Bregman Divergences. Barnabás Póczos. RLAI Tea Talk UofA, Edmonton. Aug 5, 2008
|
|
|
- Augustus Fields
- 6 years ago
- Views:
Transcription


1 Bregman Divergences Barnabás Póczos RLAI Tea Talk UofA, Edmonton Aug 5, 2008
2 Contents Bregman Divergences Bregman Matrix Divergences Relation to Exponential Family Applications Definition Properties Generalization of PCA to Exponential Family Generalized2 Linear2 Models Clustering / Coclustering with Bregman Divergences Generalized Nonnegative Matrix Factorization Conclusion 2
3 Bregman Divergences (Euclidean distance) 2 Squared Euclidean distance is a Bregman divergence 3 (upcoming figs are borrowed from Dhillon)
4 Bregman Divergences (KL-divergence) Generalized Relative Entropy (also called generalized KL-divergence) is another Bregman divergence 4
5 Bregman Divergences (Itakura-Saito) Itakura-Saito distance is another Bregman divergence (used in signal processing, also known as Burg entropy) 5
6 Examples of Bregman Divergences 6
7 Properties of the Bregman Divergences z γ a b y x c Euclidean special case: 7





8 Properties of the Bregman Divergences Nearness in Bregman divergence: the Bregman projection of y onto a convex set Ω. Ω When Ω is affine set, the Pythagoras theorem holds with equality. Generalized Pythagoras theorem: Opposite to triangle inequality: 8
9 (Regular) Exponential Families 9
10 Gaussian Distribution Note: Gaussian distribution $ Squared Loss from the expected value µ 10
11 Poisson Distribution The Poisson distribution: The Poisson distribution is a member of exponential family. Its expected value µ=λ. Is there a Divergence associated with the Poisson distribution? Yes! p(x) can be rewritten as Implication: Poisson distribution $ Relative Entropy Implication: Poisson distribution $ Relative Entropy 11
12 Exponential Distribution The Exponential distribution: The Exponential distribution is a member of exponential family. Its expected value µ=1/λ. Is there a Divergence associated with the Exponential distribution? Yes! p(x) can be rewritten as Implication: Exponential distribution $ Itakura-Saito Distribution 12
13 Fenchel Conjugate Defintion: The Fenchel conjugate of function f is defined as: Properties of the Fenchel conjugate: 13
14 Bregman Divergences and the Exponential Family Bijection Theorem 14
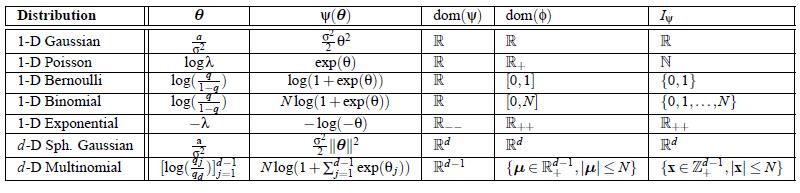
15 15
16 Bregman Matrix Divergences An immediate solution would be the componentwise sum of Bregman divergences. However, we can get more interesting divergences using the general definition. 16
17 Bregman Divergences of Hermitian matrices A complex square matrix A is Hermitian, if A = A*. The eigenvalues of a Hermitian matrix are real. Let 17
18 Burg Matrix Divergence (Logdet divergence) 18
19 Von Neumann Matrix Divergence 19
20 Applications, Matrix inequalities Hadamard inequality: Proof: Another inequality: Proof: What is more, here we can arbitrarily permute the eigenvalues! 20
21 Applications of Bregman divergences Clustering Co-clustering Partition the columns of a data matrix, so that similar columns are in the same partition (Banerjee et al. JMLR, 2005) Simultaneously partition both the rows and columns of a data matrix (Banerjee et al. JMLR, 2007) Low-Rank Matrix Approximation Exponential Family PCA (Collins et al, NIPS 2001) Non-negative matrix factorization (Dhillon & Sra, NIPS 2005) Generalized2 Linear2 Models POMDP (Gordon, NIPS,2002) (Gordon, NIPS,2002) Online learning (Warmuth, COLT2000) Metric Nearness Problem Given a matrix of distances, find the nearest matrix of distances such that all distances satisfy the triangle inequality (Dhillon et al, 2004) 21
22 Generalized2 Linear2 Models (GL)2M Goal: GLM Special cases: PCA, SVD Exp-family PCA Infomax ICA Linear regression Nonnegative matrix factorization 22

23 What is a good loss function? Euclidean metric as a loss function: instead of 1000 predicting 1010 is just as bad as predicting 3 instead of -7 Sigmoid regression exp many local minima in dim The log loss function is convex in θ! We say f(z) and the log loss match each other. 23
24 Searching for matching loss 24
25 Searching for matching loss 25
26 Special cases Thus, Log loss, entropic loss Other special cases: 26
27 Logistic regression 27
28 (GL)2M algorithm GLM goal: GLM cost: (GL)2M goal: (GL)2M cost: The (GL)2M algorithm, fix point equations:: 28
 Robot can: - sense both side walls - compute an accurate estimate of its lateral position Robot cannot: - resolve its position along the corridor, unless its near")
29 Robot Navigation A corridor in the CMU CS building with initial belief: (it doesn t know which end) Belief space = R states. (275 positons x 2 orientation) Robot can: - sense both side walls - compute an accurate estimate of its lateral position Robot cannot: - resolve its position along the corridor, unless its near an observable feature - tell whether its pointing left or right 29
