15-889e Policy Search: Gradient Methods Emma Brunskill. All slides from David Silver (with EB adding minor modificafons), unless otherwise noted
|
|
|
- Cornelius Warner
- 6 years ago
- Views:
Transcription
1 15-889e Policy Search: Gradient Methods Emma Brunskill All slides from David Silver (with EB adding minor modificafons), unless otherwise noted
2 Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient
3 Introduction Policy-Based Reinforcement Learning In past lectures we approximated the value or action-value function using parameters θ, V θ (s ) V π (s ) Q θ (s, a) Q π (s, a) A policy was generated directly from the value function e.g. using epsilon-greedy In this lecture we will directly parametrise the policy π θ (s, a) = P [a s, θ]
 Policy Based No Value Function Learn Policy Actor-Critic Learn Value Function Learn Policy Value Function Value-Based")
4 Introduction Value-Based and Policy-Based RL Value Based Learnt Value Function Implicit policy (e.g. epsilon-greedy) Policy Based No Value Function Learn Policy Actor-Critic Learn Value Function Learn Policy Value Function Value-Based Actor Critic Policy Policy-Based
5 Introduction Advantages of Policy-Based RL Advantages: Better convergence properties Effective in high-dimensional or continuous action spaces Value/Q function may be much more complicated to represent than optimal policy - (Q(s,up)=0.9872,Q(s,down)= action: go up! Can learn stochastic policies - When is this important? When is this not important? Disadvantages: Typically converge to a local rather than global optimum Evaluating a policy is typically inefficient and high variance
")
6 Introduction Rock-Paper-Scissors Example Example: Rock-Paper-Scissors Two-player game of rock-paper-scissors Scissors beats paper Rock beats scissors Paper beats rock Consider policies for iterated rock-paper-scissors A deterministic policy is easily exploited A uniform random policy is optimal (i.e. Nash equilibrium)
7 Introduction Aliased Gridworld Example Example: Aliased Gridworld (1) The agent cannot differentiate the grey states Consider features of the following form (for all N, E, S, W) φ(s, a) = 1(wall to N, a = move E) Compare value-based RL, using an approximate value function Q θ (s, a) = f (φ(s, a), θ) To policy-based RL, using a parametrised policy π θ (s, a) = g (φ(s, a), θ)
8 Introduction Aliased Gridworld Example Example: Aliased Gridworld (2) Under aliasing, an optimal deterministic policy will either move W in both grey states (shown by red arrows) move E in both grey states Either way, it can get stuck and never reach the money Value-based RL learns a near-deterministic policy e.g. greedy or -greedy So it will traverse the corridor for a long time
 = 0.5 π θ (wall to N and S, move W) = 0.5 It will reach the goal state in a few steps with high probability Policy-based RL can learn the optimal stochastic policy")
9 Introduction Aliased Gridworld Example Example: Aliased Gridworld (3) An optimal stochastic policy will randomly move E or W in grey states π θ (wall to N and S, move E) = 0.5 π θ (wall to N and S, move W) = 0.5 It will reach the goal state in a few steps with high probability Policy-based RL can learn the optimal stochastic policy
10 Introduction Policy Search Policy Objective Functions Goal: given policy π θ (s, a) with parameters θ, find best θ But how do we measure the quality of a policy π θ? In episodic environments we can use the start value In continuing environments we can use the average value θ Or the average reward per time-step where d π θ (s ) is stationary distribution of Markov chain for πθ
11 Introduction Policy Search Policy Optimisation Policy based reinforcement learning is an optimization problem Find θ that maximises J (θ) Some approaches do not use gradient Hill climbing Simplex / amoeba / Nelder Mead Genetic algorithms Greater efficiency often possible using gradient Gradient descent Conjugate gradient Quasi-newton We focus on gradient descent, many extensions possible And on methods that exploit sequential structure

12 Table from Calandra, Seyfarth, Peters & Deisenroth, 2015

13 Finite Difference Policy Gradient
