Efficient Serial and Parallel Coordinate Descent Methods for Huge-Scale Convex Optimization
|
|
|
- Fay Lane
- 6 years ago
- Views:
Transcription

1 Efficient Serial and Parallel Coordinate Descent Methods for Huge-Scale Convex Optimization Martin Takáč The University of Edinburgh Based on: P. Richtárik and M. Takáč. Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function, ERGO Tech. report , P. Richtárik and M. Takáč. Efficient serial and parallel coordinate descent methods for huge-scale truss topology design, ERGO Tech. report October 06, / 43
2 Outline 1 Randomized Coordinate Descent Method Theory GPU implementation Numerical examples 2 Facing the Multicore-Challenge II (a few insights from a conference) 3 Discussion StarSs Intel Cilk Plus SIMD and auto-vectorization 2 / 43
3 Randomized Coordinate Descent Method 3 / 43
4 Problem Formulation where f is convex and smooth min F (x) def = f (x) + Ψ(x), (P) x R N Ψ is convex, simple and block-separable N is huge (N 10 6 ) Ψ(x) meaning 0 smooth minimization λ x 1 sparsity-inducing term indicator function of a set block-separable constraints 4 / 43
5 Problem Formulation where f is convex and smooth min F (x) def = f (x) + Ψ(x), (P) x R N Ψ is convex, simple and block-separable N is huge (N 10 6 ) Ψ(x) meaning 0 smooth minimization λ x 1 sparsity-inducing term indicator function of a set block-separable constraints General Iterative Algorithm 1 choose initial point x := x 0 R n 2 iterate choose direction d := d(x) choose step length α(d, x) set x = x + αd 4 / 43
6 Problem Formulation where f is convex and smooth min F (x) def = f (x) + Ψ(x), (P) x R N Ψ is convex, simple and block-separable N is huge (N 10 6 ) Ψ(x) meaning 0 smooth minimization λ x 1 sparsity-inducing term indicator function of a set block-separable constraints General Iterative Algorithm 1 choose initial point x := x 0 R n 2 iterate choose direction d := d(x) choose step length α(d, x) set x = x + αd More sophisticated direction less iterations More sophisticated direction more work per iteration 4 / 43
7 Why Coordinate Descent? a very old optimization method (B. O Donnell 1967) can move only in directions {e 1, e 2,..., e N }, where e i = (0, 0, 0,..., 0, 1, 0,..., 0) T 5 / 43
8 Why Coordinate Descent? a very old optimization method (B. O Donnell 1967) can move only in directions {e 1, e 2,..., e N }, where e i = (0, 0, 0,..., 0, 1, 0,..., 0) T Methods for choosing direction cyclic (or essentially cyclic) coordinate with the maximal directional derivative (Greedy) RANDOM (WHY?) 5 / 43
9 Why Coordinate Descent? a very old optimization method (B. O Donnell 1967) can move only in directions {e 1, e 2,..., e N }, where e i = (0, 0, 0,..., 0, 1, 0,..., 0) T Methods for choosing direction cyclic (or essentially cyclic) coordinate with the maximal directional derivative (Greedy) RANDOM (WHY?) Applications Sparse regression, LASSO Truss topology design (Sparse) group LASSO Elastic Net... L 1 regularized linear support vector machines (SVM) with various (smooth) loss functions 5 / 43
10 Randomized Coordinate Descent: a 2D example f (x) = 1 2 x T ( ) x ( ) x, x 0 = ( 0 0 ) T 6 / 43
11 Randomized Coordinate Descent: a 2D example f (x) = 1 2 x T ( ) x ( ) x, x 0 = ( 0 0 ) T What we need? Generate random coordinate (we need n dimensional coin) 6 / 43
12 Randomized Coordinate Descent: a 2D example f (x) = 1 2 x T ( ) x ( ) x, x 0 = ( 0 0 ) T What we need? Generate random coordinate (we need n dimensional coin) Luckily in our case n = 2 6 / 43
13 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
14 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
15 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
16 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
17 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
18 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
19 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
20 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43

21 Randomized Coordinate Descent: a 2D example f (x) = 1 T 2x x x, x0 = 0 0 T 7 / 43
, where x (i) = Ui T x R i R N i.")
22 Block Structure of R N Any vector x R N can be written uniquely as n x = U i x (i), where x (i) = Ui T x R i R N i. i=1 8 / 43
23 Block Norms and Induced Norms Block norms (norms in R i ): We equip R i with a pair of conjugate Euclidean norms: t (i) = B i t, t 1/2, where B i R N i N i Induced norms (norms in R N ): t (i) = B 1 i t, t 1/2, t R i, is a positive definite matrix. For fixed positive scalars w 1,..., w n and x R N we define Conjugate norm is defined by y W = [ n 1/2 x W = w i x (i) (i)] 2. i=1 max y, x = x W 1 where W = Diag(w 1,..., w n ). [ n i=1 w 1 i ( y (i) (i) )2] 1/2, 9 / 43
24 Assumptions on f and Ψ The gradient of f is block coordinate-wise Lipschitz with positive constants L 1,..., L n : i f (x + U i t) i f (x) (i) L i t (i), x R N, t R i, i = 1,..., n, (1) where i f (x) def = ( f (x)) (i) = U T i f (x) R i. An important consequence of (1) is the following inequality f (x + U i t) f (x) + i f (x), t + L i 2 t 2 (i). (2) We denote L = Diag(L 1,..., L n ). Ψ is block-separable: n Ψ(x) = Ψ i (x (i) ). i=1 10 / 43
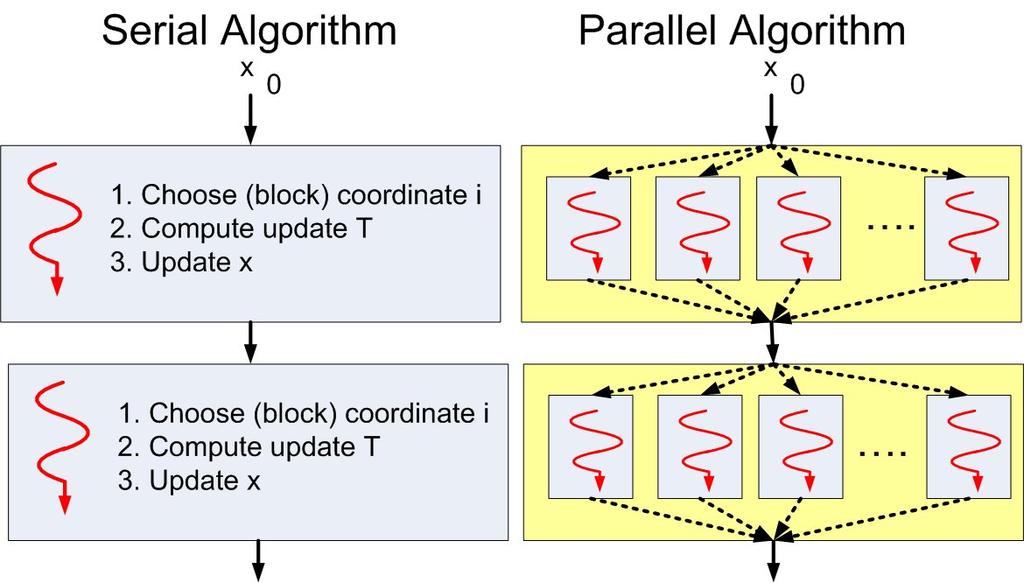
25 UCDC: Uniform Coordinate Descent for Composite Functions - Algorithm An upper bound on F (x + U i t) is readily available: F (x + U i t) = f (x + U i t) + Ψ(x + U i t) (2) Algorithm 1 UCDC(x 0 ) f (x) + i f (x), t + L i 2 t 2 (i) + Ψ i(x (i) + t) + Ψ j (x (j) ). }{{} j i def =V i (x,t) for k = 0, 1, 2,... Choose block coordinate i {1, 2,..., n} with probability 1 n T (i) (x k ) = arg min{v i (x k, t) : t R i R N i } x k+1 = x k + U i T (i) (x k ) end for In each step we minimize a function of N i variables We assume Ψ is simple: T (i) (x k ) can be computed in closed form If Ψ 0, then T (i) (x k ) = 1 L i B 1 i i f (x) 11 / 43
