Introduction to inferential statistics. Alissa Melinger IGK summer school 2006 Edinburgh
|
|
|
- Maximilian Stevens
- 6 years ago
- Views:
Transcription
1 Introduction to inferential statistics Alissa Melinger IGK summer school 2006 Edinburgh
2 Short description Prereqs: I assume no prior knowledge of stats This half day tutorial on statistical analysis will introduce the most common statistical approaches used for analyzing behavioral data, including t-tests, anovas, chisquared, correlations, regressions and nonparametric tests.
3 The focus will be on the appropriate application of these methods (when to use which test) rather than on their underlying mathematical foundations. The introduction will be presented in a very pragmatic problem-oriented manner with examples of how to conduct the analyses using SPSS, interpret the program output and report the results. One goal of the tutorial will be to generalize the use of these tests Won t learn how to conduct the analyses, but hopefully enough background to help you bootstrap up (with help from r-tutorial or Dr. Google)
4 Structure of Tutorial Hour 1: Background and fundamental underpinnings to inferential statistics Hour 2: Tests for evaluating differences Hour 3: Tests for evaluating relations between two (or more) variables
5 Background and fundamental underpinnings to inferential statistics Hour 1
6 The Experiment An experiment should allow for a systematic observation of a particular behavior under controlled circumstances. If we properly control the experiment, there should be minimal difference between the situations we create. Therefore any observed quantitative or qualitative difference must be due to our manipulation.
7 Two Types of Variables You manipulate the situations under which the behavior is observed and measured. The variables you manipulate are your independent variables. You observe and measure a particular behavior. This measurement is your dependent variable
8 Two Types of Variables The independent variable is the variable that will be manipulated and compared or that conditions or governs the behavior. Word length, sentence type, frequency, semantic relationship, instruction types, age, sex, task, etc. The dependent variable is the behavior that will be observed and measured. Reaction times, accuracy, weight, ratings, etc.
9 IV Terminology Factor is another word for independent variable, e.g., word frequency or length Level- value or state of the factor. Condition (treatments)- all the different situations you create by combining the levels of your different factors.
10 IV Terminology: Example Question: Does the frequency of an antecedent influence the ease of processing an anaphor? IV (factor) 1 Antecedent frequency with two levels (frequent vs. infrequent) Alone, this would produce two conditions IV (factor) 2 Anaphor type with two levels (repeated NP vs. Pronoun)
11 Combining levels factorially Each level of each factor is combined with each level of each other factor, we get 4 conditions Repeated NP - infrequent antecedent Repeated NP - frequent antecedent Pronoun - infrequent antecedent Pronoun - frequent antecedent Condition 1 Condition 2 Condition 3 Condition 4 2 levels x 2 levels = 4 conditions 2 levels x 3 levels = 6 conditions
12 How to choose a stat 3 issues determine what statistical test is appropriate for you and your data: What type of design do you have? What type of question do you want to ask? What type of data do you have?
13 Design Issues How many independent variables do you have? How many levels of the IVs? Is your comparison within (related/dependent/repeated measures) or between (unrelated/independent)? Within: subjects (items) are tested in all levels of an IV. Between: subjects (items) are tested only one level of an IV.
14 Types of Questions Different questions are addressed with different tests. Are my two conditions different from one another? Is there a relationship between my two factors? Which combination of factors best explains the patterns in my data?
15 What type of data do you have? Parametric tests make assumptions about your data. Normally distributed Independent ** Homogeneity of variance At least interval scale ** If your data violate these assumptions, consider using a non-parametric test.
 Evaluate normality by: histogram Kolmogorov-Smirnov test Shapiro-Wilks test.")
16 Normality Your data should be from a normally distributed population. Normal distributions are symmetrical bell-shaped distributions with the majority of scores around the center. If you collect enough data, it should be normally distributed (Central Limits Theorem) Evaluate normality by: histogram Kolmogorov-Smirnov test Shapiro-Wilks test. Data Assumptions
17 Homogeneity of Variance The variance should not change systematically throughout the data, especially not between groups of subjects or items. When you test different groups of subjects (monolinguals vs. bilinguals; test vs. control; trained vs. untrained), their variances should not differ. If you test two corpora, the variance should not differ. Evaluate with Levene s test for between tests Mauchly s test of Sphericity in Repeated Measures Data Assumptions
18 Independence Data from different subjects (items) are independent. The observations within each treatment condition must be independent. Subjects not randomly assigned to a group If observations in one condition a subset of observations in another condition correlated samples, such as a set of pre- and post-test observations on the same subjects, are not independent Some tests are specifically designed to deal with dependent (within) data. Data Assumptions
19 Types of Data Nominal scale: Numbers represent qualitative features, not quantitative. 1 not bigger than 2, just different; 1=masculine, 2 = feminine Ordinal Scale: Rankings, 1 < 2 < 3 < 4, but differences between values not important or constant; Likert scale data. Interval Scale: like ordinal, but distances are equal Differences make sense, but ratios don t (30-20 =20-10, but 20 /10 is not twice as hot) e.g., temperature, dates Ratio Scale: interval, plus a meaningful 0 point. Weight, length, reaction times, age Data Assumptions
20 What type of data do you have? Parametric tests make assumptions about your data. Normally distributed Independent ** Homogeneity of variance At least interval scale ** Parametric tests are not robust to violations of the starred assumptions Data Assumptions
21 Miller, 1984 Type of Research Design One- Sample Two-Sample K sample Correlation Related Independ ent Related Independent Type of Data Parametric Onesample Z One sample t Related t Independ ent Z- Independ ent t- Variance Ratio (F) Variance Ratio (F) Variance Ratio (F) Productmoment correlation coefficient (Pearson s r) Linear regression Non-parametric Onesample proportio ns Wilcoxon Sign Mann- Whitney χ 2 Page s L trend Jonckheere trend Spearman s rank correlation coefficient Picking a test
22 Between-subjects analyses # of conditions Parametric scores Nonparame tric - ordinal Nonparame tric - nominal two Independent samples t-test Mann- Whitney χ 2 Three or more Betweensubjects ANOVA Kruskal- Wallis χ 2 Picking a test
23 Within-subjects analyses # of conditions Parametric scores Nonparame tric - ordinal Nonparame tric - nominal two Dependent samples t Wilcoxon none Three or more Repeated Measures ANOVA Friedman none Picking a test
24 Decision Tree (Howell, 2004) Type of data Qualitative (Categorical) Quantitative Measurement Type of Categorization One Categorical Variable Type of Categorization Two Categorical Variables Type of Question Goodness-of-fit Chi-squared Contingency Table Chi-squared Relationships Differences One predictor Multiple predictors Number of Groups Continuous measurement Ranks Multiple Regression Two Multiple Primary interest Degree of Relationship Primary interest Form of Relationship Spearman's r s Independent Dependent Independent Dependent Pearson Correlation Regression Two-sample t Related Sample t One Independent variable Multiple independent variables Repeated Measures Mann-Whitney Wilcoxon One-way Anova Kruskal- Wallis Factorial ANOVA Friedman Picking a test
25 How do stats work and why do we use them? We observe some behavior, of individuals, the economy, our computer models, etc. We want to say something about this behavior. We d like to say something that extends beyond just the observations we made to future behaviors, past behaviors, unobserved behaviors.
26 Types of Statistical Analyses Descriptive statistics: summarizing and describing the important characteristics of the data. Inferential statistics: decide if a pattern, difference or relations found with a sample is representative and true of the population.
27 Why go beyond descriptives? Q: Are monks taller than brides? Monks mean height 190 Brides mean height 170 The mean might make it look like monks are taller, but maybe that that doesn t represent the truth.
28
29 Is this difference REAL? Descriptive difference Milk costs.69 at Plus and.89 at Mini-mall Is this a real difference? Subjective difference Is the difference important enough to me? Is it worth my while to travel farther to pay less? Statistical difference Is Plus generally cheaper than Mini-mall? How representative of the prices is milk? Are all Plus stores cheaper than all Mini-malls? How representative of all Plus stores is my Plus? Inferential statistics help us answer these questions without the need for an exhaustive survey.
30 How to inferential statistics work? Different statistical methods attempt to build a model of the data using hypothesized factors to account for the characteristics of the observed pattern. One simple model of the data is the MEAN

31 The mean Subjects A B C D E F # siblings How well does the mean model the data? ERROR Mean # siblings = 1.83
32 Variance Variance is an index of error between the mean and the individual observations. Sum of error is offset by positive and negative numbers Take the square of each error value Sum of squared errors (SS) will increase the more data you collect. Large number bad estimate of # of siblings Divide the sum of squared errors by N-1 Variance (s 2 ) = SS/N-1 #( x i " x) #( x i " x) 2
33 Standard Deviation Variance gives us measure in units squared, so not comparable to directly to the units measured. If your data has a range from 1-100, you could easily have a variance of > 100, which is not that informative an index of error. Standard Deviation is a measure of how well the mean represents the data. s = SS N "1
34 Sampling Sampling is a random selection of representative members of a population. If you had access to all members of a population then you would not need to conduct inferential statistics to see whether some observation generalizes to the whole population. Normally, we only have access to a (representative) subset. Most random samples tend to be fairly typical of the population, but there is always variation.
