ASSOCIATION ANALYSIS FREQUENT ITEMSETS MINING. Alexandre Termier, LIG
|
|
|
- Silvia Hunt
- 5 years ago
- Views:
Transcription
1 ASSOCIATION ANALYSIS FREQUENT ITEMSETS MINING, LIG M2 SIF DMV course 207/208
2 Market basket analysis Analyse supermarket s transaction data Transaction = «market basket» of a customer Find which items are often bought together Ex: {bread, chocolate, butter} Ex: {hamburger bread, tomato} {steak} Applications Product placement Cross selling (suggestion of other products) Promotions 2
3 Funny example Most famous itemset : {beer, diapers} Found in a chain of American supermarkets Further study : Mostly bought on Friday evenings Who? 3
4 Example Transactions Items (products bought) bread, butter, chocolate, vine, pencil 2 bread,butter, chocolate, pencil 3 chocolate 4 butter,chocolate 5 bread, butter, chocolate, vine 6 bread,butter, chocolate {bread, butter, chocolate} sold together in 4/6 = 66% of transactions {butter, chocolate} {bread} is true in 4/5 = 80% of cases {chocolate} {bread, butter} is true in 4/6 = 66% of cases 4
5 Definitions A = {a,,a n } : items, A : item base Any I A : itemset k-itemset: itemset with k items T = (t,,t m ), i t i A : transaction database tid(t j )= j : transaction index support(x I) = number of transactions containing itemset X tidlist(x I) = list of tids of transactions containing itemset X An itemset X is frequent if support(x) minsup Confidence of association rule X Y : c (X Y = ) support(x Y) support(x) An association rule with confidence c holds if c minconf 5
6 Example, rewritten Transactions Items (products bought) bread, butter, chocolate, vine, pencil 2 bread,butter, chocolate, pencil 3 chocolate 4 butter,chocolate 5 bread, butter, chocolate, vine 6 bread,butter, chocolate {bread, butter, chocolate} sold support together = 4 in 4/6 = 66% = 4/6 of transactions = 66% (relative) (absolute) {butter, {chocolate} chocolate} {bread, butter} {bread} confidence is true = 4/6 in = 66% 4/5 = 80% of cases {butter, chocolate} {bread} {chocolate} confidence = 4/5 {bread, = 80% butter} is true in 5/6 = 83% of cases 6
7 Computing association rules Two steps:. Compute frequent itemsets Discover itemsets with support minsup Very expensive computationally! 2. Compute which association rules hold Partition each itemset and discover rules with confidence minconf Much faster than discovering itemsets 7
8 How to compute frequent itemsets? Brute force approach Generate and Test method Generate all possible itemsets randomly Compute their support But highly combinatorial problem : How many possible itemsets for 000 items? 000 items = possible itemsets Infeasible in practice 8
9 The Apriori algorithm Levelwise search [Agrawal et al., 93] Discover frequent -itemsets, 2-itemsets, Apriori property : If an itemset is not frequent, then all its supersets are not frequent Ex: If {vine, pencil} is not frequent, then of course {vine, pencil, chocolate} will not be frequent Downward closure property Anti-monotonicity property 9
10 ABCDE A B C D E X X X X X 2 X X X X 3 X 4 X X ABCD 5 ABCE 2 ABDE ACDE BCDE 5 X X X X 6 X X X ABC ABD ACD BCD ABE ACE BCE CDE BDE ADE AB AC BC AD BD CD AE BE CE DE A B C D E = 2 0
11 Apriori algorithm Input: T, minsup F = {Frequent -itemsets} ; for (k=2 ; F k- ; k++) do begin = apriori-gen(f k- ) ; // Candidates generation C k foreach transaction t T do begin C t = subset(c k, t) ; // Support counting foreach candidate c C t c.count++ ; end do F k = { c C k c.count minsup } ; end return k F k ;
12 Candidate generation apriori-gen: generates candidates k-itemsets from frequent (k-)-itemsets c (size k) = merge of p, q F k- (both have size k-) p and q have exactly k-2 items in common How many combinations of such p,q to build c? 2 k! k ( k ) C k ways (at most) to derive c from F k- ( k 2)!2! 2 This is redundant work: we want a unique (p,q) for c Solution: ordering of the items in itemsets Usually items are represented by integers : classical order of k-2 prefixes of p and q must match 2
13 ABCDE A B C D E X X X X X 2 X X X X 3 X 4 X X ABCD 5 ABCE 2 ABDE ACDE BCDE 5 X X X X 6 X X X ABC ABD ACD BCD ABE ACE BCE CDE BDE ADE AB AC BC AD BD CD AE BE CE DE A B C D E = 2 3
14 apriori-gen Input: F k- // Join step insert into C k select p.item,p.item 2,,p.item k-,q.item k- from p,q F k- where p.item = q.item,,p.item k-2 =q.item k-2, // Prune step foreach itemset c C k do foreach (k-)-subset s of c do if (s F k- ) then delete c from C k ; p.item k- <q.item k- Here use of anti-monotony property! return C k 4
15 Subset For each transaction t, find all the itemsets of C k that are in t Brute force : foreach t T foreach c C k compute if c t Too much computation! The Apriori solution: Partition candidates into different buckets of limited size Store buckets in leaves of a hash tree Find candidates subset of a transaction by traversing hash tree 5
16 Hash tree construction Max bucket size = 3 C 3 in previous example abc abd abe acd ace bcd bce abc abd abe acd ace Hash on first item h(a) h(b) bcd bce Bucket too big! Bucket too big! Hash on first item h(a) Hash on 2 nd item h(b) h(c) h(b) bcd bce abc abd abe acd ace 6
17 Hash tree utilisation for subset Transaction 2 : a c d e a c d e c d e h(b) h(a) h(c) h(b) bcd bce abc abd abe acd ace acd ace 7
18 Complexity apriori_gen, step k Dominated by prune step O(k. C k ) support counting O(m. C k ) with m = T (database size) one iteration is O(m. C k ) Total complexity : O(m. k C k ) Worst case : candidates are all possible itemsets O(m.2 n ) with n = number of items Linear in database size Exponential in number of items Influence of transaction width (database density) on number of traversal of hash tree 8
