CS 175: Project in Artificial Intelligence. Slides 4: Collaborative Filtering
|
|
|
- Crystal Montgomery
- 6 years ago
- Views:
Transcription

1 CS 175: Project in Artificial Intelligence Slides 4: Collaborative Filtering 1
2 Topic 6: Collaborative Filtering Some slides taken from Prof. Smyth (with slight modifications) 2
3 Outline General aspects of recommender systems Nearest neighbor methods Matrix decomposition and singular value decomposition (SVD) 3
4 Recommender Systems Ratings or Vote data = m x n sparse binary matrix n columns = products, e.g., books for purchase or movies for viewing m rows = users Interpretation: Ratings: v(i,j) = user i s rating of product j (e.g. on a scale of 1 to 5) Purchases: v(i,j) = 1 if user i purchased product j entry = 0 if no purchase or rating Automated recommender systems Given ratings or votes by a user on a subset of items, recommend other items that the user may be interested in 4
5 Examples of Recommender Systems Shopping Amazon.com etc Movie and music recommendations: Netflix Last.fm Digital library recommendations CiteSeer (Popescul et al, 2001): m = 177,000 documents N = 33,000 users Each user accessed 18 documents on average (0.01% of the database -> very sparse!) Web page recommendations 5
6 The Recommender Space as a Bipartite Graph Links derived from similar attributes, explicit connections Users Items User-User Links Item-Item Links Observed preferences (Ratings, purchases, page views, play lists, bookmarks, etc) Links derived from similar attributes, similar content, explicit cross references 6
7 Different types of recommender algorithms Nearest-neighbor/collaborative filtering algorithms Widely used simple and intuitive Matrix factorization (e.g., SVD) Has gained popularity recent due to Netflix competition Less used Neural networks Cluster-based algorithms Probabilistic models 7
8 Nearest-Neighbor Algorithms for Collaborative Filtering r i,k = rating of user i on item k I i = items for which user i has generated a rating Mean rating for user i is Predicted vote for user i on item j is a weighted sum Normalization constant (e.g., total sum of weights) weights of K similar users Value of K can be optimized on a validation data set 8
9 Nearest-Neighbor Weighting K-nearest neighbor Pearson correlation coefficient (Resnick 94, Grouplens): Sums are over items rated by both users Can also scale weights by number of items in common Smoothing constant, e.g., 10 or 100 9
10 Comments on Neighbor-based Methods Here we emphasized user-user similarity Can also do this with item-item similarity, i.e., Find similar items (across users) to the item we need a rating for Simple and intuitive Easy to provide the user with explanations of recommendations Computational Issues In theory we need to calculate all n 2 pairwise weights So scalability is an issue (e.g., real-time) Significant engineering involved, many tricks For recent advances in neighbor-based approaches see Y. Koren, Factor in the neighbors: scalable and accurate collaborative filtering, ACM Transactions on Knowledge Discovery in Data,
11 NOTES ON MATRIX DECOMPOSITION AND SVD 11 Data Mining Lectures Lecture 15: Text Classification Padhraic Smyth, UC Irvine
12 Matrix Decomposition Matrix D = m x n - e.g., Ratings matrix with m customers, n items - assume for simplicity that m > n Typically R is sparse, e.g., less than 1% of entries have ratings n is large, e.g., movies So finding matches to less popular items will be difficult Idea: compress the columns (items) into a lower-dimensional representation 12
13 Singular Value Decomposition (SVD) D = U V t m x n m x n n x n n x n where: rows of V t are eigenvectors of D t D = basis functions is diagonal, with ii = sqrt( i ) (ith eigenvalue) rows of U are coefficients for basis functions in V (here we assumed that m > n, and rank D = n) 13
14 Data D 10 = SVD Example
15 Data D = SVD Example Note the pattern in the data above: the center column values are typically about twice the 1 st and 3 rd column values: So there is redundancy in the columns, i.e., the column values are correlated 15
16 Data D = SVD Example D = U V t where U = where = and V t =
17 Data D = SVD Example D = U V t where U = Note that first singular value is much larger than the others where = and V t =
18 Data D = SVD Example D = U V t where U = Note that first singular value is much larger than the others where = and V t = First basis function (or eigenvector) carries most of the information and it discovers the pattern of column dependence 18