30 Robot Navigation The belief space is large, but sparse and compressible. The belief vectors lie on a nonlinear manifold. This method can be used for planning, too. They factored a matrix of 400 beliefs using feature space ranks l=3,4,5. f(z)=exp(z), H*=10-12 V 2, G*= U 2+ (U) A belief vector using belief tracker algorithm Reconstructions using l=3,4,5 ranks With PCA, they need 85 dimensions to match (GL)^2M rank-5 decomposition and 25 dimension for the rank-3 decomposition 30

31 Nonnegative matrix factorization Goal: Cost functions: Algorithms: 31

32 Nonnegative matrix factorization, results With sparse constraints Without constraints CBCL face image database P. Hoyer, sparse NMF algorithm. 32
33 Exponential Family PCA PCA 1 PCA 2 Cost function Special case 33
34 Exponential family PCA, Results 34
35 Clustering with Bregman Divergences 35
36 The Original Problem of Bregman 36
37 Conclusion Introduced the Bregman divergence Relationship to Exponential family Generalization to matrices Applications: Matrix inequalities Exponential family PCA NMF GLM Clustering / Biclustering Online learning Bregman divergences propose new algorithms Lots of existing algorithms turn to be special case Matching loss function can help to decrease the number of local minima 37
38 References Matrix Nearness Problems with Bregman Divergences I. S. Dhillon and J. A. Tropp SIAM Journal on Matrix Analysis and Applications, vol. 29, no. 4, pages , November A Generalized Maximum Entropy Approach to Bregman Co-Clustering and Matrix Approximations A. Banerjee, I. S. Dhillon, J. Ghosh, S. Merugu, and D. S. Modha Journal of Machine Learning Research (JMLR), vol. 8, pages , August Clustering with Bregman Divergences A. Banerjee, S. Merugu, I. S. Dhillon, and J. Ghosh Journal of Machine Learning Research (JMLR), vol. 6, pages , October A Generalized Maximum Entropy Approach to Bregman Co-Clustering and Matrix Approximations A. Banerjee, I. S. Dhillon, J. Ghosh, S. Merugu, and D. S. Modha Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages , August Clustering with Bregman Divergences A. Banerjee, S. Merugu, I. S. Dhillon, and J. Ghosh Proceedings of the Fourth SIAM International Conference on Data Mining, pages , April 2004 Nonnegative Matrix Approximation: Algorithms and Applications S. Sra and I. S. Dhillon UTCS Technical Report #TR-06-27, June 2006 Generalized Nonnegative Matrix Approximations with Bregman Divergences I. S. Dhillon and S. Sra NIPS, pages , Vancouver Canada, December (Also appears as UTCS Technical Report #TR-05-31, June 1,
39 PPT slides Irina Rish Bregman Divergences in Clustering and Dimensionality reduction Manfred K. Warmuth COLT2000 Inderjit S. Dhillon Machine Learning with Bregman Divergences Low-Rank Kernel Learning with Bregman Matrix Divergences Matrix Nearness Problems Using Bregman Divergences Information Theoretic Clustering, Co-clustering and Matrix Approximations 39
Bregman Divergences for Data Mining Meta-Algorithms
 p.1/?? Bregman Divergences for Data Mining Meta-Algorithms Joydeep Ghosh University of Texas at Austin ghosh@ece.utexas.edu Reflects joint work with Arindam Banerjee, Srujana Merugu, Inderjit Dhillon,
p.1/?? Bregman Divergences for Data Mining Meta-Algorithms Joydeep Ghosh University of Texas at Austin ghosh@ece.utexas.edu Reflects joint work with Arindam Banerjee, Srujana Merugu, Inderjit Dhillon,
Kernel Learning with Bregman Matrix Divergences
 Kernel Learning with Bregman Matrix Divergences Inderjit S. Dhillon The University of Texas at Austin Workshop on Algorithms for Modern Massive Data Sets Stanford University and Yahoo! Research June 22,
Kernel Learning with Bregman Matrix Divergences Inderjit S. Dhillon The University of Texas at Austin Workshop on Algorithms for Modern Massive Data Sets Stanford University and Yahoo! Research June 22,
Relative Loss Bounds for Multidimensional Regression Problems
 Relative Loss Bounds for Multidimensional Regression Problems Jyrki Kivinen and Manfred Warmuth Presented by: Arindam Banerjee A Single Neuron For a training example (x, y), x R d, y [0, 1] learning solves
Relative Loss Bounds for Multidimensional Regression Problems Jyrki Kivinen and Manfred Warmuth Presented by: Arindam Banerjee A Single Neuron For a training example (x, y), x R d, y [0, 1] learning solves
A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation
 A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation ABSTRACT Arindam Banerjee Inderjit Dhillon Joydeep Ghosh Srujana Merugu University of Texas Austin, TX, USA Co-clustering
A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation ABSTRACT Arindam Banerjee Inderjit Dhillon Joydeep Ghosh Srujana Merugu University of Texas Austin, TX, USA Co-clustering
Randomized Algorithms
 Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Generalized Nonnegative Matrix Approximations with Bregman Divergences
