Bayesian Paradigm. Maximum A Posteriori Estimation
|
|
|
- Aldous Smith
- 6 years ago
- Views:
Transcription
1 Bayesian Paradigm Maximum A Posteriori Estimation
2 Simple acquisition model noise + degradation
3 Constraint minimization or
4 Equivalent formulation Constraint minimization Lagrangian (unconstraint minimization) Maximum Aposteriori (MAP)
5 Discrete representation Image is a random field Each pixel value is a realization of some random variable
6 Random variables Discrete: takes a countable number of distinct values e.g. num. of children in a family Continuous: x probability density function ( distribution ): Moments: expectation ( average ), variance
7 Random variables Expectation Variance


8 Image as a random field
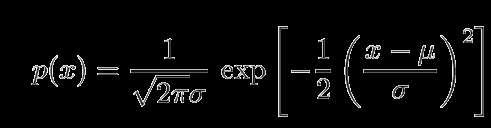
9 Normal distribution

10 Multivariate Normal Distribution
11 Multivariate Normal Distribution
12 Gamma distribution
13 Bayesian Paradigm a posteriori distribution unknown likelihood given by our problem a priori distribution our prior knowledge Maximum a posteriori (MAP): max p(u z) Maximum likelihood (MLE): max p(z u)
14 Likelihood

15 Image Prior Intensity histogram Gradient histogram



16 Image Prior Intensities Gradients (log)
17 Image Prior Gradient histogram
18 Image Prior Tikhonov regularization TV regularization
19 Image Prior Non-convex regularization
20 MAP
21 Kullback-Leibler divergence Measures similarity between two distributions
22 Convex function f(x) Jensen s inequality:
23 Kullback-Leibler divergence is strictly convex
24 Variational Bayes Approximate posterior with a simpler form Minimize with respect to E-L:
25 Variational Bayes
26 Variational Bayes Minimize with respect to all other factors
27 Variational Bayes Minimize with respect to
28 Factorized approximation

29 GM approximated by a single Gaussian depends on initialization
30 Denoising with unknown noise level Noise model: Bayes: and is unknown
31 MAP denoising Minimize the -log posterior with respect to : with respect to :
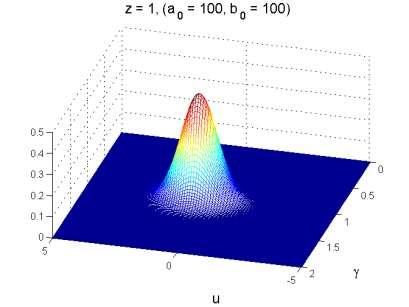
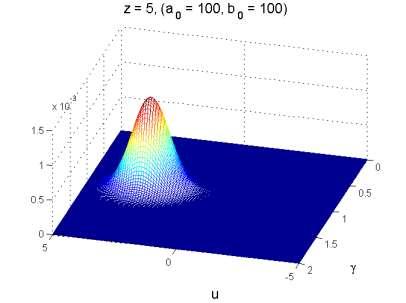
32 A Posteriori surface
33 MAP denoising
34 Marginalized denoising Expectation of marginalized posterior
35 Marginalized denoising
36 VB denoising Find the factorized approximation of the posterior: image:

37 VB denoising noise precision:
38 VB denoising
39 Comparission
40 Sparse & Redundant Representation Iterated Shrinkage Algorithms Wavelet thresholding
41 We will Talk About The minimization of the functional Substitution: and assume D is invertible : This is our original denoising functional, if Moore-Penrose pseudoinverse
42 A Closer Look at the Functional D rectangular, overcomplete dictionary -> underdetermined system a sparse representation ρ(a) measure of sparsity
43 Measure of Sparsity norms ( ) norm, counts nonzero elements many other sparsity measures smooth l 1

44 l 2 unit ball
45 l 1 unit ball
46 l 0.9 unit ball
47 l 0.5 unit ball
48 l 0.3 unit ball
49 Equivalent formulation Method of Lagrange multipliers
50 l 2 -norm Solution via pseudoinverse is simple but not sparse:
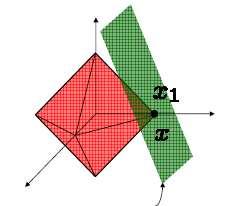
51 l 1 -norm
52 Why Seeking Sparse Representation? Assume x is 1-sparse signal in the dictionary is the perfect solution Overcomplete dictionaries => sparsity
53 Classical Solvers Steepest Descent: Hessian: Convergence depends on the condition number κ of the Hessian: Hessian is ill-conditioned => poor convergence
54 The Unitary Case (DD T = I) Use Define We have m independent 1D optimization problems l 2 is unitarily invariant
55 The 1D Task We need to solve the following 1D problem: LUT a opt b Such a Look-Up-Table (LUT) can be built for ANY sparsity measure function ρ(a), including non-convex ones and non-smooth ones (e.g., l 0 norm).
56 Shrinkage for ρ(a)= a p
57 Soft & Hard Thresholding Soft thresholding Hard thresholding
58 The Unitary Case: Summary Minimizing is done by: x Multiply by D H b LUT S, b a Multiply by D xˆ DONE! The obtained solution is the GLOBAL minimizer of f(a), even if f(a) is non-convex.