19 Rows in D = weighted sums of basis vectors 1 st row of D = [ ] Since D = U S V t, then D(1,: ) = U(1, :) * * V t = [ ] * V t V t = D(1,: ) = 24.5 v v v 3 where v 1, v 2, v 3 are rows of V t and are our basis vectors Thus, [24.5, 0.2, 0.22] are the weights that characterize row 1 in D In general, the ith row of U* is the set of weights for the ith row in D 19
20 Summary of SVD Representation D = U V t Data matrix: Rows = data vectors V t matrix: Rows = our basis functions U* matrix: Rows = weights for the rows of D 20
21 How do we compute U,, and V? SVD decomposition is a standard eigenvector/value problem The eigenvectors of D D = the rows of V The eigenvectors of D D = the columns of U The diagonal matrix elements in are square roots of the eigenvalues of D D => finding U,,V is equivalent to finding eigenvectors of D D Solving eigenvalue problems is equivalent to solving a set of linear equations time complexity is O(m n 2 + n 3 ) In MATLAB, we can calculate this using the svd.m function, i.e., [u, s, v] = svd(d); If matrix D is non-square, we can use svd(d,0) 21
22 Approximating the matrix D Example: we could approximate any row D just using a single weight Row 1: Can be approximated by D = w 1 *v 1 = 24.5*[ ] = [ ] D(1,:) = Note that this is a close approximation of the exact D(1,:) (Similarly for any other row) Basis for data compression: Sender and receiver agree on basis functions in advance Sender then sends the receiver a small number of weights Receiver then reconstructs the signal using the weights + the basis function Results in far fewer bits being sent on average trade-off is that there is some loss in the quality of the original signal 22
23 Matrix Approximation with SVD D ~ U V t m x n m x f f x f f x n where: columns of V are first f eigenvectors of R t R is diagonal with f largest eigenvalues rows of U are coefficients in reduced dimension V-space This approximation gives the best rank-f approximation to matrix R in a least squares sense (this is also known as principal components analysis) 23
24 24 A matrix D can be decomposed: Rank-f approximation: Singular Value Decomposition S U D V M N M M M N N N = B A D M M F = N N F S U D V M N F M F F F N =
25 Why do SVD? SVD provides the best f-rank approximation under the Frobenius Norm * : We often want to minimize (root) mean squared error for our ratings * Benjamin Marlin. Collaborative Filtering: A Machine Learning Perspective
26 Stochastic Gradient Descent Sometimes, matrix of ratings is too huge (i.e. Netflix is x 17770) to do full SVD Perform stochastic gradient descent to approximate A and B Repeat until convergence: Select one rating (D mn ) in our training set, randomly Update row m in A and column n in B, based on update equations Exercise: Work out these derivatives Can be done efficiently in Matlab, via vectorization With f = 300, can do about 600,000 iterations per minute 26
27 Results of SVD on Netflix (f=600): 1.08 Root Mean Squared Error Iterations 27
28 Example: Applying SVD to a Document-Term Matrix database SQL index regression likelihood linear d d d d d d d d d d
29 Results of SVD with 2 factors (f=2) database SQL index regression likelihood linear U1 U2 d d d d d d d d d d d d d d d d d d d d
30 v 1 = [0.74, 0.49, 0.27, 0.28, 0.18, 0.19] v 2 = [-0.28, , 0.74, 0.37, 0.31] D1 = database x 50 D2 = SQL x 50 30
31 Latent Semantic Indexing LSI = application of SVD to document-term data Querying Project documents into f-dimensional space Project each query q into f-dimensional space Find documents closest to query q in f-dimensional space Often works better than matching in original high-dimensional space Why is this useful? Query contains automobile, document contains vehicle can still match Q to the document since the 2 terms will be close in k- space (but not in original space), i.e., addresses synonymy problem 31
32 Related Ideas Topic Modeling Can also be viewed as matrix factorization Basis functions = topics Topics tend to be more interpretable than LSI vectors (better suited to non-negative matrices) May also perform better for document retrieval Non-negative Matrix Factorization 32
33 NETFLIX: CASE STUDY 33 Data Mining Lectures Lecture 15: Text Classification Padhraic Smyth, UC Irvine