 Generalized Nonnegative Matrix Approximations with Bregman Divergences Inderjit S. Dhillon Suvrit Sra Dept. of Computer Sciences The Univ. of Texas at Austin Austin, TX 78712. {inderjit,suvrit}@cs.utexas.edu
Generalized Nonnegative Matrix Approximations with Bregman Divergences Inderjit S. Dhillon Suvrit Sra Dept. of Computer Sciences The Univ. of Texas at Austin Austin, TX 78712. {inderjit,suvrit}@cs.utexas.edu
MULTIPLICATIVE ALGORITHM FOR CORRENTROPY-BASED NONNEGATIVE MATRIX FACTORIZATION
 MULTIPLICATIVE ALGORITHM FOR CORRENTROPY-BASED NONNEGATIVE MATRIX FACTORIZATION Ehsan Hosseini Asl 1, Jacek M. Zurada 1,2 1 Department of Electrical and Computer Engineering University of Louisville, Louisville,
MULTIPLICATIVE ALGORITHM FOR CORRENTROPY-BASED NONNEGATIVE MATRIX FACTORIZATION Ehsan Hosseini Asl 1, Jacek M. Zurada 1,2 1 Department of Electrical and Computer Engineering University of Louisville, Louisville,
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
A Generalization of Principal Component Analysis to the Exponential Family
 A Generalization of Principal Component Analysis to the Exponential Family Michael Collins Sanjoy Dasgupta Robert E. Schapire AT&T Labs Research 8 Park Avenue, Florham Park, NJ 7932 mcollins, dasgupta,
A Generalization of Principal Component Analysis to the Exponential Family Michael Collins Sanjoy Dasgupta Robert E. Schapire AT&T Labs Research 8 Park Avenue, Florham Park, NJ 7932 mcollins, dasgupta,
Riemannian Metric Learning for Symmetric Positive Definite Matrices
 CMSC 88J: Linear Subspaces and Manifolds for Computer Vision and Machine Learning Riemannian Metric Learning for Symmetric Positive Definite Matrices Raviteja Vemulapalli Guide: Professor David W. Jacobs
CMSC 88J: Linear Subspaces and Manifolds for Computer Vision and Machine Learning Riemannian Metric Learning for Symmetric Positive Definite Matrices Raviteja Vemulapalli Guide: Professor David W. Jacobs
A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation
 Bregman Co-clustering and Matrix Approximation A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation Arindam Banerjee Department of Computer Science and Engg, University
Bregman Co-clustering and Matrix Approximation A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation Arindam Banerjee Department of Computer Science and Engg, University
A Geometric View of Conjugate Priors
 Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence A Geometric View of Conjugate Priors Arvind Agarwal Department of Computer Science University of Maryland College
Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence A Geometric View of Conjugate Priors Arvind Agarwal Department of Computer Science University of Maryland College
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
arxiv: v1 [cs.lg] 1 May 2010
![arxiv: v1 [cs.lg] 1 May 2010](/thumbs/85/91908655.jpg "arxiv: v1 [cs.lg] 1 May 2010") A Geometric View of Conjugate Priors Arvind Agarwal and Hal Daumé III School of Computing, University of Utah, Salt Lake City, Utah, 84112 USA {arvind,hal}@cs.utah.edu arxiv:1005.0047v1 [cs.lg] 1 May 2010
A Geometric View of Conjugate Priors Arvind Agarwal and Hal Daumé III School of Computing, University of Utah, Salt Lake City, Utah, 84112 USA {arvind,hal}@cs.utah.edu arxiv:1005.0047v1 [cs.lg] 1 May 2010
Online Kernel PCA with Entropic Matrix Updates
 Dima Kuzmin Manfred K. Warmuth Computer Science Department, University of California - Santa Cruz dima@cse.ucsc.edu manfred@cse.ucsc.edu Abstract A number of updates for density matrices have been developed
Dima Kuzmin Manfred K. Warmuth Computer Science Department, University of California - Santa Cruz dima@cse.ucsc.edu manfred@cse.ucsc.edu Abstract A number of updates for density matrices have been developed
A Geometric View of Conjugate Priors
 A Geometric View of Conjugate Priors Arvind Agarwal and Hal Daumé III School of Computing, University of Utah, Salt Lake City, Utah, 84112 USA {arvind,hal}@cs.utah.edu Abstract. In Bayesian machine learning,
A Geometric View of Conjugate Priors Arvind Agarwal and Hal Daumé III School of Computing, University of Utah, Salt Lake City, Utah, 84112 USA {arvind,hal}@cs.utah.edu Abstract. In Bayesian machine learning,
Online Kernel PCA with Entropic Matrix Updates
 Online Kernel PCA with Entropic Matrix Updates Dima Kuzmin Manfred K. Warmuth University of California - Santa Cruz ICML 2007, Corvallis, Oregon April 23, 2008 D. Kuzmin, M. Warmuth (UCSC) Online Kernel
Online Kernel PCA with Entropic Matrix Updates Dima Kuzmin Manfred K. Warmuth University of California - Santa Cruz ICML 2007, Corvallis, Oregon April 23, 2008 D. Kuzmin, M. Warmuth (UCSC) Online Kernel
cross-language retrieval (by concatenate features of different language in X and find co-shared U). TOEFL/GRE synonym in the same way.
