Error Functions & Linear Regression (1)
|
|
|
- Erica Morton
- 6 years ago
- Views:
Transcription
1 Error Functions & Linear Regression (1) John Kelleher & Brian Mac Namee Machine DIT
2 Overview 1 Introduction Overview 2 Univariate Linear Regression Linear Regression Analytical Solution Gradient Descent 3 Multivariate Linear Regression Problem Formulation Gradient Descent 4 Summary
3 Univariate Linear Regression
4 There are a family of machine learning approaches that can be thought of as directly searching for a set of parameters that maximise the performance of a particular prediction model. In this lecture we will look at linear regression and how it can be used for both categorical and continuous prediction problems.
5 Linear Regression Linear Regression Remember that the equation of a line, y = mx + b, can be used to represent the relationship between two variables, x and y. For simplicity we will rewrite the equation of a line as: h w (x) = w 0 + w 1 x where w is the vector [w 0, w 1 ] and w 0 and w 1 are referred to as weights. We now just need to find the weight values that maximise the performance of this model - i.e. the weight values that allow us best predict y given x.
6 Linear Regression Loss Function In order to find the best values for [w 0, w 1 ] we can measure the fit of a model by measuring squared loss function, L 2 over all training examples The loss function can be defined as: Loss(h w ) = = = N L 2 (y j, h w (x)) j=1 N (y j h w (x)) 2 j=1 N (y j (w 0 + w 1 x j )) 2 j=1
7 Linear Regression House Size House Price Practice Assuming w 0 = 6.47 what would be the most accurate value of w 1 based on the given training set (select from 0.4, 0.5, 0.6, 0.7, 0.8).
8 Linear Regression w 1 L , , , , ,955
9 Linear Regression The Loss depending on the weights [w 0, w 1 ] can be viewed as a surface - in fact a surface that is convex and that has a global minimum. We need to find the lowest point on this surface and use it as our weight values.
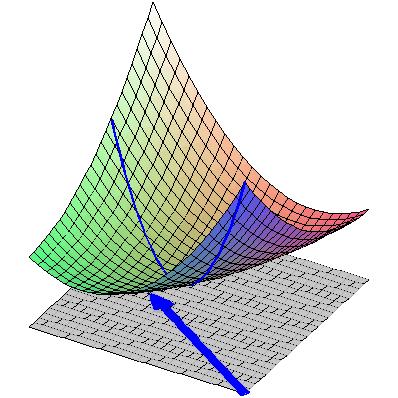
10 Linear Regression
11 Analytical Solution So we want to find w = argmin w Loss(h w ). The sum Loss(h w ) is minimised when its partial derivatives with respect to w 0 and w 1 are equal to 0.
12 Analytical Solution So we want to find w = argmin w Loss(h w ). The sum Loss(h w ) is minimised when its partial derivatives with respect to w 0 and w 1 are equal to 0. Partial What???? Who knows what a derivative is? Who knows what a partial derivative is?
13 Analytical Solution In order to compute slopes we need to know some calculus: Fundamental Calculus: In mathematics, the derivative is a measurement of how a function changes when the values of its inputs change and a partial derivative (denoted by the symbol ) of a function of several variables is its derivative with respect to one of those variables with the others held constant. There are really only three things we need to know about calculus for working on linear regression. First: x x = 1 x x 2 = 2x
14 Analytical Solution Practice Calculate the following: x x + 1 = x 6x = x x 2 = x 3x 2 = x x 2 + 2x + 4 =
15 Analytical Solution Practice Calculate the following: x x + 1 = 1 x 6x = 6 x x 2 = 2x x 3x 2 = 6x x x 2 + 2x + 4 = 2x + 2
16 Analytical Solution Fundamental Calculus: The second thing is the Chain Rule The Chain Rule allows us calculate the derivative of a composition of two or more functions. Chain rule: x g(f (x)) = f (x) g(f (x)) x f (x) Ex.1: x (x 2 + 1) 2 = 2(x 2 + 1)(2x) 1 Ex.2: x 2 (c x)2 = 2 2 (c x)( x (c x)) = (c x)( 1) = (c x)
17 Analytical Solution Practice x (x 2 + 2) 2 = x (3x 2 + 3x + 3) 2 =
18 Analytical Solution Practice x (x 2 + 2) 2 = 2(x 2 + 2)(2x) x (3x 2 + 3x + 3) 2 = 2(3x 2 + 3x + 3)(6x + 3)
19 Analytical Solution So we want to find w = argmin w Loss(h w ). The sum Loss(h w ) is minimised when its partial derivatives with respect to w 0 and w 1 are equal to 0. So: w 0 N j=1 (y j (w 0 + w 1 x j )) 2 = 0 and w 1 N j=1 (y j (w 0 + w 1 x j )) 2 = 0
20 Analytical Solution Fortunately, these equations have a unique solution : w 1 = N( x j y j ) ( x j )( y j ) N( x 2 j ) ( x j ) 2 and w 0 = ( y j w 1 ( x j )) N *based on assumptions that there is normally distributed noise and the stationarity assumption amongst other things
21 Analytical Solution Practice House Size House Price Let s work out the optimal values for [w 0, w 1 ] for the house price dataset we looked at previously. See the associated Excel sheet for the solution!