26 The Main Result Theorem 1 Choose initial point x 0 and confidence level ρ (0, 1). Further, let the target accuracy ɛ > 0 and iteration counter k be chosen in any of the following two ways: (i) ɛ < F (x 0 ) F and k 2n max{r2 L (x0),f (x0) F } ɛ (ii) ɛ < min{r 2 L (x 0), F (x 0 ) F } and ( ) 1 + log 1 ρ + 2 2n max{r2 L (x0),f (x0) F } F (x 0) F, k 2nR2 L (x0) ɛ log F (x0) F ɛρ. If x k is the random point generated by UCDC(x 0 ) as applied to F, then P(F (x k ) F ɛ) 1 ρ. R 2 W (x 0) = max x {max x X x x 2 W : F (x) F (x 0)} 12 / 43
27 Performance on Strongly Convex Functions Theorem 2 Let F be strongly convex with respect to L with convexity parameter µ > 0 and choose accuracy level ɛ > 0, confidence level 0 < ρ < 1, and ( ) k F (x0) F, n 1 γ µ log ρɛ where γ µ is given by { γ µ = 1 µ 4, if µ 2, 1 µ, otherwise. (3) If x k is the random point generated by UCDC(x 0 ), then P(F (x k ) F ɛ) 1 ρ. 13 / 43
28 Comparison with other coordinate descent methods for composite minimization Lip Ψ block coordinate choice E(F (x k ) < ɛ) 1 iter [YT09] L( f ) separable Yes greedy O( nl( f ) x x ) ɛ O(n 2 ) 1 [SST09] L i = β 1 No O( nβ x x ) n ɛ cheap [ST10] L( f ) 1 No cyclic O( nl( f ) x x ) ɛ cheap 1 Alg 1 L i separable Yes O( n x x 0 2 L ) n ɛ cheap [YT09 ]S. Yun and P. Tseng. A block-coordinate gradient descent method for linearly constrained nonsmooth separable optimization. Journal of Optimization Theory and Applications, 140: , [SST09 ]S. Shalev-Shwartz and A. Tewari. Stochastic methods for l 1 regularized loss minimization. In: ICML [ST09 ]A. Saha and A. Tewari. On the finite time convergence of cyclic coordinate descent methods. arxiv: , / 43
29 Comparison with Nesterov s randomized coordinate descent... for achieving P(F (x k ) F ɛ) 1 ρ in the general case (F not strongly convex): Alg Ψ p i norms complexity objective [N10] 0 [N10] 0 1 n Euclid. Alg1 0 > 0 general Alg2 0 8nR 2 L (x 0) log 4(f (x 0) f ) ɛ ɛρ L i Euclid. (2n + 8SR2 I (x 0) ) log 4(f (x 0) f ) S ɛ ɛρ 1 n Euclid. 2R 2 LP 1 (x 0) f (x) + ɛ x x 0 2 L 8R 2 L (x 0) f (x) + ɛ x x 0 2 I 8R 2 I (x 0) (1 + log 1 ɛ ρ ) 2 f 2nM ɛ (1 + log 1 ρ ) F 2nR 2 L (x 0) ɛ log F (x 0) F ɛρ Symbols used in the table: S = L i, M = max{r 2 L (x 0), F (x 0 ) F }. [N10] Yu. Nesterov, Efficiency of coordinate descent methods on huge-scale optimization problems. CORE Discussion Paper # 2010/2, / 43
30 Application: Sparse Regression Problem formulation & Lipschitz constants 1 min x R N 2 Ax b γ x 1 L i = a T i a i (easy to compute) Note: Lipschitz constant of f = λ max (A T A) (hard to compute) Algorithm 1 UCDC(x 0 ) for k = 0, 1, 2,... Choose block coor. i Compute T (i) (x k ) x k+1 = x k + U i T (i) (x k ) end for UCDC for Sparse Regression Choose x 0 = 0 and set g 0 = Ax 0 b = b for k = 0, 1, 2,... do Choose i k = i {1, 2,..., N} uniformly i f (x k ) = ai T g k, i f (x k )+γ L i, if x (i) k T (i) (x k ) = i f (x k ) γ L i, if x (i) k x (i) k, otherwise, x k+1 = x k + e i T (i) (x k ), g k+1 = g k + a i T (i) (x k ). end for i f (x k )+γ L i > 0, i f (x k ) γ L i < 0, 16 / 43
31 Instance 1 run on CPU: A R , A 0 = 10 8 k/n F (x k ) F x k 0 time [s] < < , < , < , < , < , < , < , < , < , < , < , < , < , < , < , < , < , / 43
32 Instance 2 run on CPU: A R , A 0 = k/n F (x k ) F x k 0 time [s] 0.01 < , < ,837, < ,567, < ,630, < ,305, < ,242, < ,157, < ,926, < , < , < , < , < , < , < , < , < , < , < , < , < , / 43


33 Acceleration on a Graphical Processing Unit (GPU) CPU GPU 1 core 448 cores 3.00 GHz 1.15 GHz 3 GFlops 1 TFlop GPU (Graphical Processing Unit): performs a single operation in parallel on multiple data (vector addition). 19 / 43
 Each core in one multiprocessor has to do the same operation on different data = SIMD (Single")
34 GPU Architecture Tesla C Multiprocessors Each Multiprocessor has 32 cores (each 1.15GHz) Each core in one multiprocessor has to do the same operation on different data = SIMD (Single Instruction Multiple Data) 20 / 43

35 Huge and Sparse Data = Small Chance of Collision 21 / 43

36 Race Conditions and Atomic Operation 22 / 43
37 23 / 43
38 CPU (C) vs GPU (CUDA): step-by-step comparison n = / 43
39 Acceleration by GPU 25 / 43
40 Naive Implementation Implementation each thread choose its coordinate independently, matrix A is naturally stored in CSC sparse format. 26 / 43


41 Naive Implementation Data access is NOT coalesced (is NOT sequential at all) is misaligned (decrease of performance ) 27 / 43
42 Misaligned copy 28 / 43
 each thread then compute its coordinate i (one wrap is working on ALIGNED and SEQUENTIAL coordinates) 29 / 43")
43 Better implementation Memory access improvement all threads in ONE WRAP generate the same random number which points to begin of memory bank (from where data will be read) each thread then compute its coordinate i (one wrap is working on ALIGNED and SEQUENTIAL coordinates) 29 / 43
44 Pipelining C++ code i n t o f f s e t =.... ; f o r ( i n t i = o f f s e t ; i < N; i ++) { A[ i ] = A[ i + o f f s e t ] s ; } Left: Offset is a constant. Right: Offset is a variable, therefore compiler cannot optimize as well as previously. 30 / 43
45 Facing the Multicore-Challenge II (a few insights from a conference) 31 / 43
46 SIMD and Auto-Vectorization CPU 2.2 GHz, 4 flops/cycle, 12 cores = GFlops (AMD Magny-Cours) GPU GFlops (Tesla C2050/C2070 GPU Computing Processor)...the memory subsystem (or at least the cache) must be able to sustain sufficient bandwidth to keep all units busy / 43
47 Intel Compiler 12+ -guide=n analyzes code and gives some recommendations -vec-report n report of loop vectorization, shows which loops where vectorized and which not #pragma ivdep vectorization, do not care on data dependences -ax auto-vectorization C++ code i n t C [N ] ;.... f o r ( i n t j = 0 ; j < C [ 7 ] ; j ++) { //C[7]=2034 A[ j ]=2 B[ j ] ; } 33 / 43