. TOEFL/GRE synonym in the same way.") 10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Information Geometry of Positive Measures and Positive-Definite Matrices: Decomposable Dually Flat Structure
 Entropy 014, 16, 131-145; doi:10.3390/e1604131 OPEN ACCESS entropy ISSN 1099-4300 www.mdpi.com/journal/entropy Article Information Geometry of Positive Measures and Positive-Definite Matrices: Decomposable
Entropy 014, 16, 131-145; doi:10.3390/e1604131 OPEN ACCESS entropy ISSN 1099-4300 www.mdpi.com/journal/entropy Article Information Geometry of Positive Measures and Positive-Definite Matrices: Decomposable
MATRIX NEARNESS PROBLEMS WITH BREGMAN DIVERGENCES
 MATRIX NEARNESS PROBLEMS WITH BREGMAN DIVERGENCES INDERJIT S. DHILLON AND JOEL A. TROPP Abstract. This paper discusses a new class of matrix nearness problems that measure approximation error using a directed
MATRIX NEARNESS PROBLEMS WITH BREGMAN DIVERGENCES INDERJIT S. DHILLON AND JOEL A. TROPP Abstract. This paper discusses a new class of matrix nearness problems that measure approximation error using a directed
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
The Free Matrix Lunch
 The Free Matrix Lunch Wouter M. Koolen Wojciech Kot lowski Manfred K. Warmuth Tuesday 24 th April, 2012 Koolen, Kot lowski, Warmuth (RHUL) The Free Matrix Lunch Tuesday 24 th April, 2012 1 / 26 Introduction
The Free Matrix Lunch Wouter M. Koolen Wojciech Kot lowski Manfred K. Warmuth Tuesday 24 th April, 2012 Koolen, Kot lowski, Warmuth (RHUL) The Free Matrix Lunch Tuesday 24 th April, 2012 1 / 26 Introduction
Journée Interdisciplinaire Mathématiques Musique
 Journée Interdisciplinaire Mathématiques Musique Music Information Geometry Arnaud Dessein 1,2 and Arshia Cont 1 1 Institute for Research and Coordination of Acoustics and Music, Paris, France 2 Japanese-French
Journée Interdisciplinaire Mathématiques Musique Music Information Geometry Arnaud Dessein 1,2 and Arshia Cont 1 1 Institute for Research and Coordination of Acoustics and Music, Paris, France 2 Japanese-French
Inderjit Dhillon The University of Texas at Austin
 Inderjit Dhillon The University of Texas at Austin ( Universidad Carlos III de Madrid; 15 th June, 2012) (Based on joint work with J. Brickell, S. Sra, J. Tropp) Introduction 2 / 29 Notion of distance
Inderjit Dhillon The University of Texas at Austin ( Universidad Carlos III de Madrid; 15 th June, 2012) (Based on joint work with J. Brickell, S. Sra, J. Tropp) Introduction 2 / 29 Notion of distance
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Expectation Maximization
 Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Non-negative matrix factorization and term structure of interest rates
 Non-negative matrix factorization and term structure of interest rates Hellinton H. Takada and Julio M. Stern Citation: AIP Conference Proceedings 1641, 369 (2015); doi: 10.1063/1.4906000 View online:
Non-negative matrix factorization and term structure of interest rates Hellinton H. Takada and Julio M. Stern Citation: AIP Conference Proceedings 1641, 369 (2015); doi: 10.1063/1.4906000 View online:
Improving Response Prediction for Dyadic Data
 Improving Response Prediction for Dyadic Data Stat 598T Statistical Network Analysis Project Report Nik Tuzov* April 2008 Keywords: Dyadic data, Co-clustering, PDLF model, Neural networks, Unsupervised
Improving Response Prediction for Dyadic Data Stat 598T Statistical Network Analysis Project Report Nik Tuzov* April 2008 Keywords: Dyadic data, Co-clustering, PDLF model, Neural networks, Unsupervised
Linear Algebra & Geometry why is linear algebra useful in computer vision?
 Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Deriving Principal Component Analysis (PCA)
") -0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
-0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
Transductive De-Noising and Dimensionality Reduction using Total Bregman Regression
 Transductive De-Noising and Dimensionality Reduction using Total Bregman Regression Sreangsu Acharyya niversity Of Texas at Austin Electrical Engineering Abstract Our goal on one hand is to use labels
Transductive De-Noising and Dimensionality Reduction using Total Bregman Regression Sreangsu Acharyya niversity Of Texas at Austin Electrical Engineering Abstract Our goal on one hand is to use labels
Mirror Descent for Metric Learning. Gautam Kunapuli Jude W. Shavlik
 Mirror Descent for Metric Learning Gautam Kunapuli Jude W. Shavlik And what do we have here? We have a metric learning algorithm that uses composite mirror descent (COMID): Unifying framework for metric
Mirror Descent for Metric Learning Gautam Kunapuli Jude W. Shavlik And what do we have here? We have a metric learning algorithm that uses composite mirror descent (COMID): Unifying framework for metric
Preserving Privacy in Data Mining using Data Distortion Approach
 Preserving Privacy in Data Mining using Data Distortion Approach Mrs. Prachi Karandikar #, Prof. Sachin Deshpande * # M.E. Comp,VIT, Wadala, University of Mumbai * VIT Wadala,University of Mumbai 1. prachiv21@yahoo.co.in
Preserving Privacy in Data Mining using Data Distortion Approach Mrs. Prachi Karandikar #, Prof. Sachin Deshpande * # M.E. Comp,VIT, Wadala, University of Mumbai * VIT Wadala,University of Mumbai 1. prachiv21@yahoo.co.in
Functional Bregman Divergence and Bayesian Estimation of Distributions Béla A. Frigyik, Santosh Srivastava, and Maya R. Gupta
 5130 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 54, NO. 11, NOVEMBER 2008 Functional Bregman Divergence and Bayesian Estimation of Distributions Béla A. Frigyik, Santosh Srivastava, and Maya R. Gupta
5130 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 54, NO. 11, NOVEMBER 2008 Functional Bregman Divergence and Bayesian Estimation of Distributions Béla A. Frigyik, Santosh Srivastava, and Maya R. Gupta
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
EUSIPCO
 EUSIPCO 2013 1569741067 CLUSERING BY NON-NEGAIVE MARIX FACORIZAION WIH INDEPENDEN PRINCIPAL COMPONEN INIIALIZAION Liyun Gong 1, Asoke K. Nandi 2,3 1 Department of Electrical Engineering and Electronics,
EUSIPCO 2013 1569741067 CLUSERING BY NON-NEGAIVE MARIX FACORIZAION WIH INDEPENDEN PRINCIPAL COMPONEN INIIALIZAION Liyun Gong 1, Asoke K. Nandi 2,3 1 Department of Electrical Engineering and Electronics,
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Orthogonal Nonnegative Matrix Factorization: Multiplicative Updates on Stiefel Manifolds
 Orthogonal Nonnegative Matrix Factorization: Multiplicative Updates on Stiefel Manifolds Jiho Yoo and Seungjin Choi Department of Computer Science Pohang University of Science and Technology San 31 Hyoja-dong,
Orthogonal Nonnegative Matrix Factorization: Multiplicative Updates on Stiefel Manifolds Jiho Yoo and Seungjin Choi Department of Computer Science Pohang University of Science and Technology San 31 Hyoja-dong,
Improved Bounds on the Dot Product under Random Projection and Random Sign Projection
 Improved Bounds on the Dot Product under Random Projection and Random Sign Projection Ata Kabán School of Computer Science The University of Birmingham Birmingham B15 2TT, UK http://www.cs.bham.ac.uk/
Improved Bounds on the Dot Product under Random Projection and Random Sign Projection Ata Kabán School of Computer Science The University of Birmingham Birmingham B15 2TT, UK http://www.cs.bham.ac.uk/
Discriminative Direction for Kernel Classifiers
 Discriminative Direction for Kernel Classifiers Polina Golland Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA 02139 polina@ai.mit.edu Abstract In many scientific and engineering
Discriminative Direction for Kernel Classifiers Polina Golland Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA 02139 polina@ai.mit.edu Abstract In many scientific and engineering
Accelerated Training of Max-Margin Markov Networks with Kernels
 Accelerated Training of Max-Margin Markov Networks with Kernels Xinhua Zhang University of Alberta Alberta Innovates Centre for Machine Learning (AICML) Joint work with Ankan Saha (Univ. of Chicago) and
Accelerated Training of Max-Margin Markov Networks with Kernels Xinhua Zhang University of Alberta Alberta Innovates Centre for Machine Learning (AICML) Joint work with Ankan Saha (Univ. of Chicago) and
ONP-MF: An Orthogonal Nonnegative Matrix Factorization Algorithm with Application to Clustering
 ONP-MF: An Orthogonal Nonnegative Matrix Factorization Algorithm with Application to Clustering Filippo Pompili 1, Nicolas Gillis 2, P.-A. Absil 2,andFrançois Glineur 2,3 1- University of Perugia, Department
ONP-MF: An Orthogonal Nonnegative Matrix Factorization Algorithm with Application to Clustering Filippo Pompili 1, Nicolas Gillis 2, P.-A. Absil 2,andFrançois Glineur 2,3 1- University of Perugia, Department
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Independent Component Analysis Barnabás Póczos Independent Component Analysis 2 Independent Component Analysis Model original signals Observations (Mixtures)
Advanced Introduction to Machine Learning CMU-10715 Independent Component Analysis Barnabás Póczos Independent Component Analysis 2 Independent Component Analysis Model original signals Observations (Mixtures)
Non-negative Matrix Factorization: Algorithms, Extensions and Applications
 Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Machine Learning (CSE 446): Learning as Minimizing Loss; Least Squares
: Learning as Minimizing Loss; Least Squares") Machine Learning (CSE 446): Learning as Minimizing Loss; Least Squares Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 13 Review 1 / 13 Alternate View of PCA: Minimizing
Machine Learning (CSE 446): Learning as Minimizing Loss; Least Squares Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 13 Review 1 / 13 Alternate View of PCA: Minimizing
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing
 Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
Online Nonnegative Matrix Factorization with General Divergences
 Online Nonnegative Matrix Factorization with General Divergences Vincent Y. F. Tan (ECE, Mathematics, NUS) Joint work with Renbo Zhao (NUS) and Huan Xu (GeorgiaTech) IWCT, Shanghai Jiaotong University
Online Nonnegative Matrix Factorization with General Divergences Vincent Y. F. Tan (ECE, Mathematics, NUS) Joint work with Renbo Zhao (NUS) and Huan Xu (GeorgiaTech) IWCT, Shanghai Jiaotong University
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization
 CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
Non-Negative Matrix Factorization with Quasi-Newton Optimization
 Non-Negative Matrix Factorization with Quasi-Newton Optimization Rafal ZDUNEK, Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing BSI, RIKEN, Wako-shi, JAPAN Abstract. Non-negative matrix
Non-Negative Matrix Factorization with Quasi-Newton Optimization Rafal ZDUNEK, Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing BSI, RIKEN, Wako-shi, JAPAN Abstract. Non-negative matrix
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center
 Fei Wang and Jimeng Sun IBM TJ Watson Research Center") Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Approximation. Inderjit S. Dhillon Dept of Computer Science UT Austin. SAMSI Massive Datasets Opening Workshop Raleigh, North Carolina.