14 Finite Difference Policy Gradient Computing Gradients By Finite Differences To evaluate policy gradient of π θ (s, a) For each dimension k [1, n] Uses n evaluations to compute policy gradient in n dimensions à Scales linearly with number of parameters in policy! Simple, noisy, inefficient - but sometimes effective Works for arbitrary policies, even if policy is not differentiable

15 For more details, see paper: Kohl and Stone, ICRA 2004
16 Finite Difference Policy Gradient AIBO example AIBO Walk Policies Before training During training After training Videos at: p=research/learned_walk
17 Monte-Carlo Policy Gradient Likelihood Ratios Score Function We now compute the policy gradient directly Assume policy π θ is differentiable whenever it is non-zero and we can compute the gradient θ π θ (s, a) Likelihood ratios exploit the following identity The score function is θ log π θ (s, a)
18 Monte-Carlo Policy Gradient Likelihood Ratios Softmax Policy We will use a softmax policy as a running example Weight actions using linear combination of features φ(s, a) > θ Probability of action is proportional to exponentiated weight The score function is π θ (s, a) e φ(s,a)t θ θ log π θ (s, a) = φ(s, a) E πθ [φ(s, )]
19 Monte-Carlo Policy Gradient Likelihood Ratios Gaussian Policy In continuous action spaces, a Gaussian policy is natural Mean is a linear combination of state features µ(s ) = φ(s ) > θ Variance may be fixed σ 2, or can also parametrised Policy is Gaussian, a N (µ(s ), σ 2 ) The score function is θ log π θ (s, a) = (a µ(s) )φ(s) σ 2
20 Monte-Carlo Policy Gradient Policy Gradient Theorem One-Step MDPs Consider a simple class of one-step MDPs Starting in state s d (s ) Terminating after one time-step with reward r = R s,a Use likelihood ratios to compute the policy gradient
21 Monte-Carlo Policy Gradient Policy Gradient Theorem Policy Gradient Theorem The policy gradient theorem generalises the likelihood ratio approach to multi-step MDPs Replaces instantaneous reward r with long-term value Q π (s, a) Policy gradient theorem applies to start state objective, average reward and average value objective Theorem For any differentiable policy π θ (s, a), for any of the policy objective functions the policy gradient is
22 See board derivafon. Reference: hvps://inst.eecs.berkeley.edu/ ~cs294-40/fa08/scribes/lecture16.pdf
23 Benefit of Likelihood RaFo Approach: - Number of samples need to approximate no longer depends on the # of policy parameters - Gradient calculafon is independent of the underlying system dynamics (rafo cancels): don t need to know dynamics!
24 Monte-Carlo Policy Gradient Policy Gradient Theorem Monte-Carlo Policy Gradient (REINFORCE) Update parameters by stochastic gradient ascent Using policy gradient theorem Using return v t as an unbiased sample of Q π θ (st, a t ) θ t = α θ log π θ (s t, a t )v t function REINFORCE Initialise θ arbitrarily for each episode {s 1, a 1, r 2,..., s T 1, a T 1, r T } π θ do for t = 1 to T 1 do θ θ + α θ log π θ (s t, a t )v t end for end for return θ end function
25
26 Actor-Critic Policy Gradient Reducing Variance Using a Critic Monte-Carlo policy gradient still has high variance We use a critic to estimate the action-value function, Q w (s, a) Q π θ (s, a) Actor-critic algorithms maintain two sets of parameters Critic Updates action-value function parameters w Actor Updates policy parameters θ, in direction suggested by critic Actor-critic algorithms follow an approximate policy gradient θ J (θ) E πθ [ θ log π θ (s, a) Q w (s, a)] θ = α θ log π θ (s, a) Q w (s, a)
27 Actor-Critic Policy Gradient Estimating the Action-Value Function The critic is solving a familiar problem: policy evaluation How good is policy π θ for current parameters θ? Policy evaluation problem. See earlier lectures. Monte-Carlo policy evaluation Temporal-Difference learning Could also use e.g. least-squares policy evaluation
28 Actor-Critic Policy Gradient Action-Value Actor-Critic Simple actor-critic algorithm based on action-value critic Using linear value fn approx. Q w (s, a) = φ(s, a) > w Critic Updates w by linear TD(0) Actor Updates θ by policy gradient function QAC Initialise s, θ Sample a π θ for each step do Sample reward r = R a ; s sample transition s 0 P a s, Sample action a 0 π θ (s 0, a 0 ) δ = r + γq w (s 0, a 0 ) Q w (s, a) θ = θ + α θ log π θ (s, a)q w (s, a) w w + βδφ(s, a) a a 0, s s 0 end for end function
29 Actor-Critic Policy Gradient Compatible Function Approximation Bias in Actor-Critic Algorithms Approximating the policy gradient introduces bias A biased policy gradient may not find the right solution e.g. if Q w (s, a) uses aliased features, can we solve gridworld example? Luckily, if we choose value function approximation carefully Then we can avoid introducing any bias i.e. We can still follow the exact policy gradient
 = θ log π θ (s, a) 2 Value function parameters w minimise the mean-squared error π θ 2 ε = E πθ (Q (s, a) Q w (s, a)) Then the")
30 Actor-Critic Policy Gradient Compatible Function Approximation Compatible Function Approximation Theorem (Compatible Function Approximation Theorem) If the following two conditions are satisfied: 1 Value function approximator is compatible to the policy w Q w (s, a) = θ log π θ (s, a) 2 Value function parameters w minimise the mean-squared error π θ 2 ε = E πθ (Q (s, a) Q w (s, a)) Then the policy gradient is exact, θ J (θ) = E πθ [ θ log π θ (s, a) Q w (s, a)]
31 Actor-Critic Policy Gradient Compatible Function Approximation Proof of Compatible Function Approximation Theorem If w is chosen to minimise mean-squared error, gradient of ε w.r.t. w must be zero, w ε = 0 θ E πθ (Q (s, a) Q w (s, a)) w Q w (s, a) = 0 θ E πθ (Q (s, a) Q w (s, a)) θ log π θ (s, a) = 0 θ E πθ Q (s, a) θ log π θ (s, a) = E π [Qθ w (s, a) θ log π θ (s, a)] So Q w (s, a) can be substituted directly into the policy gradient, θ J (θ) = E πθ [ θ log π θ (s, a)q w (s, a)]
32 Actor-Critic Policy Gradient Advantage Function Critic Reducing Variance Using a Baseline We subtract a baseline function B (s ) from the policy gradient This can reduce variance, without changing expectation X X E πθ [ θ log π θ (s, a)b (s )] = d π(s θ ) θ π θ (s, a)b (s ) s S = X d π θ B (s ) θ X πθ (s, a) s S = 0 A good baseline is the state value function B (s ) = V π θ (s ) So we can rewrite the policy gradient using the advantage function A π θ (s, a) A π θ (s, a) = Q π θ (s, a) V π θ (s ) a a A π θ θ J (θ) = E πθ [ θ log π θ (s, a) A (s, a)]
33 Actor-Critic Policy Gradient Advantage Function Critic Estimating the Advantage Function (1) The advantage function can significantly reduce variance of policy gradient So the critic should really estimate the advantage function For example, by estimating both V π θ (s ) and Q π θ (s, a) Using two function approximators and two parameter vectors, V v (s ) V π θ (s ) Q w (s, a) Q π θ (s, a) A(s, a) = Q w (s, a) V v (s ) And updating both value functions by e.g. TD learning
34 Actor-Critic Policy Gradient Advantage Function Critic Estimating the Advantage Function (2) For the true value function V π θ (s ), the TD error δ π θ δ π θ = r + γv π θ (s 0 ) V π θ (s ) is an unbiased estimate of the advantage function π θ π θ 0 π θ E πθ [δ s, a] = E πθ r + γv (s ) s, a V (s ) = Q π θ (s, a) V π θ (s) = A π θ (s, a) So we can use the TD error to compute the policy gradient θ J (θ) = E πθ [ θ log π θ (s, a) δ π θ ] In practice we can use an approximate TD error δ v = r + γv v (s 0 ) V v (s ) This approach only requires one set of critic parameters v
35 Actor-Critic Policy Gradient Natural Policy Gradient Alternative Policy Gradient Directions Gradient ascent algorithms can follow any ascent direction A good ascent direction can significantly speed convergence Also, a policy can often be reparametrised without changing action probabilities For example, increasing score of all actions in a softmax policy The vanilla gradient is sensitive to these reparametrisations

36 Actor-Critic Policy Gradient Natural Policy Gradient Natural Policy Gradient The natural policy gradient is parametrisation independent It finds ascent direction that is closest to vanilla gradient, when changing policy by a small, fixed amount where G θ is the Fisher information matrix
37 Actor-Critic Policy Gradient Natural Policy Gradient Natural Actor-Critic Using compatible function approximation, w A w (s, a) = θ log π θ (s, a) So the natural policy gradient simplifies, i.e. update actor parameters in direction of critic parameters
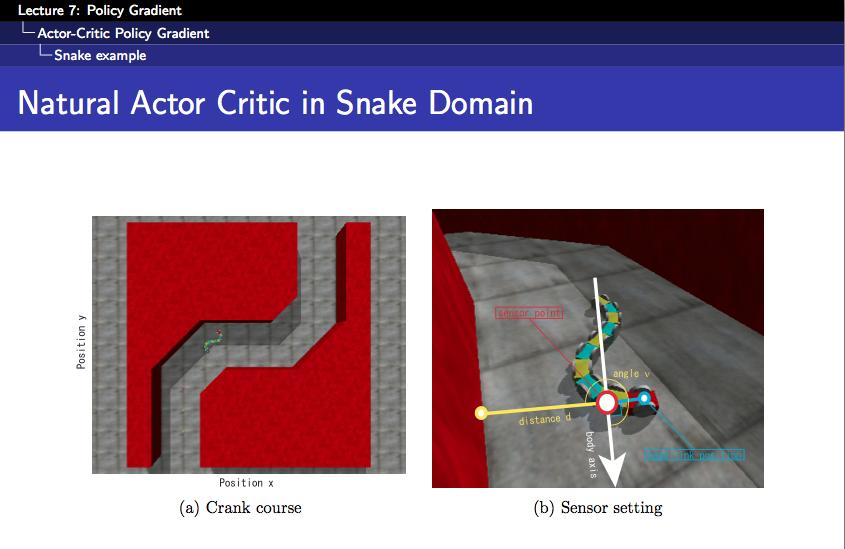
38
39 Actor-Critic Policy Gradient Snake example Nat θ u b ral Actor Critic in Snake Domain (2) Pisition y (m) Pisition y (m) ï1 ï1 ï2 ï2 ï Position x (m) (a) Before learning ï ï2 ï Position x (m) (b) After learning Figure 3: Behaviors of snake-like robot
40 Actor-Critic Policy Gradient Snake example Natural Actor Critic in Snake Domain (3) Action a Angle (rad) cos( ) Distance d (m) Time Steps
 to estimate Q π (s, a), A π (s, a) or V π (s )")
41 Actor-Critic Policy Gradient Snake example Summary of Policy Gradient Algorithms The policy gradient has many equivalent forms REINFORCE Q Actor-Critic Advantage Actor-Critic TD Actor-Critic Each leads a stochastic gradient ascent algorithm Critic uses policy evaluation (e.g. MC or TD learning) to estimate Q π (s, a), A π (s, a) or V π (s )
42 EB: Key Ideas Gradient approaches only guaranteed to find a local opfma Finite- difference methods scale with # of parameters needed to represent the policy, but don t require differenfable policy Likelihood rafo gradient approaches Cost independent of # params Don t need to know dynamics model Benefit from using a baseline to reduce variance Natural gradient approaches are more robust Be able to implement at least 1 gradient method which leverages info (from a crifc / baseline )
43 Actor-Critic Policy Gradient Eligibility Traces Critics at Different Time-Scales Critic can estimate value function V θ (s ) from many targets at different time-scales From last lecture... For MC, the target is the return v t θ = α(v t V θ (s ))φ(s ) For TD(0), the target is the TD target r + γv (s 0 ) θ = α(r + γv (s 0 ) V θ (s ))φ(s ) For forward-view TD(λ), the target is the λ-return v λ t θ = α(v λ V θ (s ))φ(s ) t For backward-view TD(λ), we use eligibility traces δ t = r t +1 + γv (s t +1 ) V (s t ) e t = γλe t 1 + φ(s t ) θ = αδ t e t
44 Actor-Critic Policy Gradient Eligibility Traces Actors at Different Time-Scales The policy gradient can also be estimated at many time-scales π θ θ J (θ) = E πθ [ θ log π θ (s, a) A (s, a)] Monte-Carlo policy gradient uses error from complete return θ = α(v t V v (s t )) θ log π θ (s t, a t ) Actor-critic policy gradient uses the one-step TD error θ = α(r + γv v (s t +1 ) V v (s t )) θ log π θ (s t, a t )
45 Actor-Critic Policy Gradient Eligibility Traces Policy Gradient with Eligibility Traces Just like forward-view TD(λ), we can mix over time-scales θ = α(v λ V v (s t )) θ log π θ (s t, a t ) t where v λ V v (s t ) is a biased estimate of advantage fn t Like backward-view TD(λ), we can also use eligibility traces By equivalence with TD(λ), substituting φ(s ) = θ log π θ (s, a) δ = r t +1 + γv v (s t +1 ) V v (s t ) e t +1 = λe t + θ log π θ (s, a) θ = αδe t This update can be applied online, to incomplete sequences
Lecture 8: Policy Gradient
 Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Lecture 8: Policy Gradient I 2
 Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
Reinforcement Learning
 Reinforcement Learning Policy Search: Actor-Critic and Gradient Policy search Mario Martin CS-UPC May 28, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 28, 2018 / 63 Goal of this lecture So far
Reinforcement Learning Policy Search: Actor-Critic and Gradient Policy search Mario Martin CS-UPC May 28, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 28, 2018 / 63 Goal of this lecture So far
Reinforcement Learning
 Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Lecture 7: Value Function Approximation
 Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
Lecture 9: Policy Gradient II 1
 Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Lecture 9: Policy Gradient II (Post lecture) 2
 2") Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Temporal Difference. Learning KENNETH TRAN. Principal Research Engineer, MSR AI
 Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Actor-critic methods. Dialogue Systems Group, Cambridge University Engineering Department. February 21, 2017
 Actor-critic methods Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department February 21, 2017 1 / 21 In this lecture... The actor-critic architecture Least-Squares Policy Iteration