34 Netflix Movie rentals by DVD (mail) and online (streaming) 100k movies, 10 million customers Ships 1.9 million disks to customers each day 50 warehouses in the US Complex logistics problem Employees: 2000 But relatively few in engineering/software And only a few people working on recommender systems Moving towards online delivery of content Significant interaction of customers with Web site 34

35 The $1 Million Question 35

36 Million Dollars Awarded Sept 21 st
37 Ratings Data 17,700 movies 480,000 users
38 Scoring Minimize root mean square error (RMSE) Mean square error = 1/ R u,i) R ( r ui - r^ ui ) 2 Does not necessarily correlate well with user satisfaction But is a widely-used well-understood quantitative measure 38
39 RMSE Baseline Scores on Test Data just predict the mean user rating for each movie Netflix s own system (Cinematch) as of nearest-neighbor method using correlation required 10% reduction to win $1 million 39
40 Why did Netflix do this? Customer satisfaction/retention is key to Netflix they would really like to improve their recommender systems Progress with internal system (Cinematch) was slow Initial prize idea from CEO Reed Hastings $1 million would likely easily pay for itself Potential downsides Negative publicity (e.g., privacy) No-one wins the prize (conspiracy theory) The prize is won within a day or 2 Person-hours at Netflix to run the competition Algorithmic solutions are not useful operationally 40
41 Matrix Factorization of Ratings Data n movies f n movies m users ~ m users x f r ui ~ a t u b i r ui ~ a t i b u 41

42 Figure from Koren, Bell, Volinksy, IEEE Computer,
43 Dealing with Missing Data r ui ~ a t i b u min a,b u,i) R ( r ui - a t i b u ) 2 sum is only over known ratings 43
44 Dealing with Missing Data r ui ~ a t i b u min a,b u,i) R ( r ui - a t i b u ) 2 Add regularization min a,b u,i) R ( r ui - a t i b u ) 2 + ( a i 2 + b u 2 ) 44
45 Time effects also important 45
46 Explanation for increase? 46
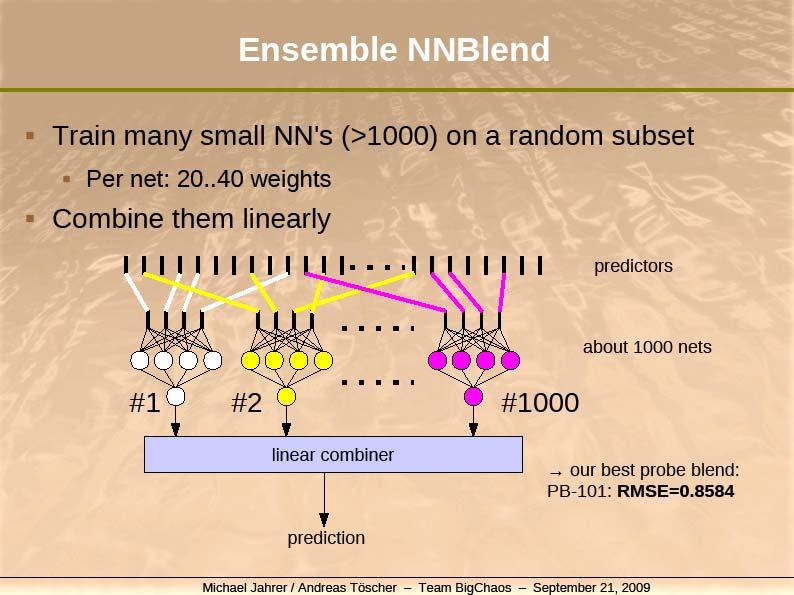
47 The Kitchen Sink Approach. Many options for modeling Variants of the ideas we have seen so far Different ways to model time Different ways to handle implicit information Different numbers of factors. Other models Nearest-neighbor models Restricted Boltzmann machines Model averaging was useful. Linear model combining Neural network combining Gradient boosted decision tree combining Note: combining weights learned on validation set ( stacking ) 47
48 48
49 Other Aspects of Model Building Automated parameter tuning Using a validation set, and grid search, various parameters such as learning rates, regularization parameters, etc., can be optimized Memory requirements Memory: can fit within roughly 1 Gbyte of RAM Training time Order of days: but achievable on commodity hardware rather than a supercomputer Some parallelization used 49
50 Matrix factorization vs Near Neighbor? From Koren, ACM Transactions on Knowledge Discovery, 2010 Latent factor models such as SVD face real difficulties when needed to explain predictions. Thus, we believe that for practical applications neighborhood models are still expected to be a common choice. 50
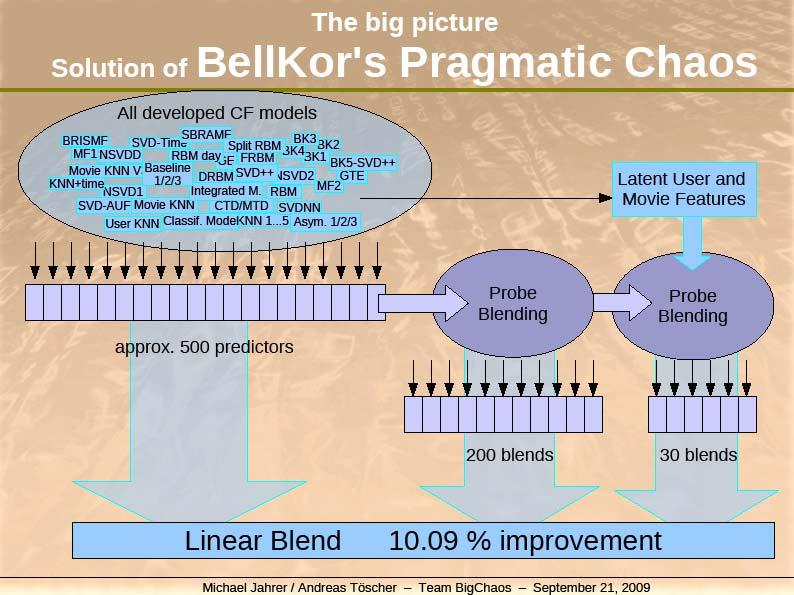
51 51

52 June 26 th 2009: after 1000 Days and nights 52
53 The Leading Team BellKorPragmaticChaos BellKor: Yehuda Koren (now Yahoo!), Bob Bell, Chris Volinsky, AT&T BigChaos: Michael Jahrer, Andreas Toscher, 2 grad students from Austria Pragmatic Theory Martin Chabert, Martin Piotte, 2 engineers from Montreal (Quebec) June 26 th submission triggers 30-day last call Submission timed purposely to coincide with vacation schedules 53
54 The Last 30 Days Ensemble team formed Group of other teams on leaderboard forms a new team Relies on combining their models Quickly also get a qualifying score over 10% BellKor Continue to eke out small improvements in their scores Realize that they are in direct competition with Ensemble Strategy Both teams carefully monitoring the leaderboard Only sure way to check for improvement is to submit a set of predictions This alerts the other team of your latest score 54
55 24 Hours from the Deadline Submissions limited to 1 a day So only 1 final submission could be made by either in the last 24 hours team 24 hours before deadline BellKor team member in Austria notices (by chance) that Ensemble posts a score that is slightly better than BellKor s Leaderboard score disappears after a few minutes (rule loophole) Frantic last 24 hours for both teams Much computer time on final optimization run times carefully calibrated to end about an hour before deadline Final submissions BellKor submits a little early (on purpose), 40 mins before deadline Ensemble submits their final entry 20 mins later.and everyone waits. 55