35 Standard Error Variance and Standard Deviation index the relationship between the mean of observations and individual observations. Comment on the SAMPLE MSE = S / Standard error is similar to SD but it applies to the relationship between a sample mean and the population. Standard errors give you a measure of how representative your sample is of the population. A large standard error means your sample is not very representative of the population. Small SE means it is representative. N
36 Normality and SD The combination of measures of variance and assumptions of normality underlie hypothesis testing and inferential statistics. Statistical tests output a probability that an observed pattern (difference or relationship) are true of the population. How does this work?
37 Normal Curves Normal curves can be defined by their mean and variance. Z-distribution has mean = 0 & SD = 1 x: N (0,1) 95% of data points are within about 2 SD of mean
38 Normal Curves Given these characteristics of normal curves, you can calculate what percentage of the data points are above or below some any value. This is a basic principle behind most of the common inferential tests.
39 Example: IQ scores X:N(x,s 2 ) x = 100 s 2 = 256; s= ( ) = 16 34% 50% What proportion of the population has an IQ of less than 84??
40 Standard normal transformation You can calculate the proportion above or below or between any (2) point(2) for any normal curve. z(x) = x " x" First, calculate how many SD a value is from s mean. Then look up value in table. z(108) = 108 " =
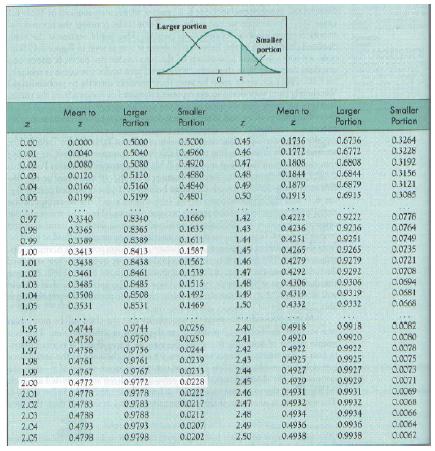
41
42 Normal curves as gateway to inferential statistic Given the distribution of normal curves, you can now identify the likelihood that two means come from the same population. Imagine you want to know if jetlag results in poor test taking ability. You test some kids who just flew from Edinburgh to Chicago. You know the population mean is 100 with SD=16. The sample you draw has a mean test result of 84. What can we conclude? We know that 16% of the general population has an IQ of 84 or below, so you want to know the chances of drawing, at random, a sample with mean IQ of 84. If the chances are p >.05 (or whatever cut off you want to use) you d conclude that jetlag doesn t have a reliable effect on IQ. If p <.05 you would conclude that it does. That is statistical significance!!!
43 Sources of Variability There are two sources of variability in your data. Variability caused by subjects and items (individual differences) Variability induced by your manipulation To find a statistically significant effect, you want the variation between conditions to be greater than within conditions. Note: if you don t have variance in your data (e.g., cuz the program is deterministic and always behaves the same way) inferential stats might not be for you.
44 Variability of results median High variability (between 2 conditions) Medium variability Low variability (difference between conditions is reliable and can be generalized)
45 Tests for finding differences Hour 2.2
46 Comparing two means If you are interested in knowing whether your two conditions differ from one another AND you have only 2 conditions. Evaluates the influence of your Independent Variable on your Dependent Variable.
47 Test options: 2 conditions Parametric data: the popular t-test 1 sample Independent pairs related pairs Non-parametric equivalents Related pairs Independent pairs
48 1-sample t-test Compares mean of sample data to theoretical population mean. Standard error used to gauge the variability between sample and population means. The difference between the sample mean and the hypothesized population mean must be greater than the normal variance found within the population to conclude that you have a significant effect of the IV. Standard error small, samples should have similar means; SE large, large diffs in means by chance are possible. µ=estimated pop mean t = X " µ standarderror ofmean Parametric tests of differences
49 How big is your t? How large should the t-statistic be? The probability of a difference reflecting a REAL effect is determined by the characteristics of the particular curve. Z and t curves are normal curves. F and χ 2 are positively skewed curves. P-values are sensitive to the size of the sample, so a t of 2.5 might be significant for a large N but not for a small N. Tables or statistical programs relate t-values, degrees of Freedom and test statistics.
50 Independent samples t-test Compares means of two independent groups (between-design). Same underlying principle (signal-to-noise) based on standard errors. Bigger t-value --> larger effects t = (X "Y) " (µ 1 "µ 2 ) Estimateof SE of difference between two sample means Parametric tests of differences
51 Related t-test Compares the means of two related groups; either matched-pairs withinsubjects designs. Test the same person in both conditions. Reduce the amount of unsystematic variation introduced into the experiment. Parametric tests of differences
52 Non-parametric tests Most non-parametric tests work on the principle of ranking the data. The analysis is conducted on the ranks, rather than the data itself. We lose information on effect magnitude, thus non-parametric tests are less powerful than parametric counterparts. Increased chance of type-ii error (false negative) Non-parametric tests of differences
53 Ranking the Responses Cond 1 Rank Cond 2 Rank Sub1a/b Sub2a/b Sub3a/b Sub4a/b Non-parametric tests of differences
54 Non-parametric tests Mann-Whitney: 2 independent pairs test. Operates on ranking the responses, independent of condition membership. Equal sample size not required. Wilcoxon sign ranked: 2 related pairs rank the absolute value of differences from a pair Equal sample size required Non-parametric tests of differences
55 Sign Test Alternative to either the 2 related or 2 independent (with random pairing) nonparametric tests. Requires equal sample size. Simply counts number of positive vs. negative differences between conditions. If no difference, 50/50 split expected. Calculate the P (n +) Non-parametric tests of differences
56 Comparing more than two means Hour 2.85
57 ANOVA Analysis of Variance Similar to t-test in that it also calculates a Signal-to-noise ratio, F. Signal = variance between conditions Noise = variance within conditions Can analyze more than 2 levels of a factor. Not appropriate to simply conduct multiple t-tests because of inflation of p-value. Can analyze more than 1 factor. Can reveal interactions between factors. Parametric tests for more than 2 conditions
58 1-way ANOVA Analogue to independent groups t-test for 3 or more levels of one factor. A 1-way anova with 2 levels is equivalent to a t-test. P-values the same: F=t 2 Sum of Squares df Mean Square F Sig. Between Groups , ,04 8 8,979,000 Within Groups , ,776 Total , Parametric tests for more than 2 conditions
59 ANCOVA Analysis of Covariance If you have continuous variable that was not manipulated but that might add variance, like word frequency, subject age, years of programming experience, sentence length, etc you can factor out the variance attributed to this covariate. This removes the error variance and makes a large ratio more likely. Available for independent and repeated measures variants Parametric tests for more than 2 conditions
60 Factorial univariate ANOVA When you have more than one IV but the analysis remains between subjects. This analysis allows you to test the main effect of each independent variable and also the interaction between the variables. If you have multiple dependent variables, you can use multivariate anova. Parametric tests for more than 2 conditions
61 Repeated Measures Anova Within subjects This analysis is appropriate for data from just 1 IV, multiple IVs, for mixed designs and can factor out covariates. Parametric tests for more than 2 conditions
62 Main effects and interactions Let s assume we have 2 factors with 2 levels each that we manipulated in an experiment: Factor one: lexical frequency of words (high frequency and low frequency) Factor two: word length (long words and short words) We measured reaction times for a naming task. In a repeated measures ANOVA we can potentially find 2 main effects and 1 interaction Interactions
