Evolution of the Theory of Mind
|
|
|
- Esmond Bennett
- 6 years ago
- Views:
Transcription
1 Evolution of the Theory of Mind Daniel Monte, São Paulo School of Economics (EESP-FGV) Nikolaus Robalino, Simon Fraser University Arthur Robson, Simon Fraser University Conference Biological Basis of Economic Preferences and Behavior Becker Friedman Institute, University of Chicago May 5, 2012
2

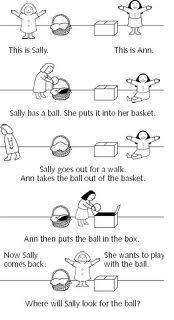
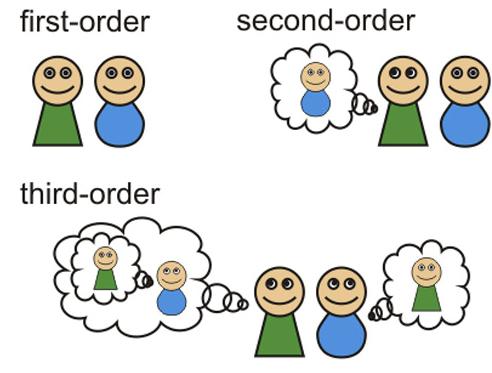
3 The Theory of Mind (TOM) refers to the ability to ascribe agency to other individuals (and to oneself), to ascribe beliefs and desires, more particularly, to one and all. This ability is manifest in non-autistic humans beyond infancy, but less obvious in other species. A key early experiment is the Sally-Ann test. (Baron- Cohen, Leslie, Frith (1985), for example.)
4
5 Onishi and Baillargeon (2005) find that even 15-month-olds exhibit behavior consistent with TOM in a non-verbal task where violation of expectation is inferred from increased length of gaze.

6 Onishi and Baillargeon (2005) find that even 15-month-olds exhibit behavior consistent with TOM in a non-verbal task where violation of expectation is inferred from increased length of gaze. Would this work on nonhuman species too?

7 Brodmann area 10
8 Such an ability is crucial to game theory. That is, it is usually necessary to understand an opponent s payoffs, to put oneself in his shoes, that is, in order to predict his behavior and therefore to choose an optimal strategy oneself.

9 Such an ability is crucial to game theory. That is, it is usually necessary to understand an opponent s payoffs, to put oneself in his shoes, that is, in order to predict his behavior and therefore to choose an optimal strategy oneself.
10 This ability might be seen as an aspect of Machiavellian Intelligence. The hypothesis here is that our intelligence evolved under pressure to outsmart our conspecifics. (See, for example, Byrne and Whiten (1998).) This is often contrasted with the Ecological Intelligence Hypothesis that the nonhuman environment provided the impetus (Robson and Kaplan AER (2003), for example).
.")
11 This ability might be seen as an aspect of Machiavellian Intelligence. The hypothesis here is that our intelligence evolved under pressure to outsmart our conspecifics. (See, for example, Byrne and Whiten (1998).) This is often contrasted with the Ecological Intelligence Hypothesis that the nonhuman environment provided the impetus (Robson and Kaplan AER (2003), for example).
12 The present approach substantially extends and generalizes Robson Why Would Nature Give Individuals Utility Functions? JPE (2001), who considered the evolutionary rationale for own utility in a decision-theoretic framework. In contrast, we consider a rationale for knowing the utility functions of others in a strategic framework. In both cases, however, it is the need to address novelty that is the evolutionary impetus.
13 The present approach substantially extends and generalizes Robson Why Would Nature Give Individuals Utility Functions? JPE (2001), who considered the evolutionary rationale for own utility in a decision-theoretic framework. In contrast, we consider a rationale for knowing the utility functions of others in a strategic framework. In both cases, however, it is the need to address novelty that is the evolutionary impetus. The approach here contrasts with that of a small literature represented by Stahl GEB (1993), who considers the evolutionary advantage of greater strategic sophistication. (See also Crawford and Iriberri (2007) and Mohlin (2012), for example.) Stahl argues that it may be better to be (lucky and) dumb than to be smart. We obtain a clearer advantage to smart mainly because we consider a game with outcomes that are randomly selected from a growing outcome set, rather than a particular fixed game.
14 Here we investigate the evolutionary basis of an ability to acquire the preferences of an opponent. We contrast such more sophisticated agents with naive agents who adapt to each game as in evolutionary game theory and as in reinforcement learning in psychology.
15 Consider an anecdote about vervet monkeys from Cheney and Seyfarth (1990). When a male vervet sought to join Kitui s group, where Kitui was bottom-ranked, Kitui might make the leopard warning cry. The interloper would stay in his tree, his plans thwarted. The TOM Kitui understood the effect of such a cry on the others and was deliberately deceptive. A naive Kitui, in contrast, had no model of other vervets preferences and beliefs. Inadvertently, perhaps, he once made the leopard warning in such a circumstance and it worked. (That the latter option was actually true was suggested by Kitui occasionally walking on the ground towards the other male, alarm calling all the while.)

16 Consider an anecdote about vervet monkeys from Cheney and Seyfarth (1990). When a male vervet sought to join Kitui s group, where Kitui was bottom-ranked, Kitui might make the leopard warning cry. The interloper would stay in his tree, his plans thwarted. The TOM Kitui understood the effect of such a cry on the others and was deliberately deceptive. A naive Kitui, in contrast, had no model of other vervets preferences and beliefs. Inadvertently, perhaps, he once made the leopard warning in such a circumstance and it worked. (That the latter option was actually true was suggested by Kitui occasionally walking on the ground towards the other male, alarm calling all the while.)
17 Here we model the contest between TOMer s and naive players. We consider games of perfect information, the simplest of which has two stages. If player 1 is naive, she must see all games before learning to play appropriately; if she is a TOMer, she must merely see player 2 confronted with all possible pairs of outcomes. The edge for the TOMer s then derives from there being many more games than pairs of outcomes.
18 Here we model the contest between TOMer s and naive players. We consider games of perfect information, the simplest of which has two stages. If player 1 is naive, she must see all games before learning to play appropriately; if she is a TOMer, she must merely see player 2 confronted with all possible pairs of outcomes. The edge for the TOMer s then derives from there being many more games than pairs of outcomes. We demonstrate this edge by considering an environment that becomes richer as time passes. If the environment rapidly becomes more complex, neither type is able to keep up; if the environment only slowly becomes more complex both types can keep up. In an intermediate range, however, the TOMers learn essentially everything, the naive types essentially nothing.

19
20 Two-Stage Model Two large populations player 1 s ( she s ) and player 2 s ( he s ). At t = 1, 2,..., randomly paired to play a simple two-stage game of perfect information. Game tree with exactly two moves at each of the non-terminal nodes. The games vary on account of the outcomes assigned to the terminal nodes. Each player has a fixed strict preference ordering over the countably infinite set X. P 2 L P 1 R P 2 L R R L x 1 x 2 x 3 x 4
21 Two-Stage Model Two large populations player 1 s ( she s ) and player 2 s ( he s ). At t = 1, 2,..., randomly paired to play a simple two-stage game of perfect information. Game tree with exactly two moves at each of the non-terminal nodes. The games vary on account of the outcomes assigned to the terminal nodes. Each player has a fixed strict preference ordering over the countably infinite set X. P 2 L P 1 R P 2 L R R L x 1 x 2 x 3 x 4
22 The two-stage game at t is Γ t. At each t Γ t is completed by a random draw of four outcomes from the finite X t X. If any two of the outcomes are identical, it is known to the sophisticated players that they are indifferent; if the outcomes are different, they induce a strict preference ordering for the player in question, but this strict preference is not known to other players.
23 The two-stage game at t is Γ t. At each t Γ t is completed by a random draw of four outcomes from the finite X t X. If any two of the outcomes are identical, it is known to the sophisticated players that they are indifferent; if the outcomes are different, they induce a strict preference ordering for the player in question, but this strict preference is not known to other players. Naive players adapt to each game; theory-of-mind (TOM) players construct the opponent s preferences.
24 Each history of outcomes and choices is public information. If a mixed strategy is used, this would be observed, although just on the nodes that are reached. We consider only symmetric strategies.
25 Each history of outcomes and choices is public information. If a mixed strategy is used, this would be observed, although just on the nodes that are reached. We consider only symmetric strategies. There are no feedback effects of individuals actions on their opponents and so there is no incentive to play non-myopically. Player 2 s have no interest in player 1 s payoffs. Further, the player 1 s react only to the distribution of player 2 choices. Since any particular player 2 has no effect on this distribution of player 2 choices, any particular player 2 is myopic.
26 Each history of outcomes and choices is public information. If a mixed strategy is used, this would be observed, although just on the nodes that are reached. We consider only symmetric strategies. There are no feedback effects of individuals actions on their opponents and so there is no incentive to play non-myopically. Player 2 s have no interest in player 1 s payoffs. Further, the player 1 s react only to the distribution of player 2 choices. Since any particular player 2 has no effect on this distribution of player 2 choices, any particular player 2 is myopic. The outcome sets increase over time, capturing growing complexity. There is a sequence t 1,..., t k,..., where t k is the arrival date of the k-th new object. The initial set of objects is X 0 with size n. Thus, in t k to t k+1 1 the number of objects is n + k. We assume t k = k α, for α 0.
27
28 A naive player adapts to each game Γ t. For simplicity, we assume that if the game Γ t is novel, the naive player plays inappropriately at t, say by randomizing at each decision node. However, the next time this same game in encountered, the naive player makes the appropriate choices. That is, the adaptive learning here is as fast as it possibly could be. Even with this advantage, however, the naive types will be outdone by the TOM types.
29 A naive player adapts to each game Γ t. For simplicity, we assume that if the game Γ t is novel, the naive player plays inappropriately at t, say by randomizing at each decision node. However, the next time this same game in encountered, the naive player makes the appropriate choices. That is, the adaptive learning here is as fast as it possibly could be. Even with this advantage, however, the naive types will be outdone by the TOM types. In contrast, a player has a theory of mind if she knows that her opponent will take binary decisions that are consistent with some initially unknown preference ordering. She does not avail herself of the transitivity of her opponent s preferences. Our comparison of the naive type with the TOM is then a comparison of the speed of the associated learning processes.
30 We now characterize the maximum amount of knowledge in this environment for naive and TOM players. For naive player 1 s or 2 s at date t the maximum amount of knowledge is simply the number of games, G t, say. We have that G t = X t 4
31 We now characterize the maximum amount of knowledge in this environment for naive and TOM players. For naive player 1 s or 2 s at date t the maximum amount of knowledge is simply the number of games, G t, say. We have that G t = X t 4 If the number of distinct games that have played before date t is Kt N, then we consider the fraction of these that are known to any naive player as L N t = KN t G t.
32 For the TOM players, consider the number of binary choices for a particular player. When that particular player makes some binary choice, that is, this is common knowledge to all TOM players. For both players, Q t is the number of outcome pairs. We then have Q t = X t 2
33 For the TOM players, consider the number of binary choices for a particular player. When that particular player makes some binary choice, that is, this is common knowledge to all TOM players. For both players, Q t is the number of outcome pairs. We then have Q t = X t 2 If Kt 2 is the number of player 2 s binary choices that have been revealed to TOM player 1 s, then the fraction of these that have been revealed is L 2 t = K2 t Q t
34 We now have the main result for the two-stage game case Theorem 1 All the results here concern player 1 i) If α [0, 2) then L 2 t 0 and LN t 0 as t in probability. That is, both the sophisticated and the naive type are overwhelmed by the rapid rate of arrival of new outcomes. ii) If α (4, ), then L 2 t 1 and LN t 1 as t in probability. That is, the rate of arrival of new outcomes is slow enough that both types are able to essentially learn everything. iii) Finally, however, if α (2, 4), then L 2 t 1 but LN t 0 as t in probability. That is, for this intermediate range of arrival rates, the TOM type learns essentially everything, while the naive type learns essentially nothing.
35 Except possibly for the values 2 and 4, the results are dramatic either everything is learnt in the limit or nothing is. Indeed, the range where nothing is learnt is inescapable in that the arrival rate of novelty outstrips there the maximum rate at which learning can occur. So the real contribution is to show the less obvious result that full learning occurs essentially whenever it is even possible that it could.
36 Except possibly for the values 2 and 4, the results are dramatic either everything is learnt in the limit or nothing is. Indeed, the range where nothing is learnt is inescapable in that the arrival rate of novelty outstrips there the maximum rate at which learning can occur. So the real contribution is to show the less obvious result that full learning occurs essentially whenever it is even possible that it could. In terms of the contest between the two types, the existence of an interval over which the TOM type learns everything and the naive type learns nothing implies we can finesse the issue of considering payoffs explicitly. Whatever these payoffs might be it is clear that the TOM type is outdoing the naive type in this intermediate range.
37 Revealed Preference Suppose that x 2 y and w 2 z for some distinct x, y, z, w X. Consider the following game P 2 L P 1 R P 2 L R R L x y z w
38 Revealed Preference Suppose that x 2 y and w 2 z for some distinct x, y, z, w X. Consider the following game P 2 L P 1 R P 2 L R R L x y z w Then, if 1 knows these aspects of 2 then she will choose L and get x, if x 1 w, but R and get w, if w 1 x. Conversely, if 1 chooses appropriately in any game like this, she has revealed that she has a correct representation of 2 s preferences.
39 There is no simpler way to ensure that player 1 always chooses correctly in all two-stage games, for all preferences 1.
40 Three (or More)-Stage Model Three equally large populations player 1 s, player 2 s, and player 3 s. At t = 1, 2,..., players matched randomly in triples to play a three-stage game of perfect information with exactly two moves at each of the non-terminal nodes. Each player has a fixed strict preference ordering over a countably infinite set of outcomes X.
41 Three (or More)-Stage Model Three equally large populations player 1 s, player 2 s, and player 3 s. At t = 1, 2,..., players matched randomly in triples to play a three-stage game of perfect information with exactly two moves at each of the non-terminal nodes. Each player has a fixed strict preference ordering over a countably infinite set of outcomes X. The three-stage game at t is Γ t which is now completed by a random draw of a set of eight outcomes from finite X t X.
42 Three (or More)-Stage Model Three equally large populations player 1 s, player 2 s, and player 3 s. At t = 1, 2,..., players matched randomly in triples to play a three-stage game of perfect information with exactly two moves at each of the non-terminal nodes. Each player has a fixed strict preference ordering over a countably infinite set of outcomes X. The three-stage game at t is Γ t which is now completed by a random draw of a set of eight outcomes from finite X t X.
43 L P 3 R L P 2 L R P 1 P x 1 x 2 x 3 x 4 L R R P 2 P 3
44 L P 3 R L P 2 L R P 1 P x 1 x 2 x 3 x 4 L R R P 2 P 3 What if the naive type of player 2, for example, were less naive, keying not on the entire three stage-game, but on the subgame deriving from each choice by player 1? A somewhat weaker version of the argument goes through.
45 The type of the last player, now player 3, is again irrelevant, since player 3 uses only his own preferences. TOM player 2 s construct a simple model of player 3 s preferences. TOM player 1 s construct simple models of the other two players preferences, and the player 1 s also need to know that the player 2 s know player 3 s preferences.
46
47 Individual players again have no incentive to mislead the opponent about one s preferences. In the three-stage case, this observation has force only for the player 2 s and 3 s. That is, the player 1 s cannot advantageously mislead the player 2 s or 3 s because the player 2 s and 3 s do not consider 1 s preferences. The player 1 s and 2 s react only to the distribution of choices made by the player 3 s. Since any particular player 3 then has no effect on the distribution of player 3 choices, and hence cannot affect the play of the player 1 s or 2 s, any such particular player 3 must behave myopically. Similarly, the player 1 s only react to the distribution of choices made by the player 2 s and so there is no incentive for the player 2 s to distort the choices made in order to influence player 1 s.
48 Individual players again have no incentive to mislead the opponent about one s preferences. In the three-stage case, this observation has force only for the player 2 s and 3 s. That is, the player 1 s cannot advantageously mislead the player 2 s or 3 s because the player 2 s and 3 s do not consider 1 s preferences. The player 1 s and 2 s react only to the distribution of choices made by the player 3 s. Since any particular player 3 then has no effect on the distribution of player 3 choices, and hence cannot affect the play of the player 1 s or 2 s, any such particular player 3 must behave myopically. Similarly, the player 1 s only react to the distribution of choices made by the player 2 s and so there is no incentive for the player 2 s to distort the choices made in order to influence player 1 s. We again focus on outcome sets that increase over time, described precisely as before.
49 As before, a player who is naive adapts to each game Γ t as a distinct circumstance, but takes only two trials to play appropriately.
50 As before, a player who is naive adapts to each game Γ t as a distinct circumstance, but takes only two trials to play appropriately. Again, in contrast, a player with a theory of mind knows her opponent will take decisions that are consistent with some preference ordering. She has the capacity to learn this ordering.
51 As before, a player who is naive adapts to each game Γ t as a distinct circumstance, but takes only two trials to play appropriately. Again, in contrast, a player with a theory of mind knows her opponent will take decisions that are consistent with some preference ordering. She has the capacity to learn this ordering.
52 For naive player 1 s, 2 s or 3 s at date t the maximum amount of knowledge is again the number of games, G t, say. Now G t = X t 8
53 For naive player 1 s, 2 s or 3 s at date t the maximum amount of knowledge is again the number of games, G t, say. Now G t = X t 8 If the number of distinct games that have played before at date t is Kt N, the fraction of games that are known to any naive player is L N t = KN t G t.
54 For the players with a theory of mind, it is convenient to consider the number of binary choices that can be made by a particular player, j, say. When player j makes some binary choice, that is, this is common knowledge to all TOM players. For all players, the number of outcome pairs is as before Q t = X t 2. If K j t is the number of player j = 2, 3 s binary choices that have been revealed to all TOM players, as common knowledge, then the fraction of these is L j t = Kj t Q t.
55 The following is then the main result for the three-stage game case. We first show that player 2 derives an advantage from TOM over naivete, essentially as in the two-stage game. Once player 2 is of TOM type, we then show that player 1 derives an advantage from TOM over naivete. Theorem 2 A) Suppose that player 1 plays in an arbitrary fashion. Then we have the following results for player 2 i) If α [0, 2) then L 3 t 0 and LN t 0 as t in probability. That is, both the sophisticated and the naive type of player 2 are overwhelmed by the rapid rate of arrival of new outcomes. ii) If α (8, ), then L 3 t 1 and LN t 1 as t in probability. That is, the rate of arrival of new outcomes is slow enough that both types are able to essentially learn everything. iii) Finally, however, if α (2, 8), then L 3 t 1 but LN t 0 as t in probability. That is, for this intermediate range of arrival rates, the TOM type learns essentially everything, while the naive type learns essentially nothing.
56 B) Suppose that player 2 is TOM. Then we have the following results for player 1 i) If α [0, 2) then L 2 t 0, L 3 t 0, and L N t 0, as t in probability. That is, both the sophisticated and the naive type are overwhelmed by the rapid rate of arrival of new outcomes. ii) If α (8, ), then L 2 t 1, L3 t 1, and LN t 1 as t in probability. That is, the rate of arrival of new outcomes is slow enough that both types are able to essentially learn everything. iii) Finally, however, if α (2, 8), then L 2 t 1, L3 t 1, but LN t 0 as t in probability. That is, for this intermediate range of arrival rates, the TOM type learns essentially everything, while the naive type learns essentially nothing.
57 Again, the results are dramatic except possibly at two points, either everything is learnt in the limit or nothing is. Again, when nothing is learnt, it is because it is simply mechanically impossible to keep up with the rate of novelty, so that the key contribution of this theorem is to show that everything is learnt essentially whenever this is not mechanically ruled out.
58 Again, the results are dramatic except possibly at two points, either everything is learnt in the limit or nothing is. Again, when nothing is learnt, it is because it is simply mechanically impossible to keep up with the rate of novelty, so that the key contribution of this theorem is to show that everything is learnt essentially whenever this is not mechanically ruled out. As in the two-stage case, there is then an interval over which the TOM type learns everything and the naive type learns nothing. This interval is larger in the three-stage game case because the naive types of player 1 or 2 face a larger set of possible games, now with eight outcomes drawn from the outcome set, and hence can only keep up with a slower rate of novelty. On the other hand, for the result in A), the TOM type of player 2 still needs to know only how player 3 would make each possible binary choice.