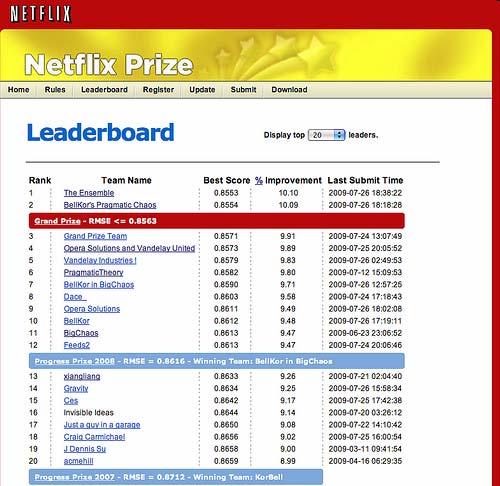
56 56
57 Training Data Held-Out Data 3 million ratings 100 million ratings 1.5m ratings 1.5m ratings Quiz Set: scores posted on leaderboard Test Set: scores known only to Netflix Scores used in determining final winner 57
58 58
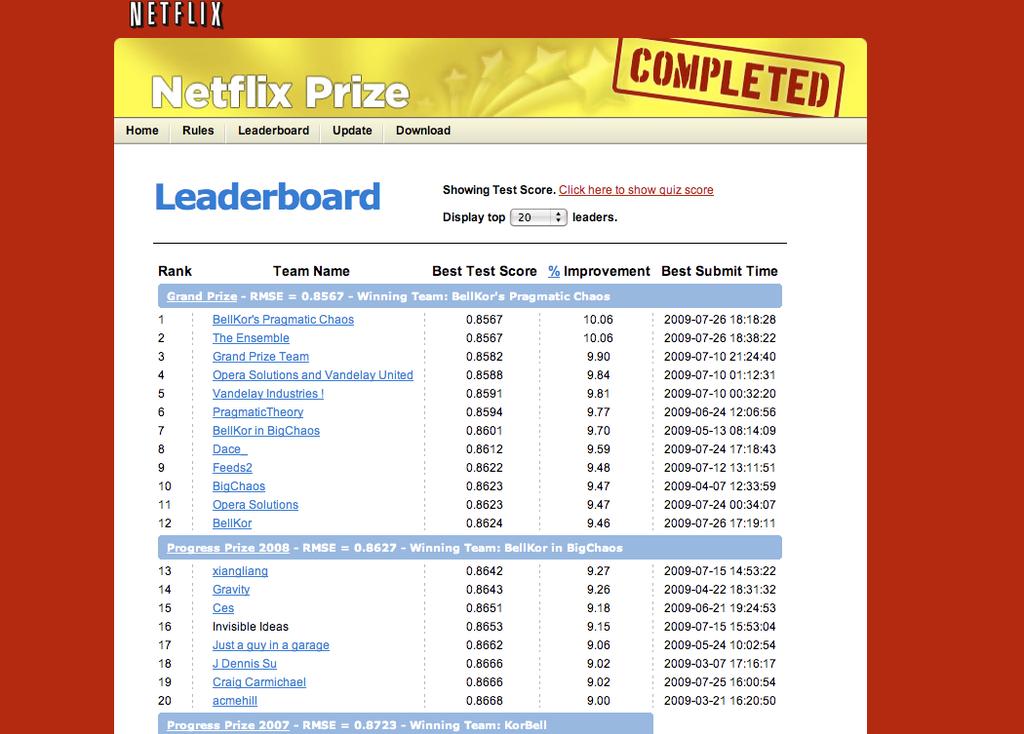
59 59

60 Million Dollars Awarded Sept 21 st
61 Lessons Learned Scalability is important e.g., stochastic gradient descent on sparse matrices Latent factor models work well on this problem Previously had not been explored for recommender systems Understanding your data is important, e.g., time-effects Combining models works surprisingly well But final 10% improvement can probably be achieved by judiciously combining about 10 models rather than 1000 s This is likely what Netflix will do in practice Surprising amount of collaboration among participants 61

62 62
63 Why Collaboration? Openness of competition structure Rules stated that winning solutions would be published Non-exclusive license of winning software to Netflix Description of algorithm to be posted on site Research workshops sponsored by Netflix Leaderboard was publicly visible: it was addictive. 63
64 64
65 Why Collaboration? Development of Online Community Active Netflix prize forum + other blogs Quickly acquired buzz Forum was well-moderated by Netflix Attracted discussion from novices and experts alike Early posting of code and solutions Early self-identification (links via leaderboard) 65
66 Why Collaboration? Academic/Research Culture Nature of competition was technical/mathematical Attracted students, hobbyists, researchers Many motivated by fundamental interest in producing better algorithms - $1 million would be a nice bonus History in academic circles of being open, publishing, sharing 66
67 Questions Does reduction in squared error metric correlate with real improvements in user satisfaction? Are these competitions good for scientific research? Should researchers be solving other more important problems? Are competitions a good strategy for companies? 67
68 Evaluation Methods Research papers use historical data to evaluate and compare different recommender algorithms predictions typically made on items whose ratings are known e.g., leave-1-out method, each positive vote for each user in a test data set is in turn left out predictions on left-out items made given rated items e.g., predict-given-k method Make predictions on rated items given k=1, k=5, k=20 ratings See Herlocker et al (2004) for detailed discussion of evaluation Approach 1: measure quality of rankings Score = weighted sum of true votes in top 10 predicted items Approach 2: directly measure prediction accuracy Mean-absolute-error (MAE) between predictions and actual votes Typical MAE on large data sets ~ 20% (normalized) E.g., on a 5-point scale predictions are within 1 point on average 68
69 Evaluation with (Implicit) Binary Purchase Data Cautionary note: It is not clear that prediction on historical data is a meaningful way to evaluate recommender algorithms, especially for purchasing Consider: User purchases products A, B, C Algorithm ranks C highly given A and B, gets a good score However, what if the user would have purchased C anyway, i.e., making this recommendation would have had no impact? (or possibly a negative impact!) What we would really like to do is reward recommender algorithms that lead the user to purchase products that they would not have purchased without the recommendation This can t be done based on historical data alone Requires direct live experiments (which is often how companies evaluate recommender algorithms) 69
Collaborative Filtering. Radek Pelánek
 Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task
 Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
CS425: Algorithms for Web Scale Data
 CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org J. Leskovec,
CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org J. Leskovec,
Collaborative Filtering Applied to Educational Data Mining
 Journal of Machine Learning Research (200) Submitted ; Published Collaborative Filtering Applied to Educational Data Mining Andreas Töscher commendo research 8580 Köflach, Austria andreas.toescher@commendo.at
Journal of Machine Learning Research (200) Submitted ; Published Collaborative Filtering Applied to Educational Data Mining Andreas Töscher commendo research 8580 Köflach, Austria andreas.toescher@commendo.at
Mining of Massive Datasets Jure Leskovec, AnandRajaraman, Jeff Ullman Stanford University
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Using SVD to Recommend Movies
 Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
Matrix Factorization Techniques for Recommender Systems
 Matrix Factorization Techniques for Recommender Systems By Yehuda Koren Robert Bell Chris Volinsky Presented by Peng Xu Supervised by Prof. Michel Desmarais 1 Contents 1. Introduction 4. A Basic Matrix
Matrix Factorization Techniques for Recommender Systems By Yehuda Koren Robert Bell Chris Volinsky Presented by Peng Xu Supervised by Prof. Michel Desmarais 1 Contents 1. Introduction 4. A Basic Matrix
Matrix Factorization In Recommender Systems. Yong Zheng, PhDc Center for Web Intelligence, DePaul University, USA March 4, 2015
 Matrix Factorization In Recommender Systems Yong Zheng, PhDc Center for Web Intelligence, DePaul University, USA March 4, 2015 Table of Contents Background: Recommender Systems (RS) Evolution of Matrix
Matrix Factorization In Recommender Systems Yong Zheng, PhDc Center for Web Intelligence, DePaul University, USA March 4, 2015 Table of Contents Background: Recommender Systems (RS) Evolution of Matrix
Recommender Systems EE448, Big Data Mining, Lecture 10. Weinan Zhang Shanghai Jiao Tong University
 2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
Algorithms for Collaborative Filtering
 Algorithms for Collaborative Filtering or How to Get Half Way to Winning $1million from Netflix Todd Lipcon Advisor: Prof. Philip Klein The Real-World Problem E-commerce sites would like to make personalized
Algorithms for Collaborative Filtering or How to Get Half Way to Winning $1million from Netflix Todd Lipcon Advisor: Prof. Philip Klein The Real-World Problem E-commerce sites would like to make personalized
* Matrix Factorization and Recommendation Systems
 Matrix Factorization and Recommendation Systems Originally presented at HLF Workshop on Matrix Factorization with Loren Anderson (University of Minnesota Twin Cities) on 25 th September, 2017 15 th March,
Matrix Factorization and Recommendation Systems Originally presented at HLF Workshop on Matrix Factorization with Loren Anderson (University of Minnesota Twin Cities) on 25 th September, 2017 15 th March,
Recommender Systems. Dipanjan Das Language Technologies Institute Carnegie Mellon University. 20 November, 2007
 Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
The Pragmatic Theory solution to the Netflix Grand Prize
 The Pragmatic Theory solution to the Netflix Grand Prize Martin Piotte Martin Chabbert August 2009 Pragmatic Theory Inc., Canada nfpragmatictheory@gmail.com Table of Contents 1 Introduction... 3 2 Common
The Pragmatic Theory solution to the Netflix Grand Prize Martin Piotte Martin Chabbert August 2009 Pragmatic Theory Inc., Canada nfpragmatictheory@gmail.com Table of Contents 1 Introduction... 3 2 Common
Matrix Factorization Techniques For Recommender Systems. Collaborative Filtering
 Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Recommendation Systems
 Recommendation Systems Popularity Recommendation Systems Predicting user responses to options Offering news articles based on users interests Offering suggestions on what the user might like to buy/consume
Recommendation Systems Popularity Recommendation Systems Predicting user responses to options Offering news articles based on users interests Offering suggestions on what the user might like to buy/consume
Andriy Mnih and Ruslan Salakhutdinov
 MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
Restricted Boltzmann Machines for Collaborative Filtering
 Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Variable Latent Semantic Indexing
 Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
CS246 Final Exam, Winter 2011
 CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Collaborative Filtering
 Collaborative Filtering Nicholas Ruozzi University of Texas at Dallas based on the slides of Alex Smola & Narges Razavian Collaborative Filtering Combining information among collaborating entities to make
Collaborative Filtering Nicholas Ruozzi University of Texas at Dallas based on the slides of Alex Smola & Narges Razavian Collaborative Filtering Combining information among collaborating entities to make
Preliminaries. Data Mining. The art of extracting knowledge from large bodies of structured data. Let s put it to use!
 Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Collaborative Filtering: A Machine Learning Perspective
 Collaborative Filtering: A Machine Learning Perspective Chapter 6: Dimensionality Reduction Benjamin Marlin Presenter: Chaitanya Desai Collaborative Filtering: A Machine Learning Perspective p.1/18 Topics
Collaborative Filtering: A Machine Learning Perspective Chapter 6: Dimensionality Reduction Benjamin Marlin Presenter: Chaitanya Desai Collaborative Filtering: A Machine Learning Perspective p.1/18 Topics
Large-scale Collaborative Ranking in Near-Linear Time
 Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
CS 277: Data Mining. Mining Web Link Structure. CS 277: Data Mining Lectures Analyzing Web Link Structure Padhraic Smyth, UC Irvine
 CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
Decoupled Collaborative Ranking
 Decoupled Collaborative Ranking Jun Hu, Ping Li April 24, 2017 Jun Hu, Ping Li WWW2017 April 24, 2017 1 / 36 Recommender Systems Recommendation system is an information filtering technique, which provides
Decoupled Collaborative Ranking Jun Hu, Ping Li April 24, 2017 Jun Hu, Ping Li WWW2017 April 24, 2017 1 / 36 Recommender Systems Recommendation system is an information filtering technique, which provides
Impact of Data Characteristics on Recommender Systems Performance
 Impact of Data Characteristics on Recommender Systems Performance Gediminas Adomavicius YoungOk Kwon Jingjing Zhang Department of Information and Decision Sciences Carlson School of Management, University
Impact of Data Characteristics on Recommender Systems Performance Gediminas Adomavicius YoungOk Kwon Jingjing Zhang Department of Information and Decision Sciences Carlson School of Management, University
Collaborative Recommendation with Multiclass Preference Context
 Collaborative Recommendation with Multiclass Preference Context Weike Pan and Zhong Ming {panweike,mingz}@szu.edu.cn College of Computer Science and Software Engineering Shenzhen University Pan and Ming
Collaborative Recommendation with Multiclass Preference Context Weike Pan and Zhong Ming {panweike,mingz}@szu.edu.cn College of Computer Science and Software Engineering Shenzhen University Pan and Ming
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
TMA4267 Linear Statistical Models V2016
 TMA4267 Linear Statistical Models V2016 Introduction to the course Part 1: Multivariate random variables, and the multivariate normal distribution Mette Langaas Department of Mathematical Sciences, NTNU
TMA4267 Linear Statistical Models V2016 Introduction to the course Part 1: Multivariate random variables, and the multivariate normal distribution Mette Langaas Department of Mathematical Sciences, NTNU
Matrix Factorization and Collaborative Filtering
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
Recommender systems, matrix factorization, variable selection and social graph data
 Recommender systems, matrix factorization, variable selection and social graph data Julien Delporte & Stéphane Canu stephane.canu@litislab.eu StatLearn, april 205, Grenoble Road map Model selection for
Recommender systems, matrix factorization, variable selection and social graph data Julien Delporte & Stéphane Canu stephane.canu@litislab.eu StatLearn, april 205, Grenoble Road map Model selection for
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Collaborative Filtering on Ordinal User Feedback
 Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Collaborative Filtering on Ordinal User Feedback Yehuda Koren Google yehudako@gmail.com Joseph Sill Analytics Consultant
Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Collaborative Filtering on Ordinal User Feedback Yehuda Koren Google yehudako@gmail.com Joseph Sill Analytics Consultant
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
TMA4267 Linear Statistical Models V2016
 TMA4267 Linear Statistical Models V206 Introduction to the course Part : Multivariate random variables, and the multivariate normal distribution Mette Langaas Department of Mathematical Sciences, NTNU
TMA4267 Linear Statistical Models V206 Introduction to the course Part : Multivariate random variables, and the multivariate normal distribution Mette Langaas Department of Mathematical Sciences, NTNU
Collaborative Filtering via Ensembles of Matrix Factorizations
 Collaborative Ftering via Ensembles of Matrix Factorizations Mingrui Wu Max Planck Institute for Biological Cybernetics Spemannstrasse 38, 72076 Tübingen, Germany mingrui.wu@tuebingen.mpg.de ABSTRACT We
Collaborative Ftering via Ensembles of Matrix Factorizations Mingrui Wu Max Planck Institute for Biological Cybernetics Spemannstrasse 38, 72076 Tübingen, Germany mingrui.wu@tuebingen.mpg.de ABSTRACT We
Singular Value Decompsition
 Singular Value Decompsition Massoud Malek One of the most useful results from linear algebra, is a matrix decomposition known as the singular value decomposition It has many useful applications in almost
Singular Value Decompsition Massoud Malek One of the most useful results from linear algebra, is a matrix decomposition known as the singular value decomposition It has many useful applications in almost
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Data Mining Recitation Notes Week 3
 Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
A Modified PMF Model Incorporating Implicit Item Associations
 A Modified PMF Model Incorporating Implicit Item Associations Qiang Liu Institute of Artificial Intelligence College of Computer Science Zhejiang University Hangzhou 31007, China Email: 01dtd@gmail.com
A Modified PMF Model Incorporating Implicit Item Associations Qiang Liu Institute of Artificial Intelligence College of Computer Science Zhejiang University Hangzhou 31007, China Email: 01dtd@gmail.com
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
Lecture 5: Web Searching using the SVD
 Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent
 Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Matrix Factorization and Factorization Machines for Recommender Systems
 Talk at SDM workshop on Machine Learning Methods on Recommender Systems, May 2, 215 Chih-Jen Lin (National Taiwan Univ.) 1 / 54 Matrix Factorization and Factorization Machines for Recommender Systems Chih-Jen
Talk at SDM workshop on Machine Learning Methods on Recommender Systems, May 2, 215 Chih-Jen Lin (National Taiwan Univ.) 1 / 54 Matrix Factorization and Factorization Machines for Recommender Systems Chih-Jen
USING SINGULAR VALUE DECOMPOSITION (SVD) AS A SOLUTION FOR SEARCH RESULT CLUSTERING
 AS A SOLUTION FOR SEARCH RESULT CLUSTERING") POZNAN UNIVE RSIY OF E CHNOLOGY ACADE MIC JOURNALS No. 80 Electrical Engineering 2014 Hussam D. ABDULLA* Abdella S. ABDELRAHMAN* Vaclav SNASEL* USING SINGULAR VALUE DECOMPOSIION (SVD) AS A SOLUION FOR
POZNAN UNIVE RSIY OF E CHNOLOGY ACADE MIC JOURNALS No. 80 Electrical Engineering 2014 Hussam D. ABDULLA* Abdella S. ABDELRAHMAN* Vaclav SNASEL* USING SINGULAR VALUE DECOMPOSIION (SVD) AS A SOLUION FOR
Lessons Learned from the Netflix Contest. Arthur Dunbar
 Lessons Learned from the Netflix Contest Arthur Dunbar Background From Wikipedia: The Netflix Prize was an open competition for the best collaborative filtering algorithm to predict user ratings for films,
Lessons Learned from the Netflix Contest Arthur Dunbar Background From Wikipedia: The Netflix Prize was an open competition for the best collaborative filtering algorithm to predict user ratings for films,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Scaling Neighbourhood Methods
 Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
13 Searching the Web with the SVD
 13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
Large-scale Ordinal Collaborative Filtering
 Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
Collaborative topic models: motivations cont
 Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Notes on Latent Semantic Analysis
 Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Modeling User Rating Profiles For Collaborative Filtering
 Modeling User Rating Profiles For Collaborative Filtering Benjamin Marlin Department of Computer Science University of Toronto Toronto, ON, M5S 3H5, CANADA marlin@cs.toronto.edu Abstract In this paper
Modeling User Rating Profiles For Collaborative Filtering Benjamin Marlin Department of Computer Science University of Toronto Toronto, ON, M5S 3H5, CANADA marlin@cs.toronto.edu Abstract In this paper
Leverage Sparse Information in Predictive Modeling
 Leverage Sparse Information in Predictive Modeling Liang Xie Countrywide Home Loans, Countrywide Bank, FSB August 29, 2008 Abstract This paper examines an innovative method to leverage information from
Leverage Sparse Information in Predictive Modeling Liang Xie Countrywide Home Loans, Countrywide Bank, FSB August 29, 2008 Abstract This paper examines an innovative method to leverage information from
9 Searching the Internet with the SVD
 9 Searching the Internet with the SVD 9.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
9 Searching the Internet with the SVD 9.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Stat 406: Algorithms for classification and prediction. Lecture 1: Introduction. Kevin Murphy. Mon 7 January,
 1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
Data Science Mastery Program
 Data Science Mastery Program Copyright Policy All content included on the Site or third-party platforms as part of the class, such as text, graphics, logos, button icons, images, audio clips, video clips,
Data Science Mastery Program Copyright Policy All content included on the Site or third-party platforms as part of the class, such as text, graphics, logos, button icons, images, audio clips, video clips,
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Collaborative Filtering with Temporal Dynamics with Using Singular Value Decomposition
 ISSN 1330-3651 (Print), ISSN 1848-6339 (Online) https://doi.org/10.17559/tv-20160708140839 Original scientific paper Collaborative Filtering with Temporal Dynamics with Using Singular Value Decomposition
ISSN 1330-3651 (Print), ISSN 1848-6339 (Online) https://doi.org/10.17559/tv-20160708140839 Original scientific paper Collaborative Filtering with Temporal Dynamics with Using Singular Value Decomposition
CSE 494/598 Lecture-6: Latent Semantic Indexing. **Content adapted from last year s slides
 CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
Introduction PCA classic Generative models Beyond and summary. PCA, ICA and beyond
 PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties
 ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
Matrix Factorization Techniques for Recommender Systems
 Matrix Factorization Techniques for Recommender Systems Patrick Seemann, December 16 th, 2014 16.12.2014 Fachbereich Informatik Recommender Systems Seminar Patrick Seemann Topics Intro New-User / New-Item
Matrix Factorization Techniques for Recommender Systems Patrick Seemann, December 16 th, 2014 16.12.2014 Fachbereich Informatik Recommender Systems Seminar Patrick Seemann Topics Intro New-User / New-Item
CS425: Algorithms for Web Scale Data
 CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org Customer
CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org Customer
Using Matrix Decompositions in Formal Concept Analysis
 Using Matrix Decompositions in Formal Concept Analysis Vaclav Snasel 1, Petr Gajdos 1, Hussam M. Dahwa Abdulla 1, Martin Polovincak 1 1 Dept. of Computer Science, Faculty of Electrical Engineering and
Using Matrix Decompositions in Formal Concept Analysis Vaclav Snasel 1, Petr Gajdos 1, Hussam M. Dahwa Abdulla 1, Martin Polovincak 1 1 Dept. of Computer Science, Faculty of Electrical Engineering and
Lecture Notes 10: Matrix Factorization
 Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
Probabilistic Low-Rank Matrix Completion with Adaptive Spectral Regularization Algorithms
 Probabilistic Low-Rank Matrix Completion with Adaptive Spectral Regularization Algorithms François Caron Department of Statistics, Oxford STATLEARN 2014, Paris April 7, 2014 Joint work with Adrien Todeschini,
Probabilistic Low-Rank Matrix Completion with Adaptive Spectral Regularization Algorithms François Caron Department of Statistics, Oxford STATLEARN 2014, Paris April 7, 2014 Joint work with Adrien Todeschini,
Quick Introduction to Nonnegative Matrix Factorization
 Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
6.034 Introduction to Artificial Intelligence
 6.34 Introduction to Artificial Intelligence Tommi Jaakkola MIT CSAIL The world is drowning in data... The world is drowning in data...... access to information is based on recommendations Recommending
6.34 Introduction to Artificial Intelligence Tommi Jaakkola MIT CSAIL The world is drowning in data... The world is drowning in data...... access to information is based on recommendations Recommending
SQL-Rank: A Listwise Approach to Collaborative Ranking
 SQL-Rank: A Listwise Approach to Collaborative Ranking Liwei Wu Depts of Statistics and Computer Science UC Davis ICML 18, Stockholm, Sweden July 10-15, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
SQL-Rank: A Listwise Approach to Collaborative Ranking Liwei Wu Depts of Statistics and Computer Science UC Davis ICML 18, Stockholm, Sweden July 10-15, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
Collaborative Filtering Matrix Completion Alternating Least Squares
 Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 19, 2016
Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 19, 2016
CS 572: Information Retrieval
 CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Domokos Miklós Kelen. Online Recommendation Systems. Eötvös Loránd University. Faculty of Natural Sciences. Advisor:
 Eötvös Loránd University Faculty of Natural Sciences Online Recommendation Systems MSc Thesis Domokos Miklós Kelen Applied Mathematics MSc Advisor: András Benczúr Ph.D. Department of Operations Research
Eötvös Loránd University Faculty of Natural Sciences Online Recommendation Systems MSc Thesis Domokos Miklós Kelen Applied Mathematics MSc Advisor: András Benczúr Ph.D. Department of Operations Research
Linear Algebra Background
 CS76A Text Retrieval and Mining Lecture 5 Recap: Clustering Hierarchical clustering Agglomerative clustering techniques Evaluation Term vs. document space clustering Multi-lingual docs Feature selection
CS76A Text Retrieval and Mining Lecture 5 Recap: Clustering Hierarchical clustering Agglomerative clustering techniques Evaluation Term vs. document space clustering Multi-lingual docs Feature selection
Circle-based Recommendation in Online Social Networks
 Circle-based Recommendation in Online Social Networks Xiwang Yang, Harald Steck*, and Yong Liu Polytechnic Institute of NYU * Bell Labs/Netflix 1 Outline q Background & Motivation q Circle-based RS Trust
Circle-based Recommendation in Online Social Networks Xiwang Yang, Harald Steck*, and Yong Liu Polytechnic Institute of NYU * Bell Labs/Netflix 1 Outline q Background & Motivation q Circle-based RS Trust
Principal Component Analysis (PCA) for Sparse High-Dimensional Data
 for Sparse High-Dimensional Data") AB Principal Component Analysis (PCA) for Sparse High-Dimensional Data Tapani Raiko, Alexander Ilin, and Juha Karhunen Helsinki University of Technology, Finland Adaptive Informatics Research Center Principal
AB Principal Component Analysis (PCA) for Sparse High-Dimensional Data Tapani Raiko, Alexander Ilin, and Juha Karhunen Helsinki University of Technology, Finland Adaptive Informatics Research Center Principal
Predictive Discrete Latent Factor Models for large incomplete dyadic data
 Predictive Discrete Latent Factor Models for large incomplete dyadic data Deepak Agarwal, Srujana Merugu, Abhishek Agarwal Y! Research MMDS Workshop, Stanford University 6/25/2008 Agenda Motivating applications
Predictive Discrete Latent Factor Models for large incomplete dyadic data Deepak Agarwal, Srujana Merugu, Abhishek Agarwal Y! Research MMDS Workshop, Stanford University 6/25/2008 Agenda Motivating applications
Structured matrix factorizations. Example: Eigenfaces
 Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Linear classifiers: Overfitting and regularization
 Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Exercise Sheet 1. 1 Probability revision 1: Student-t as an infinite mixture of Gaussians
 Exercise Sheet 1 1 Probability revision 1: Student-t as an infinite mixture of Gaussians Show that an infinite mixture of Gaussian distributions, with Gamma distributions as mixing weights in the following
Exercise Sheet 1 1 Probability revision 1: Student-t as an infinite mixture of Gaussians Show that an infinite mixture of Gaussian distributions, with Gamma distributions as mixing weights in the following
SCMF: Sparse Covariance Matrix Factorization for Collaborative Filtering
 SCMF: Sparse Covariance Matrix Factorization for Collaborative Filtering Jianping Shi Naiyan Wang Yang Xia Dit-Yan Yeung Irwin King Jiaya Jia Department of Computer Science and Engineering, The Chinese
SCMF: Sparse Covariance Matrix Factorization for Collaborative Filtering Jianping Shi Naiyan Wang Yang Xia Dit-Yan Yeung Irwin King Jiaya Jia Department of Computer Science and Engineering, The Chinese
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run