then OK > RUN This produces a model in all items are tested for DIF using a two-step procedure. In the first step, all items are assumed to be invariant to estimate focal group latent trait mean and SD. Then, in the next step, all items are freely estimated and focal group latent trait mean and SD are set at the previously estimated values.
.")
16 In this model, we see that the latent traits are not estimated but fixed. No standard errors are produced for the focal group (Group 2). Further, we examine the p-values for the Wald χ 2 statistic that tests the difference between reference and focal group item parameters (a* & b). We select items that do not have significant DIF as anchor items for our next model (alpha =.05). This includes items 1, 4, 5, 6, 9, 10, 13, &14.
, click on DIF Select Test candidate items, estimate group difference with anchor items Drag all anchor items to the Anchor items: box. And all items into Candidate items: box.")
17 STEP 6: Analyze data using simultaneous estimation (i.e., simultaneous calibration) of both groups: Using anchor items found in Model 2 (Model 3) Follow the same procedure in STEP 2 (A) through (H). For part (E), click on DIF Select Test candidate items, estimate group difference with anchor items Drag all anchor items to the Anchor items: box. And all items into Candidate items: box.
. These include items 2, 8, & 12.")
18 Then OK > RUN This tests for a model in which non-anchor items are tested for DIF. As shown below, we find the focal group trait mean and SD estimated using the anchor items. Further, the DIF statistics show that there are a number of non-anchor items that do not have significant DIF (alpha =.05). These include items 2, 8, & 12. We add these as our anchor items at the next step.

19 STEP 7: Analyze data using simultaneous estimation (i.e., simultaneous calibration) of both groups: Using anchor items found in Model 3 (Model 4) Follow the same procedure in STEP 6 (A) through (H). Select the anchor items: 1,2,4,5,6,8,9,10,12,13,14. Test all the other items for DIF. As shown in the output below, we find that all the non-anchor items have significant DIF. The iterative procedure ends at this point.
20 Illustration 2 File Name Simulated_PData.csv Comment Contains simulated data of 2000 individuals. Group = 1 represents the reference group (N = 1000); Group = 2 represents the focal group (N =1000); I1 to I15 represents items 1 to 15. See the simulated item parameters below (Table 8 in paper). Simulated_PData.irtpro Simulated_PData.SSIG Simulated_PData.Model0-irt Simulated_PData.Model1-irt Simulated_PData.Model2-irt Simulated_PData.Model3-irt Simulated_PData.Model4-irt Simulated_PData.Model5-irt IRTPRO syntax file IRTPRO data file (converted from the.csv file) Model 0 Output Simultaneous estimation (no constraints) Model 1 Output Fully constrained model Model 2 Output Testing anchor items with two-step procedure Model 3 Output Testing non-anchor items for DIF Model 4 Output Further testing non-anchor items for DIF Model 5 Output Further testing non-anchor items for DIF using different contrasts Table 10. Illustration 2: Simulated item and theta parameters Group 1 (θ mean = 0; θ sd = 1) Group 2 (θ mean = 0; θ sd = 1) Group 3 (θ mean = -.30; θ sd = 1) a b1 b2 b3 b4 a b1 b2 b3 b4 Type of DIF a b1 b2 b3 b Large ab DIF Large ab DIF Small ab DIF Small a DIF Small b DIF Small ab DIF Type of DIF Large ab DIF Large a DIF Large b DIF Small ab DIF Small a DIF Small b DIF Small ab DIF
 In STEP 2 (E), for the Models tab, the graded response model (GRM) is selected (by default) instead of the 2PLM as the responses are polytomous (ii) The testing of")
21 The same steps shown for Illustration 1 are used. The three main differences are: (i) In STEP 2 (E), for the Models tab, the graded response model (GRM) is selected (by default) instead of the 2PLM as the responses are polytomous (ii) The testing of DIF in subsequent steps requires the use of contrasts as there are multiple groups. The default two contrasts are Contrast Group 1 (Reference Group) Group 2 (Focal Group 1) Group 3 (Focal Group 2) Comment Tests whether item parameters in Group 1 differ from Group 2 and Tests whether item parameters in Group 2 differ from Group 3

 Another difference is that we also specify DIF contrasts apart from using the default values.")
22 The DIF output shows the Wald χ 2 statistic and the associated p-value for the two contrasts. When selecting anchor items, we want to select items that do not show significant p-values for both contrasts. In this sample of 8 items, we see that items 1, 2, and 8 have non-significant p-values across both contrasts. (iii) Another difference is that we also specify DIF contrasts apart from using the default values. In the Models Tab > DIF > Group contrasts In our illustration, we used the default two contrasts and then used contrasts 3 and 4 to test whether item parameters differ between reference and specific focal groups. Contrast Group 1 (Reference Group) Group 2 (Focal Group 1) Group 3 (Focal Group 2) Comment Tests whether item parameters in Group 1 differ from Group Tests whether item parameters in Group 1 differ from Group 3
; X2 is a continuous variable (e.g., age, income, etc.). Restructured Data.")
23 Illustration 3 File Name Data.sav Data_Restructure.sav Data_Restructure.LGS Simulated_3PL-irt.htm Comment Contains simulated data of 5000 individuals. X1 is a dichotomous grouping variable (0, 1) (e.g., gender, Black-White, etc.); X2 is a continuous variable (e.g., age, income, etc.). Restructured Data.sav for 3PLM IRT analysis in LG Latent GOLD syntax IRTPRO output Running IRTPRO to examine model-data fit The steps for running IRTPRO to examine model data fit are in line with Illustrations 1 and 2. The difference is that in Illustration 3 we are specifying a 3PLM. As such, in the Models tab, we need to change the 2PL to 3PL. This can be done by highlighting all the items and right clicking for additional models. Then we choose 3PL. For a 3PLM, it is helpful to specify priors for the c-parameter otherwise it is usually poorly estimated (large standard errors). We can specify a Beta distribution (α, β) for a c-prior. It has been recommended that the values chosen for the Beta distribution are based on these equations: α=mp+1 and β=m(1-p)+1 (Harwell & Baker, 1991). The value of m would range from 15 to 20 depending on the confidence one has in the prior information (higher values indicate higher levels of confidence). In BILOG, m is set at 20 by default. This is the value we use as well. The value of

 + 1=17.")
24 p is 1/Noptions, where Noptions denotes the number of response options there are. For example, if there are 5 options on the test, p = 1/5 =.20. There is on average a 20% chance of getting an answer correct with random guessing. Therefore, α = mp + 1 =5; β = m(1-p) + 1=17. To set the priors, go to Options Then click on the Priors tab > Enter prior parameters Highlight the entire third column of g values. This represents the c-parameters for the 3PLM. Then right click to choose the Beta distribution


25 Enter the desired values for the Beta distribution
26 Running Latent GOLD for DIF analysis STEP 1: Understanding the LG parameterization The parameterization for Latent GOLD is different from the parameterization used to simulate the item parameters. In addition, the simulated latent trait values need to be rescaled. We simulated item parameters in with a scaling factor of ( ) In addition, the value simulated is not standardized. ( ) ( ) + e Because in the estimation, the latent trait distribution is fixed at N(0,1), we need to divide SD of, which in this case, the expected value is.58. by the ( ) ( ) + e ( ) ( ) + e In the response equation, ( ) ( ) ( ) ( ) where = =
27 Item parameter conversions from Simulated Item parameters to LG item parameters Simulated Item parameters Reparameterized into LG parameters a b c d e a* b* c* d* e* STEP 2: Preparing the data for LG analysis Because the 3PLM is unique in that it has a guessing parameter, we need to structure the data in a unique format so that we can use generalized latent variable modeling. Specifically, we need to have a long and wide format for this analysis. Specifically, if we have 4 items Y1 to Y4, ID Y1 Y2 Y3 Y We will need to restructure it to the following ID itemnr response Y1 Y2 Y3 Y
28 The SPSS syntax is as follows: VARSTOCASES /ID=case /MAKE response FROM y1 y2 y3 y4 y5 y6 y7 y8 y9 y10 y11 y12 y13 y14 y15 /INDEX=itemnr(15) /KEEP=x1 x2 ID /NULL=KEEP. IF itemnr = 1 y1 = response. IF itemnr = 2 y2 = response. IF itemnr = 3 y3 = response. IF itemnr = 4 y4 = response. IF itemnr = 5 y5 = response. IF itemnr = 6 y6 = response. IF itemnr = 7 y7 = response. IF itemnr = 8 y8 = response. IF itemnr = 9 y9 = response. IF itemnr = 10 y10 = response. IF itemnr = 11 y11 = response. IF itemnr = 12 y12 = response. IF itemnr = 13 y13 = response. IF itemnr = 14 y14 = response. IF itemnr = 15 y15 = response. EXECUTE. Using this restructured data, we can then proceed to analyze it in Latent GOLD. For other models without the guessing parameter such as the 1PLM, 2PLM, and GRM, we do not need to have this unique format. We will show some example syntax for these other models in the last section.
.")

29 STEP 3: LG 3PL DIF analysis The proposed procedure is based on research of the IRT-C DIF analysis (Tay, Newman, & Vermunt, 2011; Tay, Vermunt, & Wang, 2013). To open the data file in Latent GOLD, we click on Open symbol and select the restructured data file. In this case, we have labeled our restructured data Data_Restructure.sav. After selecting the file, we should see that it is read in. Then right click on Model1


30 We should see a drop down box after right clicking Model1. Select Generate Syntax as we want to use the Syntax mode. We should now see that there is syntax in the black space that we can edit.
31 For a fully constrained model where all items are constrained as equal across groups options algorithm bhhh tolerance=1e-008 emtolerance=0.01 emiterations=1000 nriterations=500; startvalues seed=0 sets=0 tolerance=1e-005 iterations=50; bayes categorical=1 variances=1 latent=1 poisson=1; montecarlo seed=0 replicates=500 tolerance=1e-008; quadrature nodes=30; missing includeall; output parameters=first standarderrors=fast estimatedvalues bivariateresiduals; variables caseid id; dependent y1, y2, y3, y4, y5, y6, y7, y8, y9, y10, y11, y12, y13, y14, y15; independent itemnr nominal, x1, x2 rank=5; latent theta continuous, c dynamic nominal 2; equations (1) theta; theta <- x1 + x2 ; c <- 1 itemnr; y1 <- 1 + (+) theta + (100) c; y2 <- 1 + (+) theta + (100) c; y3 <- 1 + (+) theta + (100) c; y4 <- 1 + (+) theta + (100) c; y5 <- 1 + (+) theta + (100) c; y6 <- 1 + (+) theta + (100) c; y7 <- 1 + (+) theta + (100) c; y8 <- 1 + (+) theta + (100) c; y9 <- 1 + (+) theta + (100) c; y10 <- 1 + (+) theta + (100) c; y11 <- 1 + (+) theta + (100) c; y12 <- 1 + (+) theta + (100) c; y13 <- 1 + (+) theta + (100) c; y14 <- 1 + (+) theta + (100) c; y15 <- 1 + (+) theta + (100) c;
 is associated with -.26 lower latent trait. Here, we see that have a higher value in X2 (which is standardized) for 1SD is associated with.49 higher latent trait.")
32 In the parameter tab, the estimated regression weights for the group characteristics (x1 and x2) and the item parameters a* values and b* values are displayed Here, we see that being in X1 (0 = reference; 1 = focal) is associated with -.26 lower latent trait. Here, we see that have a higher value in X2 (which is standardized) for 1SD is associated with.49 higher latent trait. For the first item, the b* value is.85; the a* value is 1.94 b* for item 1 a* for item 1


33 In addition, the estimated c values are diplayed in the Estimated-Values Model. In this case, Item1 c-parameter is estimated at To test for DIF, we examine the output to look for the highest BVR for the item-covariate pair. In this case, it is Item13 and X2, with a BVR value of

34 We then proceed to create a model where we allow for DIF for Item13 on covariate X2. This is done by right clicking Model 1 followed by Copy Model which automatically generates Model 2 with the same exact syntax as Model 1 for editing. We edit the equations for Model 2 by adding X2 to equation y13. This effective models for uniform DIF of item 13 on X2. This revised equation shows that responses on y13 are not merely a function of the underlying theta trait value, but also dependent on group characteristic X2 (e.g., income, GPA, socioeconomic status, etc.). equations (1) theta; theta <- x1 + x2 ; c <- 1 itemnr; y1 <- 1 + (+) theta + (100) c; y2 <- 1 + (+) theta + (100) c; y3 <- 1 + (+) theta + (100) c; y4 <- 1 + (+) theta + (100) c; y5 <- 1 + (+) theta + (100) c; y6 <- 1 + (+) theta + (100) c; y7 <- 1 + (+) theta + (100) c; y8 <- 1 + (+) theta + (100) c; y9 <- 1 + (+) theta + (100) c; y10 <- 1 + (+) theta + (100) c; y11 <- 1 + (+) theta + (100) c; y12 <- 1 + (+) theta + (100) c; y13 <- 1 + (+) theta + x2 + (100) c; y14 <- 1 + (+) theta + (100) c; y15 <- 1 + (+) theta + (100) c; We run this model to examine whether the parameter associated with X2 on the equation y13 <- 1 + (+) theta + x2 + (100) c; is significant, demonstrating the uniform DIF is significant.

35 In the Parameters tab, we can scroll down to see that is the DIF parameter for X2 and it is significantly different from zero at 3.7e-16. Because it is significant, we then proceed to examine the BVRs again to look for the next itemcovariate pair that has the largest BVR. We continue testing for DIF in this manner until we find that the highest flagged BVR value is no longer significant.