59 For B), the situation for player 1 is more complex, because player 1 not only needs to know both player 2 s preferences and player 3 s, but also needs to know that player 2 knows player 3 s preferences. This would seem likely to shift the transition point from no learning to full learning for TOM player 1 s. However, the following observations apply. As long as α > 2, player 1 will learn player 3 s preferences completely in the limit. In addition, at the same time that 3 s choices reveal information about 3 s preferences to player 1, they reveal the same information to player 2 and player 1 knows this. But now, given only that α > 2, player 1 can also completely learn player 2 s preferences.
60 For B), the situation for player 1 is more complex, because player 1 not only needs to know both player 2 s preferences and player 3 s, but also needs to know that player 2 knows player 3 s preferences. This would seem likely to shift the transition point from no learning to full learning for TOM player 1 s. However, the following observations apply. As long as α > 2, player 1 will learn player 3 s preferences completely in the limit. In addition, at the same time that 3 s choices reveal information about 3 s preferences to player 1, they reveal the same information to player 2 and player 1 knows this. But now, given only that α > 2, player 1 can also completely learn player 2 s preferences. For A), the large numbers of player 1 s, 2 s and 3 s ensure that the player 2 s should be sequentially rational. It might somehow be to the player 2s overall advantage to be perceived by the player 1 s as naive rather than sophisticated. However, when there are many player 2 s, with some of these naive and some sophisticated, each individual player 2 has no effect on player 1 s perceptions of the distribution of player 2 s. Thus each sophisticated sequentially rational player 2 outperforms each naive player 2.
61 It is always clear that learning must be slow if L 2 t is close to one. When α > 2, however, the proof involves showing this is the only circumstance under which learning is slow. There are two complicating factors. The first is that there are subgames in which 2 s choice cannot reveal information about 2 s preferences because there is insufficient knowledge about 3 s preferences and therefore choices.
62 It is always clear that learning must be slow if L 2 t is close to one. When α > 2, however, the proof involves showing this is the only circumstance under which learning is slow. There are two complicating factors. The first is that there are subgames in which 2 s choice cannot reveal information about 2 s preferences because there is insufficient knowledge about 3 s preferences and therefore choices. The second factor concerns the existence of player 2 subgames with outcomes that are avoided by player 3, thus making it difficult to reveal information about 2 s preferences. Such games arise even as t. However, A1 implies that these problematic games are a vanishing fraction of all games as t.
63 These results extend straightforwardly to a perfect information game with S stages and S players. When considering the sophistication of player s we assume that players s + 1,..., S are already TOM. The critical value of α for any TOM player remains 2, for all s. The critical value of α for a naive player grows with the number of possible games that can be formed.
64 Further Extensions How much do the current results depend on the particular model described here? Although the environment is rather particular, it is best seen merely as a test to discriminate between the underlying characteristics of ToM s and of the naive players.
65 Further Extensions How much do the current results depend on the particular model described here? Although the environment is rather particular, it is best seen merely as a test to discriminate between the underlying characteristics of ToM s and of the naive players. What about games with imperfect information? With multiple Nash equilibria, it is not clear how to disentangle the lack of knowledge of payoffs from the lack of information about which equilibrium is to be played, at least in the absence of strong assumptions. Perhaps normal form games crop up along with the games of perfect information emphasized here, using outcomes drawn from the same set. Whether or not any learning can be accomplished on such normal form games, our approach shows that learning would arise based only on the games of perfect information.
66 Within the class of games of perfect information, it is only for simplicity that we restrict attention to a fixed game tree. The tree itself could be random: it might involve a random number of moves or a random order of play, for example. Similarly, players could be allowed to move multiple times, and so on.
67 Within the class of games of perfect information, it is only for simplicity that we restrict attention to a fixed game tree. The tree itself could be random: it might involve a random number of moves or a random order of play, for example. Similarly, players could be allowed to move multiple times, and so on. Similarly, the assumption that individuals have a strict ranking over each distinct pair of outcomes is basically innocuous. If indifference is allowed, suppose, for example, that individuals randomize over each pair of indifferent outcomes. The indifference of player i between z and z would then be common knowledge to the ToM types, if ever player i chose z over z and z over z.
68 We assume here that ToM types do not apply transitivity in their deductions about the preferences of other players. This might make a difference to the relevant ranges of the growth parameter α. The new value of α cannot exceed 2, since applying transitivity could not be disadvantageous. It could not lower the critical value of α below 1.
69 We assume here that ToM types do not apply transitivity in their deductions about the preferences of other players. This might make a difference to the relevant ranges of the growth parameter α. The new value of α cannot exceed 2, since applying transitivity could not be disadvantageous. It could not lower the critical value of α below 1. More sophisticated naive types could clearly do better than the ones we describe here. If naive types assign beliefs to subgames, rather than to entire games, for example, they would do as well as ToM types in the two stage game case. More generally, with three or more stages, such more sophisticated naive players would do better than the naive players considered here, but not as well as the sophisticated players.
70 Experiments It would be interest to experimentally implement the model, perhaps simplified to have no innovation. Also it seems we might not need a very large number of subjects in each of the I pools. Induce the same preferences over a large set of outcomes for each of the player i s for i = 1,..., I by using monetary payoffs. No player knows the other players payoffs. Play the game otherwise as above. How fast would players learn other players preferences? Would they be closer to the sophisticated ToM types described above or to the naive types? How would the number of stages I affect matters?
71 The End
72 Sketch of Proofs We treat a general case with I stages and A choices at each decision node.
73 Sketch of Proofs We treat a general case with I stages and A choices at each decision node. No learning in the limit If outcomes arrive at too fast a rate, it is straightforward to prove that learning cannot occur even when the greatest possible amount of information is revealed in every period.
74 Sketch of Proofs We treat a general case with I stages and A choices at each decision node. No learning in the limit If outcomes arrive at too fast a rate, it is straightforward to prove that learning cannot occur even when the greatest possible amount of information is revealed in every period. Lemma 1 In each of the following convergence is sure. i) Suppose α [0, 2). Then L t i 1,..., I. 0 for each preference type i = ii) Suppose there are T terminal nodes. If α [0, T ), then L N t 0.
75 Sketch of Proofs We treat a general case with I stages and A choices at each decision node. No learning in the limit If outcomes arrive at too fast a rate, it is straightforward to prove that learning cannot occur even when the greatest possible amount of information is revealed in every period. Lemma 1 In each of the following convergence is sure. i) Suppose α [0, 2). Then L t i 1,..., I. 0 for each preference type i = ii) Suppose there are T terminal nodes. If α [0, T ), then L N t 0.
76 Results About Learning Theorem 1 is a special case of Theorem 2. Attention is restricted to the ToM players, and so to the L i t s. (The corresponding claim about the naive types goes through with minor changes to the analysis.) As hypothesized in Theorem 2, when considering L i t, players i + 1,...,, I are taken to be ToM.
77 Results About Learning Theorem 1 is a special case of Theorem 2. Attention is restricted to the ToM players, and so to the L i t s. (The corresponding claim about the naive types goes through with minor changes to the analysis.) As hypothesized in Theorem 2, when considering L i t, players i + 1,...,, I are taken to be ToM. Auxiliary Results The first minor result, Proposition 1, relates how much is commonly known about i s preferences over pairs of outcomes to what is commonly known about i s preferences over A-tuples of outcomes. The need for this result can be finessed, for expositional simplicity, by setting A = 2.
78 The gist of Proposition 2 is the following. Suppose types i,..., I are all ToM and that L i+1 t,..., L I t each converge to one in probability. Then, in the limit, the probability of revealing new information about i s preferences is small only if the fraction of extant knowledge about preferences, L i t, is close to one. Indeed, although the probability of revealing new information about i is clearly small if 1 L i t is small, the converse is not obviously true.
79 The gist of Proposition 2 is the following. Suppose types i,..., I are all ToM and that L i+1 t,..., L I t each converge to one in probability. Then, in the limit, the probability of revealing new information about i s preferences is small only if the fraction of extant knowledge about preferences, L i t, is close to one. Indeed, although the probability of revealing new information about i is clearly small if 1 L i t is small, the converse is not obviously true. Proposition 2, however, establishes an appropriate lower bound. This bound decomposes the expected amount learnt into a factor involving of 1 L i t, reflecting what is yet to be revealed about i s preferences, and a residual term.
80 Proposition 2 Suppose each of the random variables L i+1 t,..., L I t converges to one in probability. Then for each ε [0, 1] there exists a random variable ξt iε such that E(K t+1 H t ) K t ε 2i (1 L i t) 2i ξ iε t, where ξ iε t converges in probability to a continuous function, m i : [0, 1] [0, 1] such that m i 0 as ε 0.
81 Proposition 2 Suppose each of the random variables L i+1 t,..., L I t converges to one in probability. Then for each ε [0, 1] there exists a random variable ξt iε such that E(K t+1 H t ) K t ε 2i (1 L i t) 2i ξ iε t, where ξ iε t converges in probability to a continuous function, m i : [0, 1] [0, 1] such that m i 0 as ε 0. Proposition 2 is the heart of the matter. Consider the case of player I. What is a lower bound on the probability that something new will be learned about this player s preferences? Such a lower bound arises from the event that every pair of outcomes that follows choice by player I is unfamiliar to the ToM players. This lower bound is then [1 L I t ]2I 1 [1 L I t ]2I.
82 For players who are not last, the situation is more complex. There are two complicating factors. The first is that there are i-type subgames in which i s choice cannot reveal information about i s preferences because there is insufficient knowledge about the remaining players choices.
83 For players who are not last, the situation is more complex. There are two complicating factors. The first is that there are i-type subgames in which i s choice cannot reveal information about i s preferences because there is insufficient knowledge about the remaining players choices. The second factor concerns the existence of i-type subgames with outcomes that are avoided by the remaining opponents, thus making it difficult to reveal information about i s preferences. Such games arise even as t. However, A1 implies that these problematic games are a vanishing fraction of all games as t.
84 For players who are not last, the situation is more complex. There are two complicating factors. The first is that there are i-type subgames in which i s choice cannot reveal information about i s preferences because there is insufficient knowledge about the remaining players choices. The second factor concerns the existence of i-type subgames with outcomes that are avoided by the remaining opponents, thus making it difficult to reveal information about i s preferences. Such games arise even as t. However, A1 implies that these problematic games are a vanishing fraction of all games as t. These two complicating factors account for the additional multiplicative and additive terms in the bound obtained in Proposition 2.
85 Proposition 3 then essentially completes the proof of Theorem 2 (and Theorem 1) by applying the result of Proposition 2.
86 Proposition 3 then essentially completes the proof of Theorem 2 (and Theorem 1) by applying the result of Proposition 2. Proposition 3. Suppose that, for each ε [0, 1] there exists a random variable ξt iε such that E(K t+1 H t ) K t ε 2i (1 L i t) 2i ξ iε t, where ξt iε converges in probability to a continuous function, m i : [0, 1] [0, 1] such that m i 0 as ε 0. If, in addition, α > 2, then L i t converges to one in probability.
87 Consider the case that I = 3 for simplicity of exposition and consider player 2. Assume for the moment that L 2 t converges in probability to the random variable L. Fix η > 0 and let A denote the event L < 1 η. Given the above facts about the probability of new information being revealed, the random variable E(Kt+τ 2 h t) is bounded below asymptotically by Kt 2 + η2 τ, on A, as τ., That is, on A, in the limit learning occurs at least linearly in τ. Observe now that Q t+τ is of order τ 2/α. Then, dividing through by the non-random Q t+τ, we obtain that E(L 2 t h t) on A. Since by definition L 2 t is bounded above by one surely, it must be that P (A) = 0. That is, if α > 2, and L 2 t converges in probability to L, it must be that L = 1 almost surely.
88 It remains then to show the convergence in probability just assumed. We do this by showing that the L t processes lie in a class of generalized martingales. Consider the following
89 It remains then to show the convergence in probability just assumed. We do this by showing that the L t processes lie in a class of generalized martingales. Consider the following Weak-Submartingale in the Limit: The adapted process (L t, h t ) is a weak sub-martingale in the limit (w-submil) if, for each η > 0, there is a T such that τ t T implies P (E(L τ h t ) L t η) > 1 η, a.e. and uniformly in τ.
90 It remains then to show the convergence in probability just assumed. We do this by showing that the L t processes lie in a class of generalized martingales. Consider the following Weak-Submartingale in the Limit: The adapted process (L t, h t ) is a weak sub-martingale in the limit (w-submil) if, for each η > 0, there is a T such that τ t T implies P (E(L τ h t ) L t η) > 1 η, a.e. and uniformly in τ. Egghe (1984) shows that bounded weak sub-martingales in the limit have limits in probability.
91 Given the above, we need to prove that the L t sequences are w- submils. Clearly the L t process has the sub-martingale property in between arrival dates. However, at an arrival date, L t is discounted Q by the factor t 1, and increases by at most. The key is then Q t+1 Q t+1 to show that the sequence of L t at the arrival dates is nevertheless a w-submil. This follows because there is a process converging to 1 such that L t at the arrival dates can only decrease if it is greater than this process or close to it.



92 The End
Appendix B for The Evolution of Strategic Sophistication (Intended for Online Publication)
") Appendix B for The Evolution of Strategic Sophistication (Intended for Online Publication) Nikolaus Robalino and Arthur Robson Appendix B: Proof of Theorem 2 This appendix contains the proof of Theorem
Appendix B for The Evolution of Strategic Sophistication (Intended for Online Publication) Nikolaus Robalino and Arthur Robson Appendix B: Proof of Theorem 2 This appendix contains the proof of Theorem
Definitions and Proofs
 Giving Advice vs. Making Decisions: Transparency, Information, and Delegation Online Appendix A Definitions and Proofs A. The Informational Environment The set of states of nature is denoted by = [, ],
Giving Advice vs. Making Decisions: Transparency, Information, and Delegation Online Appendix A Definitions and Proofs A. The Informational Environment The set of states of nature is denoted by = [, ],
Puri cation 1. Stephen Morris Princeton University. July Economics.
 Puri cation 1 Stephen Morris Princeton University July 2006 1 This survey was prepared as an entry for the second edition of the New Palgrave Dictionary of Economics. In a mixed strategy equilibrium of
Puri cation 1 Stephen Morris Princeton University July 2006 1 This survey was prepared as an entry for the second edition of the New Palgrave Dictionary of Economics. In a mixed strategy equilibrium of
Area I: Contract Theory Question (Econ 206)
") Theory Field Exam Winter 2011 Instructions You must complete two of the three areas (the areas being (I) contract theory, (II) game theory, and (III) psychology & economics). Be sure to indicate clearly
Theory Field Exam Winter 2011 Instructions You must complete two of the three areas (the areas being (I) contract theory, (II) game theory, and (III) psychology & economics). Be sure to indicate clearly
SF2972 Game Theory Exam with Solutions March 15, 2013
 SF2972 Game Theory Exam with s March 5, 203 Part A Classical Game Theory Jörgen Weibull and Mark Voorneveld. (a) What are N, S and u in the definition of a finite normal-form (or, equivalently, strategic-form)
SF2972 Game Theory Exam with s March 5, 203 Part A Classical Game Theory Jörgen Weibull and Mark Voorneveld. (a) What are N, S and u in the definition of a finite normal-form (or, equivalently, strategic-form)
6 Evolution of Networks
 last revised: March 2008 WARNING for Soc 376 students: This draft adopts the demography convention for transition matrices (i.e., transitions from column to row). 6 Evolution of Networks 6. Strategic network
last revised: March 2008 WARNING for Soc 376 students: This draft adopts the demography convention for transition matrices (i.e., transitions from column to row). 6 Evolution of Networks 6. Strategic network
NTU IO (I) : Classnote 03 Meng-Yu Liang March, 2009
 : Classnote 03 Meng-Yu Liang March, 2009") NTU IO (I) : Classnote 03 Meng-Yu Liang March, 2009 Kohlberg and Mertens (Econometrica 1986) We will use the term (game) tree for the extensive form of a game with perfect recall (i.e., where every player
NTU IO (I) : Classnote 03 Meng-Yu Liang March, 2009 Kohlberg and Mertens (Econometrica 1986) We will use the term (game) tree for the extensive form of a game with perfect recall (i.e., where every player
Extensive games (with perfect information)
") Extensive games (with perfect information) (also referred to as extensive-form games or dynamic games) DEFINITION An extensive game with perfect information has the following components A set N (the set
Extensive games (with perfect information) (also referred to as extensive-form games or dynamic games) DEFINITION An extensive game with perfect information has the following components A set N (the set
Reputations. Larry Samuelson. Yale University. February 13, 2013
 Reputations Larry Samuelson Yale University February 13, 2013 I. Introduction I.1 An Example: The Chain Store Game Consider the chain-store game: Out In Acquiesce 5, 0 2, 2 F ight 5,0 1, 1 If played once,
Reputations Larry Samuelson Yale University February 13, 2013 I. Introduction I.1 An Example: The Chain Store Game Consider the chain-store game: Out In Acquiesce 5, 0 2, 2 F ight 5,0 1, 1 If played once,
Refinements - change set of equilibria to find "better" set of equilibria by eliminating some that are less plausible
 efinements efinements - change set of equilibria to find "better" set of equilibria by eliminating some that are less plausible Strategic Form Eliminate Weakly Dominated Strategies - Purpose - throwing
efinements efinements - change set of equilibria to find "better" set of equilibria by eliminating some that are less plausible Strategic Form Eliminate Weakly Dominated Strategies - Purpose - throwing
Evolutionary Dynamics and Extensive Form Games by Ross Cressman. Reviewed by William H. Sandholm *
 Evolutionary Dynamics and Extensive Form Games by Ross Cressman Reviewed by William H. Sandholm * Noncooperative game theory is one of a handful of fundamental frameworks used for economic modeling. It
Evolutionary Dynamics and Extensive Form Games by Ross Cressman Reviewed by William H. Sandholm * Noncooperative game theory is one of a handful of fundamental frameworks used for economic modeling. It
Equilibria in Games with Weak Payoff Externalities
 NUPRI Working Paper 2016-03 Equilibria in Games with Weak Payoff Externalities Takuya Iimura, Toshimasa Maruta, and Takahiro Watanabe October, 2016 Nihon University Population Research Institute http://www.nihon-u.ac.jp/research/institute/population/nupri/en/publications.html
NUPRI Working Paper 2016-03 Equilibria in Games with Weak Payoff Externalities Takuya Iimura, Toshimasa Maruta, and Takahiro Watanabe October, 2016 Nihon University Population Research Institute http://www.nihon-u.ac.jp/research/institute/population/nupri/en/publications.html
Introduction to Game Theory
 COMP323 Introduction to Computational Game Theory Introduction to Game Theory Paul G. Spirakis Department of Computer Science University of Liverpool Paul G. Spirakis (U. Liverpool) Introduction to Game
COMP323 Introduction to Computational Game Theory Introduction to Game Theory Paul G. Spirakis Department of Computer Science University of Liverpool Paul G. Spirakis (U. Liverpool) Introduction to Game
EC3224 Autumn Lecture #04 Mixed-Strategy Equilibrium
 Reading EC3224 Autumn Lecture #04 Mixed-Strategy Equilibrium Osborne Chapter 4.1 to 4.10 By the end of this week you should be able to: find a mixed strategy Nash Equilibrium of a game explain why mixed
Reading EC3224 Autumn Lecture #04 Mixed-Strategy Equilibrium Osborne Chapter 4.1 to 4.10 By the end of this week you should be able to: find a mixed strategy Nash Equilibrium of a game explain why mixed
Opting Out in a War of Attrition. Abstract
 Opting Out in a War of Attrition Mercedes Adamuz Department of Business, Instituto Tecnológico Autónomo de México and Department of Economics, Universitat Autònoma de Barcelona Abstract This paper analyzes
Opting Out in a War of Attrition Mercedes Adamuz Department of Business, Instituto Tecnológico Autónomo de México and Department of Economics, Universitat Autònoma de Barcelona Abstract This paper analyzes
Bayesian Persuasion Online Appendix
 Bayesian Persuasion Online Appendix Emir Kamenica and Matthew Gentzkow University of Chicago June 2010 1 Persuasion mechanisms In this paper we study a particular game where Sender chooses a signal π whose
Bayesian Persuasion Online Appendix Emir Kamenica and Matthew Gentzkow University of Chicago June 2010 1 Persuasion mechanisms In this paper we study a particular game where Sender chooses a signal π whose
Area I: Contract Theory Question (Econ 206)
") Theory Field Exam Summer 2011 Instructions You must complete two of the four areas (the areas being (I) contract theory, (II) game theory A, (III) game theory B, and (IV) psychology & economics). Be sure
Theory Field Exam Summer 2011 Instructions You must complete two of the four areas (the areas being (I) contract theory, (II) game theory A, (III) game theory B, and (IV) psychology & economics). Be sure
Economics 209B Behavioral / Experimental Game Theory (Spring 2008) Lecture 3: Equilibrium refinements and selection
 Lecture 3: Equilibrium refinements and selection") Economics 209B Behavioral / Experimental Game Theory (Spring 2008) Lecture 3: Equilibrium refinements and selection Theory cannot provide clear guesses about with equilibrium will occur in games with multiple
Economics 209B Behavioral / Experimental Game Theory (Spring 2008) Lecture 3: Equilibrium refinements and selection Theory cannot provide clear guesses about with equilibrium will occur in games with multiple
Quantum Games Have No News for Economists 1
 Quantum Games Have No News for Economists 1 By David K. Levine 2 This version: September 1, 2005 First version: December 3, 2005 Quantum computing offers the possibility of massively parallel computing
Quantum Games Have No News for Economists 1 By David K. Levine 2 This version: September 1, 2005 First version: December 3, 2005 Quantum computing offers the possibility of massively parallel computing
Consistent Beliefs in Extensive Form Games
 Games 2010, 1, 415-421; doi:10.3390/g1040415 OPEN ACCESS games ISSN 2073-4336 www.mdpi.com/journal/games Article Consistent Beliefs in Extensive Form Games Paulo Barelli 1,2 1 Department of Economics,
Games 2010, 1, 415-421; doi:10.3390/g1040415 OPEN ACCESS games ISSN 2073-4336 www.mdpi.com/journal/games Article Consistent Beliefs in Extensive Form Games Paulo Barelli 1,2 1 Department of Economics,
THE EVOLUTION OF INTERTEMPORAL PREFERENCES
 THE EVOLUTION OF INTERTEMPORAL PREFERENCES Arthur J. Robson Department of Economics Simon Fraser University Larry Samuelson Department of Economics University of Wisconsin 8888 University Drive 80 Observatory
THE EVOLUTION OF INTERTEMPORAL PREFERENCES Arthur J. Robson Department of Economics Simon Fraser University Larry Samuelson Department of Economics University of Wisconsin 8888 University Drive 80 Observatory
Economics 201B Economic Theory (Spring 2017) Bargaining. Topics: the axiomatic approach (OR 15) and the strategic approach (OR 7).
 Bargaining. Topics: the axiomatic approach (OR 15) and the strategic approach (OR 7).") Economics 201B Economic Theory (Spring 2017) Bargaining Topics: the axiomatic approach (OR 15) and the strategic approach (OR 7). The axiomatic approach (OR 15) Nash s (1950) work is the starting point
Economics 201B Economic Theory (Spring 2017) Bargaining Topics: the axiomatic approach (OR 15) and the strategic approach (OR 7). The axiomatic approach (OR 15) Nash s (1950) work is the starting point
Preliminary Results on Social Learning with Partial Observations
 Preliminary Results on Social Learning with Partial Observations Ilan Lobel, Daron Acemoglu, Munther Dahleh and Asuman Ozdaglar ABSTRACT We study a model of social learning with partial observations from
Preliminary Results on Social Learning with Partial Observations Ilan Lobel, Daron Acemoglu, Munther Dahleh and Asuman Ozdaglar ABSTRACT We study a model of social learning with partial observations from
BELIEFS & EVOLUTIONARY GAME THEORY
 1 / 32 BELIEFS & EVOLUTIONARY GAME THEORY Heinrich H. Nax hnax@ethz.ch & Bary S. R. Pradelski bpradelski@ethz.ch May 15, 217: Lecture 1 2 / 32 Plan Normal form games Equilibrium invariance Equilibrium
1 / 32 BELIEFS & EVOLUTIONARY GAME THEORY Heinrich H. Nax hnax@ethz.ch & Bary S. R. Pradelski bpradelski@ethz.ch May 15, 217: Lecture 1 2 / 32 Plan Normal form games Equilibrium invariance Equilibrium
Equilibrium Refinements
 Equilibrium Refinements Mihai Manea MIT Sequential Equilibrium In many games information is imperfect and the only subgame is the original game... subgame perfect equilibrium = Nash equilibrium Play starting
Equilibrium Refinements Mihai Manea MIT Sequential Equilibrium In many games information is imperfect and the only subgame is the original game... subgame perfect equilibrium = Nash equilibrium Play starting
A Note on the Existence of Ratifiable Acts
 A Note on the Existence of Ratifiable Acts Joseph Y. Halpern Cornell University Computer Science Department Ithaca, NY 14853 halpern@cs.cornell.edu http://www.cs.cornell.edu/home/halpern August 15, 2018
A Note on the Existence of Ratifiable Acts Joseph Y. Halpern Cornell University Computer Science Department Ithaca, NY 14853 halpern@cs.cornell.edu http://www.cs.cornell.edu/home/halpern August 15, 2018
Wars of Attrition with Budget Constraints
 Wars of Attrition with Budget Constraints Gagan Ghosh Bingchao Huangfu Heng Liu October 19, 2017 (PRELIMINARY AND INCOMPLETE: COMMENTS WELCOME) Abstract We study wars of attrition between two bidders who
Wars of Attrition with Budget Constraints Gagan Ghosh Bingchao Huangfu Heng Liu October 19, 2017 (PRELIMINARY AND INCOMPLETE: COMMENTS WELCOME) Abstract We study wars of attrition between two bidders who
Selecting Efficient Correlated Equilibria Through Distributed Learning. Jason R. Marden
 1 Selecting Efficient Correlated Equilibria Through Distributed Learning Jason R. Marden Abstract A learning rule is completely uncoupled if each player s behavior is conditioned only on his own realized
1 Selecting Efficient Correlated Equilibria Through Distributed Learning Jason R. Marden Abstract A learning rule is completely uncoupled if each player s behavior is conditioned only on his own realized
Nonlinear Dynamics between Micromotives and Macrobehavior
 Nonlinear Dynamics between Micromotives and Macrobehavior Saori Iwanaga & kira Namatame Dept. of Computer Science, National Defense cademy, Yokosuka, 239-8686, JPN, E-mail: {g38042, nama}@nda.ac.jp Tel:
Nonlinear Dynamics between Micromotives and Macrobehavior Saori Iwanaga & kira Namatame Dept. of Computer Science, National Defense cademy, Yokosuka, 239-8686, JPN, E-mail: {g38042, nama}@nda.ac.jp Tel:
Extensive Form Games I
 Extensive Form Games I Definition of Extensive Form Game a finite game tree X with nodes x X nodes are partially ordered and have a single root (minimal element) terminal nodes are z Z (maximal elements)
Extensive Form Games I Definition of Extensive Form Game a finite game tree X with nodes x X nodes are partially ordered and have a single root (minimal element) terminal nodes are z Z (maximal elements)
Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms
 Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Department of Systems and Computer Engineering Carleton University Ottawa, Canada KS 5B6 Email: mawheda@sce.carleton.ca
Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Department of Systems and Computer Engineering Carleton University Ottawa, Canada KS 5B6 Email: mawheda@sce.carleton.ca
EVOLUTIONARY STABILITY FOR TWO-STAGE HAWK-DOVE GAMES
 ROCKY MOUNTAIN JOURNAL OF MATHEMATICS olume 25, Number 1, Winter 1995 EOLUTIONARY STABILITY FOR TWO-STAGE HAWK-DOE GAMES R. CRESSMAN ABSTRACT. Although two individuals in a biological species often interact
ROCKY MOUNTAIN JOURNAL OF MATHEMATICS olume 25, Number 1, Winter 1995 EOLUTIONARY STABILITY FOR TWO-STAGE HAWK-DOE GAMES R. CRESSMAN ABSTRACT. Although two individuals in a biological species often interact
On the Impossibility of Predicting the Behavior of Rational Agents. Dean P. Foster* and H. Peyton Young ** February, 1999 This version: October, 2000
 On the Impossibility of Predicting the Behavior of Rational Agents Dean P. Foster* and H. Peyton Young ** February, 1999 This version: October, 2000 We exhibit a class of games that almost surely cannot
On the Impossibility of Predicting the Behavior of Rational Agents Dean P. Foster* and H. Peyton Young ** February, 1999 This version: October, 2000 We exhibit a class of games that almost surely cannot
A Necessary and Sufficient Condition for Convergence of Statistical to Strategic Equilibria of Market Games
 A Necessary and Sufficient Condition for Convergence of Statistical to Strategic Equilibria of Market Games Dimitrios P. Tsomocos Dimitris Voliotis Abstract In our model, we treat a market game where traders
A Necessary and Sufficient Condition for Convergence of Statistical to Strategic Equilibria of Market Games Dimitrios P. Tsomocos Dimitris Voliotis Abstract In our model, we treat a market game where traders
Players as Serial or Parallel Random Access Machines. Timothy Van Zandt. INSEAD (France)
") Timothy Van Zandt Players as Serial or Parallel Random Access Machines DIMACS 31 January 2005 1 Players as Serial or Parallel Random Access Machines (EXPLORATORY REMARKS) Timothy Van Zandt tvz@insead.edu
Timothy Van Zandt Players as Serial or Parallel Random Access Machines DIMACS 31 January 2005 1 Players as Serial or Parallel Random Access Machines (EXPLORATORY REMARKS) Timothy Van Zandt tvz@insead.edu
WEAKLY DOMINATED STRATEGIES: A MYSTERY CRACKED
 WEAKLY DOMINATED STRATEGIES: A MYSTERY CRACKED DOV SAMET Abstract. An informal argument shows that common knowledge of rationality implies the iterative elimination of strongly dominated strategies. Rationality
WEAKLY DOMINATED STRATEGIES: A MYSTERY CRACKED DOV SAMET Abstract. An informal argument shows that common knowledge of rationality implies the iterative elimination of strongly dominated strategies. Rationality
Rationalizable Partition-Confirmed Equilibrium
 Rationalizable Partition-Confirmed Equilibrium Drew Fudenberg and Yuichiro Kamada First Version: January 29, 2011; This Version: July 30, 2014 Abstract Rationalizable partition-confirmed equilibrium (RPCE)
Rationalizable Partition-Confirmed Equilibrium Drew Fudenberg and Yuichiro Kamada First Version: January 29, 2011; This Version: July 30, 2014 Abstract Rationalizable partition-confirmed equilibrium (RPCE)
Learning by (limited) forward looking players
 forward looking players") Learning by (limited) forward looking players Friederike Mengel Maastricht University April 2009 Abstract We present a model of adaptive economic agents who are k periods forward looking. Agents in our
Learning by (limited) forward looking players Friederike Mengel Maastricht University April 2009 Abstract We present a model of adaptive economic agents who are k periods forward looking. Agents in our
Confronting Theory with Experimental Data and vice versa. Lecture VII Social learning. The Norwegian School of Economics Nov 7-11, 2011
 Confronting Theory with Experimental Data and vice versa Lecture VII Social learning The Norwegian School of Economics Nov 7-11, 2011 Quantal response equilibrium (QRE) Players do not choose best response
Confronting Theory with Experimental Data and vice versa Lecture VII Social learning The Norwegian School of Economics Nov 7-11, 2011 Quantal response equilibrium (QRE) Players do not choose best response
Rationalization of Collective Choice Functions by Games with Perfect Information. Yongsheng Xu
 Rationalization of Collective Choice Functions by Games with Perfect Information by Yongsheng Xu Department of Economics, Andrew Young School of Policy Studies Georgia State University, Atlanta, GA 30303
Rationalization of Collective Choice Functions by Games with Perfect Information by Yongsheng Xu Department of Economics, Andrew Young School of Policy Studies Georgia State University, Atlanta, GA 30303
Neuro Observational Learning
 Neuro Observational Learning Kfir Eliaz Brown University and Tel Aviv University Ariel Rubinstein Tel Aviv University and New York University Abstract. We propose a simple model in which an agent observes
Neuro Observational Learning Kfir Eliaz Brown University and Tel Aviv University Ariel Rubinstein Tel Aviv University and New York University Abstract. We propose a simple model in which an agent observes
Economics 3012 Strategic Behavior Andy McLennan October 20, 2006
 Economics 301 Strategic Behavior Andy McLennan October 0, 006 Lecture 11 Topics Problem Set 9 Extensive Games of Imperfect Information An Example General Description Strategies and Nash Equilibrium Beliefs
Economics 301 Strategic Behavior Andy McLennan October 0, 006 Lecture 11 Topics Problem Set 9 Extensive Games of Imperfect Information An Example General Description Strategies and Nash Equilibrium Beliefs
Payoff Continuity in Incomplete Information Games
 journal of economic theory 82, 267276 (1998) article no. ET982418 Payoff Continuity in Incomplete Information Games Atsushi Kajii* Institute of Policy and Planning Sciences, University of Tsukuba, 1-1-1
journal of economic theory 82, 267276 (1998) article no. ET982418 Payoff Continuity in Incomplete Information Games Atsushi Kajii* Institute of Policy and Planning Sciences, University of Tsukuba, 1-1-1
Uncertainty. Michael Peters December 27, 2013
 Uncertainty Michael Peters December 27, 20 Lotteries In many problems in economics, people are forced to make decisions without knowing exactly what the consequences will be. For example, when you buy
Uncertainty Michael Peters December 27, 20 Lotteries In many problems in economics, people are forced to make decisions without knowing exactly what the consequences will be. For example, when you buy
Robust Knowledge and Rationality
 Robust Knowledge and Rationality Sergei Artemov The CUNY Graduate Center 365 Fifth Avenue, 4319 New York City, NY 10016, USA sartemov@gc.cuny.edu November 22, 2010 Abstract In 1995, Aumann proved that
Robust Knowledge and Rationality Sergei Artemov The CUNY Graduate Center 365 Fifth Avenue, 4319 New York City, NY 10016, USA sartemov@gc.cuny.edu November 22, 2010 Abstract In 1995, Aumann proved that
Lecture December 2009 Fall 2009 Scribe: R. Ring In this lecture we will talk about
 0368.4170: Cryptography and Game Theory Ran Canetti and Alon Rosen Lecture 7 02 December 2009 Fall 2009 Scribe: R. Ring In this lecture we will talk about Two-Player zero-sum games (min-max theorem) Mixed
0368.4170: Cryptography and Game Theory Ran Canetti and Alon Rosen Lecture 7 02 December 2009 Fall 2009 Scribe: R. Ring In this lecture we will talk about Two-Player zero-sum games (min-max theorem) Mixed
Rationalizable Partition-Confirmed Equilibrium
 Rationalizable Partition-Confirmed Equilibrium Drew Fudenberg and Yuichiro Kamada First Version: January 29, 2011; This Version: May 3, 2013 Abstract Rationalizable partition-confirmed equilibrium (RPCE)
Rationalizable Partition-Confirmed Equilibrium Drew Fudenberg and Yuichiro Kamada First Version: January 29, 2011; This Version: May 3, 2013 Abstract Rationalizable partition-confirmed equilibrium (RPCE)
The Index of Nash Equilibria
 Equilibria in Games, Santiago, Chile January 10, 2017 Finite Normal-Form Games We consider in these lectures, the set of finite games with fixed strategy sets and parametrized by the payoff functions.
Equilibria in Games, Santiago, Chile January 10, 2017 Finite Normal-Form Games We consider in these lectures, the set of finite games with fixed strategy sets and parametrized by the payoff functions.
ON FORWARD INDUCTION
 Econometrica, Submission #6956, revised ON FORWARD INDUCTION SRIHARI GOVINDAN AND ROBERT WILSON Abstract. A player s pure strategy is called relevant for an outcome of a game in extensive form with perfect
Econometrica, Submission #6956, revised ON FORWARD INDUCTION SRIHARI GOVINDAN AND ROBERT WILSON Abstract. A player s pure strategy is called relevant for an outcome of a game in extensive form with perfect
Open Sequential Equilibria of Multi-Stage Games with Infinite Sets of Types and Actions
 Open Sequential Equilibria of Multi-Stage Games with Infinite Sets of Types and Actions By Roger B. Myerson and Philip J. Reny Department of Economics University of Chicago Paper can be found at https://sites.google.com/site/philipjreny/home/research
Open Sequential Equilibria of Multi-Stage Games with Infinite Sets of Types and Actions By Roger B. Myerson and Philip J. Reny Department of Economics University of Chicago Paper can be found at https://sites.google.com/site/philipjreny/home/research
Government 2005: Formal Political Theory I
 Government 2005: Formal Political Theory I Lecture 11 Instructor: Tommaso Nannicini Teaching Fellow: Jeremy Bowles Harvard University November 9, 2017 Overview * Today s lecture Dynamic games of incomplete
Government 2005: Formal Political Theory I Lecture 11 Instructor: Tommaso Nannicini Teaching Fellow: Jeremy Bowles Harvard University November 9, 2017 Overview * Today s lecture Dynamic games of incomplete
Entry under an Information-Gathering Monopoly Alex Barrachina* June Abstract
 Entry under an Information-Gathering onopoly Alex Barrachina* June 2016 Abstract The effects of information-gathering activities on a basic entry model with asymmetric information are analyzed. In the
Entry under an Information-Gathering onopoly Alex Barrachina* June 2016 Abstract The effects of information-gathering activities on a basic entry model with asymmetric information are analyzed. In the
Do Shareholders Vote Strategically? Voting Behavior, Proposal Screening, and Majority Rules. Supplement
 Do Shareholders Vote Strategically? Voting Behavior, Proposal Screening, and Majority Rules Supplement Ernst Maug Kristian Rydqvist September 2008 1 Additional Results on the Theory of Strategic Voting
Do Shareholders Vote Strategically? Voting Behavior, Proposal Screening, and Majority Rules Supplement Ernst Maug Kristian Rydqvist September 2008 1 Additional Results on the Theory of Strategic Voting
The ambiguous impact of contracts on competition in the electricity market Yves Smeers
 The ambiguous impact of contracts on competition in the electricity market Yves Smeers joint work with Frederic Murphy Climate Policy and Long Term Decisions-Investment and R&D, Bocconi University, Milan,
The ambiguous impact of contracts on competition in the electricity market Yves Smeers joint work with Frederic Murphy Climate Policy and Long Term Decisions-Investment and R&D, Bocconi University, Milan,
Observations on Cooperation
 Introduction Observations on Cooperation Yuval Heller (Bar Ilan) and Erik Mohlin (Lund) PhD Workshop, BIU, January, 2018 Heller & Mohlin Observations on Cooperation 1 / 20 Introduction Motivating Example
Introduction Observations on Cooperation Yuval Heller (Bar Ilan) and Erik Mohlin (Lund) PhD Workshop, BIU, January, 2018 Heller & Mohlin Observations on Cooperation 1 / 20 Introduction Motivating Example
Doing It Now or Later
 Doing It Now or Later Ted O Donoghue and Matthew Rabin published in American Economic Review, 1999 October 31, 2011 Introduction Economists almost always capture impatience by exponential discounting of
Doing It Now or Later Ted O Donoghue and Matthew Rabin published in American Economic Review, 1999 October 31, 2011 Introduction Economists almost always capture impatience by exponential discounting of
ECO 199 GAMES OF STRATEGY Spring Term 2004 Precepts Week 7 March Questions GAMES WITH ASYMMETRIC INFORMATION QUESTIONS
 ECO 199 GAMES OF STRATEGY Spring Term 2004 Precepts Week 7 March 22-23 Questions GAMES WITH ASYMMETRIC INFORMATION QUESTIONS Question 1: In the final stages of the printing of Games of Strategy, Sue Skeath
ECO 199 GAMES OF STRATEGY Spring Term 2004 Precepts Week 7 March 22-23 Questions GAMES WITH ASYMMETRIC INFORMATION QUESTIONS Question 1: In the final stages of the printing of Games of Strategy, Sue Skeath
Confronting Theory with Experimental Data and vice versa. European University Institute. May-Jun Lectures 7-8: Equilibrium
 Confronting Theory with Experimental Data and vice versa European University Institute May-Jun 2008 Lectures 7-8: Equilibrium Theory cannot provide clear guesses about with equilibrium will occur in games
Confronting Theory with Experimental Data and vice versa European University Institute May-Jun 2008 Lectures 7-8: Equilibrium Theory cannot provide clear guesses about with equilibrium will occur in games
Bargaining, Contracts, and Theories of the Firm. Dr. Margaret Meyer Nuffield College
 Bargaining, Contracts, and Theories of the Firm Dr. Margaret Meyer Nuffield College 2015 Course Overview 1. Bargaining 2. Hidden information and self-selection Optimal contracting with hidden information
Bargaining, Contracts, and Theories of the Firm Dr. Margaret Meyer Nuffield College 2015 Course Overview 1. Bargaining 2. Hidden information and self-selection Optimal contracting with hidden information
Cooperation in Social Dilemmas through Position Uncertainty
 Cooperation in Social Dilemmas through Position Uncertainty Andrea Gallice and Ignacio Monzón Università di Torino and Collegio Carlo Alberto North American Summer Meetings of the Econometric Society St.
Cooperation in Social Dilemmas through Position Uncertainty Andrea Gallice and Ignacio Monzón Università di Torino and Collegio Carlo Alberto North American Summer Meetings of the Econometric Society St.
Evolutionary Bargaining Strategies
 Evolutionary Bargaining Strategies Nanlin Jin http://cswww.essex.ac.uk/csp/bargain Evolutionary Bargaining Two players alternative offering game x A =?? Player A Rubinstein 1982, 1985: Subgame perfect
Evolutionary Bargaining Strategies Nanlin Jin http://cswww.essex.ac.uk/csp/bargain Evolutionary Bargaining Two players alternative offering game x A =?? Player A Rubinstein 1982, 1985: Subgame perfect
Distributed Learning based on Entropy-Driven Game Dynamics
 Distributed Learning based on Entropy-Driven Game Dynamics Bruno Gaujal joint work with Pierre Coucheney and Panayotis Mertikopoulos Inria Aug., 2014 Model Shared resource systems (network, processors)
Distributed Learning based on Entropy-Driven Game Dynamics Bruno Gaujal joint work with Pierre Coucheney and Panayotis Mertikopoulos Inria Aug., 2014 Model Shared resource systems (network, processors)
Deceptive Advertising with Rational Buyers
 Deceptive Advertising with Rational Buyers September 6, 016 ONLINE APPENDIX In this Appendix we present in full additional results and extensions which are only mentioned in the paper. In the exposition
Deceptive Advertising with Rational Buyers September 6, 016 ONLINE APPENDIX In this Appendix we present in full additional results and extensions which are only mentioned in the paper. In the exposition
Ex Post Cheap Talk : Value of Information and Value of Signals
 Ex Post Cheap Talk : Value of Information and Value of Signals Liping Tang Carnegie Mellon University, Pittsburgh PA 15213, USA Abstract. Crawford and Sobel s Cheap Talk model [1] describes an information
Ex Post Cheap Talk : Value of Information and Value of Signals Liping Tang Carnegie Mellon University, Pittsburgh PA 15213, USA Abstract. Crawford and Sobel s Cheap Talk model [1] describes an information
Imperfect Monitoring and Impermanent Reputations
 Imperfect Monitoring and Impermanent Reputations Martin W. Cripps Olin School of Business Washington University in St. Louis St. Louis, MO 63130-4899 cripps@olin.wustl.edu George J. Mailath Department
Imperfect Monitoring and Impermanent Reputations Martin W. Cripps Olin School of Business Washington University in St. Louis St. Louis, MO 63130-4899 cripps@olin.wustl.edu George J. Mailath Department
. Introduction to Game Theory Lecture Note 8: Dynamic Bayesian Games. HUANG Haifeng University of California, Merced
 .. Introduction to Game Theory Lecture Note 8: Dynamic Bayesian Games HUANG Haifeng University of California, Merced Basic terminology Now we study dynamic Bayesian games, or dynamic/extensive games of
.. Introduction to Game Theory Lecture Note 8: Dynamic Bayesian Games HUANG Haifeng University of California, Merced Basic terminology Now we study dynamic Bayesian games, or dynamic/extensive games of
Satisfaction Equilibrium: Achieving Cooperation in Incomplete Information Games
 Satisfaction Equilibrium: Achieving Cooperation in Incomplete Information Games Stéphane Ross and Brahim Chaib-draa Department of Computer Science and Software Engineering Laval University, Québec (Qc),
Satisfaction Equilibrium: Achieving Cooperation in Incomplete Information Games Stéphane Ross and Brahim Chaib-draa Department of Computer Science and Software Engineering Laval University, Québec (Qc),
Coordination and Continuous Choice
 Coordination and Continuous Choice Stephen Morris and Ming Yang Princeton University and Duke University December 2016 Abstract We study a coordination game where players choose what information to acquire
Coordination and Continuous Choice Stephen Morris and Ming Yang Princeton University and Duke University December 2016 Abstract We study a coordination game where players choose what information to acquire
Learning Equilibrium as a Generalization of Learning to Optimize
 Learning Equilibrium as a Generalization of Learning to Optimize Dov Monderer and Moshe Tennenholtz Faculty of Industrial Engineering and Management Technion Israel Institute of Technology Haifa 32000,
Learning Equilibrium as a Generalization of Learning to Optimize Dov Monderer and Moshe Tennenholtz Faculty of Industrial Engineering and Management Technion Israel Institute of Technology Haifa 32000,
Online Appendices for Large Matching Markets: Risk, Unraveling, and Conflation
 Online Appendices for Large Matching Markets: Risk, Unraveling, and Conflation Aaron L. Bodoh-Creed - Cornell University A Online Appendix: Strategic Convergence In section 4 we described the matching
Online Appendices for Large Matching Markets: Risk, Unraveling, and Conflation Aaron L. Bodoh-Creed - Cornell University A Online Appendix: Strategic Convergence In section 4 we described the matching
Microeconomics. 2. Game Theory
 Microeconomics 2. Game Theory Alex Gershkov http://www.econ2.uni-bonn.de/gershkov/gershkov.htm 18. November 2008 1 / 36 Dynamic games Time permitting we will cover 2.a Describing a game in extensive form
Microeconomics 2. Game Theory Alex Gershkov http://www.econ2.uni-bonn.de/gershkov/gershkov.htm 18. November 2008 1 / 36 Dynamic games Time permitting we will cover 2.a Describing a game in extensive form
Models of Strategic Reasoning Lecture 2
 Models of Strategic Reasoning Lecture 2 Eric Pacuit University of Maryland, College Park ai.stanford.edu/~epacuit August 7, 2012 Eric Pacuit: Models of Strategic Reasoning 1/30 Lecture 1: Introduction,
Models of Strategic Reasoning Lecture 2 Eric Pacuit University of Maryland, College Park ai.stanford.edu/~epacuit August 7, 2012 Eric Pacuit: Models of Strategic Reasoning 1/30 Lecture 1: Introduction,
Conjectural Variations in Aggregative Games: An Evolutionary Perspective
 Conjectural Variations in Aggregative Games: An Evolutionary Perspective Alex Possajennikov University of Nottingham January 2012 Abstract Suppose that in aggregative games, in which a player s payoff
Conjectural Variations in Aggregative Games: An Evolutionary Perspective Alex Possajennikov University of Nottingham January 2012 Abstract Suppose that in aggregative games, in which a player s payoff
Multiple Equilibria in the Citizen-Candidate Model of Representative Democracy.
 Multiple Equilibria in the Citizen-Candidate Model of Representative Democracy. Amrita Dhillon and Ben Lockwood This version: March 2001 Abstract De Sinopoli and Turrini (1999) present an example to show
Multiple Equilibria in the Citizen-Candidate Model of Representative Democracy. Amrita Dhillon and Ben Lockwood This version: March 2001 Abstract De Sinopoli and Turrini (1999) present an example to show
: Cryptography and Game Theory Ran Canetti and Alon Rosen. Lecture 8
 0368.4170: Cryptography and Game Theory Ran Canetti and Alon Rosen Lecture 8 December 9, 2009 Scribe: Naama Ben-Aroya Last Week 2 player zero-sum games (min-max) Mixed NE (existence, complexity) ɛ-ne Correlated
0368.4170: Cryptography and Game Theory Ran Canetti and Alon Rosen Lecture 8 December 9, 2009 Scribe: Naama Ben-Aroya Last Week 2 player zero-sum games (min-max) Mixed NE (existence, complexity) ɛ-ne Correlated
Industrial Organization Lecture 3: Game Theory
 Industrial Organization Lecture 3: Game Theory Nicolas Schutz Nicolas Schutz Game Theory 1 / 43 Introduction Why game theory? In the introductory lecture, we defined Industrial Organization as the economics
Industrial Organization Lecture 3: Game Theory Nicolas Schutz Nicolas Schutz Game Theory 1 / 43 Introduction Why game theory? In the introductory lecture, we defined Industrial Organization as the economics
Bayesian Learning in Social Networks
 Bayesian Learning in Social Networks Asu Ozdaglar Joint work with Daron Acemoglu, Munther Dahleh, Ilan Lobel Department of Electrical Engineering and Computer Science, Department of Economics, Operations
Bayesian Learning in Social Networks Asu Ozdaglar Joint work with Daron Acemoglu, Munther Dahleh, Ilan Lobel Department of Electrical Engineering and Computer Science, Department of Economics, Operations
Perfect Bayesian Equilibrium
 Perfect Bayesian Equilibrium For an important class of extensive games, a solution concept is available that is simpler than sequential equilibrium, but with similar properties. In a Bayesian extensive
Perfect Bayesian Equilibrium For an important class of extensive games, a solution concept is available that is simpler than sequential equilibrium, but with similar properties. In a Bayesian extensive
Modeling Bounded Rationality of Agents During Interactions
 Interactive Decision Theory and Game Theory: Papers from the 2 AAAI Workshop (WS--3) Modeling Bounded Rationality of Agents During Interactions Qing Guo and Piotr Gmytrasiewicz Department of Computer Science
Interactive Decision Theory and Game Theory: Papers from the 2 AAAI Workshop (WS--3) Modeling Bounded Rationality of Agents During Interactions Qing Guo and Piotr Gmytrasiewicz Department of Computer Science
EconS Advanced Microeconomics II Handout on Subgame Perfect Equilibrium (SPNE)
") EconS 3 - Advanced Microeconomics II Handout on Subgame Perfect Equilibrium (SPNE). Based on MWG 9.B.3 Consider the three-player nite game of perfect information depicted in gure. L R Player 3 l r a b
EconS 3 - Advanced Microeconomics II Handout on Subgame Perfect Equilibrium (SPNE). Based on MWG 9.B.3 Consider the three-player nite game of perfect information depicted in gure. L R Player 3 l r a b
Basics of Game Theory
 Basics of Game Theory Giacomo Bacci and Luca Sanguinetti Department of Information Engineering University of Pisa, Pisa, Italy {giacomo.bacci,luca.sanguinetti}@iet.unipi.it April - May, 2010 G. Bacci and
Basics of Game Theory Giacomo Bacci and Luca Sanguinetti Department of Information Engineering University of Pisa, Pisa, Italy {giacomo.bacci,luca.sanguinetti}@iet.unipi.it April - May, 2010 G. Bacci and
UC Berkeley Haas School of Business Game Theory (EMBA 296 & EWMBA 211) Summer 2016
 Summer 2016") UC Berkeley Haas School of Business Game Theory (EMBA 296 & EWMBA 211) Summer 2016 More on strategic games and extensive games with perfect information Block 2 Jun 12, 2016 Food for thought LUPI Many players
UC Berkeley Haas School of Business Game Theory (EMBA 296 & EWMBA 211) Summer 2016 More on strategic games and extensive games with perfect information Block 2 Jun 12, 2016 Food for thought LUPI Many players
Conditional equilibria of multi-stage games with infinite sets of signals and actions
 Conditional equilibria of multi-stage games with infinite sets of signals and actions by Roger B. Myerson and Philip J. Reny Department of Economics, University of Chicago Abstract: We develop concepts
Conditional equilibria of multi-stage games with infinite sets of signals and actions by Roger B. Myerson and Philip J. Reny Department of Economics, University of Chicago Abstract: We develop concepts
ONLINE APPENDICES FOR INCENTIVES IN EXPERIMENTS: A THEORETICAL INVESTIGATION BY AZRIELI, CHAMBERS & HEALY
 ONLINE APPENDICES FOR INCENTIVES IN EXPERIMENTS: A THEORETICAL INVESTIGATION BY AZRIELI, CHAMBERS & HEALY Appendix B. Modeling Games as Decisions In this appendix we describe how one can move seamlessly
ONLINE APPENDICES FOR INCENTIVES IN EXPERIMENTS: A THEORETICAL INVESTIGATION BY AZRIELI, CHAMBERS & HEALY Appendix B. Modeling Games as Decisions In this appendix we describe how one can move seamlessly
Reputation and Conflict
 Reputation and Conflict Sandeep Baliga Northwestern University Tomas Sjöström Rutgers University July 2011 Abstract We study reputation in conflict games. The players can use their first round actions
Reputation and Conflict Sandeep Baliga Northwestern University Tomas Sjöström Rutgers University July 2011 Abstract We study reputation in conflict games. The players can use their first round actions
On the Unique D1 Equilibrium in the Stackelberg Model with Asymmetric Information Janssen, M.C.W.; Maasland, E.
 Tilburg University On the Unique D1 Equilibrium in the Stackelberg Model with Asymmetric Information Janssen, M.C.W.; Maasland, E. Publication date: 1997 Link to publication General rights Copyright and
Tilburg University On the Unique D1 Equilibrium in the Stackelberg Model with Asymmetric Information Janssen, M.C.W.; Maasland, E. Publication date: 1997 Link to publication General rights Copyright and
Economics 209A Theory and Application of Non-Cooperative Games (Fall 2013) Extensive games with perfect information OR6and7,FT3,4and11
 Extensive games with perfect information OR6and7,FT3,4and11") Economics 209A Theory and Application of Non-Cooperative Games (Fall 2013) Extensive games with perfect information OR6and7,FT3,4and11 Perfect information A finite extensive game with perfect information
Economics 209A Theory and Application of Non-Cooperative Games (Fall 2013) Extensive games with perfect information OR6and7,FT3,4and11 Perfect information A finite extensive game with perfect information
Belief-based Learning
 Belief-based Learning Algorithmic Game Theory Marcello Restelli Lecture Outline Introdutcion to multi-agent learning Belief-based learning Cournot adjustment Fictitious play Bayesian learning Equilibrium
Belief-based Learning Algorithmic Game Theory Marcello Restelli Lecture Outline Introdutcion to multi-agent learning Belief-based learning Cournot adjustment Fictitious play Bayesian learning Equilibrium
Review of topics since what was covered in the midterm: Topics that we covered before the midterm (also may be included in final):
:") Review of topics since what was covered in the midterm: Subgame-perfect eqms in extensive games with perfect information where players choose a number (first-order conditions, boundary conditions, favoring
Review of topics since what was covered in the midterm: Subgame-perfect eqms in extensive games with perfect information where players choose a number (first-order conditions, boundary conditions, favoring
Hierarchical Bayesian Persuasion
 Hierarchical Bayesian Persuasion Weijie Zhong May 12, 2015 1 Introduction Information transmission between an informed sender and an uninformed decision maker has been extensively studied and applied in
Hierarchical Bayesian Persuasion Weijie Zhong May 12, 2015 1 Introduction Information transmission between an informed sender and an uninformed decision maker has been extensively studied and applied in
Brown s Original Fictitious Play
 manuscript No. Brown s Original Fictitious Play Ulrich Berger Vienna University of Economics, Department VW5 Augasse 2-6, A-1090 Vienna, Austria e-mail: ulrich.berger@wu-wien.ac.at March 2005 Abstract
manuscript No. Brown s Original Fictitious Play Ulrich Berger Vienna University of Economics, Department VW5 Augasse 2-6, A-1090 Vienna, Austria e-mail: ulrich.berger@wu-wien.ac.at March 2005 Abstract
Computational Evolutionary Game Theory and why I m never using PowerPoint for another presentation involving maths ever again
 Computational Evolutionary Game Theory and why I m never using PowerPoint for another presentation involving maths ever again Enoch Lau 5 September 2007 Outline What is evolutionary game theory? Why evolutionary
Computational Evolutionary Game Theory and why I m never using PowerPoint for another presentation involving maths ever again Enoch Lau 5 September 2007 Outline What is evolutionary game theory? Why evolutionary
Evidence with Uncertain Likelihoods
 Evidence with Uncertain Likelihoods Joseph Y. Halpern Cornell University Ithaca, NY 14853 USA halpern@cs.cornell.edu Riccardo Pucella Cornell University Ithaca, NY 14853 USA riccardo@cs.cornell.edu Abstract
Evidence with Uncertain Likelihoods Joseph Y. Halpern Cornell University Ithaca, NY 14853 USA halpern@cs.cornell.edu Riccardo Pucella Cornell University Ithaca, NY 14853 USA riccardo@cs.cornell.edu Abstract
Game Theory. Wolfgang Frimmel. Perfect Bayesian Equilibrium
 Game Theory Wolfgang Frimmel Perfect Bayesian Equilibrium / 22 Bayesian Nash equilibrium and dynamic games L M R 3 2 L R L R 2 2 L R L 2,, M,2, R,3,3 2 NE and 2 SPNE (only subgame!) 2 / 22 Non-credible
Game Theory Wolfgang Frimmel Perfect Bayesian Equilibrium / 22 Bayesian Nash equilibrium and dynamic games L M R 3 2 L R L R 2 2 L R L 2,, M,2, R,3,3 2 NE and 2 SPNE (only subgame!) 2 / 22 Non-credible
Guilt in Games. P. Battigalli and M. Dufwenberg (AER, 2007) Presented by Luca Ferocino. March 21 st,2014
 Presented by Luca Ferocino. March 21 st,2014") Guilt in Games P. Battigalli and M. Dufwenberg (AER, 2007) Presented by Luca Ferocino March 21 st,2014 P. Battigalli and M. Dufwenberg (AER, 2007) Guilt in Games 1 / 29 ADefinitionofGuilt Guilt is a cognitive
Guilt in Games P. Battigalli and M. Dufwenberg (AER, 2007) Presented by Luca Ferocino March 21 st,2014 P. Battigalli and M. Dufwenberg (AER, 2007) Guilt in Games 1 / 29 ADefinitionofGuilt Guilt is a cognitive
A Rothschild-Stiglitz approach to Bayesian persuasion
 A Rothschild-Stiglitz approach to Bayesian persuasion Matthew Gentzkow and Emir Kamenica Stanford University and University of Chicago December 2015 Abstract Rothschild and Stiglitz (1970) represent random
A Rothschild-Stiglitz approach to Bayesian persuasion Matthew Gentzkow and Emir Kamenica Stanford University and University of Chicago December 2015 Abstract Rothschild and Stiglitz (1970) represent random
Game Theory and its Applications to Networks - Part I: Strict Competition
 Game Theory and its Applications to Networks - Part I: Strict Competition Corinne Touati Master ENS Lyon, Fall 200 What is Game Theory and what is it for? Definition (Roger Myerson, Game Theory, Analysis
Game Theory and its Applications to Networks - Part I: Strict Competition Corinne Touati Master ENS Lyon, Fall 200 What is Game Theory and what is it for? Definition (Roger Myerson, Game Theory, Analysis
1 Lattices and Tarski s Theorem
 MS&E 336 Lecture 8: Supermodular games Ramesh Johari April 30, 2007 In this lecture, we develop the theory of supermodular games; key references are the papers of Topkis [7], Vives [8], and Milgrom and
MS&E 336 Lecture 8: Supermodular games Ramesh Johari April 30, 2007 In this lecture, we develop the theory of supermodular games; key references are the papers of Topkis [7], Vives [8], and Milgrom and
SF2972 Game Theory Written Exam with Solutions June 10, 2011
 SF97 Game Theory Written Exam with Solutions June 10, 011 Part A Classical Game Theory Jörgen Weibull and Mark Voorneveld 1. Finite normal-form games. (a) What are N, S and u in the definition of a finite
SF97 Game Theory Written Exam with Solutions June 10, 011 Part A Classical Game Theory Jörgen Weibull and Mark Voorneveld 1. Finite normal-form games. (a) What are N, S and u in the definition of a finite
First Prev Next Last Go Back Full Screen Close Quit. Game Theory. Giorgio Fagiolo
 Game Theory Giorgio Fagiolo giorgio.fagiolo@univr.it https://mail.sssup.it/ fagiolo/welcome.html Academic Year 2005-2006 University of Verona Summary 1. Why Game Theory? 2. Cooperative vs. Noncooperative
Game Theory Giorgio Fagiolo giorgio.fagiolo@univr.it https://mail.sssup.it/ fagiolo/welcome.html Academic Year 2005-2006 University of Verona Summary 1. Why Game Theory? 2. Cooperative vs. Noncooperative