Bayesian Networks Structure Learning (cont.)
|
|
|
- Lambert Bates
- 6 years ago
- Views:
Transcription
1 Koller & Friedman Chapters (handed out): Chapter 11 (short) Chapter 1: 1.1, 1., 1.3 (covered in the beginning of semester) 1.4 (Learning parameters for BNs) Chapter 13: 13.1, , , (basic structure learning) Learning BN tutorial (class website): ftp://ftp.research.microsoft.com/pub/tr/tr-95-6.pdf TAN paper (class website): Bayesian Networks Structure Learning (cont.) Machine Learning 171/15781 Carlos Guestrin Carnegie Mellon University April 3 rd, 6 1
2 Learning Bayes nets Known structure Unknown structure Fully observable data Missing data Data x (1) x (m) structure CPTs P(X i Pa Xi ) parameters
3 Learning the CPTs Data For each discrete variable X i x (1) x (M) WHY?????????? 3
4 Information-theoretic interpretation of maximum likelihood Given structure, log likelihood of data: Flu Headache Sinus Allergy Nose 4
5 Maximum likelihood (ML) for learning BN structure Possible structures Learn parameters using ML Score structure Flu Allergy Sinus Headache Nose Data <x 1 (1),,x n (1) > <x 1 (M),,x n (M) > 5
6 Information-theoretic interpretation of maximum likelihood Given structure, log likelihood of data: Flu Headache Sinus Allergy Nose 6
7 Information-theoretic interpretation of maximum likelihood 3 Given structure, log likelihood of data: Flu Headache Sinus Allergy Nose 7
8 Mutual information Independence tests Statistically difficult task! Intuitive approach: Mutual information Mutual information and independence: X i and X j independent if and only if I(X i,x j )= Conditional mutual information: 8
9 Decomposable score Log data likelihood 9
10 Scoring a tree 1: equivalent trees 1
11 Scoring a tree : similar trees 11
12 Chow-Liu tree learning algorithm 1 For each pair of variables X i,x j Compute empirical distribution: Compute mutual information: Define a graph Nodes X 1,,X n Edge (i,j) gets weight 1
13 Chow-Liu tree learning algorithm Optimal tree BN Compute maximum weight spanning tree Directions in BN: pick any node as root, breadth-firstsearch defines directions 13
14 Can we extend Chow-Liu 1 Tree augmented naïve Bayes (TAN) [Friedman et al. 97] Naïve Bayes model overcounts, because correlation between features not considered Same as Chow-Liu, but score edges with: 14
15 Can we extend Chow-Liu (Approximately learning) models with tree-width up to k [Narasimhan & Bilmes 4] But, O(n k+1 ) 15
16 Scoring general graphical models Model selection problem What s the best structure? Flu Allergy Sinus Headache Nose Data <x_1^{(1)},,x_n^{(1)}> <x_1^{(m)},,x_n^{(m)}> The more edges, the fewer independence assumptions, the higher the likelihood of the data, but will overfit 16
17 Maximum likelihood overfits! Information never hurts: Adding a parent always increases score!!! 17
18 Bayesian score avoids overfitting Given a structure, distribution over parameters Difficult integral: use Bayes information criterion (BIC) approximation (equivalent as M ) Note: regularize with MDL score Best BN under BIC still NP-hard 18
19 How many graphs are there? 19
20 Structure learning for general graphs In a tree, a node only has one parent Theorem: The problem of learning a BN structure with at most d parents is NP-hard for any (fixed) d Most structure learning approaches use heuristics Exploit score decomposition (Quickly) Describe two heuristics that exploit decomposition in different ways
21 Learn BN structure using local search Starting from Chow-Liu tree Local search, possible moves: Add edge Delete edge Invert edge Score using BIC 1
22 What you need to know about learning BNs Learning BNs Maximum likelihood or MAP learns parameters Decomposable score Best tree (Chow-Liu) Best TAN Other BNs, usually local search with BIC score
23 Unsupervised learning or Clustering K-means Gaussian mixture models Machine Learning 171/15781 Carlos Guestrin Carnegie Mellon University April 3 rd, 6 3
24 Some Data 4
25 K-means 1. Ask user how many clusters they d like. (e.g. k=5) 5
26 K-means 1. Ask user how many clusters they d like. (e.g. k=5). Randomly guess k cluster Center locations 6
27 K-means 1. Ask user how many clusters they d like. (e.g. k=5). Randomly guess k cluster Center locations 3. Each datapoint finds out which Center it s closest to. (Thus each Center owns a set of datapoints) 7
28 K-means 1. Ask user how many clusters they d like. (e.g. k=5). Randomly guess k cluster Center locations 3. Each datapoint finds out which Center it s closest to. 4. Each Center finds the centroid of the points it owns 8
29 K-means 1. Ask user how many clusters they d like. (e.g. k=5). Randomly guess k cluster Center locations 3. Each datapoint finds out which Center it s closest to. 4. Each Center finds the centroid of the points it owns 5. and jumps there 6. Repeat until terminated! 9
30 Unsupervised Learning You walk into a bar. A stranger approaches and tells you: I ve got data from k classes. Each class produces observations with a normal distribution and variance σ I. Standard simple multivariate gaussian assumptions. I can tell you all the P(w i ) s. So far, looks straightforward. I need a maximum likelihood estimate of the µ i s. No problem: There s just one thing. None of the data are labeled. I have datapoints, but I don t know what class they re from (any of them!) Uh oh!! 3
31 31 Gaussian Bayes Classifier Reminder ) ( ) ( ) ( ) ( x x x p i y P i y p i y P = = = = ( ) ( ) ) ( 1 exp ) ( 1 ) ( 1/ / x µ x Σ µ x Σ x p p i y P i i k i T i k i m = = π How do we deal with that?
32 Predicting wealth from age 3
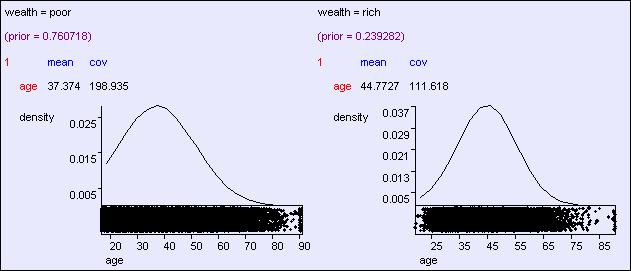
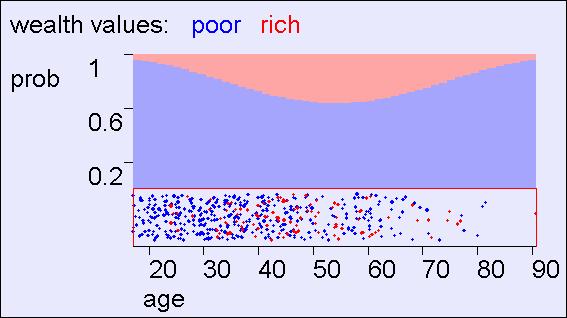
33 Predicting wealth from age 33
34 34 Learning modelyear, mpg ---> maker = m m m m m σ σ σ σ σ σ σ σ σ L M O M M L L Σ


35 35 General: O(m ) parameters = m m m m m σ σ σ σ σ σ σ σ σ L M O M M L L Σ
36 36 Aligned: O(m) parameters = m m σ σ σ σ σ L L M M O M M M L L L Σ

37 37 Aligned: O(m) parameters = m m σ σ σ σ σ L L M M O M M M L L L Σ
38 38 Spherical: O(1) cov parameters = σ σ σ σ σ L L M M O M M M L L L Σ
39 39 Spherical: O(1) cov parameters = σ σ σ σ σ L L M M O M M M L L L Σ
40 Next back to Density Estimation What if we want to do density estimation with multimodal or clumpy data? 4
41 The GMM assumption There are k components. The i th component is called ω i Component ω i has an associated mean vector µ i µ 1 µ µ 3 41
42 The GMM assumption There are k components. The i th component is called ω i Component ω i has an associated mean vector µ i Each component generates data from a Gaussian with mean µ i and covariance matrix σ I Assume that each datapoint is generated according to the following recipe: µ 1 µ µ 3 4
43 The GMM assumption There are k components. The i th component is called ω i Component ω i has an associated mean vector µ i µ Each component generates data from a Gaussian with mean µ i and covariance matrix σ I Assume that each datapoint is generated according to the following recipe: 1. Pick a component at random. Choose component i with probability P(y i ). 43
44 The GMM assumption There are k components. The i th component is called ω i Component ω i has an associated mean vector µ i µ Each component generates data from a Gaussian with mean µ i and covariance matrix σ I x Assume that each datapoint is generated according to the following recipe: 1. Pick a component at random. Choose component i with probability P(y i ).. Datapoint ~ N(µ i, σ I ) 44
45 The General GMM assumption There are k components. The i th component is called ω i Component ω i has an associated mean vector µ i Each component generates data from a Gaussian with mean µ i and covariance matrix Σ i Assume that each datapoint is generated according to the following recipe: 1. Pick a component at random. Choose component i with probability P(y i ).. Datapoint ~ N(µ i, Σ i ) µ 1 µ µ 3 45
46 Unsupervised Learning: not as hard as it looks Sometimes easy Sometimes impossible and sometimes in between IN CASE YOU RE WONDERING WHAT THESE DIAGRAMS ARE, THEY SHOW -d UNLABELED DATA (X VECTORS) DISTRIBUTED IN -d SPACE. THE TOP ONE HAS THREE VERY CLEAR GAUSSIAN CENTERS 46
47 Computing likelihoods in supervised learning case We have y 1,x 1, y,x, y N,x N Learn P(y 1 ) P(y ).. P(y k ) Learn σ, µ 1,, µ k By MLE: P(y 1,x 1, y,x, y N,x N µ i, µ k, σ) 47
48 Computing likelihoods in unsupervised case We have x 1, x, x N We know P(y 1 ) P(y ).. P(y k ) We know σ P(x y i, µ i, µ k ) = Prob that an observation from class y i would have value x given class means µ 1 µ x Can we write an expression for that? 48
49 likelihoods in unsupervised case We have x 1 x x n We have P(y 1 ).. P(y k ). We have σ. We can define, for any x, P(x y i, µ 1, µ.. µ k ) Can we define P(x µ 1, µ.. µ k )? Can we define P(x 1, x 1,.. x n µ 1, µ.. µ k )? [YES, IF WE ASSUME THE X 1 S WERE DRAWN INDEPENDENTLY] 49
50 Unsupervised Learning: Mediumly Good News We now have a procedure s.t. if you give me a guess at µ 1, µ.. µ k, I can tell you the prob of the unlabeled data given those µ s. Suppose x s are 1-dimensional. (From Duda and Hart) There are two classes; w 1 and w P(y 1 ) = 1/3 P(y ) = /3 σ = 1. There are 5 unlabeled datapoints x 1 =.68 x = x 3 =.35 x 4 = : x 5 =
51 Duda & Hart s Example We can graph the prob. dist. function of data given our µ 1 and µ estimates. We can also graph the true function from which the data was randomly generated. They are close. Good. The nd solution tries to put the /3 hump where the 1/3 hump should go, and vice versa. In this example unsupervised is almost as good as supervised. If the x 1.. x 5 are given the class which was used to learn them, then the results are (µ 1 =-.176, µ =1.684). Unsupervised got (µ 1 =-.13, µ =1.668). 51
52 Duda & Hart s Example µ Graph of log P(x 1, x.. x 5 µ 1, µ ) against µ 1 ( ) and µ ( ) µ1 Max likelihood = (µ 1 =-.13, µ =1.668) Local minimum, but very close to global at (µ 1 =.85, µ =-1.57)* * corresponds to switching y 1 with y. 5
53 Finding the max likelihood µ 1,µ..µ k We can compute P( data µ 1,µ..µ k ) How do we find the µ i s which give max. likelihood? The normal max likelihood trick: Set log Prob (.) = µ i and solve for µ i s. # Here you get non-linear non-analyticallysolvable equations Use gradient descent Slow but doable Use a much faster, cuter, and recently very popular method 53
54 Expectation Maximalization 54
55 The E.M. Algorithm DETOUR We ll get back to unsupervised learning soon. But now we ll look at an even simpler case with hidden information. The EM algorithm Can do trivial things, such as the contents of the next few slides. An excellent way of doing our unsupervised learning problem, as we ll see. Many, many other uses, including inference of Hidden Markov Models (future lecture). 55
56 Silly Example Let events be grades in a class w 1 = Gets an A P(A) = ½ w = Gets a B P(B) = µ w 3 = Gets a C P(C) = µ w 4 = Gets a D P(D) = ½-3µ (Note µ 1/6) Assume we want to estimate µ from data. In a given class there were a A s b B s c C s d D s What s the maximum likelihood estimate of µ given a,b,c,d? 56
57 Silly Example Let events be grades in a class w 1 = Gets an A P(A) = ½ w = Gets a B P(B) = µ w 3 = Gets a C P(C) = µ w 4 = Gets a D P(D) = ½-3µ (Note µ 1/6) Assume we want to estimate µ from data. In a given class there were a A s b B s c C s d D s What s the maximum likelihood estimate of µ given a,b,c,d? 57
58 Trivial Statistics P(A) = ½ P(B) = µ P(C) = µ P(D) = ½-3µ P( a,b,c,d µ) = K(½) a (µ) b (µ) c (½-3µ) d log P( a,b,c,d µ) = log K + alog ½ + blog µ + clog µ + dlog (½-3µ) LogP FOR MAX LIKE µ, SET = µ LogP b c = + µ µ µ Gives max like µ = So if class got 3d 1 / 6 b = 3µ + c ( b + c + d ) A B C D Max like µ = Boring, but true! 58
59 Same Problem with Hidden Information REMEMBER Someone tells us that Number of High grades (A s + B s) = h Number of C s = c Number of D s = d P(A) = ½ P(B) = µ P(C) = µ P(D) = ½-3µ What is the max. like estimate of µ now? 59
60 Same Problem with Hidden Information Someone tells us that Number of High grades (A s + B s) = h Number of C s = c Number of D s = d What is the max. like estimate of µ now? We can answer this question circularly: EXPECTATION MAXIMIZATION REMEMBER P(A) = ½ P(B) = µ P(C) = µ P(D) = ½-3µ If we know the value of µ we could compute the expected value of a and b 1 µ a = h b = 1 + µ 1 + µ Since the ratio a:b should be the same as the ratio ½ : µ If we know the expected values of a and b we could compute the maximum likelihood value of µ µ = 6 b + c ( b + c + d) 6 h
61 E.M. for our Trivial Problem REMEMBER We begin with a guess for µ We iterate between EXPECTATION and MAXIMALIZATION to improve our estimates of µ and a and b. P(A) = ½ P(B) = µ P(C) = µ P(D) = ½-3µ Define µ(t) the estimate of µ on the t th iteration b(t) the estimate of b on t th iteration µ() = initialguess b( t) = µ( t + 1) = 6 = 1 µ(t) h = Ε + µ( t) b() t + c ( b() t + c + d) max likeest of [ b µ( t) ] () µ given b t E-step M-step Continue iterating until converged. Good news: Converging to local optimum is assured. Bad news: I said local optimum. 61
62 E.M. Convergence Convergence proof based on fact that Prob(data µ) must increase or remain same between each iteration [NOT OBVIOUS] But it can never exceed 1 [OBVIOUS] So it must therefore converge [OBVIOUS] In our example, suppose we had h = c = 1 d = 1 µ() = Convergence is generally linear: error decreases by a constant factor each time step. t µ(t) b(t)
63 Back to Unsupervised Learning of GMMs Remember: We have unlabeled data x 1 x x R We know there are k classes We know P(y 1 ) P(y ) P(y 3 ) P(y k ) We don t know µ 1 µ.. µ k We can write P( data µ 1. µ k ) = p = = = ( x... x µ...µ ) R i= 1 R i= 1 j= 1 R 1 p i= 1 j= 1 ( x µ...µ ) k k i R p 1 ( x w,µ...µ ) P( y ) i 1 1 K exp σ j k k 1 k ( x µ ) P( y ) i j j j 63
64 E.M. for GMMs For Max likelihood we know µ j = R i= 1 R P i= 1 ( y x,µ...µ ) P j ( y x,µ...µ ) j i i 1 1 k k x i µ Some wild' n' crazy algebra turns This is n nonlinear equations in µ j s. i log Pr ob ( data µ...µ ) 1 this into :" For Max likelihood, for each If, for each x i we knew that for each w j the prob that µ j was in class y j is P(y j x i,µ 1 µ k ) Then we would easily compute µ j. k See = j, If we knew each µ j then we could easily compute P(y j x i,µ 1 µ k ) for each y j and x i. I feel an EM experience coming on!! 64
65 65 E.M. for GMMs Iterate. On the t th iteration let our estimates be λ t = { µ 1 (t), µ (t) µ c (t) } E-step Compute expected classes of all datapoints for each class ( ) ( ) ( ) ( ) ( ) ( ) = = = c j j j j k i i i k t k t i t i k t k i t p t y x t p t y x x y y x x y 1 ) ( ), (, p ) ( ), (, p p P, p, P I I σ µ σ µ λ λ λ λ M-step. Compute Max. like µ given our data s class membership distributions ( ) ( ) ( ) = + k t k i k k t k i i x y x x y t λ λ, P, P 1 µ Just evaluate a Gaussian at x k
66 E.M. Convergence Your lecturer will (unless out of time) give you a nice intuitive explanation of why this rule works. As with all EM procedures, convergence to a local optimum guaranteed. This algorithm is REALLY USED. And in high dimensional state spaces, too. E.G. Vector Quantization for Speech Data 66
67 E.M. for General GMMs 67 Iterate. On the t th iteration let our estimates be λ t = { µ 1 (t), µ (t) µ c (t), Σ 1 (t), Σ (t) Σ c (t), p 1 (t), p (t) p c (t) } E-step Compute expected classes of all datapoints for each class ( ) ( ) ( ) ( ) ( ) ( ) = Σ Σ = = c j j j j j k i i i i k t k t i t i k t k i t p t t y x t p t t y x x y y x x y 1 ) ( ) ( ), (, p ) ( ) ( ), (, p p P, p, P µ µ λ λ λ λ M-step. Compute Max. like µ given our data s class membership distributions p i (t) is shorthand for estimate of P(y i ) on t th iteration ( ) ( ) ( ) = + k t k i k k t k i i x y x x y t λ λ, P, P 1 µ ( ) ( ) ( ) [ ] ( ) [ ] ( ) + + = + Σ k t k i T i k i k k t k i i x y t x t x x y t λ µ µ λ, P 1 1, P 1 ( ) ( ) R x y t p k t k i i = +,λ P 1 R = #records Just evaluate a Gaussian at x k
68 Gaussian Mixture Example: Start Advance apologies: in Black and White this example will be incomprehensible 68
69 After first iteration 69
70 After nd iteration 7
71 After 3rd iteration 71
72 After 4th iteration 7
73 After 5th iteration 73
74 After 6th iteration 74
75 After th iteration 75
76 Some Bio Assay data 76
77 GMM clustering of the assay data 77

78 Resulting Density Estimator 78

79 Three classes of assay (each learned with it s own mixture model) 79

80 Resulting Bayes Classifier 8

81 Resulting Bayes Classifier, using posterior probabilities to alert about ambiguity and anomalousness Yellow means anomalous Cyan means ambiguous 81
82 Final Comments Remember, E.M. can get stuck in local minima, and empirically it DOES. Our unsupervised learning example assumed P(y i ) s known, and variances fixed and known. Easy to relax this. It s possible to do Bayesian unsupervised learning instead of max. likelihood. 8
83 What you should know How to learn maximum likelihood parameters (locally max. like.) in the case of unlabeled data. Be happy with this kind of probabilistic analysis. Understand the two examples of E.M. given in these notes. 83
84 Acknowledgements K-means & Gaussian mixture models presentation derived from excellent tutorial by Andrew Moore: K-means Applet: torial_html/appletkm.html Gaussian mixture models Applet: html 84
K-means. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. November 19 th, Carlos Guestrin 1
 EM Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 19 th, 2007 2005-2007 Carlos Guestrin 1 K-means 1. Ask user how many clusters they d like. e.g. k=5 2. Randomly guess
EM Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 19 th, 2007 2005-2007 Carlos Guestrin 1 K-means 1. Ask user how many clusters they d like. e.g. k=5 2. Randomly guess
Mixtures of Gaussians continued
 Mixtures of Gaussians continued Machine Learning CSE446 Carlos Guestrin University of Washington May 17, 2013 1 One) bad case for k-means n Clusters may overlap n Some clusters may be wider than others
Mixtures of Gaussians continued Machine Learning CSE446 Carlos Guestrin University of Washington May 17, 2013 1 One) bad case for k-means n Clusters may overlap n Some clusters may be wider than others
EM (cont.) November 26 th, Carlos Guestrin 1
 November 26 th, Carlos Guestrin 1") EM (cont.) Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 26 th, 2007 1 Silly Example Let events be grades in a class w 1 = Gets an A P(A) = ½ w 2 = Gets a B P(B) = µ
EM (cont.) Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 26 th, 2007 1 Silly Example Let events be grades in a class w 1 = Gets an A P(A) = ½ w 2 = Gets a B P(B) = µ
Structure Learning: the good, the bad, the ugly
 Readings: K&F: 15.1, 15.2, 15.3, 15.4, 15.5 Structure Learning: the good, the bad, the ugly Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 29 th, 2006 1 Understanding the uniform
Readings: K&F: 15.1, 15.2, 15.3, 15.4, 15.5 Structure Learning: the good, the bad, the ugly Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 29 th, 2006 1 Understanding the uniform
Readings: K&F: 16.3, 16.4, Graphical Models Carlos Guestrin Carnegie Mellon University October 6 th, 2008
 Readings: K&F: 16.3, 16.4, 17.3 Bayesian Param. Learning Bayesian Structure Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University October 6 th, 2008 10-708 Carlos Guestrin 2006-2008
Readings: K&F: 16.3, 16.4, 17.3 Bayesian Param. Learning Bayesian Structure Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University October 6 th, 2008 10-708 Carlos Guestrin 2006-2008
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
CSE446: Clustering and EM Spring 2017
 CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Expectation Maximization Algorithm
 Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
BN Semantics 3 Now it s personal! Parameter Learning 1
 Readings: K&F: 3.4, 14.1, 14.2 BN Semantics 3 Now it s personal! Parameter Learning 1 Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2006 1 Building BNs from independence
Readings: K&F: 3.4, 14.1, 14.2 BN Semantics 3 Now it s personal! Parameter Learning 1 Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2006 1 Building BNs from independence
Unsupervised Learning: K-Means, Gaussian Mixture Models
 Unsupervised Learning: K-Means, Gaussian Mixture Models These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online.
Unsupervised Learning: K-Means, Gaussian Mixture Models These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online.
Learning Bayes Net Structures
 Learning Bayes Net Structures KF, Chapter 15 15.5 (RN, Chapter 20) Some material taken from C Guesterin (CMU), K Murphy (UBC) 1 2 Learning Bayes Nets Known Structure Unknown Data Complete Missing Easy
Learning Bayes Net Structures KF, Chapter 15 15.5 (RN, Chapter 20) Some material taken from C Guesterin (CMU), K Murphy (UBC) 1 2 Learning Bayes Nets Known Structure Unknown Data Complete Missing Easy
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
Learning P-maps Param. Learning
 Readings: K&F: 3.3, 3.4, 16.1, 16.2, 16.3, 16.4 Learning P-maps Param. Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 24 th, 2008 10-708 Carlos Guestrin 2006-2008
Readings: K&F: 3.3, 3.4, 16.1, 16.2, 16.3, 16.4 Learning P-maps Param. Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 24 th, 2008 10-708 Carlos Guestrin 2006-2008
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Bayesian Networks Representation
 Bayesian Networks Representation Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University March 19 th, 2007 Handwriting recognition Character recognition, e.g., kernel SVMs a c z rr r r
Bayesian Networks Representation Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University March 19 th, 2007 Handwriting recognition Character recognition, e.g., kernel SVMs a c z rr r r
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Generative v. Discriminative classifiers Intuition
 Logistic Regression (Continued) Generative v. Discriminative Decision rees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 31 st, 2007 2005-2007 Carlos Guestrin 1 Generative
Logistic Regression (Continued) Generative v. Discriminative Decision rees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 31 st, 2007 2005-2007 Carlos Guestrin 1 Generative
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Directed Graphical Models or Bayesian Networks
 Directed Graphical Models or Bayesian Networks Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Bayesian Networks One of the most exciting recent advancements in statistical AI Compact
Directed Graphical Models or Bayesian Networks Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Bayesian Networks One of the most exciting recent advancements in statistical AI Compact
Expectation maximization
 Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
Announcements. CS 188: Artificial Intelligence Fall Causality? Example: Traffic. Topology Limits Distributions. Example: Reverse Traffic
 CS 188: Artificial Intelligence Fall 2008 Lecture 16: Bayes Nets III 10/23/2008 Announcements Midterms graded, up on glookup, back Tuesday W4 also graded, back in sections / box Past homeworks in return
CS 188: Artificial Intelligence Fall 2008 Lecture 16: Bayes Nets III 10/23/2008 Announcements Midterms graded, up on glookup, back Tuesday W4 also graded, back in sections / box Past homeworks in return
Dynamic models 1 Kalman filters, linearization,
 Koller & Friedman: Chapter 16 Jordan: Chapters 13, 15 Uri Lerner s Thesis: Chapters 3,9 Dynamic models 1 Kalman filters, linearization, Switching KFs, Assumed density filters Probabilistic Graphical Models
Koller & Friedman: Chapter 16 Jordan: Chapters 13, 15 Uri Lerner s Thesis: Chapters 3,9 Dynamic models 1 Kalman filters, linearization, Switching KFs, Assumed density filters Probabilistic Graphical Models
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 4 Learning Bayesian Networks CS/CNS/EE 155 Andreas Krause Announcements Another TA: Hongchao Zhou Please fill out the questionnaire about recitations Homework 1 out.
Probabilistic Graphical Models Lecture 4 Learning Bayesian Networks CS/CNS/EE 155 Andreas Krause Announcements Another TA: Hongchao Zhou Please fill out the questionnaire about recitations Homework 1 out.
Announcements. Inference. Mid-term. Inference by Enumeration. Reminder: Alarm Network. Introduction to Artificial Intelligence. V22.
 Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 15: Bayes Nets 3 Midterms graded Assignment 2 graded Announcements Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides
Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 15: Bayes Nets 3 Midterms graded Assignment 2 graded Announcements Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 5 Bayesian Learning of Bayesian Networks CS/CNS/EE 155 Andreas Krause Announcements Recitations: Every Tuesday 4-5:30 in 243 Annenberg Homework 1 out. Due in class
Probabilistic Graphical Models Lecture 5 Bayesian Learning of Bayesian Networks CS/CNS/EE 155 Andreas Krause Announcements Recitations: Every Tuesday 4-5:30 in 243 Annenberg Homework 1 out. Due in class
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
CSE 473: Artificial Intelligence Autumn Topics
 CSE 473: Artificial Intelligence Autumn 2014 Bayesian Networks Learning II Dan Weld Slides adapted from Jack Breese, Dan Klein, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 473 Topics
CSE 473: Artificial Intelligence Autumn 2014 Bayesian Networks Learning II Dan Weld Slides adapted from Jack Breese, Dan Klein, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 473 Topics
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Notes on Machine Learning for and
 Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
10-701/15-781, Machine Learning: Homework 4
 10-701/15-781, Machine Learning: Homewor 4 Aarti Singh Carnegie Mellon University ˆ The assignment is due at 10:30 am beginning of class on Mon, Nov 15, 2010. ˆ Separate you answers into five parts, one
10-701/15-781, Machine Learning: Homewor 4 Aarti Singh Carnegie Mellon University ˆ The assignment is due at 10:30 am beginning of class on Mon, Nov 15, 2010. ˆ Separate you answers into five parts, one
Week 5: Logistic Regression & Neural Networks
 Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Unsupervised learning (part 1) Lecture 19
 Lecture 19") Unsupervised learning (part 1) Lecture 19 David Sontag New York University Slides adapted from Carlos Guestrin, Dan Klein, Luke Ze@lemoyer, Dan Weld, Vibhav Gogate, and Andrew Moore Bayesian networks enable
Unsupervised learning (part 1) Lecture 19 David Sontag New York University Slides adapted from Carlos Guestrin, Dan Klein, Luke Ze@lemoyer, Dan Weld, Vibhav Gogate, and Andrew Moore Bayesian networks enable
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Machine Learning for Data Science (CS4786) Lecture 12
 Lecture 12") Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Directed Graphical Models
 Directed Graphical Models Instructor: Alan Ritter Many Slides from Tom Mitchell Graphical Models Key Idea: Conditional independence assumptions useful but Naïve Bayes is extreme! Graphical models express
Directed Graphical Models Instructor: Alan Ritter Many Slides from Tom Mitchell Graphical Models Key Idea: Conditional independence assumptions useful but Naïve Bayes is extreme! Graphical models express
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
Expectation Maximization
 Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
Bayes Nets III: Inference
 1 Hal Daumé III (me@hal3.name) Bayes Nets III: Inference Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 10 Apr 2012 Many slides courtesy
1 Hal Daumé III (me@hal3.name) Bayes Nets III: Inference Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 10 Apr 2012 Many slides courtesy
Mixture of Gaussians Models
 Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Approximate Inference
 Approximate Inference Simulation has a name: sampling Sampling is a hot topic in machine learning, and it s really simple Basic idea: Draw N samples from a sampling distribution S Compute an approximate
Approximate Inference Simulation has a name: sampling Sampling is a hot topic in machine learning, and it s really simple Basic idea: Draw N samples from a sampling distribution S Compute an approximate
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
CS 188: Artificial Intelligence. Bayes Nets
 CS 188: Artificial Intelligence Probabilistic Inference: Enumeration, Variable Elimination, Sampling Pieter Abbeel UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew
CS 188: Artificial Intelligence Probabilistic Inference: Enumeration, Variable Elimination, Sampling Pieter Abbeel UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew
Bayesian Learning. Two Roles for Bayesian Methods. Bayes Theorem. Choosing Hypotheses
 Bayesian Learning Two Roles for Bayesian Methods Probabilistic approach to inference. Quantities of interest are governed by prob. dist. and optimal decisions can be made by reasoning about these prob.
Bayesian Learning Two Roles for Bayesian Methods Probabilistic approach to inference. Quantities of interest are governed by prob. dist. and optimal decisions can be made by reasoning about these prob.
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Hidden Markov Models and Gaussian Mixture Models
 Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Basic Sampling Methods
 Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
Data Preprocessing. Cluster Similarity
 1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017
 COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
Structure Learning in Bayesian Networks (mostly Chow-Liu)
") Structure Learning in Bayesian Networks (mostly Chow-Liu) Sue Ann Hong /5/007 Chow-Liu Give directions to edges in MST Chow-Liu: how-to e.g. () & () I(X, X ) = x =0 val = 0, I(X i, X j ) = x i,x j ˆP (xi,
Structure Learning in Bayesian Networks (mostly Chow-Liu) Sue Ann Hong /5/007 Chow-Liu Give directions to edges in MST Chow-Liu: how-to e.g. () & () I(X, X ) = x =0 val = 0, I(X i, X j ) = x i,x j ˆP (xi,
Learning Theory Continued
 Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Machine Learning and Data Mining. Bayes Classifiers. Prof. Alexander Ihler
 + Machine Learning and Data Mining Bayes Classifiers Prof. Alexander Ihler A basic classifier Training data D={x (i),y (i) }, Classifier f(x ; D) Discrete feature vector x f(x ; D) is a con@ngency table
+ Machine Learning and Data Mining Bayes Classifiers Prof. Alexander Ihler A basic classifier Training data D={x (i),y (i) }, Classifier f(x ; D) Discrete feature vector x f(x ; D) is a con@ngency table
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
VC-dimension for characterizing classifiers
 VC-dimension for characterizing classifiers Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to
VC-dimension for characterizing classifiers Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to
Lecture 9: PGM Learning
 13 Oct 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I Learning parameters in MRFs 1 Learning parameters in MRFs Inference and Learning Given parameters (of potentials) and
13 Oct 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I Learning parameters in MRFs 1 Learning parameters in MRFs Inference and Learning Given parameters (of potentials) and
Machine Learning, Midterm Exam
 10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
1 EM Primer. CS4786/5786: Machine Learning for Data Science, Spring /24/2015: Assignment 3: EM, graphical models
 CS4786/5786: Machine Learning for Data Science, Spring 2015 4/24/2015: Assignment 3: EM, graphical models Due Tuesday May 5th at 11:59pm on CMS. Submit what you have at least once by an hour before that
CS4786/5786: Machine Learning for Data Science, Spring 2015 4/24/2015: Assignment 3: EM, graphical models Due Tuesday May 5th at 11:59pm on CMS. Submit what you have at least once by an hour before that
BN Semantics 3 Now it s personal!
 Readings: K&F: 3.3, 3.4 BN Semantics 3 Now it s personal! Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2008 10-708 Carlos Guestrin 2006-2008 1 Independencies encoded
Readings: K&F: 3.3, 3.4 BN Semantics 3 Now it s personal! Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2008 10-708 Carlos Guestrin 2006-2008 1 Independencies encoded
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 Discriminative vs Generative Models Discriminative: Just learn a decision boundary between your
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 Discriminative vs Generative Models Discriminative: Just learn a decision boundary between your
Unsupervised Learning: K- Means & PCA
 Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Mixture Models, Density Estimation, Factor Analysis Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 2: 1 late day to hand it in now. Assignment 3: Posted,
CPSC 540: Machine Learning Mixture Models, Density Estimation, Factor Analysis Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 2: 1 late day to hand it in now. Assignment 3: Posted,
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
Decision Trees. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. February 5 th, Carlos Guestrin 1
 Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Introduction to Bayesian Learning. Machine Learning Fall 2018
 Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mobile Robot Localization
 Mobile Robot Localization 1 The Problem of Robot Localization Given a map of the environment, how can a robot determine its pose (planar coordinates + orientation)? Two sources of uncertainty: - observations
Mobile Robot Localization 1 The Problem of Robot Localization Given a map of the environment, how can a robot determine its pose (planar coordinates + orientation)? Two sources of uncertainty: - observations
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
What you need to know about Kalman Filters
 Readings: K&F: 4.5, 12.2, 12.3, 12.4, 18.1, 18.2, 18.3, 18.4 Switching Kalman Filter Dynamic Bayesian Networks Graphical Models 10708 Carlos Guestrin Carnegie Mellon University November 27 th, 2006 1 What
Readings: K&F: 4.5, 12.2, 12.3, 12.4, 18.1, 18.2, 18.3, 18.4 Switching Kalman Filter Dynamic Bayesian Networks Graphical Models 10708 Carlos Guestrin Carnegie Mellon University November 27 th, 2006 1 What
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Physics 403. Segev BenZvi. Numerical Methods, Maximum Likelihood, and Least Squares. Department of Physics and Astronomy University of Rochester
 Physics 403 Numerical Methods, Maximum Likelihood, and Least Squares Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Quadratic Approximation
Physics 403 Numerical Methods, Maximum Likelihood, and Least Squares Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Quadratic Approximation