19 Association rules computation Once we have the frequent itemsets, we want the association rules. Reminder: we are only interested in rules that have a high confidence value support(x Y) Confidence of X Y: c support(x) Let F be an itemset, with F = k. How many possible rules? 2 k 2 (we eliminate F { } and { } F) What is a naive solution to compute them? For each partitions of F in X Y compute confidence of X Y output X Y if confidence minconf Is it efficient? 9
20 Monotony of confidence? Transactions Items (products bought) bread, butter, chocolate, vine, pencil 2 bread,butter, chocolate, pencil 3 chocolate 4 butter,chocolate 5 bread, butter, chocolate, vine 6 bread,butter, chocolate 7 butter 8 butter 9 butter {chocolate} {bread, butter} confidence = 4/6 = 66% {chocolate} {butter} confidence = 5/6 = 83% {butter} {chocolate} confidence = 5/8 = 62% CONFIDENCE IS NOT MONOTONE / ANTI-MONOTONE 20
21 More on monotony of confidence For rules coming from the same itemset, confidence is anti-monotone e.g., L = {A,B,C,D}: c(abc D) c(ab CD) c(a BCD) Confidence is anti-monotone w.r.t. number of items on the RHS of the rule some pruning is possible
22 Association rule generation algorithm Input: T, minsup, minconf, F all = union of F..F n H = foreach f k F all, k 2 do begin A = (k-)-itemsets a k- such that a k- f k ; foreach a k- A do begin conf = support(f k )/support(a k- ) ; if conf minconf do begin output rule a k- (f k a k- ) ; add (f k a k- ) to H ; end end ap-genrules(f k, H ) ; end
23 ap-genrules Input: f k, H m : set of m-item consequents if (k>m+) then begin end H m+ = apriori-gen(h m ) ; // Generate all possible m+ itemsets foreach h m+ H m+ do begin end conf = support(f k )/support(f k -h m+ ) ; if conf minconf then else output rule f k h m+ h m+ ; delete h m+ from H m+ ; ap-genrules(f k, H m+ ) ; Pruning by anti-monotony
24 First improvements of Apriori End of 90 s : Main memory: MB Databases: can go over GB Apriori : several passes over database need algorithms that can handle database in memory Partition [Savasere et al. 995] Cut the database in pieces fitting into memory, compute results for each piece and join them Sampling [Toivonen 996] Compute frequent itemsets on a sample of the database DIC [Brin et al. 997] Improves number of passes on database 24
25 Maximal frequent itemsets Set of maximal frequent itemsets : MFI = { I FI I I I FI} with FI set of frequent itemsets Several orders of magnitudes less MFI than FI Can be searched both bottom-up and topdown Pincer-Search [Lin & Kedem 998] Max-Miner [Bayardo et al. 998] BUT loss of information 25
26 26
27 The Eclat algorithm Apriori : DB is in horizontal format Eclat introduces the vertical format Itemset x tid-list(x) [Zaki et al., 97] A B C D E X X X X X 2 X X X X 3 X 4 X X 5 X X X X 6 X X X A B C D 5 E 2 Horizontal format Vertical format 27
28 Vertical format Support counting can be done with tid-list intersections I,J itemsets : tidlist(i J) = tidlist(i) tidlist(j) No need for costly subset tests, hash tree generation Problem If database is big, tidlists of the many candidates created will be big also, and will not hold in memory Solution Partition the lattice into equivalence classes In Eclat : equivalence relation = sharing the same prefix 28
29 29 AB 256 A 256 B 2456 C D 5 E 2 AC 256 BC 2456 AD 5 BD 5 CD 5 AE 2 BE 2 CE 2 ABC 256 ABD 5 ACD 5 BCD 5 ABE 2 ACE 2 BCE 2 ABCD 5 ABCE 2 DE CDE BDE ADE ACDE BCDE ABDE ABCDE = 2 Initial equivalence classes
30 Equivalence classes inside [A] class ABCDE ABCD ABCE ABDE ACDE 5 2 ABC ABD ABE ACD ACE ADE AB AC AD AE A 256 = 2 30
31 3
32 32
33 33
34 34
35 35
36 36
37 37
38 38
39 39
40 40
41 4
42 42
43 43

44 44

45 45
46 Eclat algorithm Input: T, minsup compute L and L 2 // like apriori Transform T in vertical representation CE 2 = Decompose L 2 in equivalence classes forall E 2 CE 2 do compute_frequent(e 2 ) end forall return k F k ; 46
47 compute_frequent(e k- ) forall itemsets I and I 2 in E k- do if tidlist(i ) tidlist(i 2 ) minsup then L k L k {I I 2 } end if end forall CE k = Decompose L k in equivalence classes forall E k CE k do compute_frequent(e k ) end forall 47
48 The FP-growth approach FP-Growth : Frequent Pattern Growth No candidate generation Compress transaction database into FP-tree (Frequent Pattern Tree) Extended prefix-tree Recursive processing of conditional databases Can be one order of magnitude faster than Apriori 48
49 FP-tree Compact structure for representing DB and frequent itemsets. Composed of : root item-prefix subtrees frequent-item-header array 2. Node = item-name count // number of transactions containing path reaching this node node-link // next node having same item-name 3. Entry in frequent-item-header array = item-name head of node-link // pointer to first node having item-name Both an horizontal (prefix-tree) and a vertical (node links) structure 49
50 FP-tree example (/2) A B C D E F A B C E C B C A B C D A B C C : 6 B : 5 A : 4 D : 2 E : 2 F : C B A D E C B A E C C B C B A D C B A C C B C B A C B A D C B A D E C B A E Original transaction database minsup = 2 Items ordered by frequency Transactions reordered by item frequency (infrequent item F pruned) Transactions sorted lexicographically 50

51 FP-tree example (2/2) Frequent-item-header array C:6 B:5 A:4 D:2 E:2 C C B C B A C B A D C B A D E C B A E Transactions sorted lexicographically C:6 B:5 A:4 D:2 Prefix-tree structure E: E: FP-tree 5
52 Exercise Draw the FP-tree for the following DB : (minsup = 3) A D F A C D E B D B C D B C A B D B D E B C E G C D F A B D 52

53
54
55 FP-Growth FP-growth(FP, prefix) foreach frequent item x in increasing order of frequency do prefix = prefix x Dx = count x = 0 foreach node-link nl x of x do D x = D x {transaction of path reaching x, with count for each item = nl x.count, without x} end count x += nl x.count if count x minsup then output (prefix x) end if FP x = FP-tree constructed from D x FP-growth(FP x, prefix) end 55
56 FP-Growth example C : 6 B : 5 A : 4 D : 2 E : 2 C:6 B:5 A:4 D:2 E: E: Original FP-tree Start with item E (lowest support) D:2 E: count E = + = 2 C:6 B:5 A:4 E is frequent Output E E: Conditional FP-tree for E D: E: update counts only transactions containing E C:2 B:2 A:2 drop E 56 E:
 Conditional FP-tree for E C:2 B:2 A:2 D: D not frequent here do not consider DE Loop on AE, BE, CE The rest is left as exercise For AE : C:2 B:2 A:2 Conditional FP-tree for AE: C:2 B:2 count AE = 2")
57 FP-Growth example (cont.) Conditional FP-tree for E C:2 B:2 A:2 D: D not frequent here do not consider DE Loop on AE, BE, CE The rest is left as exercise For AE : C:2 B:2 A:2 Conditional FP-tree for AE: C:2 B:2 count AE = 2 AE is frequent Output AE Conditional FP-tree for BAE: C:2 For BAE : C:2 B:2 count BAE = 2 BAE is frequent Output BAE For CBAE : C:2 count CBAE = 2 CBAE is frequent 57 Output CBAE
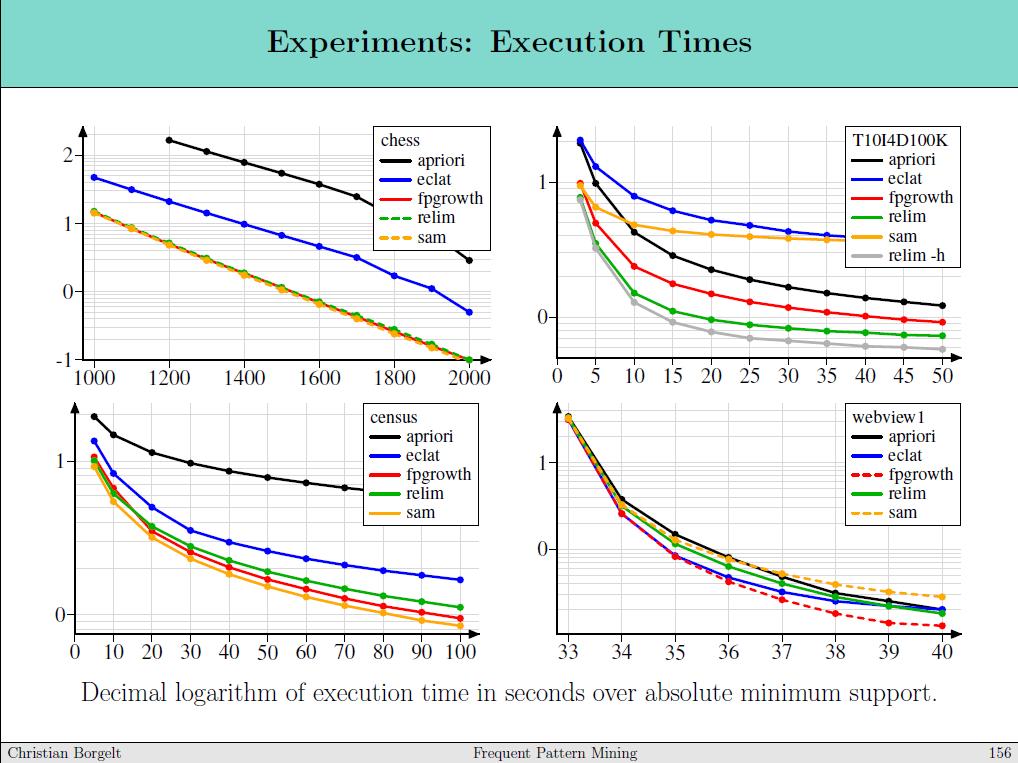
58 58
59 Problems of frequent itemsets Large computation time For low support values, huge number of frequent itemsets Lots of redundant information Simple example: Tid Transaction A B C D 2 A B C 3 A B C E minsup = 2 FIS Support Tidlist tidlist A B C 3 {,2,3} A B 3 {,2,3} A C 3 {,2,3} B C 3 {,2,3} A 3 {,2,3} B 3 {,2,3} C 3 {,2,3} REDUNDANT 59
60 Closed frequent itemsets [Pasquier et al., 99] We have seen that there is loss of information with maximal frequent itemsets Lets consider equivalence classes for frequent itemsets sharing the same tidlist The closed frequent itemsets are the maximums of these equivalence classes Set of closed frequent itemsets : CFI = { I FI I FI tq tidlist(i )=tidlist(i) I I} with FI set of frequent itemsets Sets are ordered by inclusion: MFI CFI FI 60
61 ABCDE A B C D E X X X X X 2 X X X X 3 X 4 X X ABCD 5 ABCE 2 ABDE ACDE BCDE 5 X X X X 6 X X X ABC ABD ACD BCD ABE ACE BCE CDE BDE ADE AB AC BC AD BD CD AE BE CE DE A B C D E = 2 6
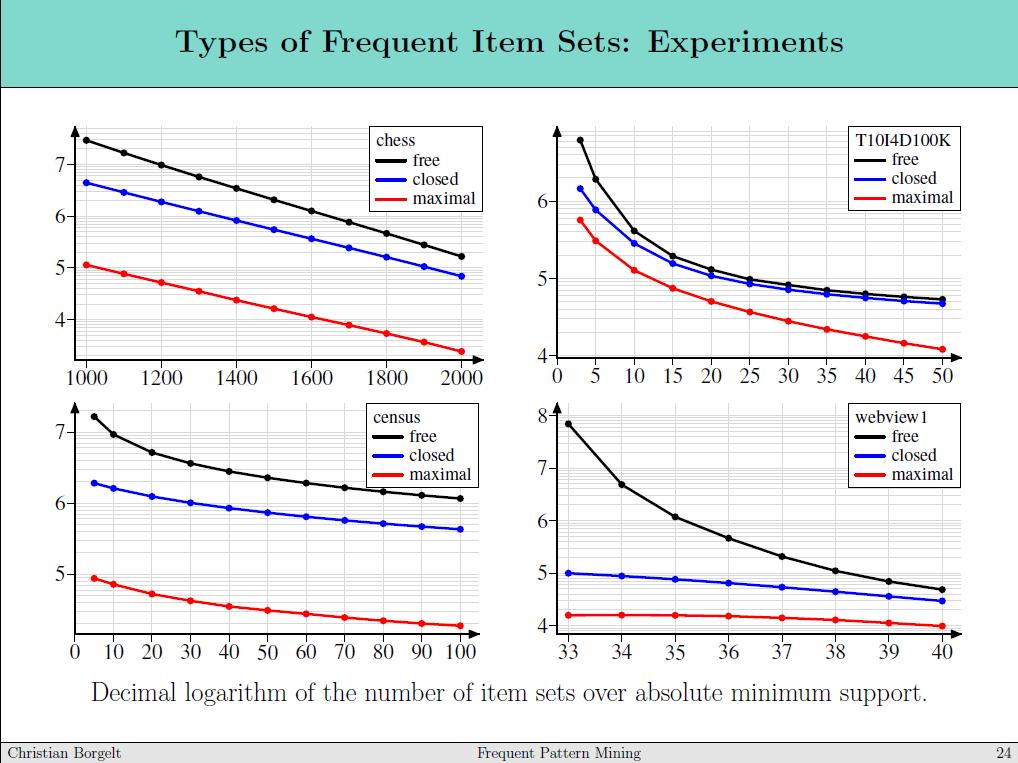
62 62
63 Computing closed frequent itemsets Brute force (frequent pattern base) Enumerate all the frequent patterns Output only closed ones Most of the time : inefficient Exception: if FI is very small Closure base Compute only closed patterns with closure operations Can be very efficient 63
64 Efficient computation First algorithms (Closet, Charm, ) Candidate-based method Try to compute as many non-closed frequent itemsets as possible OR Closure Extension: add an item to an existing closed frequent itemset, and take closure Keep in memory all closed frequent itemsets found so far Need a lot of memory during execution Reverse search (LCM) Depth First Search algorithm so no global memory needed Fast computation time, Little memory usage 64
65 Closure Extension of Itemset Usual backtracking does not work for closed itemsets, because there are possibly big gap between closed itemsets On the other hand, any closed itemset is obtained from another by add an item and take closure (maximal),2,3,2,3,4,2,3,2,4,3,4 2,3,4,4 2,3 2,4 3,4 - closure of P is the closed itemset having the same denotation to P, and computed by taking intersection of Occ(P) φ This is an adjacency structure defined on closed itemsets, thus we can perform graph search on it, with using memory

66 Reverse Search Uno and Arimura found that the closed frequent itemsets are organized in a directed spanning tree : Closed frequent itemsets : transition function they can be visited by DFS from a node of the tree, need of a transition function to compute its children 66
67 Tree of closed frequent itemsets Search space of CFIS = lattice = DAG DAG Tree : impose order of exploration Order need to: follow enumeration strategy be inexpensive to enforce Order of Arimura and Uno CFIS P, Q Q children of P if all items of Q < maxitem(p) 67
68 Pseudo-code 68




69 Database Reductions Conditional database is to reduce database by unnecessary items and transactions, for deeper levels,3,5,3,5,3,5,2,5,6,4,6,2,6 θ = 3 filtering Remove infrequent items, items included in all 3,5 3,5 3,5 5,6 6 6 filtering 3,5 3 5,6 6 2 Unify same transactions FP-tree, prefix tree Remove infrequent items, automatically unified 6 Linear time O( D log D ) time Compact if database is dense and large


70 Prize for the Award Prize is {beer, diapers} Most Frequent Itemset
Association Rules. Fundamentals
 Politecnico di Torino Politecnico di Torino 1 Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket counter Association rule
Politecnico di Torino Politecnico di Torino 1 Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket counter Association rule
D B M G Data Base and Data Mining Group of Politecnico di Torino
 Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Association rules Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
D B M G. Association Rules. Fundamentals. Fundamentals. Elena Baralis, Silvia Chiusano. Politecnico di Torino 1. Definitions.
 Definitions Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Itemset is a set including one or more items Example: {Beer, Diapers} k-itemset is an itemset that contains k
Definitions Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Itemset is a set including one or more items Example: {Beer, Diapers} k-itemset is an itemset that contains k
D B M G. Association Rules. Fundamentals. Fundamentals. Association rules. Association rule mining. Definitions. Rule quality metrics: example
 Association rules Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
Association rules Data Base and Data Mining Group of Politecnico di Torino Politecnico di Torino Objective extraction of frequent correlations or pattern from a transactional database Tickets at a supermarket
CS 484 Data Mining. Association Rule Mining 2
 CS 484 Data Mining Association Rule Mining 2 Review: Reducing Number of Candidates Apriori principle: If an itemset is frequent, then all of its subsets must also be frequent Apriori principle holds due
CS 484 Data Mining Association Rule Mining 2 Review: Reducing Number of Candidates Apriori principle: If an itemset is frequent, then all of its subsets must also be frequent Apriori principle holds due
DATA MINING LECTURE 3. Frequent Itemsets Association Rules
 DATA MINING LECTURE 3 Frequent Itemsets Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
DATA MINING LECTURE 3 Frequent Itemsets Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 04 Association Analysis Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Mining Concepts & Techniques Lecture No. 04 Association Analysis Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining and Analysis: Fundamental Concepts and Algorithms
 Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
732A61/TDDD41 Data Mining - Clustering and Association Analysis
 732A61/TDDD41 Data Mining - Clustering and Association Analysis Lecture 6: Association Analysis I Jose M. Peña IDA, Linköping University, Sweden 1/14 Outline Content Association Rules Frequent Itemsets
732A61/TDDD41 Data Mining - Clustering and Association Analysis Lecture 6: Association Analysis I Jose M. Peña IDA, Linköping University, Sweden 1/14 Outline Content Association Rules Frequent Itemsets
Lecture Notes for Chapter 6. Introduction to Data Mining
 Data Mining Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
Data Mining Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
COMP 5331: Knowledge Discovery and Data Mining
 COMP 5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Jiawei Han, Micheline Kamber, and Jian Pei And slides provide by Raymond
COMP 5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Jiawei Han, Micheline Kamber, and Jian Pei And slides provide by Raymond
DATA MINING LECTURE 4. Frequent Itemsets, Association Rules Evaluation Alternative Algorithms
 DATA MINING LECTURE 4 Frequent Itemsets, Association Rules Evaluation Alternative Algorithms RECAP Mining Frequent Itemsets Itemset A collection of one or more items Example: {Milk, Bread, Diaper} k-itemset
DATA MINING LECTURE 4 Frequent Itemsets, Association Rules Evaluation Alternative Algorithms RECAP Mining Frequent Itemsets Itemset A collection of one or more items Example: {Milk, Bread, Diaper} k-itemset
Chapter 6. Frequent Pattern Mining: Concepts and Apriori. Meng Jiang CSE 40647/60647 Data Science Fall 2017 Introduction to Data Mining
 Chapter 6. Frequent Pattern Mining: Concepts and Apriori Meng Jiang CSE 40647/60647 Data Science Fall 2017 Introduction to Data Mining Pattern Discovery: Definition What are patterns? Patterns: A set of
Chapter 6. Frequent Pattern Mining: Concepts and Apriori Meng Jiang CSE 40647/60647 Data Science Fall 2017 Introduction to Data Mining Pattern Discovery: Definition What are patterns? Patterns: A set of
CS 584 Data Mining. Association Rule Mining 2
 CS 584 Data Mining Association Rule Mining 2 Recall from last time: Frequent Itemset Generation Strategies Reduce the number of candidates (M) Complete search: M=2 d Use pruning techniques to reduce M
CS 584 Data Mining Association Rule Mining 2 Recall from last time: Frequent Itemset Generation Strategies Reduce the number of candidates (M) Complete search: M=2 d Use pruning techniques to reduce M
Association Rules Information Retrieval and Data Mining. Prof. Matteo Matteucci
 Association Rules Information Retrieval and Data Mining Prof. Matteo Matteucci Learning Unsupervised Rules!?! 2 Market-Basket Transactions 3 Bread Peanuts Milk Fruit Jam Bread Jam Soda Chips Milk Fruit
Association Rules Information Retrieval and Data Mining Prof. Matteo Matteucci Learning Unsupervised Rules!?! 2 Market-Basket Transactions 3 Bread Peanuts Milk Fruit Jam Bread Jam Soda Chips Milk Fruit
DATA MINING - 1DL360
 DATA MINING - 1DL36 Fall 212" An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht12 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
DATA MINING - 1DL36 Fall 212" An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht12 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
Association Rules. Acknowledgements. Some parts of these slides are modified from. n C. Clifton & W. Aref, Purdue University
 Association Rules CS 5331 by Rattikorn Hewett Texas Tech University 1 Acknowledgements Some parts of these slides are modified from n C. Clifton & W. Aref, Purdue University 2 1 Outline n Association Rule
Association Rules CS 5331 by Rattikorn Hewett Texas Tech University 1 Acknowledgements Some parts of these slides are modified from n C. Clifton & W. Aref, Purdue University 2 1 Outline n Association Rule
DATA MINING - 1DL360
 DATA MINING - DL360 Fall 200 An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht0 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
DATA MINING - DL360 Fall 200 An introductory class in data mining http://www.it.uu.se/edu/course/homepage/infoutv/ht0 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
Chapters 6 & 7, Frequent Pattern Mining
 CSI 4352, Introduction to Data Mining Chapters 6 & 7, Frequent Pattern Mining Young-Rae Cho Associate Professor Department of Computer Science Baylor University CSI 4352, Introduction to Data Mining Chapters
CSI 4352, Introduction to Data Mining Chapters 6 & 7, Frequent Pattern Mining Young-Rae Cho Associate Professor Department of Computer Science Baylor University CSI 4352, Introduction to Data Mining Chapters
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/17/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/17/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
Association Analysis: Basic Concepts. and Algorithms. Lecture Notes for Chapter 6. Introduction to Data Mining
 Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Association
Association Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Association
Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Chapter 5 Association Analysis: Basic Concepts Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 2/3/28 Introduction to Data Mining Association Rule Mining Given
Data Mining Chapter 5 Association Analysis: Basic Concepts Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 2/3/28 Introduction to Data Mining Association Rule Mining Given
Association Analysis Part 2. FP Growth (Pei et al 2000)
") Association Analysis art 2 Sanjay Ranka rofessor Computer and Information Science and Engineering University of Florida F Growth ei et al 2 Use a compressed representation of the database using an F-tree
Association Analysis art 2 Sanjay Ranka rofessor Computer and Information Science and Engineering University of Florida F Growth ei et al 2 Use a compressed representation of the database using an F-tree
Lecture Notes for Chapter 6. Introduction to Data Mining. (modified by Predrag Radivojac, 2017)
") Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 27) Association Rule Mining Given a set of transactions, find rules that will predict the
Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 27) Association Rule Mining Given a set of transactions, find rules that will predict the
DATA MINING LECTURE 4. Frequent Itemsets and Association Rules
 DATA MINING LECTURE 4 Frequent Itemsets and Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
DATA MINING LECTURE 4 Frequent Itemsets and Association Rules This is how it all started Rakesh Agrawal, Tomasz Imielinski, Arun N. Swami: Mining Association Rules between Sets of Items in Large Databases.
