Statistical Methods in Clinical Trials Categorical Data
|
|
|
- Brian Higgins
- 6 years ago
- Views:
Transcription
1 Statistical Methods in Clinical Trials Categorical Data
2 Types of Data quantitative Continuous Blood pressure Time to event Categorical sex qualitative Discrete No of relapses Ordered Categorical Pain level
3 Types of data analysis (Inference) Parametric Vs Non parametric Model based Vs Data driven Frequentist Vs Bayesian
4 Categorical data In a RCT, endpoints and surrogate endpoints can be categorical or ordered categorical variables. In the simplest cases we have binary responses (e.g. responders non-responders). In Outcomes research it is common to use many ordered categories (no improvement, moderate improvement, high improvement). Example: Binary outcomes: Remission Mortality Presence/absence of an AE Responder/non-responder according to some pre-defined criteria Success/Failure
5 Two proportions Sometimes, we want to compare the proportion of successes in two separate groups. For this purpose we take two samples of sizes n1 and n2. We let yi1 and pi1 be the observed number of subjects and the proportion of successes in the ith group. The difference in population proportions of successes and its large sample variance can be estimated by
6 Two proportions (continued) Assume we want to test the null hypothesis that there is no difference between the proportions of success in the two groups. Under the null hypothesis, we can estimate the common proportion by Its large sample variance is estimated by Leading to the test statistic
7 Example NINDS trial in acute ischemic stroke Treatment n responders* rt-pa (47.1%) placebo (39.1%) *early improvement defined on a neurological scale Point estimate: (s.e.=0.0397) 95% CI: (0.003 ; 0.158) p-value: 0.043
8 Two proportions (Chi square) The problem of comparing two proportions can sometimes be formulated as a problem of independence! Assume we have two groups as above (treatment and placebo). Assume further that the subjects were randomized to these groups. We can then test for independence between belonging to a certain group and the clinical endpoint (success or failure). The data can be organized in the form of a contingency table in which the marginal totals and the total number of subjects are considered as fixed.
9 2 x 2 Contingency table R E S P O N S E Failure Success Total T R E A T M E N T Drug Placebo Total N=624
10 Hyper geometric distribution n balls are drawn at random without replacement. Y is the number of white balls (successes) Y follows the Hyper geometric Distribution with parameters (N, W, n) Urn containing W white balls and R red balls: N=W+R
11 Contingency tables N subjects in total y.1 of these are special (success) y1. are drawn at random Y11 no of successes among these y1. Y11 is HG(N,y.1,y 1.) in general
12 Contingency tables The null hypothesis of independence is tested using the (Pearson) chi square statistic Which, under the null hypothesis, is chi square distributed with one degree of freedom provided the sample sizes in the two groups are large (over 30) and the expected frequency in each cell is non negligible (over 5)
13 Contingency tables For moderate sample sizes we use Fisher s exact test. According to this calculate the desired probabilities using the exact Hyper-geometric distribution. The variance can then be calculated. To illustrate consider: Using this and expectation m11 we have the randomization chi square statistic. With fixed margins only one cell is allowed to vary. Randomization is crucial for this approach.
14 The (Pearson) Chi-square test The test-statistic is: 2 p i j (O ij E ij E ij ) 2 where y ij = observed frequencies and m ij = expected frequencies (under independence) the test-statistic approximately follows a chi-square distribution
15 Example 5 Chi-square test for a 22 table Examining the independence between two treatments and a classification into responder/non-responder is equivalent to comparing the proportion of responders in the two groups NINDS again non-resp responder rt-pa Observed frequencies placebo Expected frequencies non-resp responder rt-pa placebo
16 TABLE OF GRP BY Y S A S o u t p u t Frequency Row Pct nonresp resp Total ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ placebo ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ rt-pa ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ Total STATISTICS FOR TABLE OF GRP BY Y Statistic DF Value Prob ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ Chi-Square Likelihood Ratio Chi-Square Continuity Adj. Chi-Square Mantel-Haenszel Chi-Square Fisher's Exact Test (Left) (Right) (2-Tail) Phi Coefficient Contingency Coefficient Cramer's V Sample Size = 624
17 Odds, Odds Ratios and relative Risks The odds of success in group i is estimated by The odds ratio of success between the two groups i is estimated by Define risk for success in the ith group as the proportion of cases with success. The relative risk between the two groups is estimated by Absolute Risk = AR = p 11 p 21
18 Nominal Categorical data E.g. patient residence at end of follow-up (hospital, nursing home, own home, etc.) Ordinal (ordered) E.g. some global rating Normal, not at all ill Borderline mentally ill Mildly ill Moderately ill Markedly ill Severely ill Among the most extremely ill patients
19 Categorical data & Chi-square test Other factor A B C D E i n ia n ib n ic n id n ie n i One Factor ii n iia n iib n iic n iid n iie n ii iii n iiia n iiib n iiic n iiid n iiie n iii n A n B n C n D n E n ia The chi-square test is useful for detection of a general association between treatment and categorical response (in either the nominal or ordinal scale), but it cannot identify a particular relationship, e.g. a location shift.
20 Nominal categorical data Disease category dip snip fup bop other treatment A group B Chi-square test: 2 = 3.084, df=4, p = 0.544
21 Ordered categorical data Here we assume two groups one receiving the drug and one placebo. The response is assumed to be ordered categorical with J categories. The null hypothesis is that the distribution of subjects in response categories is the same for both groups. Again the randomization and the HG distribution lead to the same chi square test statistic but this time with (J-1) df. Moreover the same relationship exists between the two versions of the chi square statistic.
22 The Mantel-Haensel statistic The aim here is to combine data from several (H) strata for comparing two groups drug and placebo. The expected frequency and the variance for each stratum are used to define the Mantel- Haensel statistic which is chi square distributed with one df.
23 Logistic regression Logistic regression is part of a category of statistical models called generalized linear models (GLM). This broad class of models includes ordinary regression and ANOVA, as well as multivariate statistics such as ANCOVA and loglinear regression. An excellent treatment of generalized linear models is presented in Agresti (1996). Logistic regression allows one to predict a discrete outcome, such as group membership, from a set of variables that may be continuous, discrete, dichotomous, or a mix of any of these. Generally, the dependent or response variable is dichotomous, such as presence/absence or success/failure.
24 Multiple logistic regression More than one independent variable Dichotomous, ordinal, nominal, continuous ln P 1-P α β 1 x 1 β 2 x 2... β i x i Interpretation of b i Increase in log-odds for a one unit increase in x i with all the other x i s constant Measures association between x i and logodds adjusted for all other x i
25 Fitting equation to the data Linear regression: Least squares or Maximum likelihood Logistic regression: Maximum likelihood Likelihood function Estimates parameters b Practically easier to work with log-likelihood
26 Statistical testing Question Does model including given independent variable provide more information about dependent variable than model without this variable? Three tests Likelihood ratio statistic (LRS) Wald test Score test
27 Likelihood ratio statistic Compares two nested models Log(odds) = + b 1 x 1 + b 2 x 2 + b 3 x 3 (model 1) Log(odds) = + b 1 x 1 + b 2 x 2 (model 2) LR statistic -2 log (likelihood model 2 / likelihood model 1) = -2 log (likelihood model 2) minus -2log (likelihood model 1) LR statistic is a 2 with DF = number of extra parameters in model
28 Example 6 Fitting a Logistic regression model to the NINDS data, using only one covariate (treatment group). NINDS again non-resp responder Observed frequencies rt-pa placebo
29 S A S o u t p u t The LOGISTIC Procedure Response Profile Ordered Binary Value Outcome Count 1 EVENT NO EVENT 355 Model Fitting Information and Testing Global Null Hypothesis BETA=0 Intercept Intercept and Criterion Only Covariates Chi-Square for Covariates AIC SC LOG L Score with 1 DF (p=0.0432) with 1 DF (p=0.0433) Analysis of Maximum Likelihood Estimates Parameter Standard Wald Pr > Standardized Odds Variable DF Estimate Error Chi-Square Chi-Square Estimate Ratio INTERCPT GRP

30

31


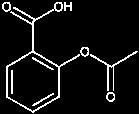
32 David Brennan CEO of AstraZeneca
33 ?