22 Gradient Descent While it was great to have a unique solution to our system of equations in the previous example, this will not always be the case. We need an alternative way to find the best weights to use in our model. Any ideas?
23 Gradient Descent We need to perform a search through the weight space for the best values to use. An exhaustive search is just not reasonable. Instead we can use the common approach of gradient descent: Start at any point in weight space Move to a neighbouring point that is downhill Repeat until we converge on the point of minimum loss. Gradient descent w any point in the parameter space loop until convergence do for each w i in w do w i w i α w i Loss(w)
24 Gradient Descent α is referred to as the learning rate and determines the amount by which weights are changed at each step. This can be a fixed constant or can decay over time as learning proceeds. Nice gradient descent animations:

25 Gradient Descent
26 Gradient Descent Imagine there was just one training example (x, y). Then the gradient would be given as (note use of chain rule): w i Loss(w) = w i (y h w (x)) 2 = 2(y h w (x)) w i (y h w (x)) = 2(y h w (x)) w i (y (w 0 + w 1 x)) Applying to both w 0 and w 1 we get: w 0 Loss(w) = 2(y h w (x)) w 1 Loss(w) = 2(y h w (x)) x
27 Gradient Descent Plugging these into our weight update rule we get: w 0 w 0 + α(y h w (x)) w 1 w 1 + α(y h w (x)) x Intuitively this makes sense: if h w (x) is too high reduce w 0 a little bit and reduce w 1 if x was positive but increase it if x was negative. if h w (x) is too low do the opposite.
28 Gradient Descent The previous example only considered a single training example. However, adjusting this to deal with a full training set of N examples simply involves introducing a sum: w 0 w 0 + α j (y j h w (x j )) w 1 w 1 + α j (y j h w (x j )) x j This is known as batch gradient descent.
29 Gradient Descent An alternative to batch gradient descent is stochastic gradient descent in which the update rule is applied one example at a time and the examples are chosen, usually randomly, from the training set.
30 Multivariate Linear Regression
31 Problem Formulation We have seen how linear regression can be used to make continuous predictions from a single variable. However, we like big data so one variable is no good to us! A multivariate linear regression does the same job using multiple variables.
32 Problem Formulation Multi-variate Linear Regression Our hypothesis space is of the form: h w (x) = w 0 + w 1 x w n x n = w 0 + i w i x i We can make this look a little neater by inventing a dummy input attribute, x 0, that is always equal to 1. Then: h w (x) = i w i x i = w x
33 Gradient Descent Gradient Descent for Multi-variate Linear Regression The best set of weights, w minimizes the squared error loss, L 2, over a set of training examples: w = argmin w L 2 (y j, w x j ) Gradient descent works for the multi-variate case just like it does for the univariate case and will minimise the loss function. The update rule for each weight is: j w i w i + α j x j,i (y i h w (x j ))
34 Summary
35 1 Introduction Overview 2 Univariate Linear Regression Linear Regression Analytical Solution Gradient Descent 3 Multivariate Linear Regression Problem Formulation Gradient Descent 4 Summary
Error Functions & Linear Regression (2)
") Error Functions & Linear Regression (2) John Kelleher & Brian Mac Namee Machine Learning @ DIT Overview 1 Introduction Overview 2 Linear Classifiers Threshold Function Perceptron Learning Rule Training/Learning
Error Functions & Linear Regression (2) John Kelleher & Brian Mac Namee Machine Learning @ DIT Overview 1 Introduction Overview 2 Linear Classifiers Threshold Function Perceptron Learning Rule Training/Learning
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011!
 Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Least Mean Squares Regression
 Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Module 2 Lecture 05 Linear Regression Good morning, welcome
Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Module 2 Lecture 05 Linear Regression Good morning, welcome
Least Mean Squares Regression. Machine Learning Fall 2018
 Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC 411: Lecture 02: Linear Regression
 CSC 411: Lecture 02: Linear Regression Richard Zemel, Raquel Urtasun and Sanja Fidler University of Toronto (Most plots in this lecture are from Bishop s book) Zemel, Urtasun, Fidler (UofT) CSC 411: 02-Regression
CSC 411: Lecture 02: Linear Regression Richard Zemel, Raquel Urtasun and Sanja Fidler University of Toronto (Most plots in this lecture are from Bishop s book) Zemel, Urtasun, Fidler (UofT) CSC 411: 02-Regression
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Linear Models for Regression
 Linear Models for Regression CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 The Regression Problem Training data: A set of input-output
Linear Models for Regression CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 The Regression Problem Training data: A set of input-output
Lecture 2: Linear regression
 Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Optimization for Machine Learning
 Optimization for Machine Learning Elman Mansimov 1 September 24, 2015 1 Modified based on Shenlong Wang s and Jake Snell s tutorials, with additional contents borrowed from Kevin Swersky and Jasper Snoek
Optimization for Machine Learning Elman Mansimov 1 September 24, 2015 1 Modified based on Shenlong Wang s and Jake Snell s tutorials, with additional contents borrowed from Kevin Swersky and Jasper Snoek
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
CSC321 Lecture 7: Optimization
 CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization
 CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Lecture 4: Types of errors. Bayesian regression models. Logistic regression
 Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Linear Models for Regression CS534
 Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
CSC321 Lecture 2: Linear Regression
 CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
Logistic Regression. Vibhav Gogate The University of Texas at Dallas. Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld.
 Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
CSC 411 Lecture 6: Linear Regression
 CSC 411 Lecture 6: Linear Regression Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 06-Linear Regression 1 / 37 A Timely XKCD UofT CSC 411: 06-Linear Regression
CSC 411 Lecture 6: Linear Regression Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 06-Linear Regression 1 / 37 A Timely XKCD UofT CSC 411: 06-Linear Regression
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Learning with Momentum, Conjugate Gradient Learning
 Learning with Momentum, Conjugate Gradient Learning Introduction to Neural Networks : Lecture 8 John A. Bullinaria, 2004 1. Visualising Learning 2. Learning with Momentum 3. Learning with Line Searches
Learning with Momentum, Conjugate Gradient Learning Introduction to Neural Networks : Lecture 8 John A. Bullinaria, 2004 1. Visualising Learning 2. Learning with Momentum 3. Learning with Line Searches
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Linear Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Linear Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Linear Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Gradient Descent. Stephan Robert
 Gradient Descent Stephan Robert Model Other inputs # of bathrooms Lot size Year built Location Lake view Price (CHF) 6 5 4 3 2 1 2 4 6 8 1 Size (m 2 ) Model How it works Linear regression with one variable
Gradient Descent Stephan Robert Model Other inputs # of bathrooms Lot size Year built Location Lake view Price (CHF) 6 5 4 3 2 1 2 4 6 8 1 Size (m 2 ) Model How it works Linear regression with one variable
Machine Learning Brett Bernstein. Recitation 1: Gradients and Directional Derivatives
 Machine Learning Brett Bernstein Recitation 1: Gradients and Directional Derivatives Intro Question 1 We are given the data set (x 1, y 1 ),, (x n, y n ) where x i R d and y i R We want to fit a linear
Machine Learning Brett Bernstein Recitation 1: Gradients and Directional Derivatives Intro Question 1 We are given the data set (x 1, y 1 ),, (x n, y n ) where x i R d and y i R We want to fit a linear