59 The minimization of Leads to two very Contradicting Observations: 1. The problem is quite hard classic optimization find it hard. 2. The problem is trivial for the case of unitary D. How Can We Enjoy This Simplicity in the General Case?
60 Iterated-Shrinkage Algorithms Common to all is a set of operations in every iteration that includes: (i) Multiplication by D (ii) Multiplication by D T, and (iii) A Scalar shrinkage on the solution S ρ,λ (a).
61 The Proximal-Point Method Aim: minimize f(a) Suppose it is found to be too hard. Define a surrogate-function g(a,a 0 )=f(a)+dist(a-a 0 ). Then, the following algorithm necessarily converges to a local minima of f(a) [Rokafellar, `76]: a 0 a 1 Minimize Minimize a 2 a k a k+1 Minimize g(a,a 0 ) g(a,a 1 ) g(a,a k ) Comments: (i) The minimization of g(a,a 0 ) should be easier. (ii) Looks like it will slow-down convergence. Really?
62 The Proposed Surrogate-Function Original function: Distance: The beauty is that vanishes! Not a function of a. Minimization of g(a,a 0 ) is done in a closed form by shrinkage, done on the vector b k, and this generates the solution a k+1 of the next iteration. We have m independent 1D optimization problems
63 Iterated-Shrinkage Algorithm While the Unitary case solution is given by x Multiply by D T b LUT S, b aˆ Multiply by D xˆ the general case, by SSF requires: x Multiply by D T /c + b k S, c b a LUT k 1 Multiply by D xˆ
64 Linear Programming Basis Pursuit: LP: Interior-point Algorithms for LP problems
65 Compressed Sensing In compressed sensing we compress the signal x of size m by exploiting its origin. This is done by p<<m random projections. The core idea: (P size: p m) holds all the information about the original signal x, even though p<<m. Reconstruction? Done by MAP and solving y M Da x Px Noise? xˆ
Sparse & Redundant Representations by Iterated-Shrinkage Algorithms
 Sparse & Redundant Representations by Michael Elad * The Computer Science Department The Technion Israel Institute of technology Haifa 3000, Israel 6-30 August 007 San Diego Convention Center San Diego,
Sparse & Redundant Representations by Michael Elad * The Computer Science Department The Technion Israel Institute of technology Haifa 3000, Israel 6-30 August 007 San Diego Convention Center San Diego,
ITERATED SRINKAGE ALGORITHM FOR BASIS PURSUIT MINIMIZATION
 ITERATED SRINKAGE ALGORITHM FOR BASIS PURSUIT MINIMIZATION Michael Elad The Computer Science Department The Technion Israel Institute o technology Haia 3000, Israel * SIAM Conerence on Imaging Science
ITERATED SRINKAGE ALGORITHM FOR BASIS PURSUIT MINIMIZATION Michael Elad The Computer Science Department The Technion Israel Institute o technology Haia 3000, Israel * SIAM Conerence on Imaging Science
Inverse problem and optimization
 Inverse problem and optimization Laurent Condat, Nelly Pustelnik CNRS, Gipsa-lab CNRS, Laboratoire de Physique de l ENS de Lyon Decembre, 15th 2016 Inverse problem and optimization 2/36 Plan 1. Examples
Inverse problem and optimization Laurent Condat, Nelly Pustelnik CNRS, Gipsa-lab CNRS, Laboratoire de Physique de l ENS de Lyon Decembre, 15th 2016 Inverse problem and optimization 2/36 Plan 1. Examples
CSE 559A: Computer Vision
 CSE 559A: Computer Vision Fall 208: T-R: :30-pm @ Lopata 0 Instructor: Ayan Chakrabarti (ayan@wustl.edu). Course Staff: Zhihao ia, Charlie Wu, Han Liu http://www.cse.wustl.edu/~ayan/courses/cse559a/ Sep
CSE 559A: Computer Vision Fall 208: T-R: :30-pm @ Lopata 0 Instructor: Ayan Chakrabarti (ayan@wustl.edu). Course Staff: Zhihao ia, Charlie Wu, Han Liu http://www.cse.wustl.edu/~ayan/courses/cse559a/ Sep
CSE 559A: Computer Vision Tomorrow Zhihao's Office Hours back in Jolley 309: 10:30am-Noon
 CSE 559A: Computer Vision ADMINISTRIVIA Tomorrow Zhihao's Office Hours back in Jolley 309: 0:30am-Noon Fall 08: T-R: :30-pm @ Lopata 0 This Friday: Regular Office Hours Net Friday: Recitation for PSET
CSE 559A: Computer Vision ADMINISTRIVIA Tomorrow Zhihao's Office Hours back in Jolley 309: 0:30am-Noon Fall 08: T-R: :30-pm @ Lopata 0 This Friday: Regular Office Hours Net Friday: Recitation for PSET
2 Regularized Image Reconstruction for Compressive Imaging and Beyond
 EE 367 / CS 448I Computational Imaging and Display Notes: Compressive Imaging and Regularized Image Reconstruction (lecture ) Gordon Wetzstein gordon.wetzstein@stanford.edu This document serves as a supplement
EE 367 / CS 448I Computational Imaging and Display Notes: Compressive Imaging and Regularized Image Reconstruction (lecture ) Gordon Wetzstein gordon.wetzstein@stanford.edu This document serves as a supplement
Sparse linear models
 Sparse linear models Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 2/22/2016 Introduction Linear transforms Frequency representation Short-time
Sparse linear models Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 2/22/2016 Introduction Linear transforms Frequency representation Short-time
2.3. Clustering or vector quantization 57
 Multivariate Statistics non-negative matrix factorisation and sparse dictionary learning The PCA decomposition is by construction optimal solution to argmin A R n q,h R q p X AH 2 2 under constraint :
Multivariate Statistics non-negative matrix factorisation and sparse dictionary learning The PCA decomposition is by construction optimal solution to argmin A R n q,h R q p X AH 2 2 under constraint :
Sparse & Redundant Signal Representation, and its Role in Image Processing
