Complete Dictionary Recovery over the Sphere II: Recovery by Riemannian Trust-Region Method
|
|
|
- Cecilia Blake
- 6 years ago
- Views:
Transcription
1 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 1 Complete Dictionary Recovery over the Sphere II: Recovery by Riemannian Trust-Region Method Ju Sun, Student Member, IEEE, Qing Qu, Student Member, IEEE, and John Wright, Member, IEEE Abstract arxiv: v3 [cs.it] 1 Sep 16 We consider the problem of recovering a complete i.e., square and invertible matrix A, from Y R n p with Y = A X, provided X is sufficiently sparse. This recovery problem is central to theoretical understanding of dictionary learning, which seeks a sparse representation for a collection of input signals and finds numerous applications in modern signal processing and machine learning. We give the first efficient algorithm that provably recovers A when X has O n nonzeros per column, under suitable probability model for X. Our algorithmic pipeline centers around solving a certain nonconvex optimization problem with a spherical constraint, and hence is naturally phrased in the language of manifold optimization. In a companion paper [3], we have showed that with high probability our nonconvex formulation has no spurious local minimizers and around any saddle point the objective function has a negative directional curvature. In this paper, we take advantage of the particular geometric structure, and describe a Riemannian trust region algorithm that provably converges to a local minimizer with from arbitrary initializations. Such minimizers give excellent approximations to rows of X. The rows are then recovered by linear programming rounding and deflation. Index Terms Dictionary learning, Nonconvex optimization, Spherical constraint, Escaping saddle points, Trust-region method, Manifold optimization, Function landscape, Second-order geometry, Inverse problems, Structured signals, Nonlinear approximation I. INTRODUCTION Recently, there is a surge of research studying nonconvex formulations and provable algorithms for a number of central problems in signal processing and machine learning, including, e.g., low-rank matrix completion/recovery [4] [5], phase retreival [6] [36], tensor recovery [37] [41], mixed regression [4], [43], structured element pursuit [41], [44], blind deconvolution [45] [49], noisy phase synchronization and community detection [5] [5], deep learning [53], [54], numerical linear algebra and optimization [55], [56]. The research efforts are fruitful in producing more practical and scalable algorithms and even significantly better performance guarantees than known convex methods. In a companion paper [3], we set out to understand the surprising effectiveness of nonconvex heuristics on the dictionary learning DL problem. In particular, we have focused on the complete dictionary recovery DR setting: given Y = A X, with A R n n complete i.e., square and invertible, and X R n p obeying an i.i.d. Bernoulli-Gaussian BG model with rate θ i.e., [X ] ij = Ω ij Z ij with Ω ij Berθ and Z ij N, 1, recover A and X. In this setting, rowy = rowx, where row denotes the row space. To first recover rows of X, we have tried to find the sparsest vectors in rowy, and proposed solving the nonconvex formulation minimize fq; Ŷ =. 1 p h q ŷ k subject to q S n 1, I.1 p where Ŷ is a proxy of Y i.e., after appropriate processing, ŷ k is the k-th column of Ŷ, and h z. = log coshz/ is a convex smooth approximation to the absolute-value function. The spherical constraint renders the problem nonconvex. JS, QQ, and JW are all with Electrical Engineering, Columbia University, New York, NY 17, USA. {js438, qq15, jw966}@columbia.edu. An extended abstract of the current work has been published in [1]. Proofs of some secondary results are contained in the combined technical report []. Manuscript received xxx; revised xxx.
2 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 Despite the apparent nonconvexity, our prior analysis in [3] has showed that all local minimizers of I.1 are qualitatively equally good, because each of them produces a close approximation to certain row of X Corollary II.4 in [3]. So the central issue is how to escape from saddle points. Fortunately, our previous results Theorem II.3 in [3] imply that all saddle points under consideration are ridable, i.e., the associated Hessians have both strictly positive and strictly negative values see the recapitulation in Section II-B. Particularly, eigenvectors of the negative eigenvalues are direction of negative curvature, which intuitively serve as directions of local descent. Second-order methods can naturally exploit the curvature information to escape from ridable saddle points. To gain some intuition, consider an unconstrained optimization problem minimize x R n φx. The second-order Taylor expansion of φ at a saddle point x is φδ; x = φx + 1 δ φx δ. When δ is chosen to align with an eigenvector of a negative eigenvalue λ neg [ φx ] <, it holds that φδ; x φx λneg [ φx] δ. Thus, minimizing φδ; x returns a direction δ that tends to decrease the objective φ, provided local approximation of φ to φ is reasonably accurate. Based on this intuition, we derive a second-order Riemannian trust-region algorithm that exploits the second-order information to escape from saddle points and provably returns a local minimizer to I.1, from arbitrary initializations. We provide rigorous guarantees for recovering a local minimizer in Section II. Obtaining a local minimizer only helps approximate one row of X. To recover the row, we derive a simple linear programming rounding procedure that provably works. To recover all rows of X, one repeats the above process based on a carefully designed deflation process. The whole algorithmic pipeline and the related recovery guarantees are provided in Section III. Particularly, we show that when p is reasonably large, with high probability w.h.p., our pipeline efficiently recovers A and X, even when each column of X contains On nonzeros. A. Prior Arts and Connections In Section II.E of the companion paper [3], we provide detailed comparisons of our results with prior theoretical results on DR; we conclude that this is the first algorithmic framework that guarantees efficient recovery of complete dictionaries when the coefficients have up to constant fraction of nonzeros. We also draw methodological connections to work on understanding nonconvex heuristics, and other nonconvex problems with similar geometric structures. Here we focus on drawing detailed connections to the optimization literature. Trust-region method TRM has a rich history dating back to 4 s; see the monograph [57] for accounts of the history and developments. The main motivation for early developments was to address limitations of the classic Newton s method see, e.g., Section 3 of [58]. The limitations include the technical subtleties to establish local and global convergence results. Moreover, when the Hessian is singular or indefinite, the movement direction is either not well-defined, or does not improve the objective function. [59] [64] initialized the line of work that addresses the limitations. Particularly, [58], [65] proposed using local second-order Taylor approximation as model function in the trust-region framework for unconstrained optimization. They showed that under mild conditions, the trust-region iterate sequence has a limit point that is critical and has positive semidefinite Hessian; see also Section of [57]. Upon inspecting the relevant proofs, it seems not hard to strengthen the results to sequence convergence to local minimizers, under a ridable saddle condition as ours, for unconstrained optimization. Research activities to port theories and algorithms of optimization in Euclidean space to Riemannian manifolds are best summarized by three monographs: [66] [68]. [69] developed Newton and conjugate-gradient methods for the Stiefel manifolds, of which the sphere is a special case; [68] presents a complete set of first- and second-order Riemannian algorithms and convergence analyses; see also the excellent associated optimization software toolbox [7]. Among these, trust-region method was first ported to the Riemannian setting in [71], with emphasis on efficient implementation which only approximately solves the trust-region subproblem according to the Cauchy point scheme. The Cauchy point definition adopted there was the usual form based on the gradient, not strong enough to ensure the algorithm escape from ridable saddle points even if the true Hessian is in use in local approximation. In comparison,
3 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 3 in this work we assume that the trust-region subproblem is exactly solved, such that ridable saddles the only possible saddles for our problem are properly skipped. By this, we obtain the strong guarantee that the iterate sequence converges to a local minimizer, in contrast to the weak global convergence gradient sequence converging to zero or local convergence sequence converging to a local minimizer within a small radius established in [71]. To the best of our knowledge, our convergence result is first of its kind for a specific problem on sphere. After our initial submission, [7] has recently established worst-case iteration complexity of Riemannian TRM to converge to second-order critical points i.e., critical points with positive semidefinite Hessians, echoing the results in the Euclidean case [73]. Their results are under mild Lipschitz-type assumptions and allow inexact subproblem solvers, and hence are very practical and general. However, on our particular problem, their result is considerably pessimistic, compared to our convergence result obtained from a specialized analysis. Solving the trust-region subproblem exactly is expensive. Practically, often a reasonable approximate solution with controlled quality is adequate to guarantee convergence. In this regard, the truncated conjugate gradient tcg solver with a good initial search direction is commonly employed in practice see, e.g., Section 7.5 in [57]. To ensure ridable saddle points be properly escaped from, the eigenpoint idea see, e.g., Section 6.6 of [57] is particularly relevant; see also Algorithm 3 and Lemma 1 in [7]. The benign function landscape we characterized in the first paper allows any reasonable iterative method that is capable of escaping from ridable saddles to find a local minimizer, with possibly different performance guarantees. The trust-region method we focus on here, and the curviliear search method [61] are second-order methods that guarantee global optimization from arbitrary initializations. Typical first-order methods such as the vanilla gradient descent can only guarantee convergence to a critical point. Nonetheless, for our particular function, noisy/stochastic gradient method guarantees to find a local minimizer from an arbitrary initialization with high probability [74]. B. Notations, and Reproducible Research We use bold capital and small letters such as X and x to denote matrices and vectors, respectively. Small letters are reserved for scalars. Several specific mathematical objects we will frequently work with: O k for the orthogonal group of order k, S n 1 for the unit sphere in R n, B n for the unit ball in R n, and [m]. = {1,..., m} for positive integers m. We use for matrix transposition, causing no confusion as we will work entirely on the real field. We use superscript to index rows of a matrix, such as x i for the i-th row of the matrix X, and subscript to index columns, such as x j. All vectors are defaulted to column vectors. So the i-th row of X as a row vector will be written as x i. For norms, is the usual l norm for a vector and the operator norm i.e., l l for a matrix; all other norms will be indexed by subscript, for example the Frobenius norm F for matrices and the element-wise max-norm. We use x L to mean that the random variable x is distributed according to the law L. Let N denote the Gaussian law. Then x N, I means that x is a standard Gaussian vector. Similarly, we use x i.i.d. L to mean elements of x are independently and identically distributed according to the law L. So the fact x N, I is equivalent to that x i.i.d. N, 1. One particular distribution of interest for this paper is the Bernoulli-Gaussian with rate θ: Z B G, with G N, 1 and B Ber θ. We also write this compactly as Z BG θ. We frequently use indexed C and c for numerical constants when stating and proving technical results. The scopes of such constants are local unless otherwise noted. We use standard notations for most other cases, with exceptions clarified locally. The codes to reproduce all the figures and experimental results are available online: focm. II. FINDING ONE LOCAL MINIMIZER VIA THE RIEMANNIAN TRUST-REGION METHOD We are interested to seek a local minimizer of I.1. The presence of saddle points have motivated us to develop a second-order Riemannian trust-region algorithm over the sphere; the existence of descent directions at nonoptimal points drives the trust-region iteration sequence towards one of the minimizers asymptotically. We will prove that under our modeling assumptions, this algorithm with an arbitrary initialization efficiently produces an accurate approximation 1 to one of the minimizers. Throughout the exposition, basic knowledge of Riemannian geometry is assumed. We will try to keep the technical requirement minimal possible; the reader can consult the excellent monograph [68] for relevant background and details. 1 By accurate we mean one can achieve an arbitrary numerical accuracy ε > with a reasonable amount of time. Here the running time of the algorithm is on the order of log log1/ε in the target accuracy ε, and polynomial in other problem parameters.
4 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 4 A. Some Basic Facts about the Sphere and f For any point q S n 1, the tangent space T q S n 1 and the orthoprojector P TqS n 1 T q S n 1 = {δ R n : q δ = }, P TqS n 1 = I qq = UU, onto T qs n 1 are given by where U R n n 1 is an arbitrary orthonormal basis for T q S n 1 note that the orthoprojector is independent of the basis U we choose. Consider any δ T q S n 1. The map γt : t q cos t δ + δ sin t δ δ defines a smooth curve on the sphere that satisfies γ = q and γ = δ. Geometrically, γt is a segment of the great circle that passes q and has δ as its tangent vector at q. The exponential map for δ is defined as It is a canonical way of pulling δ to the sphere. exp q δ. = γ1 = q cos δ + δ sin δ. δ T q S n 1 δ exp q δ q S n 1 Fig. 1: Illustrations of the tangent space T q S n 1 and exponential map exp q δ defined on the sphere S n 1. In this paper we are interested in the restriction of f to the unit sphere S n 1. For the sake of performing optimization, we need local approximations of f. Instead of directly approximating the function in R n, we form quadratic approximations of f in the tangent spaces of S n 1. We consider the smooth function f exp q δ : T q S n 1 R, where is the usual function composition operator. An applications of vector space Taylor s theorem gives f exp q δ fq; Ŷ + fq; Ŷ, δ + 1 δ fq; Ŷ fq; Ŷ, q I O δ when δ is small. Thus, we form a quadratic approximation fδ; q : T q S n 1 R as fδ; q, Ŷ. = fq; Ŷ + fq; Ŷ, δ + 1 δ fq; Ŷ fq; Ŷ, q I δ. II.1 Here fq and fq denote the usual Euclidean gradient and Hessian of f w.r.t. q in R n. For our specific f defined in I.1, it is easy to check that fq; Ŷ = 1 p q ŷ k tanh ŷ k, II. p fq; Ŷ = 1 p [ ] 1 q ŷ 1 tanh k ŷ k ŷk p. II.3 The quadratic approximation also naturally gives rise to the Riemannian gradient and Riemannian Hessian defined on T q S n 1 as grad fq; Ŷ = P T qsn 1 fq; Ŷ, II.4 Hess fq; Ŷ = P T qs n 1 fq; Ŷ fq; Ŷ, q I P TqS n 1. II.5


5 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 5 Fig. : Why is dictionary learning over S n 1 tractable? Assume the target dictionary A = I. Left: Large sample objective function E X [f q]. The only local minimizers are the standard basis vectors e i s and their negatives. Right: A visualization of the function as a height above the equatorial section e 3, i.e., span{e 1, e } B 3. The derived function is obtained by assigning values of points on the upper hemisphere to their corresponding projections on the equatorial section e 3. The minimizers for the derived function are, ±e 1, ±e. Around in e 3, the function exhibits a small region of strong convexity, a region of large gradient, and finally a region in which the direction away from is a direction of negative curvature. Thus, the above quadratic approximation can be rewritten compactly as f δ; q, Ŷ = fq; δ, Ŷ + grad fq; Ŷ + 1 δ Hess fq; Ŷ δ, δ T qs n 1. The first order necessary condition for unconstrained minimization of function f over T q S n 1 is grad fq; Ŷ + Hess fq; Ŷ δ =. II.6 If Hess fq; Ŷ is positive semidefinite and has full rank n 1 hence nondegenerate, the unique solution δ is δ = U U [ Hess fq; Ŷ ] U 1 U grad fq, which is also invariant to the choice of basis U. Given a tangent vector δ T q S n 1, let γt. = exp q tδ denote a geodesic curve on S n 1. Following the notation of [68], let P τ γ : T q S n 1 T γτ S n 1 denotes the parallel translation operator, which translates the tangent vector δ at q = γ to a tangent vector at γτ, in a parallel manner. In the sequel, we identify Pγ τ with the following n n matrix, whose restriction to T q S n 1 is the parallel translation operator the detailed derivation can be found in Chapter 8.1 of [68]: P τ γ = I δδ δ q sin τ δ δ δ + δ δ cos τ δ δ δ = I + cosτ δ 1 δδ qδ sin τ δ δ δ. Similarly, following the notation of [68], we denote the inverse of this matrix by P τ γ, where its restriction to T γτ S n 1 is the inverse of the parallel translation operator P τ γ. II.7
6 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 6 B. The Geometric Results from [3] We reproduce the main geometric theorems from [3] here for the sake of completeness. To characterize the function landscape of f q; X over S n 1, we mostly work with the function induced by the reparametrization g w; X. = f q w ; X = 1 p q w = p h q w x k, II.8 w, 1, w B n 1. II.9 Geometrically, this corresponds to projection of the function f above the equatorial section e n onto e n see Fig. right for illustration. In particular, we focus our attention to the smaller set of the ball: { } 4n 1 Γ = w : < B n 1, II.1 4n because q Γ contains all points q S n 1 with n arg max i ±[n] q e i. We can similarly characterize other parts of f on S n 1 using projection onto other equatorial sections. Theorem II.1 High-dimensional landscape - orthogonal dictionary. Suppose A = I and hence Y = A X = X. There exist positive constants c and C, such that for any θ, 1/ and < c a min { θn 1, n 5/4}, whenever p the following hold simultaneously with probability at least 1 c b p 6 : gw; X c θ w gw; X C θ n3 log n θ, II.11 I w s.t. 4, II.1 c θ w s.t. w gw; X w c θ w s.t and the function gw; X has exactly one local minimizer w over the open set Γ =. satisfies { c c w min θ Here c a through c c are all positive constants. II n 1 4n, II.14 { } 4n 1 w : < 4n, which } n log p,. II.15 p 16 Recall that the reason we just need to characterize the geometry for the case A = I is that for other orthogonal A, the function landscape is simply a rotated version of that of A = I. Theorem II. High-dimensional landscape - complete dictionary. Suppose A is complete with its condition number κ A. There exist positive constants c particularly, the same constant as in Theorem II.1 and C, such that for any θ, 1/ and < c a min { θn 1, n 5/4}, when p C c θ max { n 4 4, n5 } κ 8 A log 4 κ A n θ II.16 Note that the n n matrix Hess fq; Ŷ has rank at most n 1, as the nonzero q obviously is in its null space. When Hess fq; Ŷ has rank n 1, it has no null direction in the tangent space. Thus, in this case it acts on the tangent space like a full-rank matrix.
7 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 7 and Y =. pθ Y Y 1/ Y, UΣV = SVD A, the following hold simultaneously with probability at least 1 c b p 6 : gw; V U Y c θ I w s.t. 4, II.17 w gw; V U Y 1 c θ w s.t. w gw; V U Y w 1 c θ w s.t and the function gw; V U Y has exactly one local minimizer w over the open set Γ =. which satisfies w /7. Here c a, c b are both positive constants. II.18 4n 1 4n, II.19 { } 4n 1 w : < 4n, II. From the above theorems, it is clear that for any saddle point in the w space, the Hessian of g has at least one negative eigenvalue. Now the problem is whether all saddle points of f on S n 1 are ridable, because as alluded to in previous discussion, we need to perform actual optimization in the q space. Instead of presenting a rigorous technical statement and detailed proof, we include here just an informal argument; our actual proof for algorithmic convergence runs back and forth in w and q space and such lack will not affect our arguments there. It is very easy to verify the following fact see proof of Lemma II.13 on page 33: grad fq, q e n /q n = w, gw. Thus, grad fq, q e n /q n if and only if w, gw, implying that grad fq will never be zero in the spherical region corresponding to { w : /4 1/ 5 }. Moreover, it is shown in Lemma II.11 below that the Riemannian Hessian is positive definite for the spherical region corresponding to { w : /4 }, so there is no saddle point in this region either. Over qγ S n 1, potential saddle points lie only in the region corresponding to {w : 1/ 5 4n 1/4n}. Theorem II.1 and Theorem II. imply that around each point in this region, a cross section of the function gw is strictly concave locally. Intuitively, by the qw mapping the same happens in the q space, i.e., the Riemannian Hessian has a strictly negative eigenvalue. C. The Riemannian Trust-Region Algorithm over the Sphere For a function f in the Euclidean space, the typical TRM starts from some initialization q R n, and produces a sequence of iterates q 1, q,..., by repeatedly minimizing a quadratic approximation f to the objective function fq, over a ball centered around the current iterate. For our f defined over S n 1, given the previous iterate q r 1, the TRM produces the next movement by generating a solution δ to minimize δ Tq r 1 S n 1, δ f δ; q r 1, II.1 where f δ; q r 1 is the local quadratic approximation defined in II.1. The solution δ is then pulled back to S n 1 from T q S n 1. If we choose the exponential map to pull back the movement δ, 3 the next iterate then reads q r = q r 1 cos δ + δ sin δ. II. δ To solve the subproblem II.1 numerically, we can take any matrix U R n n 1 whose columns form an orthonormal basis for T q r 1S n 1, and produce a solution ξ to minimize ξ f Uξ; q r 1. II.3 3 The exponential map is only one of the many possibilities; also for general manifolds other retraction schemes may be more practical. See exposition on retraction in Chapter 4 of [68].
8 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 8 Solution to II.1 can then be recovered as δ = U ξ. The problem II.3 is an instance of the classic trust region subproblem, i.e., minimizing a quadratic function subject to a single quadratic constraint. Albeit potentially nonconvex, this notable subproblem can be solved in polynomial time by several numerical methods [57], [65], [75] [78]. Approximate solution of the subproblem suffices to guarantee convergence in theory, and lessens the storage and computational burden in practice. We will deploy the approximate version in simulations. For simplicity, however, our subsequent analysis assumes the subproblem is solved exactly. We next briefly describe how one can deploy the semidefinite programming SDP approach [75] [78] to solve the subproblem exactly. This choice is due to the well-known effectiveness and robustness of the SDP approach on this problem. We introduce ξ = [ξ, 1], Θ = ξ ξ, M = [ A b b ], II.4 where A = U Hess fq r 1 ; Ŷ U and b = U grad fq r 1 ; Ŷ. The resulting SDP to solve is minimize Θ M, Θ, subject to trθ + 1, E n+1, Θ = 1, Θ, II.5 where E n+1 = e n+1 e n+1. Once the problem II.5 is solved to its optimum Θ, one can provably recover the minimizer ξ of II.3 by computing the SVD of Θ = ŨΣṼ, and extract as a subvector the first n 1 coordinates of the principal eigenvector ũ 1 see Appendix B of [79]. D. Main Convergence Results Using general convergence results on Riemannian TRM see, e.g., Chapter 7 of [68], it is not difficult to prove that the gradient sequence grad fq r ; Ŷ produced by TRM converges to zero i.e., global convergence, or the sequence converges at quadratic rate to a local minimizer if the initialization is already close a local minimizer i.e., local convergence. In this section, we show that under our probabilistic assumptions, these results can be substantially strengthened. In particular, the algorithm is guaranteed to produce an accurate approximation to a local minimizer of the objective function, in a number of iterations that is polynomial in the problem size, from arbitrary initializations. The arguments in the companion paper [3] showed that w.h.p. every local minimizer of f produces a close approximation to a row of X. Taken together, this implies that the algorithm efficiently produces a close approximation to one row of X. Thorough the analysis, we assume the trust-region subproblem is exactly solved and the step size parameter is fixed. Our next two theorems summarize the convergence results for orthogonal and complete dictionaries, respectively. Theorem II.3 TRM convergence - orthogonal dictionary. Suppose the dictionary A is orthogonal. There exists a positive constant C, such that for all θ, 1/ and < c a min { θn 1, n 5/4}, whenever p C θ n3 log n θ, with probability at least 1 c b p 6, the Riemannian trust-region algorithm with input data matrix Ŷ = Y, any initialization q on the sphere, and a step size satisfying c c c 3 θ 3 n 7/ log 7/ np II.6 returns a solution q S n 1 which is ε near to one of the local minimizers q i.e., q q ε in at most { cd n 6 log 3 } np c e n max c 3 θ 3 4, c θ fq c f c θ + log log εn 3/ log 3/ II.7 np iterations. Here c is as defined in Theorem II.1, and c a through c f are all positive constants.