48 Intel Compiler 12+ -guide=n analyzes code and gives some recommendations -vec-report n report of loop vectorization, shows which loops where vectorized and which not #pragma ivdep vectorization, do not care on data dependences -ax auto-vectorization C++ code i n t C [N ] ;.... #pragma i v d e p f o r ( i n t j = 0 ; j < C [ 7 ] ; j ++) { //C[7]=2034 A[ j ]=2 B[ j ] ; } 34 / 43

49 StarSs - Introduction 35 / 43

50 StarSs - Renaming 36 / 43

51 StarSs - GPU 37 / 43

52 StarSs - GPU 38 / 43
53 Intel Cilk Plus Write parallel programs using a simple model: With only three keywords to learn, C and C++ developers move quickly into the parallel programming domain. Utilize data parallelism by simple array notations that include elemental function capabilities. Leverage existing serial tools: The serial semantics of Intel Cilk Plus allows you to debug in a familiar serial debugger. Scale for the future: The runtime system operates smoothly on systems with hundreds of cores. 39 / 43
54 Cilk - Arrays { } d e c l s p e c ( v e c t o r ) f l o a t s a x p y e l e m e n t a l ( f l o a t a, f l o a t x, f l o a t y ) return ( a x + y ) ; // Here i s how to i n v o k e such v e c t o r i z e d e l e m e n t a l // f u n c t i o n s u s i n g a r r a y n o t a t i o n : z [ : ] = s a x p y e l e m e n t a l ( a, b [ : ], c [ : ] ) ; a [ : ] = s i n ( b [ : ] ) ; // v e c t o r math l i b r a r y f u n c t i o n a [ : ] = pow ( b [ : ], c ) ; // b [ : ] c v i a a v e c t o r // math l i b r a r y f u n c t i o n 40 / 43
55 Cilk - Fibonacci - Create new thread 01 c i l k i n t f i b ( i n t n ) 02 { 03 i f ( n < 2) return n ; 04 e l s e 05 { 06 i n t x, y ; x = spawn f i b ( n 1); 09 y = spawn f i b ( n 2); sync ; return ( x+y ) ; 14 } 15 } 41 / 43
56 Any Questions? Thank you for your attention 42 / 43
57 References Georg Hager and Gerhard Wellein: Introduction to High Performance Computing for Scientists and Engineers Jesus Labarta, Rosa Badia, Eduard Ayguade, Marta Garcia, Vladimir Marjanovic: Hybrid Parallel Programming with MPI+SMPSs 43 / 43
Parallel Coordinate Optimization
 1 / 38 Parallel Coordinate Optimization Julie Nutini MLRG - Spring Term March 6 th, 2018 2 / 38 Contours of a function F : IR 2 IR. Goal: Find the minimizer of F. Coordinate Descent in 2D Contours of a
1 / 38 Parallel Coordinate Optimization Julie Nutini MLRG - Spring Term March 6 th, 2018 2 / 38 Contours of a function F : IR 2 IR. Goal: Find the minimizer of F. Coordinate Descent in 2D Contours of a
Randomized Block Coordinate Non-Monotone Gradient Method for a Class of Nonlinear Programming
 Randomized Block Coordinate Non-Monotone Gradient Method for a Class of Nonlinear Programming Zhaosong Lu Lin Xiao June 25, 2013 Abstract In this paper we propose a randomized block coordinate non-monotone
Randomized Block Coordinate Non-Monotone Gradient Method for a Class of Nonlinear Programming Zhaosong Lu Lin Xiao June 25, 2013 Abstract In this paper we propose a randomized block coordinate non-monotone
FAST DISTRIBUTED COORDINATE DESCENT FOR NON-STRONGLY CONVEX LOSSES. Olivier Fercoq Zheng Qu Peter Richtárik Martin Takáč
 FAST DISTRIBUTED COORDINATE DESCENT FOR NON-STRONGLY CONVEX LOSSES Olivier Fercoq Zheng Qu Peter Richtárik Martin Takáč School of Mathematics, University of Edinburgh, Edinburgh, EH9 3JZ, United Kingdom
FAST DISTRIBUTED COORDINATE DESCENT FOR NON-STRONGLY CONVEX LOSSES Olivier Fercoq Zheng Qu Peter Richtárik Martin Takáč School of Mathematics, University of Edinburgh, Edinburgh, EH9 3JZ, United Kingdom
Lecture 23: November 21
 10-725/36-725: Convex Optimization Fall 2016 Lecturer: Ryan Tibshirani Lecture 23: November 21 Scribes: Yifan Sun, Ananya Kumar, Xin Lu Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer:
10-725/36-725: Convex Optimization Fall 2016 Lecturer: Ryan Tibshirani Lecture 23: November 21 Scribes: Yifan Sun, Ananya Kumar, Xin Lu Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer:
Coordinate descent. Geoff Gordon & Ryan Tibshirani Optimization /
 Coordinate descent Geoff Gordon & Ryan Tibshirani Optimization 10-725 / 36-725 1 Adding to the toolbox, with stats and ML in mind We ve seen several general and useful minimization tools First-order methods
Coordinate descent Geoff Gordon & Ryan Tibshirani Optimization 10-725 / 36-725 1 Adding to the toolbox, with stats and ML in mind We ve seen several general and useful minimization tools First-order methods
On Nesterov s Random Coordinate Descent Algorithms
 On Nesterov s Random Coordinate Descent Algorithms Zheng Xu University of Texas At Arlington February 19, 2015 1 Introduction Full-Gradient Descent Coordinate Descent 2 Random Coordinate Descent Algorithm
On Nesterov s Random Coordinate Descent Algorithms Zheng Xu University of Texas At Arlington February 19, 2015 1 Introduction Full-Gradient Descent Coordinate Descent 2 Random Coordinate Descent Algorithm
Lecture 3: Huge-scale optimization problems
 Liege University: Francqui Chair 2011-2012 Lecture 3: Huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) March 9, 2012 Yu. Nesterov () Huge-scale optimization problems 1/32March 9, 2012 1
Liege University: Francqui Chair 2011-2012 Lecture 3: Huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) March 9, 2012 Yu. Nesterov () Huge-scale optimization problems 1/32March 9, 2012 1
Random coordinate descent algorithms for. huge-scale optimization problems. Ion Necoara
 Random coordinate descent algorithms for huge-scale optimization problems Ion Necoara Automatic Control and Systems Engineering Depart. 1 Acknowledgement Collaboration with Y. Nesterov, F. Glineur ( Univ.
Random coordinate descent algorithms for huge-scale optimization problems Ion Necoara Automatic Control and Systems Engineering Depart. 1 Acknowledgement Collaboration with Y. Nesterov, F. Glineur ( Univ.
Stochastic Dual Coordinate Ascent Methods for Regularized Loss Minimization
 Stochastic Dual Coordinate Ascent Methods for Regularized Loss Minimization Shai Shalev-Shwartz and Tong Zhang School of CS and Engineering, The Hebrew University of Jerusalem Optimization for Machine
Stochastic Dual Coordinate Ascent Methods for Regularized Loss Minimization Shai Shalev-Shwartz and Tong Zhang School of CS and Engineering, The Hebrew University of Jerusalem Optimization for Machine
MLCC 2018 Variable Selection and Sparsity. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 Variable Selection and Sparsity Lorenzo Rosasco UNIGE-MIT-IIT Outline Variable Selection Subset Selection Greedy Methods: (Orthogonal) Matching Pursuit Convex Relaxation: LASSO & Elastic Net
MLCC 2018 Variable Selection and Sparsity Lorenzo Rosasco UNIGE-MIT-IIT Outline Variable Selection Subset Selection Greedy Methods: (Orthogonal) Matching Pursuit Convex Relaxation: LASSO & Elastic Net
Randomized Coordinate Descent with Arbitrary Sampling: Algorithms and Complexity
 Randomized Coordinate Descent with Arbitrary Sampling: Algorithms and Complexity Zheng Qu University of Hong Kong CAM, 23-26 Aug 2016 Hong Kong based on joint work with Peter Richtarik and Dominique Cisba(University
Randomized Coordinate Descent with Arbitrary Sampling: Algorithms and Complexity Zheng Qu University of Hong Kong CAM, 23-26 Aug 2016 Hong Kong based on joint work with Peter Richtarik and Dominique Cisba(University
A Randomized Nonmonotone Block Proximal Gradient Method for a Class of Structured Nonlinear Programming
 A Randomized Nonmonotone Block Proximal Gradient Method for a Class of Structured Nonlinear Programming Zhaosong Lu Lin Xiao June 8, 2014 Abstract In this paper we propose a randomized nonmonotone block
A Randomized Nonmonotone Block Proximal Gradient Method for a Class of Structured Nonlinear Programming Zhaosong Lu Lin Xiao June 8, 2014 Abstract In this paper we propose a randomized nonmonotone block
Coordinate descent methods
 Coordinate descent methods Master Mathematics for data science and big data Olivier Fercoq November 3, 05 Contents Exact coordinate descent Coordinate gradient descent 3 3 Proximal coordinate descent 5
Coordinate descent methods Master Mathematics for data science and big data Olivier Fercoq November 3, 05 Contents Exact coordinate descent Coordinate gradient descent 3 3 Proximal coordinate descent 5
Large-scale Stochastic Optimization
 Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
Parallel Successive Convex Approximation for Nonsmooth Nonconvex Optimization
 Parallel Successive Convex Approximation for Nonsmooth Nonconvex Optimization Meisam Razaviyayn meisamr@stanford.edu Mingyi Hong mingyi@iastate.edu Zhi-Quan Luo luozq@umn.edu Jong-Shi Pang jongship@usc.edu
Parallel Successive Convex Approximation for Nonsmooth Nonconvex Optimization Meisam Razaviyayn meisamr@stanford.edu Mingyi Hong mingyi@iastate.edu Zhi-Quan Luo luozq@umn.edu Jong-Shi Pang jongship@usc.edu
Lasso: Algorithms and Extensions
 ELE 538B: Sparsity, Structure and Inference Lasso: Algorithms and Extensions Yuxin Chen Princeton University, Spring 2017 Outline Proximal operators Proximal gradient methods for lasso and its extensions
ELE 538B: Sparsity, Structure and Inference Lasso: Algorithms and Extensions Yuxin Chen Princeton University, Spring 2017 Outline Proximal operators Proximal gradient methods for lasso and its extensions
Subgradient methods for huge-scale optimization problems
 Subgradient methods for huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) May 24, 2012 (Edinburgh, Scotland) Yu. Nesterov Subgradient methods for huge-scale problems 1/24 Outline 1 Problems
Subgradient methods for huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) May 24, 2012 (Edinburgh, Scotland) Yu. Nesterov Subgradient methods for huge-scale problems 1/24 Outline 1 Problems
A random coordinate descent algorithm for optimization problems with composite objective function and linear coupled constraints
 Comput. Optim. Appl. manuscript No. (will be inserted by the editor) A random coordinate descent algorithm for optimization problems with composite objective function and linear coupled constraints Ion
Comput. Optim. Appl. manuscript No. (will be inserted by the editor) A random coordinate descent algorithm for optimization problems with composite objective function and linear coupled constraints Ion
Mini-Batch Primal and Dual Methods for SVMs
 Mini-Batch Primal and Dual Methods for SVMs Peter Richtárik School of Mathematics The University of Edinburgh Coauthors: M. Takáč (Edinburgh), A. Bijral and N. Srebro (both TTI at Chicago) arxiv:1303.2314
Mini-Batch Primal and Dual Methods for SVMs Peter Richtárik School of Mathematics The University of Edinburgh Coauthors: M. Takáč (Edinburgh), A. Bijral and N. Srebro (both TTI at Chicago) arxiv:1303.2314
CPSC 540: Machine Learning
 CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
Randomized Coordinate Descent Methods on Optimization Problems with Linearly Coupled Constraints
 Randomized Coordinate Descent Methods on Optimization Problems with Linearly Coupled Constraints By I. Necoara, Y. Nesterov, and F. Glineur Lijun Xu Optimization Group Meeting November 27, 2012 Outline
Randomized Coordinate Descent Methods on Optimization Problems with Linearly Coupled Constraints By I. Necoara, Y. Nesterov, and F. Glineur Lijun Xu Optimization Group Meeting November 27, 2012 Outline
Coordinate Descent and Ascent Methods
 Coordinate Descent and Ascent Methods Julie Nutini Machine Learning Reading Group November 3 rd, 2015 1 / 22 Projected-Gradient Methods Motivation Rewrite non-smooth problem as smooth constrained problem:
Coordinate Descent and Ascent Methods Julie Nutini Machine Learning Reading Group November 3 rd, 2015 1 / 22 Projected-Gradient Methods Motivation Rewrite non-smooth problem as smooth constrained problem:
Efficient Learning on Large Data Sets
 Department of Computer Science and Engineering Hong Kong University of Science and Technology Hong Kong Joint work with Mu Li, Chonghai Hu, Weike Pan, Bao-liang Lu Chinese Workshop on Machine Learning
Department of Computer Science and Engineering Hong Kong University of Science and Technology Hong Kong Joint work with Mu Li, Chonghai Hu, Weike Pan, Bao-liang Lu Chinese Workshop on Machine Learning
Is the test error unbiased for these programs? 2017 Kevin Jamieson
 Is the test error unbiased for these programs? 2017 Kevin Jamieson 1 Is the test error unbiased for this program? 2017 Kevin Jamieson 2 Simple Variable Selection LASSO: Sparse Regression Machine Learning
Is the test error unbiased for these programs? 2017 Kevin Jamieson 1 Is the test error unbiased for this program? 2017 Kevin Jamieson 2 Simple Variable Selection LASSO: Sparse Regression Machine Learning
LASSO Review, Fused LASSO, Parallel LASSO Solvers
 Case Study 3: fmri Prediction LASSO Review, Fused LASSO, Parallel LASSO Solvers Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 3, 2016 Sham Kakade 2016 1 Variable
Case Study 3: fmri Prediction LASSO Review, Fused LASSO, Parallel LASSO Solvers Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 3, 2016 Sham Kakade 2016 1 Variable
Optimization methods
 Optimization methods Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda /8/016 Introduction Aim: Overview of optimization methods that Tend to
Optimization methods Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda /8/016 Introduction Aim: Overview of optimization methods that Tend to
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
Accelerated Proximal Gradient Methods for Convex Optimization
 Accelerated Proximal Gradient Methods for Convex Optimization Paul Tseng Mathematics, University of Washington Seattle MOPTA, University of Guelph August 18, 2008 ACCELERATED PROXIMAL GRADIENT METHODS
Accelerated Proximal Gradient Methods for Convex Optimization Paul Tseng Mathematics, University of Washington Seattle MOPTA, University of Guelph August 18, 2008 ACCELERATED PROXIMAL GRADIENT METHODS
Primal-dual coordinate descent A Coordinate Descent Primal-Dual Algorithm with Large Step Size and Possibly Non-Separable Functions
 Primal-dual coordinate descent A Coordinate Descent Primal-Dual Algorithm with Large Step Size and Possibly Non-Separable Functions Olivier Fercoq and Pascal Bianchi Problem Minimize the convex function
Primal-dual coordinate descent A Coordinate Descent Primal-Dual Algorithm with Large Step Size and Possibly Non-Separable Functions Olivier Fercoq and Pascal Bianchi Problem Minimize the convex function
Lecture 25: November 27
 10-725: Optimization Fall 2012 Lecture 25: November 27 Lecturer: Ryan Tibshirani Scribes: Matt Wytock, Supreeth Achar Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These notes have
10-725: Optimization Fall 2012 Lecture 25: November 27 Lecturer: Ryan Tibshirani Scribes: Matt Wytock, Supreeth Achar Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These notes have
Convex Optimization Lecture 16
 Convex Optimization Lecture 16 Today: Projected Gradient Descent Conditional Gradient Descent Stochastic Gradient Descent Random Coordinate Descent Recall: Gradient Descent (Steepest Descent w.r.t Euclidean
Convex Optimization Lecture 16 Today: Projected Gradient Descent Conditional Gradient Descent Stochastic Gradient Descent Random Coordinate Descent Recall: Gradient Descent (Steepest Descent w.r.t Euclidean
StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory
 StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory S.V. N. (vishy) Vishwanathan Purdue University and Microsoft vishy@purdue.edu October 9, 2012 S.V. N. Vishwanathan (Purdue,
StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory S.V. N. (vishy) Vishwanathan Purdue University and Microsoft vishy@purdue.edu October 9, 2012 S.V. N. Vishwanathan (Purdue,
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
Supplement: Distributed Box-constrained Quadratic Optimization for Dual Linear SVM
 Supplement: Distributed Box-constrained Quadratic Optimization for Dual Linear SVM Ching-pei Lee LEECHINGPEI@GMAIL.COM Dan Roth DANR@ILLINOIS.EDU University of Illinois at Urbana-Champaign, 201 N. Goodwin
Supplement: Distributed Box-constrained Quadratic Optimization for Dual Linear SVM Ching-pei Lee LEECHINGPEI@GMAIL.COM Dan Roth DANR@ILLINOIS.EDU University of Illinois at Urbana-Champaign, 201 N. Goodwin
An Asynchronous Parallel Stochastic Coordinate Descent Algorithm
 Ji Liu JI-LIU@CS.WISC.EDU Stephen J. Wright SWRIGHT@CS.WISC.EDU Christopher Ré CHRISMRE@STANFORD.EDU Victor Bittorf BITTORF@CS.WISC.EDU Srikrishna Sridhar SRIKRIS@CS.WISC.EDU Department of Computer Sciences,
Ji Liu JI-LIU@CS.WISC.EDU Stephen J. Wright SWRIGHT@CS.WISC.EDU Christopher Ré CHRISMRE@STANFORD.EDU Victor Bittorf BITTORF@CS.WISC.EDU Srikrishna Sridhar SRIKRIS@CS.WISC.EDU Department of Computer Sciences,
Big Data Analytics: Optimization and Randomization
 Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
Sparse Principal Component Analysis via Alternating Maximization and Efficient Parallel Implementations
 Sparse Principal Component Analysis via Alternating Maximization and Efficient Parallel Implementations Martin Takáč The University of Edinburgh Joint work with Peter Richtárik (Edinburgh University) Selin
Sparse Principal Component Analysis via Alternating Maximization and Efficient Parallel Implementations Martin Takáč The University of Edinburgh Joint work with Peter Richtárik (Edinburgh University) Selin
Classification Logistic Regression
 Announcements: Classification Logistic Regression Machine Learning CSE546 Sham Kakade University of Washington HW due on Friday. Today: Review: sub-gradients,lasso Logistic Regression October 3, 26 Sham
Announcements: Classification Logistic Regression Machine Learning CSE546 Sham Kakade University of Washington HW due on Friday. Today: Review: sub-gradients,lasso Logistic Regression October 3, 26 Sham
Convex Optimization Algorithms for Machine Learning in 10 Slides
 Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
ARock: an algorithmic framework for asynchronous parallel coordinate updates
 ARock: an algorithmic framework for asynchronous parallel coordinate updates Zhimin Peng, Yangyang Xu, Ming Yan, Wotao Yin ( UCLA Math, U.Waterloo DCO) UCLA CAM Report 15-37 ShanghaiTech SSDS 15 June 25,
ARock: an algorithmic framework for asynchronous parallel coordinate updates Zhimin Peng, Yangyang Xu, Ming Yan, Wotao Yin ( UCLA Math, U.Waterloo DCO) UCLA CAM Report 15-37 ShanghaiTech SSDS 15 June 25,
Asynchronous Parallel Computing in Signal Processing and Machine Learning
 Asynchronous Parallel Computing in Signal Processing and Machine Learning Wotao Yin (UCLA Math) joint with Zhimin Peng (UCLA), Yangyang Xu (IMA), Ming Yan (MSU) Optimization and Parsimonious Modeling IMA,
Asynchronous Parallel Computing in Signal Processing and Machine Learning Wotao Yin (UCLA Math) joint with Zhimin Peng (UCLA), Yangyang Xu (IMA), Ming Yan (MSU) Optimization and Parsimonious Modeling IMA,
A Randomized Nonmonotone Block Proximal Gradient Method for a Class of Structured Nonlinear Programming
 A Randomized Nonmonotone Block Proximal Gradient Method for a Class of Structured Nonlinear Programming Zhaosong Lu Lin Xiao March 9, 2015 (Revised: May 13, 2016; December 30, 2016) Abstract We propose
A Randomized Nonmonotone Block Proximal Gradient Method for a Class of Structured Nonlinear Programming Zhaosong Lu Lin Xiao March 9, 2015 (Revised: May 13, 2016; December 30, 2016) Abstract We propose
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Sparse Recovery using L1 minimization - algorithms Yuejie Chi Department of Electrical and Computer Engineering Spring
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Sparse Recovery using L1 minimization - algorithms Yuejie Chi Department of Electrical and Computer Engineering Spring
Accelerated Randomized Primal-Dual Coordinate Method for Empirical Risk Minimization
 Accelerated Randomized Primal-Dual Coordinate Method for Empirical Risk Minimization Lin Xiao (Microsoft Research) Joint work with Qihang Lin (CMU), Zhaosong Lu (Simon Fraser) Yuchen Zhang (UC Berkeley)
Accelerated Randomized Primal-Dual Coordinate Method for Empirical Risk Minimization Lin Xiao (Microsoft Research) Joint work with Qihang Lin (CMU), Zhaosong Lu (Simon Fraser) Yuchen Zhang (UC Berkeley)
SVRG++ with Non-uniform Sampling
 SVRG++ with Non-uniform Sampling Tamás Kern András György Department of Electrical and Electronic Engineering Imperial College London, London, UK, SW7 2BT {tamas.kern15,a.gyorgy}@imperial.ac.uk Abstract
SVRG++ with Non-uniform Sampling Tamás Kern András György Department of Electrical and Electronic Engineering Imperial College London, London, UK, SW7 2BT {tamas.kern15,a.gyorgy}@imperial.ac.uk Abstract
Importance Sampling for Minibatches
 Importance Sampling for Minibatches Dominik Csiba School of Mathematics University of Edinburgh 07.09.2016, Birmingham Dominik Csiba (University of Edinburgh) Importance Sampling for Minibatches 07.09.2016,
Importance Sampling for Minibatches Dominik Csiba School of Mathematics University of Edinburgh 07.09.2016, Birmingham Dominik Csiba (University of Edinburgh) Importance Sampling for Minibatches 07.09.2016,
Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence
 Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence oé LAMDA Group H ŒÆOŽÅ Æ EâX ^ #EâI[ : liwujun@nju.edu.cn Dec 10, 2016 Wu-Jun Li (http://cs.nju.edu.cn/lwj)
Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence oé LAMDA Group H ŒÆOŽÅ Æ EâX ^ #EâI[ : liwujun@nju.edu.cn Dec 10, 2016 Wu-Jun Li (http://cs.nju.edu.cn/lwj)
Optimization methods
 Lecture notes 3 February 8, 016 1 Introduction Optimization methods In these notes we provide an overview of a selection of optimization methods. We focus on methods which rely on first-order information,
Lecture notes 3 February 8, 016 1 Introduction Optimization methods In these notes we provide an overview of a selection of optimization methods. We focus on methods which rely on first-order information,
Sparse and Regularized Optimization
 Sparse and Regularized Optimization In many applications, we seek not an exact minimizer of the underlying objective, but rather an approximate minimizer that satisfies certain desirable properties: sparsity
Sparse and Regularized Optimization In many applications, we seek not an exact minimizer of the underlying objective, but rather an approximate minimizer that satisfies certain desirable properties: sparsity
Coordinate gradient descent methods. Ion Necoara
 Coordinate gradient descent methods Ion Necoara January 2, 207 ii Contents Coordinate gradient descent methods. Motivation..................................... 5.. Coordinate minimization versus coordinate
Coordinate gradient descent methods Ion Necoara January 2, 207 ii Contents Coordinate gradient descent methods. Motivation..................................... 5.. Coordinate minimization versus coordinate
Adaptive Restarting for First Order Optimization Methods
 Adaptive Restarting for First Order Optimization Methods Nesterov method for smooth convex optimization adpative restarting schemes step-size insensitivity extension to non-smooth optimization continuation
Adaptive Restarting for First Order Optimization Methods Nesterov method for smooth convex optimization adpative restarting schemes step-size insensitivity extension to non-smooth optimization continuation
On Nesterov s Random Coordinate Descent Algorithms - Continued
 On Nesterov s Random Coordinate Descent Algorithms - Continued Zheng Xu University of Texas At Arlington February 20, 2015 1 Revisit Random Coordinate Descent The Random Coordinate Descent Upper and Lower
On Nesterov s Random Coordinate Descent Algorithms - Continued Zheng Xu University of Texas At Arlington February 20, 2015 1 Revisit Random Coordinate Descent The Random Coordinate Descent Upper and Lower
minimize x subject to (x 2)(x 4) u,
(x 4) u,") Math 6366/6367: Optimization and Variational Methods Sample Preliminary Exam Questions 1. Suppose that f : [, L] R is a C 2 -function with f () on (, L) and that you have explicit formulae for
Math 6366/6367: Optimization and Variational Methods Sample Preliminary Exam Questions 1. Suppose that f : [, L] R is a C 2 -function with f () on (, L) and that you have explicit formulae for
Block Coordinate Descent for Regularized Multi-convex Optimization
 Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
Efficient Quasi-Newton Proximal Method for Large Scale Sparse Optimization
 Efficient Quasi-Newton Proximal Method for Large Scale Sparse Optimization Xiaocheng Tang Department of Industrial and Systems Engineering Lehigh University Bethlehem, PA 18015 xct@lehigh.edu Katya Scheinberg
Efficient Quasi-Newton Proximal Method for Large Scale Sparse Optimization Xiaocheng Tang Department of Industrial and Systems Engineering Lehigh University Bethlehem, PA 18015 xct@lehigh.edu Katya Scheinberg
Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics)
") Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics) Eftychios Sifakis CS758 Guest Lecture - 19 Sept 2012 Introduction Linear systems
Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics) Eftychios Sifakis CS758 Guest Lecture - 19 Sept 2012 Introduction Linear systems
Coordinate Descent. Lecturer: Pradeep Ravikumar Co-instructor: Aarti Singh. Convex Optimization / Slides adapted from Tibshirani
 Coordinate Descent Lecturer: Pradeep Ravikumar Co-instructor: Aarti Singh Convex Optimization 10-725/36-725 Slides adapted from Tibshirani Coordinate descent We ve seen some pretty sophisticated methods
Coordinate Descent Lecturer: Pradeep Ravikumar Co-instructor: Aarti Singh Convex Optimization 10-725/36-725 Slides adapted from Tibshirani Coordinate descent We ve seen some pretty sophisticated methods
Block AIR Methods. For Multicore and GPU. Per Christian Hansen Hans Henrik B. Sørensen. Technical University of Denmark
 Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
A Sparsity Preserving Stochastic Gradient Method for Composite Optimization
 A Sparsity Preserving Stochastic Gradient Method for Composite Optimization Qihang Lin Xi Chen Javier Peña April 3, 11 Abstract We propose new stochastic gradient algorithms for solving convex composite
A Sparsity Preserving Stochastic Gradient Method for Composite Optimization Qihang Lin Xi Chen Javier Peña April 3, 11 Abstract We propose new stochastic gradient algorithms for solving convex composite
Stochastic Optimization with Variance Reduction for Infinite Datasets with Finite Sum Structure
 Stochastic Optimization with Variance Reduction for Infinite Datasets with Finite Sum Structure Alberto Bietti Julien Mairal Inria Grenoble (Thoth) March 21, 2017 Alberto Bietti Stochastic MISO March 21,
Stochastic Optimization with Variance Reduction for Infinite Datasets with Finite Sum Structure Alberto Bietti Julien Mairal Inria Grenoble (Thoth) March 21, 2017 Alberto Bietti Stochastic MISO March 21,
