Darwin Uy Math 538 Quiz 4 Dr. Behseta
|
|
|
- Victor Morgan
- 6 years ago
- Views:
Transcription
1 Darwin Uy Math 538 Quiz 4 Dr. Behseta 1) Section talks about how when sample size gets large, posterior distributions become approximately normal and centered at the MLE. This is largely due to Taylor s theorem. We first note that the Taylor expansion of the likelihood around our MLE estimate of θ, θ, is equal to l(θ) = l θ + l θ θ θ θ θ t H l θ θ θ Noticing that l θ is a constant and that l θ = 0, we get l(θ) = C θ θ t H l θ θ θ As n gets large is that the prior distribution contributes a negligible amount to the posterior; the likelihood approaches the form of the normal distribution and the prior b fixed as n increases. This is because as n gets larges the standard error of θ drops and which will cause θ θ to be small. Since this difference is small, our posterior distribution is approximately constant, π(θ) π θ. Also when n gets large, only values of θ such that θ θ is small give appreciable posterior probability. We therefore end up with an approximation for our posterior to be f(θ y) exp 1 2 θ θ t H θ θ θ, This is the kernel of a multivariate normal distribution with mean equal to the θ, and variance equal to the negative inverse of the observed information,- H 1 θ. This gives a convenient way to compute posteriors for large samples as well as shows us that with enough data, different beliefs will eventually come to an agreement. 2) Bayesian inference are great for neural data because : 1) Inferences agree reasonably well with those obtained from ML estimation 2) We can sometimes use the prior to formalize structure in the data 3) There are general computational tools to compute posteriors in many complicated statistical models
2 When we have conjugate priors, posterior probabilities can be easily calculated. This unfortunately is not always the case. When the posterior takes a form that is not easily recognizable, we run into numerical problems, such integration to find probabilities. This problem can be solved by doing posterior simulation based off of Markov Chain Monte Carlo (MCMC). We first suppose that the state at time t+1 is dependent on only the state at time t, and independent of the states before t. We also suppose that these conditional probabilities are time invariant. Then if the chain is irreducible, aperiodic, and recurrent we can say that the long term behavior of the chain will eventually hit a limiting distribution. This distribution is known as the stationary distribution and once it is reached the chain will stay there. This is important for the posterior simulation because we believe that once a chain runs for a period of time and hits the stationary distribution which we design to be the posterior distribution, we begin to simulate from the posterior distribution. The most common MCMC algorithm is known as the Metropolis-Hastings algorithm. In theory the MH algorithm works because it will eventually hit the stationary distribution. The period before the convergence of the distribution is known as the burn in period. The length of the burn is dependent on the jumping density. Ideally we can use the proposal density/ jumping density as the posterior pdf, but we really choose the jumping by its simplicity to simulate. 11.2) library("mvtnorm", lib.loc="c:/program Files/R/R /library") data=matrix(c(-.86, -.30, -.05,.73,5,5,5,5, 0,1,3,5),nrow=4,ncol=3) summary(glm(cbind(data[,3],data[,2]-data[,3])~data[,1],family=binomial(link = "logit"))) Jsig=diag(c(1^2,4^2)) sim=matrix(c( ,5.7488),nrow=1, ncol=2) for (i in 1:100000) { prop=sim[i,]+rmvnorm(1,c(0,0),jsig) r=min(1,( prod(dbinom(data[,3],5, exp(prop[1]+prop[2]*data[,1])/(1+exp(prop[1]+prop[2]*data[,1])) ))/prod(dbinom(data[,3],5, exp(sim[i,1]+sim[i,2]*data[,1])/(1+exp(sim[i,1]+sim[i,2]*data[,1])) )) )) r[is.nan(r)]=0 if (runif(1)<r) {sim=rbind(sim,prop) else sim=rbind(sim,sim[i,]) plot (sim[50000:100000,1],sim[50000:100000,2], xlim=c(-4,10),ylim=c(-10,40)) hist(sim[50000:100000,1]) hist(sim[50000:100000,2]) hdr1 <- hdr.2d(sim[50000:100000,1],sim[50000:100000,2]) plot(hdr1, pointcol="red", show.points=true, pch=3, xlab="sweat rate", ylab="sodium")
3 For this simulation we chose our starting point to be α = β = These are our least-squares estimates obtained from the GLM. We then define our jumping distribution to be the multivariate normal distribution centered at 0. We did 100,000 simulation with a 50,000 burn in period. Our simulation yields the results We can say with 95% probability that < α <

4 We can say with 95% probability that < β < Our results are fairly similar to the results yielded in the book.
5 3) library("mvtnorm", lib.loc="c:/program Files/R/R /library") library("bayesm", lib.loc="c:/program Files/R/R /library") #data reading=matrix(c( 59, 77, 43, 39, 34, 46, 32, 26, 42, 38, 38, 43, 55, 68, 67, 86, 64, 77, 45, 60, 49, 50, 72, 59, 34, 38, 70, 48, 34, 55, 50, 58, 41, 54, 52, 60, 60, 75, 34, 47, 28,48, 35, 33),nrow=22,ncol=2,byrow=T) #prior parameters Sig0=matrix(c(625, 312.5, 312.5, 625),nrow=2, ncol=2) mu0=c(50,50) sigma=matrix(0,nrow=2, ncol=2) propsigma=matrix(0,nrow=2, ncol=2) sim=matrix(c(50,50, 625, 312.5,625 ), nrow=1, ncol=5) for (i in 1:100000) { sigma=matrix(0,nrow=2, ncol=2) mu=sim[i, 1:2] for (ii in 1:2) { for (j in ii:2) {sigma[ii,j]= sim[i,1+ii+j] sigma=sigma+t(sigma)-diag(diag(sigma)) prop=sim[i,]+rmvnorm(1,c(0,0,0,0,0), diag(c(4,4,100,64,64))) propmu=prop[ 1:2] for (ii in 1:2) { for (j in ii:2) {propsigma[ii,j]= prop[1+ii+j] propsigma=propsigma+t(propsigma)-diag(diag(propsigma)) while (min(eigen(propsigma)$values)<0) {propsigma=matrix(0,nrow=2, ncol=2) prop=sim[i,]+rmvnorm(1,c(0,0,0,0,0), diag(5)) propmu=prop[ 1:2] for (ii in 1:2) { for (j in ii:2) {propsigma[ii,j]= prop[1+ii+j] propsigma=propsigma+t(propsigma)-diag(diag(propsigma))
6 r=min(1,exp((sum(log(dmvnorm(reading, propmu, propsigma))) + lndiwishart(nu=4, Sig0, propsigma) + log(dmvnorm(propmu,mu0, Sig0)))-(sum(log(dmvnorm(reading, mu, sigma))) + lndiwishart(nu=4, Sig0, sigma) + log(dmvnorm(mu,mu0, Sig0))))) r[is.nan(r)]=0 if (runif(1)<r) {sim=rbind(sim,prop) else sim=rbind(sim,sim[i,]) hist(sim[50000:100000,2]-sim[50000:100000,1], main="difference in test scores", freq=f, xlab="difference") quantile((sim[50000:100000,2]-sim[50000:100000,1]), c(0.025,.5,.975)) mean(sim[50000:100000,2]-sim[50000:100000,1]) hist(sim[50000:100000,1], main="pretest scores", freq=f, xlab="pretest score") quantile(sim[50000:100000,1], c(0.025,.5,.975)) mean(sim[50000:100000,1]) hist(sim[50000:100000,2], main="posttest scores", freq=f, xlab="pretest score") quantile(sim[50000:100000,2], c(0.025,.5,.975)) mean(sim[50000:100000,2]) hist(sim[50000:100000,5]) For this problem, I simulated directly from the joint density f(θ y, Σ) f(y θ, Σ)f(θ Σ)f(Σ) Where we assume f(y θ, Σ)~ Normal(θ, Σ ) f(θ Σ)~Normal(μ 0, Σ 0 ) f(σ)~inwishart(4, Λ) Also note that we assume the prior distribution of θ is independent from our prior distribution of Σ We let out parameters for our priors to be Λ = Σ 0 = μ 0 = We choose these parameters by starting in the center of possible scores. The variance was selected by wanting possible scores to be within 2 standard deviations of the center. We also assumed that correlation was about.50. Our Jump distribution chosen was the multivariate-normal distribution with mean 0. Since our jump is symmetric, I will not divide the distributions by the jumping density. Our jump is symmetric because it is centered around 0. This is technically a Metropolis simulation.
7 The simulation yielded The difference in scores yielded quantiles 2.5% 50% 97.5% And mean difference of This is close to our Gibbs Sampler which yields a mean difference of For our pretest we get our simulation to be
8 This has the quantiles 2.5% 50% 97.5% And has the mean This is close to our Gibbs Sampler which yields a mean of
9 Our Post test simmulation yields This has quantiles 2.5% 50% 97.5% And yields a mean of This is close to our mean from the Gibbs Sampler which yields Comparing this analysis to the analysis due to Gibbs sampler, we get very similar results. Our estimates for the scores though match up very well, differing by less than 1. Our discrepancies may be due to the different type of simulations, numerical problems, and also the number of simulations drawn. Our Gibbs sampler did 5,000 simulations while the MH algorithm did 100,000 simulations with a burn in of length 50,000.
10 4) Sweat.Data <- read.table("c:/users/darwin/dropbox/school/538/quiz 4/Sweat Data.txt", quote="\"") Data=as.matrix(Sweat.Data) rmvnorm<function(n,mu,sigma) { p<-length(mu) res<-matrix(0,nrow=n,ncol=p) if( n>0 & p>0 ) { E<-matrix(rnorm(n*p),n,p) res<-t( t(e%*%chol(sigma)) +c(mu)) res rinvwish<-function(n,nu0,is0) { sl0 <- chol(is0) S<-array( dim=c( dim(l0),n ) ) for(i in 1:n) { Z <- matrix(rnorm(nu0 * dim(l0)[1]), nu0, dim(is0)[1]) %*% sl0 S[,,i]<- solve(t(z)%*%z) S[,,1:n] ldmvnorm<-function(y,mu,sig){ # log mvn density c( -(length(mu)/2)*log(2*pi) -.5*log(det(Sig)) -.5* t(y-mu)%*%solve(sig)%*%(y-mu) ) # sample from the Wishart distribution rwish<-function(n,nu0,s0) { ss0 <- chol(s0) S<-array( dim=c( dim(s0),n ) ) for(i in 1:n) { Z <- matrix(rnorm(nu0 * dim(s0)[1]), nu0, dim(s0)[1]) %*% ss0 S[,,i]<- t(z)%*%z S[,,1:n] # Y=Data mu0<-c( 4, 50, 10) L0<-matrix( c(3,10,-2, 10,200,-6, -2, -6, 4 ),nrow=3,ncol=3) nu0<-4
11 S0<-matrix( c(3,10,-2, 10,200,-6, -2, -6, 4 ),nrow=3,ncol=3) n<-dim(y)[1] ybar<-apply(y,2,mean) Sigma<-cov(Y) THETA<-SIGMA<-NULL YS<-NULL set.seed(1) for(s in 1:5000) { update theta Ln<-solve( solve(l0) + n*solve(sigma) ) mun<-ln%*%( solve(l0)%*%mu0 + n*solve(sigma)%*%ybar ) theta<-rmvnorm(1,mun,ln) update Sigma Sn<- S0 + ( t(y)-c(theta) )%*%t( t(y)-c(theta) ) # Sigma<-rinvwish(1,nu0+n,solve(Sn)) Sigma<-solve( rwish(1, nu0+n, solve(sn)) ) YS<-rbind(YS,rmvnorm(1,theta,Sigma)) save results THETA<-rbind(THETA,theta) ; SIGMA<-rbind(SIGMA,c(Sigma)) cat(s,round(theta,2),round(c(sigma),2),"\n") quantile( SIGMA[,2]/sqrt(SIGMA[,1]*SIGMA[,4]), prob=c(.025,.5,.975) ) quantile( THETA[,2]THETA[,1], prob=c(.025,.5,.975) ) mean( THETA[,2]-THETA[,1]) mean( THETA[,2]>THETA[,1]) mean(ys[,2]>ys[,1]) Install Package: hdrcde (Bivariate Highest Density Regions) x=theta[,1] y=theta[,2] z=theta[,3] hist(x, main="sweat rate", probability=t, xlab="sweat") quantile(x,c(0.025,.5,.975) ) mean(x) hist(y, main="sodium", xlab="sodium", probability=t) quantile(y,c(0.025,.5,.975) ) mean(y) hist(z, main="potassium", xlab="potassium", probability=t) quantile(z,c(0.025,.5,.975) ) mean(z)
12 hdr1 <- hdr.2d(x,y) plot(hdr1, pointcol="red", show.points=true, pch=3, xlab="sweat rate", ylab="sodium") hdr2 <- hdr.2d(x,z) plot(hdr2, pointcol="red", show.points=true, pch=3, xlab="sweat Rate", ylab="potassium") hdr3 <- hdr.2d(y,z) plot(hdr3, pointcol="red", show.points=true, pch=3, xlab="sodium", ylab="potassium") For the sweat, we get our results from the simulation to be Sweat has the quantiles 2.5% 50% 97.5% And a mean of We have 95% probability that Sweat rate is between and
13 For our Sodium data, we get our results from our simulation to be Sodium has the quantiles 2.5% 50% 97.5% and a mean of We have 95% probability that Sodium levels are between and
14 The results from our simulation for potassium yield Potassium has the quantiles 2.5% 50% 97.5% and a mean of We have 95% probability that potassium levels are between and Looking at the pairwise relationship, we get the graphs
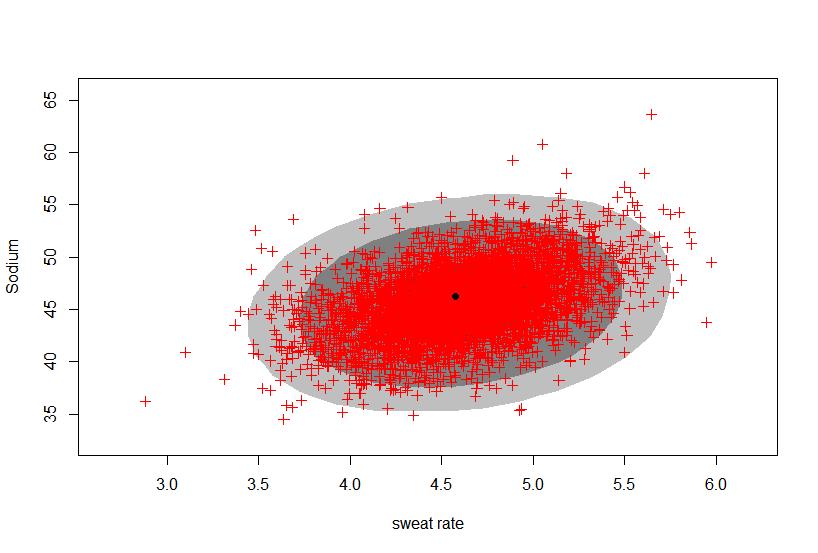
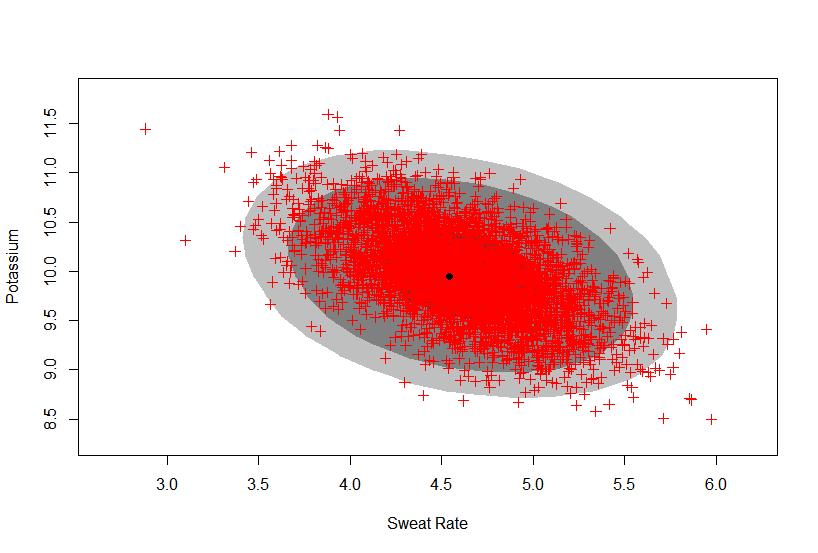
15
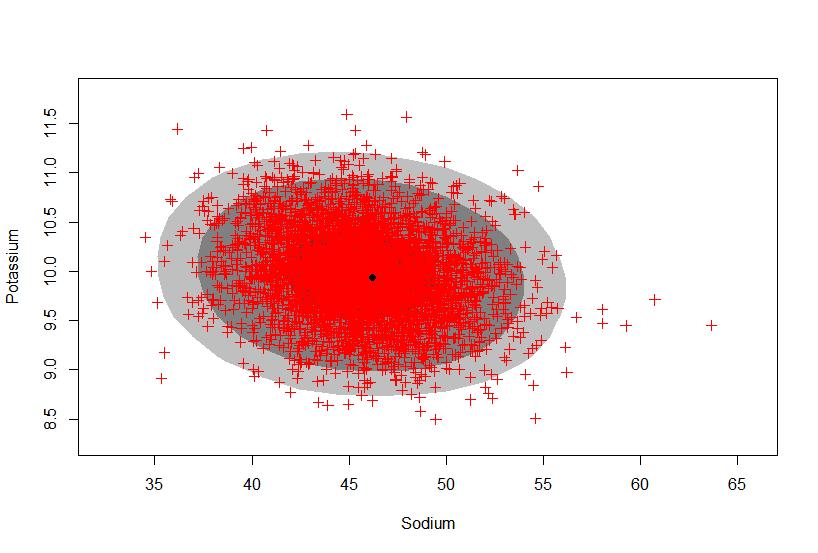
16
Bayesian GLMs and Metropolis-Hastings Algorithm
 Bayesian GLMs and Metropolis-Hastings Algorithm We have seen that with conjugate or semi-conjugate prior distributions the Gibbs sampler can be used to sample from the posterior distribution. In situations,
Bayesian GLMs and Metropolis-Hastings Algorithm We have seen that with conjugate or semi-conjugate prior distributions the Gibbs sampler can be used to sample from the posterior distribution. In situations,
Advanced Statistical Modelling
 Markov chain Monte Carlo (MCMC) Methods and Their Applications in Bayesian Statistics School of Technology and Business Studies/Statistics Dalarna University Borlänge, Sweden. Feb. 05, 2014. Outlines 1
Markov chain Monte Carlo (MCMC) Methods and Their Applications in Bayesian Statistics School of Technology and Business Studies/Statistics Dalarna University Borlänge, Sweden. Feb. 05, 2014. Outlines 1
LECTURE 15 Markov chain Monte Carlo
 LECTURE 15 Markov chain Monte Carlo There are many settings when posterior computation is a challenge in that one does not have a closed form expression for the posterior distribution. Markov chain Monte
LECTURE 15 Markov chain Monte Carlo There are many settings when posterior computation is a challenge in that one does not have a closed form expression for the posterior distribution. Markov chain Monte
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
The Metropolis Algorithm
 16 Metropolis Algorithm Lab Objective: Understand the basic principles of the Metropolis algorithm and apply these ideas to the Ising Model. The Metropolis Algorithm Sampling from a given probability distribution
16 Metropolis Algorithm Lab Objective: Understand the basic principles of the Metropolis algorithm and apply these ideas to the Ising Model. The Metropolis Algorithm Sampling from a given probability distribution
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
MCMC: Markov Chain Monte Carlo
 I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA
 BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA Intro: Course Outline and Brief Intro to Marina Vannucci Rice University, USA PASI-CIMAT 04/28-30/2010 Marina Vannucci
BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA Intro: Course Outline and Brief Intro to Marina Vannucci Rice University, USA PASI-CIMAT 04/28-30/2010 Marina Vannucci
Markov Chain Monte Carlo
 Markov Chain Monte Carlo Recall: To compute the expectation E ( h(y ) ) we use the approximation E(h(Y )) 1 n n h(y ) t=1 with Y (1),..., Y (n) h(y). Thus our aim is to sample Y (1),..., Y (n) from f(y).
Markov Chain Monte Carlo Recall: To compute the expectation E ( h(y ) ) we use the approximation E(h(Y )) 1 n n h(y ) t=1 with Y (1),..., Y (n) h(y). Thus our aim is to sample Y (1),..., Y (n) from f(y).
Metropolis-Hastings Algorithm
 Strength of the Gibbs sampler Metropolis-Hastings Algorithm Easy algorithm to think about. Exploits the factorization properties of the joint probability distribution. No difficult choices to be made to
Strength of the Gibbs sampler Metropolis-Hastings Algorithm Easy algorithm to think about. Exploits the factorization properties of the joint probability distribution. No difficult choices to be made to
Bayesian Regression Linear and Logistic Regression
 When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
Stat 451 Lecture Notes Markov Chain Monte Carlo. Ryan Martin UIC
 Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Multivariate Normal & Wishart
 Multivariate Normal & Wishart Hoff Chapter 7 October 21, 2010 Reading Comprehesion Example Twenty-two children are given a reading comprehsion test before and after receiving a particular instruction method.
Multivariate Normal & Wishart Hoff Chapter 7 October 21, 2010 Reading Comprehesion Example Twenty-two children are given a reading comprehsion test before and after receiving a particular instruction method.
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
David Giles Bayesian Econometrics
 David Giles Bayesian Econometrics 5. Bayesian Computation Historically, the computational "cost" of Bayesian methods greatly limited their application. For instance, by Bayes' Theorem: p(θ y) = p(θ)p(y
David Giles Bayesian Econometrics 5. Bayesian Computation Historically, the computational "cost" of Bayesian methods greatly limited their application. For instance, by Bayes' Theorem: p(θ y) = p(θ)p(y
Computer intensive statistical methods
 Lecture 13 MCMC, Hybrid chains October 13, 2015 Jonas Wallin jonwal@chalmers.se Chalmers, Gothenburg university MH algorithm, Chap:6.3 The metropolis hastings requires three objects, the distribution of
Lecture 13 MCMC, Hybrid chains October 13, 2015 Jonas Wallin jonwal@chalmers.se Chalmers, Gothenburg university MH algorithm, Chap:6.3 The metropolis hastings requires three objects, the distribution of
Bayesian Inference in GLMs. Frequentists typically base inferences on MLEs, asymptotic confidence
 Bayesian Inference in GLMs Frequentists typically base inferences on MLEs, asymptotic confidence limits, and log-likelihood ratio tests Bayesians base inferences on the posterior distribution of the unknowns
Bayesian Inference in GLMs Frequentists typically base inferences on MLEs, asymptotic confidence limits, and log-likelihood ratio tests Bayesians base inferences on the posterior distribution of the unknowns
Markov Chain Monte Carlo methods
 Markov Chain Monte Carlo methods By Oleg Makhnin 1 Introduction a b c M = d e f g h i 0 f(x)dx 1.1 Motivation 1.1.1 Just here Supresses numbering 1.1.2 After this 1.2 Literature 2 Method 2.1 New math As
Markov Chain Monte Carlo methods By Oleg Makhnin 1 Introduction a b c M = d e f g h i 0 f(x)dx 1.1 Motivation 1.1.1 Just here Supresses numbering 1.1.2 After this 1.2 Literature 2 Method 2.1 New math As
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
 Homework 6 Solutions set.seed(1) library(mvtnorm) samp.theta
Homework 6 Solutions set.seed(1) library(mvtnorm) samp.theta Lecture 6: Markov Chain Monte Carlo
 Lecture 6: Markov Chain Monte Carlo D. Jason Koskinen koskinen@nbi.ku.dk Photo by Howard Jackman University of Copenhagen Advanced Methods in Applied Statistics Feb - Apr 2016 Niels Bohr Institute 2 Outline
Lecture 6: Markov Chain Monte Carlo D. Jason Koskinen koskinen@nbi.ku.dk Photo by Howard Jackman University of Copenhagen Advanced Methods in Applied Statistics Feb - Apr 2016 Niels Bohr Institute 2 Outline
ST 740: Markov Chain Monte Carlo
 ST 740: Markov Chain Monte Carlo Alyson Wilson Department of Statistics North Carolina State University October 14, 2012 A. Wilson (NCSU Stsatistics) MCMC October 14, 2012 1 / 20 Convergence Diagnostics:
ST 740: Markov Chain Monte Carlo Alyson Wilson Department of Statistics North Carolina State University October 14, 2012 A. Wilson (NCSU Stsatistics) MCMC October 14, 2012 1 / 20 Convergence Diagnostics:
Computational statistics
 Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
 SC7/SM6 Bayes Methods HT18 Lecturer: Geoff Nicholls Lecture 2: Monte Carlo Methods Notes and Problem sheets are available at http://www.stats.ox.ac.uk/~nicholls/bayesmethods/ and via the MSc weblearn pages.
SC7/SM6 Bayes Methods HT18 Lecturer: Geoff Nicholls Lecture 2: Monte Carlo Methods Notes and Problem sheets are available at http://www.stats.ox.ac.uk/~nicholls/bayesmethods/ and via the MSc weblearn pages.
Markov Chain Monte Carlo (MCMC)
") Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov Chain Monte Carlo, Numerical Integration
 Markov Chain Monte Carlo, Numerical Integration (See Statistics) Trevor Gallen Fall 2015 1 / 1 Agenda Numerical Integration: MCMC methods Estimating Markov Chains Estimating latent variables 2 / 1 Numerical
Markov Chain Monte Carlo, Numerical Integration (See Statistics) Trevor Gallen Fall 2015 1 / 1 Agenda Numerical Integration: MCMC methods Estimating Markov Chains Estimating latent variables 2 / 1 Numerical
Principles of Bayesian Inference
 Principles of Bayesian Inference Sudipto Banerjee University of Minnesota July 20th, 2008 1 Bayesian Principles Classical statistics: model parameters are fixed and unknown. A Bayesian thinks of parameters
Principles of Bayesian Inference Sudipto Banerjee University of Minnesota July 20th, 2008 1 Bayesian Principles Classical statistics: model parameters are fixed and unknown. A Bayesian thinks of parameters
Metropolis Hastings. Rebecca C. Steorts Bayesian Methods and Modern Statistics: STA 360/601. Module 9
 Metropolis Hastings Rebecca C. Steorts Bayesian Methods and Modern Statistics: STA 360/601 Module 9 1 The Metropolis-Hastings algorithm is a general term for a family of Markov chain simulation methods
Metropolis Hastings Rebecca C. Steorts Bayesian Methods and Modern Statistics: STA 360/601 Module 9 1 The Metropolis-Hastings algorithm is a general term for a family of Markov chain simulation methods
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
Markov Chain Monte Carlo (MCMC) and Model Evaluation. August 15, 2017
 and Model Evaluation. August 15, 2017") Markov Chain Monte Carlo (MCMC) and Model Evaluation August 15, 2017 Frequentist Linking Frequentist and Bayesian Statistics How can we estimate model parameters and what does it imply? Want to find the
Markov Chain Monte Carlo (MCMC) and Model Evaluation August 15, 2017 Frequentist Linking Frequentist and Bayesian Statistics How can we estimate model parameters and what does it imply? Want to find the
MARKOV CHAIN MONTE CARLO
 MARKOV CHAIN MONTE CARLO RYAN WANG Abstract. This paper gives a brief introduction to Markov Chain Monte Carlo methods, which offer a general framework for calculating difficult integrals. We start with
MARKOV CHAIN MONTE CARLO RYAN WANG Abstract. This paper gives a brief introduction to Markov Chain Monte Carlo methods, which offer a general framework for calculating difficult integrals. We start with
Convex Optimization CMU-10725
 Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Stat 535 C - Statistical Computing & Monte Carlo Methods. Lecture February Arnaud Doucet
 Stat 535 C - Statistical Computing & Monte Carlo Methods Lecture 13-28 February 2006 Arnaud Doucet Email: arnaud@cs.ubc.ca 1 1.1 Outline Limitations of Gibbs sampling. Metropolis-Hastings algorithm. Proof
Stat 535 C - Statistical Computing & Monte Carlo Methods Lecture 13-28 February 2006 Arnaud Doucet Email: arnaud@cs.ubc.ca 1 1.1 Outline Limitations of Gibbs sampling. Metropolis-Hastings algorithm. Proof
Bayesian model selection in graphs by using BDgraph package
 Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
MCMC Methods: Gibbs and Metropolis
 MCMC Methods: Gibbs and Metropolis Patrick Breheny February 28 Patrick Breheny BST 701: Bayesian Modeling in Biostatistics 1/30 Introduction As we have seen, the ability to sample from the posterior distribution
MCMC Methods: Gibbs and Metropolis Patrick Breheny February 28 Patrick Breheny BST 701: Bayesian Modeling in Biostatistics 1/30 Introduction As we have seen, the ability to sample from the posterior distribution
April 20th, Advanced Topics in Machine Learning California Institute of Technology. Markov Chain Monte Carlo for Machine Learning
 for for Advanced Topics in California Institute of Technology April 20th, 2017 1 / 50 Table of Contents for 1 2 3 4 2 / 50 History of methods for Enrico Fermi used to calculate incredibly accurate predictions
for for Advanced Topics in California Institute of Technology April 20th, 2017 1 / 50 Table of Contents for 1 2 3 4 2 / 50 History of methods for Enrico Fermi used to calculate incredibly accurate predictions
Markov chain Monte Carlo
 1 / 26 Markov chain Monte Carlo Timothy Hanson 1 and Alejandro Jara 2 1 Division of Biostatistics, University of Minnesota, USA 2 Department of Statistics, Universidad de Concepción, Chile IAP-Workshop
1 / 26 Markov chain Monte Carlo Timothy Hanson 1 and Alejandro Jara 2 1 Division of Biostatistics, University of Minnesota, USA 2 Department of Statistics, Universidad de Concepción, Chile IAP-Workshop
Eco517 Fall 2013 C. Sims MCMC. October 8, 2013
 Eco517 Fall 2013 C. Sims MCMC October 8, 2013 c 2013 by Christopher A. Sims. This document may be reproduced for educational and research purposes, so long as the copies contain this notice and are retained
Eco517 Fall 2013 C. Sims MCMC October 8, 2013 c 2013 by Christopher A. Sims. This document may be reproduced for educational and research purposes, so long as the copies contain this notice and are retained
A Search and Jump Algorithm for Markov Chain Monte Carlo Sampling. Christopher Jennison. Adriana Ibrahim. Seminar at University of Kuwait
 A Search and Jump Algorithm for Markov Chain Monte Carlo Sampling Christopher Jennison Department of Mathematical Sciences, University of Bath, UK http://people.bath.ac.uk/mascj Adriana Ibrahim Institute
A Search and Jump Algorithm for Markov Chain Monte Carlo Sampling Christopher Jennison Department of Mathematical Sciences, University of Bath, UK http://people.bath.ac.uk/mascj Adriana Ibrahim Institute
Parameter estimation and forecasting. Cristiano Porciani AIfA, Uni-Bonn
 Parameter estimation and forecasting Cristiano Porciani AIfA, Uni-Bonn Questions? C. Porciani Estimation & forecasting 2 Temperature fluctuations Variance at multipole l (angle ~180o/l) C. Porciani Estimation
Parameter estimation and forecasting Cristiano Porciani AIfA, Uni-Bonn Questions? C. Porciani Estimation & forecasting 2 Temperature fluctuations Variance at multipole l (angle ~180o/l) C. Porciani Estimation
17 : Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models, Spring 2015 17 : Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Heran Lin, Bin Deng, Yun Huang 1 Review of Monte Carlo Methods 1.1 Overview Monte Carlo
10-708: Probabilistic Graphical Models, Spring 2015 17 : Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Heran Lin, Bin Deng, Yun Huang 1 Review of Monte Carlo Methods 1.1 Overview Monte Carlo
(5) Multi-parameter models - Gibbs sampling. ST440/540: Applied Bayesian Analysis
 Multi-parameter models - Gibbs sampling. ST440/540: Applied Bayesian Analysis") Summarizing a posterior Given the data and prior the posterior is determined Summarizing the posterior gives parameter estimates, intervals, and hypothesis tests Most of these computations are integrals
Summarizing a posterior Given the data and prior the posterior is determined Summarizing the posterior gives parameter estimates, intervals, and hypothesis tests Most of these computations are integrals
16 : Approximate Inference: Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
Markov chain Monte Carlo Lecture 9
 Markov chain Monte Carlo Lecture 9 David Sontag New York University Slides adapted from Eric Xing and Qirong Ho (CMU) Limitations of Monte Carlo Direct (unconditional) sampling Hard to get rare events
Markov chain Monte Carlo Lecture 9 David Sontag New York University Slides adapted from Eric Xing and Qirong Ho (CMU) Limitations of Monte Carlo Direct (unconditional) sampling Hard to get rare events
Bayesian spatial hierarchical modeling for temperature extremes
 Bayesian spatial hierarchical modeling for temperature extremes Indriati Bisono Dr. Andrew Robinson Dr. Aloke Phatak Mathematics and Statistics Department The University of Melbourne Maths, Informatics
Bayesian spatial hierarchical modeling for temperature extremes Indriati Bisono Dr. Andrew Robinson Dr. Aloke Phatak Mathematics and Statistics Department The University of Melbourne Maths, Informatics
Markov chain Monte Carlo
 Markov chain Monte Carlo Karl Oskar Ekvall Galin L. Jones University of Minnesota March 12, 2019 Abstract Practically relevant statistical models often give rise to probability distributions that are analytically
Markov chain Monte Carlo Karl Oskar Ekvall Galin L. Jones University of Minnesota March 12, 2019 Abstract Practically relevant statistical models often give rise to probability distributions that are analytically
Bayesian inference for multivariate extreme value distributions
 Bayesian inference for multivariate extreme value distributions Sebastian Engelke Clément Dombry, Marco Oesting Toronto, Fields Institute, May 4th, 2016 Main motivation For a parametric model Z F θ of
Bayesian inference for multivariate extreme value distributions Sebastian Engelke Clément Dombry, Marco Oesting Toronto, Fields Institute, May 4th, 2016 Main motivation For a parametric model Z F θ of
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation. EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016
 Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
Markov Chain Monte Carlo and Applied Bayesian Statistics
 Markov Chain Monte Carlo and Applied Bayesian Statistics Trinity Term 2005 Prof. Gesine Reinert Markov chain Monte Carlo is a stochastic simulation technique that is very useful for computing inferential
Markov Chain Monte Carlo and Applied Bayesian Statistics Trinity Term 2005 Prof. Gesine Reinert Markov chain Monte Carlo is a stochastic simulation technique that is very useful for computing inferential
Doing Bayesian Integrals
 ASTR509-13 Doing Bayesian Integrals The Reverend Thomas Bayes (c.1702 1761) Philosopher, theologian, mathematician Presbyterian (non-conformist) minister Tunbridge Wells, UK Elected FRS, perhaps due to
ASTR509-13 Doing Bayesian Integrals The Reverend Thomas Bayes (c.1702 1761) Philosopher, theologian, mathematician Presbyterian (non-conformist) minister Tunbridge Wells, UK Elected FRS, perhaps due to
CSC 446 Notes: Lecture 13
 CSC 446 Notes: Lecture 3 The Problem We have already studied how to calculate the probability of a variable or variables using the message passing method. However, there are some times when the structure
CSC 446 Notes: Lecture 3 The Problem We have already studied how to calculate the probability of a variable or variables using the message passing method. However, there are some times when the structure
Statistics & Data Sciences: First Year Prelim Exam May 2018
 Statistics & Data Sciences: First Year Prelim Exam May 2018 Instructions: 1. Do not turn this page until instructed to do so. 2. Start each new question on a new sheet of paper. 3. This is a closed book
Statistics & Data Sciences: First Year Prelim Exam May 2018 Instructions: 1. Do not turn this page until instructed to do so. 2. Start each new question on a new sheet of paper. 3. This is a closed book
SAMPLING ALGORITHMS. In general. Inference in Bayesian models
 SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
Reminder of some Markov Chain properties:
 Reminder of some Markov Chain properties: 1. a transition from one state to another occurs probabilistically 2. only state that matters is where you currently are (i.e. given present, future is independent
Reminder of some Markov Chain properties: 1. a transition from one state to another occurs probabilistically 2. only state that matters is where you currently are (i.e. given present, future is independent
The sbgcop Package. March 9, 2007
 The sbgcop Package March 9, 2007 Title Semiparametric Bayesian Gaussian copula estimation Version 0.95 Date 2007-03-09 Author Maintainer This package estimates parameters of
The sbgcop Package March 9, 2007 Title Semiparametric Bayesian Gaussian copula estimation Version 0.95 Date 2007-03-09 Author Maintainer This package estimates parameters of
Markov Chain Monte Carlo methods
 Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Metropolis-Hastings sampling
 Metropolis-Hastings sampling Gibbs sampling requires that a sample from each full conditional distribution. In all the cases we have looked at so far the conditional distributions were conjugate so sampling
Metropolis-Hastings sampling Gibbs sampling requires that a sample from each full conditional distribution. In all the cases we have looked at so far the conditional distributions were conjugate so sampling
MCMC notes by Mark Holder
 MCMC notes by Mark Holder Bayesian inference Ultimately, we want to make probability statements about true values of parameters, given our data. For example P(α 0 < α 1 X). According to Bayes theorem:
MCMC notes by Mark Holder Bayesian inference Ultimately, we want to make probability statements about true values of parameters, given our data. For example P(α 0 < α 1 X). According to Bayes theorem:
Computation and Monte Carlo Techniques
 Computation and Monte Carlo Techniques Up to now we have seen conjugate Bayesian analysis: posterior prior likelihood beta(a + x, b + n x) beta(a, b) binomial(x; n) θ a+x 1 (1 θ) b+n x 1 θ a 1 (1 θ) b
Computation and Monte Carlo Techniques Up to now we have seen conjugate Bayesian analysis: posterior prior likelihood beta(a + x, b + n x) beta(a, b) binomial(x; n) θ a+x 1 (1 θ) b+n x 1 θ a 1 (1 θ) b
A quick introduction to Markov chains and Markov chain Monte Carlo (revised version)
") A quick introduction to Markov chains and Markov chain Monte Carlo (revised version) Rasmus Waagepetersen Institute of Mathematical Sciences Aalborg University 1 Introduction These notes are intended to
A quick introduction to Markov chains and Markov chain Monte Carlo (revised version) Rasmus Waagepetersen Institute of Mathematical Sciences Aalborg University 1 Introduction These notes are intended to
INTRODUCTION TO BAYESIAN STATISTICS
 INTRODUCTION TO BAYESIAN STATISTICS Sarat C. Dass Department of Statistics & Probability Department of Computer Science & Engineering Michigan State University TOPICS The Bayesian Framework Different Types
INTRODUCTION TO BAYESIAN STATISTICS Sarat C. Dass Department of Statistics & Probability Department of Computer Science & Engineering Michigan State University TOPICS The Bayesian Framework Different Types
Bayesian Inference and Decision Theory
 Bayesian Inference and Decision Theory Instructor: Kathryn Blackmond Laskey Room 2214 ENGR (703) 993-1644 Office Hours: Tuesday and Thursday 4:30-5:30 PM, or by appointment Spring 2018 Unit 6: Gibbs Sampling
Bayesian Inference and Decision Theory Instructor: Kathryn Blackmond Laskey Room 2214 ENGR (703) 993-1644 Office Hours: Tuesday and Thursday 4:30-5:30 PM, or by appointment Spring 2018 Unit 6: Gibbs Sampling
Monte Carlo Inference Methods
 Monte Carlo Inference Methods Iain Murray University of Edinburgh http://iainmurray.net Monte Carlo and Insomnia Enrico Fermi (1901 1954) took great delight in astonishing his colleagues with his remarkably
Monte Carlo Inference Methods Iain Murray University of Edinburgh http://iainmurray.net Monte Carlo and Insomnia Enrico Fermi (1901 1954) took great delight in astonishing his colleagues with his remarkably
Fundamental Issues in Bayesian Functional Data Analysis. Dennis D. Cox Rice University
 Fundamental Issues in Bayesian Functional Data Analysis Dennis D. Cox Rice University 1 Introduction Question: What are functional data? Answer: Data that are functions of a continuous variable.... say
Fundamental Issues in Bayesian Functional Data Analysis Dennis D. Cox Rice University 1 Introduction Question: What are functional data? Answer: Data that are functions of a continuous variable.... say
Markov Chain Monte Carlo Methods
 Markov Chain Monte Carlo Methods John Geweke University of Iowa, USA 2005 Institute on Computational Economics University of Chicago - Argonne National Laboaratories July 22, 2005 The problem p (θ, ω I)
Markov Chain Monte Carlo Methods John Geweke University of Iowa, USA 2005 Institute on Computational Economics University of Chicago - Argonne National Laboaratories July 22, 2005 The problem p (θ, ω I)
MCMC Sampling for Bayesian Inference using L1-type Priors
 MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
MALA versus Random Walk Metropolis Dootika Vats June 4, 2017
 MALA versus Random Walk Metropolis Dootika Vats June 4, 2017 Introduction My research thus far has predominantly been on output analysis for Markov chain Monte Carlo. The examples on which I have implemented
MALA versus Random Walk Metropolis Dootika Vats June 4, 2017 Introduction My research thus far has predominantly been on output analysis for Markov chain Monte Carlo. The examples on which I have implemented
SAMSI Astrostatistics Tutorial. More Markov chain Monte Carlo & Demo of Mathematica software
 SAMSI Astrostatistics Tutorial More Markov chain Monte Carlo & Demo of Mathematica software Phil Gregory University of British Columbia 26 Bayesian Logical Data Analysis for the Physical Sciences Contents:
SAMSI Astrostatistics Tutorial More Markov chain Monte Carlo & Demo of Mathematica software Phil Gregory University of British Columbia 26 Bayesian Logical Data Analysis for the Physical Sciences Contents:
Spatial Statistics Chapter 4 Basics of Bayesian Inference and Computation
 Spatial Statistics Chapter 4 Basics of Bayesian Inference and Computation So far we have discussed types of spatial data, some basic modeling frameworks and exploratory techniques. We have not discussed
Spatial Statistics Chapter 4 Basics of Bayesian Inference and Computation So far we have discussed types of spatial data, some basic modeling frameworks and exploratory techniques. We have not discussed
Markov Chain Monte Carlo
 1 Motivation 1.1 Bayesian Learning Markov Chain Monte Carlo Yale Chang In Bayesian learning, given data X, we make assumptions on the generative process of X by introducing hidden variables Z: p(z): prior
1 Motivation 1.1 Bayesian Learning Markov Chain Monte Carlo Yale Chang In Bayesian learning, given data X, we make assumptions on the generative process of X by introducing hidden variables Z: p(z): prior
eqr094: Hierarchical MCMC for Bayesian System Reliability
 eqr094: Hierarchical MCMC for Bayesian System Reliability Alyson G. Wilson Statistical Sciences Group, Los Alamos National Laboratory P.O. Box 1663, MS F600 Los Alamos, NM 87545 USA Phone: 505-667-9167
eqr094: Hierarchical MCMC for Bayesian System Reliability Alyson G. Wilson Statistical Sciences Group, Los Alamos National Laboratory P.O. Box 1663, MS F600 Los Alamos, NM 87545 USA Phone: 505-667-9167
Bayesian Estimation of DSGE Models 1 Chapter 3: A Crash Course in Bayesian Inference
 1 The views expressed in this paper are those of the authors and do not necessarily reflect the views of the Federal Reserve Board of Governors or the Federal Reserve System. Bayesian Estimation of DSGE
1 The views expressed in this paper are those of the authors and do not necessarily reflect the views of the Federal Reserve Board of Governors or the Federal Reserve System. Bayesian Estimation of DSGE
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Monte Carlo Methods. Leon Gu CSD, CMU
 Monte Carlo Methods Leon Gu CSD, CMU Approximate Inference EM: y-observed variables; x-hidden variables; θ-parameters; E-step: q(x) = p(x y, θ t 1 ) M-step: θ t = arg max E q(x) [log p(y, x θ)] θ Monte
Monte Carlo Methods Leon Gu CSD, CMU Approximate Inference EM: y-observed variables; x-hidden variables; θ-parameters; E-step: q(x) = p(x y, θ t 1 ) M-step: θ t = arg max E q(x) [log p(y, x θ)] θ Monte
MCMC and Gibbs Sampling. Sargur Srihari
 MCMC and Gibbs Sampling Sargur srihari@cedar.buffalo.edu 1 Topics 1. Markov Chain Monte Carlo 2. Markov Chains 3. Gibbs Sampling 4. Basic Metropolis Algorithm 5. Metropolis-Hastings Algorithm 6. Slice
MCMC and Gibbs Sampling Sargur srihari@cedar.buffalo.edu 1 Topics 1. Markov Chain Monte Carlo 2. Markov Chains 3. Gibbs Sampling 4. Basic Metropolis Algorithm 5. Metropolis-Hastings Algorithm 6. Slice
MCMC algorithms for fitting Bayesian models
 MCMC algorithms for fitting Bayesian models p. 1/1 MCMC algorithms for fitting Bayesian models Sudipto Banerjee sudiptob@biostat.umn.edu University of Minnesota MCMC algorithms for fitting Bayesian models
MCMC algorithms for fitting Bayesian models p. 1/1 MCMC algorithms for fitting Bayesian models Sudipto Banerjee sudiptob@biostat.umn.edu University of Minnesota MCMC algorithms for fitting Bayesian models
Advanced Statistical Methods. Lecture 6
 Advanced Statistical Methods Lecture 6 Convergence distribution of M.-H. MCMC We denote the PDF estimated by the MCMC as. It has the property Convergence distribution After some time, the distribution
Advanced Statistical Methods Lecture 6 Convergence distribution of M.-H. MCMC We denote the PDF estimated by the MCMC as. It has the property Convergence distribution After some time, the distribution
Graphical Models and Kernel Methods
 Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
CS281A/Stat241A Lecture 22
 CS281A/Stat241A Lecture 22 p. 1/4 CS281A/Stat241A Lecture 22 Monte Carlo Methods Peter Bartlett CS281A/Stat241A Lecture 22 p. 2/4 Key ideas of this lecture Sampling in Bayesian methods: Predictive distribution
CS281A/Stat241A Lecture 22 p. 1/4 CS281A/Stat241A Lecture 22 Monte Carlo Methods Peter Bartlett CS281A/Stat241A Lecture 22 p. 2/4 Key ideas of this lecture Sampling in Bayesian methods: Predictive distribution
Markov Chain Monte Carlo Inference. Siamak Ravanbakhsh Winter 2018
 Graphical Models Markov Chain Monte Carlo Inference Siamak Ravanbakhsh Winter 2018 Learning objectives Markov chains the idea behind Markov Chain Monte Carlo (MCMC) two important examples: Gibbs sampling
Graphical Models Markov Chain Monte Carlo Inference Siamak Ravanbakhsh Winter 2018 Learning objectives Markov chains the idea behind Markov Chain Monte Carlo (MCMC) two important examples: Gibbs sampling
Part 6: Multivariate Normal and Linear Models
 Part 6: Multivariate Normal and Linear Models 1 Multiple measurements Up until now all of our statistical models have been univariate models models for a single measurement on each member of a sample of
Part 6: Multivariate Normal and Linear Models 1 Multiple measurements Up until now all of our statistical models have been univariate models models for a single measurement on each member of a sample of
The Mixture Approach for Simulating New Families of Bivariate Distributions with Specified Correlations
 The Mixture Approach for Simulating New Families of Bivariate Distributions with Specified Correlations John R. Michael, Significance, Inc. and William R. Schucany, Southern Methodist University The mixture
The Mixture Approach for Simulating New Families of Bivariate Distributions with Specified Correlations John R. Michael, Significance, Inc. and William R. Schucany, Southern Methodist University The mixture
Bayesian Graphical Models
 Graphical Models and Inference, Lecture 16, Michaelmas Term 2009 December 4, 2009 Parameter θ, data X = x, likelihood L(θ x) p(x θ). Express knowledge about θ through prior distribution π on θ. Inference
Graphical Models and Inference, Lecture 16, Michaelmas Term 2009 December 4, 2009 Parameter θ, data X = x, likelihood L(θ x) p(x θ). Express knowledge about θ through prior distribution π on θ. Inference
References. Markov-Chain Monte Carlo. Recall: Sampling Motivation. Problem. Recall: Sampling Methods. CSE586 Computer Vision II
 References Markov-Chain Monte Carlo CSE586 Computer Vision II Spring 2010, Penn State Univ. Recall: Sampling Motivation If we can generate random samples x i from a given distribution P(x), then we can
References Markov-Chain Monte Carlo CSE586 Computer Vision II Spring 2010, Penn State Univ. Recall: Sampling Motivation If we can generate random samples x i from a given distribution P(x), then we can
Monte Carlo integration
 Monte Carlo integration Eample of a Monte Carlo sampler in D: imagine a circle radius L/ within a square of LL. If points are randoml generated over the square, what s the probabilit to hit within circle?
Monte Carlo integration Eample of a Monte Carlo sampler in D: imagine a circle radius L/ within a square of LL. If points are randoml generated over the square, what s the probabilit to hit within circle?
Computer Vision Group Prof. Daniel Cremers. 11. Sampling Methods: Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 11. Sampling Methods: Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative
Group Prof. Daniel Cremers 11. Sampling Methods: Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative
Introduction to Computational Biology Lecture # 14: MCMC - Markov Chain Monte Carlo
 Introduction to Computational Biology Lecture # 14: MCMC - Markov Chain Monte Carlo Assaf Weiner Tuesday, March 13, 2007 1 Introduction Today we will return to the motif finding problem, in lecture 10
Introduction to Computational Biology Lecture # 14: MCMC - Markov Chain Monte Carlo Assaf Weiner Tuesday, March 13, 2007 1 Introduction Today we will return to the motif finding problem, in lecture 10
Theory of Stochastic Processes 8. Markov chain Monte Carlo
 Theory of Stochastic Processes 8. Markov chain Monte Carlo Tomonari Sei sei@mist.i.u-tokyo.ac.jp Department of Mathematical Informatics, University of Tokyo June 8, 2017 http://www.stat.t.u-tokyo.ac.jp/~sei/lec.html
Theory of Stochastic Processes 8. Markov chain Monte Carlo Tomonari Sei sei@mist.i.u-tokyo.ac.jp Department of Mathematical Informatics, University of Tokyo June 8, 2017 http://www.stat.t.u-tokyo.ac.jp/~sei/lec.html
Likelihood NIPS July 30, Gaussian Process Regression with Student-t. Likelihood. Jarno Vanhatalo, Pasi Jylanki and Aki Vehtari NIPS-2009
 with with July 30, 2010 with 1 2 3 Representation Representation for Distribution Inference for the Augmented Model 4 Approximate Laplacian Approximation Introduction to Laplacian Approximation Laplacian
with with July 30, 2010 with 1 2 3 Representation Representation for Distribution Inference for the Augmented Model 4 Approximate Laplacian Approximation Introduction to Laplacian Approximation Laplacian
MCMC and Gibbs Sampling. Kayhan Batmanghelich
 MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
Monte Carlo Methods in Bayesian Inference: Theory, Methods and Applications
 University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 1-016 Monte Carlo Methods in Bayesian Inference: Theory, Methods and Applications Huarui Zhang University of Arkansas, Fayetteville
University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 1-016 Monte Carlo Methods in Bayesian Inference: Theory, Methods and Applications Huarui Zhang University of Arkansas, Fayetteville
Likelihood-free MCMC
 Bayesian inference for stable distributions with applications in finance Department of Mathematics University of Leicester September 2, 2011 MSc project final presentation Outline 1 2 3 4 Classical Monte
Bayesian inference for stable distributions with applications in finance Department of Mathematics University of Leicester September 2, 2011 MSc project final presentation Outline 1 2 3 4 Classical Monte
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
Who was Bayes? Bayesian Phylogenetics. What is Bayes Theorem?
 Who was Bayes? Bayesian Phylogenetics Bret Larget Departments of Botany and of Statistics University of Wisconsin Madison October 6, 2011 The Reverand Thomas Bayes was born in London in 1702. He was the
Who was Bayes? Bayesian Phylogenetics Bret Larget Departments of Botany and of Statistics University of Wisconsin Madison October 6, 2011 The Reverand Thomas Bayes was born in London in 1702. He was the
Bayesian Phylogenetics
 Bayesian Phylogenetics Bret Larget Departments of Botany and of Statistics University of Wisconsin Madison October 6, 2011 Bayesian Phylogenetics 1 / 27 Who was Bayes? The Reverand Thomas Bayes was born
Bayesian Phylogenetics Bret Larget Departments of Botany and of Statistics University of Wisconsin Madison October 6, 2011 Bayesian Phylogenetics 1 / 27 Who was Bayes? The Reverand Thomas Bayes was born
Monte Carlo in Bayesian Statistics
 Monte Carlo in Bayesian Statistics Matthew Thomas SAMBa - University of Bath m.l.thomas@bath.ac.uk December 4, 2014 Matthew Thomas (SAMBa) Monte Carlo in Bayesian Statistics December 4, 2014 1 / 16 Overview
Monte Carlo in Bayesian Statistics Matthew Thomas SAMBa - University of Bath m.l.thomas@bath.ac.uk December 4, 2014 Matthew Thomas (SAMBa) Monte Carlo in Bayesian Statistics December 4, 2014 1 / 16 Overview
Bayesian Gaussian Process Regression
 Bayesian Gaussian Process Regression STAT8810, Fall 2017 M.T. Pratola October 7, 2017 Today Bayesian Gaussian Process Regression Bayesian GP Regression Recall we had observations from our expensive simulator,
Bayesian Gaussian Process Regression STAT8810, Fall 2017 M.T. Pratola October 7, 2017 Today Bayesian Gaussian Process Regression Bayesian GP Regression Recall we had observations from our expensive simulator,
Bayesian Methods with Monte Carlo Markov Chains II
 Bayesian Methods with Monte Carlo Markov Chains II Henry Horng-Shing Lu Institute of Statistics National Chiao Tung University hslu@stat.nctu.edu.tw http://tigpbp.iis.sinica.edu.tw/courses.htm 1 Part 3
Bayesian Methods with Monte Carlo Markov Chains II Henry Horng-Shing Lu Institute of Statistics National Chiao Tung University hslu@stat.nctu.edu.tw http://tigpbp.iis.sinica.edu.tw/courses.htm 1 Part 3
Paul Karapanagiotidis ECO4060
 Paul Karapanagiotidis ECO4060 The way forward 1) Motivate why Markov-Chain Monte Carlo (MCMC) is useful for econometric modeling 2) Introduce Markov-Chain Monte Carlo (MCMC) - Metropolis-Hastings (MH)
Paul Karapanagiotidis ECO4060 The way forward 1) Motivate why Markov-Chain Monte Carlo (MCMC) is useful for econometric modeling 2) Introduce Markov-Chain Monte Carlo (MCMC) - Metropolis-Hastings (MH)