Actor-critic methods Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department February 21, 2017 1 / 21 In this lecture... The actor-critic architecture Least-Squares Policy Iteration
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning
 Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Temporal difference learning
 Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
PART A and ONE question from PART B; or ONE question from PART A and TWO questions from PART B.
 Advanced Topics in Machine Learning, GI13, 2010/11 Advanced Topics in Machine Learning, GI13, 2010/11 Answer any THREE questions. Each question is worth 20 marks. Use separate answer books Answer any THREE
Advanced Topics in Machine Learning, GI13, 2010/11 Advanced Topics in Machine Learning, GI13, 2010/11 Answer any THREE questions. Each question is worth 20 marks. Use separate answer books Answer any THREE
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Approximation Methods in Reinforcement Learning
 2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
Reinforcement Learning
 Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Chapter 7: Eligibility Traces. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
 Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Notes on Reinforcement Learning
 1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
ELEC-E8119 Robotics: Manipulation, Decision Making and Learning Policy gradient approaches. Ville Kyrki
 ELEC-E8119 Robotics: Manipulation, Decision Making and Learning Policy gradient approaches Ville Kyrki 9.10.2017 Today Direct policy learning via policy gradient. Learning goals Understand basis and limitations
ELEC-E8119 Robotics: Manipulation, Decision Making and Learning Policy gradient approaches Ville Kyrki 9.10.2017 Today Direct policy learning via policy gradient. Learning goals Understand basis and limitations
Reinforcement Learning for NLP
 Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning. Summer 2017 Defining MDPs, Planning
 Reinforcement Learning Summer 2017 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Summer 2017 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
PART A and ONE question from PART B; or ONE question from PART A and TWO questions from PART B.
 Advanced Topics in Machine Learning, GI13, 2010/11 Advanced Topics in Machine Learning, GI13, 2010/11 Answer any THREE questions. Each question is worth 20 marks. Use separate answer books Answer any THREE
Advanced Topics in Machine Learning, GI13, 2010/11 Advanced Topics in Machine Learning, GI13, 2010/11 Answer any THREE questions. Each question is worth 20 marks. Use separate answer books Answer any THREE
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Olivier Sigaud. September 21, 2012
 Supervised and Reinforcement Learning Tools for Motor Learning Models Olivier Sigaud Université Pierre et Marie Curie - Paris 6 September 21, 2012 1 / 64 Introduction Who is speaking? 2 / 64 Introduction
Supervised and Reinforcement Learning Tools for Motor Learning Models Olivier Sigaud Université Pierre et Marie Curie - Paris 6 September 21, 2012 1 / 64 Introduction Who is speaking? 2 / 64 Introduction
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Variance Reduction for Policy Gradient Methods. March 13, 2017
 Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Reinforcement Learning via Policy Optimization
 Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
CS 287: Advanced Robotics Fall Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study
 CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
15-780: ReinforcementLearning
 15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Deep reinforcement learning. Dialogue Systems Group, Cambridge University Engineering Department
 Deep reinforcement learning Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 25 In this lecture... Introduction to deep reinforcement learning Value-based Deep RL Deep
Deep reinforcement learning Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 25 In this lecture... Introduction to deep reinforcement learning Value-based Deep RL Deep
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Policy Gradient Methods. February 13, 2017
 Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Introduction of Reinforcement Learning
 Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
(Deep) Reinforcement Learning
 Reinforcement Learning") Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Reinforcement Learning
 Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
The Book: Where we are and where we re going. CSE 190: Reinforcement Learning: An Introduction. Chapter 7: Eligibility Traces. Simple Monte Carlo
 CSE 190: Reinforcement Learning: An Introduction Chapter 7: Eligibility races Acknowledgment: A good number of these slides are cribbed from Rich Sutton he Book: Where we are and where we re going Part
CSE 190: Reinforcement Learning: An Introduction Chapter 7: Eligibility races Acknowledgment: A good number of these slides are cribbed from Rich Sutton he Book: Where we are and where we re going Part
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Off-Policy Actor-Critic
 Off-Policy Actor-Critic Ludovic Trottier Laval University July 25 2012 Ludovic Trottier (DAMAS Laboratory) Off-Policy Actor-Critic July 25 2012 1 / 34 Table of Contents 1 Reinforcement Learning Theory
Off-Policy Actor-Critic Ludovic Trottier Laval University July 25 2012 Ludovic Trottier (DAMAS Laboratory) Off-Policy Actor-Critic July 25 2012 1 / 34 Table of Contents 1 Reinforcement Learning Theory
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
David Silver, Google DeepMind
 Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
ECE276B: Planning & Learning in Robotics Lecture 16: Model-free Control
 ECE276B: Planning & Learning in Robotics Lecture 16: Model-free Control Lecturer: Nikolay Atanasov: natanasov@ucsd.edu Teaching Assistants: Tianyu Wang: tiw161@eng.ucsd.edu Yongxi Lu: yol070@eng.ucsd.edu
ECE276B: Planning & Learning in Robotics Lecture 16: Model-free Control Lecturer: Nikolay Atanasov: natanasov@ucsd.edu Teaching Assistants: Tianyu Wang: tiw161@eng.ucsd.edu Yongxi Lu: yol070@eng.ucsd.edu
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Reinforcement Learning with Function Approximation. Joseph Christian G. Noel
 Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Behavior Policy Gradient Supplemental Material
 Behavior Policy Gradient Supplemental Material Josiah P. Hanna 1 Philip S. Thomas 2 3 Peter Stone 1 Scott Niekum 1 A. Proof of Theorem 1 In Appendix A, we give the full derivation of our primary theoretical
Behavior Policy Gradient Supplemental Material Josiah P. Hanna 1 Philip S. Thomas 2 3 Peter Stone 1 Scott Niekum 1 A. Proof of Theorem 1 In Appendix A, we give the full derivation of our primary theoretical
Multiagent (Deep) Reinforcement Learning
 Reinforcement Learning") Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
Reinforcement Learning
 Reinforcement Learning Function Approximation Continuous state/action space, mean-square error, gradient temporal difference learning, least-square temporal difference, least squares policy iteration Vien
Reinforcement Learning Function Approximation Continuous state/action space, mean-square error, gradient temporal difference learning, least-square temporal difference, least squares policy iteration Vien
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Tutorial on Policy Gradient Methods. Jan Peters
 Tutorial on Policy Gradient Methods Jan Peters Outline 1. Reinforcement Learning 2. Finite Difference vs Likelihood-Ratio Policy Gradients 3. Likelihood-Ratio Policy Gradients 4. Conclusion General Setup
Tutorial on Policy Gradient Methods Jan Peters Outline 1. Reinforcement Learning 2. Finite Difference vs Likelihood-Ratio Policy Gradients 3. Likelihood-Ratio Policy Gradients 4. Conclusion General Setup
CS885 Reinforcement Learning Lecture 7a: May 23, 2018
 CS885 Reinforcement Learning Lecture 7a: May 23, 2018 Policy Gradient Methods [SutBar] Sec. 13.1-13.3, 13.7 [SigBuf] Sec. 5.1-5.2, [RusNor] Sec. 21.5 CS885 Spring 2018 Pascal Poupart 1 Outline Stochastic
CS885 Reinforcement Learning Lecture 7a: May 23, 2018 Policy Gradient Methods [SutBar] Sec. 13.1-13.3, 13.7 [SigBuf] Sec. 5.1-5.2, [RusNor] Sec. 21.5 CS885 Spring 2018 Pascal Poupart 1 Outline Stochastic
CSE 190: Reinforcement Learning: An Introduction. Chapter 8: Generalization and Function Approximation. Pop Quiz: What Function Are We Approximating?
 CSE 190: Reinforcement Learning: An Introduction Chapter 8: Generalization and Function Approximation Objectives of this chapter: Look at how experience with a limited part of the state set be used to
CSE 190: Reinforcement Learning: An Introduction Chapter 8: Generalization and Function Approximation Objectives of this chapter: Look at how experience with a limited part of the state set be used to
Artificial Intelligence
 Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Reinforcement Learning: the basics
 Reinforcement Learning: the basics Olivier Sigaud Université Pierre et Marie Curie, PARIS 6 http://people.isir.upmc.fr/sigaud August 6, 2012 1 / 46 Introduction Action selection/planning Learning by trial-and-error
Reinforcement Learning: the basics Olivier Sigaud Université Pierre et Marie Curie, PARIS 6 http://people.isir.upmc.fr/sigaud August 6, 2012 1 / 46 Introduction Action selection/planning Learning by trial-and-error
Condensed Table of Contents for Introduction to Stochastic Search and Optimization: Estimation, Simulation, and Control by J. C.
 Condensed Table of Contents for Introduction to Stochastic Search and Optimization: Estimation, Simulation, and Control by J. C. Spall John Wiley and Sons, Inc., 2003 Preface... xiii 1. Stochastic Search
Condensed Table of Contents for Introduction to Stochastic Search and Optimization: Estimation, Simulation, and Control by J. C. Spall John Wiley and Sons, Inc., 2003 Preface... xiii 1. Stochastic Search
Deep Reinforcement Learning: Policy Gradients and Q-Learning
 Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning via Policy Optimization
 Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
Dialogue management: Parametric approaches to policy optimisation. Dialogue Systems Group, Cambridge University Engineering Department
 Dialogue management: Parametric approaches to policy optimisation Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 30 Dialogue optimisation as a reinforcement learning
Dialogue management: Parametric approaches to policy optimisation Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 30 Dialogue optimisation as a reinforcement learning
Introduction. Reinforcement Learning
 Introduction Reinforcement Learning Learn Act Sense Scott Sanner NICTA / ANU First.Last@nicta.com.au Lecture Goals 1) To understand formal models for decisionmaking under uncertainty and their properties
Introduction Reinforcement Learning Learn Act Sense Scott Sanner NICTA / ANU First.Last@nicta.com.au Lecture Goals 1) To understand formal models for decisionmaking under uncertainty and their properties
Monte Carlo is important in practice. CSE 190: Reinforcement Learning: An Introduction. Chapter 6: Temporal Difference Learning.
 Monte Carlo is important in practice CSE 190: Reinforcement Learning: An Introduction Chapter 6: emporal Difference Learning When there are just a few possibilitieo value, out of a large state space, Monte
Monte Carlo is important in practice CSE 190: Reinforcement Learning: An Introduction Chapter 6: emporal Difference Learning When there are just a few possibilitieo value, out of a large state space, Monte
Reinforcement Learning. Value Function Updates
 Reinforcement Learning Value Function Updates Manfred Huber 2014 1 Value Function Updates Different methods for updating the value function Dynamic programming Simple Monte Carlo Temporal differencing
Reinforcement Learning Value Function Updates Manfred Huber 2014 1 Value Function Updates Different methods for updating the value function Dynamic programming Simple Monte Carlo Temporal differencing
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Course basics. CSE 190: Reinforcement Learning: An Introduction. Last Time. Course goals. The website for the class is linked off my homepage.
 Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Lecture 3: Markov Decision Processes
 Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
ilstd: Eligibility Traces and Convergence Analysis
 ilstd: Eligibility Traces and Convergence Analysis Alborz Geramifard Michael Bowling Martin Zinkevich Richard S. Sutton Department of Computing Science University of Alberta Edmonton, Alberta {alborz,bowling,maz,sutton}@cs.ualberta.ca
ilstd: Eligibility Traces and Convergence Analysis Alborz Geramifard Michael Bowling Martin Zinkevich Richard S. Sutton Department of Computing Science University of Alberta Edmonton, Alberta {alborz,bowling,maz,sutton}@cs.ualberta.ca
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Discrete Latent Variable Models
 Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms *
 Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Reinforcement learning
 Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error