36 Syntax for 1PLM (No DIF) equations (1) theta; theta <- x1 + x2 ; y1 <- 1 + (1) theta; y2 <- 1 + (1) theta; y3 <- 1 + (1) theta; y4 <- 1 + (1) theta; y5 <- 1 + (1) theta; y6 <- 1 + (1) theta; y7 <- 1 + (1) theta; y8 <- 1 + (1) theta; y9 <- 1 + (1) theta; y10 <- 1 + (1) theta; y11 <- 1 + (1) theta; y12 <- 1 + (1) theta; y13 <- 1 + (1) theta; y14 <- 1 + (1) theta; y15 <- 1 + (1) theta; Syntax for 1PLM (DIF on Item 13 for covariate x1) equations (1) theta; theta <- x1 + x2 ; y1 <- 1 + (1) theta; y2 <- 1 + (1) theta; y3 <- 1 + (1) theta; y4 <- 1 + (1) theta; y5 <- 1 + (1) theta; y6 <- 1 + (1) theta; y7 <- 1 + (1) theta; y8 <- 1 + (1) theta; y9 <- 1 + (1) theta; y10 <- 1 + (1) theta; y11 <- 1 + (1) theta; y12 <- 1 + (1) theta; y13 <- 1 + (1) theta + x1; y14 <- 1 + (1) theta; y15 <- 1 + (1) theta;
37 Syntax for 2PLM (No DIF) equations (1) theta; theta <- x1 + x2 ; y1 <- 1 + (+) theta; y2 <- 1 + (+) theta; y3 <- 1 + (+) theta; y4 <- 1 + (+) theta; y5 <- 1 + (+) theta; y6 <- 1 + (+) theta; y7 <- 1 + (+) theta; y8 <- 1 + (+) theta; y9 <- 1 + (+) theta; y10 <- 1 + (+) theta; y11 <- 1 + (+) theta; y12 <- 1 + (+) theta; y13 <- 1 + (+) theta; y14 <- 1 + (+) theta; y15 <- 1 + (+) theta; Syntax for 2PLM (DIF on Item 13 for covariate x1) equations (1) theta; theta <- x1 + x2 ; y1 <- 1 + (+) theta; y2 <- 1 + (+) theta; y3 <- 1 + (+) theta; y4 <- 1 + (+) theta; y5 <- 1 + (+) theta; y6 <- 1 + (+) theta; y7 <- 1 + (+) theta; y8 <- 1 + (+) theta; y9 <- 1 + (+) theta; y10 <- 1 + (+) theta; y11 <- 1 + (+) theta; y12 <- 1 + (+) theta; y13 <- 1 + (+) theta + x1; y14 <- 1 + (+) theta; y15 <- 1 + (+) theta;
38 Note: the Graded response model equations are the same for the 2PLM. The only difference is that the responses are cumlogit. variables dependent y1 cumlogit, y2 cumlogit, y3 cumlogit, y4 cumlogit, y5 cumlogit, y6 cumlogit, y7 cumlogit, y8 cumlogit, y9 cumlogit, y10 cumlogit, y11 cumlogit, y12 cumlogit, y13 cumlogit, y14 cumlogit, y15 cumlogit; independent itemnr nominal, x1, x2 rank=5; latent theta continuous; equations (1) theta; theta <- x1 + x2 ; y1 <- 1 + (+) theta; y2 <- 1 + (+) theta; y3 <- 1 + (+) theta; y4 <- 1 + (+) theta; y5 <- 1 + (+) theta; y6 <- 1 + (+) theta; y7 <- 1 + (+) theta; y8 <- 1 + (+) theta; y9 <- 1 + (+) theta; y10 <- 1 + (+) theta; y11 <- 1 + (+) theta; y12 <- 1 + (+) theta; Reference Harwell, M. R., & Baker, F. B. (1991). The use of prior distributions in marginalized Bayesian item parameter estimation: A didactic. Applied Psychological Measurement, 15, Tay, L., Newman, D. A., & Vermunt, J. K. (2011). Using mixed-measurement item response theory with covariates (MM-IRT-C) to ascertain observed and unobserved measurement equivalence. Organizational Research Methods, 14, doi: / Tay, L., Vermunt, J. K., & Wang, C. (2013). Assessing the item response theory with covariate (IRT-C) procedure for ascertaining DIF. International Journal of Testing. doi: /
flexmirt R : Flexible Multilevel Multidimensional Item Analysis and Test Scoring
 flexmirt R : Flexible Multilevel Multidimensional Item Analysis and Test Scoring User s Manual Version 3.0RC Authored by: Carrie R. Houts, PhD Li Cai, PhD This manual accompanies a Release Candidate version
flexmirt R : Flexible Multilevel Multidimensional Item Analysis and Test Scoring User s Manual Version 3.0RC Authored by: Carrie R. Houts, PhD Li Cai, PhD This manual accompanies a Release Candidate version
Basic IRT Concepts, Models, and Assumptions
 Basic IRT Concepts, Models, and Assumptions Lecture #2 ICPSR Item Response Theory Workshop Lecture #2: 1of 64 Lecture #2 Overview Background of IRT and how it differs from CFA Creating a scale An introduction
Basic IRT Concepts, Models, and Assumptions Lecture #2 ICPSR Item Response Theory Workshop Lecture #2: 1of 64 Lecture #2 Overview Background of IRT and how it differs from CFA Creating a scale An introduction
Investigating Models with Two or Three Categories
 Ronald H. Heck and Lynn N. Tabata 1 Investigating Models with Two or Three Categories For the past few weeks we have been working with discriminant analysis. Let s now see what the same sort of model might
Ronald H. Heck and Lynn N. Tabata 1 Investigating Models with Two or Three Categories For the past few weeks we have been working with discriminant analysis. Let s now see what the same sort of model might
Longitudinal Invariance CFA (using MLR) Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions)
 Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions)") Longitudinal Invariance CFA (using MLR) Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions) CLP 948 Example 7b page 1 These data measuring a latent trait of social functioning were collected at
Longitudinal Invariance CFA (using MLR) Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions) CLP 948 Example 7b page 1 These data measuring a latent trait of social functioning were collected at
SEM Day 1 Lab Exercises SPIDA 2007 Dave Flora
 SEM Day 1 Lab Exercises SPIDA 2007 Dave Flora 1 Today we will see how to estimate CFA models and interpret output using both SAS and LISREL. In SAS, commands for specifying SEMs are given using linear
SEM Day 1 Lab Exercises SPIDA 2007 Dave Flora 1 Today we will see how to estimate CFA models and interpret output using both SAS and LISREL. In SAS, commands for specifying SEMs are given using linear
Measurement Invariance (MI) in CFA and Differential Item Functioning (DIF) in IRT/IFA
 in CFA and Differential Item Functioning (DIF) in IRT/IFA") Topics: Measurement Invariance (MI) in CFA and Differential Item Functioning (DIF) in IRT/IFA What are MI and DIF? Testing measurement invariance in CFA Testing differential item functioning in IRT/IFA
Topics: Measurement Invariance (MI) in CFA and Differential Item Functioning (DIF) in IRT/IFA What are MI and DIF? Testing measurement invariance in CFA Testing differential item functioning in IRT/IFA
An Overview of Item Response Theory. Michael C. Edwards, PhD
 An Overview of Item Response Theory Michael C. Edwards, PhD Overview General overview of psychometrics Reliability and validity Different models and approaches Item response theory (IRT) Conceptual framework
An Overview of Item Response Theory Michael C. Edwards, PhD Overview General overview of psychometrics Reliability and validity Different models and approaches Item response theory (IRT) Conceptual framework
Chapter 7: Correlation
 Chapter 7: Correlation Oliver Twisted Please, Sir, can I have some more confidence intervals? To use this syntax open the data file CIr.sav. The data editor looks like this: The values in the table are
Chapter 7: Correlation Oliver Twisted Please, Sir, can I have some more confidence intervals? To use this syntax open the data file CIr.sav. The data editor looks like this: The values in the table are
LECTURE 4 PRINCIPAL COMPONENTS ANALYSIS / EXPLORATORY FACTOR ANALYSIS
 LECTURE 4 PRINCIPAL COMPONENTS ANALYSIS / EXPLORATORY FACTOR ANALYSIS NOTES FROM PRE- LECTURE RECORDING ON PCA PCA and EFA have similar goals. They are substantially different in important ways. The goal
LECTURE 4 PRINCIPAL COMPONENTS ANALYSIS / EXPLORATORY FACTOR ANALYSIS NOTES FROM PRE- LECTURE RECORDING ON PCA PCA and EFA have similar goals. They are substantially different in important ways. The goal
Structural Equation Modeling and Confirmatory Factor Analysis. Types of Variables
 /4/04 Structural Equation Modeling and Confirmatory Factor Analysis Advanced Statistics for Researchers Session 3 Dr. Chris Rakes Website: http://csrakes.yolasite.com Email: Rakes@umbc.edu Twitter: @RakesChris
/4/04 Structural Equation Modeling and Confirmatory Factor Analysis Advanced Statistics for Researchers Session 3 Dr. Chris Rakes Website: http://csrakes.yolasite.com Email: Rakes@umbc.edu Twitter: @RakesChris
An Equivalency Test for Model Fit. Craig S. Wells. University of Massachusetts Amherst. James. A. Wollack. Ronald C. Serlin
 Equivalency Test for Model Fit 1 Running head: EQUIVALENCY TEST FOR MODEL FIT An Equivalency Test for Model Fit Craig S. Wells University of Massachusetts Amherst James. A. Wollack Ronald C. Serlin University
Equivalency Test for Model Fit 1 Running head: EQUIVALENCY TEST FOR MODEL FIT An Equivalency Test for Model Fit Craig S. Wells University of Massachusetts Amherst James. A. Wollack Ronald C. Serlin University
Dimensionality Assessment: Additional Methods
 Dimensionality Assessment: Additional Methods In Chapter 3 we use a nonlinear factor analytic model for assessing dimensionality. In this appendix two additional approaches are presented. The first strategy
Dimensionality Assessment: Additional Methods In Chapter 3 we use a nonlinear factor analytic model for assessing dimensionality. In this appendix two additional approaches are presented. The first strategy
Overview. Multidimensional Item Response Theory. Lecture #12 ICPSR Item Response Theory Workshop. Basics of MIRT Assumptions Models Applications
 Multidimensional Item Response Theory Lecture #12 ICPSR Item Response Theory Workshop Lecture #12: 1of 33 Overview Basics of MIRT Assumptions Models Applications Guidance about estimating MIRT Lecture
Multidimensional Item Response Theory Lecture #12 ICPSR Item Response Theory Workshop Lecture #12: 1of 33 Overview Basics of MIRT Assumptions Models Applications Guidance about estimating MIRT Lecture
Class Introduction and Overview; Review of ANOVA, Regression, and Psychological Measurement
 Class Introduction and Overview; Review of ANOVA, Regression, and Psychological Measurement Introduction to Structural Equation Modeling Lecture #1 January 11, 2012 ERSH 8750: Lecture 1 Today s Class Introduction
Class Introduction and Overview; Review of ANOVA, Regression, and Psychological Measurement Introduction to Structural Equation Modeling Lecture #1 January 11, 2012 ERSH 8750: Lecture 1 Today s Class Introduction
Multiple Group CFA Invariance Example (data from Brown Chapter 7) using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each)
 using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each)") Multiple Group CFA Invariance Example (data from Brown Chapter 7) using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each) 9 items rated by clinicians on a scale of 0 to 8 (0
Multiple Group CFA Invariance Example (data from Brown Chapter 7) using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each) 9 items rated by clinicians on a scale of 0 to 8 (0
Generalized Linear Models for Non-Normal Data
 Generalized Linear Models for Non-Normal Data Today s Class: 3 parts of a generalized model Models for binary outcomes Complications for generalized multivariate or multilevel models SPLH 861: Lecture
Generalized Linear Models for Non-Normal Data Today s Class: 3 parts of a generalized model Models for binary outcomes Complications for generalized multivariate or multilevel models SPLH 861: Lecture
Equating Tests Under The Nominal Response Model Frank B. Baker
 Equating Tests Under The Nominal Response Model Frank B. Baker University of Wisconsin Under item response theory, test equating involves finding the coefficients of a linear transformation of the metric
Equating Tests Under The Nominal Response Model Frank B. Baker University of Wisconsin Under item response theory, test equating involves finding the coefficients of a linear transformation of the metric
Simple, Marginal, and Interaction Effects in General Linear Models: Part 1
 Simple, Marginal, and Interaction Effects in General Linear Models: Part 1 PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 2: August 24, 2012 PSYC 943: Lecture 2 Today s Class Centering and
Simple, Marginal, and Interaction Effects in General Linear Models: Part 1 PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 2: August 24, 2012 PSYC 943: Lecture 2 Today s Class Centering and
Lesson 7: Item response theory models (part 2)
") Lesson 7: Item response theory models (part 2) Patrícia Martinková Department of Statistical Modelling Institute of Computer Science, Czech Academy of Sciences Institute for Research and Development of
Lesson 7: Item response theory models (part 2) Patrícia Martinková Department of Statistical Modelling Institute of Computer Science, Czech Academy of Sciences Institute for Research and Development of
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model
 Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 1: August 22, 2012
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 1: August 22, 2012
2/26/2017. PSY 512: Advanced Statistics for Psychological and Behavioral Research 2
 PSY 512: Advanced Statistics for Psychological and Behavioral Research 2 When and why do we use logistic regression? Binary Multinomial Theory behind logistic regression Assessing the model Assessing predictors
PSY 512: Advanced Statistics for Psychological and Behavioral Research 2 When and why do we use logistic regression? Binary Multinomial Theory behind logistic regression Assessing the model Assessing predictors
Advanced Quantitative Data Analysis
 Chapter 24 Advanced Quantitative Data Analysis Daniel Muijs Doing Regression Analysis in SPSS When we want to do regression analysis in SPSS, we have to go through the following steps: 1 As usual, we choose
Chapter 24 Advanced Quantitative Data Analysis Daniel Muijs Doing Regression Analysis in SPSS When we want to do regression analysis in SPSS, we have to go through the following steps: 1 As usual, we choose
Class Notes: Week 8. Probit versus Logit Link Functions and Count Data
 Ronald Heck Class Notes: Week 8 1 Class Notes: Week 8 Probit versus Logit Link Functions and Count Data This week we ll take up a couple of issues. The first is working with a probit link function. While
Ronald Heck Class Notes: Week 8 1 Class Notes: Week 8 Probit versus Logit Link Functions and Count Data This week we ll take up a couple of issues. The first is working with a probit link function. While
Comparing IRT with Other Models
 Comparing IRT with Other Models Lecture #14 ICPSR Item Response Theory Workshop Lecture #14: 1of 45 Lecture Overview The final set of slides will describe a parallel between IRT and another commonly used
Comparing IRT with Other Models Lecture #14 ICPSR Item Response Theory Workshop Lecture #14: 1of 45 Lecture Overview The final set of slides will describe a parallel between IRT and another commonly used
CS Homework 3. October 15, 2009
 CS 294 - Homework 3 October 15, 2009 If you have questions, contact Alexandre Bouchard (bouchard@cs.berkeley.edu) for part 1 and Alex Simma (asimma@eecs.berkeley.edu) for part 2. Also check the class website
CS 294 - Homework 3 October 15, 2009 If you have questions, contact Alexandre Bouchard (bouchard@cs.berkeley.edu) for part 1 and Alex Simma (asimma@eecs.berkeley.edu) for part 2. Also check the class website
Step 2: Select Analyze, Mixed Models, and Linear.
 Example 1a. 20 employees were given a mood questionnaire on Monday, Wednesday and again on Friday. The data will be first be analyzed using a Covariance Pattern model. Step 1: Copy Example1.sav data file
Example 1a. 20 employees were given a mood questionnaire on Monday, Wednesday and again on Friday. The data will be first be analyzed using a Covariance Pattern model. Step 1: Copy Example1.sav data file
Passing-Bablok Regression for Method Comparison
 Chapter 313 Passing-Bablok Regression for Method Comparison Introduction Passing-Bablok regression for method comparison is a robust, nonparametric method for fitting a straight line to two-dimensional
Chapter 313 Passing-Bablok Regression for Method Comparison Introduction Passing-Bablok regression for method comparison is a robust, nonparametric method for fitting a straight line to two-dimensional
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model
 Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model EPSY 905: Multivariate Analysis Lecture 1 20 January 2016 EPSY 905: Lecture 1 -
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model EPSY 905: Multivariate Analysis Lecture 1 20 January 2016 EPSY 905: Lecture 1 -
Ratio of Polynomials Fit One Variable
 Chapter 375 Ratio of Polynomials Fit One Variable Introduction This program fits a model that is the ratio of two polynomials of up to fifth order. Examples of this type of model are: and Y = A0 + A1 X
Chapter 375 Ratio of Polynomials Fit One Variable Introduction This program fits a model that is the ratio of two polynomials of up to fifth order. Examples of this type of model are: and Y = A0 + A1 X
NELS 88. Latent Response Variable Formulation Versus Probability Curve Formulation
 NELS 88 Table 2.3 Adjusted odds ratios of eighth-grade students in 988 performing below basic levels of reading and mathematics in 988 and dropping out of school, 988 to 990, by basic demographics Variable
NELS 88 Table 2.3 Adjusted odds ratios of eighth-grade students in 988 performing below basic levels of reading and mathematics in 988 and dropping out of school, 988 to 990, by basic demographics Variable
MLMED. User Guide. Nicholas J. Rockwood The Ohio State University Beta Version May, 2017
 MLMED User Guide Nicholas J. Rockwood The Ohio State University rockwood.19@osu.edu Beta Version May, 2017 MLmed is a computational macro for SPSS that simplifies the fitting of multilevel mediation and
MLMED User Guide Nicholas J. Rockwood The Ohio State University rockwood.19@osu.edu Beta Version May, 2017 MLmed is a computational macro for SPSS that simplifies the fitting of multilevel mediation and
Chapter 19: Logistic regression
 Chapter 19: Logistic regression Self-test answers SELF-TEST Rerun this analysis using a stepwise method (Forward: LR) entry method of analysis. The main analysis To open the main Logistic Regression dialog
Chapter 19: Logistic regression Self-test answers SELF-TEST Rerun this analysis using a stepwise method (Forward: LR) entry method of analysis. The main analysis To open the main Logistic Regression dialog
Retrieve and Open the Data
 Retrieve and Open the Data 1. To download the data, click on the link on the class website for the SPSS syntax file for lab 1. 2. Open the file that you downloaded. 3. In the SPSS Syntax Editor, click
Retrieve and Open the Data 1. To download the data, click on the link on the class website for the SPSS syntax file for lab 1. 2. Open the file that you downloaded. 3. In the SPSS Syntax Editor, click
Item Response Theory (IRT) Analysis of Item Sets
 Analysis of Item Sets") University of Connecticut DigitalCommons@UConn NERA Conference Proceedings 2011 Northeastern Educational Research Association (NERA) Annual Conference Fall 10-21-2011 Item Response Theory (IRT) Analysis
University of Connecticut DigitalCommons@UConn NERA Conference Proceedings 2011 Northeastern Educational Research Association (NERA) Annual Conference Fall 10-21-2011 Item Response Theory (IRT) Analysis
Specifying Latent Curve and Other Growth Models Using Mplus. (Revised )
") Ronald H. Heck 1 University of Hawai i at Mānoa Handout #20 Specifying Latent Curve and Other Growth Models Using Mplus (Revised 12-1-2014) The SEM approach offers a contrasting framework for use in analyzing
Ronald H. Heck 1 University of Hawai i at Mānoa Handout #20 Specifying Latent Curve and Other Growth Models Using Mplus (Revised 12-1-2014) The SEM approach offers a contrasting framework for use in analyzing
A Re-Introduction to General Linear Models (GLM)
") A Re-Introduction to General Linear Models (GLM) Today s Class: You do know the GLM Estimation (where the numbers in the output come from): From least squares to restricted maximum likelihood (REML) Reviewing
A Re-Introduction to General Linear Models (GLM) Today s Class: You do know the GLM Estimation (where the numbers in the output come from): From least squares to restricted maximum likelihood (REML) Reviewing
An Introduction to Path Analysis
 An Introduction to Path Analysis PRE 905: Multivariate Analysis Lecture 10: April 15, 2014 PRE 905: Lecture 10 Path Analysis Today s Lecture Path analysis starting with multivariate regression then arriving
An Introduction to Path Analysis PRE 905: Multivariate Analysis Lecture 10: April 15, 2014 PRE 905: Lecture 10 Path Analysis Today s Lecture Path analysis starting with multivariate regression then arriving
Example name. Subgroups analysis, Regression. Synopsis
 589 Example name Effect size Analysis type Level BCG Risk ratio Subgroups analysis, Regression Advanced Synopsis This analysis includes studies where patients were randomized to receive either a vaccine
589 Example name Effect size Analysis type Level BCG Risk ratio Subgroups analysis, Regression Advanced Synopsis This analysis includes studies where patients were randomized to receive either a vaccine
Item Response Theory and Computerized Adaptive Testing
 Item Response Theory and Computerized Adaptive Testing Richard C. Gershon, PhD Department of Medical Social Sciences Feinberg School of Medicine Northwestern University gershon@northwestern.edu May 20,
Item Response Theory and Computerized Adaptive Testing Richard C. Gershon, PhD Department of Medical Social Sciences Feinberg School of Medicine Northwestern University gershon@northwestern.edu May 20,
Statistical and psychometric methods for measurement: Scale development and validation
 Statistical and psychometric methods for measurement: Scale development and validation Andrew Ho, Harvard Graduate School of Education The World Bank, Psychometrics Mini Course Washington, DC. June 11,
Statistical and psychometric methods for measurement: Scale development and validation Andrew Ho, Harvard Graduate School of Education The World Bank, Psychometrics Mini Course Washington, DC. June 11,
Systematic error, of course, can produce either an upward or downward bias.
 Brief Overview of LISREL & Related Programs & Techniques (Optional) Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised April 6, 2015 STRUCTURAL AND MEASUREMENT MODELS:
Brief Overview of LISREL & Related Programs & Techniques (Optional) Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised April 6, 2015 STRUCTURAL AND MEASUREMENT MODELS:
Ratio of Polynomials Fit Many Variables
 Chapter 376 Ratio of Polynomials Fit Many Variables Introduction This program fits a model that is the ratio of two polynomials of up to fifth order. Instead of a single independent variable, these polynomials
Chapter 376 Ratio of Polynomials Fit Many Variables Introduction This program fits a model that is the ratio of two polynomials of up to fifth order. Instead of a single independent variable, these polynomials
Copy the rules into MathLook for a better view. Close MathLook after observing the equations.
 Sample : Torsion on a Sha The Sha Design example is found the Sample Applications, Engeerg and Science section of the TK Solver Library. When it loads, the Variable and Rule Sheets appear as shown below.
Sample : Torsion on a Sha The Sha Design example is found the Sample Applications, Engeerg and Science section of the TK Solver Library. When it loads, the Variable and Rule Sheets appear as shown below.
NCSS Statistical Software. Harmonic Regression. This section provides the technical details of the model that is fit by this procedure.
 Chapter 460 Introduction This program calculates the harmonic regression of a time series. That is, it fits designated harmonics (sinusoidal terms of different wavelengths) using our nonlinear regression
Chapter 460 Introduction This program calculates the harmonic regression of a time series. That is, it fits designated harmonics (sinusoidal terms of different wavelengths) using our nonlinear regression
Two Correlated Proportions Non- Inferiority, Superiority, and Equivalence Tests
 Chapter 59 Two Correlated Proportions on- Inferiority, Superiority, and Equivalence Tests Introduction This chapter documents three closely related procedures: non-inferiority tests, superiority (by a
Chapter 59 Two Correlated Proportions on- Inferiority, Superiority, and Equivalence Tests Introduction This chapter documents three closely related procedures: non-inferiority tests, superiority (by a
A comparison of two estimation algorithms for Samejima s continuous IRT model
 Behav Res (2013) 45:54 64 DOI 10.3758/s13428-012-0229-6 A comparison of two estimation algorithms for Samejima s continuous IRT model Cengiz Zopluoglu Published online: 26 June 2012 # Psychonomic Society,
Behav Res (2013) 45:54 64 DOI 10.3758/s13428-012-0229-6 A comparison of two estimation algorithms for Samejima s continuous IRT model Cengiz Zopluoglu Published online: 26 June 2012 # Psychonomic Society,
An Introduction to Mplus and Path Analysis
 An Introduction to Mplus and Path Analysis PSYC 943: Fundamentals of Multivariate Modeling Lecture 10: October 30, 2013 PSYC 943: Lecture 10 Today s Lecture Path analysis starting with multivariate regression
An Introduction to Mplus and Path Analysis PSYC 943: Fundamentals of Multivariate Modeling Lecture 10: October 30, 2013 PSYC 943: Lecture 10 Today s Lecture Path analysis starting with multivariate regression
Center for Advanced Studies in Measurement and Assessment. CASMA Research Report
 Center for Advanced Studies in Measurement and Assessment CASMA Research Report Number 41 A Comparative Study of Item Response Theory Item Calibration Methods for the Two Parameter Logistic Model Kyung
Center for Advanced Studies in Measurement and Assessment CASMA Research Report Number 41 A Comparative Study of Item Response Theory Item Calibration Methods for the Two Parameter Logistic Model Kyung
WinLTA USER S GUIDE for Data Augmentation
 USER S GUIDE for Version 1.0 (for WinLTA Version 3.0) Linda M. Collins Stephanie T. Lanza Joseph L. Schafer The Methodology Center The Pennsylvania State University May 2002 Dev elopment of this program
USER S GUIDE for Version 1.0 (for WinLTA Version 3.0) Linda M. Collins Stephanie T. Lanza Joseph L. Schafer The Methodology Center The Pennsylvania State University May 2002 Dev elopment of this program
Non-Inferiority Tests for the Ratio of Two Proportions in a Cluster- Randomized Design
 Chapter 236 Non-Inferiority Tests for the Ratio of Two Proportions in a Cluster- Randomized Design Introduction This module provides power analysis and sample size calculation for non-inferiority tests
Chapter 236 Non-Inferiority Tests for the Ratio of Two Proportions in a Cluster- Randomized Design Introduction This module provides power analysis and sample size calculation for non-inferiority tests
Data Structures & Database Queries in GIS
 Data Structures & Database Queries in GIS Objective In this lab we will show you how to use ArcGIS for analysis of digital elevation models (DEM s), in relationship to Rocky Mountain bighorn sheep (Ovis
Data Structures & Database Queries in GIS Objective In this lab we will show you how to use ArcGIS for analysis of digital elevation models (DEM s), in relationship to Rocky Mountain bighorn sheep (Ovis
STRUCTURAL EQUATION MODELING. Khaled Bedair Statistics Department Virginia Tech LISA, Summer 2013
 STRUCTURAL EQUATION MODELING Khaled Bedair Statistics Department Virginia Tech LISA, Summer 2013 Introduction: Path analysis Path Analysis is used to estimate a system of equations in which all of the
STRUCTURAL EQUATION MODELING Khaled Bedair Statistics Department Virginia Tech LISA, Summer 2013 Introduction: Path analysis Path Analysis is used to estimate a system of equations in which all of the
Logistic Regression and Item Response Theory: Estimation Item and Ability Parameters by Using Logistic Regression in IRT.
 Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 1998 Logistic Regression and Item Response Theory: Estimation Item and Ability Parameters by Using
Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 1998 Logistic Regression and Item Response Theory: Estimation Item and Ability Parameters by Using
A NEW MODEL FOR THE FUSION OF MAXDIFF SCALING
 A NEW MODEL FOR THE FUSION OF MAXDIFF SCALING AND RATINGS DATA JAY MAGIDSON 1 STATISTICAL INNOVATIONS INC. DAVE THOMAS SYNOVATE JEROEN K. VERMUNT TILBURG UNIVERSITY ABSTRACT A property of MaxDiff (Maximum
A NEW MODEL FOR THE FUSION OF MAXDIFF SCALING AND RATINGS DATA JAY MAGIDSON 1 STATISTICAL INNOVATIONS INC. DAVE THOMAS SYNOVATE JEROEN K. VERMUNT TILBURG UNIVERSITY ABSTRACT A property of MaxDiff (Maximum
Binary Logistic Regression
 The coefficients of the multiple regression model are estimated using sample data with k independent variables Estimated (or predicted) value of Y Estimated intercept Estimated slope coefficients Ŷ = b
The coefficients of the multiple regression model are estimated using sample data with k independent variables Estimated (or predicted) value of Y Estimated intercept Estimated slope coefficients Ŷ = b
PIRLS 2016 Achievement Scaling Methodology 1
 CHAPTER 11 PIRLS 2016 Achievement Scaling Methodology 1 The PIRLS approach to scaling the achievement data, based on item response theory (IRT) scaling with marginal estimation, was developed originally
CHAPTER 11 PIRLS 2016 Achievement Scaling Methodology 1 The PIRLS approach to scaling the achievement data, based on item response theory (IRT) scaling with marginal estimation, was developed originally
Mixed Models No Repeated Measures
 Chapter 221 Mixed Models No Repeated Measures Introduction This specialized Mixed Models procedure analyzes data from fixed effects, factorial designs. These designs classify subjects into one or more
Chapter 221 Mixed Models No Repeated Measures Introduction This specialized Mixed Models procedure analyzes data from fixed effects, factorial designs. These designs classify subjects into one or more
Application of Item Response Theory Models for Intensive Longitudinal Data
 Application of Item Response Theory Models for Intensive Longitudinal Data Don Hedeker, Robin Mermelstein, & Brian Flay University of Illinois at Chicago hedeker@uic.edu Models for Intensive Longitudinal
Application of Item Response Theory Models for Intensive Longitudinal Data Don Hedeker, Robin Mermelstein, & Brian Flay University of Illinois at Chicago hedeker@uic.edu Models for Intensive Longitudinal
Analysis of Covariance (ANCOVA) with Two Groups
 with Two Groups") Chapter 226 Analysis of Covariance (ANCOVA) with Two Groups Introduction This procedure performs analysis of covariance (ANCOVA) for a grouping variable with 2 groups and one covariate variable. This procedure
Chapter 226 Analysis of Covariance (ANCOVA) with Two Groups Introduction This procedure performs analysis of covariance (ANCOVA) for a grouping variable with 2 groups and one covariate variable. This procedure
Fractional Polynomial Regression
 Chapter 382 Fractional Polynomial Regression Introduction This program fits fractional polynomial models in situations in which there is one dependent (Y) variable and one independent (X) variable. It
Chapter 382 Fractional Polynomial Regression Introduction This program fits fractional polynomial models in situations in which there is one dependent (Y) variable and one independent (X) variable. It
CHAPTER 9 EXAMPLES: MULTILEVEL MODELING WITH COMPLEX SURVEY DATA
 Examples: Multilevel Modeling With Complex Survey Data CHAPTER 9 EXAMPLES: MULTILEVEL MODELING WITH COMPLEX SURVEY DATA Complex survey data refers to data obtained by stratification, cluster sampling and/or
Examples: Multilevel Modeling With Complex Survey Data CHAPTER 9 EXAMPLES: MULTILEVEL MODELING WITH COMPLEX SURVEY DATA Complex survey data refers to data obtained by stratification, cluster sampling and/or
SEM Day 3 Lab Exercises SPIDA 2007 Dave Flora
 SEM Day 3 Lab Exercises SPIDA 2007 Dave Flora 1 Today we will see how to estimate SEM conditional latent trajectory models and interpret output using both SAS and LISREL. Exercise 1 Using SAS PROC CALIS,
SEM Day 3 Lab Exercises SPIDA 2007 Dave Flora 1 Today we will see how to estimate SEM conditional latent trajectory models and interpret output using both SAS and LISREL. Exercise 1 Using SAS PROC CALIS,
ADVANCED C. MEASUREMENT INVARIANCE SEM REX B KLINE CONCORDIA
 ADVANCED SEM C. MEASUREMENT INVARIANCE REX B KLINE CONCORDIA C C2 multiple model 2 data sets simultaneous C3 multiple 2 populations 2 occasions 2 methods C4 multiple unstandardized constrain to equal fit
ADVANCED SEM C. MEASUREMENT INVARIANCE REX B KLINE CONCORDIA C C2 multiple model 2 data sets simultaneous C3 multiple 2 populations 2 occasions 2 methods C4 multiple unstandardized constrain to equal fit
Using SPSS for One Way Analysis of Variance
 Using SPSS for One Way Analysis of Variance This tutorial will show you how to use SPSS version 12 to perform a one-way, between- subjects analysis of variance and related post-hoc tests. This tutorial
Using SPSS for One Way Analysis of Variance This tutorial will show you how to use SPSS version 12 to perform a one-way, between- subjects analysis of variance and related post-hoc tests. This tutorial
Categorical and Zero Inflated Growth Models
 Categorical and Zero Inflated Growth Models Alan C. Acock* Summer, 2009 *Alan C. Acock, Department of Human Development and Family Sciences, Oregon State University, Corvallis OR 97331 (alan.acock@oregonstate.edu).
Categorical and Zero Inflated Growth Models Alan C. Acock* Summer, 2009 *Alan C. Acock, Department of Human Development and Family Sciences, Oregon State University, Corvallis OR 97331 (alan.acock@oregonstate.edu).
Structural Equation Modelling
 Slide Email: jkanglim@unimelb.edu.au Office: Room 0 Redmond Barry Building Website: http://jeromyanglim.googlepages.com/ Appointments: For appointments regarding course or with the application of statistics
Slide Email: jkanglim@unimelb.edu.au Office: Room 0 Redmond Barry Building Website: http://jeromyanglim.googlepages.com/ Appointments: For appointments regarding course or with the application of statistics
How many states. Record high temperature
 Record high temperature How many states Class Midpoint Label 94.5 99.5 94.5-99.5 0 97 99.5 104.5 99.5-104.5 2 102 102 104.5 109.5 104.5-109.5 8 107 107 109.5 114.5 109.5-114.5 18 112 112 114.5 119.5 114.5-119.5
Record high temperature How many states Class Midpoint Label 94.5 99.5 94.5-99.5 0 97 99.5 104.5 99.5-104.5 2 102 102 104.5 109.5 104.5-109.5 8 107 107 109.5 114.5 109.5-114.5 18 112 112 114.5 119.5 114.5-119.5
Module 2A Turning Multivariable Models into Interactive Animated Simulations
 Module 2A Turning Multivariable Models into Interactive Animated Simulations Using tools available in Excel, we will turn a multivariable model into an interactive animated simulation. Projectile motion,
Module 2A Turning Multivariable Models into Interactive Animated Simulations Using tools available in Excel, we will turn a multivariable model into an interactive animated simulation. Projectile motion,
User's Guide for SCORIGHT (Version 3.0): A Computer Program for Scoring Tests Built of Testlets Including a Module for Covariate Analysis
: A Computer Program for Scoring Tests Built of Testlets Including a Module for Covariate Analysis") Research Report User's Guide for SCORIGHT (Version 3.0): A Computer Program for Scoring Tests Built of Testlets Including a Module for Covariate Analysis Xiaohui Wang Eric T. Bradlow Howard Wainer Research
Research Report User's Guide for SCORIGHT (Version 3.0): A Computer Program for Scoring Tests Built of Testlets Including a Module for Covariate Analysis Xiaohui Wang Eric T. Bradlow Howard Wainer Research
Description Remarks and examples Reference Also see
 Title stata.com example 38g Random-intercept and random-slope models (multilevel) Description Remarks and examples Reference Also see Description Below we discuss random-intercept and random-slope models
Title stata.com example 38g Random-intercept and random-slope models (multilevel) Description Remarks and examples Reference Also see Description Below we discuss random-intercept and random-slope models
Evaluating sensitivity of parameters of interest to measurement invariance using the EPC-interest
 Evaluating sensitivity of parameters of interest to measurement invariance using the EPC-interest Department of methodology and statistics, Tilburg University WorkingGroupStructuralEquationModeling26-27.02.2015,
Evaluating sensitivity of parameters of interest to measurement invariance using the EPC-interest Department of methodology and statistics, Tilburg University WorkingGroupStructuralEquationModeling26-27.02.2015,
LAB 5 INSTRUCTIONS LINEAR REGRESSION AND CORRELATION
 LAB 5 INSTRUCTIONS LINEAR REGRESSION AND CORRELATION In this lab you will learn how to use Excel to display the relationship between two quantitative variables, measure the strength and direction of the
LAB 5 INSTRUCTIONS LINEAR REGRESSION AND CORRELATION In this lab you will learn how to use Excel to display the relationship between two quantitative variables, measure the strength and direction of the
Latent Trait Reliability
 Latent Trait Reliability Lecture #7 ICPSR Item Response Theory Workshop Lecture #7: 1of 66 Lecture Overview Classical Notions of Reliability Reliability with IRT Item and Test Information Functions Concepts
Latent Trait Reliability Lecture #7 ICPSR Item Response Theory Workshop Lecture #7: 1of 66 Lecture Overview Classical Notions of Reliability Reliability with IRT Item and Test Information Functions Concepts
Hierarchical Generalized Linear Models. ERSH 8990 REMS Seminar on HLM Last Lecture!
 Hierarchical Generalized Linear Models ERSH 8990 REMS Seminar on HLM Last Lecture! Hierarchical Generalized Linear Models Introduction to generalized models Models for binary outcomes Interpreting parameter
Hierarchical Generalized Linear Models ERSH 8990 REMS Seminar on HLM Last Lecture! Hierarchical Generalized Linear Models Introduction to generalized models Models for binary outcomes Interpreting parameter
Bayesian Inference for Regression Parameters
 Bayesian Inference for Regression Parameters 1 Bayesian inference for simple linear regression parameters follows the usual pattern for all Bayesian analyses: 1. Form a prior distribution over all unknown
Bayesian Inference for Regression Parameters 1 Bayesian inference for simple linear regression parameters follows the usual pattern for all Bayesian analyses: 1. Form a prior distribution over all unknown
Geography 281 Map Making with GIS Project Four: Comparing Classification Methods
 Geography 281 Map Making with GIS Project Four: Comparing Classification Methods Thematic maps commonly deal with either of two kinds of data: Qualitative Data showing differences in kind or type (e.g.,
Geography 281 Map Making with GIS Project Four: Comparing Classification Methods Thematic maps commonly deal with either of two kinds of data: Qualitative Data showing differences in kind or type (e.g.,
CFA Loading Estimation and Comparison Example Joel S Steele, PhD
 CFA Loading Estimation and Comparison Example Joel S Steele, PhD The Common Factor Model Figure 1: Common factor diagram Model expectations Using the tracing rules and our model above in Figure 1, we can
CFA Loading Estimation and Comparison Example Joel S Steele, PhD The Common Factor Model Figure 1: Common factor diagram Model expectations Using the tracing rules and our model above in Figure 1, we can
One-Way ANOVA. Some examples of when ANOVA would be appropriate include:
 One-Way ANOVA 1. Purpose Analysis of variance (ANOVA) is used when one wishes to determine whether two or more groups (e.g., classes A, B, and C) differ on some outcome of interest (e.g., an achievement
One-Way ANOVA 1. Purpose Analysis of variance (ANOVA) is used when one wishes to determine whether two or more groups (e.g., classes A, B, and C) differ on some outcome of interest (e.g., an achievement
EDF 7405 Advanced Quantitative Methods in Educational Research. Data are available on IQ of the child and seven potential predictors.
 EDF 7405 Advanced Quantitative Methods in Educational Research Data are available on IQ of the child and seven potential predictors. Four are medical variables available at the birth of the child: Birthweight
EDF 7405 Advanced Quantitative Methods in Educational Research Data are available on IQ of the child and seven potential predictors. Four are medical variables available at the birth of the child: Birthweight
Stat 542: Item Response Theory Modeling Using The Extended Rank Likelihood
 Stat 542: Item Response Theory Modeling Using The Extended Rank Likelihood Jonathan Gruhl March 18, 2010 1 Introduction Researchers commonly apply item response theory (IRT) models to binary and ordinal
Stat 542: Item Response Theory Modeling Using The Extended Rank Likelihood Jonathan Gruhl March 18, 2010 1 Introduction Researchers commonly apply item response theory (IRT) models to binary and ordinal
Logistic Regression: Regression with a Binary Dependent Variable
 Logistic Regression: Regression with a Binary Dependent Variable LEARNING OBJECTIVES Upon completing this chapter, you should be able to do the following: State the circumstances under which logistic regression
Logistic Regression: Regression with a Binary Dependent Variable LEARNING OBJECTIVES Upon completing this chapter, you should be able to do the following: State the circumstances under which logistic regression
What is Latent Class Analysis. Tarani Chandola
 What is Latent Class Analysis Tarani Chandola methods@manchester Many names similar methods (Finite) Mixture Modeling Latent Class Analysis Latent Profile Analysis Latent class analysis (LCA) LCA is a
What is Latent Class Analysis Tarani Chandola methods@manchester Many names similar methods (Finite) Mixture Modeling Latent Class Analysis Latent Profile Analysis Latent class analysis (LCA) LCA is a
Mixtures of Rasch Models
 Mixtures of Rasch Models Hannah Frick, Friedrich Leisch, Achim Zeileis, Carolin Strobl http://www.uibk.ac.at/statistics/ Introduction Rasch model for measuring latent traits Model assumption: Item parameters
Mixtures of Rasch Models Hannah Frick, Friedrich Leisch, Achim Zeileis, Carolin Strobl http://www.uibk.ac.at/statistics/ Introduction Rasch model for measuring latent traits Model assumption: Item parameters
FleXScan User Guide. for version 3.1. Kunihiko Takahashi Tetsuji Yokoyama Toshiro Tango. National Institute of Public Health
 FleXScan User Guide for version 3.1 Kunihiko Takahashi Tetsuji Yokoyama Toshiro Tango National Institute of Public Health October 2010 http://www.niph.go.jp/soshiki/gijutsu/index_e.html User Guide version
FleXScan User Guide for version 3.1 Kunihiko Takahashi Tetsuji Yokoyama Toshiro Tango National Institute of Public Health October 2010 http://www.niph.go.jp/soshiki/gijutsu/index_e.html User Guide version
Preface. List of examples
 Contents Preface List of examples i xix 1 LISREL models and methods 1 1.1 The general LISREL model 1 Assumptions 2 The covariance matrix of the observations as implied by the LISREL model 3 Fixed, free,
Contents Preface List of examples i xix 1 LISREL models and methods 1 1.1 The general LISREL model 1 Assumptions 2 The covariance matrix of the observations as implied by the LISREL model 3 Fixed, free,
A Study of Statistical Power and Type I Errors in Testing a Factor Analytic. Model for Group Differences in Regression Intercepts
 A Study of Statistical Power and Type I Errors in Testing a Factor Analytic Model for Group Differences in Regression Intercepts by Margarita Olivera Aguilar A Thesis Presented in Partial Fulfillment of
A Study of Statistical Power and Type I Errors in Testing a Factor Analytic Model for Group Differences in Regression Intercepts by Margarita Olivera Aguilar A Thesis Presented in Partial Fulfillment of
Comparison of parametric and nonparametric item response techniques in determining differential item functioning in polytomous scale
 American Journal of Theoretical and Applied Statistics 2014; 3(2): 31-38 Published online March 20, 2014 (http://www.sciencepublishinggroup.com/j/ajtas) doi: 10.11648/j.ajtas.20140302.11 Comparison of
American Journal of Theoretical and Applied Statistics 2014; 3(2): 31-38 Published online March 20, 2014 (http://www.sciencepublishinggroup.com/j/ajtas) doi: 10.11648/j.ajtas.20140302.11 Comparison of
Fixed effects results...32
 1 MODELS FOR CONTINUOUS OUTCOMES...7 1.1 MODELS BASED ON A SUBSET OF THE NESARC DATA...7 1.1.1 The data...7 1.1.1.1 Importing the data and defining variable types...8 1.1.1.2 Exploring the data...12 Univariate
1 MODELS FOR CONTINUOUS OUTCOMES...7 1.1 MODELS BASED ON A SUBSET OF THE NESARC DATA...7 1.1.1 The data...7 1.1.1.1 Importing the data and defining variable types...8 1.1.1.2 Exploring the data...12 Univariate
A Re-Introduction to General Linear Models
 A Re-Introduction to General Linear Models Today s Class: Big picture overview Why we are using restricted maximum likelihood within MIXED instead of least squares within GLM Linear model interpretation
A Re-Introduction to General Linear Models Today s Class: Big picture overview Why we are using restricted maximum likelihood within MIXED instead of least squares within GLM Linear model interpretation
An area chart emphasizes the trend of each value over time. An area chart also shows the relationship of parts to a whole.
 Excel 2003 Creating a Chart Introduction Page 1 By the end of this lesson, learners should be able to: Identify the parts of a chart Identify different types of charts Create an Embedded Chart Create a
Excel 2003 Creating a Chart Introduction Page 1 By the end of this lesson, learners should be able to: Identify the parts of a chart Identify different types of charts Create an Embedded Chart Create a
Description Remarks and examples Reference Also see
 Title stata.com example 20 Two-factor measurement model by group Description Remarks and examples Reference Also see Description Below we demonstrate sem s group() option, which allows fitting models in
Title stata.com example 20 Two-factor measurement model by group Description Remarks and examples Reference Also see Description Below we demonstrate sem s group() option, which allows fitting models in
SC705: Advanced Statistics Instructor: Natasha Sarkisian Class notes: Model Building Strategies
 SC705: Advanced Statistics Instructor: Natasha Sarkisian Class notes: Model Building Strategies Model Diagnostics The model diagnostics and improvement strategies discussed here apply to both measurement
SC705: Advanced Statistics Instructor: Natasha Sarkisian Class notes: Model Building Strategies Model Diagnostics The model diagnostics and improvement strategies discussed here apply to both measurement
Measurement Invariance Testing with Many Groups: A Comparison of Five Approaches (Online Supplements)
") University of South Florida Scholar Commons Educational and Psychological Studies Faculty Publications Educational and Psychological Studies 2017 Measurement Invariance Testing with Many Groups: A Comparison
University of South Florida Scholar Commons Educational and Psychological Studies Faculty Publications Educational and Psychological Studies 2017 Measurement Invariance Testing with Many Groups: A Comparison
UCLA Department of Statistics Papers
 UCLA Department of Statistics Papers Title Can Interval-level Scores be Obtained from Binary Responses? Permalink https://escholarship.org/uc/item/6vg0z0m0 Author Peter M. Bentler Publication Date 2011-10-25
UCLA Department of Statistics Papers Title Can Interval-level Scores be Obtained from Binary Responses? Permalink https://escholarship.org/uc/item/6vg0z0m0 Author Peter M. Bentler Publication Date 2011-10-25
Tests for the Odds Ratio in a Matched Case-Control Design with a Quantitative X
 Chapter 157 Tests for the Odds Ratio in a Matched Case-Control Design with a Quantitative X Introduction This procedure calculates the power and sample size necessary in a matched case-control study designed
Chapter 157 Tests for the Odds Ratio in a Matched Case-Control Design with a Quantitative X Introduction This procedure calculates the power and sample size necessary in a matched case-control study designed
(Intentional blank page) Please remove this page and make both-sided copy from the next page.
 Please remove this page and make both-sided copy from the next page.") (Intentional blank page) Please remove this page and make both-sided copy from the next page. i Statistical Data Analysis by STATA For Social Researchers 2 . Text 6.. Regression Analysis
(Intentional blank page) Please remove this page and make both-sided copy from the next page. i Statistical Data Analysis by STATA For Social Researchers 2 . Text 6.. Regression Analysis
Mplus Code Corresponding to the Web Portal Customization Example
 Online supplement to Hayes, A. F., & Preacher, K. J. (2014). Statistical mediation analysis with a multicategorical independent variable. British Journal of Mathematical and Statistical Psychology, 67,
Online supplement to Hayes, A. F., & Preacher, K. J. (2014). Statistical mediation analysis with a multicategorical independent variable. British Journal of Mathematical and Statistical Psychology, 67,
A Markov chain Monte Carlo approach to confirmatory item factor analysis. Michael C. Edwards The Ohio State University
 A Markov chain Monte Carlo approach to confirmatory item factor analysis Michael C. Edwards The Ohio State University An MCMC approach to CIFA Overview Motivating examples Intro to Item Response Theory
A Markov chain Monte Carlo approach to confirmatory item factor analysis Michael C. Edwards The Ohio State University An MCMC approach to CIFA Overview Motivating examples Intro to Item Response Theory
Introduction to Structural Equation Modeling
 Introduction to Structural Equation Modeling Notes Prepared by: Lisa Lix, PhD Manitoba Centre for Health Policy Topics Section I: Introduction Section II: Review of Statistical Concepts and Regression
Introduction to Structural Equation Modeling Notes Prepared by: Lisa Lix, PhD Manitoba Centre for Health Policy Topics Section I: Introduction Section II: Review of Statistical Concepts and Regression
Introduction to lnmle: An R Package for Marginally Specified Logistic-Normal Models for Longitudinal Binary Data
 Introduction to lnmle: An R Package for Marginally Specified Logistic-Normal Models for Longitudinal Binary Data Bryan A. Comstock and Patrick J. Heagerty Department of Biostatistics University of Washington
Introduction to lnmle: An R Package for Marginally Specified Logistic-Normal Models for Longitudinal Binary Data Bryan A. Comstock and Patrick J. Heagerty Department of Biostatistics University of Washington