34 4 measures of association (effect) Quite often we are interested in risk and probabilty only as a way to measure association or effect: cure is associated with drug = the drug has an effect This can be done in different ways 1. Relative Risk (Prospective Studies) 2. Odds Ratio (Prospective or Retrospective) 3. Absolute Risk (Prospective Studies) 4. (Number Needed totreat) (Prospective Studies)
35 Absolute Risk Difference Between Proportions of outcomes in 2 groups 1 and 2. Estimated absolute risk ^ 1 n n ^ ^ 2 ^ AR 1 2 n n 95% Confidence Interval for Population Absolute Risk ^ ^ ^ ^ AR 1.96 New drug n n (0.115, 0.205) 1. 95% Standard drug AR Cured Association No association - Association Not cured 354 Group Total Total
36 Number Neede to Treat
37 NNT Assume n subjects take one treatment and n subjects take a second treatment. Let X1 and X2 be the number of successful treatments in the two cases and p1 and p2 denote the probabilities of sucess in the two groups. Assume further that we can use the binomial distribution. Then the average difference between the two groups and the number needed to treat can be calculated according to ) ( 1 1 ) ( ), ( ] [ ] [, ] [ ), ( p p n p p n p p n X E X E np X E p n Bin X i i i i
38 Number needed to treat Definition: The number needed to be treated to prevent 1 event is calculated as the inverse of the absolute risk difference: NNT 1 AR ^ NNT is frequently used in clinical trials to provide an insight into the clinical relevance of the effect of treatment under investigation. It is often claimed that its popularity depends on its simplicity and intuitive interpretation. Cured ^ 2 Not cured Group Total AR ^ ^ New drug Standard drug Total
39 Issues with NNT NNT should be completed with follow up period and unfavourable event avoided. NNT presupposes that there is statistically significant difference (*). How much NNT is good? No magic figure: (10-500) risky surgerey standard inexpensive drug with no side effect active treatment preventive treatment etc. NNT Statistical properties? Confidence intervals? When AR = 0, NNT becomes infinite! The distribution of NNT is complicated because its behavior around AR = 0; The moments of NNT do not exist; Simple calculations with NNT like can give nonsensical results. 1 AR 1 ^ ˆ ˆ1 2
40 Example 8 In a study it was reported that the absolute risk reduction for patients with moderate baseline stroke severity as being 16.6%. The number needed to treat is thus 1/0.166 or approximately 6. This benefit was statistically significant: the 95% confidence interval for the absolute risk reduction was [0.9%, 32.2%]. A 95% confidence interval for the number needed to treat is [1/0.009, 1/0.322] or approximately [3.1, 111.1]. This all seems quite straightforward, but what if we try the calculation for a non-significant result, for example, for patients with low baseline stroke severity. The absolute risk reduction was 6.6% with a 95% confidence interval of [ 20.9%, 34.1%]. Naively taking reciprocals gives a number needed to treat of about 15.2 and an apparent 95% confidence interval of [-4.8, 2.9], which does not seem to include 15.2! Clearly something s wrong.
41 To understand the source of the confusion, note first that the lower limit of the confidence interval for the absolute risk reduction is negative, because the data do not rule out the possibility that the treatment is actually harmful for this group of patients. The reciprocal of this lower limit is 4.8, or a number needed to harm of 4.8. A better description of positive and negative values of the number needed to treat would be the number needed to treat for one additional patient to benefit (or be harmed), or NNTB and NNTH respectively. The 95% confidence interval for the absolute risk reduction thus extends from a NNTH of 4.8 at one extreme to a NNTB of 2.9 at the other.
42 To understand what such a confidence interval covers, imagine for a moment that the absolute risk reduction had only just been significant, with a confidence interval extending from slightly more than 0% to 34.1%. The confidence interval for the number needed to treat would now extend from 2.9 to something approaching infinity. This would indicate that, according to the data, for one additional patient to benefit, a clinician would need to treat at least 2.9 patients (the reciprocal of 34.1%), but perhaps an extremely large number of patients. Thus, when a confidence interval for an absolute risk reduction overlaps zero, the corresponding confidence interval for the number needed to treat includes infinity. This explains the confusion in the case of the patients with low baseline stroke severity: the 95% confidence interval does, after all, contain the point estimate (see fig. below). The estimated number needed to treat and its confidence interval can be quoted as NNTB = 15.2 (95% confidence interval NNTH 4.8 to to NNTB 2.9).
43 [ 20.9%, 34.1%] [ 4, ) [2.9,,) Confidence intervals for absolute risk reduction and number needed to treat for benefit (NNTB) or harm (NNTH) for patients with low baseline stroke severity.
44 In other words, for this group of patients, it could be that, on average, treating as few as 3 patients would result in one additional patient benefiting. On the other hand, it could be that, on average, treating as few as 5 patients would result in one additional patient being harmed. It is important that a nonsignificant number needed to treat has a confidence interval with 2 parts, one allowing for the possibility that the treatment is actually harmful, and the other for the possibility that the treatment is beneficial.
45 Maximum likelihood Invariance Property of MLE s If qˆ θ is the MLE of some parameter θ and t(.) is a one-to-one function, then h(ˆθ) ˆ t ( q ) is the MLE of t (q. ) The invariance property for ML estimators cannot apply here for the following reason: For a one dimensional parameter q a function of this parameter t(q) must have a single valued inverse in order to have ˆ t ( q ) t ( ˆ) q Bimodality and the range of definition make convergence to normality difficult to achieve (slow) for small sample sizes.
46 Unbiasedeness Unbiasedness is a matter of scale: if qˆ q is unbiased for q then t(q qˆ ) will be biased for t(q) unless t is the identity function. Moreover the singularity at 0 implies that NNT cannot be bias corrected. Attempts to improve the behaviour of the estimator by reducing the bias will fail.
47 Testing No simple test of no treatment effect can be constructed for the supposedly simple and comprehensible NNT. This is because this corresponds to a value of for the parameter (a z-statistic of the form ( ˆ q ) / SE.
48 Generalized Mixed Effects Models 48 Date
49 Various forms of models and relation between them Classical statistics (Observations are random, parameters are unknown constants) LM: Assumptions: 1. independence, 2. normality, LMM: Assumptions 1) and 3) are modified Repeated measures: Assumptions 1) and 3) are modified 3. constant parameters GLM: assumption 2) Exponential family GLMM: Assumption 2) Exponential family and assumptions 1) and 3) are modified Maximum likelihood Longitudinal data LM - Linear model GLM - Generalised linear model LMM - Linear mixed model GLMM - Generalised linear mixed model Bayesian statistics Non-linear models Name, department 49 Date
50 Exponential families Exponential family comprises a set of flexible distribution ranging both continuous and discrete random variables. The members of this family have many important properties which merits discussing them in some general format. Many of the usual probability distributions are specific members of this family: Gaussian Bernoull Binomial - Von mises - Gamma Poisson Exponential - Beta: (0; 1) Weibull etc
51 Generalized linear Models: Name, department 51 Date
52 The Bernoulli distribution Name, department 52 Date
53 Generalized Linear Models Name, department 53 Date
54 Generalised Linear Mixed Models Name, department 54 Date
55 Name, department 55 Date
56 Name, department 56 Date
57 Empirical Bayes estimates Name, department 57 Date
58 Example 1 (cont d) Name, department 58 Date
59 Name, department 59 Date
60 A Bayesian alternative
61 Infection vs. poverty Some studies from the year 1990 suggested that the risk to CHD is associated with childhood poverty. Since infection with the bacterium H. Pylori is also linked to poverty, some researchers suspected H. Pylori to be the missing link. In a study where levels of infections were considered in patients and controls, the following results were obtained. Using the data below, the chi square statistic having, the value 4.37 yields a p-value of 0.03 which is less than the formal level of significance CHD Healthy Control High 60% 39% Low 40% 61%
62 Let us try a bayesian alternative: Since we have no theoretical reason to believe that the above result is true, we take P(H0)=0.5. P[H 0 D] BF 2 1 BF 1 BF 1 BF BF 1 Berger and Selke (1987) have shown that for a very wide range of cases including this one BF e Using the value 4.73 for the chi square variable leads to a BF value of at least Reference: M. A. Mendall et al Relation betweenh. Pylori infection and coronary heart disease. Heart J. (1994)).
63 Conclusion P[H 0 D] Taking other (more or less sceptical) attitude does not change a the conclusion that much: P(H0)=0.75 => P[ H0 D] > (0.5) P(H0)=0.25 => P[ H0 D] > (0.1)
64 Bayesian properties of NNT Let D = (x1, x2, n1, n2) represent data from some trial. Assuming independent Beta(αi, βi ) prior distributions for the pi leads to the joint posterior distribution of (p1, p2) as a product of independent Beta distributions. Apart from mathematical tractability, beta priors offer great flexibility of distributional shape. One can obtain the posterior distribution of the difference p=(p1 -p2) or that of NNT = 1/p by simple transformation, and using Markov chain Monte Carlo (MCMC) to simulate directly from the posterior 2 distributions. The posterior mean p μp and variance of p are respectively given by 1 E[ p i p i 2 and D] ( x i 2 p 2 i1 n ) /( n i i i i (1 i ) b 1 b 1), i i i i i 1,2.
65 Asymptotically, p will have a Normal posterior distribution with 2 mean μp and variance p. The common practice is to estimate NNT by 1/μp and the corresponding interval estimate is given by the 95% credible interval ( p 1.96 ) Making the transformation to y = 1/p = NNT, we find that the asymptotic distribution of Y is given by 1 2 ( p) 1 y f ( y D) exp p y p This density is known as the inverse normal distribution (Johnson et al., 1995, p. 171). It is a special case of the generalized inverse normal family of density functions considered by Robert (1991). The mean and variance of this distribution do not exist. p 1
66 However, the distribution has two modes at Thus the point estimate of NNT would be given by NNT2 when there is efficacy and by NNT1 when the control treatment dominates the experimental. The figure below shows graphs of for different values of μp and σp. We observe from the figure that the pdf based on μp < 0 is a mirror image of that of μp > ˆ and, 4 8 ˆ p p p p p p p p NNT NNT
67
LISA Short Course Series Generalized Linear Models (GLMs) & Categorical Data Analysis (CDA) in R. Liang (Sally) Shan Nov. 4, 2014
 & Categorical Data Analysis (CDA) in R. Liang (Sally) Shan Nov. 4, 2014") LISA Short Course Series Generalized Linear Models (GLMs) & Categorical Data Analysis (CDA) in R Liang (Sally) Shan Nov. 4, 2014 L Laboratory for Interdisciplinary Statistical Analysis LISA helps VT researchers
LISA Short Course Series Generalized Linear Models (GLMs) & Categorical Data Analysis (CDA) in R Liang (Sally) Shan Nov. 4, 2014 L Laboratory for Interdisciplinary Statistical Analysis LISA helps VT researchers
Review. Timothy Hanson. Department of Statistics, University of South Carolina. Stat 770: Categorical Data Analysis
 Review Timothy Hanson Department of Statistics, University of South Carolina Stat 770: Categorical Data Analysis 1 / 22 Chapter 1: background Nominal, ordinal, interval data. Distributions: Poisson, binomial,
Review Timothy Hanson Department of Statistics, University of South Carolina Stat 770: Categorical Data Analysis 1 / 22 Chapter 1: background Nominal, ordinal, interval data. Distributions: Poisson, binomial,
Stat 5101 Lecture Notes
 Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Testing Independence
 Testing Independence Dipankar Bandyopadhyay Department of Biostatistics, Virginia Commonwealth University BIOS 625: Categorical Data & GLM 1/50 Testing Independence Previously, we looked at RR = OR = 1
Testing Independence Dipankar Bandyopadhyay Department of Biostatistics, Virginia Commonwealth University BIOS 625: Categorical Data & GLM 1/50 Testing Independence Previously, we looked at RR = OR = 1
Discrete Multivariate Statistics
 Discrete Multivariate Statistics Univariate Discrete Random variables Let X be a discrete random variable which, in this module, will be assumed to take a finite number of t different values which are
Discrete Multivariate Statistics Univariate Discrete Random variables Let X be a discrete random variable which, in this module, will be assumed to take a finite number of t different values which are
CHL 5225 H Crossover Trials. CHL 5225 H Crossover Trials
 CHL 55 H Crossover Trials The Two-sequence, Two-Treatment, Two-period Crossover Trial Definition A trial in which patients are randomly allocated to one of two sequences of treatments (either 1 then, or
CHL 55 H Crossover Trials The Two-sequence, Two-Treatment, Two-period Crossover Trial Definition A trial in which patients are randomly allocated to one of two sequences of treatments (either 1 then, or
STA 4504/5503 Sample Exam 1 Spring 2011 Categorical Data Analysis. 1. Indicate whether each of the following is true (T) or false (F).
 or false (F).") STA 4504/5503 Sample Exam 1 Spring 2011 Categorical Data Analysis 1. Indicate whether each of the following is true (T) or false (F). (a) T In 2 2 tables, statistical independence is equivalent to a population
STA 4504/5503 Sample Exam 1 Spring 2011 Categorical Data Analysis 1. Indicate whether each of the following is true (T) or false (F). (a) T In 2 2 tables, statistical independence is equivalent to a population
Generalized, Linear, and Mixed Models
 Generalized, Linear, and Mixed Models CHARLES E. McCULLOCH SHAYLER.SEARLE Departments of Statistical Science and Biometrics Cornell University A WILEY-INTERSCIENCE PUBLICATION JOHN WILEY & SONS, INC. New
Generalized, Linear, and Mixed Models CHARLES E. McCULLOCH SHAYLER.SEARLE Departments of Statistical Science and Biometrics Cornell University A WILEY-INTERSCIENCE PUBLICATION JOHN WILEY & SONS, INC. New
Parameter estimation and forecasting. Cristiano Porciani AIfA, Uni-Bonn
 Parameter estimation and forecasting Cristiano Porciani AIfA, Uni-Bonn Questions? C. Porciani Estimation & forecasting 2 Temperature fluctuations Variance at multipole l (angle ~180o/l) C. Porciani Estimation
Parameter estimation and forecasting Cristiano Porciani AIfA, Uni-Bonn Questions? C. Porciani Estimation & forecasting 2 Temperature fluctuations Variance at multipole l (angle ~180o/l) C. Porciani Estimation
STA6938-Logistic Regression Model
 Dr. Ying Zhang STA6938-Logistic Regression Model Topic 2-Multiple Logistic Regression Model Outlines:. Model Fitting 2. Statistical Inference for Multiple Logistic Regression Model 3. Interpretation of
Dr. Ying Zhang STA6938-Logistic Regression Model Topic 2-Multiple Logistic Regression Model Outlines:. Model Fitting 2. Statistical Inference for Multiple Logistic Regression Model 3. Interpretation of
Fall 2017 STAT 532 Homework Peter Hoff. 1. Let P be a probability measure on a collection of sets A.
 1. Let P be a probability measure on a collection of sets A. (a) For each n N, let H n be a set in A such that H n H n+1. Show that P (H n ) monotonically converges to P ( k=1 H k) as n. (b) For each n
1. Let P be a probability measure on a collection of sets A. (a) For each n N, let H n be a set in A such that H n H n+1. Show that P (H n ) monotonically converges to P ( k=1 H k) as n. (b) For each n
PART I INTRODUCTION The meaning of probability Basic definitions for frequentist statistics and Bayesian inference Bayesian inference Combinatorics
 Table of Preface page xi PART I INTRODUCTION 1 1 The meaning of probability 3 1.1 Classical definition of probability 3 1.2 Statistical definition of probability 9 1.3 Bayesian understanding of probability
Table of Preface page xi PART I INTRODUCTION 1 1 The meaning of probability 3 1.1 Classical definition of probability 3 1.2 Statistical definition of probability 9 1.3 Bayesian understanding of probability
STA 4504/5503 Sample Exam 1 Spring 2011 Categorical Data Analysis. 1. Indicate whether each of the following is true (T) or false (F).
 or false (F).") STA 4504/5503 Sample Exam 1 Spring 2011 Categorical Data Analysis 1. Indicate whether each of the following is true (T) or false (F). (a) (b) (c) (d) (e) In 2 2 tables, statistical independence is equivalent
STA 4504/5503 Sample Exam 1 Spring 2011 Categorical Data Analysis 1. Indicate whether each of the following is true (T) or false (F). (a) (b) (c) (d) (e) In 2 2 tables, statistical independence is equivalent
Logistic Regression. James H. Steiger. Department of Psychology and Human Development Vanderbilt University
 Logistic Regression James H. Steiger Department of Psychology and Human Development Vanderbilt University James H. Steiger (Vanderbilt University) Logistic Regression 1 / 38 Logistic Regression 1 Introduction
Logistic Regression James H. Steiger Department of Psychology and Human Development Vanderbilt University James H. Steiger (Vanderbilt University) Logistic Regression 1 / 38 Logistic Regression 1 Introduction
Simple logistic regression
 Simple logistic regression Biometry 755 Spring 2009 Simple logistic regression p. 1/47 Model assumptions 1. The observed data are independent realizations of a binary response variable Y that follows a
Simple logistic regression Biometry 755 Spring 2009 Simple logistic regression p. 1/47 Model assumptions 1. The observed data are independent realizations of a binary response variable Y that follows a
Good Confidence Intervals for Categorical Data Analyses. Alan Agresti
 Good Confidence Intervals for Categorical Data Analyses Alan Agresti Department of Statistics, University of Florida visiting Statistics Department, Harvard University LSHTM, July 22, 2011 p. 1/36 Outline
Good Confidence Intervals for Categorical Data Analyses Alan Agresti Department of Statistics, University of Florida visiting Statistics Department, Harvard University LSHTM, July 22, 2011 p. 1/36 Outline
Subject CS1 Actuarial Statistics 1 Core Principles
 Institute of Actuaries of India Subject CS1 Actuarial Statistics 1 Core Principles For 2019 Examinations Aim The aim of the Actuarial Statistics 1 subject is to provide a grounding in mathematical and
Institute of Actuaries of India Subject CS1 Actuarial Statistics 1 Core Principles For 2019 Examinations Aim The aim of the Actuarial Statistics 1 subject is to provide a grounding in mathematical and
Binomial Model. Lecture 10: Introduction to Logistic Regression. Logistic Regression. Binomial Distribution. n independent trials
 Lecture : Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 27 Binomial Model n independent trials (e.g., coin tosses) p = probability of success on each trial (e.g., p =! =
Lecture : Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 27 Binomial Model n independent trials (e.g., coin tosses) p = probability of success on each trial (e.g., p =! =
Bayesian inference for sample surveys. Roderick Little Module 2: Bayesian models for simple random samples
 Bayesian inference for sample surveys Roderick Little Module : Bayesian models for simple random samples Superpopulation Modeling: Estimating parameters Various principles: least squares, method of moments,
Bayesian inference for sample surveys Roderick Little Module : Bayesian models for simple random samples Superpopulation Modeling: Estimating parameters Various principles: least squares, method of moments,
EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7
 Introduction to Generalized Univariate Models: Models for Binary Outcomes EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7 EPSY 905: Intro to Generalized In This Lecture A short review
Introduction to Generalized Univariate Models: Models for Binary Outcomes EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7 EPSY 905: Intro to Generalized In This Lecture A short review
Generalized Linear. Mixed Models. Methods and Applications. Modern Concepts, Walter W. Stroup. Texts in Statistical Science.
 Texts in Statistical Science Generalized Linear Mixed Models Modern Concepts, Methods and Applications Walter W. Stroup CRC Press Taylor & Francis Croup Boca Raton London New York CRC Press is an imprint
Texts in Statistical Science Generalized Linear Mixed Models Modern Concepts, Methods and Applications Walter W. Stroup CRC Press Taylor & Francis Croup Boca Raton London New York CRC Press is an imprint
Case Study in the Use of Bayesian Hierarchical Modeling and Simulation for Design and Analysis of a Clinical Trial
 Case Study in the Use of Bayesian Hierarchical Modeling and Simulation for Design and Analysis of a Clinical Trial William R. Gillespie Pharsight Corporation Cary, North Carolina, USA PAGE 2003 Verona,
Case Study in the Use of Bayesian Hierarchical Modeling and Simulation for Design and Analysis of a Clinical Trial William R. Gillespie Pharsight Corporation Cary, North Carolina, USA PAGE 2003 Verona,
Lecture 2: Linear Models. Bruce Walsh lecture notes Seattle SISG -Mixed Model Course version 23 June 2011
 Lecture 2: Linear Models Bruce Walsh lecture notes Seattle SISG -Mixed Model Course version 23 June 2011 1 Quick Review of the Major Points The general linear model can be written as y = X! + e y = vector
Lecture 2: Linear Models Bruce Walsh lecture notes Seattle SISG -Mixed Model Course version 23 June 2011 1 Quick Review of the Major Points The general linear model can be written as y = X! + e y = vector
Lecture 3.1 Basic Logistic LDA
 y Lecture.1 Basic Logistic LDA 0.2.4.6.8 1 Outline Quick Refresher on Ordinary Logistic Regression and Stata Women s employment example Cross-Over Trial LDA Example -100-50 0 50 100 -- Longitudinal Data
y Lecture.1 Basic Logistic LDA 0.2.4.6.8 1 Outline Quick Refresher on Ordinary Logistic Regression and Stata Women s employment example Cross-Over Trial LDA Example -100-50 0 50 100 -- Longitudinal Data
Multinomial Logistic Regression Models
 Stat 544, Lecture 19 1 Multinomial Logistic Regression Models Polytomous responses. Logistic regression can be extended to handle responses that are polytomous, i.e. taking r>2 categories. (Note: The word
Stat 544, Lecture 19 1 Multinomial Logistic Regression Models Polytomous responses. Logistic regression can be extended to handle responses that are polytomous, i.e. taking r>2 categories. (Note: The word
Correlation and regression
 1 Correlation and regression Yongjua Laosiritaworn Introductory on Field Epidemiology 6 July 2015, Thailand Data 2 Illustrative data (Doll, 1955) 3 Scatter plot 4 Doll, 1955 5 6 Correlation coefficient,
1 Correlation and regression Yongjua Laosiritaworn Introductory on Field Epidemiology 6 July 2015, Thailand Data 2 Illustrative data (Doll, 1955) 3 Scatter plot 4 Doll, 1955 5 6 Correlation coefficient,
Practice Problems Section Problems
 Practice Problems Section 4-4-3 4-4 4-5 4-6 4-7 4-8 4-10 Supplemental Problems 4-1 to 4-9 4-13, 14, 15, 17, 19, 0 4-3, 34, 36, 38 4-47, 49, 5, 54, 55 4-59, 60, 63 4-66, 68, 69, 70, 74 4-79, 81, 84 4-85,
Practice Problems Section 4-4-3 4-4 4-5 4-6 4-7 4-8 4-10 Supplemental Problems 4-1 to 4-9 4-13, 14, 15, 17, 19, 0 4-3, 34, 36, 38 4-47, 49, 5, 54, 55 4-59, 60, 63 4-66, 68, 69, 70, 74 4-79, 81, 84 4-85,
Semiparametric Generalized Linear Models
 Semiparametric Generalized Linear Models North American Stata Users Group Meeting Chicago, Illinois Paul Rathouz Department of Health Studies University of Chicago prathouz@uchicago.edu Liping Gao MS Student
Semiparametric Generalized Linear Models North American Stata Users Group Meeting Chicago, Illinois Paul Rathouz Department of Health Studies University of Chicago prathouz@uchicago.edu Liping Gao MS Student
ST3241 Categorical Data Analysis I Generalized Linear Models. Introduction and Some Examples
 ST3241 Categorical Data Analysis I Generalized Linear Models Introduction and Some Examples 1 Introduction We have discussed methods for analyzing associations in two-way and three-way tables. Now we will
ST3241 Categorical Data Analysis I Generalized Linear Models Introduction and Some Examples 1 Introduction We have discussed methods for analyzing associations in two-way and three-way tables. Now we will
Lecture 01: Introduction
 Lecture 01: Introduction Dipankar Bandyopadhyay, Ph.D. BMTRY 711: Analysis of Categorical Data Spring 2011 Division of Biostatistics and Epidemiology Medical University of South Carolina Lecture 01: Introduction
Lecture 01: Introduction Dipankar Bandyopadhyay, Ph.D. BMTRY 711: Analysis of Categorical Data Spring 2011 Division of Biostatistics and Epidemiology Medical University of South Carolina Lecture 01: Introduction
Department of Statistical Science FIRST YEAR EXAM - SPRING 2017
 Department of Statistical Science Duke University FIRST YEAR EXAM - SPRING 017 Monday May 8th 017, 9:00 AM 1:00 PM NOTES: PLEASE READ CAREFULLY BEFORE BEGINNING EXAM! 1. Do not write solutions on the exam;
Department of Statistical Science Duke University FIRST YEAR EXAM - SPRING 017 Monday May 8th 017, 9:00 AM 1:00 PM NOTES: PLEASE READ CAREFULLY BEFORE BEGINNING EXAM! 1. Do not write solutions on the exam;
Small n, σ known or unknown, underlying nongaussian
 READY GUIDE Summary Tables SUMMARY-1: Methods to compute some confidence intervals Parameter of Interest Conditions 95% CI Proportion (π) Large n, p 0 and p 1 Equation 12.11 Small n, any p Figure 12-4
READY GUIDE Summary Tables SUMMARY-1: Methods to compute some confidence intervals Parameter of Interest Conditions 95% CI Proportion (π) Large n, p 0 and p 1 Equation 12.11 Small n, any p Figure 12-4
Generalized Linear Models for Non-Normal Data
 Generalized Linear Models for Non-Normal Data Today s Class: 3 parts of a generalized model Models for binary outcomes Complications for generalized multivariate or multilevel models SPLH 861: Lecture
Generalized Linear Models for Non-Normal Data Today s Class: 3 parts of a generalized model Models for binary outcomes Complications for generalized multivariate or multilevel models SPLH 861: Lecture
Irr. Statistical Methods in Experimental Physics. 2nd Edition. Frederick James. World Scientific. CERN, Switzerland
 Frederick James CERN, Switzerland Statistical Methods in Experimental Physics 2nd Edition r i Irr 1- r ri Ibn World Scientific NEW JERSEY LONDON SINGAPORE BEIJING SHANGHAI HONG KONG TAIPEI CHENNAI CONTENTS
Frederick James CERN, Switzerland Statistical Methods in Experimental Physics 2nd Edition r i Irr 1- r ri Ibn World Scientific NEW JERSEY LONDON SINGAPORE BEIJING SHANGHAI HONG KONG TAIPEI CHENNAI CONTENTS
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation. EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016
 Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
8 Nominal and Ordinal Logistic Regression
 8 Nominal and Ordinal Logistic Regression 8.1 Introduction If the response variable is categorical, with more then two categories, then there are two options for generalized linear models. One relies on
8 Nominal and Ordinal Logistic Regression 8.1 Introduction If the response variable is categorical, with more then two categories, then there are two options for generalized linear models. One relies on
Lecture 10: Introduction to Logistic Regression
 Lecture 10: Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 2007 Logistic Regression Regression for a response variable that follows a binomial distribution Recall the binomial
Lecture 10: Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 2007 Logistic Regression Regression for a response variable that follows a binomial distribution Recall the binomial
Classification. Chapter Introduction. 6.2 The Bayes classifier
 Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
UNIVERSITY OF TORONTO. Faculty of Arts and Science APRIL 2010 EXAMINATIONS STA 303 H1S / STA 1002 HS. Duration - 3 hours. Aids Allowed: Calculator
 UNIVERSITY OF TORONTO Faculty of Arts and Science APRIL 2010 EXAMINATIONS STA 303 H1S / STA 1002 HS Duration - 3 hours Aids Allowed: Calculator LAST NAME: FIRST NAME: STUDENT NUMBER: There are 27 pages
UNIVERSITY OF TORONTO Faculty of Arts and Science APRIL 2010 EXAMINATIONS STA 303 H1S / STA 1002 HS Duration - 3 hours Aids Allowed: Calculator LAST NAME: FIRST NAME: STUDENT NUMBER: There are 27 pages
Non-maximum likelihood estimation and statistical inference for linear and nonlinear mixed models
 Optimum Design for Mixed Effects Non-Linear and generalized Linear Models Cambridge, August 9-12, 2011 Non-maximum likelihood estimation and statistical inference for linear and nonlinear mixed models
Optimum Design for Mixed Effects Non-Linear and generalized Linear Models Cambridge, August 9-12, 2011 Non-maximum likelihood estimation and statistical inference for linear and nonlinear mixed models
Unobservable Parameter. Observed Random Sample. Calculate Posterior. Choosing Prior. Conjugate prior. population proportion, p prior:
 Pi Priors Unobservable Parameter population proportion, p prior: π ( p) Conjugate prior π ( p) ~ Beta( a, b) same PDF family exponential family only Posterior π ( p y) ~ Beta( a + y, b + n y) Observed
Pi Priors Unobservable Parameter population proportion, p prior: π ( p) Conjugate prior π ( p) ~ Beta( a, b) same PDF family exponential family only Posterior π ( p y) ~ Beta( a + y, b + n y) Observed
Glossary for the Triola Statistics Series
 Glossary for the Triola Statistics Series Absolute deviation The measure of variation equal to the sum of the deviations of each value from the mean, divided by the number of values Acceptance sampling
Glossary for the Triola Statistics Series Absolute deviation The measure of variation equal to the sum of the deviations of each value from the mean, divided by the number of values Acceptance sampling
Mantel-Haenszel Test Statistics. for Correlated Binary Data. Department of Statistics, North Carolina State University. Raleigh, NC
 Mantel-Haenszel Test Statistics for Correlated Binary Data by Jie Zhang and Dennis D. Boos Department of Statistics, North Carolina State University Raleigh, NC 27695-8203 tel: (919) 515-1918 fax: (919)
Mantel-Haenszel Test Statistics for Correlated Binary Data by Jie Zhang and Dennis D. Boos Department of Statistics, North Carolina State University Raleigh, NC 27695-8203 tel: (919) 515-1918 fax: (919)
WU Weiterbildung. Linear Mixed Models
 Linear Mixed Effects Models WU Weiterbildung SLIDE 1 Outline 1 Estimation: ML vs. REML 2 Special Models On Two Levels Mixed ANOVA Or Random ANOVA Random Intercept Model Random Coefficients Model Intercept-and-Slopes-as-Outcomes
Linear Mixed Effects Models WU Weiterbildung SLIDE 1 Outline 1 Estimation: ML vs. REML 2 Special Models On Two Levels Mixed ANOVA Or Random ANOVA Random Intercept Model Random Coefficients Model Intercept-and-Slopes-as-Outcomes
Open Problems in Mixed Models
 xxiii Determining how to deal with a not positive definite covariance matrix of random effects, D during maximum likelihood estimation algorithms. Several strategies are discussed in Section 2.15. For
xxiii Determining how to deal with a not positive definite covariance matrix of random effects, D during maximum likelihood estimation algorithms. Several strategies are discussed in Section 2.15. For
Three-Way Contingency Tables
 Newsom PSY 50/60 Categorical Data Analysis, Fall 06 Three-Way Contingency Tables Three-way contingency tables involve three binary or categorical variables. I will stick mostly to the binary case to keep
Newsom PSY 50/60 Categorical Data Analysis, Fall 06 Three-Way Contingency Tables Three-way contingency tables involve three binary or categorical variables. I will stick mostly to the binary case to keep
TABLE OF CONTENTS CHAPTER 1 COMBINATORIAL PROBABILITY 1
 TABLE OF CONTENTS CHAPTER 1 COMBINATORIAL PROBABILITY 1 1.1 The Probability Model...1 1.2 Finite Discrete Models with Equally Likely Outcomes...5 1.2.1 Tree Diagrams...6 1.2.2 The Multiplication Principle...8
TABLE OF CONTENTS CHAPTER 1 COMBINATORIAL PROBABILITY 1 1.1 The Probability Model...1 1.2 Finite Discrete Models with Equally Likely Outcomes...5 1.2.1 Tree Diagrams...6 1.2.2 The Multiplication Principle...8
Linear Mixed Models. One-way layout REML. Likelihood. Another perspective. Relationship to classical ideas. Drawbacks.
 Linear Mixed Models One-way layout Y = Xβ + Zb + ɛ where X and Z are specified design matrices, β is a vector of fixed effect coefficients, b and ɛ are random, mean zero, Gaussian if needed. Usually think
Linear Mixed Models One-way layout Y = Xβ + Zb + ɛ where X and Z are specified design matrices, β is a vector of fixed effect coefficients, b and ɛ are random, mean zero, Gaussian if needed. Usually think
Hypothesis Testing. Part I. James J. Heckman University of Chicago. Econ 312 This draft, April 20, 2006
 Hypothesis Testing Part I James J. Heckman University of Chicago Econ 312 This draft, April 20, 2006 1 1 A Brief Review of Hypothesis Testing and Its Uses values and pure significance tests (R.A. Fisher)
Hypothesis Testing Part I James J. Heckman University of Chicago Econ 312 This draft, April 20, 2006 1 1 A Brief Review of Hypothesis Testing and Its Uses values and pure significance tests (R.A. Fisher)
Chapter 1. Modeling Basics
 Chapter 1. Modeling Basics What is a model? Model equation and probability distribution Types of model effects Writing models in matrix form Summary 1 What is a statistical model? A model is a mathematical
Chapter 1. Modeling Basics What is a model? Model equation and probability distribution Types of model effects Writing models in matrix form Summary 1 What is a statistical model? A model is a mathematical
Primer on statistics:
 Primer on statistics: MLE, Confidence Intervals, and Hypothesis Testing ryan.reece@gmail.com http://rreece.github.io/ Insight Data Science - AI Fellows Workshop Feb 16, 018 Outline 1. Maximum likelihood
Primer on statistics: MLE, Confidence Intervals, and Hypothesis Testing ryan.reece@gmail.com http://rreece.github.io/ Insight Data Science - AI Fellows Workshop Feb 16, 018 Outline 1. Maximum likelihood
Unit 9: Inferences for Proportions and Count Data
 Unit 9: Inferences for Proportions and Count Data Statistics 571: Statistical Methods Ramón V. León 12/15/2008 Unit 9 - Stat 571 - Ramón V. León 1 Large Sample Confidence Interval for Proportion ( pˆ p)
Unit 9: Inferences for Proportions and Count Data Statistics 571: Statistical Methods Ramón V. León 12/15/2008 Unit 9 - Stat 571 - Ramón V. León 1 Large Sample Confidence Interval for Proportion ( pˆ p)
Categorical Data Analysis Chapter 3
 Categorical Data Analysis Chapter 3 The actual coverage probability is usually a bit higher than the nominal level. Confidence intervals for association parameteres Consider the odds ratio in the 2x2 table,
Categorical Data Analysis Chapter 3 The actual coverage probability is usually a bit higher than the nominal level. Confidence intervals for association parameteres Consider the odds ratio in the 2x2 table,
Review: what is a linear model. Y = β 0 + β 1 X 1 + β 2 X 2 + A model of the following form:
 Outline for today What is a generalized linear model Linear predictors and link functions Example: fit a constant (the proportion) Analysis of deviance table Example: fit dose-response data using logistic
Outline for today What is a generalized linear model Linear predictors and link functions Example: fit a constant (the proportion) Analysis of deviance table Example: fit dose-response data using logistic
9 Generalized Linear Models
 9 Generalized Linear Models The Generalized Linear Model (GLM) is a model which has been built to include a wide range of different models you already know, e.g. ANOVA and multiple linear regression models
9 Generalized Linear Models The Generalized Linear Model (GLM) is a model which has been built to include a wide range of different models you already know, e.g. ANOVA and multiple linear regression models
Review of Statistics 101
 Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
Introduction to Statistical Analysis
 Introduction to Statistical Analysis Changyu Shen Richard A. and Susan F. Smith Center for Outcomes Research in Cardiology Beth Israel Deaconess Medical Center Harvard Medical School Objectives Descriptive
Introduction to Statistical Analysis Changyu Shen Richard A. and Susan F. Smith Center for Outcomes Research in Cardiology Beth Israel Deaconess Medical Center Harvard Medical School Objectives Descriptive
Logistic Regression. Interpretation of linear regression. Other types of outcomes. 0-1 response variable: Wound infection. Usual linear regression
 Logistic Regression Usual linear regression (repetition) y i = b 0 + b 1 x 1i + b 2 x 2i + e i, e i N(0,σ 2 ) or: y i N(b 0 + b 1 x 1i + b 2 x 2i,σ 2 ) Example (DGA, p. 336): E(PEmax) = 47.355 + 1.024
Logistic Regression Usual linear regression (repetition) y i = b 0 + b 1 x 1i + b 2 x 2i + e i, e i N(0,σ 2 ) or: y i N(b 0 + b 1 x 1i + b 2 x 2i,σ 2 ) Example (DGA, p. 336): E(PEmax) = 47.355 + 1.024
Glossary. The ISI glossary of statistical terms provides definitions in a number of different languages:
 Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
A simulation study for comparing testing statistics in response-adaptive randomization
 RESEARCH ARTICLE Open Access A simulation study for comparing testing statistics in response-adaptive randomization Xuemin Gu 1, J Jack Lee 2* Abstract Background: Response-adaptive randomizations are
RESEARCH ARTICLE Open Access A simulation study for comparing testing statistics in response-adaptive randomization Xuemin Gu 1, J Jack Lee 2* Abstract Background: Response-adaptive randomizations are
Statistical Data Analysis Stat 3: p-values, parameter estimation
 Statistical Data Analysis Stat 3: p-values, parameter estimation London Postgraduate Lectures on Particle Physics; University of London MSci course PH4515 Glen Cowan Physics Department Royal Holloway,
Statistical Data Analysis Stat 3: p-values, parameter estimation London Postgraduate Lectures on Particle Physics; University of London MSci course PH4515 Glen Cowan Physics Department Royal Holloway,
n y π y (1 π) n y +ylogπ +(n y)log(1 π).
 n y +ylogπ +(n y)log(1 π).") Tests for a binomial probability π Let Y bin(n,π). The likelihood is L(π) = n y π y (1 π) n y and the log-likelihood is L(π) = log n y +ylogπ +(n y)log(1 π). So L (π) = y π n y 1 π. 1 Solving for π gives
Tests for a binomial probability π Let Y bin(n,π). The likelihood is L(π) = n y π y (1 π) n y and the log-likelihood is L(π) = log n y +ylogπ +(n y)log(1 π). So L (π) = y π n y 1 π. 1 Solving for π gives
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
NATIONAL UNIVERSITY OF SINGAPORE EXAMINATION. ST3241 Categorical Data Analysis. (Semester II: ) April/May, 2011 Time Allowed : 2 Hours
 April/May, 2011 Time Allowed : 2 Hours") NATIONAL UNIVERSITY OF SINGAPORE EXAMINATION Categorical Data Analysis (Semester II: 2010 2011) April/May, 2011 Time Allowed : 2 Hours Matriculation No: Seat No: Grade Table Question 1 2 3 4 5 6 Full marks
NATIONAL UNIVERSITY OF SINGAPORE EXAMINATION Categorical Data Analysis (Semester II: 2010 2011) April/May, 2011 Time Allowed : 2 Hours Matriculation No: Seat No: Grade Table Question 1 2 3 4 5 6 Full marks
Lecture 5: Poisson and logistic regression
 Dankmar Böhning Southampton Statistical Sciences Research Institute University of Southampton, UK S 3 RI, 3-5 March 2014 introduction to Poisson regression application to the BELCAP study introduction
Dankmar Böhning Southampton Statistical Sciences Research Institute University of Southampton, UK S 3 RI, 3-5 March 2014 introduction to Poisson regression application to the BELCAP study introduction
Chapter 1 Statistical Inference
 Chapter 1 Statistical Inference causal inference To infer causality, you need a randomized experiment (or a huge observational study and lots of outside information). inference to populations Generalizations
Chapter 1 Statistical Inference causal inference To infer causality, you need a randomized experiment (or a huge observational study and lots of outside information). inference to populations Generalizations
Generalized Linear Models
 York SPIDA John Fox Notes Generalized Linear Models Copyright 2010 by John Fox Generalized Linear Models 1 1. Topics I The structure of generalized linear models I Poisson and other generalized linear
York SPIDA John Fox Notes Generalized Linear Models Copyright 2010 by John Fox Generalized Linear Models 1 1. Topics I The structure of generalized linear models I Poisson and other generalized linear
Measures of Association and Variance Estimation
 Measures of Association and Variance Estimation Dipankar Bandyopadhyay, Ph.D. Department of Biostatistics, Virginia Commonwealth University D. Bandyopadhyay (VCU) BIOS 625: Categorical Data & GLM 1 / 35
Measures of Association and Variance Estimation Dipankar Bandyopadhyay, Ph.D. Department of Biostatistics, Virginia Commonwealth University D. Bandyopadhyay (VCU) BIOS 625: Categorical Data & GLM 1 / 35
Statistical Distribution Assumptions of General Linear Models
 Statistical Distribution Assumptions of General Linear Models Applied Multilevel Models for Cross Sectional Data Lecture 4 ICPSR Summer Workshop University of Colorado Boulder Lecture 4: Statistical Distributions
Statistical Distribution Assumptions of General Linear Models Applied Multilevel Models for Cross Sectional Data Lecture 4 ICPSR Summer Workshop University of Colorado Boulder Lecture 4: Statistical Distributions
STATS 200: Introduction to Statistical Inference. Lecture 29: Course review
 STATS 200: Introduction to Statistical Inference Lecture 29: Course review Course review We started in Lecture 1 with a fundamental assumption: Data is a realization of a random process. The goal throughout
STATS 200: Introduction to Statistical Inference Lecture 29: Course review Course review We started in Lecture 1 with a fundamental assumption: Data is a realization of a random process. The goal throughout
Ronald Christensen. University of New Mexico. Albuquerque, New Mexico. Wesley Johnson. University of California, Irvine. Irvine, California
 Texts in Statistical Science Bayesian Ideas and Data Analysis An Introduction for Scientists and Statisticians Ronald Christensen University of New Mexico Albuquerque, New Mexico Wesley Johnson University
Texts in Statistical Science Bayesian Ideas and Data Analysis An Introduction for Scientists and Statisticians Ronald Christensen University of New Mexico Albuquerque, New Mexico Wesley Johnson University
Hypothesis Testing, Power, Sample Size and Confidence Intervals (Part 2)
") Hypothesis Testing, Power, Sample Size and Confidence Intervals (Part 2) B.H. Robbins Scholars Series June 23, 2010 1 / 29 Outline Z-test χ 2 -test Confidence Interval Sample size and power Relative effect
Hypothesis Testing, Power, Sample Size and Confidence Intervals (Part 2) B.H. Robbins Scholars Series June 23, 2010 1 / 29 Outline Z-test χ 2 -test Confidence Interval Sample size and power Relative effect
Statistics in medicine
 Statistics in medicine Lecture 3: Bivariate association : Categorical variables Proportion in one group One group is measured one time: z test Use the z distribution as an approximation to the binomial
Statistics in medicine Lecture 3: Bivariate association : Categorical variables Proportion in one group One group is measured one time: z test Use the z distribution as an approximation to the binomial
Multilevel Statistical Models: 3 rd edition, 2003 Contents
 Multilevel Statistical Models: 3 rd edition, 2003 Contents Preface Acknowledgements Notation Two and three level models. A general classification notation and diagram Glossary Chapter 1 An introduction
Multilevel Statistical Models: 3 rd edition, 2003 Contents Preface Acknowledgements Notation Two and three level models. A general classification notation and diagram Glossary Chapter 1 An introduction
Longitudinal Modeling with Logistic Regression
 Newsom 1 Longitudinal Modeling with Logistic Regression Longitudinal designs involve repeated measurements of the same individuals over time There are two general classes of analyses that correspond to
Newsom 1 Longitudinal Modeling with Logistic Regression Longitudinal designs involve repeated measurements of the same individuals over time There are two general classes of analyses that correspond to
STA 303 H1S / 1002 HS Winter 2011 Test March 7, ab 1cde 2abcde 2fghij 3
 STA 303 H1S / 1002 HS Winter 2011 Test March 7, 2011 LAST NAME: FIRST NAME: STUDENT NUMBER: ENROLLED IN: (circle one) STA 303 STA 1002 INSTRUCTIONS: Time: 90 minutes Aids allowed: calculator. Some formulae
STA 303 H1S / 1002 HS Winter 2011 Test March 7, 2011 LAST NAME: FIRST NAME: STUDENT NUMBER: ENROLLED IN: (circle one) STA 303 STA 1002 INSTRUCTIONS: Time: 90 minutes Aids allowed: calculator. Some formulae
EXAMINATIONS OF THE ROYAL STATISTICAL SOCIETY
 EXAMINATIONS OF THE ROYAL STATISTICAL SOCIETY GRADUATE DIPLOMA, 00 MODULE : Statistical Inference Time Allowed: Three Hours Candidates should answer FIVE questions. All questions carry equal marks. The
EXAMINATIONS OF THE ROYAL STATISTICAL SOCIETY GRADUATE DIPLOMA, 00 MODULE : Statistical Inference Time Allowed: Three Hours Candidates should answer FIVE questions. All questions carry equal marks. The
Multivariate Survival Analysis
 Multivariate Survival Analysis Previously we have assumed that either (X i, δ i ) or (X i, δ i, Z i ), i = 1,..., n, are i.i.d.. This may not always be the case. Multivariate survival data can arise in
Multivariate Survival Analysis Previously we have assumed that either (X i, δ i ) or (X i, δ i, Z i ), i = 1,..., n, are i.i.d.. This may not always be the case. Multivariate survival data can arise in
Lecture 12: Effect modification, and confounding in logistic regression
 Lecture 12: Effect modification, and confounding in logistic regression Ani Manichaikul amanicha@jhsph.edu 4 May 2007 Today Categorical predictor create dummy variables just like for linear regression
Lecture 12: Effect modification, and confounding in logistic regression Ani Manichaikul amanicha@jhsph.edu 4 May 2007 Today Categorical predictor create dummy variables just like for linear regression
Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory
 Bayesian Inference Statistical Decison Theory") Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Generalized linear models
 Generalized linear models Douglas Bates November 01, 2010 Contents 1 Definition 1 2 Links 2 3 Estimating parameters 5 4 Example 6 5 Model building 8 6 Conclusions 8 7 Summary 9 1 Generalized Linear Models
Generalized linear models Douglas Bates November 01, 2010 Contents 1 Definition 1 2 Links 2 3 Estimating parameters 5 4 Example 6 5 Model building 8 6 Conclusions 8 7 Summary 9 1 Generalized Linear Models
Statistics in medicine
 Statistics in medicine Lecture 4: and multivariable regression Fatma Shebl, MD, MS, MPH, PhD Assistant Professor Chronic Disease Epidemiology Department Yale School of Public Health Fatma.shebl@yale.edu
Statistics in medicine Lecture 4: and multivariable regression Fatma Shebl, MD, MS, MPH, PhD Assistant Professor Chronic Disease Epidemiology Department Yale School of Public Health Fatma.shebl@yale.edu
STAT 7030: Categorical Data Analysis
 STAT 7030: Categorical Data Analysis 5. Logistic Regression Peng Zeng Department of Mathematics and Statistics Auburn University Fall 2012 Peng Zeng (Auburn University) STAT 7030 Lecture Notes Fall 2012
STAT 7030: Categorical Data Analysis 5. Logistic Regression Peng Zeng Department of Mathematics and Statistics Auburn University Fall 2012 Peng Zeng (Auburn University) STAT 7030 Lecture Notes Fall 2012
Model Based Statistics in Biology. Part V. The Generalized Linear Model. Chapter 18.1 Logistic Regression (Dose - Response)
") Model Based Statistics in Biology. Part V. The Generalized Linear Model. Logistic Regression ( - Response) ReCap. Part I (Chapters 1,2,3,4), Part II (Ch 5, 6, 7) ReCap Part III (Ch 9, 10, 11), Part IV
Model Based Statistics in Biology. Part V. The Generalized Linear Model. Logistic Regression ( - Response) ReCap. Part I (Chapters 1,2,3,4), Part II (Ch 5, 6, 7) ReCap Part III (Ch 9, 10, 11), Part IV
Estimation of Operational Risk Capital Charge under Parameter Uncertainty
 Estimation of Operational Risk Capital Charge under Parameter Uncertainty Pavel V. Shevchenko Principal Research Scientist, CSIRO Mathematical and Information Sciences, Sydney, Locked Bag 17, North Ryde,
Estimation of Operational Risk Capital Charge under Parameter Uncertainty Pavel V. Shevchenko Principal Research Scientist, CSIRO Mathematical and Information Sciences, Sydney, Locked Bag 17, North Ryde,
Review. DS GA 1002 Statistical and Mathematical Models. Carlos Fernandez-Granda
 Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Linear Regression Models P8111
 Linear Regression Models P8111 Lecture 25 Jeff Goldsmith April 26, 2016 1 of 37 Today s Lecture Logistic regression / GLMs Model framework Interpretation Estimation 2 of 37 Linear regression Course started
Linear Regression Models P8111 Lecture 25 Jeff Goldsmith April 26, 2016 1 of 37 Today s Lecture Logistic regression / GLMs Model framework Interpretation Estimation 2 of 37 Linear regression Course started
Cohen s s Kappa and Log-linear Models
 Cohen s s Kappa and Log-linear Models HRP 261 03/03/03 10-11 11 am 1. Cohen s Kappa Actual agreement = sum of the proportions found on the diagonals. π ii Cohen: Compare the actual agreement with the chance
Cohen s s Kappa and Log-linear Models HRP 261 03/03/03 10-11 11 am 1. Cohen s Kappa Actual agreement = sum of the proportions found on the diagonals. π ii Cohen: Compare the actual agreement with the chance
Parametric Modelling of Over-dispersed Count Data. Part III / MMath (Applied Statistics) 1
 1") Parametric Modelling of Over-dispersed Count Data Part III / MMath (Applied Statistics) 1 Introduction Poisson regression is the de facto approach for handling count data What happens then when Poisson
Parametric Modelling of Over-dispersed Count Data Part III / MMath (Applied Statistics) 1 Introduction Poisson regression is the de facto approach for handling count data What happens then when Poisson
Poisson regression: Further topics
 Poisson regression: Further topics April 21 Overdispersion One of the defining characteristics of Poisson regression is its lack of a scale parameter: E(Y ) = Var(Y ), and no parameter is available to
Poisson regression: Further topics April 21 Overdispersion One of the defining characteristics of Poisson regression is its lack of a scale parameter: E(Y ) = Var(Y ), and no parameter is available to
Unit 9: Inferences for Proportions and Count Data
 Unit 9: Inferences for Proportions and Count Data Statistics 571: Statistical Methods Ramón V. León 1/15/008 Unit 9 - Stat 571 - Ramón V. León 1 Large Sample Confidence Interval for Proportion ( pˆ p)
Unit 9: Inferences for Proportions and Count Data Statistics 571: Statistical Methods Ramón V. León 1/15/008 Unit 9 - Stat 571 - Ramón V. León 1 Large Sample Confidence Interval for Proportion ( pˆ p)
Econ 583 Homework 7 Suggested Solutions: Wald, LM and LR based on GMM and MLE
 Econ 583 Homework 7 Suggested Solutions: Wald, LM and LR based on GMM and MLE Eric Zivot Winter 013 1 Wald, LR and LM statistics based on generalized method of moments estimation Let 1 be an iid sample
Econ 583 Homework 7 Suggested Solutions: Wald, LM and LR based on GMM and MLE Eric Zivot Winter 013 1 Wald, LR and LM statistics based on generalized method of moments estimation Let 1 be an iid sample
Test Code: STA/STB (Short Answer Type) 2013 Junior Research Fellowship for Research Course in Statistics
 2013 Junior Research Fellowship for Research Course in Statistics") Test Code: STA/STB (Short Answer Type) 2013 Junior Research Fellowship for Research Course in Statistics The candidates for the research course in Statistics will have to take two shortanswer type tests
Test Code: STA/STB (Short Answer Type) 2013 Junior Research Fellowship for Research Course in Statistics The candidates for the research course in Statistics will have to take two shortanswer type tests
Describing Contingency tables
 Today s topics: Describing Contingency tables 1. Probability structure for contingency tables (distributions, sensitivity/specificity, sampling schemes). 2. Comparing two proportions (relative risk, odds
Today s topics: Describing Contingency tables 1. Probability structure for contingency tables (distributions, sensitivity/specificity, sampling schemes). 2. Comparing two proportions (relative risk, odds
Epidemiology Wonders of Biostatistics Chapter 13 - Effect Measures. John Koval
 Epidemiology 9509 Wonders of Biostatistics Chapter 13 - Effect Measures John Koval Department of Epidemiology and Biostatistics University of Western Ontario What is being covered 1. risk factors 2. risk
Epidemiology 9509 Wonders of Biostatistics Chapter 13 - Effect Measures John Koval Department of Epidemiology and Biostatistics University of Western Ontario What is being covered 1. risk factors 2. risk
NATIONAL UNIVERSITY OF SINGAPORE EXAMINATION (SOLUTIONS) ST3241 Categorical Data Analysis. (Semester II: )
 ST3241 Categorical Data Analysis. (Semester II: )") NATIONAL UNIVERSITY OF SINGAPORE EXAMINATION (SOLUTIONS) Categorical Data Analysis (Semester II: 2010 2011) April/May, 2011 Time Allowed : 2 Hours Matriculation No: Seat No: Grade Table Question 1 2 3
NATIONAL UNIVERSITY OF SINGAPORE EXAMINATION (SOLUTIONS) Categorical Data Analysis (Semester II: 2010 2011) April/May, 2011 Time Allowed : 2 Hours Matriculation No: Seat No: Grade Table Question 1 2 3
CDA Chapter 3 part II
 CDA Chapter 3 part II Two-way tables with ordered classfications Let u 1 u 2... u I denote scores for the row variable X, and let ν 1 ν 2... ν J denote column Y scores. Consider the hypothesis H 0 : X
CDA Chapter 3 part II Two-way tables with ordered classfications Let u 1 u 2... u I denote scores for the row variable X, and let ν 1 ν 2... ν J denote column Y scores. Consider the hypothesis H 0 : X
Statistics 203: Introduction to Regression and Analysis of Variance Course review
 Statistics 203: Introduction to Regression and Analysis of Variance Course review Jonathan Taylor - p. 1/?? Today Review / overview of what we learned. - p. 2/?? General themes in regression models Specifying
Statistics 203: Introduction to Regression and Analysis of Variance Course review Jonathan Taylor - p. 1/?? Today Review / overview of what we learned. - p. 2/?? General themes in regression models Specifying
Lecture 14: Introduction to Poisson Regression
 Lecture 14: Introduction to Poisson Regression Ani Manichaikul amanicha@jhsph.edu 8 May 2007 1 / 52 Overview Modelling counts Contingency tables Poisson regression models 2 / 52 Modelling counts I Why
Lecture 14: Introduction to Poisson Regression Ani Manichaikul amanicha@jhsph.edu 8 May 2007 1 / 52 Overview Modelling counts Contingency tables Poisson regression models 2 / 52 Modelling counts I Why