Learning strategies for neuronal nets - the backpropagation algorithm
|
|
|
- Louisa Davis
- 6 years ago
- Views:
Transcription
1 Learning strategies for neuronal nets - the backpropagation algorithm In contrast to the NNs with thresholds we handled until now NNs are the NNs with non-linear activation functions f(x). The most common function is the sigmoid function ψ(x): f( x) = ψ ( x) = + e ax It approxmiates with increasing a the step function σ(x) a
2 The function ψ(x) is closely related to the tanh function. For a= applies: 2 tanh( x) = = 2 ψ (2 x) 2x + e If the two parameter a and b are added, a more general form results: ( ) = + e ψ g x a( x b) with a controlling the sheerness and with b controlling the position on the x-axis. The non-linearity of the activation function is the core reason for the existence of the multi-layer perceptron; without this property the multi-layer perceptron would coincide with a trivial linear one-layered network. The differentiability of f(x) allows us to apply neccessary constraints ( ( )/ w i,j ) for optimization of the weight coefficients w i,j. The first derivate of the sigmoid function can be ascribed to itself: dψ x = ( ) e = ( ) = ψ( x)( ψ( x)) x 2 x x dx ( + e ) + e + e
3 Figure of the extended weight matrix w,0 = b w, w,2 w, N w2,0 b2 w2, w2,2 w =, N W = w3,0 = b3 w3, w3,2 w, N = wm,0 = bm wm, wm,2 w M, N [ b, W]
4 The neural net with H layers The multi-layer NN with H layers has a peculiar weight matrix W i in every layer, but identical sigmoid-functions: x y W W 2 y 2 y H- W H yh H 2 y = ψ( W H ψ( W ψ( Wx) )) { } { 2 } 2 H yˆ y min y y J = min E = E i The learning is based on adjustment of the weight matrices with minimization of a square error criterion between target value y and approximation ŷ by the net (supervised learning) in mind. The expected value has to be formed by the available training ensemble of {ŷ j,x j }: W W Note: The one-layer nn and the linear polynom classifier are identical, if the activation function is set to ψ. i
5 Relations to the concept of function approximation by a linear combination of base functions The first layer creates the base functions in form of a hidden vector y and the second layer forms a linear combination of these base functions. Therefore the coefficient matrix W of the first layer controls the appearance of the base functions, while the weight matrix W 2 of the second layer contains the coefficients of the linear combination. Additionally the matrix is weighted through the activation function.
6 Reaction of a neuron with two inputs and a threshold function σ

7 Reaction of a neuron with two inputs and a sigmoid function ψ

8 Overlapping two neurons with two inputs each and a sigmoid function
9 Reaction of a neuron in the second layer to two neurons of first layer after valuation by sigmoid function
10 The backpropagation learning algorithm The class map is done by a multi-layer perceptron, which produces a on the output in the regions of x, that are populated by the samples of the according class, and produces a 0 in the areas allocated by other classes. In the areas inbetween and outside an interpolation resp. extrapolation is done. The network ist trained based on the optimization of the squared quality factor: { yw ˆ( i, x) y 2 } J = E This term is non-linear both in the elements of the input-vector x, and in the weight coefficients {w ijh }.
11 From insertion of the function map of the multi-layer perceptron results: J 2 H 2 = E ψ( W ψ( W ψ( W x ) )) y yˆ Sought is the global minimum. It is not clear whether such an element exists or how many local minima exist. The backpropagation algorithm solves the problem iteratively with a gradient algorithm. One iterates according to: 2 H { } W W α J with: W = W, W,, W and the gradients: J J J = = h W w nm The iteration terminates, when the gradient disappears at a (local or even global) minimum. A proper choice of α is difficult. Small values increase the number of required iterations. High values reduce the probabilty of running into a local minimum, risking the method to diverge and not finding the minimum (or giving rise to oscillations).
12 The iteration has only linear convergence (gradient algorithm). Calculating the gradient: For determination of the composed function the chain rule is needed. yˆ( x ) = ψ W ψ W ψ W x The error caused by a sample results in: H 2 ( ( ( ) )) H N 2 ˆ ˆ j = 2 yx j y j = 2 k k k= J ( ) ( y ( j) y ( j)) 2 The expected value E{...} of the gradient has to be approximated by a mean value of all sample gradients: n n J = J j= j
13 We have to distinguish between individual learning based on the last sample x, y J j j j and cumulative learning (batch learning), based on Partial derivations for one layer: For the r-th layer applies: n n J = J j= j r N r r r r ym = ψ( sm) = ψ w nmx n n= 0 r x n-th input of layer r y n r m m-th output of layer r
14 Definition of the variables of two layers for the backpropagation algorithm + f + f + f + r s j r δ j f r y j + r s k r δ k f r y k r w jk + f layer r- layer r
15 First of all we calculate the effect of the last hidden layer on the starting layer r=h. Using partial derivations of the quality function J (actually J j, but j is omitted for simplification reasons) and applying the chain rule results: introducing the sensibility of cell n J δ n = s results: δ and thus for update of weights: H H J J sn H sn = = δ H H H n H w nm sn w nm w nm J wneu = walt + w with w= α w w = αδ y = α ( y yˆ ) f ( s ) y = y H H H H H nm n m n n n m n H m H J J yˆ n H = = = ( y yˆ ) f ( s ) H H H s yˆ s H n n n n n n n N H 2 2 ( yˆ k yk)) k= yˆ n
16 For all other hidden layers r <H the thoughts behind are a litte more complex. Due to dependencies amongst each other, the values of s j r- have an effect on all elements s kr of the following layer. Using the chain rule results in: J J s = r r r sj k s k sj r δ j r k δ r k With results: r f ( s m ) w y s s r r km m r m k r r = = w ( ) r r kj f s j j sj r ( r δ ) r r j = f sj w kjδ k k i.e. the errors backpropagate from the starting layer to lower layers!
17 All learning samples are crossed without any changes of the weight coefficients, and the gradient J results by forming the mean value of the J j. Both values can be used for update of the parameter matrix W of the perceptron: W = W α J k+ k j W = W α J k+ k individual learning batch learning The gradients J and J j differ. The latter is the mean value of the first ( J = E{ J j }), or: the first value is random value of the latter.
18 The whole individual learning procedure consists of these steps: Choose interim values for the coefficient matrices W,W 2,...,W H of all layers Given a new observation [x j, ŷ j ] Calculate the discrimination function ŷ j from the given observation x j and the current weight matrices (forward calculation) Calculate the error between estimation ŷ and target vector y: y= ŷ-y Calculate the gradient J regarding to all perceptron weights (error backpropagation). To do so calculate first δ jh of the starting layer according to: δ H J J yˆ n H = = = ( y yˆ ) f ( s ) H H H s yˆ s H j j j j n n n and calculate from this backwards all values of the lower layers according to: r ( r δ ) r r j = f sj w kjδk für r = H, H,,2 k
19 considering the first derivate of the sigmoid function f(s)=ψ(s): dψ () s f () s = = ψ()( s ψ()) s = y( y) ds (Parallely) correct all perceptron weights according to: r =, 2, H J w w w y n N m=, 2, M r r r r r H nm nm α = nm αδn m für =,2, r w nm H For individual learning the weights {w nmh } are corrected with J for every sample, while for batch learning all learning samples have to be considered, in order to determine the averaged gradient J from the sequence { J}, before the weights can be corrected according to: r =, 2, H w w i y i n N r r r r H nm nm αδn () m () für =,2, i H m=, 2, M
20 Backpropagation algorithm for matrices Choose interim values for the coefficient matrices W,W 2,...,W H of all layers Given a new observation [x j, ŷ j ] Calculate the discrimination function ŷ j from the given observation x j and the current weight matrices (forward calculation). Store all values of y r and s r in all layers inbetween r =,2,,H. Calculate the error between estimation ŷ and target vector y on the output: y= ŷ-y Calculate the gradient J regarding all perceptron weights (error backpropagation). To do so first calculate δ H of the starting layer according to: H H J J yˆ H δ = = = ( y yˆ ) f ( s ) H H H s yˆ s and calculate from this backwards all values of the lower layers according to: T r r r δ = f ( s ) ( W δ ) für r = H, H,,2
21 considering the first derivate of the sigmoid function f(s)=ψ(s): dψ () s f () s = = ψ()( s ψ()) s = y( y) ds Individual leraning: (parallely) correct all perceptron weight matrices with J for every sample according to: W r r J r r ( r ) W α = α T für r =, 2, H r W W δ y Cumulative learning: all samples have to be considered, in order to determine the averaged value J from the sequence of the { J}, before the weights can be corrected according to: T W W α δ y für r =,2, H r r r ( r ) j j j
22 Properties: The backpropagation algorithm is simple to implement, but very complex especially for large coefficient matrices, which causes the number of samples to be large as well. The dependency of the method on the starting values of the weights, the correction factor α, and the order of processing the samples have also an adverse effect. Linear dependencies remain unconsidered, just like for recursive training of the polynom classifier. The gradient algorithm has the advantage that it can be used for very large problems. The dimension of the coefficient matrix W results from the dimensions of the input vector, the masked layers, and the output vector (N,N,..., N H-,K) as: H h h 0 H dim( W) ( ) with and T = = N + N N = N N = K h= N = dim( x) feature space K = dim( yˆ ) number of classes
23 Dimensioning the net The considerations for designing the multi-layer perceptron with threshold function (σ resp. sign) gives quite a good idea how many hidden-layers and how many neurons should be used for a MLPC for backpropagation learning (assumed one has a certain idea of distribution of clusters). The net is to be chosen as simple as possible. The higher the dimension the higher the risk of overfitting, accompanied by a loss of ability to generalize. Also higher dimension allows a lot of local maximas, which can cause the algorithm to get stuck! For a given number of samples, the learning phase should be stopped at a certain point. If not stopped the net is overfitted to the existing data and looses its ablility to generalize. error testing training epochs
24 Complexity of backpropagation algorithm For T=dim(W) number of weights and bias terms, linear complexity in the number of weights can be easily understood, since O(T) computation steps are needed for forward simulation, O(T) steps are needed for backpropagation of the error and also O(T) operations for correction of weights, altogether: O(T). If gradients would be determined experimentally by finite differences (on order to do so, one would have to increment each weight and determine the effect on the quality criterion by forward calculation) by calculating a differential quotient according to (i.e. no analytical evaluation): J w r ji r r J( wji + ε ) J( wji ) = + O( ε ) ε T forward calculations of complexity O(T) would result and therefore a overall (?) complexity of O(T 2 )
25 Backpropagation for training a two-layer network for function approximation (Matlab demo: Backpropagation Calculation) w, + x + w 2, + b b 2 δ s δ s 2 2 y y 2 2 w, 2 w,2 2 δ 2 s 2 b y 2 = yˆ y = ψ( W x + b ) = ψ( Wx ) = ψ( s ) w, b mit: W = und = b w2, b yˆ = y = ( + b ) mit: W Wy = w w 2 2 2,,2 Sought is an approximation of the function yx ( ) = + sin( x) for 2 x 2 π 4
26 Backpropagation for training a two-layer network for function approximation Backpropagation: For output layer or second layer with linear activation function results due to f =: ( yˆ ) 2 δ = y Backpropagation: For first layer with sigmoid function results: δ j = f ( s ) j w, jδ = yj( yj) w, jδ for j =,2 Correction of weights in the output layer: w = y b = j = , j αδ j and αδ for, 2 Correction of weights in the input layer: wj, = αδ jx and bj = αδ j for j =, 2

27 Starting Matlab demo matlab-bpc.bat
28 Backpropagation for training a two-layer network for function approximation (Matlab demo: Function Approximation) Sought is an approximation of the function yx ( ) = + sin( i x) for 2 x 2 π 4 With increasing value of i (difficulty index) the MLPC network requirements increase. The approximation based on the sigmoid function needs more and more layers in order to depict several periods of the sinus function. Problem: Convergence to local minima, even when the network is big enough to represent the function The network is too small, so that approximation is poor, i.e. the global minimum can be reached, but approximation quality is poor (i=8 and network -3-) The network is big enough, so that approximation is good, but it converges towards a local minimum (i=4 and network -3-)
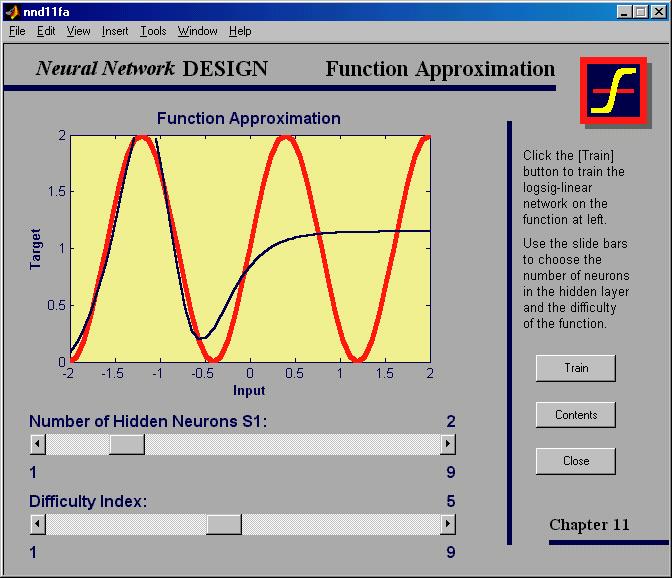
29
30 Starting Matlab demo matlab-fa.bat

31 Model big enough but only local minimum
32 Generalization ability of the network Assuming that the network is trained for samples { y, x },{ y, x }, { y, x } 2 2 How well does the network approximate the function for samples not learned depending on the complexity of the network? Starting Matlab demo (Hagan -2) matlab-general.bat Rule: The network should have fewer parameters than the available input/output pairs
33 Improving the ability to generalize of a net by adding noise If only few samples are available, the generalization ability of a nn can be improved by extending the number of samples e.g. by normally distributed noise. i.e. adding further samples, which can be found in the nearest neighbourhood with high probablity. In doing so the intra class areas are broadened and the borders between classes are sharpened. class 2 class
34 Interpolation by overlapping of normal distributions.4 W eighted Sum of Radial Basis Transfer Functions I t yx ( ) = αi fi( x ti)

35 Interpolation by overlapping of normal distributions

36 Character recognition task for 26 letters of size 7 5 with gradually increasing additive noise:
37 Two-layer neural net for symbol recognition with 35 input values (pixel), 0 neurons in the hidden layer and 26 neurons in the output layer first layer second layer x W N S N= 0 35 b + s S = 0 ψ y W 2 S = 0 S 2 S = 26 0 b 2 + s 2 S 2 = 26 ψ y 2 S 2 = 26 N=35 S = 0 S = 0 S 2 = 26 S 2 = 26 y =f (W x+b ) y 2 =f 2 (W 2 y +b 2 ) y 2 = ψ(w 2 ψ(w x+b )+b 2 )
38 Demo with MATLAB Opening Matlab Demo in Toolbox Neural Networks Character recognition (command line) Two networks are trained network without noise network 2 with noise Network 2 has better results than network considering an independent set of test data Starting Matlab demo matlab-cr.bat
39 Possibilites to accelerate the adaption Adaption of NN is simply a general parameter optimization problem. Accordingly a variety of other optimization methods from numerical mathematics could be applied in principle. This can lead to significant improvements (convergence speed, convergence area, stability, complexity). In general conclusions cannot be made easily, since the events can differ a lot and compromises have to be made! Heuristic improvements of the gradient algorithm (increment control) gradient algorithm (steepest descent) with momentum term (update of weights depends not only on gradient but also on former update) using an adaptive learning factor Conjugate gradient algorithm
40 Newton and Semi-Newton-algorithms (using the second derivatives of the error function, e.g. in form of Hesse mtrix or its estimation) Quickprop Levenberg-Marquardt-algorithm Taylor expansion of quality function in w : T T J( w+ w) = J( w) + J w+ w H w+ terms of higher order J with: J = gradient vector w 2 J and: H = Hesse matrix wi wj 2 Pruning techniques. Starting with a sufficiently big network, neurons, that have no or little effect on the quality function, are taken off the net, which can reduce overfitting of data.
41 Demo with MATLAB (Demo of Theodoridis) C:\...\matlab\PR\startdemo Example 2 (XOR) with (2-2- and ) Example 3 with three-layer network [5,5] (3000 epochs, learning rate 0,7, momentum 0,5) Two solutions of the XOR-problem: Start der Matlab-Demo matlab-theodoridis.bat does not converge! Convex area implemented with two-layer net (2-2-). Possible mal-classification for variance: Union of 2 convex areas implemented with a three-layer net (2-5-5-). Possible malclassification for variance: n > n > 0, ,35
 combination cannot be reached and the gradient")
42 XOR with high noise in order to activate second solution! With two lines a error-free (exact) combination cannot be reached and the gradient is still different from 0!
43
44
45 Demo with MATLAB (Klassifikationgui.m) Opening Matlab first invoke setmypath.m, then C:\Home\ppt\Lehre\ME_2002\matlab\KlassifikatorEntwurf- WinXX\Klassifikationgui set of data: load Samples/xor2.mat Setting: 500 epochs, learning rate 0.7 load weight matrices: models/xor-trivial.mat load weight matrices : models/xor-3.mat Two-class problem with banana shape load set of data Samples/banana_test_samples.mat load presetting from: models/mlp_7_3_2_banana.mat Starting Matlab-Demo matlab-klassifikation_gui.bat

46 Solution of the XOR-problem with two-layer nn

47 Solution of the XOR-problem with two-layer nn
48 Solution of the XOR-problem with three-layer nn
49 Solution of the XOR-problem with three-layer nn
50
51
52 Convergence behaviour of backpropagation algorithm Backpropagation with common gradient descent (steepest descent) Starting Matlab demo matlab-bp-gradient.bat Backpropagation with conjugate gradient descent (conjugate gradient) significantly better convergence! Starting Matlab demo matlab-bp-cggradient.bat
53 NN and their properties Quick and Dirty. A nn design is simple to implement and results in solutions are by all means usable (a suboptimal solution is better than just any solution). Particularly large problems can be solved. All strategies only use local optimization functions and generally do not reach a global optimum, which is a big draw back for using neural nets.
54 Using a NN for iterative calculation of Principal Component Analysis (KLT) Instead of solving the KLT explicitely by finding Eigen values, a nn can be used for iterative calculation. A two-layer perceptron is used. The output of the hidden layer w is the feature vector sought. T A A x M ˆx N w N The first layer calculates the feature vector as: w = T A x
55 Supposing a linear activation function is used. The second layer implements the reconstruction of x with the transposed weight matrix of the first layer A ˆ = x = Aw Target of optimization is to minimize: { } { } { 2 } 2 2 T xˆ x Aw x AA x x J = E = E = E The following learning rule: T A A α( Aw x) w = A α J leads to a coefficient matrix A, which can be written as a product of two matrices (without proof!): B T M B M is a N M-matrix of the M dominant Eigenvectors of E{xx T } and T a orthonormal M M matrix, which causes a rotation of the coordinate system, within the space that is spanned by the M dominant Eigenvectors of E{xx T }.
56 The learning strategy does not include translation. i.e. this strategy calculates the Eigenvectors of the moment matrix E{xx T } and not of the covariance matrix K = E{(x-µ x )(x- µ x ) T }. This can be implemented by subtracting a recursively estimated expected value µ x = E{x} before starting the recursive estimation of the feature vector. The same effect can be retrieved by using an extended observation vector: x = x instead of x
Multilayer Neural Networks
 Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Computational Intelligence Winter Term 2017/18
 Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Neuro-Fuzzy Comp. Ch. 4 March 24, R p
 4 Feedforward Multilayer Neural Networks part I Feedforward multilayer neural networks (introduced in sec 17) with supervised error correcting learning are used to approximate (synthesise) a non-linear
4 Feedforward Multilayer Neural Networks part I Feedforward multilayer neural networks (introduced in sec 17) with supervised error correcting learning are used to approximate (synthesise) a non-linear
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Neural Networks Lecture 3:Multi-Layer Perceptron
 Neural Networks Lecture 3:Multi-Layer Perceptron H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011 H. A. Talebi, Farzaneh Abdollahi Neural
Neural Networks Lecture 3:Multi-Layer Perceptron H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011 H. A. Talebi, Farzaneh Abdollahi Neural
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Computational Intelligence
 Plan for Today Single-Layer Perceptron Computational Intelligence Winter Term 00/ Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Accelerated Learning
Plan for Today Single-Layer Perceptron Computational Intelligence Winter Term 00/ Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Accelerated Learning
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Artificial Neural Networks Examination, March 2004
 Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Artificial Neural Network
 Artificial Neural Network Eung Je Woo Department of Biomedical Engineering Impedance Imaging Research Center (IIRC) Kyung Hee University Korea ejwoo@khu.ac.kr Neuron and Neuron Model McCulloch and Pitts
Artificial Neural Network Eung Je Woo Department of Biomedical Engineering Impedance Imaging Research Center (IIRC) Kyung Hee University Korea ejwoo@khu.ac.kr Neuron and Neuron Model McCulloch and Pitts
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Vasil Khalidov & Miles Hansard. C.M. Bishop s PRML: Chapter 5; Neural Networks
 C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation
 1 Introduction A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation J Wesley Hines Nuclear Engineering Department The University of Tennessee Knoxville, Tennessee,
1 Introduction A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation J Wesley Hines Nuclear Engineering Department The University of Tennessee Knoxville, Tennessee,
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Artificial Neural Networks Examination, June 2004
 Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
C4 Phenomenological Modeling - Regression & Neural Networks : Computational Modeling and Simulation Instructor: Linwei Wang
 C4 Phenomenological Modeling - Regression & Neural Networks 4040-849-03: Computational Modeling and Simulation Instructor: Linwei Wang Recall.. The simple, multiple linear regression function ŷ(x) = a
C4 Phenomenological Modeling - Regression & Neural Networks 4040-849-03: Computational Modeling and Simulation Instructor: Linwei Wang Recall.. The simple, multiple linear regression function ŷ(x) = a
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Multilayer Perceptrons (MLPs)
") CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Automatic Differentiation and Neural Networks
 Statistical Machine Learning Notes 7 Automatic Differentiation and Neural Networks Instructor: Justin Domke 1 Introduction The name neural network is sometimes used to refer to many things (e.g. Hopfield
Statistical Machine Learning Notes 7 Automatic Differentiation and Neural Networks Instructor: Justin Domke 1 Introduction The name neural network is sometimes used to refer to many things (e.g. Hopfield
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Chapter 3 Supervised learning:
 Chapter 3 Supervised learning: Multilayer Networks I Backpropagation Learning Architecture: Feedforward network of at least one layer of non-linear hidden nodes, e.g., # of layers L 2 (not counting the
Chapter 3 Supervised learning: Multilayer Networks I Backpropagation Learning Architecture: Feedforward network of at least one layer of non-linear hidden nodes, e.g., # of layers L 2 (not counting the
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
8. Lecture Neural Networks
 Soft Control (AT 3, RMA) 8. Lecture Neural Networks Learning Process Contents of the 8 th lecture 1. Introduction of Soft Control: Definition and Limitations, Basics of Intelligent" Systems 2. Knowledge
Soft Control (AT 3, RMA) 8. Lecture Neural Networks Learning Process Contents of the 8 th lecture 1. Introduction of Soft Control: Definition and Limitations, Basics of Intelligent" Systems 2. Knowledge
The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural
 learning techniques for neural") 1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
Neural Networks. Xiaojin Zhu Computer Sciences Department University of Wisconsin, Madison. slide 1
 Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Backpropagation: The Good, the Bad and the Ugly
 Backpropagation: The Good, the Bad and the Ugly The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no October 3, 2017 Supervised Learning Constant feedback from
Backpropagation: The Good, the Bad and the Ugly The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no October 3, 2017 Supervised Learning Constant feedback from
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Supervised Learning in Neural Networks
 The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no March 7, 2011 Supervised Learning Constant feedback from an instructor, indicating not only right/wrong, but
The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no March 7, 2011 Supervised Learning Constant feedback from an instructor, indicating not only right/wrong, but
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning
 LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning") CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
Neuro-Fuzzy Comp. Ch. 4 June 1, 2005
 Neuro-Fuzz Comp Ch 4 June, 25 4 Feedforward Multilaer Neural Networks part I Feedforward multilaer neural networks (introduced in sec 7) with supervised error correcting learning are used to approximate
Neuro-Fuzz Comp Ch 4 June, 25 4 Feedforward Multilaer Neural Networks part I Feedforward multilaer neural networks (introduced in sec 7) with supervised error correcting learning are used to approximate
Chapter ML:VI (continued)
") Chapter ML:VI (continued) VI Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-64 Neural Networks STEIN 2005-2018 Definition 1 (Linear Separability)
Chapter ML:VI (continued) VI Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-64 Neural Networks STEIN 2005-2018 Definition 1 (Linear Separability)
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Neural Networks DWML, /25
 DWML, 2007 /25 Neural networks: Biological and artificial Consider humans: Neuron switching time 0.00 second Number of neurons 0 0 Connections per neuron 0 4-0 5 Scene recognition time 0. sec 00 inference
DWML, 2007 /25 Neural networks: Biological and artificial Consider humans: Neuron switching time 0.00 second Number of neurons 0 0 Connections per neuron 0 4-0 5 Scene recognition time 0. sec 00 inference
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Machine Learning (CSE 446): Neural Networks
: Neural Networks") Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Lecture 7 Artificial neural networks: Supervised learning
 Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Machine Learning: Multi Layer Perceptrons
 Machine Learning: Multi Layer Perceptrons Prof. Dr. Martin Riedmiller Albert-Ludwigs-University Freiburg AG Maschinelles Lernen Machine Learning: Multi Layer Perceptrons p.1/61 Outline multi layer perceptrons
Machine Learning: Multi Layer Perceptrons Prof. Dr. Martin Riedmiller Albert-Ludwigs-University Freiburg AG Maschinelles Lernen Machine Learning: Multi Layer Perceptrons p.1/61 Outline multi layer perceptrons
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Radial-Basis Function Networks
 Radial-Basis Function etworks A function is radial basis () if its output depends on (is a non-increasing function of) the distance of the input from a given stored vector. s represent local receptors,
Radial-Basis Function etworks A function is radial basis () if its output depends on (is a non-increasing function of) the distance of the input from a given stored vector. s represent local receptors,
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Neural Networks Lecture 4: Radial Bases Function Networks
 Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
ADAPTIVE NEURO-FUZZY INFERENCE SYSTEMS
 ADAPTIVE NEURO-FUZZY INFERENCE SYSTEMS RBFN and TS systems Equivalent if the following hold: Both RBFN and TS use same aggregation method for output (weighted sum or weighted average) Number of basis functions
ADAPTIVE NEURO-FUZZY INFERENCE SYSTEMS RBFN and TS systems Equivalent if the following hold: Both RBFN and TS use same aggregation method for output (weighted sum or weighted average) Number of basis functions
Radial-Basis Function Networks
 Radial-Basis Function etworks A function is radial () if its output depends on (is a nonincreasing function of) the distance of the input from a given stored vector. s represent local receptors, as illustrated
Radial-Basis Function etworks A function is radial () if its output depends on (is a nonincreasing function of) the distance of the input from a given stored vector. s represent local receptors, as illustrated
Gradient Descent Training Rule: The Details
 Gradient Descent Training Rule: The Details 1 For Perceptrons The whole idea behind gradient descent is to gradually, but consistently, decrease the output error by adjusting the weights. The trick is
Gradient Descent Training Rule: The Details 1 For Perceptrons The whole idea behind gradient descent is to gradually, but consistently, decrease the output error by adjusting the weights. The trick is
BACKPROPAGATION. Neural network training optimization problem. Deriving backpropagation
 BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
Tutorial on Machine Learning for Advanced Electronics
 Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Feed-forward Networks Network Training Error Backpropagation Applications. Neural Networks. Oliver Schulte - CMPT 726. Bishop PRML Ch.
 Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will