Linearly-Convergent Stochastic-Gradient Methods
 Linearly-Convergent Stochastic-Gradient Methods Joint work with Francis Bach, Michael Friedlander, Nicolas Le Roux INRIA - SIERRA Project - Team Laboratoire d Informatique de l École Normale Supérieure
Linearly-Convergent Stochastic-Gradient Methods Joint work with Francis Bach, Michael Friedlander, Nicolas Le Roux INRIA - SIERRA Project - Team Laboratoire d Informatique de l École Normale Supérieure
arxiv: v2 [cs.lg] 10 Oct 2018
![arxiv: v2 [cs.lg] 10 Oct 2018](/thumbs/93/111796999.jpg "arxiv: v2 [cs.lg] 10 Oct 2018") Journal of Machine Learning Research 9 (208) -49 Submitted 0/6; Published 7/8 CoCoA: A General Framework for Communication-Efficient Distributed Optimization arxiv:6.0289v2 [cs.lg] 0 Oct 208 Virginia Smith
Journal of Machine Learning Research 9 (208) -49 Submitted 0/6; Published 7/8 CoCoA: A General Framework for Communication-Efficient Distributed Optimization arxiv:6.0289v2 [cs.lg] 0 Oct 208 Virginia Smith
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
Journal Club. A Universal Catalyst for First-Order Optimization (H. Lin, J. Mairal and Z. Harchaoui) March 8th, CMAP, Ecole Polytechnique 1/19
 March 8th, CMAP, Ecole Polytechnique 1/19") Journal Club A Universal Catalyst for First-Order Optimization (H. Lin, J. Mairal and Z. Harchaoui) CMAP, Ecole Polytechnique March 8th, 2018 1/19 Plan 1 Motivations 2 Existing Acceleration Methods 3 Universal
Journal Club A Universal Catalyst for First-Order Optimization (H. Lin, J. Mairal and Z. Harchaoui) CMAP, Ecole Polytechnique March 8th, 2018 1/19 Plan 1 Motivations 2 Existing Acceleration Methods 3 Universal
Proximal Newton Method. Zico Kolter (notes by Ryan Tibshirani) Convex Optimization
 Convex Optimization") Proximal Newton Method Zico Kolter (notes by Ryan Tibshirani) Convex Optimization 10-725 Consider the problem Last time: quasi-newton methods min x f(x) with f convex, twice differentiable, dom(f) = R
Proximal Newton Method Zico Kolter (notes by Ryan Tibshirani) Convex Optimization 10-725 Consider the problem Last time: quasi-newton methods min x f(x) with f convex, twice differentiable, dom(f) = R
Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 4 th, Emily Fox 2014
 Case Study 3: fmri Prediction Fused LASSO LARS Parallel LASSO Solvers Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 4 th, 2014 Emily Fox 2014 1 LASSO Regression
Case Study 3: fmri Prediction Fused LASSO LARS Parallel LASSO Solvers Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 4 th, 2014 Emily Fox 2014 1 LASSO Regression
Trade-Offs in Distributed Learning and Optimization
 Trade-Offs in Distributed Learning and Optimization Ohad Shamir Weizmann Institute of Science Includes joint works with Yossi Arjevani, Nathan Srebro and Tong Zhang IHES Workshop March 2016 Distributed
Trade-Offs in Distributed Learning and Optimization Ohad Shamir Weizmann Institute of Science Includes joint works with Yossi Arjevani, Nathan Srebro and Tong Zhang IHES Workshop March 2016 Distributed
Accelerating Stochastic Optimization
 Accelerating Stochastic Optimization Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem and Mobileye Master Class at Tel-Aviv, Tel-Aviv University, November 2014 Shalev-Shwartz
Accelerating Stochastic Optimization Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem and Mobileye Master Class at Tel-Aviv, Tel-Aviv University, November 2014 Shalev-Shwartz
Statistical Machine Learning II Spring 2017, Learning Theory, Lecture 4
 Statistical Machine Learning II Spring 07, Learning Theory, Lecture 4 Jean Honorio jhonorio@purdue.edu Deterministic Optimization For brevity, everywhere differentiable functions will be called smooth.
Statistical Machine Learning II Spring 07, Learning Theory, Lecture 4 Jean Honorio jhonorio@purdue.edu Deterministic Optimization For brevity, everywhere differentiable functions will be called smooth.
Iteration Complexity of Feasible Descent Methods for Convex Optimization
 Journal of Machine Learning Research 15 (2014) 1523-1548 Submitted 5/13; Revised 2/14; Published 4/14 Iteration Complexity of Feasible Descent Methods for Convex Optimization Po-Wei Wang Chih-Jen Lin Department
Journal of Machine Learning Research 15 (2014) 1523-1548 Submitted 5/13; Revised 2/14; Published 4/14 Iteration Complexity of Feasible Descent Methods for Convex Optimization Po-Wei Wang Chih-Jen Lin Department
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Proximal Newton Method. Ryan Tibshirani Convex Optimization /36-725
 Proximal Newton Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: primal-dual interior-point method Given the problem min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h
Proximal Newton Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: primal-dual interior-point method Given the problem min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
arxiv: v1 [hep-lat] 7 Oct 2010
![arxiv: v1 [hep-lat] 7 Oct 2010](/thumbs/79/80346009.jpg "arxiv: v1 [hep-lat] 7 Oct 2010") arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
Stochastic Gradient Descent with Variance Reduction
 Stochastic Gradient Descent with Variance Reduction Rie Johnson, Tong Zhang Presenter: Jiawen Yao March 17, 2015 Rie Johnson, Tong Zhang Presenter: JiawenStochastic Yao Gradient Descent with Variance Reduction
Stochastic Gradient Descent with Variance Reduction Rie Johnson, Tong Zhang Presenter: Jiawen Yao March 17, 2015 Rie Johnson, Tong Zhang Presenter: JiawenStochastic Yao Gradient Descent with Variance Reduction
Stochastic Optimization: First order method
 Stochastic Optimization: First order method Taiji Suzuki Tokyo Institute of Technology Graduate School of Information Science and Engineering Department of Mathematical and Computing Sciences JST, PRESTO
Stochastic Optimization: First order method Taiji Suzuki Tokyo Institute of Technology Graduate School of Information Science and Engineering Department of Mathematical and Computing Sciences JST, PRESTO
Coordinate Update Algorithm Short Course The Package TMAC
 Coordinate Update Algorithm Short Course The Package TMAC Instructor: Wotao Yin (UCLA Math) Summer 2016 1 / 16 TMAC: A Toolbox of Async-Parallel, Coordinate, Splitting, and Stochastic Methods C++11 multi-threading
Coordinate Update Algorithm Short Course The Package TMAC Instructor: Wotao Yin (UCLA Math) Summer 2016 1 / 16 TMAC: A Toolbox of Async-Parallel, Coordinate, Splitting, and Stochastic Methods C++11 multi-threading
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures
 A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
10-725/ Optimization Midterm Exam
 10-725/36-725 Optimization Midterm Exam November 6, 2012 NAME: ANDREW ID: Instructions: This exam is 1hr 20mins long Except for a single two-sided sheet of notes, no other material or discussion is permitted
10-725/36-725 Optimization Midterm Exam November 6, 2012 NAME: ANDREW ID: Instructions: This exam is 1hr 20mins long Except for a single two-sided sheet of notes, no other material or discussion is permitted
Is the test error unbiased for these programs?
 Is the test error unbiased for these programs? Xtrain avg N o Preprocessing by de meaning using whole TEST set 2017 Kevin Jamieson 1 Is the test error unbiased for this program? e Stott see non for f x
Is the test error unbiased for these programs? Xtrain avg N o Preprocessing by de meaning using whole TEST set 2017 Kevin Jamieson 1 Is the test error unbiased for this program? e Stott see non for f x
Welcome to MCS 572. content and organization expectations of the course. definition and classification
 Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Linear Convergence under the Polyak-Łojasiewicz Inequality
 Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini, Mark Schmidt University of British Columbia Linear of Convergence of Gradient-Based Methods Fitting most machine learning
Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini, Mark Schmidt University of British Columbia Linear of Convergence of Gradient-Based Methods Fitting most machine learning
Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption. Langshi CHEN 1,2,3 Supervised by Serge PETITON 2
 1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
Faster Machine Learning via Low-Precision Communication & Computation. Dan Alistarh (IST Austria & ETH Zurich), Hantian Zhang (ETH Zurich)
, Hantian Zhang (ETH Zurich)") Faster Machine Learning via Low-Precision Communication & Computation Dan Alistarh (IST Austria & ETH Zurich), Hantian Zhang (ETH Zurich) 2 How many bits do you need to represent a single number in machine
Faster Machine Learning via Low-Precision Communication & Computation Dan Alistarh (IST Austria & ETH Zurich), Hantian Zhang (ETH Zurich) 2 How many bits do you need to represent a single number in machine
J. Sadeghi E. Patelli M. de Angelis
 J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
Gradient Descent. Ryan Tibshirani Convex Optimization /36-725
 Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Generalized Power Method for Sparse Principal Component Analysis
 Generalized Power Method for Sparse Principal Component Analysis Peter Richtárik CORE/INMA Catholic University of Louvain Belgium VOCAL 2008, Veszprém, Hungary CORE Discussion Paper #2008/70 joint work
Generalized Power Method for Sparse Principal Component Analysis Peter Richtárik CORE/INMA Catholic University of Louvain Belgium VOCAL 2008, Veszprém, Hungary CORE Discussion Paper #2008/70 joint work
l 1 and l 2 Regularization
 David Rosenberg New York University February 5, 2015 David Rosenberg (New York University) DS-GA 1003 February 5, 2015 1 / 32 Tikhonov and Ivanov Regularization Hypothesis Spaces We ve spoken vaguely about
David Rosenberg New York University February 5, 2015 David Rosenberg (New York University) DS-GA 1003 February 5, 2015 1 / 32 Tikhonov and Ivanov Regularization Hypothesis Spaces We ve spoken vaguely about
Accelerated Stochastic Block Coordinate Gradient Descent for Sparsity Constrained Nonconvex Optimization
 Accelerated Stochastic Block Coordinate Gradient Descent for Sparsity Constrained Nonconvex Optimization Jinghui Chen Department of Systems and Information Engineering University of Virginia Quanquan Gu
Accelerated Stochastic Block Coordinate Gradient Descent for Sparsity Constrained Nonconvex Optimization Jinghui Chen Department of Systems and Information Engineering University of Virginia Quanquan Gu
Machine Learning in the Data Revolution Era
 Machine Learning in the Data Revolution Era Shai Shalev-Shwartz School of Computer Science and Engineering The Hebrew University of Jerusalem Machine Learning Seminar Series, Google & University of Waterloo,
Machine Learning in the Data Revolution Era Shai Shalev-Shwartz School of Computer Science and Engineering The Hebrew University of Jerusalem Machine Learning Seminar Series, Google & University of Waterloo,
Proximal Minimization by Incremental Surrogate Optimization (MISO)
") Proximal Minimization by Incremental Surrogate Optimization (MISO) (and a few variants) Julien Mairal Inria, Grenoble ICCOPT, Tokyo, 2016 Julien Mairal, Inria MISO 1/26 Motivation: large-scale machine
Proximal Minimization by Incremental Surrogate Optimization (MISO) (and a few variants) Julien Mairal Inria, Grenoble ICCOPT, Tokyo, 2016 Julien Mairal, Inria MISO 1/26 Motivation: large-scale machine
Machine Learning CSE546 Carlos Guestrin University of Washington. October 7, Efficiency: If size(w) = 100B, each prediction is expensive:
 = 100B, each prediction is expensive:") Simple Variable Selection LASSO: Sparse Regression Machine Learning CSE546 Carlos Guestrin University of Washington October 7, 2013 1 Sparsity Vector w is sparse, if many entries are zero: Very useful
Simple Variable Selection LASSO: Sparse Regression Machine Learning CSE546 Carlos Guestrin University of Washington October 7, 2013 1 Sparsity Vector w is sparse, if many entries are zero: Very useful
Linear Convergence under the Polyak-Łojasiewicz Inequality
 Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini and Mark Schmidt The University of British Columbia LCI Forum February 28 th, 2017 1 / 17 Linear Convergence of Gradient-Based
Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini and Mark Schmidt The University of British Columbia LCI Forum February 28 th, 2017 1 / 17 Linear Convergence of Gradient-Based
More Science per Joule: Bottleneck Computing
 More Science per Joule: Bottleneck Computing Georg Hager Erlangen Regional Computing Center (RRZE) University of Erlangen-Nuremberg Germany PPAM 2013 September 9, 2013 Warsaw, Poland Motivation (1): Scalability
More Science per Joule: Bottleneck Computing Georg Hager Erlangen Regional Computing Center (RRZE) University of Erlangen-Nuremberg Germany PPAM 2013 September 9, 2013 Warsaw, Poland Motivation (1): Scalability
CSC 576: Gradient Descent Algorithms
 CSC 576: Gradient Descent Algorithms Ji Liu Department of Computer Sciences, University of Rochester December 22, 205 Introduction The gradient descent algorithm is one of the most popular optimization
CSC 576: Gradient Descent Algorithms Ji Liu Department of Computer Sciences, University of Rochester December 22, 205 Introduction The gradient descent algorithm is one of the most popular optimization
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Proximal-Gradient Mark Schmidt University of British Columbia Winter 2018 Admin Auditting/registration forms: Pick up after class today. Assignment 1: 2 late days to hand in
CPSC 540: Machine Learning Proximal-Gradient Mark Schmidt University of British Columbia Winter 2018 Admin Auditting/registration forms: Pick up after class today. Assignment 1: 2 late days to hand in
GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications
 GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications Christopher Rodrigues, David J. Hardy, John E. Stone, Klaus Schulten, Wen-Mei W. Hwu University of Illinois at Urbana-Champaign
GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications Christopher Rodrigues, David J. Hardy, John E. Stone, Klaus Schulten, Wen-Mei W. Hwu University of Illinois at Urbana-Champaign
Gradient descent. Barnabas Poczos & Ryan Tibshirani Convex Optimization /36-725
 Gradient descent Barnabas Poczos & Ryan Tibshirani Convex Optimization 10-725/36-725 1 Gradient descent First consider unconstrained minimization of f : R n R, convex and differentiable. We want to solve
Gradient descent Barnabas Poczos & Ryan Tibshirani Convex Optimization 10-725/36-725 1 Gradient descent First consider unconstrained minimization of f : R n R, convex and differentiable. We want to solve
Minimizing Finite Sums with the Stochastic Average Gradient Algorithm
 Minimizing Finite Sums with the Stochastic Average Gradient Algorithm Joint work with Nicolas Le Roux and Francis Bach University of British Columbia Context: Machine Learning for Big Data Large-scale
Minimizing Finite Sums with the Stochastic Average Gradient Algorithm Joint work with Nicolas Le Roux and Francis Bach University of British Columbia Context: Machine Learning for Big Data Large-scale
Julian Merten. GPU Computing and Alternative Architecture
 Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg