Deep Learning: Self-Taught Learning and Deep vs. Shallow Architectures. Lecture 04
|
|
|
- Emmeline Higgins
- 6 years ago
- Views:
Transcription
1 Deep Learning: Self-Taught Learning and Deep vs. Shallow Architectures Lecture 04 Razvan C. Bunescu School of Electrical Engineering and Computer Science
2 Self-Taught Learning 1. Learn features: 1. Train sparse auto-encoder on unlabeled examples. 2. Remove last layer and its connections. => W (1) 2. Plug features into favorite ML supervised algorithm: 1. Train softmax classifier on labeled examples. => W (2) 3. Fine-tune both W (1) and W (2) : 1. Train whole network (first layer + softmax) on labeled examples. 2. Start parameter learning from pre-trained W (1), W (2) 2


3 1. Learning Features remove output layer 3


4 2. Plug Features into Softmax Regressor 4
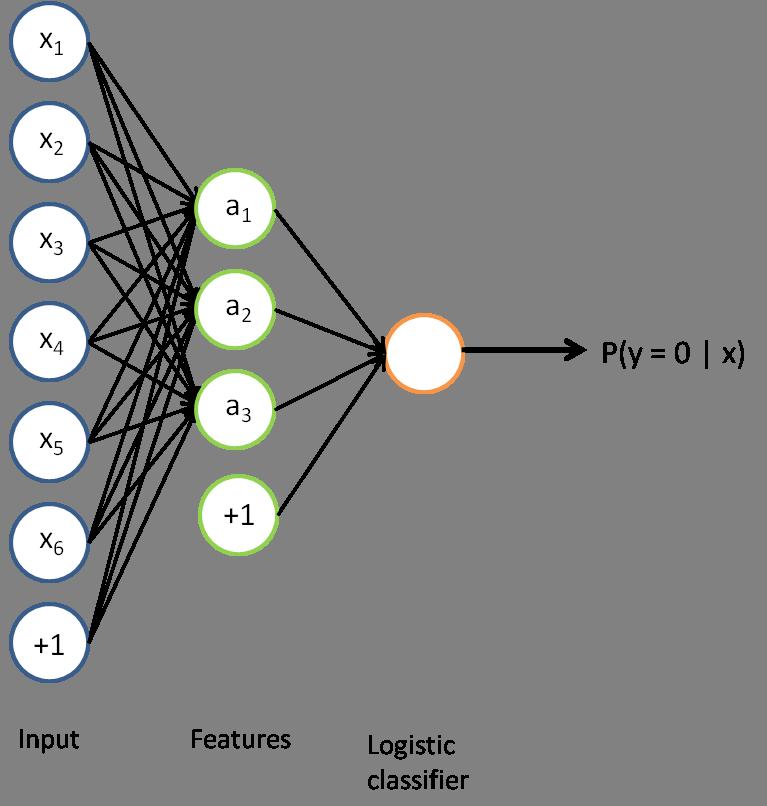
5 3. Fine-Tuning 5
6 Shallow vs. Deep Networks A 1-hidden layer network is a fairly shallow network. Effective for MNIST, but limited by simplicity of features. A deep network is a k-layer network, k > 1. Computes more complex features of the input, as k gets larger. Each hidden layer computes a non-linear transformation of the previous layer. Conjecture A deep network has significantly greater representational power than a shallow one. 6
7 Number of Linear Regions of Shallow vs. Deep Networks Conjecture [Montufar et a., NIPS 14] A deep network has significantly greater representational power than a shallow one. 7
8 Deep vs. Shallow Architectures A function is highly varying when a piecewise (linear) approximation would require a large number of pieces. Depth of an architecture refers to the number of levels of composition of non-linear operations in the function computed by the architecture. Conjecture: Deep architectures can compactly represent highly-varying functions: The expression of a function is compact when it has few computational elements. Same highly-varying functions would require very large shallow networks. 8
9 Graphs of Computations A function can be expressed by the composition of computational elements from a given set: logic operators. logistic operators. multiplication and additions. The function is defined by a graph of computations: A directed acyclic graph, with one node per computational element. Depth of architecture = depth of the graph = longest path from an input node to an output node. 9
10 Functions as Graphs of Computations [Bengio, FTML 09] 10
11 Polynomials as Graphs of Computations [Bengio, FTML 09] 11
12 Sum-Product Networks (SPNs) Rooted, weighted DAG. Nodes: Sum, Product, (Input) Indicators. Weights on edges from sums to children. [Poon & Domingos, UAI 11] 12


13 ML Models as Graphs of Computations [Bengio, FTML 09] 13

14 Deep vs. Shallow Architectures [Bengio, FTML 09] When a function can be compactly represented by a deep architecture, it might need a very large architecture to be represented by an insufficiently deep one. 14
=1[w T x+b 0] [Bengio, FTML 09] Monotone weighted threshold circuits = multi-layer neural networks with linear threshold units and positive")
15 Deep vs. Shallow Architectures Many of the results for Boolean circuits can be generalized to architectures whose computational elements are linear threshold units i.e. Mc-Cullogh & Pitts neurons: f(x)=1[w T x+b 0] [Bengio, FTML 09] Monotone weighted threshold circuits = multi-layer neural networks with linear threshold units and positive weights. 15
16 Deep vs. Shallow Architectures Deep architectures were shown to be more compact for: Boolean circuits [Hastad, 1986]. Monotone weighted threshold circuits [Hastad and Goldman, 1993]. Same holds for networks with continuous-valued activations [Maass, 1992]. Many modern neural networks use rectified linear units: 1. ReLU networks are universal approximators [Leshno et al., 1993]. 2. Are deep ReLU networks more compact than shallow ones? YES! [Montufar et al., NIPS 14] 16
17 ReLU and Generalizations It has become more common to use piecewise linear activation functions for hidden units: ReLU: the rectifier activation g(a) = max{0, a}. Absolute value ReLU: g(a) = a. Maxout: g(a 1,..., a k ) = max{a 1,..., a k }. needs k weight vectors instead of 1. Leaky ReLU: g(a) = max{0, a}+ α min(0, a). the network computes a piecewise linear function (up to the output activation function). 17
18 ReLU vs. Sigmoid and Tanh Sigmoid and Tanh saturate for values not close to 0: kill gradients, bad behavior for gradient-based learning. ReLU does not saturate for values > 0: greatly accelerates learning, fast implementation. fragile during training and can die, due to 0 gradient: initialize all b s to a small, positive value, e.g
19 ReLU vs. Softplus Softplus g(a) = ln(1+e a ) is a smooth version of the rectifier. Saturates less than ReLU, yet ReLU still does better [Glorot, 2011]. 19
 ReLU, but needs more params.")
20 ReLU and Generalizations Leaky ReLU attempts to fix the dying ReLU problem. Maxout subsumes (leaky) ReLU, but needs more params. 20
21 Maxout Networks Maxout units can learn the activation function. [Goodfellow et al., ICML 13] 21

22 Number of Linear Regions of Shallow vs. Deep Networks Theorem [Montufar et al., NIPS 14] A deep network has significantly greater representational power than a shallow one. 22
23 Folding Example ? 0 1 x 1 x 2 23
24 Folding Example x 1 x 2 24
25 Folding Example x 1 x 2?
26 Folding Example x 1 x

27 Space Foldings Each hidden layer of a deep neural network can be associated with a folding operator. 27
28 Folding Example ? x 1 x
29 Folding Example x 1 x

30 Space foldings Each hidden layer of a deep neural network can be associated with a folding operator. 30
31 Folding Example x 1 x

32 Folding Example 1? ? ? x 1 x
33 Folding Example x 1 x
34 Space Foldings [Montufar et al., NIPS 14] Each hidden layer of a deep neural network can be associated with a folding operator: Each hidden layer folds the space of activations of the previous layer. In turn, a deep neural network effectively folds its input-space recursively, starting with the first layer. Any function computed on the final folded space will apply to all the collapsed subsets identified by the map corresponding to the succession of foldings. This means that in a deep model any partitioning of the last layer s image-space is replicated in all input-space regions which are identified by the succession of foldings. 34
35 Space Foldings [Montufar et al., NIPS 14] Space foldings are not restricted to foldings along coordinate axes and they do not have to preserve lengths: The space is folded depending on the orientations and shifts encoded in: The input weights W and biases b. The nonlinear activation function used at each hidden layer. The sizes and orientations of identified input-space regions may differ from each other. For activation functions which are not piece-wise linear, the folding operations may be even more complex. 35

36 Space Foldings [Montufar et al., NIPS 14] 36
37 Space Foldings [Montufar et al., NIPS 14] Space folding of 2-D space in a non-trivial way: The folding can potentially identify symmetries in the boundary that it needs to learn. 37
38 Deep vs. Shallow Rectifier Networks [Montufar et al., NIPS 14] A linear region of a piecewise linear function F: R d > R m is a maximal connected subset of the input-space R d, on which F is linear. The number of linear regions carved out by a deep rectifier network with d inputs, depth l, and n units per hidden layer, is: In the case of maxout networks with k filters per unit, the number of linear regions is: 38
39 Why are Deep Architectures Good for AI? There is no guarantee that the kinds of functions we want to learn share this folding property. Choosing a deep model encodes a very general belief that: The function we want to learn should involve composition of several simpler functions, OR The learning problem consists of discovering a set of underlying factors of variation that can in turn be described in terms of other, simpler underlying factors of variation, OR The function we want to learn is a computer program consisting of multiple steps, where each step uses of the previous step s output. Empirically, greater depth does seem to result in better generalization for a wide variety of tasks. 39
40 Digit Recognition Accuracy vs. Depth [DL book, 2016] 40
41 Accuracy vs. Depth vs. Capacity [DL book, 2016] 41
42 Why do Cheap & Deep Architectures Work for AI? [Lin & Tegmark, 2016] Paradox: How can neural networks approximate functions well in practice, when the set of possible functions is exponentially larger than the set of practically possible networks? Example: classify megapixel greyscale images into two categories, e.g., cats or dogs. If each pixel can take one of 256 values, then there are possible images, and for each one, we wish to compute the probability that it depicts a cat. This means that an arbitrary function is defined by a list of probabilities, i.e., way more numbers than there are atoms in our universe (about ). 42
43 Why do Cheap & Deep Architectures Work for AI? [Lin & Tegmark, 2016] Paradox: How can neural networks approximate functions well in practice, when the set of possible functions is exponentially larger than the set of practically possible networks? Conjecture: The data sets and functions we care about form a minuscule minority, and it is plausible that they can also be efficiently implemented by neural networks reflecting their generative process. 43
44 Why do Cheap & Deep Architectures Work for AI? [Lin & Tegmark, 2016] 1. Cheap: The exceptional simplicity of physics-based functions hinges on properties such as symmetry, locality, compositionality and polynomial log-probability. These properties translate into exceptionally simple neural networks approximating both natural phenomena such as images and abstract representations thereof such as drawings. 2. Deep: The statistical process generating the data is of a certain hierarchical form prevalent in physics and machine learning: Therefore, a deep neural network can be more efficient than a shallow one. 44
45 Why do Cheap Architectures Work for AI? Low polynomial order: For reasons that are still not fully understood, our universe can be accurately described by polynomial Hamiltonians of low order d. Standard model: At a fundamental level, the Hamiltonian of the standard model of particle physics has d = 4. Central Limit Theorem: many probability distributions in machine-learning and statistics can be accurately approximated by multivariate Gaussians => Hamiltonian H = ln p has d = 2. Translation and rotation invariance. Locality. Symmetry. [Lin & Tegmark, 2016] 45
46 Why do Cheap Architectures Work for AI? [Lin & Tegmark, 2016] Low polynomial order: For reasons that are still not fully understood, our universe can be accurately described by polynomial Hamiltonians of low order d. Neural networks can efficiently approximate multiplication! 46

47 Polynomials as Simple NNs [Lin & Tegmark, 2016] 47
48 Why do Deep Architectures Work for AI? [Lin & Tegmark, 2016] Hierarchical Structure: One of the most striking features of the physical world is its hierarchical structure. Spatially, it is an object hierarchy: elementary particles form atoms which in turn form molecules, cells, organisms, planets, solar systems, galaxies, etc. Causally, complex structures are frequently created through a distinct sequence of simpler steps. 48
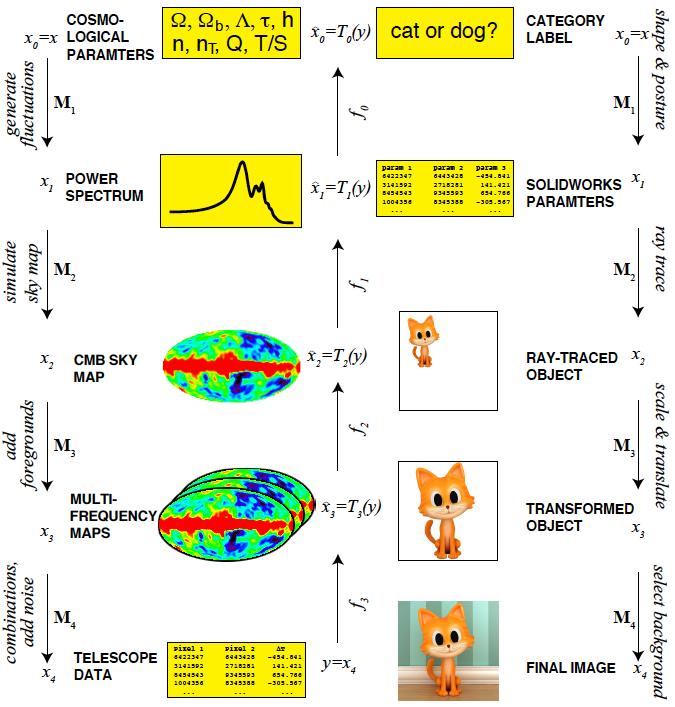
49 49
50 Why do Cheap & Deep Architectures Work for AI? [Lin & Tegmark, 2016] Cheap & Deep: Paradox: The number of parameters required to describe an arbitrary function of the input data y is beyond astronomical. Solution: The generative process can be specified by a more modest number of parameters, because each of its steps can. For a megapixel image of a galaxy, its entire prob. distribution is defined by the standard model of particle physics with its 32 parameters, which together specify the process transforming primordial hydrogen gas into galaxies. Giving the simple low-information content instruction draw a cute kitten" to a random sample of artists will produce a wide variety of images y with a complicated probability distribution over colors, postures, etc. But the pre-stored information about cat probabilities in these artists' brains is modest in size. 50
Ch.6 Deep Feedforward Networks (2/3)
") Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Learning Deep Architectures for AI. Part I - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Deep Feedforward Networks. Han Shao, Hou Pong Chan, and Hongyi Zhang
 Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Why is Deep Learning so effective?
 Ma191b Winter 2017 Geometry of Neuroscience The unreasonable effectiveness of deep learning This lecture is based entirely on the paper: Reference: Henry W. Lin and Max Tegmark, Why does deep and cheap
Ma191b Winter 2017 Geometry of Neuroscience The unreasonable effectiveness of deep learning This lecture is based entirely on the paper: Reference: Henry W. Lin and Max Tegmark, Why does deep and cheap
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 12 Feb 23, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Feed-forward Network Functions
 Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Feature Design. Feature Design. Feature Design. & Deep Learning
 Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
Introduction to Machine Learning Spring 2018 Note Neural Networks
 CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Deep Belief Networks are compact universal approximators
 1 Deep Belief Networks are compact universal approximators Nicolas Le Roux 1, Yoshua Bengio 2 1 Microsoft Research Cambridge 2 University of Montreal Keywords: Deep Belief Networks, Universal Approximation
1 Deep Belief Networks are compact universal approximators Nicolas Le Roux 1, Yoshua Bengio 2 1 Microsoft Research Cambridge 2 University of Montreal Keywords: Deep Belief Networks, Universal Approximation
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Neural networks COMS 4771
 Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Artificial Neuron (Perceptron)
") 9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
Sum-Product Networks: A New Deep Architecture
 Sum-Product Networks: A New Deep Architecture Pedro Domingos Dept. Computer Science & Eng. University of Washington Joint work with Hoifung Poon 1 Graphical Models: Challenges Bayesian Network Markov Network
Sum-Product Networks: A New Deep Architecture Pedro Domingos Dept. Computer Science & Eng. University of Washington Joint work with Hoifung Poon 1 Graphical Models: Challenges Bayesian Network Markov Network
Lecture 2: Learning with neural networks
 Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]
![Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]](/thumbs/88/117565192.jpg "Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]") Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
arxiv: v4 [cond-mat.dis-nn] 3 Aug 2017
![arxiv: v4 [cond-mat.dis-nn] 3 Aug 2017](/thumbs/74/70078483.jpg "arxiv: v4 [cond-mat.dis-nn] 3 Aug 2017") Why does deep and cheap learning work so well? arxiv:1608.08225v4 [cond-mat.dis-nn] 3 Aug 2017 Henry W. Lin, Max Tegmark, and David Rolnick Dept. of Physics, Harvard University, Cambridge, MA 02138 Dept.
Why does deep and cheap learning work so well? arxiv:1608.08225v4 [cond-mat.dis-nn] 3 Aug 2017 Henry W. Lin, Max Tegmark, and David Rolnick Dept. of Physics, Harvard University, Cambridge, MA 02138 Dept.
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Learning Deep Architectures for AI. Contents
 Foundations and Trends R in Machine Learning Vol. 2, No. 1 (2009) 1 127 c 2009 Y. Bengio DOI: 10.1561/2200000006 Learning Deep Architectures for AI By Yoshua Bengio Contents 1 Introduction 2 1.1 How do
Foundations and Trends R in Machine Learning Vol. 2, No. 1 (2009) 1 127 c 2009 Y. Bengio DOI: 10.1561/2200000006 Learning Deep Architectures for AI By Yoshua Bengio Contents 1 Introduction 2 1.1 How do
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
Notes on Adversarial Examples
 Notes on Adversarial Examples David Meyer dmm@{1-4-5.net,uoregon.edu,...} March 14, 2017 1 Introduction The surprising discovery of adversarial examples by Szegedy et al. [6] has led to new ways of thinking
Notes on Adversarial Examples David Meyer dmm@{1-4-5.net,uoregon.edu,...} March 14, 2017 1 Introduction The surprising discovery of adversarial examples by Szegedy et al. [6] has led to new ways of thinking
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Fast classification using sparsely active spiking networks. Hesham Mostafa Institute of neural computation, UCSD
 Fast classification using sparsely active spiking networks Hesham Mostafa Institute of neural computation, UCSD Artificial networks vs. spiking networks backpropagation output layer Multi-layer networks
Fast classification using sparsely active spiking networks Hesham Mostafa Institute of neural computation, UCSD Artificial networks vs. spiking networks backpropagation output layer Multi-layer networks
Learning Deep Architectures
 Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Adversarial Examples
 Adversarial Examples presentation by Ian Goodfellow Deep Learning Summer School Montreal August 9, 2015 In this presentation. - Intriguing Properties of Neural Networks. Szegedy et al., ICLR 2014. - Explaining
Adversarial Examples presentation by Ian Goodfellow Deep Learning Summer School Montreal August 9, 2015 In this presentation. - Intriguing Properties of Neural Networks. Szegedy et al., ICLR 2014. - Explaining
Deep Feedforward Networks
 Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
CS60010: Deep Learning
 CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Maxout Networks. Hien Quoc Dang
 Maxout Networks Hien Quoc Dang Outline Introduction Maxout Networks Description A Universal Approximator & Proof Experiments with Maxout Why does Maxout work? Conclusion 10/12/13 Hien Quoc Dang Machine
Maxout Networks Hien Quoc Dang Outline Introduction Maxout Networks Description A Universal Approximator & Proof Experiments with Maxout Why does Maxout work? Conclusion 10/12/13 Hien Quoc Dang Machine
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Modeling High-Dimensional Discrete Data with Multi-Layer Neural Networks
 Modeling High-Dimensional Discrete Data with Multi-Layer Neural Networks Yoshua Bengio Dept. IRO Université de Montréal Montreal, Qc, Canada, H3C 3J7 bengioy@iro.umontreal.ca Samy Bengio IDIAP CP 592,
Modeling High-Dimensional Discrete Data with Multi-Layer Neural Networks Yoshua Bengio Dept. IRO Université de Montréal Montreal, Qc, Canada, H3C 3J7 bengioy@iro.umontreal.ca Samy Bengio IDIAP CP 592,
Greedy Layer-Wise Training of Deep Networks
 Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville
 Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
Learning from Data: Multi-layer Perceptrons
 Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Artificial Neural Networks
 Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Learning Deep Architectures
 Learning Deep Architectures Yoshua Bengio, U. Montreal CIFAR NCAP Summer School 2009 August 6th, 2009, Montreal Main reference: Learning Deep Architectures for AI, Y. Bengio, to appear in Foundations and
Learning Deep Architectures Yoshua Bengio, U. Montreal CIFAR NCAP Summer School 2009 August 6th, 2009, Montreal Main reference: Learning Deep Architectures for AI, Y. Bengio, to appear in Foundations and
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
arxiv: v1 [cs.lg] 11 May 2015
![arxiv: v1 [cs.lg] 11 May 2015](/thumbs/77/75232143.jpg "arxiv: v1 [cs.lg] 11 May 2015") Improving neural networks with bunches of neurons modeled by Kumaraswamy units: Preliminary study Jakub M. Tomczak JAKUB.TOMCZAK@PWR.EDU.PL Wrocław University of Technology, wybrzeże Wyspiańskiego 7, 5-37,
Improving neural networks with bunches of neurons modeled by Kumaraswamy units: Preliminary study Jakub M. Tomczak JAKUB.TOMCZAK@PWR.EDU.PL Wrocław University of Technology, wybrzeże Wyspiańskiego 7, 5-37,
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
On the complexity of shallow and deep neural network classifiers
 On the complexity of shallow and deep neural network classifiers Monica Bianchini and Franco Scarselli Department of Information Engineering and Mathematics University of Siena Via Roma 56, I-53100, Siena,
On the complexity of shallow and deep neural network classifiers Monica Bianchini and Franco Scarselli Department of Information Engineering and Mathematics University of Siena Via Roma 56, I-53100, Siena,
Training Neural Networks Practical Issues
 Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Deep Feedforward Neural Networks Yoshua Bengio
 Deep Feedforward Neural Networks Yoshua Bengio August 28-29th, 2017 @ DS3 Data Science Summer School Input Layer, Hidden Layers, Output Layer 2 Output layer Here predicting a supervised target Hidden layers
Deep Feedforward Neural Networks Yoshua Bengio August 28-29th, 2017 @ DS3 Data Science Summer School Input Layer, Hidden Layers, Output Layer 2 Output layer Here predicting a supervised target Hidden layers
Discriminative Learning of Sum-Product Networks. Robert Gens Pedro Domingos
 Discriminative Learning of Sum-Product Networks Robert Gens Pedro Domingos X1 X1 X1 X1 X2 X2 X2 X2 X3 X3 X3 X3 X4 X4 X4 X4 X5 X5 X5 X5 X6 X6 X6 X6 Distributions X 1 X 1 X 1 X 1 X 2 X 2 X 2 X 2 X 3 X 3
Discriminative Learning of Sum-Product Networks Robert Gens Pedro Domingos X1 X1 X1 X1 X2 X2 X2 X2 X3 X3 X3 X3 X4 X4 X4 X4 X5 X5 X5 X5 X6 X6 X6 X6 Distributions X 1 X 1 X 1 X 1 X 2 X 2 X 2 X 2 X 3 X 3
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Deep unsupervised learning
 Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Deep Generative Models. (Unsupervised Learning)
") Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What