Predictive Modeling Using Logistic Regression Step-by-Step Instructions
|
|
|
- Zoe Aubrie Wiggins
- 6 years ago
- Views:
Transcription
1 Predictive Modeling Using Logistic Regression Step-by-Step Instructions This document is accompanied by the following Excel Template IntegrityM Predictive Modeling Using Logistic Regression in Excel Template.xlsx Two datasets are used to run predictive modeling based on prior information: Step 1: Training dataset - This dataset includes both historical and current data with distinction of the outcomes coded 1 for Yes and 0 for No. Steps 1 to 7 use the dataset to assess the relative importance of indicators/variables to the outcome (Weights) and to determine the strength of their association with the outcome (P-values). Scoring dataset - new data on individuals/entities/ids used to compute the probability of outcome. Input your analytical file; in our example, we downloaded data from the Office of Inspector General List of Excluded Individuals and Entities (LEIE) and from the Centers for Medicare and Medicaid Services (CMS) Public Use File (PUF). Columns A to G of the spreadsheet Predictive Model display the data. The analytical file includes columns A to G. Column A displays the provider identifier and columns B to G show summary information on the variables per provider inputted to the analysis, including the response variable informing if the provider was excluded or not (coded 1 or 0 respectively). The working dataset consists of information stored in cells B2 to G92. Steps 2 and 3: Copy values from column H (RANDBETWEEN Values) to column I (P (E)) this is necessary because of the volatile nature of the formula in column H, which will values changed every time the spreadsheet is refreshed. The rest of the columns in Step 3 will be computed automatically by the formulas embedded in them (Column J (Odds Ratio), Colum K (If Odds Ratio < 0.1 set it to 0.1) and Column L (Log (Odds Ratio)) The Excel function RANDBETWEEN assigns random probability numbers to the providers according to their original classification ( 1 or 0 ) - drawing from the range 0.50 to 0.99 for providers coded 1 (excluded) and from the range 0.01 to 0.49 for providers coded 0 (active in the health care program) Note that the RANDBETWEEN function requires as input values integers (numbers) that define the bottom and the top values from which a random number will be drawn. The values will be stored in column H, RANDBETWEEN Values. The assigned values need to be transformed to probability numbers by dividing the function output number by 100 according to the provider exclusion status and the following Excel operation: for excluded providers, =RANDBERWEEN(50, 99)/100; for non-excluded (active) providers, =RANDBERWEEN(1, 49)/100;
2 Step 4: Step 4.1: o Run the Linear Regression Model by using the Data Analysis tool of Excel as shown in the screenshot below to obtain the Initial weights (coefficients) of the variables/indicators (in our example, 5 variables). The regression input Y Range (response variable) is the Log(Odds), column L; and the five indicators in Input X Range are all values in PMT per Bene, Services per Bene, Average Age of Beneficiaries, Beneficiary cc diab percent and Average HCC Risk Score of Beneficiary columns C to G. The Regression Model results will generate a new tab labeled in our example Step 4 - Reg Initial Values. Step 4.2: o Copy the coefficients (weights) in column B from the regression model output to the Coefficients Table (in our example, the table includes cells T3 to T8 in column T of the spreadsheet Predictive Model ).
 multiplied by the corresponding indicators (columns C to G in our example).")
3 Step 5: Update the formula in Column N (variable labeled L) if you have more or less than the 5 variables that we have in our example. This formula includes the initial values of the weights from the Coefficients Table (Column T in our example) multiplied by the corresponding indicators (columns C to G in our example). Changes in the set of summation terms in the cases of 4 or 6 variables would be 4 variables, formula =T$3 + T$4*C4 + T$5*D4 + T$6*E4 + T$7*F4 + T$8*G4 6 variables, formula = T$3 + T$4*C4 + T$5*D4 + T$6*E4 + T$7*F4 + T$8*G4+T$9*H4
 = el/(1 + el)) and column Q (Y*ln[P(X)] + (1 Y)*ln[1 P(X)]) will be updated automatically (where Y = 1 for excluded providers and Y = 0 for active providers) by the")
4 Note: the mathematical constant e (= in cell T10 in our example) is required to compute the results in column O (labeled el = "e to power L"). The values of column P (P(X) = el/(1 + el)) and column Q (Y*ln[P(X)] + (1 Y)*ln[1 P(X)]) will be updated automatically (where Y = 1 for excluded providers and Y = 0 for active providers) by the embedded formulas. Step 6: Step 6.1: o Update the summation of the Log (Maximum Likelihood) if you have more rows than our example: If you have 100 rows in your data rather than the 90 rows of our example, change the formula from =SUM(Q3:Q92) to =SUM(Q3:Q102) Step 6.2: o Run the Excel Solver tool to obtain the set of final weights that define the relative importance of the indicators/variables to the outcome. The Excel Solver will work on the set of initial weights (previously generated by the logistic regression) to update the Coefficients Table with a set of final weights that maximizes the likelihood of obtaining the data (outcome variable and indicators) actually observed. The Excel Solver will generate an output tab that is labeled Step 6 - Solver Final Values in our example.
5 Note: the signs of the regression coefficients indicate whether additional units of the associated variables increase (positive sign) or decrease (negative sign) the probability that the analyzed provider will reach the target outcome (joining the OIG Exclusion List in this example). For example, the average payment per beneficiary (positively associated with the probability of exclusion) for excluded providers $ as opposed to $ for non-excluded (active) providers; on the other hand, the average risk score per beneficiary (negatively associated with the probability of exclusion) is for excluded providers in contrast with for non-excluded providers. Step 7: Steps 7.1 to 7.7 determine the strength of the association (p-values) of each Indicator/variable (explanatory variable) with the outcome variable (the probability of being excluded from the Medicare program in our example) by estimating the covariance matrix of the model. Step 7.1: o Construct an Excel table having a row per provider and a column per variable without including the provider identifier; add to the table a column of 1s (intercept). In our example the table includes columns A to F of the spreadsheet Step 7 - Covariance Matrix (intercept plus five variables - PMT per Bene, Services per Bene, Average Age of Beneficiaries, Beneficiary cc diab percent and Average HCC Risk Score of Beneficiary ). Step 7.2:
)) and column I (labeled P(X)*(1 - P(X))) will be updated automatically by the embedded formulas. Note: From steps 7.3 to 7.")
6 o Copy values from column P (labeled P(X) = el/ (1 + el)) from tab Predictive Model to column G (labeled P(X) = el/ (1 + el)) in tab Step 7 - Covariance Matrix. Values in column H (labeled (1 - P(X))) and column I (labeled P(X)*(1 - P(X))) will be updated automatically by the embedded formulas. Note: From steps 7.3 to 7.6, remember to highlight the destination cells (range of cells) BEFORE completing the formula with Shift-Control-Enter Note: The destination of the transpose operation needs to be highlighted (cells B97 to CM102 in our example) before the re-scaled table (cells K4 to P93) is transposed. Operations with matrices (tables) in Excel are explained in Notes on Matrix Operations in Excel by Ronald Larsen, Step 7.3: o Multiply every row of the table created in step 7.1 (cells A4 to G93 in our example) by the values in column I (P(X)*(1 - P(X))), to generate a re-scaled table stored in cells K4 to P93. This multiplication is accomplished in row 4 by the Excel function =I4*(A4:F4), which is copied and pasted to all rows from 5 to 93. Note: Remember to highlight the destination cells (range of cells) BEFORE completing the formula with Shift-Control-Enter Step 7.4: o Transpose the re-scaled table stored in cells K4 to P93 using the Excel matrix function TRANSPOSE(re-scaled table) to generate the transposed table stored in cells B97 to CM102 in our example. Note: Remember to highlight the destination cells (range of cells) BEFORE completing the formula with Shift-Control-Enter
 table stored in cells A4 to F93 using the Excel")
7 Step 7.5: o Multiply the transpose of the re-scaled table, computed in the previous step and stored in cells B97 to CM102, by the original (not re-scaled) table stored in cells A4 to F93 using the Excel matrix function MMULT(transpose of the re-scaled table, original table) to create a product table stored in cells B106 to G111. Note: Remember to highlight the destination cells (range of cells) BEFORE completing the formula with Shift-Control-Enter. Step 7.6: Compute the inverse of the table created in the step 7.5 using the Excel matrix function MINVERSE(product table) to create the covariance matrix, which is stored in cells B116 to G121. The highlighted main diagonal values as shown below are the variances of the variables to be used in Step 7.7. Note: Remember to highlight the destination cells (range of cells) BEFORE completing the formula with Shift-Control-Enter
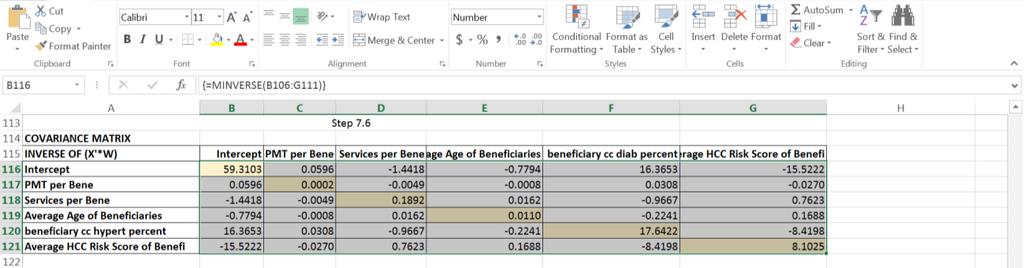
8

9 Step 7.7: Copy the coefficients (weights) computed by the Excel Solver from the cells T3 to T8 (in our example) from tab Predictive Model to the cells B126 to B131 of tab Step 7 - Covariance Matrix. The final weights are also found in the Excel Solver output tab. Copy the variances of the variables from the main diagonal of the covariance matrix cells B116, C117, D118, E119, F120 and G121 - to cells C126 to C131 in column C of tab Step 7 - Covariance Matrix. Note: the next steps will calculate new values automatically using the weights and variances inputted in the previous steps. The standard deviations are computed using the Excel function SQRT(variance) applied to values in cells C126 to C131 and store the results in cells D126 to D131 in our example. The Wald Chi-square statistic for each variable is computed as the squared value of the ratio (coefficient/standard deviation) and stored it in cells E126 to 131 under the label Wald in our example. The strength of the association p-value is computed using the Excel function CHISQ.DIST.RT(Wald,1), where the second input to the function - the number 1 - is the number of degrees of freedom in this case. The p-values are stored in cells F126 to F131. Note: The P-value of each variable assesses the strength of the association between the variable and the outcome. The lower the p-value the stronger the association between variables. The standard rule is to consider p-values <= 5% (0.05) as indicative of statistically significant association. In our example, all variables were found to be strongly associated with the outcome. The screenshot below reproduces the results of the predictive model analysis using the same data but implemented with the statistical package SAS, which generates exactly the same results as the ones obtained using Excel. Step 8:
10 Steps 8 to 10 use a new dataset of active (unclassified as excluded) providers to score their probability of joining the OIG Exclusion List Step 8.1: o Input your Scoring dataset - our example used a sample of 100 non-excluded providers. The dataset included the 5 indicators and used the final weights to score their probability of being excluded. The final weights are inputted in columns K to P in our example. Step 8.2: o The formulas embedded in columns G to I will generate values based on the data inputted. Note: the value of the mathematical constant e (= , copied to the cell N3) is used to compute values in column G (labeled L). The probabilities of exclusion P(X) of provider in row 2 are generated by using the formula =H2/(1 + H2), where the values of H2 are computed in the previous operation.
ECLT 5810 Linear Regression and Logistic Regression for Classification. Prof. Wai Lam
 ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
Additional Notes: Investigating a Random Slope. When we have fixed level-1 predictors at level 2 we show them like this:
 Ron Heck, Summer 01 Seminars 1 Multilevel Regression Models and Their Applications Seminar Additional Notes: Investigating a Random Slope We can begin with Model 3 and add a Random slope parameter. If
Ron Heck, Summer 01 Seminars 1 Multilevel Regression Models and Their Applications Seminar Additional Notes: Investigating a Random Slope We can begin with Model 3 and add a Random slope parameter. If
ECLT 5810 Linear Regression and Logistic Regression for Classification. Prof. Wai Lam
 ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
Investigating Models with Two or Three Categories
 Ronald H. Heck and Lynn N. Tabata 1 Investigating Models with Two or Three Categories For the past few weeks we have been working with discriminant analysis. Let s now see what the same sort of model might
Ronald H. Heck and Lynn N. Tabata 1 Investigating Models with Two or Three Categories For the past few weeks we have been working with discriminant analysis. Let s now see what the same sort of model might
Logistic Regression Models to Integrate Actuarial and Psychological Risk Factors For predicting 5- and 10-Year Sexual and Violent Recidivism Rates
 Logistic Regression Models to Integrate Actuarial and Psychological Risk Factors For predicting 5- and 10-Year Sexual and Violent Recidivism Rates WI-ATSA June 2-3, 2016 Overview Brief description of logistic
Logistic Regression Models to Integrate Actuarial and Psychological Risk Factors For predicting 5- and 10-Year Sexual and Violent Recidivism Rates WI-ATSA June 2-3, 2016 Overview Brief description of logistic
Advanced Quantitative Data Analysis
 Chapter 24 Advanced Quantitative Data Analysis Daniel Muijs Doing Regression Analysis in SPSS When we want to do regression analysis in SPSS, we have to go through the following steps: 1 As usual, we choose
Chapter 24 Advanced Quantitative Data Analysis Daniel Muijs Doing Regression Analysis in SPSS When we want to do regression analysis in SPSS, we have to go through the following steps: 1 As usual, we choose
Basic Medical Statistics Course
 Basic Medical Statistics Course S7 Logistic Regression November 2015 Wilma Heemsbergen w.heemsbergen@nki.nl Logistic Regression The concept of a relationship between the distribution of a dependent variable
Basic Medical Statistics Course S7 Logistic Regression November 2015 Wilma Heemsbergen w.heemsbergen@nki.nl Logistic Regression The concept of a relationship between the distribution of a dependent variable
PASS Sample Size Software. Poisson Regression
 Chapter 870 Introduction Poisson regression is used when the dependent variable is a count. Following the results of Signorini (99), this procedure calculates power and sample size for testing the hypothesis
Chapter 870 Introduction Poisson regression is used when the dependent variable is a count. Following the results of Signorini (99), this procedure calculates power and sample size for testing the hypothesis
UNIVERSITY OF TORONTO Faculty of Arts and Science
 UNIVERSITY OF TORONTO Faculty of Arts and Science December 2013 Final Examination STA442H1F/2101HF Methods of Applied Statistics Jerry Brunner Duration - 3 hours Aids: Calculator Model(s): Any calculator
UNIVERSITY OF TORONTO Faculty of Arts and Science December 2013 Final Examination STA442H1F/2101HF Methods of Applied Statistics Jerry Brunner Duration - 3 hours Aids: Calculator Model(s): Any calculator
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Confidence Intervals for the Odds Ratio in Logistic Regression with One Binary X
 Chapter 864 Confidence Intervals for the Odds Ratio in Logistic Regression with One Binary X Introduction Logistic regression expresses the relationship between a binary response variable and one or more
Chapter 864 Confidence Intervals for the Odds Ratio in Logistic Regression with One Binary X Introduction Logistic regression expresses the relationship between a binary response variable and one or more
MATH 118 FINAL EXAM STUDY GUIDE
 MATH 118 FINAL EXAM STUDY GUIDE Recommendations: 1. Take the Final Practice Exam and take note of questions 2. Use this study guide as you take the tests and cross off what you know well 3. Take the Practice
MATH 118 FINAL EXAM STUDY GUIDE Recommendations: 1. Take the Final Practice Exam and take note of questions 2. Use this study guide as you take the tests and cross off what you know well 3. Take the Practice
Logistic Regression. Interpretation of linear regression. Other types of outcomes. 0-1 response variable: Wound infection. Usual linear regression
 Logistic Regression Usual linear regression (repetition) y i = b 0 + b 1 x 1i + b 2 x 2i + e i, e i N(0,σ 2 ) or: y i N(b 0 + b 1 x 1i + b 2 x 2i,σ 2 ) Example (DGA, p. 336): E(PEmax) = 47.355 + 1.024
Logistic Regression Usual linear regression (repetition) y i = b 0 + b 1 x 1i + b 2 x 2i + e i, e i N(0,σ 2 ) or: y i N(b 0 + b 1 x 1i + b 2 x 2i,σ 2 ) Example (DGA, p. 336): E(PEmax) = 47.355 + 1.024
Statistical Techniques II
 Statistical Techniques II EST705 Regression with atrix Algebra 06a_atrix SLR atrix Algebra We will not be doing our regressions with matrix algebra, except that the computer does employ matrices. In fact,
Statistical Techniques II EST705 Regression with atrix Algebra 06a_atrix SLR atrix Algebra We will not be doing our regressions with matrix algebra, except that the computer does employ matrices. In fact,
Model Based Statistics in Biology. Part V. The Generalized Linear Model. Chapter 18.1 Logistic Regression (Dose - Response)
") Model Based Statistics in Biology. Part V. The Generalized Linear Model. Logistic Regression ( - Response) ReCap. Part I (Chapters 1,2,3,4), Part II (Ch 5, 6, 7) ReCap Part III (Ch 9, 10, 11), Part IV
Model Based Statistics in Biology. Part V. The Generalized Linear Model. Logistic Regression ( - Response) ReCap. Part I (Chapters 1,2,3,4), Part II (Ch 5, 6, 7) ReCap Part III (Ch 9, 10, 11), Part IV
6.867 Machine Learning
 6.867 Machine Learning Problem Set 2 Due date: Wednesday October 6 Please address all questions and comments about this problem set to 6867-staff@csail.mit.edu. You will need to use MATLAB for some of
6.867 Machine Learning Problem Set 2 Due date: Wednesday October 6 Please address all questions and comments about this problem set to 6867-staff@csail.mit.edu. You will need to use MATLAB for some of
1 Introduction to Minitab
 1 Introduction to Minitab Minitab is a statistical analysis software package. The software is freely available to all students and is downloadable through the Technology Tab at my.calpoly.edu. When you
1 Introduction to Minitab Minitab is a statistical analysis software package. The software is freely available to all students and is downloadable through the Technology Tab at my.calpoly.edu. When you
Simple logistic regression
 Simple logistic regression Biometry 755 Spring 2009 Simple logistic regression p. 1/47 Model assumptions 1. The observed data are independent realizations of a binary response variable Y that follows a
Simple logistic regression Biometry 755 Spring 2009 Simple logistic regression p. 1/47 Model assumptions 1. The observed data are independent realizations of a binary response variable Y that follows a
Didacticiel - Études de cas
 1 Theme Comparing the results of the Partial Least Squares Regression from various data mining tools (free: Tanagra, R; commercial: SIMCA-P, SPAD, and SAS). Comparing the behavior of tools is always a
1 Theme Comparing the results of the Partial Least Squares Regression from various data mining tools (free: Tanagra, R; commercial: SIMCA-P, SPAD, and SAS). Comparing the behavior of tools is always a
Homework Solutions Applied Logistic Regression
 Homework Solutions Applied Logistic Regression WEEK 6 Exercise 1 From the ICU data, use as the outcome variable vital status (STA) and CPR prior to ICU admission (CPR) as a covariate. (a) Demonstrate that
Homework Solutions Applied Logistic Regression WEEK 6 Exercise 1 From the ICU data, use as the outcome variable vital status (STA) and CPR prior to ICU admission (CPR) as a covariate. (a) Demonstrate that
Richter Scale and Logarithms
 activity 7.1 Richter Scale and Logarithms In this activity, you will investigate earthquake data and explore the Richter scale as a measure of the intensity of an earthquake. You will consider how numbers
activity 7.1 Richter Scale and Logarithms In this activity, you will investigate earthquake data and explore the Richter scale as a measure of the intensity of an earthquake. You will consider how numbers
Fall 07 ISQS 6348 Midterm Solutions
 Fall 07 ISQS 648 Midterm Solutions Instructions: Open notes, no books. Points out of 00 in parentheses. 1. A random vector X = 4 X 1 X X has the following mean vector and covariance matrix: E(X) = 4 1
Fall 07 ISQS 648 Midterm Solutions Instructions: Open notes, no books. Points out of 00 in parentheses. 1. A random vector X = 4 X 1 X X has the following mean vector and covariance matrix: E(X) = 4 1
Machine Learning, Fall 2009: Midterm
 10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
SPSS LAB FILE 1
 SPSS LAB FILE www.mcdtu.wordpress.com 1 www.mcdtu.wordpress.com 2 www.mcdtu.wordpress.com 3 OBJECTIVE 1: Transporation of Data Set to SPSS Editor INPUTS: Files: group1.xlsx, group1.txt PROCEDURE FOLLOWED:
SPSS LAB FILE www.mcdtu.wordpress.com 1 www.mcdtu.wordpress.com 2 www.mcdtu.wordpress.com 3 OBJECTIVE 1: Transporation of Data Set to SPSS Editor INPUTS: Files: group1.xlsx, group1.txt PROCEDURE FOLLOWED:
Virtual Beach Building a GBM Model
 Virtual Beach 3.0.6 Building a GBM Model Building, Evaluating and Validating Anytime Nowcast Models In this module you will learn how to: A. Build and evaluate an anytime GBM model B. Optimize a GBM model
Virtual Beach 3.0.6 Building a GBM Model Building, Evaluating and Validating Anytime Nowcast Models In this module you will learn how to: A. Build and evaluate an anytime GBM model B. Optimize a GBM model
Determination of Density 1
 Introduction Determination of Density 1 Authors: B. D. Lamp, D. L. McCurdy, V. M. Pultz and J. M. McCormick* Last Update: February 1, 2013 Not so long ago a statistical data analysis of any data set larger
Introduction Determination of Density 1 Authors: B. D. Lamp, D. L. McCurdy, V. M. Pultz and J. M. McCormick* Last Update: February 1, 2013 Not so long ago a statistical data analysis of any data set larger
DISPLAYING THE POISSON REGRESSION ANALYSIS
 Chapter 17 Poisson Regression Chapter Table of Contents DISPLAYING THE POISSON REGRESSION ANALYSIS...264 ModelInformation...269 SummaryofFit...269 AnalysisofDeviance...269 TypeIII(Wald)Tests...269 MODIFYING
Chapter 17 Poisson Regression Chapter Table of Contents DISPLAYING THE POISSON REGRESSION ANALYSIS...264 ModelInformation...269 SummaryofFit...269 AnalysisofDeviance...269 TypeIII(Wald)Tests...269 MODIFYING
Logistic Regression. Continued Psy 524 Ainsworth
 Logistic Regression Continued Psy 524 Ainsworth Equations Regression Equation Y e = 1 + A+ B X + B X + B X 1 1 2 2 3 3 i A+ B X + B X + B X e 1 1 2 2 3 3 Equations The linear part of the logistic regression
Logistic Regression Continued Psy 524 Ainsworth Equations Regression Equation Y e = 1 + A+ B X + B X + B X 1 1 2 2 3 3 i A+ B X + B X + B X e 1 1 2 2 3 3 Equations The linear part of the logistic regression
Lecture 14: Introduction to Poisson Regression
 Lecture 14: Introduction to Poisson Regression Ani Manichaikul amanicha@jhsph.edu 8 May 2007 1 / 52 Overview Modelling counts Contingency tables Poisson regression models 2 / 52 Modelling counts I Why
Lecture 14: Introduction to Poisson Regression Ani Manichaikul amanicha@jhsph.edu 8 May 2007 1 / 52 Overview Modelling counts Contingency tables Poisson regression models 2 / 52 Modelling counts I Why
Modelling counts. Lecture 14: Introduction to Poisson Regression. Overview
 Modelling counts I Lecture 14: Introduction to Poisson Regression Ani Manichaikul amanicha@jhsph.edu Why count data? Number of traffic accidents per day Mortality counts in a given neighborhood, per week
Modelling counts I Lecture 14: Introduction to Poisson Regression Ani Manichaikul amanicha@jhsph.edu Why count data? Number of traffic accidents per day Mortality counts in a given neighborhood, per week
Confidence Intervals for the Odds Ratio in Logistic Regression with Two Binary X s
 Chapter 866 Confidence Intervals for the Odds Ratio in Logistic Regression with Two Binary X s Introduction Logistic regression expresses the relationship between a binary response variable and one or
Chapter 866 Confidence Intervals for the Odds Ratio in Logistic Regression with Two Binary X s Introduction Logistic regression expresses the relationship between a binary response variable and one or
Paper: ST-161. Techniques for Evidence-Based Decision Making Using SAS Ian Stockwell, The Hilltop UMBC, Baltimore, MD
 Paper: ST-161 Techniques for Evidence-Based Decision Making Using SAS Ian Stockwell, The Hilltop Institute @ UMBC, Baltimore, MD ABSTRACT SAS has many tools that can be used for data analysis. From Freqs
Paper: ST-161 Techniques for Evidence-Based Decision Making Using SAS Ian Stockwell, The Hilltop Institute @ UMBC, Baltimore, MD ABSTRACT SAS has many tools that can be used for data analysis. From Freqs
An Introduction to Path Analysis
 An Introduction to Path Analysis PRE 905: Multivariate Analysis Lecture 10: April 15, 2014 PRE 905: Lecture 10 Path Analysis Today s Lecture Path analysis starting with multivariate regression then arriving
An Introduction to Path Analysis PRE 905: Multivariate Analysis Lecture 10: April 15, 2014 PRE 905: Lecture 10 Path Analysis Today s Lecture Path analysis starting with multivariate regression then arriving
Tests for Two Coefficient Alphas
 Chapter 80 Tests for Two Coefficient Alphas Introduction Coefficient alpha, or Cronbach s alpha, is a popular measure of the reliability of a scale consisting of k parts. The k parts often represent k
Chapter 80 Tests for Two Coefficient Alphas Introduction Coefficient alpha, or Cronbach s alpha, is a popular measure of the reliability of a scale consisting of k parts. The k parts often represent k
Classification. Chapter Introduction. 6.2 The Bayes classifier
 Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Tests for the Odds Ratio in Logistic Regression with One Binary X (Wald Test)
") Chapter 861 Tests for the Odds Ratio in Logistic Regression with One Binary X (Wald Test) Introduction Logistic regression expresses the relationship between a binary response variable and one or more
Chapter 861 Tests for the Odds Ratio in Logistic Regression with One Binary X (Wald Test) Introduction Logistic regression expresses the relationship between a binary response variable and one or more
1 A Review of Correlation and Regression
 1 A Review of Correlation and Regression SW, Chapter 12 Suppose we select n = 10 persons from the population of college seniors who plan to take the MCAT exam. Each takes the test, is coached, and then
1 A Review of Correlation and Regression SW, Chapter 12 Suppose we select n = 10 persons from the population of college seniors who plan to take the MCAT exam. Each takes the test, is coached, and then
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
Age 55 (x = 1) Age < 55 (x = 0)
 Age < 55 (x = 0)") Logistic Regression with a Single Dichotomous Predictor EXAMPLE: Consider the data in the file CHDcsv Instead of examining the relationship between the continuous variable age and the presence or absence
Logistic Regression with a Single Dichotomous Predictor EXAMPLE: Consider the data in the file CHDcsv Instead of examining the relationship between the continuous variable age and the presence or absence
Dependent Variable Q83: Attended meetings of your town or city council (0=no, 1=yes)
") Logistic Regression Kristi Andrasik COM 731 Spring 2017. MODEL all data drawn from the 2006 National Community Survey (class data set) BLOCK 1 (Stepwise) Lifestyle Values Q7: Value work Q8: Value friends
Logistic Regression Kristi Andrasik COM 731 Spring 2017. MODEL all data drawn from the 2006 National Community Survey (class data set) BLOCK 1 (Stepwise) Lifestyle Values Q7: Value work Q8: Value friends
The Matrix Algebra of Sample Statistics
 The Matrix Algebra of Sample Statistics James H. Steiger Department of Psychology and Human Development Vanderbilt University James H. Steiger (Vanderbilt University) The Matrix Algebra of Sample Statistics
The Matrix Algebra of Sample Statistics James H. Steiger Department of Psychology and Human Development Vanderbilt University James H. Steiger (Vanderbilt University) The Matrix Algebra of Sample Statistics
CS Homework 3. October 15, 2009
 CS 294 - Homework 3 October 15, 2009 If you have questions, contact Alexandre Bouchard (bouchard@cs.berkeley.edu) for part 1 and Alex Simma (asimma@eecs.berkeley.edu) for part 2. Also check the class website
CS 294 - Homework 3 October 15, 2009 If you have questions, contact Alexandre Bouchard (bouchard@cs.berkeley.edu) for part 1 and Alex Simma (asimma@eecs.berkeley.edu) for part 2. Also check the class website
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
ECON 5350 Class Notes Functional Form and Structural Change
 ECON 5350 Class Notes Functional Form and Structural Change 1 Introduction Although OLS is considered a linear estimator, it does not mean that the relationship between Y and X needs to be linear. In this
ECON 5350 Class Notes Functional Form and Structural Change 1 Introduction Although OLS is considered a linear estimator, it does not mean that the relationship between Y and X needs to be linear. In this
Classification: Linear Discriminant Analysis
 Classification: Linear Discriminant Analysis Discriminant analysis uses sample information about individuals that are known to belong to one of several populations for the purposes of classification. Based
Classification: Linear Discriminant Analysis Discriminant analysis uses sample information about individuals that are known to belong to one of several populations for the purposes of classification. Based
EDF 7405 Advanced Quantitative Methods in Educational Research. Data are available on IQ of the child and seven potential predictors.
 EDF 7405 Advanced Quantitative Methods in Educational Research Data are available on IQ of the child and seven potential predictors. Four are medical variables available at the birth of the child: Birthweight
EDF 7405 Advanced Quantitative Methods in Educational Research Data are available on IQ of the child and seven potential predictors. Four are medical variables available at the birth of the child: Birthweight
Section IX. Introduction to Logistic Regression for binary outcomes. Poisson regression
 Section IX Introduction to Logistic Regression for binary outcomes Poisson regression 0 Sec 9 - Logistic regression In linear regression, we studied models where Y is a continuous variable. What about
Section IX Introduction to Logistic Regression for binary outcomes Poisson regression 0 Sec 9 - Logistic regression In linear regression, we studied models where Y is a continuous variable. What about
STA 303 H1S / 1002 HS Winter 2011 Test March 7, ab 1cde 2abcde 2fghij 3
 STA 303 H1S / 1002 HS Winter 2011 Test March 7, 2011 LAST NAME: FIRST NAME: STUDENT NUMBER: ENROLLED IN: (circle one) STA 303 STA 1002 INSTRUCTIONS: Time: 90 minutes Aids allowed: calculator. Some formulae
STA 303 H1S / 1002 HS Winter 2011 Test March 7, 2011 LAST NAME: FIRST NAME: STUDENT NUMBER: ENROLLED IN: (circle one) STA 303 STA 1002 INSTRUCTIONS: Time: 90 minutes Aids allowed: calculator. Some formulae
Turning a research question into a statistical question.
 Turning a research question into a statistical question. IGINAL QUESTION: Concept Concept Concept ABOUT ONE CONCEPT ABOUT RELATIONSHIPS BETWEEN CONCEPTS TYPE OF QUESTION: DESCRIBE what s going on? DECIDE
Turning a research question into a statistical question. IGINAL QUESTION: Concept Concept Concept ABOUT ONE CONCEPT ABOUT RELATIONSHIPS BETWEEN CONCEPTS TYPE OF QUESTION: DESCRIBE what s going on? DECIDE
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Remember that C is a constant and ë and n are variables. This equation now fits the template of a straight line:
 CONVERTING NON-LINEAR GRAPHS INTO LINEAR GRAPHS Linear graphs have several important attributes. First, it is easy to recognize a graph that is linear. It is much more difficult to identify if a curved
CONVERTING NON-LINEAR GRAPHS INTO LINEAR GRAPHS Linear graphs have several important attributes. First, it is easy to recognize a graph that is linear. It is much more difficult to identify if a curved
Introduction to Matrix Algebra and the Multivariate Normal Distribution
 Introduction to Matrix Algebra and the Multivariate Normal Distribution Introduction to Structural Equation Modeling Lecture #2 January 18, 2012 ERSH 8750: Lecture 2 Motivation for Learning the Multivariate
Introduction to Matrix Algebra and the Multivariate Normal Distribution Introduction to Structural Equation Modeling Lecture #2 January 18, 2012 ERSH 8750: Lecture 2 Motivation for Learning the Multivariate
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
An Introduction to Mplus and Path Analysis
 An Introduction to Mplus and Path Analysis PSYC 943: Fundamentals of Multivariate Modeling Lecture 10: October 30, 2013 PSYC 943: Lecture 10 Today s Lecture Path analysis starting with multivariate regression
An Introduction to Mplus and Path Analysis PSYC 943: Fundamentals of Multivariate Modeling Lecture 10: October 30, 2013 PSYC 943: Lecture 10 Today s Lecture Path analysis starting with multivariate regression
Calculating Effect-Sizes. David B. Wilson, PhD George Mason University
 Calculating Effect-Sizes David B. Wilson, PhD George Mason University The Heart and Soul of Meta-analysis: The Effect Size Meta-analysis shifts focus from statistical significance to the direction and
Calculating Effect-Sizes David B. Wilson, PhD George Mason University The Heart and Soul of Meta-analysis: The Effect Size Meta-analysis shifts focus from statistical significance to the direction and
Lecture 12: Effect modification, and confounding in logistic regression
 Lecture 12: Effect modification, and confounding in logistic regression Ani Manichaikul amanicha@jhsph.edu 4 May 2007 Today Categorical predictor create dummy variables just like for linear regression
Lecture 12: Effect modification, and confounding in logistic regression Ani Manichaikul amanicha@jhsph.edu 4 May 2007 Today Categorical predictor create dummy variables just like for linear regression
Tests for the Odds Ratio in a Matched Case-Control Design with a Quantitative X
 Chapter 157 Tests for the Odds Ratio in a Matched Case-Control Design with a Quantitative X Introduction This procedure calculates the power and sample size necessary in a matched case-control study designed
Chapter 157 Tests for the Odds Ratio in a Matched Case-Control Design with a Quantitative X Introduction This procedure calculates the power and sample size necessary in a matched case-control study designed
2. We care about proportion for categorical variable, but average for numerical one.
 Probit Model 1. We apply Probit model to Bank data. The dependent variable is deny, a dummy variable equaling one if a mortgage application is denied, and equaling zero if accepted. The key regressor is
Probit Model 1. We apply Probit model to Bank data. The dependent variable is deny, a dummy variable equaling one if a mortgage application is denied, and equaling zero if accepted. The key regressor is
Logistic Regression - problem 6.14
 Logistic Regression - problem 6.14 Let x 1, x 2,, x m be given values of an input variable x and let Y 1,, Y m be independent binomial random variables whose distributions depend on the corresponding values
Logistic Regression - problem 6.14 Let x 1, x 2,, x m be given values of an input variable x and let Y 1,, Y m be independent binomial random variables whose distributions depend on the corresponding values
Analysis of Covariance (ANCOVA) with Two Groups
 with Two Groups") Chapter 226 Analysis of Covariance (ANCOVA) with Two Groups Introduction This procedure performs analysis of covariance (ANCOVA) for a grouping variable with 2 groups and one covariate variable. This procedure
Chapter 226 Analysis of Covariance (ANCOVA) with Two Groups Introduction This procedure performs analysis of covariance (ANCOVA) for a grouping variable with 2 groups and one covariate variable. This procedure
LAB 5 INSTRUCTIONS LINEAR REGRESSION AND CORRELATION
 LAB 5 INSTRUCTIONS LINEAR REGRESSION AND CORRELATION In this lab you will learn how to use Excel to display the relationship between two quantitative variables, measure the strength and direction of the
LAB 5 INSTRUCTIONS LINEAR REGRESSION AND CORRELATION In this lab you will learn how to use Excel to display the relationship between two quantitative variables, measure the strength and direction of the
Correlation and regression
 1 Correlation and regression Yongjua Laosiritaworn Introductory on Field Epidemiology 6 July 2015, Thailand Data 2 Illustrative data (Doll, 1955) 3 Scatter plot 4 Doll, 1955 5 6 Correlation coefficient,
1 Correlation and regression Yongjua Laosiritaworn Introductory on Field Epidemiology 6 July 2015, Thailand Data 2 Illustrative data (Doll, 1955) 3 Scatter plot 4 Doll, 1955 5 6 Correlation coefficient,
ST3241 Categorical Data Analysis I Multicategory Logit Models. Logit Models For Nominal Responses
 ST3241 Categorical Data Analysis I Multicategory Logit Models Logit Models For Nominal Responses 1 Models For Nominal Responses Y is nominal with J categories. Let {π 1,, π J } denote the response probabilities
ST3241 Categorical Data Analysis I Multicategory Logit Models Logit Models For Nominal Responses 1 Models For Nominal Responses Y is nominal with J categories. Let {π 1,, π J } denote the response probabilities
CLUe Training An Introduction to Machine Learning in R with an example from handwritten digit recognition
 CLUe Training An Introduction to Machine Learning in R with an example from handwritten digit recognition Ad Feelders Universiteit Utrecht Department of Information and Computing Sciences Algorithmic Data
CLUe Training An Introduction to Machine Learning in R with an example from handwritten digit recognition Ad Feelders Universiteit Utrecht Department of Information and Computing Sciences Algorithmic Data
Univariate analysis. Simple and Multiple Regression. Univariate analysis. Simple Regression How best to summarise the data?
 Univariate analysis Example - linear regression equation: y = ax + c Least squares criteria ( yobs ycalc ) = yobs ( ax + c) = minimum Simple and + = xa xc xy xa + nc = y Solve for a and c Univariate analysis
Univariate analysis Example - linear regression equation: y = ax + c Least squares criteria ( yobs ycalc ) = yobs ( ax + c) = minimum Simple and + = xa xc xy xa + nc = y Solve for a and c Univariate analysis
Virtual Beach Making Nowcast Predictions
 Virtual Beach 3.0.6 Making Nowcast Predictions In this module you will learn how to: A. Create a real-time connection to Web data services through EnDDaT B. Download real-time data to make a Nowcast prediction
Virtual Beach 3.0.6 Making Nowcast Predictions In this module you will learn how to: A. Create a real-time connection to Web data services through EnDDaT B. Download real-time data to make a Nowcast prediction
Hypothesis Tests and Estimation for Population Variances. Copyright 2014 Pearson Education, Inc.
 Hypothesis Tests and Estimation for Population Variances 11-1 Learning Outcomes Outcome 1. Formulate and carry out hypothesis tests for a single population variance. Outcome 2. Develop and interpret confidence
Hypothesis Tests and Estimation for Population Variances 11-1 Learning Outcomes Outcome 1. Formulate and carry out hypothesis tests for a single population variance. Outcome 2. Develop and interpret confidence
Ron Heck, Fall Week 3: Notes Building a Two-Level Model
 Ron Heck, Fall 2011 1 EDEP 768E: Seminar on Multilevel Modeling rev. 9/6/2011@11:27pm Week 3: Notes Building a Two-Level Model We will build a model to explain student math achievement using student-level
Ron Heck, Fall 2011 1 EDEP 768E: Seminar on Multilevel Modeling rev. 9/6/2011@11:27pm Week 3: Notes Building a Two-Level Model We will build a model to explain student math achievement using student-level
Introduction to Machine Learning
 10-701 Introduction to Machine Learning Homework 2, version 1.0 Due Oct 16, 11:59 am Rules: 1. Homework submission is done via CMU Autolab system. Please package your writeup and code into a zip or tar
10-701 Introduction to Machine Learning Homework 2, version 1.0 Due Oct 16, 11:59 am Rules: 1. Homework submission is done via CMU Autolab system. Please package your writeup and code into a zip or tar
LOOKING FOR RELATIONSHIPS
 LOOKING FOR RELATIONSHIPS One of most common types of investigation we do is to look for relationships between variables. Variables may be nominal (categorical), for example looking at the effect of an
LOOKING FOR RELATIONSHIPS One of most common types of investigation we do is to look for relationships between variables. Variables may be nominal (categorical), for example looking at the effect of an
7 Ordered Categorical Response Models
 7 Ordered Categorical Response Models In several chapters so far we have addressed modeling a binary response variable, for instance gingival bleeding upon periodontal probing, which has only two expressions,
7 Ordered Categorical Response Models In several chapters so far we have addressed modeling a binary response variable, for instance gingival bleeding upon periodontal probing, which has only two expressions,
Introduction to Bayesian Learning. Machine Learning Fall 2018
 Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Confidence Intervals for the Interaction Odds Ratio in Logistic Regression with Two Binary X s
 Chapter 867 Confidence Intervals for the Interaction Odds Ratio in Logistic Regression with Two Binary X s Introduction Logistic regression expresses the relationship between a binary response variable
Chapter 867 Confidence Intervals for the Interaction Odds Ratio in Logistic Regression with Two Binary X s Introduction Logistic regression expresses the relationship between a binary response variable
Optimal design of experiments
 Optimal design of experiments Session 4: Some theory Peter Goos / 40 Optimal design theory continuous or approximate optimal designs implicitly assume an infinitely large number of observations are available
Optimal design of experiments Session 4: Some theory Peter Goos / 40 Optimal design theory continuous or approximate optimal designs implicitly assume an infinitely large number of observations are available
Six Sigma Black Belt Study Guides
 Six Sigma Black Belt Study Guides 1 www.pmtutor.org Powered by POeT Solvers Limited. Analyze Correlation and Regression Analysis 2 www.pmtutor.org Powered by POeT Solvers Limited. Variables and relationships
Six Sigma Black Belt Study Guides 1 www.pmtutor.org Powered by POeT Solvers Limited. Analyze Correlation and Regression Analysis 2 www.pmtutor.org Powered by POeT Solvers Limited. Variables and relationships
1 EM algorithm: updating the mixing proportions {π k } ik are the posterior probabilities at the qth iteration of EM.
 Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Boyle s Law: A Multivariable Model and Interactive Animated Simulation
 Boyle s Law: A Multivariable Model and Interactive Animated Simulation Using tools available in Excel, we will turn a multivariable model into an interactive animated simulation. Projectile motion, Boyle's
Boyle s Law: A Multivariable Model and Interactive Animated Simulation Using tools available in Excel, we will turn a multivariable model into an interactive animated simulation. Projectile motion, Boyle's
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Fractional Polynomial Regression
 Chapter 382 Fractional Polynomial Regression Introduction This program fits fractional polynomial models in situations in which there is one dependent (Y) variable and one independent (X) variable. It
Chapter 382 Fractional Polynomial Regression Introduction This program fits fractional polynomial models in situations in which there is one dependent (Y) variable and one independent (X) variable. It
Example name. Subgroups analysis, Regression. Synopsis
 589 Example name Effect size Analysis type Level BCG Risk ratio Subgroups analysis, Regression Advanced Synopsis This analysis includes studies where patients were randomized to receive either a vaccine
589 Example name Effect size Analysis type Level BCG Risk ratio Subgroups analysis, Regression Advanced Synopsis This analysis includes studies where patients were randomized to receive either a vaccine
LISA Short Course Series Generalized Linear Models (GLMs) & Categorical Data Analysis (CDA) in R. Liang (Sally) Shan Nov. 4, 2014
 & Categorical Data Analysis (CDA) in R. Liang (Sally) Shan Nov. 4, 2014") LISA Short Course Series Generalized Linear Models (GLMs) & Categorical Data Analysis (CDA) in R Liang (Sally) Shan Nov. 4, 2014 L Laboratory for Interdisciplinary Statistical Analysis LISA helps VT researchers
LISA Short Course Series Generalized Linear Models (GLMs) & Categorical Data Analysis (CDA) in R Liang (Sally) Shan Nov. 4, 2014 L Laboratory for Interdisciplinary Statistical Analysis LISA helps VT researchers
Chaper 5: Matrix Approach to Simple Linear Regression. Matrix: A m by n matrix B is a grid of numbers with m rows and n columns. B = b 11 b m1 ...
 Chaper 5: Matrix Approach to Simple Linear Regression Matrix: A m by n matrix B is a grid of numbers with m rows and n columns B = b 11 b 1n b m1 b mn Element b ik is from the ith row and kth column A
Chaper 5: Matrix Approach to Simple Linear Regression Matrix: A m by n matrix B is a grid of numbers with m rows and n columns B = b 11 b 1n b m1 b mn Element b ik is from the ith row and kth column A
25. Strassen s Fast Multiplication of Matrices Algorithm and Spreadsheet Matrix Multiplications
 25.1 Introduction 25. Strassen s Fast Multiplication of Matrices Algorithm and Spreadsheet Matrix Multiplications We will use the notation A ij to indicate the element in the i-th row and j-th column of
25.1 Introduction 25. Strassen s Fast Multiplication of Matrices Algorithm and Spreadsheet Matrix Multiplications We will use the notation A ij to indicate the element in the i-th row and j-th column of
Using a graphic display calculator
 12 Using a graphic display calculator CHAPTER OBJECTIVES: This chapter shows you how to use your graphic display calculator (GDC) to solve the different types of problems that you will meet in your course.
12 Using a graphic display calculator CHAPTER OBJECTIVES: This chapter shows you how to use your graphic display calculator (GDC) to solve the different types of problems that you will meet in your course.
NCSS Statistical Software. Harmonic Regression. This section provides the technical details of the model that is fit by this procedure.
 Chapter 460 Introduction This program calculates the harmonic regression of a time series. That is, it fits designated harmonics (sinusoidal terms of different wavelengths) using our nonlinear regression
Chapter 460 Introduction This program calculates the harmonic regression of a time series. That is, it fits designated harmonics (sinusoidal terms of different wavelengths) using our nonlinear regression
Computer simulation of radioactive decay
 Computer simulation of radioactive decay y now you should have worked your way through the introduction to Maple, as well as the introduction to data analysis using Excel Now we will explore radioactive
Computer simulation of radioactive decay y now you should have worked your way through the introduction to Maple, as well as the introduction to data analysis using Excel Now we will explore radioactive
Classification 1: Linear regression of indicators, linear discriminant analysis
 Classification 1: Linear regression of indicators, linear discriminant analysis Ryan Tibshirani Data Mining: 36-462/36-662 April 2 2013 Optional reading: ISL 4.1, 4.2, 4.4, ESL 4.1 4.3 1 Classification
Classification 1: Linear regression of indicators, linear discriminant analysis Ryan Tibshirani Data Mining: 36-462/36-662 April 2 2013 Optional reading: ISL 4.1, 4.2, 4.4, ESL 4.1 4.3 1 Classification
Class Notes: Week 8. Probit versus Logit Link Functions and Count Data
 Ronald Heck Class Notes: Week 8 1 Class Notes: Week 8 Probit versus Logit Link Functions and Count Data This week we ll take up a couple of issues. The first is working with a probit link function. While
Ronald Heck Class Notes: Week 8 1 Class Notes: Week 8 Probit versus Logit Link Functions and Count Data This week we ll take up a couple of issues. The first is working with a probit link function. While
CS 195-5: Machine Learning Problem Set 1
 CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
ANOVA, ANCOVA and MANOVA as sem
 ANOVA, ANCOVA and MANOVA as sem Robin Beaumont 2017 Hoyle Chapter 24 Handbook of Structural Equation Modeling (2015 paperback), Examples converted to R and Onyx SEM diagrams. This workbook duplicates some
ANOVA, ANCOVA and MANOVA as sem Robin Beaumont 2017 Hoyle Chapter 24 Handbook of Structural Equation Modeling (2015 paperback), Examples converted to R and Onyx SEM diagrams. This workbook duplicates some
Two Correlated Proportions Non- Inferiority, Superiority, and Equivalence Tests
 Chapter 59 Two Correlated Proportions on- Inferiority, Superiority, and Equivalence Tests Introduction This chapter documents three closely related procedures: non-inferiority tests, superiority (by a
Chapter 59 Two Correlated Proportions on- Inferiority, Superiority, and Equivalence Tests Introduction This chapter documents three closely related procedures: non-inferiority tests, superiority (by a
Generalized linear models for binary data. A better graphical exploratory data analysis. The simple linear logistic regression model
 Stat 3302 (Spring 2017) Peter F. Craigmile Simple linear logistic regression (part 1) [Dobson and Barnett, 2008, Sections 7.1 7.3] Generalized linear models for binary data Beetles dose-response example
Stat 3302 (Spring 2017) Peter F. Craigmile Simple linear logistic regression (part 1) [Dobson and Barnett, 2008, Sections 7.1 7.3] Generalized linear models for binary data Beetles dose-response example
ABSTRACT INTRODUCTION
 Implementation of A Log-Linear Poisson Regression Model to Estimate the Odds of Being Technically Efficient in DEA Setting: The Case of Hospitals in Oman By Parakramaweera Sunil Dharmapala Dept. of Operations
Implementation of A Log-Linear Poisson Regression Model to Estimate the Odds of Being Technically Efficient in DEA Setting: The Case of Hospitals in Oman By Parakramaweera Sunil Dharmapala Dept. of Operations
Index. Cambridge University Press Data Analysis for Physical Scientists: Featuring Excel Les Kirkup Index More information
 χ 2 distribution, 410 χ 2 test, 410, 412 degrees of freedom, 414 accuracy, 176 adjusted coefficient of multiple determination, 323 AIC, 324 Akaike s Information Criterion, 324 correction for small data
χ 2 distribution, 410 χ 2 test, 410, 412 degrees of freedom, 414 accuracy, 176 adjusted coefficient of multiple determination, 323 AIC, 324 Akaike s Information Criterion, 324 correction for small data
SEM Day 1 Lab Exercises SPIDA 2007 Dave Flora
 SEM Day 1 Lab Exercises SPIDA 2007 Dave Flora 1 Today we will see how to estimate CFA models and interpret output using both SAS and LISREL. In SAS, commands for specifying SEMs are given using linear
SEM Day 1 Lab Exercises SPIDA 2007 Dave Flora 1 Today we will see how to estimate CFA models and interpret output using both SAS and LISREL. In SAS, commands for specifying SEMs are given using linear
Machine Learning, Midterm Exam
 10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
Hotelling s One- Sample T2
 Chapter 405 Hotelling s One- Sample T2 Introduction The one-sample Hotelling s T2 is the multivariate extension of the common one-sample or paired Student s t-test. In a one-sample t-test, the mean response
Chapter 405 Hotelling s One- Sample T2 Introduction The one-sample Hotelling s T2 is the multivariate extension of the common one-sample or paired Student s t-test. In a one-sample t-test, the mean response
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 17 2019 Logistics HW 1 is on Piazza and Gradescope Deadline: Friday, Jan. 25, 2019 Office
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 17 2019 Logistics HW 1 is on Piazza and Gradescope Deadline: Friday, Jan. 25, 2019 Office
Using Tables and Graphing Calculators in Math 11
 Using Tables and Graphing Calculators in Math 11 Graphing calculators are not required for Math 11, but they are likely to be helpful, primarily because they allow you to avoid the use of tables in some
Using Tables and Graphing Calculators in Math 11 Graphing calculators are not required for Math 11, but they are likely to be helpful, primarily because they allow you to avoid the use of tables in some