63 Main effects and interactions Main effect of word length (long words 350 ms, short words 250 ms) No main effect of frequency (high frequency 300 ms, low frequency 300 ms) Interaction between word length and frequency (i.e., frequency has a different influence on long words and short words) high frequency low frequency short words long words Interactions
64 Interactions
65 Interactions Interactions indicate that independent variable X influences the dependent variable differently depending on the level of independent variable Y. Interpret your main effects with the consideration of the interaction. You can have an interaction with no main effects. Interactions
66 Types of interactions Antagonistic interaction: the two independent variables reverse each other s effects. Synergistic interaction: a higher level of B enhances the effect of A. Ceiling-effect interaction: the higher level of B reduces the differential effect of A. Interactions
67 Antagonistic Interaction B1 B2 main Effect of A the two independent variables reverse each other s effects. 0 A1 A2 Interactions
68 Synergistic Interaction B1 B2 main Effect of A a higher level of B enhances the effect of A. 0 A1 A2 Interactions
69 Ceiling-effect Interaction B1 B2 main Effect of A The higher level of B reduces the differential effect of A. 0 A1 A2 Interactions
70 Interpreting Interactions If you want to say that two factors influence each other, you need to demonstrate an interaction If you want to say that a factor affects two DVs differently, you need to demonstrate an interaction. Interactions
71 Non-parametric alternatives If you have 1 independent variable with more than 2 levels (K levels): Kruskal Wallis independent test for between designs Friedman related samples test for within designs. Non-parametric tests of more than 2 conditions
72 Pearson s Chi-squared Appropriate if: 1 Categorical Dependent Variable (dichotomous data) 2 Independent variables with at least 2 levels Detects whether there is a significant association between two variables (no causality) Assumptions: Each person or case contributes to only one cell of the contingency table. Not appropriate for repeated measures. takes raw data, not proportions. Values in all cells should be > 5 (else do fisher s exact test) Non-parametric tests of more than 2 conditions
73 Hierarchical Loglinear Analysis If you have more than 3 Independent Variables and are interested in the Higher Order Interactions. Designed to analyze multi-way contingency tables Table entries are frequencies Functionally similar to χ 2 Non-parametric tests of more than 2 conditions
74 Summary for anovas If you have 1 independent factor with K levels between subjects: 1-way ANOVA If you have a covarying factor and one or more between subjects independent factors, use univariate ANOVA If you have repeated measures design, with 1 or more manipulated factors, with or without a covariate or an additional between subjects factor, use Repeated Measures
75 Correlations & Linear Regressions Hour 3.25
76 Question Are two conditions different? What relationship exists between two or more variables? Positively related: as x goes, so goes y. Negatively related: whatever x does, y does the opposite. No relationship. Correlations
77 Example of linear correlation 3000 Advertsing Budget (thousands of pounds) Record S ales (thousand s) Correlations
78 Covariance An association is indexed by covariance. Are changes in one variable met with a similar or opposite change in another variable? Variance (s 2 ) = SS/N-1 SS = #( x i " x) 2 We squared the error scores when looking for variance within one variable. If interested in the association between two variables, we multiply the error scores together. Correlations
79 Calculating Covariance If deviations from the mean go in the same directions for both variables, you ll get a positive number. If deviations from the mean go in opposite directions (one negative, one positive) you ll get a negative number. cov(x, y) = # ( x i " x) ( y i " y) N "1 Correlations
80 Interpreting linear relations Correlation coefficient [r] = linear relationship between two variables. Measures the amount of spread around an imaginary line through the center. r 2 = proportion of common variation in the two variables (strength or magnitude of the relationship). Proportion of the variance in 1 set of score that can be accounted for by knowing X. Outliers? A single outlier can greatly influence the strength of a correlation. Correlations
.")
81 Effect of outliers One approach to dealing with outliers is to see if they are non-representative (i.e., at the far end of the normal distribution). If so, they should be removed. Correlations
82 Types of correlations Bivariate correlation: between two variable Pearson s correlation coefficient for parametric data (interval or ratio data) Partial correlation: relationship between two variables while controlling the effect of one or more additional variables. Biserial correlation: when one variable is dichotomous (e.g., alive vs. dead, male vs. female) Correlations
83 Drawing conclusions Correlations only inform us about a relationship between two or more variables. Not able to talk about directionality or causality. An increase in X does not CAUSE an increase in Y or vise versa. Cause could be from unmeasured third variable. Correlations
84 R 2 By squaring our test statistic, we can tell how much of total variance in the data for variable x is in common with variable y. R 2 = =.056 = 5.6% of variance. (94% of variability still unaccounted for!) = = 58% Correlations
85 Non-parametric correlations Spearman s Rho For non-interval data Ranks the data and then applies Pearson s equation to ranks. Kendall s Tau Preferred for small data sets with many tied rankings. Correlations
86 Simple Linear Regressions Hour 2.75
87 Regressions Correlations detect associations between two variables. Say nothing of causal relationships or directionality Can t predict behavior on one variable given a value behavior for another variable With Regression models we can predict variable Y based on variable X. Regressions
88 Simple Linear Regressions A line is fit to the data (similar to the correlations line). Best line is one that produces the smallest sum of squares from regression line to data points. Evaluation based on improvement of prediction relative to using the mean. Regressions
89 Hypothetical Data Predictor variable outcome variable Mean Regressions
90 Error from Mean Predictor variable outcome variable Mean Regressions
91 Predictor variable Error from regression line outcome variable Regression line Mean Regressions
92 Regression Results The best regression line has the lowest sum of squared errors Evaluation of the regression model is achieved via R 2 = tells you % of variance accounted for by the regression line (as with correlations) F = Evaluates improvement of regression line compared to the mean as a model of the data. Regressions
93 Predicting New Values Equation for line: Y - output value X = predictor value β0 = intercept (constant. Value of Y without predictors) β1 = slope of line (value for predictor) ε = residual (error) Y = " 0 + " 1 X i + # i Regressions
94 Multiple Regression Extends principles of simple linear regression to situation with multiple predictor variables. We seek to find the linear combination of predictors that correlate maximally with the outcome variable. Y = " 0 + " 1 X i + " n X n + # i Predictor 1 Predictor 2 Regression
95 Multiple Regression, con t R 2 gives the % variance accounted for by the model consisting of the multiple predictors. T-test tell you independent contribution of each predictor in capturing data. Logistic Regressions are appropriate for dichotomous data! Regressions
96 Adjusted R 2 = variance in Pop R 2 & Adjusted R 2 should be similar Is the model an improvement over the mean or over a prior model? β = Change in outcome resulting in change in predictor Tests that line isn t horizontal Regressions
97 Improvement over mean Improvement over 1st block Degree each predictor effects outcome if effects of other predictors held constant T-test gives impression of whether new predictors improve model Units expressed as standard deviation for better comparison
98 Summary You should know which of the common tests are applicable to what types of data, designs and questions. You should also have enough background knowledge to help you understand what you read on-line or in statistics books. You should have an idea which tests might be useful for the type of data you have.
99 Informative Websites for spss videos! stics/investigating.htm Or, just google the test you are interested in.
CHAPTER 17 CHI-SQUARE AND OTHER NONPARAMETRIC TESTS FROM: PAGANO, R. R. (2007)
") FROM: PAGANO, R. R. (007) I. INTRODUCTION: DISTINCTION BETWEEN PARAMETRIC AND NON-PARAMETRIC TESTS Statistical inference tests are often classified as to whether they are parametric or nonparametric Parameter
FROM: PAGANO, R. R. (007) I. INTRODUCTION: DISTINCTION BETWEEN PARAMETRIC AND NON-PARAMETRIC TESTS Statistical inference tests are often classified as to whether they are parametric or nonparametric Parameter
Parametric versus Nonparametric Statistics-when to use them and which is more powerful? Dr Mahmoud Alhussami
 Parametric versus Nonparametric Statistics-when to use them and which is more powerful? Dr Mahmoud Alhussami Parametric Assumptions The observations must be independent. Dependent variable should be continuous
Parametric versus Nonparametric Statistics-when to use them and which is more powerful? Dr Mahmoud Alhussami Parametric Assumptions The observations must be independent. Dependent variable should be continuous
Glossary. The ISI glossary of statistical terms provides definitions in a number of different languages:
 Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
Textbook Examples of. SPSS Procedure
 Textbook s of IBM SPSS Procedures Each SPSS procedure listed below has its own section in the textbook. These sections include a purpose statement that describes the statistical test, identification of
Textbook s of IBM SPSS Procedures Each SPSS procedure listed below has its own section in the textbook. These sections include a purpose statement that describes the statistical test, identification of
Contents. Acknowledgments. xix
 Table of Preface Acknowledgments page xv xix 1 Introduction 1 The Role of the Computer in Data Analysis 1 Statistics: Descriptive and Inferential 2 Variables and Constants 3 The Measurement of Variables
Table of Preface Acknowledgments page xv xix 1 Introduction 1 The Role of the Computer in Data Analysis 1 Statistics: Descriptive and Inferential 2 Variables and Constants 3 The Measurement of Variables
Degrees of freedom df=1. Limitations OR in SPSS LIM: Knowing σ and µ is unlikely in large
 Z Test Comparing a group mean to a hypothesis T test (about 1 mean) T test (about 2 means) Comparing mean to sample mean. Similar means = will have same response to treatment Two unknown means are different
Z Test Comparing a group mean to a hypothesis T test (about 1 mean) T test (about 2 means) Comparing mean to sample mean. Similar means = will have same response to treatment Two unknown means are different
DETAILED CONTENTS PART I INTRODUCTION AND DESCRIPTIVE STATISTICS. 1. Introduction to Statistics
 DETAILED CONTENTS About the Author Preface to the Instructor To the Student How to Use SPSS With This Book PART I INTRODUCTION AND DESCRIPTIVE STATISTICS 1. Introduction to Statistics 1.1 Descriptive and
DETAILED CONTENTS About the Author Preface to the Instructor To the Student How to Use SPSS With This Book PART I INTRODUCTION AND DESCRIPTIVE STATISTICS 1. Introduction to Statistics 1.1 Descriptive and
Types of Statistical Tests DR. MIKE MARRAPODI
 Types of Statistical Tests DR. MIKE MARRAPODI Tests t tests ANOVA Correlation Regression Multivariate Techniques Non-parametric t tests One sample t test Independent t test Paired sample t test One sample
Types of Statistical Tests DR. MIKE MARRAPODI Tests t tests ANOVA Correlation Regression Multivariate Techniques Non-parametric t tests One sample t test Independent t test Paired sample t test One sample
Non-parametric tests, part A:
 Two types of statistical test: Non-parametric tests, part A: Parametric tests: Based on assumption that the data have certain characteristics or "parameters": Results are only valid if (a) the data are
Two types of statistical test: Non-parametric tests, part A: Parametric tests: Based on assumption that the data have certain characteristics or "parameters": Results are only valid if (a) the data are
DISCOVERING STATISTICS USING R
 DISCOVERING STATISTICS USING R ANDY FIELD I JEREMY MILES I ZOE FIELD Los Angeles London New Delhi Singapore j Washington DC CONTENTS Preface How to use this book Acknowledgements Dedication Symbols used
DISCOVERING STATISTICS USING R ANDY FIELD I JEREMY MILES I ZOE FIELD Los Angeles London New Delhi Singapore j Washington DC CONTENTS Preface How to use this book Acknowledgements Dedication Symbols used
Hypothesis testing, part 2. With some material from Howard Seltman, Blase Ur, Bilge Mutlu, Vibha Sazawal
 Hypothesis testing, part 2 With some material from Howard Seltman, Blase Ur, Bilge Mutlu, Vibha Sazawal 1 CATEGORICAL IV, NUMERIC DV 2 Independent samples, one IV # Conditions Normal/Parametric Non-parametric
Hypothesis testing, part 2 With some material from Howard Seltman, Blase Ur, Bilge Mutlu, Vibha Sazawal 1 CATEGORICAL IV, NUMERIC DV 2 Independent samples, one IV # Conditions Normal/Parametric Non-parametric
Data Analysis as a Decision Making Process
 Data Analysis as a Decision Making Process I. Levels of Measurement A. NOIR - Nominal Categories with names - Ordinal Categories with names and a logical order - Intervals Numerical Scale with logically
Data Analysis as a Decision Making Process I. Levels of Measurement A. NOIR - Nominal Categories with names - Ordinal Categories with names and a logical order - Intervals Numerical Scale with logically
Inferences About the Difference Between Two Means
 7 Inferences About the Difference Between Two Means Chapter Outline 7.1 New Concepts 7.1.1 Independent Versus Dependent Samples 7.1. Hypotheses 7. Inferences About Two Independent Means 7..1 Independent
7 Inferences About the Difference Between Two Means Chapter Outline 7.1 New Concepts 7.1.1 Independent Versus Dependent Samples 7.1. Hypotheses 7. Inferences About Two Independent Means 7..1 Independent
NON-PARAMETRIC STATISTICS * (http://www.statsoft.com)
") NON-PARAMETRIC STATISTICS * (http://www.statsoft.com) 1. GENERAL PURPOSE 1.1 Brief review of the idea of significance testing To understand the idea of non-parametric statistics (the term non-parametric
NON-PARAMETRIC STATISTICS * (http://www.statsoft.com) 1. GENERAL PURPOSE 1.1 Brief review of the idea of significance testing To understand the idea of non-parametric statistics (the term non-parametric
Workshop Research Methods and Statistical Analysis
 Workshop Research Methods and Statistical Analysis Session 2 Data Analysis Sandra Poeschl 08.04.2013 Page 1 Research process Research Question State of Research / Theoretical Background Design Data Collection
Workshop Research Methods and Statistical Analysis Session 2 Data Analysis Sandra Poeschl 08.04.2013 Page 1 Research process Research Question State of Research / Theoretical Background Design Data Collection
Basic Statistical Analysis
 indexerrt.qxd 8/21/2002 9:47 AM Page 1 Corrected index pages for Sprinthall Basic Statistical Analysis Seventh Edition indexerrt.qxd 8/21/2002 9:47 AM Page 656 Index Abscissa, 24 AB-STAT, vii ADD-OR rule,
indexerrt.qxd 8/21/2002 9:47 AM Page 1 Corrected index pages for Sprinthall Basic Statistical Analysis Seventh Edition indexerrt.qxd 8/21/2002 9:47 AM Page 656 Index Abscissa, 24 AB-STAT, vii ADD-OR rule,
Nonparametric statistic methods. Waraphon Phimpraphai DVM, PhD Department of Veterinary Public Health
 Nonparametric statistic methods Waraphon Phimpraphai DVM, PhD Department of Veterinary Public Health Measurement What are the 4 levels of measurement discussed? 1. Nominal or Classificatory Scale Gender,
Nonparametric statistic methods Waraphon Phimpraphai DVM, PhD Department of Veterinary Public Health Measurement What are the 4 levels of measurement discussed? 1. Nominal or Classificatory Scale Gender,
Intro to Parametric & Nonparametric Statistics
 Kinds of variable The classics & some others Intro to Parametric & Nonparametric Statistics Kinds of variables & why we care Kinds & definitions of nonparametric statistics Where parametric stats come
Kinds of variable The classics & some others Intro to Parametric & Nonparametric Statistics Kinds of variables & why we care Kinds & definitions of nonparametric statistics Where parametric stats come
My data doesn t look like that..
 Testing assumptions My data doesn t look like that.. We have made a big deal about testing model assumptions each week. Bill Pine Testing assumptions Testing assumptions We have made a big deal about testing
Testing assumptions My data doesn t look like that.. We have made a big deal about testing model assumptions each week. Bill Pine Testing assumptions Testing assumptions We have made a big deal about testing
Analyses of Variance. Block 2b
 Analyses of Variance Block 2b Types of analyses 1 way ANOVA For more than 2 levels of a factor between subjects ANCOVA For continuous co-varying factor, between subjects ANOVA for factorial design Multiple
Analyses of Variance Block 2b Types of analyses 1 way ANOVA For more than 2 levels of a factor between subjects ANCOVA For continuous co-varying factor, between subjects ANOVA for factorial design Multiple
Introduction to Statistics with GraphPad Prism 7
 Introduction to Statistics with GraphPad Prism 7 Outline of the course Power analysis with G*Power Basic structure of a GraphPad Prism project Analysis of qualitative data Chi-square test Analysis of quantitative
Introduction to Statistics with GraphPad Prism 7 Outline of the course Power analysis with G*Power Basic structure of a GraphPad Prism project Analysis of qualitative data Chi-square test Analysis of quantitative
Nemours Biomedical Research Statistics Course. Li Xie Nemours Biostatistics Core October 14, 2014
 Nemours Biomedical Research Statistics Course Li Xie Nemours Biostatistics Core October 14, 2014 Outline Recap Introduction to Logistic Regression Recap Descriptive statistics Variable type Example of
Nemours Biomedical Research Statistics Course Li Xie Nemours Biostatistics Core October 14, 2014 Outline Recap Introduction to Logistic Regression Recap Descriptive statistics Variable type Example of
CHI SQUARE ANALYSIS 8/18/2011 HYPOTHESIS TESTS SO FAR PARAMETRIC VS. NON-PARAMETRIC
 CHI SQUARE ANALYSIS I N T R O D U C T I O N T O N O N - P A R A M E T R I C A N A L Y S E S HYPOTHESIS TESTS SO FAR We ve discussed One-sample t-test Dependent Sample t-tests Independent Samples t-tests
CHI SQUARE ANALYSIS I N T R O D U C T I O N T O N O N - P A R A M E T R I C A N A L Y S E S HYPOTHESIS TESTS SO FAR We ve discussed One-sample t-test Dependent Sample t-tests Independent Samples t-tests
Glossary for the Triola Statistics Series
 Glossary for the Triola Statistics Series Absolute deviation The measure of variation equal to the sum of the deviations of each value from the mean, divided by the number of values Acceptance sampling
Glossary for the Triola Statistics Series Absolute deviation The measure of variation equal to the sum of the deviations of each value from the mean, divided by the number of values Acceptance sampling
ESP 178 Applied Research Methods. 2/23: Quantitative Analysis
 ESP 178 Applied Research Methods 2/23: Quantitative Analysis Data Preparation Data coding create codebook that defines each variable, its response scale, how it was coded Data entry for mail surveys and
ESP 178 Applied Research Methods 2/23: Quantitative Analysis Data Preparation Data coding create codebook that defines each variable, its response scale, how it was coded Data entry for mail surveys and
Understand the difference between symmetric and asymmetric measures
 Chapter 9 Measures of Strength of a Relationship Learning Objectives Understand the strength of association between two variables Explain an association from a table of joint frequencies Understand a proportional
Chapter 9 Measures of Strength of a Relationship Learning Objectives Understand the strength of association between two variables Explain an association from a table of joint frequencies Understand a proportional
Readings Howitt & Cramer (2014) Overview
 Overview") Readings Howitt & Cramer (4) Ch 7: Relationships between two or more variables: Diagrams and tables Ch 8: Correlation coefficients: Pearson correlation and Spearman s rho Ch : Statistical significance
Readings Howitt & Cramer (4) Ch 7: Relationships between two or more variables: Diagrams and tables Ch 8: Correlation coefficients: Pearson correlation and Spearman s rho Ch : Statistical significance
Nonparametric Statistics. Leah Wright, Tyler Ross, Taylor Brown
 Nonparametric Statistics Leah Wright, Tyler Ross, Taylor Brown Before we get to nonparametric statistics, what are parametric statistics? These statistics estimate and test population means, while holding
Nonparametric Statistics Leah Wright, Tyler Ross, Taylor Brown Before we get to nonparametric statistics, what are parametric statistics? These statistics estimate and test population means, while holding
PSY 307 Statistics for the Behavioral Sciences. Chapter 20 Tests for Ranked Data, Choosing Statistical Tests
 PSY 307 Statistics for the Behavioral Sciences Chapter 20 Tests for Ranked Data, Choosing Statistical Tests What To Do with Non-normal Distributions Tranformations (pg 382): The shape of the distribution
PSY 307 Statistics for the Behavioral Sciences Chapter 20 Tests for Ranked Data, Choosing Statistical Tests What To Do with Non-normal Distributions Tranformations (pg 382): The shape of the distribution
Repeated-Measures ANOVA in SPSS Correct data formatting for a repeated-measures ANOVA in SPSS involves having a single line of data for each
 Repeated-Measures ANOVA in SPSS Correct data formatting for a repeated-measures ANOVA in SPSS involves having a single line of data for each participant, with the repeated measures entered as separate
Repeated-Measures ANOVA in SPSS Correct data formatting for a repeated-measures ANOVA in SPSS involves having a single line of data for each participant, with the repeated measures entered as separate
Introduction to Statistical Analysis
 Introduction to Statistical Analysis Changyu Shen Richard A. and Susan F. Smith Center for Outcomes Research in Cardiology Beth Israel Deaconess Medical Center Harvard Medical School Objectives Descriptive
Introduction to Statistical Analysis Changyu Shen Richard A. and Susan F. Smith Center for Outcomes Research in Cardiology Beth Israel Deaconess Medical Center Harvard Medical School Objectives Descriptive
SPSS Guide For MMI 409
 SPSS Guide For MMI 409 by John Wong March 2012 Preface Hopefully, this document can provide some guidance to MMI 409 students on how to use SPSS to solve many of the problems covered in the D Agostino
SPSS Guide For MMI 409 by John Wong March 2012 Preface Hopefully, this document can provide some guidance to MMI 409 students on how to use SPSS to solve many of the problems covered in the D Agostino
Introduction and Descriptive Statistics p. 1 Introduction to Statistics p. 3 Statistics, Science, and Observations p. 5 Populations and Samples p.
 Preface p. xi Introduction and Descriptive Statistics p. 1 Introduction to Statistics p. 3 Statistics, Science, and Observations p. 5 Populations and Samples p. 6 The Scientific Method and the Design of
Preface p. xi Introduction and Descriptive Statistics p. 1 Introduction to Statistics p. 3 Statistics, Science, and Observations p. 5 Populations and Samples p. 6 The Scientific Method and the Design of
Turning a research question into a statistical question.
 Turning a research question into a statistical question. IGINAL QUESTION: Concept Concept Concept ABOUT ONE CONCEPT ABOUT RELATIONSHIPS BETWEEN CONCEPTS TYPE OF QUESTION: DESCRIBE what s going on? DECIDE
Turning a research question into a statistical question. IGINAL QUESTION: Concept Concept Concept ABOUT ONE CONCEPT ABOUT RELATIONSHIPS BETWEEN CONCEPTS TYPE OF QUESTION: DESCRIBE what s going on? DECIDE
Readings Howitt & Cramer (2014)
") Readings Howitt & Cramer (014) Ch 7: Relationships between two or more variables: Diagrams and tables Ch 8: Correlation coefficients: Pearson correlation and Spearman s rho Ch 11: Statistical significance
Readings Howitt & Cramer (014) Ch 7: Relationships between two or more variables: Diagrams and tables Ch 8: Correlation coefficients: Pearson correlation and Spearman s rho Ch 11: Statistical significance
N Utilization of Nursing Research in Advanced Practice, Summer 2008
 University of Michigan Deep Blue deepblue.lib.umich.edu 2008-07 536 - Utilization of ursing Research in Advanced Practice, Summer 2008 Tzeng, Huey-Ming Tzeng, H. (2008, ctober 1). Utilization of ursing
University of Michigan Deep Blue deepblue.lib.umich.edu 2008-07 536 - Utilization of ursing Research in Advanced Practice, Summer 2008 Tzeng, Huey-Ming Tzeng, H. (2008, ctober 1). Utilization of ursing
psyc3010 lecture 2 factorial between-ps ANOVA I: omnibus tests
 psyc3010 lecture 2 factorial between-ps ANOVA I: omnibus tests last lecture: introduction to factorial designs next lecture: factorial between-ps ANOVA II: (effect sizes and follow-up tests) 1 general
psyc3010 lecture 2 factorial between-ps ANOVA I: omnibus tests last lecture: introduction to factorial designs next lecture: factorial between-ps ANOVA II: (effect sizes and follow-up tests) 1 general
REVIEW 8/2/2017 陈芳华东师大英语系
 REVIEW Hypothesis testing starts with a null hypothesis and a null distribution. We compare what we have to the null distribution, if the result is too extreme to belong to the null distribution (p
REVIEW Hypothesis testing starts with a null hypothesis and a null distribution. We compare what we have to the null distribution, if the result is too extreme to belong to the null distribution (p
Exam details. Final Review Session. Things to Review
 Exam details Final Review Session Short answer, similar to book problems Formulae and tables will be given You CAN use a calculator Date and Time: Dec. 7, 006, 1-1:30 pm Location: Osborne Centre, Unit
Exam details Final Review Session Short answer, similar to book problems Formulae and tables will be given You CAN use a calculator Date and Time: Dec. 7, 006, 1-1:30 pm Location: Osborne Centre, Unit
Statistics: revision
 NST 1B Experimental Psychology Statistics practical 5 Statistics: revision Rudolf Cardinal & Mike Aitken 29 / 30 April 2004 Department of Experimental Psychology University of Cambridge Handouts: Answers
NST 1B Experimental Psychology Statistics practical 5 Statistics: revision Rudolf Cardinal & Mike Aitken 29 / 30 April 2004 Department of Experimental Psychology University of Cambridge Handouts: Answers
One-Way ANOVA Cohen Chapter 12 EDUC/PSY 6600
 One-Way ANOVA Cohen Chapter 1 EDUC/PSY 6600 1 It is easy to lie with statistics. It is hard to tell the truth without statistics. -Andrejs Dunkels Motivating examples Dr. Vito randomly assigns 30 individuals
One-Way ANOVA Cohen Chapter 1 EDUC/PSY 6600 1 It is easy to lie with statistics. It is hard to tell the truth without statistics. -Andrejs Dunkels Motivating examples Dr. Vito randomly assigns 30 individuals
Review. Number of variables. Standard Scores. Anecdotal / Clinical. Bivariate relationships. Ch. 3: Correlation & Linear Regression
 Ch. 3: Correlation & Relationships between variables Scatterplots Exercise Correlation Race / DNA Review Why numbers? Distribution & Graphs : Histogram Central Tendency Mean (SD) The Central Limit Theorem
Ch. 3: Correlation & Relationships between variables Scatterplots Exercise Correlation Race / DNA Review Why numbers? Distribution & Graphs : Histogram Central Tendency Mean (SD) The Central Limit Theorem
Chapter 15: Nonparametric Statistics Section 15.1: An Overview of Nonparametric Statistics
 Section 15.1: An Overview of Nonparametric Statistics Understand Difference between Parametric and Nonparametric Statistical Procedures Parametric statistical procedures inferential procedures that rely
Section 15.1: An Overview of Nonparametric Statistics Understand Difference between Parametric and Nonparametric Statistical Procedures Parametric statistical procedures inferential procedures that rely
Chapter Fifteen. Frequency Distribution, Cross-Tabulation, and Hypothesis Testing
 Chapter Fifteen Frequency Distribution, Cross-Tabulation, and Hypothesis Testing Copyright 2010 Pearson Education, Inc. publishing as Prentice Hall 15-1 Internet Usage Data Table 15.1 Respondent Sex Familiarity
Chapter Fifteen Frequency Distribution, Cross-Tabulation, and Hypothesis Testing Copyright 2010 Pearson Education, Inc. publishing as Prentice Hall 15-1 Internet Usage Data Table 15.1 Respondent Sex Familiarity
Statistical. Psychology
 SEVENTH у *i km m it* & П SB Й EDITION Statistical M e t h o d s for Psychology D a v i d C. Howell University of Vermont ; \ WADSWORTH f% CENGAGE Learning* Australia Biaall apan Korea Меяко Singapore
SEVENTH у *i km m it* & П SB Й EDITION Statistical M e t h o d s for Psychology D a v i d C. Howell University of Vermont ; \ WADSWORTH f% CENGAGE Learning* Australia Biaall apan Korea Меяко Singapore
sphericity, 5-29, 5-32 residuals, 7-1 spread and level, 2-17 t test, 1-13 transformations, 2-15 violations, 1-19
 additive tree structure, 10-28 ADDTREE, 10-51, 10-53 EXTREE, 10-31 four point condition, 10-29 ADDTREE, 10-28, 10-51, 10-53 adjusted R 2, 8-7 ALSCAL, 10-49 ANCOVA, 9-1 assumptions, 9-5 example, 9-7 MANOVA
additive tree structure, 10-28 ADDTREE, 10-51, 10-53 EXTREE, 10-31 four point condition, 10-29 ADDTREE, 10-28, 10-51, 10-53 adjusted R 2, 8-7 ALSCAL, 10-49 ANCOVA, 9-1 assumptions, 9-5 example, 9-7 MANOVA
ANCOVA. Lecture 9 Andrew Ainsworth
 ANCOVA Lecture 9 Andrew Ainsworth What is ANCOVA? Analysis of covariance an extension of ANOVA in which main effects and interactions are assessed on DV scores after the DV has been adjusted for by the
ANCOVA Lecture 9 Andrew Ainsworth What is ANCOVA? Analysis of covariance an extension of ANOVA in which main effects and interactions are assessed on DV scores after the DV has been adjusted for by the
Multiple Linear Regression II. Lecture 8. Overview. Readings
 Multiple Linear Regression II Lecture 8 Image source:https://commons.wikimedia.org/wiki/file:autobunnskr%c3%a4iz-ro-a201.jpg Survey Research & Design in Psychology James Neill, 2016 Creative Commons Attribution
Multiple Linear Regression II Lecture 8 Image source:https://commons.wikimedia.org/wiki/file:autobunnskr%c3%a4iz-ro-a201.jpg Survey Research & Design in Psychology James Neill, 2016 Creative Commons Attribution
Multiple Linear Regression II. Lecture 8. Overview. Readings. Summary of MLR I. Summary of MLR I. Summary of MLR I
 Multiple Linear Regression II Lecture 8 Image source:https://commons.wikimedia.org/wiki/file:autobunnskr%c3%a4iz-ro-a201.jpg Survey Research & Design in Psychology James Neill, 2016 Creative Commons Attribution
Multiple Linear Regression II Lecture 8 Image source:https://commons.wikimedia.org/wiki/file:autobunnskr%c3%a4iz-ro-a201.jpg Survey Research & Design in Psychology James Neill, 2016 Creative Commons Attribution
Data are sometimes not compatible with the assumptions of parametric statistical tests (i.e. t-test, regression, ANOVA)
") BSTT523 Pagano & Gauvreau Chapter 13 1 Nonparametric Statistics Data are sometimes not compatible with the assumptions of parametric statistical tests (i.e. t-test, regression, ANOVA) In particular, data
BSTT523 Pagano & Gauvreau Chapter 13 1 Nonparametric Statistics Data are sometimes not compatible with the assumptions of parametric statistical tests (i.e. t-test, regression, ANOVA) In particular, data
Correlation. A statistics method to measure the relationship between two variables. Three characteristics
 Correlation Correlation A statistics method to measure the relationship between two variables Three characteristics Direction of the relationship Form of the relationship Strength/Consistency Direction
Correlation Correlation A statistics method to measure the relationship between two variables Three characteristics Direction of the relationship Form of the relationship Strength/Consistency Direction
Chapter 16. Simple Linear Regression and Correlation
 Chapter 16 Simple Linear Regression and Correlation 16.1 Regression Analysis Our problem objective is to analyze the relationship between interval variables; regression analysis is the first tool we will
Chapter 16 Simple Linear Regression and Correlation 16.1 Regression Analysis Our problem objective is to analyze the relationship between interval variables; regression analysis is the first tool we will
Can you tell the relationship between students SAT scores and their college grades?
 Correlation One Challenge Can you tell the relationship between students SAT scores and their college grades? A: The higher SAT scores are, the better GPA may be. B: The higher SAT scores are, the lower
Correlation One Challenge Can you tell the relationship between students SAT scores and their college grades? A: The higher SAT scores are, the better GPA may be. B: The higher SAT scores are, the lower
Review of Statistics 101
 Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
Unit 14: Nonparametric Statistical Methods
 Unit 14: Nonparametric Statistical Methods Statistics 571: Statistical Methods Ramón V. León 8/8/2003 Unit 14 - Stat 571 - Ramón V. León 1 Introductory Remarks Most methods studied so far have been based
Unit 14: Nonparametric Statistical Methods Statistics 571: Statistical Methods Ramón V. León 8/8/2003 Unit 14 - Stat 571 - Ramón V. León 1 Introductory Remarks Most methods studied so far have been based
Nonparametric Statistics
 Nonparametric Statistics Nonparametric or Distribution-free statistics: used when data are ordinal (i.e., rankings) used when ratio/interval data are not normally distributed (data are converted to ranks)
Nonparametric Statistics Nonparametric or Distribution-free statistics: used when data are ordinal (i.e., rankings) used when ratio/interval data are not normally distributed (data are converted to ranks)
What is a Hypothesis?
 What is a Hypothesis? A hypothesis is a claim (assumption) about a population parameter: population mean Example: The mean monthly cell phone bill in this city is μ = $42 population proportion Example:
What is a Hypothesis? A hypothesis is a claim (assumption) about a population parameter: population mean Example: The mean monthly cell phone bill in this city is μ = $42 population proportion Example:
Rank-Based Methods. Lukas Meier
 Rank-Based Methods Lukas Meier 20.01.2014 Introduction Up to now we basically always used a parametric family, like the normal distribution N (µ, σ 2 ) for modeling random data. Based on observed data
Rank-Based Methods Lukas Meier 20.01.2014 Introduction Up to now we basically always used a parametric family, like the normal distribution N (µ, σ 2 ) for modeling random data. Based on observed data
R in Linguistic Analysis. Wassink 2012 University of Washington Week 6
 R in Linguistic Analysis Wassink 2012 University of Washington Week 6 Overview R for phoneticians and lab phonologists Johnson 3 Reading Qs Equivalence of means (t-tests) Multiple Regression Principal
R in Linguistic Analysis Wassink 2012 University of Washington Week 6 Overview R for phoneticians and lab phonologists Johnson 3 Reading Qs Equivalence of means (t-tests) Multiple Regression Principal
Psych 230. Psychological Measurement and Statistics
 Psych 230 Psychological Measurement and Statistics Pedro Wolf December 9, 2009 This Time. Non-Parametric statistics Chi-Square test One-way Two-way Statistical Testing 1. Decide which test to use 2. State
Psych 230 Psychological Measurement and Statistics Pedro Wolf December 9, 2009 This Time. Non-Parametric statistics Chi-Square test One-way Two-way Statistical Testing 1. Decide which test to use 2. State
Correlation and regression
 NST 1B Experimental Psychology Statistics practical 1 Correlation and regression Rudolf Cardinal & Mike Aitken 11 / 12 November 2003 Department of Experimental Psychology University of Cambridge Handouts:
NST 1B Experimental Psychology Statistics practical 1 Correlation and regression Rudolf Cardinal & Mike Aitken 11 / 12 November 2003 Department of Experimental Psychology University of Cambridge Handouts:
Everything is not normal
 Everything is not normal According to the dictionary, one thing is considered normal when it s in its natural state or conforms to standards set in advance. And this is its normal meaning. But, like many
Everything is not normal According to the dictionary, one thing is considered normal when it s in its natural state or conforms to standards set in advance. And this is its normal meaning. But, like many
Psych Jan. 5, 2005
 Psych 124 1 Wee 1: Introductory Notes on Variables and Probability Distributions (1/5/05) (Reading: Aron & Aron, Chaps. 1, 14, and this Handout.) All handouts are available outside Mija s office. Lecture
Psych 124 1 Wee 1: Introductory Notes on Variables and Probability Distributions (1/5/05) (Reading: Aron & Aron, Chaps. 1, 14, and this Handout.) All handouts are available outside Mija s office. Lecture
psychological statistics
 psychological statistics B Sc. Counselling Psychology 011 Admission onwards III SEMESTER COMPLEMENTARY COURSE UNIVERSITY OF CALICUT SCHOOL OF DISTANCE EDUCATION CALICUT UNIVERSITY.P.O., MALAPPURAM, KERALA,
psychological statistics B Sc. Counselling Psychology 011 Admission onwards III SEMESTER COMPLEMENTARY COURSE UNIVERSITY OF CALICUT SCHOOL OF DISTANCE EDUCATION CALICUT UNIVERSITY.P.O., MALAPPURAM, KERALA,
Difference in two or more average scores in different groups
 ANOVAs Analysis of Variance (ANOVA) Difference in two or more average scores in different groups Each participant tested once Same outcome tested in each group Simplest is one-way ANOVA (one variable as
ANOVAs Analysis of Variance (ANOVA) Difference in two or more average scores in different groups Each participant tested once Same outcome tested in each group Simplest is one-way ANOVA (one variable as
3. Nonparametric methods
 3. Nonparametric methods If the probability distributions of the statistical variables are unknown or are not as required (e.g. normality assumption violated), then we may still apply nonparametric tests
3. Nonparametric methods If the probability distributions of the statistical variables are unknown or are not as required (e.g. normality assumption violated), then we may still apply nonparametric tests
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model
 Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 1: August 22, 2012
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 1: August 22, 2012
ANOVA - analysis of variance - used to compare the means of several populations.
 12.1 One-Way Analysis of Variance ANOVA - analysis of variance - used to compare the means of several populations. Assumptions for One-Way ANOVA: 1. Independent samples are taken using a randomized design.
12.1 One-Way Analysis of Variance ANOVA - analysis of variance - used to compare the means of several populations. Assumptions for One-Way ANOVA: 1. Independent samples are taken using a randomized design.
Intuitive Biostatistics: Choosing a statistical test
 pagina 1 van 5 < BACK Intuitive Biostatistics: Choosing a statistical This is chapter 37 of Intuitive Biostatistics (ISBN 0-19-508607-4) by Harvey Motulsky. Copyright 1995 by Oxfd University Press Inc.
pagina 1 van 5 < BACK Intuitive Biostatistics: Choosing a statistical This is chapter 37 of Intuitive Biostatistics (ISBN 0-19-508607-4) by Harvey Motulsky. Copyright 1995 by Oxfd University Press Inc.
The goodness-of-fit test Having discussed how to make comparisons between two proportions, we now consider comparisons of multiple proportions.
 The goodness-of-fit test Having discussed how to make comparisons between two proportions, we now consider comparisons of multiple proportions. A common problem of this type is concerned with determining
The goodness-of-fit test Having discussed how to make comparisons between two proportions, we now consider comparisons of multiple proportions. A common problem of this type is concerned with determining
Analysis of variance (ANOVA) Comparing the means of more than two groups
 Comparing the means of more than two groups") Analysis of variance (ANOVA) Comparing the means of more than two groups Example: Cost of mating in male fruit flies Drosophila Treatments: place males with and without unmated (virgin) females Five treatments
Analysis of variance (ANOVA) Comparing the means of more than two groups Example: Cost of mating in male fruit flies Drosophila Treatments: place males with and without unmated (virgin) females Five treatments
Sociology 6Z03 Review II
 Sociology 6Z03 Review II John Fox McMaster University Fall 2016 John Fox (McMaster University) Sociology 6Z03 Review II Fall 2016 1 / 35 Outline: Review II Probability Part I Sampling Distributions Probability
Sociology 6Z03 Review II John Fox McMaster University Fall 2016 John Fox (McMaster University) Sociology 6Z03 Review II Fall 2016 1 / 35 Outline: Review II Probability Part I Sampling Distributions Probability
Basic IRT Concepts, Models, and Assumptions
 Basic IRT Concepts, Models, and Assumptions Lecture #2 ICPSR Item Response Theory Workshop Lecture #2: 1of 64 Lecture #2 Overview Background of IRT and how it differs from CFA Creating a scale An introduction
Basic IRT Concepts, Models, and Assumptions Lecture #2 ICPSR Item Response Theory Workshop Lecture #2: 1of 64 Lecture #2 Overview Background of IRT and how it differs from CFA Creating a scale An introduction
Week 7.1--IES 612-STA STA doc
 Week 7.1--IES 612-STA 4-573-STA 4-576.doc IES 612/STA 4-576 Winter 2009 ANOVA MODELS model adequacy aka RESIDUAL ANALYSIS Numeric data samples from t populations obtained Assume Y ij ~ independent N(μ
Week 7.1--IES 612-STA 4-573-STA 4-576.doc IES 612/STA 4-576 Winter 2009 ANOVA MODELS model adequacy aka RESIDUAL ANALYSIS Numeric data samples from t populations obtained Assume Y ij ~ independent N(μ
Course Review. Kin 304W Week 14: April 9, 2013
 Course Review Kin 304W Week 14: April 9, 2013 1 Today s Outline Format of Kin 304W Final Exam Course Review Hand back marked Project Part II 2 Kin 304W Final Exam Saturday, Thursday, April 18, 3:30-6:30
Course Review Kin 304W Week 14: April 9, 2013 1 Today s Outline Format of Kin 304W Final Exam Course Review Hand back marked Project Part II 2 Kin 304W Final Exam Saturday, Thursday, April 18, 3:30-6:30
36-309/749 Experimental Design for Behavioral and Social Sciences. Dec 1, 2015 Lecture 11: Mixed Models (HLMs)
") 36-309/749 Experimental Design for Behavioral and Social Sciences Dec 1, 2015 Lecture 11: Mixed Models (HLMs) Independent Errors Assumption An error is the deviation of an individual observed outcome (DV)
36-309/749 Experimental Design for Behavioral and Social Sciences Dec 1, 2015 Lecture 11: Mixed Models (HLMs) Independent Errors Assumption An error is the deviation of an individual observed outcome (DV)
Nominal Data. Parametric Statistics. Nonparametric Statistics. Parametric vs Nonparametric Tests. Greg C Elvers
 Nominal Data Greg C Elvers 1 Parametric Statistics The inferential statistics that we have discussed, such as t and ANOVA, are parametric statistics A parametric statistic is a statistic that makes certain
Nominal Data Greg C Elvers 1 Parametric Statistics The inferential statistics that we have discussed, such as t and ANOVA, are parametric statistics A parametric statistic is a statistic that makes certain
Statistical Distribution Assumptions of General Linear Models
 Statistical Distribution Assumptions of General Linear Models Applied Multilevel Models for Cross Sectional Data Lecture 4 ICPSR Summer Workshop University of Colorado Boulder Lecture 4: Statistical Distributions
Statistical Distribution Assumptions of General Linear Models Applied Multilevel Models for Cross Sectional Data Lecture 4 ICPSR Summer Workshop University of Colorado Boulder Lecture 4: Statistical Distributions
4/6/16. Non-parametric Test. Overview. Stephen Opiyo. Distinguish Parametric and Nonparametric Test Procedures
 Non-parametric Test Stephen Opiyo Overview Distinguish Parametric and Nonparametric Test Procedures Explain commonly used Nonparametric Test Procedures Perform Hypothesis Tests Using Nonparametric Procedures
Non-parametric Test Stephen Opiyo Overview Distinguish Parametric and Nonparametric Test Procedures Explain commonly used Nonparametric Test Procedures Perform Hypothesis Tests Using Nonparametric Procedures
Review. One-way ANOVA, I. What s coming up. Multiple comparisons
 Review One-way ANOVA, I 9.07 /15/00 Earlier in this class, we talked about twosample z- and t-tests for the difference between two conditions of an independent variable Does a trial drug work better than
Review One-way ANOVA, I 9.07 /15/00 Earlier in this class, we talked about twosample z- and t-tests for the difference between two conditions of an independent variable Does a trial drug work better than
STATISTICS REVIEW. D. Parameter: a constant for the case or population under consideration.
 STATISTICS REVIEW I. Why do we need statistics? A. As human beings, we consciously and unconsciously evaluate whether variables affect phenomena of interest, but sometimes our common sense reasoning is
STATISTICS REVIEW I. Why do we need statistics? A. As human beings, we consciously and unconsciously evaluate whether variables affect phenomena of interest, but sometimes our common sense reasoning is
One-way ANOVA Model Assumptions
 One-way ANOVA Model Assumptions STAT:5201 Week 4: Lecture 1 1 / 31 One-way ANOVA: Model Assumptions Consider the single factor model: Y ij = µ + α }{{} i ij iid with ɛ ij N(0, σ 2 ) mean structure random
One-way ANOVA Model Assumptions STAT:5201 Week 4: Lecture 1 1 / 31 One-way ANOVA: Model Assumptions Consider the single factor model: Y ij = µ + α }{{} i ij iid with ɛ ij N(0, σ 2 ) mean structure random
Statistics Toolbox 6. Apply statistical algorithms and probability models
 Statistics Toolbox 6 Apply statistical algorithms and probability models Statistics Toolbox provides engineers, scientists, researchers, financial analysts, and statisticians with a comprehensive set of
Statistics Toolbox 6 Apply statistical algorithms and probability models Statistics Toolbox provides engineers, scientists, researchers, financial analysts, and statisticians with a comprehensive set of
(Where does Ch. 7 on comparing 2 means or 2 proportions fit into this?)
") 12. Comparing Groups: Analysis of Variance (ANOVA) Methods Response y Explanatory x var s Method Categorical Categorical Contingency tables (Ch. 8) (chi-squared, etc.) Quantitative Quantitative Regression
12. Comparing Groups: Analysis of Variance (ANOVA) Methods Response y Explanatory x var s Method Categorical Categorical Contingency tables (Ch. 8) (chi-squared, etc.) Quantitative Quantitative Regression
Chapter 16: Correlation
 Chapter : Correlation So far We ve focused on hypothesis testing Is the relationship we observe between x and y in our sample true generally (i.e. for the population from which the sample came) Which answers
Chapter : Correlation So far We ve focused on hypothesis testing Is the relationship we observe between x and y in our sample true generally (i.e. for the population from which the sample came) Which answers
22s:152 Applied Linear Regression. Chapter 8: 1-Way Analysis of Variance (ANOVA) 2-Way Analysis of Variance (ANOVA)
 2-Way Analysis of Variance (ANOVA)") 22s:152 Applied Linear Regression Chapter 8: 1-Way Analysis of Variance (ANOVA) 2-Way Analysis of Variance (ANOVA) We now consider an analysis with only categorical predictors (i.e. all predictors are
22s:152 Applied Linear Regression Chapter 8: 1-Way Analysis of Variance (ANOVA) 2-Way Analysis of Variance (ANOVA) We now consider an analysis with only categorical predictors (i.e. all predictors are
THE PEARSON CORRELATION COEFFICIENT
 CORRELATION Two variables are said to have a relation if knowing the value of one variable gives you information about the likely value of the second variable this is known as a bivariate relation There
CORRELATION Two variables are said to have a relation if knowing the value of one variable gives you information about the likely value of the second variable this is known as a bivariate relation There
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model
 Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model EPSY 905: Multivariate Analysis Lecture 1 20 January 2016 EPSY 905: Lecture 1 -
Course Introduction and Overview Descriptive Statistics Conceptualizations of Variance Review of the General Linear Model EPSY 905: Multivariate Analysis Lecture 1 20 January 2016 EPSY 905: Lecture 1 -
One-Way ANOVA. Some examples of when ANOVA would be appropriate include:
 One-Way ANOVA 1. Purpose Analysis of variance (ANOVA) is used when one wishes to determine whether two or more groups (e.g., classes A, B, and C) differ on some outcome of interest (e.g., an achievement
One-Way ANOVA 1. Purpose Analysis of variance (ANOVA) is used when one wishes to determine whether two or more groups (e.g., classes A, B, and C) differ on some outcome of interest (e.g., an achievement
Statistics Boot Camp. Dr. Stephanie Lane Institute for Defense Analyses DATAWorks 2018
 Statistics Boot Camp Dr. Stephanie Lane Institute for Defense Analyses DATAWorks 2018 March 21, 2018 Outline of boot camp Summarizing and simplifying data Point and interval estimation Foundations of statistical
Statistics Boot Camp Dr. Stephanie Lane Institute for Defense Analyses DATAWorks 2018 March 21, 2018 Outline of boot camp Summarizing and simplifying data Point and interval estimation Foundations of statistical
Review for Final. Chapter 1 Type of studies: anecdotal, observational, experimental Random sampling
 Review for Final For a detailed review of Chapters 1 7, please see the review sheets for exam 1 and. The following only briefly covers these sections. The final exam could contain problems that are included
Review for Final For a detailed review of Chapters 1 7, please see the review sheets for exam 1 and. The following only briefly covers these sections. The final exam could contain problems that are included
Binary Logistic Regression
 The coefficients of the multiple regression model are estimated using sample data with k independent variables Estimated (or predicted) value of Y Estimated intercept Estimated slope coefficients Ŷ = b
The coefficients of the multiple regression model are estimated using sample data with k independent variables Estimated (or predicted) value of Y Estimated intercept Estimated slope coefficients Ŷ = b
Statistics Handbook. All statistical tables were computed by the author.
 Statistics Handbook Contents Page Wilcoxon rank-sum test (Mann-Whitney equivalent) Wilcoxon matched-pairs test 3 Normal Distribution 4 Z-test Related samples t-test 5 Unrelated samples t-test 6 Variance
Statistics Handbook Contents Page Wilcoxon rank-sum test (Mann-Whitney equivalent) Wilcoxon matched-pairs test 3 Normal Distribution 4 Z-test Related samples t-test 5 Unrelated samples t-test 6 Variance
Rama Nada. -Ensherah Mokheemer. 1 P a g e
 - 9 - Rama Nada -Ensherah Mokheemer - 1 P a g e Quick revision: Remember from the last lecture that chi square is an example of nonparametric test, other examples include Kruskal Wallis, Mann Whitney and
- 9 - Rama Nada -Ensherah Mokheemer - 1 P a g e Quick revision: Remember from the last lecture that chi square is an example of nonparametric test, other examples include Kruskal Wallis, Mann Whitney and
Chapter 19: Logistic regression
 Chapter 19: Logistic regression Self-test answers SELF-TEST Rerun this analysis using a stepwise method (Forward: LR) entry method of analysis. The main analysis To open the main Logistic Regression dialog
Chapter 19: Logistic regression Self-test answers SELF-TEST Rerun this analysis using a stepwise method (Forward: LR) entry method of analysis. The main analysis To open the main Logistic Regression dialog
Correlation and Simple Linear Regression
 Correlation and Simple Linear Regression Sasivimol Rattanasiri, Ph.D Section for Clinical Epidemiology and Biostatistics Ramathibodi Hospital, Mahidol University E-mail: sasivimol.rat@mahidol.ac.th 1 Outline
Correlation and Simple Linear Regression Sasivimol Rattanasiri, Ph.D Section for Clinical Epidemiology and Biostatistics Ramathibodi Hospital, Mahidol University E-mail: sasivimol.rat@mahidol.ac.th 1 Outline
Chapter 16. Simple Linear Regression and dcorrelation
 Chapter 16 Simple Linear Regression and dcorrelation 16.1 Regression Analysis Our problem objective is to analyze the relationship between interval variables; regression analysis is the first tool we will
Chapter 16 Simple Linear Regression and dcorrelation 16.1 Regression Analysis Our problem objective is to analyze the relationship between interval variables; regression analysis is the first tool we will
AP Statistics Cumulative AP Exam Study Guide
 AP Statistics Cumulative AP Eam Study Guide Chapters & 3 - Graphs Statistics the science of collecting, analyzing, and drawing conclusions from data. Descriptive methods of organizing and summarizing statistics
AP Statistics Cumulative AP Eam Study Guide Chapters & 3 - Graphs Statistics the science of collecting, analyzing, and drawing conclusions from data. Descriptive methods of organizing and summarizing statistics
Chapter 13 Correlation
 Chapter Correlation Page. Pearson correlation coefficient -. Inferential tests on correlation coefficients -9. Correlational assumptions -. on-parametric measures of correlation -5 5. correlational example
Chapter Correlation Page. Pearson correlation coefficient -. Inferential tests on correlation coefficients -9. Correlational assumptions -. on-parametric measures of correlation -5 5. correlational example
4.1. Introduction: Comparing Means
 4. Analysis of Variance (ANOVA) 4.1. Introduction: Comparing Means Consider the problem of testing H 0 : µ 1 = µ 2 against H 1 : µ 1 µ 2 in two independent samples of two different populations of possibly
4. Analysis of Variance (ANOVA) 4.1. Introduction: Comparing Means Consider the problem of testing H 0 : µ 1 = µ 2 against H 1 : µ 1 µ 2 in two independent samples of two different populations of possibly