 Sparse & Redundant Signal Representation, and its Role in Michael Elad The CS Department The Technion Israel Institute of technology Haifa 3000, Israel Wave 006 Wavelet and Applications Ecole Polytechnique
Sparse & Redundant Signal Representation, and its Role in Michael Elad The CS Department The Technion Israel Institute of technology Haifa 3000, Israel Wave 006 Wavelet and Applications Ecole Polytechnique
MCMC Sampling for Bayesian Inference using L1-type Priors
 MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
MMSE Denoising of 2-D Signals Using Consistent Cycle Spinning Algorithm
 Denoising of 2-D Signals Using Consistent Cycle Spinning Algorithm Bodduluri Asha, B. Leela kumari Abstract: It is well known that in a real world signals do not exist without noise, which may be negligible
Denoising of 2-D Signals Using Consistent Cycle Spinning Algorithm Bodduluri Asha, B. Leela kumari Abstract: It is well known that in a real world signals do not exist without noise, which may be negligible
Non-convex optimization. Issam Laradji
 Non-convex optimization Issam Laradji Strongly Convex Objective function f(x) x Strongly Convex Objective function Assumptions Gradient Lipschitz continuous f(x) Strongly convex x Strongly Convex Objective
Non-convex optimization Issam Laradji Strongly Convex Objective function f(x) x Strongly Convex Objective function Assumptions Gradient Lipschitz continuous f(x) Strongly convex x Strongly Convex Objective
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Machine Learning for Signal Processing Sparse and Overcomplete Representations
 Machine Learning for Signal Processing Sparse and Overcomplete Representations Abelino Jimenez (slides from Bhiksha Raj and Sourish Chaudhuri) Oct 1, 217 1 So far Weights Data Basis Data Independent ICA
Machine Learning for Signal Processing Sparse and Overcomplete Representations Abelino Jimenez (slides from Bhiksha Raj and Sourish Chaudhuri) Oct 1, 217 1 So far Weights Data Basis Data Independent ICA
cross-language retrieval (by concatenate features of different language in X and find co-shared U). TOEFL/GRE synonym in the same way.
. TOEFL/GRE synonym in the same way.") 10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
Statistical approach for dictionary learning
 Statistical approach for dictionary learning Tieyong ZENG Joint work with Alain Trouvé Page 1 Introduction Redundant dictionary Coding, denoising, compression. Existing algorithms to generate dictionary
Statistical approach for dictionary learning Tieyong ZENG Joint work with Alain Trouvé Page 1 Introduction Redundant dictionary Coding, denoising, compression. Existing algorithms to generate dictionary
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Machine Learning for Signal Processing Sparse and Overcomplete Representations. Bhiksha Raj (slides from Sourish Chaudhuri) Oct 22, 2013
 Oct 22, 2013") Machine Learning for Signal Processing Sparse and Overcomplete Representations Bhiksha Raj (slides from Sourish Chaudhuri) Oct 22, 2013 1 Key Topics in this Lecture Basics Component-based representations
Machine Learning for Signal Processing Sparse and Overcomplete Representations Bhiksha Raj (slides from Sourish Chaudhuri) Oct 22, 2013 1 Key Topics in this Lecture Basics Component-based representations
Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory
 Bayesian Inference Statistical Decison Theory") Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Independent Component Analysis. Contents
 Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Sparse regression. Optimization-Based Data Analysis. Carlos Fernandez-Granda
 Sparse regression Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 3/28/2016 Regression Least-squares regression Example: Global warming Logistic
Sparse regression Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 3/28/2016 Regression Least-squares regression Example: Global warming Logistic
Single-channel source separation using non-negative matrix factorization
 Single-channel source separation using non-negative matrix factorization Mikkel N. Schmidt Technical University of Denmark mns@imm.dtu.dk www.mikkelschmidt.dk DTU Informatics Department of Informatics
Single-channel source separation using non-negative matrix factorization Mikkel N. Schmidt Technical University of Denmark mns@imm.dtu.dk www.mikkelschmidt.dk DTU Informatics Department of Informatics
Convex Optimization and l 1 -minimization
 Convex Optimization and l 1 -minimization Sangwoon Yun Computational Sciences Korea Institute for Advanced Study December 11, 2009 2009 NIMS Thematic Winter School Outline I. Convex Optimization II. l
Convex Optimization and l 1 -minimization Sangwoon Yun Computational Sciences Korea Institute for Advanced Study December 11, 2009 2009 NIMS Thematic Winter School Outline I. Convex Optimization II. l
Least Sparsity of p-norm based Optimization Problems with p > 1
 Least Sparsity of p-norm based Optimization Problems with p > Jinglai Shen and Seyedahmad Mousavi Original version: July, 07; Revision: February, 08 Abstract Motivated by l p -optimization arising from
Least Sparsity of p-norm based Optimization Problems with p > Jinglai Shen and Seyedahmad Mousavi Original version: July, 07; Revision: February, 08 Abstract Motivated by l p -optimization arising from
Optimization. The value x is called a maximizer of f and is written argmax X f. g(λx + (1 λ)y) < λg(x) + (1 λ)g(y) 0 < λ < 1; x, y X.
y) < λg(x) + (1 λ)g(y) 0 < λ < 1; x, y X.") Optimization Background: Problem: given a function f(x) defined on X, find x such that f(x ) f(x) for all x X. The value x is called a maximizer of f and is written argmax X f. In general, argmax X f may
Optimization Background: Problem: given a function f(x) defined on X, find x such that f(x ) f(x) for all x X. The value x is called a maximizer of f and is written argmax X f. In general, argmax X f may
Large-Scale L1-Related Minimization in Compressive Sensing and Beyond
 Large-Scale L1-Related Minimization in Compressive Sensing and Beyond Yin Zhang Department of Computational and Applied Mathematics Rice University, Houston, Texas, U.S.A. Arizona State University March
Large-Scale L1-Related Minimization in Compressive Sensing and Beyond Yin Zhang Department of Computational and Applied Mathematics Rice University, Houston, Texas, U.S.A. Arizona State University March
Lecture 5 : Projections
 Lecture 5 : Projections EE227C. Lecturer: Professor Martin Wainwright. Scribe: Alvin Wan Up until now, we have seen convergence rates of unconstrained gradient descent. Now, we consider a constrained minimization
Lecture 5 : Projections EE227C. Lecturer: Professor Martin Wainwright. Scribe: Alvin Wan Up until now, we have seen convergence rates of unconstrained gradient descent. Now, we consider a constrained minimization
Recent Advances in Bayesian Inference for Inverse Problems
 Recent Advances in Bayesian Inference for Inverse Problems Felix Lucka University College London, UK f.lucka@ucl.ac.uk Applied Inverse Problems Helsinki, May 25, 2015 Bayesian Inference for Inverse Problems
Recent Advances in Bayesian Inference for Inverse Problems Felix Lucka University College London, UK f.lucka@ucl.ac.uk Applied Inverse Problems Helsinki, May 25, 2015 Bayesian Inference for Inverse Problems
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
SPARSE SIGNAL RESTORATION. 1. Introduction
 SPARSE SIGNAL RESTORATION IVAN W. SELESNICK 1. Introduction These notes describe an approach for the restoration of degraded signals using sparsity. This approach, which has become quite popular, is useful
SPARSE SIGNAL RESTORATION IVAN W. SELESNICK 1. Introduction These notes describe an approach for the restoration of degraded signals using sparsity. This approach, which has become quite popular, is useful
MLCC 2018 Variable Selection and Sparsity. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 Variable Selection and Sparsity Lorenzo Rosasco UNIGE-MIT-IIT Outline Variable Selection Subset Selection Greedy Methods: (Orthogonal) Matching Pursuit Convex Relaxation: LASSO & Elastic Net
MLCC 2018 Variable Selection and Sparsity Lorenzo Rosasco UNIGE-MIT-IIT Outline Variable Selection Subset Selection Greedy Methods: (Orthogonal) Matching Pursuit Convex Relaxation: LASSO & Elastic Net
Rigorous Dynamics and Consistent Estimation in Arbitrarily Conditioned Linear Systems
 1 Rigorous Dynamics and Consistent Estimation in Arbitrarily Conditioned Linear Systems Alyson K. Fletcher, Mojtaba Sahraee-Ardakan, Philip Schniter, and Sundeep Rangan Abstract arxiv:1706.06054v1 cs.it
1 Rigorous Dynamics and Consistent Estimation in Arbitrarily Conditioned Linear Systems Alyson K. Fletcher, Mojtaba Sahraee-Ardakan, Philip Schniter, and Sundeep Rangan Abstract arxiv:1706.06054v1 cs.it
LINEARIZED BREGMAN ITERATIONS FOR FRAME-BASED IMAGE DEBLURRING
 LINEARIZED BREGMAN ITERATIONS FOR FRAME-BASED IMAGE DEBLURRING JIAN-FENG CAI, STANLEY OSHER, AND ZUOWEI SHEN Abstract. Real images usually have sparse approximations under some tight frame systems derived
LINEARIZED BREGMAN ITERATIONS FOR FRAME-BASED IMAGE DEBLURRING JIAN-FENG CAI, STANLEY OSHER, AND ZUOWEI SHEN Abstract. Real images usually have sparse approximations under some tight frame systems derived
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Lecture 4 September 15
 IFT 6269: Probabilistic Graphical Models Fall 2017 Lecture 4 September 15 Lecturer: Simon Lacoste-Julien Scribe: Philippe Brouillard & Tristan Deleu 4.1 Maximum Likelihood principle Given a parametric
IFT 6269: Probabilistic Graphical Models Fall 2017 Lecture 4 September 15 Lecturer: Simon Lacoste-Julien Scribe: Philippe Brouillard & Tristan Deleu 4.1 Maximum Likelihood principle Given a parametric
Introduction to Alternating Direction Method of Multipliers
 Introduction to Alternating Direction Method of Multipliers Yale Chang Machine Learning Group Meeting September 29, 2016 Yale Chang (Machine Learning Group Meeting) Introduction to Alternating Direction
Introduction to Alternating Direction Method of Multipliers Yale Chang Machine Learning Group Meeting September 29, 2016 Yale Chang (Machine Learning Group Meeting) Introduction to Alternating Direction
(4D) Variational Models Preserving Sharp Edges. Martin Burger. Institute for Computational and Applied Mathematics
 Variational Models Preserving Sharp Edges. Martin Burger. Institute for Computational and Applied Mathematics") (4D) Variational Models Preserving Sharp Edges Institute for Computational and Applied Mathematics Intensity (cnt) Mathematical Imaging Workgroup @WWU 2 0.65 0.60 DNA Akrosom Flagellum Glass 0.55 0.50
(4D) Variational Models Preserving Sharp Edges Institute for Computational and Applied Mathematics Intensity (cnt) Mathematical Imaging Workgroup @WWU 2 0.65 0.60 DNA Akrosom Flagellum Glass 0.55 0.50
Wavelet Footprints: Theory, Algorithms, and Applications
 1306 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 5, MAY 2003 Wavelet Footprints: Theory, Algorithms, and Applications Pier Luigi Dragotti, Member, IEEE, and Martin Vetterli, Fellow, IEEE Abstract
1306 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 5, MAY 2003 Wavelet Footprints: Theory, Algorithms, and Applications Pier Luigi Dragotti, Member, IEEE, and Martin Vetterli, Fellow, IEEE Abstract
Optimization Algorithms for Compressed Sensing
 Optimization Algorithms for Compressed Sensing Stephen Wright University of Wisconsin-Madison SIAM Gator Student Conference, Gainesville, March 2009 Stephen Wright (UW-Madison) Optimization and Compressed
Optimization Algorithms for Compressed Sensing Stephen Wright University of Wisconsin-Madison SIAM Gator Student Conference, Gainesville, March 2009 Stephen Wright (UW-Madison) Optimization and Compressed
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Quantitative Biology II Lecture 4: Variational Methods
 10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Linear convergence of iterative soft-thresholding
 arxiv:0709.1598v3 [math.fa] 11 Dec 007 Linear convergence of iterative soft-thresholding Kristian Bredies and Dirk A. Lorenz ABSTRACT. In this article, the convergence of the often used iterative softthresholding
arxiv:0709.1598v3 [math.fa] 11 Dec 007 Linear convergence of iterative soft-thresholding Kristian Bredies and Dirk A. Lorenz ABSTRACT. In this article, the convergence of the often used iterative softthresholding
Adaptive Corrected Procedure for TVL1 Image Deblurring under Impulsive Noise
 Adaptive Corrected Procedure for TVL1 Image Deblurring under Impulsive Noise Minru Bai(x T) College of Mathematics and Econometrics Hunan University Joint work with Xiongjun Zhang, Qianqian Shao June 30,
Adaptive Corrected Procedure for TVL1 Image Deblurring under Impulsive Noise Minru Bai(x T) College of Mathematics and Econometrics Hunan University Joint work with Xiongjun Zhang, Qianqian Shao June 30,
CSCI5654 (Linear Programming, Fall 2013) Lectures Lectures 10,11 Slide# 1
 Lectures Lectures 10,11 Slide# 1") CSCI5654 (Linear Programming, Fall 2013) Lectures 10-12 Lectures 10,11 Slide# 1 Today s Lecture 1. Introduction to norms: L 1,L 2,L. 2. Casting absolute value and max operators. 3. Norm minimization problems.
CSCI5654 (Linear Programming, Fall 2013) Lectures 10-12 Lectures 10,11 Slide# 1 Today s Lecture 1. Introduction to norms: L 1,L 2,L. 2. Casting absolute value and max operators. 3. Norm minimization problems.
1 Sparsity and l 1 relaxation
 6.883 Learning with Combinatorial Structure Note for Lecture 2 Author: Chiyuan Zhang Sparsity and l relaxation Last time we talked about sparsity and characterized when an l relaxation could recover the
6.883 Learning with Combinatorial Structure Note for Lecture 2 Author: Chiyuan Zhang Sparsity and l relaxation Last time we talked about sparsity and characterized when an l relaxation could recover the
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
AM 205: lecture 18. Last time: optimization methods Today: conditions for optimality
 AM 205: lecture 18 Last time: optimization methods Today: conditions for optimality Existence of Global Minimum For example: f (x, y) = x 2 + y 2 is coercive on R 2 (global min. at (0, 0)) f (x) = x 3
AM 205: lecture 18 Last time: optimization methods Today: conditions for optimality Existence of Global Minimum For example: f (x, y) = x 2 + y 2 is coercive on R 2 (global min. at (0, 0)) f (x) = x 3
A Generalized Uncertainty Principle and Sparse Representation in Pairs of Bases
 2558 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL 48, NO 9, SEPTEMBER 2002 A Generalized Uncertainty Principle Sparse Representation in Pairs of Bases Michael Elad Alfred M Bruckstein Abstract An elementary
2558 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL 48, NO 9, SEPTEMBER 2002 A Generalized Uncertainty Principle Sparse Representation in Pairs of Bases Michael Elad Alfred M Bruckstein Abstract An elementary
Sparse Gaussian conditional random fields
 Sparse Gaussian conditional random fields Matt Wytock, J. ico Kolter School of Computer Science Carnegie Mellon University Pittsburgh, PA 53 {mwytock, zkolter}@cs.cmu.edu Abstract We propose sparse Gaussian
Sparse Gaussian conditional random fields Matt Wytock, J. ico Kolter School of Computer Science Carnegie Mellon University Pittsburgh, PA 53 {mwytock, zkolter}@cs.cmu.edu Abstract We propose sparse Gaussian
Convex Optimization. Newton s method. ENSAE: Optimisation 1/44
 Convex Optimization Newton s method ENSAE: Optimisation 1/44 Unconstrained minimization minimize f(x) f convex, twice continuously differentiable (hence dom f open) we assume optimal value p = inf x f(x)
Convex Optimization Newton s method ENSAE: Optimisation 1/44 Unconstrained minimization minimize f(x) f convex, twice continuously differentiable (hence dom f open) we assume optimal value p = inf x f(x)
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Sparsifying Transform Learning for Compressed Sensing MRI
 Sparsifying Transform Learning for Compressed Sensing MRI Saiprasad Ravishankar and Yoram Bresler Department of Electrical and Computer Engineering and Coordinated Science Laborarory University of Illinois
Sparsifying Transform Learning for Compressed Sensing MRI Saiprasad Ravishankar and Yoram Bresler Department of Electrical and Computer Engineering and Coordinated Science Laborarory University of Illinois
Lecture 3. Linear Regression II Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
AM 205: lecture 19. Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods
 AM 205: lecture 19 Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods Optimality Conditions: Equality Constrained Case As another example of equality
AM 205: lecture 19 Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods Optimality Conditions: Equality Constrained Case As another example of equality
Data Sparse Matrix Computation - Lecture 20
 Data Sparse Matrix Computation - Lecture 20 Yao Cheng, Dongping Qi, Tianyi Shi November 9, 207 Contents Introduction 2 Theorems on Sparsity 2. Example: A = [Φ Ψ]......................... 2.2 General Matrix
Data Sparse Matrix Computation - Lecture 20 Yao Cheng, Dongping Qi, Tianyi Shi November 9, 207 Contents Introduction 2 Theorems on Sparsity 2. Example: A = [Φ Ψ]......................... 2.2 General Matrix
Posterior Regularization
 Posterior Regularization 1 Introduction One of the key challenges in probabilistic structured learning, is the intractability of the posterior distribution, for fast inference. There are numerous methods
Posterior Regularization 1 Introduction One of the key challenges in probabilistic structured learning, is the intractability of the posterior distribution, for fast inference. There are numerous methods
Sparsity Regularization
 Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
A New Look at First Order Methods Lifting the Lipschitz Gradient Continuity Restriction
 A New Look at First Order Methods Lifting the Lipschitz Gradient Continuity Restriction Marc Teboulle School of Mathematical Sciences Tel Aviv University Joint work with H. Bauschke and J. Bolte Optimization
A New Look at First Order Methods Lifting the Lipschitz Gradient Continuity Restriction Marc Teboulle School of Mathematical Sciences Tel Aviv University Joint work with H. Bauschke and J. Bolte Optimization
Sparse Linear Models (10/7/13)
") STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
Non-Negative Matrix Factorization with Quasi-Newton Optimization
 Non-Negative Matrix Factorization with Quasi-Newton Optimization Rafal ZDUNEK, Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing BSI, RIKEN, Wako-shi, JAPAN Abstract. Non-negative matrix
Non-Negative Matrix Factorization with Quasi-Newton Optimization Rafal ZDUNEK, Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing BSI, RIKEN, Wako-shi, JAPAN Abstract. Non-negative matrix
Morphological Diversity and Source Separation
 Morphological Diversity and Source Separation J. Bobin, Y. Moudden, J.-L. Starck, and M. Elad Abstract This paper describes a new method for blind source separation, adapted to the case of sources having
Morphological Diversity and Source Separation J. Bobin, Y. Moudden, J.-L. Starck, and M. Elad Abstract This paper describes a new method for blind source separation, adapted to the case of sources having
Algorithmisches Lernen/Machine Learning
 Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
SPARSE signal representations have gained popularity in recent
 6958 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 10, OCTOBER 2011 Blind Compressed Sensing Sivan Gleichman and Yonina C. Eldar, Senior Member, IEEE Abstract The fundamental principle underlying
6958 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 10, OCTOBER 2011 Blind Compressed Sensing Sivan Gleichman and Yonina C. Eldar, Senior Member, IEEE Abstract The fundamental principle underlying
Gaussian Process Approximations of Stochastic Differential Equations
 Gaussian Process Approximations of Stochastic Differential Equations Cédric Archambeau Centre for Computational Statistics and Machine Learning University College London c.archambeau@cs.ucl.ac.uk CSML
Gaussian Process Approximations of Stochastic Differential Equations Cédric Archambeau Centre for Computational Statistics and Machine Learning University College London c.archambeau@cs.ucl.ac.uk CSML
Optimization methods
 Optimization methods Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda /8/016 Introduction Aim: Overview of optimization methods that Tend to
Optimization methods Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda /8/016 Introduction Aim: Overview of optimization methods that Tend to
On the interior of the simplex, we have the Hessian of d(x), Hd(x) is diagonal with ith. µd(w) + w T c. minimize. subject to w T 1 = 1,
, Hd(x) is diagonal with ith. µd(w) + w T c. minimize. subject to w T 1 = 1,") Math 30 Winter 05 Solution to Homework 3. Recognizing the convexity of g(x) := x log x, from Jensen s inequality we get d(x) n x + + x n n log x + + x n n where the equality is attained only at x = (/n,...,
Math 30 Winter 05 Solution to Homework 3. Recognizing the convexity of g(x) := x log x, from Jensen s inequality we get d(x) n x + + x n n log x + + x n n where the equality is attained only at x = (/n,...,
Recent developments on sparse representation
 Recent developments on sparse representation Zeng Tieyong Department of Mathematics, Hong Kong Baptist University Email: zeng@hkbu.edu.hk Hong Kong Baptist University Dec. 8, 2008 First Previous Next Last
Recent developments on sparse representation Zeng Tieyong Department of Mathematics, Hong Kong Baptist University Email: zeng@hkbu.edu.hk Hong Kong Baptist University Dec. 8, 2008 First Previous Next Last
Overcomplete Dictionaries for. Sparse Representation of Signals. Michal Aharon
 Overcomplete Dictionaries for Sparse Representation of Signals Michal Aharon ii Overcomplete Dictionaries for Sparse Representation of Signals Reasearch Thesis Submitted in Partial Fulfillment of The Requirements
Overcomplete Dictionaries for Sparse Representation of Signals Michal Aharon ii Overcomplete Dictionaries for Sparse Representation of Signals Reasearch Thesis Submitted in Partial Fulfillment of The Requirements
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Nonlinear Optimization for Optimal Control
 Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
Chapter 3 Numerical Methods
 Chapter 3 Numerical Methods Part 2 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization 1 Outline 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization Summary 2 Outline 3.2
Chapter 3 Numerical Methods Part 2 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization 1 Outline 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization Summary 2 Outline 3.2
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Recovery of Sparse Signals from Noisy Measurements Using an l p -Regularized Least-Squares Algorithm
 Recovery of Sparse Signals from Noisy Measurements Using an l p -Regularized Least-Squares Algorithm J. K. Pant, W.-S. Lu, and A. Antoniou University of Victoria August 25, 2011 Compressive Sensing 1 University
Recovery of Sparse Signals from Noisy Measurements Using an l p -Regularized Least-Squares Algorithm J. K. Pant, W.-S. Lu, and A. Antoniou University of Victoria August 25, 2011 Compressive Sensing 1 University
Sparse Approximation and Variable Selection
 Sparse Approximation and Variable Selection Lorenzo Rosasco 9.520 Class 07 February 26, 2007 About this class Goal To introduce the problem of variable selection, discuss its connection to sparse approximation
Sparse Approximation and Variable Selection Lorenzo Rosasco 9.520 Class 07 February 26, 2007 About this class Goal To introduce the problem of variable selection, discuss its connection to sparse approximation
Coordinate Update Algorithm Short Course Proximal Operators and Algorithms
 Coordinate Update Algorithm Short Course Proximal Operators and Algorithms Instructor: Wotao Yin (UCLA Math) Summer 2016 1 / 36 Why proximal? Newton s method: for C 2 -smooth, unconstrained problems allow
Coordinate Update Algorithm Short Course Proximal Operators and Algorithms Instructor: Wotao Yin (UCLA Math) Summer 2016 1 / 36 Why proximal? Newton s method: for C 2 -smooth, unconstrained problems allow
Convex functions, subdifferentials, and the L.a.s.s.o.
 Convex functions, subdifferentials, and the L.a.s.s.o. MATH 697 AM:ST September 26, 2017 Warmup Let us consider the absolute value function in R p u(x) = (x, x) = x 2 1 +... + x2 p Evidently, u is differentiable
Convex functions, subdifferentials, and the L.a.s.s.o. MATH 697 AM:ST September 26, 2017 Warmup Let us consider the absolute value function in R p u(x) = (x, x) = x 2 1 +... + x2 p Evidently, u is differentiable
Conditional Gradient (Frank-Wolfe) Method
 Method") Conditional Gradient (Frank-Wolfe) Method Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 1 Outline Today: Conditional gradient method Convergence analysis Properties
Conditional Gradient (Frank-Wolfe) Method Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 1 Outline Today: Conditional gradient method Convergence analysis Properties
One Picture and a Thousand Words Using Matrix Approximtions October 2017 Oak Ridge National Lab Dianne P. O Leary c 2017
 One Picture and a Thousand Words Using Matrix Approximtions October 2017 Oak Ridge National Lab Dianne P. O Leary c 2017 1 One Picture and a Thousand Words Using Matrix Approximations Dianne P. O Leary
One Picture and a Thousand Words Using Matrix Approximtions October 2017 Oak Ridge National Lab Dianne P. O Leary c 2017 1 One Picture and a Thousand Words Using Matrix Approximations Dianne P. O Leary
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Statistics 203: Introduction to Regression and Analysis of Variance Penalized models
 Statistics 203: Introduction to Regression and Analysis of Variance Penalized models Jonathan Taylor - p. 1/15 Today s class Bias-Variance tradeoff. Penalized regression. Cross-validation. - p. 2/15 Bias-variance
Statistics 203: Introduction to Regression and Analysis of Variance Penalized models Jonathan Taylor - p. 1/15 Today s class Bias-Variance tradeoff. Penalized regression. Cross-validation. - p. 2/15 Bias-variance
Machine Learning Srihari. Information Theory. Sargur N. Srihari
 Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Low-Complexity Image Denoising via Analytical Form of Generalized Gaussian Random Vectors in AWGN
 Low-Complexity Image Denoising via Analytical Form of Generalized Gaussian Random Vectors in AWGN PICHID KITTISUWAN Rajamangala University of Technology (Ratanakosin), Department of Telecommunication Engineering,
Low-Complexity Image Denoising via Analytical Form of Generalized Gaussian Random Vectors in AWGN PICHID KITTISUWAN Rajamangala University of Technology (Ratanakosin), Department of Telecommunication Engineering,
Oslo Class 6 Sparsity based regularization
 RegML2017@SIMULA Oslo Class 6 Sparsity based regularization Lorenzo Rosasco UNIGE-MIT-IIT May 4, 2017 Learning from data Possible only under assumptions regularization min Ê(w) + λr(w) w Smoothness Sparsity
RegML2017@SIMULA Oslo Class 6 Sparsity based regularization Lorenzo Rosasco UNIGE-MIT-IIT May 4, 2017 Learning from data Possible only under assumptions regularization min Ê(w) + λr(w) w Smoothness Sparsity
Multiple Change Point Detection by Sparse Parameter Estimation
 Multiple Change Point Detection by Sparse Parameter Estimation Department of Econometrics Fac. of Economics and Management University of Defence Brno, Czech Republic Dept. of Appl. Math. and Comp. Sci.
Multiple Change Point Detection by Sparse Parameter Estimation Department of Econometrics Fac. of Economics and Management University of Defence Brno, Czech Republic Dept. of Appl. Math. and Comp. Sci.
Generalized Orthogonal Matching Pursuit- A Review and Some
 Generalized Orthogonal Matching Pursuit- A Review and Some New Results Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur, INDIA Table of Contents
Generalized Orthogonal Matching Pursuit- A Review and Some New Results Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur, INDIA Table of Contents
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
COMS 4721: Machine Learning for Data Science Lecture 6, 2/2/2017
 COMS 4721: Machine Learning for Data Science Lecture 6, 2/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University UNDERDETERMINED LINEAR EQUATIONS We
COMS 4721: Machine Learning for Data Science Lecture 6, 2/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University UNDERDETERMINED LINEAR EQUATIONS We
Super-Resolution. Shai Avidan Tel-Aviv University
 Super-Resolution Shai Avidan Tel-Aviv University Slide Credits (partial list) Ric Szelisi Steve Seitz Alyosha Efros Yacov Hel-Or Yossi Rubner Mii Elad Marc Levoy Bill Freeman Fredo Durand Sylvain Paris
Super-Resolution Shai Avidan Tel-Aviv University Slide Credits (partial list) Ric Szelisi Steve Seitz Alyosha Efros Yacov Hel-Or Yossi Rubner Mii Elad Marc Levoy Bill Freeman Fredo Durand Sylvain Paris
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Expectation maximization tutorial
 Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
LECTURE 5 NOTES. n t. t Γ(a)Γ(b) pt+a 1 (1 p) n t+b 1. The marginal density of t is. Γ(t + a)γ(n t + b) Γ(n + a + b)
Γ(b) pt+a 1 (1 p) n t+b 1. The marginal density of t is. Γ(t + a)γ(n t + b) Γ(n + a + b)") LECTURE 5 NOTES 1. Bayesian point estimators. In the conventional (frequentist) approach to statistical inference, the parameter θ Θ is considered a fixed quantity. In the Bayesian approach, it is considered
LECTURE 5 NOTES 1. Bayesian point estimators. In the conventional (frequentist) approach to statistical inference, the parameter θ Θ is considered a fixed quantity. In the Bayesian approach, it is considered
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity