ELEC 515 Information Theory. Distortionless Source Coding
|
|
|
- Joella Walters
- 6 years ago
- Views:
Transcription
1 ELEC 515 Information Theory Distortionless Source Coding 1
2 Source Coding Output Alphabet Y={y 1,,y J } Source Encoder Lengths 2
3 Source Coding Two coding requirements The source sequence can be recovered from the encoded sequence with no ambiguity The average number of output symbols per source symbol is as small as possible 3
4 Typical Sequences Consider the following discrete memoryless binary source: p(1) = 1/4 p(0) = 3/4 Sequences of 20 symbols 1. 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 2. 1,0,1,0,1,0,0,0,0,0,0,0,0,0,1,1,0,0,0,1 3. 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 4
5 Tchebycheff Inequality 5
6 Weak Law of Large Numbers Sequence of N i.i.d. RVs Define a new RV 6
7 Weak Law of Large Numbers The average approaches the statistical mean 7
8 Asymptotic Equipartition Property N i.i.d. random variables X 1,, X N p(x,x,,x )=p(x )p(x ) p(x ) 1 2 N 1 2 N N 1 1 logp(x = 1,X 2,,X N) logp(x n) E[ logp(x) ] =H(X) N N n = 1 as N 8
9 Typical Sequences RV X where p(x k ) = p k Consider a sequence x of length N where x k appears Np k times 1 2 p( x) = p p p K K Np log2 p Np pk ((2 ) k= 1 k= 1 = = Np log p = 2 = 2 = 2 Np Np Np 1 2 K K k= 1 NH(X) k k k k 2 k k= 1 K K N p log p k 2 k 9
10 Summary The Tchebycheff inequality was used to prove the weak law of large numbers (WLLN) the sample average approaches the statistical mean as The WLLN was used to prove the AEP N 1 logp(x n) H(X) as N N n= 1 A typical sequence has probability p( x1, x2,, x ) 2 N N - H(X) N There are about 2 NH(X) typical sequences of length N 10
11 Typical Sequences H( X) H( X) 11
12 Typical Sequences set of typical sequences nontypical or atypical sequence set of sequences of length N 12
13 Interpretation Although there are very many results that may be produced by a random process, the one actually produced is most probably from a set of outcomes that all have approximately the same chance of being the one actually realized. Although there are individual outcomes which may have a higher probability than outcomes in this set, the vast number of outcomes in the set almost guarantees that the outcome will come from the set. ``Almost all events are almost equally surprising Cover and Thomas 13
14 Typical Sequences From the definition, the probability of occurrence of a typical sequence p(x) is 14
15 Example p(x 1 ) = p(1) = 1/4 p(x 2 ) = p(0) = 3/4 H(X) = bit N = 3 p(x 1,x 1,x 1 ) = 1/64 p(x 1,x 1,x 2 ) = p(x 1,x 2,x 1 ) = p(x 2,x 1,x 1 ) = 3/64 p(x 1,x 2,x 2 ) = p(x 2,x 2,x 1 ) = p(x 2,x 1,x 2 ) = 9/64 p(x 2,x 2,x 2 ) = 27/64 15
16 Example H(X) = bit N = 3 b = 2 2 < p( x, x, x ) < 2 3[ δ] 3[.811 δ] x 1,x 1,x 1 1/64 = 2-3[ ] x 1,x 1,x 2 3/64 = 2-3[ ] x 1,x 2,x 2 9/64 = 2-3[ ] x 2,x 2,x 2 27/64 = 2-3[ ] 16
17 Example If δ = 0.2 the typical sequences are (x 1,x 2,x 2 ), (x 2,x 1,x 2 ), (x 2,x 2,x 1 ) with probability (1,0,0), (0,1,0), (0,0,1) If δ = 0.4 the typical sequences are (x 1,x 2,x 2 ), (x 2,x 1,x 2 ), (x 2,x 2,x 1 ), (x 2,x 2,x 2 ) with probability (1,0,0), (0,1,0), (0,0,1), (0,0,0) 17
18 18
 c X( ) + X( ) =")
19 Typical Sequences Random variable X Alphabet size K Entropy H(X) Arbitrary number δ>0 Sequences x of blocklength N N 0 and probability p(x) c X( ) + X( ) = K N 19
20 Shannon-McMillan Theorem 20
21 The essence of source coding or data compression is that as N, atypical sequences almost never appear as the output of the source. Therefore, one can focus on representing typical sequences with codewords and ignore atypical sequences. Since there are only 2 NH(X) typical sequences of length N, and they are approximately equiprobable, it takes about NH(X) bits to represent them. On average it takes H(X) bits per source output symbol. 21
22 Variable Length Codes Output Alphabet Y={y 1,,y J } Lengths 22
23 23
24 Instantaneous Codes Definition: A uniquely decodable code is said to be instantaneous if it is possible to decode each codeword in a sequence without reference to succeeding codewords. A necessary and sufficient condition for a code to be instantaneous is that no codeword is a prefix of some other codeword. 24
25 Variable Length Codes Prefix code (also prefix-free or instantaneous) C 1 ={0,10,110,111} Uniquely decodable code (which is not prefix) C 2 ={0,01,011,0111} Non-singular code (which is not uniquely decodable) C 3 ={0,1,00,11} Singular code C 4 ={0,10,11,10} Example sequence of codewords:
26 26
27 Average Codeword Length K L(C) = p( xk) l k= 1 k 27
28 Two Binary Prefix Codes Five source symbols: x 1, x 2, x 3, x 4, x 5 K = 5, J = 2 c 1 = 0, c 2 = 10, c 3 = 110, c 4 = 1110, c 5 = 1111 codeword lengths 1,2,3,4,4 c 1 = 00, c 2 = 01, c 3 = 10, c 4 = 110, c 5 = 111 codeword lengths 2,2,2,3,3 28
29 Kraft Inequality for Prefix Codes 29
30 Code Tree 30
31 Five Binary Codes Source symbols Code A Code B Code C Code D Code E x 1 x 2 x 3 x 4 31
32 Ternary Code Example Ten source symbols: x 1, x 2,, x 9, x 10 K = 10, J = 3 l k = 1,2,2,2,2,2,3,3,3,3 l k = 1,2,2,2,2,2,3,3,3 l k = 1,2,2,2,2,2,3,3,4,4 32
33 Average Codeword Length Bound L(C) H(X) log b J 33
34 Four Symbol Source Information Source H p(x 1 ) = 1/2 p(x 3 ) = 1/4 p(x 2 ) = p(x 4 ) = 1/8 H(X) = 1.75 bits x 1 0 x x 3 10 x L(C) = 1.75 bits x 1 00 x 2 01 x 3 10 x 4 11 L(C) = 2 bits 34
35 Code Efficiency H(X) ζ= 1 L(C)log b J First code ζ = 1.75/1.75 = 100% Second code ζ = 1.75/2.0 = 87.5% 35
36 Compact Codes A code C is called compact for a source X if its average codeword length L(C) is less than or equal to the average length of all other uniquely decodable codes for the same source and alphabet J. 36
37 Upper and Lower Bounds for a Compact Code H(X) log b J H(X) L(C) < + 1 log J b 37
38 The Shannon Algorithm Order the symbols from largest to smallest probability Choose the codeword lengths according to l = log p( x ) k J k Construct the codewords according to the cumulative probability P k P k k 1 = p( x ) 1 i= i 38
39 Example K = 10, J = 2 p(x 1 ) = p(x 2 ) = 1/4 p(x 3 ) = p(x 4 ) = 1/8 p(x 5 ) = p(x 6 ) = 1/16 p(x 7 ) = p(x 8 ) = p(x 9 ) = p(x 10 ) = 1/32 39
40 P k 40
41 Shannon Algorithm p(x 1 ) =.4 p(x 2 ) =.3 p(x 3 ) =.2 p(x 4 ) =.1 H(X) = 1.85 bits Shannon Code x 1 00 x 2 01 x x L(C) = 2.4 bits ζ = 77.1% Alternate Code x 1 0 x 2 10 x x L(C) = 1.9 bits ζ = 97.4% 41
42 Shannon s Noiseless Coding Theorem 42


43 Robert M. Fano ( ) 43
44 The Fano Algorithm Arrange the symbols in order of decreasing probability Divide the symbols into J approximately equally probable groups Each group receives one of the J code symbols as the first symbol This division process is repeated within the groups as many times as possible 44
45 Shannon Algorithm vs Fano Algorithm p(x 1 ) =.4 p(x 2 ) =.3 p(x 3 ) =.2 p(x 4 ) =.1 H(X) = 1.85 bits Shannon Code x 1 00 x 2 01 x x L(C) = 2.4 bits ζ = 77.1% Fano Code x 1 0 x 2 10 x x L(C) = 1.9 bits ζ = 97.4% 45


46 David Huffman ( ) 46
47 ``It was the most singular moment in my life. There was the absolute lightning of sudden realization. David Huffman ``Is that all there is to it! Robert Fano 47
48 The Binary Huffman Algorithm 1. Arrange the symbols in order of decreasing probability. 2. Assign a 1 to the last digit of the Kth codeword c K and a 0 to the last digit of the (K-1)th codeword c K-1. Note that this assignment is arbitrary. 3. Form a new source X with x k = x k, k = 1,, K-2, and x K-1 = x K-1 U x K p(x K-1 ) = p(x K-1 ) + p(x K ) 4. Rearrange the new set of probabilities, set K = K Repeat Steps 2 to 4 until all symbols have been combined. To obtain the codewords, trace back to the original symbols. 48
49 Five Symbol Source p(x 1 )=.35 p(x 2 )=.22 p(x 3 )=.18 p(x 4 )=.15 p(x 5 )=.10 H(X) = 2.2 bits 49
50 Midterm Test Tuesday, October 24, 2017 In class test (11:30-12:20) 20 marks total 20% of final grade One 8.5" 11 sheet of notes allowed both sides Calculator allowed but no cellphones 50
51 51
52 Huffman Code for the English Alphabet 52
53 Six Symbol Source p(x 1 )=.4 p(x 2 )=.3 p(x 3 )=.1 p(x 4 )=.1 p(x 5 )=.06 p(x 6 )=.04 H(X) = bits 53
54 Second Five Symbol Source p(x 1 )=.4 p(x 2 )=.2 p(x 3 )=.2 p(x 4 )=.1 p(x 5 )=.1 H(X) = bits 54
55 Two Huffman Codes x 1 x 1 x 2 x 2 x 3 x 3 x 4 x 4 x 5 x 5 C 1 C 2 55
56 Two Huffman Codes C 1 C 2 x x x x x
57 Second Five Symbol Source p(x 1 )=.4 p(x 2 )=.2 p(x 3 )=.2 p(x 4 )=.1 p(x 5 )=.1 H(X) = bits L(C) = 2.2 bits variance of code C 1 0.4(1-2.2) (2-2.2) (3-2.2) (4-2.2) 2 = 1.36 variance of code C 2 0.8(2-2.2) (3-2.2) 2 = 0.16 which code is preferable? 57
58 Nonbinary Codes The Huffman algorithm for nonbinary codes (J>2) follows the same procedure as for binary codes except that J symbols are combined at each stage. This requires that the number of symbols in the source X is K =J+c(J-1), K K c K J = J 1 58
59 Nonbinary Example J=3 K=6 K J c = c=2 so K =7 J 1 Add an extra symbol x 7 with p(x 7 )=0 p(x 1 )=1/3 p(x 2 )=1/6 p(x 3 )=1/6 p(x 4 )=1/9 p(x 5 )=1/9 p(x 6 )=1/9 p(x 7 )=0 H(X) = 1.54 trits 59
60 Codes for Different Output Alphabets K=13 p(x 1 )=1/4 p(x 2 )=1/4 p(x 3 )=1/16 p(x 4 )=1/16 p(x 5 )=1/16 p(x 6 )=1/16 p(x 7 )=1/16 p(x 8 )=1/16 p(x 9 )=1/16 p(x 10 )=1/64 p(x 11 )=1/64 p(x 12 )=1/64 p(x 13 )=1/64 J=2 to 13 60
61 Codes for Different Output Alphabets p(x i ) x i J x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 x 10 x 11 x 12 x 13 L(C) 61
62 Code Efficiency ζ J 62
63 The Binary and Quaternary Codes x x x x x x x x x x x x x
64 Huffman Codes Symbol probabilities must be known a priori The redundancy of the code L(C)-H(X) (for J=b) is typically nonzero Error propagation can occur Codewords have variable length 64
65 Variable to Fixed Length Codes M sourcewords M J L Lengths m 1,m 2,,m M Variable to fixed length encoder 65
66 Variable to Fixed Length Codes Two questions: 1. What is the best mapping from sourcewords to codewords? 2. How to ensure unique encodability? 66
67 Average Bit Rate ABR = = average codeword length average sourceword length L L(S) M L(S) = p( si) m i= 1 M - number of sourcewords s i - sourceword i m i - length of sourceword i i 67
68 Variable to Fixed Length Codes Design criteria: minimize the Average Bit Rate L ABR= L(S) ABR H(X) (vs. L(C) H(X) for fixed to variable length codes) L(S) should be as large as possible so that the ABR is close to H(X) 68
69 Variable to Fixed Length Codes Fixed to variable length codes H(X) ζ= 1 L(C) Variable to fixed length codes H(X) ζ= 1 ABR 69
70 Binary Tunstall Code K=3, L=3 Let x 1 = a, x 2 = b and x 3 = c Unused codeword is
71 Tunstall Codes Tunstall codes must satisfy the Kraft inequality M i= 1 m K i 1 M - number of sourcewords K - source alphabet size m i - length of sourceword i 71
72 Binary Tunstall Code Construction Source X with K symbols Choose a codeword length L where 2 L > K 1. Form a tree with a root and K branches labelled with the symbols 2. If the number of leaves is greater than 2 L - (K-1), go to Step 4 3. Find the leaf with the highest probability and extend it to have K branches, go to Step 2 4. Assign codewords to the leaves 72
73 K=3, L=3 p(a) =.7, p(b) =.2, p(c) =.1 73
74 H(X) ζ = H(X)/ABR = 84.7% 74
75 The Codewords aaa 000 aab 001 aac 010 ab 011 ac 100 b 101 c
76 What if a or aa is left at the end of the sequence of source symbols? There are no corresponding codewords. Solution: use the unused codeword 111. a 1110 aa
77 Tunstall Code for a Binary Source L = 3, K = 2, J = 2, p(x 1 ) = 0.7, p(x 2 ) = 0.3 J L = 8 Seven sourcewords Eight sourcewords Codewords x 1 x 1 x 1 x 1 x 1 x 1 x 1 x 1 x 1 x x 1 x 1 x 1 x 1 x 2 x 1 x 1 x 1 x 1 x x 1 x 1 x 1 x 2 x 1 x 1 x 1 x x 1 x 1 x 2 x 1 x 1 x x 1 x 2 x 1 x 2 x x 2 x 1 x 1 x 2 x x 2 x 2 x 2 x x 2 x
78 Huffman Code for a Binary Source N = 3, K = 2, p(x 1 ) = 0.7, p(x 2 ) = 0.3 Eight sourcewords A = x 1 x 1 x 1 p(a) = B = x 1 x 1 x 2 p(b) = C = x 1 x 2 x 1 p(c) = D = x 2 x 1 x 1 p(d) = E = x 2 x 2 x 1 p(e) = F = x 2 x 1 x 2 p(f) = G = x 1 x 2 x 2 p(g) = H = x 2 x 2 x 2 p(h) =
79 Code Comparison H(X) =.8813 Tunstall Code (7 codewords) ABR =.9762 ζ = 90.3% Tunstall Code (8 codewords) ABR =.9138 ζ = 96.4% Huffman Code L(C) =.9087 ζ = 97.0% 79
80 Error Propagation Received Huffman codeword sequence A B A B A B Sequence with one bit error D F F 80
81 Huffman Coding The length of Huffman codewords has to be an integer number of symbols, while the selfinformation of the source symbols is almost always a non-integer. Thus the theoretical minimum message compression cannot always be achieved. For a binary source with p(x 1 ) =.1 and p(x 2 ) =.9 H(X) =.469 so the optimal average codeword length is.469 bits. An x 1 symbol should be encoded to l 1 =-log 2 (0.1)=3.32 bits and an x 2 symbol to l 2 =-log 2 (0.9)=.152 bits 81
82 Improving Huffman Coding One way to overcome the redundancy limitation is to encode blocks of several symbols. In this way the per-symbol inefficiency is spread over an entire block. N = 1: ζ = 46.9% N = 2: ζ = 72.7% However, using blocks is difficult to implement as there is a block for every possible combination of symbols, so the number of blocks increases exponentially with their length. 82

 83")
83 Peter Elias ( ) 83
84 Arithmetic Coding Arithmetic coding bypasses the idea of replacing an input symbol (or groups of symbols) with a specific codeword. Instead, a stream of input symbols is encoded to a single number in [0,1). Useful when dealing with sources with small alphabets, such as binary sources, and alphabets with highly skewed probabilities. 84
85 Arithmetic Coding Applications JPEG, MPEG-1, MPEG-2 Huffman and arithmetic coding JPEG2000, MPEG-4 ZIP Arithmetic coding only prediction by partial matching (PPMd) algorithm H.263, H
86 Arithmetic Coding The output of an arithmetic encoder is a stream of bits However we can think that there is a prefix 0, and the stream represents a fractional binary number between 0 and To explain the algorithm, numbers will be shown as decimal, but they are always binary in practice 86
87 Example 1 Encode string bccb from the alphabet {a,b,c} p(a) = p(b) = p(c) = 1/3 The arithmetic coder maintains two numbers, low and high, which represent a subinterval [low,high) of the range [0,1) Initially low=0 and high=1 87
88 Example 1 The range between low and high is divided between the symbols of the source alphabet according to their probabilities p(c)=1/3 p(b)=1/3 high c b p(a)=1/3 low 0 a 88
89 Example 1 b high c b high = low 0 a low =
90 Example 1 high p(c)=1/ c c high = p(b)=1/3 b p(a)=1/3 low a low =
91 Example 1 high c high = p(c)=1/ c p(b)=1/3 b p(a)=1/3 a low low =
92 Example 1 high b high = p(c)=1/ c p(b)=1/3 b p(a)=1/3 a low low =
93 Symbol Ranges Determine the cumulative probabilities k Pk = p( xi) k= 1,, K i= 1 where P 0 =0 and P K =1 The range for symbol x i is low = P i-1 high = P i The ranges divide [0,1) 93
94 Arithmetic Coding Algorithm Set low to 0.0 Set high to 1.0 While there are still input symbols Do get next input symbol range = high low high = low + range symbol_high_range low = low + range symbol_low_range End While output number between high and low 94
95 Arithmetic Coding Example 2 p(x 1 ) = 0.5, p(x 2 ) = 0.3, p(x 3 ) = 0.2 Symbol ranges: 0 x 1 <.5.5 x 2 <.8.8 x 3 < 1 low = 0.0 high = 1.0 Symbol sequence x 1 x 2 x 3 x 2 Iteration 1 x 1 : range = = 1.0 high = = 0.5 low = = 0.0 Iteration 2 x 2 : range = = 0.5 high = = 0.40 low = = 0.25 Iteration 3 x 3 : range = = 0.15 high = = 0.40 low = =
96 Arithmetic Coding Example 2 Iteration 3 x 3 : range = = 0.15 high = = 0.40 low = = 0.37 Iteration 4 x 2 : range = =.03 high = = low = = x 1 x 2 x 3 x 2 < = = The first 5 bits of the codeword are If there are no additional symbols to be encoded the codeword is
97 Arithmetic Coding Example 3 Suppose that we want to encode the message BILL GATES Character Probability Range SPACE 1/ r < 0.10 A 1/ r < 0.20 B 1/ r < 0.30 E 1/ r < 0.40 G 1/ r < r < 0.60 I 1/10 L 2/10 S 1/10 T 1/ r < r < r <
98 ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T ( ) A B E G I L S T
99 Arithmetic Coding Example 3 New Symbol Low Value High Value B I L L SPACE G A T E S
100 Binary Codeword in binary is in binary is The transmitted binary codeword is then bits long 100
101 Decoding Algorithm get encoded number Do find symbol whose range contains the encoded number output the symbol subtract symbol_low_range from the encoded number divide by the probability of the output symbol Until no more symbols 101
102 Decoding BILL GATES Encoded Number Output Symbol Low High Probability B I L L SPACE G A T E S
103 Finite Precision Symbol Probability (fraction) Interval (8-bit precision) fraction Interval (8-bit precision) binary Range in binary a 1/3 [0,85/256) [ , ) b 1/3 [85/256,171/256) [ , ) c 1/3 [171/256,1) [ , )
104 Renormalization Symbol Probability (fraction) Range Digits that can be output Range after renormalization a 1/ b 1/ c 1/ none
105 Terminating Symbol Symbol Probability (fraction) Interval (8-bit precision) fraction Interval (8-bit precision) binary Range in binary a 1/3 [0,85/256) [ , ) b 1/3 [85/256,170/256) [ , ) c 1/3 [170/256,255/256) [ , ) term 1/256 [255/256,1) [ , )
106 Huffman vs Arithmetic Codes X = {a,b,c,d} p(a) =.5, p(b) =.25, p(c) =.125, p(d) =.125 Huffman code a 0 b 10 c 110 d
107 Huffman vs Arithmetic Codes X = {a,b,c,d} p(a) =.5, p(b) =.25, p(c) =.125, p(d) =.125 Arithmetic code ranges a [0,.5) b [.5,.75) c [.75,.875) d [.875, 1) 107
108 Huffman vs Arithmetic Codes H(X)=2.75 bits L(C)=2.75 bits ζ=100% Encode abcdc Huffman codewords Arithmetic codeword both 12 bits 108
109 Huffman vs Arithmetic Codes X = {a,b,c,d} p(a) =.7, p(b) =.12, p(c) =.10, p(d) =.08 Huffman code a 0 b 10 c 110 d
110 Huffman vs Arithmetic Codes X = {a,b,c,d} p(a) =.7, p(b) =.12, p(c) =.10, p(d) =.08 Arithmetic code ranges a [0,.7) b [.7,.82) c [.82,.92) d [.92, 1) 110
111 Huffman vs Arithmetic Codes H(X)=1.351 bits L(C)=1.48 bits ζ=91.3% Encode aaab Huffman bits Arithmetic 01 2 bits Encode abcdaaa Huffman bits Arithmetic bits 111
112 Gadsby by Ernest Vincent Wright If youth, throughout all history, had had a champion to stand up for it; to show a doubting world that a child can think; and, possibly, do it practically; you wouldn t constantly run across folks today who claim that a child don t know anything. A child s brain starts functioning at birth; and has, amongst its many infant convolutions, thousands of dormant atoms, into which God has put a mystic possibility for noticing an adult s act, and figuring out its purport. Up to about its primary school days a child thinks, naturally, only of play. But many a form of play contains disciplinary factors. You can t do this, or that puts you out, shows a child that it must think, practically or fail. Now, if, throughout childhood, a brain has no opposition, it is plain that it will attain a position of status quo, as with our ordinary animals. Man knows not why a cow, dog or lion was not born with a brain on a par with ours; why such animals cannot add, subtract, or obtain from books and schooling, that paramount position which Man holds today. 112
113 Lossless Compression Techniques 1 Model and code The source is modelled as a random process. The probabilities (or statistics) are given or acquired. 2 Dictionary-based There is no explicit model and no explicit statistics gathering. Instead, a codebook (or dictionary) is used to map sourcewords into codewords. 113
114 Model and Code Huffman code Tunstall code Fano code Shannon code Arithmetic code 114
115 Dictionary-based Techniques Lempel-Ziv LZ77 sliding window LZ78 explicit dictionary Adaptive Huffman coding Due to patents, LZ77 and LZ78 led to many variants: LZ77 Variants LZR LZSS DEFLATE LZH LZB LZ78 Variants LZW LZC LZT LZMW LZJ LZFG Zip methods use LZH and LZR among other techniques UNIX compress uses LZC (a variant of LZW) 115
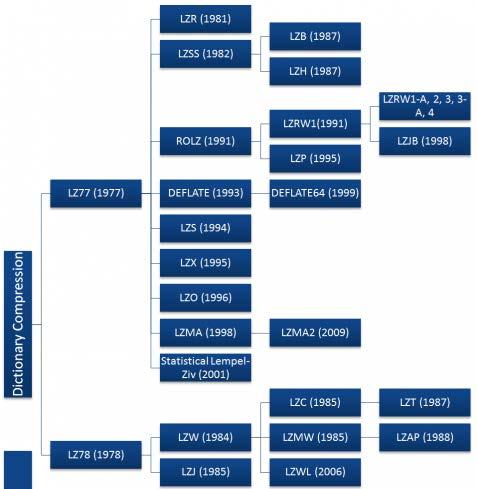
116 Dictionary-based Techniques 116
117 Lempel-Ziv Compression Source symbol sequences are replaced by codewords that are dynamically determined. The code table is encoded into the compressed data so it can be reconstructed during decoding. 117
118 Lempel-Ziv Example 118
119 119
120 120
121 Lempel-Ziv Codeword 121
122 Compression Comparison Compression as a percentage of the original file size File Type UNIX Compact Adaptive Huffman UNIX Compress Lempel-Ziv-Welch ASCII File 66% 44% Speech File 65% 64% Image File 94% 88% 122

123 Compression Comparison 123
Source Coding. Master Universitario en Ingeniería de Telecomunicación. I. Santamaría Universidad de Cantabria
 Source Coding Master Universitario en Ingeniería de Telecomunicación I. Santamaría Universidad de Cantabria Contents Introduction Asymptotic Equipartition Property Optimal Codes (Huffman Coding) Universal
Source Coding Master Universitario en Ingeniería de Telecomunicación I. Santamaría Universidad de Cantabria Contents Introduction Asymptotic Equipartition Property Optimal Codes (Huffman Coding) Universal
Source Coding Techniques
 Source Coding Techniques. Huffman Code. 2. Two-pass Huffman Code. 3. Lemple-Ziv Code. 4. Fano code. 5. Shannon Code. 6. Arithmetic Code. Source Coding Techniques. Huffman Code. 2. Two-path Huffman Code.
Source Coding Techniques. Huffman Code. 2. Two-pass Huffman Code. 3. Lemple-Ziv Code. 4. Fano code. 5. Shannon Code. 6. Arithmetic Code. Source Coding Techniques. Huffman Code. 2. Two-path Huffman Code.
Communications Theory and Engineering
 Communications Theory and Engineering Master's Degree in Electronic Engineering Sapienza University of Rome A.A. 2018-2019 AEP Asymptotic Equipartition Property AEP In information theory, the analog of
Communications Theory and Engineering Master's Degree in Electronic Engineering Sapienza University of Rome A.A. 2018-2019 AEP Asymptotic Equipartition Property AEP In information theory, the analog of
Basic Principles of Lossless Coding. Universal Lossless coding. Lempel-Ziv Coding. 2. Exploit dependences between successive symbols.
 Universal Lossless coding Lempel-Ziv Coding Basic principles of lossless compression Historical review Variable-length-to-block coding Lempel-Ziv coding 1 Basic Principles of Lossless Coding 1. Exploit
Universal Lossless coding Lempel-Ziv Coding Basic principles of lossless compression Historical review Variable-length-to-block coding Lempel-Ziv coding 1 Basic Principles of Lossless Coding 1. Exploit
Multimedia Communications. Mathematical Preliminaries for Lossless Compression
 Multimedia Communications Mathematical Preliminaries for Lossless Compression What we will see in this chapter Definition of information and entropy Modeling a data source Definition of coding and when
Multimedia Communications Mathematical Preliminaries for Lossless Compression What we will see in this chapter Definition of information and entropy Modeling a data source Definition of coding and when
Chapter 2: Source coding
 Chapter 2: meghdadi@ensil.unilim.fr University of Limoges Chapter 2: Entropy of Markov Source Chapter 2: Entropy of Markov Source Markov model for information sources Given the present, the future is independent
Chapter 2: meghdadi@ensil.unilim.fr University of Limoges Chapter 2: Entropy of Markov Source Chapter 2: Entropy of Markov Source Markov model for information sources Given the present, the future is independent
Digital Communications III (ECE 154C) Introduction to Coding and Information Theory
 Introduction to Coding and Information Theory") Digital Communications III (ECE 154C) Introduction to Coding and Information Theory Tara Javidi These lecture notes were originally developed by late Prof. J. K. Wolf. UC San Diego Spring 2014 1 / 8 I
Digital Communications III (ECE 154C) Introduction to Coding and Information Theory Tara Javidi These lecture notes were originally developed by late Prof. J. K. Wolf. UC San Diego Spring 2014 1 / 8 I
Chapter 3 Source Coding. 3.1 An Introduction to Source Coding 3.2 Optimal Source Codes 3.3 Shannon-Fano Code 3.4 Huffman Code
 Chapter 3 Source Coding 3. An Introduction to Source Coding 3.2 Optimal Source Codes 3.3 Shannon-Fano Code 3.4 Huffman Code 3. An Introduction to Source Coding Entropy (in bits per symbol) implies in average
Chapter 3 Source Coding 3. An Introduction to Source Coding 3.2 Optimal Source Codes 3.3 Shannon-Fano Code 3.4 Huffman Code 3. An Introduction to Source Coding Entropy (in bits per symbol) implies in average
UNIT I INFORMATION THEORY. I k log 2
 UNIT I INFORMATION THEORY Claude Shannon 1916-2001 Creator of Information Theory, lays the foundation for implementing logic in digital circuits as part of his Masters Thesis! (1939) and published a paper
UNIT I INFORMATION THEORY Claude Shannon 1916-2001 Creator of Information Theory, lays the foundation for implementing logic in digital circuits as part of his Masters Thesis! (1939) and published a paper
SIGNAL COMPRESSION Lecture Shannon-Fano-Elias Codes and Arithmetic Coding
 SIGNAL COMPRESSION Lecture 3 4.9.2007 Shannon-Fano-Elias Codes and Arithmetic Coding 1 Shannon-Fano-Elias Coding We discuss how to encode the symbols {a 1, a 2,..., a m }, knowing their probabilities,
SIGNAL COMPRESSION Lecture 3 4.9.2007 Shannon-Fano-Elias Codes and Arithmetic Coding 1 Shannon-Fano-Elias Coding We discuss how to encode the symbols {a 1, a 2,..., a m }, knowing their probabilities,
Shannon-Fano-Elias coding
 Shannon-Fano-Elias coding Suppose that we have a memoryless source X t taking values in the alphabet {1, 2,..., L}. Suppose that the probabilities for all symbols are strictly positive: p(i) > 0, i. The
Shannon-Fano-Elias coding Suppose that we have a memoryless source X t taking values in the alphabet {1, 2,..., L}. Suppose that the probabilities for all symbols are strictly positive: p(i) > 0, i. The
3F1 Information Theory, Lecture 3
 3F1 Information Theory, Lecture 3 Jossy Sayir Department of Engineering Michaelmas 2011, 28 November 2011 Memoryless Sources Arithmetic Coding Sources with Memory 2 / 19 Summary of last lecture Prefix-free
3F1 Information Theory, Lecture 3 Jossy Sayir Department of Engineering Michaelmas 2011, 28 November 2011 Memoryless Sources Arithmetic Coding Sources with Memory 2 / 19 Summary of last lecture Prefix-free
Motivation for Arithmetic Coding
 Motivation for Arithmetic Coding Motivations for arithmetic coding: 1) Huffman coding algorithm can generate prefix codes with a minimum average codeword length. But this length is usually strictly greater
Motivation for Arithmetic Coding Motivations for arithmetic coding: 1) Huffman coding algorithm can generate prefix codes with a minimum average codeword length. But this length is usually strictly greater
Chapter 5: Data Compression
 Chapter 5: Data Compression Definition. A source code C for a random variable X is a mapping from the range of X to the set of finite length strings of symbols from a D-ary alphabet. ˆX: source alphabet,
Chapter 5: Data Compression Definition. A source code C for a random variable X is a mapping from the range of X to the set of finite length strings of symbols from a D-ary alphabet. ˆX: source alphabet,
CMPT 365 Multimedia Systems. Lossless Compression
 CMPT 365 Multimedia Systems Lossless Compression Spring 2017 Edited from slides by Dr. Jiangchuan Liu CMPT365 Multimedia Systems 1 Outline Why compression? Entropy Variable Length Coding Shannon-Fano Coding
CMPT 365 Multimedia Systems Lossless Compression Spring 2017 Edited from slides by Dr. Jiangchuan Liu CMPT365 Multimedia Systems 1 Outline Why compression? Entropy Variable Length Coding Shannon-Fano Coding
Compression and Coding
 Compression and Coding Theory and Applications Part 1: Fundamentals Gloria Menegaz 1 Transmitter (Encoder) What is the problem? Receiver (Decoder) Transformation information unit Channel Ordering (significance)
Compression and Coding Theory and Applications Part 1: Fundamentals Gloria Menegaz 1 Transmitter (Encoder) What is the problem? Receiver (Decoder) Transformation information unit Channel Ordering (significance)
3F1 Information Theory, Lecture 3
 3F1 Information Theory, Lecture 3 Jossy Sayir Department of Engineering Michaelmas 2013, 29 November 2013 Memoryless Sources Arithmetic Coding Sources with Memory Markov Example 2 / 21 Encoding the output
3F1 Information Theory, Lecture 3 Jossy Sayir Department of Engineering Michaelmas 2013, 29 November 2013 Memoryless Sources Arithmetic Coding Sources with Memory Markov Example 2 / 21 Encoding the output
Introduction to Information Theory. By Prof. S.J. Soni Asst. Professor, CE Department, SPCE, Visnagar
 Introduction to Information Theory By Prof. S.J. Soni Asst. Professor, CE Department, SPCE, Visnagar Introduction [B.P. Lathi] Almost in all the means of communication, none produces error-free communication.
Introduction to Information Theory By Prof. S.J. Soni Asst. Professor, CE Department, SPCE, Visnagar Introduction [B.P. Lathi] Almost in all the means of communication, none produces error-free communication.
Bandwidth: Communicate large complex & highly detailed 3D models through lowbandwidth connection (e.g. VRML over the Internet)
") Compression Motivation Bandwidth: Communicate large complex & highly detailed 3D models through lowbandwidth connection (e.g. VRML over the Internet) Storage: Store large & complex 3D models (e.g. 3D scanner
Compression Motivation Bandwidth: Communicate large complex & highly detailed 3D models through lowbandwidth connection (e.g. VRML over the Internet) Storage: Store large & complex 3D models (e.g. 3D scanner
Multimedia. Multimedia Data Compression (Lossless Compression Algorithms)
") Course Code 005636 (Fall 2017) Multimedia Multimedia Data Compression (Lossless Compression Algorithms) Prof. S. M. Riazul Islam, Dept. of Computer Engineering, Sejong University, Korea E-mail: riaz@sejong.ac.kr
Course Code 005636 (Fall 2017) Multimedia Multimedia Data Compression (Lossless Compression Algorithms) Prof. S. M. Riazul Islam, Dept. of Computer Engineering, Sejong University, Korea E-mail: riaz@sejong.ac.kr
CSCI 2570 Introduction to Nanocomputing
 CSCI 2570 Introduction to Nanocomputing Information Theory John E Savage What is Information Theory Introduced by Claude Shannon. See Wikipedia Two foci: a) data compression and b) reliable communication
CSCI 2570 Introduction to Nanocomputing Information Theory John E Savage What is Information Theory Introduced by Claude Shannon. See Wikipedia Two foci: a) data compression and b) reliable communication
Data Compression. Limit of Information Compression. October, Examples of codes 1
 Data Compression Limit of Information Compression Radu Trîmbiţaş October, 202 Outline Contents Eamples of codes 2 Kraft Inequality 4 2. Kraft Inequality............................ 4 2.2 Kraft inequality
Data Compression Limit of Information Compression Radu Trîmbiţaş October, 202 Outline Contents Eamples of codes 2 Kraft Inequality 4 2. Kraft Inequality............................ 4 2.2 Kraft inequality
Image and Multidimensional Signal Processing
 Image and Multidimensional Signal Processing Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ Image Compression 2 Image Compression Goal: Reduce amount
Image and Multidimensional Signal Processing Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ Image Compression 2 Image Compression Goal: Reduce amount
Lecture 4 : Adaptive source coding algorithms
 Lecture 4 : Adaptive source coding algorithms February 2, 28 Information Theory Outline 1. Motivation ; 2. adaptive Huffman encoding ; 3. Gallager and Knuth s method ; 4. Dictionary methods : Lempel-Ziv
Lecture 4 : Adaptive source coding algorithms February 2, 28 Information Theory Outline 1. Motivation ; 2. adaptive Huffman encoding ; 3. Gallager and Knuth s method ; 4. Dictionary methods : Lempel-Ziv
Entropy as a measure of surprise
 Entropy as a measure of surprise Lecture 5: Sam Roweis September 26, 25 What does information do? It removes uncertainty. Information Conveyed = Uncertainty Removed = Surprise Yielded. How should we quantify
Entropy as a measure of surprise Lecture 5: Sam Roweis September 26, 25 What does information do? It removes uncertainty. Information Conveyed = Uncertainty Removed = Surprise Yielded. How should we quantify
Summary of Last Lectures
 Lossless Coding IV a k p k b k a 0.16 111 b 0.04 0001 c 0.04 0000 d 0.16 110 e 0.23 01 f 0.07 1001 g 0.06 1000 h 0.09 001 i 0.15 101 100 root 1 60 1 0 0 1 40 0 32 28 23 e 17 1 0 1 0 1 0 16 a 16 d 15 i
Lossless Coding IV a k p k b k a 0.16 111 b 0.04 0001 c 0.04 0000 d 0.16 110 e 0.23 01 f 0.07 1001 g 0.06 1000 h 0.09 001 i 0.15 101 100 root 1 60 1 0 0 1 40 0 32 28 23 e 17 1 0 1 0 1 0 16 a 16 d 15 i
repetition, part ii Ole-Johan Skrede INF Digital Image Processing
 repetition, part ii Ole-Johan Skrede 24.05.2017 INF2310 - Digital Image Processing Department of Informatics The Faculty of Mathematics and Natural Sciences University of Oslo today s lecture Coding and
repetition, part ii Ole-Johan Skrede 24.05.2017 INF2310 - Digital Image Processing Department of Informatics The Faculty of Mathematics and Natural Sciences University of Oslo today s lecture Coding and
1 Ex. 1 Verify that the function H(p 1,..., p n ) = k p k log 2 p k satisfies all 8 axioms on H.
 = k p k log 2 p k satisfies all 8 axioms on H.") Problem sheet Ex. Verify that the function H(p,..., p n ) = k p k log p k satisfies all 8 axioms on H. Ex. (Not to be handed in). looking at the notes). List as many of the 8 axioms as you can, (without
Problem sheet Ex. Verify that the function H(p,..., p n ) = k p k log p k satisfies all 8 axioms on H. Ex. (Not to be handed in). looking at the notes). List as many of the 8 axioms as you can, (without
10-704: Information Processing and Learning Fall Lecture 10: Oct 3
 0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 0: Oct 3 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy of
0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 0: Oct 3 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy of
Lecture 3 : Algorithms for source coding. September 30, 2016
 Lecture 3 : Algorithms for source coding September 30, 2016 Outline 1. Huffman code ; proof of optimality ; 2. Coding with intervals : Shannon-Fano-Elias code and Shannon code ; 3. Arithmetic coding. 1/39
Lecture 3 : Algorithms for source coding September 30, 2016 Outline 1. Huffman code ; proof of optimality ; 2. Coding with intervals : Shannon-Fano-Elias code and Shannon code ; 3. Arithmetic coding. 1/39
Coding for Discrete Source
 EGR 544 Communication Theory 3. Coding for Discrete Sources Z. Aliyazicioglu Electrical and Computer Engineering Department Cal Poly Pomona Coding for Discrete Source Coding Represent source data effectively
EGR 544 Communication Theory 3. Coding for Discrete Sources Z. Aliyazicioglu Electrical and Computer Engineering Department Cal Poly Pomona Coding for Discrete Source Coding Represent source data effectively
EE376A: Homework #3 Due by 11:59pm Saturday, February 10th, 2018
 Please submit the solutions on Gradescope. EE376A: Homework #3 Due by 11:59pm Saturday, February 10th, 2018 1. Optimal codeword lengths. Although the codeword lengths of an optimal variable length code
Please submit the solutions on Gradescope. EE376A: Homework #3 Due by 11:59pm Saturday, February 10th, 2018 1. Optimal codeword lengths. Although the codeword lengths of an optimal variable length code
Run-length & Entropy Coding. Redundancy Removal. Sampling. Quantization. Perform inverse operations at the receiver EEE
 General e Image Coder Structure Motion Video x(s 1,s 2,t) or x(s 1,s 2 ) Natural Image Sampling A form of data compression; usually lossless, but can be lossy Redundancy Removal Lossless compression: predictive
General e Image Coder Structure Motion Video x(s 1,s 2,t) or x(s 1,s 2 ) Natural Image Sampling A form of data compression; usually lossless, but can be lossy Redundancy Removal Lossless compression: predictive
CSEP 521 Applied Algorithms Spring Statistical Lossless Data Compression
 CSEP 52 Applied Algorithms Spring 25 Statistical Lossless Data Compression Outline for Tonight Basic Concepts in Data Compression Entropy Prefix codes Huffman Coding Arithmetic Coding Run Length Coding
CSEP 52 Applied Algorithms Spring 25 Statistical Lossless Data Compression Outline for Tonight Basic Concepts in Data Compression Entropy Prefix codes Huffman Coding Arithmetic Coding Run Length Coding
EECS 229A Spring 2007 * * (a) By stationarity and the chain rule for entropy, we have
 By stationarity and the chain rule for entropy, we have") EECS 229A Spring 2007 * * Solutions to Homework 3 1. Problem 4.11 on pg. 93 of the text. Stationary processes (a) By stationarity and the chain rule for entropy, we have H(X 0 ) + H(X n X 0 ) = H(X 0,
EECS 229A Spring 2007 * * Solutions to Homework 3 1. Problem 4.11 on pg. 93 of the text. Stationary processes (a) By stationarity and the chain rule for entropy, we have H(X 0 ) + H(X n X 0 ) = H(X 0,
Chapter 2 Date Compression: Source Coding. 2.1 An Introduction to Source Coding 2.2 Optimal Source Codes 2.3 Huffman Code
 Chapter 2 Date Compression: Source Coding 2.1 An Introduction to Source Coding 2.2 Optimal Source Codes 2.3 Huffman Code 2.1 An Introduction to Source Coding Source coding can be seen as an efficient way
Chapter 2 Date Compression: Source Coding 2.1 An Introduction to Source Coding 2.2 Optimal Source Codes 2.3 Huffman Code 2.1 An Introduction to Source Coding Source coding can be seen as an efficient way
MARKOV CHAINS A finite state Markov chain is a sequence of discrete cv s from a finite alphabet where is a pmf on and for
 MARKOV CHAINS A finite state Markov chain is a sequence S 0,S 1,... of discrete cv s from a finite alphabet S where q 0 (s) is a pmf on S 0 and for n 1, Q(s s ) = Pr(S n =s S n 1 =s ) = Pr(S n =s S n 1
MARKOV CHAINS A finite state Markov chain is a sequence S 0,S 1,... of discrete cv s from a finite alphabet S where q 0 (s) is a pmf on S 0 and for n 1, Q(s s ) = Pr(S n =s S n 1 =s ) = Pr(S n =s S n 1
Homework Set #2 Data Compression, Huffman code and AEP
 Homework Set #2 Data Compression, Huffman code and AEP 1. Huffman coding. Consider the random variable ( x1 x X = 2 x 3 x 4 x 5 x 6 x 7 0.50 0.26 0.11 0.04 0.04 0.03 0.02 (a Find a binary Huffman code
Homework Set #2 Data Compression, Huffman code and AEP 1. Huffman coding. Consider the random variable ( x1 x X = 2 x 3 x 4 x 5 x 6 x 7 0.50 0.26 0.11 0.04 0.04 0.03 0.02 (a Find a binary Huffman code
Ch 0 Introduction. 0.1 Overview of Information Theory and Coding
 Ch 0 Introduction 0.1 Overview of Information Theory and Coding Overview The information theory was founded by Shannon in 1948. This theory is for transmission (communication system) or recording (storage
Ch 0 Introduction 0.1 Overview of Information Theory and Coding Overview The information theory was founded by Shannon in 1948. This theory is for transmission (communication system) or recording (storage
2018/5/3. YU Xiangyu
 2018/5/3 YU Xiangyu yuxy@scut.edu.cn Entropy Huffman Code Entropy of Discrete Source Definition of entropy: If an information source X can generate n different messages x 1, x 2,, x i,, x n, then the
2018/5/3 YU Xiangyu yuxy@scut.edu.cn Entropy Huffman Code Entropy of Discrete Source Definition of entropy: If an information source X can generate n different messages x 1, x 2,, x i,, x n, then the
Information and Entropy
 Information and Entropy Shannon s Separation Principle Source Coding Principles Entropy Variable Length Codes Huffman Codes Joint Sources Arithmetic Codes Adaptive Codes Thomas Wiegand: Digital Image Communication
Information and Entropy Shannon s Separation Principle Source Coding Principles Entropy Variable Length Codes Huffman Codes Joint Sources Arithmetic Codes Adaptive Codes Thomas Wiegand: Digital Image Communication
ECE 587 / STA 563: Lecture 5 Lossless Compression
 ECE 587 / STA 563: Lecture 5 Lossless Compression Information Theory Duke University, Fall 2017 Author: Galen Reeves Last Modified: October 18, 2017 Outline of lecture: 5.1 Introduction to Lossless Source
ECE 587 / STA 563: Lecture 5 Lossless Compression Information Theory Duke University, Fall 2017 Author: Galen Reeves Last Modified: October 18, 2017 Outline of lecture: 5.1 Introduction to Lossless Source
CMPT 365 Multimedia Systems. Final Review - 1
 CMPT 365 Multimedia Systems Final Review - 1 Spring 2017 CMPT365 Multimedia Systems 1 Outline Entropy Lossless Compression Shannon-Fano Coding Huffman Coding LZW Coding Arithmetic Coding Lossy Compression
CMPT 365 Multimedia Systems Final Review - 1 Spring 2017 CMPT365 Multimedia Systems 1 Outline Entropy Lossless Compression Shannon-Fano Coding Huffman Coding LZW Coding Arithmetic Coding Lossy Compression
Lecture 1 : Data Compression and Entropy
 CPS290: Algorithmic Foundations of Data Science January 8, 207 Lecture : Data Compression and Entropy Lecturer: Kamesh Munagala Scribe: Kamesh Munagala In this lecture, we will study a simple model for
CPS290: Algorithmic Foundations of Data Science January 8, 207 Lecture : Data Compression and Entropy Lecturer: Kamesh Munagala Scribe: Kamesh Munagala In this lecture, we will study a simple model for
Information Theory CHAPTER. 5.1 Introduction. 5.2 Entropy
 Haykin_ch05_pp3.fm Page 207 Monday, November 26, 202 2:44 PM CHAPTER 5 Information Theory 5. Introduction As mentioned in Chapter and reiterated along the way, the purpose of a communication system is
Haykin_ch05_pp3.fm Page 207 Monday, November 26, 202 2:44 PM CHAPTER 5 Information Theory 5. Introduction As mentioned in Chapter and reiterated along the way, the purpose of a communication system is
ECE 587 / STA 563: Lecture 5 Lossless Compression
 ECE 587 / STA 563: Lecture 5 Lossless Compression Information Theory Duke University, Fall 28 Author: Galen Reeves Last Modified: September 27, 28 Outline of lecture: 5. Introduction to Lossless Source
ECE 587 / STA 563: Lecture 5 Lossless Compression Information Theory Duke University, Fall 28 Author: Galen Reeves Last Modified: September 27, 28 Outline of lecture: 5. Introduction to Lossless Source
Autumn Coping with NP-completeness (Conclusion) Introduction to Data Compression
 Introduction to Data Compression") Autumn Coping with NP-completeness (Conclusion) Introduction to Data Compression Kirkpatrick (984) Analogy from thermodynamics. The best crystals are found by annealing. First heat up the material to let
Autumn Coping with NP-completeness (Conclusion) Introduction to Data Compression Kirkpatrick (984) Analogy from thermodynamics. The best crystals are found by annealing. First heat up the material to let
Lecture 16. Error-free variable length schemes (contd.): Shannon-Fano-Elias code, Huffman code
: Shannon-Fano-Elias code, Huffman code") Lecture 16 Agenda for the lecture Error-free variable length schemes (contd.): Shannon-Fano-Elias code, Huffman code Variable-length source codes with error 16.1 Error-free coding schemes 16.1.1 The Shannon-Fano-Elias
Lecture 16 Agenda for the lecture Error-free variable length schemes (contd.): Shannon-Fano-Elias code, Huffman code Variable-length source codes with error 16.1 Error-free coding schemes 16.1.1 The Shannon-Fano-Elias
1 Introduction to information theory
 1 Introduction to information theory 1.1 Introduction In this chapter we present some of the basic concepts of information theory. The situations we have in mind involve the exchange of information through
1 Introduction to information theory 1.1 Introduction In this chapter we present some of the basic concepts of information theory. The situations we have in mind involve the exchange of information through
Chapter 9 Fundamental Limits in Information Theory
 Chapter 9 Fundamental Limits in Information Theory Information Theory is the fundamental theory behind information manipulation, including data compression and data transmission. 9.1 Introduction o For
Chapter 9 Fundamental Limits in Information Theory Information Theory is the fundamental theory behind information manipulation, including data compression and data transmission. 9.1 Introduction o For
Stream Codes. 6.1 The guessing game
 About Chapter 6 Before reading Chapter 6, you should have read the previous chapter and worked on most of the exercises in it. We ll also make use of some Bayesian modelling ideas that arrived in the vicinity
About Chapter 6 Before reading Chapter 6, you should have read the previous chapter and worked on most of the exercises in it. We ll also make use of some Bayesian modelling ideas that arrived in the vicinity
EC2252 COMMUNICATION THEORY UNIT 5 INFORMATION THEORY
 EC2252 COMMUNICATION THEORY UNIT 5 INFORMATION THEORY Discrete Messages and Information Content, Concept of Amount of Information, Average information, Entropy, Information rate, Source coding to increase
EC2252 COMMUNICATION THEORY UNIT 5 INFORMATION THEORY Discrete Messages and Information Content, Concept of Amount of Information, Average information, Entropy, Information rate, Source coding to increase
COMM901 Source Coding and Compression. Quiz 1
 German University in Cairo - GUC Faculty of Information Engineering & Technology - IET Department of Communication Engineering Winter Semester 2013/2014 Students Name: Students ID: COMM901 Source Coding
German University in Cairo - GUC Faculty of Information Engineering & Technology - IET Department of Communication Engineering Winter Semester 2013/2014 Students Name: Students ID: COMM901 Source Coding
 CS6304 / Analog and Digital Communication UNIT IV - SOURCE AND ERROR CONTROL CODING PART A 1. What is the use of error control coding? The main use of error control coding is to reduce the overall probability
CS6304 / Analog and Digital Communication UNIT IV - SOURCE AND ERROR CONTROL CODING PART A 1. What is the use of error control coding? The main use of error control coding is to reduce the overall probability
Introduction to information theory and coding
 Introduction to information theory and coding Louis WEHENKEL Set of slides No 5 State of the art in data compression Stochastic processes and models for information sources First Shannon theorem : data
Introduction to information theory and coding Louis WEHENKEL Set of slides No 5 State of the art in data compression Stochastic processes and models for information sources First Shannon theorem : data
Entropy and Ergodic Theory Lecture 3: The meaning of entropy in information theory
 Entropy and Ergodic Theory Lecture 3: The meaning of entropy in information theory 1 The intuitive meaning of entropy Modern information theory was born in Shannon s 1948 paper A Mathematical Theory of
Entropy and Ergodic Theory Lecture 3: The meaning of entropy in information theory 1 The intuitive meaning of entropy Modern information theory was born in Shannon s 1948 paper A Mathematical Theory of
Lecture 5: Asymptotic Equipartition Property
 Lecture 5: Asymptotic Equipartition Property Law of large number for product of random variables AEP and consequences Dr. Yao Xie, ECE587, Information Theory, Duke University Stock market Initial investment
Lecture 5: Asymptotic Equipartition Property Law of large number for product of random variables AEP and consequences Dr. Yao Xie, ECE587, Information Theory, Duke University Stock market Initial investment
CSEP 590 Data Compression Autumn Arithmetic Coding
 CSEP 590 Data Compression Autumn 2007 Arithmetic Coding Reals in Binary Any real number x in the interval [0,1) can be represented in binary as.b 1 b 2... where b i is a bit. x 0 0 1 0 1... binary representation
CSEP 590 Data Compression Autumn 2007 Arithmetic Coding Reals in Binary Any real number x in the interval [0,1) can be represented in binary as.b 1 b 2... where b i is a bit. x 0 0 1 0 1... binary representation
An instantaneous code (prefix code, tree code) with the codeword lengths l 1,..., l N exists if and only if. 2 l i. i=1
 with the codeword lengths l 1,..., l N exists if and only if. 2 l i. i=1") Kraft s inequality An instantaneous code (prefix code, tree code) with the codeword lengths l 1,..., l N exists if and only if N 2 l i 1 Proof: Suppose that we have a tree code. Let l max = max{l 1,...,
Kraft s inequality An instantaneous code (prefix code, tree code) with the codeword lengths l 1,..., l N exists if and only if N 2 l i 1 Proof: Suppose that we have a tree code. Let l max = max{l 1,...,
4. Quantization and Data Compression. ECE 302 Spring 2012 Purdue University, School of ECE Prof. Ilya Pollak
 4. Quantization and Data Compression ECE 32 Spring 22 Purdue University, School of ECE Prof. What is data compression? Reducing the file size without compromising the quality of the data stored in the
4. Quantization and Data Compression ECE 32 Spring 22 Purdue University, School of ECE Prof. What is data compression? Reducing the file size without compromising the quality of the data stored in the
SIGNAL COMPRESSION Lecture 7. Variable to Fix Encoding
 SIGNAL COMPRESSION Lecture 7 Variable to Fix Encoding 1. Tunstall codes 2. Petry codes 3. Generalized Tunstall codes for Markov sources (a presentation of the paper by I. Tabus, G. Korodi, J. Rissanen.
SIGNAL COMPRESSION Lecture 7 Variable to Fix Encoding 1. Tunstall codes 2. Petry codes 3. Generalized Tunstall codes for Markov sources (a presentation of the paper by I. Tabus, G. Korodi, J. Rissanen.
Entropy Coding. Connectivity coding. Entropy coding. Definitions. Lossles coder. Input: a set of symbols Output: bitstream. Idea
 Connectivity coding Entropy Coding dd 7, dd 6, dd 7, dd 5,... TG output... CRRRLSLECRRE Entropy coder output Connectivity data Edgebreaker output Digital Geometry Processing - Spring 8, Technion Digital
Connectivity coding Entropy Coding dd 7, dd 6, dd 7, dd 5,... TG output... CRRRLSLECRRE Entropy coder output Connectivity data Edgebreaker output Digital Geometry Processing - Spring 8, Technion Digital
Coding of memoryless sources 1/35
 Coding of memoryless sources 1/35 Outline 1. Morse coding ; 2. Definitions : encoding, encoding efficiency ; 3. fixed length codes, encoding integers ; 4. prefix condition ; 5. Kraft and Mac Millan theorems
Coding of memoryless sources 1/35 Outline 1. Morse coding ; 2. Definitions : encoding, encoding efficiency ; 3. fixed length codes, encoding integers ; 4. prefix condition ; 5. Kraft and Mac Millan theorems
PROBABILITY AND INFORMATION THEORY. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
U Logo Use Guidelines
 COMP2610/6261 - Information Theory Lecture 15: Arithmetic Coding U Logo Use Guidelines Mark Reid and Aditya Menon logo is a contemporary n of our heritage. presents our name, d and our motto: arn the nature
COMP2610/6261 - Information Theory Lecture 15: Arithmetic Coding U Logo Use Guidelines Mark Reid and Aditya Menon logo is a contemporary n of our heritage. presents our name, d and our motto: arn the nature
10-704: Information Processing and Learning Fall Lecture 9: Sept 28
 10-704: Information Processing and Learning Fall 2016 Lecturer: Siheng Chen Lecture 9: Sept 28 Note: These notes are based on scribed notes from Spring15 offering of this course. LaTeX template courtesy
10-704: Information Processing and Learning Fall 2016 Lecturer: Siheng Chen Lecture 9: Sept 28 Note: These notes are based on scribed notes from Spring15 offering of this course. LaTeX template courtesy
Lecture 3. Mathematical methods in communication I. REMINDER. A. Convex Set. A set R is a convex set iff, x 1,x 2 R, θ, 0 θ 1, θx 1 + θx 2 R, (1)
") 3- Mathematical methods in communication Lecture 3 Lecturer: Haim Permuter Scribe: Yuval Carmel, Dima Khaykin, Ziv Goldfeld I. REMINDER A. Convex Set A set R is a convex set iff, x,x 2 R, θ, θ, θx + θx
3- Mathematical methods in communication Lecture 3 Lecturer: Haim Permuter Scribe: Yuval Carmel, Dima Khaykin, Ziv Goldfeld I. REMINDER A. Convex Set A set R is a convex set iff, x,x 2 R, θ, θ, θx + θx
Information Theory and Coding Techniques
 Information Theory and Coding Techniques Lecture 1.2: Introduction and Course Outlines Information Theory 1 Information Theory and Coding Techniques Prof. Ja-Ling Wu Department of Computer Science and
Information Theory and Coding Techniques Lecture 1.2: Introduction and Course Outlines Information Theory 1 Information Theory and Coding Techniques Prof. Ja-Ling Wu Department of Computer Science and
lossless, optimal compressor
 6. Variable-length Lossless Compression The principal engineering goal of compression is to represent a given sequence a, a 2,..., a n produced by a source as a sequence of bits of minimal possible length.
6. Variable-length Lossless Compression The principal engineering goal of compression is to represent a given sequence a, a 2,..., a n produced by a source as a sequence of bits of minimal possible length.
Information Theory and Statistics Lecture 2: Source coding
 Information Theory and Statistics Lecture 2: Source coding Łukasz Dębowski ldebowsk@ipipan.waw.pl Ph. D. Programme 2013/2014 Injections and codes Definition (injection) Function f is called an injection
Information Theory and Statistics Lecture 2: Source coding Łukasz Dębowski ldebowsk@ipipan.waw.pl Ph. D. Programme 2013/2014 Injections and codes Definition (injection) Function f is called an injection
DCSP-3: Minimal Length Coding. Jianfeng Feng
 DCSP-3: Minimal Length Coding Jianfeng Feng Department of Computer Science Warwick Univ., UK Jianfeng.feng@warwick.ac.uk http://www.dcs.warwick.ac.uk/~feng/dcsp.html Automatic Image Caption (better than
DCSP-3: Minimal Length Coding Jianfeng Feng Department of Computer Science Warwick Univ., UK Jianfeng.feng@warwick.ac.uk http://www.dcs.warwick.ac.uk/~feng/dcsp.html Automatic Image Caption (better than
Solutions to Set #2 Data Compression, Huffman code and AEP
 Solutions to Set #2 Data Compression, Huffman code and AEP. Huffman coding. Consider the random variable ( ) x x X = 2 x 3 x 4 x 5 x 6 x 7 0.50 0.26 0. 0.04 0.04 0.03 0.02 (a) Find a binary Huffman code
Solutions to Set #2 Data Compression, Huffman code and AEP. Huffman coding. Consider the random variable ( ) x x X = 2 x 3 x 4 x 5 x 6 x 7 0.50 0.26 0. 0.04 0.04 0.03 0.02 (a) Find a binary Huffman code
Quantum-inspired Huffman Coding
 Quantum-inspired Huffman Coding A. S. Tolba, M. Z. Rashad, and M. A. El-Dosuky Dept. of Computer Science, Faculty of Computers and Information Sciences, Mansoura University, Mansoura, Egypt. tolba_954@yahoo.com,
Quantum-inspired Huffman Coding A. S. Tolba, M. Z. Rashad, and M. A. El-Dosuky Dept. of Computer Science, Faculty of Computers and Information Sciences, Mansoura University, Mansoura, Egypt. tolba_954@yahoo.com,
Optimal codes - I. A code is optimal if it has the shortest codeword length L. i i. This can be seen as an optimization problem. min.
 Huffman coding Optimal codes - I A code is optimal if it has the shortest codeword length L L m = i= pl i i This can be seen as an optimization problem min i= li subject to D m m i= lp Gabriele Monfardini
Huffman coding Optimal codes - I A code is optimal if it has the shortest codeword length L L m = i= pl i i This can be seen as an optimization problem min i= li subject to D m m i= lp Gabriele Monfardini
Information Theory. David Rosenberg. June 15, New York University. David Rosenberg (New York University) DS-GA 1003 June 15, / 18
 DS-GA 1003 June 15, / 18") Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Chapter 2 Source Models and Entropy. Any information-generating process can be viewed as. computer program in executed form: binary 0
 Part II Information Theory Concepts Chapter 2 Source Models and Entropy Any information-generating process can be viewed as a source: { emitting a sequence of symbols { symbols from a nite alphabet text:
Part II Information Theory Concepts Chapter 2 Source Models and Entropy Any information-generating process can be viewed as a source: { emitting a sequence of symbols { symbols from a nite alphabet text:
Information Theory with Applications, Math6397 Lecture Notes from September 30, 2014 taken by Ilknur Telkes
 Information Theory with Applications, Math6397 Lecture Notes from September 3, 24 taken by Ilknur Telkes Last Time Kraft inequality (sep.or) prefix code Shannon Fano code Bound for average code-word length
Information Theory with Applications, Math6397 Lecture Notes from September 3, 24 taken by Ilknur Telkes Last Time Kraft inequality (sep.or) prefix code Shannon Fano code Bound for average code-word length
Data Compression Techniques
 Data Compression Techniques Part 1: Entropy Coding Lecture 4: Asymmetric Numeral Systems Juha Kärkkäinen 08.11.2017 1 / 19 Asymmetric Numeral Systems Asymmetric numeral systems (ANS) is a recent entropy
Data Compression Techniques Part 1: Entropy Coding Lecture 4: Asymmetric Numeral Systems Juha Kärkkäinen 08.11.2017 1 / 19 Asymmetric Numeral Systems Asymmetric numeral systems (ANS) is a recent entropy
MAHALAKSHMI ENGINEERING COLLEGE-TRICHY QUESTION BANK UNIT V PART-A. 1. What is binary symmetric channel (AUC DEC 2006)
") MAHALAKSHMI ENGINEERING COLLEGE-TRICHY QUESTION BANK SATELLITE COMMUNICATION DEPT./SEM.:ECE/VIII UNIT V PART-A 1. What is binary symmetric channel (AUC DEC 2006) 2. Define information rate? (AUC DEC 2007)
MAHALAKSHMI ENGINEERING COLLEGE-TRICHY QUESTION BANK SATELLITE COMMUNICATION DEPT./SEM.:ECE/VIII UNIT V PART-A 1. What is binary symmetric channel (AUC DEC 2006) 2. Define information rate? (AUC DEC 2007)
Multimedia Information Systems
 Multimedia Information Systems Samson Cheung EE 639, Fall 2004 Lecture 3 & 4: Color, Video, and Fundamentals of Data Compression 1 Color Science Light is an electromagnetic wave. Its color is characterized
Multimedia Information Systems Samson Cheung EE 639, Fall 2004 Lecture 3 & 4: Color, Video, and Fundamentals of Data Compression 1 Color Science Light is an electromagnetic wave. Its color is characterized
1. Basics of Information
 1. Basics of Information 6.004x Computation Structures Part 1 Digital Circuits Copyright 2015 MIT EECS 6.004 Computation Structures L1: Basics of Information, Slide #1 What is Information? Information,
1. Basics of Information 6.004x Computation Structures Part 1 Digital Circuits Copyright 2015 MIT EECS 6.004 Computation Structures L1: Basics of Information, Slide #1 What is Information? Information,
4F5: Advanced Communications and Coding Handout 2: The Typical Set, Compression, Mutual Information
 4F5: Advanced Communications and Coding Handout 2: The Typical Set, Compression, Mutual Information Ramji Venkataramanan Signal Processing and Communications Lab Department of Engineering ramji.v@eng.cam.ac.uk
4F5: Advanced Communications and Coding Handout 2: The Typical Set, Compression, Mutual Information Ramji Venkataramanan Signal Processing and Communications Lab Department of Engineering ramji.v@eng.cam.ac.uk
Introduction p. 1 Compression Techniques p. 3 Lossless Compression p. 4 Lossy Compression p. 5 Measures of Performance p. 5 Modeling and Coding p.
 Preface p. xvii Introduction p. 1 Compression Techniques p. 3 Lossless Compression p. 4 Lossy Compression p. 5 Measures of Performance p. 5 Modeling and Coding p. 6 Summary p. 10 Projects and Problems
Preface p. xvii Introduction p. 1 Compression Techniques p. 3 Lossless Compression p. 4 Lossy Compression p. 5 Measures of Performance p. 5 Modeling and Coding p. 6 Summary p. 10 Projects and Problems
Reduce the amount of data required to represent a given quantity of information Data vs information R = 1 1 C
 Image Compression Background Reduce the amount of data to represent a digital image Storage and transmission Consider the live streaming of a movie at standard definition video A color frame is 720 480
Image Compression Background Reduce the amount of data to represent a digital image Storage and transmission Consider the live streaming of a movie at standard definition video A color frame is 720 480
Information Theory, Statistics, and Decision Trees
 Information Theory, Statistics, and Decision Trees Léon Bottou COS 424 4/6/2010 Summary 1. Basic information theory. 2. Decision trees. 3. Information theory and statistics. Léon Bottou 2/31 COS 424 4/6/2010
Information Theory, Statistics, and Decision Trees Léon Bottou COS 424 4/6/2010 Summary 1. Basic information theory. 2. Decision trees. 3. Information theory and statistics. Léon Bottou 2/31 COS 424 4/6/2010
PART III. Outline. Codes and Cryptography. Sources. Optimal Codes (I) Jorge L. Villar. MAMME, Fall 2015
 Jorge L. Villar. MAMME, Fall 2015") Outline Codes and Cryptography 1 Information Sources and Optimal Codes 2 Building Optimal Codes: Huffman Codes MAMME, Fall 2015 3 Shannon Entropy and Mutual Information PART III Sources Information source:
Outline Codes and Cryptography 1 Information Sources and Optimal Codes 2 Building Optimal Codes: Huffman Codes MAMME, Fall 2015 3 Shannon Entropy and Mutual Information PART III Sources Information source:
Intro to Information Theory
 Intro to Information Theory Math Circle February 11, 2018 1. Random variables Let us review discrete random variables and some notation. A random variable X takes value a A with probability P (a) 0. Here
Intro to Information Theory Math Circle February 11, 2018 1. Random variables Let us review discrete random variables and some notation. A random variable X takes value a A with probability P (a) 0. Here
Lecture 10 : Basic Compression Algorithms
 Lecture 10 : Basic Compression Algorithms Modeling and Compression We are interested in modeling multimedia data. To model means to replace something complex with a simpler (= shorter) analog. Some models
Lecture 10 : Basic Compression Algorithms Modeling and Compression We are interested in modeling multimedia data. To model means to replace something complex with a simpler (= shorter) analog. Some models
Lecture 6: Kraft-McMillan Inequality and Huffman Coding
 EE376A/STATS376A Information Theory Lecture 6-0/25/208 Lecture 6: Kraft-McMillan Inequality and Huffman Coding Lecturer: Tsachy Weissman Scribe: Akhil Prakash, Kai Yee Wan In this lecture, we begin with
EE376A/STATS376A Information Theory Lecture 6-0/25/208 Lecture 6: Kraft-McMillan Inequality and Huffman Coding Lecturer: Tsachy Weissman Scribe: Akhil Prakash, Kai Yee Wan In this lecture, we begin with
EE5585 Data Compression January 29, Lecture 3. x X x X. 2 l(x) 1 (1)
 1 (1)") EE5585 Data Compression January 29, 2013 Lecture 3 Instructor: Arya Mazumdar Scribe: Katie Moenkhaus Uniquely Decodable Codes Recall that for a uniquely decodable code with source set X, if l(x) is the
EE5585 Data Compression January 29, 2013 Lecture 3 Instructor: Arya Mazumdar Scribe: Katie Moenkhaus Uniquely Decodable Codes Recall that for a uniquely decodable code with source set X, if l(x) is the
MAHALAKSHMI ENGINEERING COLLEGE QUESTION BANK. SUBJECT CODE / Name: EC2252 COMMUNICATION THEORY UNIT-V INFORMATION THEORY PART-A
 MAHALAKSHMI ENGINEERING COLLEGE QUESTION BANK DEPARTMENT: ECE SEMESTER: IV SUBJECT CODE / Name: EC2252 COMMUNICATION THEORY UNIT-V INFORMATION THEORY PART-A 1. What is binary symmetric channel (AUC DEC
MAHALAKSHMI ENGINEERING COLLEGE QUESTION BANK DEPARTMENT: ECE SEMESTER: IV SUBJECT CODE / Name: EC2252 COMMUNICATION THEORY UNIT-V INFORMATION THEORY PART-A 1. What is binary symmetric channel (AUC DEC
Source Coding: Part I of Fundamentals of Source and Video Coding
 Foundations and Trends R in sample Vol. 1, No 1 (2011) 1 217 c 2011 Thomas Wiegand and Heiko Schwarz DOI: xxxxxx Source Coding: Part I of Fundamentals of Source and Video Coding Thomas Wiegand 1 and Heiko
Foundations and Trends R in sample Vol. 1, No 1 (2011) 1 217 c 2011 Thomas Wiegand and Heiko Schwarz DOI: xxxxxx Source Coding: Part I of Fundamentals of Source and Video Coding Thomas Wiegand 1 and Heiko
CSEP 590 Data Compression Autumn Dictionary Coding LZW, LZ77
 CSEP 590 Data Compression Autumn 2007 Dictionary Coding LZW, LZ77 Dictionary Coding Does not use statistical knowledge of data. Encoder: As the input is processed develop a dictionary and transmit the
CSEP 590 Data Compression Autumn 2007 Dictionary Coding LZW, LZ77 Dictionary Coding Does not use statistical knowledge of data. Encoder: As the input is processed develop a dictionary and transmit the
(Classical) Information Theory III: Noisy channel coding
 Information Theory III: Noisy channel coding") (Classical) Information Theory III: Noisy channel coding Sibasish Ghosh The Institute of Mathematical Sciences CIT Campus, Taramani, Chennai 600 113, India. p. 1 Abstract What is the best possible way
(Classical) Information Theory III: Noisy channel coding Sibasish Ghosh The Institute of Mathematical Sciences CIT Campus, Taramani, Chennai 600 113, India. p. 1 Abstract What is the best possible way
Introduction to information theory and coding
 Introduction to information theory and coding Louis WEHENKEL Set of slides No 4 Source modeling and source coding Stochastic processes and models for information sources First Shannon theorem : data compression
Introduction to information theory and coding Louis WEHENKEL Set of slides No 4 Source modeling and source coding Stochastic processes and models for information sources First Shannon theorem : data compression
Lecture 4 Noisy Channel Coding
 Lecture 4 Noisy Channel Coding I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw October 9, 2015 1 / 56 I-Hsiang Wang IT Lecture 4 The Channel Coding Problem
Lecture 4 Noisy Channel Coding I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw October 9, 2015 1 / 56 I-Hsiang Wang IT Lecture 4 The Channel Coding Problem
Basics of DCT, Quantization and Entropy Coding
 Basics of DCT, Quantization and Entropy Coding Nimrod Peleg Update: April. 7 Discrete Cosine Transform (DCT) First used in 97 (Ahmed, Natarajan and Rao). Very close to the Karunen-Loeve * (KLT) transform
Basics of DCT, Quantization and Entropy Coding Nimrod Peleg Update: April. 7 Discrete Cosine Transform (DCT) First used in 97 (Ahmed, Natarajan and Rao). Very close to the Karunen-Loeve * (KLT) transform
An introduction to basic information theory. Hampus Wessman
 An introduction to basic information theory Hampus Wessman Abstract We give a short and simple introduction to basic information theory, by stripping away all the non-essentials. Theoretical bounds on
An introduction to basic information theory Hampus Wessman Abstract We give a short and simple introduction to basic information theory, by stripping away all the non-essentials. Theoretical bounds on
ELEMENTS O F INFORMATION THEORY
 ELEMENTS O F INFORMATION THEORY THOMAS M. COVER JOY A. THOMAS Preface to the Second Edition Preface to the First Edition Acknowledgments for the Second Edition Acknowledgments for the First Edition x
ELEMENTS O F INFORMATION THEORY THOMAS M. COVER JOY A. THOMAS Preface to the Second Edition Preface to the First Edition Acknowledgments for the Second Edition Acknowledgments for the First Edition x
17.1 Binary Codes Normal numbers we use are in base 10, which are called decimal numbers. Each digit can be 10 possible numbers: 0, 1, 2, 9.
 ( c ) E p s t e i n, C a r t e r, B o l l i n g e r, A u r i s p a C h a p t e r 17: I n f o r m a t i o n S c i e n c e P a g e 1 CHAPTER 17: Information Science 17.1 Binary Codes Normal numbers we use
( c ) E p s t e i n, C a r t e r, B o l l i n g e r, A u r i s p a C h a p t e r 17: I n f o r m a t i o n S c i e n c e P a g e 1 CHAPTER 17: Information Science 17.1 Binary Codes Normal numbers we use