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayesian Learning. Tobias Scheffer, Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Linear Regression. S. Sumitra
 Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Advanced computational methods X Selected Topics: SGD
 Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
Lecture 13 Back-propagation
 Lecture 13 Bac-propagation 02 March 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/21 Notes: Problem set 4 is due this Friday Problem set 5 is due a wee from Monday (for those of you with a midterm
Lecture 13 Bac-propagation 02 March 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/21 Notes: Problem set 4 is due this Friday Problem set 5 is due a wee from Monday (for those of you with a midterm
CSC321 Lecture 9: Generalization
 CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
Linear Regression. Udacity
 Linear Regression Udacity What is a Linear Equation? Equation of a line : y = mx+b, wherem is the slope of the line and (0,b)isthey-intercept. Notice that the degree of this equation is 1. In higher dimensions
Linear Regression Udacity What is a Linear Equation? Equation of a line : y = mx+b, wherem is the slope of the line and (0,b)isthey-intercept. Notice that the degree of this equation is 1. In higher dimensions
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
LINEAR REGRESSION, RIDGE, LASSO, SVR
 LINEAR REGRESSION, RIDGE, LASSO, SVR Supervised Learning Katerina Tzompanaki Linear regression one feature* Price (y) What is the estimated price of a new house of area 30 m 2? 30 Area (x) *Also called
LINEAR REGRESSION, RIDGE, LASSO, SVR Supervised Learning Katerina Tzompanaki Linear regression one feature* Price (y) What is the estimated price of a new house of area 30 m 2? 30 Area (x) *Also called
Solutions. Part I Logistic regression backpropagation with a single training example
 Solutions Part I Logistic regression backpropagation with a single training example In this part, you are using the Stochastic Gradient Optimizer to train your Logistic Regression. Consequently, the gradients
Solutions Part I Logistic regression backpropagation with a single training example In this part, you are using the Stochastic Gradient Optimizer to train your Logistic Regression. Consequently, the gradients
Least Mean Squares Regression. Machine Learning Fall 2017
 Least Mean Squares Regression Machine Learning Fall 2017 1 Lecture Overview Linear classifiers What func?ons do linear classifiers express? Least Squares Method for Regression 2 Where are we? Linear classifiers
Least Mean Squares Regression Machine Learning Fall 2017 1 Lecture Overview Linear classifiers What func?ons do linear classifiers express? Least Squares Method for Regression 2 Where are we? Linear classifiers
Machine Learning. Regression. Manfred Huber
 Machine Learning Regression Manfred Huber 2015 1 Regression Regression refers to supervised learning problems where the target output is one or more continuous values Continuous output values imply that
Machine Learning Regression Manfred Huber 2015 1 Regression Regression refers to supervised learning problems where the target output is one or more continuous values Continuous output values imply that
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
CSC321 Lecture 5 Learning in a Single Neuron
 CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks
 Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
Contents. 1 Introduction. 1.1 History of Optimization ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016
 ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
Comparison of Modern Stochastic Optimization Algorithms
 Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
17 Neural Networks NEURAL NETWORKS. x XOR 1. x Jonathan Richard Shewchuk
 94 Jonathan Richard Shewchuk 7 Neural Networks NEURAL NETWORKS Can do both classification & regression. [They tie together several ideas from the course: perceptrons, logistic regression, ensembles of
94 Jonathan Richard Shewchuk 7 Neural Networks NEURAL NETWORKS Can do both classification & regression. [They tie together several ideas from the course: perceptrons, logistic regression, ensembles of
CS260: Machine Learning Algorithms
 CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
Machine Learning (CS 567) Lecture 5
 Lecture 5") Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
Deep Learning. Authors: I. Goodfellow, Y. Bengio, A. Courville. Chapter 4: Numerical Computation. Lecture slides edited by C. Yim. C.
 Chapter 4: Numerical Computation Deep Learning Authors: I. Goodfellow, Y. Bengio, A. Courville Lecture slides edited by 1 Chapter 4: Numerical Computation 4.1 Overflow and Underflow 4.2 Poor Conditioning
Chapter 4: Numerical Computation Deep Learning Authors: I. Goodfellow, Y. Bengio, A. Courville Lecture slides edited by 1 Chapter 4: Numerical Computation 4.1 Overflow and Underflow 4.2 Poor Conditioning
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Regression with Numerical Optimization. Logistic
 CSG220 Machine Learning Fall 2008 Regression with Numerical Optimization. Logistic regression Regression with Numerical Optimization. Logistic regression based on a document by Andrew Ng October 3, 204
CSG220 Machine Learning Fall 2008 Regression with Numerical Optimization. Logistic regression Regression with Numerical Optimization. Logistic regression based on a document by Andrew Ng October 3, 204
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Mustafa Jarrar. Machine Learning Linear Regression. Birzeit University. Mustafa Jarrar: Lecture Notes on Linear Regression Birzeit University, 2018
 Mustafa Jarrar: Lecture Notes on Linear Regression Birzeit University, 2018 Version 1 Machine Learning Linear Regression Mustafa Jarrar Birzeit University 1 Watch this lecture and download the slides Course
Mustafa Jarrar: Lecture Notes on Linear Regression Birzeit University, 2018 Version 1 Machine Learning Linear Regression Mustafa Jarrar Birzeit University 1 Watch this lecture and download the slides Course
Lecture 11 Linear regression
 Advanced Algorithms Floriano Zini Free University of Bozen-Bolzano Faculty of Computer Science Academic Year 2013-2014 Lecture 11 Linear regression These slides are taken from Andrew Ng, Machine Learning
Advanced Algorithms Floriano Zini Free University of Bozen-Bolzano Faculty of Computer Science Academic Year 2013-2014 Lecture 11 Linear regression These slides are taken from Andrew Ng, Machine Learning
Optimization in the Big Data Regime 2: SVRG & Tradeoffs in Large Scale Learning. Sham M. Kakade
 Optimization in the Big Data Regime 2: SVRG & Tradeoffs in Large Scale Learning. Sham M. Kakade Machine Learning for Big Data CSE547/STAT548 University of Washington S. M. Kakade (UW) Optimization for
Optimization in the Big Data Regime 2: SVRG & Tradeoffs in Large Scale Learning. Sham M. Kakade Machine Learning for Big Data CSE547/STAT548 University of Washington S. M. Kakade (UW) Optimization for
Classification: Logistic Regression from Data
 Classification: Logistic Regression from Data Machine Learning: Alvin Grissom II University of Colorado Boulder Slides adapted from Emily Fox Machine Learning: Alvin Grissom II Boulder Classification:
Classification: Logistic Regression from Data Machine Learning: Alvin Grissom II University of Colorado Boulder Slides adapted from Emily Fox Machine Learning: Alvin Grissom II Boulder Classification:
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Lecture 3. Linear Regression
 Lecture 3. Linear Regression COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne Weeks 2 to 8 inclusive Lecturer: Andrey Kan MS: Moscow, PhD:
Lecture 3. Linear Regression COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne Weeks 2 to 8 inclusive Lecturer: Andrey Kan MS: Moscow, PhD:
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
Introduction to Machine Learning
 Introduction to Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland LOGISTIC REGRESSION FROM TEXT Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber UMD Introduction
Introduction to Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland LOGISTIC REGRESSION FROM TEXT Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber UMD Introduction
Gradient Descent. Sargur Srihari
 Gradient Descent Sargur srihari@cedar.buffalo.edu 1 Topics Simple Gradient Descent/Ascent Difficulties with Simple Gradient Descent Line Search Brent s Method Conjugate Gradient Descent Weight vectors
Gradient Descent Sargur srihari@cedar.buffalo.edu 1 Topics Simple Gradient Descent/Ascent Difficulties with Simple Gradient Descent Line Search Brent s Method Conjugate Gradient Descent Weight vectors
A thorough derivation of back-propagation for people who really want to understand it by: Mike Gashler, September 2010
 A thorough derivation of back-propagation for people who really want to understand it by: Mike Gashler, September 2010 Define the problem: Suppose we have a 5-layer feed-forward neural network. (I intentionally
A thorough derivation of back-propagation for people who really want to understand it by: Mike Gashler, September 2010 Define the problem: Suppose we have a 5-layer feed-forward neural network. (I intentionally
CSE446: non-parametric methods Spring 2017
 CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
Linear Regression (9/11/13)
") STA561: Probabilistic machine learning Linear Regression (9/11/13) Lecturer: Barbara Engelhardt Scribes: Zachary Abzug, Mike Gloudemans, Zhuosheng Gu, Zhao Song 1 Why use linear regression? Figure 1: Scatter
STA561: Probabilistic machine learning Linear Regression (9/11/13) Lecturer: Barbara Engelhardt Scribes: Zachary Abzug, Mike Gloudemans, Zhuosheng Gu, Zhao Song 1 Why use linear regression? Figure 1: Scatter
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
CSC321 Lecture 9: Generalization
 CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 27 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 27 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 17 2019 Logistics HW 1 is on Piazza and Gradescope Deadline: Friday, Jan. 25, 2019 Office
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 17 2019 Logistics HW 1 is on Piazza and Gradescope Deadline: Friday, Jan. 25, 2019 Office
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Introduction to Optimization
 Introduction to Optimization Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Machine learning is important and interesting The general concept: Fitting models to data So far Machine
Introduction to Optimization Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Machine learning is important and interesting The general concept: Fitting models to data So far Machine
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Motivation Subgradient Method Stochastic Subgradient Method. Convex Optimization. Lecture 15 - Gradient Descent in Machine Learning
 Convex Optimization Lecture 15 - Gradient Descent in Machine Learning Instructor: Yuanzhang Xiao University of Hawaii at Manoa Fall 2017 1 / 21 Today s Lecture 1 Motivation 2 Subgradient Method 3 Stochastic
Convex Optimization Lecture 15 - Gradient Descent in Machine Learning Instructor: Yuanzhang Xiao University of Hawaii at Manoa Fall 2017 1 / 21 Today s Lecture 1 Motivation 2 Subgradient Method 3 Stochastic
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods.
 Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Linear Regression, Neural Networks, etc.
 Linear Regression, Neural Networks, etc. Gradient Descent Many machine learning problems can be cast as optimization problems Define a function that corresponds to learning error. (More on this later)
Linear Regression, Neural Networks, etc. Gradient Descent Many machine learning problems can be cast as optimization problems Define a function that corresponds to learning error. (More on this later)
Machine Learning Basics Lecture 3: Perceptron. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 3: Perceptron Princeton University COS 495 Instructor: Yingyu Liang Perceptron Overview Previous lectures: (Principle for loss function) MLE to derive loss Example: linear
Machine Learning Basics Lecture 3: Perceptron Princeton University COS 495 Instructor: Yingyu Liang Perceptron Overview Previous lectures: (Principle for loss function) MLE to derive loss Example: linear
Ordinary Least Squares Linear Regression
 Ordinary Least Squares Linear Regression Ryan P. Adams COS 324 Elements of Machine Learning Princeton University Linear regression is one of the simplest and most fundamental modeling ideas in statistics
Ordinary Least Squares Linear Regression Ryan P. Adams COS 324 Elements of Machine Learning Princeton University Linear regression is one of the simplest and most fundamental modeling ideas in statistics
ECE521: Inference Algorithms and Machine Learning University of Toronto. Assignment 1: k-nn and Linear Regression
 ECE521: Inference Algorithms and Machine Learning University of Toronto Assignment 1: k-nn and Linear Regression TA: Use Piazza for Q&A Due date: Feb 7 midnight, 2017 Electronic submission to: ece521ta@gmailcom
ECE521: Inference Algorithms and Machine Learning University of Toronto Assignment 1: k-nn and Linear Regression TA: Use Piazza for Q&A Due date: Feb 7 midnight, 2017 Electronic submission to: ece521ta@gmailcom
CSC321 Lecture 6: Backpropagation
 CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
1 Review and Overview
 DRAFT a final version will be posted shortly CS229T/STATS231: Statistical Learning Theory Lecturer: Tengyu Ma Lecture # 16 Scribe: Chris Cundy, Ananya Kumar November 14, 2018 1 Review and Overview Last
DRAFT a final version will be posted shortly CS229T/STATS231: Statistical Learning Theory Lecturer: Tengyu Ma Lecture # 16 Scribe: Chris Cundy, Ananya Kumar November 14, 2018 1 Review and Overview Last
Stochastic gradient descent; Classification
 Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Stochastic Gradient Descent: The Workhorse of Machine Learning. CS6787 Lecture 1 Fall 2017
 Stochastic Gradient Descent: The Workhorse of Machine Learning CS6787 Lecture 1 Fall 2017 Fundamentals of Machine Learning? Machine Learning in Practice this course What s missing in the basic stuff? Efficiency!
Stochastic Gradient Descent: The Workhorse of Machine Learning CS6787 Lecture 1 Fall 2017 Fundamentals of Machine Learning? Machine Learning in Practice this course What s missing in the basic stuff? Efficiency!