 Using Quadratic Approximation Inderjit S. Dhillon Dept of Computer Science UT Austin SAMSI Massive Datasets Opening Workshop Raleigh, North Carolina Sept 12, 2012 Joint work with C. Hsieh, M. Sustik and
Using Quadratic Approximation Inderjit S. Dhillon Dept of Computer Science UT Austin SAMSI Massive Datasets Opening Workshop Raleigh, North Carolina Sept 12, 2012 Joint work with C. Hsieh, M. Sustik and
CS Lecture 19. Exponential Families & Expectation Propagation
 CS 6347 Lecture 19 Exponential Families & Expectation Propagation Discrete State Spaces We have been focusing on the case of MRFs over discrete state spaces Probability distributions over discrete spaces
CS 6347 Lecture 19 Exponential Families & Expectation Propagation Discrete State Spaces We have been focusing on the case of MRFs over discrete state spaces Probability distributions over discrete spaces
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
The Bregman Variational Dual-Tree Framework
 The Bregman Variational Dual-Tree Framework Saeed Amizadeh Intelligent Systems Program University of Pittsburgh Pittsburgh, PA 15213 Bo Thiesson Department of Computer Science Aalborg University Aalborg,
The Bregman Variational Dual-Tree Framework Saeed Amizadeh Intelligent Systems Program University of Pittsburgh Pittsburgh, PA 15213 Bo Thiesson Department of Computer Science Aalborg University Aalborg,
Dimensionality Reduction with Generalized Linear Models
 Dimensionality Reduction with Generalized Linear Models Mo Chen 1 Wei Li 1 Wei Zhang 2 Xiaogang Wang 1 1 Department of Electronic Engineering 2 Department of Information Engineering The Chinese University
Dimensionality Reduction with Generalized Linear Models Mo Chen 1 Wei Li 1 Wei Zhang 2 Xiaogang Wang 1 1 Department of Electronic Engineering 2 Department of Information Engineering The Chinese University
Unsupervised learning: beyond simple clustering and PCA
 Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
The Informativeness of k-means for Learning Mixture Models
 The Informativeness of k-means for Learning Mixture Models Vincent Y. F. Tan (Joint work with Zhaoqiang Liu) National University of Singapore June 18, 2018 1/35 Gaussian distribution For F dimensions,
The Informativeness of k-means for Learning Mixture Models Vincent Y. F. Tan (Joint work with Zhaoqiang Liu) National University of Singapore June 18, 2018 1/35 Gaussian distribution For F dimensions,
Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY
 Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY OUTLINE Why We Need Matrix Decomposition SVD (Singular Value Decomposition) NMF (Nonnegative
Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY OUTLINE Why We Need Matrix Decomposition SVD (Singular Value Decomposition) NMF (Nonnegative
Fast Bregman Divergence NMF using Taylor Expansion and Coordinate Descent
 Fast Bregman Divergence NMF using Taylor Expansion and Coordinate Descent Liangda Li, Guy Lebanon, Haesun Park School of Computational Science and Engineering Georgia Institute of Technology Atlanta, GA
Fast Bregman Divergence NMF using Taylor Expansion and Coordinate Descent Liangda Li, Guy Lebanon, Haesun Park School of Computational Science and Engineering Georgia Institute of Technology Atlanta, GA
Matrix factorization models for patterns beyond blocks. Pauli Miettinen 18 February 2016
 Matrix factorization models for patterns beyond blocks 18 February 2016 What does a matrix factorization do?? A = U V T 2 For SVD that s easy! 3 Inner-product interpretation Element (AB) ij is the inner
Matrix factorization models for patterns beyond blocks 18 February 2016 What does a matrix factorization do?? A = U V T 2 For SVD that s easy! 3 Inner-product interpretation Element (AB) ij is the inner
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
Independent Component Analysis and Unsupervised Learning. Jen-Tzung Chien
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
Independent Component Analysis and Unsupervised Learning
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
 This article was published in an Elsevier journal. The attached copy is furnished to the author for non-commercial research and education use, including for instruction at the author s institution, sharing
This article was published in an Elsevier journal. The attached copy is furnished to the author for non-commercial research and education use, including for instruction at the author s institution, sharing
Fast Coordinate Descent methods for Non-Negative Matrix Factorization
 Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
Must-read Material : Multimedia Databases and Data Mining. Indexing - Detailed outline. Outline. Faloutsos
 Must-read Material 15-826: Multimedia Databases and Data Mining Tamara G. Kolda and Brett W. Bader. Tensor decompositions and applications. Technical Report SAND2007-6702, Sandia National Laboratories,
Must-read Material 15-826: Multimedia Databases and Data Mining Tamara G. Kolda and Brett W. Bader. Tensor decompositions and applications. Technical Report SAND2007-6702, Sandia National Laboratories,
Relational Learning via Collective Matrix Factorization. June 2008 CMU-ML
 Relational Learning via Collective Matrix Factorization Ajit P. Singh Geoffrey J. Gordon June 2008 CMU-ML-08-109 Relational Learning via Collective Matrix Factorization Ajit P. Singh Geoffrey J. Gordon
Relational Learning via Collective Matrix Factorization Ajit P. Singh Geoffrey J. Gordon June 2008 CMU-ML-08-109 Relational Learning via Collective Matrix Factorization Ajit P. Singh Geoffrey J. Gordon
CPSC 340: Machine Learning and Data Mining. Sparse Matrix Factorization Fall 2018
 CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
Support Vector Machines
 Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Online Passive-Aggressive Algorithms
 Online Passive-Aggressive Algorithms Koby Crammer Ofer Dekel Shai Shalev-Shwartz Yoram Singer School of Computer Science & Engineering The Hebrew University, Jerusalem 91904, Israel {kobics,oferd,shais,singer}@cs.huji.ac.il
Online Passive-Aggressive Algorithms Koby Crammer Ofer Dekel Shai Shalev-Shwartz Yoram Singer School of Computer Science & Engineering The Hebrew University, Jerusalem 91904, Israel {kobics,oferd,shais,singer}@cs.huji.ac.il
Big Data Analytics. Special Topics for Computer Science CSE CSE Jan 21
 Big Data Analytics Special Topics for Computer Science CSE 09-001 CSE 09-00 Jan 1 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Project Rules Literature
Big Data Analytics Special Topics for Computer Science CSE 09-001 CSE 09-00 Jan 1 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Project Rules Literature
The Information Bottleneck Revisited or How to Choose a Good Distortion Measure
 The Information Bottleneck Revisited or How to Choose a Good Distortion Measure Peter Harremoës Centrum voor Wiskunde en Informatica PO 94079, 1090 GB Amsterdam The Nederlands PHarremoes@cwinl Naftali
The Information Bottleneck Revisited or How to Choose a Good Distortion Measure Peter Harremoës Centrum voor Wiskunde en Informatica PO 94079, 1090 GB Amsterdam The Nederlands PHarremoes@cwinl Naftali
A Unified View of Matrix Factorization Models
 A Unified View of Matrix Factorization Models Ajit P. Singh and Geoffrey J. Gordon Machine Learning Department Carnegie Mellon University Pittsburgh PA 15213, USA, {ajit,ggordon}@cs.cmu.edu Abstract. We
A Unified View of Matrix Factorization Models Ajit P. Singh and Geoffrey J. Gordon Machine Learning Department Carnegie Mellon University Pittsburgh PA 15213, USA, {ajit,ggordon}@cs.cmu.edu Abstract. We
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Collaborative Filtering Using Orthogonal Nonnegative Matrix Tri-factorization
 Collaborative Filtering Using Orthogonal Nonnegative Matrix Tri-factorization Gang Chen 1,FeiWang 1, Changshui Zhang 2 State Key Laboratory of Intelligent Technologies and Systems Tsinghua University 1
Collaborative Filtering Using Orthogonal Nonnegative Matrix Tri-factorization Gang Chen 1,FeiWang 1, Changshui Zhang 2 State Key Laboratory of Intelligent Technologies and Systems Tsinghua University 1
Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory
 Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory Bin Gao Tie-an Liu Wei-ing Ma Microsoft Research Asia 4F Sigma Center No. 49 hichun Road Beijing 00080
Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory Bin Gao Tie-an Liu Wei-ing Ma Microsoft Research Asia 4F Sigma Center No. 49 hichun Road Beijing 00080
Part 2: Generalized output representations and structure
 Part 2: Generalized output representations and structure Dale Schuurmans University of Alberta Output transformation Output transformation What if targets y special? E.g. what if y nonnegative y 0 y probability
Part 2: Generalized output representations and structure Dale Schuurmans University of Alberta Output transformation Output transformation What if targets y special? E.g. what if y nonnegative y 0 y probability
Tailored Bregman Ball Trees for Effective Nearest Neighbors
 Tailored Bregman Ball Trees for Effective Nearest Neighbors Frank Nielsen 1 Paolo Piro 2 Michel Barlaud 2 1 Ecole Polytechnique, LIX, Palaiseau, France 2 CNRS / University of Nice-Sophia Antipolis, Sophia
Tailored Bregman Ball Trees for Effective Nearest Neighbors Frank Nielsen 1 Paolo Piro 2 Michel Barlaud 2 1 Ecole Polytechnique, LIX, Palaiseau, France 2 CNRS / University of Nice-Sophia Antipolis, Sophia
Approximate Principal Components Analysis of Large Data Sets
 Approximate Principal Components Analysis of Large Data Sets Daniel J. McDonald Department of Statistics Indiana University mypage.iu.edu/ dajmcdon April 27, 2016 Approximation-Regularization for Analysis
Approximate Principal Components Analysis of Large Data Sets Daniel J. McDonald Department of Statistics Indiana University mypage.iu.edu/ dajmcdon April 27, 2016 Approximation-Regularization for Analysis
Compressive Sensing, Low Rank models, and Low Rank Submatrix
 Compressive Sensing,, and Low Rank Submatrix NICTA Short Course 2012 yi.li@nicta.com.au http://users.cecs.anu.edu.au/~yili Sep 12, 2012 ver. 1.8 http://tinyurl.com/brl89pk Outline Introduction 1 Introduction
Compressive Sensing,, and Low Rank Submatrix NICTA Short Course 2012 yi.li@nicta.com.au http://users.cecs.anu.edu.au/~yili Sep 12, 2012 ver. 1.8 http://tinyurl.com/brl89pk Outline Introduction 1 Introduction
Visual Tracking via Geometric Particle Filtering on the Affine Group with Optimal Importance Functions
 Monday, June 22 Visual Tracking via Geometric Particle Filtering on the Affine Group with Optimal Importance Functions Junghyun Kwon 1, Kyoung Mu Lee 1, and Frank C. Park 2 1 Department of EECS, 2 School
Monday, June 22 Visual Tracking via Geometric Particle Filtering on the Affine Group with Optimal Importance Functions Junghyun Kwon 1, Kyoung Mu Lee 1, and Frank C. Park 2 1 Department of EECS, 2 School
Linear Algebra & Geometry why is linear algebra useful in computer vision?
 Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
From Last Meeting. Studied Fisher Linear Discrimination. - Mathematics. - Point Cloud view. - Likelihood view. - Toy examples
 From Last Meeting Studied Fisher Linear Discrimination - Mathematics - Point Cloud view - Likelihood view - Toy eamples - Etensions (e.g. Principal Discriminant Analysis) Polynomial Embedding Aizerman,
From Last Meeting Studied Fisher Linear Discrimination - Mathematics - Point Cloud view - Likelihood view - Toy eamples - Etensions (e.g. Principal Discriminant Analysis) Polynomial Embedding Aizerman,
Unsupervised Learning: K- Means & PCA
 Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
Information-Theoretic Metric Learning
 Jason V. Davis Brian Kulis Prateek Jain Suvrit Sra Inderjit S. Dhillon Dept. of Computer Science, University of Texas at Austin, Austin, TX 7872 Abstract In this paper, we present an information-theoretic
Jason V. Davis Brian Kulis Prateek Jain Suvrit Sra Inderjit S. Dhillon Dept. of Computer Science, University of Texas at Austin, Austin, TX 7872 Abstract In this paper, we present an information-theoretic
A geometric view of conjugate priors
 Mach Learn (2010) 81: 99 113 DOI 10.1007/s10994-010-5203-x A geometric view of conjugate priors Arvind Agarwal Hal Daumé III Received: 30 April 2010 / Accepted: 20 June 2010 / Published online: 22 July
Mach Learn (2010) 81: 99 113 DOI 10.1007/s10994-010-5203-x A geometric view of conjugate priors Arvind Agarwal Hal Daumé III Received: 30 April 2010 / Accepted: 20 June 2010 / Published online: 22 July
Neural Networks and Machine Learning research at the Laboratory of Computer and Information Science, Helsinki University of Technology
 Neural Networks and Machine Learning research at the Laboratory of Computer and Information Science, Helsinki University of Technology Erkki Oja Department of Computer Science Aalto University, Finland
Neural Networks and Machine Learning research at the Laboratory of Computer and Information Science, Helsinki University of Technology Erkki Oja Department of Computer Science Aalto University, Finland
c Springer, Reprinted with permission.
 Zhijian Yuan and Erkki Oja. A FastICA Algorithm for Non-negative Independent Component Analysis. In Puntonet, Carlos G.; Prieto, Alberto (Eds.), Proceedings of the Fifth International Symposium on Independent
Zhijian Yuan and Erkki Oja. A FastICA Algorithm for Non-negative Independent Component Analysis. In Puntonet, Carlos G.; Prieto, Alberto (Eds.), Proceedings of the Fifth International Symposium on Independent
CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu
 Professor Jian Peng Teaching Assistant: Rongda Zhu") CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu Feature engineering is hard 1. Extract informative features from domain knowledge
CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu Feature engineering is hard 1. Extract informative features from domain knowledge
Machine Learning Basics Lecture 7: Multiclass Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Tensor intro 1. SIAM Rev., 51(3), Tensor Decompositions and Applications, Kolda, T.G. and Bader, B.W.,
, Tensor Decompositions and Applications, Kolda, T.G. and Bader, B.W.,") Overview 1. Brief tensor introduction 2. Stein s lemma 3. Score and score matching for fitting models 4. Bringing it all together for supervised deep learning Tensor intro 1 Tensors are multidimensional
Overview 1. Brief tensor introduction 2. Stein s lemma 3. Score and score matching for fitting models 4. Bringing it all together for supervised deep learning Tensor intro 1 Tensors are multidimensional
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Data Mining and Matrices
 Data Mining and Matrices 08 Boolean Matrix Factorization Rainer Gemulla, Pauli Miettinen June 13, 2013 Outline 1 Warm-Up 2 What is BMF 3 BMF vs. other three-letter abbreviations 4 Binary matrices, tiles,
Data Mining and Matrices 08 Boolean Matrix Factorization Rainer Gemulla, Pauli Miettinen June 13, 2013 Outline 1 Warm-Up 2 What is BMF 3 BMF vs. other three-letter abbreviations 4 Binary matrices, tiles,
Memory Efficient Kernel Approximation
 Si Si Department of Computer Science University of Texas at Austin ICML Beijing, China June 23, 2014 Joint work with Cho-Jui Hsieh and Inderjit S. Dhillon Outline Background Motivation Low-Rank vs. Block
Si Si Department of Computer Science University of Texas at Austin ICML Beijing, China June 23, 2014 Joint work with Cho-Jui Hsieh and Inderjit S. Dhillon Outline Background Motivation Low-Rank vs. Block
POSITIVE DEFINITE MATRICES AND THE S-DIVERGENCE
 PROCEEDINGS OF THE AMERICAN MATHEMATICAL SOCIETY Volume 00, Number 0, Pages 000 000 S 000-9939(XX)0000-0 POSITIVE DEFINITE MATRICES AND THE S-DIVERGENCE SUVRIT SRA (Communicated by ) Abstract. Hermitian
PROCEEDINGS OF THE AMERICAN MATHEMATICAL SOCIETY Volume 00, Number 0, Pages 000 000 S 000-9939(XX)0000-0 POSITIVE DEFINITE MATRICES AND THE S-DIVERGENCE SUVRIT SRA (Communicated by ) Abstract. Hermitian