Frequent Itemset Mining
 ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team (PART I) IMAGINA 17/18 Webpage: http://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge
ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team (PART I) IMAGINA 17/18 Webpage: http://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge
Frequent Itemset Mining
 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM IMAGINA 15/16 2 Frequent Itemset Mining: Motivations Frequent Itemset Mining is a method for market basket analysis. It aims at finding regulariges in
1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM IMAGINA 15/16 2 Frequent Itemset Mining: Motivations Frequent Itemset Mining is a method for market basket analysis. It aims at finding regulariges in
Association Rule. Lecturer: Dr. Bo Yuan. LOGO
 Association Rule Lecturer: Dr. Bo Yuan LOGO E-mail: yuanb@sz.tsinghua.edu.cn Overview Frequent Itemsets Association Rules Sequential Patterns 2 A Real Example 3 Market-Based Problems Finding associations
Association Rule Lecturer: Dr. Bo Yuan LOGO E-mail: yuanb@sz.tsinghua.edu.cn Overview Frequent Itemsets Association Rules Sequential Patterns 2 A Real Example 3 Market-Based Problems Finding associations
Machine Learning: Pattern Mining
 Machine Learning: Pattern Mining Information Systems and Machine Learning Lab (ISMLL) University of Hildesheim Wintersemester 2007 / 2008 Pattern Mining Overview Itemsets Task Naive Algorithm Apriori Algorithm
Machine Learning: Pattern Mining Information Systems and Machine Learning Lab (ISMLL) University of Hildesheim Wintersemester 2007 / 2008 Pattern Mining Overview Itemsets Task Naive Algorithm Apriori Algorithm
Association Analysis. Part 1
 Association Analysis Part 1 1 Market-basket analysis DATA: A large set of items: e.g., products sold in a supermarket A large set of baskets: e.g., each basket represents what a customer bought in one
Association Analysis Part 1 1 Market-basket analysis DATA: A large set of items: e.g., products sold in a supermarket A large set of baskets: e.g., each basket represents what a customer bought in one
CS 412 Intro. to Data Mining
 CS 412 Intro. to Data Mining Chapter 6. Mining Frequent Patterns, Association and Correlations: Basic Concepts and Methods Jiawei Han, Computer Science, Univ. Illinois at Urbana -Champaign, 2017 1 2 3
CS 412 Intro. to Data Mining Chapter 6. Mining Frequent Patterns, Association and Correlations: Basic Concepts and Methods Jiawei Han, Computer Science, Univ. Illinois at Urbana -Champaign, 2017 1 2 3
Descrip9ve data analysis. Example. Example. Example. Example. Data Mining MTAT (6EAP)
") 3.9.2 Descrip9ve data analysis Data Mining MTAT.3.83 (6EAP) hp://courses.cs.ut.ee/2/dm/ Frequent itemsets and associa@on rules Jaak Vilo 2 Fall Aims to summarise the main qualita9ve traits of data. Used
3.9.2 Descrip9ve data analysis Data Mining MTAT.3.83 (6EAP) hp://courses.cs.ut.ee/2/dm/ Frequent itemsets and associa@on rules Jaak Vilo 2 Fall Aims to summarise the main qualita9ve traits of data. Used
Basic Data Structures and Algorithms for Data Profiling Felix Naumann
 Basic Data Structures and Algorithms for 8.5.2017 Overview 1. The lattice 2. Apriori lattice traversal 3. Position List Indices 4. Bloom filters Slides with Thorsten Papenbrock 2 Definitions Lattice Partially
Basic Data Structures and Algorithms for 8.5.2017 Overview 1. The lattice 2. Apriori lattice traversal 3. Position List Indices 4. Bloom filters Slides with Thorsten Papenbrock 2 Definitions Lattice Partially
Frequent Itemsets and Association Rule Mining. Vinay Setty Slides credit:
 Frequent Itemsets and Association Rule Mining Vinay Setty vinay.j.setty@uis.no Slides credit: http://www.mmds.org/ Association Rule Discovery Supermarket shelf management Market-basket model: Goal: Identify
Frequent Itemsets and Association Rule Mining Vinay Setty vinay.j.setty@uis.no Slides credit: http://www.mmds.org/ Association Rule Discovery Supermarket shelf management Market-basket model: Goal: Identify
Exercise 1. min_sup = 0.3. Items support Type a 0.5 C b 0.7 C c 0.5 C d 0.9 C e 0.6 F
 Exercise 1 min_sup = 0.3 Items support Type a 0.5 C b 0.7 C c 0.5 C d 0.9 C e 0.6 F Items support Type ab 0.3 M ac 0.2 I ad 0.4 F ae 0.4 F bc 0.3 M bd 0.6 C be 0.4 F cd 0.4 C ce 0.2 I de 0.6 C Items support
Exercise 1 min_sup = 0.3 Items support Type a 0.5 C b 0.7 C c 0.5 C d 0.9 C e 0.6 F Items support Type ab 0.3 M ac 0.2 I ad 0.4 F ae 0.4 F bc 0.3 M bd 0.6 C be 0.4 F cd 0.4 C ce 0.2 I de 0.6 C Items support
Descrip<ve data analysis. Example. E.g. set of items. Example. Example. Data Mining MTAT (6EAP)
") 25.2.5 Descrip
25.2.5 Descrip
Frequent Itemset Mining
 Frequent Itemset Mining prof. dr Arno Siebes Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht Battling Size The previous time we saw that Big Data has
Frequent Itemset Mining prof. dr Arno Siebes Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht Battling Size The previous time we saw that Big Data has
A New Concise and Lossless Representation of Frequent Itemsets Using Generators and A Positive Border
 A New Concise and Lossless Representation of Frequent Itemsets Using Generators and A Positive Border Guimei Liu a,b Jinyan Li a Limsoon Wong b a Institute for Infocomm Research, Singapore b School of
A New Concise and Lossless Representation of Frequent Itemsets Using Generators and A Positive Border Guimei Liu a,b Jinyan Li a Limsoon Wong b a Institute for Infocomm Research, Singapore b School of
FP-growth and PrefixSpan
 FP-growth and PrefixSpan n Challenges of Frequent Pattern Mining n Improving Apriori n Fp-growth n Fp-tree n Mining frequent patterns with FP-tree n PrefixSpan Challenges of Frequent Pattern Mining n Challenges
FP-growth and PrefixSpan n Challenges of Frequent Pattern Mining n Improving Apriori n Fp-growth n Fp-tree n Mining frequent patterns with FP-tree n PrefixSpan Challenges of Frequent Pattern Mining n Challenges
Unit II Association Rules
 Unit II Association Rules Basic Concepts Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set Frequent Itemset
Unit II Association Rules Basic Concepts Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set Frequent Itemset
Descriptive data analysis. E.g. set of items. Example: Items in baskets. Sort or renumber in any way. Example
 .3.6 Descriptive data analysis Data Mining MTAT.3.83 (6EAP) Frequent itemsets and association rules Jaak Vilo 26 Spring Aims to summarise the main qualitative traits of data. Used mainly for discovering
.3.6 Descriptive data analysis Data Mining MTAT.3.83 (6EAP) Frequent itemsets and association rules Jaak Vilo 26 Spring Aims to summarise the main qualitative traits of data. Used mainly for discovering
Associa'on Rule Mining
 Associa'on Rule Mining Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 4 and 7, 2014 1 Market Basket Analysis Scenario: customers shopping at a supermarket Transaction
Associa'on Rule Mining Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 4 and 7, 2014 1 Market Basket Analysis Scenario: customers shopping at a supermarket Transaction
Frequent Itemset Mining
 ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team IMAGINA 16/17 Webpage: h;p://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge Discovery
ì 1 Frequent Itemset Mining Nadjib LAZAAR LIRMM- UM COCONUT Team IMAGINA 16/17 Webpage: h;p://www.lirmm.fr/~lazaar/teaching.html Email: lazaar@lirmm.fr 2 Data Mining ì Data Mining (DM) or Knowledge Discovery
Outline. Fast Algorithms for Mining Association Rules. Applications of Data Mining. Data Mining. Association Rule. Discussion
 Outline Fast Algorithms for Mining Association Rules Rakesh Agrawal Ramakrishnan Srikant Introduction Algorithm Apriori Algorithm AprioriTid Comparison of Algorithms Conclusion Presenter: Dan Li Discussion:
Outline Fast Algorithms for Mining Association Rules Rakesh Agrawal Ramakrishnan Srikant Introduction Algorithm Apriori Algorithm AprioriTid Comparison of Algorithms Conclusion Presenter: Dan Li Discussion:
Course Content. Association Rules Outline. Chapter 6 Objectives. Chapter 6: Mining Association Rules. Dr. Osmar R. Zaïane. University of Alberta 4
 Principles of Knowledge Discovery in Data Fall 2004 Chapter 6: Mining Association Rules Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Data warehousing and OLAP Data
Principles of Knowledge Discovery in Data Fall 2004 Chapter 6: Mining Association Rules Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Data warehousing and OLAP Data
Introduction to Data Mining
 Introduction to Data Mining Lecture #12: Frequent Itemsets Seoul National University 1 In This Lecture Motivation of association rule mining Important concepts of association rules Naïve approaches for
Introduction to Data Mining Lecture #12: Frequent Itemsets Seoul National University 1 In This Lecture Motivation of association rule mining Important concepts of association rules Naïve approaches for
Temporal Data Mining
 Temporal Data Mining Christian Moewes cmoewes@ovgu.de Otto-von-Guericke University of Magdeburg Faculty of Computer Science Department of Knowledge Processing and Language Engineering Zittau Fuzzy Colloquium
Temporal Data Mining Christian Moewes cmoewes@ovgu.de Otto-von-Guericke University of Magdeburg Faculty of Computer Science Department of Knowledge Processing and Language Engineering Zittau Fuzzy Colloquium
Association Analysis. Part 2
 Association Analysis Part 2 1 Limitations of the Support/Confidence framework 1 Redundancy: many of the returned patterns may refer to the same piece of information 2 Difficult control of output size:
Association Analysis Part 2 1 Limitations of the Support/Confidence framework 1 Redundancy: many of the returned patterns may refer to the same piece of information 2 Difficult control of output size:
Encyclopedia of Machine Learning Chapter Number Book CopyRight - Year 2010 Frequent Pattern. Given Name Hannu Family Name Toivonen
 Book Title Encyclopedia of Machine Learning Chapter Number 00403 Book CopyRight - Year 2010 Title Frequent Pattern Author Particle Given Name Hannu Family Name Toivonen Suffix Email hannu.toivonen@cs.helsinki.fi
Book Title Encyclopedia of Machine Learning Chapter Number 00403 Book CopyRight - Year 2010 Title Frequent Pattern Author Particle Given Name Hannu Family Name Toivonen Suffix Email hannu.toivonen@cs.helsinki.fi
Association Rule Mining on Web
 Association Rule Mining on Web What Is Association Rule Mining? Association rule mining: Finding interesting relationships among items (or objects, events) in a given data set. Example: Basket data analysis
Association Rule Mining on Web What Is Association Rule Mining? Association rule mining: Finding interesting relationships among items (or objects, events) in a given data set. Example: Basket data analysis
Descriptive data analysis. E.g. set of items. Example: Items in baskets. Sort or renumber in any way. Example item id s
 7.3.7 Descriptive data analysis Data Mining MTAT.3.83 (6EAP) Frequent itemsets and association rules Jaak Vilo 27 Spring Aims to summarise the main qualitative traits of data. Used mainly for discovering
7.3.7 Descriptive data analysis Data Mining MTAT.3.83 (6EAP) Frequent itemsets and association rules Jaak Vilo 27 Spring Aims to summarise the main qualitative traits of data. Used mainly for discovering
Frequent Pattern Mining: Exercises
 Frequent Pattern Mining: Exercises Christian Borgelt School of Computer Science tto-von-guericke-university of Magdeburg Universitätsplatz 2, 39106 Magdeburg, Germany christian@borgelt.net http://www.borgelt.net/
Frequent Pattern Mining: Exercises Christian Borgelt School of Computer Science tto-von-guericke-university of Magdeburg Universitätsplatz 2, 39106 Magdeburg, Germany christian@borgelt.net http://www.borgelt.net/
Lars Schmidt-Thieme, Information Systems and Machine Learning Lab (ISMLL), University of Hildesheim, Germany
, University of Hildesheim, Germany") Syllabus Fri. 21.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 27.10. (2) A.1 Linear Regression Fri. 3.11. (3) A.2 Linear Classification Fri. 10.11. (4) A.3 Regularization
Syllabus Fri. 21.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 27.10. (2) A.1 Linear Regression Fri. 3.11. (3) A.2 Linear Classification Fri. 10.11. (4) A.3 Regularization
Positive Borders or Negative Borders: How to Make Lossless Generator Based Representations Concise
 Positive Borders or Negative Borders: How to Make Lossless Generator Based Representations Concise Guimei Liu 1,2 Jinyan Li 1 Limsoon Wong 2 Wynne Hsu 2 1 Institute for Infocomm Research, Singapore 2 School
Positive Borders or Negative Borders: How to Make Lossless Generator Based Representations Concise Guimei Liu 1,2 Jinyan Li 1 Limsoon Wong 2 Wynne Hsu 2 1 Institute for Infocomm Research, Singapore 2 School
Association Analysis 1
 Association Analysis 1 Association Rules 1 3 Learning Outcomes Motivation Association Rule Mining Definition Terminology Apriori Algorithm Reducing Output: Closed and Maximal Itemsets 4 Overview One of
Association Analysis 1 Association Rules 1 3 Learning Outcomes Motivation Association Rule Mining Definition Terminology Apriori Algorithm Reducing Output: Closed and Maximal Itemsets 4 Overview One of
Knowledge Discovery and Data Mining I
 Ludwig-Maximilians-Universität München Lehrstuhl für Datenbanksysteme und Data Mining Prof. Dr. Thomas Seidl Knowledge Discovery and Data Mining I Winter Semester 2018/19 Agenda 1. Introduction 2. Basics
Ludwig-Maximilians-Universität München Lehrstuhl für Datenbanksysteme und Data Mining Prof. Dr. Thomas Seidl Knowledge Discovery and Data Mining I Winter Semester 2018/19 Agenda 1. Introduction 2. Basics
Effective Elimination of Redundant Association Rules
 Effective Elimination of Redundant Association Rules James Cheng Yiping Ke Wilfred Ng Department of Computer Science and Engineering The Hong Kong University of Science and Technology Clear Water Bay,
Effective Elimination of Redundant Association Rules James Cheng Yiping Ke Wilfred Ng Department of Computer Science and Engineering The Hong Kong University of Science and Technology Clear Water Bay,
Discovering Threshold-based Frequent Closed Itemsets over Probabilistic Data
 Discovering Threshold-based Frequent Closed Itemsets over Probabilistic Data Yongxin Tong #1, Lei Chen #, Bolin Ding *3 # Department of Computer Science and Engineering, Hong Kong Univeristy of Science
Discovering Threshold-based Frequent Closed Itemsets over Probabilistic Data Yongxin Tong #1, Lei Chen #, Bolin Ding *3 # Department of Computer Science and Engineering, Hong Kong Univeristy of Science
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 2017 Road map The Apriori algorithm Step 1: Mining all frequent
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 2017 Road map The Apriori algorithm Step 1: Mining all frequent
Handling a Concept Hierarchy
 Food Electronics Handling a Concept Hierarchy Bread Milk Computers Home Wheat White Skim 2% Desktop Laptop Accessory TV DVD Foremost Kemps Printer Scanner Data Mining: Association Rules 5 Why should we
Food Electronics Handling a Concept Hierarchy Bread Milk Computers Home Wheat White Skim 2% Desktop Laptop Accessory TV DVD Foremost Kemps Printer Scanner Data Mining: Association Rules 5 Why should we
Meelis Kull Autumn Meelis Kull - Autumn MTAT Data Mining - Lecture 05
 Meelis Kull meelis.kull@ut.ee Autumn 2017 1 Sample vs population Example task with red and black cards Statistical terminology Permutation test and hypergeometric test Histogram on a sample vs population
Meelis Kull meelis.kull@ut.ee Autumn 2017 1 Sample vs population Example task with red and black cards Statistical terminology Permutation test and hypergeometric test Histogram on a sample vs population
Association Rules. Jones & Bartlett Learning, LLC NOT FOR SALE OR DISTRIBUTION. Jones & Bartlett Learning, LLC NOT FOR SALE OR DISTRIBUTION
 CHAPTER2 Association Rules 2.1 Introduction Many large retail organizations are interested in instituting information-driven marketing processes, managed by database technology, that enable them to Jones
CHAPTER2 Association Rules 2.1 Introduction Many large retail organizations are interested in instituting information-driven marketing processes, managed by database technology, that enable them to Jones
Four Paradigms in Data Mining
 Four Paradigms in Data Mining dataminingbook.info Wagner Meira Jr. 1 1 Department of Computer Science Universidade Federal de Minas Gerais, Belo Horizonte, Brazil October 13, 2015 Meira Jr. (UFMG) Four
Four Paradigms in Data Mining dataminingbook.info Wagner Meira Jr. 1 1 Department of Computer Science Universidade Federal de Minas Gerais, Belo Horizonte, Brazil October 13, 2015 Meira Jr. (UFMG) Four
CS5112: Algorithms and Data Structures for Applications
 CS5112: Algorithms and Data Structures for Applications Lecture 19: Association rules Ramin Zabih Some content from: Wikipedia/Google image search; Harrington; J. Leskovec, A. Rajaraman, J. Ullman: Mining