9 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 9 Theorem II.4 TRM convergence - complete dictionary. Suppose the dictionary A is complete with condition number κ A. There exists a positive constant C, such that for all θ, 1/, and < c a min { θn 1, n 5/4}, whenever p C { } n 4 c θ max 4, n5 κ κ 8 A log 4 A n, θ with probability at least 1 c b p 6, the Riemannian trust-region algorithm with input data matrix Y. = pθ Y Y 1/ Y where UΣV = SVD A, any initialization q on the sphere and a step size satisfying c c c 3 θ 3 n 7/ log 7/ np II.8 returns a solution q S n 1 which is ε near to one of the local minimizers q i.e., q q ε in at most { cd n 6 log 3 } np c e n max c 3 θ 3 4, c θ fq c f c θ + log log εn 3/ log 3/ II.9 np iterations. Here c is as in Theorem II.1, and c a through c f are all positive constants. Our convergence result shows that for any target accuracy ε > the algorithm terminates within polynomially many steps. Specifically, the first summand in II.7 or II.9 is the number of steps the sequence takes to enter the strongly convex region and be reasonably close to a local minimizer. All subsequent trust-region subproblems are then unconstrained proved below the constraint is inactive at optimal point, and hence the steps behave like Newton steps. The second summand reflects the typical quadratic local convergence of the Newton steps. Our estimate of the number of steps is pessimistic: the running time is a relatively high-degree polynomial in p and n. We will discuss practical implementation details that help speed up in Section IV. Our goal in stating the above results is not to provide a tight analysis, but to prove that the Riemannian TRM algorithm finds a local minimizer in polynomial time. For nonconvex problems, this is not entirely trivial results of [8] show that in general it is NP-hard to find a local minimizer of a nonconvex function. E. Sketch of Proof for Orthogonal Dictionaries The reason that our algorithm is successful derives from the geometry formalized in Theorem II.1. Basically, the sphere S n 1 can be divided into three regions. Near each local minimizer, the function is strongly convex, and the algorithm behaves like a standard Euclidean TRM algorithm applied to a strongly convex function in particular, it exhibits a quadratic asymptotic rate of convergence. Away from local minimizers, the function always exhibits either a strong gradient, or a direction of negative curvature i.e., the Hessian has a strictly negative eigenvalue. The Riemannian TRM algorithm is capable of exploiting these quantities to reduce the objective value by at least a fixed amount in each iteration. The total number of iterations spent away from the vicinity of the local minimizers can be bounded by comparing this amount to the initial objective value. Our proofs follow exactly this line and make the various quantities precise. Note that for any orthogonal A, f q; A X = f A q; X. In words, this is the established fact that the function landscape of fq; A X is a rotated version of that of fq; X. Thus, any local minimizer q of fq; X is rotated to A q, a local minimizer of fq; A X. Also if our algorithm generates iteration sequence q, q 1, q,... for fq; X upon initialization q, it will generate the iteration sequence A q, A q 1, A q,... for f q; A X. So w.l.o.g. it is adequate that we prove the convergence results for the case A = I. So in this section Section II-E, we write fq to mean fq; X. We partition the sphere into three regions, for which we label as R I, R II, R III, corresponding to the strongly convex, nonzero gradient, and negative curvature regions, respectively see Theorem II.1. That is, R I consists of a union of n spherical caps of radius /4, each centered around a signed standard basis vector ±e i. R II consist of the set difference of a union of n spherical caps of radius 1/ 5, centered around the standard basis vectors ±e i, and R I. Finally, R III covers the rest of the sphere. We say a trust-region step takes an R I step if the current iterate is in R I ; similarly for R II and R III steps. Since we use the geometric structures derived in Theorem II.1 and Corollary II. in [3], the conditions { θ, 1/, < c min θn 1, n 5/4}, p C θ n3 log n II.3 θ
10 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 1 are always in force. At step r of the algorithm, suppose δ r is the minimizer of the trust-region subproblem II.1. We call the step constrained if δ r = the minimizer lies on the boundary and hence the constraint is active, and call it unconstrained if δ r < the minimizer lies in the relative interior and hence the constraint is not in force. Thus, in the unconstrained case the optimality condition is II.6. The next lemma provides some estimates about f and f that are useful in various contexts. Lemma II.5. We have the following estimates about f and f: sup f q =. M n X, q S n 1 sup f q =. M n q S X, n 1 f q f q sup q,q S n 1,q q q q f q f q sup q,q S n 1,q q q q. = L n X,. = L n3/ X 3. Proof: See Page 5 under Section VI. Our next lemma says if the trust-region step size is small enough, one Riemannian trust-region step reduces the objective value by a certain amount when there is any descent direction. Lemma II.6. Suppose that the trust region size 1, and there exists a tangent vector δ T q S n 1 with δ, such that fexp q δ fq s for some positive scalar s R. Then the trust region subproblem produces a point δ with fexp q δ fq s η f 3, where η f. = M + M + L + L and M, M, L, L are the quantities defined in Lemma II.5. Proof: See Page 6 under Section VI. To show decrease in objective value for R II and R III, now it is enough to exhibit a descent direction for each point in these regions. The next two lemmas help us almost accomplish the goal. For convenience again we choose to state the results for the canonical section that is in the vicinity of e n and the projection map q w = [w; 1 1/ ], with the idea that similar statements hold for other symmetric sections. Lemma II.7. Suppose that the trust region size 1, w gw/ β g for some scalar β g, and that w 3 gw/ is L g -Lipschitz on an open ball B w, π centered at w. Then there exists a tangent vector n δ T q S n 1 with δ, such that { } β g fexp q δ fq min, 3β g L g 4π. n Proof: See Page 7 under Section VI. Lemma II.8. Suppose that the trust-region size 1, w gww/ β S, for some β S, and that w gww/ 3 is L S Lipschitz on the open ball B w, π centered at w. Then there exists a tangent n vector δ T q S n 1 with δ, such that { } β 3 fexp q δ fq min S 3L, 3 β S S 8π. n Proof: See Page 8 under Section VI. One can take β g = β S = c θ as shown in Theorem II.1, and take the Lipschitz results in Proposition B.4 and Proposition B.3 note that X 4 log 1/ np w.h.p. by Lemma B.6, repeat the argument for other n 1
11 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX symmetric regions, and conclude that w.h.p. the objective value decreases by at least a constant amount. The next proposition summarizes the results. Proposition II.9. Assume II.3. In regions R II and R III, each trust-region step reduces the objective value by at least d II = 1 c min c a θ n log np, 3 c θ 4π, and d III = 1 c 3 n min c b θ 3 4 n 6 log 3 np, 3 c θ 8π II.31 n respectively, provided that < c c c θ n 5/ log 3/ np, where c a to c c are positive constants, and c is as defined in Theorem II.1. II.3 Proof: We only consider the symmetric section in the vicinity of e n and the claims carry on to others by symmetry. If the current iterate q r is in the region R II, by Theorem II.1, w.h.p., we have w g w / c θ for the constant c. By Proposition B.4 and Lemma B.6, w.h.p., w g w / is C n log np /-Lipschitz. Therefore, By Lemma II.6 and Lemma II.7, a trust-region step decreases the objective value by at least. c d II = min θ C n log np, 3c θ 4π c n 3/ log 3/ np n 3 3. Similarly, if q r is in the region R III, by Proposition B.3, Theorem II.1 and Lemma B.6, w.h.p., w g w w/ is C 3 n 3 log 3/ np / -Lipschitz and upper bounded by c θ. By Lemma II.6 and Lemma II.8, a trust-region step decreases the objective value by at least d III. = min c 3 θ 3 4 3C3 n6 log 3 np, 3 c θ 8π n c n 3/ log 3/ np 3 3. It can be easily verified that when obeys II.31, II.3 holds. The analysis for R I is slightly trickier. In this region, near each local minimizer, the objective function is strongly convex. So we still expect each trust-region step decreases the objective value. On the other hand, it is very unlikely that we can provide a universal lower bound for the amount of decrease - as the iteration sequence approaches a local minimizer, the movement is expected to be diminishing. Nevertheless, close to the minimizer the trust-region algorithm takes unconstrained steps. For constrained R I steps, we will again show reduction in objective value by at least a fixed amount; for unconstrained step, we will show the distance between the iterate and the nearest local minimizer drops down rapidly. The next lemma concerns the function value reduction for constrained R I steps. Lemma II.1. Suppose the trust-region size 1, and that at a given iterate r, Hess f q r m H P Tq r S Hess f q r MH. Further assume the optimal solution δ T q rs n 1 to the trust-region subproblem II.1 satisfies δ =, i.e., the norm constraint is active. Then there exists a tangent vector δ T q rs n 1 with δ, such that fexp q rδ f q r m H + 1 M H 6 η f 3, where η f is defined the same as Lemma II.6. n 1, and Proof: See Page 8 under Section VI. The next lemma provides an estimate of m H. Again we will only state the result for the canonical section with the canonical qw mapping. Lemma II.11. There exists a positive constant C, such that for all θ, 1/ and < θ/1, whenever p Cn 3 log n θ /θ, it holds with probability at least 1 cp 7 that for all q with w q /4, Hess f q c θ P T qs n 1.
12 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 1 Here c is as in Theorem II.1 and Theorem II., and c > is another constant. Proof: See Page 9 under Section VI. We know that X 4 log 1/ np w.h.p., and hence by the definition of Riemannian Hessian and Lemma II.5, M H. = Hess fq fq + fq M + M n X 16n lognp. Combining this estimate and Lemma II.11 and Lemma II.6, we obtain a concrete lower bound for the reduction of objective value for each constrained R I step. Proposition II.1. Assume II.3. Each constrained R I trust-region step i.e., δ = reduces the objective value by at least provided d I = cc θ n lognp, II.33 c c θ n 5/ log 5/ np. Here c is as in Theorem II.1 and Theorem II., and c, c are positive constants. II.34 Proof: We only consider the symmetric section in the vicinity of e n and the claims carry on to others by symmetry. We have that w.h.p. Hess fq 16n lognp, and Hess fq c θ P T n 1. qs Combining these estimates with Lemma II.6 and Lemma II.1, one trust-region step will find next iterate q r+1 that decreases the objective value by at least d I. = c θ / n log np / c n 3/ log 3/ np 3. Finally, by the condition on in II.34 and the assumed conditions II.3, we obtain d I c θ n lognp c n 3/ log 3/ np 3 c θ 4n lognp, as desired. By the proof strategy for R I we sketched before Lemma II.1, we expect the iteration sequence ultimately always takes unconstrained steps when it moves very close to a local minimizer. We will show that the following is true: when is small enough, once the iteration sequence starts to take unconstrained R I step, it will take consecutive unconstrained R I steps afterwards. It takes two steps to show this: 1 upon an unconstrained R I step, the next iterate will stay in R I. It is obvious we can make O1 to ensure the next iterate stays in R I R II. To strengthen the result, we use the gradient information. From Theorem II.1, we expect the magnitudes of the gradients in R II to be lower bounded; on the other hand, in R I where points are near local minimizers, continuity argument implies that the magnitudes of gradients should be upper bounded. We will show that when is small enough, there is a gap between these two bounds, implying the next iterate stays in R I ; when is small enough, the step is in fact unconstrained. Again we will only state the result for the canonical section with the canonical qw mapping. The next lemma exhibits an absolute lower bound for magnitudes of gradients in R II. Lemma II.13. For all q satisfying /4 w q 1/ 5, it holds that grad f q 9 1 w g w. Proof: See Page 33 under Section VI. Assuming II.3, Theorem II.1 gives that w.h.p. w gw/ c θ. Thus, w.h.p, grad fq 9c θ/1 for all q R II. The next lemma compares the magnitudes of gradients before and after taking one unconstrained R I
13 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX step. This is crucial to providing upper bound for magnitude of gradient for the next iterate, and also to establishing the ultimate quadratic sequence convergence. Lemma II.14. Suppose the trust-region size 1, and at a given iterate r, Hess f q r m H P Tq r Sn 1, and that the unique minimizer δ T q rs n 1 to the trust region subproblem II.1 satisfies δ < i.e., the constraint is inactive. Then, for q r+1 = exp q r δ, we have grad fq r+1 L H m H grad fq r, where L H. = 5n 3/ / X 3 + 9n/ X + 9 n X. Proof: See Page 34 under Section VI. We can now bound the Riemannian gradient of the next iterate as grad fq r+1 L H m grad fq r H L H m [U Hess fq r U][U Hess fq r U] 1 grad fq r H L H m Hess fq r = L HMH H m. H Obviously, one can make the upper bound small by tuning down. Combining the above lower bound for grad fq for q R II, one can conclude that when is small, the next iterate q r+1 stays in R I. Another application of the optimality condition II.6 gives conditions on that guarantees the next trust-region step is also unconstrained. Detailed argument can be found in proof of the following proposition. Proposition II.15. Assume II.3. W.h.p, once the trust-region algorithm takes an unconstrained R I step i.e., δ <, it always takes unconstrained R I steps, provided that cc 3 θ 3 n 7/ log 7/ np, Here c is as in Theorem II.1 and Theorem II., and c > is another constant. II.35 Proof: We only consider the symmetric section in the vicinity of e n and the claims carry on to others by symmetry. Suppose that step k is an unconstrained R I step. Then 5 wq r+1 wq r q r+1 q r = exp q r δ q r = cos δ = sin δ / δ <. Thus, if 1 4, qr+1 will be in R I R II. Next, we show that if is sufficiently small, q r+1 will be indeed in R I. By Lemma II.14, grad f grad f q r q r+1 L H m H L HM H m H where we have used the fact that [ U Hess f δ r = [U Hess f q r 1 U] U grad f q r q r 1 U] U grad f q r <, as the step is unconstrained. On the other hand, by Theorem II.1 and Lemma II.13, w.h.p. L HMH m, H II.36 grad f q β grad. = 9 1 c θ, q R II. II.37
14 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX Hence, provided < m H M H β grad L H, II.38 we have q r+1 R I. We next show that when is small enough, the next step is also unconstrained. Straight forward calculations give [U U Hess f q r+1 1 U] U grad f q r+1 L HMH m 3. H Hence, provided that we will have [U U Hess f < m3 H L H MH, II.39 q r+1 1 U] U grad f q r+1 < ; in words, the minimizer to the trust-region subproblem for the next step lies in the relative interior of the trust region - the constraint is inactive. By Lemma II.14 and Lemma B.6, we have L H = C 1 n 3/ log 3/ np /, II.4 w.h.p.. Combining this and our previous estimates of m H, M H, we conclude whenever { } 1 min 5 3/ 4, c 1 c θ 3/ n 7/4 log 7/4 np, c c 3 θ 3 n 7/ log 7/, np w.h.p., our next trust-region step is also an unconstrained R I step. Simplifying the above bound completes the proof. Finally, we want to show that ultimate unconstrained R I iterates actually converges to one nearby local minimizer rapidly. Lemma II.14 has established the gradient is diminishing. The next lemma shows the magnitude of gradient serves as a good proxy for distance to the local minimizer. Lemma II.16. Let q S n 1 such that grad fq =, and δ T q S n 1. Consider a geodesic γt = exp q tδ, and suppose that on [, τ], Hess fγt m H P TγtSn 1. Then grad fγτ m H τ δ. Proof: See Page 34 under Section VI. To see this relates the magnitude of gradient to the distance away from the nearby local minimizer, w.l.o.g., one can assume τ = 1 and consider the point q = exp q δ. Then q q = expq δ q = cos δ = sin δ / δ grad fq /m H, where at the last inequality above we have used Lemma II.16. Hence, combining this observation with Lemma II.14, we can derive the asymptotic sequence convergence rate as follows. Proposition II.17. Assume II.3 and the conditions in Lemma II.15. Let q r R I and the r -th step the first unconstrained R I step and q be the unique local minimizer of f over one connected component of R I that contains q r. Then w.h.p., for any positive integer r 1, q r+r cc θ q, II.41 n 3/ log 3/ np r provided that c c θ n 5/ log 5/ np. II.4
15 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX Here c is as in Theorem II.1 and Theorem II., and c, c are both positive constants. Proof: By the geometric characterization in Theorem II.1 and corollary II. in [3], f has n separated local minimizers, each located in R I and within distance /16 of one of the n signed basis vectors {±e i } i [n]. Moreover, it is obvious when 1, R I consists of n disjoint connected components. We only consider the symmetric component in the vicinity of e n and the claims carry on to others by symmetry. Suppose that r is the index of the first unconstrained iterate in region R I, i.e., q r R I. By Lemma II.14, for any integer r 1, we have grad f q r+r m H LH L H m H grad f q r r. II.43 where L H is as defined in Lemma II.14, m H as the strong convexity parameter for R I defined above. Now suppose q is the unique local minimizer of f, lies in the same R I component that q r is located. Let γ r t = exp q tδ to be the unique geodesic that connects q and q r+r with γ r = q and γ r 1 = q r+r. We have q r+r q expq δ q = cos δ = sin δ / δ 1 m H grad f q r+r m H L H LH where at the second line we have repeatedly applied Lemma II.16. By the optimality condition II.6 and the fact that δ r <, we have L H m H Thus, provided m H grad f q r r, grad f q r L H m M H [U Hess f q r 1 U] U grad f q r L HM H H m H < m H L H M H, we can combine the above results and obtain q r+r m H q L H r. Based on the previous estimates for m H, M H and L H, we obtain that w.h.p., q r+r c 1 c θ q n 3/ log 3/ np r Moreover, by II.44, w.h.p., it is sufficient to have the trust region size c c θ n 5/ log 5/ np. Thus, we complete the proof. Now we are ready to piece together the above technical proposition to prove Theorem II.3. Proof: of Theorem II.3 Assuming II.3 and in addition that < c 1 c 3 θ 3 n 7/ log 7/ np,.. II.44 it can be verified that the conditions of all the above propositions are satisfied. By the preceding four propositions, a step will either be R III, R II, or constrained R I step that decreases the objective value by at least a certain fixed amount we call this Type A, or be an unconstrained R I step Type B, such that all future steps are unconstrained R I and the sequence converges to a local minimizer quadratically. Hence, regardless the initialization, the whole iteration sequence consists of consecutive Type A steps, followed by
16 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX consecutive Type B steps. Depending on the initialization, either the Type A phase or the Type B phase can be absent. In any case, from q it takes at most note fq always holds f q min {d I, d II, d III } II.45 steps for the iterate sequence to start take consecutive unconstrained R I steps, or to already terminate. In case the iterate sequence continues to take consecutive unconstrained R I steps, Proposition II.17 implies that it takes at most c c θ log log εn 3/ log 3/ II.46 np steps to obtain an ε-near solution to the q that is contained in the connected subset of R I that the sequence entered. Thus, the number of iterations to obtain an ε-near solution to q can be grossly bounded by f q c c θ #Iter + log log min {d I, d II, d III } εn 3/ log 3/ np [ { c3 c 3 min θ 3 4 n 6 log 3 np, c 4c θ }] 1 n f q c c θ + log log εn 3/ log 3/. np Finally, the claimed failure probability comes from a simple union bound with careful bookkeeping. F. Extending to Convergence for Complete Dictionaries Recall that in this case we consider the preconditioned input Y. = pθy Y 1/ Y. II.47 Note that for any complete A with condition number κ A, from Lemma B.7 we know when p is large enough, w.h.p. one can write the preconditioned Y as Y = UV X + ΞX for a certain Ξ with small magnitude, and UΣV = SVD A. Particularly, when p is chosen by Theorem II., the perturbation is bounded as { } n 3/ 1 Ξ cc θ max, n log np 3/ II.48 for a certain constant c which can be made arbitrarily small by making the constant C in p large. Since UV is orthogonal, f q; UV X + ΞX = f V U q; X + V U ΞX. In words, the function landscape of fq; UV X +ΞX is a rotated version of that of fq; X +V U ΞX. Thus, any local minimizer q of fq; X + V U ΞX is rotated to UV q, one minimizer of fq; UV X + ΞX. Also if our algorithm generates iteration sequence q, q 1, q,... for fq; X + V U ΞX upon initialization q, it will generate the iteration sequence UV q, UV q 1, UV q,... for f q; UV X + ΞX. So w.l.o.g. it is adequate that we prove the convergence results for the case fq; X + V U ΞX, corresponding to A = I with perturbation Ξ =. V U Ξ. So in this section Section II-F, we write fq; X to mean fq; X + ΞX. Theorem II. has shown that when θ, 1, c min { θ n, 1 n 5/4 }, p C { } n 4 c θ max 4, n5 κ κ 8 A log 4 A n, II.49 θ the geometric structure of the landscape is qualitatively unchanged from the orthogonal case, and the parameter c constant can be replaced with c /. Particularly, for this choice of p, Lemma B.7 implies { } n Ξ = V U 3/ 1 Ξ cc θ max, n log np 3/ II.5
17 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX for a constant c that can be made arbitrarily small by setting the constant C in p sufficiently large. The whole proof is quite similar to that of orthogonal case in the last section. We will only sketch the major changes below. To distinguish with the corresponding quantities in the last section, we use to denote the corresponding perturbed quantities here. Lemma II.5: Note that X + ΞX X + ΞX X + n Ξ X 3 X /, where by II.5 we have used Ξ 1/ n to simplify the above result. So we obtain Lemma II.6: Now we have M 3 M, M 9 4 M, L 9 4 L, L 7 8 L. η f. = M + M + L + L 4η f. Lemma II.7 and Lemma II.8 are generic and nothing changes. Proposition II.9: We have now w gw; X / c θ/ by Theorem II., w.h.p. w gw; X / is C 1 n lognp/-lipschitz by Proposition B.4, and X + ΞX 3 X / as shown above. Similarly, w gw; X / c θ/ by Theorem II., and w gw; X w/ is C n 3 log 3/ np/ -Lipschitz. Moreover, η f 4η f as shown above. Since there are only multiplicative constant changes to the various quantities, we conclude provided d II = c 1 d II, diii = c 1 d III II.51 < c c θ n 5/ log 3/ np. Lemma II.1: η f is changed to η f with η f 4η f as shown above. Lemma II.11: By II.3, we have fq; X fq; X 1 p p { Lḧ Ξ x k + 1 x k x k x kx } k II.5 p Ξ Lḧ + / + Ξ / x k Ξ Lḧ + 3/ n X, where Lḧ is the Lipschitz constant for the function ḧ and we have used the fact that Ξ 1. Similarly, by II., fq; X fq; X 1 p { } Lḣ Ξ x k + Ξ x k Lḣ + 1 Ξ n X p, where Lḣ is the Lipschitz constant for the function ḣ. Since Lḧ / and Lḣ 1/, and X 4 lognp w.h.p. Lemma B.6. By II.5, w.h.p. we have fq; X fq; X 1 c θ, and fq; X fq; X 1 c θ, provided the constant C in II.49 for p is large enough. Thus, by II.5 and the above estimates we have Hess fq; X Hess fq; X fq; X fq; X + fq; X fq; X c θ 1 c θ,
18 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX provided 1/. So we conclude Hess fq; X 1 c θ P T q S n 1 = m H 1 c θ. II.53 Proposition II.1: From the estimate of M H above Proposition II.1 and the last point, we have Hess fq; X 36 lognp, and Hess fq; X 1 c θ P T q S n 1. Also since η f 4η f in Lemma II.6 and Lemma II.1, there are only multiplicative constant change to the various quantities. We conclude that provided that d I = c 3 d I c 4 c θ n 5/ log 5/ np. II.54 II.55 Lemma II.13 is generic and nothing changes. Lemma II.14: LH 7L H /8. Proposition II.15: All the quantities involved in determining, m H, M H, and L H, β grad are modified by at most constant multiplicative factors and changed to their respective tilde version, so we conclude that the TRM algorithm always takes unconstrained R I step after taking one, provided that c 5 c 3 θ 3 n 7/ log 7/ np. II.56 Lemma II.16:is generic and nothing changes. Proposition II.17: Again m H, M H, L H are changed to m H, MH, and LH, respectively, differing by at most constant multiplicative factors. So we conclude for any integer k 1, q k+k c 6 c θ q, II.57 n 3/ log 3/ np k provided c 7 c θ n 5/ log 5/ np. II.58 The final proof to Theorem II. is almost identical to that of Theorem II.1, except that d I, d II, and d III are changed to d I, dii, and d III as defined above, respectively. The final iteration complexity to each an ε-near solution is hence [ { c8 c 3 #Iter min θ 3 4 n 6 log 3 np, c 9c θ }] 1 n f q c 1 c θ f q + log log εn 3/ log 3/. np Hence overall the qualitative behavior of the algorithm is not changed, as compared to that for the orthogonal case. III. COMPLETE ALGORITHM PIPELINE AND MAIN RESULTS For orthogonal dictionaries, from Theorem II.1 and Corollary II. in [3], we know that all the minimizers q are O away from their respective nearest target q, with q Ŷ = αe i X for a certain α and i [n]; in Theorem II.3, we have shown that w.h.p. the Riemannian TRM algorithm produces a solution q S n 1 that is ε away to one of the minimizers, say q. Thus, the q returned by the TRM algorithm is Oε + away from q. For exact recovery, we use a simple linear programming rounding procedure, which guarantees to produce the target q. We then use deflation to sequentially recover other rows of X. Overall, w.h.p. both the dictionary A and sparse coefficient X are exactly recovered up to sign permutation, when θ Ω1, for orthogonal dictionaries. We summarize relevant technical lemmas and main results in Section III-A. The same procedure can be used to recover complete dictionaries, though the analysis is slightly more complicated; we present the results in Section III-B. Our overall algorithmic pipeline for recovering orthogonal dictionaries is sketched as follows.
19 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX Estimating one row of X by the Riemannian TRM algorithm. By Theorem II.1 resp. Theorem II. and Theorem II.3 resp. Theorem II.4, starting from any q S n 1, when the relevant parameters are set appropriately say as and, w.h.p., our Riemannian TRM algorithm finds a local minimizer q, with q the nearest target that exactly recovers a row of X and q q O by setting the target accuracy of the TRM as, say, ε =. Recovering one row of X by rounding. To obtain the target solution q and hence recover up to scale one row of X, we solve the following linear program: q minimize q Ŷ, subject to r, q = 1, III.1 1 with r = q. We show in Lemma III. resp. Lemma III.4 that when q, q is sufficiently large, implied by being sufficiently small, w.h.p. the minimizer of III.1 is exactly q, and hence one row of X is recovered by q Ŷ. 3 Recovering all rows of X by deflation. Once l rows of X 1 l n have been recovered, say, by unit vectors q, 1..., q, l one takes an orthonormal basis U for [span q, 1..., q l ], and minimizes the new function hz =. fuz; Ŷ on the sphere Sn l 1 with the Riemannian TRM algorithm though conservative, one can again set parameters as,, as in Step 1 to produce a ẑ. Another row of X is then recovered via the LP rounding III.1 with input r = Uẑ to produce q l+1. Finally, by repeating the procedure until depletion, one can recover all the rows of X. 4 Reconstructing the dictionary A. By solving the linear system Y = AX, one can obtain the dictionary A = Y X X X 1. A. Recovering Orthogonal Dictionaries Theorem III.1 Main theorem - recovering orthogonal dictionaries. Assume the dictionary A is orthogonal and we take Ŷ = Y. Suppose θ, 1/3, < c a min { θn 1, n 5/4}, and p Cn 3 log n / θ θ. The above algorithmic pipeline with parameter setting = c b c 3 θ 3 n 7/ log 7/ np, III. recovers the dictionary A and X in polynomial time, with failure probability bounded by c c p 6. Here c is as defined in Theorem II.1, and c a through c c, and C are all positive constants. Towards a proof of the above theorem, it remains to be shown the correctness of the rounding and deflation procedures. a Proof of LP rounding.: The following lemma shows w.h.p. the rounding will return the desired q, provided the estimated q is already near to it. Lemma III. LP rounding - orthogonal dictionary. For any θ, 1/3, whenever p Cn logn/θ/θ, with probability at least 1 cp 6, the rounding procedure III.1 returns q for any input vector r that satisfies Here C, c are both positive constants. r, q 49/5. Proof: See Page 36 under Section VII. Since q, q = 1 q q /, and q q O, it is sufficient when is smaller than some small constant. b Proof sketch of deflation.: We show the deflation works by induction. To understand the deflation procedure, it is important to keep in mind that the target solutions { q } i n are orthogonal to each other. W.l.o.g., suppose i=1 we have found the first l unit vectors q, 1..., q l which recover the first l rows of X. Correspondingly, we partition the target dictionary A and X as A = [V, V ], X = [ ] [l] X, III.3 X [n l]
20 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 where V R n l, and X [l] R l n denotes the submatrix with the first l rows of X. Let us define a function: f n l : Rn l R by f n l z; W. = 1 p p h z w k, III.4 for any matrix W R n l p. Then by I.1, our objective function is equivalent to hz = fuz; A X = f n l z; U A X = f n l z; U V X [l] + U V X [n l]. Since the columns of the orthogonal matrix U R n n l forms the orthogonal complement of span q 1,, q l, it is obvious that U V =. Therefore, we obtain hz = f n l z; U V X [n l]. Since U V is orthogonal and X [n l] i.i.d. BGθ, this is another instance of orthogonal dictionary learning problem with reduced dimension. If we keep the parameter settings and as Theorem III.1, the conditions of Theorem II.1 and Theorem II.3 for all cases with reduced dimensions are still valid. So w.h.p., the TRM algorithm returns a ẑ such that ẑ z O where z is a target solution that recovers a row of X : z U V X [n l] = z U A X = αe i X, for some i [l]. So pulling everything back in the original space, the effective target is q l+1 obtained from the TRM algorithm. Moreover, Uẑ Uz = ẑ z O.. = Uz, and Uẑ is our estimation Thus, by Lemma III., one successfully recovers Uz from Uẑ w.h.p. when is smaller than a constant. The overall failure probability can be obtained via a simple union bound and simplification of the exponential tails with inverse polynomials in p. B. Recovering Complete Dictionaries By working with the preconditioned data samples Ŷ = Y as described above to recover complete dictionaries.. = θp Y Y 1/ Y, 4 we can use the same procedure Theorem III.3 Main theorem - recovering complete dictionaries. Assume the dictionary A is complete with a condition number κ A and we take Ŷ = Y. Suppose θ, 1/3, < c a min { { } θn 1, n 5/4}, and p C c max n 4 θ, n5 4 κ 8 A log 4 κa n θ. The algorithmic pipeline with parameter setting = c d c 3 θ 3 n 7/ log 7/ np III.5 recovers the dictionary A and X in polynomial time, with failure probability bounded by c b p 6. Here c is as defined in Theorem II.1, and c a, c b are both positive constants. Similar to the orthogonal case, we need to show the correctness of the rounding and deflation procedures so that the theorem above holds. 4 In practice, the parameter θ might not be know beforehand. However, because it only scales the problem, it does not affect the overall qualitative aspect of results.
21 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 1 c Proof of LP rounding: The result of the LP rounding is only slightly different from that of the orthogonal case in Lemma III., so is the proof. Lemma III.4 LP rounding - complete dictionary. For any θ, 1/3, whenever p C { } n 4 c θ max 4, n5 κ κ 8 A log 4 A n, θ with probability at least 1 cp 6, the rounding procedure III.1 returns q for any input vector r that satisfies Here C, c are both positive constants. r, q 49/5. Proof: See Page 37 under Section VII. d Proof sketch of deflation.: We use a similar induction argument to show the deflation works. Compared to the orthogonal case, the tricky part here is that the target vectors { q } i n are not necessarily orthogonal to i=1 each other, but they are almost so. W.l.o.g., let us again assume that q, 1..., q l recover the first l rows of X, and similarly partition the matrix X as in III.3. By Lemma B.7 and II.48, we can write Y = Q + ΞX for some orthogonal matrix Q and small perturbation Ξ with Ξ δ < 1/1 for some large p as usual. Similar to the orthogonal case, we have hz = fuz; Q + ΞX = f n l z; U Q + ΞX, where f n l is defined the same as in III.4. Next, we show that the matrix U Q + ΞX can be decomposed as U V X [n l] +, where V R n l n is orthogonal and is a small perturbation matrix. More specifically, we show that Lemma III.5. Suppose the matrices U R n n l, Q R n n are orthogonal as defined above, Ξ is a perturbation matrix with Ξ 1/, then U Q + Ξ X = U V X [n l] +, III.6 where V R n n l is an orthogonal matrix spanning the same subspace as that of U, and the norms of is bounded by l1 l 16 n Ξ X, 16 Ξ X, III.7 where W l1 l = sup z 1 =1 W z = max k w k denotes the max column l -norm of a matrix W. Proof: See Page 38 under Section VII. Since UV is orthogonal and X [n l] i.i.d. BGθ, we come into another instance of perturbed dictionary learning problem with a reduced dimension hz = f n l z; U V X [n l] +. Since our perturbation analysis in proving Theorem II. and Theorem II.4 solely relies on the fact that l1 l C Ξ n X, it is enough to make p large enough so that the theorems are still applicable for the reduced version f n l z; U V X [n l] +. Thus, by invoking Theorem II. and Theorem II.4, the TRM algorithm provably returns one ẑ such that ẑ is near to a perturbed optimal ẑ with ẑ U V X [n l] = z U V X [n l] + z = αe i X, for some i [l], III.8 where z with z = 1 is the exact solution. More specifically, Corollary II.4 in [3] implies that ẑ ẑ /7. Next, we show that ẑ is also very near to the exact solution z. Indeed, the identity III.8 suggests ẑ z U V X [n l] = z [ = ẑ z = X [n l] V U] z = U V [ X [n l] ] z III.9
22 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 where W = W W 1 W denotes the pseudo inverse of a matrix W with full column rank. Hence, by III.9 we can bound the distance between ẑ and z by [ ẑ z X [n l] ] σmin 1 X[n l] By Lemma B.1, when p Ωn log n, w.h.p., θp/ σ min X [n l] X [n l] X [n l] X [n l] X X 3θp/. Hence, combined with Lemma III.5, we obtain σ 1 min X[n l] θp, 8 θp Ξ /, which implies that ẑ z 8 Ξ. Thus, combining the results above, we obtain ẑ z ẑ ẑ + ẑ z /7 + 8 Ξ. Lemma B.7, and in particular II.48, for our choice of p as in Theorem II., Ξ c n 3/, where c can be made smaller by making the constant in p larger. For sufficiently small, we conclude that Uẑ Uz = ẑ z /7. In words, the TRM algorithm returns a ẑ such that Uẑ is very near to one of the unit vectors { q } i n, such that i=1 q i Y = αe i X for some α. For smaller than a fixed constant, one will have Uẑ, q i 49/5, and hence by Lemma III.4, the LP rounding exactly returns the optimal solution q i upon the input Uẑ. The proof sketch above explains why the recursive TRM plus rounding works. The overall failure probability can be obtained via a simple union bound and simplifications of the exponential tails with inverse polynomials in p. A. Practical TRM Implementation IV. SIMULATIONS Fixing a small step size and solving the trust-region subproblem exactly eases the analysis, but also renders the TRM algorithm impractical. In practice, the trust-region subproblem is never exactly solved, and the trust-region step size is adjusted to the local geometry, say by backtracking. It is possible to modify our algorithmic analysis to account for inexact subproblem solvers and adaptive step size; for sake of brevity, we do not pursue it here. Recent theoretical results on the practical version include [7], [73]. Here we describe a practical implementation based on the Manopt toolbox [7] 5. Manopt is a user-friendly Matlab toolbox that implements several sophisticated solvers for tackling optimization problems over Riemannian manifolds. The most developed solver is based on the TRM. This solver uses the truncated conjugate gradient tcg; see, e.g., Section of [57] method to approximately solve the trust-region subproblem vs. the exact solver in our analysis. It also dynamically adjusts the step size using backtracking. However, the original implementation Manopt. is not adequate for our purposes. Their tcg solver uses the gradient as the initial search direction, which does not ensure that the TRM solver can escape from saddle points [68], [71]. We modify the tcg solver, such that when the current gradient is small and there is a negative curvature direction i.e., the current point is near a saddle point or a local maximizer of fq, the tcg solver explicitly uses the negative curvature direction 6 as the initial search direction. This modification ensures the TRM solver always escape from saddle points/local maximizers with negative directional curvature. Hence, the modified TRM algorithm based on Manopt is expected to have the same qualitative behavior as the idealized version we analyzed above, with better scalability. We will perform our numerical simulations using the modified TRM algorithm whenever necessary. Algorithm 3 together with Lemmas 9 and 1 and the surrounding discussion in the very recent work [7] provides a detailed description of this practical version. 5 Available online: adjusted in sign to ensure positive correlation with the gradient if it does not vanish.


23 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX 16 3 Fig. 3: Phase transition for recovering a single sparse vector. Left: We fix p = 5n log n and vary the dimension n and sparsity level k; Right: We fix the sparsity level as. n and vary the dimension n and number of samples p. For each configuration, the experiment is independently repeated for five times. White indicates success, and black indicates failure. B. Simulated Data To corroborate our theory, we experiment with dictionary recovery on simulated data. 7 For simplicity, we focus on recovering orthogonal dictionaries and we declare success once a single row of the coefficient matrix is recovered. Since the problem is invariant to rotations, w.l.o.g. we set the dictionary as A = I R n n. For any fixed sparsity k, each column of the coefficient matrix X R n p has exactly k nonzero entries, chosen uniformly random from [n] k. These nonzero entries are i.i.d. standard normals. This is slightly different from the Bernoulli-Gaussian model we assumed for analysis. For n reasonably large, these two models have similar behaviors. For our sparsity surrogate, we fix the smoothing parameter as = 1. Because the target points are the signed basis vector ±e i s to recover rows of X, for a solution q returned by the TRM algorithm, we define the reconstruction error RE to be RE = min i [n] q e i, q + e i. IV.1 One trial is determined to be a success once RE, with the idea that this indicates q is already very near the target and the target can likely be recovered via the LP rounding we described which we do not implement here. We consider two settings: 1 fix p = 5n log n and vary the dimension n and sparsity k; fix the sparsity level as. n and vary the dimension n and number of samples p. For each pair of k, n for 1, and each pair of p, n for, we repeat the simulations independently for T = 5 times. Fig. 3 shows the phase transition for the two settings. It seems that our TRM algorithm can work well into the linear region whenever p On log n Fig. 3-Left, but p should have order greater than Ωn Fig. 3-Right. The sample complexity from our theory is significantly suboptimal compared to this. C. Image Data Again Our algorithmic framework has been derived based on the BG model on the coefficients. Real data may not admit sparse representations w.r.t. complete dictionaries, or even so, the coefficients may not obey the BG model. In this experiment, we explore how our algorithm performs in learning complete dictionaries for image patches, emulating our motivational experiment in the companion paper [3] Section I.B. Thanks to research on image compression, we know patches of natural images tend to admit sparse representation, even w.r.t. simple orthogonal bases, such as Fourier basis or wavelets. We take the three images that we used in the motivational experiment. For each image, we divide it into 8 8 non-overlapping patches, vectorize the patches, and then stack the vectorized patches into a data matrix Y. Y is 7 The code is available online: focm



















![paper [3].](/docs-images/74/71097248/images/24-19.jpg "The way we")









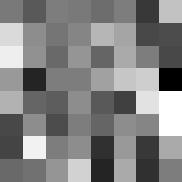
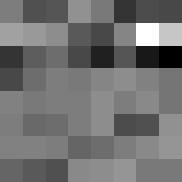
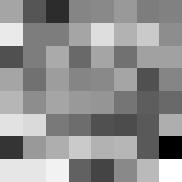
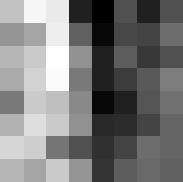

























24 IEEE TRANSACTION ON INFORMATION THEORY, VOL. XX, NO. XX, XXXX  1 Y 1 15  1 Y 1 15  1 Y Repetition Index Repetition Index Repetition Index Fig. 4: Results of learning complete dictionaries from image patches, using the algorithmic pipeline in Section III. Top: Images we used for the experiment. These are the three images we used in our motivational experiment Section I.B in the companion paper [3]. The way we formed the data matrix Y is exactly the same as in that experiment. Middle: The 64 dictionary elements we learned. Bottom: Let  be the final dictionary matrix at convergence. This row shows the value  1 Y 1 across one hundred independent runs. The values are almost the same, with a relative difference less than 1 3. preconditioned as Y = Y Y 1/ Y, and the resulting Y is fed to the dictionary learning pipeline described in Section III. The smoothing parameter is fixed to 1. Fig. 4 contains the learned dictionaries: the dictionaries generally contain localized, directional features that resemble subset of wavelets and generalizations. These are very reasonable representing elements for natural images. Thus, the BG coefficient model may be a sensible, simple model for natural images. Another piece of strong evidence in support of the above claim is as follows. For each image, we repeat the learning pipeline for one hundred times, with independent initializations across the runs. Let  be the final learned dictionary for each run, we plot the value of  1 Y 1 across the one hundred independent runs. Strikingly, the values are virtually the same, with a relative difference of 1 3! This is predicted by our theory, under the BG
Complete Dictionary Recovery over the Sphere I: Overview and the Geometric Picture
 IEEE TRANSACTION ON INFORMATION THEORY, VOL XX, NO XX, XXXX 06 Complete Dictionary Recovery over the Sphere I: Overview and the Geometric Picture Ju Sun, Student Member, IEEE, Qing Qu, Student Member,
IEEE TRANSACTION ON INFORMATION THEORY, VOL XX, NO XX, XXXX 06 Complete Dictionary Recovery over the Sphere I: Overview and the Geometric Picture Ju Sun, Student Member, IEEE, Qing Qu, Student Member,
SPARSE signal representations have gained popularity in recent
 6958 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 10, OCTOBER 2011 Blind Compressed Sensing Sivan Gleichman and Yonina C. Eldar, Senior Member, IEEE Abstract The fundamental principle underlying
6958 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 10, OCTOBER 2011 Blind Compressed Sensing Sivan Gleichman and Yonina C. Eldar, Senior Member, IEEE Abstract The fundamental principle underlying
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Low-rank matrix recovery via nonconvex optimization Yuejie Chi Department of Electrical and Computer Engineering Spring
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Low-rank matrix recovery via nonconvex optimization Yuejie Chi Department of Electrical and Computer Engineering Spring
Higher-Order Methods
 Higher-Order Methods Stephen J. Wright 1 2 Computer Sciences Department, University of Wisconsin-Madison. PCMI, July 2016 Stephen Wright (UW-Madison) Higher-Order Methods PCMI, July 2016 1 / 25 Smooth
Higher-Order Methods Stephen J. Wright 1 2 Computer Sciences Department, University of Wisconsin-Madison. PCMI, July 2016 Stephen Wright (UW-Madison) Higher-Order Methods PCMI, July 2016 1 / 25 Smooth
On fast trust region methods for quadratic models with linear constraints. M.J.D. Powell
 DAMTP 2014/NA02 On fast trust region methods for quadratic models with linear constraints M.J.D. Powell Abstract: Quadratic models Q k (x), x R n, of the objective function F (x), x R n, are used by many
DAMTP 2014/NA02 On fast trust region methods for quadratic models with linear constraints M.J.D. Powell Abstract: Quadratic models Q k (x), x R n, of the objective function F (x), x R n, are used by many
approximation algorithms I
 SUM-OF-SQUARES method and approximation algorithms I David Steurer Cornell Cargese Workshop, 201 meta-task encoded as low-degree polynomial in R x example: f(x) = i,j n w ij x i x j 2 given: functions
SUM-OF-SQUARES method and approximation algorithms I David Steurer Cornell Cargese Workshop, 201 meta-task encoded as low-degree polynomial in R x example: f(x) = i,j n w ij x i x j 2 given: functions
1 Lyapunov theory of stability
 M.Kawski, APM 581 Diff Equns Intro to Lyapunov theory. November 15, 29 1 1 Lyapunov theory of stability Introduction. Lyapunov s second (or direct) method provides tools for studying (asymptotic) stability
M.Kawski, APM 581 Diff Equns Intro to Lyapunov theory. November 15, 29 1 1 Lyapunov theory of stability Introduction. Lyapunov s second (or direct) method provides tools for studying (asymptotic) stability
Part 3: Trust-region methods for unconstrained optimization. Nick Gould (RAL)
") Part 3: Trust-region methods for unconstrained optimization Nick Gould (RAL) minimize x IR n f(x) MSc course on nonlinear optimization UNCONSTRAINED MINIMIZATION minimize x IR n f(x) where the objective
Part 3: Trust-region methods for unconstrained optimization Nick Gould (RAL) minimize x IR n f(x) MSc course on nonlinear optimization UNCONSTRAINED MINIMIZATION minimize x IR n f(x) where the objective
PCA with random noise. Van Ha Vu. Department of Mathematics Yale University
 PCA with random noise Van Ha Vu Department of Mathematics Yale University An important problem that appears in various areas of applied mathematics (in particular statistics, computer science and numerical
PCA with random noise Van Ha Vu Department of Mathematics Yale University An important problem that appears in various areas of applied mathematics (in particular statistics, computer science and numerical
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Matrices and Vectors. Definition of Matrix. An MxN matrix A is a two-dimensional array of numbers A =
 30 MATHEMATICS REVIEW G A.1.1 Matrices and Vectors Definition of Matrix. An MxN matrix A is a two-dimensional array of numbers A = a 11 a 12... a 1N a 21 a 22... a 2N...... a M1 a M2... a MN A matrix can
30 MATHEMATICS REVIEW G A.1.1 Matrices and Vectors Definition of Matrix. An MxN matrix A is a two-dimensional array of numbers A = a 11 a 12... a 1N a 21 a 22... a 2N...... a M1 a M2... a MN A matrix can
Design and Analysis of Algorithms Lecture Notes on Convex Optimization CS 6820, Fall Nov 2 Dec 2016
 Design and Analysis of Algorithms Lecture Notes on Convex Optimization CS 6820, Fall 206 2 Nov 2 Dec 206 Let D be a convex subset of R n. A function f : D R is convex if it satisfies f(tx + ( t)y) tf(x)
Design and Analysis of Algorithms Lecture Notes on Convex Optimization CS 6820, Fall 206 2 Nov 2 Dec 206 Let D be a convex subset of R n. A function f : D R is convex if it satisfies f(tx + ( t)y) tf(x)
DS-GA 1002 Lecture notes 0 Fall Linear Algebra. These notes provide a review of basic concepts in linear algebra.
 DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
STAT 200C: High-dimensional Statistics
 STAT 200C: High-dimensional Statistics Arash A. Amini May 30, 2018 1 / 57 Table of Contents 1 Sparse linear models Basis Pursuit and restricted null space property Sufficient conditions for RNS 2 / 57
STAT 200C: High-dimensional Statistics Arash A. Amini May 30, 2018 1 / 57 Table of Contents 1 Sparse linear models Basis Pursuit and restricted null space property Sufficient conditions for RNS 2 / 57
arxiv: v5 [math.na] 16 Nov 2017
![arxiv: v5 [math.na] 16 Nov 2017](/thumbs/78/78774947.jpg "arxiv: v5 [math.na] 16 Nov 2017") RANDOM PERTURBATION OF LOW RANK MATRICES: IMPROVING CLASSICAL BOUNDS arxiv:3.657v5 [math.na] 6 Nov 07 SEAN O ROURKE, VAN VU, AND KE WANG Abstract. Matrix perturbation inequalities, such as Weyl s theorem
RANDOM PERTURBATION OF LOW RANK MATRICES: IMPROVING CLASSICAL BOUNDS arxiv:3.657v5 [math.na] 6 Nov 07 SEAN O ROURKE, VAN VU, AND KE WANG Abstract. Matrix perturbation inequalities, such as Weyl s theorem
Trust Regions. Charles J. Geyer. March 27, 2013
 Trust Regions Charles J. Geyer March 27, 2013 1 Trust Region Theory We follow Nocedal and Wright (1999, Chapter 4), using their notation. Fletcher (1987, Section 5.1) discusses the same algorithm, but
Trust Regions Charles J. Geyer March 27, 2013 1 Trust Region Theory We follow Nocedal and Wright (1999, Chapter 4), using their notation. Fletcher (1987, Section 5.1) discusses the same algorithm, but
Math 350 Fall 2011 Notes about inner product spaces. In this notes we state and prove some important properties of inner product spaces.
 Math 350 Fall 2011 Notes about inner product spaces In this notes we state and prove some important properties of inner product spaces. First, recall the dot product on R n : if x, y R n, say x = (x 1,...,
Math 350 Fall 2011 Notes about inner product spaces In this notes we state and prove some important properties of inner product spaces. First, recall the dot product on R n : if x, y R n, say x = (x 1,...,
IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 11, NOVEMBER On the Performance of Sparse Recovery
 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 11, NOVEMBER 2011 7255 On the Performance of Sparse Recovery Via `p-minimization (0 p 1) Meng Wang, Student Member, IEEE, Weiyu Xu, and Ao Tang, Senior
IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 11, NOVEMBER 2011 7255 On the Performance of Sparse Recovery Via `p-minimization (0 p 1) Meng Wang, Student Member, IEEE, Weiyu Xu, and Ao Tang, Senior
Least Sparsity of p-norm based Optimization Problems with p > 1
 Least Sparsity of p-norm based Optimization Problems with p > Jinglai Shen and Seyedahmad Mousavi Original version: July, 07; Revision: February, 08 Abstract Motivated by l p -optimization arising from
Least Sparsity of p-norm based Optimization Problems with p > Jinglai Shen and Seyedahmad Mousavi Original version: July, 07; Revision: February, 08 Abstract Motivated by l p -optimization arising from
Optimization methods
 Lecture notes 3 February 8, 016 1 Introduction Optimization methods In these notes we provide an overview of a selection of optimization methods. We focus on methods which rely on first-order information,
Lecture notes 3 February 8, 016 1 Introduction Optimization methods In these notes we provide an overview of a selection of optimization methods. We focus on methods which rely on first-order information,
Least singular value of random matrices. Lewis Memorial Lecture / DIMACS minicourse March 18, Terence Tao (UCLA)
") Least singular value of random matrices Lewis Memorial Lecture / DIMACS minicourse March 18, 2008 Terence Tao (UCLA) 1 Extreme singular values Let M = (a ij ) 1 i n;1 j m be a square or rectangular matrix
Least singular value of random matrices Lewis Memorial Lecture / DIMACS minicourse March 18, 2008 Terence Tao (UCLA) 1 Extreme singular values Let M = (a ij ) 1 i n;1 j m be a square or rectangular matrix
Structural and Multidisciplinary Optimization. P. Duysinx and P. Tossings
 Structural and Multidisciplinary Optimization P. Duysinx and P. Tossings 2018-2019 CONTACTS Pierre Duysinx Institut de Mécanique et du Génie Civil (B52/3) Phone number: 04/366.91.94 Email: P.Duysinx@uliege.be
Structural and Multidisciplinary Optimization P. Duysinx and P. Tossings 2018-2019 CONTACTS Pierre Duysinx Institut de Mécanique et du Génie Civil (B52/3) Phone number: 04/366.91.94 Email: P.Duysinx@uliege.be
A fast randomized algorithm for overdetermined linear least-squares regression
 A fast randomized algorithm for overdetermined linear least-squares regression Vladimir Rokhlin and Mark Tygert Technical Report YALEU/DCS/TR-1403 April 28, 2008 Abstract We introduce a randomized algorithm
A fast randomized algorithm for overdetermined linear least-squares regression Vladimir Rokhlin and Mark Tygert Technical Report YALEU/DCS/TR-1403 April 28, 2008 Abstract We introduce a randomized algorithm
In English, this means that if we travel on a straight line between any two points in C, then we never leave C.
 Convex sets In this section, we will be introduced to some of the mathematical fundamentals of convex sets. In order to motivate some of the definitions, we will look at the closest point problem from
Convex sets In this section, we will be introduced to some of the mathematical fundamentals of convex sets. In order to motivate some of the definitions, we will look at the closest point problem from
1 Computing with constraints
 Notes for 2017-04-26 1 Computing with constraints Recall that our basic problem is minimize φ(x) s.t. x Ω where the feasible set Ω is defined by equality and inequality conditions Ω = {x R n : c i (x)
Notes for 2017-04-26 1 Computing with constraints Recall that our basic problem is minimize φ(x) s.t. x Ω where the feasible set Ω is defined by equality and inequality conditions Ω = {x R n : c i (x)
CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares
 CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares Robert Bridson October 29, 2008 1 Hessian Problems in Newton Last time we fixed one of plain Newton s problems by introducing line search
CS 542G: Robustifying Newton, Constraints, Nonlinear Least Squares Robert Bridson October 29, 2008 1 Hessian Problems in Newton Last time we fixed one of plain Newton s problems by introducing line search
Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization
 Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization Jialin Dong ShanghaiTech University 1 Outline Introduction FourVignettes: System Model and Problem Formulation Problem Analysis
Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization Jialin Dong ShanghaiTech University 1 Outline Introduction FourVignettes: System Model and Problem Formulation Problem Analysis
CHAPTER 11. A Revision. 1. The Computers and Numbers therein
 CHAPTER A Revision. The Computers and Numbers therein Traditional computer science begins with a finite alphabet. By stringing elements of the alphabet one after another, one obtains strings. A set of
CHAPTER A Revision. The Computers and Numbers therein Traditional computer science begins with a finite alphabet. By stringing elements of the alphabet one after another, one obtains strings. A set of
Conditions for Robust Principal Component Analysis
 Rose-Hulman Undergraduate Mathematics Journal Volume 12 Issue 2 Article 9 Conditions for Robust Principal Component Analysis Michael Hornstein Stanford University, mdhornstein@gmail.com Follow this and
Rose-Hulman Undergraduate Mathematics Journal Volume 12 Issue 2 Article 9 Conditions for Robust Principal Component Analysis Michael Hornstein Stanford University, mdhornstein@gmail.com Follow this and
Vectors. January 13, 2013
 Vectors January 13, 2013 The simplest tensors are scalars, which are the measurable quantities of a theory, left invariant by symmetry transformations. By far the most common non-scalars are the vectors,
Vectors January 13, 2013 The simplest tensors are scalars, which are the measurable quantities of a theory, left invariant by symmetry transformations. By far the most common non-scalars are the vectors,
Jim Lambers MAT 610 Summer Session Lecture 2 Notes
 Jim Lambers MAT 610 Summer Session 2009-10 Lecture 2 Notes These notes correspond to Sections 2.2-2.4 in the text. Vector Norms Given vectors x and y of length one, which are simply scalars x and y, the
Jim Lambers MAT 610 Summer Session 2009-10 Lecture 2 Notes These notes correspond to Sections 2.2-2.4 in the text. Vector Norms Given vectors x and y of length one, which are simply scalars x and y, the
Optimization. Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison
 Optimization Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison optimization () cost constraints might be too much to cover in 3 hours optimization (for big
Optimization Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison optimization () cost constraints might be too much to cover in 3 hours optimization (for big
On Acceleration with Noise-Corrupted Gradients. + m k 1 (x). By the definition of Bregman divergence:
. By the definition of Bregman divergence:") A Omitted Proofs from Section 3 Proof of Lemma 3 Let m x) = a i On Acceleration with Noise-Corrupted Gradients fxi ), u x i D ψ u, x 0 ) denote the function under the minimum in the lower bound By Proposition
A Omitted Proofs from Section 3 Proof of Lemma 3 Let m x) = a i On Acceleration with Noise-Corrupted Gradients fxi ), u x i D ψ u, x 0 ) denote the function under the minimum in the lower bound By Proposition
How to Escape Saddle Points Efficiently? Praneeth Netrapalli Microsoft Research India
 How to Escape Saddle Points Efficiently? Praneeth Netrapalli Microsoft Research India Chi Jin UC Berkeley Michael I. Jordan UC Berkeley Rong Ge Duke Univ. Sham M. Kakade U Washington Nonconvex optimization
How to Escape Saddle Points Efficiently? Praneeth Netrapalli Microsoft Research India Chi Jin UC Berkeley Michael I. Jordan UC Berkeley Rong Ge Duke Univ. Sham M. Kakade U Washington Nonconvex optimization
Lecture Notes: Geometric Considerations in Unconstrained Optimization
 Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
CALCULUS ON MANIFOLDS. 1. Riemannian manifolds Recall that for any smooth manifold M, dim M = n, the union T M =
 CALCULUS ON MANIFOLDS 1. Riemannian manifolds Recall that for any smooth manifold M, dim M = n, the union T M = a M T am, called the tangent bundle, is itself a smooth manifold, dim T M = 2n. Example 1.
CALCULUS ON MANIFOLDS 1. Riemannian manifolds Recall that for any smooth manifold M, dim M = n, the union T M = a M T am, called the tangent bundle, is itself a smooth manifold, dim T M = 2n. Example 1.
APPENDIX A. Background Mathematics. A.1 Linear Algebra. Vector algebra. Let x denote the n-dimensional column vector with components x 1 x 2.
 APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
Linear Algebra Massoud Malek
 CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
Research Statement Qing Qu
 Qing Qu Research Statement 1/4 Qing Qu (qq2105@columbia.edu) Today we are living in an era of information explosion. As the sensors and sensing modalities proliferate, our world is inundated by unprecedented
Qing Qu Research Statement 1/4 Qing Qu (qq2105@columbia.edu) Today we are living in an era of information explosion. As the sensors and sensing modalities proliferate, our world is inundated by unprecedented
Accelerated Block-Coordinate Relaxation for Regularized Optimization
 Accelerated Block-Coordinate Relaxation for Regularized Optimization Stephen J. Wright Computer Sciences University of Wisconsin, Madison October 09, 2012 Problem descriptions Consider where f is smooth
Accelerated Block-Coordinate Relaxation for Regularized Optimization Stephen J. Wright Computer Sciences University of Wisconsin, Madison October 09, 2012 Problem descriptions Consider where f is smooth
arxiv: v1 [math.oc] 1 Jul 2016
![arxiv: v1 [math.oc] 1 Jul 2016](/thumbs/78/78221552.jpg "arxiv: v1 [math.oc] 1 Jul 2016") Convergence Rate of Frank-Wolfe for Non-Convex Objectives Simon Lacoste-Julien INRIA - SIERRA team ENS, Paris June 8, 016 Abstract arxiv:1607.00345v1 [math.oc] 1 Jul 016 We give a simple proof that the
Convergence Rate of Frank-Wolfe for Non-Convex Objectives Simon Lacoste-Julien INRIA - SIERRA team ENS, Paris June 8, 016 Abstract arxiv:1607.00345v1 [math.oc] 1 Jul 016 We give a simple proof that the
IV. Matrix Approximation using Least-Squares
 IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
A Geometric Analysis of Phase Retrieval
 A Geometric Analysis of Phase Retrieval Ju Sun, Qing Qu, John Wright js4038, qq2105, jw2966}@columbiaedu Dept of Electrical Engineering, Columbia University, New York NY 10027, USA Abstract Given measurements
A Geometric Analysis of Phase Retrieval Ju Sun, Qing Qu, John Wright js4038, qq2105, jw2966}@columbiaedu Dept of Electrical Engineering, Columbia University, New York NY 10027, USA Abstract Given measurements
Duke University, Department of Electrical and Computer Engineering Optimization for Scientists and Engineers c Alex Bronstein, 2014
 Duke University, Department of Electrical and Computer Engineering Optimization for Scientists and Engineers c Alex Bronstein, 2014 Linear Algebra A Brief Reminder Purpose. The purpose of this document
Duke University, Department of Electrical and Computer Engineering Optimization for Scientists and Engineers c Alex Bronstein, 2014 Linear Algebra A Brief Reminder Purpose. The purpose of this document
1 Introduction
 2018-06-12 1 Introduction The title of this course is Numerical Methods for Data Science. What does that mean? Before we dive into the course technical material, let s put things into context. I will not
2018-06-12 1 Introduction The title of this course is Numerical Methods for Data Science. What does that mean? Before we dive into the course technical material, let s put things into context. I will not
A Cross-Associative Neural Network for SVD of Nonsquared Data Matrix in Signal Processing
 IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 12, NO. 5, SEPTEMBER 2001 1215 A Cross-Associative Neural Network for SVD of Nonsquared Data Matrix in Signal Processing Da-Zheng Feng, Zheng Bao, Xian-Da Zhang
IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 12, NO. 5, SEPTEMBER 2001 1215 A Cross-Associative Neural Network for SVD of Nonsquared Data Matrix in Signal Processing Da-Zheng Feng, Zheng Bao, Xian-Da Zhang
Stability of Feedback Solutions for Infinite Horizon Noncooperative Differential Games
 Stability of Feedback Solutions for Infinite Horizon Noncooperative Differential Games Alberto Bressan ) and Khai T. Nguyen ) *) Department of Mathematics, Penn State University **) Department of Mathematics,
Stability of Feedback Solutions for Infinite Horizon Noncooperative Differential Games Alberto Bressan ) and Khai T. Nguyen ) *) Department of Mathematics, Penn State University **) Department of Mathematics,
Second Order Optimization Algorithms I
 Second Order Optimization Algorithms I Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapters 7, 8, 9 and 10 1 The
Second Order Optimization Algorithms I Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapters 7, 8, 9 and 10 1 The
min f(x). (2.1) Objectives consisting of a smooth convex term plus a nonconvex regularization term;
. (2.1) Objectives consisting of a smooth convex term plus a nonconvex regularization term;") Chapter 2 Gradient Methods The gradient method forms the foundation of all of the schemes studied in this book. We will provide several complementary perspectives on this algorithm that highlight the many
Chapter 2 Gradient Methods The gradient method forms the foundation of all of the schemes studied in this book. We will provide several complementary perspectives on this algorithm that highlight the many
Convex Functions and Optimization
 Chapter 5 Convex Functions and Optimization 5.1 Convex Functions Our next topic is that of convex functions. Again, we will concentrate on the context of a map f : R n R although the situation can be generalized
Chapter 5 Convex Functions and Optimization 5.1 Convex Functions Our next topic is that of convex functions. Again, we will concentrate on the context of a map f : R n R although the situation can be generalized
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gradient Descent. Dr. Xiaowei Huang
 Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
Implicit Functions, Curves and Surfaces
 Chapter 11 Implicit Functions, Curves and Surfaces 11.1 Implicit Function Theorem Motivation. In many problems, objects or quantities of interest can only be described indirectly or implicitly. It is then
Chapter 11 Implicit Functions, Curves and Surfaces 11.1 Implicit Function Theorem Motivation. In many problems, objects or quantities of interest can only be described indirectly or implicitly. It is then
The Steepest Descent Algorithm for Unconstrained Optimization
 The Steepest Descent Algorithm for Unconstrained Optimization Robert M. Freund February, 2014 c 2014 Massachusetts Institute of Technology. All rights reserved. 1 1 Steepest Descent Algorithm The problem
The Steepest Descent Algorithm for Unconstrained Optimization Robert M. Freund February, 2014 c 2014 Massachusetts Institute of Technology. All rights reserved. 1 1 Steepest Descent Algorithm The problem
Introduction to gradient descent
 6-1: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction to gradient descent Derivation and intuitions Hessian 6-2: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction Our
6-1: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction to gradient descent Derivation and intuitions Hessian 6-2: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction Our
How to Characterize the Worst-Case Performance of Algorithms for Nonconvex Optimization
 How to Characterize the Worst-Case Performance of Algorithms for Nonconvex Optimization Frank E. Curtis Department of Industrial and Systems Engineering, Lehigh University Daniel P. Robinson Department
How to Characterize the Worst-Case Performance of Algorithms for Nonconvex Optimization Frank E. Curtis Department of Industrial and Systems Engineering, Lehigh University Daniel P. Robinson Department
Essential Matrix Estimation via Newton-type Methods
 Essential Matrix Estimation via Newton-type Methods Uwe Helmke 1, Knut Hüper, Pei Yean Lee 3, John Moore 3 1 Abstract In this paper camera parameters are assumed to be known and a novel approach for essential
Essential Matrix Estimation via Newton-type Methods Uwe Helmke 1, Knut Hüper, Pei Yean Lee 3, John Moore 3 1 Abstract In this paper camera parameters are assumed to be known and a novel approach for essential
Lebesgue Measure on R n
 CHAPTER 2 Lebesgue Measure on R n Our goal is to construct a notion of the volume, or Lebesgue measure, of rather general subsets of R n that reduces to the usual volume of elementary geometrical sets
CHAPTER 2 Lebesgue Measure on R n Our goal is to construct a notion of the volume, or Lebesgue measure, of rather general subsets of R n that reduces to the usual volume of elementary geometrical sets
Algorithms for Constrained Optimization
 1 / 42 Algorithms for Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University April 19, 2015 2 / 42 Outline 1. Convergence 2. Sequential quadratic
1 / 42 Algorithms for Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University April 19, 2015 2 / 42 Outline 1. Convergence 2. Sequential quadratic
Robust Principal Component Pursuit via Alternating Minimization Scheme on Matrix Manifolds
 Robust Principal Component Pursuit via Alternating Minimization Scheme on Matrix Manifolds Tao Wu Institute for Mathematics and Scientific Computing Karl-Franzens-University of Graz joint work with Prof.
Robust Principal Component Pursuit via Alternating Minimization Scheme on Matrix Manifolds Tao Wu Institute for Mathematics and Scientific Computing Karl-Franzens-University of Graz joint work with Prof.
Multichannel Sparse Blind Deconvolution on the Sphere
 LAST REVISED: 01:45, Tuesday 19 th March, 2019 1 Multichannel Sparse Blind Deconvolution on the Sphere Yanjun Li, and Yoram Bresler, Fellow, IEEE arxiv:1805.10437v2 [cs.it] 16 Mar 2019 Abstract Multichannel
LAST REVISED: 01:45, Tuesday 19 th March, 2019 1 Multichannel Sparse Blind Deconvolution on the Sphere Yanjun Li, and Yoram Bresler, Fellow, IEEE arxiv:1805.10437v2 [cs.it] 16 Mar 2019 Abstract Multichannel
Tangent spaces, normals and extrema
 Chapter 3 Tangent spaces, normals and extrema If S is a surface in 3-space, with a point a S where S looks smooth, i.e., without any fold or cusp or self-crossing, we can intuitively define the tangent
Chapter 3 Tangent spaces, normals and extrema If S is a surface in 3-space, with a point a S where S looks smooth, i.e., without any fold or cusp or self-crossing, we can intuitively define the tangent
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
DEVELOPMENT OF MORSE THEORY
 DEVELOPMENT OF MORSE THEORY MATTHEW STEED Abstract. In this paper, we develop Morse theory, which allows us to determine topological information about manifolds using certain real-valued functions defined
DEVELOPMENT OF MORSE THEORY MATTHEW STEED Abstract. In this paper, we develop Morse theory, which allows us to determine topological information about manifolds using certain real-valued functions defined
ECE 275A Homework #3 Solutions
 ECE 75A Homework #3 Solutions. Proof of (a). Obviously Ax = 0 y, Ax = 0 for all y. To show sufficiency, note that if y, Ax = 0 for all y, then it must certainly be true for the particular value of y =
ECE 75A Homework #3 Solutions. Proof of (a). Obviously Ax = 0 y, Ax = 0 for all y. To show sufficiency, note that if y, Ax = 0 for all y, then it must certainly be true for the particular value of y =
Rank Determination for Low-Rank Data Completion
 Journal of Machine Learning Research 18 017) 1-9 Submitted 7/17; Revised 8/17; Published 9/17 Rank Determination for Low-Rank Data Completion Morteza Ashraphijuo Columbia University New York, NY 1007,
Journal of Machine Learning Research 18 017) 1-9 Submitted 7/17; Revised 8/17; Published 9/17 Rank Determination for Low-Rank Data Completion Morteza Ashraphijuo Columbia University New York, NY 1007,
5742 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 55, NO. 12, DECEMBER /$ IEEE
 5742 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 55, NO. 12, DECEMBER 2009 Uncertainty Relations for Shift-Invariant Analog Signals Yonina C. Eldar, Senior Member, IEEE Abstract The past several years
5742 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 55, NO. 12, DECEMBER 2009 Uncertainty Relations for Shift-Invariant Analog Signals Yonina C. Eldar, Senior Member, IEEE Abstract The past several years
NOTES ON FIRST-ORDER METHODS FOR MINIMIZING SMOOTH FUNCTIONS. 1. Introduction. We consider first-order methods for smooth, unconstrained
 NOTES ON FIRST-ORDER METHODS FOR MINIMIZING SMOOTH FUNCTIONS 1. Introduction. We consider first-order methods for smooth, unconstrained optimization: (1.1) minimize f(x), x R n where f : R n R. We assume
NOTES ON FIRST-ORDER METHODS FOR MINIMIZING SMOOTH FUNCTIONS 1. Introduction. We consider first-order methods for smooth, unconstrained optimization: (1.1) minimize f(x), x R n where f : R n R. We assume
arxiv: v2 [math.oc] 5 May 2018
![arxiv: v2 [math.oc] 5 May 2018](/thumbs/87/96320479.jpg "arxiv: v2 [math.oc] 5 May 2018") The Impact of Local Geometry and Batch Size on Stochastic Gradient Descent for Nonconvex Problems Viva Patel a a Department of Statistics, University of Chicago, Illinois, USA arxiv:1709.04718v2 [math.oc]
The Impact of Local Geometry and Batch Size on Stochastic Gradient Descent for Nonconvex Problems Viva Patel a a Department of Statistics, University of Chicago, Illinois, USA arxiv:1709.04718v2 [math.oc]
MTH Linear Algebra. Study Guide. Dr. Tony Yee Department of Mathematics and Information Technology The Hong Kong Institute of Education
 MTH 3 Linear Algebra Study Guide Dr. Tony Yee Department of Mathematics and Information Technology The Hong Kong Institute of Education June 3, ii Contents Table of Contents iii Matrix Algebra. Real Life
MTH 3 Linear Algebra Study Guide Dr. Tony Yee Department of Mathematics and Information Technology The Hong Kong Institute of Education June 3, ii Contents Table of Contents iii Matrix Algebra. Real Life
Optimization and Optimal Control in Banach Spaces
 Optimization and Optimal Control in Banach Spaces Bernhard Schmitzer October 19, 2017 1 Convex non-smooth optimization with proximal operators Remark 1.1 (Motivation). Convex optimization: easier to solve,
Optimization and Optimal Control in Banach Spaces Bernhard Schmitzer October 19, 2017 1 Convex non-smooth optimization with proximal operators Remark 1.1 (Motivation). Convex optimization: easier to solve,
The speed of Shor s R-algorithm
 IMA Journal of Numerical Analysis 2008) 28, 711 720 doi:10.1093/imanum/drn008 Advance Access publication on September 12, 2008 The speed of Shor s R-algorithm J. V. BURKE Department of Mathematics, University
IMA Journal of Numerical Analysis 2008) 28, 711 720 doi:10.1093/imanum/drn008 Advance Access publication on September 12, 2008 The speed of Shor s R-algorithm J. V. BURKE Department of Mathematics, University
IPAM Summer School Optimization methods for machine learning. Jorge Nocedal
 IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
Lecture Notes 9: Constrained Optimization
 Optimization-based data analysis Fall 017 Lecture Notes 9: Constrained Optimization 1 Compressed sensing 1.1 Underdetermined linear inverse problems Linear inverse problems model measurements of the form
Optimization-based data analysis Fall 017 Lecture Notes 9: Constrained Optimization 1 Compressed sensing 1.1 Underdetermined linear inverse problems Linear inverse problems model measurements of the form
The Hilbert Space of Random Variables
 The Hilbert Space of Random Variables Electrical Engineering 126 (UC Berkeley) Spring 2018 1 Outline Fix a probability space and consider the set H := {X : X is a real-valued random variable with E[X 2
The Hilbert Space of Random Variables Electrical Engineering 126 (UC Berkeley) Spring 2018 1 Outline Fix a probability space and consider the set H := {X : X is a real-valued random variable with E[X 2
Complexity analysis of second-order algorithms based on line search for smooth nonconvex optimization
 Complexity analysis of second-order algorithms based on line search for smooth nonconvex optimization Clément Royer - University of Wisconsin-Madison Joint work with Stephen J. Wright MOPTA, Bethlehem,
Complexity analysis of second-order algorithms based on line search for smooth nonconvex optimization Clément Royer - University of Wisconsin-Madison Joint work with Stephen J. Wright MOPTA, Bethlehem,
LARGE DEVIATIONS OF TYPICAL LINEAR FUNCTIONALS ON A CONVEX BODY WITH UNCONDITIONAL BASIS. S. G. Bobkov and F. L. Nazarov. September 25, 2011
 LARGE DEVIATIONS OF TYPICAL LINEAR FUNCTIONALS ON A CONVEX BODY WITH UNCONDITIONAL BASIS S. G. Bobkov and F. L. Nazarov September 25, 20 Abstract We study large deviations of linear functionals on an isotropic
LARGE DEVIATIONS OF TYPICAL LINEAR FUNCTIONALS ON A CONVEX BODY WITH UNCONDITIONAL BASIS S. G. Bobkov and F. L. Nazarov September 25, 20 Abstract We study large deviations of linear functionals on an isotropic
ON THE REGULARITY OF SAMPLE PATHS OF SUB-ELLIPTIC DIFFUSIONS ON MANIFOLDS
 Bendikov, A. and Saloff-Coste, L. Osaka J. Math. 4 (5), 677 7 ON THE REGULARITY OF SAMPLE PATHS OF SUB-ELLIPTIC DIFFUSIONS ON MANIFOLDS ALEXANDER BENDIKOV and LAURENT SALOFF-COSTE (Received March 4, 4)
Bendikov, A. and Saloff-Coste, L. Osaka J. Math. 4 (5), 677 7 ON THE REGULARITY OF SAMPLE PATHS OF SUB-ELLIPTIC DIFFUSIONS ON MANIFOLDS ALEXANDER BENDIKOV and LAURENT SALOFF-COSTE (Received March 4, 4)
Supremum of simple stochastic processes
 Subspace embeddings Daniel Hsu COMS 4772 1 Supremum of simple stochastic processes 2 Recap: JL lemma JL lemma. For any ε (0, 1/2), point set S R d of cardinality 16 ln n S = n, and k N such that k, there
Subspace embeddings Daniel Hsu COMS 4772 1 Supremum of simple stochastic processes 2 Recap: JL lemma JL lemma. For any ε (0, 1/2), point set S R d of cardinality 16 ln n S = n, and k N such that k, there
Unconstrained optimization
 Chapter 4 Unconstrained optimization An unconstrained optimization problem takes the form min x Rnf(x) (4.1) for a target functional (also called objective function) f : R n R. In this chapter and throughout
Chapter 4 Unconstrained optimization An unconstrained optimization problem takes the form min x Rnf(x) (4.1) for a target functional (also called objective function) f : R n R. In this chapter and throughout
LECTURE 15: COMPLETENESS AND CONVEXITY
 LECTURE 15: COMPLETENESS AND CONVEXITY 1. The Hopf-Rinow Theorem Recall that a Riemannian manifold (M, g) is called geodesically complete if the maximal defining interval of any geodesic is R. On the other
LECTURE 15: COMPLETENESS AND CONVEXITY 1. The Hopf-Rinow Theorem Recall that a Riemannian manifold (M, g) is called geodesically complete if the maximal defining interval of any geodesic is R. On the other
The nonsmooth Newton method on Riemannian manifolds
 The nonsmooth Newton method on Riemannian manifolds C. Lageman, U. Helmke, J.H. Manton 1 Introduction Solving nonlinear equations in Euclidean space is a frequently occurring problem in optimization and
The nonsmooth Newton method on Riemannian manifolds C. Lageman, U. Helmke, J.H. Manton 1 Introduction Solving nonlinear equations in Euclidean space is a frequently occurring problem in optimization and
1 Directional Derivatives and Differentiability
 Wednesday, January 18, 2012 1 Directional Derivatives and Differentiability Let E R N, let f : E R and let x 0 E. Given a direction v R N, let L be the line through x 0 in the direction v, that is, L :=
Wednesday, January 18, 2012 1 Directional Derivatives and Differentiability Let E R N, let f : E R and let x 0 E. Given a direction v R N, let L be the line through x 0 in the direction v, that is, L :=
Stochastic Optimization with Inequality Constraints Using Simultaneous Perturbations and Penalty Functions
 International Journal of Control Vol. 00, No. 00, January 2007, 1 10 Stochastic Optimization with Inequality Constraints Using Simultaneous Perturbations and Penalty Functions I-JENG WANG and JAMES C.
International Journal of Control Vol. 00, No. 00, January 2007, 1 10 Stochastic Optimization with Inequality Constraints Using Simultaneous Perturbations and Penalty Functions I-JENG WANG and JAMES C.
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
The properties of L p -GMM estimators
 The properties of L p -GMM estimators Robert de Jong and Chirok Han Michigan State University February 2000 Abstract This paper considers Generalized Method of Moment-type estimators for which a criterion
The properties of L p -GMM estimators Robert de Jong and Chirok Han Michigan State University February 2000 Abstract This paper considers Generalized Method of Moment-type estimators for which a criterion
The Hodge Star Operator
 The Hodge Star Operator Rich Schwartz April 22, 2015 1 Basic Definitions We ll start out by defining the Hodge star operator as a map from k (R n ) to n k (R n ). Here k (R n ) denotes the vector space
The Hodge Star Operator Rich Schwartz April 22, 2015 1 Basic Definitions We ll start out by defining the Hodge star operator as a map from k (R n ) to n k (R n ). Here k (R n ) denotes the vector space
5 Handling Constraints
 5 Handling Constraints Engineering design optimization problems are very rarely unconstrained. Moreover, the constraints that appear in these problems are typically nonlinear. This motivates our interest
5 Handling Constraints Engineering design optimization problems are very rarely unconstrained. Moreover, the constraints that appear in these problems are typically nonlinear. This motivates our interest
Iterative Methods for Solving A x = b
 Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Lecture 13 The Fundamental Forms of a Surface
 Lecture 13 The Fundamental Forms of a Surface In the following we denote by F : O R 3 a parametric surface in R 3, F(u, v) = (x(u, v), y(u, v), z(u, v)). We denote partial derivatives with respect to the
Lecture 13 The Fundamental Forms of a Surface In the following we denote by F : O R 3 a parametric surface in R 3, F(u, v) = (x(u, v), y(u, v), z(u, v)). We denote partial derivatives with respect to the
Orthogonal tensor decomposition
 Orthogonal tensor decomposition Daniel Hsu Columbia University Largely based on 2012 arxiv report Tensor decompositions for learning latent variable models, with Anandkumar, Ge, Kakade, and Telgarsky.
Orthogonal tensor decomposition Daniel Hsu Columbia University Largely based on 2012 arxiv report Tensor decompositions for learning latent variable models, with Anandkumar, Ge, Kakade, and Telgarsky.
CHAPTER 3. Gauss map. In this chapter we will study the Gauss map of surfaces in R 3.
 CHAPTER 3 Gauss map In this chapter we will study the Gauss map of surfaces in R 3. 3.1. Surfaces in R 3 Let S R 3 be a submanifold of dimension 2. Let {U i, ϕ i } be a DS on S. For any p U i we have a
CHAPTER 3 Gauss map In this chapter we will study the Gauss map of surfaces in R 3. 3.1. Surfaces in R 3 Let S R 3 be a submanifold of dimension 2. Let {U i, ϕ i } be a DS on S. For any p U i we have a
8 Numerical methods for unconstrained problems
 8 Numerical methods for unconstrained problems Optimization is one of the important fields in numerical computation, beside solving differential equations and linear systems. We can see that these fields
8 Numerical methods for unconstrained problems Optimization is one of the important fields in numerical computation, beside solving differential equations and linear systems. We can see that these fields
MATH 590: Meshfree Methods
 MATH 590: Meshfree Methods Chapter 14: The Power Function and Native Space Error Estimates Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Fall 2010 fasshauer@iit.edu
MATH 590: Meshfree Methods Chapter 14: The Power Function and Native Space Error Estimates Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Fall 2010 fasshauer@iit.edu
COMP 558 lecture 18 Nov. 15, 2010
 Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
Fast Angular Synchronization for Phase Retrieval via Incomplete Information
 Fast Angular Synchronization for Phase Retrieval via Incomplete Information Aditya Viswanathan a and Mark Iwen b a Department of Mathematics, Michigan State University; b Department of Mathematics & Department
Fast Angular Synchronization for Phase Retrieval via Incomplete Information Aditya Viswanathan a and Mark Iwen b a Department of Mathematics, Michigan State University; b Department of Mathematics & Department
Inexact alternating projections on nonconvex sets
 Inexact alternating projections on nonconvex sets D. Drusvyatskiy A.S. Lewis November 3, 2018 Dedicated to our friend, colleague, and inspiration, Alex Ioffe, on the occasion of his 80th birthday. Abstract
Inexact alternating projections on nonconvex sets D. Drusvyatskiy A.S. Lewis November 3, 2018 Dedicated to our friend, colleague, and inspiration, Alex Ioffe, on the occasion of his 80th birthday. Abstract
Elements of Convex Optimization Theory
 Elements of Convex Optimization Theory Costis Skiadas August 2015 This is a revised and extended version of Appendix A of Skiadas (2009), providing a self-contained overview of elements of convex optimization
Elements of Convex Optimization Theory Costis Skiadas August 2015 This is a revised and extended version of Appendix A of Skiadas (2009), providing a self-contained overview of elements of convex optimization
CS 435, 2018 Lecture 6, Date: 12 April 2018 Instructor: Nisheeth Vishnoi. Newton s Method
 CS 435, 28 Lecture 6, Date: 2 April 28 Instructor: Nisheeth Vishnoi Newton s Method In this lecture we derive and analyze Newton s method which is an example of a second order optimization method. We argue
CS 435, 28 Lecture 6, Date: 2 April 28 Instructor: Nisheeth Vishnoi Newton s Method In this lecture we derive and analyze Newton s method which is an example of a second order optimization method. We argue
1 Differentiable manifolds and smooth maps
 1 Differentiable manifolds and smooth maps Last updated: April 14, 2011. 1.1 Examples and definitions Roughly, manifolds are sets where one can introduce coordinates. An n-dimensional manifold is a set
1 Differentiable manifolds and smooth maps Last updated: April 14, 2011. 1.1 Examples and definitions Roughly, manifolds are sets where one can introduce coordinates. An n-dimensional manifold is a set