CS5112: Algorithms and Data Structures for Applications Lecture 19: Association rules Ramin Zabih Some content from: Wikipedia/Google image search; Harrington; J. Leskovec, A. Rajaraman, J. Ullman: Mining
Association)Rule Mining. Pekka Malo, Assist. Prof. (statistics) Aalto BIZ / Department of Information and Service Management
Rule Mining. Pekka Malo, Assist. Prof. (statistics) Aalto BIZ / Department of Information and Service Management") Association)Rule Mining Pekka Malo, Assist. Prof. (statistics) Aalto BIZ / Department of Information and Service Management What)is)Association)Rule)Mining? Finding frequent patterns,1associations,1correlations,1or
Association)Rule Mining Pekka Malo, Assist. Prof. (statistics) Aalto BIZ / Department of Information and Service Management What)is)Association)Rule)Mining? Finding frequent patterns,1associations,1correlations,1or
Interesting Patterns. Jilles Vreeken. 15 May 2015
 Interesting Patterns Jilles Vreeken 15 May 2015 Questions of the Day What is interestingness? what is a pattern? and how can we mine interesting patterns? What is a pattern? Data Pattern y = x - 1 What
Interesting Patterns Jilles Vreeken 15 May 2015 Questions of the Day What is interestingness? what is a pattern? and how can we mine interesting patterns? What is a pattern? Data Pattern y = x - 1 What
On Condensed Representations of Constrained Frequent Patterns
 Under consideration for publication in Knowledge and Information Systems On Condensed Representations of Constrained Frequent Patterns Francesco Bonchi 1 and Claudio Lucchese 2 1 KDD Laboratory, ISTI Area
Under consideration for publication in Knowledge and Information Systems On Condensed Representations of Constrained Frequent Patterns Francesco Bonchi 1 and Claudio Lucchese 2 1 KDD Laboratory, ISTI Area
The Market-Basket Model. Association Rules. Example. Support. Applications --- (1) Applications --- (2)
 Applications --- (2)") The Market-Basket Model Association Rules Market Baskets Frequent sets A-priori Algorithm A large set of items, e.g., things sold in a supermarket. A large set of baskets, each of which is a small set
The Market-Basket Model Association Rules Market Baskets Frequent sets A-priori Algorithm A large set of items, e.g., things sold in a supermarket. A large set of baskets, each of which is a small set
Mining Molecular Fragments: Finding Relevant Substructures of Molecules
 Mining Molecular Fragments: Finding Relevant Substructures of Molecules Christian Borgelt, Michael R. Berthold Proc. IEEE International Conference on Data Mining, 2002. ICDM 2002. Lecturers: Carlo Cagli
Mining Molecular Fragments: Finding Relevant Substructures of Molecules Christian Borgelt, Michael R. Berthold Proc. IEEE International Conference on Data Mining, 2002. ICDM 2002. Lecturers: Carlo Cagli
Data Analytics Beyond OLAP. Prof. Yanlei Diao
 Data Analytics Beyond OLAP Prof. Yanlei Diao OPERATIONAL DBs DB 1 DB 2 DB 3 EXTRACT TRANSFORM LOAD (ETL) METADATA STORE DATA WAREHOUSE SUPPORTS OLAP DATA MINING INTERACTIVE DATA EXPLORATION Overview of
Data Analytics Beyond OLAP Prof. Yanlei Diao OPERATIONAL DBs DB 1 DB 2 DB 3 EXTRACT TRANSFORM LOAD (ETL) METADATA STORE DATA WAREHOUSE SUPPORTS OLAP DATA MINING INTERACTIVE DATA EXPLORATION Overview of
COMP 5331: Knowledge Discovery and Data Mining
 COMP 5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Tan, Steinbach, Kumar And Jiawei Han, Micheline Kamber, and Jian Pei 1 10
COMP 5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Tan, Steinbach, Kumar And Jiawei Han, Micheline Kamber, and Jian Pei 1 10
Sequential Pattern Mining
 Sequential Pattern Mining Lecture Notes for Chapter 7 Introduction to Data Mining Tan, Steinbach, Kumar From itemsets to sequences Frequent itemsets and association rules focus on transactions and the
Sequential Pattern Mining Lecture Notes for Chapter 7 Introduction to Data Mining Tan, Steinbach, Kumar From itemsets to sequences Frequent itemsets and association rules focus on transactions and the
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #11: Frequent Itemsets
 Data Management Systems. B. Aditya Prakash Lecture #11: Frequent Itemsets") CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #11: Frequent Itemsets Refer Chapter 6. MMDS book. VT CS 5614 2 Associa=on Rule Discovery Supermarket shelf management Market-basket model:
CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #11: Frequent Itemsets Refer Chapter 6. MMDS book. VT CS 5614 2 Associa=on Rule Discovery Supermarket shelf management Market-basket model:
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 05 Sequential Pattern Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Mining Concepts & Techniques Lecture No. 05 Sequential Pattern Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Density-Based Clustering
 Density-Based Clustering idea: Clusters are dense regions in feature space F. density: objects volume ε here: volume: ε-neighborhood for object o w.r.t. distance measure dist(x,y) dense region: ε-neighborhood
Density-Based Clustering idea: Clusters are dense regions in feature space F. density: objects volume ε here: volume: ε-neighborhood for object o w.r.t. distance measure dist(x,y) dense region: ε-neighborhood
CS246 Final Exam. March 16, :30AM - 11:30AM
 CS246 Final Exam March 16, 2016 8:30AM - 11:30AM Name : SUID : I acknowledge and accept the Stanford Honor Code. I have neither given nor received unpermitted help on this examination. (signed) Directions
CS246 Final Exam March 16, 2016 8:30AM - 11:30AM Name : SUID : I acknowledge and accept the Stanford Honor Code. I have neither given nor received unpermitted help on this examination. (signed) Directions
CPT+: A Compact Model for Accurate Sequence Prediction
 CPT+: A Compact Model for Accurate Sequence Prediction Ted Gueniche 1, Philippe Fournier-Viger 1, Rajeev Raman 2, Vincent S. Tseng 3 1 University of Moncton, Canada 2 University of Leicester, UK 3 National
CPT+: A Compact Model for Accurate Sequence Prediction Ted Gueniche 1, Philippe Fournier-Viger 1, Rajeev Raman 2, Vincent S. Tseng 3 1 University of Moncton, Canada 2 University of Leicester, UK 3 National
Chapter 4: Frequent Itemsets and Association Rules
 Chapter 4: Frequent Itemsets and Association Rules Jilles Vreeken Revision 1, November 9 th Notation clarified, Chi-square: clarified Revision 2, November 10 th details added of derivability example Revision
Chapter 4: Frequent Itemsets and Association Rules Jilles Vreeken Revision 1, November 9 th Notation clarified, Chi-square: clarified Revision 2, November 10 th details added of derivability example Revision
EFFICIENT MINING OF WEIGHTED QUANTITATIVE ASSOCIATION RULES AND CHARACTERIZATION OF FREQUENT ITEMSETS
 EFFICIENT MINING OF WEIGHTED QUANTITATIVE ASSOCIATION RULES AND CHARACTERIZATION OF FREQUENT ITEMSETS Arumugam G Senior Professor and Head, Department of Computer Science Madurai Kamaraj University Madurai,
EFFICIENT MINING OF WEIGHTED QUANTITATIVE ASSOCIATION RULES AND CHARACTERIZATION OF FREQUENT ITEMSETS Arumugam G Senior Professor and Head, Department of Computer Science Madurai Kamaraj University Madurai,
Pattern Space Maintenance for Data Updates. and Interactive Mining
 Pattern Space Maintenance for Data Updates and Interactive Mining Mengling Feng, 1,3,4 Guozhu Dong, 2 Jinyan Li, 1 Yap-Peng Tan, 1 Limsoon Wong 3 1 Nanyang Technological University, 2 Wright State University
Pattern Space Maintenance for Data Updates and Interactive Mining Mengling Feng, 1,3,4 Guozhu Dong, 2 Jinyan Li, 1 Yap-Peng Tan, 1 Limsoon Wong 3 1 Nanyang Technological University, 2 Wright State University
1 Frequent Pattern Mining
 Decision Support Systems MEIC - Alameda 2010/2011 Homework #5 Due date: 31.Oct.2011 1 Frequent Pattern Mining 1. The Apriori algorithm uses prior knowledge about subset support properties. In particular,
Decision Support Systems MEIC - Alameda 2010/2011 Homework #5 Due date: 31.Oct.2011 1 Frequent Pattern Mining 1. The Apriori algorithm uses prior knowledge about subset support properties. In particular,
FREQUENT PATTERN SPACE MAINTENANCE: THEORIES & ALGORITHMS
 FREQUENT PATTERN SPACE MAINTENANCE: THEORIES & ALGORITHMS FENG MENGLING SCHOOL OF ELECTRICAL & ELECTRONIC ENGINEERING NANYANG TECHNOLOGICAL UNIVERSITY 2009 FREQUENT PATTERN SPACE MAINTENANCE: THEORIES
FREQUENT PATTERN SPACE MAINTENANCE: THEORIES & ALGORITHMS FENG MENGLING SCHOOL OF ELECTRICAL & ELECTRONIC ENGINEERING NANYANG TECHNOLOGICAL UNIVERSITY 2009 FREQUENT PATTERN SPACE MAINTENANCE: THEORIES
OPPA European Social Fund Prague & EU: We invest in your future.
 OPPA European Social Fund Prague & EU: We invest in your future. Frequent itemsets, association rules Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz
OPPA European Social Fund Prague & EU: We invest in your future. Frequent itemsets, association rules Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz
Distributed Mining of Frequent Closed Itemsets: Some Preliminary Results
 Distributed Mining of Frequent Closed Itemsets: Some Preliminary Results Claudio Lucchese Ca Foscari University of Venice clucches@dsi.unive.it Raffaele Perego ISTI-CNR of Pisa perego@isti.cnr.it Salvatore
Distributed Mining of Frequent Closed Itemsets: Some Preliminary Results Claudio Lucchese Ca Foscari University of Venice clucches@dsi.unive.it Raffaele Perego ISTI-CNR of Pisa perego@isti.cnr.it Salvatore
Mining Statistically Important Equivalence Classes and Delta-Discriminative Emerging Patterns
 Mining Statistically Important Equivalence Classes and Delta-Discriminative Emerging Patterns Jinyan Li Institute for Infocomm Research (I 2 R) & Nanyang Technological University, Singapore jyli@ntu.edu.sg
Mining Statistically Important Equivalence Classes and Delta-Discriminative Emerging Patterns Jinyan Li Institute for Infocomm Research (I 2 R) & Nanyang Technological University, Singapore jyli@ntu.edu.sg
On the Complexity of Mining Itemsets from the Crowd Using Taxonomies
 On the Complexity of Mining Itemsets from the Crowd Using Taxonomies Antoine Amarilli 1,2 Yael Amsterdamer 1 Tova Milo 1 1 Tel Aviv University, Tel Aviv, Israel 2 École normale supérieure, Paris, France
On the Complexity of Mining Itemsets from the Crowd Using Taxonomies Antoine Amarilli 1,2 Yael Amsterdamer 1 Tova Milo 1 1 Tel Aviv University, Tel Aviv, Israel 2 École normale supérieure, Paris, France
sor exam What Is Association Rule Mining?
 Mining Association Rules Mining Association Rules What is Association rule mining Apriori Algorithm Measures of rule interestingness Advanced Techniques 1 2 What Is Association Rule Mining? i Association
Mining Association Rules Mining Association Rules What is Association rule mining Apriori Algorithm Measures of rule interestingness Advanced Techniques 1 2 What Is Association Rule Mining? i Association
Un nouvel algorithme de génération des itemsets fermés fréquents
 Un nouvel algorithme de génération des itemsets fermés fréquents Huaiguo Fu CRIL-CNRS FRE2499, Université d Artois - IUT de Lens Rue de l université SP 16, 62307 Lens cedex. France. E-mail: fu@cril.univ-artois.fr
Un nouvel algorithme de génération des itemsets fermés fréquents Huaiguo Fu CRIL-CNRS FRE2499, Université d Artois - IUT de Lens Rue de l université SP 16, 62307 Lens cedex. France. E-mail: fu@cril.univ-artois.fr
10/19/2017 MIST.6060 Business Intelligence and Data Mining 1. Association Rules
 10/19/2017 MIST6060 Business Intelligence and Data Mining 1 Examples of Association Rules Association Rules Sixty percent of customers who buy sheets and pillowcases order a comforter next, followed by
10/19/2017 MIST6060 Business Intelligence and Data Mining 1 Examples of Association Rules Association Rules Sixty percent of customers who buy sheets and pillowcases order a comforter next, followed by
Maintaining Frequent Itemsets over High-Speed Data Streams
 Maintaining Frequent Itemsets over High-Speed Data Streams James Cheng, Yiping Ke, and Wilfred Ng Department of Computer Science Hong Kong University of Science and Technology Clear Water Bay, Kowloon,
Maintaining Frequent Itemsets over High-Speed Data Streams James Cheng, Yiping Ke, and Wilfred Ng Department of Computer Science Hong Kong University of Science and Technology Clear Water Bay, Kowloon,
Approximate counting: count-min data structure. Problem definition
 Approximate counting: count-min data structure G. Cormode and S. Muthukrishhan: An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms 55 (2005) 58-75. Problem
Approximate counting: count-min data structure G. Cormode and S. Muthukrishhan: An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms 55 (2005) 58-75. Problem
Data Warehousing & Data Mining
 9. Business Intelligence Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence
9. Business Intelligence Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence
FARMER: Finding Interesting Rule Groups in Microarray Datasets
 FARMER: Finding Interesting Rule Groups in Microarray Datasets Gao Cong, Anthony K. H. Tung, Xin Xu, Feng Pan Dept. of Computer Science Natl. University of Singapore {conggao,atung,xuxin,panfeng}@comp.nus.edu.sg
FARMER: Finding Interesting Rule Groups in Microarray Datasets Gao Cong, Anthony K. H. Tung, Xin Xu, Feng Pan Dept. of Computer Science Natl. University of Singapore {conggao,atung,xuxin,panfeng}@comp.nus.edu.sg
A Global Constraint for Closed Frequent Pattern Mining
 A Global Constraint for Closed Frequent Pattern Mining N. Lazaar 1, Y. Lebbah 2, S. Loudni 3, M. Maamar 1,2, V. Lemière 3, C. Bessiere 1, P. Boizumault 3 1 LIRMM, University of Montpellier, France 2 LITIO,
A Global Constraint for Closed Frequent Pattern Mining N. Lazaar 1, Y. Lebbah 2, S. Loudni 3, M. Maamar 1,2, V. Lemière 3, C. Bessiere 1, P. Boizumault 3 1 LIRMM, University of Montpellier, France 2 LITIO,
Discovering Non-Redundant Association Rules using MinMax Approximation Rules
 Discovering Non-Redundant Association Rules using MinMax Approximation Rules R. Vijaya Prakash Department Of Informatics Kakatiya University, Warangal, India vijprak@hotmail.com Dr.A. Govardhan Department.
Discovering Non-Redundant Association Rules using MinMax Approximation Rules R. Vijaya Prakash Department Of Informatics Kakatiya University, Warangal, India vijprak@hotmail.com Dr.A. Govardhan Department.
Data Warehousing & Data Mining
 Data Warehousing & Data Mining Wolf-Tilo Balke Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence 9. Business Intelligence
Data Warehousing & Data Mining Wolf-Tilo Balke Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 9. Business Intelligence 9. Business Intelligence
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
CS738 Class Notes. Steve Revilak
 CS738 Class Notes Steve Revilak January 2008 May 2008 Copyright c 2008 Steve Revilak. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation
CS738 Class Notes Steve Revilak January 2008 May 2008 Copyright c 2008 Steve Revilak. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation